Uczenie maszynowe - krótki przewodnik
Dzisiejsza sztuczna inteligencja (AI) znacznie przewyższyła szum związany z blockchainem i komputerami kwantowymi. Wynika to z faktu, że ogromne zasoby obliczeniowe są łatwo dostępne dla zwykłego człowieka. Programiści wykorzystują to teraz do tworzenia nowych modeli uczenia maszynowego i ponownego szkolenia istniejących modeli w celu uzyskania lepszej wydajności i wyników. Łatwa dostępność obliczeń o wysokiej wydajności (HPC) spowodowała nagły wzrost zapotrzebowania na specjalistów IT posiadających umiejętności uczenia maszynowego.
W tym samouczku dowiesz się szczegółowo o -
Na czym polega sedno uczenia maszynowego?
Jakie są różne typy uczenia maszynowego?
Jakie są dostępne różne algorytmy do tworzenia modeli uczenia maszynowego?
Jakie narzędzia są dostępne do tworzenia tych modeli?
Jakie są dostępne języki programowania?
Jakie platformy obsługują tworzenie i wdrażanie aplikacji do uczenia maszynowego?
Jakie IDE (zintegrowane środowisko programistyczne) są dostępne?
Jak szybko ulepszyć swoje umiejętności w tym ważnym obszarze?
Kiedy oznaczysz twarz na zdjęciu na Facebooku, to sztuczna inteligencja działa za kulisami i identyfikuje twarze na zdjęciu. Oznaczanie twarzy jest obecnie wszechobecne w kilku aplikacjach wyświetlających obrazy z ludzkimi twarzami. Dlaczego tylko ludzkie twarze? Istnieje kilka aplikacji, które wykrywają obiekty, takie jak koty, psy, butelki, samochody itp. Po naszych drogach poruszają się autonomiczne samochody, które wykrywają obiekty w czasie rzeczywistym i sterują samochodem. Podczas podróży korzystasz z GoogleDirectionsaby poznać sytuacje drogowe w czasie rzeczywistym i podążać najlepszą ścieżką sugerowaną przez Google w danym momencie. To kolejna implementacja techniki wykrywania obiektów w czasie rzeczywistym.
Rozważmy przykład Google Translateaplikacja, której zwykle używamy podczas odwiedzania innych krajów. Aplikacja Google do tłumaczenia online na telefon komórkowy pomaga komunikować się z lokalnymi mieszkańcami mówiącymi w obcym dla Ciebie języku.
Istnieje kilka zastosowań sztucznej inteligencji, z których praktycznie dzisiaj korzystamy. W rzeczywistości każdy z nas używa sztucznej inteligencji w wielu aspektach naszego życia, nawet bez naszej wiedzy. Dzisiejsza sztuczna inteligencja może wykonywać niezwykle złożone zadania z dużą dokładnością i szybkością. Omówmy przykład złożonego zadania, aby zrozumieć, jakie możliwości są oczekiwane od aplikacji AI, którą będziesz rozwijać dzisiaj dla swoich klientów.
Przykład
Wszyscy używamy Google Directionspodczas naszej podróży w dowolne miejsce w mieście na codzienne dojazdy, a nawet podróże międzymiastowe. Aplikacja Google Directions podpowiada najszybszą w danym momencie drogę do celu. Idąc tą ścieżką zauważyliśmy, że Google ma prawie 100% racji w swoich sugestiach i oszczędzamy nasz cenny czas w podróży.
Możesz sobie wyobrazić złożoność związaną z tworzeniem tego rodzaju aplikacji, biorąc pod uwagę, że do miejsca docelowego prowadzi wiele ścieżek, a aplikacja musi ocenić sytuację na drogach na każdej możliwej ścieżce, aby oszacować czas podróży dla każdej z nich. Poza tym weź pod uwagę fakt, że Google Directions obejmuje cały świat. Niewątpliwie pod maską takich aplikacji w użyciu jest wiele technik sztucznej inteligencji i uczenia maszynowego.
Biorąc pod uwagę ciągłe zapotrzebowanie na rozwój takich aplikacji, z pewnością docenisz, dlaczego nagle pojawia się zapotrzebowanie na informatyków z umiejętnościami AI.
W następnym rozdziale dowiemy się, co jest potrzebne do tworzenia programów AI.
Podróż AI rozpoczęła się w latach pięćdziesiątych XX wieku, kiedy moc obliczeniowa była ułamkiem tego, czym jest dzisiaj. Sztuczna inteligencja rozpoczęła się od przewidywań dokonywanych przez maszynę w taki sposób, że statystyka wykonuje prognozy za pomocą swojego kalkulatora. Tak więc początkowy cały rozwój sztucznej inteligencji opierał się głównie na technikach statystycznych.
W tym rozdziale omówimy szczegółowo, czym są te techniki statystyczne.
Techniki statystyczne
Rozwój dzisiejszych aplikacji sztucznej inteligencji rozpoczął się od wykorzystania odwiecznych tradycyjnych technik statystycznych. Musiałeś użyć interpolacji liniowej w szkołach, aby przewidzieć przyszłą wartość. Istnieje kilka innych takich technik statystycznych, które są z powodzeniem stosowane w tworzeniu tak zwanych programów AI. Mówimy „tak zwane”, ponieważ programy AI, które mamy dzisiaj, są znacznie bardziej złożone i wykorzystują techniki daleko wykraczające poza techniki statystyczne używane we wczesnych programach AI.
Oto kilka przykładów technik statystycznych, które są używane do tworzenia aplikacji AI w tamtych czasach i nadal są w praktyce -
- Regression
- Classification
- Clustering
- Teorie prawdopodobieństwa
- Drzewa decyzyjne
Tutaj wymieniliśmy tylko niektóre podstawowe techniki, które wystarczą, aby rozpocząć pracę ze sztuczną inteligencją, nie przerażając Cię ogromem, jakiego wymaga sztuczna inteligencja. Jeśli tworzysz aplikacje AI w oparciu o ograniczone dane, używałbyś tych technik statystycznych.
Jednak dzisiaj danych jest wiele. Analiza tego rodzaju ogromnych danych, którymi dysponujemy, nie jest zbyt pomocna, ponieważ mają one swoje własne ograniczenia. W związku z tym opracowuje się bardziej zaawansowane metody, takie jak głębokie uczenie się, w celu rozwiązywania wielu złożonych problemów.
W miarę postępów w tym samouczku zrozumiemy, czym jest uczenie maszynowe i jak jest wykorzystywane do tworzenia tak złożonych aplikacji AI.
