Аналитика больших данных - Краткое руководство
Объем данных, с которыми приходится иметь дело, за последнее десятилетие резко вырос до невообразимого уровня, и в то же время стоимость хранения данных систематически снижалась. Частные компании и исследовательские учреждения собирают терабайты данных о взаимодействиях своих пользователей, бизнесе, социальных сетях, а также датчиках с таких устройств, как мобильные телефоны и автомобили. Задача этой эпохи - разобраться в этом море данных. Это гдеbig data analytics входит в картину.
Аналитика больших данных в значительной степени включает в себя сбор данных из разных источников, преобразование их таким образом, чтобы они стали доступными для использования аналитиками, и, наконец, предоставление продуктов данных, полезных для бизнеса организации.

Процесс преобразования больших объемов неструктурированных исходных данных, полученных из разных источников, в информационный продукт, полезный для организаций, составляет основу аналитики больших данных.
Жизненный цикл традиционного интеллектуального анализа данных
Чтобы обеспечить основу для организации работы, необходимой организации, и получить четкое представление о больших данных, полезно рассматривать это как цикл с различными этапами. Это ни в коем случае не линейно, то есть все этапы связаны друг с другом. Этот цикл имеет внешнее сходство с более традиционным циклом интеллектуального анализа данных, описанным вCRISP methodology.
Методология CRISP-DM
В CRISP-DM methodologyчто расшифровывается как Cross Industry Standard Process for Data Mining, это цикл, который описывает часто используемые подходы, которые эксперты по интеллектуальному анализу данных используют для решения проблем в традиционном интеллектуальном анализе данных. Он все еще используется в традиционных командах интеллектуального анализа данных.
Взгляните на следующую иллюстрацию. На нем показаны основные этапы цикла, описанные в методологии CRISP-DM, и их взаимосвязь.
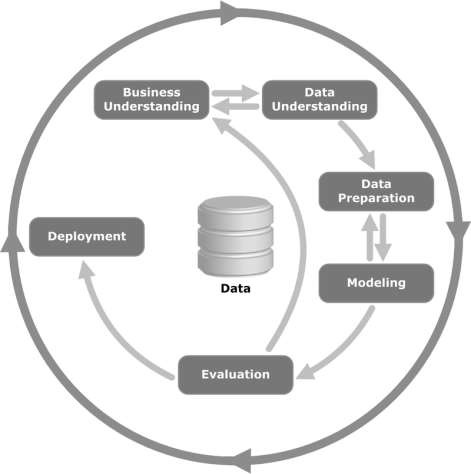
CRISP-DM был задуман в 1996 году, а в следующем году он начал свою работу как проект Европейского Союза в рамках инициативы финансирования ESPRIT. Проект возглавляли пять компаний: SPSS, Teradata, Daimler AG, NCR Corporation и OHRA (страховая компания). Наконец, проект был включен в SPSS. Методология чрезвычайно детально ориентирована на то, как следует определять проект интеллектуального анализа данных.
Давайте теперь узнаем немного больше о каждом из этапов жизненного цикла CRISP-DM -
Business Understanding- Этот начальный этап направлен на понимание целей и требований проекта с точки зрения бизнеса, а затем на преобразование этих знаний в определение проблемы интеллектуального анализа данных. Предварительный план разработан для достижения целей. Можно использовать модель решения, особенно построенную с использованием модели принятия решений и стандарта нотации.
Data Understanding - Этап понимания данных начинается с первоначального сбора данных и продолжается действиями по ознакомлению с данными, выявлению проблем с качеством данных, обнаружению первых взглядов на данные или обнаружению интересных подмножеств для формирования гипотез для скрытой информации.
Data Preparation- Этап подготовки данных охватывает все действия по созданию окончательного набора данных (данные, которые будут загружены в инструмент (ы) моделирования) из исходных исходных данных. Задачи подготовки данных, вероятно, будут выполняться несколько раз, а не в любом предписанном порядке. Задачи включают выбор таблицы, записи и атрибута, а также преобразование и очистку данных для инструментов моделирования.
Modeling- На этом этапе выбираются и применяются различные методы моделирования, а их параметры калибруются до оптимальных значений. Обычно для решения одного и того же типа проблемы интеллектуального анализа данных существует несколько методов. Некоторые методы предъявляют особые требования к форме данных. Поэтому часто требуется вернуться к этапу подготовки данных.
