DIP - Hướng dẫn nhanh
Giới thiệu
Xử lý tín hiệu là một ngành trong kỹ thuật điện và toán học liên quan đến phân tích và xử lý các tín hiệu tương tự và kỹ thuật số, đồng thời giải quyết việc lưu trữ, lọc và các hoạt động khác trên tín hiệu. Những tín hiệu này bao gồm tín hiệu truyền, tín hiệu âm thanh hoặc giọng nói, tín hiệu hình ảnh và các tín hiệu khác, v.v.
Trong số tất cả các tín hiệu này, trường xử lý loại tín hiệu mà đầu vào là hình ảnh và đầu ra cũng là hình ảnh được thực hiện trong xử lý hình ảnh. Như tên gọi của nó, nó xử lý hình ảnh.
Nó có thể được chia thành xử lý hình ảnh tương tự và xử lý hình ảnh kỹ thuật số.
Xử lý hình ảnh tương tự
Xử lý hình ảnh tương tự được thực hiện trên tín hiệu tương tự. Nó bao gồm xử lý tín hiệu tương tự hai chiều. Trong kiểu xử lý này, hình ảnh được điều khiển bằng điện bằng cách thay đổi tín hiệu điện. Ví dụ phổ biến bao gồm là hình ảnh truyền hình.
Xử lý hình ảnh kỹ thuật số đã chiếm ưu thế hơn so với xử lý hình ảnh tương tự theo thời gian do phạm vi ứng dụng rộng hơn của nó.
Xử lý hình ảnh kỹ thuật số
Xử lý hình ảnh kỹ thuật số liên quan đến việc phát triển một hệ thống kỹ thuật số thực hiện các hoạt động trên một hình ảnh kỹ thuật số.
Hình ảnh là gì
Một hình ảnh không hơn gì một tín hiệu hai chiều. Nó được định nghĩa bởi hàm toán học f (x, y) trong đó x và y là hai tọa độ theo chiều ngang và chiều dọc.
Giá trị của f (x, y) tại bất kỳ điểm nào là giá trị pixel tại điểm đó của ảnh.

Hình trên là một ví dụ về hình ảnh kỹ thuật số mà bạn đang xem trên màn hình máy tính của mình. Nhưng thực ra, hình ảnh này chẳng qua là một mảng số hai chiều nằm trong khoảng từ 0 đến 255.
| 128 | 30 | 123 |
| 232 | 123 | 321 |
| 123 | 77 | 89 |
| 80 | 255 | 255 |
Mỗi số đại diện cho giá trị của hàm f (x, y) tại một điểm bất kỳ. Trong trường hợp này, mỗi giá trị 128, 230, 123 đại diện cho một giá trị pixel riêng lẻ. Kích thước của bức tranh thực sự là kích thước của mảng hai chiều này.
Mối quan hệ giữa hình ảnh kỹ thuật số và tín hiệu
Nếu hình ảnh là một mảng hai chiều thì nó phải làm gì với một tín hiệu? Để hiểu được điều đó, trước hết chúng ta cần hiểu tín hiệu là gì?
Tín hiệu
Trong thế giới vật chất, bất kỳ đại lượng nào có thể đo lường được thông qua thời gian trong không gian hoặc bất kỳ chiều cao hơn nào đều có thể được coi là tín hiệu. Tín hiệu là một hàm toán học và nó truyền tải một số thông tin. Một tín hiệu có thể là một chiều hoặc hai chiều hoặc tín hiệu chiều cao hơn. Tín hiệu một chiều là tín hiệu được đo theo thời gian. Ví dụ phổ biến là tín hiệu thoại. Tín hiệu hai chiều là những tín hiệu được đo bằng một số đại lượng vật lý khác. Ví dụ về tín hiệu hai chiều là một hình ảnh kỹ thuật số. Chúng ta sẽ xem xét chi tiết hơn trong hướng dẫn tiếp theo về cách các tín hiệu một chiều hoặc hai chiều và các tín hiệu cao hơn được hình thành và giải thích.
Mối quan hệ
Vì bất cứ thứ gì truyền tải thông tin hoặc phát đi một thông điệp trong thế giới vật chất giữa hai người quan sát đều là một tín hiệu. Điều đó bao gồm lời nói hoặc (giọng nói của con người) hoặc một hình ảnh như một tín hiệu. Kể từ khi chúng ta nói, giọng nói của chúng ta được chuyển đổi thành tín hiệu / sóng âm thanh và biến đổi theo thời gian với người mà chúng ta đang nói chuyện. Không chỉ điều này, mà cách thức hoạt động của máy ảnh kỹ thuật số, cũng như khi thu được hình ảnh từ máy ảnh kỹ thuật số liên quan đến việc chuyển tín hiệu từ phần này sang phần khác của hệ thống.
Hình ảnh kỹ thuật số được hình thành như thế nào
Vì chụp ảnh từ máy ảnh là một quá trình vật lý. Ánh sáng mặt trời được sử dụng như một nguồn năng lượng. Một mảng cảm biến được sử dụng để thu nhận hình ảnh. Vì vậy, khi ánh sáng mặt trời chiếu vào đối tượng, thì lượng ánh sáng phản xạ bởi đối tượng đó sẽ được cảm biến bởi các cảm biến và một tín hiệu điện áp liên tục được tạo ra bởi lượng dữ liệu được cảm nhận. Để tạo ra một hình ảnh kỹ thuật số, chúng ta cần chuyển dữ liệu này sang dạng kỹ thuật số. Điều này liên quan đến việc lấy mẫu và lượng tử hóa. (Chúng sẽ được thảo luận ở phần sau). Kết quả của việc lấy mẫu và lượng tử hóa tạo ra một mảng hoặc ma trận số hai chiều không là gì khác ngoài một hình ảnh kỹ thuật số.
Trường chồng chéo
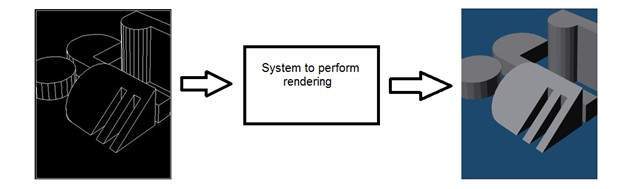
Máy / Thị giác máy tính
Thị giác máy hay thị giác máy tính liên quan đến việc phát triển một hệ thống trong đó đầu vào là hình ảnh và đầu ra là một số thông tin. Ví dụ: Phát triển một hệ thống quét khuôn mặt người và mở bất kỳ loại khóa nào. Hệ thống này sẽ trông giống như thế này.

Đô họa may tinh
Đồ họa máy tính xử lý việc hình thành hình ảnh từ các mô hình đối tượng, thay vì sau đó hình ảnh được chụp bởi một số thiết bị. Ví dụ: Kết xuất đối tượng. Tạo hình ảnh từ mô hình đối tượng. Một hệ thống như vậy sẽ trông giống như thế này.
Trí tuệ nhân tạo
Trí tuệ nhân tạo ít nhiều là nghiên cứu đưa trí tuệ con người vào máy móc. Trí tuệ nhân tạo có nhiều ứng dụng trong xử lý ảnh. Ví dụ: phát triển hệ thống chẩn đoán có sự hỗ trợ của máy tính giúp bác sĩ giải thích hình ảnh chụp X-quang, MRI, v.v. và sau đó làm nổi bật phần dễ thấy để bác sĩ kiểm tra.
Xử lý tín hiệu
Xử lý tín hiệu là một cái ô và xử lý hình ảnh nằm dưới nó. Lượng ánh sáng được phản xạ bởi một vật thể trong thế giới vật chất (thế giới 3d) đi qua ống kính của máy ảnh và nó trở thành tín hiệu 2d và do đó dẫn đến hình ảnh. Hình ảnh này sau đó được số hóa bằng các phương pháp xử lý tín hiệu và sau đó hình ảnh kỹ thuật số này được thao tác trong xử lý hình ảnh kỹ thuật số.
Hướng dẫn này bao gồm các khái niệm cơ bản về tín hiệu và hệ thống cần thiết để hiểu các khái niệm về xử lý hình ảnh kỹ thuật số. Trước khi đi vào các khái niệm chi tiết, trước tiên hãy xác định các thuật ngữ đơn giản.
Tín hiệu
Trong kỹ thuật điện, đại lượng cơ bản đại diện cho một số thông tin được gọi là tín hiệu. Không quan trọng thông tin là gì, tức là: Thông tin tương tự hay kỹ thuật số. Trong toán học, tín hiệu là một hàm truyền đạt một số thông tin. Trên thực tế, bất kỳ đại lượng nào có thể đo được thông qua thời gian trong không gian hoặc bất kỳ chiều cao hơn nào đều có thể được coi là tín hiệu. Một tín hiệu có thể ở bất kỳ thứ nguyên nào và có thể ở bất kỳ hình thức nào.
Tín hiệu tương tự
Một tín hiệu có thể là một đại lượng tương tự có nghĩa là nó được xác định theo thời gian. Đó là một tín hiệu liên tục. Các tín hiệu này được xác định trên các biến độc lập liên tục. Chúng rất khó phân tích, vì chúng mang một số lượng lớn các giá trị. Chúng rất chính xác do có một lượng lớn các giá trị. Để lưu trữ các tín hiệu này, bạn yêu cầu một bộ nhớ vô hạn vì nó có thể đạt được giá trị vô hạn trên một dòng thực. Tín hiệu tương tự được ký hiệu bằng sóng sin.
Ví dụ:
Tiếng người
Giọng nói của con người là một ví dụ về tín hiệu tương tự. Khi bạn nói, giọng nói được tạo ra sẽ truyền trong không khí dưới dạng sóng áp suất và do đó thuộc về một hàm toán học, có các biến độc lập về không gian và thời gian và một giá trị tương ứng với áp suất không khí.
Một ví dụ khác là sóng sin được thể hiện trong hình bên dưới.
Y = sin (x) trong đó x là thụt lề

Tín hiệu kỹ thuật số
So với tín hiệu tương tự, tín hiệu kỹ thuật số rất dễ phân tích. Chúng là những tín hiệu không liên tục. Chúng là sự chiếm đoạt của các tín hiệu tương tự.
Từ kỹ thuật số là viết tắt của các giá trị rời rạc và do đó nó có nghĩa là chúng sử dụng các giá trị cụ thể để đại diện cho bất kỳ thông tin nào. Trong tín hiệu kỹ thuật số, chỉ có hai giá trị được sử dụng để biểu diễn một cái gì đó, tức là: 1 và 0 (giá trị nhị phân). Tín hiệu số kém chính xác hơn so với tín hiệu tương tự vì chúng là các mẫu rời rạc của tín hiệu tương tự được lấy trong một khoảng thời gian. Tuy nhiên tín hiệu kỹ thuật số không bị nhiễu. Vì vậy, chúng tồn tại lâu dài và dễ diễn giải. Tín hiệu số được ký hiệu bằng sóng vuông.
Ví dụ:
Bàn phím máy tính
Bất cứ khi nào một phím được nhấn từ bàn phím, tín hiệu điện thích hợp sẽ được gửi đến bộ điều khiển bàn phím có chứa giá trị ASCII của phím cụ thể đó. Ví dụ, tín hiệu điện được tạo ra khi nhấn phím a trên bàn phím, mang thông tin của chữ số 97 ở dạng 0 và 1, là giá trị ASCII của ký tự a.
Sự khác biệt giữa tín hiệu tương tự và tín hiệu kỹ thuật số
| Yếu tố so sánh | Tín hiệu tương tự | Tín hiệu kĩ thuật số |
|---|---|---|
| Phân tích | Khó khăn | Có thể phân tích |
| Đại diện | Tiếp diễn | Không liên tục |
| Sự chính xác | Chính xác hơn | Kém chính xác hơn |
| Lưu trữ | Bộ nhớ vô hạn | Dễ dàng lưu trữ |
| Chịu tiếng ồn | Đúng | Không |
| Kỹ thuật ghi âm | Tín hiệu gốc được bảo toàn | Các mẫu tín hiệu được lấy và bảo quản |
| Ví dụ | Giọng người, nhiệt kế, điện thoại tương tự, v.v. | Máy tính, điện thoại kỹ thuật số, bút kỹ thuật số, v.v. |
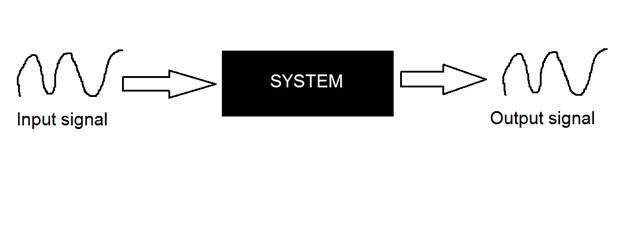
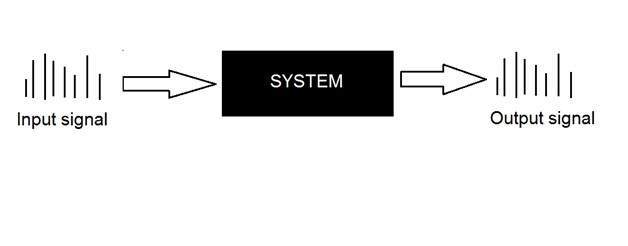
Hệ thống
Hệ thống được xác định bởi kiểu đầu vào và đầu ra mà nó xử lý. Vì chúng tôi đang xử lý các tín hiệu, vì vậy trong trường hợp của chúng tôi, hệ thống của chúng tôi sẽ là một mô hình toán học, một đoạn mã / phần mềm hoặc một thiết bị vật lý hoặc một hộp đen có đầu vào là tín hiệu và nó thực hiện một số xử lý trên tín hiệu đó, và đầu ra là một tín hiệu. Đầu vào được gọi là kích thích và đầu ra được gọi là phản ứng.

Trong hình trên, một hệ thống đã được chỉ ra mà cả đầu vào và đầu ra đều là tín hiệu nhưng đầu vào là tín hiệu tương tự. Và đầu ra là tín hiệu kỹ thuật số. Nó có nghĩa là hệ thống của chúng tôi thực sự là một hệ thống chuyển đổi chuyển đổi tín hiệu tương tự sang tín hiệu kỹ thuật số.
Hãy xem bên trong của hệ thống hộp đen này
Chuyển đổi tín hiệu tương tự sang tín hiệu kỹ thuật số
Vì có rất nhiều khái niệm liên quan đến chuyển đổi tương tự sang kỹ thuật số này và ngược lại. Chúng tôi sẽ chỉ thảo luận về những thứ liên quan đến xử lý hình ảnh kỹ thuật số. Có hai khái niệm chính liên quan đến sự che đậy.
Sampling
Quantization
Lấy mẫu
Lấy mẫu như tên gọi của nó có thể được định nghĩa là lấy mẫu. Lấy mẫu tín hiệu kỹ thuật số trên trục x. Việc lấy mẫu được thực hiện trên một biến độc lập. Trong trường hợp của phương trình toán học này:
Việc lấy mẫu được thực hiện trên biến x. Chúng ta cũng có thể nói rằng việc chuyển đổi trục x (giá trị vô hạn) sang kỹ thuật số được thực hiện theo mẫu.
Lấy mẫu được chia thành lấy mẫu lên và lấy mẫu xuống. Nếu phạm vi giá trị trên trục x ít hơn thì chúng tôi sẽ tăng mẫu giá trị. Điều này được gọi là lấy mẫu lên và ngược lại được gọi là lấy mẫu xuống
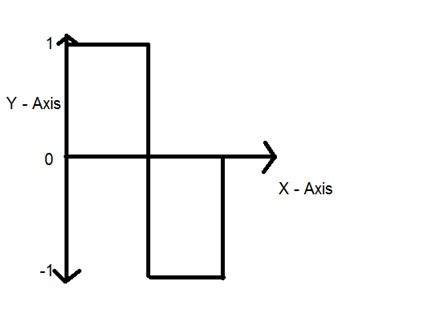
Lượng tử hóa
Lượng tử hóa như tên gọi của nó gợi ý có thể được định nghĩa là phân chia thành các lượng tử (phân vùng). Lượng tử hóa được thực hiện trên biến phụ thuộc. Nó ngược lại với lấy mẫu.
Trong trường hợp của phương trình toán học này, y = sin (x)
Lượng tử hóa được thực hiện trên biến Y. Nó được thực hiện trên trục y. Việc chuyển đổi các giá trị vô hạn trục y thành 1, 0, -1 (hoặc bất kỳ mức nào khác) được gọi là Lượng tử hóa.
Đây là hai bước cơ bản có liên quan trong khi chuyển đổi tín hiệu tương tự sang tín hiệu kỹ thuật số.
Lượng tử hóa một tín hiệu được thể hiện trong hình bên dưới.
Tại sao chúng ta cần chuyển đổi tín hiệu tương tự sang tín hiệu số.
Lý do đầu tiên và rõ ràng là xử lý hình ảnh kỹ thuật số xử lý hình ảnh kỹ thuật số, đó là tín hiệu kỹ thuật số. Vì vậy, bao giờ hình ảnh được chụp, nó được chuyển đổi thành định dạng kỹ thuật số và sau đó nó được xử lý.
Lý do thứ hai và quan trọng là, để thực hiện các hoạt động trên một tín hiệu tương tự với máy tính kỹ thuật số, bạn phải lưu trữ tín hiệu tương tự đó trong máy tính. Và để lưu trữ một tín hiệu tương tự, cần phải có bộ nhớ vô hạn để lưu trữ tín hiệu đó. Và vì điều đó là không thể, đó là lý do tại sao chúng tôi chuyển đổi tín hiệu đó thành định dạng kỹ thuật số và sau đó lưu trữ trong máy tính kỹ thuật số và sau đó thực hiện các hoạt động trên đó.
Hệ thống liên tục và hệ thống rời rạc
Hệ thống liên tục
Loại hệ thống mà đầu vào và đầu ra đều là tín hiệu liên tục hoặc tín hiệu tương tự được gọi là hệ thống liên tục.
Hệ thống rời rạc
Loại hệ thống mà đầu vào và đầu ra đều là tín hiệu rời rạc hoặc tín hiệu kỹ thuật số được gọi là hệ thống kỹ thuật số
Nguồn gốc của máy ảnh
Lịch sử của máy ảnh và nhiếp ảnh không hoàn toàn giống nhau. Các khái niệm về máy ảnh đã được giới thiệu rất nhiều trước khi có khái niệm về nhiếp ảnh
Camera Obscura
Lịch sử của máy ảnh nằm ở CHÂU Á. Các nguyên tắc của máy ảnh lần đầu tiên được giới thiệu bởi một nhà triết học Trung Quốc MOZI. Nó được gọi là camera obscura. Máy ảnh đã phát triển từ nguyên tắc này.
Từ camera obscura được phát triển từ hai từ khác nhau. Camera và Obscura. Ý nghĩa của từ camera là một căn phòng hoặc một số loại hầm và Obscura là viết tắt của bóng tối.
Khái niệm được đưa ra bởi nhà triết học Trung Quốc bao gồm một thiết bị, chiếu hình ảnh xung quanh nó lên tường. Tuy nhiên nó không được xây dựng bởi người Trung Quốc.
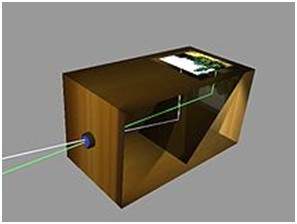
Sự ra đời của camera obscura
Khái niệm về tiếng Trung Quốc đã được đưa vào thực tế bởi một nhà khoa học Hồi giáo Abu Ali Al-Hassan Ibn al-Haitham thường được gọi là Ibn al-Haitham. Ông đã chế tạo chiếc máy ảnh đầu tiên obscura. Máy ảnh của anh ấy tuân theo các nguyên tắc của máy ảnh lỗ kim. Anh ấy chế tạo thiết bị này ở đâu đó khoảng 1000.
Máy ảnh di động
Năm 1685, một chiếc máy ảnh cầm tay đầu tiên được chế tạo bởi Johann Zahn. Trước khi thiết bị này ra đời, máy ảnh có kích thước bằng một căn phòng và không thể di chuyển. Mặc dù một thiết bị được chế tạo bởi nhà khoa học người Ireland Robert Boyle và Robert Hooke là một chiếc máy ảnh có thể vận chuyển, nhưng thiết bị đó vẫn rất lớn để mang nó từ nơi này đến nơi khác.
Nguồn gốc của nhiếp ảnh
Mặc dù camera obscura được chế tạo vào năm 1000 bởi một nhà khoa học Hồi giáo. Nhưng việc sử dụng thực tế đầu tiên của nó đã được một nhà triết học người Anh Roger Bacon mô tả vào thế kỷ 13. Roger đề nghị sử dụng máy ảnh để quan sát nhật thực.
Da Vinci
Mặc dù nhiều cải tiến đã được thực hiện trước thế kỷ 15, nhưng những cải tiến và phát hiện do Leonardo di ser Piero da Vinci thực hiện là rất đáng chú ý. Da Vinci là một nghệ sĩ vĩ đại, nhạc sĩ, nhà giải phẫu học và một người chiến tranh. Ông được ghi nhận cho nhiều phát minh. Một trong những bức tranh nổi tiếng nhất của ông bao gồm bức tranh Mona Lisa.

Da vinci không chỉ chế tạo một chiếc máy ảnh obscura theo nguyên tắc của một chiếc máy ảnh có lỗ ghim mà còn sử dụng nó như một dụng cụ hỗ trợ vẽ cho tác phẩm nghệ thuật của mình. Trong tác phẩm của ông, được mô tả trong Codex Atlanticus, nhiều nguyên tắc của camera che khuất đã được xác định.
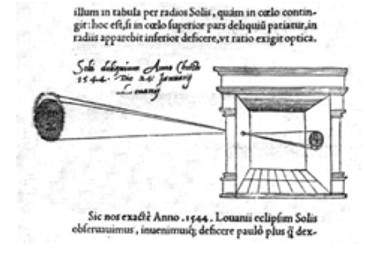
Máy ảnh của anh ấy tuân theo nguyên tắc của một máy ảnh lỗ kim có thể được mô tả là
Khi hình ảnh của các vật thể được chiếu sáng xuyên qua một lỗ nhỏ vào một căn phòng rất tối, bạn sẽ nhìn thấy [ở bức tường đối diện] những vật thể này ở dạng và màu sắc phù hợp, giảm kích thước ở một vị trí đảo ngược do sự giao nhau giữa các tia.
Bức ảnh đầu tiên
Bức ảnh đầu tiên được chụp vào năm 1814 bởi một nhà phát minh người Pháp Joseph Nicephore Niepce. Ông chụp bức ảnh đầu tiên về quang cảnh từ cửa sổ ở Le Gras, bằng cách phủ bitum lên tấm pewter và sau đó để tấm đó ra ánh sáng.

Bức ảnh đầu tiên dưới nước
Bức ảnh chụp dưới nước đầu tiên được chụp bởi một nhà toán học người Anh William Thomson bằng cách sử dụng một hộp kín nước. Điều này đã được thực hiện vào năm 1856.

Nguồn gốc của phim
Nguồn gốc của phim được giới thiệu bởi một nhà phát minh người Mỹ và một nhà từ thiện được gọi là George Eastman, người được coi là người tiên phong của nhiếp ảnh.
Ông thành lập công ty có tên Eastman Kodak, nổi tiếng với việc phát triển các bộ phim. Công ty bắt đầu sản xuất phim giấy vào năm 1885. Đầu tiên ông tạo ra máy ảnh Kodak và sau đó là Brownie. Brownie là một chiếc máy ảnh dạng hộp và trở nên phổ biến nhờ tính năng Chụp nhanh.

Sau sự ra đời của bộ phim, ngành công nghiệp máy ảnh lại một lần nữa bùng nổ và phát minh này dẫn đến phát minh khác.
Leica và Argus
Leica và argus lần lượt là hai máy ảnh analog được phát triển vào năm 1925 và năm 1939. Máy ảnh Leica được chế tạo bằng phim điện ảnh 35mm.

Argus là một máy ảnh analog khác sử dụng định dạng 35mm và khá rẻ so với Leica và trở nên rất phổ biến.

Camera quan sát analog
Năm 1942, một kỹ sư người Đức Walter Bruch đã phát triển và lắp đặt hệ thống camera quan sát analog đầu tiên. Ông cũng được ghi nhận vì đã phát minh ra tivi màu vào năm 1960.
Ảnh Pac
Máy ảnh dùng một lần đầu tiên được giới thiệu vào năm 1949 bởi Photo Pac. Máy ảnh chỉ là máy ảnh sử dụng một lần với một cuộn phim đã được bao gồm trong đó. Các phiên bản sau của Photo pac có khả năng chống nước và thậm chí có cả đèn flash.

Máy ảnh kĩ thuật số
Mavica của Sony
Mavica (máy quay video từ tính) được Sony tung ra vào năm 1981 là công cụ thay đổi cuộc chơi đầu tiên trong thế giới máy ảnh kỹ thuật số. Hình ảnh được ghi trên đĩa mềm và hình ảnh có thể được xem sau trên bất kỳ màn hình điều khiển nào.
Nó không phải là một chiếc máy ảnh kỹ thuật số thuần túy, mà là một chiếc máy ảnh analog. Nhưng nó đã trở nên phổ biến do khả năng lưu trữ hình ảnh trên đĩa mềm. Có nghĩa là bây giờ bạn có thể lưu trữ hình ảnh trong một thời gian dài và bạn có thể lưu một số lượng lớn hình ảnh trên đĩa mềm được thay thế bằng đĩa trắng mới, khi chúng đã đầy. Mavica có khả năng lưu trữ 25 hình ảnh trên một đĩa.
Một điều quan trọng nữa mà mavica giới thiệu là khả năng chụp ảnh 0,3 mega pixel.

Máy ảnh kĩ thuật số
Fuji DS-1P camera của Fuji phim 1988 là máy ảnh kỹ thuật số thực sự đầu tiên
Nikon D1 là một máy ảnh 2,74 mega pixel và là máy ảnh SLR kỹ thuật số thương mại đầu tiên được phát triển bởi Nikon và có giá cả rất phải chăng đối với các chuyên gia.

Ngày nay máy ảnh kỹ thuật số được đưa vào điện thoại di động với độ phân giải và chất lượng rất cao.
Vì xử lý ảnh kỹ thuật số có các ứng dụng rất rộng rãi và hầu như tất cả các lĩnh vực kỹ thuật đều bị ảnh hưởng bởi DIP, chúng ta sẽ chỉ thảo luận một số ứng dụng chính của DIP.
Xử lý hình ảnh kỹ thuật số không chỉ giới hạn ở việc điều chỉnh độ phân giải không gian của hình ảnh hàng ngày được chụp bởi máy ảnh. Nó không chỉ giới hạn trong việc tăng độ sáng của bức ảnh, v.v. Mà còn hơn thế nữa.
Sóng điện từ có thể được coi là dòng hạt, trong đó mỗi hạt chuyển động với tốc độ ánh sáng. Mỗi hạt chứa một gói năng lượng. Gói năng lượng này được gọi là một photon.
Quang phổ điện từ theo năng lượng của photon được biểu diễn dưới đây.

Trong phổ điện từ này, chúng ta chỉ có thể nhìn thấy phổ khả kiến. Quang phổ nhìn thấy chủ yếu bao gồm bảy màu khác nhau thường được gọi là (VIBGOYR). VIBGOYR là viết tắt của tím, chàm, lam, lục, cam, vàng và đỏ.
Nhưng điều đó không vô hiệu hóa sự tồn tại của những thứ khác trong quang phổ. Mắt người của chúng ta chỉ có thể nhìn thấy phần nhìn thấy được, trong đó chúng ta nhìn thấy tất cả các vật thể. Nhưng máy ảnh có thể nhìn thấy những thứ khác mà mắt thường không thể nhìn thấy. Ví dụ: tia x, tia gamma, v.v. Do đó, việc phân tích tất cả những thứ đó cũng được thực hiện trong xử lý hình ảnh kỹ thuật số.
Cuộc thảo luận này dẫn đến một câu hỏi khác là
tại sao chúng ta cần phân tích tất cả những thứ khác trong phổ EM?
Câu trả lời cho câu hỏi này nằm ở thực tế, vì những thứ khác như XRay đã được sử dụng rộng rãi trong lĩnh vực y tế. Việc phân tích tia Gamma là cần thiết vì nó được sử dụng rộng rãi trong y học hạt nhân và quan sát thiên văn. Tương tự với những thứ còn lại trong phổ EM.
Các ứng dụng của xử lý hình ảnh kỹ thuật số
Một số lĩnh vực chính trong đó xử lý hình ảnh kỹ thuật số được sử dụng rộng rãi được đề cập dưới đây
Làm sắc nét và phục hồi hình ảnh
Lĩnh vực y tế
Viễn thám
Truyền và mã hóa
Thị giác máy / Robot
Xử lý màu
Nhận dạng mẫu
Xử lý video
Hình ảnh hiển vi
Others
Làm sắc nét và phục hồi hình ảnh
Làm sắc nét và phục hồi hình ảnh ở đây đề cập đến quá trình xử lý hình ảnh đã được chụp từ máy ảnh hiện đại để làm cho chúng có hình ảnh tốt hơn hoặc chỉnh sửa những hình ảnh đó theo cách để đạt được kết quả mong muốn. Nó đề cập đến những gì Photoshop thường làm.
Điều này bao gồm Thu phóng, làm mờ, làm sắc nét, thang màu xám thành chuyển đổi màu sắc, phát hiện các cạnh và ngược lại, Truy xuất hình ảnh và Nhận dạng hình ảnh. Các ví dụ phổ biến là:
Ảnh gốc

Hình ảnh được phóng to

Hình ảnh mờ

Hình ảnh sắc nét

Cạnh

Lĩnh vực y tế
Các ứng dụng phổ biến của DIP trong lĩnh vực y tế là
Hình ảnh tia gamma
Quét thú vật
Hình ảnh X Ray
CT y tế
Hình ảnh UV
Hình ảnh UV
Trong lĩnh vực viễn thám, khu vực của trái đất được quét bởi vệ tinh hoặc từ một mặt đất rất cao và sau đó nó được phân tích để thu được thông tin về nó. Một ứng dụng cụ thể của xử lý ảnh kỹ thuật số trong lĩnh vực viễn thám là phát hiện các thiệt hại về cơ sở hạ tầng do động đất gây ra.
Vì cần nhiều thời gian hơn để nắm bắt thiệt hại, ngay cả khi các thiệt hại nghiêm trọng được tập trung vào. Vì khu vực chịu ảnh hưởng của trận động đất đôi khi rất rộng, nên không thể quan sát bằng mắt người để ước tính thiệt hại. Ngay cả khi có, thì đó là thủ tục rất bận rộn và tốn thời gian. Vì vậy, một giải pháp cho điều này được tìm thấy trong xử lý hình ảnh kỹ thuật số. Hình ảnh của khu vực bị ảnh hưởng được chụp từ mặt đất trên và sau đó nó được phân tích để phát hiện các loại thiệt hại do trận động đất gây ra.
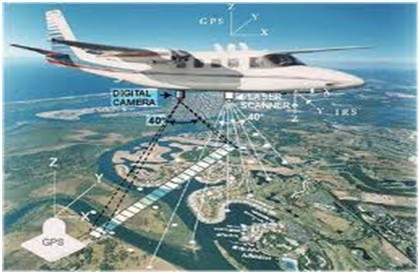
Các bước chính bao gồm trong phân tích là
Việc khai thác các cạnh
Phân tích và nâng cao các loại cạnh khác nhau
Truyền và mã hóa
Hình ảnh đầu tiên được truyền qua dây là từ London đến New York qua cáp ngầm. Hình ảnh đã được gửi được hiển thị bên dưới.
Bức ảnh được gửi đi mất ba giờ đồng hồ để chuyển từ nơi này đến nơi khác.
Bây giờ chỉ cần tưởng tượng, rằng ngày nay chúng ta có thể xem nguồn cấp dữ liệu video trực tiếp hoặc cảnh cctv trực tiếp từ lục địa này sang lục địa khác chỉ với độ trễ vài giây. Nó có nghĩa là rất nhiều công việc đã được thực hiện trong lĩnh vực này. Trường này không chỉ tập trung vào truyền mà còn tập trung vào mã hóa. Nhiều định dạng khác nhau đã được phát triển cho băng thông cao hoặc thấp để mã hóa ảnh và sau đó phát trực tuyến qua internet hoặc v.v.
Thị giác máy / Robot
Ngoài nhiều thách thức mà robot phải đối mặt ngày nay, một trong những thách thức lớn nhất vẫn là tăng tầm nhìn của robot. Làm cho robot có thể nhìn thấy mọi thứ, xác định chúng, xác định các rào cản, v.v. Nhiều công việc đã được đóng góp bởi lĩnh vực này và một lĩnh vực thị giác máy tính hoàn chỉnh khác đã được giới thiệu để làm việc trên đó.
Phát hiện nhanh
Phát hiện vật cản là một trong những nhiệm vụ phổ biến được thực hiện thông qua xử lý hình ảnh, bằng cách xác định các loại vật thể khác nhau trong hình ảnh và sau đó tính toán khoảng cách giữa robot và các chướng ngại vật.