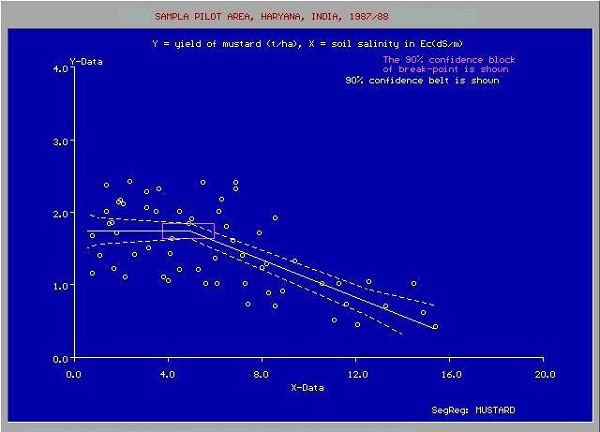
Rozważ poniższy wykres, który przedstawia wykres cen domów w zależności od ich wielkości w stopach kwadratowych.

Po narysowaniu różnych punktów danych na wykresie XY, rysujemy najlepiej dopasowaną linię, aby wykonać nasze prognozy dla dowolnego innego domu, biorąc pod uwagę jego rozmiar. Podasz znane dane do maszyny i poprosisz ją o znalezienie najlepiej dopasowanej linii. Gdy maszyna znajdzie najlepiej dopasowaną linię, przetestujesz jej przydatność, wprowadzając ją do budynku o znanej wielkości, tj. Wartość Y na powyższej krzywej. Maszyna zwróci teraz szacunkową wartość X, tj. Oczekiwaną cenę domu. Wykres można ekstrapolować, aby ustalić cenę domu o powierzchni 3000 stóp kwadratowych lub nawet większego. Nazywa się to regresją w statystykach. W szczególności ten rodzaj regresji nazywany jest regresją liniową, ponieważ związek między punktami danych X i Y jest liniowy.
W wielu przypadkach zależność między punktami danych X i Y może nie być linią prostą, a może to być krzywa ze złożonym równaniem. Twoim zadaniem byłoby teraz znaleźć najlepszą krzywą dopasowania, którą można ekstrapolować, aby przewidzieć przyszłe wartości. Jeden taki wykres aplikacji pokazano na poniższym rysunku.
Źródło:
https://upload.wikimedia.org/wikipedia/commons/c/c9/
Użyjesz tutaj statystycznych technik optymalizacji, aby znaleźć równanie dla najlepiej dopasowanej krzywej. I na tym właśnie polega uczenie maszynowe. Korzystasz ze znanych technik optymalizacji, aby znaleźć najlepsze rozwiązanie problemu.
Następnie przyjrzyjmy się różnym kategoriom uczenia maszynowego.
Uczenie maszynowe jest ogólnie podzielone na następujące nagłówki -
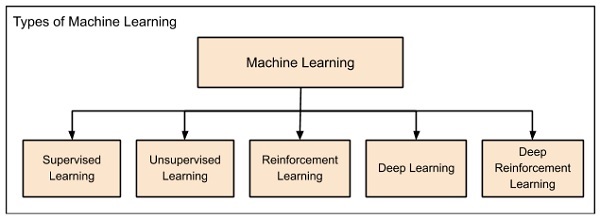
Uczenie maszynowe ewoluowało od lewej do prawej, jak pokazano na powyższym diagramie.
Początkowo badacze rozpoczęli naukę nadzorowaną. Tak jest w przypadku omawianej wcześniej prognozy cen mieszkań.
Następnie nastąpiło uczenie bez nadzoru, w którym maszyna jest zmuszona do samodzielnego uczenia się bez żadnego nadzoru.
Naukowcy odkryli dalej, że dobrym pomysłem może być nagradzanie maszyny, gdy wykonuje ona swoją pracę w oczekiwany sposób i nadeszła nauka ze wzmocnieniem.
Bardzo szybko dostępne obecnie dane stały się tak ogromne, że konwencjonalne techniki opracowane do tej pory nie pozwoliły na analizę dużych zbiorów danych i dostarczenie nam prognoz.
W ten sposób doszło do głębokiego uczenia się, w którym ludzki mózg jest symulowany w sztucznych sieciach neuronowych (SSN) utworzonych w naszych komputerach binarnych.
Maszyna uczy się teraz samodzielnie, korzystając z dużej mocy obliczeniowej i ogromnych zasobów pamięci, które są obecnie dostępne.
Obecnie obserwuje się, że uczenie głębokie rozwiązało wiele wcześniej nierozwiązywalnych problemów.
Technika jest teraz bardziej zaawansowana, dając zachęty dla sieci Deep Learning w postaci nagród i wreszcie pojawia się Deep Reinforcement Learning.
Przeanalizujmy teraz bardziej szczegółowo każdą z tych kategorii.
Nadzorowana nauka
Uczenie się nadzorowane jest analogiczne do uczenia dziecka chodzenia. Będziesz trzymać dziecko za rękę, pokazywać mu, jak iść do przodu, chodzić na pokaz i tak dalej, aż dziecko nauczy się chodzić samodzielnie.
Regresja
Podobnie, w przypadku uczenia się nadzorowanego, podajesz komputerowi konkretne znane przykłady. Mówisz, że dla danej wartości cechy x1 wyjście to y1, dla x2 to y2, dla x3 to y3 i tak dalej. Na podstawie tych danych pozwalasz komputerowi obliczyć empiryczny związek między x i y.
Gdy maszyna zostanie przeszkolona w ten sposób z wystarczającą liczbą punktów danych, teraz poprosisz maszynę o przewidzenie Y dla danego X. Zakładając, że znasz rzeczywistą wartość Y dla tego danego X, będziesz mógł wywnioskować czy przewidywania maszyny są poprawne.
W ten sposób sprawdzisz, czy maszyna nauczyła się, korzystając ze znanych danych testowych. Gdy upewnisz się, że maszyna jest w stanie wykonać prognozy z wymaganym poziomem dokładności (powiedzmy 80 do 90%), możesz przerwać dalsze szkolenie maszyny.
Teraz możesz bezpiecznie używać maszyny do prognozowania nieznanych punktów danych lub poprosić maszynę o przewidzenie Y dla danego X, dla którego nie znasz rzeczywistej wartości Y. To szkolenie podlega regresji, o której mówiliśmy wcześniej.
Klasyfikacja
Możesz również użyć technik uczenia maszynowego do rozwiązywania problemów z klasyfikacją. W problemach klasyfikacyjnych klasyfikujesz obiekty o podobnym charakterze do jednej grupy. Na przykład w grupie 100 uczniów powiedz, że możesz podzielić ich na trzy grupy na podstawie ich wzrostu - niski, średni i długi. Mierząc wzrost każdego ucznia, umieścisz go w odpowiedniej grupie.
Teraz, gdy przyjdzie nowy uczeń, umieścisz go w odpowiedniej grupie, mierząc jego wzrost. Przestrzegając zasad treningu regresji, nauczysz maszynę klasyfikować ucznia na podstawie jego cechy - wzrostu. Kiedy maszyna nauczy się, jak tworzone są grupy, będzie w stanie poprawnie zaklasyfikować każdego nieznanego nowego ucznia. Ponownie wykorzystasz dane testowe do sprawdzenia, czy maszyna nauczyła się Twojej techniki klasyfikacji przed wprowadzeniem opracowanego modelu do produkcji.