Evaluation- На этом этапе проекта вы построили модель (или модели), которая кажется высококачественной с точки зрения анализа данных. Прежде чем приступить к окончательному развертыванию модели, важно тщательно оценить модель и просмотреть шаги, выполняемые для построения модели, чтобы убедиться, что она должным образом достигает бизнес-целей.
Основная цель - определить, есть ли какой-то важный деловой вопрос, который не был должным образом рассмотрен. В конце этого этапа должно быть принято решение об использовании результатов интеллектуального анализа данных.
Deployment- Создание модели - это вообще не конец проекта. Даже если цель модели - расширить знания о данных, полученные знания необходимо организовать и представить таким образом, чтобы это было полезно для клиента.
В зависимости от требований этап развертывания может быть таким же простым, как создание отчета, или сложным, например, реализация повторяемой оценки данных (например, выделение сегментов) или процесса интеллектуального анализа данных.
Во многих случаях этапы развертывания будет выполнять заказчик, а не аналитик данных. Даже если аналитик развернет модель, важно, чтобы заказчик заранее понимал действия, которые необходимо будет выполнить, чтобы на самом деле использовать созданные модели.
Методология SEMMA
SEMMA - это еще одна методология, разработанная SAS для моделирования интеллектуального анализа данных. Это означаетSдостаточно, Explore, Modify, Mодель, и Aссес. Вот краткое описание его этапов -
Sample- Процесс начинается с выборки данных, например, выбора набора данных для моделирования. Набор данных должен быть достаточно большим, чтобы содержать достаточно информации для извлечения, но достаточно маленьким, чтобы его можно было эффективно использовать. На этом этапе также происходит разделение данных.
Explore - Этот этап охватывает понимание данных путем обнаружения ожидаемых и непредвиденных взаимосвязей между переменными, а также отклонений от нормы с помощью визуализации данных.
Modify - Этап изменения содержит методы выбора, создания и преобразования переменных для подготовки к моделированию данных.
Model - На этапе моделирования основное внимание уделяется применению различных методов моделирования (интеллектуального анализа данных) к подготовленным переменным с целью создания моделей, которые могут обеспечить желаемый результат.
Assess - Оценка результатов моделирования показывает надежность и полезность созданных моделей.
Основное различие между CRISM – DM и SEMMA заключается в том, что SEMMA фокусируется на аспекте моделирования, тогда как CRISP-DM придает большее значение этапам цикла до моделирования, таким как понимание бизнес-проблемы, которую необходимо решить, понимание и предварительная обработка данных, которые будут используются в качестве входных данных, например, алгоритмы машинного обучения.
Жизненный цикл больших данных
В сегодняшнем контексте больших данных предыдущие подходы либо неполны, либо неоптимальны. Например, методология SEMMA полностью игнорирует сбор данных и предварительную обработку различных источников данных. Эти этапы обычно составляют большую часть работы в успешном проекте больших данных.
Цикл аналитики больших данных можно описать следующим этапом -
- Определение бизнес-проблемы
- Research
- Оценка человеческих ресурсов
- Получение данных
- Изменение данных
- Хранилище данных
- Исследовательский анализ данных
- Подготовка данных для моделирования и оценки
- Modeling
- Implementation
В этом разделе мы пролим свет на каждую из этих стадий жизненного цикла больших данных.
Определение бизнес-проблемы
Это общая точка жизненного цикла традиционного бизнес-анализа и анализа больших данных. Обычно определение проблемы и правильная оценка потенциальной выгоды для организации - это нетривиальный этап проекта больших данных. Упоминание об этом кажется очевидным, но необходимо оценить, каковы ожидаемые выгоды и затраты по проекту.
Исследование
Проанализируйте, что сделали другие компании в такой же ситуации. Это предполагает поиск решений, которые подходят для вашей компании, даже если это включает в себя адаптацию других решений к ресурсам и требованиям вашей компании. На этом этапе должна быть определена методология будущих этапов.
Оценка человеческих ресурсов
Как только проблема определена, разумно продолжить анализ, сможет ли текущий персонал успешно завершить проект. Традиционные команды бизнес-аналитики могут быть не в состоянии предоставить оптимальное решение для всех этапов, поэтому перед запуском проекта следует подумать, есть ли необходимость передать часть проекта на аутсорсинг или нанять больше людей.
