Аналитика больших данных - жизненный цикл данных
Жизненный цикл традиционного интеллектуального анализа данных
Чтобы обеспечить основу для организации работы, необходимой организации, и получить четкое представление о больших данных, полезно рассматривать это как цикл с различными этапами. Это ни в коем случае не линейно, то есть все этапы связаны друг с другом. Этот цикл имеет внешнее сходство с более традиционным циклом интеллектуального анализа данных, описанным вCRISP methodology.
Методология CRISP-DM
В CRISP-DM methodologyчто расшифровывается как Cross Industry Standard Process for Data Mining, это цикл, который описывает часто используемые подходы, которые эксперты по интеллектуальному анализу данных используют для решения проблем в традиционном интеллектуальном анализе данных бизнес-аналитики. Он все еще используется в традиционных командах интеллектуального анализа данных.
Взгляните на следующую иллюстрацию. В нем показаны основные этапы цикла, описанные в методологии CRISP-DM, и их взаимосвязь.
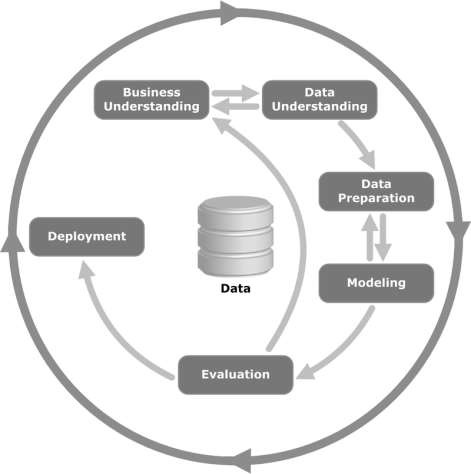
CRISP-DM был задуман в 1996 году, а в следующем году он начал свою работу как проект Европейского Союза в рамках инициативы финансирования ESPRIT. Проект возглавляли пять компаний: SPSS, Teradata, Daimler AG, NCR Corporation и OHRA (страховая компания). Наконец, проект был включен в SPSS. Методология чрезвычайно детально ориентирована на то, как следует определять проект интеллектуального анализа данных.
Давайте теперь узнаем немного больше о каждом из этапов жизненного цикла CRISP-DM -
Business Understanding- На этом начальном этапе основное внимание уделяется пониманию целей и требований проекта с точки зрения бизнеса, а затем преобразованию этих знаний в определение проблемы интеллектуального анализа данных. Предварительный план разработан для достижения целей. Можно использовать модель решения, особенно построенную с использованием модели принятия решений и стандарта нотации.
Data Understanding - Этап понимания данных начинается с первоначального сбора данных и продолжается действиями по ознакомлению с данными, выявлению проблем с качеством данных, обнаружению первого понимания данных или выявлению интересных подмножеств для формирования гипотез для скрытой информации.
Data Preparation- Этап подготовки данных охватывает все действия по созданию окончательного набора данных (данные, которые будут введены в инструмент (ы) моделирования) из исходных исходных данных. Задачи подготовки данных, вероятно, будут выполняться несколько раз, а не в любом предписанном порядке. Задачи включают выбор таблицы, записи и атрибута, а также преобразование и очистку данных для инструментов моделирования.
Modeling- На этом этапе выбираются и применяются различные методы моделирования, а их параметры калибруются до оптимальных значений. Как правило, для решения одного и того же типа проблемы интеллектуального анализа данных существует несколько методов. Некоторые методы предъявляют особые требования к форме данных. Поэтому часто требуется вернуться к этапу подготовки данных.
Evaluation- На этом этапе проекта вы построили модель (или модели), которая кажется высококачественной с точки зрения анализа данных. Прежде чем приступить к окончательному развертыванию модели, важно тщательно оценить модель и просмотреть шаги, выполняемые для построения модели, чтобы убедиться, что она должным образом достигает бизнес-целей.
Основная цель - определить, есть ли какой-то важный бизнес-вопрос, который не был достаточно рассмотрен. В конце этого этапа должно быть принято решение об использовании результатов интеллектуального анализа данных.
