Big Data Analytics - Guia rápido
O volume de dados com que se deve lidar explodiu a níveis inimagináveis na última década e, ao mesmo tempo, o preço do armazenamento de dados foi sistematicamente reduzido. Empresas privadas e instituições de pesquisa capturam terabytes de dados sobre as interações de seus usuários, negócios, mídia social e também sensores de dispositivos como telefones celulares e automóveis. O desafio desta era é dar sentido a esse mar de dados. Aqui é ondebig data analytics entra em cena.
Big Data Analytics envolve em grande parte a coleta de dados de diferentes fontes, misturá-los de forma que fiquem disponíveis para serem consumidos por analistas e, finalmente, fornecer produtos de dados úteis para os negócios da organização.

O processo de conversão de grandes quantidades de dados brutos não estruturados, recuperados de diferentes fontes em um produto de dados útil para organizações, forma o núcleo do Big Data Analytics.
Ciclo de vida tradicional de mineração de dados
Para fornecer uma estrutura para organizar o trabalho necessário para uma organização e fornecer percepções claras de Big Data, é útil pensar nisso como um ciclo com diferentes estágios. Não é de forma alguma linear, o que significa que todos os estágios estão relacionados entre si. Este ciclo tem semelhanças superficiais com o ciclo de mineração de dados mais tradicional, conforme descrito emCRISP methodology.
Metodologia CRISP-DM
o CRISP-DM methodologyque significa Cross Industry Standard Process for Data Mining, é um ciclo que descreve abordagens comumente usadas que os especialistas em mineração de dados usam para resolver problemas na mineração de dados de BI tradicional. Ele ainda está sendo usado em equipes tradicionais de mineração de dados de BI.
Dê uma olhada na ilustração a seguir. Mostra os principais estágios do ciclo, conforme descrito pela metodologia CRISP-DM e como eles estão inter-relacionados.
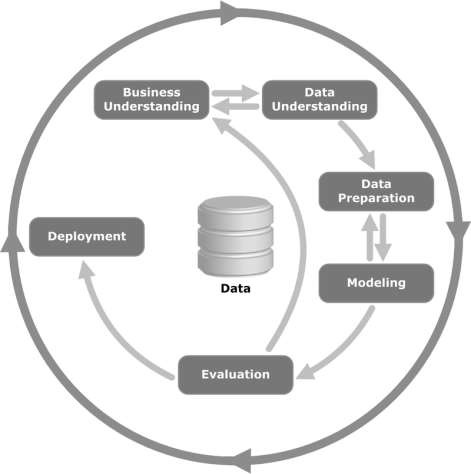
O CRISP-DM foi concebido em 1996 e no ano seguinte iniciou-se como um projeto da União Europeia no âmbito da iniciativa de financiamento ESPRIT. O projeto foi liderado por cinco empresas: SPSS, Teradata, Daimler AG, NCR Corporation e OHRA (uma seguradora). O projeto foi finalmente incorporado ao SPSS. A metodologia é extremamente detalhada e orientada em como um projeto de mineração de dados deve ser especificado.
Vamos agora aprender um pouco mais sobre cada um dos estágios envolvidos no ciclo de vida CRISP-DM -
Business Understanding- Esta fase inicial concentra-se em compreender os objetivos e requisitos do projeto de uma perspectiva de negócios e, em seguida, converter esse conhecimento em uma definição de problema de mineração de dados. Um plano preliminar é elaborado para atingir os objetivos. Um modelo de decisão, especialmente aquele construído usando o padrão de Modelo de Decisão e Notação, pode ser usado.
Data Understanding - A fase de compreensão de dados começa com uma coleta de dados inicial e prossegue com atividades a fim de se familiarizar com os dados, para identificar problemas de qualidade de dados, para descobrir os primeiros insights sobre os dados ou para detectar subconjuntos interessantes para formar hipóteses para informações ocultas.
Data Preparation- A fase de preparação de dados cobre todas as atividades para construir o conjunto de dados final (dados que serão alimentados na (s) ferramenta (s) de modelagem) a partir dos dados brutos iniciais. As tarefas de preparação de dados provavelmente serão realizadas várias vezes, e não em qualquer ordem prescrita. As tarefas incluem tabela, registro e seleção de atributos, bem como transformação e limpeza de dados para ferramentas de modelagem.
Modeling- Nesta fase, várias técnicas de modelagem são selecionadas e aplicadas e seus parâmetros são calibrados para valores ótimos. Normalmente, existem várias técnicas para o mesmo tipo de problema de mineração de dados. Algumas técnicas possuem requisitos específicos na forma dos dados. Portanto, muitas vezes é necessário voltar à fase de preparação de dados.
Evaluation- Nesta fase do projeto, você construiu um modelo (ou modelos) que parece ter alta qualidade, do ponto de vista da análise de dados. Antes de prosseguir para a implantação final do modelo, é importante avaliá-lo completamente e revisar as etapas executadas para construí-lo, para ter certeza de que ele atende adequadamente os objetivos de negócios.
Um objetivo principal é determinar se há alguma questão comercial importante que não foi suficientemente considerada. No final desta fase, uma decisão sobre o uso dos resultados da mineração de dados deve ser tomada.
Deployment- A criação do modelo geralmente não é o fim do projeto. Mesmo que o objetivo do modelo seja aumentar o conhecimento dos dados, o conhecimento adquirido precisará ser organizado e apresentado de uma forma que seja útil para o cliente.
Dependendo dos requisitos, a fase de implantação pode ser tão simples quanto gerar um relatório ou tão complexa quanto implementar uma pontuação de dados repetível (por exemplo, alocação de segmento) ou processo de mineração de dados.
Em muitos casos, será o cliente, não o analista de dados, quem executará as etapas de implantação. Mesmo que o analista implante o modelo, é importante que o cliente entenda de antemão as ações que deverão ser realizadas para que realmente faça uso dos modelos criados.
Metodologia SEMMA
SEMMA é outra metodologia desenvolvida pelo SAS para modelagem de mineração de dados. Ele significaSamplo, Explore, Modificar, Model, e Asses. Aqui está uma breve descrição de seus estágios -
Sample- O processo começa com a amostragem de dados, por exemplo, selecionando o conjunto de dados para modelagem. O conjunto de dados deve ser grande o suficiente para conter informações suficientes para recuperar, mas pequeno o suficiente para ser usado com eficiência. Esta fase também lida com o particionamento de dados.
Explore - Esta fase abrange a compreensão dos dados, descobrindo relações antecipadas e imprevistas entre as variáveis, e também anormalidades, com o auxílio da visualização dos dados.
Modify - A fase de modificação contém métodos para selecionar, criar e transformar variáveis em preparação para a modelagem de dados.
Model - Na fase de Modelo, o foco está na aplicação de várias técnicas de modelagem (mineração de dados) nas variáveis preparadas, a fim de criar modelos que possam fornecer o resultado desejado.
Assess - A avaliação dos resultados da modelagem mostra a confiabilidade e utilidade dos modelos criados.
A principal diferença entre CRISM-DM e SEMMA é que SEMMA foca no aspecto de modelagem, enquanto CRISP-DM dá mais importância às etapas do ciclo anteriores à modelagem, como entender o problema de negócio a ser resolvido, entender e pré-processar os dados a serem usado como entrada, por exemplo, algoritmos de aprendizado de máquina.
Ciclo de vida de Big Data
No contexto de big data de hoje, as abordagens anteriores são incompletas ou subótimas. Por exemplo, a metodologia SEMMA desconsidera completamente a coleta de dados e o pré-processamento de diferentes fontes de dados. Esses estágios normalmente constituem a maior parte do trabalho em um projeto de Big Data de sucesso.
Um ciclo de análise de big data pode ser descrito pelo seguinte estágio -
- Definição de problema de negócios
- Research
- Avaliação de Recursos Humanos
- Aquisição de dados
- Manipulação de dados
- Armazenamento de dados
- Análise exploratória de dados
- Preparação de dados para modelagem e avaliação
- Modeling
- Implementation
Nesta seção, lançaremos alguma luz sobre cada um desses estágios do ciclo de vida de big data.
Definição de problema de negócios
Este é um ponto comum no ciclo de vida tradicional de BI e analítica de big data. Normalmente, é um estágio não trivial de um projeto de big data definir o problema e avaliar corretamente quanto ganho potencial ele pode ter para uma organização. Parece óbvio mencionar isso, mas é preciso avaliar quais são os ganhos e custos esperados do projeto.
Pesquisa
Analise o que outras empresas fizeram na mesma situação. Trata-se de procurar soluções que sejam razoáveis para a sua empresa, embora implique a adaptação de outras soluções aos recursos e requisitos que a sua empresa possui. Nesta etapa, deve ser definida uma metodologia para as etapas futuras.
Avaliação de Recursos Humanos
Uma vez que o problema esteja definido, é razoável continuar analisando se a equipe atual é capaz de concluir o projeto com sucesso. As equipes tradicionais de BI podem não ser capazes de entregar uma solução ideal para todas as etapas, portanto, deve-se considerar antes de iniciar o projeto se houver necessidade de terceirizar uma parte do projeto ou contratar mais pessoas.
Aquisição de dados
Esta seção é fundamental em um ciclo de vida de big data; ele define quais tipos de perfis seriam necessários para entregar o produto de dados resultante. A coleta de dados é uma etapa não trivial do processo; normalmente envolve a coleta de dados não estruturados de fontes diferentes. Para dar um exemplo, poderia envolver a criação de um rastreador para recuperar comentários de um site. Isso envolve lidar com texto, talvez em diferentes idiomas, normalmente exigindo uma quantidade significativa de tempo para ser concluído.
Manipulação de dados
Assim que os dados são recuperados, por exemplo, da web, eles precisam ser armazenados em um formato fácil de usar. Para continuar com os exemplos de revisões, vamos supor que os dados sejam recuperados de sites diferentes, onde cada um tem uma exibição diferente dos dados.
Suponha que uma fonte de dados forneça avaliações em termos de classificação em estrelas, portanto, é possível ler isso como um mapeamento para a variável de resposta y ∈ {1, 2, 3, 4, 5}. Outra fonte de dados fornece avaliações usando o sistema de duas setas, uma para votação positiva e outra para votação negativa. Isso implicaria em uma variável de resposta do formulárioy ∈ {positive, negative}.
Para combinar as duas fontes de dados, uma decisão deve ser tomada para tornar essas duas representações de resposta equivalentes. Isso pode envolver a conversão da primeira representação de resposta da fonte de dados para a segunda forma, considerando uma estrela como negativa e cinco estrelas como positiva. Esse processo geralmente requer uma grande alocação de tempo para ser entregue com boa qualidade.
Armazenamento de dados
Uma vez que os dados são processados, às vezes eles precisam ser armazenados em um banco de dados. As tecnologias de big data oferecem muitas alternativas em relação a esse ponto. A alternativa mais comum é usar o Hadoop File System para armazenamento que fornece aos usuários uma versão limitada de SQL, conhecida como HIVE Query Language. Isso permite que a maioria das tarefas analíticas sejam feitas de maneiras semelhantes às que seriam feitas em data warehouses tradicionais de BI, da perspectiva do usuário. Outras opções de armazenamento a serem consideradas são MongoDB, Redis e SPARK.
Esta etapa do ciclo está relacionada ao conhecimento dos recursos humanos em termos de suas habilidades para implementar diferentes arquiteturas. Versões modificadas de data warehouses tradicionais ainda estão sendo usadas em aplicativos de grande escala. Por exemplo, teradata e IBM oferecem bancos de dados SQL que podem lidar com terabytes de dados; soluções de código aberto como postgreSQL e MySQL ainda estão sendo usadas para aplicativos de grande escala.
Embora haja diferenças em como os diferentes armazenamentos funcionam em segundo plano, do lado do cliente, a maioria das soluções fornece uma API SQL. Conseqüentemente, ter um bom entendimento de SQL ainda é uma habilidade fundamental para a análise de big data.
Essa etapa a priori parece ser o tema mais importante, na prática isso não é verdade. Não é nem mesmo uma etapa essencial. É possível implementar uma solução de big data que estaria trabalhando com dados em tempo real, portanto, neste caso, só precisamos coletar dados para desenvolver o modelo e depois implementá-lo em tempo real. Portanto, não haveria necessidade de armazenar formalmente os dados.
Análise exploratória de dados
Uma vez que os dados tenham sido limpos e armazenados de forma que as percepções possam ser recuperadas deles, a fase de exploração de dados é obrigatória. O objetivo desta etapa é entender os dados, isso normalmente é feito com técnicas estatísticas e também plotando os dados. Este é um bom estágio para avaliar se a definição do problema faz sentido ou é viável.
Preparação de dados para modelagem e avaliação
Esse estágio envolve a remodelagem dos dados limpos recuperados anteriormente e o uso de pré-processamento estatístico para imputação de valores ausentes, detecção de outlier, normalização, extração de recursos e seleção de recursos.
Modelagem
O estágio anterior deve ter produzido vários conjuntos de dados para treinamento e teste, por exemplo, um modelo preditivo. Este estágio envolve experimentar diferentes modelos e buscar a solução do problema de negócios em questão. Na prática, normalmente é desejável que o modelo forneça alguns insights sobre o negócio. Finalmente, o melhor modelo ou combinação de modelos é selecionado avaliando seu desempenho em um conjunto de dados deixado de fora.
Implementação
Nesta etapa, o produto de dados desenvolvido é implementado no pipeline de dados da empresa. Isso envolve configurar um esquema de validação enquanto o produto de dados está funcionando, a fim de rastrear seu desempenho. Por exemplo, no caso de implementação de um modelo preditivo, esta etapa envolveria a aplicação do modelo a novos dados e, uma vez que a resposta estivesse disponível, avalie o modelo.
Em termos de metodologia, a análise de big data difere significativamente da abordagem estatística tradicional de design experimental. Analytics começa com dados. Normalmente modelamos os dados de forma a explicar uma resposta. Os objetivos desta abordagem são prever o comportamento da resposta ou compreender como as variáveis de entrada se relacionam com uma resposta. Normalmente em projetos experimentais estatísticos, um experimento é desenvolvido e os dados são recuperados como resultado. Isso permite gerar dados de uma forma que podem ser usados por um modelo estatístico, onde certas premissas são válidas, como independência, normalidade e randomização.
