ビッグデータ分析-データライフサイクル
従来のデータマイニングのライフサイクル
組織が必要とする作業を整理し、ビッグデータから明確な洞察を提供するためのフレームワークを提供するには、それをさまざまな段階のサイクルと考えると便利です。これは決して線形ではありません。つまり、すべてのステージが相互に関連しています。このサイクルは、で説明されているように、従来のデータマイニングサイクルと表面的に類似しています。CRISP methodology。
CRISP-DM方法論
ザ・ CRISP-DM methodologyこれは、データマイニングの業界標準プロセスの略で、データマイニングの専門家が従来のBIデータマイニングの問題に取り組むために使用する一般的に使用されるアプローチを説明するサイクルです。従来のBIデータマイニングチームで引き続き使用されています。
次の図を見てください。これは、CRISP-DM方法論で説明されているサイクルの主要な段階と、それらがどのように相互に関連しているかを示しています。
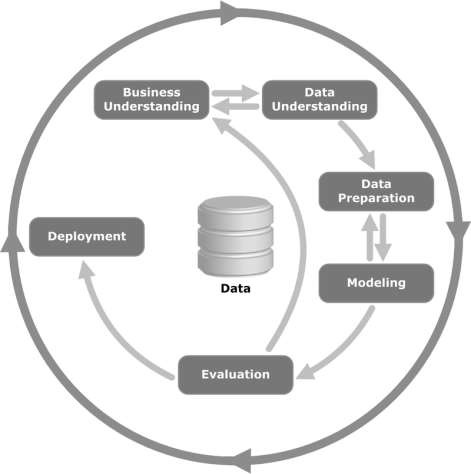
CRISP-DMは1996年に考案され、翌年、ESPRITの資金提供イニシアチブの下で欧州連合のプロジェクトとして開始されました。このプロジェクトは、SPSS、Teradata、Daimler AG、NCR Corporation、およびOHRA(保険会社)の5社が主導しました。プロジェクトは最終的にSPSSに組み込まれました。方法論は、データマイニングプロジェクトをどのように指定するかという点で非常に詳細です。
ここで、CRISP-DMライフサイクルに含まれる各段階についてもう少し学びましょう。
Business Understanding−この初期段階では、ビジネスの観点からプロジェクトの目的と要件を理解し、この知識をデータマイニングの問題定義に変換することに重点を置いています。予備計画は、目的を達成するために設計されています。意思決定モデル、特に意思決定モデルと表記法の標準を使用して構築されたモデルを使用できます。
Data Understanding −データ理解フェーズは、最初のデータ収集から始まり、データに精通し、データ品質の問題を特定し、データへの最初の洞察を発見し、または興味深いサブセットを検出して隠された情報の仮説を立てるためのアクティビティに進みます。
Data Preparation−データ準備フェーズは、最初の生データから最終データセット(モデリングツールに入力されるデータ)を構築するためのすべてのアクティビティをカバーします。データ準備タスクは、指定された順序ではなく、複数回実行される可能性があります。タスクには、テーブル、レコード、属性の選択、およびモデリングツールのデータの変換とクリーニングが含まれます。
Modeling−このフェーズでは、さまざまなモデリング手法が選択および適用され、それらのパラメーターが最適値に調整されます。通常、同じデータマイニングの問題タイプにはいくつかの手法があります。一部の手法には、データの形式に関する特定の要件があります。したがって、多くの場合、データ準備フェーズに戻る必要があります。
Evaluation−プロジェクトのこの段階で、データ分析の観点から、高品質に見える1つまたは複数のモデルを作成しました。モデルの最終的な展開に進む前に、モデルを徹底的に評価し、モデルを構築するために実行された手順を確認して、ビジネス目標が適切に達成されていることを確認することが重要です。
主な目的は、十分に考慮されていない重要なビジネス上の問題があるかどうかを判断することです。このフェーズの終わりに、データマイニング結果の使用に関する決定に達する必要があります。
Deployment−モデルの作成は、通常、プロジェクトの終わりではありません。モデルの目的がデータの知識を増やすことである場合でも、得られた知識は、顧客にとって有用な方法で編成および提示される必要があります。
要件に応じて、展開フェーズは、レポートの生成のように単純な場合もあれば、繰り返し可能なデータスコアリング(セグメント割り当てなど)またはデータマイニングプロセスの実装のように複雑な場合もあります。
