Fuzzy Logic - Kurzanleitung
Das Wort fuzzybezieht sich auf Dinge, die nicht klar oder vage sind. Jedes Ereignis, jeder Prozess oder jede Funktion, die sich ständig ändert, kann nicht immer als wahr oder falsch definiert werden. Dies bedeutet, dass wir solche Aktivitäten auf unscharfe Weise definieren müssen.
Was ist Fuzzy Logic?
Fuzzy Logic ähnelt der menschlichen Entscheidungsfindungsmethode. Es handelt sich um vage und ungenaue Informationen. Dies ist eine grobe Vereinfachung der Probleme der realen Welt und basiert eher auf Wahrheitsgraden als auf der üblichen wahr / falsch oder 1/0 wie der Booleschen Logik.
Schauen Sie sich das folgende Diagramm an. Es zeigt, dass in Fuzzy-Systemen die Werte durch eine Zahl im Bereich von 0 bis 1 angezeigt werden. Hier steht 1,0absolute truth und 0,0 steht für absolute falseness. Die Zahl, die den Wert in Fuzzy-Systemen angibt, wird als bezeichnettruth value.

Mit anderen Worten, wir können sagen, dass Fuzzy-Logik keine Fuzzy-Logik ist, sondern Logik, die zur Beschreibung von Fuzziness verwendet wird. Es kann zahlreiche andere Beispiele wie dieses geben, mit deren Hilfe wir das Konzept der Fuzzy-Logik verstehen können.
Fuzzy Logic wurde 1965 von Lofti A. Zadeh in seiner Forschungsarbeit „Fuzzy Sets“ eingeführt. Er gilt als der Vater von Fuzzy Logic.
EIN setist eine ungeordnete Sammlung verschiedener Elemente. Es kann explizit geschrieben werden, indem seine Elemente mit der eingestellten Klammer aufgelistet werden. Wenn die Reihenfolge der Elemente geändert oder ein Element einer Menge wiederholt wird, werden keine Änderungen an der Menge vorgenommen.
Beispiel
- Eine Menge aller positiven ganzen Zahlen.
- Eine Reihe aller Planeten im Sonnensystem.
- Eine Reihe aller Staaten in Indien.
- Ein Satz aller Kleinbuchstaben des Alphabets.
Mathematische Darstellung einer Menge
Sets können auf zwei Arten dargestellt werden:
Dienstplan oder Tabellenform
In dieser Form wird eine Menge dargestellt, indem alle Elemente aufgelistet werden, aus denen sie besteht. Die Elemente sind in geschweiften Klammern eingeschlossen und durch Kommas getrennt.
Es folgen die Beispiele für Set in Dienstplan- oder Tabellenform -
- Satz von Vokalen im englischen Alphabet, A = {a, e, i, o, u}
- Satz ungerader Zahlen kleiner als 10, B = {1,3,5,7,9}
Legen Sie die Builder-Notation fest
In dieser Form wird die Menge definiert, indem eine Eigenschaft angegeben wird, die Elemente der Menge gemeinsam haben. Die Menge wird beschrieben als A = {x: p (x)}
Example 1 - Die Menge {a, e, i, o, u} ist geschrieben als
A = {x: x ist ein Vokal im englischen Alphabet}
Example 2 - Die Menge {1,3,5,7,9} ist geschrieben als
B = {x: 1 ≤ x <10 und (x% 2) ≤ 0}
Wenn ein Element x ein Mitglied einer Menge S ist, wird es mit x∈S bezeichnet, und wenn ein Element y kein Mitglied der Menge S ist, wird es mit y∉S bezeichnet.
Example - Wenn S = {1,1.2,1.7,2}, 1 ∈ S, aber 1,5 ∉ S.
Kardinalität einer Menge
Die Kardinalität einer Menge S, bezeichnet mit | S || S |, ist die Anzahl der Elemente der Menge. Die Nummer wird auch als Kardinalzahl bezeichnet. Wenn eine Menge unendlich viele Elemente hat, ist ihre Kardinalität ∞∞.
Example- | {1,4,3,5} | = 4, | {1,2,3,4,5,…} | = ∞
Wenn es zwei Mengen X und Y gibt, | X | = | Y | bezeichnet zwei Sätze X und Y mit derselben Kardinalität. Es tritt auf, wenn die Anzahl der Elemente in X genau der Anzahl der Elemente in Y entspricht. In diesem Fall existiert eine bijektive Funktion 'f' von X nach Y.
| X | ≤ | Y | bedeutet, dass die Kardinalität von Satz X kleiner oder gleich der Kardinalität von Satz Y ist. Es tritt auf, wenn die Anzahl der Elemente in X kleiner oder gleich der von Y ist. Hier existiert eine Injektionsfunktion 'f' von X nach Y.
| X | <| Y | bedeutet, dass die Kardinalität von Satz X geringer ist als die Kardinalität von Satz Y. Es tritt auf, wenn die Anzahl der Elemente in X geringer als die von Y ist. Hier ist die Funktion 'f' von X nach Y eine injektive Funktion, aber keine bijektive.
Wenn | X | ≤ | Y | und | X | ≤ | Y | dann | X | = | Y | . Die Mengen X und Y werden üblicherweise als bezeichnetequivalent sets.
Arten von Sets
Sets können in viele Typen eingeteilt werden. Einige davon sind endlich, unendlich, Teilmenge, universell, richtig, Singleton-Menge usw.
Endliche Menge
Eine Menge, die eine bestimmte Anzahl von Elementen enthält, wird als endliche Menge bezeichnet.
Example - S = {x | x ∈ N und 70> x> 50}
Unendliches Set
Eine Menge, die unendlich viele Elemente enthält, wird als unendliche Menge bezeichnet.
Example - S = {x | x ∈ N und x> 10}
Teilmenge
Eine Menge X ist eine Teilmenge der Menge Y (geschrieben als X ⊆ Y), wenn jedes Element von X ein Element der Menge Y ist.
Example 1- Sei X = {1,2,3,4,5,6} und Y = {1,2}. Hier ist Menge Y eine Teilmenge von Menge X, da sich alle Elemente von Menge Y in Menge X befinden. Daher können wir Y⊆X schreiben.
Example 2- Sei X = {1,2,3} und Y = {1,2,3}. Hier ist die Menge Y eine Teilmenge (keine richtige Teilmenge) der Menge X, da sich alle Elemente der Menge Y in der Menge X befinden. Daher können wir Y⊆X schreiben.
Echte Teilmenge
Der Begriff "richtige Teilmenge" kann als "Teilmenge von, aber nicht gleich" definiert werden. Eine Menge X ist eine richtige Teilmenge der Menge Y (geschrieben als X ⊂ Y), wenn jedes Element von X ein Element der Menge Y und | X | ist <| Y |.
Example- Sei X = {1,2,3,4,5,6} und Y = {1,2}. Hier setzen Sie Y ⊂ X, da alle Elemente in Y auch in X enthalten sind und X mindestens ein Element hat, das mehr als die Menge Y ist.
Universelles Set
Es ist eine Sammlung aller Elemente in einem bestimmten Kontext oder einer bestimmten Anwendung. Alle Mengen in diesem Kontext oder in dieser Anwendung sind im Wesentlichen Teilmengen dieser universellen Menge. Universalsätze werden als U dargestellt.
Example- Wir können U als die Menge aller Tiere auf der Erde definieren. In diesem Fall ist eine Menge aller Säugetiere eine Teilmenge von U, eine Menge aller Fische ist eine Teilmenge von U, eine Menge aller Insekten ist eine Teilmenge von U und so weiter.
Leerer Satz oder Nullsatz
Ein leerer Satz enthält keine Elemente. Es wird mit Φ bezeichnet. Da die Anzahl der Elemente in einer leeren Menge endlich ist, ist die leere Menge eine endliche Menge. Die Kardinalität der leeren Menge oder der Nullmenge ist Null.
Example - S = {x | x ∈ N und 7 <x <8} = Φ
Singleton Set oder Unit Set
Ein Singleton-Set oder Unit-Set enthält nur ein Element. Eine Singleton-Menge wird mit {s} bezeichnet.
Example - S = {x | x ∈ N, 7 <x <9} = {8}
Gleicher Satz
Wenn zwei Mengen dieselben Elemente enthalten, werden sie als gleich bezeichnet.
Example - Wenn A = {1,2,6} und B = {6,1,2}, sind sie gleich, da jedes Element der Menge A ein Element der Menge B und jedes Element der Menge B ein Element der Menge A ist.
Äquivalenter Satz
Wenn die Kardinalitäten zweier Mengen gleich sind, werden sie als äquivalente Mengen bezeichnet.
Example- Wenn A = {1,2,6} und B = {16,17,22}, sind sie äquivalent, da die Kardinalität von A gleich der Kardinalität von B ist, dh | A | = | B | = 3
Überlappender Satz
Zwei Mengen mit mindestens einem gemeinsamen Element werden als überlappende Mengen bezeichnet. Bei überlappenden Mengen -
$$ n \ left (A \ cup B \ right) = n \ left (A \ right) + n \ left (B \ right) - n \ left (A \ cap B \ right) $$
$$ n \ links (A \ Tasse B \ rechts) = n \ links (AB \ rechts) + n \ links (BA \ rechts) + n \ links (A \ Kappe B \ rechts) $$
$$ n \ left (A \ right) = n \ left (AB \ right) + n \ left (A \ cap B \ right) $$
$$ n \ left (B \ right) = n \ left (BA \ right) + n \ left (A \ cap B \ right) $$
Example- Sei A = {1,2,6} und B = {6,12,42}. Es gibt ein gemeinsames Element '6', daher sind diese Mengen überlappende Mengen.
Disjunktes Set
Zwei Mengen A und B werden disjunkte Mengen genannt, wenn sie nicht einmal ein Element gemeinsam haben. Daher haben disjunkte Mengen die folgenden Eigenschaften:
$$ n \ left (A \ cap B \ right) = \ phi $$
$$ n \ left (A \ cup B \ right) = n \ left (A \ right) + n \ left (B \ right) $$
Example - Sei A = {1,2,6} und B = {7,9,14}, es gibt kein einziges gemeinsames Element, daher sind diese Mengen überlappende Mengen.
Operationen an klassischen Mengen
Zu den Set-Operationen gehören Set Union, Set Intersection, Set Difference, Complement of Set und Cartesian Product.
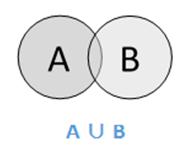
Union
Die Vereinigung der Mengen A und B (bezeichnet mit A ∪ BA ∪ B) ist die Menge der Elemente, die sich in A, in B oder sowohl in A als auch in B befinden. Daher ist A ∪ B = {x | x ∈ A ODER x ∈ B}.