Robot theo dõi dòng
Hầu hết các rô bốt ngày nay hoạt động theo dòng và do đó được gọi là rô bốt theo dòng. Điều này giúp robot di chuyển trên đường đi của nó và thực hiện một số nhiệm vụ. Điều này cũng đã đạt được thông qua xử lý hình ảnh.

Xử lý màu
Xử lý màu bao gồm xử lý các hình ảnh có màu và các không gian màu khác nhau được sử dụng. Ví dụ: mô hình màu RGB, YCbCr, HSV. Nó cũng liên quan đến việc nghiên cứu việc truyền tải, lưu trữ và mã hóa các hình ảnh màu này.
Nhận dạng mẫu
Nhận dạng mẫu bao gồm nghiên cứu từ xử lý hình ảnh và từ nhiều lĩnh vực khác bao gồm học máy (một nhánh của trí tuệ nhân tạo). Trong nhận dạng mẫu, xử lý ảnh được sử dụng để xác định các đối tượng trong ảnh và sau đó học máy được sử dụng để huấn luyện hệ thống về sự thay đổi trong mẫu. Nhận dạng mẫu được sử dụng trong chẩn đoán có sự hỗ trợ của máy tính, nhận dạng chữ viết tay, nhận dạng hình ảnh, v.v.
Xử lý video
Một video không là gì khác ngoài chuyển động rất nhanh của các bức tranh. Chất lượng của video phụ thuộc vào số khung hình / hình ảnh mỗi phút và chất lượng của từng khung hình đang được sử dụng. Xử lý video bao gồm giảm nhiễu, tăng cường chi tiết, phát hiện chuyển động, chuyển đổi tốc độ khung hình, chuyển đổi tỷ lệ khung hình, chuyển đổi không gian màu, v.v.
Chúng ta sẽ xem xét ví dụ này để hiểu khái niệm về thứ nguyên.
Hãy xem xét bạn có một người bạn sống trên mặt trăng và anh ấy muốn gửi cho bạn một món quà vào dịp sinh nhật của bạn. Anh ấy hỏi bạn về nơi ở của bạn trên trái đất. Vấn đề duy nhất là dịch vụ chuyển phát nhanh trên mặt trăng không hiểu địa chỉ theo bảng chữ cái, thay vào đó nó chỉ hiểu các tọa độ số. Vì vậy, làm thế nào để bạn gửi cho anh ta vị trí của bạn trên trái đất?
Đó là nơi xuất hiện khái niệm kích thước. Kích thước xác định số điểm tối thiểu cần thiết để trỏ vị trí của bất kỳ đối tượng cụ thể nào trong một không gian.
Vì vậy, hãy quay lại ví dụ của chúng tôi một lần nữa, trong đó bạn phải gửi vị trí của mình trên trái đất cho người bạn của bạn trên mặt trăng. Bạn gửi cho anh ta ba cặp phối hợp. Cái đầu tiên được gọi là kinh độ, cái thứ hai được gọi là vĩ độ, và cái thứ ba được gọi là độ cao.
Ba tọa độ này xác định vị trí của bạn trên trái đất. Hai cái đầu tiên xác định vị trí của bạn và cái thứ ba xác định độ cao của bạn trên mực nước biển.
Vì vậy, điều đó có nghĩa là chỉ cần ba tọa độ để xác định vị trí của bạn trên trái đất. Điều đó có nghĩa là bạn đang sống trong thế giới 3 chiều. Và do đó, điều này không chỉ trả lời câu hỏi về chiều không gian, mà còn trả lời lý do tại sao chúng ta sống trong thế giới 3D.
Vì chúng tôi đang nghiên cứu khái niệm này liên quan đến xử lý hình ảnh kỹ thuật số, vì vậy bây giờ chúng tôi sẽ liên hệ khái niệm kích thước này với một hình ảnh.
Kích thước của hình ảnh
Vì vậy, nếu chúng ta sống trong thế giới 3d, nghĩa là thế giới 3 chiều, thì kích thước của một hình ảnh mà chúng ta chụp là gì. Hình ảnh là một hình ảnh hai chiều, đó là lý do tại sao chúng ta cũng định nghĩa một hình ảnh là một tín hiệu 2 chiều. Một hình ảnh chỉ có chiều cao và chiều rộng. Một hình ảnh không có chiều sâu. Chỉ cần nhìn vào hình ảnh này dưới đây.
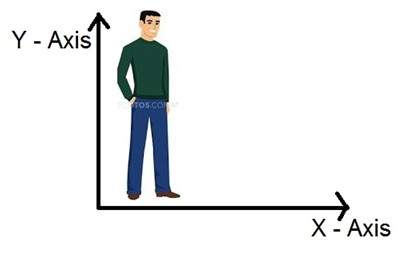
Nếu bạn nhìn vào hình trên, nó chỉ có hai trục là trục chiều cao và chiều rộng. Bạn không thể cảm nhận độ sâu từ hình ảnh này. Đó là lý do tại sao chúng ta nói rằng một hình ảnh là tín hiệu hai chiều. Nhưng mắt của chúng ta có thể cảm nhận các vật thể ba chiều, nhưng điều này sẽ được giải thích rõ hơn trong phần hướng dẫn tiếp theo về cách máy ảnh hoạt động và hình ảnh được cảm nhận.
Cuộc thảo luận này dẫn đến một số câu hỏi khác rằng làm thế nào hệ thống 3 chiều được hình thành từ 2 chiều.
Truyền hình hoạt động như thế nào?
Nếu chúng ta nhìn vào hình trên, chúng ta sẽ thấy rằng đó là một hình ảnh hai chiều. Để chuyển đổi nó thành ba chiều, chúng ta cần một chiều khác. Hãy coi thời gian là chiều thứ ba, trong trường hợp đó chúng ta sẽ di chuyển hình ảnh hai chiều này theo thời gian của chiều thứ ba. Khái niệm tương tự cũng xảy ra trong truyền hình, giúp chúng ta cảm nhận độ sâu của các đối tượng khác nhau trên màn hình. Điều đó có nghĩa là những gì hiển thị trên TV hoặc những gì chúng ta nhìn thấy trên màn hình TV là 3D. Vâng, chúng tôi có thể có. Lý do là, trong trường hợp của TV, chúng tôi nếu chúng tôi đang phát video. Sau đó, một đoạn video không là gì khác ngoài những bức tranh hai chiều chuyển động theo chiều thời gian. Vì các vật thể hai chiều đang di chuyển trên chiều thứ ba, tức là một thời gian nên chúng ta có thể nói nó là 3 chiều.
Các kích thước khác nhau của tín hiệu
Tín hiệu 1 chiều
Ví dụ phổ biến của tín hiệu 1 chiều là dạng sóng. Nó có thể được biểu diễn bằng toán học là
F (x) = dạng sóng
Trong đó x là một biến độc lập. Vì nó là tín hiệu một chiều, đó là lý do tại sao chỉ có một biến x được sử dụng.
Biểu diễn hình ảnh của tín hiệu một chiều được đưa ra dưới đây:
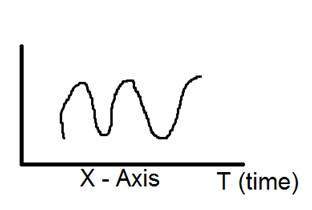
Hình trên cho thấy một tín hiệu một chiều.
Bây giờ điều này dẫn đến một câu hỏi khác, đó là, mặc dù nó là tín hiệu một chiều, vậy tại sao nó lại có hai trục? Câu trả lời cho câu hỏi này là mặc dù nó là một tín hiệu một chiều, nhưng chúng ta đang vẽ nó trong một không gian hai chiều. Hoặc chúng ta có thể nói rằng không gian mà chúng ta đang biểu diễn tín hiệu này là hai chiều. Đó là lý do tại sao nó trông giống như một tín hiệu hai chiều.
Có lẽ bạn có thể hiểu rõ hơn về khái niệm một chiều bằng cách nhìn vào hình bên dưới.

Bây giờ hãy quay lại thảo luận ban đầu của chúng ta về thứ nguyên, Hãy coi hình trên là một đường thẳng thực với các số dương từ điểm này đến điểm kia. Bây giờ nếu chúng ta phải giải thích vị trí của bất kỳ điểm nào trên đường thẳng này, chúng ta chỉ cần một con số, có nghĩa là chỉ một chiều.
Tín hiệu 2 chiều
Ví dụ phổ biến về tín hiệu hai chiều là một hình ảnh, đã được thảo luận ở trên.

Như chúng ta đã thấy rằng một hình ảnh là tín hiệu hai chiều, tức là: nó có hai chiều. Nó có thể được biểu diễn toán học như sau:
F (x, y) = Hình ảnh
Trong đó x và y là hai biến. Khái niệm hai chiều cũng có thể được giải thích về mặt toán học như:
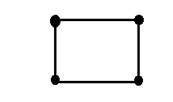
Bây giờ trong hình trên, đánh dấu bốn góc của hình vuông lần lượt là A, B, C và D. Gọi một đoạn thẳng trong hình AB và một đoạn thẳng CD thì chúng ta thấy hai đoạn thẳng song song này nối tiếp nhau tạo thành một hình vuông. Mỗi đoạn thẳng tương ứng với một thứ nguyên, vì vậy hai đoạn thẳng này tương ứng với 2 thứ nguyên.
Tín hiệu 3 chiều
Tín hiệu ba chiều như tên gọi của nó đề cập đến những tín hiệu có ba chiều. Ví dụ phổ biến nhất đã được thảo luận ngay từ đầu là về thế giới của chúng ta. Chúng ta đang sống trong một thế giới ba chiều. Ví dụ này đã được thảo luận rất công phu. Một ví dụ khác về tín hiệu ba chiều là một khối lập phương hoặc một dữ liệu thể tích hoặc ví dụ phổ biến nhất là nhân vật hoạt hình hoặc hoạt hình 3d.
Biểu diễn toán học của tín hiệu ba chiều là:
F (x, y, z) = ký tự hoạt hình.
Một trục hoặc chiều Z khác liên quan đến một chiều không gian ba, tạo ra ảo giác về chiều sâu. Trong một hệ tọa độ Descartes, nó có thể được xem như:

Tín hiệu 4 chiều
Trong một tín hiệu bốn chiều, bốn chiều có liên quan. Ba tín hiệu đầu tiên giống với tín hiệu ba chiều là: (X, Y, Z) và tín hiệu thứ tư được thêm vào chúng là T (thời gian). Thời gian thường được gọi là chiều thời gian, là một cách để đo lường sự thay đổi. Về mặt toán học, tín hiệu bốn d có thể được phát biểu là:
F (x, y, z, t) = phim hoạt hình.
Ví dụ phổ biến về tín hiệu 4 chiều có thể là một bộ phim hoạt hình 3d. Vì mỗi nhân vật là một nhân vật 3D và sau đó họ bị di chuyển theo thời gian, do đó chúng tôi thấy ảo ảnh về một bộ phim ba chiều giống như một thế giới thực hơn.
Vì vậy, điều đó có nghĩa là trong thực tế các bộ phim hoạt hình là 4 chiều tức là: chuyển động của các nhân vật 3D trong thời gian của chiều thứ tư.
Mắt người hoạt động như thế nào?
Trước khi chúng ta thảo luận về sự hình thành hình ảnh trên máy ảnh analog và kỹ thuật số, trước tiên chúng ta phải thảo luận về sự hình thành hình ảnh trên mắt người. Bởi vì nguyên tắc cơ bản mà máy ảnh tuân theo đã được lấy từ cách thức hoạt động của mắt người.
Khi ánh sáng chiếu vào một vật thể cụ thể, nó sẽ bị phản xạ trở lại sau khi chiếu qua vật thể đó. Các tia sáng khi đi qua thấu kính của mắt sẽ tạo thành một góc cụ thể và hình ảnh được tạo thành trên võng mạc, mặt sau của bức tường. Hình ảnh được tạo thành bị đảo ngược. Hình ảnh này sau đó được não bộ giải thích và điều đó khiến chúng ta có thể hiểu được mọi thứ. Do sự hình thành góc, chúng ta có thể cảm nhận được chiều cao và độ sâu của vật thể mà chúng ta đang nhìn thấy. Điều này đã được giải thích rõ hơn trong phần hướng dẫn chuyển đổi phối cảnh.
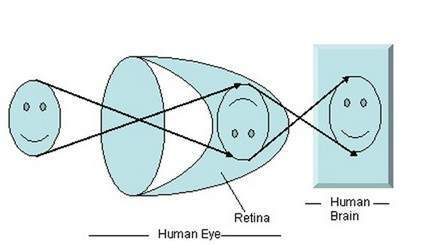
Như bạn có thể thấy trong hình trên, khi ánh sáng mặt trời chiếu vào vật thể (trong trường hợp vật thể là khuôn mặt), nó bị phản xạ trở lại và các tia khác nhau tạo thành góc khác nhau khi chúng đi qua thấu kính và tạo ra hình ảnh đảo ngược của đối tượng đã được hình thành trên bức tường phía sau. Phần cuối cùng của hình biểu thị rằng đối tượng đã được não bộ diễn giải và đảo ngược lại.
Bây giờ chúng ta hãy đưa cuộc thảo luận của chúng ta trở lại sự hình thành hình ảnh trên máy ảnh kỹ thuật số và tương tự.
Hình ảnh trên camera analog
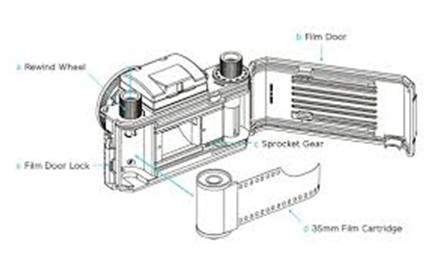
Trong các máy ảnh analog, sự hình thành hình ảnh là do phản ứng hóa học diễn ra trên dải được sử dụng để hình thành hình ảnh.
Dải 35mm được sử dụng trong camera analog. Nó được biểu thị trong hình bằng hộp phim 35mm. Dải này được phủ một lớp bạc halogenua (một chất hóa học).

Dải 35mm được sử dụng trong camera analog. Nó được biểu thị trong hình bằng hộp phim 35mm. Dải này được phủ một lớp bạc halogenua (một chất hóa học).
Ánh sáng không là gì mà chỉ là những hạt nhỏ gọi là hạt photon Vì vậy, khi những hạt photon này đi qua máy ảnh, nó sẽ phản ứng với các hạt bạc halogenua trên dải và nó tạo ra màu bạc là âm của hình ảnh.
Để hiểu rõ hơn, hãy xem phương trình này.
Photon (hạt ánh sáng) + bạc halogenua? bạc ? hình ảnh âm bản.

Đây chỉ là những điều cơ bản, mặc dù sự hình thành hình ảnh liên quan đến nhiều khái niệm khác liên quan đến sự truyền ánh sáng vào bên trong, và các khái niệm về tốc độ màn trập và tốc độ màn trập, khẩu độ và độ mở của nó nhưng bây giờ chúng ta sẽ chuyển sang phần tiếp theo. Mặc dù hầu hết các khái niệm này đã được thảo luận trong hướng dẫn của chúng tôi về màn trập và khẩu độ.
Đây chỉ là những điều cơ bản, mặc dù sự hình thành hình ảnh liên quan đến nhiều khái niệm khác liên quan đến sự truyền ánh sáng vào bên trong, và các khái niệm về tốc độ màn trập và tốc độ màn trập, khẩu độ và độ mở của nó nhưng bây giờ chúng ta sẽ chuyển sang phần tiếp theo. Mặc dù hầu hết các khái niệm này đã được thảo luận trong hướng dẫn của chúng tôi về màn trập và khẩu độ.
Hình ảnh trên máy ảnh kỹ thuật số
Trong máy ảnh kỹ thuật số, sự hình thành hình ảnh không phải do phản ứng hóa học xảy ra, mà nó phức tạp hơn một chút. Trong máy ảnh kỹ thuật số, một dãy cảm biến CCD được sử dụng để tạo hình ảnh.
Hình ảnh thông qua mảng CCD

CCD là viết tắt của thiết bị tích điện. Nó là một cảm biến hình ảnh, và giống như các cảm biến khác, nó cảm nhận các giá trị và chuyển đổi chúng thành tín hiệu điện. Trong trường hợp CCD, nó cảm nhận hình ảnh và chuyển nó thành tín hiệu điện, v.v.
CCD này thực sự có dạng mảng hoặc lưới hình chữ nhật. Nó giống như một ma trận với mỗi ô trong ma trận chứa một bộ kiểm duyệt cảm nhận cường độ của photon.
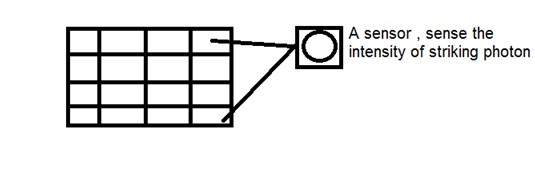
Giống như máy ảnh analog, trong trường hợp kỹ thuật số cũng vậy, khi ánh sáng chiếu vào vật thể, ánh sáng sẽ phản xạ trở lại sau khi chạm vào vật thể và được phép đi vào bên trong máy ảnh.
Bản thân mỗi cảm biến của mảng CCD là một cảm biến tương tự. Khi các photon ánh sáng tác động vào chip, nó được giữ như một điện tích nhỏ trong mỗi cảm biến ảnh. Phản ứng của mỗi cảm biến trực tiếp bằng lượng ánh sáng hoặc (photon) năng lượng trên bề mặt của cảm biến.
Vì chúng ta đã định nghĩa một hình ảnh là một tín hiệu hai chiều và do sự hình thành hai chiều của mảng CCD, một hình ảnh hoàn chỉnh có thể đạt được từ mảng CCD này.
Nó có số lượng cảm biến hạn chế và điều đó có nghĩa là nó có thể chụp được một số chi tiết hạn chế. Ngoài ra, mỗi cảm biến chỉ có thể có một giá trị so với mỗi hạt photon đập vào nó.
Vì vậy, số lượng các photon tấn công (hiện tại) được đếm và lưu trữ. Để đo chính xác những điều này, cảm biến CMOS bên ngoài cũng được gắn với mảng CCD.
Giới thiệu về pixel
Giá trị của mỗi cảm biến của mảng CCD đề cập đến từng giá trị của pixel riêng lẻ. Số lượng cảm biến = số lượng pixel. Điều đó cũng có nghĩa là mỗi cảm biến chỉ có thể có một và chỉ một giá trị.
Lưu trữ hình ảnh
Các điện tích được lưu trữ bởi mảng CCD được chuyển đổi thành điện áp một pixel tại một thời điểm. Với sự trợ giúp của các mạch bổ sung, điện áp này được chuyển đổi thành thông tin kỹ thuật số và sau đó nó được lưu trữ.
Mỗi công ty sản xuất máy ảnh kỹ thuật số, sản xuất cảm biến CCD của riêng họ. Điều đó bao gồm, Sony, Mistubishi, Nikon, Samsung, Toshiba, FujiFilm, Canon, v.v.
Ngoài các yếu tố khác, chất lượng hình ảnh thu được cũng phụ thuộc vào loại và chất lượng của mảng CCD đã được sử dụng.
Trong hướng dẫn này, chúng ta sẽ thảo luận về một số khái niệm máy ảnh cơ bản, như khẩu độ, cửa trập, tốc độ màn trập, ISO và chúng ta sẽ thảo luận về việc sử dụng chung các khái niệm này để chụp được một bức ảnh đẹp.
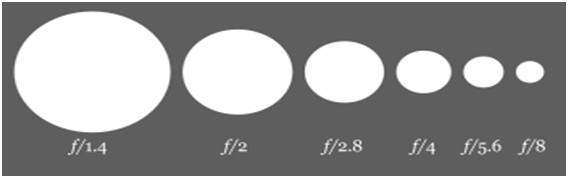
Miệng vỏ
Khẩu độ là một khe hở nhỏ cho phép ánh sáng truyền vào bên trong máy ảnh. Đây là hình ảnh của khẩu độ.

Bạn sẽ thấy một số lưỡi nhỏ giống như những thứ bên trong khẩu độ. Các cánh này tạo ra một hình bát giác có thể đóng mở. Và do đó nó có ý nghĩa rằng, càng nhiều cánh quạt sẽ mở ra, lỗ mà từ đó ánh sáng phải đi qua sẽ lớn hơn. Lỗ thủng càng lớn thì ánh sáng lọt vào càng nhiều.
Hiệu ứng
Hiệu ứng của khẩu độ tương ứng trực tiếp với độ sáng và độ tối của ảnh. Nếu khẩu độ mở rộng, nó sẽ cho phép nhiều ánh sáng đi vào máy ảnh hơn. Nhiều ánh sáng hơn sẽ tạo ra nhiều photon hơn, điều này cuối cùng dẫn đến hình ảnh sáng hơn.
Ví dụ về điều này được hiển thị bên dưới
Hãy xem xét hai bức ảnh này


Hình bên phải trông sáng hơn, có nghĩa là khi nó được chụp bởi máy ảnh, khẩu độ mở rộng. Khi so sánh với bức ảnh khác ở phía bên trái, rất tối so với bức ảnh đầu tiên, cho thấy rằng khi ảnh đó được chụp, khẩu độ của nó không được mở rộng.
Kích thước
Bây giờ chúng ta hãy thảo luận về các phép toán đằng sau khẩu độ. Kích thước của khẩu độ được biểu thị bằng giá trị af. Và nó tỷ lệ nghịch với độ mở của khẩu độ.
Đây là hai phương trình giải thích tốt nhất khái niệm này.
Kích thước khẩu độ lớn = Giá trị f nhỏ
Kích thước khẩu độ nhỏ = Giá trị f lớn hơn
Về cơ bản, nó có thể được biểu thị là:
Màn trập
Sau khẩu độ, có màn trập. Ánh sáng khi được phép truyền từ khẩu độ sẽ chiếu trực tiếp vào cửa trập. Cửa chớp thực chất là một tấm che, một cửa sổ đóng lại, hoặc có thể được hiểu như một tấm rèm. Hãy nhớ khi chúng ta nói về cảm biến mảng CCD mà hình ảnh được hình thành. Đằng sau màn trập là cảm biến. Vì vậy, màn trập là thứ duy nhất nằm giữa sự hình thành hình ảnh và ánh sáng, khi nó được truyền từ khẩu độ.
Ngay khi màn trập mở, ánh sáng chiếu vào cảm biến hình ảnh và hình ảnh được tạo thành trên mảng.
Hiệu ứng
Nếu màn trập cho phép ánh sáng đi qua lâu hơn một chút, hình ảnh sẽ sáng hơn. Tương tự, một bức ảnh tối hơn được tạo ra, khi màn trập được phép di chuyển rất nhanh và do đó, ánh sáng được phép đi qua có rất ít photon, và hình ảnh được tạo trên cảm biến mảng CCD rất tối.
Màn trập có thêm hai khái niệm chính:
Tốc độ màn trập
Thời gian màn trập
Tốc độ màn trập
Tốc độ cửa trập có thể được coi là số lần cửa trập mở hoặc đóng. Hãy nhớ rằng chúng ta không nói về việc cửa trập mở hoặc đóng trong bao lâu.
Thời gian màn trập
Thời gian cửa trập có thể được xác định là
Khi màn trập mở, thì khoảng thời gian chờ đợi cho đến khi đóng lại được gọi là thời gian cửa trập.
Trong trường hợp này, chúng ta không nói về việc cửa trập mở hay đóng bao nhiêu lần, mà chúng ta đang nói về việc nó vẫn mở trong bao lâu.
Ví dụ:
Chúng ta có thể hiểu rõ hơn về hai khái niệm này theo cách này. Điều đó cho phép một màn trập mở ra 15 lần rồi đóng lại, và mỗi lần mở ra trong 1 giây rồi đóng lại. Trong ví dụ này, 15 là tốc độ cửa trập và 1 giây là thời gian cửa trập.
Mối quan hệ
Mối quan hệ giữa tốc độ cửa trập và thời gian cửa trập là cả hai đều tỷ lệ nghịch với nhau.
Mối quan hệ này có thể được xác định trong phương trình dưới đây.
Tốc độ màn trập cao hơn = thời gian cửa trập ít hơn
Tốc độ màn trập thấp hơn = thời gian màn trập nhiều hơn.
Giải trình:
Thời gian cần thiết càng ít, thì tốc độ càng nhiều. Và thời gian cần thiết càng lớn thì tốc độ càng giảm.
Các ứng dụng
Hai khái niệm này cùng nhau tạo nên nhiều ứng dụng khác nhau. Một số trong số chúng được đưa ra dưới đây.
Các đối tượng chuyển động nhanh:
Nếu bạn muốn chụp hình ảnh của một vật thể chuyển động nhanh, có thể là một chiếc ô tô hoặc bất cứ thứ gì. Việc điều chỉnh tốc độ cửa trập và thời gian của nó sẽ ảnh hưởng rất nhiều.
Vì vậy, để chụp được một bức ảnh như thế này, chúng tôi sẽ thực hiện hai sửa đổi:
Tăng tốc độ cửa trập
Giảm thời gian cửa trập
Điều xảy ra là khi chúng ta tăng tốc độ cửa trập, càng nhiều lần, cửa trập sẽ mở hoặc đóng. Điều đó có nghĩa là các mẫu ánh sáng khác nhau sẽ cho phép truyền vào. Và khi chúng ta giảm thời gian cửa trập, điều đó có nghĩa là chúng ta sẽ ngay lập tức chụp cảnh và đóng cửa trập.
Nếu bạn làm được điều này, bạn sẽ có được hình ảnh sắc nét của một đối tượng chuyển động nhanh.
Để hiểu nó, chúng ta sẽ xem xét ví dụ này. Giả sử bạn muốn ghi lại hình ảnh của dòng nước chuyển động nhanh.
Bạn đặt tốc độ cửa trập thành 1 giây và bạn chụp một bức ảnh. Đây là những gì bạn nhận được

Sau đó, bạn đặt tốc độ cửa trập của mình thành tốc độ nhanh hơn và bạn nhận được.

Sau đó, một lần nữa, bạn đặt tốc độ cửa trập của mình nhanh hơn nữa và bạn sẽ nhận được.

Bạn có thể thấy trong hình cuối cùng, rằng chúng tôi đã tăng tốc độ cửa trập lên rất nhanh, có nghĩa là cửa trập được mở hoặc đóng trong 200 giây của 1 giây và do đó chúng tôi có được hình ảnh sắc nét.
ISO
Hệ số ISO được đo bằng số. Nó biểu thị độ nhạy của ánh sáng đối với máy ảnh. Nếu số ISO được giảm xuống, điều đó có nghĩa là máy ảnh của chúng tôi ít nhạy cảm hơn với ánh sáng và nếu số ISO cao, nó có nghĩa là nó nhạy cảm hơn.
Hiệu ứng
ISO càng cao thì ảnh càng sáng. NẾU ISO được đặt thành 1600, hình ảnh sẽ rất sáng hơn và ngược lại.
Tác dụng phụ
Nếu ISO tăng, nhiễu trong ảnh cũng tăng. Ngày nay, hầu hết các công ty sản xuất máy ảnh đang làm việc để loại bỏ nhiễu khỏi ảnh khi ISO được đặt ở tốc độ cao hơn.
Pixel
Pixel là phần tử nhỏ nhất của hình ảnh. Mỗi pixel tương ứng với một giá trị bất kỳ. Trong hình ảnh thang màu xám 8 bit, giá trị của pixel từ 0 đến 255. Giá trị của pixel tại bất kỳ điểm nào tương ứng với cường độ của các photon ánh sáng chiếu vào điểm đó. Mỗi pixel lưu trữ một giá trị tỷ lệ với cường độ ánh sáng tại vị trí cụ thể đó.
PEL
Một pixel còn được gọi là PEL. Bạn có thể hiểu rõ hơn về pixel từ các hình ảnh dưới đây.
Trong hình trên, có thể có hàng nghìn pixel, cùng nhau tạo nên hình ảnh này. Chúng tôi sẽ phóng to hình ảnh đó đến mức chúng tôi có thể thấy một số phân chia pixel. Nó được hiển thị trong hình ảnh dưới đây.

