Kibana-集計と指標
Kibanaの学習中に頻繁に出くわす2つの用語は、バケットとメトリックの集約です。この章では、Kibanaでそれらが果たす役割とその詳細について説明します。
Kibana Aggregationとは何ですか?
集約とは、特定の検索クエリまたはフィルターから取得されたドキュメントのコレクションまたはドキュメントのセットを指します。集約は、Kibanaで目的の視覚化を構築するための主要な概念を形成します。
視覚化を実行するときはいつでも、基準を決定する必要があります。つまり、データをグループ化してメトリックを実行する方法を決定する必要があります。
このセクションでは、2つのタイプの集約について説明します-
- バケットの集約
- メトリック集約
バケットの集約
バケットは主にキーとドキュメントで構成されます。集計が実行されると、ドキュメントはそれぞれのバケットに配置されます。したがって、最後にバケットのリストがあり、それぞれにドキュメントのリストがあります。Kibanaでビジュアライゼーションを作成するときに表示されるバケットアグリゲーションのリストを以下に示します-
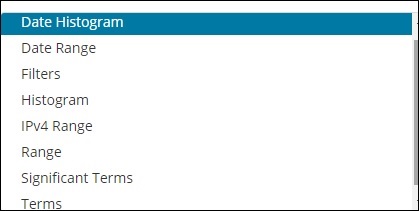
BucketAggregationには次のリストがあります-
- 日付ヒストグラム
- 日付範囲
- Filters
- Histogram
- IPv4範囲
- Range
- 重要な用語
- Terms
作成中に、バケット集約用にそれらの1つを決定する必要があります。つまり、バケット内のドキュメントをグループ化します。
例として、分析のために、このチュートリアルの開始時にアップロードした国のデータについて考えてみます。国インデックスで使用できるフィールドは、国名、地域、人口、地域です。国のデータには、国の名前とその人口、地域、および地域が含まれています。
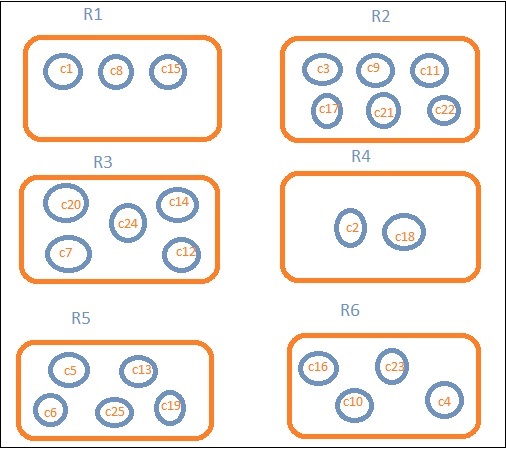
地域ごとのデータが必要だとしましょう。次に、各地域で利用可能な国が検索クエリになるため、この場合、地域がバケットを形成します。以下のブロック図は、R1、R2、R3、R4、R5、およびR6が取得したバケットであり、c1、c2 ..c25がバケットR1〜R6の一部であるドキュメントのリストであることを示しています。
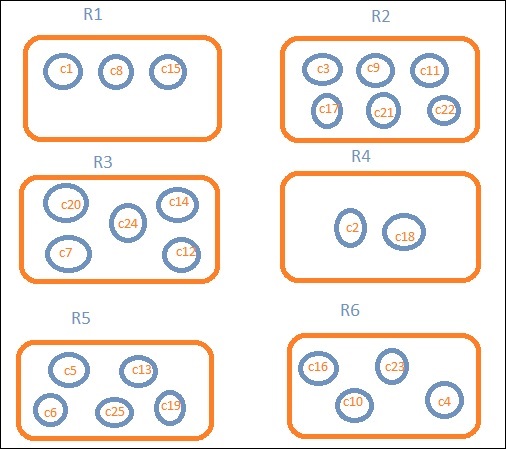
各バケットにいくつかの円があることがわかります。これらは、検索条件に基づいたドキュメントのセットであり、各バケットに分類されると見なされます。バケットR1には、ドキュメントc1、c8、およびc15があります。これらの文書は、他の人と同じように、その地域に該当する国です。したがって、バケットR1の国を数えると、R2は3、6、R3は6、R4は2、R5は5、R6は4になります。
したがって、バケットの集約により、ドキュメントをバケットに集約し、上記のようにそれらのバケットにドキュメントのリストを含めることができます。
これまでのバケット集約のリストは次のとおりです。
- 日付ヒストグラム
- 日付範囲
- Filters
- Histogram
- IPv4範囲
- Range
- 重要な用語
- Terms
