Projekt kompilatora - analiza składni
Analiza składni lub parsowanie to druga faza kompilatora. W tym rozdziale poznamy podstawowe pojęcia używane w konstrukcji parsera.
Widzieliśmy, że analizator leksykalny może identyfikować tokeny za pomocą wyrażeń regularnych i reguł wzorców. Jednak analizator leksykalny nie może sprawdzić składni danego zdania ze względu na ograniczenia wyrażeń regularnych. Wyrażenia regularne nie mogą sprawdzać tokenów równoważących, takich jak nawiasy. Dlatego w tej fazie stosowana jest gramatyka bezkontekstowa (CFG), która jest rozpoznawana przez automaty przesuwające w dół.
Z drugiej strony CFG to nadzbiór gramatyki regularnej, jak pokazano poniżej:

Oznacza to, że każda gramatyka regularna jest również bezkontekstowa, ale istnieją pewne problemy, które wykraczają poza zakres gramatyki regularnej. CFG to narzędzie pomocne w opisywaniu składni języków programowania.
Gramatyka bezkontekstowa
W tej sekcji najpierw zobaczymy definicję gramatyki bezkontekstowej i przedstawimy terminologię używaną w technologii analizowania.
Gramatyka bezkontekstowa składa się z czterech elementów:
Zestaw non-terminals(V). Terminale to zmienne składniowe, które oznaczają zestawy łańcuchów. Nieterminale definiują zestawy łańcuchów, które pomagają zdefiniować język generowany przez gramatykę.
Zestaw tokenów, znany jako terminal symbols(Σ). Terminale to podstawowe symbole, z których tworzone są łańcuchy.
Zestaw productions(P). Produkcje gramatyki określają sposób, w jaki terminale i nieterminale mogą być łączone w łańcuchy. Każda produkcja składa się znon-terminal zwana lewą stroną produkcji, strzałką i sekwencją żetonów i / lub on- terminals, zwana prawą stroną produkcji.
Jeden z nieterminali jest oznaczony jako symbol startu (S); skąd zaczyna się produkcja.
Ciągi są wyprowadzane z symbolu początkowego przez wielokrotne zastępowanie nieterminalnego (początkowo symbolu początkowego) prawą stroną produkcji, dla tego nieterminala.
Przykład
Podejmiemy problem języka palindromowego, którego nie da się opisać za pomocą wyrażeń regularnych. To znaczy L = {w | w = w R } nie jest językiem zwykłym. Ale można to opisać za pomocą CFG, jak pokazano poniżej:
G = ( V, Σ, P, S )Gdzie:
V = { Q, Z, N }
Σ = { 0, 1 }
P = { Q → Z | Q → N | Q → ℇ | Z → 0Q0 | N → 1Q1 }
S = { Q }Ta gramatyka opisuje język palindromowy, taki jak: 1001, 11100111, 00100, 1010101, 11111 itd.
Analizatory składni
Analizator składni lub parser pobiera dane wejściowe z analizatora leksykalnego w postaci strumieni tokenów. Parser analizuje kod źródłowy (strumień tokenów) pod kątem reguł produkcji, aby wykryć wszelkie błędy w kodzie. Wyjście tej fazy toparse tree.

W ten sposób parser wykonuje dwa zadania, tj. Analizuje kod, szuka błędów i generuje drzewo parsowania jako wynik fazy.
Parsery powinny przeanalizować cały kod, nawet jeśli w programie występują błędy. Parsery używają strategii naprawiania błędów, o których dowiemy się w dalszej części tego rozdziału.
Pochodzenie
Wyprowadzenie jest w zasadzie sekwencją reguł produkcji, aby uzyskać ciąg wejściowy. Podczas analizowania podejmujemy dwie decyzje dotyczące pewnej zdaniowej formy danych wejściowych:
- Decydowanie o nieterminalu, który ma zostać wymieniony.
- Decydowanie o zasadzie produkcji, według której nieterminal zostanie zastąpiony.