Получение данных
Этот раздел является ключевым в жизненном цикле больших данных; он определяет, какие типы профилей потребуются для доставки конечного продукта данных. Сбор данных - нетривиальный этап процесса; обычно это включает сбор неструктурированных данных из разных источников. Например, это может включать написание поискового робота для получения отзывов с веб-сайта. Это включает в себя работу с текстом, возможно, на разных языках, обычно требующим значительного количества времени для завершения.
Изменение данных
После получения данных, например, из Интернета, их необходимо сохранить в удобном для использования формате. Чтобы продолжить примеры обзоров, предположим, что данные извлекаются с разных сайтов, на каждом из которых данные отображаются по-разному.
Предположим, что один источник данных дает обзоры с точки зрения рейтинга в звездах, поэтому его можно прочитать как отображение для переменной ответа. y ∈ {1, 2, 3, 4, 5}. Другой источник данных дает обзоры с использованием системы двух стрелок, одна для голосования "за", а другая для голосования "вниз". Это будет означать, что переменная ответа имеет видy ∈ {positive, negative}.
Чтобы объединить оба источника данных, необходимо принять решение, чтобы эти два представления ответа были эквивалентными. Это может включать преобразование первого представления ответа источника данных во вторую форму, считая одну звездочку отрицательной, а пять - положительной. Этот процесс часто требует больших затрат времени, чтобы выполнить его с хорошим качеством.
Хранилище данных
После обработки данные иногда необходимо сохранить в базе данных. Технологии больших данных предлагают множество альтернатив в этом отношении. Наиболее распространенной альтернативой является использование файловой системы Hadoop для хранения, которая предоставляет пользователям ограниченную версию SQL, известную как язык запросов HIVE. С точки зрения пользователя, это позволяет выполнять большинство аналитических задач аналогично тому, как это делалось бы в традиционных хранилищах данных бизнес-аналитики. Также следует рассмотреть другие варианты хранения: MongoDB, Redis и SPARK.
Этот этап цикла связан со знаниями человеческих ресурсов с точки зрения их способностей к реализации различных архитектур. Модифицированные версии традиционных хранилищ данных все еще используются в крупномасштабных приложениях. Например, teradata и IBM предлагают базы данных SQL, которые могут обрабатывать терабайты данных; решения с открытым исходным кодом, такие как postgreSQL и MySQL, все еще используются для крупномасштабных приложений.
Несмотря на то, что существуют различия в том, как разные хранилища работают в фоновом режиме, со стороны клиента большинство решений предоставляют SQL API. Следовательно, хорошее понимание SQL по-прежнему является ключевым навыком для анализа больших данных.
Этот этап априори кажется важнейшей темой, на практике это не так. Это даже не существенный этап. Возможно реализовать решение для больших данных, которое будет работать с данными в реальном времени, поэтому в этом случае нам нужно только собрать данные для разработки модели, а затем реализовать ее в реальном времени. Таким образом, вообще не было бы необходимости формально хранить данные.
Исследовательский анализ данных
После того, как данные были очищены и сохранены таким образом, чтобы из них можно было извлечь полезную информацию, этап исследования данных является обязательным. Цель этого этапа - понять данные, обычно это делается с помощью статистических методов, а также построения графиков данных. Это хороший этап для оценки того, имеет ли определение проблемы смысл или выполнимо.
Подготовка данных для моделирования и оценки
Этот этап включает изменение формы очищенных данных, полученных ранее, и использование предварительной статистической обработки для вменения пропущенных значений, обнаружения выбросов, нормализации, извлечения признаков и выбора признаков.
Моделирование
На предыдущем этапе должно было быть создано несколько наборов данных для обучения и тестирования, например, прогнозная модель. Этот этап включает в себя опробование различных моделей и ожидание решения стоящей бизнес-задачи. На практике обычно желательно, чтобы модель давала некоторое представление о бизнесе. Наконец, выбирается лучшая модель или комбинация моделей, оценивающая ее эффективность на оставленном наборе данных.
Реализация
На этом этапе разработанный информационный продукт внедряется в конвейер данных компании. Это включает в себя настройку схемы проверки во время работы продукта данных, чтобы отслеживать его производительность. Например, в случае реализации модели прогнозирования, этот этап будет включать применение модели к новым данным и, как только будет получен ответ, оценка модели.
