R - คู่มือฉบับย่อ
R เป็นภาษาโปรแกรมและสภาพแวดล้อมซอฟต์แวร์สำหรับการวิเคราะห์ทางสถิติการแสดงกราฟิกและการรายงาน R ถูกสร้างขึ้นโดย Ross Ihaka และ Robert Gentleman จากมหาวิทยาลัยโอ๊คแลนด์นิวซีแลนด์และปัจจุบันได้รับการพัฒนาโดยทีม R Development Core
แกนกลางของ R เป็นภาษาคอมพิวเตอร์ที่ตีความซึ่งช่วยให้สามารถแยกสาขาและวนซ้ำได้เช่นเดียวกับการเขียนโปรแกรมแบบแยกส่วนโดยใช้ฟังก์ชัน R อนุญาตให้รวมกับโพรซีเดอร์ที่เขียนในภาษา C, C ++, .Net, Python หรือ FORTRAN เพื่อประสิทธิภาพ
R สามารถใช้ได้อย่างอิสระภายใต้สัญญาอนุญาตสาธารณะทั่วไปของ GNU และเวอร์ชันไบนารีที่คอมไพล์ไว้ล่วงหน้ามีให้สำหรับระบบปฏิบัติการต่างๆเช่น Linux, Windows และ Mac
R เป็นซอฟต์แวร์ฟรีที่แจกจ่ายภายใต้สำเนาแบบ GNU ทางซ้ายและเป็นส่วนหนึ่งของโครงการ GNU ที่เรียกว่า GNU S.
วิวัฒนาการของ R
R เขียนโดย Ross Ihaka และ Robert Gentlemanที่ภาควิชาสถิติของมหาวิทยาลัยโอ๊คแลนด์ในโอ๊คแลนด์นิวซีแลนด์ R ปรากฏตัวครั้งแรกในปีพ. ศ. 2536
กลุ่มบุคคลจำนวนมากมีส่วนร่วมใน R โดยการส่งโค้ดและรายงานข้อบกพร่อง
ตั้งแต่กลางปี 1997 เป็นต้นมามีกลุ่มหลัก ("R Core Team") ที่สามารถแก้ไขไฟล์ซอร์สโค้ด R ได้
คุณสมบัติของ R
ตามที่ระบุไว้ก่อนหน้านี้ R เป็นภาษาโปรแกรมและสภาพแวดล้อมซอฟต์แวร์สำหรับการวิเคราะห์ทางสถิติการแสดงกราฟิกและการรายงาน ต่อไปนี้เป็นคุณสมบัติที่สำคัญของ R -
R เป็นภาษาการเขียนโปรแกรมที่พัฒนามาอย่างดีเรียบง่ายและมีประสิทธิภาพซึ่งรวมถึงเงื่อนไขการวนซ้ำฟังก์ชันการเรียกซ้ำที่ผู้ใช้กำหนดและสิ่งอำนวยความสะดวกอินพุตและเอาต์พุต
R มีระบบจัดการและจัดเก็บข้อมูลที่มีประสิทธิภาพ
R จัดเตรียมชุดตัวดำเนินการสำหรับการคำนวณอาร์เรย์รายการเวกเตอร์และเมทริกซ์
R จัดเตรียมชุดเครื่องมือขนาดใหญ่ที่สอดคล้องกันและครบวงจรสำหรับการวิเคราะห์ข้อมูล
R จัดเตรียมสิ่งอำนวยความสะดวกด้านกราฟิกสำหรับการวิเคราะห์ข้อมูลและแสดงผลโดยตรงที่คอมพิวเตอร์หรือพิมพ์ที่กระดาษ
สรุปได้ว่า R เป็นภาษาโปรแกรมสถิติที่ใช้กันอย่างแพร่หลายมากที่สุดในโลก เป็นตัวเลือกอันดับ 1 ของนักวิทยาศาสตร์ข้อมูลและได้รับการสนับสนุนจากชุมชนผู้ให้ข้อมูลที่มีชีวิตชีวาและมีความสามารถ R ได้รับการสอนในมหาวิทยาลัยและนำไปใช้ในงานด้านธุรกิจที่สำคัญ บทช่วยสอนนี้จะสอนการเขียนโปรแกรม R พร้อมกับตัวอย่างที่เหมาะสมในขั้นตอนที่ง่ายและสะดวก
การตั้งค่าสภาพแวดล้อมท้องถิ่น
หากคุณยังเต็มใจที่จะตั้งค่าสภาพแวดล้อมของคุณสำหรับ R คุณสามารถทำตามขั้นตอนที่ระบุด้านล่าง
การติดตั้ง Windows
คุณสามารถดาวน์โหลดตัวติดตั้ง Windows รุ่น R จากR-3.2.2 สำหรับ Windows (32/64 บิต)และบันทึกลงในไดเร็กทอรีภายในเครื่อง
เนื่องจากเป็นโปรแกรมติดตั้ง Windows (.exe) ที่มีชื่อ "R-version-win.exe" คุณสามารถดับเบิลคลิกและเรียกใช้โปรแกรมติดตั้งที่ยอมรับการตั้งค่าเริ่มต้น หาก Windows ของคุณเป็นเวอร์ชัน 32 บิตแสดงว่าติดตั้งเวอร์ชัน 32 บิต แต่ถ้า Windows ของคุณเป็น 64 บิตแสดงว่าติดตั้งทั้งเวอร์ชัน 32 บิตและ 64 บิต
หลังจากการติดตั้งคุณสามารถค้นหาไอคอนเพื่อเรียกใช้โปรแกรมในโครงสร้างไดเร็กทอรี "R \ R3.2.2 \ bin \ i386 \ Rgui.exe" ภายใต้ Windows Program Files การคลิกไอคอนนี้จะเป็นการเปิด R-GUI ซึ่งเป็นคอนโซล R เพื่อทำการเขียนโปรแกรม R
การติดตั้ง Linux
R สามารถใช้ได้เป็นไบนารีสำหรับหลายรุ่นของลินุกซ์ในสถานที่ที่R ไบนารี
คำแนะนำในการติดตั้ง Linux จะแตกต่างกันไปในแต่ละรสชาติ ขั้นตอนเหล่านี้กล่าวถึงภายใต้เวอร์ชันของ Linux แต่ละประเภทในลิงค์ที่กล่าวถึง อย่างไรก็ตามหากคุณรีบคุณสามารถใช้yum คำสั่งในการติดตั้ง R ดังต่อไปนี้ -
$ yum install Rคำสั่งด้านบนจะติดตั้งฟังก์ชันหลักของการเขียนโปรแกรม R พร้อมกับแพ็คเกจมาตรฐาน แต่คุณยังต้องการแพ็คเกจเพิ่มเติมจากนั้นคุณสามารถเปิดใช้งานพรอมต์ได้ดังนี้ -
$ R
R version 3.2.0 (2015-04-16) -- "Full of Ingredients"
Copyright (C) 2015 The R Foundation for Statistical Computing
Platform: x86_64-redhat-linux-gnu (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
>ตอนนี้คุณสามารถใช้คำสั่งติดตั้งที่พรอมต์ R เพื่อติดตั้งแพ็คเกจที่ต้องการ ตัวอย่างเช่นคำสั่งต่อไปนี้จะติดตั้งplotrix แพ็คเกจที่จำเป็นสำหรับแผนภูมิ 3 มิติ
> install.packages("plotrix")ตามแบบแผนเราจะเริ่มเรียนรู้การเขียนโปรแกรม R โดยเขียนคำว่า "Hello, World!" โปรแกรม. ขึ้นอยู่กับความต้องการคุณสามารถตั้งโปรแกรมที่พรอมต์คำสั่ง R หรือคุณสามารถใช้ไฟล์สคริปต์ R เพื่อเขียนโปรแกรมของคุณ ลองตรวจสอบทั้งสองอย่างทีละรายการ
พร้อมรับคำสั่ง R
เมื่อคุณตั้งค่าสภาพแวดล้อม R แล้วคุณสามารถเริ่มพรอมต์คำสั่ง R ได้อย่างง่ายดายเพียงพิมพ์คำสั่งต่อไปนี้ที่พรอมต์คำสั่งของคุณ -
$ Rสิ่งนี้จะเปิดตัวล่าม R และคุณจะได้รับข้อความแจ้ง> ซึ่งคุณสามารถเริ่มพิมพ์โปรแกรมของคุณได้ดังนี้ -
> myString <- "Hello, World!"
> print ( myString)
[1] "Hello, World!"ต่อไปนี้คำสั่งแรกกำหนดตัวแปรสตริง myString ซึ่งเรากำหนดสตริง "Hello, World!" จากนั้นคำสั่งถัดไป print () จะถูกใช้เพื่อพิมพ์ค่าที่เก็บไว้ในตัวแปร myString
ไฟล์ R Script
โดยปกติคุณจะทำการเขียนโปรแกรมของคุณโดยเขียนโปรแกรมของคุณในไฟล์สคริปต์จากนั้นคุณเรียกใช้สคริปต์เหล่านั้นที่พรอมต์คำสั่งของคุณด้วยความช่วยเหลือของล่าม R ที่เรียกว่า Rscript. เริ่มจากเขียนโค้ดต่อไปนี้ในไฟล์ข้อความที่เรียกว่า test.R ตาม -
# My first program in R Programming
myString <- "Hello, World!"
print ( myString)บันทึกรหัสด้านบนในการทดสอบไฟล์ R และดำเนินการที่พรอมต์คำสั่ง Linux ตามที่ระบุด้านล่าง แม้ว่าคุณจะใช้ Windows หรือระบบอื่นไวยากรณ์จะยังคงเหมือนเดิม
$ Rscript test.Rเมื่อเรารันโปรแกรมข้างต้นจะให้ผลลัพธ์ดังต่อไปนี้
[1] "Hello, World!"ความคิดเห็น
ความคิดเห็นเป็นเหมือนข้อความช่วยในโปรแกรม R ของคุณและล่ามจะไม่สนใจในขณะที่เรียกใช้โปรแกรมจริงของคุณ ความคิดเห็นเดียวเขียนโดยใช้ # ขึ้นต้นข้อความดังนี้ -
# My first program in R ProgrammingR ไม่รองรับการแสดงความคิดเห็นแบบหลายบรรทัด แต่คุณสามารถใช้กลอุบายได้ดังต่อไปนี้ -
if(FALSE) {
"This is a demo for multi-line comments and it should be put inside either a
single OR double quote"
}
myString <- "Hello, World!"
print ( myString)[1] "Hello, World!"แม้ว่าความคิดเห็นข้างต้นจะดำเนินการโดยล่าม R แต่จะไม่รบกวนโปรแกรมจริงของคุณ คุณควรใส่ความคิดเห็นดังกล่าวไว้ข้างในไม่ว่าจะเป็นคำพูดเดี่ยวหรือคู่
โดยทั่วไปในขณะที่ทำการเขียนโปรแกรมด้วยภาษาการเขียนโปรแกรมใด ๆ คุณจำเป็นต้องใช้ตัวแปรต่างๆเพื่อจัดเก็บข้อมูลต่างๆ ตัวแปรไม่ใช่อะไรเลยนอกจากตำแหน่งหน่วยความจำที่สงวนไว้เพื่อเก็บค่า ซึ่งหมายความว่าเมื่อคุณสร้างตัวแปรคุณจะสงวนพื้นที่ในหน่วยความจำไว้
คุณอาจต้องการจัดเก็บข้อมูลประเภทข้อมูลต่างๆเช่นอักขระอักขระแบบกว้างจำนวนเต็มจุดลอยตัวจุดลอยตัวคู่บูลีนเป็นต้นตามประเภทข้อมูลของตัวแปรระบบปฏิบัติการจะจัดสรรหน่วยความจำและตัดสินใจว่าจะจัดเก็บอะไรใน หน่วยความจำที่สงวนไว้
ตรงกันข้ามกับภาษาโปรแกรมอื่น ๆ เช่น C และ java ใน R ตัวแปรจะไม่ถูกประกาศเป็นข้อมูลบางประเภท ตัวแปรถูกกำหนดด้วย R-Objects และชนิดข้อมูลของ R-object จะกลายเป็นชนิดข้อมูลของตัวแปร วัตถุ R มีหลายประเภท คนที่ใช้บ่อยคือ -
- Vectors
- Lists
- Matrices
- Arrays
- Factors
- เฟรมข้อมูล
สิ่งที่ง่ายที่สุดของวัตถุเหล่านี้คือ vector objectและมีข้อมูลหกประเภทของเวกเตอร์อะตอมเหล่านี้เรียกอีกอย่างว่าหกคลาสของเวกเตอร์ R-Objects อื่น ๆ ถูกสร้างขึ้นจากเวกเตอร์อะตอม
| ประเภทข้อมูล | ตัวอย่าง | ตรวจสอบ |
|---|---|---|
| ตรรกะ | ถูกผิด |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
| ตัวเลข | 12.3, 5, 999 |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
| จำนวนเต็ม | 2L, 34L, 0L |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
| ซับซ้อน | 3 + 2i |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
| ตัวละคร | 'a', '"ดี", "TRUE", '23 .4' |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
| ดิบ | "สวัสดี" ถูกจัดเก็บเป็น 48 65 6c 6c 6f |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
ในการเขียนโปรแกรม R ชนิดข้อมูลพื้นฐานคือ R-objects ที่เรียกว่า vectorsซึ่งมีองค์ประกอบของคลาสต่างๆดังที่แสดงไว้ด้านบน โปรดทราบใน R จำนวนชั้นเรียนไม่ได้ จำกัด เฉพาะหกประเภทข้างต้น ตัวอย่างเช่นเราสามารถใช้เวกเตอร์อะตอมจำนวนมากและสร้างอาร์เรย์ซึ่งคลาสจะกลายเป็นอาร์เรย์
เวกเตอร์
เมื่อคุณต้องการสร้างเวกเตอร์ที่มีองค์ประกอบมากกว่าหนึ่งองค์ประกอบคุณควรใช้ c() ฟังก์ชันซึ่งหมายถึงการรวมองค์ประกอบเป็นเวกเตอร์
# Create a vector.
apple <- c('red','green',"yellow")
print(apple)
# Get the class of the vector.
print(class(apple))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] "red" "green" "yellow"
[1] "character"รายการ
รายการคือวัตถุ R ซึ่งสามารถมีองค์ประกอบหลายประเภทอยู่ภายในเช่นเวกเตอร์ฟังก์ชันและแม้แต่รายการอื่น ๆ ภายใน
# Create a list.
list1 <- list(c(2,5,3),21.3,sin)
# Print the list.
print(list1)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[[1]]
[1] 2 5 3
[[2]]
[1] 21.3
[[3]]
function (x) .Primitive("sin")เมทริกซ์
เมทริกซ์คือชุดข้อมูลสี่เหลี่ยมสองมิติ สามารถสร้างได้โดยใช้อินพุตเวกเตอร์ไปยังฟังก์ชันเมทริกซ์
# Create a matrix.
M = matrix( c('a','a','b','c','b','a'), nrow = 2, ncol = 3, byrow = TRUE)
print(M)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[,1] [,2] [,3]
[1,] "a" "a" "b"
[2,] "c" "b" "a"อาร์เรย์
ในขณะที่เมทริกซ์ถูก จำกัด ไว้ที่สองมิติอาร์เรย์อาจมีขนาดเท่าใดก็ได้ ฟังก์ชันอาร์เรย์รับแอตทริบิวต์สลัวซึ่งสร้างจำนวนมิติที่ต้องการ ในตัวอย่างด้านล่างเราสร้างอาร์เรย์ที่มีสององค์ประกอบซึ่งแต่ละเมทริกซ์ 3x3
# Create an array.
a <- array(c('green','yellow'),dim = c(3,3,2))
print(a)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
, , 1
[,1] [,2] [,3]
[1,] "green" "yellow" "green"
[2,] "yellow" "green" "yellow"
[3,] "green" "yellow" "green"
, , 2
[,1] [,2] [,3]
[1,] "yellow" "green" "yellow"
[2,] "green" "yellow" "green"
[3,] "yellow" "green" "yellow"ปัจจัย
ปัจจัยคือวัตถุ r ที่สร้างขึ้นโดยใช้เวกเตอร์ จะจัดเก็บเวกเตอร์พร้อมกับค่าที่แตกต่างกันขององค์ประกอบในเวกเตอร์เป็นป้ายกำกับ ป้ายกำกับเป็นอักขระเสมอไม่ว่าจะเป็นตัวเลขหรืออักขระหรือบูลีนเป็นต้นในเวกเตอร์อินพุต มีประโยชน์ในการสร้างแบบจำลองทางสถิติ
ปัจจัยถูกสร้างขึ้นโดยใช้ไฟล์ factor()ฟังก์ชัน nlevels ฟังก์ชันให้การนับระดับ
# Create a vector.
apple_colors <- c('green','green','yellow','red','red','red','green')
# Create a factor object.
factor_apple <- factor(apple_colors)
# Print the factor.
print(factor_apple)
print(nlevels(factor_apple))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] green green yellow red red red green
Levels: green red yellow
[1] 3เฟรมข้อมูล
เฟรมข้อมูลคือออบเจ็กต์ข้อมูลแบบตาราง ซึ่งแตกต่างจากเมทริกซ์ในกรอบข้อมูลแต่ละคอลัมน์สามารถมีโหมดข้อมูลที่แตกต่างกันได้ คอลัมน์แรกสามารถเป็นตัวเลขในขณะที่คอลัมน์ที่สองสามารถเป็นอักขระและคอลัมน์ที่สามสามารถเป็นตรรกะได้ เป็นรายการเวกเตอร์ที่มีความยาวเท่ากัน
เฟรมข้อมูลถูกสร้างขึ้นโดยใช้ data.frame() ฟังก์ชัน
# Create the data frame.
BMI <- data.frame(
gender = c("Male", "Male","Female"),
height = c(152, 171.5, 165),
weight = c(81,93, 78),
Age = c(42,38,26)
)
print(BMI)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
gender height weight Age
1 Male 152.0 81 42
2 Male 171.5 93 38
3 Female 165.0 78 26ตัวแปรช่วยให้เรามีพื้นที่จัดเก็บที่มีชื่อซึ่งโปรแกรมของเราสามารถจัดการได้ ตัวแปรใน R สามารถจัดเก็บเวกเตอร์อะตอมกลุ่มของเวกเตอร์อะตอมหรือการรวมกันของ Robjects จำนวนมาก ชื่อตัวแปรที่ถูกต้องประกอบด้วยตัวอักษรตัวเลขและจุดหรืออักขระขีดเส้นใต้ ชื่อตัวแปรเริ่มต้นด้วยตัวอักษรหรือจุดที่ไม่ได้ตามด้วยตัวเลข
| ชื่อตัวแปร | ความถูกต้อง | เหตุผล |
|---|---|---|
| var_name2. | ถูกต้อง | มีตัวอักษรตัวเลขจุดและขีดล่าง |
| var_name% | ไม่ถูกต้อง | มีอักขระ '%' อนุญาตเฉพาะจุด (.) และขีดล่างเท่านั้น |
| 2var_name | ไม่ถูกต้อง | เริ่มต้นด้วยตัวเลข |
.var_name, var.name |
ถูกต้อง | สามารถเริ่มต้นด้วยจุด (.) แต่ไม่ควรตามด้วยตัวเลข |
| .2var_name | ไม่ถูกต้อง | จุดเริ่มต้นตามด้วยตัวเลขทำให้ไม่ถูกต้อง |
| _var_name | ไม่ถูกต้อง | เริ่มต้นด้วย _ ซึ่งไม่ถูกต้อง |
การกำหนดตัวแปร
ตัวแปรสามารถกำหนดค่าได้โดยใช้ตัวดำเนินการซ้ายขวาและเท่ากับตัวดำเนินการ สามารถพิมพ์ค่าของตัวแปรได้โดยใช้print() หรือ cat()ฟังก์ชัน cat() ฟังก์ชั่นรวมหลายรายการเป็นผลงานพิมพ์ต่อเนื่อง
# Assignment using equal operator.
var.1 = c(0,1,2,3)
# Assignment using leftward operator.
var.2 <- c("learn","R")
# Assignment using rightward operator.
c(TRUE,1) -> var.3
print(var.1)
cat ("var.1 is ", var.1 ,"\n")
cat ("var.2 is ", var.2 ,"\n")
cat ("var.3 is ", var.3 ,"\n")เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] 0 1 2 3
var.1 is 0 1 2 3
var.2 is learn R
var.3 is 1 1Note- เวกเตอร์ c (TRUE, 1) มีคลาสตรรกะและตัวเลขผสมกัน ดังนั้นคลาสตรรกะจึงถูกบังคับให้คลาสตัวเลขทำให้ TRUE เป็น 1
ชนิดข้อมูลของตัวแปร
ใน R ตัวแปรจะไม่ได้รับการประกาศประเภทข้อมูลใด ๆ แต่จะได้รับชนิดข้อมูลของวัตถุ R ที่กำหนดให้ ดังนั้น R จึงเรียกว่าภาษาพิมพ์แบบไดนามิกซึ่งหมายความว่าเราสามารถเปลี่ยนชนิดข้อมูลของตัวแปรเดียวกันซ้ำแล้วซ้ำอีกเมื่อใช้ในโปรแกรม
var_x <- "Hello"
cat("The class of var_x is ",class(var_x),"\n")
var_x <- 34.5
cat(" Now the class of var_x is ",class(var_x),"\n")
var_x <- 27L
cat(" Next the class of var_x becomes ",class(var_x),"\n")เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
The class of var_x is character
Now the class of var_x is numeric
Next the class of var_x becomes integerการค้นหาตัวแปร
หากต้องการทราบตัวแปรทั้งหมดที่มีอยู่ในพื้นที่ทำงานเราใช้ ls()ฟังก์ชัน นอกจากนี้ฟังก์ชัน ls () ยังสามารถใช้รูปแบบเพื่อจับคู่ชื่อตัวแปร
print(ls())เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] "my var" "my_new_var" "my_var" "var.1"
[5] "var.2" "var.3" "var.name" "var_name2."
[9] "var_x" "varname"Note - เป็นผลลัพธ์ตัวอย่างขึ้นอยู่กับตัวแปรที่ประกาศในสภาพแวดล้อมของคุณ
ฟังก์ชัน ls () สามารถใช้รูปแบบเพื่อจับคู่ชื่อตัวแปร
# List the variables starting with the pattern "var".
print(ls(pattern = "var"))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] "my var" "my_new_var" "my_var" "var.1"
[5] "var.2" "var.3" "var.name" "var_name2."
[9] "var_x" "varname"ตัวแปรที่ขึ้นต้นด้วย dot(.) ถูกซ่อนไว้สามารถแสดงรายการได้โดยใช้อาร์กิวเมนต์ "all.names = TRUE" กับฟังก์ชัน ls ()
print(ls(all.name = TRUE))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] ".cars" ".Random.seed" ".var_name" ".varname" ".varname2"
[6] "my var" "my_new_var" "my_var" "var.1" "var.2"
[11]"var.3" "var.name" "var_name2." "var_x"การลบตัวแปร
ตัวแปรสามารถลบได้โดยใช้ rm()ฟังก์ชัน ด้านล่างเราจะลบตัวแปร var.3 ในการพิมพ์ค่าของข้อผิดพลาดตัวแปรจะถูกโยนทิ้ง
rm(var.3)
print(var.3)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] "var.3"
Error in print(var.3) : object 'var.3' not foundตัวแปรทั้งหมดสามารถลบได้โดยใช้ rm() และ ls() ทำงานร่วมกัน
rm(list = ls())
print(ls())เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
character(0)ตัวดำเนินการคือสัญลักษณ์ที่บอกให้คอมไพเลอร์ดำเนินการจัดการทางคณิตศาสตร์หรือตรรกะเฉพาะ ภาษา R อุดมไปด้วยตัวดำเนินการในตัวและมีตัวดำเนินการประเภทต่อไปนี้
ประเภทของตัวดำเนินการ
เรามีตัวดำเนินการประเภทต่อไปนี้ในการเขียนโปรแกรม R -
- ตัวดำเนินการเลขคณิต
- ตัวดำเนินการเชิงสัมพันธ์
- ตัวดำเนินการทางตรรกะ
- ผู้ดำเนินการมอบหมาย
- ตัวดำเนินการเบ็ดเตล็ด
ตัวดำเนินการเลขคณิต
ตารางต่อไปนี้แสดงตัวดำเนินการทางคณิตศาสตร์ที่รองรับโดยภาษา R ตัวดำเนินการทำหน้าที่กับแต่ละองค์ประกอบของเวกเตอร์
| ตัวดำเนินการ | คำอธิบาย | ตัวอย่าง |
|---|---|---|
| + | เพิ่มเวกเตอร์สองตัว |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
| - | ลบเวกเตอร์ที่สองออกจากเวกเตอร์แรก |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
| * | คูณทั้งเวกเตอร์ |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
| / | หารเวกเตอร์แรกกับตัวที่สอง |
เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ - |
| %% | ให้ส่วนที่เหลือของเวกเตอร์แรกกับเวกเตอร์ที่สอง |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
| % /% | ผลของการหารเวกเตอร์แรกกับวินาที (ผลหาร) |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
| ^ | เวกเตอร์แรกยกกำลังเป็นเลขชี้กำลังของเวกเตอร์ที่สอง |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
ตัวดำเนินการเชิงสัมพันธ์
ตารางต่อไปนี้แสดงตัวดำเนินการเชิงสัมพันธ์ที่รองรับโดยภาษา R แต่ละองค์ประกอบของเวกเตอร์แรกจะถูกเปรียบเทียบกับองค์ประกอบที่สอดคล้องกันของเวกเตอร์ที่สอง ผลลัพธ์ของการเปรียบเทียบคือค่าบูลีน
| ตัวดำเนินการ | คำอธิบาย | ตัวอย่าง |
|---|---|---|
| > | ตรวจสอบว่าแต่ละองค์ประกอบของเวกเตอร์แรกมีค่ามากกว่าองค์ประกอบที่สอดคล้องกันของเวกเตอร์ที่สองหรือไม่ |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
| < | ตรวจสอบว่าแต่ละองค์ประกอบของเวกเตอร์แรกน้อยกว่าองค์ประกอบที่สอดคล้องกันของเวกเตอร์ที่สองหรือไม่ |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
| == | ตรวจสอบว่าแต่ละองค์ประกอบของเวกเตอร์แรกเท่ากับองค์ประกอบที่สอดคล้องกันของเวกเตอร์ที่สองหรือไม่ |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
| <= | ตรวจสอบว่าแต่ละองค์ประกอบของเวกเตอร์แรกน้อยกว่าหรือเท่ากับองค์ประกอบที่สอดคล้องกันของเวกเตอร์ที่สองหรือไม่ |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
| > = | ตรวจสอบว่าแต่ละองค์ประกอบของเวกเตอร์แรกมีค่ามากกว่าหรือเท่ากับองค์ประกอบที่สอดคล้องกันของเวกเตอร์ที่สองหรือไม่ |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
| ! = | ตรวจสอบว่าแต่ละองค์ประกอบของเวกเตอร์แรกไม่เท่ากันกับองค์ประกอบที่สอดคล้องกันของเวกเตอร์ที่สองหรือไม่ |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
ตัวดำเนินการทางตรรกะ
ตารางต่อไปนี้แสดงตัวดำเนินการทางตรรกะที่รองรับโดยภาษา R ใช้ได้กับเวกเตอร์ประเภทตรรกะตัวเลขหรือเชิงซ้อนเท่านั้น ตัวเลขทั้งหมดที่มากกว่า 1 ถือเป็นค่าตรรกะ TRUE
แต่ละองค์ประกอบของเวกเตอร์แรกจะถูกเปรียบเทียบกับองค์ประกอบที่สอดคล้องกันของเวกเตอร์ที่สอง ผลลัพธ์ของการเปรียบเทียบคือค่าบูลีน
| ตัวดำเนินการ | คำอธิบาย | ตัวอย่าง |
|---|---|---|
| & | เรียกว่า Element-wise Logical AND operator มันรวมแต่ละองค์ประกอบของเวกเตอร์แรกกับองค์ประกอบที่สอดคล้องกันของเวกเตอร์ที่สองและให้ผลลัพธ์เป็น TRUE หากองค์ประกอบทั้งสองเป็น TRUE |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
| | | เรียกว่า Element-wise Logical OR operator มันรวมแต่ละองค์ประกอบของเวกเตอร์แรกกับองค์ประกอบที่สอดคล้องกันของเวกเตอร์ที่สองและให้ผลลัพธ์เป็น TRUE หากองค์ประกอบหนึ่งเป็น TRUE |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
| ! | เรียกว่าตัวดำเนินการ Logical NOT ใช้แต่ละองค์ประกอบของเวกเตอร์และให้ค่าตรรกะตรงกันข้าม |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
ตัวดำเนินการตรรกะ && และ || พิจารณาเฉพาะองค์ประกอบแรกของเวกเตอร์และให้เวกเตอร์ขององค์ประกอบเดียวเป็นเอาต์พุต
| ตัวดำเนินการ | คำอธิบาย | ตัวอย่าง |
|---|---|---|
| && | เรียกว่าตัวดำเนินการ Logical AND รับองค์ประกอบแรกของทั้งเวกเตอร์และให้ค่า TRUE ก็ต่อเมื่อทั้งคู่เป็น TRUE |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
| || | เรียกว่า Logical OR operator รับองค์ประกอบแรกของเวกเตอร์ทั้งสองและให้ค่า TRUE หากหนึ่งในนั้นเป็น TRUE |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
ผู้ดำเนินการมอบหมาย
ตัวดำเนินการเหล่านี้ใช้เพื่อกำหนดค่าให้กับเวกเตอร์
| ตัวดำเนินการ | คำอธิบาย | ตัวอย่าง |
|---|---|---|
| <- หรือ = หรือ << - |
เรียกว่า Left Assignment |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
| -> หรือ - >> |
เรียกว่าการมอบหมายสิทธิ์ |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
ตัวดำเนินการเบ็ดเตล็ด
ตัวดำเนินการเหล่านี้ใช้เพื่อวัตถุประสงค์เฉพาะและไม่ใช่การคำนวณทางคณิตศาสตร์หรือตรรกะทั่วไป
| ตัวดำเนินการ | คำอธิบาย | ตัวอย่าง |
|---|---|---|
| : | ตัวดำเนินการลำไส้ใหญ่ สร้างชุดของตัวเลขตามลำดับสำหรับเวกเตอร์ |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
| %ใน% | ตัวดำเนินการนี้ใช้เพื่อระบุว่าองค์ประกอบเป็นของเวกเตอร์หรือไม่ |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
| % *% | ตัวดำเนินการนี้ใช้เพื่อคูณเมทริกซ์ด้วยทรานสโพส |
มันให้ผลลัพธ์ดังต่อไปนี้ - |
โครงสร้างการตัดสินใจกำหนดให้โปรแกรมเมอร์ระบุเงื่อนไขอย่างน้อยหนึ่งเงื่อนไขที่จะประเมินหรือทดสอบโดยโปรแกรมพร้อมกับคำสั่งหรือคำสั่งที่จะดำเนินการหากเงื่อนไขถูกกำหนดให้เป็น trueและเป็นทางเลือกที่จะเรียกใช้คำสั่งอื่น ๆ หากเงื่อนไขถูกกำหนดให้เป็น false.
