Kerasによるディープラーニング-クイックガイド
ディープラーニングは、最近、人工知能(AI)の分野で流行語になっています。長年にわたり、機械にインテリジェンスを与えるために機械学習(ML)を使用していました。最近では、従来のML手法と比較して予測が優れているため、ディープラーニングの人気が高まっています。
ディープラーニングとは、本質的に、大量のデータを使用して人工ニューラルネットワーク(ANN)をトレーニングすることを意味します。ディープラーニングでは、ネットワークはそれ自体で学習するため、学習には膨大なデータが必要になります。従来の機械学習は基本的に、データを解析してそこから学習する一連のアルゴリズムです。次に、この学習を使用してインテリジェントな意思決定を行いました。
さて、Kerasに登場したのは、エンドツーエンドのオープンソース機械学習プラットフォームであるTensorFlow上で実行される高レベルのニューラルネットワークAPIです。Kerasを使用すると、複雑なANNアーキテクチャを簡単に定義して、ビッグデータを試すことができます。KerasはGPUもサポートしています。これは、大量のデータを処理し、機械学習モデルを開発するために不可欠になります。
このチュートリアルでは、ディープニューラルネットワークの構築におけるKerasの使用法を学習します。教育の実践例を見ていきましょう。当面の問題は、深層学習で訓練されたニューラルネットワークを使用して手書き数字を認識することです。
ディープラーニングにもっとワクワクするために、以下はディープラーニングに関するGoogleトレンドのスクリーンショットです-

図からわかるように、ディープラーニングへの関心はここ数年で着実に高まっています。コンピュータビジョン、自然言語処理、音声認識、バイオインフォマティクス、ドラッグデザインなど、ディープラーニングがうまく適用されている分野はたくさんあります。このチュートリアルでは、ディープラーニングをすぐに開始できます。
だから読み続けてください!
冒頭で述べたように、ディープラーニングは大量のデータを使用して人工ニューラルネットワークをトレーニングするプロセスです。トレーニングが完了すると、ネットワークは目に見えないデータの予測を提供できるようになります。ディープラーニングとは何かを説明する前に、ニューラルネットワークのトレーニングで使用されるいくつかの用語について簡単に説明します。
ニューラルネットワーク
人工ニューラルネットワークのアイデアは、私たちの脳のニューラルネットワークから派生しました。典型的なニューラルネットワークは、下の図に示すように、入力、出力、および隠れ層の3つの層で構成されています。

これは、 shallow隠れ層が1つしかないニューラルネットワーク。上記のアーキテクチャに隠しレイヤーを追加して、より複雑なアーキテクチャを作成します。
ディープネットワーク
次の図は、入力層と出力層の4つの隠れ層で構成される深いネットワークを示しています。
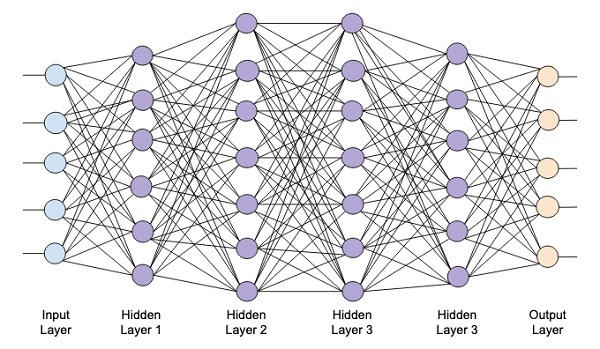
隠れ層の数がネットワークに追加されると、そのトレーニングは、必要なリソースとネットワークを完全にトレーニングするのにかかる時間の点でより複雑になります。
ネットワークトレーニング
ネットワークアーキテクチャを定義したら、特定の種類の予測を行うためにネットワークアーキテクチャをトレーニングします。ネットワークのトレーニングは、ネットワーク内の各リンクの適切な重みを見つけるプロセスです。トレーニング中、データは入力レイヤーから出力レイヤーにさまざまな非表示レイヤーを介して流れます。データは常に入力から出力へ一方向に移動するため、このネットワークをフィードフォワードネットワークと呼び、データ伝播をフォワード伝播と呼びます。
活性化関数
各レイヤーで、入力の加重和を計算し、それを活性化関数にフィードします。活性化関数は、ネットワークに非線形性をもたらします。出力を離散化するのは、単に数学関数です。最も一般的に使用される活性化関数には、シグモイド、双曲線、タンジェント(tanh)、ReLU、およびSoftmaxがあります。
誤差逆伝播法
バックプロパゲーションは、教師あり学習のアルゴリズムです。バックプロパゲーションでは、エラーは出力層から入力層に逆方向に伝播します。誤差関数が与えられると、各接続で割り当てられた重みに関する誤差関数の勾配を計算します。勾配の計算は、ネットワークを逆方向に進みます。重みの最後の層の勾配が最初に計算され、重みの最初の層の勾配が最後に計算されます。
各レイヤーで、勾配の部分的な計算は、前のレイヤーの勾配の計算で再利用されます。これは最急降下法と呼ばれます。
このプロジェクトベースのチュートリアルでは、フィードフォワードディープニューラルネットワークを定義し、バックプロパゲーションと勾配降下法を使用してトレーニングします。幸い、Kerasは、ネットワークアーキテクチャを定義し、勾配降下法を使用してトレーニングするためのすべての高レベルAPIを提供します。次に、Kerasでこれを行う方法を学習します。
手書き数字認識システム
このミニプロジェクトでは、前述の手法を適用します。手書き数字を認識するためのトレーニングを受ける深層学習ニューラルネットワークを作成します。機械学習プロジェクトでは、最初の課題はデータの収集です。特に、深層学習ネットワークの場合、膨大なデータが必要です。幸い、私たちが解決しようとしている問題について、誰かがすでにトレーニング用のデータセットを作成しています。これはmnistと呼ばれ、Kerasライブラリの一部として利用できます。データセットは、手書き数字のいくつかの28x28ピクセル画像で構成されています。このデータセットの大部分でモデルをトレーニングし、残りのデータはトレーニングしたモデルの検証に使用されます。
プロジェクトの説明
ザ・ mnistデータセットは、手書き数字の70000枚の画像で構成されています。参考までに、いくつかのサンプル画像をここに複製します