Uczenie nadzorowane to miejsce, w którym sztuczna inteligencja naprawdę rozpoczęła swoją podróż. Technika ta została z powodzeniem zastosowana w kilku przypadkach. Użyłeś tego modelu podczas odręcznego rozpoznawania na komputerze. Opracowano kilka algorytmów do nadzorowanego uczenia się. Dowiesz się o nich w kolejnych rozdziałach.
Uczenie się bez nadzoru
W uczeniu się bez nadzoru nie określamy docelowej zmiennej maszyny, a raczej pytamy maszynę „Co możesz mi powiedzieć o X?”. Mówiąc dokładniej, możemy zadawać pytania, na przykład mając ogromny zbiór danych X, „Jakie pięć najlepszych grup możemy wyliczyć z X?” lub „Jakie funkcje występują razem najczęściej w X?”. Aby uzyskać odpowiedzi na takie pytania, można zrozumieć, że liczba punktów danych, których maszyna wymagałaby do wydedukowania strategii, byłaby bardzo duża. W przypadku uczenia nadzorowanego maszynę można szkolić nawet z kilkoma tysiącami punktów danych. Jednak w przypadku uczenia się bez nadzoru liczba punktów danych, które są rozsądnie akceptowane do uczenia się, zaczyna się od kilku milionów. Obecnie dane są ogólnie obfite. Dane idealnie wymagają selekcji. Jednak ze względu na ilość danych, które stale przepływają w sieci społecznościowej, w większości przypadków ich przechowywanie jest niemożliwe.
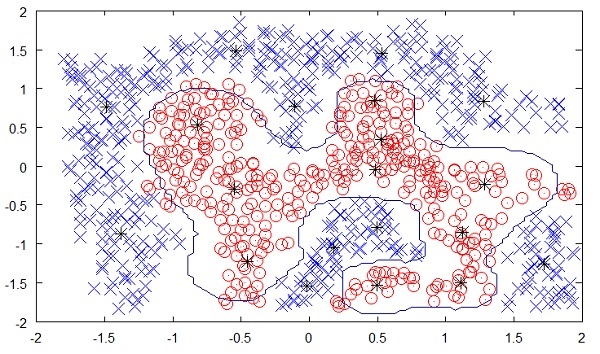
Poniższy rysunek przedstawia granicę między żółtymi i czerwonymi kropkami określoną przez nienadzorowane uczenie maszynowe. Widać wyraźnie, że maszyna byłaby w stanie określić klasę każdej z czarnych kropek z dość dobrą dokładnością.
Źródło:
https://chrisjmccormick.files.wordpress.com/2013/08/approx_decision_boun dary.png
Uczenie się bez nadzoru okazało się wielkim sukcesem w wielu nowoczesnych aplikacjach sztucznej inteligencji, takich jak wykrywanie twarzy, wykrywanie obiektów i tak dalej.
Uczenie się ze wzmocnieniem
Zastanów się nad wyszkoleniem psa, trenujemy naszego zwierzaka, aby przynosił nam piłkę. Rzucamy piłkę na pewną odległość i prosimy psa, żeby nam ją przyniósł. Za każdym razem, gdy pies robi to dobrze, nagradzamy go. Pies powoli dowiaduje się, że właściwe wykonanie pracy daje mu nagrodę, a następnie zaczyna wykonywać swoją pracę we właściwy sposób za każdym razem w przyszłości. Dokładnie, ta koncepcja jest stosowana w uczeniu się typu „Wzmocnienie”. Technika ta została początkowo opracowana dla maszyn do grania w gry. Maszyna otrzymuje algorytm do analizy wszystkich możliwych ruchów na każdym etapie gry. Maszyna może wybrać losowo jeden z ruchów. Jeśli ruch jest prawidłowy, maszyna jest nagradzana, w przeciwnym razie może zostać ukarana. Powoli maszyna zacznie rozróżniać dobre i złe ruchy i po kilku iteracjach nauczy się rozwiązywać zagadkę z większą dokładnością. Dokładność wygrywania gry poprawiłaby się, gdy maszyna gra coraz więcej gier.
Cały proces można przedstawić na poniższym schemacie -
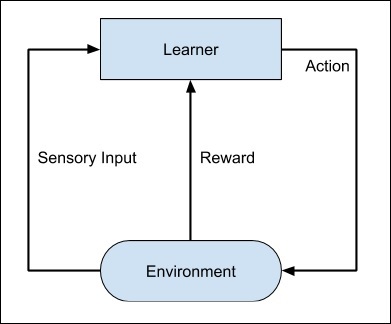
Ta technika uczenia maszynowego różni się od uczenia nadzorowanego tym, że nie ma potrzeby dostarczania oznaczonych par wejście / wyjście. Nacisk kładzie się na znalezienie równowagi między odkrywaniem nowych rozwiązań a wykorzystaniem poznanych rozwiązań.
Głęboka nauka
Głębokie uczenie się to model oparty na sztucznych sieciach neuronowych (ANN), a dokładniej konwolucyjnych sieciach neuronowych (CNN). Istnieje kilka architektur wykorzystywanych w uczeniu głębokim, takich jak głębokie sieci neuronowe, sieci głębokich przekonań, nawracające sieci neuronowe i konwolucyjne sieci neuronowe.
Sieci te zostały z powodzeniem zastosowane w rozwiązywaniu problemów widzenia komputerowego, rozpoznawania mowy, przetwarzania języka naturalnego, bioinformatyki, projektowania leków, analizy obrazu medycznego i gier. Istnieje kilka innych dziedzin, w których głębokie uczenie się jest aktywnie stosowane. Głębokie uczenie wymaga ogromnej mocy obliczeniowej i ogromnych danych, które są obecnie ogólnie łatwo dostępne.
Bardziej szczegółowo omówimy głębokie uczenie się w kolejnych rozdziałach.
Uczenie się o głębokim wzmocnieniu
Głębokie uczenie się ze wzmocnieniem (DRL) łączy techniki uczenia się głębokiego i wzmacniania. Algorytmy uczenia ze wzmocnieniem, takie jak Q-learning, są teraz połączone z głębokim uczeniem, aby stworzyć potężny model DRL. Technika ta odniosła wielki sukces w dziedzinie robotyki, gier wideo, finansów i opieki zdrowotnej. Wiele wcześniej nierozwiązywalnych problemów rozwiązuje się teraz, tworząc modele DRL. W tej dziedzinie prowadzi się wiele badań i są one bardzo aktywnie prowadzone w przemyśle.
Do tej pory masz krótkie wprowadzenie do różnych modeli uczenia maszynowego, teraz przyjrzyjmy się nieco głębiej różnym algorytmom, które są dostępne w tych modelach.