Trong hình trên, có thể có hàng nghìn pixel, cùng nhau tạo nên hình ảnh này. Chúng tôi sẽ phóng to hình ảnh đó đến mức chúng tôi có thể thấy một số phân chia pixel. Nó được hiển thị trong hình ảnh dưới đây.
Tàu quan hệ với mảng CCD
Chúng ta đã thấy rằng một hình ảnh được hình thành như thế nào trong mảng CCD. Vì vậy, một pixel cũng có thể được định nghĩa là
Sự phân chia nhỏ nhất của mảng CCD còn được gọi là pixel.
Mỗi phân chia của mảng CCD chứa giá trị chống lại cường độ của photon chiếu vào nó. Giá trị này cũng có thể được gọi là pixel
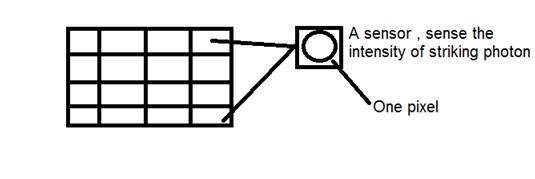
Tính toán tổng số pixel
Chúng tôi đã xác định một hình ảnh là một tín hiệu hoặc ma trận hai chiều. Sau đó, trong trường hợp đó, số lượng PEL sẽ bằng số hàng nhân với số cột.
Điều này có thể được biểu diễn bằng toán học như sau:
Tổng số pixel = số hàng (X) số cột
Hoặc chúng ta có thể nói rằng số cặp tọa độ (x, y) tạo nên tổng số pixel.
Chúng tôi sẽ xem xét chi tiết hơn trong hướng dẫn về các loại hình ảnh, rằng cách chúng tôi tính toán các pixel trong một hình ảnh màu.
Mức xám
Giá trị của pixel tại bất kỳ điểm nào biểu thị cường độ của hình ảnh tại vị trí đó và đó còn được gọi là mức xám.
Chúng ta sẽ xem chi tiết hơn về giá trị của pixel trong bộ lưu trữ hình ảnh và hướng dẫn bit per pixel, nhưng bây giờ chúng ta sẽ chỉ xem xét khái niệm chỉ một giá trị pixel.
Giá trị pixel. (0)
Như nó đã được xác định ở phần đầu của hướng dẫn này, mỗi pixel chỉ có thể có một giá trị và mỗi giá trị biểu thị cường độ ánh sáng tại điểm đó của hình ảnh.
Bây giờ chúng ta sẽ xem xét một giá trị rất độc đáo 0. Giá trị 0 có nghĩa là không có ánh sáng. Nó có nghĩa là 0 biểu thị màu tối, và điều đó còn có nghĩa là khi một pixel nào đó có giá trị bằng 0, điều đó có nghĩa là tại thời điểm đó, màu đen sẽ được hình thành.
Hãy xem ma trận hình ảnh này
| 0 | 0 | 0 |
| 0 | 0 | 0 |
| 0 | 0 | 0 |
Bây giờ ma trận hình ảnh này đã được lấp đầy bằng 0. Tất cả các pixel có giá trị bằng 0. Nếu chúng ta tính tổng số pixel tạo thành ma trận này, đây là cách chúng ta sẽ thực hiện.
Tổng số pixel = tổng số không. tổng số hàng X không. cột
= 3 X 3
= 9.
Nó có nghĩa là một hình ảnh sẽ được tạo thành với 9 pixel, và hình ảnh đó sẽ có kích thước 3 hàng và 3 cột và quan trọng nhất là hình ảnh đó sẽ có màu đen.
Hình ảnh kết quả sẽ được tạo ra sẽ giống như thế này

Bây giờ tại sao hình ảnh này chỉ toàn màu đen. Bởi vì tất cả các pixel trong hình ảnh có giá trị là 0.
Khi mắt người nhìn thấy những vật ở gần, họ trông to hơn so với những người ở xa. Đây được gọi là phối cảnh một cách tổng quát. Trong khi phép chuyển đổi là việc chuyển một đối tượng, v.v. từ trạng thái này sang trạng thái khác.
Vì vậy, về tổng thể, phép chuyển đổi phối cảnh liên quan đến việc chuyển đổi thế giới 3d thành hình ảnh 2D. Cùng một nguyên tắc mà thị giác của con người hoạt động và cùng một nguyên tắc mà máy ảnh hoạt động.
Chúng ta sẽ tìm hiểu chi tiết về lý do tại sao điều này xảy ra, rằng những vật thể ở gần bạn trông lớn hơn, trong khi những vật thể ở xa trông nhỏ hơn mặc dù chúng trông lớn hơn khi bạn chạm tới.
Chúng ta sẽ bắt đầu cuộc thảo luận này bằng khái niệm hệ quy chiếu:
Khung tham chiếu:
Hệ quy chiếu về cơ bản là một tập hợp các giá trị liên quan đến việc chúng ta đo lường một thứ gì đó.
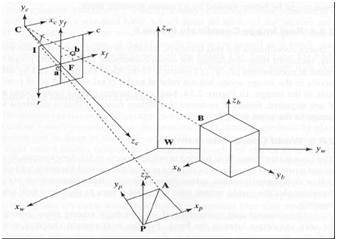
5 hệ quy chiếu
Để phân tích thế giới / hình ảnh / cảnh 3D, cần có 5 khung tham chiếu khác nhau.
Object
World
Camera
Image
Pixel
Khung tọa độ đối tượng
Khung tọa độ đối tượng được sử dụng để mô hình hóa các đối tượng. Ví dụ, kiểm tra xem một đối tượng cụ thể có ở một vị trí thích hợp so với đối tượng kia hay không. Nó là một hệ tọa độ 3d.
Khung tọa độ thế giới
Khung tọa độ thế giới được sử dụng cho các đối tượng đồng liên quan trong thế giới 3 chiều. Nó là một hệ tọa độ 3d.
Khung tọa độ máy ảnh
Khung tọa độ máy ảnh được sử dụng để liên kết các đối tượng với máy ảnh. Nó là một hệ tọa độ 3d.
Khung tọa độ hình ảnh
Nó không phải là một hệ tọa độ 3d, đúng hơn nó là một hệ thống 2d. Nó được sử dụng để mô tả cách các điểm 3d được ánh xạ trong mặt phẳng hình ảnh 2d.
Khung tọa độ pixel
Nó cũng là một hệ tọa độ 2d. Mỗi pixel có một giá trị tọa độ pixel.
Chuyển đổi giữa 5 khung này
Đó là cách một cảnh 3D được chuyển đổi thành 2d, với hình ảnh của các pixel.
Bây giờ chúng ta sẽ giải thích khái niệm này bằng toán học.
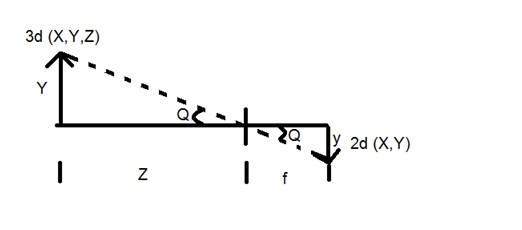
Y = vật thể 3d
y = 2d Hình ảnh
f = độ dài tiêu cự của máy ảnh
Z = khoảng cách giữa hình ảnh và máy ảnh
Bây giờ có hai góc khác nhau được tạo thành trong phép biến hình này được biểu diễn bằng Q.
Góc đầu tiên là
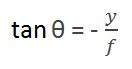
Trường hợp dấu trừ biểu thị hình ảnh đó bị đảo ngược. Góc thứ hai được tạo thành là:

So sánh hai phương trình này, chúng tôi nhận được

Từ phương trình này, chúng ta có thể thấy rằng khi tia sáng phản xạ trở lại sau khi chiếu từ vật thể, truyền từ máy ảnh, một hình ảnh đảo ngược được hình thành.
Chúng ta có thể hiểu rõ hơn về điều này, với ví dụ này.
Ví dụ
Tính kích thước của hình ảnh được tạo thành
Giả sử người ta chụp ảnh một người cao 5m, đứng cách máy ảnh 50m và cho biết ảnh của người đó có kích thước như thế nào, với máy ảnh có tiêu cự là 50mm.
Giải pháp:
Vì độ dài tiêu cự tính bằng milimét, vì vậy chúng ta phải chuyển đổi mọi thứ sang milimét để tính toán nó.
Vì thế,
Y = 5000 mm.
f = 50 mm.
Z = 50000 mm.
Đặt các giá trị trong công thức, chúng tôi nhận được
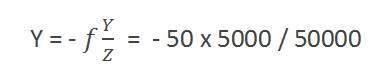
= -5 mm.
Một lần nữa, dấu trừ cho biết hình ảnh bị đảo ngược.
Bpp hoặc bit trên mỗi pixel biểu thị số bit trên mỗi pixel. Số lượng màu sắc khác nhau trong một hình ảnh phụ thuộc vào độ sâu của màu sắc hoặc các bit trên mỗi pixel.
Bits trong toán học:
Nó giống như chơi với các bit nhị phân.
Có bao nhiêu số có thể được biểu diễn bằng một bit.
0
1
Có bao nhiêu kết hợp hai bit có thể được thực hiện.
00
01
10
11
Nếu chúng ta nghĩ ra một công thức để tính tổng số kết hợp có thể được tạo ra từ bit, nó sẽ như thế này.
Trong đó bpp biểu thị các bit trên mỗi pixel. Đặt 1 vào công thức bạn nhận được 2, đặt 2 vào công thức, bạn nhận được 4. Nó lớn lên theo số mũ.
Số lượng màu sắc khác nhau:
Như chúng ta đã nói ở phần đầu, số lượng màu sắc khác nhau phụ thuộc vào số lượng bit trên mỗi pixel.
Bảng cho một số bit và màu của chúng được đưa ra dưới đây.
| Bit trên mỗi pixel | Số lượng màu |
|---|---|
| 1 bpp | 2 màu |
| 2 bpp | 4 màu |
| 3 bpp | 8 màu |
| 4 bpp | 16 màu |
| 5 bpp | 32 màu |
| 6 bpp | 64 màu |
| 7 bpp | 128 màu |
| 8 bpp | 256 màu |
| 10 bpp | 1024 màu |
| 16 bpp | 65536 màu |
| 24 bpp | 16777216 màu (16,7 triệu màu) |
| 32 bpp | 4294967296 màu (4294 triệu màu) |
Bảng này hiển thị các bit khác nhau trên mỗi pixel và lượng màu mà chúng chứa.
Sắc thái
Bạn có thể dễ dàng nhận thấy mô hình của sự tăng trưởng lũy thừa. Hình ảnh thang màu xám nổi tiếng là 8 bpp, có nghĩa là nó có 256 màu khác nhau hoặc 256 sắc thái.
Các sắc thái có thể được biểu diễn dưới dạng:
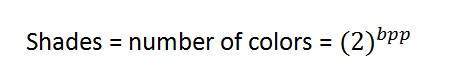
Hình ảnh màu thường có định dạng 24 bpp hoặc 16 bpp.
Chúng ta sẽ xem thêm về các định dạng màu và kiểu ảnh khác trong phần hướng dẫn về các kiểu ảnh.
Giá trị màu:
Màu đen:
Màu trắng:
Giá trị biểu thị màu trắng có thể được tính như sau:
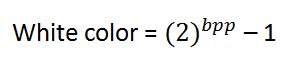
Trong trường hợp 1 bpp, 0 biểu thị màu đen và 1 biểu thị màu trắng.
Trong trường hợp 8 bpp, 0 biểu thị màu đen và 255 biểu thị màu trắng.
Màu xám:
Khi bạn tính toán giá trị màu đen và trắng, thì bạn có thể tính giá trị pixel của màu xám.
Màu xám thực sự là điểm giữa của màu đen và trắng. Mà nói,
Trong trường hợp 8bpp, giá trị pixel biểu thị màu xám là 127 hoặc 128bpp (nếu bạn đếm từ 1, không phải từ 0).
Yêu cầu lưu trữ hình ảnh
Sau khi thảo luận về bit trên pixel, bây giờ chúng ta có mọi thứ mà chúng ta cần để tính toán kích thước của một hình ảnh.
Kích thước ảnh
Kích thước của một hình ảnh phụ thuộc vào ba điều.
Số hàng
Số cột
Số bit trên mỗi pixel
Công thức tính kích thước được đưa ra dưới đây.
Kích thước của hình ảnh = hàng * cols * bpp
Có nghĩa là nếu bạn có một hình ảnh, hãy nói điều này:
Giả sử nó có 1024 hàng và nó có 1024 cột. Và vì nó là một hình ảnh tỷ lệ xám, nó có 256 sắc thái khác nhau của màu xám hoặc nó có các bit trên mỗi pixel. Sau đó đặt các giá trị này vào công thức, chúng tôi nhận được
Kích thước của hình ảnh = hàng * cols * bpp
= 1024 * 1024 * 8
= 8388608 bit.
Nhưng vì nó không phải là một câu trả lời tiêu chuẩn mà chúng tôi nhận ra, vì vậy sẽ chuyển đổi nó thành định dạng của chúng tôi.
Chuyển nó thành byte = 8388608/8 = 1048576 byte.
Chuyển đổi thành kilo byte = 1048576/1024 = 1024kb.
Chuyển đổi thành Mega byte = 1024/1024 = 1 Mb.
Đó là cách một kích thước hình ảnh được tính toán và nó được lưu trữ. Bây giờ trong công thức, nếu bạn được cung cấp kích thước của hình ảnh và số bit trên mỗi pixel, bạn cũng có thể tính các hàng và cột của hình ảnh, miễn là hình ảnh là hình vuông (cùng hàng và cùng cột).
Có nhiều loại hình ảnh và chúng ta sẽ xem xét chi tiết về các loại hình ảnh khác nhau và sự phân bố màu sắc trong đó.
Hình ảnh nhị phân
Hình ảnh nhị phân như nó đặt tên, chỉ chứa hai giá trị pixel.
0 và 1.
Trong hướng dẫn trước đây của chúng tôi về bit trên pixel, chúng tôi đã giải thích chi tiết điều này về cách biểu diễn các giá trị pixel thành màu tương ứng của chúng.
Ở đây 0 đề cập đến màu đen và 1 đề cập đến màu trắng. Nó còn được gọi là Monochrome.
Hình ảnh đen trắng:
Hình ảnh kết quả được tạo thành do đó chỉ bao gồm màu đen và trắng và do đó cũng có thể được gọi là hình ảnh Đen trắng.

Không có mức xám
Một trong những điều thú vị về hình ảnh nhị phân này là không có mức xám trong đó. Chỉ có hai màu đen và trắng được tìm thấy trong đó.
định dạng
Hình ảnh nhị phân có định dạng PBM (Bản đồ bit di động)
Định dạng màu 2, 3, 4, 5, 6 bit
Các hình ảnh có định dạng màu 2, 3, 4, 5 và 6 bit không được sử dụng rộng rãi ngày nay. Thời xưa chúng được sử dụng cho các màn hình TV cũ hay màn hình điều khiển.
Nhưng mỗi màu này có nhiều hơn hai mức xám, và do đó có màu xám không giống như hình ảnh nhị phân.
Trong 2 bit 4, trong 3 bit 8, trong 4 bit 16, trong 5 bit 32, trong 6 bit 64 màu sắc khác nhau hiện diện.
Định dạng màu 8 bit
Định dạng màu 8 bit là một trong những định dạng hình ảnh nổi tiếng nhất. Nó có 256 sắc thái màu khác nhau trong đó. Nó thường được gọi là hình ảnh Thang độ xám.
Phạm vi màu trong 8 bit thay đổi từ 0-255. Trong đó 0 là màu đen, và 255 là màu trắng và 127 là màu xám.
Định dạng này ban đầu được sử dụng bởi các mô hình đầu tiên của hệ điều hành UNIX và Macintoshes màu sơ khai.
Hình ảnh thang độ xám của Einstein được hiển thị dưới đây:
định dạng
Định dạng của những hình ảnh này là PGM (Bản đồ màu xám di động).
Định dạng này không được hỗ trợ theo mặc định từ windows. Để xem hình ảnh tỷ lệ xám, bạn cần có một trình xem hình ảnh hoặc hộp công cụ xử lý hình ảnh như Matlab.
Đằng sau hình ảnh thang màu xám:
Như chúng tôi đã giải thích nhiều lần trong các bài hướng dẫn trước, rằng một hình ảnh không là gì ngoài một hàm hai chiều và có thể được biểu diễn bằng một mảng hoặc ma trận hai chiều. Vì vậy, trong trường hợp hình ảnh của Einstein được hiển thị ở trên, sẽ có ma trận hai chiều ở phía sau với các giá trị nằm trong khoảng từ 0 đến 255.
Nhưng đó không phải là trường hợp với các hình ảnh màu.
Định dạng màu 16 bit
Nó là một định dạng hình ảnh màu. Nó có 65.536 màu sắc khác nhau trong đó. Nó còn được gọi là định dạng màu Cao.
Nó đã được Microsoft sử dụng trong các hệ thống của họ hỗ trợ nhiều hơn định dạng màu 8 bit. Bây giờ ở định dạng 16 bit này và định dạng tiếp theo chúng ta sẽ thảo luận về định dạng nào là định dạng 24 bit đều là định dạng màu.
Sự phân bố màu sắc trong ảnh màu không đơn giản như trong ảnh thang độ xám.
Định dạng 16 bit thực sự được chia thành ba định dạng khác là Đỏ, Xanh lục và Xanh lam. Định dạng (RGB) nổi tiếng.
Nó được thể hiện bằng hình ảnh dưới đây.
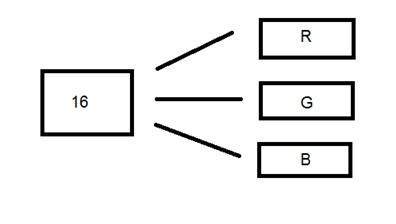
Bây giờ câu hỏi đặt ra, rằng bạn sẽ phân phối 16 thành ba như thế nào. Nếu bạn làm như thế này,
5 bit cho R, 5 bit cho G, 5 bit cho B
Sau đó, cuối cùng vẫn còn một bit.
Vì vậy, việc phân phối 16 bit đã được thực hiện như thế này.
5 bit cho R, 6 bit cho G, 5 bit cho B.
Bit bổ sung bị bỏ lại được thêm vào bit màu xanh lá cây. Bởi vì màu xanh lá cây là màu dịu mắt nhất trong cả 3 màu này.
Lưu ý rằng đây là sự phân phối không được tuân theo bởi tất cả các hệ thống. Một số đã giới thiệu một kênh alpha trong 16 bit.
Một phân phối khác của định dạng 16 bit là như thế này:
4 bit cho R, 4 bit cho G, 4 bit cho B, 4 bit cho kênh alpha.
Hoặc một số phân phối nó như thế này
5 bit cho R, 5 bit cho G, 5 bit cho B, 1 bit cho kênh alpha.
Định dạng màu 24 bit
Định dạng màu 24 bit còn được gọi là định dạng màu thực. Giống như định dạng màu 16 bit, ở định dạng màu 24 bit, 24 bit lại được phân phối ở ba định dạng khác nhau là Đỏ, Xanh lục và Xanh lam.
Vì 24 được chia đều trên 8, vì vậy nó đã được phân phối đều giữa ba kênh màu khác nhau.
Sự phân bố của chúng là như thế này.
8 bit cho R, 8 bit cho G, 8 bit cho B.
Đằng sau một hình ảnh 24 bit.
Không giống như hình ảnh tỷ lệ xám 8 bit, có một ma trận phía sau, hình ảnh 24 bit có ba ma trận khác nhau là R, G, B.
định dạng
Đây là định dạng được sử dụng phổ biến nhất. Định dạng của nó là PPM (Portable pixMap) được hỗ trợ bởi hệ điều hành Linux. Các cửa sổ nổi tiếng có định dạng riêng cho nó là BMP (Bitmap).
Trong hướng dẫn này, chúng ta sẽ thấy rằng cách các mã màu khác nhau có thể được kết hợp để tạo ra các màu khác và cách chúng ta có thể chuyển mã màu RGB thành hex và ngược lại.
Mã màu khác nhau
Tất cả các màu ở đây đều có định dạng 24 bit, nghĩa là mỗi màu có 8 bit đỏ, 8 bit xanh lục, 8 bit xanh lam. Hoặc chúng ta có thể nói mỗi màu có ba phần khác nhau. Bạn chỉ cần thay đổi số lượng của ba phần này để tạo ra bất kỳ màu nào.
Định dạng màu nhị phân
Màu đen
Hình ảnh:
Mã thập phân:
(0,0,0)
Giải trình:
Như đã được giải thích trong các hướng dẫn trước, rằng ở định dạng 8-bit, 0 đề cập đến màu đen. Vì vậy, nếu chúng ta phải tạo ra một màu đen thuần túy, chúng ta phải làm cho cả ba phần của R, G, B bằng 0.
Màu trắng
Hình ảnh:

Mã thập phân:
(255,255,255)
Giải trình:
Vì mỗi phần của R, G, B là một phần 8 bit. Vì vậy, trong 8-bit, màu trắng được tạo thành bởi 255. Nó được giải thích trong hướng dẫn của pixel. Vì vậy, để tạo ra màu trắng, chúng tôi đặt mỗi phần là 255 và đó là cách chúng tôi có màu trắng. Bằng cách đặt mỗi giá trị thành 255, chúng tôi nhận được giá trị tổng thể là 255, điều đó làm cho màu trắng.
Mô hình màu RGB:
Màu đỏ
Hình ảnh:

Mã thập phân:
(255,0,0)
Giải trình:
Vì chúng ta chỉ cần màu đỏ, vì vậy chúng ta loại bỏ phần còn lại của hai phần màu xanh lá cây và xanh lam, và chúng ta đặt phần màu đỏ ở mức tối đa là 255.
Màu xanh lá cây
Hình ảnh:

Mã thập phân:
(0,255,0)
Giải trình:
Vì chúng ta chỉ cần màu xanh lục, vì vậy chúng ta loại bỏ phần còn lại của hai phần màu đỏ và xanh lam, và chúng ta đặt phần màu xanh lá cây ở mức tối đa là 255.
Màu sắc: Xanh lam
Hình ảnh:

Mã thập phân:
(0,0,255)
Giải trình:
Vì chúng tôi chỉ cần màu xanh lam, vì vậy chúng tôi loại bỏ phần còn lại của hai phần màu đỏ và xanh lục, và chúng tôi đặt phần màu xanh lam ở mức tối đa là 255
Màu xám:
Màu xám
Hình ảnh:

Mã thập phân:
(128,128,128)
Giải trình:
Như chúng ta đã xác định trong hướng dẫn về pixel, màu xám đó thực sự là điểm giữa. Ở định dạng 8 bit, điểm giữa là 128 hoặc 127. Trong trường hợp này, chúng tôi chọn 128. Vì vậy, chúng tôi đặt từng phần thành điểm giữa của nó là 128 và điều đó dẫn đến giá trị giữa tổng thể và chúng tôi nhận được màu xám.
Mô hình màu CMYK:
CMYK là một kiểu màu khác trong đó c là viết tắt của lục lam, m là viết tắt của đỏ tươi, y là viết tắt của màu vàng và k là màu đen. Mô hình CMYK thường được sử dụng trong máy in màu, trong đó có hai hộp mực màu được sử dụng. Một bao gồm CMY và một bao gồm màu đen.
Màu sắc của CMY cũng có thể được tạo ra từ việc thay đổi số lượng hoặc một phần màu đỏ, xanh lá cây và xanh lam.
Màu: Lục lam
Hình ảnh:

Mã thập phân:
(0,255,255)
Giải trình:
Màu lục lam được hình thành từ sự kết hợp của hai màu khác nhau là xanh lá cây và xanh lam. Vì vậy, chúng tôi đặt hai cái đó thành cực đại và chúng tôi loại bỏ phần màu đỏ. Và chúng tôi nhận được màu lục lam.
Màu sắc: Đỏ tươi
Hình ảnh:

Mã thập phân:
(255,0,255)
Giải trình:
Màu đỏ tươi được hình thành từ sự kết hợp của hai màu khác nhau là Đỏ và Xanh. Vì vậy, chúng tôi đặt hai mức đó thành tối đa và chúng tôi loại bỏ phần màu xanh lá cây. Và chúng tôi nhận được màu đỏ tươi.
Màu vàng
Hình ảnh:

Mã thập phân:
(255,255,0)
Giải trình:
Màu vàng được hình thành từ sự kết hợp của hai màu khác nhau là Đỏ và Xanh lá cây. Vì vậy, chúng tôi đặt hai mức đó thành tối đa và chúng tôi loại bỏ phần màu xanh lam. Và chúng tôi nhận được màu vàng.
Chuyển đổi
Bây giờ chúng ta sẽ thấy rằng màu sắc được chuyển đổi từ định dạng này sang định dạng khác như thế nào.
Chuyển đổi từ mã RGB sang mã Hex:
Chuyển đổi từ Hex sang rgb được thực hiện thông qua phương pháp này:
Chụp một màu. Vd: Trắng = (255, 255, 255).
Lấy phần đầu tiên, ví dụ 255.
Chia nó cho 16. Như thế này:
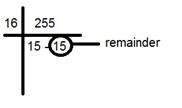
Lấy hai số dưới dòng, thừa số và số dư. Trong trường hợp này, nó là 15 15 là FF.
Lặp lại bước 2 cho hai phần tiếp theo.
Kết hợp tất cả mã hex thành một.
Trả lời: #FFFFFF
Chuyển đổi từ Hex sang RGB:
Việc chuyển đổi từ mã hex sang định dạng thập phân rgb được thực hiện theo cách này.
Lấy một số hex. Vd: #FFFFFF
Chia con số này thành 3 phần: FF FF FF
Lấy phần đầu tiên và tách các thành phần của nó: FF
Chuyển đổi từng phần riêng biệt thành nhị phân: (1111) (1111)
Bây giờ kết hợp các tệp nhị phân riêng lẻ thành một: 11111111
Chuyển đổi nhị phân này thành thập phân: 255
Bây giờ lặp lại bước 2, hai lần nữa.
Giá trị ở bước đầu tiên là R, bước thứ hai là G và bước thứ ba thuộc về B.
Trả lời: (255, 255, 255)
Các màu phổ biến và mã Hex của chúng đã được đưa ra trong bảng này.
| Màu sắc | Mã Hex |
|---|---|
| Đen | # 000000 |
| trắng | #FFFFFF |
| Màu xám | # 808080 |
| Đỏ | # FF0000 |
| màu xanh lá | # 00FF00 |
| Màu xanh da trời | # 0000FF |
| Lục lam | # 00FFFF |
| Đỏ tươi | # FF00FF |
| Màu vàng | # FFFF00 |
Phương pháp trung bình
Phương pháp trọng số hoặc phương pháp độ sáng
Phương pháp trung bình
Phương pháp trung bình là phương pháp đơn giản nhất. Bạn chỉ cần lấy trung bình của ba màu. Vì nó là hình ảnh RGB, vì vậy có nghĩa là bạn thêm r với g với b rồi chia nó cho 3 để có được hình ảnh thang độ xám mong muốn.
Nó được thực hiện theo cách này.
Thang độ xám = (R + G + B) / 3
Ví dụ:

Nếu bạn có một hình ảnh màu như hình trên và bạn muốn chuyển nó thành thang độ xám bằng phương pháp trung bình. Kết quả sau sẽ xuất hiện.

Giải trình
Có một điều chắc chắn rằng, có điều gì đó sẽ xảy ra với các tác phẩm gốc. Nó có nghĩa là phương pháp trung bình của chúng tôi hoạt động. Nhưng kết quả không được như mong đợi. Chúng tôi muốn chuyển đổi hình ảnh thành thang độ xám, nhưng điều này hóa ra lại là một hình ảnh khá đen.
Vấn đề
Vấn đề này nảy sinh do thực tế là chúng tôi lấy trung bình của ba màu. Vì ba màu khác nhau có ba bước sóng khác nhau và có đóng góp riêng trong việc hình thành ảnh, nên chúng ta phải lấy giá trị trung bình theo đóng góp của chúng, không lấy trung bình theo phương pháp trung bình. Ngay bây giờ những gì chúng tôi đang làm là đây,
33% màu đỏ, 33% màu xanh lá cây, 33% màu xanh lam
Chúng tôi đang lấy 33% mỗi phần, có nghĩa là mỗi phần đều có đóng góp như nhau trong hình ảnh. Nhưng thực tế không phải vậy. Giải pháp cho điều này đã được đưa ra bằng phương pháp đo độ sáng.
Phương pháp trọng số hoặc phương pháp độ sáng
Bạn đã thấy vấn đề xảy ra trong phương pháp trung bình. Phương pháp trọng số có một giải pháp cho vấn đề đó. Vì màu đỏ có nhiều bước sóng hơn trong cả ba màu, và màu xanh lá cây là màu không chỉ có ít bước sóng hơn màu đỏ mà còn xanh lục là màu mang lại hiệu ứng dịu mắt hơn.
Có nghĩa là chúng ta phải giảm sự đóng góp của màu đỏ, và tăng sự đóng góp của màu xanh lá cây, và đưa sự đóng góp của màu xanh lam vào giữa hai màu này.
Vì vậy, phương trình mới có dạng là:
Hình ảnh thang độ xám mới = ((0,3 * R) + (0,59 * G) + (0,11 * B)).
Theo phương trình này, Màu đỏ đóng góp 30%, Màu xanh lá cây đóng góp 59%, cao hơn trong cả ba màu và Màu xanh lam đóng góp 11%.
Áp dụng phương trình này cho hình ảnh, chúng tôi nhận được
Ảnh gốc:
Hình ảnh thang độ xám:

Giải trình
Như bạn có thể thấy ở đây, hình ảnh hiện đã được chuyển đổi đúng sang thang độ xám bằng phương pháp có trọng số. So với kết quả của phương pháp trung bình, hình ảnh này sáng hơn.
Chuyển đổi tín hiệu tương tự sang tín hiệu kỹ thuật số:
Đầu ra của hầu hết các cảm biến hình ảnh là tín hiệu tương tự và chúng tôi không thể áp dụng xử lý kỹ thuật số trên đó vì chúng tôi không thể lưu trữ. Chúng ta không thể lưu trữ nó vì nó yêu cầu bộ nhớ vô hạn để lưu trữ một tín hiệu có thể có giá trị vô hạn.
Vì vậy chúng ta phải chuyển đổi tín hiệu tương tự thành tín hiệu số.
Để tạo ra một hình ảnh là kỹ thuật số, chúng ta cần chuyển dữ liệu liên tục sang dạng kỹ thuật số. Có hai bước để nó được thực hiện.
Sampling
Quantization
Bây giờ chúng ta sẽ thảo luận về việc lấy mẫu, và lượng tử hóa sẽ được thảo luận sau nhưng bây giờ chúng ta sẽ thảo luận một chút về sự khác biệt giữa hai bước này và sự cần thiết của hai bước này.
Ý kiến cơ bản:
Ý tưởng cơ bản đằng sau việc chuyển đổi tín hiệu tương tự sang tín hiệu kỹ thuật số là

