ビッグデータ分析-データ探索
Exploratory data analysisは、統計の新しい視点からなるJohn Tuckey(1977)によって開発された概念です。Tuckeyの考えは、従来の統計では、データはグラフィカルに調査されておらず、仮説をテストするために使用されているだけであるというものでした。ツールを開発する最初の試みはスタンフォードで行われ、プロジェクトはprim9と呼ばれていました。このツールは、データを9次元で視覚化することができたため、データの多変量の視点を提供することができました。
最近では、探索的データ分析は必須であり、ビッグデータ分析のライフサイクルに含まれています。洞察を見つけて組織内で効果的に伝達できる能力は、強力なEDA機能によって支えられています。
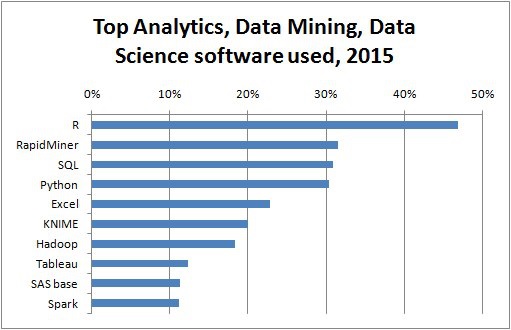
タッキーのアイデアに基づいて、ベル研究所は S programming language統計を行うためのインタラクティブなインターフェースを提供するため。Sのアイデアは、使いやすい言語で広範なグラフィカル機能を提供することでした。今日の世界では、ビッグデータのコンテキストでは、R それはに基づいています S プログラミング言語は、分析のための最も人気のあるソフトウェアです。
次のプログラムは、探索的データ分析の使用法を示しています。
以下は、探索的データ分析の例です。このコードは、part1/eda/exploratory_data_analysis.R ファイル。
library(nycflights13)
library(ggplot2)
library(data.table)
library(reshape2)
# Using the code from the previous section
# This computes the mean arrival and departure delays by carrier.
DT <- as.data.table(flights)
mean2 = DT[, list(mean_departure_delay = mean(dep_delay, na.rm = TRUE),
mean_arrival_delay = mean(arr_delay, na.rm = TRUE)),
by = carrier]
# In order to plot data in R usign ggplot, it is normally needed to reshape the data
# We want to have the data in long format for plotting with ggplot
dt = melt(mean2, id.vars = ’carrier’)
# Take a look at the first rows
print(head(dt))
# Take a look at the help for ?geom_point and geom_line to find similar examples
# Here we take the carrier code as the x axis
# the value from the dt data.table goes in the y axis
# The variable column represents the color
p = ggplot(dt, aes(x = carrier, y = value, color = variable, group = variable)) +
geom_point() + # Plots points
geom_line() + # Plots lines
theme_bw() + # Uses a white background
labs(list(title = 'Mean arrival and departure delay by carrier',
x = 'Carrier', y = 'Mean delay'))
print(p)
# Save the plot to disk
ggsave('mean_delay_by_carrier.png', p,
width = 10.4, height = 5.07)コードは次のような画像を生成する必要があります-
