R - สี่เหลี่ยมน้อยที่สุดไม่เชิงเส้น
เมื่อสร้างแบบจำลองข้อมูลโลกแห่งความเป็นจริงสำหรับการวิเคราะห์การถดถอยเราสังเกตได้ว่าไม่ค่อยเป็นเช่นนั้นสมการของแบบจำลองเป็นสมการเชิงเส้นที่ให้กราฟเชิงเส้น โดยส่วนใหญ่แล้วสมการของแบบจำลองข้อมูลในโลกแห่งความเป็นจริงจะเกี่ยวข้องกับฟังก์ชันทางคณิตศาสตร์ในระดับที่สูงกว่าเช่นเลขชี้กำลังของ 3 หรือฟังก์ชันบาป ในสถานการณ์ดังกล่าวพล็อตของแบบจำลองให้เส้นโค้งแทนที่จะเป็นเส้น เป้าหมายของการถดถอยทั้งเชิงเส้นและไม่เชิงเส้นคือการปรับค่าของพารามิเตอร์ของแบบจำลองเพื่อค้นหาเส้นหรือเส้นโค้งที่เข้ามาใกล้ข้อมูลของคุณมากที่สุด ในการหาค่าเหล่านี้เราจะสามารถประมาณตัวแปรการตอบสนองได้อย่างแม่นยำ
ในการถดถอยกำลังสองอย่างน้อยเราสร้างแบบจำลองการถดถอยซึ่งผลรวมของกำลังสองของระยะทางแนวตั้งของจุดต่าง ๆ จากเส้นโค้งการถดถอยจะถูกย่อให้เล็กสุด โดยทั่วไปเราเริ่มต้นด้วยแบบจำลองที่กำหนดไว้และถือว่าค่าสัมประสิทธิ์บางอย่าง จากนั้นเราใช้ไฟล์nls() ฟังก์ชันของ R เพื่อให้ได้ค่าที่แม่นยำยิ่งขึ้นพร้อมกับช่วงความเชื่อมั่น
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการสร้างการทดสอบกำลังสองน้อยที่สุดที่ไม่ใช่เชิงเส้นใน R คือ -
nls(formula, data, start)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
formula เป็นสูตรแบบไม่เชิงเส้นรวมถึงตัวแปรและพารามิเตอร์
data คือกรอบข้อมูลที่ใช้ประเมินตัวแปรในสูตร
start คือรายการที่มีชื่อหรือเวกเตอร์ตัวเลขที่มีชื่อของการประมาณการเริ่มต้น
ตัวอย่าง
เราจะพิจารณาแบบจำลองที่ไม่เป็นเชิงเส้นโดยมีสมมติฐานค่าเริ่มต้นของสัมประสิทธิ์ ต่อไปเราจะดูว่าช่วงความเชื่อมั่นของค่าสมมติเหล่านี้คืออะไรเพื่อที่เราจะได้ตัดสินว่าค่าเหล่านี้เข้ากับโมเดลได้ดีเพียงใด
ลองพิจารณาสมการด้านล่างเพื่อจุดประสงค์นี้ -
a = b1*x^2+b2สมมติว่าค่าสัมประสิทธิ์เริ่มต้นเป็น 1 และ 3 และใส่ค่าเหล่านี้ลงในฟังก์ชัน nls ()
xvalues <- c(1.6,2.1,2,2.23,3.71,3.25,3.4,3.86,1.19,2.21)
yvalues <- c(5.19,7.43,6.94,8.11,18.75,14.88,16.06,19.12,3.21,7.58)
# Give the chart file a name.
png(file = "nls.png")
# Plot these values.
plot(xvalues,yvalues)
# Take the assumed values and fit into the model.
model <- nls(yvalues ~ b1*xvalues^2+b2,start = list(b1 = 1,b2 = 3))
# Plot the chart with new data by fitting it to a prediction from 100 data points.
new.data <- data.frame(xvalues = seq(min(xvalues),max(xvalues),len = 100))
lines(new.data$xvalues,predict(model,newdata = new.data))
# Save the file.
dev.off()
# Get the sum of the squared residuals.
print(sum(resid(model)^2))
# Get the confidence intervals on the chosen values of the coefficients.
print(confint(model))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] 1.081935
Waiting for profiling to be done...
2.5% 97.5%
b1 1.137708 1.253135
b2 1.497364 2.496484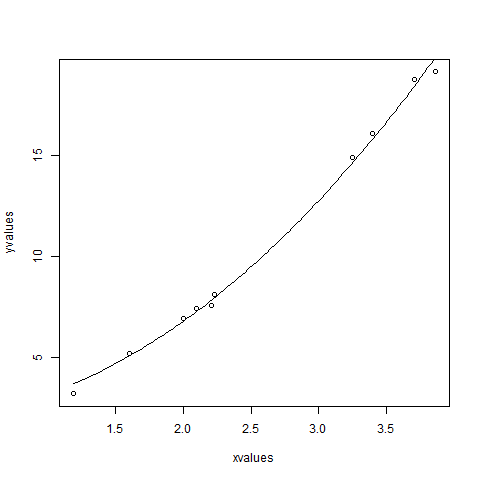
เราสามารถสรุปได้ว่าค่าของ b1 ใกล้เคียงกับ 1 มากกว่าในขณะที่ค่าของ b2 ใกล้เคียงกับ 2 และไม่ใช่ 3