С точки зрения методологии, аналитика больших данных существенно отличается от традиционного статистического подхода к планированию экспериментов. Аналитика начинается с данных. Обычно мы моделируем данные таким образом, чтобы объяснить ответ. Цели этого подхода - предсказать поведение ответа или понять, как входные переменные соотносятся с ответом. Обычно в статистических экспериментальных планах проводится эксперимент, и в результате извлекаются данные. Это позволяет генерировать данные таким образом, чтобы их можно было использовать в статистической модели, где выполняются определенные допущения, такие как независимость, нормальность и рандомизация.
В аналитике больших данных нам представлены данные. Мы не можем разработать эксперимент, который соответствует нашей любимой статистической модели. В крупномасштабных приложениях аналитики большой объем работы (обычно 80% усилий) требуется только для очистки данных, поэтому их можно использовать в модели машинного обучения.
У нас нет уникальной методологии, которой можно было бы следовать в реальных крупномасштабных приложениях. Обычно после определения бизнес-проблемы требуется этап исследования, чтобы разработать методологию, которая будет использоваться. Однако следует упомянуть общие рекомендации, которые применимы почти ко всем проблемам.
Одна из важнейших задач аналитики больших данных - statistical modeling, что означает контролируемые и неконтролируемые задачи классификации или регрессии. После того, как данные очищены и предварительно обработаны и доступны для моделирования, следует внимательно отнестись к оценке различных моделей с разумными показателями потерь, а затем, когда модель будет реализована, следует сообщить о дальнейшей оценке и результатах. Распространенная ошибка в прогнозном моделировании - просто реализовать модель и никогда не измерять ее производительность.
Как упоминалось в жизненном цикле больших данных, продукты данных, которые являются результатом разработки продукта больших данных, в большинстве случаев являются одними из следующих:
Machine learning implementation - Это может быть алгоритм классификации, регрессионная модель или модель сегментации.
Recommender system - Цель состоит в том, чтобы разработать систему, которая рекомендует выбор на основе поведения пользователя. Netflix является характерным примером этого информационного продукта, где на основе оценок пользователей рекомендуются другие фильмы.
Dashboard- Бизнесу обычно нужны инструменты для визуализации агрегированных данных. Информационная панель - это графический механизм, делающий эти данные доступными.
Ad-Hoc analysis - Обычно в сферах бизнеса есть вопросы, гипотезы или мифы, на которые можно ответить с помощью специального анализа данных.
В крупных организациях для успешной разработки проекта по работе с большими данными необходимо, чтобы руководство поддерживало проект. Обычно это включает в себя поиск способа показать бизнес-преимущества проекта. У нас нет уникального решения проблемы поиска спонсоров для проекта, но несколько рекомендаций приведены ниже:
Узнайте, кто и где спонсирует другие проекты, похожие на интересующий вас.
Наличие личных контактов на ключевых руководящих должностях помогает, так что любой контакт может быть инициирован, если проект перспективен.
Кому будет полезен ваш проект? Кто будет вашим клиентом, когда проект будет реализован?
Разработайте простое, понятное и интересное предложение и поделитесь им с ключевыми игроками в вашей организации.
Лучший способ найти спонсоров для проекта - это понять проблему и то, каков будет полученный информационный продукт после его реализации. Это понимание даст преимущество в убеждении руководства в важности проекта больших данных.
Аналитик данных имеет профиль, ориентированный на отчетность, имеет опыт извлечения и анализа данных из традиционных хранилищ данных с использованием SQL. Их задачи обычно связаны либо с хранением данных, либо с составлением отчетов об общих бизнес-результатах. Хранилище данных отнюдь не простое дело, оно просто отличается от того, что делает специалист по данным.
Многим организациям сложно найти на рынке компетентных специалистов по данным. Тем не менее, рекомендуется выбрать потенциальных аналитиков данных и обучить их соответствующим навыкам, чтобы стать специалистом по анализу данных. Это отнюдь не тривиальная задача, и обычно для нее требуется получить степень магистра в области количественных исследований, но это определенно жизнеспособный вариант. Основные навыки, которыми должен обладать компетентный аналитик данных, перечислены ниже:
- Деловое понимание
- SQL программирование
- Дизайн и реализация отчета
- Разработка дашбордов
Роль специалиста по данным обычно связана с такими задачами, как прогнозное моделирование, разработка алгоритмов сегментации, рекомендательные системы, фреймворки A / B-тестирования и часто работа с необработанными неструктурированными данными.
Характер их работы требует глубокого понимания математики, прикладной статистики и программирования. Между аналитиком данных и специалистом по анализу данных есть несколько общих навыков, например, способность запрашивать базы данных. Оба анализируют данные, но решение специалиста по данным может иметь большее влияние на организацию.