Uczenie nadzorowane jest jednym z ważnych modeli uczenia się stosowanych w maszynach szkoleniowych. W tym rozdziale szczegółowo omówiono to samo.
Algorytmy uczenia nadzorowanego
Dostępnych jest kilka algorytmów uczenia nadzorowanego. Poniżej przedstawiono niektóre z powszechnie stosowanych algorytmów uczenia nadzorowanego:
- k-Najbliżsi sąsiedzi
- Drzewa decyzyjne
- Naiwny Bayes
- Regresja logistyczna
- Wsparcie maszyn wektorowych
Idąc dalej w tym rozdziale, omówmy szczegółowo każdy z algorytmów.
k-Najbliżsi sąsiedzi
K-Nearest Neighbors, czyli po prostu kNN, to technika statystyczna, której można użyć do rozwiązywania problemów związanych z klasyfikacją i regresją. Omówmy przypadek sklasyfikowania nieznanego obiektu za pomocą kNN. Rozważ rozmieszczenie obiektów, jak pokazano na poniższym obrazku -
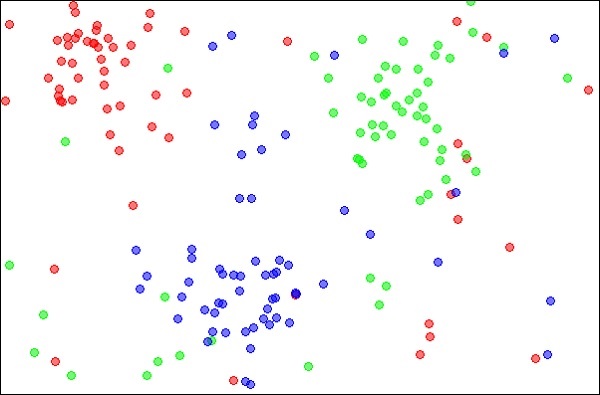
Źródło:
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
Diagram przedstawia trzy rodzaje obiektów, zaznaczone kolorem czerwonym, niebieskim i zielonym. Po uruchomieniu klasyfikatora kNN na powyższym zbiorze danych granice dla każdego typu obiektu zostaną zaznaczone, jak pokazano poniżej -

Źródło:
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
Teraz rozważ nowy nieznany obiekt, który chcesz sklasyfikować jako czerwony, zielony lub niebieski. Przedstawiono to na poniższym rysunku.
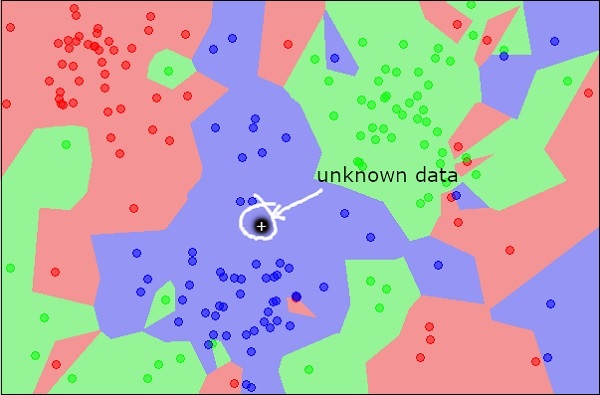
Jak widać naocznie, nieznany punkt danych należy do klasy niebieskich obiektów. Matematycznie można to wywnioskować, mierząc odległość tego nieznanego punktu z każdym innym punktem w zestawie danych. Kiedy to zrobisz, będziesz wiedział, że większość jego sąsiadów ma kolor niebieski. Średnia odległość do obiektów czerwonych i zielonych byłaby zdecydowanie większa niż średnia odległość do obiektów niebieskich. Zatem ten nieznany obiekt można zaklasyfikować jako należący do klasy niebieskiej.
Algorytm kNN może być również używany w przypadku problemów z regresją. Algorytm kNN jest dostępny jako gotowy do użycia w większości bibliotek ML.
Drzewa decyzyjne
Poniżej przedstawiono proste drzewo decyzyjne w formacie schematu blokowego -
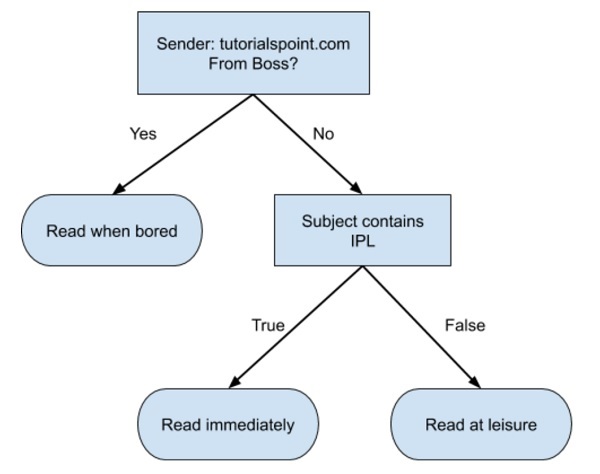
Napisałbyś kod klasyfikujący dane wejściowe na podstawie tego schematu blokowego. Schemat blokowy jest oczywisty i trywialny. W tym scenariuszu próbujesz sklasyfikować przychodzącą wiadomość e-mail, aby zdecydować, kiedy ją przeczytać.
W rzeczywistości drzewa decyzyjne mogą być duże i złożone. Dostępnych jest kilka algorytmów tworzenia i przemierzania tych drzew. Jako entuzjasta uczenia maszynowego musisz zrozumieć i opanować te techniki tworzenia i przechodzenia przez drzewa decyzyjne.
Naiwny Bayes
Naiwny Bayes służy do tworzenia klasyfikatorów. Załóżmy, że chcesz posortować (sklasyfikować) różne rodzaje owoców z koszyka z owocami. Możesz używać takich cech jak kolor, rozmiar i kształt owocu. Na przykład każdy owoc, który jest czerwony, ma okrągły kształt i ma około 10 cm średnicy, może być uważany za jabłko. Tak więc, aby wytrenować model, należy użyć tych funkcji i przetestować prawdopodobieństwo, że dana cecha pasuje do pożądanych ograniczeń. Następnie łączy się prawdopodobieństwa różnych cech, aby otrzymać prawdopodobieństwo, że dany owoc to jabłko. Naiwny Bayes generalnie wymaga niewielkiej liczby danych treningowych do klasyfikacji.
Regresja logistyczna
Spójrz na poniższy diagram. Pokazuje rozkład punktów danych w płaszczyźnie XY.

Na diagramie możemy wizualnie sprawdzić oddzielenie czerwonych kropek od zielonych kropek. Możesz narysować linię graniczną, aby oddzielić te kropki. Teraz, aby sklasyfikować nowy punkt danych, wystarczy określić, po której stronie linii leży punkt.
