Análise de Big Data - Ciclo de Vida dos Dados
Ciclo de vida tradicional de mineração de dados
Para fornecer uma estrutura para organizar o trabalho necessário para uma organização e fornecer percepções claras de Big Data, é útil pensar nisso como um ciclo com diferentes estágios. Não é de forma alguma linear, o que significa que todos os estágios estão relacionados entre si. Este ciclo tem semelhanças superficiais com o ciclo de mineração de dados mais tradicional, conforme descrito emCRISP methodology.
Metodologia CRISP-DM
o CRISP-DM methodologyque significa Cross Industry Standard Process for Data Mining, é um ciclo que descreve as abordagens comumente usadas que os especialistas em mineração de dados usam para resolver problemas na mineração de dados de BI tradicional. Ele ainda está sendo usado em equipes tradicionais de mineração de dados de BI.
Dê uma olhada na ilustração a seguir. Mostra os principais estágios do ciclo, conforme descrito pela metodologia CRISP-DM e como eles estão inter-relacionados.
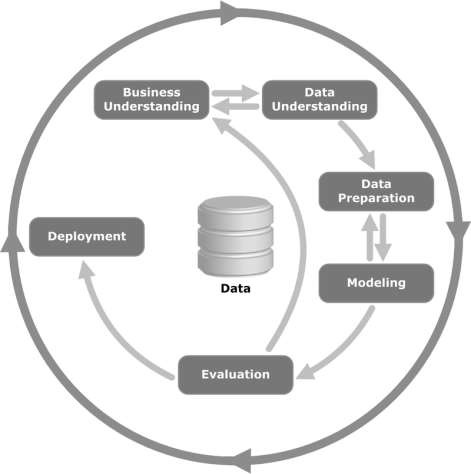
O CRISP-DM foi concebido em 1996 e no ano seguinte iniciou-se como um projeto da União Europeia no âmbito da iniciativa de financiamento ESPRIT. O projeto foi liderado por cinco empresas: SPSS, Teradata, Daimler AG, NCR Corporation e OHRA (uma seguradora). O projeto foi finalmente incorporado ao SPSS. A metodologia é extremamente detalhada e orientada em como um projeto de mineração de dados deve ser especificado.
Vamos agora aprender um pouco mais sobre cada uma das etapas envolvidas no ciclo de vida do CRISP-DM -
Business Understanding- Esta fase inicial se concentra em compreender os objetivos e requisitos do projeto de uma perspectiva de negócios e, em seguida, converter esse conhecimento em uma definição de problema de mineração de dados. Um plano preliminar é elaborado para atingir os objetivos. Um modelo de decisão, especialmente um construído usando o modelo de decisão e padrão de notação pode ser usado.
Data Understanding - A fase de compreensão de dados começa com uma coleta de dados inicial e prossegue com atividades a fim de se familiarizar com os dados, para identificar problemas de qualidade de dados, para descobrir os primeiros insights sobre os dados ou para detectar subconjuntos interessantes para formar hipóteses para informações ocultas.
Data Preparation- A fase de preparação de dados cobre todas as atividades para construir o conjunto de dados final (dados que serão alimentados na (s) ferramenta (s) de modelagem) a partir dos dados brutos iniciais. As tarefas de preparação de dados provavelmente serão realizadas várias vezes, e não em qualquer ordem prescrita. As tarefas incluem tabela, registro e seleção de atributos, bem como transformação e limpeza de dados para ferramentas de modelagem.
Modeling- Nesta fase, várias técnicas de modelagem são selecionadas e aplicadas e seus parâmetros são calibrados para valores ótimos. Normalmente, existem várias técnicas para o mesmo tipo de problema de mineração de dados. Algumas técnicas possuem requisitos específicos na forma dos dados. Portanto, muitas vezes é necessário voltar para a fase de preparação de dados.
Evaluation- Nesta fase do projeto, você construiu um modelo (ou modelos) que parece ter alta qualidade, do ponto de vista da análise de dados. Antes de prosseguir para a implantação final do modelo, é importante avaliá-lo completamente e revisar as etapas executadas para construir o modelo, para ter certeza de que ele atende adequadamente os objetivos de negócios.
Um objetivo principal é determinar se há alguma questão comercial importante que não foi suficientemente considerada. Ao final desta fase, deve-se tomar uma decisão sobre o uso dos resultados da mineração de dados.