để chuyển đổi cả hai trục của nó (x, y) thành định dạng kỹ thuật số.
Vì một hình ảnh là liên tục không chỉ trong tọa độ của nó (trục x) mà còn theo biên độ của nó (trục y), nên phần xử lý số hóa tọa độ được gọi là lấy mẫu. Và phần xử lý số hóa biên độ được gọi là lượng tử hóa.
Lấy mẫu.
Lấy mẫu đã được giới thiệu trong hướng dẫn giới thiệu về tín hiệu và hệ thống của chúng tôi. Nhưng chúng ta sẽ thảo luận ở đây nhiều hơn.
Đây là những gì chúng ta đã thảo luận về việc lấy mẫu.
Thuật ngữ lấy mẫu đề cập đến việc lấy mẫu
Chúng tôi số hóa trục x trong lấy mẫu
Nó được thực hiện trên biến độc lập
Trong trường hợp phương trình y = sin (x), nó được thực hiện trên biến x
Nó được chia thành hai phần, lấy mẫu lên và lấy mẫu xuống
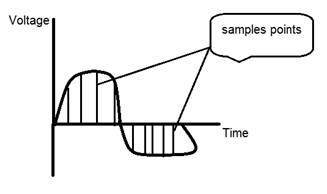
Nếu bạn nhìn vào hình trên, bạn sẽ thấy rằng có một số biến thể ngẫu nhiên trong tín hiệu. Những biến thể này là do nhiễu. Trong quá trình lấy mẫu, chúng tôi giảm nhiễu này bằng cách lấy mẫu. Rõ ràng là chúng tôi chụp nhiều mẫu hơn, chất lượng hình ảnh sẽ tốt hơn, nhiễu sẽ được loại bỏ nhiều hơn và ngược lại cũng xảy ra tương tự.
Tuy nhiên, nếu bạn lấy mẫu trên trục x, tín hiệu không được chuyển đổi sang định dạng kỹ thuật số, trừ khi bạn cũng lấy mẫu trên trục y, được gọi là lượng tử hóa. Càng nhiều mẫu cuối cùng có nghĩa là bạn đang thu thập nhiều dữ liệu hơn và trong trường hợp hình ảnh, nó có nghĩa là nhiều pixel hơn.
Tàu quan hệ với pixel
Vì pixel là phần tử nhỏ nhất trong ảnh. Tổng số pixel trong một hình ảnh có thể được tính bằng
Điểm ảnh = tổng số không có hàng * tổng số không có cột.
Giả sử chúng ta có tổng cộng 25 pixel, điều đó có nghĩa là chúng ta có một hình ảnh vuông 5 X 5. Sau đó, như chúng ta đã đề cập ở trên trong việc lấy mẫu, nhiều mẫu hơn cuối cùng dẫn đến nhiều pixel hơn. Vì vậy, nó có nghĩa là tín hiệu liên tục của chúng tôi, chúng tôi đã lấy 25 mẫu trên trục x. Điều đó đề cập đến 25 pixel của hình ảnh này.
Điều này dẫn đến một kết luận khác rằng vì pixel cũng là phần chia nhỏ nhất của mảng CCD. Vì vậy, nó có nghĩa là nó cũng có mối quan hệ với mảng CCD, có thể được giải thích như thế này.
Mối quan hệ với mảng CCD
Số lượng cảm biến trên một mảng CCD trực tiếp bằng số pixel. Và vì chúng tôi đã kết luận rằng số pixel trực tiếp bằng số mẫu, điều đó có nghĩa là số mẫu đó trực tiếp bằng số cảm biến trên mảng CCD.
Lấy mẫu quá mức.
Ngay từ đầu, chúng tôi đã định nghĩa rằng lấy mẫu được phân loại thành hai loại. Đó là lấy mẫu lên và lấy mẫu xuống. Lấy mẫu lên cũng được gọi là lấy mẫu quá mức.
Quá trình lấy mẫu có một ứng dụng rất sâu trong xử lý hình ảnh được gọi là Phóng to.
Thu phóng
Chúng tôi sẽ chính thức giới thiệu về tính năng phóng to trong hướng dẫn sắp tới, nhưng hiện tại, chúng tôi sẽ chỉ giải thích ngắn gọn về tính năng thu phóng.
Phóng to đề cập đến việc tăng số lượng pixel, để khi bạn thu phóng hình ảnh, bạn sẽ thấy chi tiết hơn.
Việc tăng số lượng pixel được thực hiện thông qua việc lấy mẫu quá mức. Một cách để thu phóng, hoặc để tăng mẫu, là thu phóng quang học, thông qua chuyển động cơ của ống kính và sau đó chụp ảnh. Nhưng chúng ta phải làm điều đó, một khi hình ảnh đã được chụp.
Có sự khác biệt giữa thu phóng và lấy mẫu.
Khái niệm là giống nhau, đó là, tăng mẫu. Nhưng sự khác biệt chính là trong khi lấy mẫu được thực hiện trên các tín hiệu, thì việc thu phóng được thực hiện trên hình ảnh kỹ thuật số.
Trước khi chúng tôi xác định độ phân giải pixel, cần phải xác định pixel.
Pixel
Chúng tôi đã định nghĩa pixel trong phần hướng dẫn về khái niệm pixel, trong đó chúng tôi định nghĩa pixel là phần tử nhỏ nhất của hình ảnh. Chúng tôi cũng xác định rằng một pixel có thể lưu trữ một giá trị tỷ lệ với cường độ ánh sáng tại vị trí cụ thể đó.
Bây giờ vì chúng ta đã xác định pixel, chúng ta sẽ định nghĩa độ phân giải là gì.
Độ phân giải
Độ phân giải có thể được định nghĩa theo nhiều cách. Chẳng hạn như độ phân giải pixel, độ phân giải không gian, độ phân giải thời gian, độ phân giải quang phổ. Chúng ta sẽ thảo luận về độ phân giải pixel.
Bạn có thể đã thấy rằng trong cài đặt máy tính của riêng mình, bạn có độ phân giải màn hình là 800 x 600, 640 x 480, v.v.
Trong độ phân giải pixel, thuật ngữ độ phân giải đề cập đến tổng số lượng pixel trong một hình ảnh kỹ thuật số. Ví dụ. Nếu một hình ảnh có M hàng và N cột, thì độ phân giải của nó có thể được xác định là MX N.
Nếu chúng ta định nghĩa độ phân giải là tổng số pixel, thì độ phân giải pixel có thể được xác định với bộ hai số. Số đầu tiên là chiều rộng của hình ảnh hoặc pixel trên các cột và số thứ hai là chiều cao của hình ảnh hoặc pixel trên chiều rộng của hình ảnh.
Có thể nói rằng độ phân giải pixel càng cao thì chất lượng hình ảnh càng cao.
Chúng ta có thể xác định độ phân giải pixel của hình ảnh là 4500 X 5500.
Megapixels
Chúng tôi có thể tính toán mega pixel của một máy ảnh bằng cách sử dụng độ phân giải pixel.
Pixel cột (chiều rộng) X pixel hàng (chiều cao) / 1 Triệu.
Kích thước của một hình ảnh có thể được xác định bằng độ phân giải pixel của nó.
Kích thước = độ phân giải pixel X bpp (bit trên pixel)
Tính toán mega pixel của máy ảnh
Giả sử chúng ta có một hình ảnh có kích thước: 2500 X 3192.
Độ phân giải pixel của nó = 2500 * 3192 = 7982350 byte.
Chia nó cho 1 triệu = 7.9 = 8 mega pixel (ước chừng).
Tỷ lệ khung hình
Một khái niệm quan trọng khác với độ phân giải pixel là tỷ lệ khung hình.
Tỷ lệ khung hình là tỷ lệ giữa chiều rộng của hình ảnh và chiều cao của hình ảnh. Nó thường được giải thích là hai số được phân tách bằng dấu hai chấm (8: 9). Tỷ lệ này khác nhau trong các hình ảnh khác nhau và trong các màn hình khác nhau. Các tỷ lệ khía cạnh phổ biến là:
1,33: 1, 1,37: 1, 1,43: 1, 1,50: 1, 1,56: 1, 1,66: 1, 1,75: 1, 1,78: 1, 1,85: 1, 2,00: 1, v.v.
Lợi thế:
Tỷ lệ khung hình duy trì sự cân bằng giữa sự xuất hiện của hình ảnh trên màn hình, có nghĩa là nó duy trì tỷ lệ giữa pixel ngang và dọc. Nó không để cho hình ảnh bị méo khi tăng tỷ lệ khung hình.
Ví dụ:
Đây là hình ảnh mẫu, có 100 hàng và 100 cột. Nếu chúng ta muốn làm nhỏ hơn, và điều kiện là chất lượng vẫn giữ nguyên hoặc theo cách khác là hình ảnh không bị biến dạng, thì đây là cách nó xảy ra.
Ảnh gốc:

Thay đổi các hàng và cột bằng cách duy trì tỷ lệ co trong MS Paint.
Kết quả

Hình ảnh nhỏ hơn, nhưng có cùng độ cân bằng.
Bạn có thể đã thấy tỷ lệ khung hình trong trình phát video, nơi bạn có thể điều chỉnh video theo độ phân giải màn hình của mình.
Tìm kích thước của hình ảnh từ tỷ lệ co:
Tỷ lệ khung hình cho chúng ta biết nhiều điều. Với tỷ lệ khung hình, bạn có thể tính toán kích thước của hình ảnh cùng với kích thước của hình ảnh.
Ví dụ
Nếu bạn được cung cấp một hình ảnh có tỷ lệ khung hình là 6: 2 của một hình ảnh có độ phân giải pixel là 480000 pixel thì hình ảnh đó là hình ảnh tỷ lệ xám.
Và bạn được yêu cầu tính toán hai điều.
Phân giải độ phân giải pixel để tính toán kích thước của hình ảnh
Tính kích thước của hình ảnh
Giải pháp:
Được:
Tỷ lệ co: c: r = 6: 2
Độ phân giải pixel: c * r = 480000
Số bit trên mỗi pixel: hình ảnh thang độ xám = 8bpp
Tìm thấy:
Số hàng =?
Số cols =?
Giải quyết phần đầu tiên:
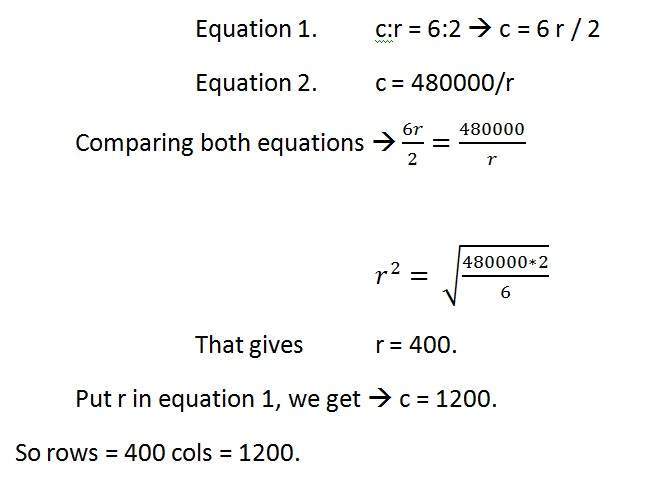
Giải phần 2:
Kích thước = hàng * cột * bpp
Kích thước hình ảnh tính bằng bit = 400 * 1200 * 8 = 3840000 bit
Kích thước của hình ảnh tính bằng byte = 480000 byte
Kích thước của hình ảnh tính bằng kilo byte = 48 kb (ước chừng).
Trong hướng dẫn này, chúng tôi sẽ giới thiệu khái niệm thu phóng và các kỹ thuật phổ biến được sử dụng để thu phóng hình ảnh.
Thu phóng
Phóng to đơn giản có nghĩa là phóng to hình ảnh theo nghĩa là các chi tiết trong hình ảnh trở nên rõ ràng và rõ ràng hơn. Phóng to hình ảnh có nhiều ứng dụng rộng rãi khác nhau, từ phóng to qua ống kính máy ảnh, thu phóng hình ảnh trên internet, v.v.
Ví dụ
được phóng to

Bạn có thể phóng to thứ gì đó ở hai bước khác nhau.
Bước đầu tiên bao gồm thu phóng trước khi chụp một hình ảnh cụ thể. Đây được gọi là thu phóng xử lý trước. Thu phóng này liên quan đến chuyển động phần cứng và cơ học.
Bước thứ hai là thu phóng khi một hình ảnh đã được chụp. Nó được thực hiện thông qua nhiều thuật toán khác nhau, trong đó chúng tôi thao tác các pixel để phóng to phần cần thiết.
Chúng tôi sẽ thảo luận chi tiết về chúng trong hướng dẫn tiếp theo.
Zoom quang học so với Zoom kỹ thuật số
Hai loại zoom này được hỗ trợ bởi máy ảnh.
Zoom quang học:
Thu phóng quang học đạt được bằng cách sử dụng chuyển động của ống kính máy ảnh của bạn. Zoom quang học thực sự là một zoom thực sự. Kết quả của zoom quang học tốt hơn nhiều so với zoom kỹ thuật số. Trong thu phóng quang học, một hình ảnh được ống kính phóng đại theo cách sao cho các đối tượng trong hình ảnh có vẻ gần máy ảnh hơn. Ở chế độ thu phóng quang học, ống kính được mở rộng về mặt vật lý để thu phóng hoặc phóng đại một đối tượng.
Zoom kỹ thuật số:
Zoom kỹ thuật số về cơ bản là xử lý hình ảnh trong máy ảnh. Trong quá trình thu phóng kỹ thuật số, trung tâm của hình ảnh được phóng to và các cạnh của hình ảnh bị cắt ra. Do trung tâm được phóng đại, có vẻ như vật thể ở gần bạn hơn.
Trong quá trình thu phóng kỹ thuật số, các điểm ảnh được mở rộng, do đó chất lượng của hình ảnh bị ảnh hưởng.
Hiệu ứng tương tự của thu phóng kỹ thuật số có thể được nhìn thấy sau khi hình ảnh được chụp qua máy tính của bạn bằng cách sử dụng hộp công cụ / phần mềm xử lý hình ảnh, chẳng hạn như Photoshop.
Hình ảnh sau đây là kết quả thu phóng kỹ thuật số được thực hiện thông qua một trong các phương pháp sau được đưa ra dưới đây trong các phương pháp thu phóng.

Bây giờ vì chúng tôi đang nghiêng về xử lý hình ảnh kỹ thuật số, chúng tôi sẽ không tập trung vào cách một hình ảnh có thể được thu phóng quang học bằng cách sử dụng ống kính hoặc các thứ khác. Thay vào đó, chúng tôi sẽ tập trung vào các phương pháp cho phép thu phóng hình ảnh kỹ thuật số.
Các phương pháp thu phóng:
Mặc dù có nhiều phương pháp thực hiện công việc này, nhưng chúng ta sẽ thảo luận về phương pháp phổ biến nhất ở đây.
Chúng được liệt kê dưới đây.
Sao chép pixel hoặc (Nội suy hàng xóm gần nhất)
Phương pháp giữ lệnh bằng 0
Thu phóng K lần
Tất cả ba phương pháp này được chính thức giới thiệu trong hướng dẫn tiếp theo.
Trong hướng dẫn này, chúng tôi sẽ chính thức giới thiệu ba phương pháp phóng to đã được giới thiệu trong hướng dẫn Giới thiệu về phóng to.
Phương pháp
Sao chép pixel hoặc (Nội suy hàng xóm gần nhất)
Phương pháp giữ lệnh bằng 0
Thu phóng K lần
Mỗi phương pháp đều có những ưu nhược điểm riêng. Chúng ta sẽ bắt đầu bằng cách thảo luận về nhân rộng pixel.
Phương pháp 1: Sao chép pixel:
Giới thiệu:
Nó còn được gọi là phép nội suy hàng xóm gần nhất. Như tên gọi của nó cho thấy, trong phương pháp này, chúng tôi chỉ sao chép các pixel lân cận. Như chúng ta đã thảo luận trong hướng dẫn Lấy mẫu, việc phóng to không là gì ngoài việc tăng lượng mẫu hoặc pixel. Thuật toán này hoạt động trên nguyên tắc tương tự.
Đang làm việc:
Trong phương pháp này, chúng tôi tạo các pixel mới tạo thành các pixel đã cho sẵn. Mỗi pixel được sao chép trong phương pháp này n lần hàng và cột khôn ngoan và bạn có một hình ảnh được thu phóng. Nó đơn giản như vậy.
Ví dụ:
Nếu bạn có một hình ảnh gồm 2 hàng và 2 cột và bạn muốn phóng to nó hai lần hoặc 2 lần bằng cách sử dụng tính năng sao chép pixel, thì đây là cách thực hiện.
Để hiểu rõ hơn, hình ảnh đã được chụp dưới dạng ma trận với các giá trị pixel của hình ảnh.
| 1 | 2 |
| 3 | 4 |
Hình trên có hai hàng và hai cột, trước tiên chúng ta sẽ thu phóng nó theo hàng khôn ngoan.
Hàng phóng to khôn ngoan:
Khi chúng tôi thu phóng hàng một cách khôn ngoan, chúng tôi sẽ chỉ đơn giản sao chép các pixel hàng vào ô mới liền kề của nó.
Đây là cách nó sẽ được thực hiện.
| 1 | 1 | 2 | 2 |
| 3 | 3 | 4 | 4 |
Như bạn có thể làm trong ma trận trên, mỗi pixel được sao chép hai lần trong các hàng.
Thu phóng kích thước cột:
Bước tiếp theo là sao chép từng cột pixel một cách khôn ngoan, chúng ta sẽ chỉ cần sao chép pixel cột vào cột mới liền kề của nó hoặc đơn giản là bên dưới nó.
Đây là cách nó sẽ được thực hiện.
| 1 | 1 | 2 | 2 |
| 1 | 1 | 2 | 2 |
| 3 | 3 | 4 | 4 |
| 3 | 3 | 4 | 4 |
Kích thước hình ảnh mới:
Như có thể thấy từ ví dụ trên, một hình ảnh gốc gồm 2 hàng và 2 cột đã được chuyển đổi thành 4 hàng và 4 cột sau khi phóng to. Điều đó có nghĩa là hình ảnh mới có kích thước
(Hàng ảnh gốc * hệ số phóng to, hàng ảnh gốc * hệ số phóng to)
Thuận lợi và khó khăn:
Một trong những ưu điểm của kỹ thuật phóng to này là, nó rất đơn giản. Bạn chỉ cần sao chép các pixel và không có gì khác.
Nhược điểm của kỹ thuật này là hình ảnh được phóng to nhưng đầu ra rất mờ. Và khi hệ số phóng to tăng lên, hình ảnh ngày càng bị mờ hơn. Điều đó cuối cùng sẽ dẫn đến hình ảnh bị mờ hoàn toàn.
Phương pháp 2: Không giữ lệnh
Giới thiệu
Phương pháp giữ lệnh bằng 0 là một phương pháp thu phóng khác. Nó còn được gọi là phóng to hai lần. Vì nó chỉ có thể phóng to hai lần. Chúng ta sẽ thấy trong ví dụ dưới đây rằng tại sao nó lại làm như vậy.
Đang làm việc
Trong phương pháp giữ thứ tự 0, chúng tôi chọn hai phần tử liền kề từ các hàng tương ứng, sau đó chúng tôi thêm chúng và chia kết quả cho hai, và đặt kết quả của chúng vào giữa hai phần tử đó. Đầu tiên chúng ta thực hiện hàng này một cách khôn ngoan và sau đó chúng ta làm cho cột này một cách khôn ngoan.
Ví dụ
Cho phép chụp ảnh có kích thước của 2 hàng và 2 cột và thu phóng ảnh hai lần bằng cách sử dụng giữ thứ tự bằng không.
| 1 | 2 |
| 3 | 4 |
Đầu tiên, chúng tôi sẽ thu phóng nó theo hàng khôn ngoan và sau đó là cột khôn ngoan.
Hàng phóng to khôn ngoan
| 1 | 1 | 2 |
| 3 | 3 | 4 |
Khi chúng ta lấy hai số đầu tiên: (2 + 1) = 3 và sau đó chúng ta chia nó cho 2, chúng ta nhận được 1,5 gần đúng với 1. Phương pháp tương tự cũng được áp dụng cho hàng 2.
Thu phóng cột khôn ngoan
| 1 | 1 | 2 |
| 2 | 2 | 3 |
| 3 | 3 | 4 |
Chúng tôi lấy hai giá trị pixel cột liền kề là 1 và 3. Chúng tôi thêm chúng và nhận được 4. 4 sau đó chia cho 2 và chúng tôi nhận được 2 được đặt ở giữa chúng. Phương pháp tương tự được áp dụng trong tất cả các cột.
Kích thước hình ảnh mới
Như bạn có thể thấy rằng kích thước của hình ảnh mới là 3 x 3 trong khi kích thước của hình ảnh gốc là 2 x 2. Vì vậy, có nghĩa là kích thước của hình ảnh mới dựa trên công thức sau
(2 (số hàng) trừ 1) X (2 (số cột) trừ 1)
Ưu điểm và nhược điểm.
Một trong những ưu điểm của kỹ thuật phóng to này, đó là nó không tạo ra hình ảnh mờ như so với phương pháp nội suy lân cận gần nhất. Nhưng nó cũng có một nhược điểm là nó chỉ có thể chạy bằng công suất của 2. Có thể chứng minh ở đây.
Lý do đằng sau việc phóng to hai lần:
Xét hình ảnh trên gồm 2 hàng và 2 cột. Nếu chúng ta phải thu phóng nó 6 lần, sử dụng phương pháp giữ lệnh bằng 0, chúng ta không thể làm được. Như công thức cho chúng ta thấy điều này.
Nó chỉ có thể phóng to sức mạnh của 2 2,4,8,16,32 và v.v.
Ngay cả khi bạn cố gắng thu phóng nó, bạn không thể. Bởi vì lúc đầu, bạn sẽ phóng to nó hai lần, và kết quả sẽ giống như trong cột phóng to khôn ngoan với kích thước bằng 3x3. Sau đó, bạn sẽ thu phóng nó một lần nữa và bạn sẽ nhận được kích thước bằng 5 x 5. Bây giờ nếu bạn thực hiện lại, bạn sẽ nhận được kích thước bằng 9 x 9.
Trong khi theo công thức của bạn thì câu trả lời phải là 11x11. Như (6 (2) trừ 1) X (6 (2) trừ 1) cho 11 x 11.
Phương pháp 3: Phóng to K-Times
Giới thiệu:
K lần là phương pháp phóng to thứ ba mà chúng ta sẽ thảo luận. Nó là một trong những thuật toán thu phóng hoàn hảo nhất được thảo luận cho đến nay. Nó đáp ứng các thách thức của cả hai lần phóng to và sao chép pixel. K trong thuật toán phóng to này là viết tắt của hệ số phóng to.
Đang làm việc:
Nó hoạt động như thế này.
Trước hết, bạn phải lấy hai pixel liền kề như khi bạn đã phóng to hai lần. Sau đó, bạn phải trừ nhỏ hơn với lớn hơn. Chúng tôi gọi đây là đầu ra (OP).
Chia đầu ra (OP) với hệ số thu phóng (K). Bây giờ bạn phải thêm kết quả vào giá trị nhỏ hơn và đặt kết quả vào giữa hai giá trị đó.
Thêm giá trị OP một lần nữa vào giá trị bạn vừa đặt và đặt nó một lần nữa bên cạnh giá trị đã đặt trước đó. Bạn phải làm điều đó cho đến khi bạn đặt k-1 giá trị vào đó.
Lặp lại bước tương tự cho tất cả các hàng và cột, và bạn sẽ có được hình ảnh được thu phóng.
Ví dụ:
Giả sử bạn có một hình ảnh gồm 2 hàng và 3 cột, được cho bên dưới. Và bạn phải thu phóng nó ba lần hoặc ba lần.
| 15 | 30 | 15 |
| 30 | 15 | 30 |
K trong trường hợp này là 3. K = 3.
Số giá trị cần được chèn là k-1 = 3-1 = 2.
Hàng phóng to khôn ngoan
Lấy hai pixel liền kề đầu tiên. Đó là 15 và 30.
Trừ 15 cho 30. 30-15 = 15.
Chia 15 cho k. 15 / k = 15/3 = 5. Chúng tôi gọi nó là OP. (Trong đó op chỉ là một cái tên)
Thêm OP đến số thấp hơn. 15 + OP = 15 + 5 = 20.
Thêm OP đến 20 một lần nữa. 20 + OP = 20 + 5 = 25.
Chúng tôi làm điều đó 2 lần vì chúng tôi phải chèn các giá trị k-1.
Bây giờ lặp lại bước này cho hai pixel liền kề tiếp theo. Nó được hiển thị trong bảng đầu tiên.
Sau khi chèn các giá trị, bạn phải sắp xếp các giá trị được chèn theo thứ tự tăng dần, do đó vẫn có sự đối xứng giữa chúng.
Nó được hiển thị trong bảng thứ hai
Bảng 1.
| 15 | 20 | 25 | 30 | 20 | 25 | 15 |
| 30 | 20 | 25 | 15 | 20 | 25 | 30 |
Ban 2.

Thu phóng cột khôn ngoan
Quy trình tương tự phải được thực hiện theo cột khôn ngoan. Quy trình bao gồm lấy hai giá trị pixel liền kề, sau đó lấy giá trị lớn hơn trừ đi giá trị nhỏ hơn. Sau đó, bạn phải chia nó cho k. Lưu trữ kết quả dưới dạng OP. Thêm OP vào nhỏ hơn, và sau đó lại thêm OP vào giá trị có thêm OP đầu tiên. Chèn các giá trị mới.
Đây là những gì bạn nhận được sau tất cả những điều đó.
| 15 | 20 | 25 | 30 | 25 | 20 | 15 |
| 20 | 21 | 21 | 25 | 21 | 21 | 20 |
| 25 | 22 | 22 | 20 | 22 | 22 | 25 |
| 30 | 25 | 20 | 15 | 20 | 25 | 30 |
Kích thước hình ảnh mới
Cách tốt nhất để tính toán công thức cho kích thước của hình ảnh mới là so sánh kích thước của hình ảnh gốc và hình ảnh cuối cùng. Kích thước của hình ảnh ban đầu là 2 X 3. Và kích thước của hình ảnh mới là 4 x 7.
Công thức do đó là:
(K (số hàng trừ đi 1) + 1) X (K (số hàng trừ đi 1) + 1)
Ưu điểm và nhược điểm
Một trong những lợi thế rõ ràng mà thuật toán thu phóng k thời gian có được là nó có thể tính toán thu phóng của bất kỳ yếu tố nào là sức mạnh của thuật toán sao chép pixel, đồng thời nó cũng cho kết quả được cải thiện (ít mờ hơn), đó là sức mạnh của phương pháp giữ thứ tự không. Vì vậy, nó bao gồm sức mạnh của hai thuật toán.
Khó khăn duy nhất mà thuật toán này gặp phải là nó phải được sắp xếp cuối cùng, đây là một bước bổ sung, và do đó làm tăng chi phí tính toán.
Độ phân giải hình ảnh
Độ phân giải hình ảnh có thể được xác định theo nhiều cách. Một loại của nó là độ phân giải pixel đã được thảo luận trong hướng dẫn về độ phân giải pixel và tỷ lệ khung hình.
Trong hướng dẫn này, chúng ta sẽ định nghĩa một loại độ phân giải khác là độ phân giải không gian.
Độ phân giải không gian:
Độ phân giải không gian nói rằng độ rõ nét của hình ảnh không thể được xác định bằng độ phân giải pixel. Số lượng pixel trong một hình ảnh không quan trọng.
Độ phân giải không gian có thể được định nghĩa là
chi tiết rõ ràng nhất trong một hình ảnh. (Xử lý hình ảnh kỹ thuật số - Gonzalez, Woods - Phiên bản thứ 2)
Hoặc theo cách khác, chúng ta có thể định nghĩa độ phân giải không gian là số lượng giá trị pixel độc lập trên mỗi inch.
Nói tóm lại, độ phân giải không gian đề cập đến là chúng ta không thể so sánh hai loại hình ảnh khác nhau để xem cái nào rõ nét hay cái nào không. Nếu chúng ta phải so sánh hai hình ảnh, để xem cái nào rõ hơn hoặc cái nào có độ phân giải không gian hơn, chúng ta phải so sánh hai hình ảnh có cùng kích thước.
Ví dụ:
Bạn không thể so sánh hai hình ảnh này để xem độ rõ của hình ảnh.
Mặc dù cả hai hình ảnh là của cùng một người, nhưng đó không phải là điều kiện mà chúng tôi đang đánh giá. Hình bên trái là hình thu nhỏ của Einstein với kích thước 227 x 222. Trong khi hình bên phải có kích thước 980 X 749 và nó cũng là hình ảnh phóng to. Chúng ta không thể so sánh chúng để xem cái nào rõ ràng hơn. Hãy nhớ yếu tố zoom không quan trọng trong điều kiện này, điều quan trọng duy nhất là hai bức ảnh này không bằng nhau.
Vì vậy, để đo độ phân giải không gian, các hình ảnh dưới đây sẽ thể hiện mục đích.

Bây giờ bạn có thể so sánh hai hình ảnh này. Cả hai hình ảnh đều có cùng kích thước là 227 X 222. Bây giờ khi bạn so sánh chúng, bạn sẽ thấy rằng hình ảnh ở bên trái có độ phân giải không gian cao hơn hoặc rõ ràng hơn là hình ảnh ở phía bên phải. Đó là bởi vì hình ảnh bên phải là một hình ảnh mờ.
Đo độ phân giải không gian:
Vì độ phân giải không gian đề cập đến độ rõ ràng, vì vậy đối với các thiết bị khác nhau, các biện pháp khác nhau đã được thực hiện để đo lường nó.
Ví dụ:
Dấu chấm trên inch
Dòng trên inch
Pixel trên mỗi inch
Chúng sẽ được thảo luận chi tiết hơn trong phần hướng dẫn tiếp theo nhưng chỉ giới thiệu ngắn gọn bên dưới.
Dấu chấm trên inch:
Dấu chấm trên inch hoặc DPI thường được sử dụng trong màn hình.
Dòng trên inch:
Dòng trên inch hoặc LPI thường được sử dụng trong máy in laser.
Pixel mỗi inch:
Pixel trên inch hoặc PPI được đo cho các thiết bị khác nhau như máy tính bảng, điện thoại di động, v.v.
Trong hướng dẫn trước về độ phân giải không gian, chúng ta đã thảo luận về giới thiệu ngắn gọn về PPI, DPI, LPI. Bây giờ chúng ta sẽ chính thức thảo luận về tất cả chúng.
Pixel trên mỗi inch.
Mật độ điểm ảnh hoặc Điểm ảnh trên inch là thước đo độ phân giải không gian cho các thiết bị khác nhau bao gồm máy tính bảng, điện thoại di động.
PPI càng cao thì chất lượng càng cao. Để hiểu thêm về nó, nó đã tính toán như thế nào. Cho phép tính toán PPI của điện thoại di động.
Tính toán pixel trên inch (PPI) của Samsung galaxy S4:

Samsung galaxy s4 có PPI hoặc mật độ điểm ảnh là 441. Nhưng nó được tính như thế nào?
Trước hết, chúng ta sẽ định lý Pythagoras để tính độ phân giải đường chéo tính bằng pixel.
Nó có thể được đưa ra như:
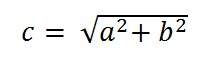
Trong đó a và b là độ phân giải chiều cao và chiều rộng tính bằng pixel và c là độ phân giải đường chéo tính bằng pixel.
Đối với Samsung galaxy s4, nó là 1080 x 1920 pixel.
Vì vậy, đưa các giá trị đó vào phương trình sẽ cho kết quả
C = 2202.90717
Bây giờ chúng ta sẽ tính toán PPI
PPI = c / kích thước đường chéo tính bằng inch
Kích thước đường chéo tính bằng inch của Samsun galaxy s4 là 5,0 inch, có thể được xác nhận từ bất kỳ đâu.
PPI = 2202.90717 / 5.0
PPI = 440,58
PPI = 441 (ước chừng)
Điều đó có nghĩa là mật độ điểm ảnh của Samsung galaxy s4 là 441 PPI.
Dấu chấm trên inch.
Dpi thường liên quan đến PPI, trong khi có sự khác biệt giữa hai chỉ số này. DPI hoặc số chấm trên inch là thước đo độ phân giải không gian của máy in. Trong trường hợp máy in, dpi có nghĩa là có bao nhiêu chấm mực được in trên mỗi inch khi một hình ảnh được in ra từ máy in.
Hãy nhớ rằng không nhất thiết mỗi Pixel trên inch được in bằng một chấm trên inch. Có thể có nhiều chấm trên mỗi inch được sử dụng để in một pixel. Lý do đằng sau điều này là hầu hết các máy in màu sử dụng mô hình CMYK. Màu sắc có hạn. Máy in phải chọn từ những màu này để tạo màu cho pixel trong khi trong máy tính, bạn có hàng trăm nghìn màu.
Dpi của máy in càng cao thì chất lượng của tài liệu hoặc hình ảnh được in trên giấy càng cao.
Thông thường một số máy in laser có dpi là 300 và một số có từ 600 trở lên.
Dòng trên inch.
Khi dpi đề cập đến các điểm trên inch, lót trên inch đề cập đến các đường chấm trên inch. Độ phân giải của màn hình bán sắc được đo bằng dòng trên inch.
Bảng sau đây cho thấy một số công suất dòng trên inch của máy in.
| Máy in | LPI |
|---|---|
| In lụa | 45-65 lpi |
| Máy in laser (300 dpi) | 65 lpi |
| Máy in laser (600 dpi) | 85-105 lpi |
| Offset Press (giấy in báo) | 85 lpi |
| Offset Press (giấy tráng) | 85-185 lpi |
Độ phân giải hình ảnh:
Độ phân giải mức xám:
Độ phân giải mức xám đề cập đến sự thay đổi có thể dự đoán hoặc xác định được trong các sắc thái hoặc mức độ xám trong hình ảnh.
Trong ngắn hạn, độ phân giải mức xám bằng số bit trên mỗi pixel.
Chúng tôi đã thảo luận về bit trên pixel trong hướng dẫn của chúng tôi về bit trên pixel và yêu cầu lưu trữ hình ảnh. Chúng tôi sẽ định nghĩa bpp ở đây một cách ngắn gọn.
BPP:
Số lượng màu sắc khác nhau trong một hình ảnh phụ thuộc vào độ sâu của màu sắc hoặc các bit trên mỗi pixel.
Về mặt toán học:
Mối quan hệ toán học có thể được thiết lập giữa độ phân giải mức xám và bit trên mỗi pixel có thể được đưa ra dưới dạng.