Wsparcie maszyn wektorowych
Spójrz na następujący rozkład danych. Tutaj tych trzech klas danych nie można oddzielić liniowo. Krzywe graniczne są nieliniowe. W takim przypadku znalezienie równania krzywej staje się złożonym zadaniem.
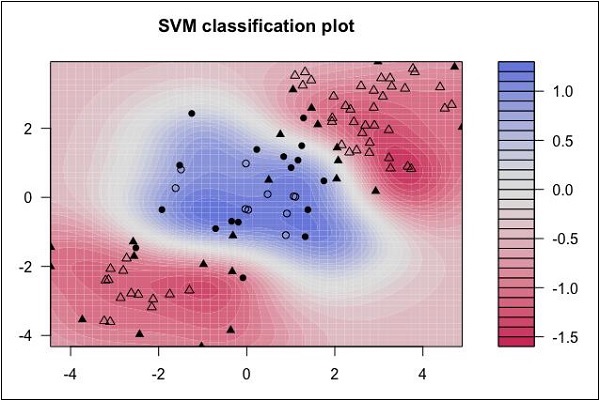
Źródło: http://uc-r.github.io/svm
Maszyny wektorów nośnych (SVM) są przydatne w określaniu granic separacji w takich sytuacjach.
Na szczęście w większości przypadków nie musisz kodować algorytmów, o których mowa w poprzedniej lekcji. Istnieje wiele standardowych bibliotek, które zapewniają gotową do użycia implementację tych algorytmów. Jednym z powszechnie używanych zestawów narzędzi jest scikit-learn. Poniższy rysunek ilustruje rodzaj algorytmów, które są dostępne do użytku w tej bibliotece.

Źródło: https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
Użycie tych algorytmów jest trywialne, a ponieważ są one dobrze sprawdzone w praktyce, możesz bezpiecznie używać ich w swoich aplikacjach AI. Większość z tych bibliotek można używać bezpłatnie, nawet w celach komercyjnych.
Jak dotąd to, co widzieliście, sprawia, że maszyna uczy się znajdować rozwiązanie naszego celu. W regresji trenujemy maszynę do przewidywania przyszłej wartości. W klasyfikacji trenujemy maszynę do klasyfikowania nieznanego obiektu w jednej z zdefiniowanych przez nas kategorii. Krótko mówiąc, trenowaliśmy maszyny, aby mogły przewidywać Y dla naszych danych X. Biorąc pod uwagę ogromny zbiór danych i brak szacowania kategorii, byłoby nam trudno trenować maszynę przy użyciu nadzorowanego uczenia się. A co, jeśli maszyna może wyszukać i przeanalizować duże zbiory danych składające się z kilku gigabajtów i terabajtów i powiedzieć nam, że te dane zawierają tak wiele różnych kategorii?
Jako przykład rozważ dane wyborcy. Biorąc pod uwagę niektóre dane wejściowe od każdego wyborcy (w terminologii sztucznej inteligencji nazywane są one funkcjami), pozwól maszynie przewidzieć, że jest tak wielu wyborców, którzy głosowaliby na partię polityczną X, a tylu głosowałoby na Y, i tak dalej. Tak więc ogólnie pytamy maszynę, mając ogromny zestaw punktów danych X, „Co możesz mi powiedzieć o X?”. Albo może to być pytanie typu „Jakie pięć najlepszych grup możemy stworzyć z X?”. A może nawet w stylu „Jakie trzy cechy występują razem najczęściej w X?”.
Na tym właśnie polega uczenie się nienadzorowane.
Algorytmy uczenia się bez nadzoru
Omówmy teraz jeden z szeroko stosowanych algorytmów klasyfikacji w uczeniu maszynowym bez nadzoru.
grupowanie k-średnich
Wybory prezydenckie w 2000 i 2004 roku w Stanach Zjednoczonych były bliskie - bardzo wyrównane. Największy odsetek głosów, jakie uzyskał każdy kandydat, wyniósł 50,7%, a najniższy 47,9%. Gdyby pewien procent wyborców zmienił strony, wynik wyborów byłby inny. Są małe grupy wyborców, którzy po odpowiednim wezwaniu zmienią stronę. Te grupy mogą nie są ogromne, ale przy tak bliskich dystansach mogą być na tyle duże, że zmienią wynik wyborów. Jak znajdujesz te grupy ludzi? Jak przyciągasz do nich ograniczony budżet? Odpowiedź brzmi: klaster.
Zrozummy, jak to się robi.
Po pierwsze, zbierasz informacje o ludziach za ich zgodą lub bez: wszelkie informacje, które mogą dać wskazówkę, co jest dla nich ważne i co wpłynie na sposób głosowania.
Następnie umieszczasz te informacje w jakimś algorytmie klastrowym.
Następnie dla każdego klastra (mądrze byłoby wybrać najpierw największy) tworzysz komunikat, który spodoba się tym wyborcom.
Na koniec dostarczasz kampanię i mierzysz, aby sprawdzić, czy działa.
Klasteryzacja to rodzaj uczenia się bez nadzoru, które automatycznie tworzy skupiska podobnych rzeczy. To jest jak automatyczna klasyfikacja. Możesz skupić prawie wszystko, a im bardziej podobne elementy znajdują się w klastrze, tym lepsze są klastry. W tym rozdziale przyjrzymy się jednemu typowi algorytmu grupowania zwanego k-średnich. Nazywa się to k-średnimi, ponieważ znajduje unikatowe klastry „k”, a środek każdego skupienia jest średnią wartości w tym skupieniu.
Identyfikacja klastra
Identyfikacja klastra mówi algorytmowi: „Oto trochę danych. Teraz pogrupuj razem podobne rzeczy i opowiedz mi o tych grupach ”. Kluczowa różnica w stosunku do klasyfikacji polega na tym, że w klasyfikacji wiesz, czego szukasz. Nie dotyczy to jednak klastrów.
Grupowanie jest czasami nazywane klasyfikacją nienadzorowaną, ponieważ daje taki sam wynik jak klasyfikacja, ale bez wcześniej zdefiniowanych klas.
Teraz czujemy się komfortowo zarówno w uczeniu się nadzorowanym, jak i nienadzorowanym. Aby zrozumieć pozostałe kategorie uczenia maszynowego, musimy najpierw zrozumieć sztuczne sieci neuronowe (SSN), o których dowiemy się w następnym rozdziale.
