Kompilator - pośrednie generowanie kodu
Kod źródłowy można bezpośrednio przetłumaczyć na docelowy kod maszynowy, więc dlaczego w ogóle musimy przetłumaczyć kod źródłowy na kod pośredni, który jest następnie tłumaczony na kod docelowy? Zobaczmy, dlaczego potrzebujemy kodu pośredniego.
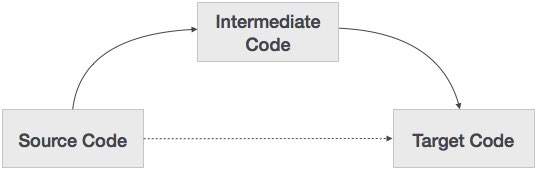
Jeśli kompilator tłumaczy język źródłowy na docelowy język maszynowy bez opcji generowania kodu pośredniego, to dla każdej nowej maszyny wymagany jest pełny natywny kompilator.
Kod pośredni eliminuje potrzebę nowego pełnego kompilatora dla każdej unikalnej maszyny, zachowując tę samą część analizy dla wszystkich kompilatorów.
Druga część kompilatora, synteza, jest zmieniana w zależności od maszyny docelowej.
Zastosowanie modyfikacji kodu źródłowego w celu poprawy wydajności kodu staje się łatwiejsze dzięki zastosowaniu technik optymalizacji kodu w kodzie pośrednim.
Reprezentacja pośrednia
Kody pośrednie mogą być przedstawiane na różne sposoby i mają swoje własne zalety.
High Level IR- Reprezentacja kodu pośredniego wysokiego poziomu jest bardzo zbliżona do samego języka źródłowego. Można je łatwo wygenerować z kodu źródłowego, a my możemy łatwo zastosować modyfikacje kodu w celu zwiększenia wydajności. Ale w przypadku optymalizacji maszyny docelowej jest mniej preferowana.
Low Level IR - Ten jest blisko maszyny docelowej, co sprawia, że nadaje się do przydzielania rejestrów i pamięci, wyboru zestawu instrukcji itp. Jest dobry do optymalizacji zależnych od maszyny.
Kod pośredni może być specyficzny dla języka (np. Kod bajtowy dla Java) lub niezależny od języka (kod trójadresowy).
Kod trójadresowy
Generator kodu pośredniego otrzymuje dane wejściowe z poprzedniej fazy, analizatora semantycznego, w postaci drzewa składni z adnotacjami. To drzewo składni można następnie przekształcić w reprezentację liniową, np. Notację postfiksową. Kod pośredni jest zwykle kodem niezależnym od maszyny. Dlatego generator kodu zakłada, że ma nieograniczoną ilość pamięci (rejestru) do generowania kodu.
Na przykład:
a = b + c * d;Generator kodu pośredniego spróbuje podzielić to wyrażenie na wyrażenia podrzędne, a następnie wygeneruje odpowiedni kod.
r1 = c * d;
r2 = b + r1;
a = r2r jest używany jako rejestry w programie docelowym.
Kod z trzema adresami ma co najwyżej trzy lokalizacje adresowe do obliczenia wyrażenia. Kod trójadresowy można przedstawić w dwóch postaciach: poczwórnej i potrójnej.
Czteroosobowe
Każda instrukcja w prezentacji poczwórnej jest podzielona na cztery pola: operator, arg1, arg2 i wynik. Powyższy przykład jest przedstawiony poniżej w formacie poczwórnym:
| Op | arg 1 | arg 2 | wynik |
| * | do | re | r1 |
| + | b | r1 | r2 |
| + | r2 | r1 | r3 |
| = | r3 | za |
Potrójne
Każda instrukcja w prezentacji trójek ma trzy pola: op, arg1 i arg2. Wyniki odpowiednich wyrażeń podrzędnych są oznaczone pozycją wyrażenia. Trójki reprezentują podobieństwo do DAG i drzewa składni. Są równoważne DAG podczas reprezentowania wyrażeń.
| Op | arg 1 | arg 2 |
| * | do | re |
| + | b | (0) |
| + | (1) | (0) |
| = | (2) |
Podczas optymalizacji trzykrotnie boryka się z problemem unieruchomienia kodu, ponieważ wyniki mają charakter pozycyjny, a zmiana kolejności lub pozycji wyrażenia może powodować problemy.
Pośrednie potrójne
Ta reprezentacja jest ulepszeniem w stosunku do reprezentacji potrójnej. Używa wskaźników zamiast pozycji do przechowywania wyników. Umożliwia to optymalizatorom swobodną zmianę pozycji wyrażenia podrzędnego w celu utworzenia zoptymalizowanego kodu.
Deklaracje
Przed użyciem należy zadeklarować zmienną lub procedurę. Deklaracja polega na przydzieleniu miejsca w pamięci i wpisaniu typu i nazwy w tablicy symboli. Program może być zakodowany i zaprojektowany z uwzględnieniem struktury maszyny docelowej, ale nie zawsze może być możliwe dokładne przekonwertowanie kodu źródłowego na język docelowy.
Przyjmując cały program jako zbiór procedur i podprocedur, możliwe staje się zadeklarowanie wszystkich nazw jako lokalnych dla procedury. Alokacja pamięci odbywa się w sposób sekwencyjny, a nazwy są przydzielane do pamięci w kolejności zadeklarowanej w programie. Używamy zmiennej offset i ustawiamy ją na zero {offset = 0}, które oznacza adres bazowy.
Źródłowy język programowania i architektura maszyny docelowej mogą różnić się sposobem przechowywania nazw, dlatego używane jest adresowanie względne. Podczas gdy pamięć jest przydzielana pierwszej nazwie zaczynając od komórki pamięci 0 {offset = 0}, następna nazwa zadeklarowana później powinna zostać przydzielona pamięć obok pierwszej.
Example:
Bierzemy przykład języka programowania C, w którym zmiennej całkowitej są przypisane 2 bajty pamięci, a zmiennej zmiennoprzecinkowej są przypisane 4 bajty pamięci.
int a;
float b;
Allocation process:
{offset = 0}
int a;
id.type = int
id.width = 2
offset = offset + id.width
{offset = 2}
float b;
id.type = float
id.width = 4
offset = offset + id.width
{offset = 6}Aby wprowadzić ten szczegół do tabeli symboli, można użyć procedury enter . Ta metoda może mieć następującą strukturę:
enter(name, type, offset)Procedura ta powinna utworzyć wpis w tablicy symboli, dla nazwy zmiennej , mając jej typ ustawiony na typ i względne przesunięcie adresu w obszarze danych.