Trong phương trình này, L đề cập đến số lượng mức xám. Nó cũng có thể được định nghĩa là các sắc thái của màu xám. Và k đề cập đến bpp hoặc bit trên mỗi pixel. Vì vậy, 2 nâng lên sức mạnh của bit trên mỗi pixel bằng với độ phân giải mức xám.
Ví dụ:
Hình ảnh trên của Einstein là một hình ảnh thang màu xám. Có nghĩa là nó là một hình ảnh có 8 bit mỗi pixel hoặc 8bpp.
Bây giờ nếu để tính toán độ phân giải mức xám, đây là cách chúng ta sẽ thực hiện.
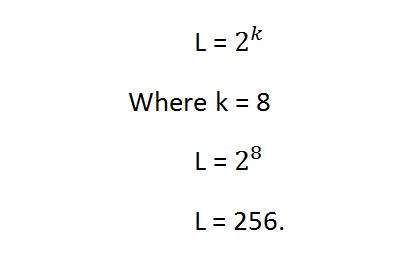
Nó có nghĩa là độ phân giải mức xám của nó là 256. Hay nói cách khác, hình ảnh này có 256 sắc thái xám khác nhau.
Càng nhiều bit trên mỗi pixel của một hình ảnh, thì càng nhiều là độ phân giải mức xám của nó.
Xác định độ phân giải mức xám theo bpp:
Không nhất thiết độ phân giải mức xám chỉ nên được xác định theo các mức. Chúng tôi cũng có thể định nghĩa nó theo bit trên pixel.
Ví dụ:
Nếu bạn được cung cấp một hình ảnh 4 bpp và bạn được yêu cầu tính toán độ phân giải mức xám của nó. Có hai câu trả lời cho câu hỏi đó.
Câu trả lời đầu tiên là 16 cấp độ.
Câu trả lời thứ hai là 4 bit.
Tìm bpp từ độ phân giải cấp độ Xám:
Bạn cũng có thể tìm các bit trên mỗi pixel từ độ phân giải mức xám đã cho. Đối với điều này, chúng ta chỉ cần thay đổi công thức một chút.
Phương trình 1.
Công thức này tìm các cấp độ. Bây giờ nếu chúng ta tìm các bit trên mỗi pixel hoặc trong trường hợp này là k, chúng ta sẽ đơn giản thay đổi nó như thế này.
K = log cơ số 2 (L) Phương trình (2)
Bởi vì trong phương trình đầu tiên, mối quan hệ giữa Mức (L) và bit trên mỗi pixel (k) là lũy thừa. Bây giờ chúng ta phải hoàn nguyên nó, và do đó nghịch đảo của lũy thừa là log.
Hãy lấy một ví dụ để tìm các bit trên mỗi pixel từ độ phân giải mức xám.
Ví dụ:
Nếu bạn được cung cấp một hình ảnh 256 cấp độ. Các bit trên mỗi pixel cần thiết cho nó là bao nhiêu.
Đặt 256 vào phương trình, chúng tôi nhận được.
K = log cơ số 2 (256)
K = 8.
Vì vậy, câu trả lời là 8 bit trên mỗi pixel.
Độ phân giải và lượng tử hóa mức xám:
Lượng tử hóa sẽ được giới thiệu chính thức trong hướng dẫn tiếp theo, nhưng ở đây chúng ta sẽ giải thích mối quan hệ giữa độ phân giải mức xám và lượng tử hóa.
Độ phân giải mức xám được tìm thấy trên trục y của tín hiệu. Trong phần hướng dẫn Giới thiệu về tín hiệu và hệ thống, chúng tôi đã nghiên cứu rằng số hóa một tín hiệu tương tự cần hai bước. Lấy mẫu và lượng tử hóa.
Việc lấy mẫu được thực hiện trên trục x. Và lượng tử hóa được thực hiện theo trục Y.
Vì vậy, điều đó có nghĩa là số hóa độ phân giải mức xám của một hình ảnh được thực hiện trong quá trình lượng tử hóa.
Chúng tôi đã giới thiệu lượng tử hóa trong hướng dẫn của chúng tôi về tín hiệu và hệ thống. Chúng tôi sẽ chính thức liên hệ nó với các hình ảnh kỹ thuật số trong hướng dẫn này. Đầu tiên chúng ta hãy thảo luận một chút về lượng tử hóa.
Số hóa một tín hiệu.
Như chúng ta đã thấy trong các hướng dẫn trước, để số hóa một tín hiệu tương tự thành kỹ thuật số, cần hai bước cơ bản. Lấy mẫu và lượng tử hóa. Việc lấy mẫu được thực hiện trên trục x. Nó là sự chuyển đổi trục x (giá trị vô hạn) sang giá trị kỹ thuật số.
Hình dưới đây cho thấy lấy mẫu của một tín hiệu.
Lấy mẫu liên quan đến hình ảnh kỹ thuật số:
Khái niệm lấy mẫu liên quan trực tiếp đến việc thu phóng. Bạn lấy càng nhiều mẫu, bạn nhận được càng nhiều pixel. Lấy mẫu quá mức cũng có thể được gọi là phóng to. Điều này đã được thảo luận trong hướng dẫn lấy mẫu và phóng to.
Nhưng câu chuyện số hóa một tín hiệu không chỉ dừng lại ở việc lấy mẫu, còn một bước khác liên quan được gọi là Lượng tử hóa.
Lượng tử hóa là gì.
Lượng tử hóa ngược lại với lấy mẫu. Nó được thực hiện trên trục y. Khi bạn đang chuẩn hóa một hình ảnh, bạn thực sự đang chia tín hiệu thành các lượng tử (phân vùng).
Trên trục x của tín hiệu, là các giá trị tọa độ và trên trục y, chúng ta có biên độ. Vì vậy, số hóa các biên độ được gọi là Lượng tử hóa.
Đây là cách nó được thực hiện
Bạn có thể thấy trong hình ảnh này, rằng tín hiệu đã được định lượng thành ba mức khác nhau. Điều đó có nghĩa là khi chúng tôi lấy mẫu một hình ảnh, chúng tôi thực sự thu thập rất nhiều giá trị và trong quá trình lượng tử hóa, chúng tôi đặt các mức cho các giá trị này. Điều này có thể rõ ràng hơn trong hình ảnh bên dưới.
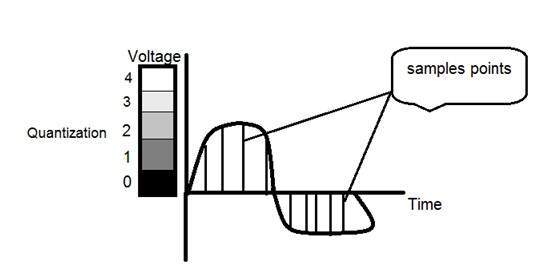
Trong hình minh họa khi lấy mẫu, mặc dù các mẫu đã được lấy, nhưng chúng vẫn trải dài theo chiều dọc đến một dải giá trị mức xám liên tục. Trong hình trên, các giá trị dao động theo chiều dọc này đã được lượng tử hóa thành 5 mức hoặc phân vùng khác nhau. Phạm vi từ 0 đen đến 4 trắng. Mức độ này có thể thay đổi tùy theo loại hình ảnh bạn muốn.
Mối quan hệ của lượng tử hóa với mức xám đã được thảo luận thêm dưới đây.
Mối quan hệ của Lượng tử hóa với độ phân giải mức xám:
Hình trên có 5 mức xám khác nhau. Có nghĩa là hình ảnh được hình thành từ tín hiệu này sẽ chỉ có 5 màu khác nhau. Nó sẽ là một hình ảnh đen trắng ít nhiều với một số màu xám. Bây giờ nếu bạn muốn làm cho chất lượng của hình ảnh tốt hơn, có một điều bạn có thể làm ở đây. Đó là, để tăng mức độ hoặc độ phân giải mức xám lên. Nếu bạn tăng mức này lên 256, có nghĩa là bạn có một hình ảnh tỷ lệ xám. Tốt hơn nhiều so với hình ảnh đen trắng đơn giản.
Bây giờ 256, hoặc 5 hoặc mức mà bạn chọn từng được gọi là mức xám. Hãy nhớ công thức mà chúng ta đã thảo luận trong hướng dẫn trước về độ phân giải mức xám là,
Chúng ta đã thảo luận rằng mức xám có thể được xác định theo hai cách. Đó là hai.
Mức xám = số bit trên mỗi pixel (BPP). (K trong phương trình)
Mức xám = số mức trên mỗi pixel.
Trong trường hợp này, chúng ta có mức xám bằng 256. Nếu chúng ta phải tính số bit, chúng ta chỉ cần đưa các giá trị vào phương trình. Trong trường hợp 256 mức, chúng tôi có 256 sắc thái khác nhau của màu xám và 8 bit trên mỗi pixel, do đó hình ảnh sẽ là hình ảnh tỷ lệ xám.
Giảm mức xám
Bây giờ chúng ta sẽ giảm mức xám của ảnh để xem hiệu ứng trên ảnh.
Ví dụ:
Giả sử bạn có một hình ảnh 8bpp, có 256 cấp độ khác nhau. Đó là một hình ảnh thang độ xám và hình ảnh trông giống như thế này.
256 mức xám
Bây giờ chúng ta sẽ bắt đầu giảm mức xám. Trước tiên, chúng tôi sẽ giảm mức xám từ 256 xuống 128.
128 cấp độ xám

Không có nhiều ảnh hưởng đến hình ảnh sau khi giảm mức xám xuống một nửa. Hãy giảm thêm một số nữa.
64 mức xám

Vẫn không có nhiều tác dụng, sau đó hãy giảm mức độ nhiều hơn.
32 cấp độ xám

Ngạc nhiên khi thấy rằng vẫn còn một số tác dụng nhỏ. Có thể là do lý do, rằng đó là bức tranh của Einstein, nhưng hãy giảm mức độ nhiều hơn.
16 cấp độ xám

Bùng nổ ở đây, chúng tôi bắt đầu, hình ảnh cuối cùng cũng tiết lộ, rằng nó được ảnh hưởng bởi các cấp độ.
8 cấp độ xám

4 mức xám

Bây giờ trước khi giảm nó, thêm 2 mức nữa, bạn có thể dễ dàng nhận thấy rằng hình ảnh đã bị bóp méo nặng do giảm mức xám. Bây giờ chúng ta sẽ giảm nó xuống còn 2 cấp, không có gì khác ngoài cấp độ đen và trắng đơn giản. Nó có nghĩa là hình ảnh sẽ là hình ảnh đen trắng đơn giản.
2 mức xám

Đó là mức cuối cùng mà chúng ta có thể đạt được, bởi vì nếu giảm thêm nữa, nó sẽ chỉ đơn giản là một hình ảnh đen, không thể giải thích được.
Đường viền:
Có một quan sát thú vị ở đây, đó là khi chúng ta giảm số lượng mức xám, có một loại hiệu ứng đặc biệt bắt đầu xuất hiện trong ảnh, có thể thấy rõ trong bức ảnh 16 mức xám. Hiệu ứng này được gọi là Contouring.
Iso đường cong ưu tiên:
Câu trả lời cho hiệu ứng này, lý do tại sao nó xuất hiện, nằm trong các đường cong ưu tiên Iso. Chúng được thảo luận trong hướng dẫn tiếp theo của chúng tôi về Đường cong tùy chọn Contouring và Iso.
Đường viền là gì?
Khi chúng tôi giảm số lượng mức xám trong một hình ảnh, một số màu sai hoặc các cạnh bắt đầu xuất hiện trên hình ảnh. Điều này đã được hiển thị trong hướng dẫn cuối cùng của chúng tôi về Lượng tử hóa.
Chúng ta hãy nhìn vào nó.
Hãy xem xét chúng ta, có một hình ảnh 8bpp (một hình ảnh thang độ xám) với 256 mức độ xám hoặc xám khác nhau.
Hình trên có 256 màu xám khác nhau. Bây giờ khi chúng ta giảm nó xuống 128 và tiếp tục giảm nó 64, hình ảnh ít nhiều giống nhau. Nhưng khi giảm nó xuống thêm 32 cấp độ khác nhau, chúng ta có một bức tranh như thế này
Nếu bạn quan sát kỹ, bạn sẽ thấy rằng các hiệu ứng bắt đầu xuất hiện trên hình ảnh, các hiệu ứng này rõ ràng hơn khi chúng ta giảm nó xuống 16 cấp và chúng ta có một hình ảnh như thế này.
Những đường bắt đầu xuất hiện trên hình ảnh này được gọi là đường viền có thể nhìn thấy rất nhiều trong hình ảnh trên.
Tăng và giảm đường viền
Hiệu ứng của đường viền tăng lên khi chúng ta giảm số lượng cấp độ xám và hiệu ứng giảm khi chúng ta tăng số lượng cấp độ xám. Cả hai đều ngược lại
VS
Điều đó có nghĩa là lượng tử hóa nhiều hơn, sẽ tạo ra nhiều đường viền hơn và ngược lại. Nhưng điều này luôn luôn xảy ra. Câu trả lời là Không. Điều đó phụ thuộc vào một số thứ khác được thảo luận bên dưới.
Đường cong tham chiếu
Một nghiên cứu được thực hiện về ảnh hưởng này của mức xám và đường viền, và kết quả được thể hiện trong biểu đồ dưới dạng đường cong, được gọi là đường cong ưu tiên Iso.
Hiện tượng của đường cong Isopreference cho thấy rằng ảnh hưởng của đường viền không chỉ phụ thuộc vào sự giảm độ phân giải mức xám mà còn phụ thuộc vào chi tiết hình ảnh.
Bản chất của nghiên cứu là:
Nếu một hình ảnh có nhiều chi tiết hơn, hiệu ứng của đường viền sẽ bắt đầu xuất hiện trên hình ảnh này sau đó, so với một hình ảnh có ít chi tiết hơn, khi mức xám được lượng tử hóa.
Theo nghiên cứu ban đầu, các nhà nghiên cứu đã chụp ba hình ảnh này và chúng thay đổi độ phân giải cấp độ Xám ở cả ba hình ảnh.
Những hình ảnh đã



Mức độ chi tiết:
Hình ảnh đầu tiên chỉ có một khuôn mặt trong đó và do đó rất ít chi tiết. Hình ảnh thứ hai cũng có một số đối tượng khác trong hình ảnh, chẳng hạn như người cầm máy, máy ảnh, giá đỡ máy ảnh và các đối tượng nền, v.v. Trong khi hình ảnh thứ ba có nhiều chi tiết hơn thì tất cả các hình ảnh khác.
Thí nghiệm:
Độ phân giải mức xám khác nhau trong tất cả các hình ảnh và khán giả được yêu cầu đánh giá ba hình ảnh này một cách chủ quan. Sau khi xếp hạng, một biểu đồ được vẽ theo kết quả.
Kết quả:
Kết quả được vẽ trên đồ thị. Mỗi đường cong trên biểu đồ đại diện cho một hình ảnh. Các giá trị trên trục x biểu thị số lượng mức xám và các giá trị trên trục y biểu thị các bit trên mỗi pixel (k).
Biểu đồ đã được hiển thị bên dưới.
Theo biểu đồ này, chúng ta có thể thấy rằng hình ảnh đầu tiên có khuôn mặt, chịu sự tạo đường viền sớm hơn tất cả hai hình ảnh còn lại. Hình ảnh thứ hai, là của người quay phim có thể bị đường viền một chút sau hình ảnh đầu tiên khi mức xám của nó được giảm bớt. Điều này là do nó có nhiều chi tiết hơn hình ảnh đầu tiên. Và hình ảnh thứ ba chịu nhiều đường viền sau hai hình ảnh đầu tiên, tức là: sau 4 bpp. Điều này là do, hình ảnh này có nhiều chi tiết hơn.
Phần kết luận:
Vì vậy, đối với hình ảnh chi tiết hơn, các đường cong đẳng cầu ngày càng trở nên thẳng đứng hơn. Điều đó cũng có nghĩa là đối với một hình ảnh có lượng chi tiết lớn, cần rất ít mức xám.
Trong hai hướng dẫn trước về Lượng tử hóa và tạo đường nét, chúng ta đã thấy rằng việc giảm mức xám của hình ảnh sẽ làm giảm số lượng màu cần thiết để biểu thị một hình ảnh. Nếu giảm mức xám đi 2 2, hình ảnh xuất hiện không có nhiều độ phân giải không gian hoặc không hấp dẫn lắm.
Phối màu:
Phối màu là quá trình chúng ta tạo ra ảo ảnh về màu sắc mà thực tế không có. Nó được thực hiện bởi sự sắp xếp ngẫu nhiên của các pixel.
Ví dụ. Hãy xem xét hình ảnh này.

Đây là hình ảnh chỉ có các pixel đen và trắng trong đó. Các pixel của nó được sắp xếp theo thứ tự để tạo thành một hình ảnh khác được hiển thị bên dưới. Lưu ý ở cách sắp xếp các pixel đã được thay đổi, nhưng không thay đổi số lượng pixel.

Tại sao lại phối màu?
Tại sao chúng ta cần phối màu, câu trả lời của điều này nằm ở mối quan hệ của nó với lượng tử hóa.
Phối màu với lượng tử hóa.
Khi chúng ta thực hiện lượng tử hóa, đến mức cuối cùng, chúng ta thấy rằng hình ảnh ở mức cuối cùng (mức 2) trông như thế này.
Như chúng ta có thể thấy từ hình ảnh ở đây, rằng hình ảnh không được rõ ràng lắm, đặc biệt nếu bạn nhìn vào cánh tay trái và mặt sau của hình ảnh Einstein. Ngoài ra bức tranh này không có nhiều thông tin hay chi tiết của Einstein.
Bây giờ, nếu chúng ta thay đổi hình ảnh này thành một hình ảnh nào đó có nhiều chi tiết hơn thì điều này, chúng ta phải thực hiện phối màu.
Thực hiện phối màu.
Trước hết, chúng tôi sẽ làm việc về việc giữ lại. Phối màu thường đang làm việc để cải thiện ngưỡng. Trong quá trình giữ lại, các cạnh sắc nét xuất hiện ở những nơi có độ dốc mịn trong hình ảnh.
Trong tạo ngưỡng, chúng tôi chỉ cần chọn một giá trị không đổi. Tất cả các pixel phía trên giá trị đó được coi là 1 và tất cả giá trị bên dưới nó được coi là 0.
Chúng tôi nhận được hình ảnh này sau khi ngưỡng.

Vì không có nhiều thay đổi trong hình ảnh, vì các giá trị đã là 0 và 1 hoặc màu đen và trắng trong hình ảnh này.
Bây giờ chúng tôi thực hiện một số phối màu ngẫu nhiên cho nó. Một số sắp xếp ngẫu nhiên của các pixel.

Chúng tôi nhận được một hình ảnh có nhiều chi tiết hơn, nhưng độ tương phản của nó rất thấp.
Vì vậy, chúng tôi thực hiện thêm một số phối màu để tăng độ tương phản. Hình ảnh mà chúng tôi nhận được là:

Bây giờ chúng tôi kết hợp các khái niệm về phối màu ngẫu nhiên, cùng với ngưỡng và chúng tôi có một hình ảnh như thế này.

Bây giờ bạn thấy đấy, chúng tôi có tất cả những hình ảnh này chỉ bằng cách sắp xếp lại các pixel của hình ảnh. Việc sắp xếp lại này có thể là ngẫu nhiên hoặc có thể theo một số biện pháp.
Trước khi thảo luận về việc sử dụng Biểu đồ trong xử lý ảnh, trước tiên chúng ta sẽ xem biểu đồ là gì, nó được sử dụng như thế nào và sau đó là ví dụ về biểu đồ để có thêm hiểu biết về biểu đồ.
Biểu đồ:
Biểu đồ là một biểu đồ. Một biểu đồ hiển thị tần suất của bất kỳ thứ gì. Thông thường, biểu đồ có các thanh thể hiện tần suất xuất hiện của dữ liệu trong toàn bộ tập dữ liệu.
Biểu đồ có hai trục là trục x và trục y.
Trục x chứa sự kiện có tần suất bạn phải đếm.
Trục y chứa tần số.
Các độ cao khác nhau của thanh hiển thị tần suất xuất hiện dữ liệu khác nhau.
Thông thường một biểu đồ trông như thế này.
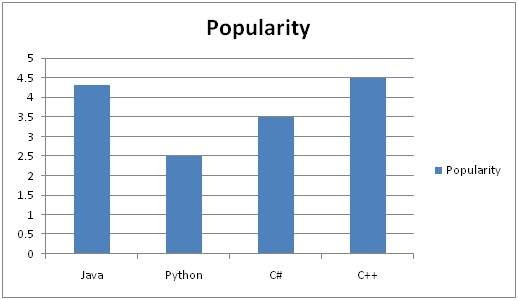
Bây giờ chúng ta sẽ thấy một ví dụ về biểu đồ này được xây dựng
Thí dụ:
Hãy xem xét một lớp sinh viên lập trình và bạn đang dạy python cho họ.
Vào cuối học kỳ, bạn nhận được kết quả này được hiển thị trong bảng. Nhưng nó rất lộn xộn và không thể hiện được kết quả chung của lớp. Vì vậy, bạn phải tạo một biểu đồ về kết quả của mình, cho thấy tần suất xuất hiện chung của các điểm trong lớp của bạn. Đây là cách bạn sẽ làm điều đó.
Bảng kết quả:
| Tên | Cấp |
|---|---|
| John | A |
| Jack | D |
| Carter | B |
| Tommy | A |
| Lisa | C + |
| Derek | A- |
| Tom | B + |
Biểu đồ của bảng kết quả:
Bây giờ những gì bạn sẽ làm là bạn phải tìm những gì xuất hiện trên trục x và y.
Có một điều chắc chắn rằng trục y chứa tần số, vậy thì trục x sẽ thế nào. Trục X chứa sự kiện có tần suất phải được tính toán. Trong trường hợp này trục x chứa điểm.
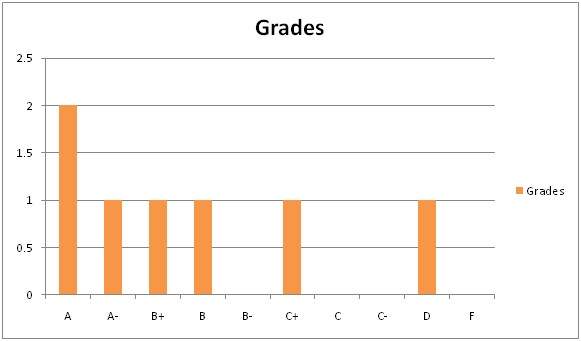
Bây giờ chúng ta sẽ làm cách nào để chúng ta sử dụng biểu đồ trong một hình ảnh.
Biểu đồ của một hình ảnh
Biểu đồ của một hình ảnh, giống như các biểu đồ khác cũng hiển thị tần suất. Nhưng một biểu đồ hình ảnh, hiển thị tần số của các giá trị cường độ pixel. Trong biểu đồ hình ảnh, trục x hiển thị các cường độ màu xám và trục y hiển thị tần suất của các cường độ này.
Ví dụ:
Biểu đồ của bức ảnh trên của Einstein sẽ giống như thế này
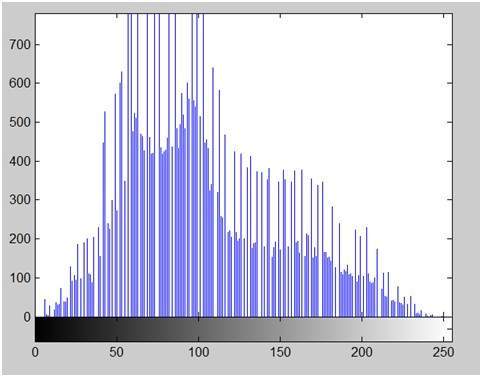
Trục x của biểu đồ hiển thị phạm vi giá trị pixel. Vì nó là một hình ảnh 8 bpp, điều đó có nghĩa là nó có 256 mức màu xám hoặc các sắc thái của màu xám trong đó. Đó là lý do tại sao phạm vi của trục x bắt đầu từ 0 và kết thúc ở 255 với khoảng cách là 50. Trong khi trên trục y, là số lượng các cường độ này.
Như bạn có thể thấy từ biểu đồ, hầu hết các thanh có tần suất cao nằm ở phần nửa đầu, phần tối hơn. Điều đó có nghĩa là hình ảnh chúng ta có sẽ tối hơn. Và điều này cũng có thể được chứng minh từ hình ảnh.
Các ứng dụng của Biểu đồ:
Biểu đồ có nhiều công dụng trong xử lý ảnh. Việc sử dụng đầu tiên như nó cũng đã được thảo luận ở trên là phân tích hình ảnh. Chúng ta có thể dự đoán về một hình ảnh chỉ bằng cách nhìn vào biểu đồ của nó. Nó giống như một bức ảnh X quang của một bộ xương của một cơ thể.
Cách sử dụng thứ hai của biểu đồ là cho mục đích độ sáng. Biểu đồ có ứng dụng rộng rãi trong độ sáng hình ảnh. Không chỉ về độ sáng mà biểu đồ cũng được sử dụng để điều chỉnh độ tương phản của hình ảnh.
Một công dụng quan trọng khác của biểu đồ là cân bằng hình ảnh.
Và cuối cùng nhưng không kém phần quan trọng, biểu đồ được sử dụng rộng rãi trong việc tạo ngưỡng. Điều này chủ yếu được sử dụng trong thị giác máy tính.
Độ sáng:
Độ sáng là một thuật ngữ tương đối. Nó phụ thuộc vào nhận thức thị giác của bạn. Vì độ sáng là một thuật ngữ tương đối, do đó độ sáng có thể được định nghĩa là lượng năng lượng do một nguồn sáng phát ra so với nguồn mà chúng ta đang so sánh với nguồn đó. Trong một số trường hợp, chúng ta có thể dễ dàng nói rằng hình ảnh sáng, và trong một số trường hợp, nó không dễ cảm nhận.
Ví dụ:
Chỉ cần nhìn vào cả hai hình ảnh này và so sánh cái nào sáng hơn.

Chúng ta có thể dễ dàng nhận thấy, hình ảnh bên phải sáng hơn so với hình ảnh bên trái.
Nhưng nếu hình ảnh bên phải được làm tối hơn so với hình ảnh đầu tiên, thì chúng ta có thể nói rằng hình ảnh bên trái sáng hơn so với hình ảnh bên trái.
Cách làm cho hình ảnh sáng hơn.
Độ sáng có thể được tăng hoặc giảm đơn giản bằng phép cộng hoặc trừ đơn giản, vào ma trận hình ảnh.
Hãy xem xét hình ảnh màu đen này gồm 5 hàng và 5 cột

Vì chúng ta đã biết, mỗi hình ảnh có một ma trận phía sau chứa các giá trị pixel. Ma trận hình ảnh này được đưa ra dưới đây.
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 |
Vì toàn bộ ma trận được điền bằng 0, và hình ảnh tối hơn rất nhiều.
Bây giờ chúng ta sẽ so sánh nó với một hình ảnh màu đen tương tự khác để xem hình ảnh này có sáng hơn hay không.

Vẫn là cả hai hình ảnh giống nhau, bây giờ chúng ta sẽ thực hiện một số thao tác trên image1, do đó nó trở nên sáng hơn so với hình thứ hai.
Những gì chúng ta sẽ làm là chúng ta chỉ cần thêm giá trị 1 vào mỗi giá trị ma trận của hình ảnh 1. Sau khi thêm hình ảnh 1 sẽ giống như thế này.
Bây giờ chúng ta sẽ một lần nữa so sánh nó với hình ảnh 2, và xem bất kỳ sự khác biệt nào.
Chúng tôi thấy, chúng tôi vẫn không thể nói hình ảnh nào sáng hơn vì cả hai hình ảnh trông giống nhau.
Bây giờ những gì chúng ta sẽ làm, là chúng ta sẽ thêm 50 vào mỗi giá trị ma trận của hình ảnh 1 và xem hình ảnh đó đã trở thành gì.
Kết quả được đưa ra bên dưới.

Bây giờ một lần nữa, chúng ta sẽ so sánh nó với hình ảnh 2.
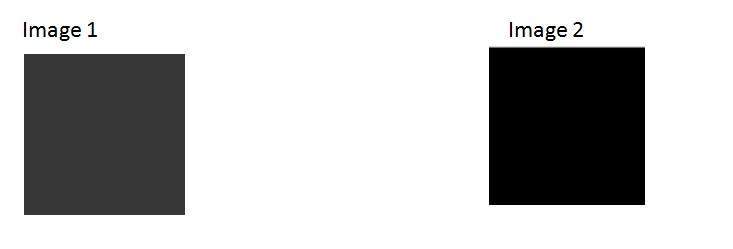
Bây giờ bạn có thể thấy rằng hình ảnh 1 sáng hơn một chút so với hình ảnh 2. Chúng tôi tiếp tục, và thêm một giá trị 45 khác vào ma trận của hình ảnh 1, và lần này chúng tôi so sánh lại cả hai hình ảnh.

Bây giờ khi bạn so sánh nó, bạn có thể thấy rằng hình ảnh này rõ ràng là sáng hơn so với hình ảnh 2.
Ngay cả khi nó sáng hơn thì hình ảnh cũ1. Tại thời điểm này, ma trận của image1 chứa 100 ở mỗi chỉ mục khi đầu tiên thêm 5, sau đó 50, rồi 45. Vì vậy, 5 + 50 + 45 = 100.
Tương phản
Độ tương phản có thể được giải thích một cách đơn giản là sự khác biệt giữa cường độ pixel tối đa và tối thiểu trong một hình ảnh.
Ví dụ.
Hãy xem xét hình ảnh cuối cùng 1 về độ sáng.