Example - Wenn A = {10,11,12,13} und B = {13,14,15}, dann ist A ∪ B = {10,11,12,13,14,15} - Das gemeinsame Element kommt nur einmal vor.
Überschneidung
Der Schnittpunkt der Mengen A und B (bezeichnet mit A ∩ B) ist die Menge der Elemente, die sich sowohl in A als auch in B befinden. Daher ist A ∩ B = {x | x ∈ A UND x ∈ B}.

Unterschied / relative Ergänzung
Die Mengenunterschiede der Mengen A und B (bezeichnet mit A - B) sind die Mengen von Elementen, die nur in A, nicht aber in B vorliegen. Daher ist A - B = {x | x ∈ A UND x ∉ B}.
Example- Wenn A = {10,11,12,13} und B = {13,14,15}, dann ist (A - B) = {10,11,12} und (B - A) = {14,15} . Hier sehen wir (A - B) ≠ (B - A)

Ergänzung eines Sets
Das Komplement einer Menge A (bezeichnet mit A ') ist die Menge von Elementen, die nicht in Menge A enthalten sind. Daher ist A' = {x | x ∉ A}.
Insbesondere ist A '= (U - A), wobei U eine universelle Menge ist, die alle Objekte enthält.
Example - Wenn A = {x | x zur Menge der addierten Ganzzahlen gehört}, dann gehört A ′ = {y | y nicht zur Menge der ungeraden ganzen Zahlen}

Kartesisches Produkt / Kreuzprodukt
Das kartesische Produkt von n Mengen von Mengen A1, A2,… An, bezeichnet als A1 × A2 ... × An, kann als alle möglichen geordneten Paare (x1, x2,… xn) definiert werden, wobei x1 ∈ A1, x2 ∈ A2,… xn ∈ An
Example - Wenn wir zwei Mengen A = {a, b} und B = {1,2} nehmen,
Das kartesische Produkt von A und B wird geschrieben als - A × B = {(a, 1), (a, 2), (b, 1), (b, 2)}
Und das kartesische Produkt von B und A wird geschrieben als - B × A = {(1, a), (1, b), (2, a), (2, b)}
Eigenschaften klassischer Mengen
Eigenschaften von Sets spielen eine wichtige Rolle, um die Lösung zu erhalten. Es folgen die verschiedenen Eigenschaften klassischer Sets -
Kommutativgesetz
Zwei Sätze haben A und B, diese Eigenschaft besagt -
$$ A \ Tasse B = B \ Tasse A $$
$$ A \ cap B = B \ cap A $$
Assoziatives Eigentum
Mit drei Sätzen A, B und C, diese Eigenschaft besagt -
$$ A \ Tasse \ links (B \ Tasse C \ rechts) = \ links (A \ Tasse B \ rechts) \ Tasse C $$
$$ A \ cap \ left (B \ cap C \ right) = \ left (A \ cap B \ right) \ cap C $$
Verteilungseigenschaft
Mit drei Sätzen A, B und C, diese Eigenschaft besagt -
$$ A \ Tasse \ links (B \ Kappe C \ rechts) = \ links (A \ Tasse B \ rechts) \ Kappe \ links (A \ Tasse C \ rechts) $$
$$ A \ cap \ left (B \ cup C \ right) = \ left (A \ cap B \ right) \ cup \ left (A \ cap C \ right) $$
Idempotenz-Eigenschaft
Für jeden Satz A, diese Eigenschaft besagt -
$$ A \ cup A = A $$
$$ A \ cap A = A $$
Identitätseigenschaft
Für Set A und universelles Set X, diese Eigenschaft besagt -
$$ A \ cup \ varphi = A $$
$$ A \ cap X = A $$
$$ A \ cap \ varphi = \ varphi $$
$$ A \ cup X = X $$
Transitive Eigenschaft
Mit drei Sätzen A, B und C, die Eigenschaft besagt -
Wenn $ A \ subseteq B \ subseteq C $, dann $ A \ subseteq C $
Involution-Eigenschaft
Für jeden Satz A, diese Eigenschaft besagt -
$$ \ overline {{\ overline {A}}} = A $$
De Morgans Gesetz
Es ist ein sehr wichtiges Gesetz und unterstützt den Nachweis von Tautologien und Widersprüchen. Dieses Gesetz besagt -
$$ \ overline {A \ cap B} = \ overline {A} \ cup \ overline {B} $$
$$ \ overline {A \ cup B} = \ overline {A} \ cap \ overline {B} $$
Fuzzy-Mengen können als Erweiterung und grobe Vereinfachung klassischer Mengen betrachtet werden. Dies kann am besten im Zusammenhang mit der festgelegten Mitgliedschaft verstanden werden. Grundsätzlich erlaubt es eine teilweise Mitgliedschaft, was bedeutet, dass es Elemente enthält, die unterschiedliche Zugehörigkeitsgrade in der Menge haben. Daraus können wir den Unterschied zwischen klassischer Menge und Fuzzy-Menge verstehen. Die klassische Menge enthält Elemente, die genaue Eigenschaften der Mitgliedschaft erfüllen, während die Fuzzy-Menge Elemente enthält, die ungenaue Eigenschaften der Mitgliedschaft erfüllen.

Mathematisches Konzept
Eine Fuzzy-Menge $ \ widetilde {A} $ im Informationsuniversum $ U $ kann als eine Menge geordneter Paare definiert und mathematisch dargestellt werden als -
$$ \ widetilde {A} = \ left \ {\ left (y, \ mu _ {\ widetilde {A}} \ left (y \ right) \ right) | y \ in U \ right \} $$
Hier nimmt $ \ mu _ {\ widetilde {A}} \ left (y \ right) $ = Zugehörigkeitsgrad von $ y $ in \ widetilde {A} Werte im Bereich von 0 bis 1 an, dh $ \ mu _ {\ widetilde {A}} (y) \ in \ left [0,1 \ right] $.
Darstellung der Fuzzy-Menge
Betrachten wir nun zwei Fälle von Informationsuniversum und verstehen, wie eine Fuzzy-Menge dargestellt werden kann.
Fall 1
Wenn das Informationsuniversum $ U $ diskret und endlich ist -
$$ \ widetilde {A} = \ left \ {\ frac {\ mu _ {\ widetilde {A}} \ left (y_1 \ right)} {y_1} + \ frac {\ mu _ {\ widetilde {A}} \ left (y_2 \ right)} {y_2} + \ frac {\ mu _ {\ widetilde {A}} \ left (y_3 \ right)} {y_3} + ... \ right \} $$
$ = \ left \ {\ sum_ {i = 1} ^ {n} \ frac {\ mu _ {\ widetilde {A}} \ left (y_i \ right)} {y_i} \ right \} $
Fall 2
Wenn das Informationsuniversum $ U $ kontinuierlich und unendlich ist -
$$ \ widetilde {A} = \ left \ {\ int \ frac {\ mu _ {\ widetilde {A}} \ left (y \ right)} {y} \ right \} $$
In der obigen Darstellung repräsentiert das Summationssymbol die Sammlung jedes Elements.
Operationen an Fuzzy-Sets
Mit zwei Fuzzy-Mengen $ \ widetilde {A} $ und $ \ widetilde {B} $, dem Informationsuniversum $ U $ und einem Element ð ?? '¦ des Universums drücken die folgenden Beziehungen die Vereinigung, Schnittmenge und Komplementoperation aus auf Fuzzy-Sets.
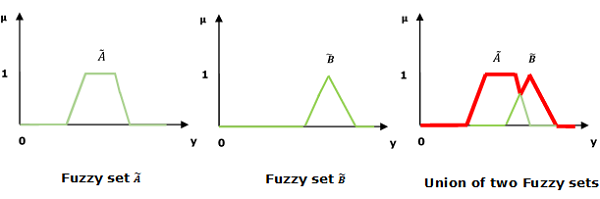
Union / Fuzzy â € žORâ € œ
Betrachten wir die folgende Darstellung, um zu verstehen, wie die Union/Fuzzy ‘OR’ Beziehung funktioniert -
$$ \ mu _ {{\ widetilde {A} \ cup \ widetilde {B}}} \ left (y \ right) = \ mu _ {\ widetilde {A}} \ vee \ mu _ \ widetilde {B} \ quad \ forall y \ in U $$
Hier steht ∨ für die "Max" -Operation.
Intersection / Fuzzy â € žANDâ € œ
Betrachten wir die folgende Darstellung, um zu verstehen, wie die Intersection/Fuzzy ‘AND’ Beziehung funktioniert -
$$ \ mu _ {{\ widetilde {A} \ cap \ widetilde {B}}} \ left (y \ right) = \ mu _ {\ widetilde {A}} \ wedge \ mu _ \ widetilde {B} \ quad \ forall y \ in U $$
Hier steht min für die Min-Operation.

Komplement / Fuzzy â € žNOTâ € œ
Betrachten wir die folgende Darstellung, um zu verstehen, wie die Complement/Fuzzy ‘NOT’ Beziehung funktioniert -
$$ \ mu _ {\ widetilde {A}} = 1- \ mu _ {\ widetilde {A}} \ left (y \ right) \ quad y \ in U $$

Eigenschaften von Fuzzy-Mengen
Lassen Sie uns die verschiedenen Eigenschaften von Fuzzy-Mengen diskutieren.