各画像のサイズは28x 28ピクセルで、さまざまなグレースケールレベルの合計768ピクセルになります。ほとんどのピクセルは黒の色合いになる傾向がありますが、白のピクセルはごくわずかです。これらのピクセルの分布を配列またはベクトルに配置します。たとえば、4桁目と5桁目の典型的な画像のピクセルの分布を次の図に示します。
各画像のサイズは28x 28ピクセルで、さまざまなグレースケールレベルの合計768ピクセルになります。ほとんどのピクセルは黒の色合いになる傾向がありますが、白のピクセルはごくわずかです。これらのピクセルの分布を配列またはベクトルに配置します。たとえば、4桁目と5桁目の典型的な画像のピクセルの分布を次の図に示します。

明らかに、ピクセルの分布(特に白いトーンになりがちなピクセル)が異なることがわかります。これにより、ピクセルが表す数字が区別されます。この784ピクセルの分布を、入力としてネットワークにフィードします。ネットワークの出力は、0から9までの数字を表す10のカテゴリで構成されます。
私たちのネットワークは、1つの入力レイヤー、1つの出力レイヤー、2つの非表示レイヤーの4つのレイヤーで構成されます。各隠れ層には512ノードが含まれます。各レイヤーは次のレイヤーに完全に接続されています。ネットワークをトレーニングするとき、各接続の重みを計算します。前に説明したバックプロパゲーションと勾配降下法を適用して、ネットワークをトレーニングします。
このような背景から、プロジェクトの作成を始めましょう。
プロジェクトの設定
我々は使用するだろう Jupyter 使って Anaconda私たちのプロジェクトのナビゲーター。私たちのプロジェクトはTensorFlowとKerasを使用しているため、Anacondaセットアップにそれらをインストールする必要があります。Tensorflowをインストールするには、コンソールウィンドウで次のコマンドを実行します。
>conda install -c anaconda tensorflowKerasをインストールするには、次のコマンドを使用します-
>conda install -c anaconda kerasこれで、Jupyterを起動する準備が整いました。
Jupyterを起動しています
アナコンダナビゲーターを起動すると、次のオープニング画面が表示されます。

クリック ‘Jupyter’それを開始します。画面には、ドライブに既存のプロジェクトがある場合はそれが表示されます。
新しいプロジェクトの開始
次のメニューオプションを選択して、Anacondaで新しいPython3プロジェクトを開始します-
File | New Notebook | Python 3クイックリファレンスとして、メニュー選択のスクリーンショットが表示されます-