Ma trận của hình ảnh này là:
| 100 | 100 | 100 | 100 | 100 |
| 100 | 100 | 100 | 100 | 100 |
| 100 | 100 | 100 | 100 | 100 |
| 100 | 100 | 100 | 100 | 100 |
| 100 | 100 | 100 | 100 | 100 |
Giá trị lớn nhất trong ma trận này là 100.
Giá trị nhỏ nhất trong ma trận này là 100.
Độ tương phản = cường độ pixel tối đa (trừ đi) cường độ pixel tối thiểu
= 100 (trừ đi) 100
= 0
0 có nghĩa là hình ảnh này có độ tương phản 0.
Trước khi thảo luận về phép biến hình là gì, chúng ta sẽ thảo luận về phép biến hình là gì.
Sự biến đổi.
Chuyển đổi là một chức năng. Một hàm ánh xạ một bộ này sang một bộ khác sau khi thực hiện một số thao tác.
Hệ thống xử lý hình ảnh kỹ thuật số:
Chúng tôi đã thấy trong các hướng dẫn giới thiệu rằng trong xử lý hình ảnh kỹ thuật số, chúng tôi sẽ phát triển một hệ thống có đầu vào là hình ảnh và đầu ra cũng là hình ảnh. Và hệ thống sẽ thực hiện một số xử lý trên hình ảnh đầu vào và đưa ra đầu ra của nó dưới dạng hình ảnh đã xử lý. Nó được hiển thị bên dưới.
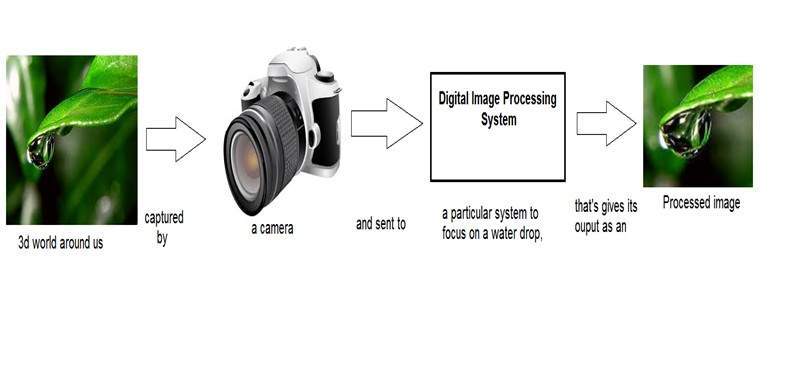
Bây giờ hàm được áp dụng bên trong hệ thống kỹ thuật số này xử lý một hình ảnh và chuyển nó thành đầu ra có thể được gọi là hàm chuyển đổi.
Vì nó cho thấy sự chuyển đổi hoặc mối quan hệ, rằng cách hình ảnh1 được chuyển đổi thành hình ảnh2.
Sự biến đổi hình ảnh.
Hãy xem xét phương trình này
G (x, y) = T {f (x, y)}
Trong phương trình này,
F (x, y) = hình ảnh đầu vào mà hàm biến đổi phải được áp dụng.
G (x, y) = hình ảnh đầu ra hoặc hình ảnh đã xử lý.
T là hàm biến đổi.
Mối quan hệ này giữa hình ảnh đầu vào và hình ảnh đầu ra đã xử lý cũng có thể được biểu diễn dưới dạng.
s = T (r)
trong đó r thực sự là giá trị pixel hoặc cường độ mức xám của f (x, y) tại bất kỳ điểm nào. Và s là giá trị pixel hoặc cường độ mức xám của g (x, y) tại bất kỳ điểm nào.
Chuyển đổi mức xám cơ bản đã được thảo luận trong hướng dẫn của chúng tôi về các chuyển đổi mức xám cơ bản.
Bây giờ chúng ta sẽ thảo luận về một số hàm biến đổi rất cơ bản.
Ví dụ:
Hãy xem xét hàm biến đổi này.
Cho phép lấy điểm r là 256 và điểm p là 127. Coi hình ảnh này là một hình ảnh bpp. Điều đó có nghĩa là chúng ta chỉ có hai mức cường độ là 0 và 1. Vì vậy, trong trường hợp này, phép biến đổi được biểu thị bằng biểu đồ có thể được giải thích là.
Tất cả các giá trị cường độ pixel dưới 127 (điểm p) là 0, có nghĩa là màu đen. Và tất cả các giá trị cường độ pixel lớn hơn 127, là 1, có nghĩa là màu trắng. Nhưng tại điểm chính xác của 127, có một sự thay đổi đột ngột trong quá trình truyền dẫn, vì vậy chúng ta không thể nói rằng tại thời điểm chính xác đó, giá trị sẽ là 0 hay 1.
Về mặt toán học, hàm biến đổi này có thể được ký hiệu là:
Hãy xem xét một chuyển đổi khác như thế này:
Bây giờ nếu bạn nhìn vào biểu đồ cụ thể này, bạn sẽ thấy một đường chuyển tiếp thẳng giữa hình ảnh đầu vào và hình ảnh đầu ra.
Nó cho thấy rằng đối với mỗi pixel hoặc giá trị cường độ của hình ảnh đầu vào, có cùng một giá trị cường độ của hình ảnh đầu ra. Điều đó có nghĩa là hình ảnh đầu ra là bản sao chính xác của hình ảnh đầu vào.
Nó có thể được biểu diễn toán học như sau:
g (x, y) = f (x, y)
hình ảnh đầu vào và đầu ra trong trường hợp này được hiển thị bên dưới.

Khái niệm cơ bản về biểu đồ đã được thảo luận trong phần hướng dẫn Giới thiệu về biểu đồ. Nhưng chúng tôi sẽ giới thiệu sơ lược về biểu đồ ở đây.
Biểu đồ:
Biểu đồ không là gì khác ngoài một biểu đồ thể hiện tần suất xuất hiện của dữ liệu. Biểu đồ có nhiều công dụng trong xử lý hình ảnh, trong đó chúng ta sẽ thảo luận về một người dùng ở đây được gọi là biểu đồ trượt.
Biểu đồ trượt.
Trong biểu đồ trượt, chúng ta chỉ cần chuyển một biểu đồ hoàn chỉnh sang phải hoặc sang trái. Do sự dịch chuyển hoặc trượt của biểu đồ về phía phải hoặc trái, có thể thấy sự thay đổi rõ ràng trong hình ảnh. Trong hướng dẫn này, chúng ta sẽ sử dụng biểu đồ trượt để điều chỉnh độ sáng.
Thuật ngữ tức là: Độ sáng đã được thảo luận trong hướng dẫn giới thiệu về độ sáng và độ tương phản của chúng tôi. Nhưng chúng ta sẽ định nghĩa ngắn gọn ở đây.
Độ sáng:
Độ sáng là một thuật ngữ tương đối. Độ sáng có thể được định nghĩa là cường độ ánh sáng do một nguồn sáng cụ thể phát ra.
Tương phản:
Độ tương phản có thể được định nghĩa là sự khác biệt giữa cường độ pixel tối đa và tối thiểu trong một hình ảnh.
Biểu đồ trượt
Tăng độ sáng bằng cách sử dụng trượt biểu đồ
Biểu đồ của hình ảnh này đã được hiển thị bên dưới.
Trên trục y của biểu đồ này là tần suất hoặc số lượng. Và trên trục x, chúng ta có các giá trị mức xám. Như bạn có thể thấy từ biểu đồ trên, các cường độ mức xám đó có số lượng lớn hơn 700, nằm ở phần nửa đầu, có nghĩa là ở phần đen hơn. Đó là lý do tại sao chúng tôi có một hình ảnh tối hơn một chút.
Để làm sáng nó, chúng ta sẽ trượt biểu đồ của nó sang phải hoặc về phía trắng hơn. Để làm được điều đó, chúng ta cần thêm giá trị ít nhất là 50 vào hình ảnh này. Bởi vì chúng ta có thể thấy từ biểu đồ ở trên, rằng hình ảnh này cũng có cường độ 0 pixel, có màu đen tuyền. Vì vậy, nếu chúng ta thêm 0 đến 50, chúng ta sẽ chuyển tất cả các giá trị nằm ở cường độ 0 sang cường độ 50 và tất cả các giá trị còn lại sẽ được dịch chuyển tương ứng.
Hãy làm nó.
Đây là những gì chúng tôi nhận được sau khi thêm 50 vào cường độ mỗi pixel.
Hình ảnh đã được hiển thị bên dưới.

Và biểu đồ của nó đã được hiển thị bên dưới.
Hãy so sánh hai hình ảnh này và biểu đồ của chúng để thấy rằng thay đổi nào cần phải có.
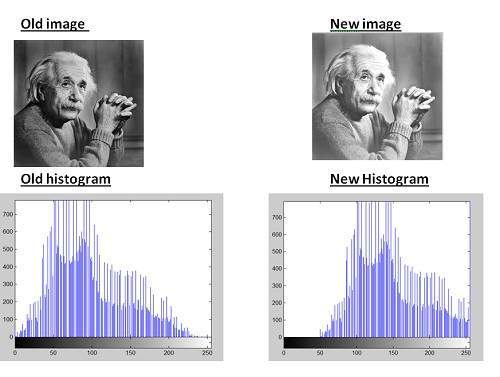
Phần kết luận:
Như chúng ta có thể thấy rõ ràng từ biểu đồ mới rằng tất cả các giá trị pixel đã được chuyển sang bên phải và hiệu ứng của nó có thể được nhìn thấy trong hình ảnh mới.
Giảm độ sáng bằng cách sử dụng trượt biểu đồ
Bây giờ nếu chúng ta giảm độ sáng của hình ảnh mới này đến mức sao cho hình ảnh cũ trông sáng hơn, chúng ta phải trừ một số giá trị khỏi tất cả ma trận của hình ảnh mới. Giá trị mà chúng ta sẽ trừ là 80. Bởi vì chúng ta đã thêm 50 vào hình ảnh ban đầu và chúng ta có một hình ảnh mới sáng hơn, bây giờ nếu chúng ta muốn làm cho nó tối hơn, chúng ta phải trừ ít nhất hơn 50 từ nó.
Và đây là những gì chúng tôi nhận được sau khi trừ đi 80 từ hình ảnh mới.
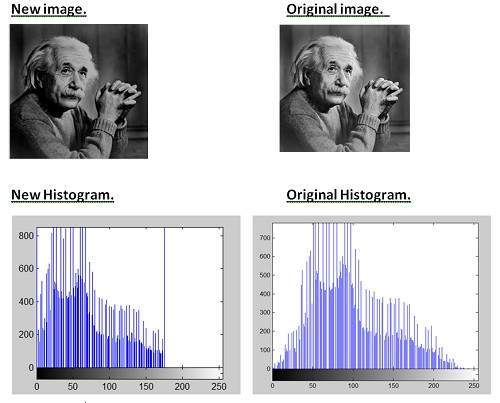
Phần kết luận:
Rõ ràng từ biểu đồ của hình ảnh mới, tất cả các giá trị pixel đã được chuyển sang phải và do đó, nó có thể được xác nhận từ hình ảnh rằng hình ảnh mới tối hơn và bây giờ hình ảnh gốc trông sáng hơn khi so sánh với hình ảnh mới này.
Một trong những ưu điểm khác của Biểu đồ mà chúng ta đã thảo luận trong phần hướng dẫn giới thiệu về biểu đồ là tăng cường độ tương phản.
Có hai phương pháp tăng cường độ tương phản. Cái đầu tiên được gọi là kéo dài Histogram để tăng độ tương phản. Phương thức thứ hai được gọi là cân bằng biểu đồ để tăng cường độ tương phản và nó đã được thảo luận trong hướng dẫn của chúng tôi về cân bằng biểu đồ.
Trước khi chúng ta thảo luận về việc kéo giãn biểu đồ để tăng độ tương phản, chúng ta sẽ định nghĩa ngắn gọn về độ tương phản.
Tương phản.
Độ tương phản là sự khác biệt giữa cường độ pixel tối đa và tối thiểu.
Hãy xem xét hình ảnh này.

Biểu đồ của hình ảnh này được hiển thị bên dưới.
Bây giờ chúng ta tính toán độ tương phản từ hình ảnh này.
Độ tương phản = 225.
Bây giờ chúng ta sẽ tăng độ tương phản của hình ảnh.
Tăng độ tương phản của hình ảnh:
Công thức kéo dài biểu đồ của hình ảnh để tăng độ tương phản là
Công thức yêu cầu tìm cường độ pixel tối thiểu và tối đa nhân với các mức độ xám. Trong trường hợp của chúng tôi, hình ảnh là 8bpp, do đó, mức độ xám là 256.
Giá trị nhỏ nhất là 0 và giá trị lớn nhất là 225. Vì vậy, công thức trong trường hợp của chúng ta là
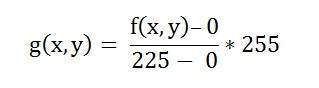
trong đó f (x, y) biểu thị giá trị của mỗi cường độ pixel. Với mỗi f (x, y) trong một hình ảnh, chúng ta sẽ tính công thức này.
Sau khi làm điều này, chúng ta sẽ có thể nâng cao độ tương phản của mình.
Hình ảnh sau đây xuất hiện sau khi áp dụng kéo giãn biểu đồ.

Biểu đồ kéo dài của hình ảnh này đã được hiển thị bên dưới.
Lưu ý hình dạng và tính đối xứng của biểu đồ. Biểu đồ hiện được kéo dài hoặc nói cách khác là mở rộng. Hãy xem nó.
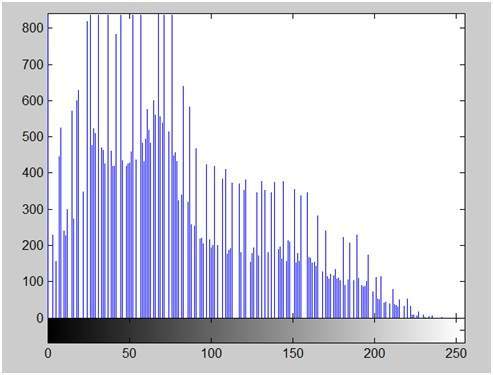
Trong trường hợp này, độ tương phản của hình ảnh có thể được tính như
Độ tương phản = 240
Do đó, chúng ta có thể nói rằng độ tương phản của hình ảnh được tăng lên.
Lưu ý: phương pháp tăng độ tương phản này không phải lúc nào cũng hoạt động, nhưng nó không thành công trong một số trường hợp.
Không kéo dài biểu đồ
Như chúng ta đã thảo luận, thuật toán không thành công trong một số trường hợp. Những trường hợp đó bao gồm hình ảnh khi có cường độ pixel 0 và 255 hiện diện trong hình ảnh
Bởi vì khi cường độ pixel 0 và 255 có trong một hình ảnh, thì trong trường hợp đó, chúng trở thành cường độ pixel tối thiểu và tối đa, điều này làm hỏng công thức như thế này.
Công thức gốc
Đặt các giá trị trường hợp không thành công trong công thức:
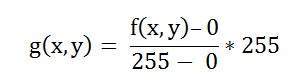
Đơn giản hóa mà biểu thức mang lại
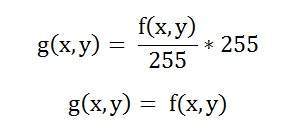
Điều đó có nghĩa là hình ảnh đầu ra bằng với hình ảnh đã xử lý. Điều đó có nghĩa là không có hiệu ứng kéo giãn biểu đồ nào được thực hiện ở hình ảnh này.
PMF và CDF đều thuộc về xác suất và thống kê. Bây giờ câu hỏi sẽ nảy sinh trong đầu bạn, đó là tại sao chúng ta lại nghiên cứu xác suất. Đó là vì hai khái niệm PMF và CDF sẽ được sử dụng trong phần hướng dẫn tiếp theo về cân bằng biểu đồ. Vì vậy, nếu bạn không biết cách tính PMF và CDF, bạn không thể áp dụng cân bằng biểu đồ trên hình ảnh của mình
PMF là gì?
PMF là viết tắt của hàm khối lượng xác suất. Như tên gợi ý, nó cung cấp xác suất của mỗi số trong tập dữ liệu hoặc bạn có thể nói rằng về cơ bản nó cung cấp số lượng hoặc tần suất của mỗi phần tử.
PMF được tính như thế nào:
Chúng tôi sẽ tính PMF từ hai cách khác nhau. Đầu tiên từ ma trận, vì trong hướng dẫn tiếp theo, chúng ta phải tính PMF từ ma trận, và một hình ảnh không hơn gì một ma trận hai chiều.
Sau đó, chúng ta sẽ lấy một ví dụ khác, trong đó chúng ta sẽ tính PMF từ biểu đồ.
Hãy xem xét ma trận này.
| 1 | 2 | 7 | 5 | 6 |
| 7 | 2 | 3 | 4 | 5 |
| 0 | 1 | 5 | 7 | 3 |
| 1 | 2 | 5 | 6 | 7 |
| 6 | 1 | 0 | 3 | 4 |
Bây giờ nếu chúng ta tính toán PMF của ma trận này, thì đây là cách chúng ta sẽ thực hiện.
Lúc đầu, chúng ta sẽ lấy giá trị đầu tiên trong ma trận, và sau đó chúng ta sẽ đếm, thời gian giá trị này xuất hiện trong toàn bộ ma trận là bao nhiêu. Sau khi đếm, chúng có thể được biểu diễn trong biểu đồ hoặc trong một bảng như sau.
PMF
| 0 | 2 | 25/2 |
| 1 | 4 | 25/4 |
| 2 | 3 | 3/25 |
| 3 | 3 | 3/25 |
| 4 | 2 | 25/2 |
| 5 | 4 | 25/4 |
| 6 | 3 | 3/25 |
| 7 | 4 | 25/4 |
Lưu ý rằng tổng số đếm phải bằng tổng số giá trị.
Tính toán PMF từ biểu đồ
Biểu đồ trên hiển thị tần số của các giá trị mức xám cho hình ảnh 8 bit trên mỗi pixel.
Bây giờ nếu chúng ta phải tính PMF của nó, chúng ta sẽ đơn giản nhìn vào số lượng của mỗi thanh từ trục tung và sau đó chia nó cho tổng số.
Vì vậy, PMF của biểu đồ trên là thế này.
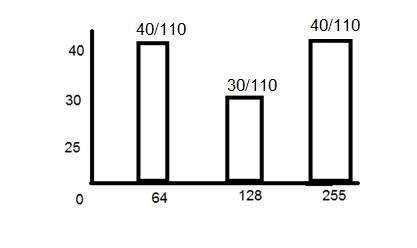
Một điều quan trọng khác cần lưu ý trong biểu đồ trên là nó không tăng đơn điệu. Vì vậy, để tăng nó một cách đơn điệu, chúng ta sẽ tính CDF của nó.
CDF là gì?
CDF là viết tắt của hàm phân phối tích lũy. Đây là một hàm tính tổng tích lũy của tất cả các giá trị được tính bằng PMF. Về cơ bản nó tính tổng số trước đó.
Nó được tính như thế nào?
Chúng tôi sẽ tính CDF bằng cách sử dụng biểu đồ. Đây là cách nó được thực hiện. Xem xét biểu đồ hiển thị ở trên cho thấy PMF.
Vì biểu đồ này không tăng đơn điệu, vì vậy sẽ làm cho nó phát triển đơn điệu.
Chúng tôi chỉ cần giữ nguyên giá trị đầu tiên, sau đó ở giá trị thứ 2, chúng tôi sẽ thêm giá trị đầu tiên, v.v.
Đây là CDF của hàm PMF ở trên.
Bây giờ, như bạn có thể thấy từ biểu đồ trên, giá trị đầu tiên của PMF vẫn như cũ. Giá trị thứ hai của PMF được thêm vào giá trị đầu tiên và được đặt trên 128. Giá trị thứ ba của PMF được thêm vào giá trị thứ hai của CDF, cho 110/110, bằng 1.
Và giờ đây, hàm đang phát triển đơn điệu, đây là điều kiện cần thiết để cân bằng biểu đồ.
Sử dụng PMF và CDF trong cân bằng biểu đồ
Biểu đồ cân bằng.
Cân bằng biểu đồ được thảo luận trong hướng dẫn tiếp theo nhưng phần giới thiệu ngắn gọn về cân bằng biểu đồ được đưa ra bên dưới.
Cân bằng biểu đồ được sử dụng để nâng cao độ tương phản của hình ảnh.
PMF và CDF đều được sử dụng trong việc cân bằng biểu đồ như nó được mô tả trong phần đầu của hướng dẫn này. Trong cân bằng biểu đồ, bước đầu tiên và bước thứ hai là PMF và CDF. Vì trong cân bằng biểu đồ, chúng ta phải cân bằng tất cả các giá trị pixel của một hình ảnh. Vì vậy, PMF giúp chúng ta tính toán xác suất của mỗi giá trị pixel trong một hình ảnh. Và CDF cho chúng ta tổng tích lũy của các giá trị này. Hơn nữa, CDF này được nhân với các cấp, để tìm cường độ pixel mới, được ánh xạ thành các giá trị cũ và biểu đồ của bạn được cân bằng.
Chúng tôi đã thấy rằng độ tương phản có thể được tăng lên bằng cách sử dụng kéo giãn biểu đồ. Trong hướng dẫn này, chúng ta sẽ thấy rằng cách cân bằng biểu đồ có thể được sử dụng để nâng cao độ tương phản.
Trước khi thực hiện cân bằng biểu đồ, bạn phải biết hai khái niệm quan trọng được sử dụng để cân bằng biểu đồ. Hai khái niệm này được gọi là PMF và CDF.
Chúng được thảo luận trong hướng dẫn của chúng tôi về PMF và CDF. Vui lòng truy cập chúng để nắm bắt thành công khái niệm cân bằng biểu đồ.
Biểu đồ cân bằng:
Cân bằng biểu đồ được sử dụng để nâng cao độ tương phản. Điều này không cần thiết phải luôn tăng độ tương phản. Có thể có một số trường hợp cân bằng biểu đồ có thể tồi tệ hơn. Trong trường hợp đó, độ tương phản bị giảm.
Hãy bắt đầu cân bằng biểu đồ bằng cách lấy hình ảnh dưới đây làm hình ảnh đơn giản.
Hình ảnh
Biểu đồ của hình ảnh này:
Biểu đồ của hình ảnh này đã được hiển thị bên dưới.
Bây giờ chúng ta sẽ thực hiện cân bằng biểu đồ cho nó.
PMF:
First we have to calculate the PMF (probability mass function) of all the pixels in this image. If you donot know how to calculate PMF, please visit our tutorial of PMF calculation.
CDF:
Our next step involves calculation of CDF (cumulative distributive function). Again if you donot know how to calculate CDF , please visit our tutorial of CDF calculation.
Calculate CDF according to gray levels
Lets for instance consider this , that the CDF calculated in the second step looks like this.
| Gray Level Value | CDF |
|---|---|
| 0 | 0.11 |
| 1 | 0.22 |
| 2 | 0.55 |
| 3 | 0.66 |
| 4 | 0.77 |
| 5 | 0.88 |
| 6 | 0.99 |
| 7 | 1 |
Then in this step you will multiply the CDF value with (Gray levels (minus) 1) .
Considering we have an 3 bpp image. Then number of levels we have are 8. And 1 subtracts 8 is 7. So we multiply CDF by 7. Here what we got after multiplying.
| Gray Level Value | CDF | CDF * (Levels-1) |
|---|---|---|
| 0 | 0.11 | 0 |
| 1 | 0.22 | 1 |
| 2 | 0.55 | 3 |
| 3 | 0.66 | 4 |
| 4 | 0.77 | 5 |
| 5 | 0.88 | 6 |
| 6 | 0.99 | 6 |
| 7 | 1 | 7 |
Now we have is the last step , in which we have to map the new gray level values into number of pixels.
Lets assume our old gray levels values has these number of pixels.
| Gray Level Value | Frequency |
|---|---|
| 0 | 2 |
| 1 | 4 |
| 2 | 6 |
| 3 | 8 |
| 4 | 10 |
| 5 | 12 |
| 6 | 14 |
| 7 | 16 |
Now if we map our new values to , then this is what we got.
| Gray Level Value | New Gray Level Value | Frequency |
|---|---|---|
| 0 | 0 | 2 |
| 1 | 1 | 4 |
| 2 | 3 | 6 |
| 3 | 4 | 8 |
| 4 | 5 | 10 |
| 5 | 6 | 12 |
| 6 | 6 | 14 |
| 7 | 7 | 16 |
Now map these new values you are onto histogram , and you are done.
Lets apply this technique to our original image. After applying we got the following image and its following histogram.
Histogram Equalization Image

Cumulative Distributive function of this image
Histogram Equalization histogram
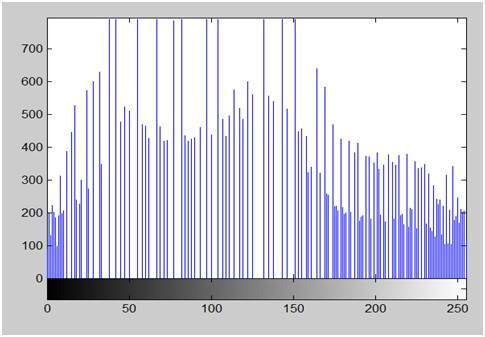
Comparing both the histograms and images

Conclusion
As you can clearly see from the images that the new image contrast has been enhanced and its histogram has also been equalized. There is also one important thing to be note here that during histogram equalization the overall shape of the histogram changes, where as in histogram stretching the overall shape of histogram remains same.
We have discussed some of the basic transformations in our tutorial of Basic transformation. In this tutorial we will look at some of the basic gray level transformations.
Image enhancement
Enhancing an image provides better contrast and a more detailed image as compare to non enhanced image. Image enhancement has very applications. It is used to enhance medical images , images captured in remote sensing , images from satellite e.t.c
The transformation function has been given below
s = T ( r )
where r is the pixels of the input image and s is the pixels of the output image. T is a transformation function that maps each value of r to each value of s. Image enhancement can be done through gray level transformations which are discussed below.
Gray level transformation
There are three basic gray level transformation.
Linear
Logarithmic
Power – law
The overall graph of these transitions has been shown below.
Linear transformation
First we will look at the linear transformation. Linear transformation includes simple identity and negative transformation. Identity transformation has been discussed in our tutorial of image transformation, but a brief description of this transformation has been given here.
Identity transition is shown by a straight line. In this transition, each value of the input image is directly mapped to each other value of output image. That results in the same input image and output image. And hence is called identity transformation. It has been shown below
Negative transformation
The second linear transformation is negative transformation, which is invert of identity transformation. In negative transformation, each value of the input image is subtracted from the L-1 and mapped onto the output image.
The result is somewhat like this.
Input Image

Output Image

In this case the following transition has been done.
s = (L – 1) – r
since the input image of Einstein is an 8 bpp image , so the number of levels in this image are 256. Putting 256 in the equation, we get this
s = 255 – r
So each value is subtracted by 255 and the result image has been shown above. So what happens is that , the lighter pixels become dark and the darker picture becomes light. And it results in image negative.
It has been shown in the graph below.
Logarithmic transformations:
Logarithmic transformation further contains two type of transformation. Log transformation and inverse log transformation.
Log transformation
The log transformations can be defined by this formula
s = c log(r + 1).
Where s and r are the pixel values of the output and the input image and c is a constant. The value 1 is added to each of the pixel value of the input image because if there is a pixel intensity of 0 in the image, then log (0) is equal to infinity. So 1 is added , to make the minimum value at least 1.
During log transformation , the dark pixels in an image are expanded as compare to the higher pixel values. The higher pixel values are kind of compressed in log transformation. This result in following image enhancement.
The value of c in the log transform adjust the kind of enhancement you are looking for.
Hình ảnh đầu vào

Nhật ký Tranform Image

Phép biến đổi log nghịch đảo ngược lại với phép biến đổi log.
Quyền lực - Các phép biến đổi luật
Còn có hai phép biến đổi nữa là phép biến đổi luật lũy thừa, bao gồm phép biến đổi lũy thừa thứ n và phép biến đổi gốc thứ n. Các phép biến đổi này có thể được cho bởi biểu thức:
s = cr ^ γ
Ký hiệu γ này được gọi là gamma, do đó biến đổi này còn được gọi là biến đổi gamma.
Sự thay đổi trong giá trị của γ sẽ thay đổi mức độ nâng cao của hình ảnh. Các thiết bị / màn hình hiển thị khác nhau có hiệu chỉnh gamma riêng, đó là lý do tại sao chúng hiển thị hình ảnh ở cường độ khác nhau.
Loại biến đổi này được sử dụng để nâng cao hình ảnh cho các loại thiết bị hiển thị khác nhau. Gamma của các thiết bị hiển thị khác nhau là khác nhau. Ví dụ Gamma của CRT nằm trong khoảng từ 1,8 đến 2,5, có nghĩa là hình ảnh hiển thị trên CRT là tối.
Hiệu chỉnh gamma.
s = cr ^ γ
s = cr ^ (1 / 2,5)
Cùng một hình ảnh nhưng với các giá trị gamma khác nhau đã được hiển thị ở đây.
Ví dụ:
Gamma = 10

Gamma = 8

Gamma = 6

Hướng dẫn này nói về một trong những khái niệm rất quan trọng về tín hiệu và hệ thống. Chúng ta sẽ hoàn toàn thảo luận về tích chập. Nó là gì? Tại sao lại như vậy? Chúng ta có thể đạt được gì với nó?
Chúng ta sẽ bắt đầu thảo luận về tích chập từ những điều cơ bản về xử lý ảnh.
Xử lý ảnh là gì.
Như chúng ta đã thảo luận trong phần giới thiệu về hướng dẫn xử lý hình ảnh và tín hiệu và hệ thống rằng xử lý hình ảnh ít nhiều là nghiên cứu các tín hiệu và hệ thống bởi vì hình ảnh không là gì ngoài tín hiệu hai chiều.
Chúng tôi cũng đã thảo luận rằng trong xử lý hình ảnh, chúng tôi đang phát triển một hệ thống có đầu vào là hình ảnh và đầu ra sẽ là hình ảnh. Điều này được biểu thị bằng hình ảnh.
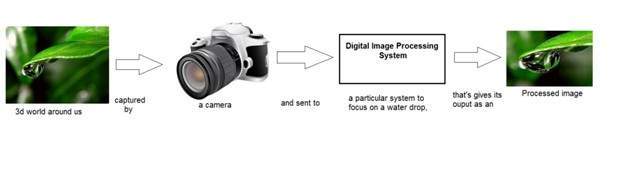
Hộp được hiển thị trong hình trên được gắn nhãn là “Hệ thống xử lý hình ảnh kỹ thuật số” có thể được coi là hộp đen
Nó có thể được trình bày tốt hơn là:

Chúng ta đã đến đâu cho đến bây giờ
Cho đến bây giờ chúng ta đã thảo luận về hai phương pháp quan trọng để thao tác hình ảnh. Hay nói cách khác, chúng ta có thể nói rằng, hộp đen của chúng ta hoạt động theo hai cách khác nhau cho đến thời điểm hiện tại.
Hai cách khác nhau để điều khiển hình ảnh là
Graphs (Histograms)

Phương pháp này được gọi là xử lý biểu đồ. Chúng tôi đã thảo luận chi tiết về nó trong các hướng dẫn trước để tăng độ tương phản, cải thiện hình ảnh, độ sáng, v.v.
Transformation functions
Phương pháp này được gọi là phép biến đổi, trong đó chúng ta đã thảo luận về các loại phép biến đổi khác nhau và một số phép biến đổi mức xám
Một cách khác để xử lý hình ảnh
Ở đây chúng ta sẽ thảo luận về một phương pháp xử lý hình ảnh khác. Phương pháp khác này được gọi là tích chập. Thông thường hộp đen (hệ thống) được sử dụng để xử lý ảnh là hệ thống LTI hoặc hệ thống bất biến thời gian tuyến tính. Theo tuyến tính, chúng tôi có nghĩa là một hệ thống mà đầu ra luôn luôn tuyến tính, không phải log hay số mũ hay bất kỳ thứ gì khác. Và theo thời gian bất biến, chúng tôi có nghĩa là một hệ thống vẫn giữ nguyên trong thời gian.
Vì vậy, bây giờ chúng ta sẽ sử dụng phương pháp thứ ba này. Nó có thể được biểu diễn dưới dạng.