Kommutativgesetz
Mit zwei Fuzzy-Mengen $ \ widetilde {A} $ und $ \ widetilde {B} $ heißt es in dieser Eigenschaft:
$$ \ widetilde {A} \ cup \ widetilde {B} = \ widetilde {B} \ cup \ widetilde {A} $$
$$ \ widetilde {A} \ cap \ widetilde {B} = \ widetilde {B} \ cap \ widetilde {A} $$
Assoziatives Eigentum
Mit drei Fuzzy-Mengen $ \ widetilde {A} $, $ \ widetilde {B} $ und $ \ widetilde {C} $ heißt es in dieser Eigenschaft:
$$ (\ widetilde {A} \ cup \ left \ widetilde {B}) \ cup \ widetilde {C} \ right = \ left \ widetilde {A} \ cup (\ widetilde {B} \ right) \ cup \ widetilde {C}) $$
$$ (\ widetilde {A} \ cap \ left \ widetilde {B}) \ cap \ widetilde {C} \ right = \ left \ widetilde {A} \ cup (\ widetilde {B} \ right \ cap \ widetilde { C}) $$
Verteilungseigenschaft
Mit drei Fuzzy-Mengen $ \ widetilde {A} $, $ \ widetilde {B} $ und $ \ widetilde {C} $ heißt es in dieser Eigenschaft:
$$ \ widetilde {A} \ cup \ left (\ widetilde {B} \ cap \ widetilde {C} \ right) = \ left (\ widetilde {A} \ cup \ widetilde {B} \ right) \ cap \ left (\ widetilde {A} \ cup \ widetilde {C} \ right) $$
$$ \ widetilde {A} \ cap \ left (\ widetilde {B} \ cup \ widetilde {C} \ right) = \ left (\ widetilde {A} \ cap \ widetilde {B} \ right) \ cup \ left (\ widetilde {A} \ cap \ widetilde {C} \ right) $$
Idempotenz-Eigenschaft
Für jede Fuzzy-Menge $ \ widetilde {A} $ gibt diese Eigenschaft an:
$$ \ widetilde {A} \ cup \ widetilde {A} = \ widetilde {A} $$
$$ \ widetilde {A} \ cap \ widetilde {A} = \ widetilde {A} $$
Identitätseigenschaft
Für die Fuzzy-Menge $ \ widetilde {A} $ und die universelle Menge $ U $ lautet diese Eigenschaft:
$$ \ widetilde {A} \ cup \ varphi = \ widetilde {A} $$
$$ \ widetilde {A} \ cap U = \ widetilde {A} $$
$$ \ widetilde {A} \ cap \ varphi = \ varphi $$
$$ \ widetilde {A} \ cup U = U $$
Transitive Eigenschaft
Mit drei Fuzzy-Mengen $ \ widetilde {A} $, $ \ widetilde {B} $ und $ \ widetilde {C} $ heißt es in dieser Eigenschaft:
$$ Wenn \: \ widetilde {A} \ subseteq \ widetilde {B} \ subseteq \ widetilde {C}, \: dann \: \ widetilde {A} \ subseteq \ widetilde {C} $$
Involution-Eigenschaft
Für jede Fuzzy-Menge $ \ widetilde {A} $ gibt diese Eigenschaft an:
$$ \ overline {\ overline {\ widetilde {A}}} = \ widetilde {A} $$
De Morgans Gesetz
Dieses Gesetz spielt eine entscheidende Rolle beim Nachweis von Tautologien und Widersprüchen. Dieses Gesetz besagt -
$$ \ overline {{\ widetilde {A} \ cap \ widetilde {B}}} = \ overline {\ widetilde {A}} \ cup \ overline {\ widetilde {B}} $$
$$ \ overline {{\ widetilde {A} \ cup \ widetilde {B}}} = \ overline {\ widetilde {A}} \ cap \ overline {\ widetilde {B}} $$
Wir wissen bereits, dass Fuzzy-Logik keine Fuzzy-Logik ist, sondern eine Logik, die zur Beschreibung von Fuzziness verwendet wird. Diese Unschärfe wird am besten durch ihre Zugehörigkeitsfunktion charakterisiert. Mit anderen Worten können wir sagen, dass die Zugehörigkeitsfunktion den Grad der Wahrheit in der Fuzzy-Logik darstellt.

Im Folgenden sind einige wichtige Punkte im Zusammenhang mit der Mitgliedschaftsfunktion aufgeführt:
Die Mitgliedschaftsfunktionen wurden erstmals 1965 von Lofti A. Zadeh in seinem ersten Forschungsbericht „Fuzzy Sets“ eingeführt.
Zugehörigkeitsfunktionen charakterisieren Unschärfe (dh alle Informationen in Fuzzy-Mengen), unabhängig davon, ob die Elemente in Fuzzy-Mengen diskret oder kontinuierlich sind.
Mitgliedschaftsfunktionen können als eine Technik definiert werden, um praktische Probleme eher durch Erfahrung als durch Wissen zu lösen.
Mitgliedschaftsfunktionen werden durch grafische Formulare dargestellt.
Die Regeln zum Definieren von Unschärfe sind ebenfalls unscharf.
Mathematische Notation
Wir haben bereits untersucht , dass eine Fuzzy - Menge à im Universum von Informationen U als ein Satz geordneter Paare definiert werden kann , und es kann als mathematisch dargestellt werden -
$$ \ widetilde {A} = \ left \ {\ left (y, \ mu _ {\ widetilde {A}} \ left (y \ right) \ right) | y \ in U \ right \} $$
Hier $ \ mu \ widetilde {A} \ left (\ bullet \ right) $ = Zugehörigkeitsfunktion von $ \ widetilde {A} $; Dies setzt Werte im Bereich von 0 bis 1 voraus, dh $ \ mu \ widetilde {A} \ left (\ bullet \ right) \ in \ left [0,1 \ right] $. Die Zugehörigkeitsfunktion $ \ mu \ widetilde {A} \ left (\ bullet \ right) $ ordnet $ U $ dem Mitgliederbereich $ M $ zu.
Der Punkt $ \ left (\ bullet \ right) $ in der oben beschriebenen Zugehörigkeitsfunktion repräsentiert das Element in einer Fuzzy-Menge. ob es diskret oder kontinuierlich ist.
Merkmale der Mitgliedschaftsfunktionen
Wir werden nun die verschiedenen Funktionen der Mitgliedschaftsfunktionen diskutieren.
Ader
Für jede Fuzzy-Menge $ \ widetilde {A} $ ist der Kern einer Zugehörigkeitsfunktion die Region des Universums, die durch die Vollmitgliedschaft in der Menge gekennzeichnet ist. Daher besteht der Kern aus all diesen Elementen $ y $ des Informationsuniversums, so dass
$$ \ mu _ {\ widetilde {A}} \ left (y \ right) = 1 $$
Unterstützung
Für jede Fuzzy-Menge $ \ widetilde {A} $ ist die Unterstützung einer Zugehörigkeitsfunktion die Region des Universums, die durch eine Mitgliedschaft ungleich Null in der Menge gekennzeichnet ist. Daher besteht der Kern aus all diesen Elementen $ y $ des Informationsuniversums, so dass
$$ \ mu _ {\ widetilde {A}} \ left (y \ right)> 0 $$
Grenze
Für jede Fuzzy-Menge $ \ widetilde {A} $ ist die Grenze einer Zugehörigkeitsfunktion die Region des Universums, die durch eine ungleich Null, aber unvollständige Zugehörigkeit zur Menge gekennzeichnet ist. Daher besteht der Kern aus all diesen Elementen $ y $ des Informationsuniversums, so dass
$$ 1> \ mu _ {\ widetilde {A}} \ left (y \ right)> 0 $$

Fuzzifizierung
Es kann definiert werden als der Prozess der Umwandlung eines knackigen Satzes in einen unscharfen Satz oder eines unscharfen Satzes in einen unschärferen Satz. Grundsätzlich übersetzt diese Operation genaue, gestochen scharfe Eingabewerte in sprachliche Variablen.
Im Folgenden sind die beiden wichtigen Methoden der Fuzzifizierung aufgeführt:
Support Fuzzification (S-Fuzzification) -Methode
Bei dieser Methode kann die unscharfe Menge mit Hilfe der folgenden Beziehung ausgedrückt werden:
$$ \ widetilde {A} = \ mu _1Q \ left (x_1 \ right) + \ mu _2Q \ left (x_2 \ right) + ... + \ mu _nQ \ left (x_n \ right) $$
Hier wird die Fuzzy-Menge $ Q \ left (x_i \ right) $ als Kernel der Fuzzifizierung bezeichnet. Diese Methode wird implementiert, indem $ \ mu _i $ konstant gehalten wird und $ x_i $ in eine Fuzzy-Menge $ Q \ left (x_i \ right) $ transformiert wird.
Grade Fuzzification (g-Fuzzification) -Methode
Es ist der obigen Methode ziemlich ähnlich, aber der Hauptunterschied besteht darin, dass $ x_i $ konstant gehalten wird und $ \ mu _i $ als Fuzzy-Menge ausgedrückt wird.
Defuzzifizierung
Es kann definiert werden als der Prozess des Reduzierens eines Fuzzy-Satzes in einen knackigen Satz oder des Umwandelns eines Fuzzy-Elements in einen knackigen Element.
Wir haben bereits untersucht, dass der Fuzzifizierungsprozess die Umwandlung von knackigen Mengen in unscharfe Mengen beinhaltet. In einer Reihe von technischen Anwendungen ist es erforderlich, das Ergebnis bzw. das „unscharfe Ergebnis“ zu defuzzifizieren, damit es in ein klares Ergebnis umgewandelt werden muss. Mathematisch wird der Prozess der Defuzzifizierung auch als "Abrunden" bezeichnet.
Die verschiedenen Methoden der Defuzzifizierung werden nachfolgend beschrieben -
Max-Membership-Methode
Diese Methode ist auf Spitzenausgabefunktionen beschränkt und wird auch als Höhenmethode bezeichnet. Mathematisch kann es wie folgt dargestellt werden:
$$ \ mu _ {\ widetilde {A}} \ left (x ^ * \ right)> \ mu _ {\ widetilde {A}} \ left (x \ right) \: for \: all \: x \ in X $$
Hier ist $ x ^ * $ die defuzzifizierte Ausgabe.
Schwerpunktmethode
Diese Methode wird auch als Flächenschwerpunkt- oder Schwerpunktmethode bezeichnet. Mathematisch wird die defuzzifizierte Ausgabe $ x ^ * $ dargestellt als -
$$ x ^ * = \ frac {\ int \ mu _ {\ widetilde {A}} \ left (x \ right) .xdx} {\ int \ mu _ {\ widetilde {A}} \ left (x \ right) ) .dx} $$
Gewichtete Durchschnittsmethode
Bei dieser Methode wird jede Zugehörigkeitsfunktion mit ihrem maximalen Mitgliedschaftswert gewichtet. Mathematisch wird die defuzzifizierte Ausgabe $ x ^ * $ dargestellt als -
$$ x ^ * = \ frac {\ sum \ mu _ {\ widetilde {A}} \ left (\ overline {x_i} \ right). \ overline {x_i}} {\ sum \ mu _ {\ widetilde {A. }} \ left (\ overline {x_i} \ right)} $$
Mean-Max-Mitgliedschaft
Diese Methode wird auch als Mitte der Maxima bezeichnet. Mathematisch wird die defuzzifizierte Ausgabe $ x ^ * $ dargestellt als -
$$ x ^ * = \ frac {\ displaystyle \ sum_ {i = 1} ^ {n} \ overline {x_i}} {n} $$
Die Logik, die ursprünglich nur die Untersuchung dessen war, was vernünftige Argumente von unsoliden Argumenten unterscheidet, hat sich nun zu einem mächtigen und strengen System entwickelt, mit dem wahre Aussagen entdeckt werden können, wenn andere Aussagen bereits als wahr bekannt sind.
Prädikatenlogik
Diese Logik befasst sich mit Prädikaten, bei denen es sich um Sätze handelt, die Variablen enthalten.