Aby zdecydować, który nieterminal ma zostać zastąpiony regułą produkcji, możemy mieć dwie opcje.
Wyprowadzenie skrajnie lewe
Jeśli zdaniowa forma wejścia jest skanowana i zastępowana od lewej do prawej, nazywa się to wyprowadzeniem najbardziej z lewej strony. Forma zdań wyprowadzona przez lewe wyprowadzenie nazywa się formą zdaniową po lewej stronie.
Wyprowadzenie najbardziej po prawej
Jeśli zeskanujemy i zastąpimy dane wejściowe regułami produkcji, od prawej do lewej, jest to znane jako wyprowadzenie najbardziej na prawo. Forma zdań wywodząca się z najbardziej prawej wyprowadzenia nazywana jest formą zdaniową po prawej stronie.
Example
Zasady produkcji:
E → E + E
E → E * E
E → idCiąg wejściowy: id + id * id
Najbardziej lewe wyprowadzenie to:
E → E * E
E → E + E * E
E → id + E * E
E → id + id * E
E → id + id * idZwróć uwagę, że nieterminalowa skrajna lewa strona jest zawsze przetwarzana jako pierwsza.
Najbardziej prawe wyprowadzenie to:
E → E + E
E → E + E * E
E → E + E * id
E → E + id * id
E → id + id * idDrzewo analizy
Drzewo parsowania to graficzne przedstawienie wyprowadzenia. Wygodne jest zobaczenie, jak ciągi są wyprowadzane z symbolu początkowego. Symbol początkowy wyprowadzenia staje się korzeniem drzewa parsowania. Zobaczmy to na przykładzie z ostatniego tematu.
Bierzemy skrajne lewe wyprowadzenie a + b * c
Najbardziej lewe wyprowadzenie to:
E → E * E
E → E + E * E
E → id + E * E
E → id + id * E
E → id + id * idKrok 1:
| E → E * E |
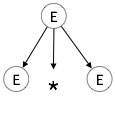
|
Krok 2:
| E → E + E * E |
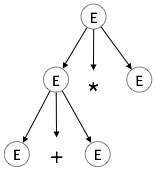
|
Krok 3:
| E → id + E * E |
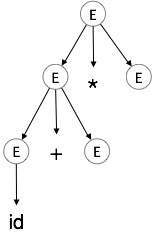
|
Krok 4:
| E → id + id * E |
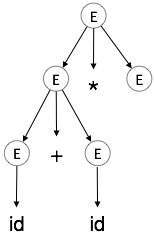
|
Krok 5:
| E → id + id * id |
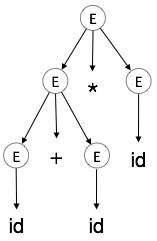
|
W drzewie parsowania:
- Wszystkie węzły liściowe są terminalami.
- Wszystkie węzły wewnętrzne nie są terminalami.
- Przechodzenie w kolejności daje oryginalny ciąg wejściowy.
Drzewo analizy przedstawia asocjatywność i pierwszeństwo operatorów. Najgłębsze poddrzewo jest przeszukiwane jako pierwsze, dlatego operator w tym poddrzewie ma pierwszeństwo przed operatorem, który znajduje się w węzłach nadrzędnych.
Dwuznaczność
Mówi się, że gramatyka G jest niejednoznaczna, jeśli ma więcej niż jedno drzewo analizy (lewe lub prawe wyprowadzenie) dla co najmniej jednego ciągu.
Example
E → E + E
E → E – E
E → idDla ciągu id + id - id, powyższa gramatyka generuje dwa drzewa parsowania:

Mówi się, że język generowany przez niejednoznaczną gramatykę jest inherently ambiguous. Niejednoznaczność gramatyczna nie jest dobra dla konstrukcji kompilatora. Żadna metoda nie może automatycznie wykryć i usunąć niejednoznaczności, ale można ją usunąć przez ponowne napisanie całej gramatyki bez niejasności lub ustawienie i przestrzeganie ograniczeń asocjatywności i pierwszeństwa.