Idea sztucznych sieci neuronowych wywodzi się z sieci neuronowych w ludzkim mózgu. Ludzki mózg jest naprawdę złożony. Dokładnie badając mózg, naukowcy i inżynierowie opracowali architekturę, która mogłaby pasować do naszego cyfrowego świata komputerów binarnych. Jedną z takich typowych architektur pokazano na poniższym schemacie -
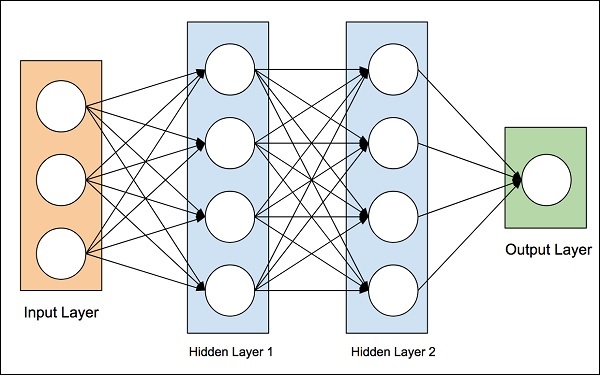
Istnieje warstwa wejściowa, która ma wiele czujników do zbierania danych ze świata zewnętrznego. Po prawej stronie mamy warstwę wyjściową, która daje nam wynik przewidywany przez sieć. Między tymi dwoma warstwami jest ukrytych. Każda dodatkowa warstwa dodatkowo komplikuje szkolenie sieci, ale zapewnia lepsze wyniki w większości sytuacji. Zaprojektowano kilka typów architektur, które teraz omówimy.
ANN Architectures
Poniższy diagram przedstawia kilka architektur ANN opracowanych w pewnym okresie i obecnie stosowanych w praktyce.
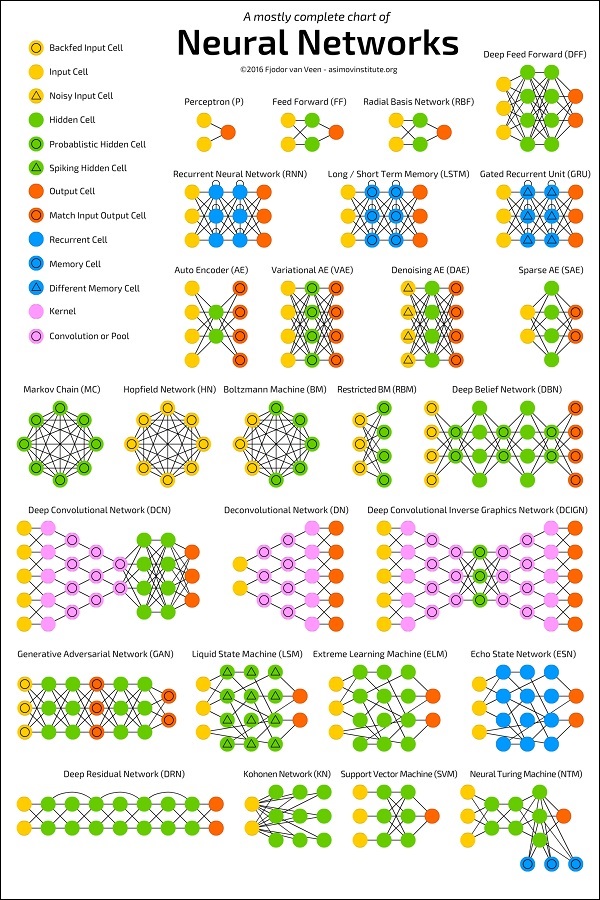
Źródło:
https://towardsdatascience.com/the-mostly-complete-chart-of-neural-networks-explained-3fb6f2367464
Każda architektura jest opracowywana pod kątem określonego typu aplikacji. Tak więc, kiedy używasz sieci neuronowej do aplikacji uczenia maszynowego, będziesz musiał użyć jednej z istniejących architektur lub zaprojektować własną. Rodzaj aplikacji, na który ostatecznie zdecydujesz się, zależy od Twoich potrzeb. Nie ma jednej wskazówki, która mówi, że należy używać określonej architektury sieci.
Deep Learning wykorzystuje ANN. Najpierw przyjrzymy się kilku aplikacjom do głębokiego uczenia się, które dadzą ci wyobrażenie o jego mocy.
Aplikacje
Deep Learning odniósł duży sukces w kilku obszarach zastosowań uczenia maszynowego.
Self-driving Cars- Autonomiczne samojezdne samochody wykorzystują techniki głębokiego uczenia. Generalnie dostosowują się do ciągle zmieniających się sytuacji na drogach i coraz lepiej radzą sobie z prowadzeniem pojazdu w miarę upływu czasu.
Speech Recognition- Innym interesującym zastosowaniem Deep Learning jest rozpoznawanie mowy. Każdy z nas korzysta obecnie z kilku aplikacji mobilnych, które są w stanie rozpoznawać naszą mowę. Siri firmy Apple, Alexa Amazona, Cortena firmy Microsoft i Asystent Google - wszystkie one wykorzystują techniki głębokiego uczenia.
Mobile Apps- Używamy kilku aplikacji internetowych i mobilnych do porządkowania naszych zdjęć. Wykrywanie twarzy, identyfikacja twarzy, tagowanie twarzy, identyfikacja obiektów na obrazie - wszystko to wykorzystuje głębokie uczenie się.
Niewykorzystane możliwości głębokiego uczenia się
Po przyjrzeniu się, jak wielkie sukcesy odniosły aplikacje głębokiego uczenia się w wielu dziedzinach, ludzie zaczęli badać inne domeny, w których uczenie maszynowe nie było dotychczas stosowane. Istnieje kilka dziedzin, w których techniki głębokiego uczenia się są z powodzeniem stosowane i istnieje wiele innych, które można wykorzystać. Niektóre z nich omówiono tutaj.
Rolnictwo jest jedną z takich gałęzi przemysłu, w której ludzie mogą stosować techniki głębokiego uczenia się, aby poprawić plony.
Consumer Finance to kolejny obszar, w którym uczenie maszynowe może bardzo pomóc we wczesnym wykrywaniu oszustw i analizowaniu zdolności klienta do płacenia.
Techniki głębokiego uczenia są również stosowane w medycynie w celu tworzenia nowych leków i dostarczania pacjentowi spersonalizowanej recepty.
Możliwości są nieograniczone i trzeba obserwować, jak często pojawiają się nowe pomysły i osiągnięcia.
Co jest potrzebne, aby osiągnąć więcej przy użyciu głębokiego uczenia
Aby korzystać z uczenia głębokiego, moc obliczeniowa superkomputera jest niezbędna. Do tworzenia modeli głębokiego uczenia potrzebujesz zarówno pamięci, jak i procesora. Na szczęście dzisiaj mamy łatwy dostęp do HPC - High Performance Computing. Z tego powodu rozwój aplikacji do głębokiego uczenia się, o których wspomnieliśmy powyżej, stał się rzeczywistością dzisiaj, a także w przyszłości możemy zobaczyć aplikacje w tych niewykorzystanych obszarach, które omówiliśmy wcześniej.
Teraz przyjrzymy się niektórym ograniczeniom głębokiego uczenia się, które musimy wziąć pod uwagę przed użyciem go w naszej aplikacji do uczenia maszynowego.
