Projekt kompilatora - optymalizacja kodu
Optymalizacja to technika transformacji programu, która próbuje ulepszyć kod, sprawiając, że zużywa mniej zasobów (np. Procesor, pamięć) i zapewnia dużą prędkość.
W optymalizacji ogólne konstrukcje programowania wysokiego poziomu są zastępowane bardzo wydajnymi kodami programowania niskiego poziomu. Proces optymalizacji kodu musi przestrzegać trzech zasad podanych poniżej:
Kod wyjściowy nie może w żaden sposób zmieniać znaczenia programu.
Optymalizacja powinna zwiększyć szybkość programu i jeśli to możliwe, program powinien wymagać mniejszej liczby zasobów.
Optymalizacja powinna być szybka i nie powinna opóźniać całego procesu kompilacji.
Wysiłki mające na celu zoptymalizowanie kodu mogą być podejmowane na różnych poziomach kompilacji procesu.
Na początku użytkownicy mogą zmienić / przestawić kod lub użyć lepszych algorytmów do napisania kodu.
Po wygenerowaniu kodu pośredniego kompilator może zmodyfikować kod pośredni poprzez obliczenia adresu i ulepszenie pętli.
Podczas tworzenia docelowego kodu maszynowego kompilator może korzystać z hierarchii pamięci i rejestrów procesora.
Optymalizację można ogólnie podzielić na dwa typy: niezależne od maszyny i zależne od maszyny.
Optymalizacja niezależna od maszyny
W tej optymalizacji kompilator przyjmuje kod pośredni i przekształca część kodu, która nie zawiera żadnych rejestrów procesora i / lub bezwzględnych lokalizacji pamięci. Na przykład:
do
{
item = 10;
value = value + item;
} while(value<100);Ten kod polega na ponownym przypisaniu elementu identyfikatora, który jeśli umieścimy w ten sposób:
Item = 10;
do
{
value = value + item;
} while(value<100);powinien nie tylko zapisywać cykle procesora, ale może być używany na dowolnym procesorze.
Optymalizacja zależna od maszyny
Optymalizacja zależna od maszyny jest wykonywana po wygenerowaniu kodu docelowego i po przekształceniu kodu zgodnie z architekturą maszyny docelowej. Obejmuje rejestry procesora i może mieć raczej bezwzględne odniesienia do pamięci niż odniesienia względne. Optymalizatory zależne od komputera dokładają wszelkich starań, aby maksymalnie wykorzystać hierarchię pamięci.
Podstawowe bloki
Kody źródłowe zazwyczaj zawierają szereg instrukcji, które są zawsze wykonywane w sekwencji i są uważane za podstawowe bloki kodu. Te podstawowe bloki nie zawierają między sobą żadnych instrukcji skoku, tzn. Gdy wykonywana jest pierwsza instrukcja, wszystkie instrukcje w tym samym bloku podstawowym zostaną wykonane w kolejności ich pojawiania się bez utraty kontroli przepływu programu.
Program może mieć różne konstrukcje jako podstawowe bloki, takie jak IF-THEN-ELSE, instrukcje warunkowe SWITCH-CASE i pętle, takie jak DO-WHILE, FOR i REPEAT-UNTIL itp.
Podstawowa identyfikacja bloku
Aby znaleźć podstawowe bloki w programie, możemy użyć następującego algorytmu:
Wyszukaj instrukcje nagłówka wszystkich podstawowych bloków, od których zaczyna się podstawowy blok:
- Pierwsza instrukcja programu.
- Instrukcje, które są kierowane do dowolnej gałęzi (warunkowe / bezwarunkowe).
- Instrukcje występujące po każdej instrukcji gałęzi.
Instrukcje nagłówkowe i następujące po nich instrukcje tworzą podstawowy blok.
Podstawowy blok nie zawiera żadnej instrukcji nagłówka żadnego innego podstawowego bloku.
Podstawowe bloki są ważnymi pojęciami zarówno z punktu widzenia generowania kodu, jak i optymalizacji.
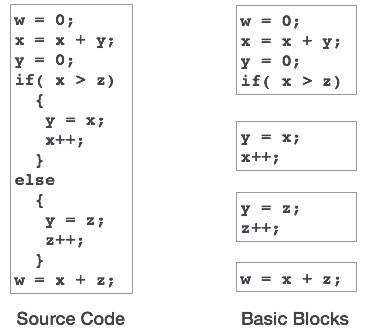
Podstawowe bloki odgrywają ważną rolę w identyfikowaniu zmiennych, które są używane więcej niż raz w jednym bloku podstawowym. Jeśli jakakolwiek zmienna jest używana więcej niż raz, pamięć rejestrów przydzielona tej zmiennej nie musi być opróżniana, chyba że blok zakończy wykonywanie.
