Kibana-サンプルデータの読み込み
logstashからelasticsearchにデータをアップロードする方法を見てきました。ここでは、logstashとelasticsearchを使用してデータをアップロードします。ただし、使用する必要のある日付、経度、緯度フィールドを持つデータについては、次の章で学習します。CSVファイルがない場合は、Kibanaに直接データをアップロードする方法も説明します。
この章では、次のトピックについて説明します-
- Elasticsearchで日付、経度、緯度のフィールドを持つLogstashアップロードデータを使用する
- 開発ツールを使用してバルクデータをアップロードする
Elasticsearchのフィールドを持つデータにLogstashアップロードを使用する
CSV形式のデータを使用します。同じものを、分析に使用できるデータを扱うKaggle.comから取得します。
ここで使用される在宅医療訪問のデータは、サイトKaggle.comから取得されます。
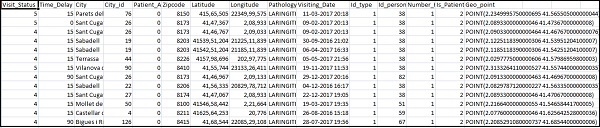
CSVファイルで使用できるフィールドは次のとおりです-
["Visit_Status","Time_Delay","City","City_id","Patient_Age","Zipcode","Latitude","Longitude",
"Pathology","Visiting_Date","Id_type","Id_personal","Number_Home_Visits","Is_Patient_Minor","Geo_point"]Home_visits.csvは次のとおりです-
以下は、logstashで使用されるconfファイルです-
input {
file {
path => "C:/kibanaproject/home_visits.csv"
start_position => "beginning"
sincedb_path => "NUL"
}
}
filter {
csv {
separator => ","
columns =>
["Visit_Status","Time_Delay","City","City_id","Patient_Age",
"Zipcode","Latitude","Longitude","Pathology","Visiting_Date",
"Id_type","Id_personal","Number_Home_Visits","Is_Patient_Minor","Geo_point"]
}
date {
match => ["Visiting_Date","dd-MM-YYYY HH:mm"]
target => "Visiting_Date"
}
mutate {convert => ["Number_Home_Visits", "integer"]}
mutate {convert => ["City_id", "integer"]}
mutate {convert => ["Id_personal", "integer"]}
mutate {convert => ["Id_type", "integer"]}
mutate {convert => ["Zipcode", "integer"]}
mutate {convert => ["Patient_Age", "integer"]}
mutate {
convert => { "Longitude" => "float" }
convert => { "Latitude" => "float" }
}
mutate {
rename => {
"Longitude" => "[location][lon]"
"Latitude" => "[location][lat]"
}
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "medicalvisits-%{+dd.MM.YYYY}"
}
stdout {codec => json_lines }
}デフォルトでは、logstashはelasticsearchにアップロードされたすべてのものを文字列と見なします。CSVファイルに日付フィールドがある場合は、日付形式を取得するために次の手順を実行する必要があります。
For date field −
date {
match => ["Visiting_Date","dd-MM-YYYY HH:mm"]
target => "Visiting_Date"
}地理的位置の場合、elasticsearchは-と同じように理解します
"location": {
"lat":41.565505000000044,
"lon": 2.2349995750000695
}したがって、elasticsearchが必要とする形式で経度と緯度があることを確認する必要があります。したがって、最初に経度と緯度を浮動小数点に変換し、後で名前を変更して、の一部として使用できるようにする必要があります。location jsonオブジェクトと lat そして lon。同じためのコードはここに示されています-
mutate {
convert => { "Longitude" => "float" }
convert => { "Latitude" => "float" }
}
mutate {
rename => {
"Longitude" => "[location][lon]"
"Latitude" => "[location][lat]"
}
}フィールドを整数に変換するには、次のコードを使用します-
mutate {convert => ["Number_Home_Visits", "integer"]}
mutate {convert => ["City_id", "integer"]}
mutate {convert => ["Id_personal", "integer"]}
mutate {convert => ["Id_type", "integer"]}
mutate {convert => ["Zipcode", "integer"]}
mutate {convert => ["Patient_Age", "integer"]}フィールドが処理されたら、次のコマンドを実行してelasticsearchにデータをアップロードします-
- Logstash binディレクトリ内に移動し、次のコマンドを実行します。
logstash -f logstash_homevisists.conf- 完了すると、以下に示すように、elasticsearchのlogstashconfファイルに記載されているインデックスが表示されます。
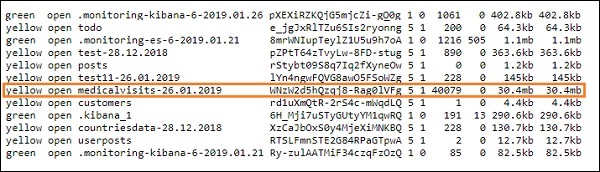
これで、アップロードされた上記のインデックスにインデックスパターンを作成し、それをさらに視覚化の作成に使用できます。
開発ツールを使用してバルクデータをアップロードする
KibanaUIの開発ツールを使用します。開発ツールは、Logstashを使用せずにElasticsearchにデータをアップロードするのに役立ちます。開発ツールを使用して、Kibanaに必要なデータを投稿、配置、削除、検索できます。
このセクションでは、サンプルデータをKibana自体にロードしてみます。これを使用してサンプルデータを練習し、Kibanaの機能を試して、Kibanaをよく理解することができます。
次のURLからjsonデータを取得し、Kibanaにアップロードしましょう。同様に、サンプルのjsonデータをKibana内にロードしてみることができます。
サンプルデータのアップロードを開始する前に、elasticsearchで使用するインデックス付きのjsonデータを用意する必要があります。logstashを使用してアップロードする場合、logstashはインデックスを追加するように注意し、ユーザーはelasticsearchに必要なインデックスについて気にする必要はありません。
通常のJsonデータ
[
{"type":"act","line_id":1,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":"ACT I"},
{"type":"scene","line_id":2,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":"SCENE I.London. The palace."},
{"type":"line","line_id":3,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":
"Enter KING HENRY, LORD JOHN OF LANCASTER, the
EARL of WESTMORELAND, SIR WALTER BLUNT, and others"}
]Kibanaで使用するjsonコードは、次のようにインデックスを付ける必要があります-
{"index":{"_index":"shakespeare","_id":0}}
{"type":"act","line_id":1,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":"ACT I"}
{"index":{"_index":"shakespeare","_id":1}}
{"type":"scene","line_id":2,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"",
"text_entry":"SCENE I. London. The palace."}
{"index":{"_index":"shakespeare","_id":2}}
{"type":"line","line_id":3,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":
"Enter KING HENRY, LORD JOHN OF LANCASTER, the EARL
of WESTMORELAND, SIR WALTER BLUNT, and others"}jsonfileに入る追加のデータがあることに注意してください-{"index":{"_index":"nameofindex","_id":key}}。
elasticsearchと互換性のあるサンプルjsonファイルを変換するために、ここにphpに小さなコードがあり、elasticsearchが必要とする形式で指定されたjsonファイルを出力します。
PHPコード
<?php
$myfile = fopen("todo.json", "r") or die("Unable to open file!"); // your json
file here
$alldata = fread($myfile,filesize("todo.json"));
fclose($myfile);
$farray = json_decode($alldata);
$afinalarray = [];
$index_name = "todo";
$i=0;
$myfile1 = fopen("todonewfile.json", "w") or die("Unable to open file!"); //
writes a new file to be used in kibana dev tool
foreach ($farray as $a => $value) {
$_index = json_decode('{"index": {"_index": "'.$index_name.'", "_id": "'.$i.'"}}');
fwrite($myfile1, json_encode($_index));
fwrite($myfile1, "\n");
fwrite($myfile1, json_encode($value));
fwrite($myfile1, "\n");
$i++;
}
?>todojsonファイルをから取得しました https://jsonplaceholder.typicode.com/todos phpコードを使用して、Kibanaにアップロードする必要のある形式に変換します。
サンプルデータをロードするには、以下に示すように[開発ツール]タブを開きます-
上記のようにコンソールを使用します。phpコードで実行した後に取得したjsonデータを取得します。
jsonデータをアップロードするために開発ツールで使用されるコマンドは次のとおりです。
POST _bulk作成しているインデックスの名前はtodoであることに注意してください。
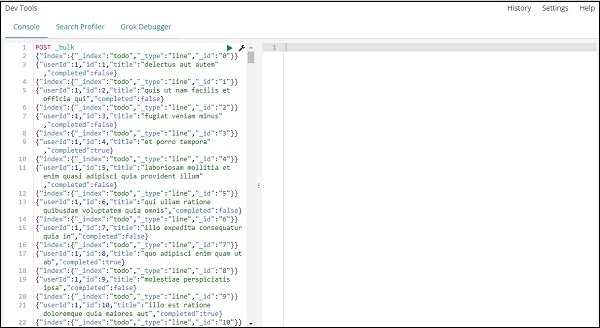