Wady uczenia głębokiego
Poniżej wymieniono kilka ważnych punktów, które należy wziąć pod uwagę przed użyciem uczenia głębokiego:
- Podejście czarnej skrzynki
- Czas trwania rozwoju
- Ilość danych
- Kosztowne obliczeniowo
Przeanalizujemy teraz szczegółowo każde z tych ograniczeń.
Podejście czarnej skrzynki
Sieć ANN jest jak czarna skrzynka. Dajesz mu określone dane wejściowe, a to zapewni ci określone wyjście. Poniższy diagram przedstawia jedną z takich aplikacji, w której podajesz obraz zwierzęcia do sieci neuronowej i informuje Cię, że obraz przedstawia psa.
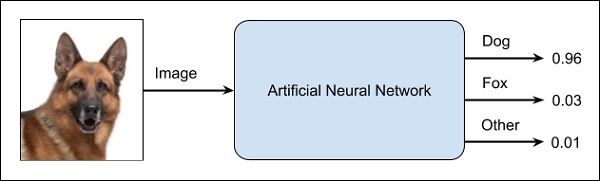
Dlaczego nazywa się to podejściem czarnej skrzynki, nie wiadomo, dlaczego sieć uzyskała określony wynik. Nie wiesz, jak sieć doszła do wniosku, że to pies? Rozważmy teraz aplikację bankową, w której bank chce decydować o zdolności kredytowej klienta. Sieć na pewno udzieli Ci odpowiedzi na to pytanie. Czy jednak potrafisz to uzasadnić klientowi? Banki muszą wyjaśnić swoim klientom, dlaczego kredyt nie jest sankcjonowany?
Czas trwania rozwoju
Proces uczenia sieci neuronowej przedstawiono na poniższym schemacie -

Najpierw określasz problem, który chcesz rozwiązać, tworzysz dla niego specyfikację, decydujesz o funkcjach wejściowych, projektujesz sieć, wdrażasz ją i testujesz wynik. Jeśli wynik nie jest zgodny z oczekiwaniami, potraktuj to jako informację zwrotną, aby zrestrukturyzować swoją sieć. Jest to proces iteracyjny i może wymagać kilku iteracji, dopóki sieć czasu nie zostanie w pełni przeszkolona do wytwarzania pożądanych wyników.
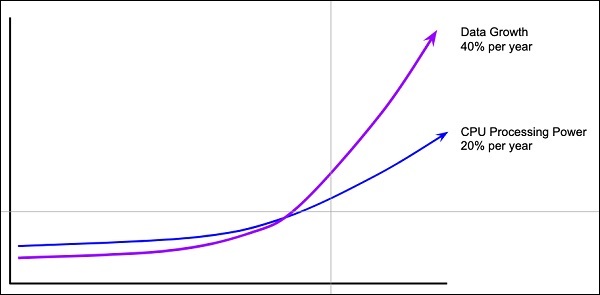
Ilość danych
Sieci głębokiego uczenia zwykle wymagają ogromnej ilości danych do szkolenia, podczas gdy tradycyjne algorytmy uczenia maszynowego mogą być używane z dużym powodzeniem nawet przy zaledwie kilku tysiącach punktów danych. Na szczęście obfitość danych rośnie o 40% rocznie, a moc obliczeniowa procesora rośnie o 20% rocznie, jak widać na poniższym diagramie -
Kosztowne obliczeniowo
Uczenie sieci neuronowej wymaga kilkukrotnie większej mocy obliczeniowej niż ta wymagana do uruchamiania tradycyjnych algorytmów. Pomyślne szkolenie głębokich sieci neuronowych może wymagać kilku tygodni szkolenia.
W przeciwieństwie do tego, tradycyjne algorytmy uczenia maszynowego zajmują tylko kilka minut / godzin. Ponadto ilość mocy obliczeniowej potrzebnej do uczenia głębokich sieci neuronowych w dużym stopniu zależy od rozmiaru danych oraz od tego, jak głęboka i złożona jest sieć?
Po zapoznaniu się z tym, czym jest uczenie maszynowe, jego możliwościami, ograniczeniami i aplikacjami, przejdźmy teraz do nauki „uczenia maszynowego”.
Uczenie maszynowe ma bardzo dużą szerokość i wymaga umiejętności w kilku dziedzinach. Umiejętności, które musisz zdobyć, aby zostać ekspertem w dziedzinie uczenia maszynowego, są wymienione poniżej -
- Statistics
- Teorie prawdopodobieństwa
- Calculus
- Techniki optymalizacji
- Visualization
Konieczność różnych umiejętności uczenia maszynowego
Aby dać ci krótkie wyobrażenie o umiejętnościach, które musisz zdobyć, omówimy kilka przykładów -
Notacja matematyczna
Większość algorytmów uczenia maszynowego opiera się w dużej mierze na matematyce. Poziom matematyki, który musisz znać, to prawdopodobnie poziom początkujący. Ważne jest, abyś był w stanie przeczytać notację, której matematycy używają w swoich równaniach. Na przykład - jeśli jesteś w stanie przeczytać notację i zrozumieć, co to znaczy, jesteś gotowy do nauki uczenia maszynowego. Jeśli nie, być może będziesz musiał odświeżyć swoją wiedzę matematyczną.
$$ f_ {AN} (net- \ theta) = \ begin {cases} \ gamma & if \: net- \ theta \ geq \ epsilon \\ net- \ theta & if - \ epsilon <net- \ theta <\ epsilon \\ - \ gamma & if \: net- \ theta \ leq- \ epsilon \ end {sprawy} $$
$$ \ Displaystyle \\\ max \ limity _ {\ alfa} \ rozpocząć {bmatrix} \ Displaystyle \ sum \ limity_ {i = 1} ^ m \ alpha- \ Frac {1} {2} \ Displaystyle \ sum \ limity_ { i, j = 1} ^ m label ^ \ left (\ begin {array} {c} i \\ \ end {array} \ right) \ cdot \: label ^ \ left (\ begin {tablica} {c} j \\ \ end {array} \ right) \ cdot \: a_ {i} \ cdot \: a_ {j} \ langle x ^ \ left (\ begin {array} {c} i \\ \ end {array} \ po prawej), x ^ \ left (\ begin {array} {c} j \\ \ end {array} \ right) \ rangle \ end {bmatrix} $$
$$ f_ {AN} (net- \ theta) = \ left (\ frac {e ^ {\ lambda (net- \ theta)} - e ^ {- \ lambda (net- \ theta)}} {e ^ { \ lambda (net- \ theta)} + e ^ {- \ lambda (net- \ theta)}} \ right) \; $$
Teoria prawdopodobieństwa
Oto przykład, aby sprawdzić swoją obecną wiedzę na temat teorii prawdopodobieństwa: Klasyfikacja za pomocą prawdopodobieństw warunkowych.
$$ p (c_ {i} | x, y) \; = \ frac {p (x, y | c_ {i}) \; p (c_ {i}) \;} {p (x, y) \ ;} $$
Dzięki tym definicjom możemy zdefiniować regułę klasyfikacji Bayesa -
- Jeśli P (c1 | x, y)> P (c2 | x, y), klasa to c1.
