Projekt VLSI - technologia FPGA
FPGA - Wprowadzenie
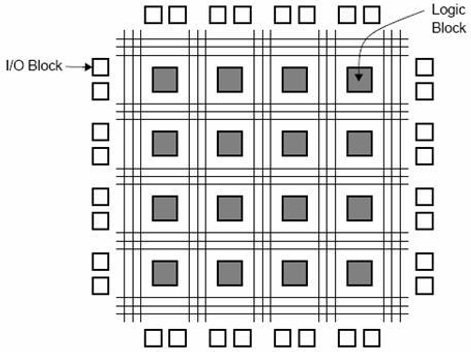
Pełna forma FPGA jest "Field Programmable Gate Array”. Zawiera od dziesięciu tysięcy do ponad miliona bramek logicznych z programowalnymi połączeniami. Programowalne połączenia są dostępne dla użytkowników lub projektantów w celu łatwego wykonywania określonych funkcji. Na rysunku pokazano typowy model układu FPGA. Istnieją bloki I / O, które są zaprojektowane i ponumerowane zgodnie z funkcją. Dla każdego modułu kompozycji poziomu logiki sąCLB’s (Configurable Logic Blocks).
CLB wykonuje operację logiczną przekazaną modułowi. Połączenia między CLB a blokami I / O są realizowane za pomocą poziomych kanałów routingu, pionowych kanałów routingu i PSM (programowalnych multiplekserów).
Liczba zawartych w nim CLB decyduje tylko o złożoności FPGA. Funkcjonalność CLB i PSM są projektowane przez VHDL lub inny język opisu sprzętu. Po zaprogramowaniu CLB i PSM są umieszczane na chipie i łączone ze sobą kanałami routingu.
Zalety
- Zajmuje bardzo mało czasu; począwszy od procesu projektowania do funkcjonalnego chipa.
- Nie są zaangażowane żadne fizyczne etapy produkcji.
- Jedyną wadą jest to, że jest kosztowny niż inne style.
Projekt tablicy bramkowej
Plik gate array (GA)zajmuje drugie miejsce po FPGA pod względem możliwości szybkiego prototypowania. Podczas gdy programowanie użytkownika jest ważne dla implementacji projektu układu FPGA, projektowanie i przetwarzanie maski metalowej jest wykorzystywane w przypadku GA. Implementacja macierzy bramkowej wymaga dwuetapowego procesu produkcyjnego.
Pierwsza faza skutkuje tablicą niezatwierdzonych tranzystorów na każdym układzie GA. Te niezaangażowane chipy można przechowywać w celu późniejszego dostosowania, co jest zakończone przez zdefiniowanie metalowych połączeń między tranzystorami macierzy. Modelowanie metalowych interkonektów odbywa się pod koniec procesu wytwarzania chipa, tak że czas realizacji może być nadal krótki, od kilku dni do kilku tygodni. Poniższy rysunek przedstawia podstawowe kroki przetwarzania dla implementacji tablicy bramek.

Typowe platformy z tablicami bramek wykorzystują wydzielone obszary zwane kanałami do routingu międzykomórkowego między rzędami lub kolumnami tranzystorów MOS. Upraszczają połączenia. Wzorce połączeń, które wykonują podstawowe bramki logiczne, są przechowywane w bibliotece, której można następnie użyć do dostosowania rzędów niezatwierdzonych tranzystorów zgodnie z listą sieci.
W większości nowoczesnych GA do trasowania kanałów używa się wielu warstw metalu. Dzięki zastosowaniu wielu połączonych ze sobą warstw, trasowanie można uzyskać na aktywnych obszarach komórek; dzięki czemu kanały routingu można usunąć, tak jak w układach Sea-of-Gates (SOG). Tutaj cała powierzchnia chipa jest pokryta niezatwierdzonymi tranzystorami nMOS i pMOS. Sąsiednie tranzystory można dostosować za pomocą metalowej maski w celu utworzenia podstawowych bramek logicznych.