ต่อไปนี้เป็นรูปแบบทั่วไปของโครงสร้างการตัดสินใจทั่วไปที่พบในภาษาโปรแกรมส่วนใหญ่ -
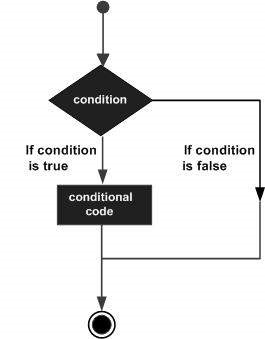
R แสดงประเภทของข้อความประกอบการตัดสินใจดังต่อไปนี้ คลิกลิงก์ต่อไปนี้เพื่อตรวจสอบรายละเอียด
| ซีเนียร์ | คำชี้แจงและคำอธิบาย |
|---|---|
| 1 | ถ้าคำสั่ง อัน if คำสั่งประกอบด้วยนิพจน์บูลีนตามด้วยหนึ่งคำสั่งหรือมากกว่า |
| 2 | if ... else คำสั่ง อัน if ตามด้วยคำสั่งก็ได้ else คำสั่งซึ่งดำเนินการเมื่อนิพจน์บูลีนเป็นเท็จ |
| 3 | สลับคำสั่ง ก switch คำสั่งอนุญาตให้ทดสอบตัวแปรเพื่อความเท่าเทียมกับรายการค่า |
อาจมีสถานการณ์ที่คุณต้องเรียกใช้บล็อกโค้ดหลาย ๆ ครั้ง โดยทั่วไปคำสั่งจะดำเนินการตามลำดับ คำสั่งแรกในฟังก์ชันจะดำเนินการก่อนตามด้วยคำสั่งที่สองและอื่น ๆ
ภาษาโปรแกรมจัดเตรียมโครงสร้างการควบคุมต่างๆที่ช่วยให้เส้นทางการดำเนินการซับซ้อนมากขึ้น
คำสั่งแบบวนซ้ำช่วยให้เราดำเนินการคำสั่งหรือกลุ่มของคำสั่งได้หลายครั้งและต่อไปนี้เป็นรูปแบบทั่วไปของคำสั่งลูปในภาษาโปรแกรมส่วนใหญ่ -
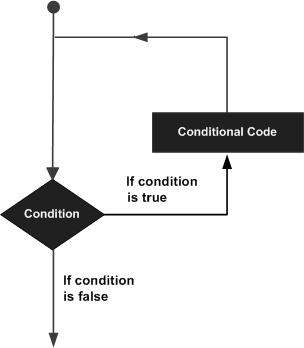
ภาษาการเขียนโปรแกรม R จัดเตรียมลูปประเภทต่อไปนี้เพื่อจัดการกับข้อกำหนดการวนซ้ำ คลิกลิงก์ต่อไปนี้เพื่อตรวจสอบรายละเอียด
| ซีเนียร์ | ประเภทห่วงและคำอธิบาย |
|---|---|
| 1 | วนซ้ำ เรียกใช้ลำดับของคำสั่งหลาย ๆ ครั้งและย่อโค้ดที่จัดการตัวแปรลูป |
| 2 | ในขณะที่วนซ้ำ ทำซ้ำคำสั่งหรือกลุ่มของคำสั่งในขณะที่เงื่อนไขที่กำหนดเป็นจริง จะทดสอบเงื่อนไขก่อนที่จะดำเนินการร่างกายลูป |
| 3 | สำหรับห่วง เช่นเดียวกับคำสั่ง while ยกเว้นว่าจะทดสอบเงื่อนไขที่ส่วนท้ายของตัวห่วง |
คำสั่งควบคุมลูป
คำสั่งควบคุมแบบวนซ้ำเปลี่ยนการดำเนินการจากลำดับปกติ เมื่อการดำเนินการออกจากขอบเขตอ็อบเจ็กต์อัตโนมัติทั้งหมดที่สร้างขึ้นในขอบเขตนั้นจะถูกทำลาย
R สนับสนุนคำสั่งควบคุมต่อไปนี้ คลิกลิงก์ต่อไปนี้เพื่อตรวจสอบรายละเอียด
| ซีเนียร์ | คำชี้แจงและคำอธิบายการควบคุม |
|---|---|
| 1 | คำสั่งทำลาย ยุติไฟล์ loop คำสั่งและโอนการดำเนินการไปยังคำสั่งทันทีตามลูป |
| 2 | คำสั่งถัดไป next คำสั่งจำลองพฤติกรรมของสวิตช์ R |
ฟังก์ชันคือชุดของคำสั่งที่จัดระเบียบร่วมกันเพื่อดำเนินงานเฉพาะ R มีฟังก์ชันในตัวจำนวนมากและผู้ใช้สามารถสร้างฟังก์ชันของตนเองได้
ใน R ฟังก์ชันคืออ็อบเจกต์ดังนั้นตัวแปลภาษา R จึงสามารถส่งผ่านการควบคุมไปยังฟังก์ชันพร้อมกับอาร์กิวเมนต์ที่อาจจำเป็นสำหรับฟังก์ชันเพื่อให้การดำเนินการบรรลุผล
ในทางกลับกันฟังก์ชันจะทำหน้าที่และส่งคืนการควบคุมไปยังล่ามรวมทั้งผลลัพธ์ใด ๆ ที่อาจถูกเก็บไว้ในวัตถุอื่น
นิยามฟังก์ชัน
ฟังก์ชัน R ถูกสร้างขึ้นโดยใช้คำสำคัญ function. ไวยากรณ์พื้นฐานของนิยามฟังก์ชัน R มีดังต่อไปนี้ -
function_name <- function(arg_1, arg_2, ...) {
Function body
}ส่วนประกอบของฟังก์ชัน
ส่วนต่างๆของฟังก์ชันคือ -
Function Name- นี่คือชื่อจริงของฟังก์ชัน มันถูกเก็บไว้ในสภาพแวดล้อม R เป็นวัตถุที่มีชื่อนี้
Arguments- อาร์กิวเมนต์เป็นตัวยึด เมื่อเรียกใช้ฟังก์ชันคุณจะส่งค่าไปยังอาร์กิวเมนต์ อาร์กิวเมนต์เป็นทางเลือก นั่นคือฟังก์ชันอาจไม่มีข้อโต้แย้ง นอกจากนี้อาร์กิวเมนต์สามารถมีค่าเริ่มต้นได้
Function Body - เนื้อความของฟังก์ชันประกอบด้วยชุดของคำสั่งที่กำหนดสิ่งที่ฟังก์ชันทำ
Return Value - ค่าที่ส่งคืนของฟังก์ชันคือนิพจน์สุดท้ายในเนื้อหาของฟังก์ชันที่จะประเมิน
R มีมากมาย in-builtฟังก์ชั่นที่สามารถเรียกได้โดยตรงในโปรแกรมโดยไม่ต้องกำหนดก่อน เรายังสามารถสร้างและใช้ฟังก์ชันของเราเองที่เรียกว่าuser defined ฟังก์ชั่น.
ฟังก์ชันในตัว
ตัวอย่างง่ายๆของฟังก์ชันที่สร้างขึ้นคือ seq(), mean(), max(), sum(x) และ paste(...)ฯลฯ พวกเขาเรียกโดยตรงจากโปรแกรมที่ผู้ใช้เขียนขึ้น คุณสามารถอ้างถึงฟังก์ชัน R ที่ใช้กันอย่างแพร่หลาย
# Create a sequence of numbers from 32 to 44.
print(seq(32,44))
# Find mean of numbers from 25 to 82.
print(mean(25:82))
# Find sum of numbers frm 41 to 68.
print(sum(41:68))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] 32 33 34 35 36 37 38 39 40 41 42 43 44
[1] 53.5
[1] 1526ฟังก์ชันที่ผู้ใช้กำหนดเอง
เราสามารถสร้างฟังก์ชันที่ผู้ใช้กำหนดเองได้ใน R ซึ่งเป็นฟังก์ชันเฉพาะสำหรับสิ่งที่ผู้ใช้ต้องการและเมื่อสร้างขึ้นแล้วสามารถใช้งานได้เหมือนกับฟังก์ชันในตัว ด้านล่างนี้เป็นตัวอย่างวิธีสร้างและใช้ฟังก์ชัน
# Create a function to print squares of numbers in sequence.
new.function <- function(a) {
for(i in 1:a) {
b <- i^2
print(b)
}
}เรียกใช้ฟังก์ชัน
# Create a function to print squares of numbers in sequence.
new.function <- function(a) {
for(i in 1:a) {
b <- i^2
print(b)
}
}
# Call the function new.function supplying 6 as an argument.
new.function(6)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] 1
[1] 4
[1] 9
[1] 16
[1] 25
[1] 36การเรียกใช้ฟังก์ชันโดยไม่มีอาร์กิวเมนต์
# Create a function without an argument.
new.function <- function() {
for(i in 1:5) {
print(i^2)
}
}
# Call the function without supplying an argument.
new.function()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] 1
[1] 4
[1] 9
[1] 16
[1] 25การเรียกใช้ฟังก์ชันด้วยค่าอาร์กิวเมนต์ (ตามตำแหน่งและตามชื่อ)
อาร์กิวเมนต์สำหรับการเรียกใช้ฟังก์ชันสามารถจัดเรียงตามลำดับเดียวกันกับที่กำหนดไว้ในฟังก์ชันหรือสามารถจัดเรียงในลำดับที่ต่างกัน แต่กำหนดให้กับชื่อของอาร์กิวเมนต์
# Create a function with arguments.
new.function <- function(a,b,c) {
result <- a * b + c
print(result)
}
# Call the function by position of arguments.
new.function(5,3,11)
# Call the function by names of the arguments.
new.function(a = 11, b = 5, c = 3)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] 26
[1] 58การเรียกใช้ฟังก์ชันด้วยอาร์กิวเมนต์เริ่มต้น
เราสามารถกำหนดค่าของอาร์กิวเมนต์ในนิยามฟังก์ชันและเรียกใช้ฟังก์ชันโดยไม่ต้องระบุอาร์กิวเมนต์ใด ๆ เพื่อให้ได้ผลลัพธ์เริ่มต้น แต่เรายังสามารถเรียกใช้ฟังก์ชันดังกล่าวได้โดยการจัดหาค่าใหม่ของอาร์กิวเมนต์และรับผลลัพธ์ที่ไม่ใช่ค่าเริ่มต้น
# Create a function with arguments.
new.function <- function(a = 3, b = 6) {
result <- a * b
print(result)
}
# Call the function without giving any argument.
new.function()
# Call the function with giving new values of the argument.
new.function(9,5)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] 18
[1] 45ขี้เกียจประเมินฟังก์ชัน
อาร์กิวเมนต์ของฟังก์ชันจะได้รับการประเมินอย่างเฉื่อยชาซึ่งหมายความว่าจะได้รับการประเมินเมื่อจำเป็นโดยร่างกายของฟังก์ชันเท่านั้น
# Create a function with arguments.
new.function <- function(a, b) {
print(a^2)
print(a)
print(b)
}
# Evaluate the function without supplying one of the arguments.
new.function(6)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] 36
[1] 6
Error in print(b) : argument "b" is missing, with no defaultค่าใด ๆ ที่เขียนภายในคู่ของอัญประกาศเดี่ยวหรือเครื่องหมายคำพูดคู่ใน R จะถือว่าเป็นสตริง R ภายในเก็บทุกสตริงภายในเครื่องหมายคำพูดคู่แม้ว่าคุณจะสร้างด้วยเครื่องหมายคำพูดเดียวก็ตาม
กฎที่ใช้ในการสร้างสตริง
อัญประกาศที่จุดเริ่มต้นและจุดสิ้นสุดของสตริงควรเป็นทั้งอัญประกาศคู่หรืออัญประกาศเดี่ยว พวกเขาไม่สามารถผสม
สามารถแทรกเครื่องหมายคำพูดคู่ลงในสตริงที่เริ่มต้นและลงท้ายด้วยเครื่องหมายคำพูดเดี่ยว
คำพูดเดี่ยวสามารถแทรกลงในสตริงที่ขึ้นต้นและลงท้ายด้วยเครื่องหมายคำพูดคู่
ไม่สามารถแทรกเครื่องหมายคำพูดคู่ลงในสตริงที่เริ่มต้นและลงท้ายด้วยเครื่องหมายคำพูดคู่
ไม่สามารถใส่เครื่องหมายคำพูดเดี่ยวลงในสตริงที่เริ่มต้นและลงท้ายด้วยเครื่องหมายคำพูดเดี่ยว
ตัวอย่างของสตริงที่ถูกต้อง
ตัวอย่างต่อไปนี้อธิบายกฎเกี่ยวกับการสร้างสตริงใน R
a <- 'Start and end with single quote'
print(a)
b <- "Start and end with double quotes"
print(b)
c <- "single quote ' in between double quotes"
print(c)
d <- 'Double quotes " in between single quote'
print(d)เมื่อรันโค้ดด้านบนเราจะได้ผลลัพธ์ต่อไปนี้ -
[1] "Start and end with single quote"
[1] "Start and end with double quotes"
[1] "single quote ' in between double quote"
[1] "Double quote \" in between single quote"ตัวอย่างของสตริงที่ไม่ถูกต้อง
e <- 'Mixed quotes"
print(e)
f <- 'Single quote ' inside single quote'
print(f)
g <- "Double quotes " inside double quotes"
print(g)เมื่อเรารันสคริปต์มันล้มเหลวในการให้ผลลัพธ์ด้านล่าง
Error: unexpected symbol in:
"print(e)
f <- 'Single"
Execution haltedการจัดการสตริง
การต่อสตริง - ฟังก์ชั่นวาง ()
สตริงจำนวนมากใน R ถูกรวมเข้าด้วยกันโดยใช้ paste()ฟังก์ชัน สามารถนำอาร์กิวเมนต์จำนวนเท่าใดก็ได้มารวมเข้าด้วยกัน
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับฟังก์ชันวางคือ -
paste(..., sep = " ", collapse = NULL)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
... แทนอาร์กิวเมนต์จำนวนเท่าใดก็ได้ที่จะรวมกัน
sepแสดงถึงตัวคั่นใด ๆ ระหว่างอาร์กิวเมนต์ เป็นทางเลือก
collapseใช้เพื่อกำจัดช่องว่างระหว่างสองสตริง แต่ไม่ใช่ช่องว่างภายในสองคำของสตริงเดียว
ตัวอย่าง
a <- "Hello"
b <- 'How'
c <- "are you? "
print(paste(a,b,c))
print(paste(a,b,c, sep = "-"))
print(paste(a,b,c, sep = "", collapse = ""))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] "Hello How are you? "
[1] "Hello-How-are you? "
[1] "HelloHoware you? "การจัดรูปแบบตัวเลขและสตริง - ฟังก์ชัน format ()
ตัวเลขและสตริงสามารถจัดรูปแบบให้เป็นสไตล์เฉพาะได้โดยใช้ format() ฟังก์ชัน
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับฟังก์ชันรูปแบบคือ -
format(x, digits, nsmall, scientific, width, justify = c("left", "right", "centre", "none"))ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
x คืออินพุตเวกเตอร์
digits คือจำนวนตัวเลขทั้งหมดที่แสดง
nsmall คือจำนวนหลักขั้นต่ำทางด้านขวาของจุดทศนิยม
scientific ถูกตั้งค่าเป็น TRUE เพื่อแสดงสัญกรณ์ทางวิทยาศาสตร์
width ระบุความกว้างต่ำสุดที่จะแสดงโดยการเติมช่องว่างในตอนต้น
justify คือการแสดงสตริงไปทางซ้ายขวาหรือตรงกลาง
ตัวอย่าง
# Total number of digits displayed. Last digit rounded off.
result <- format(23.123456789, digits = 9)
print(result)
# Display numbers in scientific notation.
result <- format(c(6, 13.14521), scientific = TRUE)
print(result)
# The minimum number of digits to the right of the decimal point.
result <- format(23.47, nsmall = 5)
print(result)
# Format treats everything as a string.
result <- format(6)
print(result)
# Numbers are padded with blank in the beginning for width.
result <- format(13.7, width = 6)
print(result)
# Left justify strings.
result <- format("Hello", width = 8, justify = "l")
print(result)
# Justfy string with center.
result <- format("Hello", width = 8, justify = "c")
print(result)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] "23.1234568"
[1] "6.000000e+00" "1.314521e+01"
[1] "23.47000"
[1] "6"
[1] " 13.7"
[1] "Hello "
[1] " Hello "การนับจำนวนอักขระในสตริง - ฟังก์ชัน nchar ()
ฟังก์ชันนี้จะนับจำนวนอักขระรวมถึงช่องว่างในสตริง
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับฟังก์ชัน nchar () คือ -
nchar(x)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
x คืออินพุตเวกเตอร์
ตัวอย่าง
result <- nchar("Count the number of characters")
print(result)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] 30การเปลี่ยนเคส - ฟังก์ชัน toupper () & tolower ()
ฟังก์ชันเหล่านี้เปลี่ยนกรณีของอักขระของสตริง
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับฟังก์ชัน toupper () & tolower () คือ -
toupper(x)
tolower(x)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
x คืออินพุตเวกเตอร์
ตัวอย่าง
# Changing to Upper case.
result <- toupper("Changing To Upper")
print(result)
# Changing to lower case.
result <- tolower("Changing To Lower")
print(result)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] "CHANGING TO UPPER"
[1] "changing to lower"การแยกส่วนของฟังก์ชันสตริง - สตริงย่อย ()
ฟังก์ชันนี้จะแยกส่วนต่างๆของสตริง
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับฟังก์ชันสตริงย่อย () คือ -
substring(x,first,last)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
x คืออินพุตเวกเตอร์อักขระ
first คือตำแหน่งของอักขระตัวแรกที่จะแยกออกมา
last คือตำแหน่งของอักขระสุดท้ายที่จะแยกออกมา
ตัวอย่าง
# Extract characters from 5th to 7th position.
result <- substring("Extract", 5, 7)
print(result)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] "act"เวกเตอร์เป็นวัตถุข้อมูล R พื้นฐานที่สุดและเวกเตอร์อะตอมมีหกประเภท เป็นตรรกะจำนวนเต็มคู่ซับซ้อนอักขระและดิบ
การสร้างเวกเตอร์
เวกเตอร์องค์ประกอบเดียว
แม้ว่าคุณจะเขียนเพียงค่าเดียวใน R แต่มันก็กลายเป็นเวกเตอร์ที่มีความยาว 1 และเป็นของเวกเตอร์ประเภทใดประเภทหนึ่งข้างต้น
# Atomic vector of type character.
print("abc");
# Atomic vector of type double.
print(12.5)
# Atomic vector of type integer.
print(63L)
# Atomic vector of type logical.
print(TRUE)
# Atomic vector of type complex.
print(2+3i)
# Atomic vector of type raw.
print(charToRaw('hello'))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] "abc"
[1] 12.5
[1] 63
[1] TRUE
[1] 2+3i
[1] 68 65 6c 6c 6fเวกเตอร์หลายองค์ประกอบ
Using colon operator with numeric data
# Creating a sequence from 5 to 13.
v <- 5:13
print(v)
# Creating a sequence from 6.6 to 12.6.
v <- 6.6:12.6
print(v)
# If the final element specified does not belong to the sequence then it is discarded.
v <- 3.8:11.4
print(v)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] 5 6 7 8 9 10 11 12 13
[1] 6.6 7.6 8.6 9.6 10.6 11.6 12.6
[1] 3.8 4.8 5.8 6.8 7.8 8.8 9.8 10.8Using sequence (Seq.) operator
# Create vector with elements from 5 to 9 incrementing by 0.4.
print(seq(5, 9, by = 0.4))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] 5.0 5.4 5.8 6.2 6.6 7.0 7.4 7.8 8.2 8.6 9.0Using the c() function
ค่าที่ไม่ใช่อักขระจะถูกบังคับให้เป็นประเภทอักขระหากองค์ประกอบใดองค์ประกอบหนึ่งเป็นอักขระ
# The logical and numeric values are converted to characters.
s <- c('apple','red',5,TRUE)
print(s)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] "apple" "red" "5" "TRUE"การเข้าถึงองค์ประกอบเวกเตอร์
องค์ประกอบของเวกเตอร์เข้าถึงได้โดยใช้การสร้างดัชนี [ ] bracketsใช้สำหรับการจัดทำดัชนี การสร้างดัชนีเริ่มต้นด้วยตำแหน่ง 1 การให้ค่าลบในดัชนีจะทำให้องค์ประกอบนั้นลดลงจากผลลัพธ์TRUE, FALSE หรือ 0 และ 1 ยังสามารถใช้สำหรับการจัดทำดัชนี
# Accessing vector elements using position.
t <- c("Sun","Mon","Tue","Wed","Thurs","Fri","Sat")
u <- t[c(2,3,6)]
print(u)
# Accessing vector elements using logical indexing.
v <- t[c(TRUE,FALSE,FALSE,FALSE,FALSE,TRUE,FALSE)]
print(v)
# Accessing vector elements using negative indexing.
x <- t[c(-2,-5)]
print(x)
# Accessing vector elements using 0/1 indexing.
y <- t[c(0,0,0,0,0,0,1)]
print(y)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] "Mon" "Tue" "Fri"
[1] "Sun" "Fri"
[1] "Sun" "Tue" "Wed" "Fri" "Sat"
[1] "Sun"การจัดการเวกเตอร์
เวกเตอร์เลขคณิต
เวกเตอร์สองตัวที่มีความยาวเท่ากันสามารถบวกลบคูณหรือหารให้ผลลัพธ์เป็นเวกเตอร์เอาต์พุต
# Create two vectors.
v1 <- c(3,8,4,5,0,11)
v2 <- c(4,11,0,8,1,2)
# Vector addition.
add.result <- v1+v2
print(add.result)
# Vector subtraction.
sub.result <- v1-v2
print(sub.result)
# Vector multiplication.
multi.result <- v1*v2
print(multi.result)
# Vector division.
divi.result <- v1/v2
print(divi.result)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] 7 19 4 13 1 13
[1] -1 -3 4 -3 -1 9
[1] 12 88 0 40 0 22
[1] 0.7500000 0.7272727 Inf 0.6250000 0.0000000 5.5000000การรีไซเคิลองค์ประกอบเวกเตอร์
ถ้าเราใช้การคำนวณทางคณิตศาสตร์กับเวกเตอร์สองตัวที่มีความยาวไม่เท่ากันองค์ประกอบของเวกเตอร์ที่สั้นกว่าจะถูกรีไซเคิลเพื่อให้การดำเนินการเสร็จสมบูรณ์
v1 <- c(3,8,4,5,0,11)
v2 <- c(4,11)
# V2 becomes c(4,11,4,11,4,11)
add.result <- v1+v2
print(add.result)
sub.result <- v1-v2
print(sub.result)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] 7 19 8 16 4 22
[1] -1 -3 0 -6 -4 0การเรียงลำดับองค์ประกอบเวกเตอร์
องค์ประกอบในเวกเตอร์สามารถจัดเรียงได้โดยใช้ sort() ฟังก์ชัน
v <- c(3,8,4,5,0,11, -9, 304)
# Sort the elements of the vector.
sort.result <- sort(v)
print(sort.result)
# Sort the elements in the reverse order.
revsort.result <- sort(v, decreasing = TRUE)
print(revsort.result)
# Sorting character vectors.
v <- c("Red","Blue","yellow","violet")
sort.result <- sort(v)
print(sort.result)