Deployment- A criação do modelo geralmente não é o fim do projeto. Mesmo que o objetivo do modelo seja aumentar o conhecimento dos dados, o conhecimento adquirido precisará ser organizado e apresentado de uma forma que seja útil para o cliente.
Dependendo dos requisitos, a fase de implantação pode ser tão simples quanto gerar um relatório ou tão complexa quanto implementar uma pontuação de dados repetível (por exemplo, alocação de segmento) ou processo de mineração de dados.
Em muitos casos, será o cliente, não o analista de dados, quem executará as etapas de implantação. Mesmo que o analista implante o modelo, é importante que o cliente entenda de antemão as ações que deverão ser realizadas para que realmente faça uso dos modelos criados.
Metodologia SEMMA
SEMMA é outra metodologia desenvolvida pelo SAS para modelagem de mineração de dados. Ele significaSamplo, Explore, Modificar, Model, e Asses. Aqui está uma breve descrição de seus estágios -
Sample- O processo começa com a amostragem de dados, por exemplo, selecionando o conjunto de dados para modelagem. O conjunto de dados deve ser grande o suficiente para conter informações suficientes para recuperação, mas pequeno o suficiente para ser usado com eficiência. Esta fase também lida com o particionamento de dados.
Explore - Esta fase abrange a compreensão dos dados, descobrindo relações antecipadas e imprevistas entre as variáveis, e também anormalidades, com o auxílio da visualização dos dados.
Modify - A fase de modificação contém métodos para selecionar, criar e transformar variáveis na preparação para a modelagem de dados.
Model - Na fase de Modelo, o foco está na aplicação de várias técnicas de modelagem (mineração de dados) nas variáveis preparadas para criar modelos que possivelmente forneçam o resultado desejado.
Assess - A avaliação dos resultados da modelagem mostra a confiabilidade e utilidade dos modelos criados.
A principal diferença entre CRISM-DM e SEMMA é que SEMMA foca no aspecto de modelagem, enquanto CRISP-DM dá mais importância às etapas do ciclo anteriores à modelagem, como compreensão do problema de negócio a ser resolvido, compreensão e pré-processamento dos dados a serem usado como entrada, por exemplo, algoritmos de aprendizado de máquina.
Ciclo de vida de Big Data
No contexto de big data de hoje, as abordagens anteriores são incompletas ou subótimas. Por exemplo, a metodologia SEMMA desconsidera completamente a coleta de dados e o pré-processamento de diferentes fontes de dados. Esses estágios normalmente constituem a maior parte do trabalho em um projeto de Big Data de sucesso.
Um ciclo de análise de big data pode ser descrito pelo seguinte estágio -
- Definição de problema de negócios
- Research
- Avaliação de Recursos Humanos
- Aquisição de dados
- Manipulação de dados
- Armazenamento de dados
- Análise exploratória de dados
- Preparação de dados para modelagem e avaliação
- Modeling
- Implementation
Nesta seção, lançaremos alguma luz sobre cada um desses estágios do ciclo de vida do big data.
Definição de problema de negócios
Este é um ponto comum no ciclo de vida tradicional de BI e análise de big data. Normalmente, é um estágio não trivial de um projeto de big data definir o problema e avaliar corretamente quanto ganho potencial ele pode ter para uma organização. Parece óbvio mencionar isso, mas é preciso avaliar quais são os ganhos e custos esperados do projeto.
Pesquisa
Analise o que outras empresas fizeram na mesma situação. Trata-se de procurar soluções que sejam razoáveis para a sua empresa, embora implique a adaptação de outras soluções aos recursos e requisitos que a sua empresa possui. Nesta etapa, deve ser definida uma metodologia para as etapas futuras.
Avaliação de Recursos Humanos
Uma vez que o problema esteja definido, é razoável continuar analisando se a equipe atual é capaz de concluir o projeto com sucesso. As equipes tradicionais de BI podem não ser capazes de entregar uma solução ideal para todas as etapas, portanto, deve-se considerar antes de iniciar o projeto se houver necessidade de terceirizar uma parte do projeto ou contratar mais pessoas.
Aquisição de dados
Esta seção é fundamental em um ciclo de vida de big data; ele define quais tipos de perfis seriam necessários para entregar o produto de dados resultante. A coleta de dados é uma etapa não trivial do processo; normalmente envolve a coleta de dados não estruturados de fontes diferentes. Para dar um exemplo, pode envolver escrever um rastreador para recuperar comentários de um site. Isso envolve lidar com texto, talvez em diferentes idiomas, normalmente exigindo uma quantidade significativa de tempo para ser concluído.