Ein Prädikat ist ein Ausdruck einer oder mehrerer Variablen, die in einer bestimmten Domäne definiert sind. Ein Prädikat mit Variablen kann zu einem Satz gemacht werden, indem entweder der Variablen ein Wert zugewiesen oder die Variable quantifiziert wird.
Es folgen einige Beispiele für Prädikate -
- Es sei E (x, y) "x = y"
- X (a, b, c) bezeichne "a + b + c = 0".
- Es sei M (x, y) "x ist mit y verheiratet"
Aussagelogik
Ein Satz ist eine Sammlung deklarativer Aussagen, die entweder einen Wahrheitswert "wahr" oder einen Wahrheitswert "falsch" haben. Ein Satz besteht aus Satzvariablen und Konnektiven. Die Satzvariablen sind durch Großbuchstaben (A, B usw.) verbeult. Die Konnektive verbinden die Aussagenvariablen.
Einige Beispiele für Vorschläge sind unten angegeben -
- "Man is Mortal" gibt den Wahrheitswert "TRUE" zurück.
- "12 + 9 = 3 - 2" gibt den Wahrheitswert "FALSE" zurück.
Das Folgende ist kein Vorschlag -
"A is less than 2" - Es liegt daran, dass wir nicht sagen können, ob die Aussage wahr oder falsch ist, wenn wir nicht einen bestimmten Wert von A angeben.
Konnektiva
In der Aussagenlogik verwenden wir die folgenden fünf Konnektiva:
- ODER (∨∨)
- UND (∧∧)
- Negation / NOT (¬¬)
- Implikation / Wenn-Dann (→ Bungal)
- Wenn und nur wenn (⇔⇔)
ODER (∨∨)
Die ODER-Verknüpfung zweier Sätze A und B (geschrieben als A∨BA∨B) ist wahr, wenn mindestens eine der Satzvariablen A oder B wahr ist.
Die Wahrheitstabelle lautet wie folgt:
| EIN | B. | A ∨ B. |
|---|---|---|
| Wahr | Wahr | Wahr |
| Wahr | Falsch | Wahr |
| Falsch | Wahr | Wahr |
| Falsch | Falsch | Falsch |
UND (∧∧)
Die UND-Verknüpfung zweier Sätze A und B (geschrieben als A∧BA∧B) ist wahr, wenn sowohl die Satzvariable A als auch B wahr sind.
Die Wahrheitstabelle lautet wie folgt:
| EIN | B. | A ∧ B. |
|---|---|---|
| Wahr | Wahr | Wahr |
| Wahr | Falsch | Falsch |
| Falsch | Wahr | Falsch |
| Falsch | Falsch | Falsch |
Negation (¬¬)
Die Negation eines Satzes A (geschrieben als ¬A¬A) ist falsch, wenn A wahr ist, und ist wahr, wenn A falsch ist.
Die Wahrheitstabelle lautet wie folgt:
| EIN | ¬A |
|---|---|
| Wahr | Falsch |
| Falsch | Wahr |
Implikation / Wenn-Dann (→ Bungal)
Eine Implikation A → BA → B ist der Satz „wenn A, dann B“. Es ist falsch, wenn A wahr und B falsch ist. Die übrigen Fälle sind wahr.
Die Wahrheitstabelle lautet wie folgt:
| EIN | B. | A → B. |
|---|---|---|
| Wahr | Wahr | Wahr |
| Wahr | Falsch | Falsch |
| Falsch | Wahr | Wahr |
| Falsch | Falsch | Wahr |
Wenn und nur wenn (⇔⇔)
A⇔BA⇔B ist eine bikonditionale logische Verbindung, die wahr ist, wenn p und q gleich sind, dh beide sind falsch oder beide sind wahr.
Die Wahrheitstabelle lautet wie folgt:
| EIN | B. | A⇔B |
|---|---|---|
| Wahr | Wahr | Wahr |
| Wahr | Falsch | Falsch |
| Falsch | Wahr | Falsch |
| Falsch | Falsch | Wahr |
Gut geformte Formel
Well Formed Formula (wff) ist ein Prädikat mit einer der folgenden Eigenschaften:
- Alle Satzkonstanten und Satzvariablen sind wffs.
- Wenn x eine Variable und Y eine wff ist, sind auch ∀xY und ∃xY wff.
- Wahrheitswert und falsche Werte sind wffs.
- Jede Atomformel ist eine wff.
- Alle Verbindungen, die wffs verbinden, sind wffs.
Quantifizierer
Die Variable der Prädikate wird durch Quantifizierer quantifiziert. In der Prädikatenlogik gibt es zwei Arten von Quantifizierern:
- Universal Quantifier
- Existenzieller Quantifizierer
Universal Quantifier
Der universelle Quantifizierer gibt an, dass die Aussagen in seinem Geltungsbereich für jeden Wert der spezifischen Variablen zutreffen. Es ist mit dem Symbol ∀ gekennzeichnet.
∀xP(x) wird gelesen, da für jeden Wert von x P (x) wahr ist.
Example- "Der Mensch ist sterblich" kann in die Satzform ∀xP (x) umgewandelt werden. Hier ist P (x) das Prädikat, das angibt, dass x sterblich ist und das Universum des Diskurses alle Menschen sind.
Existenzieller Quantifizierer
Der Existenzquantifizierer gibt an, dass die Anweisungen in seinem Bereich für einige Werte der spezifischen Variablen zutreffen. Es ist mit dem Symbol ∃ gekennzeichnet.
∃xP(x) für einige Werte von x wird gelesen, dass P (x) wahr ist.
Example - "Manche Menschen sind unehrlich" kann in die Satzform ∃x P (x) umgewandelt werden, wobei P (x) das Prädikat ist, das bedeutet, dass x unehrlich ist und das Diskursuniversum manche Menschen sind.
Verschachtelte Quantifizierer
Wenn wir einen Quantifizierer verwenden, der im Rahmen eines anderen Quantifizierers erscheint, wird er als verschachtelter Quantifizierer bezeichnet.
Example
- ∀ a∃bP (x, y) wobei P (a, b) a + b = 0 bezeichnet
- ∀ a∀b∀cP (a, b, c) wobei P (a, b) a + (b + c) = (a + b) + c bezeichnet
Note - ∀a∃bP (x, y) ≠ ≠a∀bP (x, y)
Im Folgenden sind die verschiedenen Arten des ungefähren Denkens aufgeführt:
Kategoriales Denken
In dieser Art des ungefähren Denkens wird angenommen, dass die Antezedenzien, die keine Fuzzy-Quantifizierer und Fuzzy-Wahrscheinlichkeiten enthalten, in kanonischer Form vorliegen.
Qualitatives Denken
In dieser Art des ungefähren Denkens haben die Antezedenzien und Konsequenzen unscharfe sprachliche Variablen; Die Eingabe-Ausgabe-Beziehung eines Systems wird als Sammlung von Fuzzy-IF-THEN-Regeln ausgedrückt. Diese Argumentation wird hauptsächlich in der Analyse von Steuerungssystemen verwendet.
Syllogistisches Denken
In dieser Art des Näherungsdenkens beziehen sich Antezedenzien mit Fuzzy-Quantifizierern auf Inferenzregeln. Dies wird ausgedrückt als -
x = S 1 A's sind B's
y = S 2 C's sind D's
------------------------
z = S 3 E's sind F's
Hier sind A, B, C, D, E, F unscharfe Prädikate.
S 1 und S 2 erhalten Fuzzy-Quantifizierer.
S 3 ist der Fuzzy-Quantifizierer, der entschieden werden muss.
Dispositional Reasoning
In dieser Art der Näherungsüberlegung sind die Antezedenzien Dispositionen, die den Fuzzy-Quantifizierer "normalerweise" enthalten können. Der QuantifiziererUsuallyverbindet das dispositionelle und das syllogistische Denken miteinander; Daher spielt es eine wichtige Rolle.
Zum Beispiel kann die Projektionsregel der Folgerung im dispositionellen Denken wie folgt angegeben werden:
normalerweise ((L, M) ist R) ⇒ normalerweise (L ist [R ↓ L])
Hier [R ↓ L] ist die Projektion der Fuzzy-Beziehung R auf L
Fuzzy-Logik-Regelbasis
Es ist bekannt, dass es einem Menschen immer angenehm ist, Gespräche in natürlicher Sprache zu führen. Die Darstellung des menschlichen Wissens kann mit Hilfe des Ausdrucks der natürlichen Sprache erfolgen -
IF vorausgegangen THEN konsequent
Der oben angegebene Ausdruck wird als Fuzzy-IF-THEN-Regelbasis bezeichnet.
Kanonische Form
Es folgt die kanonische Form der Fuzzy Logic Rule Base -
Rule 1 - Wenn Bedingung C1, dann Einschränkung R1
Rule 2 - Wenn Bedingung C1, dann Einschränkung R2
.
.
.
Rule n - Wenn Bedingung C1, dann Restriktion Rn
Interpretationen von Fuzzy IF-THEN-Regeln
Fuzzy IF-THEN-Regeln können in den folgenden vier Formen interpretiert werden:
Zuweisungsanweisungen
Diese Art von Anweisungen verwenden zum Zweck der Zuweisung "=" (gleich Vorzeichen). Sie haben die folgende Form -
a = hallo
Klima = Sommer
Bedingte Anweisungen
Diese Art von Anweisungen verwenden zum Zweck der Bedingung das Regelbasisformular „IF-THEN“. Sie haben die folgende Form -
WENN die Temperatur hoch ist DANN ist das Klima heiß
WENN das Essen frisch ist, dann essen.
Bedingungslose Anweisungen
Sie haben die folgende Form -
GOTO 10
Schalten Sie den Lüfter aus
Sprachvariable
Wir haben untersucht, dass die Fuzzy-Logik sprachliche Variablen verwendet, bei denen es sich um Wörter oder Sätze in einer natürlichen Sprache handelt. Wenn wir zum Beispiel Temperatur sagen, ist es eine sprachliche Variable; Die Werte sind sehr heiß oder kalt, leicht heiß oder kalt, sehr warm, leicht warm usw. Die Wörter sind sehr, leicht die sprachlichen Absicherungen.
Charakterisierung der sprachlichen Variablen
Die folgenden vier Begriffe charakterisieren die sprachliche Variable -
- Name der Variablen, im Allgemeinen dargestellt durch x.
- Termmenge der Variablen, im Allgemeinen dargestellt durch t (x).
- Syntaktische Regeln zum Generieren der Werte der Variablen x.
- Semantische Regeln zum Verknüpfen jedes Wertes von x und seiner Bedeutung.