# Sorting character vectors in reverse order.
revsort.result <- sort(v, decreasing = TRUE)
print(revsort.result)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] -9 0 3 4 5 8 11 304
[1] 304 11 8 5 4 3 0 -9
[1] "Blue" "Red" "violet" "yellow"
[1] "yellow" "violet" "Red" "Blue"รายการคือวัตถุ R ซึ่งมีองค์ประกอบประเภทต่างๆเช่น - ตัวเลขสตริงเวกเตอร์และรายการอื่นอยู่ รายการยังสามารถมีเมทริกซ์หรือฟังก์ชันเป็นองค์ประกอบได้ สร้างรายการโดยใช้ไฟล์list() ฟังก์ชัน
การสร้างรายการ
ต่อไปนี้เป็นตัวอย่างในการสร้างรายการที่มีสตริงตัวเลขเวกเตอร์และค่าตรรกะ
# Create a list containing strings, numbers, vectors and a logical
# values.
list_data <- list("Red", "Green", c(21,32,11), TRUE, 51.23, 119.1)
print(list_data)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[[1]]
[1] "Red"
[[2]]
[1] "Green"
[[3]]
[1] 21 32 11
[[4]]
[1] TRUE
[[5]]
[1] 51.23
[[6]]
[1] 119.1การตั้งชื่อองค์ประกอบรายการ
องค์ประกอบรายการสามารถกำหนดชื่อและสามารถเข้าถึงได้โดยใช้ชื่อเหล่านี้
# Create a list containing a vector, a matrix and a list.
list_data <- list(c("Jan","Feb","Mar"), matrix(c(3,9,5,1,-2,8), nrow = 2),
list("green",12.3))
# Give names to the elements in the list.
names(list_data) <- c("1st Quarter", "A_Matrix", "A Inner list")
# Show the list.
print(list_data)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
$`1st_Quarter` [1] "Jan" "Feb" "Mar" $A_Matrix
[,1] [,2] [,3]
[1,] 3 5 -2
[2,] 9 1 8
$A_Inner_list $A_Inner_list[[1]]
[1] "green"
$A_Inner_list[[2]]
[1] 12.3การเข้าถึงองค์ประกอบรายการ
องค์ประกอบของรายการสามารถเข้าถึงได้โดยดัชนีขององค์ประกอบในรายการ ในกรณีของรายการที่ระบุชื่อสามารถเข้าถึงได้โดยใช้ชื่อ
เรายังคงใช้รายการในตัวอย่างข้างต้น -
# Create a list containing a vector, a matrix and a list.
list_data <- list(c("Jan","Feb","Mar"), matrix(c(3,9,5,1,-2,8), nrow = 2),
list("green",12.3))
# Give names to the elements in the list.
names(list_data) <- c("1st Quarter", "A_Matrix", "A Inner list")
# Access the first element of the list.
print(list_data[1])
# Access the thrid element. As it is also a list, all its elements will be printed.
print(list_data[3])
# Access the list element using the name of the element.
print(list_data$A_Matrix)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
$`1st_Quarter` [1] "Jan" "Feb" "Mar" $A_Inner_list
$A_Inner_list[[1]] [1] "green" $A_Inner_list[[2]]
[1] 12.3
[,1] [,2] [,3]
[1,] 3 5 -2
[2,] 9 1 8การจัดการองค์ประกอบรายการ
เราสามารถเพิ่มลบและอัปเดตองค์ประกอบรายการได้ดังรูปด้านล่าง เราสามารถเพิ่มและลบองค์ประกอบได้เฉพาะในตอนท้ายของรายการ แต่เราสามารถอัปเดตองค์ประกอบใดก็ได้
# Create a list containing a vector, a matrix and a list.
list_data <- list(c("Jan","Feb","Mar"), matrix(c(3,9,5,1,-2,8), nrow = 2),
list("green",12.3))
# Give names to the elements in the list.
names(list_data) <- c("1st Quarter", "A_Matrix", "A Inner list")
# Add element at the end of the list.
list_data[4] <- "New element"
print(list_data[4])
# Remove the last element.
list_data[4] <- NULL
# Print the 4th Element.
print(list_data[4])
# Update the 3rd Element.
list_data[3] <- "updated element"
print(list_data[3])เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[[1]]
[1] "New element"
$<NA> NULL $`A Inner list`
[1] "updated element"การรวมรายการ
คุณสามารถรวมหลายรายการเป็นรายการเดียวโดยวางรายการทั้งหมดไว้ในฟังก์ชัน list () เดียว
# Create two lists.
list1 <- list(1,2,3)
list2 <- list("Sun","Mon","Tue")
# Merge the two lists.
merged.list <- c(list1,list2)
# Print the merged list.
print(merged.list)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[[1]]
[1] 1
[[2]]
[1] 2
[[3]]
[1] 3
[[4]]
[1] "Sun"
[[5]]
[1] "Mon"
[[6]]
[1] "Tue"การแปลงรายการเป็นเวกเตอร์
รายการสามารถแปลงเป็นเวกเตอร์เพื่อให้สามารถใช้องค์ประกอบของเวกเตอร์สำหรับการปรับแต่งเพิ่มเติมได้ การคำนวณทางคณิตศาสตร์ทั้งหมดบนเวกเตอร์สามารถนำไปใช้ได้หลังจากที่รายการถูกแปลงเป็นเวกเตอร์ ในการแปลงนี้เราใช้ไฟล์unlist()ฟังก์ชัน ใช้รายการเป็นอินพุตและสร้างเวกเตอร์
# Create lists.
list1 <- list(1:5)
print(list1)
list2 <-list(10:14)
print(list2)
# Convert the lists to vectors.
v1 <- unlist(list1)
v2 <- unlist(list2)
print(v1)
print(v2)
# Now add the vectors
result <- v1+v2
print(result)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[[1]]
[1] 1 2 3 4 5
[[1]]
[1] 10 11 12 13 14
[1] 1 2 3 4 5
[1] 10 11 12 13 14
[1] 11 13 15 17 19เมทริกซ์คือวัตถุ R ที่องค์ประกอบต่างๆถูกจัดเรียงในรูปแบบสี่เหลี่ยมสองมิติ ประกอบด้วยองค์ประกอบของอะตอมประเภทเดียวกัน แม้ว่าเราสามารถสร้างเมทริกซ์ที่มีเพียงอักขระหรือเฉพาะค่าตรรกะ แต่ก็ไม่ได้ใช้ประโยชน์มากนัก เราใช้เมทริกซ์ที่มีองค์ประกอบตัวเลขเพื่อใช้ในการคำนวณทางคณิตศาสตร์
เมทริกซ์ถูกสร้างขึ้นโดยใช้ matrix() ฟังก์ชัน
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการสร้างเมทริกซ์ใน R คือ -
matrix(data, nrow, ncol, byrow, dimnames)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
data คือเวกเตอร์อินพุตซึ่งกลายเป็นองค์ประกอบข้อมูลของเมทริกซ์
nrow คือจำนวนแถวที่จะสร้าง
ncol คือจำนวนคอลัมน์ที่จะสร้าง
byrowเป็นเงื่อนงำเชิงตรรกะ ถ้าเป็น TRUE องค์ประกอบเวกเตอร์อินพุตจะถูกจัดเรียงตามแถว
dimname คือชื่อที่กำหนดให้กับแถวและคอลัมน์
ตัวอย่าง
สร้างเมทริกซ์โดยใช้เวกเตอร์ของตัวเลขเป็นอินพุต
# Elements are arranged sequentially by row.
M <- matrix(c(3:14), nrow = 4, byrow = TRUE)
print(M)
# Elements are arranged sequentially by column.
N <- matrix(c(3:14), nrow = 4, byrow = FALSE)
print(N)
# Define the column and row names.
rownames = c("row1", "row2", "row3", "row4")
colnames = c("col1", "col2", "col3")
P <- matrix(c(3:14), nrow = 4, byrow = TRUE, dimnames = list(rownames, colnames))
print(P)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[,1] [,2] [,3]
[1,] 3 4 5
[2,] 6 7 8
[3,] 9 10 11
[4,] 12 13 14
[,1] [,2] [,3]
[1,] 3 7 11
[2,] 4 8 12
[3,] 5 9 13
[4,] 6 10 14
col1 col2 col3
row1 3 4 5
row2 6 7 8
row3 9 10 11
row4 12 13 14การเข้าถึงองค์ประกอบของเมทริกซ์
องค์ประกอบของเมทริกซ์สามารถเข้าถึงได้โดยใช้ดัชนีคอลัมน์และแถวขององค์ประกอบ เราพิจารณาเมทริกซ์ P ด้านบนเพื่อค้นหาองค์ประกอบเฉพาะด้านล่าง
# Define the column and row names.
rownames = c("row1", "row2", "row3", "row4")
colnames = c("col1", "col2", "col3")
# Create the matrix.
P <- matrix(c(3:14), nrow = 4, byrow = TRUE, dimnames = list(rownames, colnames))
# Access the element at 3rd column and 1st row.
print(P[1,3])
# Access the element at 2nd column and 4th row.
print(P[4,2])
# Access only the 2nd row.
print(P[2,])
# Access only the 3rd column.
print(P[,3])เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] 5
[1] 13
col1 col2 col3
6 7 8
row1 row2 row3 row4
5 8 11 14การคำนวณเมทริกซ์
การดำเนินการทางคณิตศาสตร์ต่างๆจะดำเนินการกับเมทริกซ์โดยใช้ตัวดำเนินการ R ผลลัพธ์ของการดำเนินการยังเป็นเมทริกซ์
มิติข้อมูล (จำนวนแถวและคอลัมน์) ควรเหมือนกันสำหรับเมทริกซ์ที่เกี่ยวข้องกับการดำเนินการ
การบวกและการลบเมทริกซ์
# Create two 2x3 matrices.
matrix1 <- matrix(c(3, 9, -1, 4, 2, 6), nrow = 2)
print(matrix1)
matrix2 <- matrix(c(5, 2, 0, 9, 3, 4), nrow = 2)
print(matrix2)
# Add the matrices.
result <- matrix1 + matrix2
cat("Result of addition","\n")
print(result)
# Subtract the matrices
result <- matrix1 - matrix2
cat("Result of subtraction","\n")
print(result)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[,1] [,2] [,3]
[1,] 3 -1 2
[2,] 9 4 6
[,1] [,2] [,3]
[1,] 5 0 3
[2,] 2 9 4
Result of addition
[,1] [,2] [,3]
[1,] 8 -1 5
[2,] 11 13 10
Result of subtraction
[,1] [,2] [,3]
[1,] -2 -1 -1
[2,] 7 -5 2การคูณและหารเมทริกซ์
# Create two 2x3 matrices.
matrix1 <- matrix(c(3, 9, -1, 4, 2, 6), nrow = 2)
print(matrix1)
matrix2 <- matrix(c(5, 2, 0, 9, 3, 4), nrow = 2)
print(matrix2)
# Multiply the matrices.
result <- matrix1 * matrix2
cat("Result of multiplication","\n")
print(result)
# Divide the matrices
result <- matrix1 / matrix2
cat("Result of division","\n")
print(result)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[,1] [,2] [,3]
[1,] 3 -1 2
[2,] 9 4 6
[,1] [,2] [,3]
[1,] 5 0 3
[2,] 2 9 4
Result of multiplication
[,1] [,2] [,3]
[1,] 15 0 6
[2,] 18 36 24
Result of division
[,1] [,2] [,3]
[1,] 0.6 -Inf 0.6666667
[2,] 4.5 0.4444444 1.5000000อาร์เรย์เป็นวัตถุข้อมูล R ซึ่งสามารถจัดเก็บข้อมูลได้มากกว่าสองมิติ ตัวอย่างเช่น - ถ้าเราสร้างอาร์เรย์ของมิติข้อมูล (2, 3, 4) มันจะสร้างเมทริกซ์สี่เหลี่ยม 4 อันแต่ละอันมี 2 แถวและ 3 คอลัมน์ อาร์เรย์สามารถจัดเก็บได้เฉพาะประเภทข้อมูลเท่านั้น
อาร์เรย์ถูกสร้างขึ้นโดยใช้ array()ฟังก์ชัน ใช้เวกเตอร์เป็นอินพุตและใช้ค่าในไฟล์dim พารามิเตอร์เพื่อสร้างอาร์เรย์
ตัวอย่าง
ตัวอย่างต่อไปนี้สร้างอาร์เรย์ของเมทริกซ์ 3x3 สองตัวแต่ละตัวมี 3 แถวและ 3 คอลัมน์
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
# Take these vectors as input to the array.
result <- array(c(vector1,vector2),dim = c(3,3,2))
print(result)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
, , 1
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15
, , 2
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15การตั้งชื่อคอลัมน์และแถว
เราสามารถตั้งชื่อให้กับแถวคอลัมน์และเมทริกซ์ในอาร์เรย์ได้โดยใช้ dimnames พารามิเตอร์.
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
column.names <- c("COL1","COL2","COL3")
row.names <- c("ROW1","ROW2","ROW3")
matrix.names <- c("Matrix1","Matrix2")
# Take these vectors as input to the array.
result <- array(c(vector1,vector2),dim = c(3,3,2),dimnames = list(row.names,column.names,
matrix.names))
print(result)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
, , Matrix1
COL1 COL2 COL3
ROW1 5 10 13
ROW2 9 11 14
ROW3 3 12 15
, , Matrix2
COL1 COL2 COL3
ROW1 5 10 13
ROW2 9 11 14
ROW3 3 12 15การเข้าถึงองค์ประกอบอาร์เรย์
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
column.names <- c("COL1","COL2","COL3")
row.names <- c("ROW1","ROW2","ROW3")
matrix.names <- c("Matrix1","Matrix2")
# Take these vectors as input to the array.
result <- array(c(vector1,vector2),dim = c(3,3,2),dimnames = list(row.names,
column.names, matrix.names))
# Print the third row of the second matrix of the array.
print(result[3,,2])
# Print the element in the 1st row and 3rd column of the 1st matrix.
print(result[1,3,1])
# Print the 2nd Matrix.
print(result[,,2])เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
COL1 COL2 COL3
3 12 15
[1] 13
COL1 COL2 COL3
ROW1 5 10 13
ROW2 9 11 14
ROW3 3 12 15การจัดการองค์ประกอบอาร์เรย์
เนื่องจากอาร์เรย์ประกอบด้วยเมทริกซ์ในหลายมิติการดำเนินการกับองค์ประกอบของอาร์เรย์จะดำเนินการโดยการเข้าถึงองค์ประกอบของเมทริกซ์
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
# Take these vectors as input to the array.
array1 <- array(c(vector1,vector2),dim = c(3,3,2))
# Create two vectors of different lengths.
vector3 <- c(9,1,0)
vector4 <- c(6,0,11,3,14,1,2,6,9)
array2 <- array(c(vector1,vector2),dim = c(3,3,2))
# create matrices from these arrays.
matrix1 <- array1[,,2]
matrix2 <- array2[,,2]
# Add the matrices.
result <- matrix1+matrix2
print(result)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[,1] [,2] [,3]
[1,] 10 20 26
[2,] 18 22 28
[3,] 6 24 30การคำนวณข้ามองค์ประกอบอาร์เรย์
เราสามารถคำนวณองค์ประกอบต่างๆในอาร์เรย์โดยใช้ apply() ฟังก์ชัน
ไวยากรณ์
apply(x, margin, fun)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
x คืออาร์เรย์
margin คือชื่อของชุดข้อมูลที่ใช้
fun เป็นฟังก์ชันที่จะใช้กับองค์ประกอบของอาร์เรย์
ตัวอย่าง
เราใช้ฟังก์ชัน apply () ด้านล่างเพื่อคำนวณผลรวมขององค์ประกอบในแถวของอาร์เรย์ในเมทริกซ์ทั้งหมด
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
# Take these vectors as input to the array.
new.array <- array(c(vector1,vector2),dim = c(3,3,2))
print(new.array)
# Use apply to calculate the sum of the rows across all the matrices.
result <- apply(new.array, c(1), sum)
print(result)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
, , 1
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15
, , 2
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15
[1] 56 68 60ปัจจัยคือวัตถุข้อมูลที่ใช้ในการจัดหมวดหมู่ข้อมูลและจัดเก็บเป็นระดับ สามารถจัดเก็บทั้งสตริงและจำนวนเต็ม มีประโยชน์ในคอลัมน์ที่มีค่าเฉพาะจำนวน จำกัด เช่น "ชาย" หญิง "และจริงเท็จเป็นต้นซึ่งมีประโยชน์ในการวิเคราะห์ข้อมูลสำหรับการสร้างแบบจำลองทางสถิติ
ปัจจัยถูกสร้างขึ้นโดยใช้ไฟล์ factor () ฟังก์ชันโดยใช้เวกเตอร์เป็นอินพุต
ตัวอย่าง
# Create a vector as input.
data <- c("East","West","East","North","North","East","West","West","West","East","North")
print(data)
print(is.factor(data))
# Apply the factor function.
factor_data <- factor(data)
print(factor_data)
print(is.factor(factor_data))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] "East" "West" "East" "North" "North" "East" "West" "West" "West" "East" "North"
[1] FALSE
[1] East West East North North East West West West East North
Levels: East North West
[1] TRUEปัจจัยในกรอบข้อมูล
ในการสร้างกรอบข้อมูลใด ๆ ที่มีคอลัมน์ของข้อมูลข้อความ R จะถือว่าคอลัมน์ข้อความเป็นข้อมูลที่จัดหมวดหมู่และสร้างปัจจัยขึ้นมา
# Create the vectors for data frame.
height <- c(132,151,162,139,166,147,122)
weight <- c(48,49,66,53,67,52,40)
gender <- c("male","male","female","female","male","female","male")
# Create the data frame.
input_data <- data.frame(height,weight,gender)
print(input_data)
# Test if the gender column is a factor.
print(is.factor(input_data$gender)) # Print the gender column so see the levels. print(input_data$gender)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
height weight gender
1 132 48 male
2 151 49 male
3 162 66 female
4 139 53 female
5 166 67 male
6 147 52 female
7 122 40 male
[1] TRUE
[1] male male female female male female male
Levels: female maleการเปลี่ยนลำดับของระดับ
ลำดับของระดับในตัวประกอบสามารถเปลี่ยนแปลงได้โดยใช้ฟังก์ชันแฟกเตอร์อีกครั้งพร้อมลำดับใหม่ของระดับ
data <- c("East","West","East","North","North","East","West",
"West","West","East","North")
# Create the factors
factor_data <- factor(data)
print(factor_data)
# Apply the factor function with required order of the level.
new_order_data <- factor(factor_data,levels = c("East","West","North"))
print(new_order_data)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] East West East North North East West West West East North
Levels: East North West
[1] East West East North North East West West West East North
Levels: East West Northการสร้างระดับปัจจัย
เราสามารถสร้างระดับปัจจัยโดยใช้ gl()ฟังก์ชัน ใช้จำนวนเต็มสองจำนวนเป็นอินพุตซึ่งระบุจำนวนระดับและจำนวนครั้งในแต่ละระดับ
ไวยากรณ์
gl(n, k, labels)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
n คือจำนวนเต็มที่ให้จำนวนระดับ
k คือจำนวนเต็มที่ให้จำนวนการจำลองแบบ
labels เป็นเวกเตอร์ของป้ายกำกับสำหรับระดับปัจจัยที่เป็นผลลัพธ์
ตัวอย่าง
v <- gl(3, 4, labels = c("Tampa", "Seattle","Boston"))
print(v)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
Tampa Tampa Tampa Tampa Seattle Seattle Seattle Seattle Boston
[10] Boston Boston Boston
Levels: Tampa Seattle Bostonกรอบข้อมูลคือตารางหรือโครงสร้างคล้ายอาร์เรย์สองมิติซึ่งแต่ละคอลัมน์มีค่าของตัวแปรหนึ่งตัวและแต่ละแถวมีชุดค่าหนึ่งชุดจากแต่ละคอลัมน์
ต่อไปนี้เป็นลักษณะของกรอบข้อมูล
- ชื่อคอลัมน์ไม่ควรว่างเปล่า
- ชื่อแถวควรไม่ซ้ำกัน
- ข้อมูลที่จัดเก็บในกรอบข้อมูลอาจเป็นประเภทตัวเลขตัวประกอบหรืออักขระ
- แต่ละคอลัมน์ควรมีรายการข้อมูลจำนวนเท่ากัน
สร้างกรอบข้อมูล
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Print the data frame.
print(emp.data)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
emp_id emp_name salary start_date
1 1 Rick 623.30 2012-01-01
2 2 Dan 515.20 2013-09-23
3 3 Michelle 611.00 2014-11-15
4 4 Ryan 729.00 2014-05-11
5 5 Gary 843.25 2015-03-27รับโครงสร้างของ Data Frame
โครงสร้างของกรอบข้อมูลสามารถมองเห็นได้โดยใช้ str() ฟังก์ชัน
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Get the structure of the data frame.
str(emp.data)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
'data.frame': 5 obs. of 4 variables:
$ emp_id : int 1 2 3 4 5 $ emp_name : chr "Rick" "Dan" "Michelle" "Ryan" ...
$ salary : num 623 515 611 729 843 $ start_date: Date, format: "2012-01-01" "2013-09-23" "2014-11-15" "2014-05-11" ...สรุปข้อมูลใน Data Frame
สรุปทางสถิติและลักษณะของข้อมูลได้โดยการนำไปใช้ summary() ฟังก์ชัน
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Print the summary.
print(summary(emp.data))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
emp_id emp_name salary start_date
Min. :1 Length:5 Min. :515.2 Min. :2012-01-01
1st Qu.:2 Class :character 1st Qu.:611.0 1st Qu.:2013-09-23
Median :3 Mode :character Median :623.3 Median :2014-05-11
Mean :3 Mean :664.4 Mean :2014-01-14
3rd Qu.:4 3rd Qu.:729.0 3rd Qu.:2014-11-15
Max. :5 Max. :843.2 Max. :2015-03-27ดึงข้อมูลจาก Data Frame
แยกคอลัมน์เฉพาะจากกรอบข้อมูลโดยใช้ชื่อคอลัมน์
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01","2013-09-23","2014-11-15","2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Extract Specific columns.
result <- data.frame(emp.data$emp_name,emp.data$salary)
print(result)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
emp.data.emp_name emp.data.salary
1 Rick 623.30
2 Dan 515.20
3 Michelle 611.00
4 Ryan 729.00
5 Gary 843.25แยกสองแถวแรกและคอลัมน์ทั้งหมด
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Extract first two rows.
result <- emp.data[1:2,]
print(result)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
emp_id emp_name salary start_date
1 1 Rick 623.3 2012-01-01
2 2 Dan 515.2 2013-09-23สารสกัดจาก 3 RDและ 5 THแถวมี 2 ครั้งที่ 4 และครั้งที่คอลัมน์
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Extract 3rd and 5th row with 2nd and 4th column.
result <- emp.data[c(3,5),c(2,4)]
print(result)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
emp_name start_date
3 Michelle 2014-11-15
5 Gary 2015-03-27ขยาย Data Frame
กรอบข้อมูลสามารถขยายได้โดยการเพิ่มคอลัมน์และแถว
เพิ่มคอลัมน์
เพียงเพิ่มเวกเตอร์คอลัมน์โดยใช้ชื่อคอลัมน์ใหม่
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Add the "dept" coulmn.
emp.data$dept <- c("IT","Operations","IT","HR","Finance")
v <- emp.data
print(v)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
emp_id emp_name salary start_date dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 5 Gary 843.25 2015-03-27 Financeเพิ่มแถว
ในการเพิ่มแถวอย่างถาวรใน data frame ที่มีอยู่เราจำเป็นต้องนำแถวใหม่เข้ามาในโครงสร้างเดียวกันกับ data frame ที่มีอยู่และใช้ rbind() ฟังก์ชัน
ในตัวอย่างด้านล่างเราสร้างเฟรมข้อมูลที่มีแถวใหม่และรวมเข้ากับเฟรมข้อมูลที่มีอยู่เพื่อสร้างเฟรมข้อมูลสุดท้าย
# Create the first data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
dept = c("IT","Operations","IT","HR","Finance"),
stringsAsFactors = FALSE
)
# Create the second data frame
emp.newdata <- data.frame(
emp_id = c (6:8),
emp_name = c("Rasmi","Pranab","Tusar"),
salary = c(578.0,722.5,632.8),
start_date = as.Date(c("2013-05-21","2013-07-30","2014-06-17")),
dept = c("IT","Operations","Fianance"),
stringsAsFactors = FALSE
)
# Bind the two data frames.
emp.finaldata <- rbind(emp.data,emp.newdata)
print(emp.finaldata)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
emp_id emp_name salary start_date dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 5 Gary 843.25 2015-03-27 Finance
6 6 Rasmi 578.00 2013-05-21 IT
7 7 Pranab 722.50 2013-07-30 Operations
8 8 Tusar 632.80 2014-06-17 Fiananceแพ็กเกจ R คือชุดของฟังก์ชัน R โค้ดที่สอดคล้องและข้อมูลตัวอย่าง พวกเขาถูกเก็บไว้ภายใต้ไดเร็กทอรีที่เรียกว่า"library"ในสภาพแวดล้อม R ตามค่าเริ่มต้น R จะติดตั้งชุดแพ็กเกจระหว่างการติดตั้ง มีการเพิ่มแพ็คเกจเพิ่มเติมในภายหลังเมื่อจำเป็นสำหรับวัตถุประสงค์เฉพาะบางอย่าง เมื่อเราเริ่มคอนโซล R จะมีเฉพาะแพ็กเกจเริ่มต้นที่พร้อมใช้งานตามค่าเริ่มต้น แพคเกจอื่น ๆ ที่ติดตั้งไว้แล้วจะต้องถูกโหลดอย่างชัดเจนเพื่อให้โปรแกรม R ที่จะใช้งานได้
แพ็คเกจทั้งหมดที่มีอยู่ในภาษา R แสดงอยู่ในแพ็คเกจ R
ด้านล่างนี้คือรายการคำสั่งที่จะใช้ตรวจสอบตรวจสอบและใช้แพ็กเกจ R
ตรวจสอบแพ็คเกจ R ที่มี
รับตำแหน่งห้องสมุดที่มีแพ็คเกจ R
.libPaths()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังต่อไปนี้ อาจแตกต่างกันไปขึ้นอยู่กับการตั้งค่าท้องถิ่นของพีซีของคุณ
[2] "C:/Program Files/R/R-3.2.2/library"รับรายการแพ็คเกจทั้งหมดที่ติดตั้ง
library()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังต่อไปนี้ อาจแตกต่างกันไปขึ้นอยู่กับการตั้งค่าท้องถิ่นของพีซีของคุณ
Packages in library ‘C:/Program Files/R/R-3.2.2/library’:
base The R Base Package
boot Bootstrap Functions (Originally by Angelo Canty
for S)
class Functions for Classification
cluster "Finding Groups in Data": Cluster Analysis
Extended Rousseeuw et al.
codetools Code Analysis Tools for R
compiler The R Compiler Package
datasets The R Datasets Package
foreign Read Data Stored by 'Minitab', 'S', 'SAS',
'SPSS', 'Stata', 'Systat', 'Weka', 'dBase', ...