Na análise de big data, são apresentados os dados. Não podemos projetar um experimento que satisfaça nosso modelo estatístico favorito. Em aplicativos de análise em grande escala, uma grande quantidade de trabalho (normalmente 80% do esforço) é necessária apenas para limpar os dados, para que possa ser usada por um modelo de aprendizado de máquina.
Não temos uma metodologia única a seguir em aplicações reais de grande escala. Normalmente, uma vez que o problema de negócio é definido, uma etapa de pesquisa é necessária para projetar a metodologia a ser utilizada. No entanto, as diretrizes gerais são relevantes para serem mencionadas e se aplicam a quase todos os problemas.
Uma das tarefas mais importantes na análise de big data é statistical modeling, significando classificação supervisionada e não supervisionada ou problemas de regressão. Uma vez que os dados são limpos e pré-processados, disponíveis para modelagem, deve-se tomar cuidado ao avaliar diferentes modelos com métricas de perda razoáveis e, em seguida, uma vez que o modelo seja implementado, avaliações e resultados adicionais devem ser relatados. Uma armadilha comum na modelagem preditiva é apenas implementar o modelo e nunca medir seu desempenho.
Conforme mencionado no ciclo de vida de big data, os produtos de dados que resultam do desenvolvimento de um produto de big data são, na maioria dos casos, alguns dos seguintes -
Machine learning implementation - Pode ser um algoritmo de classificação, um modelo de regressão ou um modelo de segmentação.
Recommender system - O objetivo é desenvolver um sistema que recomende escolhas com base no comportamento do usuário. Netflix é o exemplo característico deste produto de dados, onde com base nas avaliações dos usuários, outros filmes são recomendados.
Dashboard- As empresas normalmente precisam de ferramentas para visualizar dados agregados. Um painel é um mecanismo gráfico para tornar esses dados acessíveis.
Ad-Hoc analysis - Normalmente as áreas de negócios têm dúvidas, hipóteses ou mitos que podem ser respondidos fazendo análises ad-hoc com dados.
Em grandes organizações, para desenvolver com sucesso um projeto de big data, é necessário ter uma gerência fazendo o backup do projeto. Normalmente, isso envolve encontrar uma maneira de mostrar as vantagens comerciais do projeto. Não temos uma solução única para o problema de encontrar patrocinadores para um projeto, mas algumas diretrizes são fornecidas abaixo -
Verifique quem são e onde são os patrocinadores de outros projetos semelhantes ao que lhe interessa.
Ter contatos pessoais em posições-chave de gerenciamento ajuda, portanto, qualquer contato pode ser acionado se o projeto for promissor.
Quem se beneficiaria com seu projeto? Quem seria seu cliente quando o projeto estiver em andamento?
Desenvolva uma proposta simples, clara e interessante e compartilhe-a com os principais participantes da sua organização.
A melhor maneira de encontrar patrocinadores para um projeto é entender o problema e qual seria o produto de dados resultante depois de implementado. Esse entendimento proporcionará uma vantagem para convencer a gerência da importância do projeto de big data.
Um analista de dados possui perfil orientado a relatórios, com experiência em extrair e analisar dados de data warehouses tradicionais usando SQL. Suas tarefas normalmente estão no armazenamento de dados ou na geração de relatórios de resultados gerais de negócios. O armazenamento de dados não é nada simples, é apenas diferente do que um cientista de dados faz.
Muitas organizações lutam muito para encontrar cientistas de dados competentes no mercado. No entanto, é uma boa ideia selecionar potenciais analistas de dados e ensinar-lhes as habilidades relevantes para se tornarem cientistas de dados. Esta não é uma tarefa trivial e normalmente envolveria a pessoa que faz um mestrado em uma área quantitativa, mas é definitivamente uma opção viável. As habilidades básicas que um analista de dados competente deve ter estão listadas abaixo -
- Compreensão de negócios
- Programação SQL
- Elaboração e implementação de relatórios
- Desenvolvimento de painel
A função de um cientista de dados normalmente está associada a tarefas como modelagem preditiva, desenvolvimento de algoritmos de segmentação, sistemas de recomendação, estruturas de teste A / B e, muitas vezes, trabalhar com dados não estruturados brutos.
A natureza do seu trabalho exige um conhecimento profundo de matemática, estatística aplicada e programação. Existem algumas habilidades comuns entre um analista de dados e um cientista de dados, por exemplo, a capacidade de consultar bancos de dados. Ambos analisam dados, mas a decisão de um cientista de dados pode ter um impacto maior em uma organização.
Aqui está um conjunto de habilidades que um cientista de dados normalmente precisa ter -
- Programação em um pacote estatístico como: R, Python, SAS, SPSS ou Julia
- Capaz de limpar, extrair e explorar dados de diferentes fontes
- Pesquisa, projeto e implementação de modelos estatísticos
- Conhecimento profundo de estatística, matemática e ciência da computação
Na análise de big data, as pessoas normalmente confundem a função de um cientista de dados com a de um arquiteto de dados. Na realidade, a diferença é bastante simples. Um arquiteto de dados define as ferramentas e a arquitetura em que os dados seriam armazenados, enquanto um cientista de dados usa essa arquitetura. Obviamente, um cientista de dados deve ser capaz de configurar novas ferramentas se necessário para projetos ad-hoc, mas a definição e o design da infraestrutura não devem fazer parte de sua tarefa.
Através deste tutorial, desenvolveremos um projeto. Cada capítulo subsequente neste tutorial trata de uma parte do projeto maior na seção de miniprojetos. Esta é considerada uma seção de tutorial aplicada que fornecerá exposição a um problema do mundo real. Nesse caso, começaríamos com a definição do problema do projeto.
Descrição do Projeto
O objetivo deste projeto seria desenvolver um modelo de aprendizado de máquina para prever o salário por hora de pessoas usando o texto do seu curriculum vitae (CV) como entrada.
Usando a estrutura definida acima, é simples definir o problema. Podemos definir X = {x 1 , x 2 ,…, x n } como os currículos dos usuários, onde cada característica pode ser, da forma mais simples possível, a quantidade de vezes que essa palavra aparece. Então a resposta é avaliada em reais, estamos tentando prever o salário por hora dos indivíduos em dólares.
Essas duas considerações são suficientes para concluir que o problema apresentado pode ser resolvido com um algoritmo de regressão supervisionado.
Definição de problema
Problem Definitioné provavelmente um dos estágios mais complexos e altamente negligenciados no pipeline de análise de big data. Para definir o problema que um produto de dados resolveria, a experiência é obrigatória. A maioria dos aspirantes a cientistas de dados tem pouca ou nenhuma experiência nesse estágio.
A maioria dos problemas de big data pode ser categorizada das seguintes maneiras -
- Classificação supervisionada
- Regressão supervisionada
- Aprendizagem não supervisionada
- Aprendendo a classificar
Vamos agora aprender mais sobre esses quatro conceitos.
Classificação Supervisionada
Dada uma matriz de características X = {x 1 , x 2 , ..., x n } desenvolvemos um modelo M para prever diferentes classes definidas como y = {c 1 , c 2 , ..., c n } . Por exemplo: Dados os dados transacionais de clientes em uma seguradora, é possível desenvolver um modelo que irá prever se um cliente se desligaria ou não. O último é um problema de classificação binária, onde existem duas classes ou variáveis de destino: churn e não churn.
Outros problemas envolvem prever mais de uma classe, poderíamos estar interessados em fazer o reconhecimento de dígitos, portanto, o vetor de resposta seria definido como: y = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9} , um modelo de última geração seria uma rede neural convolucional e a matriz de recursos seria definida como os pixels da imagem.
Regressão Supervisionada
Nesse caso, a definição do problema é bastante semelhante ao exemplo anterior; a diferença depende da resposta. Em um problema de regressão, a resposta y ∈ ℜ, isso significa que a resposta tem um valor real. Por exemplo, podemos desenvolver um modelo para prever o salário por hora de indivíduos com base no corpus de seu currículo.
Aprendizagem Não Supervisionada
A administração geralmente tem sede de novos insights. Os modelos de segmentação podem fornecer esse insight para que o departamento de marketing desenvolva produtos para diferentes segmentos. Uma boa abordagem para desenvolver um modelo de segmentação, em vez de pensar em algoritmos, é selecionar recursos que sejam relevantes para a segmentação desejada.
Por exemplo, em uma empresa de telecomunicações, é interessante segmentar os clientes pelo uso do celular. Isso envolveria desconsiderar recursos que nada têm a ver com o objetivo da segmentação e incluir apenas aqueles que têm. Nesse caso, isso seria selecionar recursos como o número de SMS usados em um mês, o número de minutos de entrada e saída, etc.
Aprendendo a classificar
Esse problema pode ser considerado um problema de regressão, mas tem características particulares e merece um tratamento separado. O problema envolve dada uma coleção de documentos que procuramos encontrar a ordenação mais relevante dada uma consulta. Para desenvolver um algoritmo de aprendizagem supervisionada, é necessário rotular o quão relevante é uma ordenação, dada uma consulta.
É relevante notar que, para desenvolver um algoritmo de aprendizagem supervisionada, é necessário rotular os dados de treinamento. Isso significa que, para treinar um modelo que irá, por exemplo, reconhecer dígitos de uma imagem, precisamos rotular uma quantidade significativa de exemplos à mão. Existem serviços da web que podem acelerar esse processo e são comumente usados para essa tarefa, como o turk mecânico amazon. Está provado que algoritmos de aprendizagem melhoram seu desempenho quando fornecidos com mais dados, então rotular uma quantidade razoável de exemplos é praticamente obrigatório no aprendizado supervisionado.
A coleta de dados desempenha o papel mais importante no ciclo de Big Data. A Internet fornece fontes quase ilimitadas de dados para uma variedade de tópicos. A importância dessa área depende do tipo de negócio, mas os setores tradicionais podem adquirir uma fonte diversificada de dados externos e combiná-los com seus dados transacionais.
Por exemplo, vamos supor que gostaríamos de construir um sistema que recomendasse restaurantes. O primeiro passo seria reunir dados, neste caso, avaliações de restaurantes de diferentes sites e armazená-los em um banco de dados. Como estamos interessados em texto bruto e usaríamos isso para análises, não é tão relevante onde os dados para desenvolver o modelo seriam armazenados. Isso pode parecer contraditório com as principais tecnologias de big data, mas para implementar um aplicativo de big data, simplesmente precisamos fazê-lo funcionar em tempo real.
Twitter Mini Project
Definido o problema, a etapa seguinte é a coleta dos dados. A ideia do miniprojeto a seguir é trabalhar na coleta de dados da web e estruturá-los para serem usados em um modelo de aprendizado de máquina. Vamos coletar alguns tweets da API de resto do Twitter usando a linguagem de programação R.
Em primeiro lugar, crie uma conta no Twitter e, em seguida, siga as instruções no twitteRvinheta de pacote para criar uma conta de desenvolvedor do Twitter. Este é um resumo dessas instruções -
Vamos para https://twitter.com/apps/new e faça login.
Após preencher as informações básicas, vá até a guia "Configurações" e selecione "Ler, escrever e acessar mensagens diretas".
Certifique-se de clicar no botão Salvar após fazer isso
Na guia "Detalhes", anote sua chave e segredo do consumidor
Em sua sessão R, você usará a chave da API e os valores secretos da API
Por fim, execute o seguinte script. Isso irá instalar otwitteR pacote de seu repositório no github.
install.packages(c("devtools", "rjson", "bit64", "httr"))
# Make sure to restart your R session at this point
library(devtools)
install_github("geoffjentry/twitteR")Estamos interessados em obter dados onde a string "big mac" está incluída e em descobrir quais tópicos se destacam sobre isso. Para fazer isso, a primeira etapa é coletar os dados do twitter. Abaixo está nosso script R para coletar os dados necessários do Twitter. Este código também está disponível no arquivo bda / part1 / collect_data / collect_data_twitter.R.
rm(list = ls(all = TRUE)); gc() # Clears the global environment
library(twitteR)
Sys.setlocale(category = "LC_ALL", locale = "C")
### Replace the xxx’s with the values you got from the previous instructions
# consumer_key = "xxxxxxxxxxxxxxxxxxxx"
# consumer_secret = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# access_token = "xxxxxxxxxx-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# access_token_secret= "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# Connect to twitter rest API
setup_twitter_oauth(consumer_key, consumer_secret, access_token, access_token_secret)
# Get tweets related to big mac
tweets <- searchTwitter(’big mac’, n = 200, lang = ’en’)
df <- twListToDF(tweets)
# Take a look at the data
head(df)
# Check which device is most used
sources <- sapply(tweets, function(x) x$getStatusSource())
sources <- gsub("</a>", "", sources)
sources <- strsplit(sources, ">")
sources <- sapply(sources, function(x) ifelse(length(x) > 1, x[2], x[1]))
source_table = table(sources)
source_table = source_table[source_table > 1]
freq = source_table[order(source_table, decreasing = T)]
as.data.frame(freq)
# Frequency
# Twitter for iPhone 71
# Twitter for Android 29
# Twitter Web Client 25
# recognia 20Depois que os dados são coletados, normalmente temos diversas fontes de dados com características diferentes. O passo mais imediato seria tornar essas fontes de dados homogêneas e continuar a desenvolver nosso produto de dados. No entanto, depende do tipo de dados. Devemos nos perguntar se é prático homogeneizar os dados.
Talvez as fontes de dados sejam completamente diferentes e a perda de informações será grande se as fontes forem homogeneizadas. Nesse caso, podemos pensar em alternativas. Uma fonte de dados pode me ajudar a construir um modelo de regressão e a outra um modelo de classificação? É possível trabalhar com a heterogeneidade a nosso favor, em vez de apenas perder informações? Tomar essas decisões é o que torna a análise interessante e desafiadora.
No caso de resenhas, é possível ter um idioma para cada fonte de dados. Novamente, temos duas opções -
Homogenization- Trata-se de traduzir diferentes idiomas para o idioma onde temos mais dados. A qualidade dos serviços de tradução é aceitável, mas se quisermos traduzir grandes quantidades de dados com uma API, o custo seria significativo. Existem ferramentas de software disponíveis para essa tarefa, mas isso também seria caro.
