Uczenie maszynowe - nadzorowane
Uczenie nadzorowane jest jednym z ważnych modeli uczenia się stosowanych w maszynach szkoleniowych. W tym rozdziale szczegółowo omówiono to samo.
Algorytmy uczenia nadzorowanego
Dostępnych jest kilka algorytmów uczenia nadzorowanego. Poniżej przedstawiono niektóre z powszechnie stosowanych algorytmów uczenia nadzorowanego:
- k-Najbliżsi sąsiedzi
- Drzewa decyzyjne
- Naiwny Bayes
- Regresja logistyczna
- Wsparcie maszyn wektorowych
Idąc dalej w tym rozdziale, omówmy szczegółowo każdy z algorytmów.
k-Najbliżsi sąsiedzi
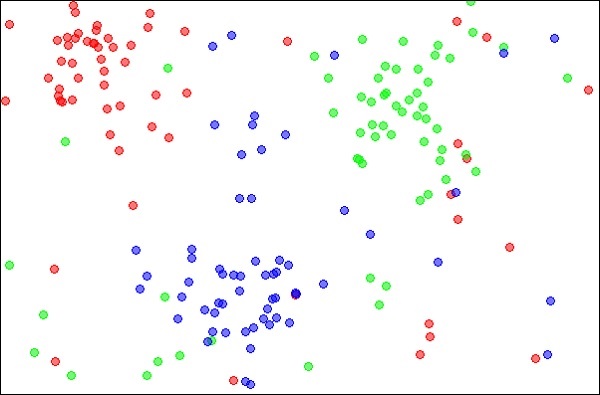
K-Nearest Neighbors, zwane po prostu kNN, to technika statystyczna, której można używać do rozwiązywania problemów związanych z klasyfikacją i regresją. Omówmy przypadek sklasyfikowania nieznanego obiektu za pomocą kNN. Rozważ rozmieszczenie obiektów, jak pokazano na poniższym obrazku -
Źródło:
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
Diagram przedstawia trzy rodzaje obiektów, zaznaczone kolorem czerwonym, niebieskim i zielonym. Po uruchomieniu klasyfikatora kNN na powyższym zbiorze danych granice dla każdego typu obiektu zostaną zaznaczone, jak pokazano poniżej -

Źródło:
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
Teraz rozważ nowy nieznany obiekt, który chcesz sklasyfikować jako czerwony, zielony lub niebieski. Przedstawiono to na poniższym rysunku.
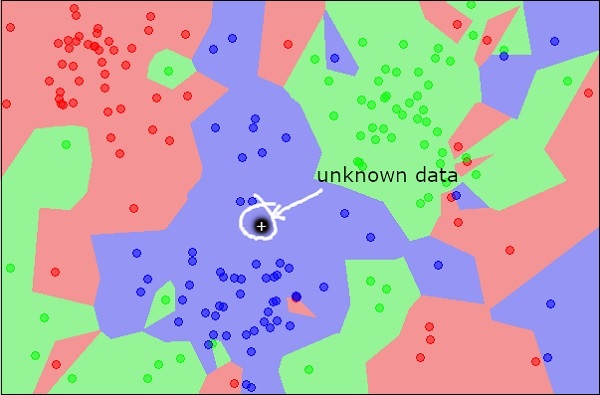
Jak widać naocznie, nieznany punkt danych należy do klasy niebieskich obiektów. Matematycznie można to wywnioskować, mierząc odległość tego nieznanego punktu z każdym innym punktem w zestawie danych. Kiedy to zrobisz, będziesz wiedział, że większość jego sąsiadów ma kolor niebieski. Średnia odległość do obiektów czerwonych i zielonych byłaby zdecydowanie większa niż średnia odległość do obiektów niebieskich. Zatem ten nieznany obiekt można zaklasyfikować jako należący do klasy niebieskiej.
Algorytm kNN może być również używany w przypadku problemów z regresją. Algorytm kNN jest dostępny jako gotowy do użycia w większości bibliotek ML.