graphics The R Graphics Package
grDevices The R Graphics Devices and Support for Colours
and Fonts
grid The Grid Graphics Package
KernSmooth Functions for Kernel Smoothing Supporting Wand
& Jones (1995)
lattice Trellis Graphics for R
MASS Support Functions and Datasets for Venables and
Ripley's MASS
Matrix Sparse and Dense Matrix Classes and Methods
methods Formal Methods and Classes
mgcv Mixed GAM Computation Vehicle with GCV/AIC/REML
Smoothness Estimation
nlme Linear and Nonlinear Mixed Effects Models
nnet Feed-Forward Neural Networks and Multinomial
Log-Linear Models
parallel Support for Parallel computation in R
rpart Recursive Partitioning and Regression Trees
spatial Functions for Kriging and Point Pattern
Analysis
splines Regression Spline Functions and Classes
stats The R Stats Package
stats4 Statistical Functions using S4 Classes
survival Survival Analysis
tcltk Tcl/Tk Interface
tools Tools for Package Development
utils The R Utils Packageรับแพ็คเกจทั้งหมดที่โหลดในสภาพแวดล้อม R
search()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังต่อไปนี้ อาจแตกต่างกันไปขึ้นอยู่กับการตั้งค่าท้องถิ่นของพีซีของคุณ
[1] ".GlobalEnv" "package:stats" "package:graphics"
[4] "package:grDevices" "package:utils" "package:datasets"
[7] "package:methods" "Autoloads" "package:base"ติดตั้งแพ็คเกจใหม่
มีสองวิธีในการเพิ่มแพ็คเกจ R ใหม่ หนึ่งกำลังติดตั้งโดยตรงจากไดเรกทอรี CRAN และอีกรายการหนึ่งกำลังดาวน์โหลดแพ็คเกจไปยังระบบภายในของคุณและติดตั้งด้วยตนเอง
ติดตั้งโดยตรงจาก CRAN
คำสั่งต่อไปนี้รับแพ็กเกจโดยตรงจากเว็บเพจ CRAN และติดตั้งแพ็กเกจในสภาวะแวดล้อม R คุณอาจได้รับแจ้งให้เลือกกระจกที่ใกล้ที่สุด เลือกสถานที่ที่เหมาะสมกับตำแหน่งของคุณ
install.packages("Package Name")
# Install the package named "XML".
install.packages("XML")ติดตั้งแพ็คเกจด้วยตนเอง
ไปที่ลิงค์R แพ็คเกจเพื่อดาวน์โหลดแพ็คเกจที่ต้องการ บันทึกแพ็กเกจเป็นไฟล์.zip ไฟล์ในตำแหน่งที่เหมาะสมในระบบโลคัล
ตอนนี้คุณสามารถรันคำสั่งต่อไปนี้เพื่อติดตั้งแพ็คเกจนี้ในสภาพแวดล้อม R
install.packages(file_name_with_path, repos = NULL, type = "source")
# Install the package named "XML"
install.packages("E:/XML_3.98-1.3.zip", repos = NULL, type = "source")โหลด Package ไปที่ Library
ก่อนที่จะสามารถใช้แพ็กเกจในโค้ดได้ต้องโหลดไปยังสภาวะแวดล้อม R ปัจจุบัน คุณต้องโหลดแพ็กเกจที่ติดตั้งไว้แล้วก่อนหน้านี้ แต่ไม่สามารถใช้ได้ในสภาพแวดล้อมปัจจุบัน
แพ็กเกจถูกโหลดโดยใช้คำสั่งต่อไปนี้ -
library("package Name", lib.loc = "path to library")
# Load the package named "XML"
install.packages("E:/XML_3.98-1.3.zip", repos = NULL, type = "source")การปรับรูปร่างข้อมูลใน R เป็นเรื่องเกี่ยวกับการเปลี่ยนวิธีจัดระเบียบข้อมูลเป็นแถวและคอลัมน์ การประมวลผลข้อมูลเวลาส่วนใหญ่ใน R ทำได้โดยการรับข้อมูลเข้าเป็นกรอบข้อมูล ง่ายต่อการดึงข้อมูลจากแถวและคอลัมน์ของ data frame แต่มีสถานการณ์เมื่อเราต้องการ data frame ในรูปแบบที่แตกต่างจากรูปแบบที่เราได้รับ R มีฟังก์ชันมากมายในการแยกรวมและเปลี่ยนแถวเป็นคอลัมน์และในทางกลับกันในกรอบข้อมูล
การเข้าร่วมคอลัมน์และแถวในกรอบข้อมูล
เราสามารถรวมเวกเตอร์หลายตัวเพื่อสร้างกรอบข้อมูลโดยใช้ไฟล์ cbind()ฟังก์ชัน นอกจากนี้เราสามารถผสานสองเฟรมข้อมูลโดยใช้rbind() ฟังก์ชัน
# Create vector objects.
city <- c("Tampa","Seattle","Hartford","Denver")
state <- c("FL","WA","CT","CO")
zipcode <- c(33602,98104,06161,80294)
# Combine above three vectors into one data frame.
addresses <- cbind(city,state,zipcode)
# Print a header.
cat("# # # # The First data frame\n")
# Print the data frame.
print(addresses)
# Create another data frame with similar columns
new.address <- data.frame(
city = c("Lowry","Charlotte"),
state = c("CO","FL"),
zipcode = c("80230","33949"),
stringsAsFactors = FALSE
)
# Print a header.
cat("# # # The Second data frame\n")
# Print the data frame.
print(new.address)
# Combine rows form both the data frames.
all.addresses <- rbind(addresses,new.address)
# Print a header.
cat("# # # The combined data frame\n")
# Print the result.
print(all.addresses)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
# # # # The First data frame
city state zipcode
[1,] "Tampa" "FL" "33602"
[2,] "Seattle" "WA" "98104"
[3,] "Hartford" "CT" "6161"
[4,] "Denver" "CO" "80294"
# # # The Second data frame
city state zipcode
1 Lowry CO 80230
2 Charlotte FL 33949
# # # The combined data frame
city state zipcode
1 Tampa FL 33602
2 Seattle WA 98104
3 Hartford CT 6161
4 Denver CO 80294
5 Lowry CO 80230
6 Charlotte FL 33949การผสานกรอบข้อมูล
เราสามารถผสานสองเฟรมข้อมูลโดยใช้ merge()ฟังก์ชัน เฟรมข้อมูลต้องมีชื่อคอลัมน์เดียวกันกับที่เกิดการผสาน
ในตัวอย่างด้านล่างเราพิจารณาชุดข้อมูลเกี่ยวกับโรคเบาหวานใน Pima Indian Women ที่มีอยู่ในห้องสมุดชื่อ "MASS" เรารวมชุดข้อมูลสองชุดโดยพิจารณาจากค่าความดันโลหิต ("bp") และดัชนีมวลกาย ("bmi") ในการเลือกสองคอลัมน์นี้สำหรับการรวมระเบียนที่ค่าของตัวแปรทั้งสองนี้ตรงกันในชุดข้อมูลทั้งสองชุดจะถูกรวมเข้าด้วยกันเพื่อสร้างกรอบข้อมูลเดียว
library(MASS)
merged.Pima <- merge(x = Pima.te, y = Pima.tr,
by.x = c("bp", "bmi"),
by.y = c("bp", "bmi")
)
print(merged.Pima)
nrow(merged.Pima)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
bp bmi npreg.x glu.x skin.x ped.x age.x type.x npreg.y glu.y skin.y ped.y
1 60 33.8 1 117 23 0.466 27 No 2 125 20 0.088
2 64 29.7 2 75 24 0.370 33 No 2 100 23 0.368
3 64 31.2 5 189 33 0.583 29 Yes 3 158 13 0.295
4 64 33.2 4 117 27 0.230 24 No 1 96 27 0.289
5 66 38.1 3 115 39 0.150 28 No 1 114 36 0.289
6 68 38.5 2 100 25 0.324 26 No 7 129 49 0.439
7 70 27.4 1 116 28 0.204 21 No 0 124 20 0.254
8 70 33.1 4 91 32 0.446 22 No 9 123 44 0.374
9 70 35.4 9 124 33 0.282 34 No 6 134 23 0.542
10 72 25.6 1 157 21 0.123 24 No 4 99 17 0.294
11 72 37.7 5 95 33 0.370 27 No 6 103 32 0.324
12 74 25.9 9 134 33 0.460 81 No 8 126 38 0.162
13 74 25.9 1 95 21 0.673 36 No 8 126 38 0.162
14 78 27.6 5 88 30 0.258 37 No 6 125 31 0.565
15 78 27.6 10 122 31 0.512 45 No 6 125 31 0.565
16 78 39.4 2 112 50 0.175 24 No 4 112 40 0.236
17 88 34.5 1 117 24 0.403 40 Yes 4 127 11 0.598
age.y type.y
1 31 No
2 21 No
3 24 No
4 21 No
5 21 No
6 43 Yes
7 36 Yes
8 40 No
9 29 Yes
10 28 No
11 55 No
12 39 No
13 39 No
14 49 Yes
15 49 Yes
16 38 No
17 28 No
[1] 17การหลอมและการหล่อ
สิ่งที่น่าสนใจที่สุดอย่างหนึ่งของการเขียนโปรแกรม R คือการเปลี่ยนรูปร่างของข้อมูลในหลายขั้นตอนเพื่อให้ได้รูปร่างที่ต้องการ ฟังก์ชันที่ใช้ในการทำเช่นนี้เรียกว่าmelt() และ cast().
เราพิจารณาชุดข้อมูลที่เรียกว่าเรือที่มีอยู่ในไลบรารีที่เรียกว่า "MASS"
library(MASS)
print(ships)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
type year period service incidents
1 A 60 60 127 0
2 A 60 75 63 0
3 A 65 60 1095 3
4 A 65 75 1095 4
5 A 70 60 1512 6
.............
.............
8 A 75 75 2244 11
9 B 60 60 44882 39
10 B 60 75 17176 29
11 B 65 60 28609 58
............
............
17 C 60 60 1179 1
18 C 60 75 552 1
19 C 65 60 781 0
............
............ละลายข้อมูล
ตอนนี้เราหลอมรวมข้อมูลเพื่อจัดระเบียบโดยแปลงคอลัมน์ทั้งหมดนอกเหนือจากประเภทและปีเป็นหลายแถว
molten.ships <- melt(ships, id = c("type","year"))
print(molten.ships)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
type year variable value
1 A 60 period 60
2 A 60 period 75
3 A 65 period 60
4 A 65 period 75
............
............
9 B 60 period 60
10 B 60 period 75
11 B 65 period 60
12 B 65 period 75
13 B 70 period 60
...........
...........
41 A 60 service 127
42 A 60 service 63
43 A 65 service 1095
...........
...........
70 D 70 service 1208
71 D 75 service 0
72 D 75 service 2051
73 E 60 service 45
74 E 60 service 0
75 E 65 service 789
...........
...........
101 C 70 incidents 6
102 C 70 incidents 2
103 C 75 incidents 0
104 C 75 incidents 1
105 D 60 incidents 0
106 D 60 incidents 0
...........
...........ส่งข้อมูล Molten
เราสามารถโยนข้อมูลที่หลอมเหลวให้อยู่ในรูปแบบใหม่ที่สร้างการรวมของเรือแต่ละประเภทในแต่ละปี ทำได้โดยใช้ไฟล์cast() ฟังก์ชัน
recasted.ship <- cast(molten.ships, type+year~variable,sum)
print(recasted.ship)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
type year period service incidents
1 A 60 135 190 0
2 A 65 135 2190 7
3 A 70 135 4865 24
4 A 75 135 2244 11
5 B 60 135 62058 68
6 B 65 135 48979 111
7 B 70 135 20163 56
8 B 75 135 7117 18
9 C 60 135 1731 2
10 C 65 135 1457 1
11 C 70 135 2731 8
12 C 75 135 274 1
13 D 60 135 356 0
14 D 65 135 480 0
15 D 70 135 1557 13
16 D 75 135 2051 4
17 E 60 135 45 0
18 E 65 135 1226 14
19 E 70 135 3318 17
20 E 75 135 542 1ใน R เราสามารถอ่านข้อมูลจากไฟล์ที่จัดเก็บนอกสภาพแวดล้อม R นอกจากนี้เรายังสามารถเขียนข้อมูลลงในไฟล์ซึ่งจะถูกจัดเก็บและเข้าถึงโดยระบบปฏิบัติการ R สามารถอ่านและเขียนเป็นรูปแบบไฟล์ต่างๆเช่น csv, excel, xml เป็นต้น
ในบทนี้เราจะเรียนรู้การอ่านข้อมูลจากไฟล์ csv แล้วเขียนข้อมูลลงในไฟล์ csv ไฟล์ควรอยู่ในไดเร็กทอรีการทำงานปัจจุบันเพื่อให้ R สามารถอ่านได้ แน่นอนว่าเราสามารถตั้งไดเร็กทอรีของเราเองและอ่านไฟล์ได้จากที่นั่น
การรับและการตั้งค่าไดเร็กทอรีการทำงาน
คุณสามารถตรวจสอบไดเร็กทอรีที่เวิร์กสเปซ R ชี้ไปที่โดยใช้ getwd()ฟังก์ชัน คุณยังสามารถตั้งค่าไดเร็กทอรีการทำงานใหม่โดยใช้ไฟล์setwd()ฟังก์ชัน
# Get and print current working directory.
print(getwd())
# Set current working directory.
setwd("/web/com")
# Get and print current working directory.
print(getwd())เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] "/web/com/1441086124_2016"
[1] "/web/com"ผลลัพธ์นี้ขึ้นอยู่กับระบบปฏิบัติการและไดเร็กทอรีปัจจุบันของคุณที่คุณทำงานอยู่
ป้อนข้อมูลเป็นไฟล์ CSV
ไฟล์ csv เป็นไฟล์ข้อความที่ค่าในคอลัมน์ถูกคั่นด้วยเครื่องหมายจุลภาค ลองพิจารณาข้อมูลต่อไปนี้ที่มีอยู่ในไฟล์ชื่อinput.csv.
คุณสามารถสร้างไฟล์นี้โดยใช้ windows notepad โดยการคัดลอกและวางข้อมูลนี้ บันทึกไฟล์เป็นinput.csv โดยใช้ตัวเลือกบันทึกเป็นไฟล์ทั้งหมด (*. *) ในแผ่นจดบันทึก
id,name,salary,start_date,dept
1,Rick,623.3,2012-01-01,IT
2,Dan,515.2,2013-09-23,Operations
3,Michelle,611,2014-11-15,IT
4,Ryan,729,2014-05-11,HR
5,Gary,843.25,2015-03-27,Finance
6,Nina,578,2013-05-21,IT
7,Simon,632.8,2013-07-30,Operations
8,Guru,722.5,2014-06-17,Financeการอ่านไฟล์ CSV
ต่อไปนี้เป็นตัวอย่างง่ายๆของ read.csv() ฟังก์ชันเพื่ออ่านไฟล์ CSV ที่มีอยู่ในไดเร็กทอรีการทำงานปัจจุบันของคุณ -
data <- read.csv("input.csv")
print(data)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
id, name, salary, start_date, dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
6 6 Nina 578.00 2013-05-21 IT
7 7 Simon 632.80 2013-07-30 Operations
8 8 Guru 722.50 2014-06-17 Financeการวิเคราะห์ไฟล์ CSV
โดยค่าเริ่มต้น read.csv()ฟังก์ชันให้เอาต์พุตเป็นกรอบข้อมูล สามารถตรวจสอบได้ง่ายๆดังนี้ นอกจากนี้เราสามารถตรวจสอบจำนวนคอลัมน์และแถว
data <- read.csv("input.csv")
print(is.data.frame(data))
print(ncol(data))
print(nrow(data))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] TRUE
[1] 5
[1] 8เมื่อเราอ่านข้อมูลใน data frame แล้วเราสามารถใช้ฟังก์ชันทั้งหมดที่เกี่ยวข้องกับ data frames ได้ตามที่อธิบายไว้ในส่วนต่อไป
รับเงินเดือนสูงสุด
# Create a data frame.
data <- read.csv("input.csv")
# Get the max salary from data frame.
sal <- max(data$salary)
print(sal)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] 843.25รับรายละเอียดของบุคคลที่มีเงินเดือนสูงสุด
เราสามารถดึงแถวที่ตรงตามเกณฑ์การกรองเฉพาะที่คล้ายกับ SQL โดยที่อนุประโยค
# Create a data frame.
data <- read.csv("input.csv")
# Get the max salary from data frame.
sal <- max(data$salary)
# Get the person detail having max salary.
retval <- subset(data, salary == max(salary))
print(retval)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
id name salary start_date dept
5 NA Gary 843.25 2015-03-27 Financeรับทุกคนที่ทำงานในแผนกไอที
# Create a data frame.
data <- read.csv("input.csv")
retval <- subset( data, dept == "IT")
print(retval)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
id name salary start_date dept
1 1 Rick 623.3 2012-01-01 IT
3 3 Michelle 611.0 2014-11-15 IT
6 6 Nina 578.0 2013-05-21 ITรับบุคคลในแผนกไอทีที่มีเงินเดือนมากกว่า 600
# Create a data frame.
data <- read.csv("input.csv")
info <- subset(data, salary > 600 & dept == "IT")
print(info)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
id name salary start_date dept
1 1 Rick 623.3 2012-01-01 IT
3 3 Michelle 611.0 2014-11-15 ITรับคนที่เข้าร่วมในหรือหลังปี 2014
# Create a data frame.
data <- read.csv("input.csv")
retval <- subset(data, as.Date(start_date) > as.Date("2014-01-01"))
print(retval)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
id name salary start_date dept
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
8 8 Guru 722.50 2014-06-17 Financeการเขียนลงในไฟล์ CSV
R สามารถสร้างไฟล์ csv จากเฟรมข้อมูลที่มีอยู่ write.csv()ฟังก์ชันถูกใช้เพื่อสร้างไฟล์ csv ไฟล์นี้ถูกสร้างขึ้นในไดเร็กทอรีการทำงาน
# Create a data frame.
data <- read.csv("input.csv")
retval <- subset(data, as.Date(start_date) > as.Date("2014-01-01"))
# Write filtered data into a new file.
write.csv(retval,"output.csv")
newdata <- read.csv("output.csv")
print(newdata)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
X id name salary start_date dept
1 3 3 Michelle 611.00 2014-11-15 IT
2 4 4 Ryan 729.00 2014-05-11 HR
3 5 NA Gary 843.25 2015-03-27 Finance
4 8 8 Guru 722.50 2014-06-17 Financeคอลัมน์ X มาจากชุดข้อมูลที่ใหม่กว่า สิ่งนี้สามารถทิ้งได้โดยใช้พารามิเตอร์เพิ่มเติมขณะเขียนไฟล์
# Create a data frame.
data <- read.csv("input.csv")
retval <- subset(data, as.Date(start_date) > as.Date("2014-01-01"))
# Write filtered data into a new file.
write.csv(retval,"output.csv", row.names = FALSE)
newdata <- read.csv("output.csv")
print(newdata)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
id name salary start_date dept
1 3 Michelle 611.00 2014-11-15 IT
2 4 Ryan 729.00 2014-05-11 HR
3 NA Gary 843.25 2015-03-27 Finance
4 8 Guru 722.50 2014-06-17 FinanceMicrosoft Excel เป็นโปรแกรมสเปรดชีตที่ใช้กันอย่างแพร่หลายซึ่งเก็บข้อมูลในรูปแบบ. xls หรือ. xlsx R สามารถอ่านได้โดยตรงจากไฟล์เหล่านี้โดยใช้แพ็คเกจเฉพาะของ excel ไม่กี่แพ็กเกจดังกล่าว ได้แก่ - XLConnect, xlsx, gdata เป็นต้นเราจะใช้แพ็คเกจ xlsx R ยังสามารถเขียนลงในไฟล์ excel โดยใช้แพ็คเกจนี้
ติดตั้งแพ็คเกจ xlsx
คุณสามารถใช้คำสั่งต่อไปนี้ในคอนโซล R เพื่อติดตั้งแพ็กเกจ "xlsx" อาจขอให้ติดตั้งแพ็คเกจเพิ่มเติมบางอย่างซึ่งขึ้นอยู่กับแพ็คเกจนี้ ปฏิบัติตามคำสั่งเดียวกันกับชื่อแพ็กเกจที่ต้องการเพื่อติดตั้งแพ็กเกจเพิ่มเติม
install.packages("xlsx")ตรวจสอบและโหลดแพ็คเกจ "xlsx"
ใช้คำสั่งต่อไปนี้เพื่อตรวจสอบและโหลดแพ็กเกจ "xlsx"
# Verify the package is installed.
any(grepl("xlsx",installed.packages()))
# Load the library into R workspace.
library("xlsx")เมื่อเรียกใช้สคริปต์เราจะได้ผลลัพธ์ต่อไปนี้
[1] TRUE
Loading required package: rJava
Loading required package: methods
Loading required package: xlsxjarsป้อนข้อมูลเป็นไฟล์ xlsx
เปิด Microsoft excel คัดลอกและวางข้อมูลต่อไปนี้ในแผ่นงานที่มีชื่อว่า sheet1
id name salary start_date dept
1 Rick 623.3 1/1/2012 IT
2 Dan 515.2 9/23/2013 Operations
3 Michelle 611 11/15/2014 IT
4 Ryan 729 5/11/2014 HR
5 Gary 43.25 3/27/2015 Finance
6 Nina 578 5/21/2013 IT
7 Simon 632.8 7/30/2013 Operations
8 Guru 722.5 6/17/2014 Financeคัดลอกและวางข้อมูลต่อไปนี้ลงในแผ่นงานอื่นและเปลี่ยนชื่อแผ่นงานนี้เป็น "เมือง"
name city
Rick Seattle
Dan Tampa
Michelle Chicago
Ryan Seattle
Gary Houston
Nina Boston
Simon Mumbai
Guru Dallasบันทึกไฟล์ Excel เป็น "input.xlsx" คุณควรบันทึกไว้ในไดเร็กทอรีการทำงานปัจจุบันของพื้นที่ทำงาน R
การอ่านไฟล์ Excel
input.xlsx ถูกอ่านโดยใช้ read.xlsx()ฟังก์ชันดังที่แสดงด้านล่าง ผลลัพธ์จะถูกจัดเก็บเป็นกรอบข้อมูลในสภาพแวดล้อม R
# Read the first worksheet in the file input.xlsx.
data <- read.xlsx("input.xlsx", sheetIndex = 1)
print(data)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
id, name, salary, start_date, dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
6 6 Nina 578.00 2013-05-21 IT
7 7 Simon 632.80 2013-07-30 Operations
8 8 Guru 722.50 2014-06-17 Financeไฟล์ไบนารีคือไฟล์ที่มีข้อมูลที่จัดเก็บในรูปแบบของบิตและไบต์เท่านั้น (0 และ 1) พวกเขาไม่สามารถอ่านได้โดยมนุษย์เนื่องจากไบต์ในนั้นแปลเป็นอักขระและสัญลักษณ์ซึ่งมีอักขระที่ไม่สามารถพิมพ์ได้อื่น ๆ อีกมากมาย การพยายามอ่านไฟล์ไบนารีโดยใช้โปรแกรมแก้ไขข้อความใด ๆ จะแสดงอักขระเช่นØและð
ไฟล์ไบนารีจะต้องถูกอ่านโดยโปรแกรมเฉพาะจึงจะใช้งานได้ ตัวอย่างเช่นไฟล์ไบนารีของโปรแกรม Microsoft Word สามารถอ่านเป็นรูปแบบที่มนุษย์อ่านได้โดยโปรแกรม Word เท่านั้น ซึ่งบ่งชี้ว่านอกจากข้อความที่มนุษย์อ่านได้แล้วยังมีข้อมูลอื่น ๆ อีกมากมายเช่นการจัดรูปแบบอักขระและหมายเลขหน้าเป็นต้นซึ่งจะจัดเก็บไว้พร้อมกับอักขระที่เป็นตัวอักษรและตัวเลข และสุดท้ายไฟล์ไบนารีคือลำดับไบต์ที่ต่อเนื่องกัน ตัวแบ่งบรรทัดที่เราเห็นในไฟล์ข้อความคืออักขระที่เชื่อมบรรทัดแรกไปยังบรรทัดถัดไป
บางครั้งข้อมูลที่สร้างโดยโปรแกรมอื่นจำเป็นต้องประมวลผลโดย R เป็นไฟล์ไบนารี จำเป็นต้องใช้ R ในการสร้างไฟล์ไบนารีซึ่งสามารถแชร์กับโปรแกรมอื่นได้
R มีสองฟังก์ชัน WriteBin() และ readBin() เพื่อสร้างและอ่านไฟล์ไบนารี
ไวยากรณ์
writeBin(object, con)
readBin(con, what, n )ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
con เป็นวัตถุเชื่อมต่อเพื่ออ่านหรือเขียนไฟล์ไบนารี
object คือไฟล์ไบนารีที่จะเขียน
what เป็นโหมดเช่นอักขระจำนวนเต็ม ฯลฯ แทนไบต์ที่จะอ่าน
n คือจำนวนไบต์ที่จะอ่านจากไฟล์ไบนารี
ตัวอย่าง
เราพิจารณาข้อมูล R inbuilt "mtcars" ก่อนอื่นเราสร้างไฟล์ csv จากไฟล์และแปลงเป็นไฟล์ไบนารีและจัดเก็บเป็นไฟล์ OS ต่อไปเราจะอ่านไฟล์ไบนารีที่สร้างขึ้นใน R
การเขียนไฟล์ไบนารี
เราอ่าน data frame "mtcars" เป็นไฟล์ csv จากนั้นจึงเขียนเป็นไฟล์ไบนารีไปยัง OS
# Read the "mtcars" data frame as a csv file and store only the columns
"cyl", "am" and "gear".
write.table(mtcars, file = "mtcars.csv",row.names = FALSE, na = "",
col.names = TRUE, sep = ",")
# Store 5 records from the csv file as a new data frame.
new.mtcars <- read.table("mtcars.csv",sep = ",",header = TRUE,nrows = 5)
# Create a connection object to write the binary file using mode "wb".
write.filename = file("/web/com/binmtcars.dat", "wb")
# Write the column names of the data frame to the connection object.
writeBin(colnames(new.mtcars), write.filename)
# Write the records in each of the column to the file.
writeBin(c(new.mtcars$cyl,new.mtcars$am,new.mtcars$gear), write.filename)
# Close the file for writing so that it can be read by other program.
close(write.filename)การอ่านไฟล์ไบนารี
ไฟล์ไบนารีที่สร้างขึ้นด้านบนจะเก็บข้อมูลทั้งหมดเป็นไบต์ต่อเนื่อง ดังนั้นเราจะอ่านโดยเลือกค่าที่เหมาะสมของชื่อคอลัมน์และค่าคอลัมน์
# Create a connection object to read the file in binary mode using "rb".
read.filename <- file("/web/com/binmtcars.dat", "rb")
# First read the column names. n = 3 as we have 3 columns.
column.names <- readBin(read.filename, character(), n = 3)
# Next read the column values. n = 18 as we have 3 column names and 15 values.
read.filename <- file("/web/com/binmtcars.dat", "rb")
bindata <- readBin(read.filename, integer(), n = 18)
# Print the data.
print(bindata)
# Read the values from 4th byte to 8th byte which represents "cyl".
cyldata = bindata[4:8]
print(cyldata)
# Read the values form 9th byte to 13th byte which represents "am".
amdata = bindata[9:13]
print(amdata)
# Read the values form 9th byte to 13th byte which represents "gear".
geardata = bindata[14:18]
print(geardata)
# Combine all the read values to a dat frame.
finaldata = cbind(cyldata, amdata, geardata)
colnames(finaldata) = column.names
print(finaldata)เมื่อเรารันโค้ดด้านบนจะสร้างผลลัพธ์และแผนภูมิต่อไปนี้ -
[1] 7108963 1728081249 7496037 6 6 4
[7] 6 8 1 1 1 0
[13] 0 4 4 4 3 3
[1] 6 6 4 6 8
[1] 1 1 1 0 0
[1] 4 4 4 3 3
cyl am gear
[1,] 6 1 4
[2,] 6 1 4
[3,] 4 1 4
[4,] 6 0 3
[5,] 8 0 3อย่างที่เราเห็นเราได้ข้อมูลดั้งเดิมกลับมาโดยการอ่านไฟล์ไบนารีใน R
XML เป็นรูปแบบไฟล์ที่แชร์ทั้งรูปแบบไฟล์และข้อมูลบนเวิลด์ไวด์เว็บอินทราเน็ตและที่อื่น ๆ โดยใช้ข้อความ ASCII มาตรฐาน ย่อมาจาก Extensible Markup Language (XML) คล้ายกับ HTML มีแท็กมาร์กอัป แต่แตกต่างจาก HTML ตรงที่แท็กมาร์กอัปอธิบายโครงสร้างของหน้าใน xml แท็กมาร์กอัปจะอธิบายความหมายของข้อมูลที่อยู่ในไฟล์
คุณสามารถอ่านไฟล์ xml ใน R โดยใช้แพ็กเกจ "XML" สามารถติดตั้งแพ็คเกจนี้ได้โดยใช้คำสั่งต่อไปนี้
install.packages("XML")ป้อนข้อมูล
สร้างไฟล์ XMl โดยคัดลอกข้อมูลด้านล่างลงในโปรแกรมแก้ไขข้อความเช่น notepad บันทึกไฟล์ด้วยไฟล์.xml และเลือกประเภทไฟล์เป็น all files(*.*).