Deployment- Создание модели - это вообще не конец проекта. Даже если цель модели - расширить знания о данных, полученные знания необходимо будет организовать и представить таким образом, чтобы это было полезно для клиента.
В зависимости от требований, этап развертывания может быть таким же простым, как создание отчета, или сложным, например, реализация повторяемой оценки данных (например, распределение сегментов) или процесса анализа данных.
Во многих случаях этапы развертывания будет выполнять заказчик, а не аналитик данных. Даже если аналитик развернет модель, для клиента важно заранее понять действия, которые необходимо будет выполнить, чтобы фактически использовать созданные модели.
Методология SEMMA
SEMMA - еще одна методология, разработанная SAS для моделирования интеллектуального анализа данных. Это означаетSдостаточно, Explore, Modify, Mодель, и Aссес. Вот краткое описание его этапов -
Sample- Процесс начинается с выборки данных, например, выбора набора данных для моделирования. Набор данных должен быть достаточно большим, чтобы содержать достаточно информации для извлечения, но при этом достаточно маленьким, чтобы его можно было эффективно использовать. На этом этапе также выполняется разделение данных.
Explore - Этот этап охватывает понимание данных путем обнаружения ожидаемых и непредвиденных взаимосвязей между переменными, а также отклонений от нормы с помощью визуализации данных.
Modify - Этап изменения содержит методы выбора, создания и преобразования переменных для подготовки к моделированию данных.
Model - На этапе моделирования основное внимание уделяется применению различных методов моделирования (интеллектуального анализа данных) к подготовленным переменным с целью создания моделей, которые могут обеспечить желаемый результат.
Assess - Оценка результатов моделирования показывает надежность и полезность созданных моделей.
Основное различие между CRISM – DM и SEMMA заключается в том, что SEMMA фокусируется на аспекте моделирования, тогда как CRISP-DM придает большее значение этапам цикла до моделирования, таким как понимание бизнес-проблемы, которую необходимо решить, понимание и предварительная обработка данных, которые будут используются в качестве входных данных, например, алгоритмы машинного обучения.
Жизненный цикл больших данных
В сегодняшнем контексте больших данных предыдущие подходы либо неполны, либо неоптимальны. Например, методология SEMMA полностью игнорирует сбор данных и предварительную обработку различных источников данных. Эти этапы обычно составляют большую часть работы в успешном проекте больших данных.
Цикл аналитики больших данных можно описать следующим этапом -
- Определение бизнес-проблемы
- Research
- Оценка человеческих ресурсов
- Получение данных
- Изменение данных
- Хранилище данных
- Исследовательский анализ данных
- Подготовка данных для моделирования и оценки
- Modeling
- Implementation
В этом разделе мы пролим свет на каждую из этих стадий жизненного цикла больших данных.
Определение бизнес-проблемы
Это общая точка жизненного цикла традиционного бизнес-анализа и анализа больших данных. Обычно определение проблемы и правильная оценка потенциальной выгоды для организации представляет собой нетривиальный этап проекта больших данных. Упоминание об этом кажется очевидным, но необходимо оценить, каковы ожидаемые выгоды и затраты по проекту.
Исследование
Проанализируйте, что сделали другие компании в такой же ситуации. Это включает в себя поиск решений, которые подходят для вашей компании, даже если это предполагает адаптацию других решений к ресурсам и требованиям вашей компании. На этом этапе следует определить методологию будущих этапов.
Оценка человеческих ресурсов
Как только проблема определена, разумно продолжить анализ, сможет ли текущий персонал успешно завершить проект. Традиционные команды бизнес-аналитики могут быть не в состоянии предоставить оптимальное решение для всех этапов, поэтому перед запуском проекта следует подумать, есть ли необходимость передать часть проекта на аутсорсинг или нанять больше людей.
Получение данных
Этот раздел является ключевым в жизненном цикле больших данных; он определяет, какие типы профилей потребуются для доставки итогового информационного продукта. Сбор данных - нетривиальный этап процесса; обычно это включает сбор неструктурированных данных из разных источников. Например, это может включать в себя написание поискового робота для получения отзывов с веб-сайта. Это включает в себя работу с текстом, возможно, на разных языках, обычно требующим значительного количества времени для завершения.