多くの場合、展開手順を実行するのはデータアナリストではなく、顧客です。アナリストがモデルを展開する場合でも、作成されたモデルを実際に利用するために実行する必要のあるアクションを顧客が事前に理解することが重要です。
SEMMA方法論
SEMMAは、データマイニングモデリングのためにSASによって開発されたもう1つの方法です。それはの略ですS十分な、 Explore、 Modify、 Model、および Asses。これがその段階の簡単な説明です-
Sample−プロセスは、データのサンプリングから始まります。たとえば、モデリング用のデータセットを選択します。データセットは、取得するのに十分な情報を含むのに十分な大きさでありながら、効率的に使用するのに十分な小ささである必要があります。このフェーズでは、データのパーティション化も扱います。
Explore −このフェーズでは、データの視覚化を利用して、変数間の予期される関係と予期されない関係、および異常を発見することにより、データの理解をカバーします。
Modify −変更フェーズには、データモデリングの準備として変数を選択、作成、および変換するメソッドが含まれています。
Model −モデルフェーズでは、目的の結果を提供する可能性のあるモデルを作成するために、準備された変数にさまざまなモデリング(データマイニング)手法を適用することに重点が置かれます。
Assess −モデリング結果の評価は、作成されたモデルの信頼性と有用性を示しています。
CRISM-DMとSEMMAの主な違いは、SEMMAはモデリングの側面に重点を置いているのに対し、CRISP-DMは、解決すべきビジネス上の問題の理解、データの理解と前処理など、モデリング前のサイクルの段階をより重要視していることです。機械学習アルゴリズムなどの入力として使用されます。
ビッグデータのライフサイクル
今日のビッグデータのコンテキストでは、以前のアプローチは不完全であるか、最適ではありません。たとえば、SEMMA方法論は、さまざまなデータソースのデータ収集と前処理を完全に無視します。これらの段階は通常、成功するビッグデータプロジェクトのほとんどの作業を構成します。
ビッグデータ分析サイクルは、次の段階で説明できます。
- ビジネス上の問題の定義
- Research
- 人事評価
- データ収集
- データの変更
- データストレージ
- 探索的データ分析
- モデリングと評価のためのデータ準備
- Modeling
- Implementation
このセクションでは、ビッグデータのライフサイクルのこれらの各段階に光を当てます。
ビジネス上の問題の定義
これは、従来のBIおよびビッグデータ分析のライフサイクルに共通するポイントです。通常、問題を定義し、組織にとってどれだけの潜在的な利益が得られるかを正しく評価することは、ビッグデータプロジェクトの重要な段階です。これに言及するのは明らかなようですが、プロジェクトの期待される利益とコストを評価する必要があります。
研究
同じ状況で他の企業が行ったことを分析します。これには、会社が持っているリソースや要件に他のソリューションを適応させる必要がある場合でも、会社にとって合理的なソリューションを探すことが含まれます。この段階では、将来の段階の方法論を定義する必要があります。
人事評価
問題が定義されたら、現在のスタッフがプロジェクトを正常に完了できるかどうかを分析し続けるのが妥当です。従来のBIチームは、すべての段階に最適なソリューションを提供できない可能性があるため、プロジェクトの一部を外部委託したり、より多くの人を雇ったりする必要がある場合は、プロジェクトを開始する前に検討する必要があります。
データ収集
このセクションは、ビッグデータのライフサイクルにおいて重要です。結果のデータ製品を配信するために必要なプロファイルのタイプを定義します。データ収集は、プロセスの重要なステップです。通常、さまざまなソースから非構造化データを収集する必要があります。例を挙げると、Webサイトからレビューを取得するクローラーを作成する必要があります。これには、おそらく通常は完了するのにかなりの時間が必要なさまざまな言語のテキストの処理が含まれます。
データの変更