<RECORDS>
<EMPLOYEE>
<ID>1</ID>
<NAME>Rick</NAME>
<SALARY>623.3</SALARY>
<STARTDATE>1/1/2012</STARTDATE>
<DEPT>IT</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>2</ID>
<NAME>Dan</NAME>
<SALARY>515.2</SALARY>
<STARTDATE>9/23/2013</STARTDATE>
<DEPT>Operations</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>3</ID>
<NAME>Michelle</NAME>
<SALARY>611</SALARY>
<STARTDATE>11/15/2014</STARTDATE>
<DEPT>IT</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>4</ID>
<NAME>Ryan</NAME>
<SALARY>729</SALARY>
<STARTDATE>5/11/2014</STARTDATE>
<DEPT>HR</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>5</ID>
<NAME>Gary</NAME>
<SALARY>843.25</SALARY>
<STARTDATE>3/27/2015</STARTDATE>
<DEPT>Finance</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>6</ID>
<NAME>Nina</NAME>
<SALARY>578</SALARY>
<STARTDATE>5/21/2013</STARTDATE>
<DEPT>IT</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>7</ID>
<NAME>Simon</NAME>
<SALARY>632.8</SALARY>
<STARTDATE>7/30/2013</STARTDATE>
<DEPT>Operations</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>8</ID>
<NAME>Guru</NAME>
<SALARY>722.5</SALARY>
<STARTDATE>6/17/2014</STARTDATE>
<DEPT>Finance</DEPT>
</EMPLOYEE>
</RECORDS>การอ่านไฟล์ XML
ไฟล์ xml ถูกอ่านโดย R โดยใช้ฟังก์ชัน xmlParse(). มันถูกเก็บไว้เป็นรายการใน R
# Load the package required to read XML files.
library("XML")
# Also load the other required package.
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Print the result.
print(result)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
1
Rick
623.3
1/1/2012
IT
2
Dan
515.2
9/23/2013
Operations
3
Michelle
611
11/15/2014
IT
4
Ryan
729
5/11/2014
HR
5
Gary
843.25
3/27/2015
Finance
6
Nina
578
5/21/2013
IT
7
Simon
632.8
7/30/2013
Operations
8
Guru
722.5
6/17/2014
Financeรับจำนวนโหนดที่มีอยู่ในไฟล์ XML
# Load the packages required to read XML files.
library("XML")
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Exract the root node form the xml file.
rootnode <- xmlRoot(result)
# Find number of nodes in the root.
rootsize <- xmlSize(rootnode)
# Print the result.
print(rootsize)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
output
[1] 8รายละเอียดของโหนดแรก
มาดูบันทึกแรกของไฟล์ที่แยกวิเคราะห์ มันจะทำให้เราทราบถึงองค์ประกอบต่างๆที่มีอยู่ในโหนดระดับบนสุด
# Load the packages required to read XML files.
library("XML")
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Exract the root node form the xml file.
rootnode <- xmlRoot(result)
# Print the result.
print(rootnode[1])เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
$EMPLOYEE
1
Rick
623.3
1/1/2012
IT
attr(,"class")
[1] "XMLInternalNodeList" "XMLNodeList"รับองค์ประกอบต่างๆของโหนด
# Load the packages required to read XML files.
library("XML")
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Exract the root node form the xml file.
rootnode <- xmlRoot(result)
# Get the first element of the first node.
print(rootnode[[1]][[1]])
# Get the fifth element of the first node.
print(rootnode[[1]][[5]])
# Get the second element of the third node.
print(rootnode[[3]][[2]])เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
1
IT
MichelleXML ไปยัง Data Frame
ในการจัดการข้อมูลอย่างมีประสิทธิภาพในไฟล์ขนาดใหญ่เราอ่านข้อมูลในไฟล์ xml เป็น data frame จากนั้นประมวลผลกรอบข้อมูลเพื่อวิเคราะห์ข้อมูล
# Load the packages required to read XML files.
library("XML")
library("methods")
# Convert the input xml file to a data frame.
xmldataframe <- xmlToDataFrame("input.xml")
print(xmldataframe)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
ID NAME SALARY STARTDATE DEPT
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
6 6 Nina 578.00 2013-05-21 IT
7 7 Simon 632.80 2013-07-30 Operations
8 8 Guru 722.50 2014-06-17 Financeเนื่องจากข้อมูลพร้อมใช้งานในรูปแบบดาต้าเฟรมแล้วเราจึงสามารถใช้ฟังก์ชันที่เกี่ยวข้องกับเฟรมข้อมูลเพื่ออ่านและจัดการไฟล์ได้
ไฟล์ JSON เก็บข้อมูลเป็นข้อความในรูปแบบที่มนุษย์อ่านได้ Json ย่อมาจาก JavaScript Object Notation R สามารถอ่านไฟล์ JSON โดยใช้แพ็คเกจ rjson
ติดตั้งแพ็คเกจ rjson
ในคอนโซล R คุณสามารถใช้คำสั่งต่อไปนี้เพื่อติดตั้งแพ็กเกจ rjson
install.packages("rjson")ป้อนข้อมูล
สร้างไฟล์ JSON โดยคัดลอกข้อมูลด้านล่างลงในโปรแกรมแก้ไขข้อความเช่น notepad บันทึกไฟล์ด้วยไฟล์.json และเลือกประเภทไฟล์เป็น all files(*.*).
{
"ID":["1","2","3","4","5","6","7","8" ],
"Name":["Rick","Dan","Michelle","Ryan","Gary","Nina","Simon","Guru" ],
"Salary":["623.3","515.2","611","729","843.25","578","632.8","722.5" ],
"StartDate":[ "1/1/2012","9/23/2013","11/15/2014","5/11/2014","3/27/2015","5/21/2013",
"7/30/2013","6/17/2014"],
"Dept":[ "IT","Operations","IT","HR","Finance","IT","Operations","Finance"]
}อ่านไฟล์ JSON
ไฟล์ JSON ถูกอ่านโดย R โดยใช้ฟังก์ชัน from JSON(). มันถูกเก็บไว้เป็นรายการใน R
# Load the package required to read JSON files.
library("rjson")
# Give the input file name to the function.
result <- fromJSON(file = "input.json")
# Print the result.
print(result)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
$ID
[1] "1" "2" "3" "4" "5" "6" "7" "8"
$Name [1] "Rick" "Dan" "Michelle" "Ryan" "Gary" "Nina" "Simon" "Guru" $Salary
[1] "623.3" "515.2" "611" "729" "843.25" "578" "632.8" "722.5"
$StartDate [1] "1/1/2012" "9/23/2013" "11/15/2014" "5/11/2014" "3/27/2015" "5/21/2013" "7/30/2013" "6/17/2014" $Dept
[1] "IT" "Operations" "IT" "HR" "Finance" "IT"
"Operations" "Finance"แปลง JSON เป็น Data Frame
เราสามารถแปลงข้อมูลที่แยกด้านบนเป็นเฟรมข้อมูล R เพื่อการวิเคราะห์เพิ่มเติมโดยใช้ไฟล์ as.data.frame() ฟังก์ชัน
# Load the package required to read JSON files.
library("rjson")
# Give the input file name to the function.
result <- fromJSON(file = "input.json")
# Convert JSON file to a data frame.
json_data_frame <- as.data.frame(result)
print(json_data_frame)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
id, name, salary, start_date, dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
6 6 Nina 578.00 2013-05-21 IT
7 7 Simon 632.80 2013-07-30 Operations
8 8 Guru 722.50 2014-06-17 Financeเว็บไซต์จำนวนมากให้ข้อมูลสำหรับการบริโภคโดยผู้ใช้ ตัวอย่างเช่นองค์การอนามัยโลก (WHO) จัดทำรายงานเกี่ยวกับสุขภาพและข้อมูลทางการแพทย์ในรูปแบบไฟล์ CSV, txt และ XML การใช้โปรแกรม R เราสามารถดึงข้อมูลเฉพาะจากเว็บไซต์ดังกล่าวโดยใช้โปรแกรม แพ็กเกจบางอย่างใน R ซึ่งใช้ในการคัดลอกข้อมูลจากเว็บ ได้แก่ - "RCurl", XML "และ" stringr "ใช้เพื่อเชื่อมต่อกับ URL ระบุลิงก์ที่จำเป็นสำหรับไฟล์และดาวน์โหลดไปยังสภาพแวดล้อมภายในเครื่อง
ติดตั้งแพ็คเกจ R
แพ็กเกจต่อไปนี้จำเป็นสำหรับการประมวลผล URL และลิงก์ไปยังไฟล์ หากไม่มีใน R Environment ของคุณคุณสามารถติดตั้งได้โดยใช้คำสั่งต่อไปนี้
install.packages("RCurl")
install.packages("XML")
install.packages("stringr")
install.packages("plyr")ป้อนข้อมูล
เราจะไปที่ข้อมูลสภาพอากาศของ URL และดาวน์โหลดไฟล์ CSV โดยใช้ R สำหรับปี 2015
ตัวอย่าง
เราจะใช้ฟังก์ชัน getHTMLLinks()เพื่อรวบรวม URL ของไฟล์ จากนั้นเราจะใช้ฟังก์ชันdownload.file()เพื่อบันทึกไฟล์ลงในระบบโลคัล เนื่องจากเราจะใช้รหัสเดิมซ้ำแล้วซ้ำอีกสำหรับไฟล์หลายไฟล์เราจะสร้างฟังก์ชันที่จะเรียกหลาย ๆ ครั้ง ชื่อไฟล์จะถูกส่งผ่านเป็นพารามิเตอร์ในรูปแบบของวัตถุรายการ R ไปยังฟังก์ชันนี้
# Read the URL.
url <- "http://www.geos.ed.ac.uk/~weather/jcmb_ws/"
# Gather the html links present in the webpage.
links <- getHTMLLinks(url)
# Identify only the links which point to the JCMB 2015 files.
filenames <- links[str_detect(links, "JCMB_2015")]
# Store the file names as a list.
filenames_list <- as.list(filenames)
# Create a function to download the files by passing the URL and filename list.
downloadcsv <- function (mainurl,filename) {
filedetails <- str_c(mainurl,filename)
download.file(filedetails,filename)
}
# Now apply the l_ply function and save the files into the current R working directory.
l_ply(filenames,downloadcsv,mainurl = "http://www.geos.ed.ac.uk/~weather/jcmb_ws/")ตรวจสอบการดาวน์โหลดไฟล์
หลังจากรันโค้ดด้านบนแล้วคุณสามารถค้นหาไฟล์ต่อไปนี้ในไดเร็กทอรีการทำงาน R ปัจจุบัน
"JCMB_2015.csv" "JCMB_2015_Apr.csv" "JCMB_2015_Feb.csv" "JCMB_2015_Jan.csv"
"JCMB_2015_Mar.csv"ข้อมูลเป็นระบบฐานข้อมูลเชิงสัมพันธ์จะถูกจัดเก็บในรูปแบบปกติ ดังนั้นในการคำนวณทางสถิติเราจำเป็นต้องมีการสืบค้น Sql ขั้นสูงและซับซ้อนมาก แต่ R สามารถเชื่อมต่อกับฐานข้อมูลเชิงสัมพันธ์ได้อย่างง่ายดายเช่น MySql, Oracle, Sql server และอื่น ๆ และดึงข้อมูลจากฐานข้อมูลเหล่านี้เป็นกรอบข้อมูล เมื่อข้อมูลพร้อมใช้งานในสภาพแวดล้อม R ข้อมูลนั้นจะกลายเป็นชุดข้อมูล R ปกติและสามารถจัดการหรือวิเคราะห์ได้โดยใช้แพ็คเกจและฟังก์ชันที่มีประสิทธิภาพทั้งหมด
ในบทช่วยสอนนี้เราจะใช้ MySql เป็นฐานข้อมูลอ้างอิงสำหรับเชื่อมต่อกับ R
แพ็คเกจ RMySQL
R มีแพ็คเกจในตัวชื่อ "RMySQL" ซึ่งให้การเชื่อมต่อแบบเนทีฟระหว่างกับฐานข้อมูล MySql คุณสามารถติดตั้งแพ็กเกจนี้ในสภาวะแวดล้อม R โดยใช้คำสั่งต่อไปนี้
install.packages("RMySQL")การเชื่อมต่อ R กับ MySql
เมื่อติดตั้งแพคเกจแล้วเราจะสร้างวัตถุการเชื่อมต่อใน R เพื่อเชื่อมต่อกับฐานข้อมูล ใช้ชื่อผู้ใช้รหัสผ่านชื่อฐานข้อมูลและชื่อโฮสต์เป็นอินพุต
# Create a connection Object to MySQL database.
# We will connect to the sampel database named "sakila" that comes with MySql installation.
mysqlconnection = dbConnect(MySQL(), user = 'root', password = '', dbname = 'sakila',
host = 'localhost')
# List the tables available in this database.
dbListTables(mysqlconnection)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] "actor" "actor_info"
[3] "address" "category"
[5] "city" "country"
[7] "customer" "customer_list"
[9] "film" "film_actor"
[11] "film_category" "film_list"
[13] "film_text" "inventory"
[15] "language" "nicer_but_slower_film_list"
[17] "payment" "rental"
[19] "sales_by_film_category" "sales_by_store"
[21] "staff" "staff_list"
[23] "store"การสืบค้นตาราง
เราสามารถสอบถามตารางฐานข้อมูลใน MySql โดยใช้ฟังก์ชัน dbSendQuery(). แบบสอบถามจะถูกดำเนินการใน MySql และชุดผลลัพธ์จะถูกส่งกลับโดยใช้ Rfetch()ฟังก์ชัน ในที่สุดก็จะถูกเก็บเป็นกรอบข้อมูลใน R
# Query the "actor" tables to get all the rows.
result = dbSendQuery(mysqlconnection, "select * from actor")
# Store the result in a R data frame object. n = 5 is used to fetch first 5 rows.
data.frame = fetch(result, n = 5)
print(data.fame)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
actor_id first_name last_name last_update
1 1 PENELOPE GUINESS 2006-02-15 04:34:33
2 2 NICK WAHLBERG 2006-02-15 04:34:33
3 3 ED CHASE 2006-02-15 04:34:33
4 4 JENNIFER DAVIS 2006-02-15 04:34:33
5 5 JOHNNY LOLLOBRIGIDA 2006-02-15 04:34:33ค้นหาด้วย Filter Clause
เราสามารถส่งแบบสอบถามเลือกที่ถูกต้องเพื่อให้ได้ผลลัพธ์
result = dbSendQuery(mysqlconnection, "select * from actor where last_name = 'TORN'")
# Fetch all the records(with n = -1) and store it as a data frame.
data.frame = fetch(result, n = -1)
print(data)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
actor_id first_name last_name last_update
1 18 DAN TORN 2006-02-15 04:34:33
2 94 KENNETH TORN 2006-02-15 04:34:33
3 102 WALTER TORN 2006-02-15 04:34:33การอัปเดตแถวในตาราง
เราสามารถอัปเดตแถวในตาราง Mysql ได้โดยส่งแบบสอบถามการอัปเดตไปยังฟังก์ชัน dbSendQuery ()
dbSendQuery(mysqlconnection, "update mtcars set disp = 168.5 where hp = 110")หลังจากดำเนินการตามโค้ดด้านบนเราจะเห็นตารางที่อัปเดตใน MySql Environment
การแทรกข้อมูลลงในตาราง
dbSendQuery(mysqlconnection,
"insert into mtcars(row_names, mpg, cyl, disp, hp, drat, wt, qsec, vs, am, gear, carb)
values('New Mazda RX4 Wag', 21, 6, 168.5, 110, 3.9, 2.875, 17.02, 0, 1, 4, 4)"
)หลังจากรันโค้ดด้านบนแล้วเราจะเห็นแถวที่แทรกลงในตารางใน MySql Environment
การสร้างตารางใน MySql
เราสามารถสร้างตารางใน MySql โดยใช้ฟังก์ชัน dbWriteTable(). จะเขียนทับตารางหากมีอยู่แล้วและใช้กรอบข้อมูลเป็นอินพุต
# Create the connection object to the database where we want to create the table.
mysqlconnection = dbConnect(MySQL(), user = 'root', password = '', dbname = 'sakila',
host = 'localhost')
# Use the R data frame "mtcars" to create the table in MySql.
# All the rows of mtcars are taken inot MySql.
dbWriteTable(mysqlconnection, "mtcars", mtcars[, ], overwrite = TRUE)หลังจากรันโค้ดด้านบนแล้วเราจะเห็นตารางที่สร้างขึ้นใน MySql Environment
การวางตารางใน MySql
เราสามารถวางตารางในฐานข้อมูล MySql โดยส่งผ่านคำสั่ง drop table ไปยัง dbSendQuery () ในลักษณะเดียวกับที่เราใช้ในการสืบค้นข้อมูลจากตาราง
dbSendQuery(mysqlconnection, 'drop table if exists mtcars')หลังจากดำเนินการตามโค้ดด้านบนเราจะเห็นว่าตารางถูกทิ้งใน MySql Environment
R ภาษาการเขียนโปรแกรมมีไลบรารีมากมายสำหรับสร้างแผนภูมิและกราฟ แผนภูมิวงกลมคือการแสดงค่าเป็นส่วนของวงกลมที่มีสีต่างกัน ชิ้นส่วนจะมีป้ายกำกับและตัวเลขที่ตรงกับแต่ละชิ้นจะแสดงในแผนภูมิด้วย
ใน R แผนภูมิวงกลมถูกสร้างขึ้นโดยใช้ pie()ฟังก์ชันที่ใช้ตัวเลขบวกเป็นอินพุตเวกเตอร์ พารามิเตอร์เพิ่มเติมใช้เพื่อควบคุมป้ายกำกับสีชื่อเรื่อง ฯลฯ
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการสร้างแผนภูมิวงกลมโดยใช้ R คือ -
pie(x, labels, radius, main, col, clockwise)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
x เป็นเวกเตอร์ที่มีค่าตัวเลขที่ใช้ในแผนภูมิวงกลม
labels ใช้เพื่อให้คำอธิบายกับชิ้นส่วน
radius แสดงรัศมีของวงกลมของแผนภูมิวงกลม (ค่าระหว่าง −1 ถึง +1)
main ระบุชื่อของแผนภูมิ
col แสดงจานสี
clockwise เป็นค่าตรรกะที่ระบุว่าชิ้นส่วนถูกวาดตามเข็มนาฬิกาหรือทวนเข็มนาฬิกา
ตัวอย่าง
แผนภูมิวงกลมที่เรียบง่ายมากถูกสร้างขึ้นโดยใช้เพียงเวกเตอร์และป้ายกำกับ สคริปต์ด้านล่างจะสร้างและบันทึกแผนภูมิวงกลมในไดเรกทอรีการทำงาน R ปัจจุบัน
# Create data for the graph.
x <- c(21, 62, 10, 53)
labels <- c("London", "New York", "Singapore", "Mumbai")
# Give the chart file a name.
png(file = "city.png")
# Plot the chart.
pie(x,labels)
# Save the file.
dev.off()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
ชื่อแผนภูมิวงกลมและสี
เราสามารถขยายคุณสมบัติของแผนภูมิได้โดยการเพิ่มพารามิเตอร์ให้กับฟังก์ชัน เราจะใช้พารามิเตอร์main เพื่อเพิ่มชื่อในแผนภูมิและพารามิเตอร์อื่นคือ colซึ่งจะใช้ประโยชน์จากพาเลทสีรุ้งในขณะที่วาดแผนภูมิ ความยาวของพาเลทควรเท่ากับจำนวนค่าที่เรามีสำหรับแผนภูมิ ดังนั้นเราจึงใช้ความยาว (x)
ตัวอย่าง
สคริปต์ด้านล่างจะสร้างและบันทึกแผนภูมิวงกลมในไดเรกทอรีการทำงาน R ปัจจุบัน
# Create data for the graph.
x <- c(21, 62, 10, 53)
labels <- c("London", "New York", "Singapore", "Mumbai")
# Give the chart file a name.
png(file = "city_title_colours.jpg")
# Plot the chart with title and rainbow color pallet.
pie(x, labels, main = "City pie chart", col = rainbow(length(x)))
# Save the file.
dev.off()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
Slice Percentages และ Chart Legend
เราสามารถเพิ่มเปอร์เซ็นต์สไลซ์และคำอธิบายแผนภูมิได้โดยการสร้างตัวแปรแผนภูมิเพิ่มเติม
# Create data for the graph.
x <- c(21, 62, 10,53)
labels <- c("London","New York","Singapore","Mumbai")
piepercent<- round(100*x/sum(x), 1)
# Give the chart file a name.
png(file = "city_percentage_legends.jpg")
# Plot the chart.
pie(x, labels = piepercent, main = "City pie chart",col = rainbow(length(x)))
legend("topright", c("London","New York","Singapore","Mumbai"), cex = 0.8,
fill = rainbow(length(x)))
# Save the file.
dev.off()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
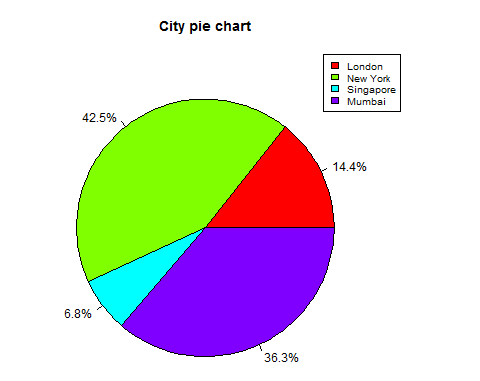
แผนภูมิวงกลม 3 มิติ
แผนภูมิวงกลมที่มี 3 มิติสามารถวาดได้โดยใช้แพ็คเกจเพิ่มเติม แพคเกจplotrix มีฟังก์ชันที่เรียกว่า pie3D() ที่ใช้สำหรับสิ่งนี้
# Get the library.
library(plotrix)
# Create data for the graph.
x <- c(21, 62, 10,53)
lbl <- c("London","New York","Singapore","Mumbai")
# Give the chart file a name.
png(file = "3d_pie_chart.jpg")
# Plot the chart.
pie3D(x,labels = lbl,explode = 0.1, main = "Pie Chart of Countries ")
# Save the file.
dev.off()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
แผนภูมิแท่งแสดงข้อมูลเป็นแท่งสี่เหลี่ยมโดยมีความยาวของแท่งเป็นสัดส่วนกับค่าของตัวแปร R ใช้ฟังก์ชันbarplot()เพื่อสร้างแผนภูมิแท่ง R สามารถวาดแท่งทั้งแนวตั้งและแนวนอนในแผนภูมิแท่ง ในแผนภูมิแท่งแต่ละแท่งสามารถกำหนดสีที่แตกต่างกันได้
ไวยากรณ์
ไวยากรณ์พื้นฐานในการสร้างแผนภูมิแท่งใน R คือ -
barplot(H,xlab,ylab,main, names.arg,col)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
- H เป็นเวกเตอร์หรือเมทริกซ์ที่มีค่าตัวเลขที่ใช้ในแผนภูมิแท่ง
- xlab คือป้ายกำกับสำหรับแกน x
- ylab คือป้ายกำกับสำหรับแกน y
- main คือชื่อของแผนภูมิแท่ง
- names.arg คือเวกเตอร์ของชื่อที่ปรากฏใต้แต่ละแถบ
- col ใช้เพื่อให้สีกับแท่งในกราฟ
ตัวอย่าง
แผนภูมิแท่งอย่างง่ายถูกสร้างขึ้นโดยใช้เพียงเวกเตอร์อินพุตและชื่อของแต่ละแท่ง
สคริปต์ด้านล่างนี้จะสร้างและบันทึกแผนภูมิแท่งในไดเรกทอรีการทำงาน R ปัจจุบัน
# Create the data for the chart
H <- c(7,12,28,3,41)
# Give the chart file a name
png(file = "barchart.png")
# Plot the bar chart
barplot(H)
# Save the file
dev.off()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
ฉลากแผนภูมิแท่งชื่อเรื่องและสี
คุณสมบัติของแผนภูมิแท่งสามารถขยายได้โดยการเพิ่มพารามิเตอร์เพิ่มเติม main ใช้พารามิเตอร์เพื่อเพิ่ม title. colพารามิเตอร์ใช้เพื่อเพิ่มสีให้กับแท่ง args.name คือเวกเตอร์ที่มีค่าจำนวนเท่ากันกับเวกเตอร์อินพุตเพื่ออธิบายความหมายของแต่ละแท่ง
ตัวอย่าง
สคริปต์ด้านล่างนี้จะสร้างและบันทึกแผนภูมิแท่งในไดเรกทอรีการทำงาน R ปัจจุบัน
# Create the data for the chart
H <- c(7,12,28,3,41)
M <- c("Mar","Apr","May","Jun","Jul")
# Give the chart file a name
png(file = "barchart_months_revenue.png")
# Plot the bar chart
barplot(H,names.arg=M,xlab="Month",ylab="Revenue",col="blue",
main="Revenue chart",border="red")
# Save the file
dev.off()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
แผนภูมิแท่งกลุ่มและแผนภูมิแท่งแบบเรียงซ้อน
เราสามารถสร้างแผนภูมิแท่งที่มีกลุ่มแท่งและสแต็กในแต่ละแท่งโดยใช้เมทริกซ์เป็นค่าอินพุต
มากกว่าสองตัวแปรจะแสดงเป็นเมทริกซ์ซึ่งใช้ในการสร้างแผนภูมิแท่งกลุ่มและแผนภูมิแท่งแบบเรียงซ้อน
# Create the input vectors.
colors = c("green","orange","brown")
months <- c("Mar","Apr","May","Jun","Jul")
regions <- c("East","West","North")