Вот набор навыков, которые обычно необходимы специалисту по данным:
- Программирование в статистическом пакете, таком как: R, Python, SAS, SPSS или Julia
- Возможность очищать, извлекать и исследовать данные из разных источников
- Исследование, разработка и внедрение статистических моделей
- Глубокие статистические, математические и компьютерные знания
В аналитике больших данных люди обычно путают роль специалиста по данным с ролью архитектора данных. На самом деле разница довольно проста. Архитектор данных определяет инструменты и архитектуру, в которой будут храниться данные, тогда как специалист по анализу данных использует эту архитектуру. Конечно, специалист по данным должен иметь возможность настраивать новые инструменты, если это необходимо для специальных проектов, но определение и проектирование инфраструктуры не должны быть частью его задачи.
С помощью этого урока мы разработаем проект. Каждая последующая глава в этом руководстве посвящена части более крупного проекта в разделе мини-проектов. Считается, что это прикладной учебный раздел, который познакомит вас с реальной проблемой. В этом случае мы бы начали с постановки задачи проекта.
Описание Проекта
Целью этого проекта будет разработка модели машинного обучения для прогнозирования почасовой оплаты труда людей, использующих текст их биографических данных (CV) в качестве входных данных.
Используя структуру, определенную выше, легко определить проблему. Мы можем определить X = {x 1 , x 2 ,…, x n } как резюме пользователей, где каждая особенность может быть, самым простым способом, количеством раз, когда это слово появляется. Тогда ответ реально оценивается, мы пытаемся предсказать почасовую зарплату людей в долларах.
Этих двух соображений достаточно, чтобы сделать вывод, что представленная проблема может быть решена с помощью контролируемого алгоритма регрессии.
Определение проблемы
Problem Definitionвероятно, один из самых сложных и часто игнорируемых этапов в конвейере анализа больших данных. Чтобы определить проблему, которую решит информационный продукт, необходим опыт. Большинство кандидатов в специалисты по анализу данных практически не имеют опыта на этой стадии.
Большинство проблем с большими данными можно разделить на следующие категории:
- Контролируемая классификация
- Контролируемая регрессия
- Обучение без учителя
- Учимся ранжировать
Давайте теперь узнаем больше об этих четырех концепциях.
Контролируемая классификация
Учитывая матрицу признаков X = {x 1 , x 2 , ..., x n }, мы разрабатываем модель M для прогнозирования различных классов, определенных как y = {c 1 , c 2 , ..., c n } . Например: учитывая данные о транзакциях клиентов в страховой компании, можно разработать модель, которая предскажет, откажется клиент от услуг или нет. Последнее является проблемой бинарной классификации, где есть два класса или целевые переменные: отток и не отток.
Другие проблемы связаны с прогнозированием более чем одного класса, нас может заинтересовать распознавание цифр, поэтому вектор ответа будет определен как: y = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9} , современная модель будет сверточной нейронной сетью, а матрица функций будет определяться как пиксели изображения.
Контролируемая регрессия
В этом случае определение проблемы очень похоже на предыдущий пример; разница зависит от ответа. В задаче регрессии ответ y ∈ ℜ, это означает, что ответ является действительным. Например, мы можем разработать модель для прогнозирования почасовой оплаты труда людей с учетом корпуса их резюме.
Неконтролируемое обучение
Менеджмент часто жаждет новых идей. Модели сегментации могут предоставить эту информацию, чтобы отдел маркетинга мог разрабатывать продукты для различных сегментов. Хороший подход к разработке модели сегментации вместо того, чтобы думать об алгоритмах, - это выбрать функции, которые имеют отношение к желаемой сегментации.
Например, в телекоммуникационной компании интересно сегментировать клиентов по использованию мобильных телефонов. Это предполагает игнорирование функций, которые не имеют ничего общего с целью сегментации, и включение только тех, которые имеют отношение. В этом случае это будет выбор функций, таких как количество SMS, используемых в месяц, количество минут для входящих и исходящих сообщений и т. Д.
Учимся ранжировать
Эту проблему можно рассматривать как проблему регрессии, но она имеет определенные особенности и заслуживает отдельного рассмотрения. Проблема связана с набором документов, который мы стремимся найти наиболее релевантное упорядочение по запросу. Чтобы разработать алгоритм обучения с учителем, необходимо обозначить, насколько релевантно упорядочивание для данного запроса.