Łączność
Jeśli operand ma operatory po obu stronach, strona, po której operator przyjmuje ten operand, jest określana przez asocjatywność tych operatorów. Jeśli operacja jest lewostronna, operand zostanie pobrany przez lewy operator lub jeśli operacja jest prawostronna, prawy operator zajmie operand.
Example
Operacje takie jak dodawanie, mnożenie, odejmowanie i dzielenie są lewostronne. Jeśli wyrażenie zawiera:
id op id op idzostanie oceniony jako:
(id op id) op idNa przykład (id + id) + id
Operacje takie jak potęgowanie są prawostronnie asocjacyjne, tj. Kolejność oceny w tym samym wyrażeniu będzie następująca:
id op (id op id)Na przykład id ^ (id ^ id)
Precedens
Jeśli dwa różne operatory mają wspólny operand, pierwszeństwo operatorów decyduje, który operand zajmie. Oznacza to, że 2 + 3 * 4 może mieć dwa różne drzewa analizy, jedno odpowiadające (2 + 3) * 4, a drugie odpowiadające 2+ (3 * 4). Ustawiając pierwszeństwo między operatorami, problem ten można łatwo usunąć. Podobnie jak w poprzednim przykładzie, matematycznie * (mnożenie) ma pierwszeństwo przed + (dodawanie), więc wyrażenie 2 + 3 * 4 będzie zawsze interpretowane jako:
2 + (3 * 4)Te metody zmniejszają prawdopodobieństwo niejednoznaczności w języku lub jego gramatyce.
Rekursja lewostronna
Gramatyka staje się lewostronnie rekurencyjna, jeśli ma jakieś nieterminalne „A”, którego wyprowadzenie zawiera „A” jako skrajny lewy symbol. Gramatyka lewostronna jest uważana za problematyczną dla parserów odgórnych. Parsery odgórne rozpoczynają analizę od symbolu Start, który sam w sobie nie jest terminalem. Tak więc, gdy parser napotyka ten sam nieterminalowy w swoim wyprowadzeniu, trudno jest mu ocenić, kiedy przestać analizować lewy nieterminal i przechodzi w nieskończoną pętlę.
Example:
(1) A => Aα | β
(2) S => Aα | β
A => Sd(1) jest przykładem natychmiastowej lewostronnej rekurencji, gdzie A jest dowolnym symbolem nieterminalnym, a α reprezentuje ciąg znaków nieterminalnych.
(2) jest przykładem rekursji pośredniej lewostronnej.
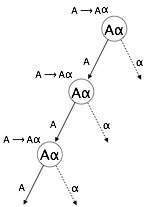
Parser odgórny najpierw przeanalizuje A, co z kolei da ciąg składający się z samego A, a parser może przejść do pętli na zawsze.
Usunięcie lewostronnej rekursji
Jednym ze sposobów usunięcia rekurencji lewej jest użycie następującej techniki:
Produkcja
A => Aα | βjest konwertowana na kolejne produkcje
A => βA'
A'=> αA' | εNie ma to wpływu na ciągi wywodzące się z gramatyki, ale usuwa natychmiastową lewą rekursję.
Drugą metodą jest użycie następującego algorytmu, który powinien wyeliminować wszystkie bezpośrednie i pośrednie lewe rekursje.
START
Arrange non-terminals in some order like A1, A2, A3,…, An
for each i from 1 to n
{
for each j from 1 to i-1
{
replace each production of form Ai ⟹Aj
with Ai ⟹ δ1 | δ2 | δ3 |…|
where Aj ⟹ δ1 | δ2|…| δn are current Aj productions
}
}
eliminate immediate left-recursion
ENDExample
Zestaw produkcyjny
S => Aα | β
A => Sdpo zastosowaniu powyższego algorytmu powinno stać się
S => Aα | β
A => Aαd | βda następnie usuń natychmiastową lewą rekursję, używając pierwszej techniki.