# Create the matrix of the values.
Values <- matrix(c(2,9,3,11,9,4,8,7,3,12,5,2,8,10,11), nrow = 3, ncol = 5, byrow = TRUE)
# Give the chart file a name
png(file = "barchart_stacked.png")
# Create the bar chart
barplot(Values, main = "total revenue", names.arg = months, xlab = "month", ylab = "revenue", col = colors)
# Add the legend to the chart
legend("topleft", regions, cex = 1.3, fill = colors)
# Save the file
dev.off()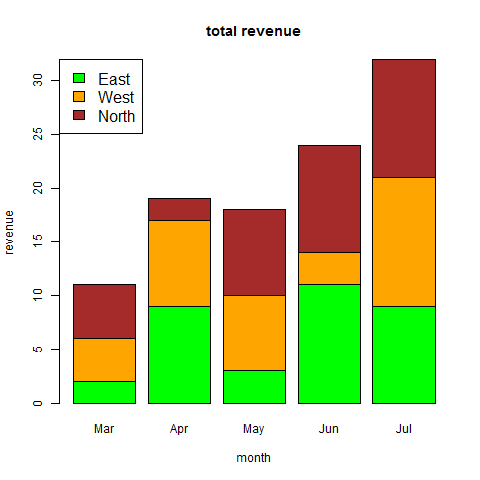
Boxplots เป็นการวัดว่าข้อมูลในชุดข้อมูลกระจายได้ดีเพียงใด แบ่งชุดข้อมูลออกเป็นสามควอไทล์ กราฟนี้แสดงค่าต่ำสุดค่าสูงสุดค่ามัธยฐานควอร์ไทล์แรกและควอร์ไทล์ที่สามในชุดข้อมูล นอกจากนี้ยังมีประโยชน์ในการเปรียบเทียบการกระจายของข้อมูลระหว่างชุดข้อมูลด้วยการวาดบ็อกซ์พล็อตสำหรับแต่ละชุด
Boxplots ถูกสร้างขึ้นใน R โดยใช้ไฟล์ boxplot() ฟังก์ชัน
ไวยากรณ์
ไวยากรณ์พื้นฐานในการสร้าง boxplot ใน R คือ -
boxplot(x, data, notch, varwidth, names, main)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
x เป็นเวกเตอร์หรือสูตร
data คือกรอบข้อมูล
notchเป็นค่าตรรกะ ตั้งค่าเป็น TRUE เพื่อวาดรอย
varwidthเป็นค่าตรรกะ กำหนดเป็นจริงเพื่อวาดความกว้างของกล่องตามสัดส่วนของขนาดตัวอย่าง
names คือป้ายกำกับกลุ่มที่จะพิมพ์ภายใต้แต่ละบ็อกซ์พล็อต
main ใช้เพื่อตั้งชื่อให้กับกราฟ
ตัวอย่าง
เราใช้ชุดข้อมูล "mtcars" ที่มีอยู่ในสภาพแวดล้อม R เพื่อสร้างบ็อกซ์พล็อตพื้นฐาน ลองดูคอลัมน์ "mpg" และ "cyl" ใน mtcars
input <- mtcars[,c('mpg','cyl')]
print(head(input))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
mpg cyl
Mazda RX4 21.0 6
Mazda RX4 Wag 21.0 6
Datsun 710 22.8 4
Hornet 4 Drive 21.4 6
Hornet Sportabout 18.7 8
Valiant 18.1 6การสร้าง Boxplot
สคริปต์ด้านล่างนี้จะสร้างกราฟบ็อกซ์พล็อตสำหรับความสัมพันธ์ระหว่าง mpg (ไมล์ต่อแกลลอน) และสูบ (จำนวนกระบอกสูบ)
# Give the chart file a name.
png(file = "boxplot.png")
# Plot the chart.
boxplot(mpg ~ cyl, data = mtcars, xlab = "Number of Cylinders",
ylab = "Miles Per Gallon", main = "Mileage Data")
# Save the file.
dev.off()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
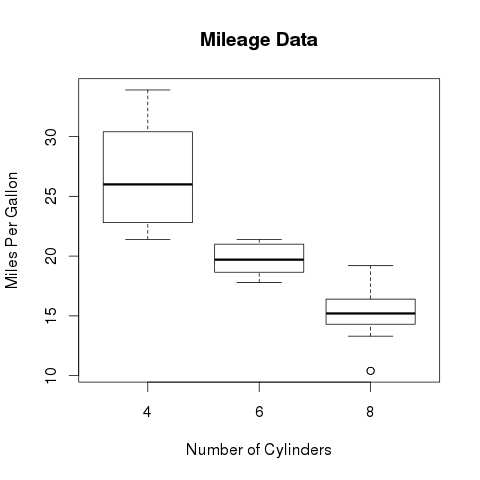
Boxplot พร้อม Notch
เราสามารถวาด boxplot ด้วยรอยบากเพื่อดูว่าค่ามัธยฐานของกลุ่มข้อมูลต่างๆจับคู่กันอย่างไร
สคริปต์ด้านล่างนี้จะสร้างกราฟบ็อกซ์พล็อตที่มีรอยบากสำหรับแต่ละกลุ่มข้อมูล
# Give the chart file a name.
png(file = "boxplot_with_notch.png")
# Plot the chart.
boxplot(mpg ~ cyl, data = mtcars,
xlab = "Number of Cylinders",
ylab = "Miles Per Gallon",
main = "Mileage Data",
notch = TRUE,
varwidth = TRUE,
col = c("green","yellow","purple"),
names = c("High","Medium","Low")
)
# Save the file.
dev.off()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
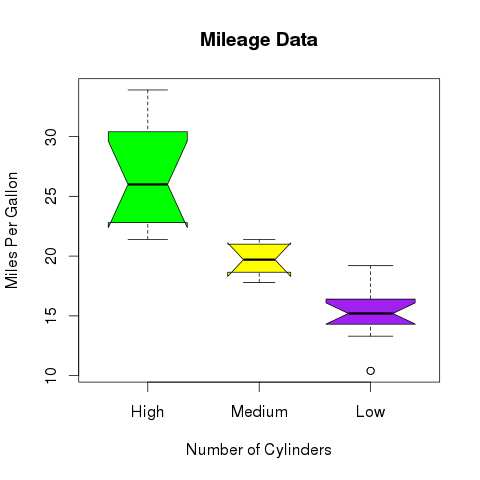
ฮิสโตแกรมแสดงถึงความถี่ของค่าของตัวแปรที่จัดเก็บเป็นช่วง ฮิสโตแกรมคล้ายกับการแชทแบบบาร์ แต่ความแตกต่างคือการจัดกลุ่มค่าเป็นช่วงต่อเนื่อง แต่ละแท่งในฮิสโตแกรมแสดงถึงความสูงของจำนวนค่าที่มีอยู่ในช่วงนั้น
R สร้างฮิสโตแกรมโดยใช้ hist()ฟังก์ชัน ฟังก์ชันนี้ใช้เวกเตอร์เป็นอินพุตและใช้พารามิเตอร์เพิ่มเติมเพื่อลงจุดฮิสโทแกรม
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการสร้างฮิสโตแกรมโดยใช้ R คือ -
hist(v,main,xlab,xlim,ylim,breaks,col,border)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
v เป็นเวกเตอร์ที่มีค่าตัวเลขที่ใช้ในฮิสโตแกรม
main ระบุชื่อของแผนภูมิ
col ใช้เพื่อกำหนดสีของแท่ง
border ใช้เพื่อกำหนดสีเส้นขอบของแต่ละแท่ง
xlab ใช้เพื่อให้คำอธิบายของแกน x
xlim ใช้เพื่อระบุช่วงของค่าบนแกน x
ylim ใช้เพื่อระบุช่วงของค่าบนแกน y
breaks ใช้เพื่อระบุความกว้างของแต่ละแท่ง
ตัวอย่าง
ฮิสโตแกรมอย่างง่ายถูกสร้างขึ้นโดยใช้พารามิเตอร์อินพุตเวกเตอร์ฉลากคอลัมน์และเส้นขอบ
สคริปต์ที่ระบุด้านล่างจะสร้างและบันทึกฮิสโตแกรมในไดเรกทอรีการทำงาน R ปัจจุบัน
# Create data for the graph.
v <- c(9,13,21,8,36,22,12,41,31,33,19)
# Give the chart file a name.
png(file = "histogram.png")
# Create the histogram.
hist(v,xlab = "Weight",col = "yellow",border = "blue")
# Save the file.
dev.off()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
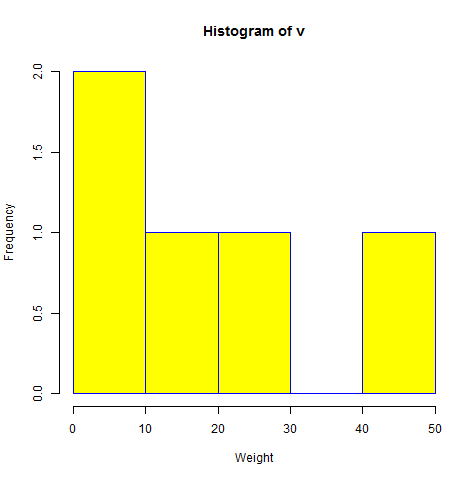
ช่วงของค่า X และ Y
ในการระบุช่วงของค่าที่อนุญาตในแกน X และแกน Y เราสามารถใช้พารามิเตอร์ xlim และ ylim
ความกว้างของแต่ละแท่งสามารถตัดสินใจได้โดยใช้ตัวแบ่ง
# Create data for the graph.
v <- c(9,13,21,8,36,22,12,41,31,33,19)
# Give the chart file a name.
png(file = "histogram_lim_breaks.png")
# Create the histogram.
hist(v,xlab = "Weight",col = "green",border = "red", xlim = c(0,40), ylim = c(0,5),
breaks = 5)
# Save the file.
dev.off()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
แผนภูมิเส้นคือกราฟที่เชื่อมต่อชุดของจุดต่างๆโดยวาดส่วนของเส้นระหว่างจุดเหล่านั้น จุดเหล่านี้เรียงลำดับตามพิกัด (โดยปกติคือค่าพิกัด x) โดยปกติแผนภูมิเส้นจะใช้ในการระบุแนวโน้มของข้อมูล
plot() ฟังก์ชันใน R ใช้เพื่อสร้างกราฟเส้น
ไวยากรณ์
ไวยากรณ์พื้นฐานในการสร้างแผนภูมิเส้นใน R คือ -
plot(v,type,col,xlab,ylab)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
v เป็นเวกเตอร์ที่มีค่าตัวเลข
type ใช้ค่า "p" เพื่อวาดเฉพาะจุด "l" เพื่อวาดเฉพาะเส้นและ "o" เพื่อวาดทั้งจุดและเส้น
xlab คือป้ายกำกับสำหรับแกน x
ylab คือป้ายกำกับสำหรับแกน y
main คือชื่อของแผนภูมิ
col ใช้เพื่อให้สีทั้งจุดและเส้น
ตัวอย่าง
แผนภูมิเส้นอย่างง่ายถูกสร้างขึ้นโดยใช้เวกเตอร์อินพุตและพารามิเตอร์ type เป็น "O" สคริปต์ด้านล่างจะสร้างและบันทึกแผนภูมิเส้นในไดเรกทอรีการทำงาน R ปัจจุบัน
# Create the data for the chart.
v <- c(7,12,28,3,41)
# Give the chart file a name.
png(file = "line_chart.jpg")
# Plot the bar chart.
plot(v,type = "o")
# Save the file.
dev.off()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
ชื่อแผนภูมิเส้นสีและป้ายกำกับ
คุณสมบัติของแผนภูมิเส้นสามารถขยายได้โดยใช้พารามิเตอร์เพิ่มเติม เราเพิ่มสีให้กับจุดและเส้นตั้งชื่อให้กับแผนภูมิและเพิ่มป้ายกำกับให้กับแกน
ตัวอย่าง
# Create the data for the chart.
v <- c(7,12,28,3,41)
# Give the chart file a name.
png(file = "line_chart_label_colored.jpg")
# Plot the bar chart.
plot(v,type = "o", col = "red", xlab = "Month", ylab = "Rain fall",
main = "Rain fall chart")
# Save the file.
dev.off()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
หลายบรรทัดในแผนภูมิเส้น
สามารถลากเส้นได้มากกว่าหนึ่งบรรทัดบนแผนภูมิเดียวกันโดยใช้ lines()ฟังก์ชัน
หลังจากพล็อตบรรทัดแรกแล้วฟังก์ชัน lines () สามารถใช้เวกเตอร์เพิ่มเติมเป็นอินพุตเพื่อวาดเส้นที่สองในแผนภูมิ
# Create the data for the chart.
v <- c(7,12,28,3,41)
t <- c(14,7,6,19,3)
# Give the chart file a name.
png(file = "line_chart_2_lines.jpg")
# Plot the bar chart.
plot(v,type = "o",col = "red", xlab = "Month", ylab = "Rain fall",
main = "Rain fall chart")
lines(t, type = "o", col = "blue")
# Save the file.
dev.off()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
Scatterplots แสดงหลายจุดที่พล็อตในระนาบคาร์ทีเซียน แต่ละจุดแทนค่าของสองตัวแปร ตัวแปรหนึ่งถูกเลือกในแกนนอนและอีกตัวแปรหนึ่งในแกนแนวตั้ง
scatterplot อย่างง่ายถูกสร้างขึ้นโดยใช้ไฟล์ plot() ฟังก์ชัน
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการสร้าง scatterplot ใน R คือ -
plot(x, y, main, xlab, ylab, xlim, ylim, axes)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
x คือชุดข้อมูลที่มีค่าเป็นพิกัดแนวนอน
y คือชุดข้อมูลที่มีค่าเป็นพิกัดแนวตั้ง
main คือไทล์ของกราฟ
xlab คือป้ายกำกับในแกนแนวนอน
ylab คือป้ายกำกับในแกนแนวตั้ง
xlim คือขีด จำกัด ของค่า x ที่ใช้ในการพล็อต
ylim คือขีด จำกัด ของค่า y ที่ใช้สำหรับการพล็อต
axes ระบุว่าควรวาดแกนทั้งสองบนพล็อตหรือไม่
ตัวอย่าง
เราใช้ชุดข้อมูล "mtcars"พร้อมใช้งานในสภาพแวดล้อม R เพื่อสร้าง scatterplot พื้นฐาน ลองใช้คอลัมน์ "wt" และ "mpg" ใน mtcars
input <- mtcars[,c('wt','mpg')]
print(head(input))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
wt mpg
Mazda RX4 2.620 21.0
Mazda RX4 Wag 2.875 21.0
Datsun 710 2.320 22.8
Hornet 4 Drive 3.215 21.4
Hornet Sportabout 3.440 18.7
Valiant 3.460 18.1การสร้าง Scatterplot
สคริปต์ด้านล่างนี้จะสร้างกราฟ scatterplot สำหรับความสัมพันธ์ระหว่าง wt (น้ำหนัก) และ mpg (ไมล์ต่อแกลลอน)
# Get the input values.
input <- mtcars[,c('wt','mpg')]
# Give the chart file a name.
png(file = "scatterplot.png")
# Plot the chart for cars with weight between 2.5 to 5 and mileage between 15 and 30.
plot(x = input$wt,y = input$mpg,
xlab = "Weight",
ylab = "Milage",
xlim = c(2.5,5),
ylim = c(15,30),
main = "Weight vs Milage"
)
# Save the file.
dev.off()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
เมทริกซ์ Scatterplot
เมื่อเรามีตัวแปรมากกว่าสองตัวแปรและเราต้องการหาความสัมพันธ์ระหว่างตัวแปรหนึ่งกับตัวแปรที่เหลือเราจะใช้เมทริกซ์ scatterplot เราใช้pairs() ฟังก์ชันสร้างเมทริกซ์ของ scatterplots
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการสร้างเมทริกซ์ scatterplot ใน R คือ -
pairs(formula, data)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
formula แสดงถึงชุดของตัวแปรที่ใช้เป็นคู่
data แสดงถึงชุดข้อมูลที่จะใช้ตัวแปร
ตัวอย่าง
ตัวแปรแต่ละตัวจะจับคู่กับตัวแปรที่เหลือแต่ละตัว มีการพล็อต scatterplot สำหรับแต่ละคู่
# Give the chart file a name.
png(file = "scatterplot_matrices.png")
# Plot the matrices between 4 variables giving 12 plots.
# One variable with 3 others and total 4 variables.
pairs(~wt+mpg+disp+cyl,data = mtcars,
main = "Scatterplot Matrix")
# Save the file.
dev.off()เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้
การวิเคราะห์ทางสถิติใน R ทำได้โดยใช้ฟังก์ชันที่สร้างขึ้นมากมาย ฟังก์ชันเหล่านี้ส่วนใหญ่เป็นส่วนหนึ่งของแพ็กเกจฐาน R ฟังก์ชันเหล่านี้ใช้เวกเตอร์ R เป็นอินพุตพร้อมกับอาร์กิวเมนต์และให้ผลลัพธ์
ฟังก์ชันที่เรากำลังพูดถึงในบทนี้ ได้แก่ ค่าเฉลี่ยค่ามัธยฐานและโหมด
ค่าเฉลี่ย
คำนวณโดยการหาผลรวมของค่าและหารด้วยจำนวนค่าในชุดข้อมูล
ฟังก์ชั่น mean() ใช้คำนวณค่านี้ใน R
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการคำนวณค่าเฉลี่ยใน R คือ -
mean(x, trim = 0, na.rm = FALSE, ...)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
x คือเวกเตอร์อินพุต
trim ใช้เพื่อวางข้อสังเกตจากปลายทั้งสองด้านของเวกเตอร์ที่เรียงลำดับ
na.rm ใช้เพื่อลบค่าที่ขาดหายไปจากเวกเตอร์อินพุต
ตัวอย่าง
# Create a vector.
x <- c(12,7,3,4.2,18,2,54,-21,8,-5)
# Find Mean.
result.mean <- mean(x)
print(result.mean)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] 8.22การใช้ตัวเลือกการตัดแต่ง
เมื่อใส่พารามิเตอร์ตัดแต่งค่าในเวกเตอร์จะได้รับการจัดเรียงจากนั้นจำนวนการสังเกตที่ต้องการจะลดลงจากการคำนวณค่าเฉลี่ย
เมื่อตัดแต่ง = 0.3 ค่า 3 ค่าจากปลายแต่ละด้านจะหลุดออกจากการคำนวณเพื่อหาค่าเฉลี่ย
ในกรณีนี้เวกเตอร์ที่เรียงลำดับคือ (−21, −5, 2, 3, 4.2, 7, 8, 12, 18, 54) และค่าที่ลบออกจากเวกเตอร์สำหรับการคำนวณค่าเฉลี่ยคือ (−21, −5,2) จากซ้ายและ (12,18,54) จากขวา
# Create a vector.
x <- c(12,7,3,4.2,18,2,54,-21,8,-5)
# Find Mean.
result.mean <- mean(x,trim = 0.3)
print(result.mean)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] 5.55การใช้ตัวเลือก NA
หากไม่มีค่าที่ขาดหายไปฟังก์ชัน mean จะส่งกลับ NA
หากต้องการทิ้งค่าที่หายไปจากการคำนวณให้ใช้ na.rm = TRUE ซึ่งหมายถึงลบค่า NA
# Create a vector.
x <- c(12,7,3,4.2,18,2,54,-21,8,-5,NA)
# Find mean.
result.mean <- mean(x)
print(result.mean)
# Find mean dropping NA values.
result.mean <- mean(x,na.rm = TRUE)
print(result.mean)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] NA
[1] 8.22ค่ามัธยฐาน
ค่ากลางที่สุดในชุดข้อมูลเรียกว่าค่ามัธยฐาน median() ฟังก์ชันถูกใช้ใน R เพื่อคำนวณค่านี้
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการคำนวณค่ามัธยฐานใน R คือ -
median(x, na.rm = FALSE)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
x คือเวกเตอร์อินพุต
na.rm ใช้เพื่อลบค่าที่ขาดหายไปจากเวกเตอร์อินพุต
ตัวอย่าง
# Create the vector.
x <- c(12,7,3,4.2,18,2,54,-21,8,-5)
# Find the median.
median.result <- median(x)
print(median.result)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] 5.6โหมด
โหมดคือค่าที่มีจำนวนครั้งสูงสุดในชุดข้อมูล ค่าเฉลี่ยและค่ามัธยฐานที่ไม่เหมือนกันโหมดสามารถมีได้ทั้งข้อมูลตัวเลขและตัวอักษร
R ไม่มีฟังก์ชันมาตรฐานในตัวเพื่อคำนวณโหมด ดังนั้นเราจึงสร้างฟังก์ชันผู้ใช้เพื่อคำนวณโหมดของชุดข้อมูลใน R ฟังก์ชันนี้ใช้เวกเตอร์เป็นอินพุตและให้ค่าโหมดเป็นเอาต์พุต
ตัวอย่าง
# Create the function.
getmode <- function(v) {
uniqv <- unique(v)
uniqv[which.max(tabulate(match(v, uniqv)))]
}
# Create the vector with numbers.
v <- c(2,1,2,3,1,2,3,4,1,5,5,3,2,3)
# Calculate the mode using the user function.
result <- getmode(v)
print(result)
# Create the vector with characters.
charv <- c("o","it","the","it","it")
# Calculate the mode using the user function.
result <- getmode(charv)
print(result)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] 2
[1] "it"การวิเคราะห์การถดถอยเป็นเครื่องมือทางสถิติที่ใช้กันอย่างแพร่หลายในการสร้างแบบจำลองความสัมพันธ์ระหว่างสองตัวแปร หนึ่งในตัวแปรเหล่านี้เรียกว่าตัวแปรทำนายซึ่งรวบรวมค่าผ่านการทดลอง ตัวแปรอื่นเรียกว่าตัวแปรการตอบสนองซึ่งมีค่ามาจากตัวแปรทำนาย
ในการถดถอยเชิงเส้นตัวแปรทั้งสองนี้เกี่ยวข้องกันโดยใช้สมการโดยเลขชี้กำลัง (กำลัง) ของตัวแปรทั้งสองคือ 1 ในทางคณิตศาสตร์ความสัมพันธ์เชิงเส้นจะแสดงถึงเส้นตรงเมื่อลงจุดเป็นกราฟ ความสัมพันธ์แบบไม่เป็นเชิงเส้นที่เลขชี้กำลังของตัวแปรใด ๆ ไม่เท่ากับ 1 จะสร้างเส้นโค้ง
สมการทางคณิตศาสตร์ทั่วไปสำหรับการถดถอยเชิงเส้นคือ -
y = ax + bต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
y คือตัวแปรตอบสนอง
x คือตัวแปรทำนาย
a และ b คือค่าคงที่ซึ่งเรียกว่าสัมประสิทธิ์
ขั้นตอนในการสร้างการถดถอย
ตัวอย่างง่ายๆของการถดถอยคือการทำนายน้ำหนักของบุคคลเมื่อทราบส่วนสูง ในการทำเช่นนี้เราต้องมีความสัมพันธ์ระหว่างความสูงและน้ำหนักของบุคคล
ขั้นตอนในการสร้างความสัมพันธ์คือ -
ทำการทดลองรวบรวมตัวอย่างค่าที่สังเกตได้ของความสูงและน้ำหนักที่สอดคล้องกัน
สร้างแบบจำลองความสัมพันธ์โดยใช้ lm() ฟังก์ชันใน R
ค้นหาค่าสัมประสิทธิ์จากแบบจำลองที่สร้างขึ้นและสร้างสมการทางคณิตศาสตร์โดยใช้สิ่งเหล่านี้
รับข้อมูลสรุปของโมเดลความสัมพันธ์เพื่อให้ทราบถึงข้อผิดพลาดโดยเฉลี่ยในการทำนาย เรียกอีกอย่างว่าresiduals.
ในการทำนายน้ำหนักของบุคคลใหม่ให้ใช้ predict() ฟังก์ชันใน R
ป้อนข้อมูล
ด้านล่างนี้เป็นข้อมูลตัวอย่างที่แสดงถึงการสังเกต -
# Values of height
151, 174, 138, 186, 128, 136, 179, 163, 152, 131
# Values of weight.
63, 81, 56, 91, 47, 57, 76, 72, 62, 48lm () ฟังก์ชัน
ฟังก์ชันนี้สร้างแบบจำลองความสัมพันธ์ระหว่างตัวทำนายและตัวแปรตอบสนอง
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับ lm() ฟังก์ชันในการถดถอยเชิงเส้นคือ -
lm(formula,data)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
formula เป็นสัญลักษณ์ที่แสดงความสัมพันธ์ระหว่าง x และ y
data คือเวกเตอร์ที่จะนำสูตรไปใช้
สร้างแบบจำลองความสัมพันธ์และรับค่าสัมประสิทธิ์
x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131)
y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48)
# Apply the lm() function.
relation <- lm(y~x)
print(relation)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
Call:
lm(formula = y ~ x)
Coefficients:
(Intercept) x
-38.4551 0.6746รับข้อมูลสรุปของความสัมพันธ์
x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131)
y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48)
# Apply the lm() function.
relation <- lm(y~x)
print(summary(relation))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-6.3002 -1.6629 0.0412 1.8944 3.9775
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -38.45509 8.04901 -4.778 0.00139 **
x 0.67461 0.05191 12.997 1.16e-06 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 3.253 on 8 degrees of freedom
Multiple R-squared: 0.9548, Adjusted R-squared: 0.9491
F-statistic: 168.9 on 1 and 8 DF, p-value: 1.164e-06ทำนาย () ฟังก์ชัน
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการทำนาย () ในการถดถอยเชิงเส้นคือ -
predict(object, newdata)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
object คือสูตรที่สร้างขึ้นแล้วโดยใช้ฟังก์ชัน lm ()
newdata คือเวกเตอร์ที่มีค่าใหม่สำหรับตัวแปรทำนาย
คาดการณ์น้ำหนักของบุคคลใหม่
# The predictor vector.
x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131)
# The resposne vector.
y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48)
# Apply the lm() function.
relation <- lm(y~x)
# Find weight of a person with height 170.
a <- data.frame(x = 170)
result <- predict(relation,a)
print(result)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
1
76.22869แสดงภาพการถดถอยแบบกราฟิก
# Create the predictor and response variable.
x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131)
y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48)
relation <- lm(y~x)
# Give the chart file a name.
png(file = "linearregression.png")
# Plot the chart.
plot(y,x,col = "blue",main = "Height & Weight Regression",
abline(lm(x~y)),cex = 1.3,pch = 16,xlab = "Weight in Kg",ylab = "Height in cm")
# Save the file.
dev.off()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
การถดถอยพหุคูณเป็นส่วนขยายของการถดถอยเชิงเส้นไปสู่ความสัมพันธ์ระหว่างตัวแปรมากกว่าสองตัว ในความสัมพันธ์เชิงเส้นอย่างง่ายเรามีตัวทำนายหนึ่งตัวและตัวแปรตอบสนองหนึ่งตัว แต่ในการถดถอยพหุคูณเรามีตัวแปรทำนายมากกว่าหนึ่งตัวและตัวแปรตอบสนองหนึ่งตัว
สมการทางคณิตศาสตร์ทั่วไปสำหรับการถดถอยพหุคูณคือ -
y = a + b1x1 + b2x2 +...bnxnต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
y คือตัวแปรตอบสนอง
a, b1, b2...bn คือสัมประสิทธิ์
x1, x2, ...xn เป็นตัวแปรทำนาย
เราสร้างแบบจำลองการถดถอยโดยใช้ lm()ฟังก์ชันใน R แบบจำลองกำหนดค่าของสัมประสิทธิ์โดยใช้ข้อมูลอินพุต จากนั้นเราสามารถทำนายค่าของตัวแปรตอบสนองสำหรับชุดของตัวแปรทำนายโดยใช้สัมประสิทธิ์เหล่านี้
lm () ฟังก์ชัน
ฟังก์ชันนี้สร้างแบบจำลองความสัมพันธ์ระหว่างตัวทำนายและตัวแปรตอบสนอง
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับ lm() ฟังก์ชันในการถดถอยพหุคูณคือ -
lm(y ~ x1+x2+x3...,data)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
formula เป็นสัญลักษณ์ที่แสดงความสัมพันธ์ระหว่างตัวแปรตอบสนองและตัวแปรทำนาย
data คือเวกเตอร์ที่จะนำสูตรไปใช้
ตัวอย่าง
ป้อนข้อมูล
พิจารณาชุดข้อมูล "mtcars" ที่มีอยู่ในสภาพแวดล้อม R ให้การเปรียบเทียบระหว่างรถยนต์รุ่นต่างๆในแง่ของระยะทางต่อแกลลอน (mpg) การกระจัดของกระบอกสูบ ("disp") กำลังม้า ("hp") น้ำหนักของรถ ("wt") และพารามิเตอร์อื่น ๆ
เป้าหมายของแบบจำลองคือการสร้างความสัมพันธ์ระหว่าง "mpg" เป็นตัวแปรตอบสนองโดยมี "disp", "hp" และ "wt" เป็นตัวแปรทำนาย เราสร้างชุดย่อยของตัวแปรเหล่านี้จากชุดข้อมูล mtcars เพื่อจุดประสงค์นี้
input <- mtcars[,c("mpg","disp","hp","wt")]
print(head(input))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
mpg disp hp wt
Mazda RX4 21.0 160 110 2.620
Mazda RX4 Wag 21.0 160 110 2.875
Datsun 710 22.8 108 93 2.320
Hornet 4 Drive 21.4 258 110 3.215
Hornet Sportabout 18.7 360 175 3.440
Valiant 18.1 225 105 3.460สร้างแบบจำลองความสัมพันธ์และรับค่าสัมประสิทธิ์
input <- mtcars[,c("mpg","disp","hp","wt")]