Изменение данных
После получения данных, например, из Интернета, их необходимо сохранить в удобном для использования формате. Чтобы продолжить примеры обзоров, предположим, что данные извлекаются с разных сайтов, на каждом из которых данные отображаются по-разному.
Предположим, что один источник данных дает обзоры с точки зрения рейтинга в звездах, поэтому его можно прочитать как отображение для переменной ответа. y ∈ {1, 2, 3, 4, 5}. Другой источник данных дает обзоры с использованием системы двух стрелок, одна для голосования "за", а другая для голосования "вниз". Это будет означать, что переменная ответа имеет видy ∈ {positive, negative}.
Чтобы объединить оба источника данных, необходимо принять решение, чтобы эти два представления ответа были эквивалентными. Это может включать преобразование первого представления ответа источника данных во вторую форму, считая одну звезду отрицательной, а пять - положительной. Этот процесс часто требует больших затрат времени, чтобы выполнить его с хорошим качеством.
Хранилище данных
После обработки данные иногда необходимо сохранить в базе данных. Технологии больших данных предлагают множество альтернатив на этот счет. Наиболее распространенной альтернативой является использование файловой системы Hadoop для хранения, которая предоставляет пользователям ограниченную версию SQL, известную как язык запросов HIVE. Это позволяет выполнять большинство аналитических задач аналогично тому, как это делается в традиционных хранилищах данных бизнес-аналитики, с точки зрения пользователя. Также следует рассмотреть другие варианты хранения: MongoDB, Redis и SPARK.
Этот этап цикла связан со знаниями человеческих ресурсов с точки зрения их способностей к реализации различных архитектур. Модифицированные версии традиционных хранилищ данных все еще используются в крупномасштабных приложениях. Например, teradata и IBM предлагают базы данных SQL, которые могут обрабатывать терабайты данных; решения с открытым исходным кодом, такие как postgreSQL и MySQL, все еще используются для крупномасштабных приложений.
Несмотря на различия в том, как разные хранилища работают в фоновом режиме, со стороны клиента большинство решений предоставляют SQL API. Следовательно, хорошее понимание SQL по-прежнему является ключевым навыком для анализа больших данных.
Этот этап априори кажется важнейшей темой, на практике это не так. Это даже не существенный этап. Возможно реализовать решение для больших данных, которое будет работать с данными в реальном времени, поэтому в этом случае нам нужно только собрать данные для разработки модели, а затем реализовать ее в реальном времени. Таким образом, вообще не было бы необходимости формально хранить данные.
Исследовательский анализ данных
После того, как данные были очищены и сохранены таким образом, чтобы из них можно было извлечь полезную информацию, этап исследования данных становится обязательным. Цель этого этапа - понять данные, обычно это делается с помощью статистических методов, а также построения графиков данных. Это хороший этап для оценки того, имеет ли определение проблемы смысл или выполнимо.
Подготовка данных для моделирования и оценки
Этот этап включает изменение формы очищенных данных, полученных ранее, и использование предварительной статистической обработки для вменения пропущенных значений, обнаружения выбросов, нормализации, извлечения признаков и выбора признаков.
Моделирование
На предыдущем этапе должно было быть создано несколько наборов данных для обучения и тестирования, например, прогнозная модель. Этот этап включает в себя опробование различных моделей и ожидание решения стоящей бизнес-задачи. На практике обычно желательно, чтобы модель давала некоторое представление о бизнесе. Наконец, выбирается лучшая модель или комбинация моделей, оценивающая ее эффективность на оставленном наборе данных.
Реализация
На этом этапе разработанный информационный продукт внедряется в конвейер данных компании. Это включает в себя настройку схемы проверки во время работы продукта данных, чтобы отслеживать его производительность. Например, в случае реализации модели прогнозирования, этот этап будет включать применение модели к новым данным и, как только будет получен ответ, оценка модели.