ここで、これらのバケットを1つずつ形成する方法について詳しく説明します。
日付ヒストグラム
日付ヒストグラムの集計は、日付フィールドで使用されます。したがって、視覚化に使用するインデックス。そのインデックスに日付フィールドがある場合は、この集計タイプのみを使用できます。これはマルチバケットアグリゲーションです。つまり、複数のバケットの一部として一部のドキュメントを含めることができます。この集計には間隔があり、詳細は以下のとおりです。
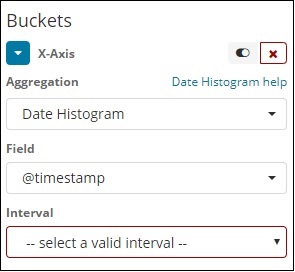
日付ヒストグラムとしてバケット集計を選択すると、日付関連のフィールドのみを表示する[フィールド]オプションが表示されます。フィールドを選択したら、次の詳細を持つ間隔を選択する必要があります-
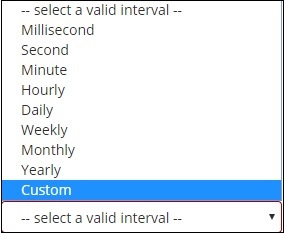
したがって、選択されたインデックスからのドキュメントは、選択されたフィールドと間隔に基づいて、バケット内のドキュメントを分類します。たとえば、間隔を月単位として選択した場合、日付に基づくドキュメントはバケットに変換され、月に基づいて、つまり1月から12月に基づいてドキュメントがバケットに配置されます。ここでは、1月、2月、.. 12月がバケツになります。
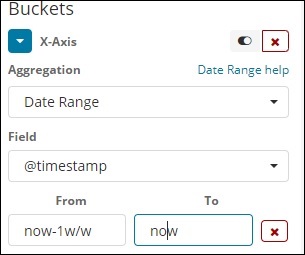
日付範囲
この集計タイプを使用するには、日付フィールドが必要です。ここでは、日付範囲があります。つまり、日付から日付までが指定されます。バケットには、フォームと指定された日付に基づいたドキュメントがあります。
フィルター
フィルタタイプの集計では、バケットはフィルタに基づいて形成されます。ここでは、1つのドキュメントが1つ以上のバケットに存在できるフィルター基準に基づいて形成されたマルチバケットを取得します。
フィルタを使用すると、ユーザーは次のようにフィルタオプションでクエリを記述できます-
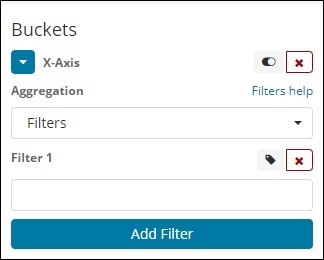
[フィルターの追加]ボタンを使用して、選択した複数のフィルターを追加できます。
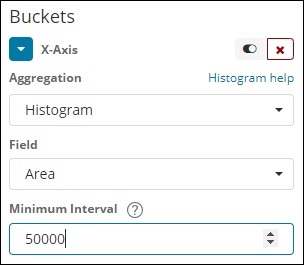
ヒストグラム
このタイプの集計は数値フィールドに適用され、適用された間隔に基づいてバケット内のドキュメントをグループ化します。たとえば、0-50、50-100、100-150などです。
IPv4範囲
このタイプの集約は、主にIPアドレスに使用されます。
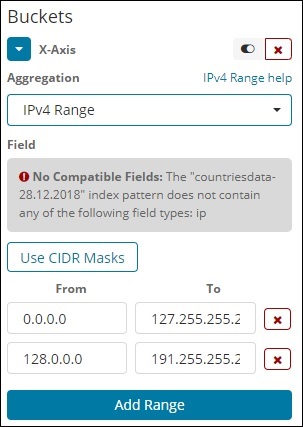
contriesdata-28.12.2018であるインデックスには、タイプIPのフィールドがないため、上記のようなメッセージが表示されます。IPフィールドがある場合は、上記のようにFrom値とTo値を指定できます。
範囲
このタイプの集約では、フィールドがタイプ番号である必要があります。範囲を指定する必要があり、ドキュメントは範囲内のバケットに一覧表示されます。
必要に応じて、[範囲の追加]ボタンをクリックして範囲を追加できます。
重要な用語
このタイプの集計は、主に文字列フィールドで使用されます。
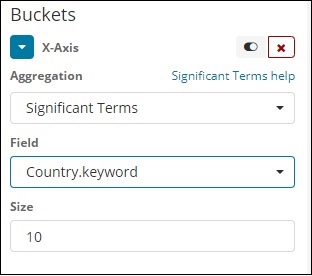