データがアップロードされている緑色のボタンをクリックすると、次のようにElasticsearchでインデックスが作成されているかどうかを確認できます-

次のように開発ツール自体で同じことを確認できます-
Command −
GET /_cat/indices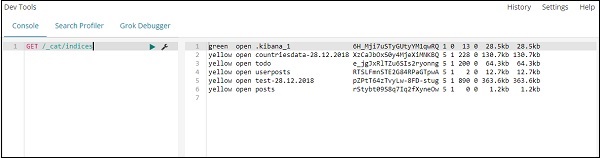
index:todoで何かを検索したい場合は、以下に示すようにそれを行うことができます-
Command in dev tool
GET /todo/_search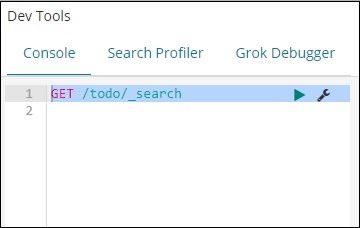
上記の検索の出力は次のとおりです-

todoindexに存在するすべてのレコードを提供します。私たちが取得している合計レコードは200です。
todoインデックスでレコードを検索する
次のコマンドを使用してそれを行うことができます-
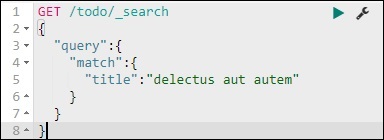
GET /todo/_search
{
"query":{
"match":{
"title":"delectusautautem"
}
}
}

与えたタイトルと一致するレコードをフェッチすることができます。