以下に示すように、新しい空白のプロジェクトが画面に表示されます-
プロジェクト名をに変更します DeepLearningDigitRecognition デフォルト名をクリックして編集する “UntitledXX”。
まず、プロジェクトのコードに必要なさまざまなライブラリをインポートします。
配列の処理とプロット
通常、使用します numpy 配列処理および matplotlibプロット用。これらのライブラリは、以下を使用してプロジェクトにインポートされますimport ステートメント
import numpy as np
import matplotlib
import matplotlib.pyplot as plot警告の抑制
TensorflowとKerasの両方が改訂を続けているため、プロジェクトで適切なバージョンを同期しないと、実行時に多くの警告エラーが表示されます。彼らはあなたの注意を学習からそらすので、私たちはこのプロジェクトのすべての警告を抑制します。これは、次のコード行で実行されます-
# silent all warnings
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='3'
import warnings
warnings.filterwarnings('ignore')
from tensorflow.python.util import deprecation
deprecation._PRINT_DEPRECATION_WARNINGS = Falseケラス
Kerasライブラリを使用してデータセットをインポートします。を使用しますmnist手書き数字のデータセット。次のステートメントを使用して、必要なパッケージをインポートします
from keras.datasets import mnistKerasパッケージを使用して深層学習ニューラルネットワークを定義します。をインポートしますSequential, Dense, Dropout そして Activationネットワークアーキテクチャを定義するためのパッケージ。を使用しておりますload_modelモデルを保存および取得するためのパッケージ。私たちも使用しますnp_utils私たちのプロジェクトで必要ないくつかのユーティリティのために。これらのインポートは、次のプログラムステートメントで実行されます-
from keras.models import Sequential, load_model
from keras.layers.core import Dense, Dropout, Activation
from keras.utils import np_utilsこのコードを実行すると、KerasがバックエンドでTensorFlowを使用していることを示すメッセージがコンソールに表示されます。この段階のスクリーンショットを次に示します-

これで、プロジェクトに必要なすべてのインポートが完了したので、ディープラーニングネットワークのアーキテクチャの定義に進みます。
私たちのニューラルネットワークモデルは、層の線形スタックで構成されます。このようなモデルを定義するために、Sequential 関数-
model = Sequential()入力レイヤー
次のプログラムステートメントを使用して、ネットワークの最初のレイヤーである入力レイヤーを定義します。
model.add(Dense(512, input_shape=(784,)))これにより、784個の入力ノードを持つ512個のノード(ニューロン)を持つレイヤーが作成されます。これを下の図に示します-

すべての入力ノードがレイヤー1に完全に接続されていることに注意してください。つまり、各入力ノードはレイヤー1の512ノードすべてに接続されています。
次に、レイヤー1の出力にアクティベーション関数を追加する必要があります。アクティベーションとしてReLUを使用します。活性化関数は、次のプログラムステートメントを使用して追加されます-
model.add(Activation('relu'))次に、以下のステートメントを使用して20%のドロップアウトを追加します。ドロップアウトは、モデルの過剰適合を防ぐために使用される手法です。
model.add(Dropout(0.2))この時点で、入力レイヤーは完全に定義されています。次に、隠しレイヤーを追加します。
隠しレイヤー
隠れ層は512ノードで構成されます。非表示レイヤーへの入力は、以前に定義した入力レイヤーから取得されます。前の場合と同様に、すべてのノードが完全に接続されています。隠れ層の出力は、ネットワーク内の次の層に送られます。これが、最終的な出力層になります。前のレイヤーと同じReLUアクティベーションを使用し、20%のドロップアウトを使用します。このレイヤーを追加するためのコードはここにあります-
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.2))この段階のネットワークは、次のように視覚化できます。

次に、ネットワークに最後のレイヤーである出力レイヤーを追加します。ここで使用したものと同様のコードを使用して、任意の数の非表示レイヤーを追加できることに注意してください。レイヤーを追加すると、トレーニングのためにネットワークが複雑になります。ただし、すべてではありませんが、多くの場合、より良い結果が得られるという明確な利点があります。
出力層
指定された画像を10桁で分類するため、出力レイヤーは10ノードのみで構成されます。次のステートメントを使用して、このレイヤーを追加します-
model.add(Dense(10))出力を10の異なる単位に分類したいので、softmaxアクティベーションを使用します。ReLUの場合、出力はバイナリです。次のステートメントを使用してアクティベーションを追加します-
model.add(Activation('softmax'))この時点で、次の図に示すようにネットワークを視覚化できます。

この時点で、ネットワークモデルはソフトウェアで完全に定義されています。コードセルを実行すると、エラーがない場合は、下のスクリーンショットに示すように画面に確認メッセージが表示されます-