Nó có thể được biểu diễn bằng toán học theo hai cách
g(x,y) = h(x,y) * f(x,y)
Nó có thể được giải thích là "mặt nạ biến đổi với một hình ảnh".
Hoặc là
g(x,y) = f(x,y) * h(x,y)
Nó có thể được giải thích là "hình ảnh biến đổi với mặt nạ".
Có hai cách để biểu diễn điều này vì toán tử tích chập (*) là giao hoán. H (x, y) là mặt nạ hoặc bộ lọc.
Mặt nạ là gì?
Mặt nạ cũng là một tín hiệu. Nó có thể được biểu diễn bằng một ma trận hai chiều. Mặt nạ thường có thứ tự là 1x1, 3x3, 5x5, 7x7. Một mặt nạ luôn phải ở số lẻ, bởi vì khôn ngoan khác bạn không thể tìm thấy phần giữa của mặt nạ. Tại sao chúng ta cần tìm phần giữa của mặt nạ. Câu trả lời nằm bên dưới, về chủ đề, làm thế nào để thực hiện tích chập?
Làm thế nào để thực hiện tích chập?
Để thực hiện tích chập trên một hình ảnh, cần thực hiện các bước sau.
Chỉ lật mặt nạ (theo chiều ngang và chiều dọc) một lần
Trượt mặt nạ lên hình ảnh.
Nhân các phần tử tương ứng và sau đó thêm chúng
Lặp lại quy trình này cho đến khi tất cả các giá trị của hình ảnh đã được tính toán.
Ví dụ về tích chập
Hãy thực hiện một số tích chập. Bước 1 là lật mặt nạ.
Mặt nạ:
Hãy lấy mặt nạ của chúng tôi để làm điều này.
| 1 | 2 | 3 |
| 4 | 5 | 6 |
| 7 | số 8 | 9 |
Lật mặt nạ theo chiều ngang
| 3 | 2 | 1 |
| 6 | 5 | 4 |
| 9 | số 8 | 7 |
Lật mặt nạ theo chiều dọc
| 9 | số 8 | 7 |
| 6 | 5 | 4 |
| 3 | 2 | 1 |
Hình ảnh:
Hãy coi một hình ảnh như thế này
| 2 | 4 | 6 |
| số 8 | 10 | 12 |
| 14 | 16 | 18 |
Convolution
Chuyển đổi mặt nạ trên hình ảnh. Nó được thực hiện theo cách này. Đặt tâm của mặt nạ tại mỗi phần tử của hình ảnh. Nhân các phần tử tương ứng, sau đó thêm chúng và dán kết quả vào phần tử của hình ảnh mà bạn đặt tâm mặt nạ.
Hộp có màu đỏ là mặt nạ và các giá trị màu cam là giá trị của mặt nạ. Hộp màu đen và các giá trị thuộc về hình ảnh. Bây giờ đối với pixel đầu tiên của hình ảnh, giá trị sẽ được tính là
Pixel đầu tiên = (5 * 2) + (4 * 4) + (2 * 8) + (1 * 10)
= 10 + 16 + 16 + 10
= 52
Đặt 52 trong ảnh gốc ở chỉ mục đầu tiên và lặp lại quy trình này cho mỗi pixel của ảnh.
Tại sao Convolution
Convolution có thể đạt được điều gì đó mà hai phương pháp điều khiển hình ảnh trước đây không thể đạt được. Chúng bao gồm làm mờ, làm sắc nét, phát hiện cạnh, giảm tiếng ồn, v.v.
Mặt nạ là gì.
Mặt nạ là một bộ lọc. Khái niệm về che hay còn được gọi là lọc không gian. Mặt nạ còn được gọi là lọc. Trong khái niệm này, chúng ta chỉ xử lý hoạt động lọc được thực hiện trực tiếp trên hình ảnh.
Một mặt nạ mẫu đã được hiển thị bên dưới
| -1 | 0 | 1 |
| -1 | 0 | 1 |
| -1 | 0 | 1 |
Lọc là gì.
Quá trình lọc còn được gọi là biến đổi mặt nạ với một hình ảnh. Vì quá trình này giống với quá trình tích chập nên mặt nạ bộ lọc còn được gọi là mặt nạ tích chập.
Nó được thực hiện như thế nào.
Quy trình chung của lọc và áp dụng mặt nạ bao gồm việc di chuyển mặt nạ bộ lọc từ điểm này sang điểm khác trong hình ảnh. Tại mỗi điểm (x, y) của ảnh gốc, phản hồi của một bộ lọc được tính bằng một mối quan hệ xác định trước. Tất cả các giá trị bộ lọc đã được xác định trước và là một tiêu chuẩn.
Các loại bộ lọc
Nói chung có hai loại bộ lọc. Một được gọi là bộ lọc tuyến tính hoặc bộ lọc làm mịn và những bộ khác được gọi là bộ lọc miền tần số.
Tại sao bộ lọc được sử dụng?
Bộ lọc được áp dụng trên hình ảnh cho nhiều mục đích. Hai cách sử dụng phổ biến nhất như sau:
Bộ lọc được sử dụng để làm mờ và giảm nhiễu
Bộ lọc được sử dụng hoặc phát hiện cạnh và độ sắc nét
Làm mờ và giảm tiếng ồn:
Bộ lọc được sử dụng phổ biến nhất để làm mờ và giảm nhiễu. Làm mờ được sử dụng trong các bước xử lý trước, chẳng hạn như loại bỏ các chi tiết nhỏ khỏi hình ảnh trước khi trích xuất đối tượng lớn.
Mặt nạ để làm mờ.
Các mặt nạ phổ biến để làm mờ là.
Bộ lọc hộp
Bộ lọc trung bình có trọng số
Trong quá trình làm mờ, chúng tôi giảm nội dung cạnh trong hình ảnh và cố gắng làm cho quá trình chuyển đổi giữa các cường độ pixel khác nhau mượt mà nhất có thể.
Giảm nhiễu cũng có thể với sự trợ giúp của hiệu ứng làm mờ.
Phát hiện cạnh và độ sắc nét:
Mặt nạ hoặc bộ lọc cũng có thể được sử dụng để phát hiện cạnh trong hình ảnh và để tăng độ sắc nét của hình ảnh.
Các cạnh là gì.
Chúng ta cũng có thể nói rằng những thay đổi đột ngột của sự gián đoạn trong một hình ảnh được gọi là các cạnh. Các chuyển đổi đáng kể trong một hình ảnh được gọi là các cạnh. Hình ảnh có các cạnh được hiển thị bên dưới.
Hình ảnh gốc.

Cùng một hình với các cạnh

Giới thiệu ngắn gọn về làm mờ đã được thảo luận trong hướng dẫn trước đây của chúng tôi về khái niệm mặt nạ, nhưng chúng tôi sẽ chính thức thảo luận ở đây.
Làm mờ
Khi làm mờ, chúng tôi đơn giản làm mờ một hình ảnh. Một hình ảnh trông sắc nét hơn hoặc chi tiết hơn nếu chúng ta có thể cảm nhận chính xác tất cả các đối tượng và hình dạng của chúng trong đó. Ví dụ. Một hình ảnh có khuôn mặt, trông rõ ràng khi chúng ta có thể xác định được mắt, tai, mũi, môi, trán ... rất rõ ràng. Hình dạng này của một vật thể là do các cạnh của nó. Vì vậy, trong việc làm mờ, chúng tôi đơn giản giảm nội dung cạnh và làm cho hình thức chuyển đổi màu này sang màu khác rất mượt mà.
Làm mờ và thu phóng.
Bạn có thể đã thấy hình ảnh bị mờ khi bạn phóng to hình ảnh. Khi bạn thu phóng hình ảnh bằng cách sử dụng sao chép pixel và hệ số thu phóng được tăng lên, bạn sẽ thấy hình ảnh bị mờ. Hình ảnh này cũng có ít chi tiết hơn, nhưng nó không phải là mờ thực sự.
Bởi vì khi phóng to, bạn thêm các pixel mới vào hình ảnh, điều này làm tăng tổng số pixel trong một hình ảnh, trong khi khi làm mờ, số pixel của hình ảnh bình thường và hình ảnh bị mờ vẫn như nhau.
Ví dụ phổ biến về một hình ảnh bị mờ.

Các loại bộ lọc.
Làm mờ có thể đạt được bằng nhiều cách. Loại bộ lọc phổ biến được sử dụng để thực hiện làm mờ là.
Bộ lọc trung bình
Bộ lọc trung bình có trọng số
Bộ lọc Gaussian
Trong số ba điều này, chúng ta sẽ thảo luận về hai điều đầu tiên ở đây và Gaussian sẽ được thảo luận sau trong các hướng dẫn sắp tới.
Bộ lọc trung bình.
Bộ lọc trung bình còn được gọi là bộ lọc hộp và bộ lọc trung bình. Bộ lọc trung bình có các thuộc tính sau.
Nó phải được đặt hàng lẻ
Tổng của tất cả các phần tử phải là 1
Tất cả các yếu tố phải giống nhau
Nếu chúng ta tuân theo quy tắc này, thì đối với mặt nạ 3x3. Chúng tôi nhận được kết quả sau đây.
| 1/9 | 1/9 | 1/9 |
| 1/9 | 1/9 | 1/9 |
| 1/9 | 1/9 | 1/9 |
Vì nó là mặt nạ 3x3, có nghĩa là nó có 9 ô. Điều kiện để tất cả các tổng phần tử phải bằng 1 có thể đạt được bằng cách chia mỗi giá trị cho 9. Như
1/9 + 1/9 + 1/9 + 1/9 + 1/9 + 1/9 + 1/9 + 1/9 + 1/9 = 9/9 = 1
Kết quả của một mặt nạ 3x3 trên một hình ảnh được hiển thị bên dưới.
Ảnh gốc:

Bức ảnh bị mờ

Có thể là kết quả không rõ ràng. Hãy tăng độ mờ. Độ mờ có thể được tăng lên bằng cách tăng kích thước của mặt nạ. Kích thước của mặt nạ càng nhiều thì càng có nhiều vết mờ. Bởi vì với mặt nạ lớn hơn, số lượng pixel được cung cấp nhiều hơn và một quá trình chuyển đổi mượt mà được xác định.
Kết quả của mặt nạ 5x5 trên một hình ảnh được hiển thị bên dưới.
Ảnh gốc:

Bức ảnh bị mờ:

Tương tự như vậy nếu chúng ta tăng mặt nạ, độ mờ sẽ nhiều hơn và kết quả được hiển thị bên dưới.
Kết quả của một mặt nạ 7x7 trên một hình ảnh được hiển thị bên dưới.
Ảnh gốc:

Bức ảnh bị mờ:

Kết quả của một mặt nạ là 9x9 trên một hình ảnh được hiển thị bên dưới.
Ảnh gốc:

Bức ảnh bị mờ:

Kết quả của một mặt nạ 11x11 trên một hình ảnh được hiển thị bên dưới.
Ảnh gốc:

Bức ảnh bị mờ:

Bộ lọc trung bình có trọng số.
Trong bộ lọc trung bình có trọng số, chúng tôi đã cung cấp nhiều trọng số hơn cho giá trị trung tâm. Do đó sự đóng góp của trung tâm trở nên nhiều hơn so với phần còn lại của các giá trị. Do tính năng lọc trung bình có trọng số, chúng tôi thực sự có thể kiểm soát độ mờ.
Thuộc tính của bộ lọc trung bình có trọng số là.
Nó phải được đặt hàng lẻ
Tổng của tất cả các phần tử phải là 1
Trọng lượng của phần tử trung tâm phải nhiều hơn tất cả các phần tử khác
Bộ lọc 1
| 1 | 1 | 1 |
| 1 | 2 | 1 |
| 1 | 1 | 1 |
Hai thuộc tính thỏa mãn là (1 và 3). Nhưng tài sản 2 không hài lòng. Vì vậy, để thỏa mãn điều đó, chúng ta sẽ đơn giản chia toàn bộ bộ lọc cho 10 hoặc nhân nó với 1/10.
Bộ lọc 2
| 1 | 1 | 1 |
| 1 | 10 | 1 |
| 1 | 1 | 1 |
Hệ số chia = 18.
Chúng tôi đã thảo luận ngắn gọn về phát hiện cạnh trong hướng dẫn giới thiệu về mặt nạ của chúng tôi. Chúng tôi sẽ chính thức thảo luận về phát hiện cạnh ở đây.
Các cạnh là gì.
Chúng ta cũng có thể nói rằng những thay đổi đột ngột của sự gián đoạn trong một hình ảnh được gọi là các cạnh. Các chuyển đổi đáng kể trong một hình ảnh được gọi là các cạnh.
Các loại cạnh.
Nhìn chung các cạnh có ba loại:
Các cạnh ngang
Cạnh dọc
Cạnh chéo
Tại sao lại phát hiện các cạnh.
Hầu hết thông tin hình dạng của một hình ảnh được bao quanh trong các cạnh. Vì vậy, đầu tiên chúng tôi phát hiện các cạnh này trong một hình ảnh và bằng cách sử dụng các bộ lọc này và sau đó bằng cách tăng cường các vùng hình ảnh có chứa các cạnh, độ sắc nét của hình ảnh sẽ tăng lên và hình ảnh sẽ trở nên rõ ràng hơn.
Dưới đây là một số mặt nạ để phát hiện cạnh mà chúng ta sẽ thảo luận trong các hướng dẫn sắp tới.
Nhà điều hành Prewitt
Nhà điều hành Sobel
Mặt nạ la bàn Robinson
Mặt nạ la bàn Krisch
Nhà điều hành Laplacian.
Ở trên đã đề cập tất cả các bộ lọc là bộ lọc Tuyến tính hoặc bộ lọc làm mịn.
Nhà điều hành Prewitt
Toán tử Prewitt được sử dụng để phát hiện các cạnh theo chiều ngang và chiều dọc.
Nhà điều hành Sobel
Toán tử sobel rất giống với toán tử Prewitt. Nó cũng là một mặt nạ phái sinh và được sử dụng để phát hiện cạnh. Nó cũng tính toán các cạnh theo cả chiều ngang và chiều dọc.
Mặt nạ la bàn Robinson
Toán tử này còn được gọi là mặt nạ định hướng. Trong toán tử này, chúng ta lấy một mặt nạ và xoay nó theo tất cả 8 hướng chính của la bàn để tính các cạnh của mỗi hướng.
Mặt nạ Kirsch La bàn
Kirsch Compass Mask cũng là một mặt nạ phái sinh được sử dụng để tìm các cạnh. Kirsch mask cũng được sử dụng để tính toán các cạnh theo tất cả các hướng.
Nhà điều hành Laplacian.
Toán tử Laplacian cũng là một toán tử đạo hàm được sử dụng để tìm các cạnh trong một hình ảnh. Laplacian là một mặt nạ phái sinh bậc hai. Nó có thể được chia thành laplacian dương và laplacian tiêu cực.
Tất cả những mặt nạ này đều tìm thấy các cạnh. Một số tìm theo chiều ngang và chiều dọc, một số chỉ tìm theo một hướng và một số tìm thấy ở tất cả các hướng. Khái niệm tiếp theo xuất hiện sau điều này là làm sắc nét có thể được thực hiện khi các cạnh được trích xuất khỏi hình ảnh
Mài sắc:
Làm sắc nét ngược lại với làm mờ. Khi làm mờ, chúng tôi giảm nội dung cạnh và trong sharpneng, chúng tôi tăng nội dung cạnh. Vì vậy, để tăng nội dung cạnh trong một hình ảnh, trước tiên chúng ta phải tìm các cạnh.
Các cạnh có thể được tìm thấy bằng một trong bất kỳ phương pháp nào được mô tả ở trên bằng cách sử dụng bất kỳ toán tử nào. Sau khi tìm thấy các cạnh, chúng ta sẽ thêm các cạnh đó vào một hình ảnh và như vậy hình ảnh sẽ có nhiều cạnh hơn và trông nó sẽ sắc nét hơn.
Đây là một cách để làm sắc nét hình ảnh.
Hình ảnh sắc nét được hiển thị bên dưới.
Ảnh gốc

Làm sắc nét hình ảnh

Toán tử Prewitt được sử dụng để phát hiện cạnh trong ảnh. Nó phát hiện hai loại cạnh:
Các cạnh ngang
Cạnh dọc
Các cạnh được tính bằng cách sử dụng chênh lệch giữa các cường độ pixel tương ứng của một hình ảnh. Tất cả các mặt nạ được sử dụng để phát hiện cạnh còn được gọi là mặt nạ phái sinh. Bởi vì như chúng tôi đã nói nhiều lần trước đây trong loạt bài hướng dẫn rằng hình ảnh cũng là một tín hiệu nên những thay đổi trong tín hiệu chỉ có thể được tính bằng cách sử dụng sự khác biệt. Vì vậy, đó là lý do tại sao các toán tử này còn được gọi là toán tử phái sinh hoặc mặt nạ phái sinh.
Tất cả các mặt nạ phái sinh phải có các thuộc tính sau:
Dấu hiệu đối diện nên có trong mặt nạ.
Tổng mặt nạ phải bằng không.
Nhiều trọng lượng hơn đồng nghĩa với việc phát hiện nhiều cạnh hơn.
Toán tử Prewitt cung cấp cho chúng ta hai mặt nạ một để phát hiện các cạnh theo hướng ngang và một mặt nạ khác để phát hiện các cạnh theo hướng dọc.
Hướng dọc:
| -1 | 0 | 1 |
| -1 | 0 | 1 |
| -1 | 0 | 1 |
Mặt nạ trên sẽ tìm thấy các cạnh theo hướng dọc và đó là do cột số không theo hướng dọc. Khi bạn xoay mặt nạ này trên một hình ảnh, nó sẽ cung cấp cho bạn các cạnh dọc trong hình ảnh.
Làm thế nào nó hoạt động:
Khi chúng tôi áp dụng mặt nạ này trên hình ảnh, nó sẽ nổi bật các cạnh dọc. Nó đơn giản hoạt động giống như đơn hàng đầu tiên lấy và tính toán sự khác biệt của cường độ pixel trong một vùng cạnh. Vì cột trung tâm bằng 0 nên nó không bao gồm các giá trị ban đầu của hình ảnh mà nó tính toán sự khác biệt của các giá trị pixel bên phải và bên trái xung quanh cạnh đó. Điều này làm tăng cường độ cạnh và nó được nâng cao so với hình ảnh gốc.
Hướng ngang:
| -1 | -1 | -1 |
| 0 | 0 | 0 |
| 1 | 1 | 1 |
Mặt nạ trên sẽ tìm thấy các cạnh theo hướng ngang và đó là vì cột số không đó là theo hướng ngang. Khi bạn chuyển mặt nạ này vào một hình ảnh, nó sẽ làm nổi bật các cạnh ngang trong hình ảnh.
Làm thế nào nó hoạt động:
Mặt nạ này sẽ làm nổi bật các cạnh ngang trong hình ảnh. Nó cũng hoạt động trên nguyên tắc của mặt nạ trên và tính toán sự khác biệt giữa các cường độ pixel của một cạnh cụ thể. Vì hàng trung tâm của mặt nạ bao gồm các số không nên nó không bao gồm các giá trị ban đầu của cạnh trong hình ảnh mà nó tính toán sự khác biệt của cường độ pixel trên và dưới của cạnh cụ thể. Do đó làm tăng sự thay đổi đột ngột của cường độ và làm cho cạnh rõ hơn. Cả hai loại mặt nạ trên đều tuân theo nguyên tắc của mặt nạ dẫn xuất. Cả hai mặt nạ đều có dấu hiệu trái ngược nhau và cả hai mặt nạ tổng bằng không. Điều kiện thứ ba sẽ không được áp dụng trong toán tử này vì cả hai mặt nạ trên đều được chuẩn hóa và chúng tôi không thể thay đổi giá trị trong chúng.
Bây giờ là lúc để xem những mặt nạ này hoạt động:
Hình ảnh mẫu:
Sau đây là một hình ảnh mẫu mà chúng tôi sẽ áp dụng hai mặt nạ trên cùng một lúc.

Sau khi áp dụng Mặt nạ dọc:
Sau khi áp dụng mặt nạ dọc trên hình ảnh mẫu trên, sẽ thu được hình ảnh sau. Hình ảnh này có các cạnh dọc. Bạn có thể đánh giá nó một cách chính xác hơn bằng cách so sánh với hình ảnh các cạnh ngang.

Sau khi áp dụng Mặt nạ ngang:
Sau khi áp dụng mặt nạ ngang trên hình ảnh mẫu trên, sẽ thu được hình ảnh sau.

So sánh:
Như bạn có thể thấy rằng trong hình đầu tiên mà chúng tôi áp dụng mặt nạ dọc, tất cả các cạnh dọc đều hiển thị hơn hình ảnh ban đầu. Tương tự trong hình thứ hai, chúng tôi đã áp dụng mặt nạ ngang và kết quả là tất cả các cạnh ngang đều có thể nhìn thấy. Vì vậy, bằng cách này, bạn có thể thấy rằng chúng tôi có thể phát hiện cả các cạnh ngang và dọc từ một hình ảnh.
Toán tử sobel rất giống với toán tử Prewitt. Nó cũng là một mặt nạ phái sinh và được sử dụng để phát hiện cạnh. Giống như toán tử Prewitt, toán tử sobel cũng được sử dụng để phát hiện hai loại cạnh trong một hình ảnh:
Hướng dọc
Hướng ngang
Sự khác biệt với Nhà điều hành Prewitt:
Sự khác biệt chính là trong toán tử sobel, các hệ số của mặt nạ không cố định và chúng có thể được điều chỉnh theo yêu cầu của chúng tôi trừ khi chúng không vi phạm bất kỳ tính chất nào của mặt nạ phái sinh.
Sau đây là Mặt nạ dọc của Toán tử Sobel:
| -1 | 0 | 1 |
| -2 | 0 | 2 |
| -1 | 0 | 1 |
Mặt nạ này hoạt động giống hệt như mặt nạ dọc của toán tử Prewitt. Chỉ có một điểm khác biệt là nó có các giá trị “2” và “-2” ở giữa cột đầu tiên và cột thứ ba. Khi được áp dụng trên một hình ảnh, mặt nạ này sẽ làm nổi bật các cạnh dọc.
Làm thế nào nó hoạt động:
Khi chúng tôi áp dụng mặt nạ này trên hình ảnh, nó sẽ nổi bật các cạnh dọc. Nó đơn giản hoạt động giống như đơn hàng đầu tiên lấy và tính toán sự khác biệt của cường độ pixel trong một vùng cạnh.
Vì cột trung tâm bằng 0 nên nó không bao gồm các giá trị ban đầu của hình ảnh mà nó tính toán sự khác biệt của các giá trị pixel bên phải và bên trái xung quanh cạnh đó. Ngoài ra, giá trị trung tâm của cả cột thứ nhất và cột thứ ba lần lượt là 2 và -2.
Điều này cung cấp thêm tuổi trọng số cho các giá trị pixel xung quanh vùng cạnh. Điều này làm tăng cường độ cạnh và nó được nâng cao so với hình ảnh gốc.
Sau đây là Mặt nạ ngang của Toán tử Sobel:
| -1 | -2 | -1 |
| 0 | 0 | 0 |
| 1 | 2 | 1 |
Mặt nạ trên sẽ tìm thấy các cạnh theo hướng ngang và đó là vì cột số không đó là theo hướng ngang. Khi bạn chuyển mặt nạ này vào một hình ảnh, nó sẽ làm nổi bật các cạnh ngang trong hình ảnh. Sự khác biệt duy nhất giữa nó là nó có 2 và -2 là phần tử trung tâm của hàng thứ nhất và thứ ba.
Làm thế nào nó hoạt động:
Mặt nạ này sẽ làm nổi bật các cạnh ngang trong hình ảnh. Nó cũng hoạt động trên nguyên tắc của mặt nạ trên và tính toán sự khác biệt giữa các cường độ pixel của một cạnh cụ thể. Vì hàng trung tâm của mặt nạ bao gồm các số không nên nó không bao gồm các giá trị ban đầu của cạnh trong hình ảnh mà nó tính toán sự khác biệt của cường độ pixel trên và dưới của cạnh cụ thể. Do đó làm tăng sự thay đổi đột ngột của cường độ và làm cho cạnh rõ hơn.
Bây giờ là lúc để xem những mặt nạ này hoạt động:
Hình ảnh mẫu:
Sau đây là một hình ảnh mẫu mà chúng tôi sẽ áp dụng hai mặt nạ trên cùng một lúc.

Sau khi áp dụng Mặt nạ dọc:
Sau khi áp dụng mặt nạ dọc trên hình ảnh mẫu trên, sẽ thu được hình ảnh sau.

Sau khi áp dụng Mặt nạ ngang:
Sau khi đắp mặt nạ ngang trên hình ảnh mẫu trên, sẽ có được hình ảnh sau

So sánh:
Như bạn có thể thấy rằng trong hình đầu tiên mà chúng tôi áp dụng mặt nạ dọc, tất cả các cạnh dọc đều hiển thị hơn hình ảnh ban đầu. Tương tự trong hình thứ hai, chúng tôi đã áp dụng mặt nạ ngang và kết quả là tất cả các cạnh ngang đều có thể nhìn thấy.
Vì vậy, theo cách này, bạn có thể thấy rằng chúng tôi có thể phát hiện cả các cạnh ngang và dọc từ một hình ảnh. Ngoài ra, nếu bạn so sánh kết quả của toán tử sobel với toán tử Prewitt, bạn sẽ thấy rằng toán tử sobel tìm thấy nhiều cạnh hơn hoặc làm cho các cạnh hiển thị hơn so với Toán tử Prewitt.
Điều này là do trong toán tử sobel, chúng tôi đã phân bổ nhiều trọng lượng hơn cho cường độ pixel xung quanh các cạnh.
Đắp mặt nạ nhiều cân hơn
Bây giờ chúng ta cũng có thể thấy rằng nếu chúng ta đặt càng nhiều trọng lượng vào mặt nạ, thì nó sẽ càng có nhiều cạnh hơn đối với chúng ta. Cũng như đã đề cập ở phần đầu của hướng dẫn rằng không có hệ số cố định trong toán tử sobel, vì vậy đây là một toán tử có trọng số khác
| -1 | 0 | 1 |
| -5 | 0 | 5 |
| -1 | 0 | 1 |
Nếu bạn có thể so sánh kết quả của mặt nạ này với mặt nạ dọc Prewitt, rõ ràng là mặt nạ này sẽ tạo ra nhiều góc cạnh hơn so với mặt nạ Prewitt một chỉ vì chúng ta đã phân bổ nhiều trọng lượng hơn trong mặt nạ.
Mặt nạ la bàn Robinson là một loại mặt nạ riêng biệt khác được sử dụng để phát hiện cạnh. Toán tử này còn được gọi là mặt nạ định hướng. Trong toán tử này, chúng tôi lấy một mặt nạ và xoay nó theo tất cả 8 hướng chính của la bàn như sau:
North
Tây Bắc
West
Tây nam
South
Đông Nam
East
Đông bắc
Không có mặt nạ cố định. Bạn có thể lấy bất kỳ mặt nạ nào và bạn phải xoay nó để tìm các cạnh theo tất cả các hướng đã đề cập ở trên. Tất cả các mặt nạ được xoay trên cơ sở hướng của cột không.
Ví dụ, chúng ta hãy xem mặt nạ sau ở Hướng Bắc và sau đó xoay nó để tạo tất cả các mặt nạ hướng.
Mặt nạ hướng Bắc
| -1 | 0 | 1 |
| -2 | 0 | 2 |
| -1 | 0 | 1 |
Mặt nạ hướng Tây Bắc
| 0 | 1 | 2 |
| -1 | 0 | 1 |
| -2 | -1 | 0 |
Mặt nạ hướng Tây
| 1 | 2 | 1 |
| 0 | 0 | 0 |
| -1 | -2 | -1 |
Mặt nạ hướng Tây Nam
| 2 | 1 | 0 |
| 1 | 0 | -1 |
| 0 | -1 | -2 |
Mặt nạ hướng Nam
| 1 | 0 | -1 |
| 2 | 0 | -2 |
| 1 | 0 | -1 |
Mặt nạ hướng Đông Nam
| 0 | -1 | -2 |
| 1 | 0 | -1 |
| 2 | 1 | 0 |
Mặt nạ hướng đông
| -1 | -2 | -1 |
| 0 | 0 | 0 |
| 1 | 2 | 1 |
Mặt nạ hướng Đông Bắc
| -2 | -1 | 0 |
| -1 | 0 | 1 |
| 0 | 1 | 2 |
Như bạn có thể thấy rằng tất cả các hướng được bao phủ trên cơ sở hướng số không. Mỗi mặt nạ sẽ cung cấp cho bạn các cạnh trên hướng của nó. Bây giờ chúng ta hãy xem kết quả của toàn bộ mặt nạ trên. Giả sử chúng ta có một bức tranh mẫu mà từ đó chúng ta phải tìm tất cả các cạnh. Đây là hình ảnh mẫu của chúng tôi:
Hình ảnh mẫu, ảnh mẫu:

Bây giờ chúng ta sẽ áp dụng tất cả các bộ lọc trên trên hình ảnh này và chúng ta nhận được kết quả sau.
Cạnh hướng Bắc

Các cạnh hướng Tây Bắc

Cạnh hướng Tây

Viền hướng Tây Nam

Cạnh hướng Nam

Cạnh hướng Đông Nam

Cạnh hướng đông

Các cạnh hướng Đông Bắc

Như bạn có thể thấy rằng bằng cách áp dụng tất cả các mặt nạ ở trên, bạn sẽ nhận được các cạnh theo mọi hướng. Kết quả cũng phụ thuộc vào hình ảnh. Giả sử có một hình ảnh không có cạnh hướng Đông Bắc thì mặt nạ đó sẽ mất tác dụng.
Kirsch Compass Mask cũng là một mặt nạ phái sinh được sử dụng để tìm các cạnh. Điều này cũng giống như la bàn Robinson tìm các cạnh ở tất cả tám hướng của la bàn. Sự khác biệt duy nhất giữa mặt nạ la bàn Robinson và kirsch là ở Kirsch chúng tôi có một mặt nạ tiêu chuẩn nhưng ở Kirsch chúng tôi thay đổi mặt nạ theo yêu cầu của riêng mình.
Với sự trợ giúp của Mặt nạ Kirsch La bàn, chúng ta có thể tìm thấy các cạnh theo tám hướng sau đây.
North
Tây Bắc
West
Tây nam
South
Đông Nam
East
Đông bắc
Chúng tôi lấy một mặt nạ tiêu chuẩn tuân theo tất cả các thuộc tính của một mặt nạ phái sinh và sau đó xoay nó để tìm các cạnh.
Ví dụ, chúng ta hãy xem mặt nạ sau ở Hướng Bắc và sau đó xoay nó để tạo tất cả các mặt nạ hướng.
Mặt nạ hướng Bắc
| -3 | -3 | 5 |
| -3 | 0 | 5 |
| -3 | -3 | 5 |
North West Direction Mask
| -3 | 5 | 5 |
| -3 | 0 | 5 |
| -3 | -3 | -3 |
West Direction Mask
| 5 | 5 | 5 |
| -3 | 0 | -3 |
| -3 | -3 | -3 |
South West Direction Mask
| 5 | 5 | -3 |
| 5 | 0 | -3 |
| -3 | -3 | -3 |
South Direction Mask
| 5 | -3 | -3 |
| 5 | 0 | -3 |
| 5 | -3 | -3 |
South East Direction Mask
| -3 | -3 | -3 |
| 5 | 0 | -3 |
| 5 | 5 | -3 |
East Direction Mask
| -3 | -3 | -3 |
| -3 | 0 | -3 |
| 5 | 5 | 5 |
North East Direction Mask
| -3 | -3 | -3 |
| -3 | 0 | 5 |
| -3 | 5 | 5 |
As you can see that all the directions are covered and each mask will give you the edges of its own direction. Now to help you better understand the concept of these masks we will apply it on a real image. Suppose we have a sample picture from which we have to find all the edges. Here is our sample picture:
Sample Picture

Now we will apply all the above filters on this image and we get the following result.
North Direction Edges

North West Direction Edges

West Direction Edges

South West Direction Edges

South Direction Edges

South East Direction Edges

East Direction Edges

North East Direction Edges

As you can see that by applying all the above masks you will get edges in all the direction. Result is also depends on the image. Suppose there is an image, which do not have any North East direction edges so then that mask will be ineffective.
Laplacian Operator is also a derivative operator which is used to find edges in an image. The major difference between Laplacian and other operators like Prewitt, Sobel, Robinson and Kirsch is that these all are first order derivative masks but Laplacian is a second order derivative mask. In this mask we have two further classifications one is Positive Laplacian Operator and other is Negative Laplacian Operator.
Another difference between Laplacian and other operators is that unlike other operators Laplacian didn’t take out edges in any particular direction but it take out edges in following classification.
Inward Edges
Outward Edges
Let’s see that how Laplacian operator works.
Positive Laplacian Operator:
In Positive Laplacian we have standard mask in which center element of the mask should be negative and corner elements of mask should be zero.
| 0 | 1 | 0 |
| 1 | -4 | 1 |
| 0 | 1 | 0 |
Positive Laplacian Operator is use to take out outward edges in an image.
Negative Laplacian Operator:
In negative Laplacian operator we also have a standard mask, in which center element should be positive. All the elements in the corner should be zero and rest of all the elements in the mask should be -1.
| 0 | -1 | 0 |
| -1 | 4 | -1 |
| 0 | -1 | 0 |
Negative Laplacian operator is use to take out inward edges in an image
How it works:
Laplacian is a derivative operator; its uses highlight gray level discontinuities in an image and try to deemphasize regions with slowly varying gray levels. This operation in result produces such images which have grayish edge lines and other discontinuities on a dark background. This produces inward and outward edges in an image
The important thing is how to apply these filters onto image. Remember we can’t apply both the positive and negative Laplacian operator on the same image. we have to apply just one but the thing to remember is that if we apply positive Laplacian operator on the image then we subtract the resultant image from the original image to get the sharpened image. Similarly if we apply negative Laplacian operator then we have to add the resultant image onto original image to get the sharpened image.
Let’s apply these filters onto an image and see how it will get us inward and outward edges from an image. Suppose we have a following sample image.
Sample Image

After applying Positive Laplacian Operator:
After applying positive Laplacian operator we will get the following image.