A => βdA'
A' => αdA' | εTeraz żadna z produkcji nie ma bezpośredniej ani pośredniej rekurencji lewej.
Faktoring lewy
Jeśli więcej niż jedna reguła produkcji gramatyki ma wspólny ciąg przedrostka, wówczas parser odgórny nie może dokonać wyboru, który z produkcji powinien wykonać, aby przeanalizować ciąg w ręku.
Example
Jeśli odgórny parser napotka produkcję taką jak
A ⟹ αβ | α | …Wtedy nie może określić, którą produkcję należy wykonać, aby przeanalizować ciąg, ponieważ obie produkcje zaczynają się od tego samego terminala (lub nieterminala). Aby usunąć to zamieszanie, używamy techniki zwanej faktoringiem lewostronnym.
Faktoring lewy przekształca gramatykę, aby była użyteczna dla parserów odgórnych. W tej technice tworzymy jedną produkcję dla każdego wspólnego przedrostka, a resztę wyprowadzenia dodajemy w nowych produkcjach.
Example
Powyższe produkcje można zapisać jako
A => αA'
A'=> β | | …Teraz parser ma tylko jedną produkcję na prefiks, co ułatwia podejmowanie decyzji.
Zestawy First i Follow
Ważną częścią konstrukcji tablicy parsera jest tworzenie pierwszych i następujących po sobie zestawów. Te zestawy mogą zapewnić rzeczywistą pozycję dowolnego terminala w wyprowadzeniu. Ma to na celu utworzenie tabeli parsowania, w której decyzja o zastąpieniu T [A, t] = α jakąś regułą produkcji.
Pierwszy zestaw
Ten zestaw jest tworzony, aby wiedzieć, jaki symbol terminala jest wyprowadzany na pierwszej pozycji przez nieterminal. Na przykład,
α → t βCzyli α wyprowadza t (terminal) na pierwszej pozycji. Zatem t ∈ PIERWSZY (α).
Algorytm obliczania pierwszego zbioru
Spójrz na definicję pierwszego zbioru (α):
- jeśli α jest końcem, to PIERWSZA (α) = {α}.
- jeśli α jest nieterminalnym i α → ℇ jest produkcją, to PIERWSZA (α) = {ℇ}.
- jeśli α jest niekońcem i α → 1 2 3… n i każda FIRST () zawiera t, to t jest w FIRST (α).
Pierwszy zestaw można zobaczyć jako:
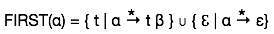
Śledź Set
Podobnie, obliczamy, który symbol końcowy występuje bezpośrednio po nieterminalnej α w regułach produkcji. Nie bierzemy pod uwagę tego, co może wygenerować nieterminal, ale zamiast tego widzimy, jaki byłby następny symbol terminala, który następuje po produkcji nieterminala.
Algorytm obliczania zbioru Follow:
jeśli α jest symbolem początkowym, to FOLLOW () = $
jeśli α jest nieterminalnym i ma produkcję α → AB, to FIRST (B) jest w FOLLOW (A) z wyjątkiem ℇ.
jeśli α jest nieterminalnym i ma produkcję α → AB, gdzie B ℇ, to FOLLOW (A) jest w FOLLOW (α).
Zbiór następujący można zobaczyć jako: FOLLOW (α) = {t | S * αt *}
Ograniczenia analizatorów składni
Analizatory składni otrzymują dane wejściowe w postaci tokenów z analizatorów leksykalnych. Analizatory leksykalne są odpowiedzialne za ważność tokenu dostarczonego przez analizator składni. Analizatory składni mają następujące wady -
- nie może określić, czy token jest ważny,
- nie może określić, czy token został zadeklarowany przed jego użyciem,
- nie może określić, czy token jest inicjalizowany przed użyciem,
- nie może określić, czy operacja wykonana na typie tokena jest prawidłowa, czy nie.
Zadania te wykonuje analizator semantyczny, który będziemy badać w ramach analizy semantycznej.