次に、モデルをコンパイルする必要があります。
コンパイルは、と呼ばれる単一のメソッド呼び出しを使用して実行されます compile。
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='adam')ザ・ compileメソッドにはいくつかのパラメーターが必要です。損失パラメータはタイプを持つように指定されています'categorical_crossentropy'。メトリックパラメータはに設定されています'accuracy' そして最後に adamネットワークをトレーニングするためのオプティマイザ。この段階での出力を以下に示します-

これで、データをネットワークにフィードする準備が整いました。
データのロード
前に述べたように、 mnistKerasによって提供されたデータセット。データをシステムにロードするときに、トレーニングデータとテストデータに分割します。データは、を呼び出すことによってロードされますload_data 次のような方法-
(X_train, y_train), (X_test, y_test) = mnist.load_data()この段階での出力は次のようになります-

次に、ロードされたデータセットの構造を学習します。
提供されるデータは、サイズが28 x 28ピクセルのグラフィック画像で、それぞれに0から9までの1桁が含まれています。最初の10枚の画像をコンソールに表示します。そのためのコードを以下に示します-
# printing first 10 images
for i in range(10):
plot.subplot(3,5,i+1)
plot.tight_layout()
plot.imshow(X_train[i], cmap='gray', interpolation='none')
plot.title("Digit: {}".format(y_train[i]))
plot.xticks([])
plot.yticks([])10カウントの反復ループでは、各反復でサブプロットを作成し、からの画像を表示します。 X_trainその中のベクトル。対応する画像の各画像にタイトルを付けますy_trainベクター。注意してくださいy_train ベクトルには、対応する画像の実際の値が含まれています X_trainベクター。2つのメソッドを呼び出すことにより、x軸とy軸のマーキングを削除しますxticks そして yticksnull引数付き。コードを実行すると、次の出力が表示されます-

次に、ネットワークにフィードするためのデータを準備します。
データをネットワークにフィードする前に、ネットワークで必要な形式に変換する必要があります。これは、ネットワーク用のデータの準備と呼ばれます。これは通常、多次元入力を1次元ベクトルに変換し、データポイントを正規化することで構成されます。
入力ベクトルの再形成
データセット内の画像は28x28ピクセルで構成されています。これをネットワークに供給するために、サイズ28 * 28 = 784の1次元ベクトルに変換する必要があります。私たちは電話することによってそうしますreshape ベクトルのメソッド。
X_train = X_train.reshape(60000, 784)
X_test = X_test.reshape(10000, 784)これで、トレーニングベクトルは60000個のデータポイントで構成され、それぞれがサイズ784の単一次元ベクトルで構成されます。同様に、テストベクトルはサイズ784の単一次元ベクトルの10000個のデータポイントで構成されます。
データの正規化
入力ベクトルに含まれるデータには、現在0〜255の離散値(グレースケールレベル)があります。これらのピクセル値を0から1の間で正規化すると、トレーニングのスピードアップに役立ちます。確率的勾配降下法を使用するため、データを正規化することで、局所最適点にとらわれる可能性を減らすこともできます。
データを正規化するために、次のコードスニペットに示すように、データをfloat型として表し、255で除算します。
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255次に、正規化されたデータがどのように見えるかを見てみましょう。
正規化されたデータの調査
正規化されたデータを表示するために、ここに示すようにヒストグラム関数を呼び出します-
plot.hist(X_train[0])
plot.title("Digit: {}".format(y_train[0]))ここでは、の最初の要素のヒストグラムをプロットします。 X_trainベクター。また、このデータポイントで表される数字も印刷します。上記のコードを実行した結果を次に示します-

値がゼロに近い点の密度が高いことに気付くでしょう。これらは画像内の黒い点であり、明らかに画像の主要部分です。白色に近い残りのグレースケールポイントは、数字を表します。別の桁のピクセルの分布を確認できます。以下のコードは、トレーニングデータセットのインデックス2の数字のヒストグラムを出力します。
plot.hist(X_train[2])
plot.title("Digit: {}".format(y_train[2])上記のコードを実行した結果を以下に示します-