Sätze in Fuzzy Logic
Wie wir wissen, sind Sätze Sätze, die in jeder Sprache ausgedrückt werden und im Allgemeinen in der folgenden kanonischen Form ausgedrückt werden:
s als P.
Hier ist s das Subjekt und P ist das Prädikat.
Zum Beispiel " Delhi ist die Hauptstadt von Indien ", dies ist ein Satz, in dem " Delhi " das Subjekt ist und " ist die Hauptstadt von Indien " das Prädikat ist, das das Eigentum des Subjekts zeigt.
Wir wissen, dass Logik die Grundlage des Denkens ist und Fuzzy-Logik die Fähigkeit des Denkens erweitert, indem Fuzzy-Prädikate, Fuzzy-Prädikat-Modifikatoren, Fuzzy-Quantifizierer und Fuzzy-Qualifizierer in Fuzzy-Aussagen verwendet werden, was den Unterschied zur klassischen Logik erzeugt.
Sätze in der Fuzzy-Logik umfassen Folgendes:
Fuzzy-Prädikat
Fast jedes Prädikat in natürlicher Sprache ist von Natur aus unscharf, daher hat die unscharfe Logik Prädikate wie groß, kurz, warm, heiß, schnell usw.
Fuzzy-Prädikat-Modifikatoren
Wir haben oben über sprachliche Absicherungen gesprochen. Wir haben auch viele Fuzzy-Prädikat-Modifikatoren, die als Absicherungen dienen. Sie sind sehr wichtig, um die Werte einer sprachlichen Variablen zu erzeugen. Zum Beispiel sind die Wörter sehr, leicht Modifikatoren und die Sätze können wie " Wasser ist leicht heiß " sein.
Fuzzy-Quantifizierer
Es kann als eine Fuzzy-Zahl definiert werden, die eine vage Klassifizierung der Kardinalität einer oder mehrerer Fuzzy- oder Nicht-Fuzzy-Mengen ergibt. Es kann verwendet werden, um die Wahrscheinlichkeit innerhalb der Fuzzy-Logik zu beeinflussen. Zum Beispiel werden die Wörter viele, am häufigsten, als Fuzzy-Quantifizierer verwendet, und die Aussagen können lauten: "Die meisten Menschen sind allergisch dagegen ."
Fuzzy-Qualifikation
Lassen Sie uns nun Fuzzy Qualifiers verstehen. Ein Fuzzy-Qualifizierer ist auch ein Vorschlag von Fuzzy Logic. Die Fuzzy-Qualifikation hat folgende Formen:
Fuzzy-Qualifikation basierend auf Wahrheit
Es behauptet den Grad der Wahrheit eines unscharfen Satzes.
Expression- Es wird ausgedrückt als x ist t . Hier ist t ein unscharfer Wahrheitswert.
Example - (Auto ist schwarz) ist nicht sehr wahr.
Fuzzy-Qualifikation basierend auf Wahrscheinlichkeit
Es behauptet die Wahrscheinlichkeit eines Fuzzy-Satzes, entweder numerisch oder als Intervall.
Expression- Es wird ausgedrückt als x ist λ . Hier ist λ eine Fuzzy-Wahrscheinlichkeit.
Example - (Auto ist schwarz) ist wahrscheinlich.
Fuzzy-Qualifikation basierend auf der Möglichkeit
Es behauptet die Möglichkeit eines unscharfen Satzes.
Expression- Es wird ausgedrückt als x ist π . Hier ist π eine unscharfe Möglichkeit.
Example - (Auto ist schwarz) ist fast unmöglich.
Das Fuzzy-Inferenzsystem ist die Schlüsseleinheit eines Fuzzy-Logik-Systems, dessen Hauptaufgabe die Entscheidungsfindung ist. Es verwendet die Regeln „WENN… DANN“ zusammen mit den Konnektoren „ODER“ oder „UND“, um wichtige Entscheidungsregeln zu zeichnen.
Eigenschaften des Fuzzy-Inferenzsystems
Im Folgenden sind einige Merkmale der FIS aufgeführt:
Die Ausgabe von FIS ist immer eine Fuzzy-Menge, unabhängig von ihrer Eingabe, die unscharf oder scharf sein kann.
Es ist ein Fuzzy-Ausgang erforderlich, wenn er als Controller verwendet wird.
Mit FIS wäre eine Defuzzifizierungseinheit vorhanden, um Fuzzy-Variablen in gestochen scharfe Variablen umzuwandeln.
Funktionsblöcke der FIS
Die folgenden fünf Funktionsblöcke helfen Ihnen, die Konstruktion von FIS zu verstehen -
Rule Base - Es enthält unscharfe IF-THEN-Regeln.
Database - Es definiert die Zugehörigkeitsfunktionen von Fuzzy-Mengen, die in Fuzzy-Regeln verwendet werden.
Decision-making Unit - Es führt Operationen an Regeln durch.
Fuzzification Interface Unit - Es wandelt die knackigen Mengen in unscharfe Mengen um.
Defuzzification Interface Unit- Es wandelt die unscharfen Mengen in knackige Mengen um. Es folgt ein Blockdiagramm eines Fuzzy-Interferenzsystems.

Arbeiten der FIS
Die Arbeitsweise der FIS besteht aus folgenden Schritten:
Eine Fuzzifizierungseinheit unterstützt die Anwendung zahlreicher Fuzzifizierungsmethoden und wandelt die gestochen scharfe Eingabe in eine unscharfe Eingabe um.
Eine Wissensbasis - Sammlung von Regelbasis und Datenbank wird gebildet, wenn scharfe Eingaben in unscharfe Eingaben umgewandelt werden.
Die Fuzzy-Eingabe der Defuzzifizierungseinheit wird schließlich in eine gestochen scharfe Ausgabe umgewandelt.
Methoden der FIS
Lassen Sie uns nun die verschiedenen Methoden der FIS diskutieren. Im Folgenden sind die beiden wichtigen Methoden von FIS aufgeführt, die unterschiedliche Konsequenzen von Fuzzy-Regeln haben:
- Mamdani Fuzzy Inference System
- Takagi-Sugeno-Fuzzy-Modell (TS-Methode)
Mamdani Fuzzy Inference System
Dieses System wurde 1975 von Ebhasim Mamdani vorgeschlagen. Grundsätzlich wurde erwartet, eine Kombination aus Dampfmaschine und Kessel durch Synthese eines Satzes von Fuzzy-Regeln zu steuern, die von Personen erhalten wurden, die an dem System arbeiten.
Schritte zum Berechnen der Ausgabe
Die folgenden Schritte müssen ausgeführt werden, um die Ausgabe von diesem FIS zu berechnen:
Step 1 - In diesem Schritt müssen einige Fuzzy-Regeln festgelegt werden.
Step 2 - In diesem Schritt wird durch Verwendung der Eingangszugehörigkeitsfunktion die Eingabe unscharf gemacht.
Step 3 - Stellen Sie nun die Regelstärke fest, indem Sie die unscharfen Eingaben nach unscharfen Regeln kombinieren.
Step 4 - Bestimmen Sie in diesem Schritt die Konsequenz der Regel, indem Sie die Regelstärke und die Ausgabe-Zugehörigkeitsfunktion kombinieren.
Step 5 - Um die Leistungsverteilung zu erhalten, kombinieren Sie alle Konsequenzen.
Step 6 - Schließlich wird eine defuzzifizierte Ausgabeverteilung erhalten.
Es folgt ein Blockdiagramm des Mamdani Fuzzy Interface Systems.

Takagi-Sugeno-Fuzzy-Modell (TS-Methode)
Dieses Modell wurde 1985 von Takagi, Sugeno und Kang vorgeschlagen. Das Format dieser Regel lautet:
WENN x A und y B ist, DANN Z = f (x, y)
Hier sind AB Fuzzy-Mengen in Antezedenzien und z = f (x, y) ist in der Folge eine knackige Funktion.
Fuzzy-Inferenzprozess
Der Fuzzy-Inferenzprozess unter dem Takagi-Sugeno-Fuzzy-Modell (TS-Methode) funktioniert folgendermaßen:
Step 1: Fuzzifying the inputs - Hier werden die Eingänge des Systems unscharf gemacht.
Step 2: Applying the fuzzy operator - In diesem Schritt müssen die Fuzzy-Operatoren angewendet werden, um die Ausgabe zu erhalten.
Regelformat des Sugeno-Formulars
Das Regelformat der Sugeno-Form ist gegeben durch -
Wenn 7 = x und 9 = y, ist die Ausgabe z = ax + by + c
Vergleich zwischen den beiden Methoden
Lassen Sie uns nun den Vergleich zwischen dem Mamdani-System und dem Sugeno-Modell verstehen.
Output Membership Function- Der Hauptunterschied zwischen ihnen besteht in der Funktion der Ausgabemitgliedschaft. Die Sugeno-Ausgangsmitgliedschaftsfunktionen sind entweder linear oder konstant.
Aggregation and Defuzzification Procedure - Der Unterschied zwischen ihnen liegt auch in der Konsequenz von Fuzzy-Regeln und aufgrund derselben unterscheidet sich auch ihr Aggregations- und Defuzzifizierungsverfahren.
Mathematical Rules - Für die Sugeno-Regel existieren mehr mathematische Regeln als für die Mamdani-Regel.
Adjustable Parameters - Der Sugeno-Controller verfügt über mehr einstellbare Parameter als der Mamdani-Controller.
In unseren vorherigen Kapiteln haben wir untersucht, dass Fuzzy Logic ein Ansatz zur Berechnung ist, der auf "Wahrheitsgraden" und nicht auf der üblichen "wahren oder falschen" Logik basiert. Es handelt sich eher um eine ungefähre als eine präzise Argumentation, um Probleme auf eine Weise zu lösen, die der menschlichen Logik ähnlicher ist. Daher ist ein Datenbankabfrageprozess durch die zweiwertige Realisierung der Booleschen Algebra nicht ausreichend.
Fuzzy-Szenario für Beziehungen in Datenbanken
Das Fuzzy-Szenario der Beziehungen zu Datenbanken kann anhand des folgenden Beispiels verstanden werden:
Beispiel
Angenommen, wir haben eine Datenbank mit den Aufzeichnungen von Personen, die Indien besucht haben. In einer einfachen Datenbank werden die Einträge folgendermaßen vorgenommen:
| Name | Alter | Bürger | Besuchtes Land | Tage verbracht | Jahr des Besuchs |
|---|---|---|---|---|---|
| John Smith | 35 | UNS | Indien | 41 | 1999 |
| John Smith | 35 | UNS | Italien | 72 | 1999 |
| John Smith | 35 | UNS | Japan | 31 | 1999 |
Wenn jemand Fragen zu der Person stellt, die im Jahr 99 Indien und Japan besucht hat und Staatsbürger der USA ist, werden in der Ausgabe zwei Einträge mit dem Namen John Smith angezeigt. Dies ist eine einfache Abfrage, die eine einfache Ausgabe generiert.