Уместно отметить, что для разработки алгоритма обучения с учителем необходимо пометить данные обучения. Это означает, что для обучения модели, которая, например, будет распознавать цифры на изображении, нам необходимо вручную пометить значительное количество примеров. Существуют веб-службы, которые могут ускорить этот процесс и обычно используются для этой задачи, такие как amazon Mechanical turk. Доказано, что алгоритмы обучения улучшают свою производительность, когда им предоставляется больше данных, поэтому маркировка приличного количества примеров практически обязательна при обучении с учителем.
Сбор данных играет важнейшую роль в цикле больших данных. Интернет предоставляет практически неограниченные источники данных по самым разным темам. Важность этой области зависит от типа бизнеса, но традиционные отрасли могут получать различные источники внешних данных и комбинировать их со своими транзакционными данными.
Например, предположим, что мы хотим создать систему, которая рекомендует рестораны. Первым шагом будет сбор данных, в данном случае обзоров ресторанов с разных веб-сайтов, и их сохранение в базе данных. Поскольку нас интересует необработанный текст и мы будем использовать его для аналитики, не так важно, где будут храниться данные для разработки модели. Это может показаться противоречащим основным технологиям больших данных, но для реализации приложения для работы с большими данными нам просто нужно заставить его работать в режиме реального времени.
Мини-проект Twitter
После определения проблемы следующим этапом является сбор данных. Следующая идея минипроекта заключается в сборе данных из Интернета и их структурировании для использования в модели машинного обучения. Мы будем собирать твиты из twitter rest API, используя язык программирования R.
Прежде всего создайте учетную запись Twitter, а затем следуйте инструкциям в twitteRпакет виньетки для создания учетной записи разработчика Twitter. Это краткое изложение этих инструкций -
Идти к https://twitter.com/apps/new и авторизуйтесь.
После заполнения основной информации перейдите на вкладку «Настройки» и выберите «Чтение, запись и доступ к прямым сообщениям».
После этого обязательно нажмите кнопку сохранения.
На вкладке «Подробности» запишите свой ключ клиента и секрет клиента.
В сеансе R вы будете использовать ключ API и секретные значения API.
Наконец, запустите следующий сценарий. Это установитtwitteR пакет из своего репозитория на github.
install.packages(c("devtools", "rjson", "bit64", "httr"))
# Make sure to restart your R session at this point
library(devtools)
install_github("geoffjentry/twitteR")Мы заинтересованы в получении данных, в которые включена строка «big mac», и в выяснении, какие темы выделяются по этому поводу. Для этого первым делом нужно собрать данные из твиттера. Ниже представлен наш R-скрипт для сбора необходимых данных из твиттера. Этот код также доступен в файле bda / part1 / collect_data / collect_data_twitter.R.
rm(list = ls(all = TRUE)); gc() # Clears the global environment
library(twitteR)
Sys.setlocale(category = "LC_ALL", locale = "C")
### Replace the xxx’s with the values you got from the previous instructions
# consumer_key = "xxxxxxxxxxxxxxxxxxxx"
# consumer_secret = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# access_token = "xxxxxxxxxx-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# access_token_secret= "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# Connect to twitter rest API
setup_twitter_oauth(consumer_key, consumer_secret, access_token, access_token_secret)
# Get tweets related to big mac
tweets <- searchTwitter(’big mac’, n = 200, lang = ’en’)
df <- twListToDF(tweets)
# Take a look at the data
head(df)
# Check which device is most used
sources <- sapply(tweets, function(x) x$getStatusSource())
sources <- gsub("</a>", "", sources)
sources <- strsplit(sources, ">")
sources <- sapply(sources, function(x) ifelse(length(x) > 1, x[2], x[1]))
source_table = table(sources)
source_table = source_table[source_table > 1]
freq = source_table[order(source_table, decreasing = T)]
as.data.frame(freq)
# Frequency
# Twitter for iPhone 71
# Twitter for Android 29
# Twitter Web Client 25
# recognia 20После сбора данных у нас обычно есть разные источники данных с разными характеристиками. Самым немедленным шагом было бы сделать эти источники данных однородными и продолжить развитие нашего информационного продукта. Однако это зависит от типа данных. Мы должны спросить себя, практично ли гомогенизировать данные.