Drzewa decyzyjne
Poniżej przedstawiono proste drzewo decyzyjne w formacie schematu blokowego -
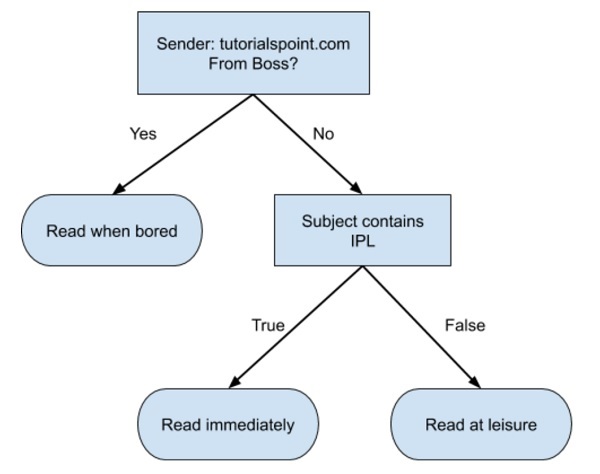
Napisałbyś kod klasyfikujący dane wejściowe na podstawie tego schematu blokowego. Schemat blokowy jest oczywisty i trywialny. W tym scenariuszu próbujesz sklasyfikować przychodzącą wiadomość e-mail, aby zdecydować, kiedy ją przeczytać.
W rzeczywistości drzewa decyzyjne mogą być duże i złożone. Dostępnych jest kilka algorytmów tworzenia i przemierzania tych drzew. Jako entuzjasta uczenia maszynowego musisz zrozumieć i opanować te techniki tworzenia i przechodzenia przez drzewa decyzyjne.
Naiwny Bayes
Naiwny Bayes służy do tworzenia klasyfikatorów. Załóżmy, że chcesz posortować (sklasyfikować) różne rodzaje owoców z koszyka z owocami. Możesz używać takich cech jak kolor, rozmiar i kształt owocu. Na przykład każdy owoc, który jest czerwony, ma okrągły kształt i ma około 10 cm średnicy, może być uważany za jabłko. Tak więc, aby wytrenować model, należy użyć tych funkcji i przetestować prawdopodobieństwo, że dana funkcja pasuje do pożądanych ograniczeń. Następnie łączy się prawdopodobieństwa różnych cech, aby otrzymać prawdopodobieństwo, że dany owoc to jabłko. Naiwny Bayes generalnie wymaga niewielkiej liczby danych treningowych do klasyfikacji.
Regresja logistyczna
Spójrz na poniższy diagram. Pokazuje rozkład punktów danych w płaszczyźnie XY.

Na diagramie możemy wizualnie sprawdzić oddzielenie czerwonych kropek od zielonych kropek. Możesz narysować linię graniczną, aby oddzielić te kropki. Teraz, aby sklasyfikować nowy punkt danych, wystarczy określić, po której stronie linii leży punkt.
Wsparcie maszyn wektorowych
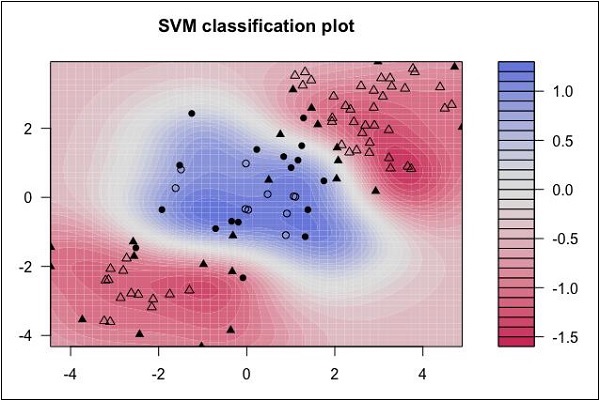
Spójrz na następujący rozkład danych. Tutaj tych trzech klas danych nie można oddzielić liniowo. Krzywe graniczne są nieliniowe. W takim przypadku znalezienie równania krzywej staje się złożonym zadaniem.
Źródło: http://uc-r.github.io/svm
Maszyny wektorów nośnych (SVM) są przydatne w określaniu granic separacji w takich sytuacjach.