Heterogenization- Seria possível desenvolver uma solução para cada idioma? Como é simples detectar a linguagem de um corpus, poderíamos desenvolver um recomendador para cada linguagem. Isso envolveria mais trabalho em termos de ajuste de cada recomendador de acordo com a quantidade de idiomas disponíveis, mas é definitivamente uma opção viável se tivermos alguns idiomas disponíveis.
Twitter Mini Project
No caso presente, precisamos primeiro limpar os dados não estruturados e, em seguida, convertê-los em uma matriz de dados para aplicar a modelagem de tópicos nela. Em geral, ao obter dados do twitter, existem vários personagens que não temos interesse em usar, pelo menos na primeira fase do processo de limpeza de dados.
Por exemplo, depois de obter os tweets, obtemos estes caracteres estranhos: "<ed> <U + 00A0> <U + 00BD> <ed> <U + 00B8> <U + 008B>". Provavelmente são emoticons, então, para limpar os dados, vamos apenas removê-los usando o seguinte script. Este código também está disponível no arquivo bda / part1 / collect_data / cleaning_data.R.
rm(list = ls(all = TRUE)); gc() # Clears the global environment
source('collect_data_twitter.R')
# Some tweets
head(df$text)
[1] "I’m not a big fan of turkey but baked Mac &
cheese <ed><U+00A0><U+00BD><ed><U+00B8><U+008B>"
[2] "@Jayoh30 Like no special sauce on a big mac. HOW"
### We are interested in the text - Let’s clean it!
# We first convert the encoding of the text from latin1 to ASCII
df$text <- sapply(df$text,function(row) iconv(row, "latin1", "ASCII", sub = ""))
# Create a function to clean tweets
clean.text <- function(tx) {
tx <- gsub("htt.{1,20}", " ", tx, ignore.case = TRUE)
tx = gsub("[^#[:^punct:]]|@|RT", " ", tx, perl = TRUE, ignore.case = TRUE)
tx = gsub("[[:digit:]]", " ", tx, ignore.case = TRUE)
tx = gsub(" {1,}", " ", tx, ignore.case = TRUE)
tx = gsub("^\\s+|\\s+$", " ", tx, ignore.case = TRUE) return(tx) } clean_tweets <- lapply(df$text, clean.text)
# Cleaned tweets
head(clean_tweets)
[1] " WeNeedFeminlsm MAC s new make up line features men woc and big girls "
[1] " TravelsPhoto What Happens To Your Body One Hour After A Big Mac "A etapa final do miniprojeto de limpeza de dados é limpar o texto que podemos converter em uma matriz e aplicar um algoritmo. A partir do texto armazenado noclean_tweets vetor podemos facilmente convertê-lo em uma matriz de saco de palavras e aplicar um algoritmo de aprendizagem não supervisionado.
Os relatórios são muito importantes na análise de big data. Cada organização deve ter um fornecimento regular de informações para apoiar seu processo de tomada de decisão. Essa tarefa é normalmente realizada por analistas de dados com experiência em SQL e ETL (extrair, transferir e carregar).
A equipa responsável por esta tarefa tem a responsabilidade de divulgar a informação produzida no departamento de big data analytics para as diferentes áreas da organização.
O exemplo a seguir demonstra o que significa sumarização de dados. Navegue até a pastabda/part1/summarize_data e dentro da pasta, abra o summarize_data.Rprojarquivo clicando duas vezes nele. Então, abra osummarize_data.R script e dê uma olhada no código, e siga as explicações apresentadas.
# Install the following packages by running the following code in R.
pkgs = c('data.table', 'ggplot2', 'nycflights13', 'reshape2')
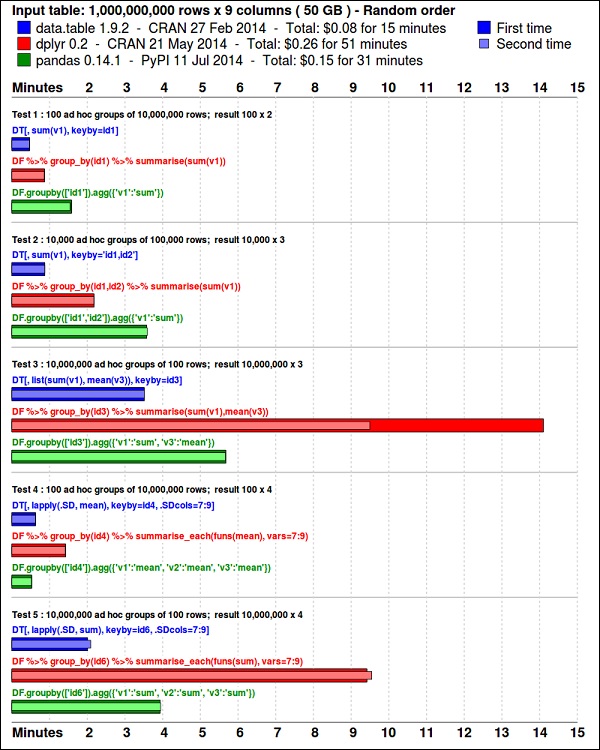
install.packages(pkgs)o ggplot2pacote é ótimo para visualização de dados. odata.table pacote é uma ótima opção para fazer um resumo rápido e eficiente de memória em R. Um benchmark recente mostra que é ainda mais rápido do quepandas, a biblioteca python usada para tarefas semelhantes.
Dê uma olhada nos dados usando o código a seguir. Este código também está disponível embda/part1/summarize_data/summarize_data.Rproj Arquivo.
library(nycflights13)
library(ggplot2)
library(data.table)
library(reshape2)
# Convert the flights data.frame to a data.table object and call it DT
DT <- as.data.table(flights)
# The data has 336776 rows and 16 columns
dim(DT)
# Take a look at the first rows
head(DT)
# year month day dep_time dep_delay arr_time arr_delay carrier
# 1: 2013 1 1 517 2 830 11 UA
# 2: 2013 1 1 533 4 850 20 UA
# 3: 2013 1 1 542 2 923 33 AA
# 4: 2013 1 1 544 -1 1004 -18 B6
# 5: 2013 1 1 554 -6 812 -25 DL
# 6: 2013 1 1 554 -4 740 12 UA
# tailnum flight origin dest air_time distance hour minute
# 1: N14228 1545 EWR IAH 227 1400 5 17
# 2: N24211 1714 LGA IAH 227 1416 5 33
# 3: N619AA 1141 JFK MIA 160 1089 5 42
# 4: N804JB 725 JFK BQN 183 1576 5 44
# 5: N668DN 461 LGA ATL 116 762 5 54
# 6: N39463 1696 EWR ORD 150 719 5 54O código a seguir tem um exemplo de resumo de dados.
### Data Summarization
# Compute the mean arrival delay
DT[, list(mean_arrival_delay = mean(arr_delay, na.rm = TRUE))]
# mean_arrival_delay
# 1: 6.895377
# Now, we compute the same value but for each carrier
mean1 = DT[, list(mean_arrival_delay = mean(arr_delay, na.rm = TRUE)),
by = carrier]
print(mean1)
# carrier mean_arrival_delay
# 1: UA 3.5580111
# 2: AA 0.3642909
# 3: B6 9.4579733
# 4: DL 1.6443409
# 5: EV 15.7964311
# 6: MQ 10.7747334
# 7: US 2.1295951
# 8: WN 9.6491199
# 9: VX 1.7644644
# 10: FL 20.1159055
# 11: AS -9.9308886
# 12: 9E 7.3796692
# 13: F9 21.9207048
# 14: HA -6.9152047
# 15: YV 15.5569853
# 16: OO 11.9310345
# Now let’s compute to means in the same line of code
mean2 = DT[, list(mean_departure_delay = mean(dep_delay, na.rm = TRUE),
mean_arrival_delay = mean(arr_delay, na.rm = TRUE)),
by = carrier]
print(mean2)
# carrier mean_departure_delay mean_arrival_delay
# 1: UA 12.106073 3.5580111
# 2: AA 8.586016 0.3642909
# 3: B6 13.022522 9.4579733
# 4: DL 9.264505 1.6443409
# 5: EV 19.955390 15.7964311
# 6: MQ 10.552041 10.7747334
# 7: US 3.782418 2.1295951
# 8: WN 17.711744 9.6491199
# 9: VX 12.869421 1.7644644
# 10: FL 18.726075 20.1159055
# 11: AS 5.804775 -9.9308886
# 12: 9E 16.725769 7.3796692
# 13: F9 20.215543 21.9207048
# 14: HA 4.900585 -6.9152047
# 15: YV 18.996330 15.5569853
# 16: OO 12.586207 11.9310345
### Create a new variable called gain
# this is the difference between arrival delay and departure delay
DT[, gain:= arr_delay - dep_delay]
# Compute the median gain per carrier
median_gain = DT[, median(gain, na.rm = TRUE), by = carrier]
print(median_gain)Exploratory data analysisé um conceito desenvolvido por John Tuckey (1977) que consiste em uma nova perspectiva da estatística. A ideia de Tuckey era que na estatística tradicional os dados não eram explorados graficamente, apenas para testar hipóteses. A primeira tentativa de desenvolver uma ferramenta foi feita em Stanford, o projeto foi denominado prim9 . A ferramenta foi capaz de visualizar dados em nove dimensões, portanto, foi capaz de fornecer uma perspectiva multivariada dos dados.
Nos últimos dias, a análise exploratória de dados é obrigatória e foi incluída no ciclo de vida analítico de big data. A capacidade de encontrar insights e comunicá-los com eficácia em uma organização é alimentada por fortes recursos de EDA.
Com base nas ideias de Tuckey, Bell Labs desenvolveu o S programming languagea fim de fornecer uma interface interativa para fazer estatísticas. A ideia do S era fornecer recursos gráficos abrangentes com uma linguagem fácil de usar. No mundo de hoje, no contexto de Big Data,R que é baseado no S linguagem de programação é o software mais popular para análise.
O programa a seguir demonstra o uso da análise exploratória de dados.
A seguir está um exemplo de análise exploratória de dados. Este código também está disponível empart1/eda/exploratory_data_analysis.R Arquivo.
library(nycflights13)
library(ggplot2)
library(data.table)
library(reshape2)
# Using the code from the previous section
# This computes the mean arrival and departure delays by carrier.
DT <- as.data.table(flights)
mean2 = DT[, list(mean_departure_delay = mean(dep_delay, na.rm = TRUE),
mean_arrival_delay = mean(arr_delay, na.rm = TRUE)),
by = carrier]
# In order to plot data in R usign ggplot, it is normally needed to reshape the data
# We want to have the data in long format for plotting with ggplot
dt = melt(mean2, id.vars = ’carrier’)
# Take a look at the first rows
print(head(dt))
# Take a look at the help for ?geom_point and geom_line to find similar examples
# Here we take the carrier code as the x axis
# the value from the dt data.table goes in the y axis
# The variable column represents the color
p = ggplot(dt, aes(x = carrier, y = value, color = variable, group = variable)) +
geom_point() + # Plots points
geom_line() + # Plots lines
theme_bw() + # Uses a white background
labs(list(title = 'Mean arrival and departure delay by carrier',
x = 'Carrier', y = 'Mean delay'))
print(p)
# Save the plot to disk
ggsave('mean_delay_by_carrier.png', p,
width = 10.4, height = 5.07)O código deve produzir uma imagem como a seguinte -

Para entender os dados, geralmente é útil visualizá-los. Normalmente em aplicativos de Big Data, o interesse reside em encontrar insights, em vez de apenas fazer gráficos bonitos. A seguir estão exemplos de diferentes abordagens para compreender os dados usando gráficos.
Para começar a analisar os dados dos voos, podemos começar verificando se existem correlações entre as variáveis numéricas. Este código também está disponível embda/part1/data_visualization/data_visualization.R Arquivo.
# Install the package corrplot by running
install.packages('corrplot')
# then load the library
library(corrplot)
# Load the following libraries
library(nycflights13)
library(ggplot2)
library(data.table)
library(reshape2)
# We will continue working with the flights data
DT <- as.data.table(flights)
head(DT) # take a look
# We select the numeric variables after inspecting the first rows.
numeric_variables = c('dep_time', 'dep_delay',
'arr_time', 'arr_delay', 'air_time', 'distance')
# Select numeric variables from the DT data.table
dt_num = DT[, numeric_variables, with = FALSE]
# Compute the correlation matrix of dt_num
cor_mat = cor(dt_num, use = "complete.obs")
print(cor_mat)
### Here is the correlation matrix
# dep_time dep_delay arr_time arr_delay air_time distance
# dep_time 1.00000000 0.25961272 0.66250900 0.23230573 -0.01461948 -0.01413373
# dep_delay 0.25961272 1.00000000 0.02942101 0.91480276 -0.02240508 -0.02168090
# arr_time 0.66250900 0.02942101 1.00000000 0.02448214 0.05429603 0.04718917
# arr_delay 0.23230573 0.91480276 0.02448214 1.00000000 -0.03529709 -0.06186776
# air_time -0.01461948 -0.02240508 0.05429603 -0.03529709 1.00000000 0.99064965
# distance -0.01413373 -0.02168090 0.04718917 -0.06186776 0.99064965 1.00000000
# We can display it visually to get a better understanding of the data
corrplot.mixed(cor_mat, lower = "circle", upper = "ellipse")
# save it to disk
png('corrplot.png')
print(corrplot.mixed(cor_mat, lower = "circle", upper = "ellipse"))
dev.off()Este código gera a seguinte visualização da matriz de correlação -

Podemos ver no gráfico que há uma forte correlação entre algumas das variáveis no conjunto de dados. Por exemplo, o atraso na chegada e o atraso na partida parecem estar altamente correlacionados. Podemos ver isso porque a elipse mostra uma relação quase linear entre as duas variáveis, no entanto, não é simples encontrar a causalidade a partir desse resultado.
