Projekt kompilatora - Parser odgórny
W poprzednim rozdziale dowiedzieliśmy się, że technika analizy odgórnej analizuje dane wejściowe i zaczyna konstruować drzewo parsowania od węzła głównego stopniowo do węzłów liści. Poniżej przedstawiono typy analizy odgórnej:
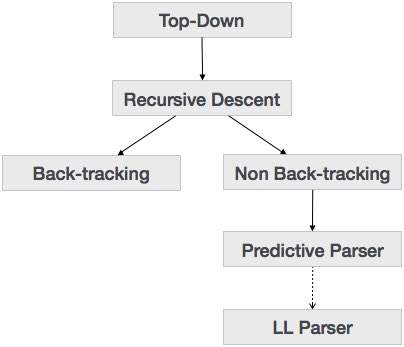
Rekurencyjne analizowanie zejścia
Zejście rekurencyjne to technika analizy zstępującej, która konstruuje drzewo analizy od góry, a dane wejściowe są odczytywane od lewej do prawej. Używa procedur dla każdego terminala i nieterminala. Ta technika analizowania rekurencyjnie analizuje dane wejściowe, aby utworzyć drzewo analizy, które może wymagać śledzenia wstecznego lub nie. Ale gramatyka z tym związana (jeśli nie zostanie uwzględniona) nie może uniknąć śledzenia wstecznego. Forma analizy zstępującej rekurencyjnej, która nie wymaga śledzenia wstecznego, jest znana jakopredictive parsing.
Ta technika analizowania jest uważana za rekurencyjną, ponieważ wykorzystuje gramatykę bezkontekstową, która ma charakter rekurencyjny.
Śledzenie wstecz
Parsery odgórne zaczynają się od węzła głównego (symbol początkowy) i dopasowują ciąg wejściowy do reguł produkcji, aby je zastąpić (jeśli są dopasowane). Aby to zrozumieć, weźmy następujący przykład CFG:
S → rXd | rZd
X → oa | ea
Z → aiDla ciągu wejściowego: read, odgórny parser, będzie się zachowywał następująco:
Rozpoczyna się literą S z reguł produkcji i dopasowuje swój zysk do litery wejścia znajdującej się najbardziej po lewej stronie, tj. „R”. Pasuje do niego sama produkcja S (S → rXd). Zatem odgórny parser przechodzi do następnej litery wejściowej (tj. „E”). Parser próbuje rozwinąć nieterminalowe „X” i sprawdza jego produkcję od lewej strony (X → oa). Nie pasuje do następnego symbolu wejściowego. Zatem odgórny parser cofa się, aby uzyskać następną regułę produkcji X, (X → ea).
Teraz parser dopasowuje wszystkie wprowadzone litery w uporządkowany sposób. Ciąg jest akceptowany.
|
|
|
|
|
Parser predykcyjny
Parser predykcyjny to rekurencyjny parser zstępujący, który ma możliwość przewidywania, która produkcja ma zostać użyta do zastąpienia ciągu wejściowego. Parser predykcyjny nie cierpi z powodu wycofywania.
Aby wykonać swoje zadania, parser predykcyjny używa wskaźnika wyprzedzającego, który wskazuje kolejne symbole wejściowe. Aby parser był wolny od śledzenia wstecznego, parser predykcyjny nakłada pewne ograniczenia na gramatykę i akceptuje tylko klasę gramatyki znaną jako gramatyka LL (k).
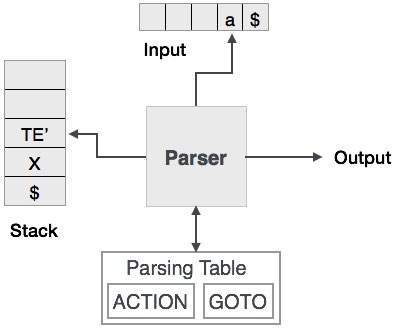
Analiza predykcyjna wykorzystuje stos i tabelę analizy do analizowania danych wejściowych i generowania drzewa analizy. Zarówno stos, jak i wejście zawierają symbol końca$aby wskazać, że stos jest pusty, a wejście jest zużywane. Parser odwołuje się do tablicy parsowania, aby podjąć jakąkolwiek decyzję dotyczącą kombinacji elementów wejściowych i stosu.
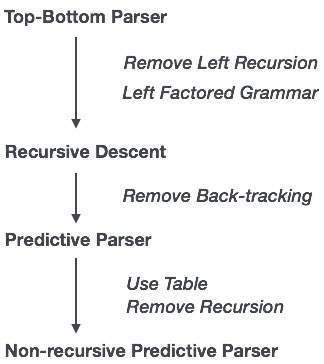
W analizowaniu zstępującym rekurencyjnym parser może mieć do wyboru więcej niż jedną produkcję dla jednej instancji danych wejściowych, podczas gdy w analizatorze predykcyjnym każdy krok ma co najwyżej jedną produkcję do wyboru. Mogą wystąpić przypadki, w których nie ma produkcji pasującej do ciągu wejściowego, co powoduje niepowodzenie procedury analizy.
LL Parser
Parser LL akceptuje gramatykę LL. Gramatyka LL jest podzbiorem gramatyki bezkontekstowej, ale z pewnymi ograniczeniami, aby uzyskać wersję uproszczoną w celu osiągnięcia łatwej implementacji. Gramatyka LL może być implementowana za pomocą obu algorytmów, mianowicie rekurencyjno-zstępującego lub sterowanego tabelami.
Parser LL jest oznaczony jako LL (k). Pierwsze L w LL (k) analizuje dane wejściowe od lewej do prawej, drugie L w LL (k) oznacza wyprowadzenie najbardziej na lewo, a samo k reprezentuje liczbę wyprzedzeń wyprzedzających. Generalnie k = 1, więc LL (k) można również zapisać jako LL (1).
Algorytm analizy LL
Możemy trzymać się deterministycznego LL (1) dla wyjaśnienia analizatora składni, ponieważ rozmiar tabeli rośnie wykładniczo wraz z wartością k. Po drugie, jeśli dana gramatyka nie jest LL (1), to zwykle nie jest LL (k) dla dowolnego podanego k.
Poniżej podano algorytm parsowania LL (1):
Input:
string ω
parsing table M for grammar G
Output:
If ω is in L(G) then left-most derivation of ω,
error otherwise.
Initial State : $S on stack (with S being start symbol)
ω$ in the input buffer
SET ip to point the first symbol of ω$.
repeat
let X be the top stack symbol and a the symbol pointed by ip.
if X∈ Vt or $
if X = a
POP X and advance ip.
else
error()
endif
else /* X is non-terminal */
if M[X,a] = X → Y1, Y2,... Yk
POP X
PUSH Yk, Yk-1,... Y1 /* Y1 on top */
Output the production X → Y1, Y2,... Yk
else
error()
endif
endif
until X = $ /* empty stack */Gramatyka G to LL (1), jeśli A → α | β to dwie odrębne produkcje G:
dla braku terminala, zarówno α, jak i β wyprowadzają ciągi zaczynające się od a.
co najwyżej jeden z α i β może wyprowadzić pusty łańcuch.
jeśli β → t, to α nie wyprowadza żadnego łańcucha zaczynającego się od końca w FOLLOW (A).