W przypadku routingu międzykomórkowego niektóre niezatwierdzone tranzystory muszą zostać poświęcone. Ten styl projektowania zapewnia większą elastyczność połączeń międzysystemowych i zwykle większą gęstość. Współczynnik wykorzystania wiórów GA jest mierzony przez wykorzystany obszar wióra podzielony przez całkowitą powierzchnię wióra. Jest wyższa niż w FPGA, podobnie jak prędkość chipa.
Standardowa konstrukcja oparta na komórkach
Standardowy projekt oparty na komórkach wymaga opracowania pełnego zestawu masek niestandardowych. Standardowa komórka jest również nazywana polikomórką. W tym podejściu wszystkie powszechnie używane komórki logiczne są opracowywane, charakteryzowane i przechowywane w standardowej bibliotece komórek.
Biblioteka może zawierać kilkaset komórek, w tym inwertery, bramki NAND, bramki NOR, złożone AOI, bramki OAI, zatrzaski typu D i przerzutniki. Każdy typ bramy można zaimplementować w kilku wersjach, aby zapewnić odpowiednią zdolność jazdy dla różnych fan-outów. Bramka falownika może mieć rozmiar standardowy, podwójny i poczwórny, aby projektant chipa mógł wybrać odpowiedni rozmiar, aby uzyskać dużą prędkość obwodu i gęstość układu.
Każda komórka jest scharakteryzowana według kilku różnych kategorii charakteryzacji, takich jak
- Czas opóźnienia a pojemność obciążenia
- Model symulacyjny obwodu
- Model symulacji rozrządu
- Model symulacji uszkodzeń
- Dane komórkowe dotyczące miejsca i trasy
- Maskuj dane
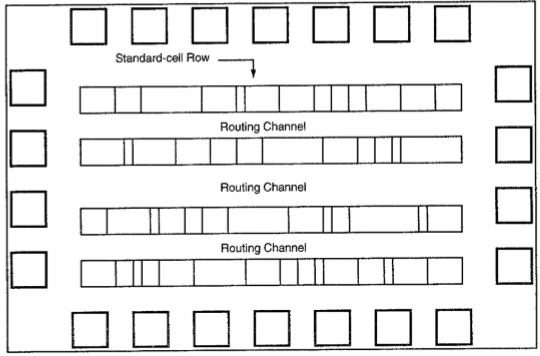
W celu automatycznego umieszczania komórek i trasowania każdy układ komórek ma ustaloną wysokość, tak aby wiele komórek można było ograniczać obok siebie, tworząc wiersze. Szyny zasilające i uziemiające biegną równolegle do górnej i dolnej granicy komórki. Tak więc sąsiednie komórki mają wspólną szynę zasilającą i wspólną szynę uziemiającą. Poniższy rysunek przedstawia plan piętra dla projektu opartego na standardowych ogniwach.
Pełny projekt niestandardowy
W całkowicie niestandardowym projekcie cały projekt maski jest nowy, bez użycia jakiejkolwiek biblioteki. Koszt rozwoju tego stylu projektowania rośnie. W związku z tym koncepcja ponownego wykorzystania projektu staje się sławna ze względu na redukcję czasu cyklu projektowania i kosztów rozwoju.
Najtrudniejszym całkowicie niestandardowym projektem może być konstrukcja komórki pamięci, statyczna lub dynamiczna. W przypadku projektowania układów logicznych dobre negocjacje można uzyskać, stosując kombinację różnych stylów projektowych na tym samym chipie, tj. Komórki standardowe, komórki ścieżki danych iprogrammable logic arrays (PLAs).
Praktycznie projektant wykonuje pełny układ niestandardowy, tj. Geometrię, orientację i położenie każdego tranzystora. Wydajność projektowa jest zwykle bardzo niska; zwykle kilkadziesiąt tranzystorów dziennie, na projektanta. W przypadku cyfrowego CMOS VLSI, projektowanie w pełni niestandardowe jest rzadko używane ze względu na wysokie koszty pracy. Te style projektowania obejmują projektowanie produktów o dużej objętości, takich jak chipy pamięci, wysokowydajne mikroprocesory i FPGA.