Não podemos dizer que, como duas variáveis estão correlacionadas, uma tem efeito sobre a outra. Também encontramos no gráfico uma forte correlação entre o tempo de ar e a distância, o que é bastante razoável de se esperar, pois com mais distância, o tempo de vôo deve aumentar.
Também podemos fazer análises univariadas dos dados. Uma maneira simples e eficaz de visualizar as distribuições sãobox-plots. O código a seguir demonstra como produzir box-plots e gráficos de treliça usando a biblioteca ggplot2. Este código também está disponível embda/part1/data_visualization/boxplots.R Arquivo.
source('data_visualization.R')
### Analyzing Distributions using box-plots
# The following shows the distance as a function of the carrier
p = ggplot(DT, aes(x = carrier, y = distance, fill = carrier)) + # Define the carrier
in the x axis and distance in the y axis
geom_box-plot() + # Use the box-plot geom
theme_bw() + # Leave a white background - More in line with tufte's
principles than the default
guides(fill = FALSE) + # Remove legend
labs(list(title = 'Distance as a function of carrier', # Add labels
x = 'Carrier', y = 'Distance'))
p
# Save to disk
png(‘boxplot_carrier.png’)
print(p)
dev.off()
# Let's add now another variable, the month of each flight
# We will be using facet_wrap for this
p = ggplot(DT, aes(carrier, distance, fill = carrier)) +
geom_box-plot() +
theme_bw() +
guides(fill = FALSE) +
facet_wrap(~month) + # This creates the trellis plot with the by month variable
labs(list(title = 'Distance as a function of carrier by month',
x = 'Carrier', y = 'Distance'))
p
# The plot shows there aren't clear differences between distance in different months
# Save to disk
png('boxplot_carrier_by_month.png')
print(p)
dev.off()Esta seção é dedicada a apresentar aos usuários a linguagem de programação R. R pode ser baixado do site do cran . Para usuários do Windows, é útil instalar o rtools e o IDE rstudio .
O conceito geral por trás R é servir como uma interface para outro software desenvolvido em linguagens compiladas como C, C ++ e Fortran e fornecer ao usuário uma ferramenta interativa para analisar dados.
Navegue até a pasta do arquivo zip do livro bda/part2/R_introduction e abra o R_introduction.RprojArquivo. Isso abrirá uma sessão RStudio. Em seguida, abra o arquivo 01_vectors.R. Execute o script linha por linha e siga os comentários no código. Outra opção útil para aprender é apenas digitar o código, isso o ajudará a se acostumar com a sintaxe R. No R, os comentários são escritos com o símbolo #.
Para exibir os resultados da execução do código R no livro, depois que o código é avaliado, os resultados que R retorna são comentados. Dessa forma, você pode copiar e colar o código no livro e experimentar diretamente as seções dele em R.
# Create a vector of numbers
numbers = c(1, 2, 3, 4, 5)
print(numbers)
# [1] 1 2 3 4 5
# Create a vector of letters
ltrs = c('a', 'b', 'c', 'd', 'e')
# [1] "a" "b" "c" "d" "e"
# Concatenate both
mixed_vec = c(numbers, ltrs)
print(mixed_vec)
# [1] "1" "2" "3" "4" "5" "a" "b" "c" "d" "e"Vamos analisar o que aconteceu no código anterior. Podemos ver que é possível criar vetores com números e com letras. Não precisamos dizer a R que tipo de dados queríamos de antemão. Finalmente, fomos capazes de criar um vetor com números e letras. O vetor mixed_vec coagiu os números a caracteres, podemos ver isso visualizando como os valores são impressos entre aspas.
O código a seguir mostra o tipo de dados de diferentes vetores conforme retornado pela classe de função. É comum usar a função de classe para "interrogar" um objeto, perguntando-lhe o que é sua classe.
### Evaluate the data types using class
### One dimensional objects
# Integer vector
num = 1:10
class(num)
# [1] "integer"
# Numeric vector, it has a float, 10.5
num = c(1:10, 10.5)
class(num)
# [1] "numeric"
# Character vector
ltrs = letters[1:10]
class(ltrs)
# [1] "character"
# Factor vector
fac = as.factor(ltrs)
class(fac)
# [1] "factor"R também suporta objetos bidimensionais. No código a seguir, há exemplos das duas estruturas de dados mais populares usadas em R: a matriz e data.frame.
# Matrix
M = matrix(1:12, ncol = 4)
# [,1] [,2] [,3] [,4]
# [1,] 1 4 7 10
# [2,] 2 5 8 11
# [3,] 3 6 9 12
lM = matrix(letters[1:12], ncol = 4)
# [,1] [,2] [,3] [,4]
# [1,] "a" "d" "g" "j"
# [2,] "b" "e" "h" "k"
# [3,] "c" "f" "i" "l"
# Coerces the numbers to character
# cbind concatenates two matrices (or vectors) in one matrix
cbind(M, lM)
# [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8]
# [1,] "1" "4" "7" "10" "a" "d" "g" "j"
# [2,] "2" "5" "8" "11" "b" "e" "h" "k"
# [3,] "3" "6" "9" "12" "c" "f" "i" "l"
class(M)
# [1] "matrix"
class(lM)
# [1] "matrix"
# data.frame
# One of the main objects of R, handles different data types in the same object.
# It is possible to have numeric, character and factor vectors in the same data.frame
df = data.frame(n = 1:5, l = letters[1:5])
df
# n l
# 1 1 a
# 2 2 b
# 3 3 c
# 4 4 d
# 5 5 eConforme demonstrado no exemplo anterior, é possível usar diferentes tipos de dados no mesmo objeto. Em geral, é assim que os dados são apresentados em bancos de dados, APIs parte dos dados são texto ou vetores de caracteres e outros numéricos. Em é o trabalho do analista para determinar qual tipo de dados estatísticos atribuir e, em seguida, usar o tipo de dados R correto para ele. Em estatísticas, normalmente consideramos que as variáveis são dos seguintes tipos -
- Numeric
- Nominal ou categórico
- Ordinal
Em R, um vetor pode ser das seguintes classes -
- Numérico - Inteiro
- Factor
- Fator ordenado
R fornece um tipo de dados para cada tipo de variável estatística. O fator ordenado, entretanto, raramente é usado, mas pode ser criado pelo fator de função ou ordenado.
A seção a seguir trata do conceito de indexação. Esta é uma operação bastante comum e lida com o problema de selecionar seções de um objeto e fazer transformações nelas.
# Let's create a data.frame
df = data.frame(numbers = 1:26, letters)
head(df)
# numbers letters
# 1 1 a
# 2 2 b
# 3 3 c
# 4 4 d
# 5 5 e
# 6 6 f
# str gives the structure of a data.frame, it’s a good summary to inspect an object
str(df)
# 'data.frame': 26 obs. of 2 variables:
# $ numbers: int 1 2 3 4 5 6 7 8 9 10 ... # $ letters: Factor w/ 26 levels "a","b","c","d",..: 1 2 3 4 5 6 7 8 9 10 ...
# The latter shows the letters character vector was coerced as a factor.
# This can be explained by the stringsAsFactors = TRUE argumnet in data.frame
# read ?data.frame for more information
class(df)
# [1] "data.frame"
### Indexing
# Get the first row
df[1, ]
# numbers letters
# 1 1 a
# Used for programming normally - returns the output as a list
df[1, , drop = TRUE]
# $numbers # [1] 1 # # $letters
# [1] a
# Levels: a b c d e f g h i j k l m n o p q r s t u v w x y z
# Get several rows of the data.frame
df[5:7, ]
# numbers letters
# 5 5 e
# 6 6 f
# 7 7 g
### Add one column that mixes the numeric column with the factor column
df$mixed = paste(df$numbers, df$letters, sep = ’’) str(df) # 'data.frame': 26 obs. of 3 variables: # $ numbers: int 1 2 3 4 5 6 7 8 9 10 ...
# $ letters: Factor w/ 26 levels "a","b","c","d",..: 1 2 3 4 5 6 7 8 9 10 ... # $ mixed : chr "1a" "2b" "3c" "4d" ...
### Get columns
# Get the first column
df[, 1]
# It returns a one dimensional vector with that column
# Get two columns
df2 = df[, 1:2]
head(df2)
# numbers letters
# 1 1 a
# 2 2 b
# 3 3 c
# 4 4 d
# 5 5 e
# 6 6 f
# Get the first and third columns
df3 = df[, c(1, 3)]
df3[1:3, ]
# numbers mixed
# 1 1 1a
# 2 2 2b
# 3 3 3c
### Index columns from their names
names(df)
# [1] "numbers" "letters" "mixed"
# This is the best practice in programming, as many times indeces change, but
variable names don’t
# We create a variable with the names we want to subset
keep_vars = c("numbers", "mixed")
df4 = df[, keep_vars]
head(df4)
# numbers mixed
# 1 1 1a
# 2 2 2b
# 3 3 3c
# 4 4 4d
# 5 5 5e
# 6 6 6f
### subset rows and columns
# Keep the first five rows
df5 = df[1:5, keep_vars]
df5
# numbers mixed
# 1 1 1a
# 2 2 2b
# 3 3 3c
# 4 4 4d
# 5 5 5e
# subset rows using a logical condition
df6 = df[df$numbers < 10, keep_vars]
df6
# numbers mixed
# 1 1 1a
# 2 2 2b
# 3 3 3c
# 4 4 4d
# 5 5 5e
# 6 6 6f
# 7 7 7g
# 8 8 8h
# 9 9 9iSQL significa linguagem de consulta estruturada. É uma das linguagens mais amplamente utilizadas para extrair dados de bancos de dados em data warehouses tradicionais e tecnologias de big data. Para demonstrar o básico do SQL, trabalharemos com exemplos. Para focar na linguagem em si, usaremos SQL dentro de R. Em termos de escrever código SQL, isso é exatamente como seria feito em um banco de dados.
O núcleo do SQL são três instruções: SELECT, FROM e WHERE. Os exemplos a seguir fazem uso dos casos de uso mais comuns de SQL. Navegue até a pastabda/part2/SQL_introduction e abra o SQL_introduction.RprojArquivo. Em seguida, abra o script 01_select.R. Para escrever o código SQL em R, precisamos instalar osqldf pacote conforme demonstrado no código a seguir.
# Install the sqldf package
install.packages('sqldf')
# load the library
library('sqldf')
library(nycflights13)
# We will be working with the fligths dataset in order to introduce SQL
# Let’s take a look at the table
str(flights)
# Classes 'tbl_d', 'tbl' and 'data.frame': 336776 obs. of 16 variables:
# $ year : int 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 ...
# $ month : int 1 1 1 1 1 1 1 1 1 1 ... # $ day : int 1 1 1 1 1 1 1 1 1 1 ...
# $ dep_time : int 517 533 542 544 554 554 555 557 557 558 ... # $ dep_delay: num 2 4 2 -1 -6 -4 -5 -3 -3 -2 ...
# $ arr_time : int 830 850 923 1004 812 740 913 709 838 753 ... # $ arr_delay: num 11 20 33 -18 -25 12 19 -14 -8 8 ...
# $ carrier : chr "UA" "UA" "AA" "B6" ... # $ tailnum : chr "N14228" "N24211" "N619AA" "N804JB" ...
# $ flight : int 1545 1714 1141 725 461 1696 507 5708 79 301 ... # $ origin : chr "EWR" "LGA" "JFK" "JFK" ...
# $ dest : chr "IAH" "IAH" "MIA" "BQN" ... # $ air_time : num 227 227 160 183 116 150 158 53 140 138 ...
# $ distance : num 1400 1416 1089 1576 762 ... # $ hour : num 5 5 5 5 5 5 5 5 5 5 ...
# $ minute : num 17 33 42 44 54 54 55 57 57 58 ...A instrução select é usada para recuperar colunas de tabelas e fazer cálculos sobre elas. A instrução SELECT mais simples é demonstrada emej1. Também podemos criar novas variáveis, conforme mostrado emej2.
### SELECT statement
ej1 = sqldf("
SELECT
dep_time
,dep_delay
,arr_time
,carrier
,tailnum
FROM
flights
")
head(ej1)
# dep_time dep_delay arr_time carrier tailnum
# 1 517 2 830 UA N14228
# 2 533 4 850 UA N24211
# 3 542 2 923 AA N619AA
# 4 544 -1 1004 B6 N804JB
# 5 554 -6 812 DL N668DN
# 6 554 -4 740 UA N39463
# In R we can use SQL with the sqldf function. It works exactly the same as in
a database
# The data.frame (in this case flights) represents the table we are querying
and goes in the FROM statement
# We can also compute new variables in the select statement using the syntax:
# old_variables as new_variable
ej2 = sqldf("
SELECT
arr_delay - dep_delay as gain,
carrier
FROM
flights
")
ej2[1:5, ]
# gain carrier
# 1 9 UA
# 2 16 UA
# 3 31 AA
# 4 -17 B6
# 5 -19 DLUm dos recursos mais usados do SQL é o agrupamento por instrução. Isso permite calcular um valor numérico para diferentes grupos de outra variável. Abra o script 02_group_by.R.