- Jeśli P (c1 | x, y) <P (c2 | x, y), klasa to c2.
Problem optymalizacji
Oto funkcja optymalizacji
$$ \ Displaystyle \\\ max \ limity _ {\ alfa} \ rozpocząć {bmatrix} \ Displaystyle \ sum \ limity_ {i = 1} ^ m \ alpha- \ Frac {1} {2} \ Displaystyle \ sum \ limity_ { i, j = 1} ^ m label ^ \ left (\ begin {array} {c} i \\ \ end {array} \ right) \ cdot \: label ^ \ left (\ begin {tablica} {c} j \\ \ end {array} \ right) \ cdot \: a_ {i} \ cdot \: a_ {j} \ langle x ^ \ left (\ begin {array} {c} i \\ \ end {array} \ po prawej), x ^ \ left (\ begin {array} {c} j \\ \ end {array} \ right) \ rangle \ end {bmatrix} $$
Z zastrzeżeniem następujących ograniczeń -
$$ \ alpha \ geq0 i \: \ displaystyle \ sum \ limit_ {i-1} ^ m \ alpha_ {i} \ cdot \: etykieta ^ \ lewo (\ początek {tablica} {c} ja \\ \ koniec {tablica} \ right) = 0 $$
Jeśli potrafisz przeczytać i zrozumieć powyższe, wszystko jest gotowe.
Wyobrażanie sobie
W wielu przypadkach będziesz musiał zrozumieć różne typy wykresów wizualizacyjnych, aby zrozumieć dystrybucję danych i zinterpretować wyniki algorytmu.
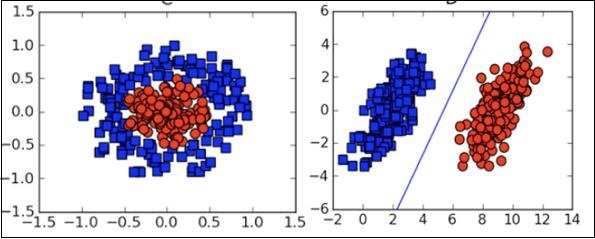
Oprócz powyższych teoretycznych aspektów uczenia maszynowego, do kodowania tych algorytmów potrzebne są dobre umiejętności programistyczne.
Więc co trzeba zrobić, aby wdrożyć ML? Przyjrzyjmy się temu w następnym rozdziale.
Aby opracować aplikacje ML, będziesz musiał zdecydować o platformie, IDE i języku programowania. Dostępnych jest kilka opcji. Większość z nich z łatwością spełniłaby Twoje wymagania, ponieważ wszystkie zapewniają implementację omówionych do tej pory algorytmów AI.
Jeśli samodzielnie opracowujesz algorytm ML, musisz dokładnie zrozumieć następujące aspekty:
Język, który wybierzesz - jest to zasadniczo Twoja znajomość jednego z języków obsługiwanych w rozwoju ML.
IDE, którego używasz - zależy to od twojej znajomości istniejących IDE i twojego poziomu komfortu.
Development platform- Dostępnych jest kilka platform do programowania i wdrażania. Większość z nich jest bezpłatna. W niektórych przypadkach może być konieczne poniesienie opłaty licencyjnej poza określoną ilość użytkowania. Oto krótka lista języków, IDE i platform do wyboru.
Wybór języka
Oto lista języków obsługujących rozwój ML -
- Python
- R
- Matlab
- Octave
- Julia
- C++
- C
Ta lista nie jest zasadniczo wyczerpująca; jednak obejmuje wiele popularnych języków używanych w rozwoju systemów uczących się. W zależności od poziomu komfortu wybierz język do rozwoju, opracuj modele i przetestuj.
IDE
Oto lista IDE, które obsługują rozwój ML -
- R Studio
- Pycharm
- Notatnik iPython / Jupyter
- Julia
- Spyder
- Anaconda
- Rodeo
- Google –Colab
Powyższa lista nie jest zasadniczo wyczerpująca. Każdy ma swoje zalety i wady. Czytelnik jest zachęcany do wypróbowania tych różnych IDE przed zawężeniem do jednego.
Platformy
Oto lista platform, na których można wdrażać aplikacje ML -
- IBM
- Microsoft Azure
- Google Cloud
- Amazon
- Mlflow
Po raz kolejny ta lista nie jest wyczerpująca. Zachęcamy czytelnika do zarejestrowania się w wyżej wymienionych usługach i samodzielnego wypróbowania ich.
Ten samouczek wprowadził Cię w uczenie maszynowe. Teraz wiesz, że uczenie maszynowe to technika uczenia maszyn do wykonywania czynności, które może wykonywać ludzki mózg, chociaż nieco szybciej i lepiej niż przeciętny człowiek. Dzisiaj widzieliśmy, że maszyny mogą pokonać ludzkich mistrzów w grach takich jak Szachy, AlphaGO, które są uważane za bardzo złożone. Widzieliście, że maszyny można wyszkolić do wykonywania czynności ludzkich w kilku obszarach i mogą pomóc ludziom żyć lepiej.
Uczenie maszynowe może być nadzorowane lub nienadzorowane. Jeśli masz mniejszą ilość danych i wyraźnie oznaczone dane do szkolenia, wybierz nadzorowaną naukę. Uczenie się nienadzorowane generalnie zapewnia lepszą wydajność i wyniki w przypadku dużych zbiorów danych. Jeśli masz duży, łatwo dostępny zestaw danych, skorzystaj z technik uczenia głębokiego. Nauczyłeś się również uczenia ze wzmocnieniem i uczenia się z głębokim wzmocnieniem. Wiesz już, czym są sieci neuronowe, ich zastosowania i ograniczenia.
Wreszcie, jeśli chodzi o tworzenie własnych modeli uczenia maszynowego, przyjrzałeś się wyborom różnych języków programowania, IDE i platform. Następną rzeczą, którą musisz zrobić, to zacząć uczyć się i ćwiczyć każdą technikę uczenia maszynowego. Temat jest rozległy, to znaczy, że jest szeroki, ale biorąc pod uwagę głębię, każdego tematu można się nauczyć w kilka godzin. Każdy temat jest od siebie niezależny. Musisz brać pod uwagę jeden temat na raz, nauczyć się go, przećwiczyć i zaimplementować algorytm (y) w nim używając wybranego języka. To najlepszy sposób na rozpoczęcie nauki uczenia maszynowego. Ćwicząc jeden temat na raz, bardzo szybko uzyskasz szerokość, która jest ostatecznie wymagana od eksperta ds. Uczenia maszynowego.
Powodzenia!