上記の2つの図を比較すると、2つの画像の白いピクセルの分布が異なり、上記の2つの画像の「5」と「4」という異なる数字の表現を示していることがわかります。
次に、完全なトレーニングデータセット内のデータの分布を調べます。
データ分布の調査
データセットで機械学習モデルをトレーニングする前に、データセット内の一意の数字の分布を知っておく必要があります。画像は0から9までの10桁の数字を表しています。データセット内の0、1などの桁数を知りたいです。この情報は、unique Numpyの方法。
次のコマンドを使用して、一意の値の数とそれぞれの出現回数を出力します
print(np.unique(y_train, return_counts=True))上記のコマンドを実行すると、次の出力が表示されます-
(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8), array([5923, 6742, 5958, 6131, 5842, 5421, 5918, 6265, 5851, 5949]))これは、0から9までの10個の異なる値があることを示しています。数字0は5923回、数字1は6742回などです。出力のスクリーンショットを次に示します-

データ準備の最後のステップとして、データをエンコードする必要があります。
データのエンコード
データセットには10のカテゴリがあります。したがって、ワンホットエンコーディングを使用して、これらの10のカテゴリに出力をエンコードします。Numpyユーティリティのto_categorialメソッドを使用してエンコードを実行します。出力データがエンコードされた後、各データポイントはサイズ10の1次元ベクトルに変換されます。たとえば、数字5は[0,0,0,0,0,1,0,0,0として表されます。 、0]。
次のコードを使用してデータをエンコードします-
n_classes = 10
Y_train = np_utils.to_categorical(y_train, n_classes)分類されたY_trainベクトルの最初の5つの要素を出力することにより、エンコードの結果を確認できます。
次のコードを使用して、最初の5つのベクトルを出力します-
for i in range(5):
print (Y_train[i])次の出力が表示されます-
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]最初の要素は数字5を表し、2番目の要素は数字0を表します。
最後に、テストデータも分類する必要があります。これは次のステートメントを使用して行われます。
Y_test = np_utils.to_categorical(y_test, n_classes)この段階で、データはネットワークにフィードするために完全に準備されます。
次に、最も重要な部分があります。それは、ネットワークモデルのトレーニングです。
モデルのトレーニングは、以下のコードに示すように、いくつかのパラメーターを使用するfitと呼ばれる1つのメソッド呼び出しで実行されます。
history = model.fit(X_train, Y_train,
batch_size=128, epochs=20,
verbose=2,
validation_data=(X_test, Y_test)))fitメソッドの最初の2つのパラメーターは、トレーニングデータセットの機能と出力を指定します。
ザ・ epochs20に設定されています。トレーニングは最大20エポック(反復)で収束すると想定しています。トレーニングされたモデルは、最後のパラメーターで指定されたテストデータで検証されます。
上記のコマンドを実行した場合の部分的な出力を次に示します。
Train on 60000 samples, validate on 10000 samples
Epoch 1/20
- 9s - loss: 0.2488 - acc: 0.9252 - val_loss: 0.1059 - val_acc: 0.9665
Epoch 2/20
- 9s - loss: 0.1004 - acc: 0.9688 - val_loss: 0.0850 - val_acc: 0.9715
Epoch 3/20
- 9s - loss: 0.0723 - acc: 0.9773 - val_loss: 0.0717 - val_acc: 0.9765
Epoch 4/20
- 9s - loss: 0.0532 - acc: 0.9826 - val_loss: 0.0665 - val_acc: 0.9795
Epoch 5/20
- 9s - loss: 0.0457 - acc: 0.9856 - val_loss: 0.0695 - val_acc: 0.9792クイックリファレンスとして、出力のスクリーンショットを以下に示します-

ここで、モデルがトレーニングデータでトレーニングされるので、そのパフォーマンスを評価します。
モデルのパフォーマンスを評価するために、 evaluate 次のような方法-
loss_and_metrics = model.evaluate(X_test, Y_test, verbose=2)モデルのパフォーマンスを評価するために、 evaluate 次のような方法-
loss_and_metrics = model.evaluate(X_test, Y_test, verbose=2)次の2つのステートメントを使用して、損失と精度を出力します。
print("Test Loss", loss_and_metrics[0])
print("Test Accuracy", loss_and_metrics[1])上記のステートメントを実行すると、次の出力が表示されます-
Test Loss 0.08041584826191042
Test Accuracy 0.9837これは98%のテスト精度を示しており、これは私たちに受け入れられるはずです。2%のケースで、手書きの数字が正しく分類されないということは、私たちにとって何を意味しますか。また、精度と損失のメトリックをプロットして、モデルがテストデータでどのように機能するかを確認します。
精度メトリックのプロット
記録したものを使用します history精度メトリックのプロットを取得するためのトレーニング中。次のコードは、各エポックの精度をプロットします。プロットのために、トレーニングデータの精度(「acc」)と検証データの精度(「val_acc」)を取得します。
plot.subplot(2,1,1)
plot.plot(history.history['acc'])
plot.plot(history.history['val_acc'])
plot.title('model accuracy')
plot.ylabel('accuracy')
plot.xlabel('epoch')
plot.legend(['train', 'test'], loc='lower right')出力プロットを以下に示します-