### GROUP BY
# Computing the average
ej3 = sqldf("
SELECT
avg(arr_delay) as mean_arr_delay,
avg(dep_delay) as mean_dep_delay,
carrier
FROM
flights
GROUP BY
carrier
")
# mean_arr_delay mean_dep_delay carrier
# 1 7.3796692 16.725769 9E
# 2 0.3642909 8.586016 AA
# 3 -9.9308886 5.804775 AS
# 4 9.4579733 13.022522 B6
# 5 1.6443409 9.264505 DL
# 6 15.7964311 19.955390 EV
# 7 21.9207048 20.215543 F9
# 8 20.1159055 18.726075 FL
# 9 -6.9152047 4.900585 HA
# 10 10.7747334 10.552041 MQ
# 11 11.9310345 12.586207 OO
# 12 3.5580111 12.106073 UA
# 13 2.1295951 3.782418 US
# 14 1.7644644 12.869421 VX
# 15 9.6491199 17.711744 WN
# 16 15.5569853 18.996330 YV
# Other aggregations
ej4 = sqldf("
SELECT
avg(arr_delay) as mean_arr_delay,
min(dep_delay) as min_dep_delay,
max(dep_delay) as max_dep_delay,
carrier
FROM
flights
GROUP BY
carrier
")
# We can compute the minimun, mean, and maximum values of a numeric value
ej4
# mean_arr_delay min_dep_delay max_dep_delay carrier
# 1 7.3796692 -24 747 9E
# 2 0.3642909 -24 1014 AA
# 3 -9.9308886 -21 225 AS
# 4 9.4579733 -43 502 B6
# 5 1.6443409 -33 960 DL
# 6 15.7964311 -32 548 EV
# 7 21.9207048 -27 853 F9
# 8 20.1159055 -22 602 FL
# 9 -6.9152047 -16 1301 HA
# 10 10.7747334 -26 1137 MQ
# 11 11.9310345 -14 154 OO
# 12 3.5580111 -20 483 UA
# 13 2.1295951 -19 500 US
# 14 1.7644644 -20 653 VX
# 15 9.6491199 -13 471 WN
# 16 15.5569853 -16 387 YV
### We could be also interested in knowing how many observations each carrier has
ej5 = sqldf("
SELECT
carrier, count(*) as count
FROM
flights
GROUP BY
carrier
")
ej5
# carrier count
# 1 9E 18460
# 2 AA 32729
# 3 AS 714
# 4 B6 54635
# 5 DL 48110
# 6 EV 54173
# 7 F9 685
# 8 FL 3260
# 9 HA 342
# 10 MQ 26397
# 11 OO 32
# 12 UA 58665
# 13 US 20536
# 14 VX 5162
# 15 WN 12275
# 16 YV 601O recurso mais útil do SQL são as junções. Uma junção significa que queremos combinar a tabela A e a tabela B em uma tabela usando uma coluna para corresponder aos valores de ambas as tabelas. Existem diferentes tipos de junções, em termos práticos, para começar, estas serão as mais úteis: junção interna e junção externa esquerda.
# Let’s create two tables: A and B to demonstrate joins.
A = data.frame(c1 = 1:4, c2 = letters[1:4])
B = data.frame(c1 = c(2,4,5,6), c2 = letters[c(2:5)])
A
# c1 c2
# 1 a
# 2 b
# 3 c
# 4 d
B
# c1 c2
# 2 b
# 4 c
# 5 d
# 6 e
### INNER JOIN
# This means to match the observations of the column we would join the tables by.
inner = sqldf("
SELECT
A.c1, B.c2
FROM
A INNER JOIN B
ON A.c1 = B.c1
")
# Only the rows that match c1 in both A and B are returned
inner
# c1 c2
# 2 b
# 4 c
### LEFT OUTER JOIN
# the left outer join, sometimes just called left join will return the
# first all the values of the column used from the A table
left = sqldf("
SELECT
A.c1, B.c2
FROM
A LEFT OUTER JOIN B
ON A.c1 = B.c1
")
# Only the rows that match c1 in both A and B are returned
left
# c1 c2
# 1 <NA>
# 2 b
# 3 <NA>
# 4 cA primeira abordagem para analisar dados é analisá-los visualmente. Os objetivos de fazer isso normalmente são encontrar relações entre variáveis e descrições univariadas das variáveis. Podemos dividir essas estratégias como -
- Análise univariada
- Análise multivariada
Métodos Gráficos Univariados
Univariateé um termo estatístico. Na prática, significa que queremos analisar uma variável independentemente do resto dos dados. Os gráficos que permitem fazer isso de forma eficiente são -
Box-Plots
Box-Plots são normalmente usados para comparar distribuições. É uma ótima maneira de inspecionar visualmente se há diferenças entre as distribuições. Podemos ver se existem diferenças entre o preço dos diamantes para diferentes cortes.
# We will be using the ggplot2 library for plotting
library(ggplot2)
data("diamonds")
# We will be using the diamonds dataset to analyze distributions of numeric variables
head(diamonds)
# carat cut color clarity depth table price x y z
# 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
# 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
# 3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
# 4 0.29 Premium I VS2 62.4 58 334 4.20 4.23 2.63
# 5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
# 6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
### Box-Plots
p = ggplot(diamonds, aes(x = cut, y = price, fill = cut)) +
geom_box-plot() +
theme_bw()
print(p)Podemos observar no gráfico que existem diferenças na distribuição do preço dos diamantes nos diferentes tipos de corte.

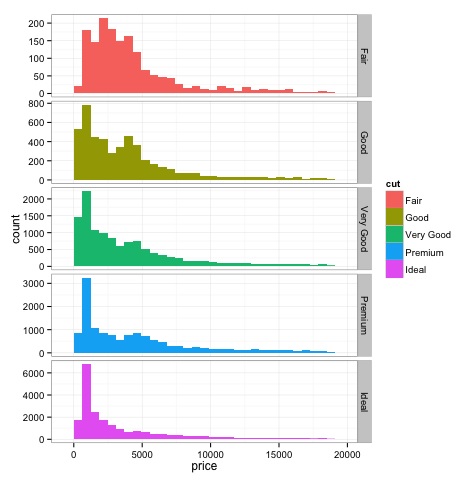
Histogramas
source('01_box_plots.R')
# We can plot histograms for each level of the cut factor variable using
facet_grid
p = ggplot(diamonds, aes(x = price, fill = cut)) +
geom_histogram() +
facet_grid(cut ~ .) +
theme_bw()
p
# the previous plot doesn’t allow to visuallize correctly the data because of
the differences in scale
# we can turn this off using the scales argument of facet_grid
p = ggplot(diamonds, aes(x = price, fill = cut)) +
geom_histogram() +
facet_grid(cut ~ ., scales = 'free') +
theme_bw()
p
png('02_histogram_diamonds_cut.png')
print(p)
dev.off()A saída do código acima será a seguinte -
Métodos gráficos multivariados
Métodos gráficos multivariados na análise exploratória de dados têm o objetivo de encontrar relações entre diferentes variáveis. Existem duas maneiras de fazer isso que são comumente usadas: traçar uma matriz de correlação de variáveis numéricas ou simplesmente traçar os dados brutos como uma matriz de gráficos de dispersão.
Para demonstrar isso, usaremos o conjunto de dados de diamantes. Para seguir o código, abra o scriptbda/part2/charts/03_multivariate_analysis.R.
library(ggplot2)
data(diamonds)
# Correlation matrix plots
keep_vars = c('carat', 'depth', 'price', 'table')
df = diamonds[, keep_vars]
# compute the correlation matrix
M_cor = cor(df)
# carat depth price table
# carat 1.00000000 0.02822431 0.9215913 0.1816175
# depth 0.02822431 1.00000000 -0.0106474 -0.2957785
# price 0.92159130 -0.01064740 1.0000000 0.1271339
# table 0.18161755 -0.29577852 0.1271339 1.0000000
# plots
heat-map(M_cor)O código produzirá a seguinte saída -

Este é um resumo, nos diz que existe uma forte correlação entre preço e circunflexo, e não muito entre as outras variáveis.
Uma matriz de correlação pode ser útil quando temos um grande número de variáveis, caso em que traçar os dados brutos não seria prático. Como mencionado, é possível mostrar os dados brutos também -
library(GGally)
ggpairs(df)Podemos ver no gráfico que os resultados exibidos no mapa de calor são confirmados, há uma correlação de 0,922 entre as variáveis de preço e quilate.
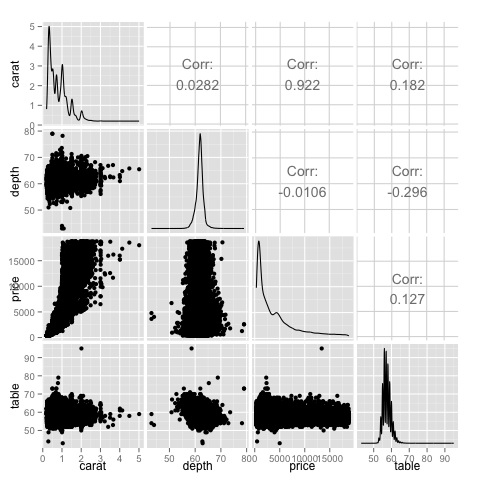
É possível visualizar essa relação no gráfico de dispersão preço-quilate localizado no índice (3, 1) da matriz do gráfico de dispersão.
Há uma variedade de ferramentas que permitem a um cientista de dados analisar os dados de maneira eficaz. Normalmente, o aspecto de engenharia da análise de dados se concentra em bancos de dados, enquanto o cientista de dados se concentra em ferramentas que podem implementar produtos de dados. A seção a seguir discute as vantagens de diferentes ferramentas com foco nos pacotes estatísticos que os cientistas usam na prática com mais frequência.
Linguagem de programação R
R é uma linguagem de programação de código aberto com foco em análise estatística. É competitivo com ferramentas comerciais como SAS, SPSS em termos de capacidades estatísticas. É considerada uma interface para outras linguagens de programação, como C, C ++ ou Fortran.
Outra vantagem do R é o grande número de bibliotecas de código aberto disponíveis. No CRAN existem mais de 6.000 pacotes que podem ser baixados gratuitamente e emGithub há uma grande variedade de pacotes R disponíveis.
Em termos de desempenho, R é lento para operações intensivas, devido à grande quantidade de bibliotecas disponíveis, as seções lentas do código são escritas em linguagens compiladas. Mas se você pretende fazer operações que requerem a escrita profunda de loops for, então R não seria sua melhor alternativa. Para fins de análise de dados, existem boas bibliotecas, comodata.table, glmnet, ranger, xgboost, ggplot2, caret que permitem usar R como uma interface para linguagens de programação mais rápidas.
Python para análise de dados
Python é uma linguagem de programação de propósito geral e contém um número significativo de bibliotecas dedicadas à análise de dados, como pandas, scikit-learn, theano, numpy e scipy.
Muito do que está disponível em R também pode ser feito em Python, mas descobrimos que R é mais simples de usar. Caso você esteja trabalhando com grandes conjuntos de dados, normalmente Python é uma escolha melhor do que R. Python pode ser usado de forma bastante eficaz para limpar e processar dados linha por linha. Isso é possível a partir de R, mas não é tão eficiente quanto Python para tarefas de script.
Para aprendizado de máquina, scikit-learné um ambiente agradável que possui uma grande quantidade de algoritmos que podem lidar com conjuntos de dados de tamanho médio sem problemas. Comparado com a biblioteca equivalente de R (circunflexo),scikit-learn tem uma API mais limpa e consistente.
Julia
Julia é uma linguagem de programação dinâmica de alto nível e alto desempenho para computação técnica. Sua sintaxe é bastante semelhante a R ou Python, então se você já está trabalhando com R ou Python, deve ser bem simples escrever o mesmo código em Julia. O idioma é bastante novo e cresceu significativamente nos últimos anos, então é definitivamente uma opção no momento.
Recomendamos Julia para algoritmos de prototipagem que são computacionalmente intensivos, como redes neurais. É uma ótima ferramenta de pesquisa. Em termos de implementação de um modelo em produção, provavelmente o Python tem alternativas melhores. No entanto, isso está se tornando menos problemático, pois há serviços da web que fazem a engenharia de implementação de modelos em R, Python e Julia.
SAS
SAS é uma linguagem comercial que ainda está sendo usada para inteligência de negócios. Possui uma linguagem base que permite ao usuário programar uma ampla variedade de aplicações. Ele contém alguns produtos comerciais que oferecem aos usuários não especialistas a capacidade de usar ferramentas complexas, como uma biblioteca de rede neural, sem a necessidade de programação.
Além da desvantagem óbvia das ferramentas comerciais, o SAS não se adapta bem a grandes conjuntos de dados. Mesmo conjuntos de dados de tamanho médio terão problemas com SAS e farão o servidor travar. Somente se você estiver trabalhando com pequenos conjuntos de dados e os usuários não forem cientistas especialistas em dados, o SAS é recomendado. Para usuários avançados, R e Python fornecem um ambiente mais produtivo.
SPSS
SPSS, é atualmente um produto da IBM para análise estatística. É usado principalmente para analisar dados de pesquisas e para usuários que não são capazes de programar, é uma alternativa decente. Provavelmente é tão simples de usar quanto o SAS, mas em termos de implementação de um modelo, é mais simples porque fornece um código SQL para pontuar um modelo. Este código normalmente não é eficiente, mas é um começo, enquanto o SAS vende o produto que pontua modelos para cada banco de dados separadamente. Para dados pequenos e uma equipe inexperiente, o SPSS é uma opção tão boa quanto o SAS.
O software, no entanto, é bastante limitado e usuários experientes serão muito mais produtivos usando R ou Python.
Matlab, Octave
Existem outras ferramentas disponíveis, como Matlab ou sua versão de código aberto (Octave). Essas ferramentas são usadas principalmente para pesquisa. Em termos de recursos, R ou Python podem fazer tudo o que está disponível em Matlab ou Octave. Só faz sentido comprar uma licença do produto se você estiver interessado no suporte que eles fornecem.
Ao analisar os dados, é possível ter uma abordagem estatística. As ferramentas básicas necessárias para realizar a análise básica são -
- Análise de correlação
- Análise de variação
- Testando hipóteses
Ao trabalhar com grandes conjuntos de dados, isso não envolve um problema, pois esses métodos não são computacionalmente intensivos, com exceção da Análise de Correlação. Nesse caso, sempre é possível tirar uma amostra e os resultados devem ser robustos.
Análise de correlação
A Análise de Correlação busca encontrar relações lineares entre variáveis numéricas. Isso pode ser útil em diferentes circunstâncias. Um uso comum é a análise exploratória de dados, na seção 16.0.2 do livro há um exemplo básico dessa abordagem. Em primeiro lugar, a métrica de correlação usada no exemplo mencionado é baseada naPearson coefficient. No entanto, há outra métrica interessante de correlação que não é afetada por outliers. Essa métrica é chamada de correlação spearman.
o spearman correlation métrica é mais robusta à presença de outliers do que o método de Pearson e fornece melhores estimativas das relações lineares entre as variáveis numéricas quando os dados não são normalmente distribuídos.
library(ggplot2)
# Select variables that are interesting to compare pearson and spearman
correlation methods.
x = diamonds[, c('x', 'y', 'z', 'price')]
# From the histograms we can expect differences in the correlations of both
metrics.
