Kibana-エルクスタックの紹介
Kibanaは、主に線グラフ、棒グラフ、円グラフ、ヒートマップなどの形式で大量のログを分析するために使用されるオープンソースの視覚化ツールです。KibanaはElasticsearchおよびLogstashと同期して動作し、これらが一緒になっていわゆる ELK スタック。
ELK Elasticsearch、Logstash、およびKibanaの略です。 ELK は、ログ分析に世界中で使用されている人気のあるログ管理プラットフォームの1つです。
ELKスタック内-
Logstashさまざまな入力ソースからログデータまたはその他のイベントを抽出します。イベントを処理し、後でElasticsearchに保存します。
Kibana Elasticsearchからログにアクセスし、折れ線グラフ、棒グラフ、円グラフなどの形式でユーザーに表示できる視覚化ツールです。
このチュートリアルでは、KibanaおよびElasticsearchと緊密に連携し、さまざまな形式でデータを視覚化します。
この章では、ELKスタックを一緒に使用する方法を理解しましょう。その上、あなたはまたどのようにするかを見るでしょう-
- LogstashからElasticsearchにCSVデータをロードします。
- KibanaのElasticsearchのインデックスを使用します。
LogstashからElasticsearchにCSVデータをロードする
CSVデータを使用して、Logstashを使用してElasticsearchにデータをアップロードします。データ分析に取り組むために、kaggle.comのWebサイトからデータを取得できます。Kaggle.comサイトにはすべての種類のデータがアップロードされており、ユーザーはそれを使用してデータ分析に取り組むことができます。
ここからcountries.csvデータを取得しました: https://www.kaggle.com/fernandol/countries-of-the-world。csvファイルをダウンロードして使用できます。
使用するcsvファイルには以下の詳細があります。
ファイル名-countriesdata.csv
列- 「国」、「地域」、「人口」、「地域」
ダミーのcsvファイルを作成して使用することもできます。logstashを使用して、このデータをcountriesdata.csvからelasticsearchにダンプします。
ターミナルでelasticsearchとKibanaを起動し、実行を続けます。以下に示すlogstash-configファイルに示すように、CSVファイルの列に関する詳細とその他の詳細を含むlogstashの構成ファイルを作成する必要があります。
input {
file {
path => "C:/kibanaproject/countriesdata.csv"
start_position => "beginning"
sincedb_path => "NUL"
}
}
filter {
csv {
separator => ","
columns => ["Country","Region","Population","Area"]
}
mutate {convert => ["Population", "integer"]}
mutate {convert => ["Area", "integer"]}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
=> "countriesdata-%{+dd.MM.YYYY}"
}
stdout {codec => json_lines }
}設定ファイルでは、3つのコンポーネントを作成しました-
入力
入力ファイルのパスを指定する必要があります。この場合はcsvファイルです。csvファイルが保存されているパスがパスフィールドに指定されます。