図からわかるように、最初の2つのエポックで精度が急速に向上し、ネットワークが高速に学習していることを示しています。その後、曲線は平坦になり、モデルをさらにトレーニングするために必要なエポックが多すぎないことを示します。一般に、トレーニングデータの精度(「acc」)が向上し続け、検証データの精度(「val_acc」)が悪化する場合は、過剰適合が発生しています。モデルがデータを記憶し始めていることを示します。
また、モデルのパフォーマンスを確認するために損失メトリックをプロットします。
損失メトリックのプロット
ここでも、トレーニング(「loss」)データとテスト(「val_loss」)データの両方に損失をプロットします。これは、次のコードを使用して行われます-
plot.subplot(2,1,2)
plot.plot(history.history['loss'])
plot.plot(history.history['val_loss'])
plot.title('model loss')
plot.ylabel('loss')
plot.xlabel('epoch')
plot.legend(['train', 'test'], loc='upper right')このコードの出力を以下に示します-

図からわかるように、トレーニングセットの損失は、最初の2つのエポックで急速に減少します。テストセットの場合、損失はトレーニングセットと同じ割合で減少しませんが、複数のエポックでほぼフラットのままです。これは、私たちのモデルが目に見えないデータにうまく一般化していることを意味します。
次に、トレーニング済みモデルを使用して、テストデータの桁を予測します。
見えないデータの数字を予測するのはとても簡単です。あなたは単に電話する必要がありますpredict_classes の方法 model 未知のデータポイントで構成されるベクトルに渡すことによって。
predictions = model.predict_classes(X_test)メソッド呼び出しは、実際の値に対して0と1をテストできるベクトルで予測を返します。これは、次の2つのステートメントを使用して行われます-
correct_predictions = np.nonzero(predictions == y_test)[0]
incorrect_predictions = np.nonzero(predictions != y_test)[0]最後に、次の2つのプログラムステートメントを使用して、正しい予測と誤った予測の数を出力します。
print(len(correct_predictions)," classified correctly")
print(len(incorrect_predictions)," classified incorrectly")コードを実行すると、次の出力が得られます-
9837 classified correctly
163 classified incorrectlyこれで、モデルを十分にトレーニングしたので、将来の使用のために保存します。
トレーニングしたモデルを、現在の作業ディレクトリのmodelsフォルダーにあるローカルドライブに保存します。モデルを保存するには、次のコードを実行します-
directory = "./models/"
name = 'handwrittendigitrecognition.h5'
path = os.path.join(save_dir, name)
model.save(path)
print('Saved trained model at %s ' % path)コード実行後の出力を以下に示します-

これで、トレーニング済みモデルを保存したので、後でそれを使用して未知のデータを処理できます。
見えないデータを予測するには、最初にトレーニング済みモデルをメモリにロードする必要があります。これは、次のコマンドを使用して実行されます-
model = load_model ('./models/handwrittendigitrecognition.h5').h5ファイルをメモリにロードしているだけであることに注意してください。これにより、各層に割り当てられた重みとともに、ニューラルネットワーク全体がメモリに設定されます。
ここで、見えないデータに対して予測を行うには、データをロードし、1つ以上のアイテムとしてメモリに入れます。上記のトレーニングおよびテストデータで行ったように、モデルの入力要件を満たすようにデータを前処理します。前処理後、ネットワークにフィードします。モデルはその予測を出力します。
Kerasは、ディープニューラルネットワークを作成するための高レベルのAPIを提供します。このチュートリアルでは、手書きテキストの数字を見つけるためにトレーニングされたディープニューラルネットワークを作成する方法を学びました。この目的のために、多層ネットワークが作成されました。Kerasを使用すると、各レイヤーで選択した活性化関数を定義できます。勾配降下法を使用して、ネットワークはトレーニングデータでトレーニングされました。見えないデータを予測する際の訓練されたネットワークの精度は、テストデータでテストされました。精度とエラーの指標をプロットする方法を学びました。ネットワークが完全にトレーニングされたら、将来使用するためにネットワークモデルを保存しました。