# In this case as the variables are clearly not normally distributed, the
spearman correlation
# is a better estimate of the linear relation among numeric variables.
par(mfrow = c(2,2))
colnm = names(x)
for(i in 1:4) {
hist(x[[i]], col = 'deepskyblue3', main = sprintf('Histogram of %s', colnm[i]))
}
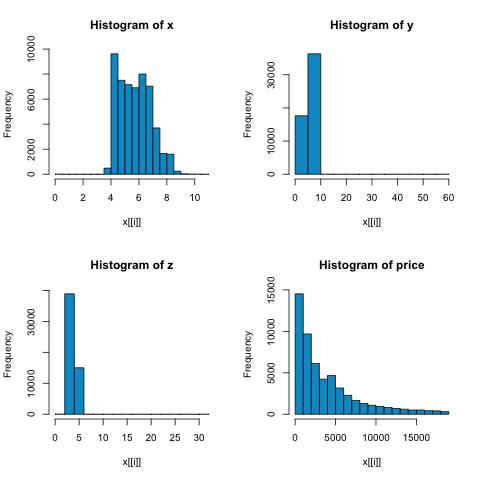
par(mfrow = c(1,1))A partir dos histogramas da figura a seguir, podemos esperar diferenças nas correlações de ambas as métricas. Nesse caso, como as variáveis claramente não têm distribuição normal, a correlação de Spearman é uma estimativa melhor da relação linear entre as variáveis numéricas.
Para calcular a correlação em R, abra o arquivo bda/part2/statistical_methods/correlation/correlation.R que tem esta seção de código.
## Correlation Matrix - Pearson and spearman
cor_pearson <- cor(x, method = 'pearson')
cor_spearman <- cor(x, method = 'spearman')
### Pearson Correlation
print(cor_pearson)
# x y z price
# x 1.0000000 0.9747015 0.9707718 0.8844352
# y 0.9747015 1.0000000 0.9520057 0.8654209
# z 0.9707718 0.9520057 1.0000000 0.8612494
# price 0.8844352 0.8654209 0.8612494 1.0000000
### Spearman Correlation
print(cor_spearman)
# x y z price
# x 1.0000000 0.9978949 0.9873553 0.9631961
# y 0.9978949 1.0000000 0.9870675 0.9627188
# z 0.9873553 0.9870675 1.0000000 0.9572323
# price 0.9631961 0.9627188 0.9572323 1.0000000Teste Qui-quadrado
O teste qui-quadrado nos permite testar se duas variáveis aleatórias são independentes. Isso significa que a distribuição de probabilidade de cada variável não influencia a outra. Para avaliar o teste em R, precisamos primeiro criar uma tabela de contingência e, em seguida, passá-la para ochisq.test R função.
Por exemplo, vamos verificar se existe associação entre as variáveis: corte e cor do conjunto de dados de diamantes. O teste é formalmente definido como -
- H0: O corte variável e o diamante são independentes
- H1: O corte variável e o diamante não são independentes
Suporíamos que existe uma relação entre essas duas variáveis por seus nomes, mas o teste pode fornecer uma "regra" objetiva dizendo o quão significativo é esse resultado ou não.
No fragmento de código a seguir, descobrimos que o valor p do teste é 2,2e-16, isso é quase zero em termos práticos. Então, depois de executar o teste, faça umMonte Carlo simulation, descobrimos que o valor p é 0,0004998, que ainda é bastante inferior ao limite 0,05. Este resultado significa que rejeitamos a hipótese nula (H0), então acreditamos nas variáveiscut e color não são independentes.
library(ggplot2)
# Use the table function to compute the contingency table
tbl = table(diamonds$cut, diamonds$color)
tbl
# D E F G H I J
# Fair 163 224 312 314 303 175 119
# Good 662 933 909 871 702 522 307
# Very Good 1513 2400 2164 2299 1824 1204 678
# Premium 1603 2337 2331 2924 2360 1428 808
# Ideal 2834 3903 3826 4884 3115 2093 896
# In order to run the test we just use the chisq.test function.
chisq.test(tbl)
# Pearson’s Chi-squared test
# data: tbl
# X-squared = 310.32, df = 24, p-value < 2.2e-16
# It is also possible to compute the p-values using a monte-carlo simulation
# It's needed to add the simulate.p.value = TRUE flag and the amount of
simulations
chisq.test(tbl, simulate.p.value = TRUE, B = 2000)
# Pearson’s Chi-squared test with simulated p-value (based on 2000 replicates)
# data: tbl
# X-squared = 310.32, df = NA, p-value = 0.0004998Teste t
A ideia de t-testé avaliar se existem diferenças na distribuição de uma variável numérica # entre diferentes grupos de uma variável nominal. Para demonstrar isso, selecionarei os níveis dos níveis Justo e Ideal do fator de corte variável, em seguida, compararemos os valores de uma variável numérica entre esses dois grupos.
data = diamonds[diamonds$cut %in% c('Fair', 'Ideal'), ]
data$cut = droplevels.factor(data$cut) # Drop levels that aren’t used from the
cut variable
df1 = data[, c('cut', 'price')]
# We can see the price means are different for each group
tapply(df1$price, df1$cut, mean)
# Fair Ideal
# 4358.758 3457.542Os testes t são implementados em R com o t.testfunção. A interface da fórmula para t.test é a maneira mais simples de usá-la, a ideia é que uma variável numérica é explicada por uma variável de grupo.
Por exemplo: t.test(numeric_variable ~ group_variable, data = data). No exemplo anterior, onumeric_variable é price e a group_variable é cut.
Do ponto de vista estatístico, estamos testando se há diferenças nas distribuições da variável numérica entre dois grupos. Formalmente, o teste de hipótese é descrito com uma hipótese nula (H0) e uma hipótese alternativa (H1).
H0: Não há diferenças nas distribuições da variável preço entre os grupos Justo e Ideal
H1 Existem diferenças nas distribuições da variável preço entre os grupos Justo e Ideal
O seguinte pode ser implementado em R com o seguinte código -
t.test(price ~ cut, data = data)
# Welch Two Sample t-test
#
# data: price by cut
# t = 9.7484, df = 1894.8, p-value < 2.2e-16
# alternative hypothesis: true difference in means is not equal to 0
# 95 percent confidence interval:
# 719.9065 1082.5251
# sample estimates:
# mean in group Fair mean in group Ideal
# 4358.758 3457.542
# Another way to validate the previous results is to just plot the
distributions using a box-plot
plot(price ~ cut, data = data, ylim = c(0,12000),
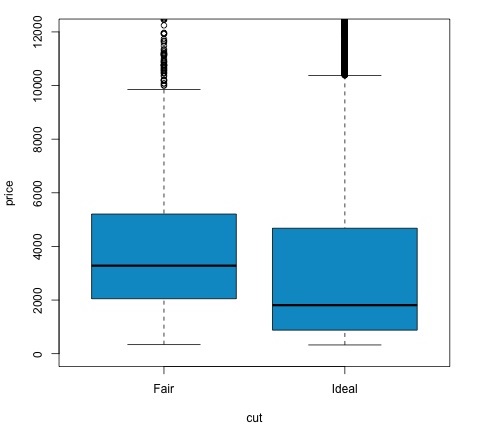
col = 'deepskyblue3')Podemos analisar o resultado do teste verificando se o valor p é menor que 0,05. Se for esse o caso, mantemos a hipótese alternativa. Isso significa que encontramos diferenças de preço entre os dois níveis do fator de corte. Pelos nomes dos níveis, esperaríamos esse resultado, mas não esperaríamos que o preço médio no grupo Falha fosse maior do que no grupo Ideal. Podemos ver isso comparando as médias de cada fator.
o plotcomando produz um gráfico que mostra a relação entre o preço e a variável de corte. É um enredo de caixa; cobrimos esse gráfico na seção 16.0.1, mas basicamente mostra a distribuição da variável de preço para os dois níveis de corte que estamos analisando.
Análise de variação
A Análise de Variância (ANOVA) é um modelo estatístico usado para analisar as diferenças entre a distribuição dos grupos comparando a média e a variância de cada grupo, o modelo foi desenvolvido por Ronald Fisher. ANOVA fornece um teste estatístico de se as médias de vários grupos são iguais ou não e, portanto, generaliza o teste t para mais de dois grupos.
ANOVAs são úteis para comparar três ou mais grupos para significância estatística porque fazer vários testes t de duas amostras resultaria em uma chance maior de cometer um erro estatístico tipo I.
Em termos de fornecer uma explicação matemática, o seguinte é necessário para compreender o teste.
x ij = x + (x i - x) + (x ij - x)
Isso leva ao seguinte modelo -
x ij = μ + α i + ∈ ij
onde μ é a grande média e α i é a i-ésima média do grupo. O termo de erro ∈ ij é assumido como sendo iid de uma distribuição normal. A hipótese nula do teste é que -
α 1 = α 2 =… = α k
Em termos de cálculo da estatística de teste, precisamos calcular dois valores -
- Soma dos quadrados para diferença entre os grupos -
$$SSD_B = \sum_{i}^{k} \sum_{j}^{n}(\bar{x_{\bar{i}}} - \bar{x})^2$$
- Soma dos quadrados dentro dos grupos
$$SSD_W = \sum_{i}^{k} \sum_{j}^{n}(\bar{x_{\bar{ij}}} - \bar{x_{\bar{i}}})^2$$
onde SSD B tem um grau de liberdade de k − 1 e SSD W tem um grau de liberdade de N − k. Em seguida, podemos definir as diferenças médias quadradas para cada métrica.
MS B = SSD B / (k - 1)
MS w = SSD w / (N - k)
Finalmente, a estatística de teste em ANOVA é definida como a razão das duas quantidades acima
F = MS B / MS w
que segue uma distribuição F com k − 1 e N − k graus de liberdade. Se a hipótese nula for verdadeira, F provavelmente seria próximo de 1. Caso contrário, o MSB do quadrado médio entre os grupos provavelmente será grande, o que resulta em um valor F grande.
Basicamente, ANOVA examina as duas fontes da variância total e vê qual parte contribui mais. É por isso que é chamada de análise de variância, embora a intenção seja comparar as médias dos grupos.
Em termos de cálculo da estatística, é realmente bastante simples de fazer em R. O exemplo a seguir demonstrará como isso é feito e representará os resultados.
library(ggplot2)
# We will be using the mtcars dataset
head(mtcars)
# mpg cyl disp hp drat wt qsec vs am gear carb
# Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
# Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
# Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
# Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
# Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
# Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
# Let's see if there are differences between the groups of cyl in the mpg variable.
data = mtcars[, c('mpg', 'cyl')]
fit = lm(mpg ~ cyl, data = mtcars)
anova(fit)
# Analysis of Variance Table
# Response: mpg
# Df Sum Sq Mean Sq F value Pr(>F)
# cyl 1 817.71 817.71 79.561 6.113e-10 ***
# Residuals 30 308.33 10.28
# Signif. codes: 0 *** 0.001 ** 0.01 * 0.05 .
# Plot the distribution
plot(mpg ~ as.factor(cyl), data = mtcars, col = 'deepskyblue3')O código produzirá a seguinte saída -

O valor de p obtido no exemplo é significativamente menor do que 0,05, então R retorna o símbolo '***' para denotar isso. Isso significa que rejeitamos a hipótese nula e que encontramos diferenças entre as médias de mpg entre os diferentes grupos docyl variável.
O aprendizado de máquina é um subcampo da ciência da computação que lida com tarefas como reconhecimento de padrões, visão computacional, reconhecimento de fala, análise de texto e tem uma forte ligação com estatística e otimização matemática. As aplicações incluem o desenvolvimento de motores de busca, filtragem de spam, Optical Character Recognition (OCR), entre outros. Os limites entre a mineração de dados, o reconhecimento de padrões e o campo do aprendizado estatístico não são claros e basicamente todos se referem a problemas semelhantes.
O aprendizado de máquina pode ser dividido em dois tipos de tarefa -
- Aprendizagem Supervisionada
- Aprendizagem Não Supervisionada
Aprendizagem Supervisionada
A aprendizagem supervisionada refere-se a um tipo de problema em que existe um dado de entrada definido como uma matriz X e estamos interessados em prever uma resposta y . Onde X = {x 1 , x 2 ,…, x n } tem n preditores e tem dois valores y = {c 1 , c 2 } .
Um exemplo de aplicação seria prever a probabilidade de um usuário da web clicar em anúncios usando recursos demográficos como preditores. Isso geralmente é chamado para prever a taxa de cliques (CTR). Então y = {clique, não - clique} e os preditores poderiam ser o endereço IP usado, o dia em que ele entrou no site, a cidade do usuário, país entre outros recursos que poderiam estar disponíveis.
Aprendizagem Não Supervisionada
A aprendizagem não supervisionada lida com o problema de encontrar grupos que sejam semelhantes entre si sem ter uma classe com a qual aprender. Existem várias abordagens para a tarefa de aprender um mapeamento de preditores para encontrar grupos que compartilham instâncias semelhantes em cada grupo e são diferentes entre si.
Um exemplo de aplicação de aprendizagem não supervisionada é a segmentação de clientes. Por exemplo, no setor de telecomunicações, uma tarefa comum é segmentar os usuários de acordo com o uso que dão ao telefone. Isso permitiria ao departamento de marketing direcionar cada grupo a um produto diferente.
Naive Bayes é uma técnica probabilística para construir classificadores. A suposição característica do classificador Bayes ingênuo é considerar que o valor de uma característica particular é independente do valor de qualquer outra característica, dada a variável de classe.
Apesar das suposições simplificadas mencionadas anteriormente, os classificadores Bayes ingênuos têm bons resultados em situações complexas do mundo real. Uma vantagem do Bayes ingênuo é que ele requer apenas uma pequena quantidade de dados de treinamento para estimar os parâmetros necessários para a classificação e que o classificador pode ser treinado de forma incremental.