フィルタ
区切り文字が使用されたcsvコンポーネント(この場合はコンマ)と、csvファイルで使用可能な列があります。logstashは、入ってくるすべてのデータを文字列と見なすため、任意の列を整数として使用する場合は、上記のようにmutateを使用して同じものを指定する必要があります。
出力
出力については、データを配置する必要がある場所を指定する必要があります。ここでは、elasticsearchを使用しています。Elasticsearchに提供する必要のあるデータは、elasticsearchが実行されているホストであり、localhostと呼びます。の次のフィールドは、countries- currentdateという名前を付けたインデックスです。Elasticsearchでデータが更新されたら、Kibanaで同じインデックスを使用する必要があります。
上記の設定ファイルをlogstash_countries.configとして保存します。次のステップで、この構成のパスをlogstashコマンドに指定する必要があることに注意してください。
csvファイルからelasticsearchにデータをロードするには、elasticsearchサーバーを起動する必要があります-
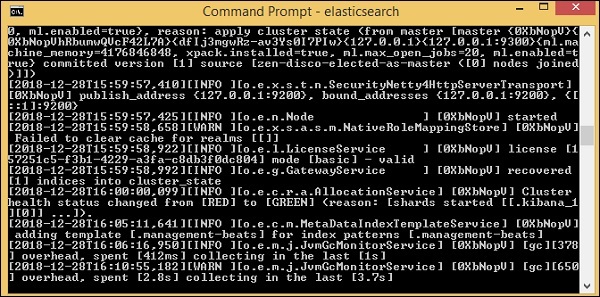
今、実行します http://localhost:9200 ブラウザでelasticsearchが正常に実行されているかどうかを確認します。
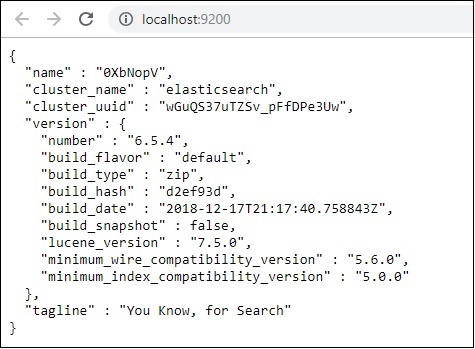
Elasticsearchを実行しています。次に、logstashがインストールされているパスに移動し、次のコマンドを実行してデータをelasticsearchにアップロードします。
> logstash -f logstash_countries.conf
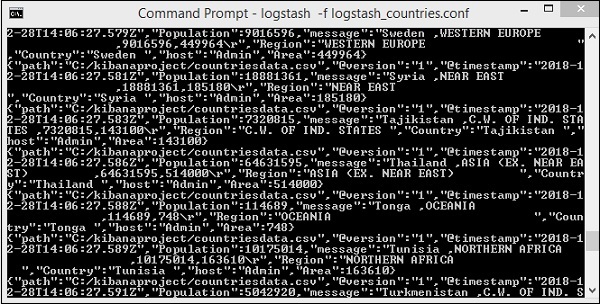
上の画面は、CSVファイルからElasticsearchへのデータの読み込みを示しています。Elasticsearchでインデックスが作成されているかどうかを知るには、次のように確認できます。
上記のように作成されたcountriesdata-28.12.2018インデックスを確認できます。

インデックスの詳細-国-2018年12月28日は次のとおりです-
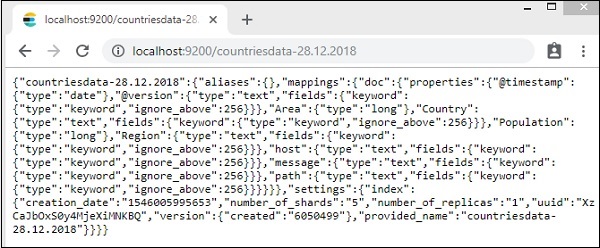
プロパティ付きのマッピングの詳細は、データがlogstashからelasticsearchにアップロードされるときに作成されることに注意してください。
KibanaでElasticsearchのデータを使用する
現在、ローカルホストのポート5601でKibanaを実行しています。 http://localhost:5601。KibanaのUIをここに示します-
KibanaはすでにElasticsearchに接続されており、表示できるはずです。 index :countries-28.12.2018 キバナの中。
Kibana UIで、左側の[管理メニュー]オプションをクリックします-
次に、[インデックス管理]-をクリックします。
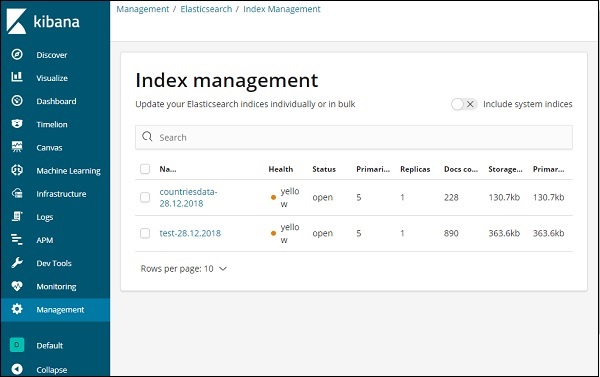
Elasticsearchに存在するインデックスは、インデックス管理に表示されます。Kibanaで使用するインデックスはcountriesdata-28.12.2018です。
したがって、Kibanaにはすでにelasticsearchインデックスがあるので、次に、Kibanaのインデックスを使用して、円グラフ、棒グラフ、折れ線グラフなどの形式でデータを視覚化する方法を理解します。