After applying Negative Laplacian Operator:
After applying negative Laplacian operator we will get the following image.

We have deal with images in many domains. Now we are processing signals (images) in frequency domain. Since this Fourier series and frequency domain is purely mathematics , so we will try to minimize that math’s part and focus more on its use in DIP.
Frequency domain analysis
Till now , all the domains in which we have analyzed a signal , we analyze it with respect to time. But in frequency domain we don’t analyze signal with respect to time , but with respect of frequency.
Difference between spatial domain and frequency domain.
In spatial domain , we deal with images as it is. The value of the pixels of the image change with respect to scene. Whereas in frequency domain , we deal with the rate at which the pixel values are changing in spatial domain.
For simplicity , Let’s put it this way.
Spatial domain

In simple spatial domain , we directly deal with the image matrix. Whereas in frequency domain , we deal an image like this.
Frequency Domain
We first transform the image to its frequency distribution. Then our black box system perform what ever processing it has to performed , and the output of the black box in this case is not an image , but a transformation. After performing inverse transformation , it is converted into an image which is then viewed in spatial domain.
It can be pictorially viewed as
Here we have used the word transformation. What does it actually mean?
Transformation.
A signal can be converted from time domain into frequency domain using mathematical operators called transforms. There are many kind of transformation that does this. Some of them are given below.
Fourier Series
Fourier transformation
Laplace transform
Z transform
Out of all these , we will thoroughly discuss Fourier series and Fourier transformation in our next tutorial.
Frequency components
Any image in spatial domain can be represented in a frequency domain. But what do this frequencies actually mean.
We will divide frequency components into two major components.
High frequency components
High frequency components correspond to edges in an image.
Low frequency components
Low frequency components in an image correspond to smooth regions.
In the last tutorial of Frequency domain analysis, we discussed that Fourier series and Fourier transform are used to convert a signal to frequency domain.
Fourier
Fourier was a mathematician in 1822. He give Fourier series and Fourier transform to convert a signal into frequency domain.
Fourier Series
Fourier series simply states that , periodic signals can be represented into sum of sines and cosines when multiplied with a certain weight.It further states that periodic signals can be broken down into further signals with the following properties.
The signals are sines and cosines
The signals are harmonics of each other
It can be pictorially viewed as
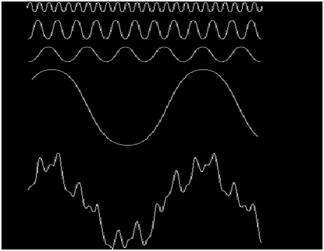
In the above signal , the last signal is actually the sum of all the above signals. This was the idea of the Fourier.
How it is calculated.
Since as we have seen in the frequency domain , that in order to process an image in frequency domain , we need to first convert it using into frequency domain and we have to take inverse of the output to convert it back into spatial domain. That’s why both Fourier series and Fourier transform has two formulas. One for conversion and one converting it back to the spatial domain.
Fourier series
The Fourier series can be denoted by this formula.
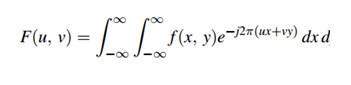
The inverse can be calculated by this formula.
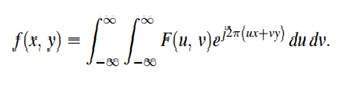
Fourier transform
The Fourier transform simply states that that the non periodic signals whose area under the curve is finite can also be represented into integrals of the sines and cosines after being multiplied by a certain weight.
The Fourier transform has many wide applications that include , image compression (e.g JPEG compression) , filtrering and image analysis.
Difference between Fourier series and transform
Although both Fourier series and Fourier transform are given by Fourier , but the difference between them is Fourier series is applied on periodic signals and Fourier transform is applied for non periodic signals
Which one is applied on images.
Now the question is that which one is applied on the images , the Fourier series or the Fourier transform. Well , the answer to this question lies in the fact that what images are. Images are non – periodic. And since the images are non periodic , so Fourier transform is used to convert them into frequency domain.
Discrete fourier transform.
Since we are dealing with images, and infact digital images , so for digital images we will be working on discrete fourier transform

Consider the above Fourier term of a sinusoid. It include three things.
Spatial Frequency
Magnitude
Phase
The spatial frequency directly relates with the brightness of the image. The magnitude of the sinusoid directly relates with the contrast. Contrast is the difference between maximum and minimum pixel intensity. Phase contains the color information.
The formula for 2 dimensional discrete Fourier transform is given below.
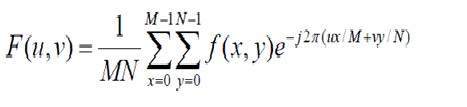
The discrete Fourier transform is actually the sampled Fourier transform, so it contains some samples that denotes an image. In the above formula f(x,y) denotes the image , and F(u,v) denotes the discrete Fourier transform. The formula for 2 dimensional inverse discrete Fourier transform is given below.
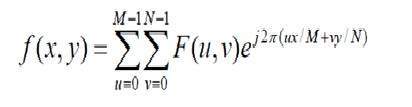
The inverse discrete Fourier transform converts the Fourier transform back to the image
Consider this signal.
Now we will see an image , whose we will calculate FFT magnitude spectrum and then shifted FFT magnitude spectrum and then we will take Log of that shifted spectrum.
Original Image

The Fourier transform magnitude spectrum

The Shifted Fourier transform

The Shifted Magnitude Spectrum

In the last tutorial , we discussed about the images in frequency domain. In this tutorial , we are going to define a relationship between frequency domain and the images(spatial domain).
For example:
Consider this example.

The same image in the frequency domain can be represented as.

Now what’s the relationship between image or spatial domain and frequency domain. This relationship can be explained by a theorem which is called as Convolution theorem.
Convolution Theorem
The relationship between the spatial domain and the frequency domain can be established by convolution theorem.
The convolution theorem can be represented as.
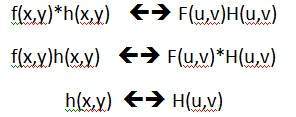
It can be stated as the convolution in spatial domain is equal to filtering in frequency domain and vice versa.
The filtering in frequency domain can be represented as following:

The steps in filtering are given below.
At first step we have to do some pre – processing an image in spatial domain, means increase its contrast or brightness
Then we will take discrete Fourier transform of the image
Then we will center the discrete Fourier transform , as we will bring the discrete Fourier transform in center from corners
Then we will apply filtering , means we will multiply the Fourier transform by a filter function
Then we will again shift the DFT from center to the corners
Last step would be take to inverse discrete Fourier transform , to bring the result back from frequency domain to spatial domain
And this step of post processing is optional , just like pre processing , in which we just increase the appearance of image.
Filters
The concept of filter in frequency domain is same as the concept of a mask in convolution.
After converting an image to frequency domain, some filters are applied in filtering process to perform different kind of processing on an image. The processing include blurring an image , sharpening an image e.t.c.
The common type of filters for these purposes are:
Ideal high pass filter
Ideal low pass filter
Gaussian high pass filter
Gaussian low pass filter
In the next tutorial, we will discuss about filter in detail.
In the last tutorial , we briefly discuss about filters. In this tutorial we will thoroughly discuss about them. Before discussing about let’s talk about masks first. The concept of mask has been discussed in our tutorial of convolution and masks.
Blurring masks vs derivative masks.
We are going to perform a comparison between blurring masks and derivative masks.
Blurring masks:
A blurring mask has the following properties.
All the values in blurring masks are positive
The sum of all the values is equal to 1
The edge content is reduced by using a blurring mask
As the size of the mask grow, more smoothing effect will take place
Derrivative masks:
A derivative mask has the following properties.
A derivative mask have positive and as well as negative values
The sum of all the values in a derivative mask is equal to zero
The edge content is increased by a derivative mask
As the size of the mask grows , more edge content is increased
Relationship between blurring mask and derivative mask with high pass filters and low pass filters.
The relationship between blurring mask and derivative mask with a high pass filter and low pass filter can be defined simply as.
Blurring masks are also called as low pass filter
Derivative masks are also called as high pass filter
High pass frequency components and Low pass frequency components
The high pass frequency components denotes edges whereas the low pass frequency components denotes smooth regions.
Ideal low pass and Ideal High pass filters
This is the common example of low pass filter.
When one is placed inside and the zero is placed outside , we got a blurred image. Now as we increase the size of 1, blurring would be increased and the edge content would be reduced.
This is a common example of high pass filter.
When 0 is placed inside, we get edges , which gives us a sketched image. An ideal low pass filter in frequency domain is given below

The ideal low pass filter can be graphically represented as
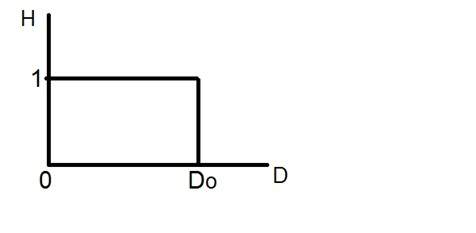
Now let’s apply this filter to an actual image and let’s see what we got.
Sample image.

Image in frequency domain

Applying filter over this image

Resultant Image

With the same way , an ideal high pass filter can be applied on an image. But obviously the results would be different as , the low pass reduces the edged content and the high pass increase it.
Gaussian Low pass and Gaussian High pass filter
Gaussian low pass and Gaussian high pass filter minimize the problem that occur in ideal low pass and high pass filter.
This problem is known as ringing effect. This is due to reason because at some points transition between one color to the other cannot be defined precisely, due to which the ringing effect appears at that point.
Have a look at this graph.
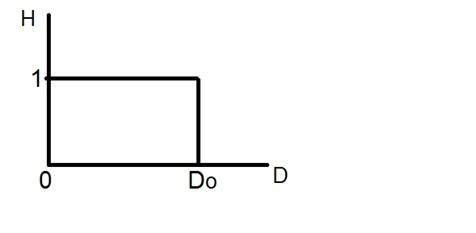
This is the representation of ideal low pass filter. Now at the exact point of Do , you cannot tell that the value would be 0 or 1. Due to which the ringing effect appears at that point.
So in order to reduce the effect that appears is ideal low pass and ideal high pass filter , the following Gaussian low pass filter and Gaussian high pass filter is introduced.
Gaussian Low pass filter
The concept of filtering and low pass remains the same, but only the transition becomes different and become more smooth.
The Gaussian low pass filter can be represented as

Note the smooth curve transition, due to which at each point, the value of Do , can be exactly defined.
Gaussian high pass filter
Gaussian high pass filter has the same concept as ideal high pass filter , but again the transition is more smooth as compared to the ideal one.
In this tutorial, we are going to talk about color spaces.
What are color spaces?
Color spaces are different types of color modes, used in image processing and signals and system for various purposes. Some of the common color spaces are:
RGB
CMY’K
Y’UV
YIQ
Y’CbCr
HSV
RGB
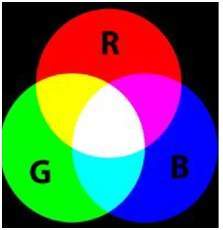
RGB is the most widely used color space , and we have already discussed it in the past tutorials. RGB stands for red green and blue.
What RGB model states , that each color image is actually formed of three different images. Red image , Blue image , and black image. A normal grayscale image can be defined by only one matrix, but a color image is actually composed of three different matrices.
One color image matrix = red matrix + blue matrix + green matrix
This can be best seen in this example below.
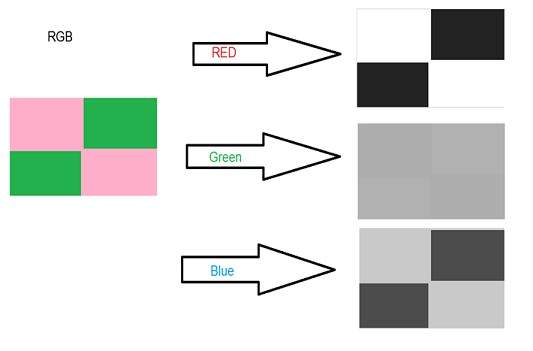
Applications of RGB
The common applications of RGB model are
Cathode ray tube (CRT)
Liquid crystal display (LCD)
Plasma Display or LED display such as a television
A compute monitor or a large scale screen
CMYK

RGB to CMY conversion
The conversion from RGB to CMY is done using this method.
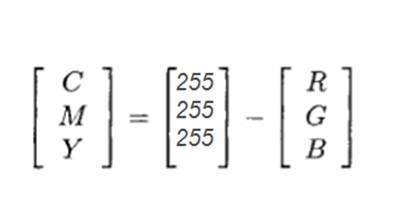
Consider you have an color image , means you have three different arrays of RED , GREEN and BLUE. Now if you want to convert it into CMY , here’s what you have to do. You have to subtract it by the maximum number of levels – 1. Each matrix is subtracted and its respective CMY matrix is filled with result.
Y’UV
Y’UV defines a color space in terms of one luma (Y’) and two chrominance (UV) components. The Y’UV color model is used in the following composite color video standards.
NTSC ( National Television System Committee)
PAL (Phase Alternating Line)
SECAM (Sequential couleur a amemoire, French for “sequential color with memory)

Y’CbCr
Y’CbCr color model contains Y’ , the luma component and cb and cr are the blue-differnece and red difference chroma components.
It is not an absolute color space. It is mainly used for digital systems
Các ứng dụng phổ biến của nó bao gồm nén JPEG và MPEG.
Y'UV thường được sử dụng làm thuật ngữ cho Y'CbCr, tuy nhiên chúng là các định dạng hoàn toàn khác nhau. Sự khác biệt chính giữa hai cái này là cái trước là analog trong khi cái sau là kỹ thuật số.

Trong hướng dẫn cuối cùng của chúng tôi về nén hình ảnh, chúng tôi thảo luận về một số kỹ thuật được sử dụng để nén
Chúng ta sẽ thảo luận về nén JPEG là nén mất dữ liệu, vì cuối cùng một số dữ liệu sẽ bị mất.
Trước tiên hãy thảo luận về nén ảnh là gì.
Nén hình ảnh
Nén ảnh là phương pháp nén dữ liệu trên ảnh kỹ thuật số.
Mục tiêu chính trong nén hình ảnh là:
Lưu trữ dữ liệu ở dạng hiệu quả
Truyền dữ liệu ở dạng hiệu quả
Nén hình ảnh có thể bị mất hoặc không mất dữ liệu.
Nén JPEG
JPEG là viết tắt của Nhóm chuyên gia nhiếp ảnh chung. Đây là tiêu chuẩn liên quốc gia đầu tiên trong việc nén hình ảnh. Nó được sử dụng rộng rãi ngày nay. Nó có thể là mất mát cũng như mất mát. Nhưng kỹ thuật mà chúng ta sẽ thảo luận ở đây hôm nay là kỹ thuật nén mất dữ liệu.
Cách nén jpeg hoạt động:
Bước đầu tiên là chia một hình ảnh thành các khối với kích thước mỗi khối là 8 x8.

Giả sử hình ảnh 8x8 này chứa các giá trị sau.
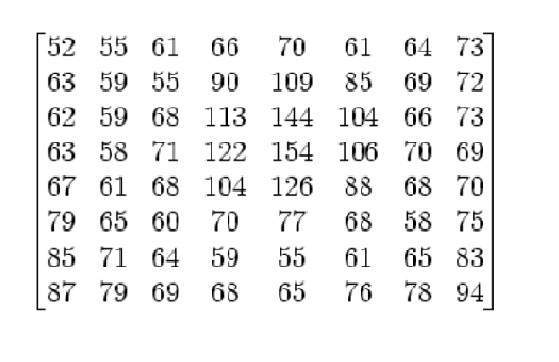
Phạm vi cường độ pixel bây giờ là từ 0 đến 255. Chúng tôi sẽ thay đổi phạm vi từ -128 thành 127.
Trừ 128 cho mỗi giá trị pixel sẽ thu được giá trị pixel từ -128 đến 127. Sau khi trừ 128 cho mỗi giá trị pixel, chúng tôi nhận được kết quả sau.

Bây giờ chúng ta sẽ tính toán bằng công thức này.
Kết quả đến từ điều này được lưu trữ trong ma trận A (j, k) giả sử.
Có một ma trận tiêu chuẩn được sử dụng để tính toán nén JPEG, được cung cấp bởi một ma trận được gọi là ma trận Độ chói.
Ma trận này được đưa ra dưới đây
Áp dụng công thức sau

Chúng tôi nhận được kết quả này sau khi nộp đơn.

Bây giờ chúng ta sẽ thực hiện thủ thuật thực sự được thực hiện trong nén JPEG, đó là chuyển động ZIG-ZAG. Trình tự zig zag cho ma trận trên được hiển thị bên dưới. Bạn phải thực hiện zig zag cho đến khi bạn tìm thấy tất cả các số 0 phía trước. Do đó hình ảnh của chúng tôi hiện đã được nén.
Summarizing JPEG compression
Bước đầu tiên là chuyển đổi một hình ảnh thành Y'CbCr và chỉ cần chọn kênh Y 'và chia thành các khối 8 x 8. Sau đó, bắt đầu từ khối đầu tiên, ánh xạ phạm vi từ -128 đến 127. Sau đó, bạn phải tìm phép biến đổi fourier rời rạc của ma trận. Kết quả của điều này nên được lượng tử hóa. Bước cuối cùng là áp dụng mã hóa theo cách zig zag và thực hiện cho đến khi bạn tìm thấy tất cả số 0.
Lưu mảng một chiều này và bạn đã hoàn tất.
Note. You have to repeat this procedure for all the block of 8 x 8.
Nhận dạng ký tự quang học thường được viết tắt là OCR. Nó bao gồm chuyển đổi cơ học và điện của hình ảnh quét của văn bản viết tay, đánh máy thành văn bản máy. Đây là phương pháp phổ biến để số hóa các văn bản in để chúng có thể được tìm kiếm điện tử, lưu trữ nhỏ gọn hơn, hiển thị trên dòng và được sử dụng trong các quy trình máy như dịch máy, chuyển văn bản thành giọng nói và khai thác văn bản.
Trong những năm gần đây, công nghệ OCR (Nhận dạng ký tự quang học) đã được áp dụng trong toàn bộ các ngành công nghiệp, tạo ra một cuộc cách mạng trong quy trình quản lý tài liệu. OCR đã cho phép các tài liệu được quét không chỉ đơn thuần là các tệp hình ảnh, biến thành các tài liệu hoàn toàn có thể tìm kiếm được với nội dung văn bản được máy tính nhận dạng. Với sự trợ giúp của OCR, mọi người không còn cần phải gõ lại thủ công các tài liệu quan trọng khi nhập chúng vào cơ sở dữ liệu điện tử. Thay vào đó, OCR trích xuất thông tin có liên quan và tự động nhập vào. Kết quả là xử lý thông tin chính xác, hiệu quả trong thời gian ngắn hơn.
Nhận dạng ký tự quang học có nhiều lĩnh vực nghiên cứu nhưng các lĩnh vực phổ biến nhất như sau:
Banking:
việc sử dụng OCR khác nhau trên các lĩnh vực khác nhau. Một ứng dụng được biết đến rộng rãi là trong ngân hàng, nơi OCR được sử dụng để xử lý séc mà không cần sự tham gia của con người. Một tấm séc có thể được đưa vào máy, chữ viết trên đó được quét ngay lập tức và số tiền chính xác được chuyển. Công nghệ này gần như đã được hoàn thiện cho séc in và cũng khá chính xác đối với séc viết tay, mặc dù đôi khi nó yêu cầu xác nhận thủ công. Nhìn chung, điều này làm giảm thời gian chờ đợi ở nhiều ngân hàng.
Blind and visually impaired persons:
Một trong những yếu tố chính trong quá trình bắt đầu nghiên cứu đằng sau OCR là nhà khoa học muốn tạo ra một máy tính hoặc thiết bị có thể đọc to sách cho người mù. Trong nghiên cứu này, nhà khoa học đã tạo ra máy quét phẳng mà chúng ta thường gọi là máy quét tài liệu.
Legal department:
Trong ngành luật, cũng đã có một phong trào đáng kể để số hóa tài liệu giấy. Để tiết kiệm không gian và loại bỏ nhu cầu sàng lọc qua các hộp tập tin giấy, tài liệu đang được quét và nhập vào cơ sở dữ liệu máy tính. OCR đơn giản hóa hơn nữa quy trình bằng cách làm cho tài liệu có thể tìm kiếm được ở dạng văn bản, để chúng dễ dàng hơn trong việc định vị và làm việc với một lần trong cơ sở dữ liệu. Các chuyên gia pháp lý giờ đây có thể truy cập nhanh chóng, dễ dàng vào một thư viện tài liệu khổng lồ ở định dạng điện tử mà họ có thể tìm thấy chỉ cần gõ một vài từ khóa.
Retail Industry:
Công nghệ nhận dạng mã vạch cũng liên quan đến OCR. Chúng tôi thấy việc sử dụng công nghệ này trong việc sử dụng hàng ngày của chúng tôi.
Other Uses:
OCR được sử dụng rộng rãi trong nhiều lĩnh vực khác, bao gồm giáo dục, tài chính và các cơ quan chính phủ. OCR đã cung cấp vô số văn bản trực tuyến, tiết kiệm tiền cho sinh viên và cho phép chia sẻ kiến thức. Các ứng dụng chụp ảnh hóa đơn được sử dụng trong nhiều doanh nghiệp để theo dõi hồ sơ tài chính và ngăn chặn tình trạng tồn đọng các khoản thanh toán chồng chất. Trong các cơ quan chính phủ và các tổ chức độc lập, OCR đơn giản hóa việc thu thập và phân tích dữ liệu, trong số các quy trình khác. Khi công nghệ tiếp tục phát triển, ngày càng nhiều ứng dụng được tìm thấy cho công nghệ OCR, bao gồm cả việc tăng cường sử dụng nhận dạng chữ viết tay.
Tầm nhìn máy tính
Thị giác máy tính liên quan đến việc mô hình hóa và tái tạo tầm nhìn của con người bằng phần mềm và phần cứng máy tính. Về mặt hình thức, nếu chúng ta định nghĩa thị giác máy tính thì định nghĩa của nó sẽ là thị giác máy tính là một ngành học nghiên cứu cách tái tạo, ngắt và hiểu một cảnh 3D từ các hình ảnh 2D của nó về các đặc tính của cấu trúc hiện diện trong cảnh.
Nó cần kiến thức từ các lĩnh vực sau để hiểu và kích thích hoạt động của hệ thống thị giác con người.
Khoa học máy tính
Kỹ thuật điện
Mathematics
Physiology
Biology
Nhận thức khoa học
Cấu trúc phân cấp thị giác máy tính:
Thị giác máy tính được chia thành ba loại cơ bản như sau:
Tầm nhìn cấp thấp: bao gồm hình ảnh quy trình để trích xuất đối tượng địa lý.
Tầm nhìn cấp độ trung bình: bao gồm nhận dạng đối tượng và diễn giải cảnh 3D
Tầm nhìn cấp cao: bao gồm mô tả khái niệm về một cảnh như hoạt động, ý định và hành vi.
Các trường liên quan:
Computer Vision trùng lặp đáng kể với các trường sau:
Xử lý hình ảnh: nó tập trung vào thao tác hình ảnh.
Nhận dạng mẫu: nó nghiên cứu các kỹ thuật khác nhau để phân loại các mẫu.
Đo quang: nó liên quan đến việc thu được các phép đo chính xác từ hình ảnh.
Xử lý hình ảnh Computer Vision Vs:
Xử lý ảnh nghiên cứu sự chuyển đổi ảnh sang ảnh. Đầu vào và đầu ra của quá trình xử lý hình ảnh đều là hình ảnh.
Thị giác máy tính là việc xây dựng các mô tả rõ ràng, có ý nghĩa về các đối tượng vật lý từ hình ảnh của chúng. Đầu ra của thị giác máy tính là mô tả hoặc diễn giải các cấu trúc trong cảnh 3D.
Ứng dụng Ví dụ:
Robotics
Medicine
Security
Transportation
Tự động trong công nghiệp
Ứng dụng người máy:
Bản địa hóa-xác định vị trí rô bốt tự động
Navigation
Tránh chướng ngại vật
Lắp ráp (chốt trong lỗ, hàn, sơn)
Thao tác (ví dụ: người điều khiển robot PUMA)
Tương tác với người máy (HRI): Robot thông minh để tương tác và phục vụ con người
Ứng dụng thuốc:
Phân loại và phát hiện (ví dụ như phân loại tổn thương hoặc tế bào và phát hiện khối u)
Phân đoạn 2D / 3D
Tái tạo nội tạng người 3D (MRI hoặc siêu âm)
Phẫu thuật robot có hướng dẫn thị giác
Ứng dụng tự động hóa công nghiệp:
Kiểm tra công nghiệp (phát hiện khuyết tật)
Assembly
Đọc mã vạch và nhãn gói
Phân loại đối tượng
Hiểu tài liệu (ví dụ OCR)
Ứng dụng bảo mật:
Sinh trắc học (mống mắt, vân tay, nhận dạng khuôn mặt)
Giám sát - phát hiện một số hoạt động hoặc hành vi đáng ngờ
Ứng dụng Vận chuyển:
Xe tự hành
An toàn, ví dụ, giám sát cảnh giác của người lái xe
Đô họa may tinh
Đồ họa máy tính là đồ họa được tạo ra bằng máy tính và việc biểu diễn dữ liệu hình ảnh bằng máy tính đặc biệt với sự trợ giúp của phần cứng và phần mềm đồ họa chuyên dụng. Về mặt hình thức, chúng ta có thể nói rằng Đồ họa máy tính là tạo ra, thao tác và lưu trữ các đối tượng hình học (mô hình hóa) và hình ảnh của chúng (Kết xuất).
Lĩnh vực đồ họa máy tính phát triển cùng với sự xuất hiện của phần cứng đồ họa máy tính. Ngày nay đồ họa máy tính được sử dụng trong hầu hết các lĩnh vực. Nhiều công cụ mạnh mẽ đã được phát triển để trực quan hóa dữ liệu. Lĩnh vực đồ họa máy tính trở nên phổ biến hơn khi các công ty bắt đầu sử dụng nó trong trò chơi điện tử. Ngày nay, nó là một ngành công nghiệp trị giá hàng tỷ đô la và là động lực chính thúc đẩy sự phát triển đồ họa máy tính. Một số lĩnh vực ứng dụng phổ biến như sau:
Máy tính hỗ trợ thiết kế (CAD)
Đồ họa trình bày
phim hoạt hình 3D
Giao dục va đao tạo
Giao diện người dùng đồ họa
Máy tính hỗ trợ thiết kế:
Được sử dụng trong thiết kế các tòa nhà, ô tô, máy bay và nhiều sản phẩm khác
Sử dụng để làm hệ thống thực tế ảo.
Đồ họa trình bày:
Thường được sử dụng để tóm tắt dữ liệu thống kê, tài chính
Sử dụng để tạo các trang trình bày
phim hoạt hình 3D:
Được sử dụng nhiều trong ngành công nghiệp điện ảnh bởi các công ty như Pixar, DresmsWorks
Để thêm các hiệu ứng đặc biệt trong trò chơi và phim.
Giao dục va đao tạo:
Máy tính tạo ra các mô hình hệ thống vật lý
Hình ảnh y tế
MRI 3D
Quét răng và xương
Các chất kích thích để đào tạo phi công v.v.
Giao diện người dùng đồ họa:
Nó được sử dụng để tạo các đối tượng giao diện người dùng đồ họa như các nút, biểu tượng và các thành phần khác