Naive Bayes é um modelo de probabilidade condicional: dada uma instância de problema a ser classificada, representada por um vetor x= (x 1 ,…, x n ) representando algumas n características (variáveis independentes), ele atribui a esta instância probabilidades para cada um dos K resultados ou classes possíveis.
$$p(C_k|x_1,....., x_n)$$
O problema com a formulação acima é que se o número de características n for grande ou se uma característica puder assumir um grande número de valores, então basear tal modelo em tabelas de probabilidade é inviável. Portanto, reformulamos o modelo para torná-lo mais simples. Usando o teorema de Bayes, a probabilidade condicional pode ser decomposta como -
$$p(C_k|x) = \frac{p(C_k)p(x|C_k)}{p(x)}$$
Isso significa que, sob as premissas de independência acima, a distribuição condicional sobre a variável de classe C é -
$$p(C_k|x_1,....., x_n)\: = \: \frac{1}{Z}p(C_k)\prod_{i = 1}^{n}p(x_i|C_k)$$
onde a evidência Z = p (x) é um fator de escala dependente apenas de x 1 ,…, x n , que é uma constante se os valores das variáveis de recurso forem conhecidos. Uma regra comum é escolher a hipótese mais provável; isso é conhecido como regra de decisão máxima a posteriori ou MAP. O classificador correspondente, um classificador Bayes, é a função que atribui um rótulo de classe$\hat{y} = C_k$ por algum k como segue -
$$\hat{y} = argmax\: p(C_k)\prod_{i = 1}^{n}p(x_i|C_k)$$
Implementar o algoritmo em R é um processo direto. O exemplo a seguir demonstra como treinar um classificador Naive Bayes e usá-lo para predição em um problema de filtragem de spam.
O seguinte script está disponível no bda/part3/naive_bayes/naive_bayes.R Arquivo.
# Install these packages
pkgs = c("klaR", "caret", "ElemStatLearn")
install.packages(pkgs)
library('ElemStatLearn')
library("klaR")
library("caret")
# Split the data in training and testing
inx = sample(nrow(spam), round(nrow(spam) * 0.9))
train = spam[inx,]
test = spam[-inx,]
# Define a matrix with features, X_train
# And a vector with class labels, y_train
X_train = train[,-58]
y_train = train$spam X_test = test[,-58] y_test = test$spam
# Train the model
nb_model = train(X_train, y_train, method = 'nb',
trControl = trainControl(method = 'cv', number = 3))
# Compute
preds = predict(nb_model$finalModel, X_test)$class
tbl = table(y_test, yhat = preds)
sum(diag(tbl)) / sum(tbl)
# 0.7217391Como podemos ver no resultado, a precisão do modelo Naive Bayes é de 72%. Isso significa que o modelo classifica corretamente 72% das instâncias.
O agrupamento k-means visa particionar n observações em k clusters em que cada observação pertence ao cluster com a média mais próxima, servindo como um protótipo do cluster. Isso resulta em um particionamento do espaço de dados em células Voronoi.
Dado um conjunto de observações (x 1 , x 2 , ..., x n ) , onde cada observação é um vetor real d-dimensional, o agrupamento de k-médias visa particionar as n observações em k grupos G = {G 1 , G 2 ,…, G k } de modo a minimizar a soma dos quadrados dentro do cluster (WCSS) definida a seguir -
$$argmin \: \sum_{i = 1}^{k} \sum_{x \in S_{i}}\parallel x - \mu_{i}\parallel ^2$$
A última fórmula mostra a função objetivo que é minimizada para encontrar os protótipos ótimos no agrupamento de k-means. A intuição da fórmula é que gostaríamos de encontrar grupos diferentes uns dos outros e cada membro de cada grupo deve ser semelhante aos outros membros de cada cluster.
O exemplo a seguir demonstra como executar o algoritmo de agrupamento k-means em R.
library(ggplot2)
# Prepare Data
data = mtcars
# We need to scale the data to have zero mean and unit variance
data <- scale(data)
# Determine number of clusters
wss <- (nrow(data)-1)*sum(apply(data,2,var))
for (i in 2:dim(data)[2]) {
wss[i] <- sum(kmeans(data, centers = i)$withinss)
}
# Plot the clusters
plot(1:dim(data)[2], wss, type = "b", xlab = "Number of Clusters",
ylab = "Within groups sum of squares")Para encontrar um bom valor para K, podemos representar graficamente a soma dos quadrados dentro dos grupos para diferentes valores de K. Esta métrica normalmente diminui à medida que mais grupos são adicionados, gostaríamos de encontrar um ponto onde a diminuição na soma dos grupos de quadrados começa a diminuir lentamente. No gráfico, esse valor é melhor representado por K = 6.

Agora que o valor de K foi definido, é necessário executar o algoritmo com esse valor.
# K-Means Cluster Analysis
fit <- kmeans(data, 5) # 5 cluster solution
# get cluster means
aggregate(data,by = list(fit$cluster),FUN = mean)
# append cluster assignment
data <- data.frame(data, fit$cluster)Seja I = i 1 , i 2 , ..., i n um conjunto de n atributos binários chamados itens. Seja D = t 1 , t 2 , ..., t m um conjunto de transações denominado banco de dados. Cada transação em D possui um ID de transação exclusivo e contém um subconjunto dos itens em I. Uma regra é definida como uma implicação da forma X ⇒ Y, onde X, Y ⊆ I e X ∩ Y = ∅.
Os conjuntos de itens (para conjuntos de itens curtos) X e Y são chamados de antecedentes (lado esquerdo ou LHS) e conseqüentes (lado direito ou RHS) da regra.
Para ilustrar os conceitos, usamos um pequeno exemplo do domínio do supermercado. O conjunto de itens é I = {leite, pão, manteiga, cerveja} e um pequeno banco de dados contendo os itens é mostrado na tabela a seguir.
| ID de transação | Itens |
|---|---|
| 1 | leite pão |
| 2 | pão manteiga |
| 3 | Cerveja |
| 4 | leite, pão, manteiga |
| 5 | pão manteiga |
Um exemplo de regra para o supermercado poderia ser {leite, pão} ⇒ {manteiga}, o que significa que se o leite e o pão forem comprados, os clientes também comprarão manteiga. Para selecionar regras interessantes do conjunto de todas as regras possíveis, podem ser usadas restrições sobre várias medidas de significância e interesse. As restrições mais conhecidas são os limites mínimos de suporte e confiança.
O suporte supp (X) de um conjunto de itens X é definido como a proporção de transações no conjunto de dados que contém o conjunto de itens. No banco de dados de exemplo na Tabela 1, o conjunto de itens {leite, pão} tem um suporte de 2/5 = 0,4, pois ocorre em 40% de todas as transações (2 de 5 transações). Encontrar conjuntos de itens frequentes pode ser visto como uma simplificação do problema de aprendizagem não supervisionada.
A confiança de uma regra é definida conf (X ⇒ Y) = supp (X ∪ Y) / supp (X). Por exemplo, a regra {leite, pão} ⇒ {manteiga} tem uma confiança de 0,2 / 0,4 = 0,5 no banco de dados da Tabela 1, o que significa que para 50% das transações contendo leite e pão a regra está correta. A confiança pode ser interpretada como uma estimativa da probabilidade P (Y | X), a probabilidade de encontrar o RHS da regra em transações sob a condição de que essas transações também contenham o LHS.
No script localizado em bda/part3/apriori.R o código para implementar o apriori algorithm pode ser encontrado.
# Load the library for doing association rules
# install.packages(’arules’)
library(arules)
# Data preprocessing
data("AdultUCI")
AdultUCI[1:2,]
AdultUCI[["fnlwgt"]] <- NULL
AdultUCI[["education-num"]] <- NULL
AdultUCI[[ "age"]] <- ordered(cut(AdultUCI[[ "age"]], c(15,25,45,65,100)),
labels = c("Young", "Middle-aged", "Senior", "Old"))
AdultUCI[[ "hours-per-week"]] <- ordered(cut(AdultUCI[[ "hours-per-week"]],
c(0,25,40,60,168)), labels = c("Part-time", "Full-time", "Over-time", "Workaholic"))
AdultUCI[[ "capital-gain"]] <- ordered(cut(AdultUCI[[ "capital-gain"]],
c(-Inf,0,median(AdultUCI[[ "capital-gain"]][AdultUCI[[ "capitalgain"]]>0]),Inf)),
labels = c("None", "Low", "High"))
AdultUCI[[ "capital-loss"]] <- ordered(cut(AdultUCI[[ "capital-loss"]],
c(-Inf,0, median(AdultUCI[[ "capital-loss"]][AdultUCI[[ "capitalloss"]]>0]),Inf)),
labels = c("none", "low", "high"))Para gerar regras usando o algoritmo apriori, precisamos criar uma matriz de transação. O código a seguir mostra como fazer isso em R.
# Convert the data into a transactions format
Adult <- as(AdultUCI, "transactions")
Adult
# transactions in sparse format with
# 48842 transactions (rows) and
# 115 items (columns)
summary(Adult)
# Plot frequent item-sets
itemFrequencyPlot(Adult, support = 0.1, cex.names = 0.8)
# generate rules
min_support = 0.01
confidence = 0.6
rules <- apriori(Adult, parameter = list(support = min_support, confidence = confidence))
rules
inspect(rules[100:110, ])
# lhs rhs support confidence lift
# {occupation = Farming-fishing} => {sex = Male} 0.02856148 0.9362416 1.4005486
# {occupation = Farming-fishing} => {race = White} 0.02831579 0.9281879 1.0855456
# {occupation = Farming-fishing} => {native-country 0.02671881 0.8758389 0.9759474
= United-States}Uma árvore de decisão é um algoritmo usado para problemas de aprendizagem supervisionada, como classificação ou regressão. Uma árvore de decisão ou uma árvore de classificação é uma árvore na qual cada nó interno (não-folha) é rotulado com um recurso de entrada. Os arcos vindos de um nó rotulado com um recurso são rotulados com cada um dos valores possíveis do recurso. Cada folha da árvore é rotulada com uma classe ou distribuição de probabilidade entre as classes.
Uma árvore pode ser "aprendida" dividindo o conjunto de origem em subconjuntos com base em um teste de valor de atributo. Este processo é repetido em cada subconjunto derivado de uma maneira recursiva chamadarecursive partitioning. A recursão é concluída quando o subconjunto em um nó tem o mesmo valor da variável de destino ou quando a divisão não agrega mais valor às previsões. Este processo de indução de cima para baixo de árvores de decisão é um exemplo de algoritmo guloso e é a estratégia mais comum para aprender árvores de decisão.
As árvores de decisão usadas na mineração de dados são de dois tipos principais -
Classification tree - quando a resposta é uma variável nominal, por exemplo, se um e-mail é spam ou não.
Regression tree - quando o resultado previsto pode ser considerado um número real (por exemplo, o salário de um trabalhador).
As árvores de decisão são um método simples e, como tal, apresentam alguns problemas. Um desses problemas é a alta variação nos modelos resultantes que as árvores de decisão produzem. Para amenizar esse problema, foram desenvolvidos métodos de agrupamento de árvores de decisão. Existem dois grupos de métodos de conjunto usados extensivamente -
Bagging decision trees- Essas árvores são usadas para construir várias árvores de decisão, reamostrando repetidamente os dados de treinamento com substituição e votando nas árvores para uma previsão de consenso. Este algoritmo foi denominado floresta aleatória.
Boosting decision trees- O aumento de gradiente combina alunos fracos; neste caso, árvores de decisão em um único aluno forte, de forma iterativa. Ele ajusta uma árvore fraca aos dados e continua ajustando os alunos fracos de forma iterativa para corrigir o erro do modelo anterior.
# Install the party package
# install.packages('party')
library(party)
library(ggplot2)
head(diamonds)
# We will predict the cut of diamonds using the features available in the
diamonds dataset.
ct = ctree(cut ~ ., data = diamonds)
# plot(ct, main="Conditional Inference Tree")
# Example output
# Response: cut
# Inputs: carat, color, clarity, depth, table, price, x, y, z
# Number of observations: 53940
#
# 1) table <= 57; criterion = 1, statistic = 10131.878
# 2) depth <= 63; criterion = 1, statistic = 8377.279
# 3) table <= 56.4; criterion = 1, statistic = 226.423
# 4) z <= 2.64; criterion = 1, statistic = 70.393
# 5) clarity <= VS1; criterion = 0.989, statistic = 10.48
# 6) color <= E; criterion = 0.997, statistic = 12.829
# 7)* weights = 82
# 6) color > E
#Table of prediction errors
table(predict(ct), diamonds$cut)
# Fair Good Very Good Premium Ideal
# Fair 1388 171 17 0 14
# Good 102 2912 499 26 27
# Very Good 54 998 3334 249 355
# Premium 44 711 5054 11915 1167
# Ideal 22 114 3178 1601 19988
# Estimated class probabilities
probs = predict(ct, newdata = diamonds, type = "prob")
probs = do.call(rbind, probs)
head(probs)A regressão logística é um modelo de classificação em que a variável de resposta é categórica. É um algoritmo que vem de estatísticas e é usado para problemas de classificação supervisionada. Na regressão logística buscamos encontrar o vetor β de parâmetros na seguinte equação que minimiza a função de custo.
$$logit(p_i) = ln \left ( \frac{p_i}{1 - p_i} \right ) = \beta_0 + \beta_1x_{1,i} + ... + \beta_kx_{k,i}$$
O código a seguir demonstra como ajustar um modelo de regressão logística em R. Usaremos aqui o conjunto de dados de spam para demonstrar a regressão logística, o mesmo que foi usado para Naive Bayes.