Aber was ist, wenn wir wissen wollen, ob die Person in der obigen Abfrage jung ist oder nicht? Nach dem obigen Ergebnis beträgt das Alter der Person 35 Jahre. Aber können wir davon ausgehen, dass die Person jung ist oder nicht? Ebenso kann das Gleiche auf die anderen Bereiche angewendet werden, z. B. Tage, Besuchsjahr usw.
Die Lösung der oben genannten Probleme kann mithilfe von Fuzzy-Wertesätzen wie folgt gefunden werden:
FV (Alter) {sehr jung, jung, etwas alt, alt}
FV (Days Spent) {kaum ein paar Tage, ein paar Tage, ein paar Tage, viele Tage}
FV (Jahr des Besuchs) {ferne Vergangenheit, jüngste Vergangenheit, jüngste}
Wenn eine Abfrage den Fuzzy-Wert hat, ist das Ergebnis ebenfalls unscharf.
Fuzzy-Abfragesystem
Ein Fuzzy-Abfragesystem ist eine Schnittstelle für Benutzer, um Informationen aus der Datenbank mithilfe von (quasi) Sätzen in natürlicher Sprache abzurufen. Es wurden viele Fuzzy-Abfrage-Implementierungen vorgeschlagen, die zu leicht unterschiedlichen Sprachen führen. Obwohl es je nach den Besonderheiten verschiedener Implementierungen einige Variationen gibt, ist die Antwort auf einen Fuzzy-Abfragesatz im Allgemeinen eine Liste von Datensätzen, sortiert nach dem Grad der Übereinstimmung.
Bei der Modellierung von Aussagen in natürlicher Sprache spielen quantifizierte Aussagen eine wichtige Rolle. Dies bedeutet, dass NL stark von der Quantifizierung der Konstruktion abhängt, die häufig unscharfe Konzepte wie „fast alle“, „viele“ usw. enthält. Nachfolgend einige Beispiele für die Quantifizierung von Aussagen -
- Jeder Schüler hat die Prüfung bestanden.
- Jeder Sportwagen ist teuer.
- Viele Studenten haben die Prüfung bestanden.
- Viele Sportwagen sind teuer.
In den obigen Beispielen werden die Quantifizierer "Jeder" und "Viele" auf die knackigen Einschränkungen "Studenten" sowie den knackigen Bereich "(Person, die) die Prüfung bestanden hat" und "Autos" sowie den knackigen Bereich "Sport" angewendet.
Fuzzy-Ereignisse, Fuzzy-Mittel und Fuzzy-Varianzen
Anhand eines Beispiels können wir die obigen Konzepte verstehen. Nehmen wir an, wir sind Aktionär eines Unternehmens namens ABC. Gegenwärtig verkauft das Unternehmen jeden seiner Anteile für 40 GBP. Es gibt drei verschiedene Unternehmen, deren Geschäft ABC ähnelt, aber diese bieten ihre Aktien zu unterschiedlichen Kursen an - 100 GBP pro Aktie, 85 GBP pro Aktie bzw. 60 GBP pro Aktie.
Nun ist die Wahrscheinlichkeitsverteilung dieser Preisübernahme wie folgt:
| Preis | £ 100 | £ 85 | £ 60 |
|---|---|---|---|
| Wahrscheinlichkeit | 0,3 | 0,5 | 0,2 |
Aus der Standardwahrscheinlichkeitstheorie ergibt die obige Verteilung einen Mittelwert des erwarteten Preises wie folgt:
$ 100 × 0,3 + 85 × 0,5 + 60 × 0,2 = 84,5 $
Und aus der Standardwahrscheinlichkeitstheorie ergibt die obige Verteilung eine Varianz des erwarteten Preises wie folgt:
$ (100 - 84,5) 2 × 0,3 + (85 - 84,5) 2 × 0,5 + (60 - 84,5) 2 × 0,2 = 124,825 $
Angenommen, der Zugehörigkeitsgrad von 100 in dieser Menge beträgt 0,7, der von 85 ist 1 und der Zugehörigkeitsgrad beträgt 0,5 für den Wert 60. Diese können sich in der folgenden Fuzzy-Menge widerspiegeln:
$$ \ left \ {\ frac {0.7} {100}, \: \ frac {1} {85}, \: \ frac {0.5} {60}, \ right \} $$
Die auf diese Weise erhaltene Fuzzy-Menge wird als Fuzzy-Ereignis bezeichnet.
Wir wollen die Wahrscheinlichkeit des Fuzzy-Ereignisses, für das unsere Berechnung ergibt -
$ 0,7 × 0,3 + 1 × 0,5 + 0,5 × 0,2 = 0,21 + 0,5 + 0,1 = 0,81 $
Nun müssen wir den Fuzzy-Mittelwert und die Fuzzy-Varianz berechnen. Die Berechnung lautet wie folgt:
Fuzzy_mean $ = \ left (\ frac {1} {0,81} \ right) × (100 × 0,7 × 0,3 + 85 × 1 × 0,5 + 60 × 0,5 × 0,2) $
$ = 85,8 $
Fuzzy_Variance $ = 7496,91 - 7361,91 = 135,27 $
Es ist eine Aktivität, die die Schritte umfasst, die unternommen werden müssen, um eine geeignete Alternative aus denjenigen auszuwählen, die zur Verwirklichung eines bestimmten Ziels erforderlich sind.
Schritte zur Entscheidungsfindung
Lassen Sie uns nun die Schritte diskutieren, die mit dem Entscheidungsprozess verbunden sind -
Determining the Set of Alternatives - In diesem Schritt müssen die Alternativen festgelegt werden, aus denen die Entscheidung getroffen werden muss.
Evaluating Alternative - Hier müssen die Alternativen bewertet werden, damit die Entscheidung über eine der Alternativen getroffen werden kann.
Comparison between Alternatives - In diesem Schritt wird ein Vergleich zwischen den bewerteten Alternativen durchgeführt.
Arten von Entscheidungen
Treffen Wir werden nun die verschiedenen Arten der Entscheidungsfindung verstehen.
Individuelle Entscheidungsfindung
Bei dieser Art der Entscheidungsfindung ist nur eine einzige Person für die Entscheidungsfindung verantwortlich. Das Entscheidungsmodell dieser Art kann charakterisiert werden als -
Reihe möglicher Aktionen
Satz von Zielen $ G_i \ left (i \: \ in \: X_n \ right); $
Satz von Einschränkungen $ C_j \ left (j \: \ in \: X_m \ right) $
Die oben genannten Ziele und Einschränkungen werden in Fuzzy-Mengen ausgedrückt.
Betrachten Sie nun eine Menge A. Dann sind das Ziel und die Einschränkungen für diese Menge gegeben durch -
$ G_i \ left (a \ right) $ = Komposition $ \ left [G_i \ left (a \ right) \ right] $ = $ G_i ^ 1 \ left (G_i \ left (a \ right) \ right) $ with $ G_i ^ 1 $
$ C_j \ left (a \ right) $ = Komposition $ \ left [C_j \ left (a \ right) \ right] $ = $ C_j ^ 1 \ left (C_j \ left (a \ right) \ right) $ with $ C_j ^ 1 $ für $ a \: \ in \: A $
Die Fuzzy-Entscheidung im obigen Fall ist gegeben durch -
$$ F_D = min [i \ in X_ {n} ^ {in} fG_i \ links (a \ rechts), j \ in X_ {m} ^ {in} fC_j \ links (a \ rechts)] $$
Entscheidungsfindung für mehrere Personen
Die Entscheidungsfindung umfasst in diesem Fall mehrere Personen, so dass das Expertenwissen verschiedener Personen zur Entscheidungsfindung genutzt wird.
Die Berechnung hierfür kann wie folgt erfolgen:
Number of persons preferring $x_i$ to $x_j$ = $ N \ left (x_i, \: x_j \ right) $
Total number of decision makers = $ n $
Dann ist $ SC \ left (x_i, \: x_j \ right) = \ frac {N \ left (x_i, \: x_j \ right)} {n} $
Entscheidungsfindung mit mehreren Zielen
Die Entscheidungsfindung mit mehreren Zielen erfolgt, wenn mehrere Ziele verwirklicht werden müssen. Bei dieser Art der Entscheidungsfindung gibt es zwei Probleme:
Angemessene Informationen in Bezug auf die Erreichung der Ziele durch verschiedene Alternativen zu erhalten.
Abwägen der relativen Bedeutung jedes Ziels.
Mathematisch können wir ein Universum von n Alternativen definieren als -
$ A = \ left [a_1, \: a_2, \: ..., \: a_i, \: ..., \: a_n \ right] $
Und die Menge der "m" -Ziele als $ O = \ left [o_1, \: o_2, \: ..., \: o_i, \: ..., \: o_n \ right] $
Entscheidungsfindung mit mehreren Attributen
Die Entscheidungsfindung mit mehreren Attributen findet statt, wenn die Bewertung von Alternativen basierend auf mehreren Attributen des Objekts durchgeführt werden kann. Die Attribute können numerische Daten, Sprachdaten und qualitative Daten sein.
Mathematisch wird die Mehrfachattributbewertung auf der Basis einer linearen Gleichung wie folgt durchgeführt:
$$ Y = A_1X_1 + A_2X_2 + ... + A_iX_i + ... + A_rX_r $$
Fuzzy-Logik wird mit großem Erfolg in verschiedenen Steuerungsanwendungen angewendet. Fast alle Konsumgüter haben eine Fuzzy-Kontrolle. Einige Beispiele umfassen die Steuerung Ihrer Raumtemperatur mithilfe einer Klimaanlage, eines in Fahrzeugen verwendeten Bremsschutzsystems, der Steuerung von Ampeln, Waschmaschinen, großen Wirtschaftssystemen usw.
Warum Fuzzy Logic in Steuerungssystemen verwenden?
Ein Steuersystem ist eine Anordnung von physikalischen Komponenten, die dazu ausgelegt sind, ein anderes physikalisches System so zu verändern, dass dieses System bestimmte gewünschte Eigenschaften aufweist. Im Folgenden sind einige Gründe für die Verwendung von Fuzzy Logic in Steuerungssystemen aufgeführt:
Bei der Anwendung der traditionellen Steuerung muss man das Modell und die Zielform kennen, die präzise formuliert sind. Dies macht es in vielen Fällen sehr schwierig, sich zu bewerben.
Durch Anwendung der Fuzzy-Logik zur Steuerung können wir das menschliche Fachwissen und die Erfahrung für den Entwurf einer Steuerung nutzen.