たとえば、Webからデータを取得したら、使いやすい形式で保存する必要があります。レビューの例を続けるために、データが異なるサイトから取得され、それぞれが異なる表示のデータを持っていると仮定しましょう。
1つのデータソースが星の評価の観点からレビューを提供するとします。したがって、これを応答変数のマッピングとして読み取ることができます。 y ∈ {1, 2, 3, 4, 5}。別のデータソースは、2つの矢印システムを使用してレビューを提供します。1つは賛成票、もう1つは反対票です。これは、次の形式の応答変数を意味しますy ∈ {positive, negative}。
両方のデータソースを組み合わせるには、これら2つの応答表現を同等にするための決定を行う必要があります。これには、1つの星を負、5つの星を正と見なして、最初のデータソース応答表現を2番目の形式に変換することが含まれます。このプロセスでは、多くの場合、高品質で配信するために多大な時間の割り当てが必要になります。
データストレージ
データが処理されると、データベースに保存する必要がある場合があります。ビッグデータテクノロジーは、この点に関して多くの選択肢を提供します。最も一般的な代替手段は、HIVEクエリ言語と呼ばれる限定バージョンのSQLをユーザーに提供するストレージにHadoopファイルシステムを使用することです。これにより、ユーザーの観点から、ほとんどの分析タスクを従来のBIデータウェアハウスで実行されるのと同様の方法で実行できます。考慮すべき他のストレージオプションは、MongoDB、Redis、およびSPARKです。
サイクルのこの段階は、さまざまなアーキテクチャを実装する能力という点で、人事の知識に関連しています。従来のデータウェアハウスの修正バージョンは、依然として大規模なアプリケーションで使用されています。たとえば、teradataとIBMは、テラバイトのデータを処理できるSQLデータベースを提供しています。postgreSQLやMySQLなどのオープンソースソリューションは、現在も大規模なアプリケーションに使用されています。
さまざまなストレージがバックグラウンドでどのように機能するかには違いがありますが、クライアント側から見ると、ほとんどのソリューションはSQLAPIを提供します。したがって、SQLを十分に理解することは、ビッグデータ分析にとって依然として重要なスキルです。
この段階は先験的に最も重要なトピックのようですが、実際にはそうではありません。それは本質的な段階でさえありません。リアルタイムデータを処理するビッグデータソリューションを実装することは可能であるため、この場合、モデルを開発するためにデータを収集し、それをリアルタイムで実装するだけで済みます。したがって、データを正式に保存する必要はまったくありません。
探索的データ分析
データがクリーンアップされ、そこから洞察を取得できるように保存されたら、データ探索フェーズは必須です。この段階の目的は、データを理解することです。これは通常、統計的手法を使用して行われ、データをプロットします。これは、問題の定義が理にかなっているか、実行可能かを評価するのに適した段階です。
モデリングと評価のためのデータ準備
この段階では、以前に取得したクリーンなデータを再形成し、欠測値の補完、外れ値の検出、正規化、特徴抽出、特徴選択のための統計的前処理を使用します。
モデリング
前の段階では、予測モデルなど、トレーニングとテスト用のいくつかのデータセットを作成する必要がありました。この段階では、さまざまなモデルを試し、目前のビジネス上の問題を解決することを楽しみにしています。実際には、通常、モデルがビジネスへの洞察を与えることが望まれます。最後に、除外されたデータセットでのパフォーマンスを評価するために、最適なモデルまたはモデルの組み合わせが選択されます。
実装
この段階で、開発されたデータ製品は会社のデータパイプラインに実装されます。これには、データ製品のパフォーマンスを追跡するために、データ製品の動作中に検証スキームを設定することが含まれます。たとえば、予測モデルを実装する場合、この段階では、モデルを新しいデータに適用し、応答が利用可能になったら、モデルを評価します。