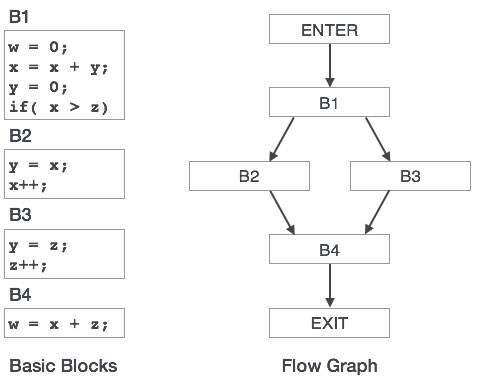
Wykres przepływu sterowania
Podstawowe bloki w programie można przedstawić za pomocą grafów sterowania. Wykres przepływu sterowania przedstawia sposób przekazywania sterowania programem między blokami. Jest to przydatne narzędzie, które pomaga w optymalizacji, pomagając w lokalizowaniu niechcianych pętli w programie.
Optymalizacja pętli
Większość programów działa jako pętla w systemie. Konieczna staje się optymalizacja pętli, aby zaoszczędzić cykle procesora i pamięć. Pętle można optymalizować za pomocą następujących technik:
Invariant code: Fragment kodu, który znajduje się w pętli i oblicza tę samą wartość w każdej iteracji, nazywany jest kodem niezmiennym w pętli. Ten kod można usunąć z pętli, zapisując go do obliczenia tylko raz, a nie przy każdej iteracji.
Induction analysis : Zmienna nazywana jest zmienną indukcyjną, jeśli jej wartość zostanie zmieniona w pętli o wartość niezmienną w pętli.
Strength reduction: Istnieją wyrażenia, które zajmują więcej cykli procesora, czasu i pamięci. Te wyrażenia powinny zostać zastąpione tańszymi wyrażeniami bez narażania wyjścia wyrażenia. Na przykład mnożenie (x * 2) jest kosztowne pod względem cykli procesora niż (x << 1) i daje ten sam wynik.
Eliminacja martwego kodu
Martwy kod to jedna lub więcej instrukcji kodu, którymi są:
- Albo nigdy nie stracony, albo nieosiągalny,
- Lub po wykonaniu ich dane wyjściowe nigdy nie są używane.
Tak więc martwy kod nie odgrywa żadnej roli w działaniu żadnego programu i dlatego można go po prostu wyeliminować.
Częściowo martwy kod
Istnieją pewne instrukcje kodu, których obliczone wartości są używane tylko w określonych okolicznościach, tj. Czasami wartości są używane, a czasami nie. Takie kody są znane jako częściowo martwy kod.
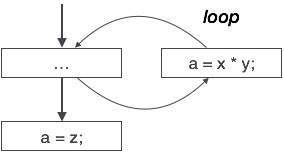
Powyższy wykres przepływu sterowania przedstawia fragment programu, w którym zmienna „a” jest używana do przypisania wyniku wyrażenia „x * y”. Załóżmy, że wartość przypisana do 'a' nigdy nie jest używana wewnątrz pętli. Natychmiast po wyjściu kontrolki z pętli, 'a' przypisywana jest wartość zmiennej 'z', która zostanie użyta później w programie. Dochodzimy tutaj do wniosku, że kod przypisania „a” nigdy nie jest nigdzie używany, dlatego kwalifikuje się do usunięcia.
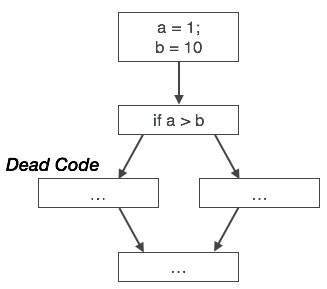
Podobnie, powyższy obrazek pokazuje, że instrukcja warunkowa jest zawsze fałszywa, co oznacza, że kod napisany w prawdziwym przypadku nigdy nie zostanie wykonany, dlatego można go usunąć.
Częściowa nadmiarowość
Zbędne wyrażenia są obliczane więcej niż raz w ścieżce równoległej, bez żadnych zmian w operandach, podczas gdy wyrażenia częściowo nadmiarowe są obliczane więcej niż raz na ścieżce, bez żadnych zmian w operandach. Na przykład,
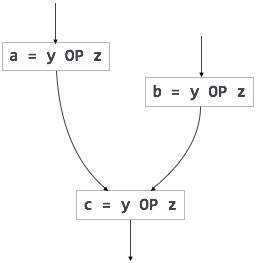
[zbędne wyrażenie] |
[częściowo zbędne wyrażenie] |
Kod niezmienny w pętli jest częściowo nadmiarowy i można go wyeliminować za pomocą techniki ruchu kodu.
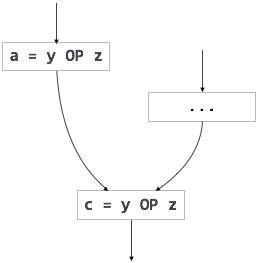
Innym przykładem częściowo nadmiarowego kodu może być:
If (condition)
{
a = y OP z;
}
else
{
...
}
c = y OP z;Zakładamy, że wartości argumentów (y i z) nie są zmieniane od przypisania zmiennej a do zmiennej c. Tutaj, jeśli warunek jest prawdziwy, to y OP z jest obliczane dwukrotnie, w przeciwnym razie raz. Ruch kodu można wykorzystać do wyeliminowania tej nadmiarowości, jak pokazano poniżej:
If (condition)
{
...
tmp = y OP z;
a = tmp;
...
}
else
{
...
tmp = y OP z;
}
c = tmp;Tutaj, czy warunek jest prawdziwy czy fałszywy; y OP z należy obliczyć tylko raz.