Manipulação de dados
Assim que os dados são recuperados, por exemplo, da web, eles precisam ser armazenados em um formato fácil de usar. Para continuar com os exemplos de revisões, vamos supor que os dados sejam recuperados de sites diferentes, onde cada um tem uma exibição diferente dos dados.
Suponha que uma fonte de dados forneça comentários em termos de classificação em estrelas, portanto, é possível ler isso como um mapeamento para a variável de resposta y ∈ {1, 2, 3, 4, 5}. Outra fonte de dados fornece avaliações usando o sistema de duas setas, uma para votação positiva e outra para votação negativa. Isso implicaria em uma variável de resposta do formulárioy ∈ {positive, negative}.
Para combinar as duas fontes de dados, uma decisão deve ser tomada a fim de tornar essas duas representações de resposta equivalentes. Isso pode envolver a conversão da primeira representação de resposta da fonte de dados para a segunda forma, considerando uma estrela como negativa e cinco estrelas como positiva. Esse processo geralmente requer uma grande alocação de tempo para ser entregue com boa qualidade.
Armazenamento de dados
Depois que os dados são processados, às vezes eles precisam ser armazenados em um banco de dados. As tecnologias de big data oferecem muitas alternativas em relação a esse ponto. A alternativa mais comum é usar o Hadoop File System para armazenamento que fornece aos usuários uma versão limitada de SQL, conhecida como HIVE Query Language. Isso permite que a maioria das tarefas analíticas sejam feitas de maneiras semelhantes às que seriam feitas em data warehouses tradicionais de BI, da perspectiva do usuário. Outras opções de armazenamento a serem consideradas são MongoDB, Redis e SPARK.
Esta etapa do ciclo está relacionada ao conhecimento dos recursos humanos em termos de suas habilidades para implementar diferentes arquiteturas. Versões modificadas de data warehouses tradicionais ainda estão sendo usadas em aplicativos de grande escala. Por exemplo, teradata e IBM oferecem bancos de dados SQL que podem lidar com terabytes de dados; soluções de código aberto como postgreSQL e MySQL ainda estão sendo usadas para aplicativos de grande escala.
Embora haja diferenças em como os diferentes armazenamentos funcionam em segundo plano, do lado do cliente, a maioria das soluções fornece uma API SQL. Conseqüentemente, ter um bom conhecimento de SQL ainda é uma habilidade fundamental para a análise de big data.
Essa etapa a priori parece ser o tópico mais importante, na prática isso não é verdade. Não é nem mesmo uma etapa essencial. É possível implementar uma solução de big data que estaria trabalhando com dados em tempo real, portanto, neste caso, só precisamos coletar os dados para desenvolver o modelo e depois implementá-lo em tempo real. Portanto, não haveria necessidade de armazenar formalmente os dados.
Análise exploratória de dados
Uma vez que os dados tenham sido limpos e armazenados de forma que as percepções possam ser recuperadas deles, a fase de exploração de dados é obrigatória. O objetivo desta etapa é entender os dados, isso normalmente é feito com técnicas estatísticas e também plotando os dados. Este é um bom estágio para avaliar se a definição do problema faz sentido ou é viável.
Preparação de dados para modelagem e avaliação
Este estágio envolve a remodelagem dos dados limpos recuperados anteriormente e o uso de pré-processamento estatístico para imputação de valores ausentes, detecção de outlier, normalização, extração de recursos e seleção de recursos.
Modelagem
O estágio anterior deve ter produzido vários conjuntos de dados para treinamento e teste, por exemplo, um modelo preditivo. Este estágio envolve experimentar diferentes modelos e buscar a solução do problema de negócios em questão. Na prática, normalmente é desejável que o modelo forneça alguns insights sobre o negócio. Finalmente, o melhor modelo ou combinação de modelos é selecionado avaliando seu desempenho em um conjunto de dados deixado de fora.
Implementação
Nesta etapa, o produto de dados desenvolvido é implementado no pipeline de dados da empresa. Isso envolve a configuração de um esquema de validação enquanto o produto de dados está funcionando, a fim de monitorar seu desempenho. Por exemplo, no caso de implementação de um modelo preditivo, esse estágio envolveria a aplicação do modelo a novos dados e, uma vez que a resposta estivesse disponível, avalie o modelo.