# Create the relationship model.
model <- lm(mpg~disp+hp+wt, data = input)
# Show the model.
print(model)
# Get the Intercept and coefficients as vector elements.
cat("# # # # The Coefficient Values # # # ","\n")
a <- coef(model)[1]
print(a)
Xdisp <- coef(model)[2]
Xhp <- coef(model)[3]
Xwt <- coef(model)[4]
print(Xdisp)
print(Xhp)
print(Xwt)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
Call:
lm(formula = mpg ~ disp + hp + wt, data = input)
Coefficients:
(Intercept) disp hp wt
37.105505 -0.000937 -0.031157 -3.800891
# # # # The Coefficient Values # # #
(Intercept)
37.10551
disp
-0.0009370091
hp
-0.03115655
wt
-3.800891สร้างสมการสำหรับแบบจำลองการถดถอย
จากค่าการสกัดกั้นและค่าสัมประสิทธิ์ข้างต้นเราสร้างสมการทางคณิตศาสตร์
Y = a+Xdisp.x1+Xhp.x2+Xwt.x3
or
Y = 37.15+(-0.000937)*x1+(-0.0311)*x2+(-3.8008)*x3ใช้สมการเพื่อทำนายค่าใหม่
เราสามารถใช้สมการการถดถอยที่สร้างขึ้นข้างต้นเพื่อทำนายระยะทางเมื่อมีการระบุค่าชุดใหม่สำหรับการกระจัดกำลังม้าและน้ำหนัก
สำหรับรถที่มี disp = 221 แรงม้า = 102 และ wt = 2.91 ระยะทางที่คาดการณ์ไว้คือ -
Y = 37.15+(-0.000937)*221+(-0.0311)*102+(-3.8008)*2.91 = 22.7104Logistic Regression คือรูปแบบการถดถอยที่ตัวแปรตอบสนอง (ตัวแปรตาม) มีค่าหมวดหมู่เช่น True / False หรือ 0/1 จริง ๆ แล้วมันวัดความน่าจะเป็นของการตอบสนองแบบไบนารีเป็นค่าของตัวแปรตอบสนองตามสมการทางคณิตศาสตร์ที่เกี่ยวข้องกับตัวแปรทำนาย
สมการทางคณิตศาสตร์ทั่วไปสำหรับการถดถอยโลจิสติกคือ -
y = 1/(1+e^-(a+b1x1+b2x2+b3x3+...))ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
y คือตัวแปรตอบสนอง
x คือตัวแปรทำนาย
a และ b คือค่าสัมประสิทธิ์ซึ่งเป็นค่าคงที่เป็นตัวเลข
ฟังก์ชันที่ใช้ในการสร้างแบบจำลองการถดถอยคือ glm() ฟังก์ชัน
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับ glm() ฟังก์ชันในการถดถอยโลจิสติกคือ -
glm(formula,data,family)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
formula คือสัญลักษณ์ที่แสดงความสัมพันธ์ระหว่างตัวแปร
data คือชุดข้อมูลที่ให้ค่าของตัวแปรเหล่านี้
familyเป็นวัตถุ R เพื่อระบุรายละเอียดของโมเดล ค่าเป็นทวินามสำหรับการถดถอยโลจิสติก
ตัวอย่าง
ชุดข้อมูลที่สร้างขึ้น "mtcars" อธิบายถึงรถยนต์รุ่นต่างๆพร้อมข้อมูลจำเพาะเครื่องยนต์ที่หลากหลาย ในชุดข้อมูล "mtcars" โหมดเกียร์ (อัตโนมัติหรือแบบแมนนวล) จะอธิบายโดยคอลัมน์ am ซึ่งเป็นค่าไบนารี (0 หรือ 1) เราสามารถสร้างแบบจำลองการถดถอยโลจิสติกระหว่างคอลัมน์ "am" และคอลัมน์อื่น ๆ อีก 3 คอลัมน์ - hp, wt และ cyl
# Select some columns form mtcars.
input <- mtcars[,c("am","cyl","hp","wt")]
print(head(input))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
am cyl hp wt
Mazda RX4 1 6 110 2.620
Mazda RX4 Wag 1 6 110 2.875
Datsun 710 1 4 93 2.320
Hornet 4 Drive 0 6 110 3.215
Hornet Sportabout 0 8 175 3.440
Valiant 0 6 105 3.460สร้างแบบจำลองการถดถอย
เราใช้ไฟล์ glm() ฟังก์ชันสร้างแบบจำลองการถดถอยและรับข้อมูลสรุปสำหรับการวิเคราะห์
input <- mtcars[,c("am","cyl","hp","wt")]
am.data = glm(formula = am ~ cyl + hp + wt, data = input, family = binomial)
print(summary(am.data))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
Call:
glm(formula = am ~ cyl + hp + wt, family = binomial, data = input)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.17272 -0.14907 -0.01464 0.14116 1.27641
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 19.70288 8.11637 2.428 0.0152 *
cyl 0.48760 1.07162 0.455 0.6491
hp 0.03259 0.01886 1.728 0.0840 .
wt -9.14947 4.15332 -2.203 0.0276 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 43.2297 on 31 degrees of freedom
Residual deviance: 9.8415 on 28 degrees of freedom
AIC: 17.841
Number of Fisher Scoring iterations: 8สรุป
โดยสรุปเนื่องจากค่า p ในคอลัมน์สุดท้ายมีค่ามากกว่า 0.05 สำหรับตัวแปร "cyl" และ "hp" เราถือว่าค่าเหล่านี้ไม่มีนัยสำคัญในการให้ค่าตัวแปร "am" เฉพาะน้ำหนัก (wt) เท่านั้นที่ส่งผลต่อค่า "am" ในแบบจำลองการถดถอยนี้
ในการรวบรวมข้อมูลแบบสุ่มจากแหล่งข้อมูลอิสระโดยทั่วไปจะสังเกตได้ว่าการกระจายของข้อมูลเป็นเรื่องปกติ ซึ่งหมายความว่าในการพล็อตกราฟด้วยค่าของตัวแปรในแกนนอนและจำนวนค่าในแกนแนวตั้งเราจะได้เส้นโค้งรูประฆัง จุดศูนย์กลางของเส้นโค้งแสดงถึงค่าเฉลี่ยของชุดข้อมูล ในกราฟห้าสิบเปอร์เซ็นต์ของค่าจะอยู่ทางด้านซ้ายของค่าเฉลี่ยและอีก 50 เปอร์เซ็นต์อยู่ทางด้านขวาของกราฟ สิ่งนี้เรียกว่าการแจกแจงปกติในสถิติ
R มีฟังก์ชันในตัวสี่ฟังก์ชันเพื่อสร้างการแจกแจงแบบปกติ มีอธิบายไว้ด้านล่าง
dnorm(x, mean, sd)
pnorm(x, mean, sd)
qnorm(p, mean, sd)
rnorm(n, mean, sd)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ในฟังก์ชันข้างต้น -
x เป็นเวกเตอร์ของตัวเลข
p คือเวกเตอร์ของความน่าจะเป็น
n คือจำนวนการสังเกต (ขนาดตัวอย่าง)
meanคือค่าเฉลี่ยของข้อมูลตัวอย่าง ค่าเริ่มต้นคือศูนย์
sdคือค่าเบี่ยงเบนมาตรฐาน ค่าเริ่มต้นคือ 1
dnorm ()
ฟังก์ชันนี้ให้ความสูงของการแจกแจงความน่าจะเป็นในแต่ละจุดสำหรับค่าเฉลี่ยและส่วนเบี่ยงเบนมาตรฐานที่กำหนด
# Create a sequence of numbers between -10 and 10 incrementing by 0.1.
x <- seq(-10, 10, by = .1)
# Choose the mean as 2.5 and standard deviation as 0.5.
y <- dnorm(x, mean = 2.5, sd = 0.5)
# Give the chart file a name.
png(file = "dnorm.png")
plot(x,y)
# Save the file.
dev.off()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
pnorm ()
ฟังก์ชันนี้ให้ความน่าจะเป็นของจำนวนสุ่มที่กระจายตามปกติน้อยกว่าค่าของตัวเลขที่กำหนด เรียกอีกอย่างว่า "ฟังก์ชันการกระจายสะสม"
# Create a sequence of numbers between -10 and 10 incrementing by 0.2.
x <- seq(-10,10,by = .2)
# Choose the mean as 2.5 and standard deviation as 2.
y <- pnorm(x, mean = 2.5, sd = 2)
# Give the chart file a name.
png(file = "pnorm.png")
# Plot the graph.
plot(x,y)
# Save the file.
dev.off()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
qnorm ()
ฟังก์ชันนี้รับค่าความน่าจะเป็นและให้ตัวเลขที่มีค่าสะสมตรงกับค่าความน่าจะเป็น
# Create a sequence of probability values incrementing by 0.02.
x <- seq(0, 1, by = 0.02)
# Choose the mean as 2 and standard deviation as 3.
y <- qnorm(x, mean = 2, sd = 1)
# Give the chart file a name.
png(file = "qnorm.png")
# Plot the graph.
plot(x,y)
# Save the file.
dev.off()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
rnorm ()
ฟังก์ชันนี้ใช้เพื่อสร้างตัวเลขสุ่มที่มีการแจกแจงเป็นปกติ ใช้ขนาดตัวอย่างเป็นอินพุตและสร้างตัวเลขสุ่มจำนวนมาก เราวาดฮิสโตแกรมเพื่อแสดงการแจกแจงของตัวเลขที่สร้างขึ้น
# Create a sample of 50 numbers which are normally distributed.
y <- rnorm(50)
# Give the chart file a name.
png(file = "rnorm.png")
# Plot the histogram for this sample.
hist(y, main = "Normal DIstribution")
# Save the file.
dev.off()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
แบบจำลองการแจกแจงแบบทวินามเกี่ยวข้องกับการค้นหาความน่าจะเป็นของความสำเร็จของเหตุการณ์ซึ่งมีผลลัพธ์ที่เป็นไปได้เพียงสองรายการในชุดการทดลอง ตัวอย่างเช่นการโยนเหรียญจะให้หัวหรือก้อยเสมอ ความน่าจะเป็นที่จะพบว่า 3 หัวในการโยนเหรียญซ้ำ ๆ เป็นเวลา 10 ครั้งนั้นจะถูกประมาณในระหว่างการแจกแจงแบบทวินาม
R มีฟังก์ชันในตัวสี่ฟังก์ชันเพื่อสร้างการแจกแจงแบบทวินาม มีอธิบายไว้ด้านล่าง
dbinom(x, size, prob)
pbinom(x, size, prob)
qbinom(p, size, prob)
rbinom(n, size, prob)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
x เป็นเวกเตอร์ของตัวเลข
p คือเวกเตอร์ของความน่าจะเป็น
n คือจำนวนการสังเกต
size คือจำนวนการทดลอง
prob คือความน่าจะเป็นของความสำเร็จของการทดลองแต่ละครั้ง
dbinom ()
ฟังก์ชันนี้ให้การแจกแจงความหนาแน่นของความน่าจะเป็นในแต่ละจุด
# Create a sample of 50 numbers which are incremented by 1.
x <- seq(0,50,by = 1)
# Create the binomial distribution.
y <- dbinom(x,50,0.5)
# Give the chart file a name.
png(file = "dbinom.png")
# Plot the graph for this sample.
plot(x,y)
# Save the file.
dev.off()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
pbinom ()
ฟังก์ชันนี้ให้ความน่าจะเป็นสะสมของเหตุการณ์ เป็นค่าเดียวที่แสดงถึงความน่าจะเป็น
# Probability of getting 26 or less heads from a 51 tosses of a coin.
x <- pbinom(26,51,0.5)
print(x)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] 0.610116qbinom ()
ฟังก์ชันนี้รับค่าความน่าจะเป็นและให้ตัวเลขที่มีค่าสะสมตรงกับค่าความน่าจะเป็น
# How many heads will have a probability of 0.25 will come out when a coin
# is tossed 51 times.
x <- qbinom(0.25,51,1/2)
print(x)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] 23rbinom ()
ฟังก์ชันนี้สร้างจำนวนค่าสุ่มที่ต้องการของความน่าจะเป็นที่กำหนดจากตัวอย่างที่กำหนด
# Find 8 random values from a sample of 150 with probability of 0.4.
x <- rbinom(8,150,.4)
print(x)เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] 58 61 59 66 55 60 61 67การถดถอยแบบปัวซองเกี่ยวข้องกับโมเดลการถดถอยซึ่งตัวแปรตอบสนองอยู่ในรูปของจำนวนนับและไม่ใช่ตัวเลขเศษส่วน ตัวอย่างเช่นการนับจำนวนการเกิดหรือจำนวนครั้งที่ชนะในซีรีส์การแข่งขันฟุตบอล นอกจากนี้ค่าของตัวแปรตอบสนองจะเป็นไปตามการแจกแจงแบบปัวซอง
สมการทางคณิตศาสตร์ทั่วไปสำหรับการถดถอยปัวซองคือ -
log(y) = a + b1x1 + b2x2 + bnxn.....ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
y คือตัวแปรตอบสนอง
a และ b คือค่าสัมประสิทธิ์ตัวเลข
x คือตัวแปรทำนาย
ฟังก์ชันที่ใช้ในการสร้างแบบจำลองการถดถอยปัวซองคือ glm() ฟังก์ชัน
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับ glm() ฟังก์ชันในการถดถอยปัวซองคือ -
glm(formula,data,family)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ในฟังก์ชันข้างต้น -
formula คือสัญลักษณ์ที่แสดงความสัมพันธ์ระหว่างตัวแปร
data คือชุดข้อมูลที่ให้ค่าของตัวแปรเหล่านี้
familyเป็นวัตถุ R เพื่อระบุรายละเอียดของโมเดล ค่าคือ 'Poisson' สำหรับ Logistic Regression
ตัวอย่าง
เรามีชุดข้อมูลที่สร้างขึ้น "warpbreaks" ซึ่งอธิบายถึงผลกระทบของประเภทขนสัตว์ (A หรือ B) และความตึงเครียด (ต่ำปานกลางหรือสูง) ต่อจำนวนการบิดงอต่อกี่ทอผ้า ลองพิจารณา "ช่วงพัก" เป็นตัวแปรตอบสนองซึ่งเป็นการนับจำนวนการหยุดพัก "ประเภท" และ "ความตึง" ของขนสัตว์ถูกนำมาเป็นตัวแปรทำนาย
Input Data
input <- warpbreaks
print(head(input))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
breaks wool tension
1 26 A L
2 30 A L
3 54 A L
4 25 A L
5 70 A L
6 52 A Lสร้างแบบจำลองการถดถอย
output <-glm(formula = breaks ~ wool+tension, data = warpbreaks,
family = poisson)
print(summary(output))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
Call:
glm(formula = breaks ~ wool + tension, family = poisson, data = warpbreaks)
Deviance Residuals:
Min 1Q Median 3Q Max
-3.6871 -1.6503 -0.4269 1.1902 4.2616
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.69196 0.04541 81.302 < 2e-16 ***
woolB -0.20599 0.05157 -3.994 6.49e-05 ***
tensionM -0.32132 0.06027 -5.332 9.73e-08 ***
tensionH -0.51849 0.06396 -8.107 5.21e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 297.37 on 53 degrees of freedom
Residual deviance: 210.39 on 50 degrees of freedom
AIC: 493.06
Number of Fisher Scoring iterations: 4โดยสรุปเรามองหาค่า p ในคอลัมน์สุดท้ายให้น้อยกว่า 0.05 เพื่อพิจารณาผลกระทบของตัวแปรทำนายที่มีต่อตัวแปรการตอบสนอง ดังที่เห็นผ้าขนสัตว์ชนิด B ที่มีความตึงเครียดประเภท M และ H มีผลกระทบต่อจำนวนการหยุดพัก
เราใช้การวิเคราะห์การถดถอยเพื่อสร้างแบบจำลองที่อธิบายผลของการเปลี่ยนแปลงในตัวแปรทำนายที่มีต่อตัวแปรตอบสนอง บางครั้งถ้าเรามีตัวแปรจัดหมวดหมู่ที่มีค่าเช่นใช่ / ไม่ใช่หรือชาย / หญิงเป็นต้นการวิเคราะห์การถดถอยอย่างง่ายจะให้ผลลัพธ์หลายค่าสำหรับแต่ละค่าของตัวแปรจัดหมวดหมู่ ในสถานการณ์ดังกล่าวเราสามารถศึกษาผลของตัวแปรจัดหมวดหมู่โดยใช้มันร่วมกับตัวแปรทำนายและเปรียบเทียบเส้นการถดถอยสำหรับแต่ละระดับของตัวแปรจัดหมวดหมู่ การวิเคราะห์ดังกล่าวเรียกว่าAnalysis of Covariance เรียกอีกอย่างว่า ANCOVA.
ตัวอย่าง
พิจารณาชุดข้อมูล R ที่สร้างขึ้นใน mtcars ในนั้นเราสังเกตว่าฟิลด์ "am" แสดงถึงประเภทของเกียร์ (อัตโนมัติหรือด้วยตนเอง) เป็นตัวแปรประเภทที่มีค่า 0 และ 1 ค่าไมล์ต่อแกลลอน (mpg) ของรถยนต์อาจขึ้นอยู่กับค่านี้นอกเหนือจากค่ากำลังม้า ("แรงม้า")
เราศึกษาผลของค่า "am" ต่อการถดถอยระหว่าง "mpg" และ "hp" ทำได้โดยใช้ไฟล์aov() ตามด้วย anova() ฟังก์ชันเพื่อเปรียบเทียบการถดถอยแบบทวีคูณ
ป้อนข้อมูล
สร้างกรอบข้อมูลที่มีฟิลด์ "mpg" "hp" และ "am" จากชุดข้อมูล mtcars ที่นี่เราใช้ "mpg" เป็นตัวแปรการตอบสนอง "hp" เป็นตัวแปรทำนายและ "am" เป็นตัวแปรจัดหมวดหมู่
input <- mtcars[,c("am","mpg","hp")]
print(head(input))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
am mpg hp
Mazda RX4 1 21.0 110
Mazda RX4 Wag 1 21.0 110
Datsun 710 1 22.8 93
Hornet 4 Drive 0 21.4 110
Hornet Sportabout 0 18.7 175
Valiant 0 18.1 105การวิเคราะห์ ANCOVA
เราสร้างแบบจำลองการถดถอยโดยใช้ "hp" เป็นตัวแปรทำนายและ "mpg" เป็นตัวแปรตอบสนองโดยคำนึงถึงปฏิสัมพันธ์ระหว่าง "am" และ "hp"
แบบจำลองที่มีปฏิสัมพันธ์ระหว่างตัวแปรเชิงหมวดหมู่และตัวแปรทำนาย
# Get the dataset.
input <- mtcars
# Create the regression model.
result <- aov(mpg~hp*am,data = input)
print(summary(result))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
Df Sum Sq Mean Sq F value Pr(>F)
hp 1 678.4 678.4 77.391 1.50e-09 ***
am 1 202.2 202.2 23.072 4.75e-05 ***
hp:am 1 0.0 0.0 0.001 0.981
Residuals 28 245.4 8.8
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1ผลลัพธ์นี้แสดงให้เห็นว่าทั้งกำลังม้าและประเภทเกียร์มีผลอย่างมีนัยสำคัญต่อไมล์ต่อแกลลอนเนื่องจากค่า p ในทั้งสองกรณีมีค่าน้อยกว่า 0.05 แต่ปฏิสัมพันธ์ระหว่างสองตัวแปรนี้ไม่มีนัยสำคัญเนื่องจาก p-value มากกว่า 0.05
แบบจำลองที่ไม่มีปฏิสัมพันธ์ระหว่างตัวแปรเชิงหมวดหมู่และตัวแปรทำนาย
# Get the dataset.
input <- mtcars
# Create the regression model.
result <- aov(mpg~hp+am,data = input)
print(summary(result))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
Df Sum Sq Mean Sq F value Pr(>F)
hp 1 678.4 678.4 80.15 7.63e-10 ***
am 1 202.2 202.2 23.89 3.46e-05 ***
Residuals 29 245.4 8.5
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1ผลลัพธ์นี้แสดงให้เห็นว่าทั้งกำลังม้าและประเภทเกียร์มีผลอย่างมีนัยสำคัญต่อไมล์ต่อแกลลอนเนื่องจากค่า p ในทั้งสองกรณีมีค่าน้อยกว่า 0.05
เปรียบเทียบสองรุ่น
ตอนนี้เราสามารถเปรียบเทียบทั้งสองแบบเพื่อสรุปว่าปฏิสัมพันธ์ของตัวแปรมีนัยสำคัญอย่างแท้จริงหรือไม่ สำหรับสิ่งนี้เราใช้ไฟล์anova() ฟังก์ชัน
# Get the dataset.
input <- mtcars
# Create the regression models.
result1 <- aov(mpg~hp*am,data = input)
result2 <- aov(mpg~hp+am,data = input)
# Compare the two models.
print(anova(result1,result2))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
Model 1: mpg ~ hp * am
Model 2: mpg ~ hp + am
Res.Df RSS Df Sum of Sq F Pr(>F)
1 28 245.43
2 29 245.44 -1 -0.0052515 6e-04 0.9806เนื่องจากค่า p มีค่ามากกว่า 0.05 เราจึงสรุปได้ว่าปฏิสัมพันธ์ระหว่างกำลังม้าและประเภทการส่งผ่านไม่มีนัยสำคัญ ดังนั้นระยะทางต่อแกลลอนจะขึ้นอยู่กับพลังม้าของรถในลักษณะเดียวกันทั้งในโหมดเกียร์อัตโนมัติและเกียร์ธรรมดา
อนุกรมเวลาคือชุดของจุดข้อมูลที่จุดข้อมูลแต่ละจุดเชื่อมโยงกับการประทับเวลา ตัวอย่างง่ายๆคือราคาของหุ้นในตลาดหุ้น ณ ช่วงเวลาที่ต่างกันในวันหนึ่ง ๆ อีกตัวอย่างหนึ่งคือปริมาณน้ำฝนในภูมิภาคในเดือนต่างๆของปี ภาษา R ใช้ฟังก์ชันมากมายในการสร้างจัดการและลงจุดข้อมูลอนุกรมเวลา ข้อมูลสำหรับอนุกรมเวลาจะถูกเก็บไว้ในวัตถุ R ที่เรียกว่าtime-series object. นอกจากนี้ยังเป็นวัตถุข้อมูล R เช่นเวกเตอร์หรือกรอบข้อมูล
วัตถุอนุกรมเวลาถูกสร้างขึ้นโดยใช้ ts() ฟังก์ชัน
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับ ts() ฟังก์ชันในการวิเคราะห์อนุกรมเวลาคือ -
timeseries.object.name <- ts(data, start, end, frequency)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
data คือเวกเตอร์หรือเมทริกซ์ที่มีค่าที่ใช้ในอนุกรมเวลา
start ระบุเวลาเริ่มต้นสำหรับการสังเกตครั้งแรกในอนุกรมเวลา
end ระบุเวลาสิ้นสุดสำหรับการสังเกตครั้งสุดท้ายในอนุกรมเวลา
frequency ระบุจำนวนการสังเกตต่อหน่วยเวลา
ยกเว้นพารามิเตอร์ "data" พารามิเตอร์อื่น ๆ ทั้งหมดเป็นทางเลือก
ตัวอย่าง
พิจารณารายละเอียดปริมาณน้ำฝนประจำปี ณ สถานที่เริ่มตั้งแต่เดือนมกราคม 2555 เราสร้างออบเจ็กต์อนุกรมเวลา R เป็นระยะเวลา 12 เดือนและวางพล็อต
# Get the data points in form of a R vector.
rainfall <- c(799,1174.8,865.1,1334.6,635.4,918.5,685.5,998.6,784.2,985,882.8,1071)
# Convert it to a time series object.
rainfall.timeseries <- ts(rainfall,start = c(2012,1),frequency = 12)
# Print the timeseries data.
print(rainfall.timeseries)
# Give the chart file a name.
png(file = "rainfall.png")
# Plot a graph of the time series.
plot(rainfall.timeseries)
# Save the file.
dev.off()เมื่อเรารันโค้ดด้านบนจะสร้างผลลัพธ์และแผนภูมิต่อไปนี้ -
Jan Feb Mar Apr May Jun Jul Aug Sep
2012 799.0 1174.8 865.1 1334.6 635.4 918.5 685.5 998.6 784.2
Oct Nov Dec
2012 985.0 882.8 1071.0แผนภูมิอนุกรมเวลา -
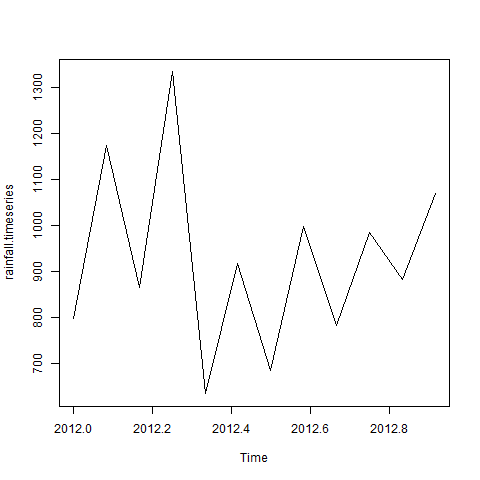
ช่วงเวลาที่แตกต่างกัน
ค่าของ frequencyพารามิเตอร์ในฟังก์ชัน ts () กำหนดช่วงเวลาที่จุดข้อมูลถูกวัด ค่า 12 แสดงว่าอนุกรมเวลาเป็นเวลา 12 เดือน ค่าอื่น ๆ และความหมายมีดังต่อไปนี้ -
frequency = 12 ตรึงจุดข้อมูลทุกเดือนของปี
frequency = 4 ตรึงจุดข้อมูลทุกไตรมาสของปี
frequency = 6 ตรึงจุดข้อมูลทุกๆ 10 นาทีของหนึ่งชั่วโมง
frequency = 24*6 ตรึงจุดข้อมูลทุกๆ 10 นาทีของวัน
อนุกรมเวลาหลาย
เราสามารถพล็อตอนุกรมเวลาหลาย ๆ ชุดในแผนภูมิเดียวได้โดยการรวมอนุกรมทั้งสองเป็นเมทริกซ์