A partir dos resultados das previsões em termos de precisão, descobrimos que o modelo de regressão atinge uma precisão de 92,5% no conjunto de teste, em comparação com os 72% alcançados pelo classificador Naive Bayes.
library(ElemStatLearn)
head(spam)
# Split dataset in training and testing
inx = sample(nrow(spam), round(nrow(spam) * 0.8))
train = spam[inx,]
test = spam[-inx,]
# Fit regression model
fit = glm(spam ~ ., data = train, family = binomial())
summary(fit)
# Call:
# glm(formula = spam ~ ., family = binomial(), data = train)
#
# Deviance Residuals:
# Min 1Q Median 3Q Max
# -4.5172 -0.2039 0.0000 0.1111 5.4944
# Coefficients:
# Estimate Std. Error z value Pr(>|z|)
# (Intercept) -1.511e+00 1.546e-01 -9.772 < 2e-16 ***
# A.1 -4.546e-01 2.560e-01 -1.776 0.075720 .
# A.2 -1.630e-01 7.731e-02 -2.108 0.035043 *
# A.3 1.487e-01 1.261e-01 1.179 0.238591
# A.4 2.055e+00 1.467e+00 1.401 0.161153
# A.5 6.165e-01 1.191e-01 5.177 2.25e-07 ***
# A.6 7.156e-01 2.768e-01 2.585 0.009747 **
# A.7 2.606e+00 3.917e-01 6.652 2.88e-11 ***
# A.8 6.750e-01 2.284e-01 2.955 0.003127 **
# A.9 1.197e+00 3.362e-01 3.559 0.000373 ***
# Signif. codes: 0 *** 0.001 ** 0.01 * 0.05 . 0.1 1
### Make predictions
preds = predict(fit, test, type = ’response’)
preds = ifelse(preds > 0.5, 1, 0)
tbl = table(target = test$spam, preds)
tbl
# preds
# target 0 1
# email 535 23
# spam 46 316
sum(diag(tbl)) / sum(tbl)
# 0.925A série temporal é uma sequência de observações de variáveis categóricas ou numéricas indexadas por uma data ou registro de data e hora. Um exemplo claro de dados de série temporal é a série temporal do preço de uma ação. Na tabela a seguir, podemos ver a estrutura básica dos dados da série temporal. Neste caso, as observações são registradas a cada hora.
| Timestamp | Estoque - Preço |
|---|---|
| 11/10/2015 09:00:00 | 100 |
| 11/10/2015 10:00:00 | 110 |
| 11/10/2015 11:00:00 | 105 |
| 11/10/2015 12:00:00 | 90 |
| 11/10/2015 13:00:00 | 120 |
Normalmente, a primeira etapa na análise da série temporal é plotar a série; isso normalmente é feito com um gráfico de linha.
A aplicação mais comum da análise de série temporal é prever valores futuros de um valor numérico usando a estrutura temporal dos dados. Isso significa que as observações disponíveis são usadas para prever valores do futuro.
A ordenação temporal dos dados implica que os métodos tradicionais de regressão não são úteis. Para construir uma previsão robusta, precisamos de modelos que levem em consideração a ordenação temporal dos dados.
O modelo mais usado para Análise de Séries Temporais é chamado Autoregressive Moving Average(ARMA). O modelo consiste em duas partes, umautoregressive (AR) parte e um moving average(MA) parte. O modelo é geralmente referido como modelo ARMA (p, q) , onde p é a ordem da parte autorregressiva eq é a ordem da parte média móvel.
Modelo Autoregressivo
O AR (p) é lido como um modelo autoregressivo de ordem p. Matematicamente, é escrito como -
$$ X_t = c + \ sum_ {i = 1} ^ {P} \ phi_i X_ {t - i} + \ varejpsilon_ {t} $$
onde {φ 1 ,…, φ p } são parâmetros a serem estimados, c é uma constante e a variável aleatória ε t representa o ruído branco. Algumas restrições são necessárias nos valores dos parâmetros para que o modelo permaneça estacionário.
Média Móvel
A notação MA (q) refere-se ao modelo de média móvel de ordem q -
$$ X_t = \ mu + \ varepsilon_t + \ sum_ {i = 1} ^ {q} \ theta_i \ varepsilon_ {t - i} $$
onde θ 1 , ..., θ q são os parâmetros do modelo, μ é a expectativa de X t , e ε t , ε t - 1 , ... são, termos de erro de ruído branco.
Média Móvel Autoregressiva
O modelo ARMA (p, q) combina p termos autorregressivos e q termos de média móvel. Matematicamente, o modelo é expresso com a seguinte fórmula -
$$ X_t = c + \ varepsilon_t + \ sum_ {i = 1} ^ {P} \ phi_iX_ {t - 1} + \ sum_ {i = 1} ^ {q} \ theta_i \ varejpsilon_ {ti} $$
Podemos ver que o modelo ARMA (p, q) é uma combinação dos modelos AR (p) e MA (q) .
Para dar alguma intuição do modelo, considere que a parte AR da equação busca estimar parâmetros para X t - i observações de a fim de prever o valor da variável em X t . É no final uma média ponderada dos valores anteriores. A seção MA usa a mesma abordagem, mas com o erro das observações anteriores, ε t - i . Portanto, no final, o resultado do modelo é uma média ponderada.
O seguinte trecho de código demonstra como implementar uma ARMA (p, q) em R .
# install.packages("forecast")
library("forecast")
# Read the data
data = scan('fancy.dat')
ts_data <- ts(data, frequency = 12, start = c(1987,1))
ts_data
plot.ts(ts_data)Traçar os dados normalmente é a primeira etapa para descobrir se há uma estrutura temporal nos dados. Podemos ver no gráfico que há fortes picos no final de cada ano.
O código a seguir ajusta um modelo ARMA aos dados. Executa várias combinações de modelos e seleciona aquele que apresenta menos erro.
# Fit the ARMA model
fit = auto.arima(ts_data)
summary(fit)
# Series: ts_data
# ARIMA(1,1,1)(0,1,1)[12]
# Coefficients:
# ar1 ma1 sma1
# 0.2401 -0.9013 0.7499
# s.e. 0.1427 0.0709 0.1790
#
# sigma^2 estimated as 15464184: log likelihood = -693.69
# AIC = 1395.38 AICc = 1395.98 BIC = 1404.43
# Training set error measures:
# ME RMSE MAE MPE MAPE MASE ACF1
# Training set 328.301 3615.374 2171.002 -2.481166 15.97302 0.4905797 -0.02521172Neste capítulo, usaremos os dados coletados na parte 1 do livro. Os dados contêm um texto que descreve perfis de freelancers e a taxa por hora que eles cobram em dólares americanos. A ideia da seção a seguir é se adequar a um modelo que, dadas as habilidades de um freelancer, possamos prever seu salário por hora.
O código a seguir mostra como converter o texto bruto que neste caso possui as habilidades de um usuário em uma matriz de saco de palavras. Para isso, usamos uma biblioteca R chamada tm. Isso significa que para cada palavra do corpus criamos uma variável com a quantidade de ocorrências de cada variável.
library(tm)
library(data.table)
source('text_analytics/text_analytics_functions.R')
data = fread('text_analytics/data/profiles.txt')
rate = as.numeric(data$rate)
keep = !is.na(rate)
rate = rate[keep]
### Make bag of words of title and body
X_all = bag_words(data$user_skills[keep])
X_all = removeSparseTerms(X_all, 0.999)
X_all
# <<DocumentTermMatrix (documents: 389, terms: 1422)>>
# Non-/sparse entries: 4057/549101
# Sparsity : 99%
# Maximal term length: 80
# Weighting : term frequency - inverse document frequency (normalized) (tf-idf)
### Make a sparse matrix with all the data
X_all <- as_sparseMatrix(X_all)Agora que temos o texto representado como uma matriz esparsa, podemos ajustar um modelo que fornecerá uma solução esparsa. Uma boa alternativa para este caso é usar o LASSO (menor contração absoluta e operador de seleção). Este é um modelo de regressão que é capaz de selecionar os recursos mais relevantes para prever o destino.
train_inx = 1:200
X_train = X_all[train_inx, ]
y_train = rate[train_inx]
X_test = X_all[-train_inx, ]
y_test = rate[-train_inx]
# Train a regression model
library(glmnet)
fit <- cv.glmnet(x = X_train, y = y_train,
family = 'gaussian', alpha = 1,
nfolds = 3, type.measure = 'mae')
plot(fit)
# Make predictions
predictions = predict(fit, newx = X_test)
predictions = as.vector(predictions[,1])
head(predictions)
# 36.23598 36.43046 51.69786 26.06811 35.13185 37.66367
# We can compute the mean absolute error for the test data
mean(abs(y_test - predictions))
# 15.02175Agora temos um modelo que, dado um conjunto de habilidades, é capaz de prever o salário por hora de um freelancer. Se mais dados forem coletados, o desempenho do modelo melhorará, mas o código para implementar esse pipeline será o mesmo.
O aprendizado online é um subcampo do aprendizado de máquina que permite dimensionar modelos de aprendizado supervisionado para conjuntos de dados massivos. A ideia básica é que não precisamos ler todos os dados na memória para ajustar um modelo, precisamos apenas ler cada instância de cada vez.
Neste caso, mostraremos como implementar um algoritmo de aprendizagem online usando regressão logística. Como na maioria dos algoritmos de aprendizado supervisionado, existe uma função de custo que é minimizada. Na regressão logística, a função de custo é definida como -
$$ J (\ theta) \: = \: \ frac {-1} {m} \ left [\ sum_ {i = 1} ^ {m} y ^ {(i)} log (h _ {\ theta} ( x ^ {(i)})) + (1 - y ^ {(i)}) log (1 - h _ {\ theta} (x ^ {(i)})) \ right] $$
onde J (θ) representa a função de custo eh θ (x) representa a hipótese. No caso de regressão logística, ela é definida com a seguinte fórmula -
$$ h_ \ theta (x) = \ frac {1} {1 + e ^ {\ theta ^ T x}} $$
Agora que definimos a função de custo, precisamos encontrar um algoritmo para minimizá-la. O algoritmo mais simples para conseguir isso é chamado de descida gradiente estocástica. A regra de atualização do algoritmo para os pesos do modelo de regressão logística é definida como -
$$ \ theta_j: = \ theta_j - \ alpha (h_ \ theta (x) - y) x $$
Existem várias implementações do algoritmo a seguir, mas a implementada na biblioteca wabbit vowpal é de longe a mais desenvolvida. A biblioteca permite o treinamento de modelos de regressão em grande escala e usa pequenas quantidades de RAM. Nas próprias palavras dos criadores, ele é descrito como: "O projeto Vowpal Wabbit (VW) é um sistema de aprendizagem fora do núcleo rápido patrocinado pela Microsoft Research e (anteriormente) Yahoo! Research".
Estaremos trabalhando com o conjunto de dados titânico de um kaggleconcorrência. Os dados originais podem ser encontrados nobda/part3/vwpasta. Aqui, temos dois arquivos -
- Temos dados de treinamento (train_titanic.csv), e
- dados não rotulados para fazer novas previsões (test_titanic.csv).
Para converter o formato csv para o vowpal wabbit formato de entrada use o csv_to_vowpal_wabbit.pyscript python. Obviamente, você precisará ter o python instalado para isso. Navegue até obda/part3/vw pasta, abra o terminal e execute o seguinte comando -
python csv_to_vowpal_wabbit.pyObserve que para esta seção, se você estiver usando o Windows, você precisará instalar uma linha de comando Unix, entre no site do cygwin para isso.
Abra o terminal e também na pasta bda/part3/vw e execute o seguinte comando -
vw train_titanic.vw -f model.vw --binary --passes 20 -c -q ff --sgd --l1
0.00000001 --l2 0.0000001 --learning_rate 0.5 --loss_function logisticVamos quebrar o que cada argumento do vw call significa.
-f model.vw - significa que estamos salvando o modelo no arquivo model.vw para fazer previsões mais tarde
--binary - Relatórios de perda como classificação binária com -1,1 rótulos
--passes 20 - Os dados são usados 20 vezes para aprender os pesos
-c - criar um arquivo de cache
-q ff - Use recursos quadráticos no namespace f
--sgd - usar atualização de gradiente descendente estocástico regular / clássico / simples, ou seja, não adaptativo, não normalizado e não invariante.
--l1 --l2 - Regularização das normas L1 e L2
--learning_rate 0.5 - A taxa de aprendizagem α conforme definida na fórmula da regra de atualização
O código a seguir mostra os resultados da execução do modelo de regressão na linha de comando. Nos resultados, obtemos a perda de log média e um pequeno relatório do desempenho do algoritmo.
-loss_function logistic
creating quadratic features for pairs: ff
using l1 regularization = 1e-08
using l2 regularization = 1e-07
final_regressor = model.vw
Num weight bits = 18
learning rate = 0.5
initial_t = 1
power_t = 0.5
decay_learning_rate = 1
using cache_file = train_titanic.vw.cache
ignoring text input in favor of cache input
num sources = 1
average since example example current current current
loss last counter weight label predict features
0.000000 0.000000 1 1.0 -1.0000 -1.0000 57
0.500000 1.000000 2 2.0 1.0000 -1.0000 57
0.250000 0.000000 4 4.0 1.0000 1.0000 57
0.375000 0.500000 8 8.0 -1.0000 -1.0000 73
0.625000 0.875000 16 16.0 -1.0000 1.0000 73
0.468750 0.312500 32 32.0 -1.0000 -1.0000 57
0.468750 0.468750 64 64.0 -1.0000 1.0000 43
0.375000 0.281250 128 128.0 1.0000 -1.0000 43
0.351562 0.328125 256 256.0 1.0000 -1.0000 43
0.359375 0.367188 512 512.0 -1.0000 1.0000 57
0.274336 0.274336 1024 1024.0 -1.0000 -1.0000 57 h
0.281938 0.289474 2048 2048.0 -1.0000 -1.0000 43 h
0.246696 0.211454 4096 4096.0 -1.0000 -1.0000 43 h
0.218922 0.191209 8192 8192.0 1.0000 1.0000 43 h
finished run
number of examples per pass = 802
passes used = 11
weighted example sum = 8822
weighted label sum = -2288
average loss = 0.179775 h
best constant = -0.530826
best constant’s loss = 0.659128
total feature number = 427878Agora podemos usar o model.vw treinamos para gerar previsões com novos dados.
vw -d test_titanic.vw -t -i model.vw -p predictions.txtAs previsões geradas no comando anterior não são normalizadas para caber entre o intervalo [0, 1]. Para fazer isso, usamos uma transformação sigmóide.
# Read the predictions
preds = fread('vw/predictions.txt')
# Define the sigmoid function
sigmoid = function(x) {
1 / (1 + exp(-x))
}
probs = sigmoid(preds[[1]])
# Generate class labels
preds = ifelse(probs > 0.5, 1, 0)
head(preds)
# [1] 0 1 0 0 1 0