Die Fuzzy-Steuerungsregeln, im Grunde die IF-THEN-Regeln, können am besten beim Entwerfen einer Steuerung verwendet werden.
Annahmen im Fuzzy Logic Control (FLC) -Design
Beim Entwurf eines Fuzzy-Steuerungssystems sollten die folgenden sechs Grundannahmen getroffen werden:
The plant is observable and controllable - Es ist davon auszugehen, dass die Eingabe-, Ausgabe- und Zustandsvariablen zu Beobachtungs- und Steuerungszwecken zur Verfügung stehen.
Existence of a knowledge body - Es muss davon ausgegangen werden, dass es einen Wissenskörper mit sprachlichen Regeln und einem Satz von Eingabe-Ausgabe-Datensätzen gibt, aus denen Regeln extrahiert werden können.
Existence of solution - Es ist davon auszugehen, dass es eine Lösung gibt.
‘Good enough’ solution is enough - Die Steuerungstechnik muss eher nach einer ausreichend guten als nach einer optimalen Lösung suchen.
Range of precision - Die Fuzzy-Logik-Steuerung muss in einem akzeptablen Genauigkeitsbereich ausgelegt sein.
Issues regarding stability and optimality - Die Fragen der Stabilität und Optimalität müssen beim Entwurf eines Fuzzy-Logik-Controllers offen sein und dürfen nicht explizit behandelt werden.
Architektur der Fuzzy-Logik-Steuerung
Das folgende Diagramm zeigt die Architektur von Fuzzy Logic Control (FLC).

Hauptkomponenten von FLC
Das Folgende sind die Hauptkomponenten des FLC, wie in der obigen Abbildung gezeigt -
Fuzzifier - Die Rolle von Fuzzifier besteht darin, die gestochen scharfen Eingabewerte in Fuzzy-Werte umzuwandeln.
Fuzzy Knowledge Base- Es speichert das Wissen über alle Fuzzy-Beziehungen zwischen Eingabe und Ausgabe. Es hat auch die Zugehörigkeitsfunktion, die die Eingangsvariablen für die Fuzzy-Regelbasis und die Ausgangsvariablen für die kontrollierte Anlage definiert.
Fuzzy Rule Base - Es speichert das Wissen über die Funktionsweise des Domain-Prozesses.
Inference Engine- Es fungiert als Kernel eines FLC. Grundsätzlich simuliert es menschliche Entscheidungen durch ungefähre Argumentation.
Defuzzifier - Die Rolle des Defuzzifiers besteht darin, die Fuzzy-Werte in scharfe Werte umzuwandeln, die von der Fuzzy-Inferenz-Engine stammen.
Schritte zum Entwerfen von FLC
Im Folgenden sind die Schritte zum Entwerfen von FLC aufgeführt:
Identification of variables - Hier müssen die Eingabe-, Ausgabe- und Zustandsvariablen der betreffenden Anlage identifiziert werden.
Fuzzy subset configuration- Das Informationsuniversum ist in die Anzahl der Fuzzy-Teilmengen unterteilt, und jeder Teilmenge wird eine sprachliche Bezeichnung zugewiesen. Stellen Sie immer sicher, dass diese unscharfen Teilmengen alle Elemente des Universums enthalten.
Obtaining membership function - Erhalten Sie nun die Zugehörigkeitsfunktion für jede Fuzzy-Teilmenge, die wir im obigen Schritt erhalten.
Fuzzy rule base configuration - Formulieren Sie nun die Fuzzy-Regelbasis, indem Sie die Beziehung zwischen Fuzzy-Eingabe und Ausgabe zuweisen.
Fuzzification - In diesem Schritt wird der Fuzzifizierungsprozess eingeleitet.
Combining fuzzy outputs - Suchen Sie durch Anwenden der unscharfen Fuzzy-Argumentation die Fuzzy-Ausgabe und führen Sie sie zusammen.
Defuzzification - Starten Sie abschließend den Defuzzifizierungsprozess, um eine gestochen scharfe Ausgabe zu erzielen.
Vorteile der Fuzzy-Logik-Steuerung
Lassen Sie uns nun die Vorteile von Fuzzy Logic Control diskutieren.
Cheaper - Die Entwicklung eines FLC ist in Bezug auf die Leistung vergleichsweise billiger als die Entwicklung eines modellbasierten oder eines anderen Controllers.
Robust - FLCs sind robuster als PID-Regler, da sie einen großen Bereich von Betriebsbedingungen abdecken können.
Customizable - FLCs sind anpassbar.
Emulate human deductive thinking - Grundsätzlich ist FLC darauf ausgelegt, menschliches deduktives Denken zu emulieren, den Prozess, mit dem Menschen Schlussfolgerungen aus dem ziehen, was sie wissen.
Reliability - FLC ist zuverlässiger als herkömmliche Steuerungssysteme.
Efficiency - Fuzzy-Logik bietet mehr Effizienz bei der Anwendung im Steuerungssystem.
Nachteile der Fuzzy-Logik-Steuerung
Wir werden nun diskutieren, was die Nachteile von Fuzzy Logic Control sind.
Requires lots of data - FLC benötigt viele Daten, um angewendet zu werden.
Useful in case of moderate historical data - FLC ist nicht nützlich für Programme, die viel kleiner oder größer als historische Daten sind.
Needs high human expertise - Dies ist ein Nachteil, da die Genauigkeit des Systems vom Wissen und der Sachkenntnis des Menschen abhängt.
Needs regular updating of rules - Die Regeln müssen mit der Zeit aktualisiert werden.
In diesem Kapitel werden wir diskutieren, was ein adaptiver Fuzzy-Controller ist und wie er funktioniert. Der adaptive Fuzzy-Controller verfügt über einige einstellbare Parameter sowie einen eingebetteten Mechanismus zum Einstellen dieser Parameter. Der adaptive Controller wurde zur Verbesserung der Leistung des Controllers verwendet.
Grundlegende Schritte zur Implementierung des adaptiven Algorithmus
Lassen Sie uns nun die grundlegenden Schritte zur Implementierung des adaptiven Algorithmus diskutieren.
Collection of observable data - Die beobachtbaren Daten werden gesammelt, um die Leistung des Controllers zu berechnen.
Adjustment of controller parameters - Mit Hilfe der Reglerleistung würde nun die Berechnung der Anpassung der Reglerparameter durchgeführt.
Improvement in performance of controller - In diesem Schritt werden die Reglerparameter angepasst, um die Leistung des Reglers zu verbessern.
Betriebskonzepte
Der Entwurf einer Steuerung basiert auf einem angenommenen mathematischen Modell, das einem realen System ähnelt. Der Fehler zwischen dem tatsächlichen System und seiner mathematischen Darstellung wird berechnet, und wenn er relativ unbedeutend ist, wird angenommen, dass das Modell effektiv funktioniert.
Es gibt auch eine Schwellenwertkonstante, die eine Grenze für die Wirksamkeit eines Controllers festlegt. Der Steuereingang wird sowohl in das reale System als auch in das mathematische Modell eingespeist. Nehmen wir hier an, $ x \ left (t \ right) $ ist die Ausgabe des realen Systems und $ y \ left (t \ right) $ ist die Ausgabe des mathematischen Modells. Dann kann der Fehler $ \ epsilon \ left (t \ right) $ wie folgt berechnet werden:
$$ \ epsilon \ left (t \ right) = x \ left (t \ right) - y \ left (t \ right) $$
Hier ist $ x $ gewünscht die Ausgabe, die wir vom System wollen, und $ \ mu \ left (t \ right) $ ist die Ausgabe, die vom Controller kommt und sowohl zum realen als auch zum mathematischen Modell geht.
Das folgende Diagramm zeigt, wie die Fehlerfunktion zwischen der Ausgabe eines realen Systems und dem mathematischen Modell verfolgt wird.

Parametrierung des Systems
Ein Fuzzy-Controller, dessen Design auf dem Fuzzy-mathematischen Modell basiert, hat die folgende Form von Fuzzy-Regeln:
Rule 1 - WENN $ x_1 \ left (t_n \ right) \ in X_ {11} \: AND ... AND \: x_i \ left (t_n \ right) \ in X_ {1i} $
DANN $ \ mu _1 \ left (t_n \ right) = K_ {11} x_1 \ left (t_n \ right) + K_ {12} x_2 \ left (t_n \ right) \: + ... + \: K_ {1i } x_i \ left (t_n \ right) $
Rule 2 - WENN $ x_1 \ left (t_n \ right) \ in X_ {21} \: AND ... AND \: x_i \ left (t_n \ right) \ in X_ {2i} $
DANN $ \ mu _2 \ left (t_n \ right) = K_ {21} x_1 \ left (t_n \ right) + K_ {22} x_2 \ left (t_n \ right) \: + ... + \: K_ {2i } x_i \ left (t_n \ right) $
.
.
.
Rule j - WENN $ x_1 \ left (t_n \ right) \ in X_ {k1} \: AND ... AND \: x_i \ left (t_n \ right) \ in X_ {ki} $
DANN $ \ mu _j \ left (t_n \ right) = K_ {j1} x_1 \ left (t_n \ right) + K_ {j2} x_2 \ left (t_n \ right) \: + ... + \: K_ {ji } x_i \ left (t_n \ right) $
Der obige Parametersatz kennzeichnet die Steuerung.
Mechanismuseinstellung
Die Reglerparameter werden angepasst, um die Leistung des Reglers zu verbessern. Der Prozess der Berechnung der Anpassung an die Parameter ist der Einstellmechanismus.
Mathematisch sei $ \ theta ^ \ left (n \ right) $ ein Satz von Parametern, die zum Zeitpunkt $ t = t_n $ angepasst werden müssen. Die Anpassung kann die Neuberechnung der Parameter sein,
$$ \ theta ^ \ left (n \ right) = \ Theta \ left (D_0, \: D_1, \: ..., \: D_n \ right) $$
Hier sind $ D_n $ die zum Zeitpunkt $ t = t_n $ gesammelten Daten.
Diese Formulierung wird nun durch die Aktualisierung des Parametersatzes basierend auf seinem vorherigen Wert wie folgt umformuliert:
$$ \ theta ^ \ left (n \ right) = \ phi (\ theta ^ {n-1}, \: D_n) $$
Parameter zur Auswahl eines adaptiven Fuzzy-Controllers
Die folgenden Parameter müssen bei der Auswahl eines adaptiven Fuzzy-Controllers berücksichtigt werden:
Kann das System vollständig durch ein Fuzzy-Modell angenähert werden?
Wenn ein System vollständig durch ein Fuzzy-Modell approximiert werden kann, sind die Parameter dieses Fuzzy-Modells leicht verfügbar oder müssen sie online ermittelt werden?