条項
このタイプの集計は、使用可能なすべてのフィールド、つまり数値、文字列、日付、ブール値、IPアドレス、タイムスタンプなどで使用されます。これは、これで作業するすべての視覚化で使用する集計であることに注意してください。チュートリアル。
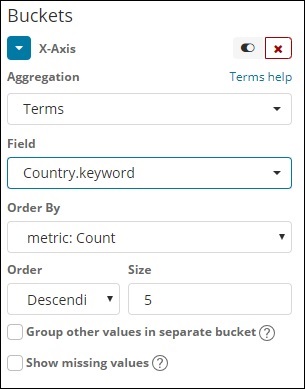
選択したメトリックに基づいてデータをグループ化するオプションの順序があります。サイズは、ビジュアライゼーションに表示するバケットの数を指します。
次に、メトリック集約について説明します。
メトリック集約
メトリック集約は、主にバケットに存在するドキュメントに対して実行される数学計算を指します。たとえば、数値フィールドを選択した場合、そのフィールドで実行できるメトリック計算は、COUNT、SUM、MIN、MAX、AVERAGEなどです。
ここで説明するメトリック集計のリストを示します-
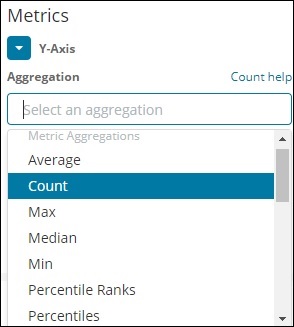
このセクションでは、私たちが頻繁に使用する重要なものについて説明しましょう-
- Average
- Count
- Max
- Min
- Sum
このメトリックは、前述の個々のバケット集計に適用されます。
次に、ここでメトリック集約のリストについて説明します-
平均
これにより、バケットに存在するドキュメントの値の平均が得られます。例-
R1からR6はバケットです。R1には、c1、c8、およびc15があります。c1の値が300、c8が500、c15が700であるとします。次に、R1バケットの平均値を取得します。
R1 = c1の値+ c8の値+ c15 / 3の値= 300 + 500 + 700/3 = 500。
バケットR1の平均は500です。ここで、ドキュメントの値は、国のデータを考慮すると、その地域の国の領域である可能性があります。
カウント
これにより、バケットに存在するドキュメントの数がわかります。地域に存在する国の数が必要な場合、バケットに存在するドキュメントの総数になります。たとえば、R1は3、R2 = 6、R3 = 5、R4 = 2、R5 = 5、R6 = 4になります。
マックス
これにより、バケットに存在するドキュメントの最大値が得られます。地域バケットに地域ごとの国のデータがある場合は、上記の例を検討してください。各地域の最大値は、最大面積を持つ国になります。したがって、各地域、つまりR1からR6に1つの国があります。
に
これにより、バケットに存在するドキュメントの最小値が得られます。地域バケットに地域ごとの国のデータがある場合は、上記の例を検討してください。各地域の最小値は、最小面積の国になります。したがって、各地域、つまりR1からR6に1つの国があります。
和
これにより、バケットに存在するドキュメントの値の合計が得られます。たとえば、上記の例を検討する場合、地域内の1つまたは複数の国の合計が必要な場合、それは地域に存在するドキュメントの合計になります。
たとえば、地域R1の合計国を知るには、3、R2 = 6、R3 = 5、R4 = 2、R5 = 5、R6 = 4になります。
地域内にR1からR6よりも面積のあるドキュメントがある場合は、国ごとの面積が地域ごとに合計されます。