# Get the data points in form of a R vector.
rainfall1 <- c(799,1174.8,865.1,1334.6,635.4,918.5,685.5,998.6,784.2,985,882.8,1071)
rainfall2 <-
c(655,1306.9,1323.4,1172.2,562.2,824,822.4,1265.5,799.6,1105.6,1106.7,1337.8)
# Convert them to a matrix.
combined.rainfall <- matrix(c(rainfall1,rainfall2),nrow = 12)
# Convert it to a time series object.
rainfall.timeseries <- ts(combined.rainfall,start = c(2012,1),frequency = 12)
# Print the timeseries data.
print(rainfall.timeseries)
# Give the chart file a name.
png(file = "rainfall_combined.png")
# Plot a graph of the time series.
plot(rainfall.timeseries, main = "Multiple Time Series")
# Save the file.
dev.off()เมื่อเรารันโค้ดด้านบนจะสร้างผลลัพธ์และแผนภูมิต่อไปนี้ -
Series 1 Series 2
Jan 2012 799.0 655.0
Feb 2012 1174.8 1306.9
Mar 2012 865.1 1323.4
Apr 2012 1334.6 1172.2
May 2012 635.4 562.2
Jun 2012 918.5 824.0
Jul 2012 685.5 822.4
Aug 2012 998.6 1265.5
Sep 2012 784.2 799.6
Oct 2012 985.0 1105.6
Nov 2012 882.8 1106.7
Dec 2012 1071.0 1337.8แผนภูมิอนุกรมหลายเวลา -
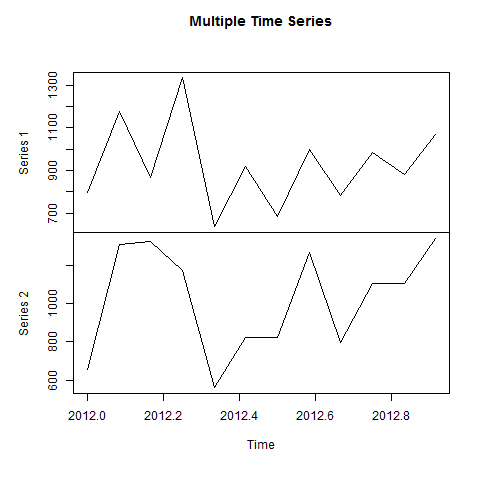
เมื่อสร้างแบบจำลองข้อมูลโลกแห่งความเป็นจริงสำหรับการวิเคราะห์การถดถอยเราสังเกตได้ว่าไม่ค่อยเป็นเช่นนั้นสมการของแบบจำลองเป็นสมการเชิงเส้นที่ให้กราฟเชิงเส้น โดยส่วนใหญ่แล้วสมการของแบบจำลองของข้อมูลในโลกแห่งความจริงจะเกี่ยวข้องกับฟังก์ชันทางคณิตศาสตร์ในระดับที่สูงกว่าเช่นเลขชี้กำลังของ 3 หรือฟังก์ชันบาป ในสถานการณ์ดังกล่าวพล็อตของแบบจำลองให้เส้นโค้งแทนที่จะเป็นเส้น เป้าหมายของการถดถอยทั้งเชิงเส้นและไม่เชิงเส้นคือการปรับค่าของพารามิเตอร์ของแบบจำลองเพื่อค้นหาเส้นหรือเส้นโค้งที่เข้ามาใกล้ข้อมูลของคุณมากที่สุด ในการหาค่าเหล่านี้เราจะสามารถประมาณตัวแปรการตอบสนองได้อย่างแม่นยำ
ในการถดถอยอย่างน้อยกำลังสองเราสร้างแบบจำลองการถดถอยซึ่งผลรวมของกำลังสองของระยะทางแนวตั้งของจุดต่าง ๆ จากเส้นโค้งการถดถอยจะถูกย่อให้เล็กสุด โดยทั่วไปเราเริ่มต้นด้วยแบบจำลองที่กำหนดไว้และถือว่าค่าสัมประสิทธิ์บางอย่าง จากนั้นเราใช้ไฟล์nls() ฟังก์ชันของ R เพื่อรับค่าที่แม่นยำยิ่งขึ้นพร้อมกับช่วงความเชื่อมั่น
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการสร้างการทดสอบกำลังสองน้อยที่สุดที่ไม่ใช่เชิงเส้นใน R คือ -
nls(formula, data, start)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
formula เป็นสูตรแบบไม่เชิงเส้นรวมถึงตัวแปรและพารามิเตอร์
data คือกรอบข้อมูลที่ใช้ประเมินตัวแปรในสูตร
start คือรายการที่มีชื่อหรือเวกเตอร์ตัวเลขที่มีชื่อของการประมาณการเริ่มต้น
ตัวอย่าง
เราจะพิจารณาแบบจำลองที่ไม่เป็นเชิงเส้นโดยมีสมมติฐานค่าเริ่มต้นของสัมประสิทธิ์ ต่อไปเราจะดูว่าช่วงความเชื่อมั่นของค่าสมมติเหล่านี้คืออะไรเพื่อที่เราจะได้ตัดสินว่าค่าเหล่านี้เข้ากับโมเดลได้ดีเพียงใด
ลองพิจารณาสมการด้านล่างเพื่อจุดประสงค์นี้ -
a = b1*x^2+b2สมมติว่าค่าสัมประสิทธิ์เริ่มต้นเป็น 1 และ 3 และใส่ค่าเหล่านี้ลงในฟังก์ชัน nls ()
xvalues <- c(1.6,2.1,2,2.23,3.71,3.25,3.4,3.86,1.19,2.21)
yvalues <- c(5.19,7.43,6.94,8.11,18.75,14.88,16.06,19.12,3.21,7.58)
# Give the chart file a name.
png(file = "nls.png")
# Plot these values.
plot(xvalues,yvalues)
# Take the assumed values and fit into the model.
model <- nls(yvalues ~ b1*xvalues^2+b2,start = list(b1 = 1,b2 = 3))
# Plot the chart with new data by fitting it to a prediction from 100 data points.
new.data <- data.frame(xvalues = seq(min(xvalues),max(xvalues),len = 100))
lines(new.data$xvalues,predict(model,newdata = new.data))
# Save the file.
dev.off()
# Get the sum of the squared residuals.
print(sum(resid(model)^2))
# Get the confidence intervals on the chosen values of the coefficients.
print(confint(model))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
[1] 1.081935
Waiting for profiling to be done...
2.5% 97.5%
b1 1.137708 1.253135
b2 1.497364 2.496484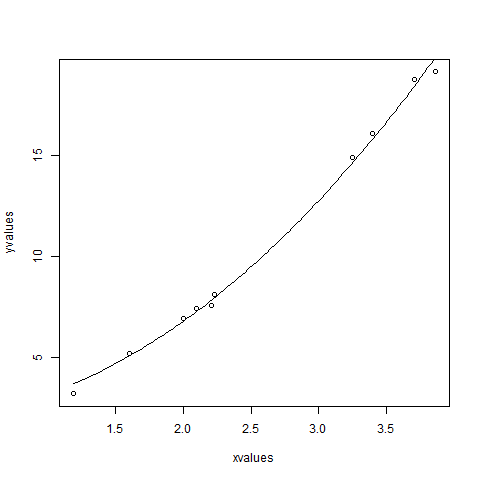
เราสามารถสรุปได้ว่าค่าของ b1 ใกล้เคียงกับ 1 มากกว่าในขณะที่ค่าของ b2 ใกล้เคียงกับ 2 และไม่ใช่ 3
ต้นไม้ตัดสินใจคือกราฟเพื่อแสดงถึงตัวเลือกและผลลัพธ์ในรูปแบบของต้นไม้ โหนดในกราฟแสดงถึงเหตุการณ์หรือทางเลือกและขอบของกราฟแสดงถึงกฎหรือเงื่อนไขการตัดสินใจ ส่วนใหญ่จะใช้ในแอปพลิเคชัน Machine Learning และ Data Mining โดยใช้ R
ตัวอย่างของการใช้การตัดสินใจคือ - การทำนายอีเมลว่าเป็นสแปมหรือไม่ใช่สแปมการทำนายเนื้องอกเป็นมะเร็งหรือการคาดการณ์เงินกู้ว่าเป็นความเสี่ยงด้านเครดิตที่ดีหรือไม่ดีขึ้นอยู่กับปัจจัยในแต่ละข้อ โดยทั่วไปโมเดลจะถูกสร้างขึ้นด้วยข้อมูลที่สังเกตได้หรือที่เรียกว่าข้อมูลการฝึกอบรม จากนั้นชุดข้อมูลการตรวจสอบจะถูกใช้เพื่อตรวจสอบและปรับปรุงโมเดล R มีแพ็คเกจที่ใช้ในการสร้างและแสดงภาพแผนผังการตัดสินใจ สำหรับตัวแปรทำนายชุดใหม่เราใช้โมเดลนี้เพื่อตัดสินใจเกี่ยวกับหมวดหมู่ (ใช่ / ไม่ใช่สแปม / ไม่ใช่สแปม) ของข้อมูล
แพ็คเกจ R "party" ใช้ในการสร้างต้นไม้การตัดสินใจ
ติดตั้งแพ็คเกจ R
ใช้คำสั่งด้านล่างในคอนโซล R เพื่อติดตั้งแพ็คเกจ คุณต้องติดตั้งแพ็กเกจที่เกี่ยวข้องด้วยถ้ามี
install.packages("party")แพ็กเกจ "ปาร์ตี้" มีฟังก์ชัน ctree() ซึ่งใช้ในการสร้างและวิเคราะห์ต้นไม้เดซิสัน
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการสร้างแผนผังการตัดสินใจใน R คือ -
ctree(formula, data)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
formula เป็นสูตรที่อธิบายตัวทำนายและตัวแปรตอบสนอง
data คือชื่อของชุดข้อมูลที่ใช้
ป้อนข้อมูล
เราจะใช้ชุดข้อมูลในตัว R ที่มีชื่อว่า readingSkillsเพื่อสร้างแผนผังการตัดสินใจ อธิบายถึงคะแนนของการอ่านทักษะของผู้อื่นหากเราทราบตัวแปร "อายุ" "ขนาดรองเท้า" "คะแนน" และบุคคลนั้นเป็นเจ้าของภาษาหรือไม่
นี่คือข้อมูลตัวอย่าง
# Load the party package. It will automatically load other
# dependent packages.
library(party)
# Print some records from data set readingSkills.
print(head(readingSkills))เมื่อเรารันโค้ดด้านบนจะสร้างผลลัพธ์และแผนภูมิต่อไปนี้ -
nativeSpeaker age shoeSize score
1 yes 5 24.83189 32.29385
2 yes 6 25.95238 36.63105
3 no 11 30.42170 49.60593
4 yes 7 28.66450 40.28456
5 yes 11 31.88207 55.46085
6 yes 10 30.07843 52.83124
Loading required package: methods
Loading required package: grid
...............................
...............................ตัวอย่าง
เราจะใช้ไฟล์ ctree() ฟังก์ชันสร้างแผนผังการตัดสินใจและดูกราฟ
# Load the party package. It will automatically load other
# dependent packages.
library(party)
# Create the input data frame.
input.dat <- readingSkills[c(1:105),]
# Give the chart file a name.
png(file = "decision_tree.png")
# Create the tree.
output.tree <- ctree(
nativeSpeaker ~ age + shoeSize + score,
data = input.dat)
# Plot the tree.
plot(output.tree)
# Save the file.
dev.off()เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
null device
1
Loading required package: methods
Loading required package: grid
Loading required package: mvtnorm
Loading required package: modeltools
Loading required package: stats4
Loading required package: strucchange
Loading required package: zoo
Attaching package: ‘zoo’
The following objects are masked from ‘package:base’:
as.Date, as.Date.numeric
Loading required package: sandwich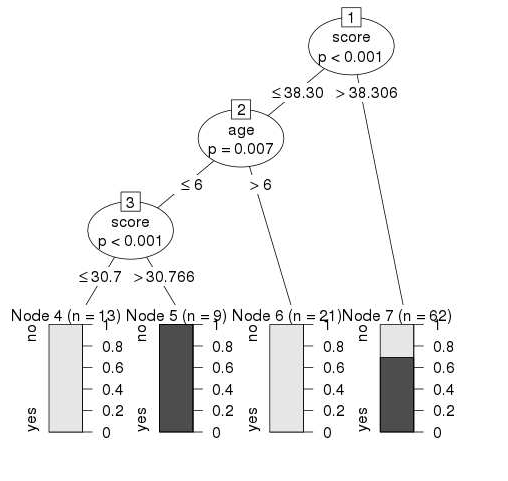
สรุป
จากแผนผังการตัดสินใจที่แสดงด้านบนเราสามารถสรุปได้ว่าใครก็ตามที่มีคะแนนทักษะการอ่านน้อยกว่า 38.3 และอายุมากกว่า 6 ปีจะไม่ใช่เจ้าของภาษา
ในแนวทางสุ่มฟอเรสต์จะมีการสร้างทรีการตัดสินใจจำนวนมาก ทุกการสังเกตจะถูกป้อนเข้าไปในโครงสร้างการตัดสินใจทั้งหมด ผลลัพธ์ที่พบบ่อยที่สุดสำหรับการสังเกตแต่ละครั้งจะใช้เป็นผลลัพธ์สุดท้าย การสังเกตใหม่จะถูกป้อนเข้าไปในต้นไม้ทั้งหมดและใช้คะแนนเสียงข้างมากสำหรับรูปแบบการจำแนกแต่ละประเภท
มีการประมาณการข้อผิดพลาดสำหรับกรณีที่ไม่ได้ใช้ในขณะที่สร้างต้นไม้ ที่เรียกว่าOOB (Out-of-bag) ประมาณการข้อผิดพลาดซึ่งกล่าวถึงเป็นเปอร์เซ็นต์
แพ็คเกจ R "randomForest" ใช้ในการสร้างป่าสุ่ม
ติดตั้งแพ็คเกจ R
ใช้คำสั่งด้านล่างในคอนโซล R เพื่อติดตั้งแพ็คเกจ คุณต้องติดตั้งแพ็กเกจที่เกี่ยวข้องด้วยถ้ามี
install.packages("randomForest)แพ็กเกจ "randomForest" มีฟังก์ชัน randomForest() ซึ่งใช้ในการสร้างและวิเคราะห์ป่าไม้แบบสุ่ม
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการสร้างฟอเรสต์แบบสุ่มใน R คือ -
randomForest(formula, data)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
formula เป็นสูตรที่อธิบายตัวทำนายและตัวแปรตอบสนอง
data คือชื่อของชุดข้อมูลที่ใช้
ป้อนข้อมูล
เราจะใช้ชุดข้อมูลในตัว R ชื่อ readingSkills เพื่อสร้างแผนผังการตัดสินใจ อธิบายถึงคะแนนของการอ่านทักษะของผู้อื่นหากเราทราบตัวแปร "อายุ" "รองเท้าขนาด" "คะแนน" และบุคคลนั้นเป็นเจ้าของภาษาหรือไม่
นี่คือข้อมูลตัวอย่าง
# Load the party package. It will automatically load other
# required packages.
library(party)
# Print some records from data set readingSkills.
print(head(readingSkills))เมื่อเรารันโค้ดด้านบนจะสร้างผลลัพธ์และแผนภูมิต่อไปนี้ -
nativeSpeaker age shoeSize score
1 yes 5 24.83189 32.29385
2 yes 6 25.95238 36.63105
3 no 11 30.42170 49.60593
4 yes 7 28.66450 40.28456
5 yes 11 31.88207 55.46085
6 yes 10 30.07843 52.83124
Loading required package: methods
Loading required package: grid
...............................
...............................ตัวอย่าง
เราจะใช้ไฟล์ randomForest() เพื่อสร้างโครงสร้างการตัดสินใจและดูกราฟ
# Load the party package. It will automatically load other
# required packages.
library(party)
library(randomForest)
# Create the forest.
output.forest <- randomForest(nativeSpeaker ~ age + shoeSize + score,
data = readingSkills)
# View the forest results.
print(output.forest)
# Importance of each predictor.
print(importance(fit,type = 2))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
Call:
randomForest(formula = nativeSpeaker ~ age + shoeSize + score,
data = readingSkills)
Type of random forest: classification
Number of trees: 500
No. of variables tried at each split: 1
OOB estimate of error rate: 1%
Confusion matrix:
no yes class.error
no 99 1 0.01
yes 1 99 0.01
MeanDecreaseGini
age 13.95406
shoeSize 18.91006
score 56.73051สรุป
จากฟอเรสต์แบบสุ่มที่แสดงด้านบนเราสามารถสรุปได้ว่าขนาดรองเท้าและคะแนนเป็นปัจจัยสำคัญในการตัดสินว่าใครเป็นเจ้าของภาษาหรือไม่ นอกจากนี้แบบจำลองยังมีข้อผิดพลาดเพียง 1% ซึ่งหมายความว่าเราสามารถทำนายได้อย่างแม่นยำ 99%
การวิเคราะห์การอยู่รอดเกี่ยวข้องกับการคาดการณ์เวลาที่จะเกิดเหตุการณ์เฉพาะ เรียกอีกอย่างว่าการวิเคราะห์เวลาล้มเหลวหรือการวิเคราะห์เวลาสู่ความตาย ตัวอย่างเช่นการทำนายจำนวนวันที่ผู้ป่วยมะเร็งจะรอดชีวิตหรือทำนายเวลาที่ระบบกลไกจะล้มเหลว
ชื่อแพ็กเกจ R survivalใช้ในการวิเคราะห์การอยู่รอด แพคเกจนี้ประกอบด้วยฟังก์ชันSurv()ซึ่งใช้ข้อมูลอินพุตเป็นสูตร R และสร้างอ็อบเจ็กต์การอยู่รอดท่ามกลางตัวแปรที่เลือกสำหรับการวิเคราะห์ จากนั้นเราใช้ฟังก์ชันsurvfit() เพื่อสร้างพล็อตสำหรับการวิเคราะห์
ติดตั้ง Package
install.packages("survival")ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการสร้างการวิเคราะห์การอยู่รอดใน R คือ -
Surv(time,event)
survfit(formula)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
time เป็นเวลาติดตามผลจนกว่าเหตุการณ์จะเกิดขึ้น
event แสดงสถานะของการเกิดเหตุการณ์ที่คาดไว้
formula คือความสัมพันธ์ระหว่างตัวแปรทำนาย
ตัวอย่าง
เราจะพิจารณาชุดข้อมูลที่ชื่อ "pbc" ที่มีอยู่ในแพ็คเกจการอยู่รอดที่ติดตั้งด้านบน อธิบายถึงจุดข้อมูลการรอดชีวิตเกี่ยวกับผู้ที่ได้รับผลกระทบจากโรคตับแข็งน้ำดีขั้นต้น (PBC) ของตับ ในบรรดาคอลัมน์จำนวนมากที่มีอยู่ในชุดข้อมูลเราจะคำนึงถึงฟิลด์ "เวลา" และ "สถานะ" เป็นหลัก เวลาแสดงถึงจำนวนวันระหว่างการลงทะเบียนผู้ป่วยและก่อนหน้าของเหตุการณ์ระหว่างผู้ป่วยที่ได้รับการปลูกถ่ายตับหรือผู้ป่วยเสียชีวิต
# Load the library.
library("survival")
# Print first few rows.
print(head(pbc))เมื่อเรารันโค้ดด้านบนจะสร้างผลลัพธ์และแผนภูมิต่อไปนี้ -
id time status trt age sex ascites hepato spiders edema bili chol
1 1 400 2 1 58.76523 f 1 1 1 1.0 14.5 261
2 2 4500 0 1 56.44627 f 0 1 1 0.0 1.1 302
3 3 1012 2 1 70.07255 m 0 0 0 0.5 1.4 176
4 4 1925 2 1 54.74059 f 0 1 1 0.5 1.8 244
5 5 1504 1 2 38.10541 f 0 1 1 0.0 3.4 279
6 6 2503 2 2 66.25873 f 0 1 0 0.0 0.8 248
albumin copper alk.phos ast trig platelet protime stage
1 2.60 156 1718.0 137.95 172 190 12.2 4
2 4.14 54 7394.8 113.52 88 221 10.6 3
3 3.48 210 516.0 96.10 55 151 12.0 4
4 2.54 64 6121.8 60.63 92 183 10.3 4
5 3.53 143 671.0 113.15 72 136 10.9 3
6 3.98 50 944.0 93.00 63 NA 11.0 3จากข้อมูลข้างต้นเรากำลังพิจารณาเวลาและสถานะสำหรับการวิเคราะห์ของเรา
การใช้ฟังก์ชัน Surv () และ Survfit ()
ตอนนี้เราดำเนินการต่อเพื่อใช้ไฟล์ Surv() ไปยังชุดข้อมูลข้างต้นและสร้างพล็อตที่จะแสดงแนวโน้ม
# Load the library.
library("survival")
# Create the survival object.
survfit(Surv(pbc$time,pbc$status == 2)~1) # Give the chart file a name. png(file = "survival.png") # Plot the graph. plot(survfit(Surv(pbc$time,pbc$status == 2)~1))
# Save the file.
dev.off()เมื่อเรารันโค้ดด้านบนจะสร้างผลลัพธ์และแผนภูมิต่อไปนี้ -
Call: survfit(formula = Surv(pbc$time, pbc$status == 2) ~ 1)
n events median 0.95LCL 0.95UCL
418 161 3395 3090 3853
แนวโน้มในกราฟด้านบนช่วยให้เราคาดการณ์ความน่าจะเป็นของการอยู่รอดเมื่อสิ้นสุดจำนวนวันที่กำหนด
Chi-Square testเป็นวิธีการทางสถิติเพื่อตรวจสอบว่าตัวแปรเชิงหมวดหมู่สองตัวแปรมีความสัมพันธ์กันอย่างมีนัยสำคัญหรือไม่ ตัวแปรทั้งสองควรมาจากประชากรกลุ่มเดียวกันและควรอยู่ในหมวดหมู่เช่น - ใช่ / ไม่ใช่ชาย / หญิงแดง / เขียวเป็นต้น
ตัวอย่างเช่นเราสามารถสร้างชุดข้อมูลด้วยการสังเกตรูปแบบการซื้อไอศกรีมของผู้คนและพยายามเชื่อมโยงเพศของบุคคลกับรสชาติของไอศกรีมที่พวกเขาต้องการ หากพบความสัมพันธ์เราสามารถวางแผนสำหรับสต็อกของรสชาติที่เหมาะสมได้โดยทราบจำนวนเพศของผู้ที่เข้าเยี่ยมชม
ไวยากรณ์
ฟังก์ชันที่ใช้ในการทดสอบไคสแควร์คือ chisq.test().
ไวยากรณ์พื้นฐานสำหรับการสร้างการทดสอบไคสแควร์ใน R คือ -
chisq.test(data)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
data คือข้อมูลในรูปแบบตารางที่มีค่าการนับของตัวแปรในการสังเกต
ตัวอย่าง
เราจะนำข้อมูล Cars93 ในไลบรารี "MASS" ซึ่งแสดงถึงยอดขายรถยนต์รุ่นต่างๆในปี 1993
library("MASS")
print(str(Cars93))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
'data.frame': 93 obs. of 27 variables:
$ Manufacturer : Factor w/ 32 levels "Acura","Audi",..: 1 1 2 2 3 4 4 4 4 5 ...
$ Model : Factor w/ 93 levels "100","190E","240",..: 49 56 9 1 6 24 54 74 73 35 ... $ Type : Factor w/ 6 levels "Compact","Large",..: 4 3 1 3 3 3 2 2 3 2 ...
$ Min.Price : num 12.9 29.2 25.9 30.8 23.7 14.2 19.9 22.6 26.3 33 ... $ Price : num 15.9 33.9 29.1 37.7 30 15.7 20.8 23.7 26.3 34.7 ...
$ Max.Price : num 18.8 38.7 32.3 44.6 36.2 17.3 21.7 24.9 26.3 36.3 ... $ MPG.city : int 25 18 20 19 22 22 19 16 19 16 ...
$ MPG.highway : int 31 25 26 26 30 31 28 25 27 25 ... $ AirBags : Factor w/ 3 levels "Driver & Passenger",..: 3 1 2 1 2 2 2 2 2 2 ...
$ DriveTrain : Factor w/ 3 levels "4WD","Front",..: 2 2 2 2 3 2 2 3 2 2 ... $ Cylinders : Factor w/ 6 levels "3","4","5","6",..: 2 4 4 4 2 2 4 4 4 5 ...
$ EngineSize : num 1.8 3.2 2.8 2.8 3.5 2.2 3.8 5.7 3.8 4.9 ... $ Horsepower : int 140 200 172 172 208 110 170 180 170 200 ...
$ RPM : int 6300 5500 5500 5500 5700 5200 4800 4000 4800 4100 ... $ Rev.per.mile : int 2890 2335 2280 2535 2545 2565 1570 1320 1690 1510 ...
$ Man.trans.avail : Factor w/ 2 levels "No","Yes": 2 2 2 2 2 1 1 1 1 1 ... $ Fuel.tank.capacity: num 13.2 18 16.9 21.1 21.1 16.4 18 23 18.8 18 ...
$ Passengers : int 5 5 5 6 4 6 6 6 5 6 ... $ Length : int 177 195 180 193 186 189 200 216 198 206 ...
$ Wheelbase : int 102 115 102 106 109 105 111 116 108 114 ... $ Width : int 68 71 67 70 69 69 74 78 73 73 ...
$ Turn.circle : int 37 38 37 37 39 41 42 45 41 43 ... $ Rear.seat.room : num 26.5 30 28 31 27 28 30.5 30.5 26.5 35 ...
$ Luggage.room : int 11 15 14 17 13 16 17 21 14 18 ... $ Weight : int 2705 3560 3375 3405 3640 2880 3470 4105 3495 3620 ...
$ Origin : Factor w/ 2 levels "USA","non-USA": 2 2 2 2 2 1 1 1 1 1 ... $ Make : Factor w/ 93 levels "Acura Integra",..: 1 2 4 3 5 6 7 9 8 10 ...ผลลัพธ์ข้างต้นแสดงให้เห็นว่าชุดข้อมูลมีตัวแปร Factor หลายตัวซึ่งถือได้ว่าเป็นตัวแปรหมวดหมู่ สำหรับโมเดลของเราเราจะพิจารณาตัวแปร "AirBags" และ "Type" เรามุ่งหวังที่จะค้นหาความสัมพันธ์ที่สำคัญระหว่างประเภทของรถยนต์ที่ขายและประเภทของถุงลมนิรภัย หากสังเกตความสัมพันธ์เราสามารถประมาณได้ว่ารถยนต์ประเภทใดขายได้ดีกว่ากับถุงลมนิรภัยประเภทใด
# Load the library.
library("MASS")
# Create a data frame from the main data set.
car.data <- data.frame(Cars93$AirBags, Cars93$Type)
# Create a table with the needed variables.
car.data = table(Cars93$AirBags, Cars93$Type)
print(car.data)
# Perform the Chi-Square test.
print(chisq.test(car.data))เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
Compact Large Midsize Small Sporty Van
Driver & Passenger 2 4 7 0 3 0
Driver only 9 7 11 5 8 3
None 5 0 4 16 3 6
Pearson's Chi-squared test
data: car.data
X-squared = 33.001, df = 10, p-value = 0.0002723
Warning message:
In chisq.test(car.data) : Chi-squared approximation may be incorrectสรุป
ผลลัพธ์จะแสดงค่า p ที่น้อยกว่า 0.05 ซึ่งบ่งบอกถึงความสัมพันธ์ของสตริง