Wenn ein System nicht vollständig durch ein Fuzzy-Modell approximiert werden kann, kann es dann stückweise durch einen Satz von Fuzzy-Modellen approximiert werden?
Wenn ein System durch eine Reihe von Fuzzy-Modellen approximiert werden kann, haben diese Modelle dasselbe Format mit unterschiedlichen Parametern oder unterschiedliche Formate?
Wenn ein System durch eine Reihe von Fuzzy-Modellen mit demselben Format und jeweils unterschiedlichen Parametern approximiert werden kann, sind diese Parametersätze leicht verfügbar oder müssen sie online ermittelt werden?
Das künstliche neuronale Netzwerk (ANN) ist ein Netzwerk effizienter Computersysteme, deren zentrales Thema der Analogie biologischer neuronaler Netzwerke entlehnt ist. ANNs werden auch als "künstliche neuronale Systeme", parallel verteilte Verarbeitungssysteme "," verbindungsorientierte Systeme "bezeichnet. ANN erwirbt eine große Sammlung von Einheiten, die in einem bestimmten Muster miteinander verbunden sind, um die Kommunikation zwischen Einheiten zu ermöglichen. Diese Einheiten, auch als Knoten oder Neuronen bezeichnet, sind einfache Prozessoren, die parallel arbeiten.
Jedes Neuron ist über eine Verbindungsverbindung mit einem anderen Neuron verbunden. Jeder Verbindungsverbindung ist ein Gewicht zugeordnet, das die Informationen über das Eingangssignal enthält. Dies ist die nützlichste Information für Neuronen, um ein bestimmtes Problem zu lösen, da das Gewicht normalerweise das übertragene Signal hemmt. Jedes Neuron hat seinen internen Zustand, der als Aktivierungssignal bezeichnet wird. Ausgangssignale, die nach dem Kombinieren der Eingangssignale und der Aktivierungsregel erzeugt werden, können an andere Einheiten gesendet werden. Es besteht auch aus einer Vorspannung 'b', deren Gewicht immer 1 ist.

Warum Fuzzy Logic im neuronalen Netz verwenden?
Wie wir oben diskutiert haben, ist jedes Neuron in ANN über eine Verbindungsverbindung mit einem anderen Neuron verbunden, und diese Verbindung ist einem Gewicht zugeordnet, das die Information über das Eingangssignal enthält. Daher können wir sagen, dass Gewichte die nützlichen Informationen über die Eingabe haben, um die Probleme zu lösen.
Im Folgenden sind einige Gründe für die Verwendung von Fuzzy-Logik in neuronalen Netzen aufgeführt:
Fuzzy-Logik wird hauptsächlich verwendet, um die Gewichte aus Fuzzy-Mengen in neuronalen Netzen zu definieren.
Wenn keine scharfen Werte angewendet werden können, werden Fuzzy-Werte verwendet.
Wir haben bereits untersucht, dass Training und Lernen dazu beitragen, dass neuronale Netze in unerwarteten Situationen eine bessere Leistung erbringen. Zu diesem Zeitpunkt wären Fuzzy-Werte besser anwendbar als scharfe Werte.
Wenn wir Fuzzy-Logik in neuronalen Netzen verwenden, dürfen die Werte nicht scharf sein und die Verarbeitung kann parallel erfolgen.
Fuzzy Cognitive Map
Es ist eine Form der Unschärfe in neuronalen Netzen. Grundsätzlich ist FCM wie eine dynamische Zustandsmaschine mit Fuzzy-Zuständen (nicht nur 1 oder 0).
Schwierigkeiten bei der Verwendung von Fuzzy Logic in neuronalen Netzen
Trotz zahlreicher Vorteile gibt es auch einige Schwierigkeiten bei der Verwendung von Fuzzy-Logik in neuronalen Netzen. Die Schwierigkeit hängt mit den Mitgliedschaftsregeln zusammen, der Notwendigkeit, ein Fuzzy-System aufzubauen, da es manchmal kompliziert ist, es mit dem gegebenen Satz komplexer Daten abzuleiten.
Neuronale Fuzzy-Logik
Die umgekehrte Beziehung zwischen dem neuronalen Netzwerk und der Fuzzy-Logik, dh dem neuronalen Netzwerk, das zum Trainieren der Fuzzy-Logik verwendet wird, ist ebenfalls ein gutes Untersuchungsgebiet. Im Folgenden sind zwei Hauptgründe aufgeführt, um eine neuraltrainierte Fuzzy-Logik aufzubauen:
Neue Datenmuster können mit Hilfe neuronaler Netze leicht erlernt werden, daher können Daten in Fuzzy-Systemen vorverarbeitet werden.
Das neuronale Netzwerk kann aufgrund seiner Fähigkeit, neue Beziehungen zu neuen Eingabedaten zu lernen, verwendet werden, um Fuzzy-Regeln zu verfeinern, um ein Fuzzy-adaptives System zu erstellen.
Beispiele für ein neuronales Fuzzy-System
Neuronale Fuzzy-Systeme werden in vielen kommerziellen Anwendungen eingesetzt. Lassen Sie uns nun einige Beispiele sehen, in denen das neuronale Fuzzy-System angewendet wird -
Das Labor für internationale Fuzzy-Engineering-Forschung (LIFE) in Yokohama, Japan, verfügt über ein neuronales Netzwerk mit Rückausbreitung, das Fuzzy-Regeln ableitet. Dieses System wurde erfolgreich auf das Devisenhandelssystem mit ungefähr 5000 Fuzzy-Regeln angewendet.
Die Ford Motor Company hat trainierbare Fuzzy-Systeme für die Leerlaufregelung von Kraftfahrzeugen entwickelt.
NeuFuz, Softwareprodukt der National Semiconductor Corporation, unterstützt die Generierung von Fuzzy-Regeln mit einem neuronalen Netzwerk für Steuerungsanwendungen.
Die AEG Corporation of Germany verwendet für ihre wasser- und energiesparende Maschine ein neuronales Fuzzy-Steuerungssystem. Es hat insgesamt 157 Fuzzy-Regeln.
In diesem Kapitel werden wir die Bereiche diskutieren, in denen die Konzepte der Fuzzy-Logik ausführlich angewendet werden.
Luft- und Raumfahrt
In der Luft- und Raumfahrt wird in den folgenden Bereichen Fuzzy-Logik verwendet:
- Höhenkontrolle von Raumfahrzeugen
- Satellitenhöhensteuerung
- Durchfluss- und Gemischregulierung in Flugzeugenteisungsfahrzeugen
Automobil
In der Automobilindustrie wird Fuzzy-Logik in den folgenden Bereichen verwendet:
- Trainierbare Fuzzy-Systeme zur Steuerung der Leerlaufdrehzahl
- Schichtplanungsmethode für Automatikgetriebe
- Intelligente Autobahnsysteme
- Verkehrskontrolle
- Verbesserung der Effizienz von Automatikgetrieben
Geschäft
In der Wirtschaft wird Fuzzy-Logik in den folgenden Bereichen verwendet:
- Entscheidungsunterstützungssysteme
- Personalbewertung in einem großen Unternehmen
Verteidigung
In der Verteidigung wird in den folgenden Bereichen Fuzzy-Logik verwendet:
- Unterwasserzielerkennung
- Automatische Zielerkennung von thermischen Infrarotbildern
- Hilfsmittel zur Unterstützung der Seeentscheidung
- Steuerung eines Hypervelocity-Interceptors
- Fuzzy-Set-Modellierung der NATO-Entscheidungsfindung
Elektronik
In der Elektronik wird Fuzzy-Logik in den folgenden Bereichen verwendet:
- Steuerung der automatischen Belichtung in Videokameras
- Luftfeuchtigkeit in einem Reinraum
- Klimaanlagen
- Waschmaschinen-Timing
- Mikrowellen
- Staubsauger
Finanzen
Im Finanzbereich wird in den folgenden Bereichen Fuzzy-Logik verwendet:
- Kontrolle der Banknotenübertragung
- Fondsverwaltung
- Börsenprognosen
Industriebereich
In der Industrie wird Fuzzy-Logik in folgenden Bereichen verwendet:
- Zementofen steuert die Wärmetauschersteuerung
- Kontrolle des Belebtschlamm-Abwasserbehandlungsprozesses
- Kontrolle der Wasseraufbereitungsanlage
- Quantitative Musteranalyse zur industriellen Qualitätssicherung
- Kontrolle von Problemen mit der Erfüllung von Einschränkungen bei der Tragwerksplanung
- Kontrolle von Wasseraufbereitungsanlagen
Herstellung
In der Fertigungsindustrie wird Fuzzy-Logik in folgenden Bereichen verwendet:
- Optimierung der Käseproduktion
- Optimierung der Milchproduktion
Marine
Im Meeresbereich wird in den folgenden Bereichen Fuzzy-Logik verwendet:
- Autopilot für Schiffe
- Optimale Routenauswahl
- Kontrolle autonomer Unterwasserfahrzeuge
- Schiffssteuerung
Medizinisch
Im medizinischen Bereich wird Fuzzy-Logik in den folgenden Bereichen verwendet:
- Medizinisches diagnostisches Unterstützungssystem
- Kontrolle des arteriellen Drucks während der Anästhesie
- Multivariable Kontrolle der Anästhesie
- Modellierung neuropathologischer Befunde bei Alzheimer-Patienten
- Radiologische Diagnosen
- Fuzzy-Inferenzdiagnose von Diabetes und Prostatakrebs
Wertpapiere
In Wertpapieren wird Fuzzy-Logik in folgenden Bereichen verwendet:
- Entscheidungssysteme für den Wertpapierhandel
- Verschiedene Sicherheitsgeräte
Transport
Beim Transport wird in den folgenden Bereichen Fuzzy-Logik verwendet:
- Automatischer U-Bahn-Betrieb
- Zugfahrplankontrolle
- Eisenbahnbeschleunigung
- Bremsen und Anhalten
Mustererkennung und -klassifizierung
In der Mustererkennung und -klassifizierung wird in den folgenden Bereichen Fuzzy-Logik verwendet:
- Fuzzy-Logik-basierte Spracherkennung
- Fuzzy-Logik basiert
- Handschrifterkennung
- Fuzzy-Logik-basierte Analyse der Gesichtsmerkmale
- Befehlsanalyse
- Fuzzy-Bildsuche
Psychologie
In der Psychologie wird Fuzzy-Logik in folgenden Bereichen verwendet:
- Fuzzy-Logik-basierte Analyse des menschlichen Verhaltens
- Kriminalpolizei und -prävention auf der Grundlage von Fuzzy-Logik-Überlegungen