Возможно, источники данных совершенно разные, и потери информации будут большими, если источники будут гомогенизированы. В этом случае мы можем думать об альтернативах. Может ли один источник данных помочь мне построить регрессионную модель, а другой - модель классификации? Можно ли работать с неоднородностью в наших интересах, а не просто терять информацию? Именно эти решения делают аналитику интересной и сложной.
В случае обзоров можно указать язык для каждого источника данных. Опять же, у нас есть два варианта -
Homogenization- Это включает перевод разных языков на язык, на котором у нас больше данных. Качество услуг перевода приемлемое, но если мы хотим переводить большие объемы данных с помощью API, стоимость будет значительной. Для этой задачи доступны программные инструменты, но это тоже будет дорогостоящим.
Heterogenization- Можно ли разработать решение для каждого языка? Поскольку определить язык корпуса несложно, мы могли бы разработать рекомендации для каждого языка. Это потребует дополнительных усилий с точки зрения настройки каждого рекомендателя в соответствии с количеством доступных языков, но это определенно жизнеспособный вариант, если у нас есть несколько доступных языков.
Мини-проект Twitter
В данном случае нам нужно сначала очистить неструктурированные данные, а затем преобразовать их в матрицу данных, чтобы применить к ней моделирование тем. В общем, при получении данных из твиттера есть несколько символов, которые мы не заинтересованы в использовании, по крайней мере, на первом этапе процесса очистки данных.
Например, после получения твитов мы получаем эти странные символы: «<ed> <U + 00A0> <U + 00BD> <ed> <U + 00B8> <U + 008B>». Вероятно, это смайлики, поэтому для очистки данных мы просто удалим их с помощью следующего скрипта. Этот код также доступен в файле bda / part1 / collect_data / Cleaning_data.R.
rm(list = ls(all = TRUE)); gc() # Clears the global environment
source('collect_data_twitter.R')
# Some tweets
head(df$text)
[1] "I’m not a big fan of turkey but baked Mac &
cheese <ed><U+00A0><U+00BD><ed><U+00B8><U+008B>"
[2] "@Jayoh30 Like no special sauce on a big mac. HOW"
### We are interested in the text - Let’s clean it!
# We first convert the encoding of the text from latin1 to ASCII
df$text <- sapply(df$text,function(row) iconv(row, "latin1", "ASCII", sub = ""))
# Create a function to clean tweets
clean.text <- function(tx) {
tx <- gsub("htt.{1,20}", " ", tx, ignore.case = TRUE)
tx = gsub("[^#[:^punct:]]|@|RT", " ", tx, perl = TRUE, ignore.case = TRUE)
tx = gsub("[[:digit:]]", " ", tx, ignore.case = TRUE)
tx = gsub(" {1,}", " ", tx, ignore.case = TRUE)
tx = gsub("^\\s+|\\s+$", " ", tx, ignore.case = TRUE) return(tx) } clean_tweets <- lapply(df$text, clean.text)
# Cleaned tweets
head(clean_tweets)
[1] " WeNeedFeminlsm MAC s new make up line features men woc and big girls "
[1] " TravelsPhoto What Happens To Your Body One Hour After A Big Mac "Заключительный шаг мини-проекта по очистке данных - это очищенный текст, который мы можем преобразовать в матрицу и применить к нему алгоритм. Из текста, хранящегося вclean_tweets vector, мы можем легко преобразовать его в матрицу набора слов и применить алгоритм обучения без учителя.
Отчетность очень важна в аналитике больших данных. Каждая организация должна регулярно предоставлять информацию для поддержки процесса принятия решений. Эта задача обычно выполняется аналитиками данных, имеющими опыт работы с SQL и ETL (извлечение, передача и загрузка).
Команда, отвечающая за эту задачу, несет ответственность за распространение информации, полученной в отделе анализа больших данных, в различные области организации.
В следующем примере показано, что означает суммирование данных. Перейдите в папкуbda/part1/summarize_data и внутри папки откройте summarize_data.Rprojфайл, дважды щелкнув по нему. Затем откройтеsummarize_data.R script, взгляните на код и следуйте представленным объяснениям.
# Install the following packages by running the following code in R.
pkgs = c('data.table', 'ggplot2', 'nycflights13', 'reshape2')
install.packages(pkgs)В ggplot2пакет отлично подходит для визуализации данных. Вdata.table package - отличный вариант для быстрого и эффективного суммирования в R. Недавний тест показывает, что он даже быстрее, чемpandas, библиотека Python, используемая для аналогичных задач.
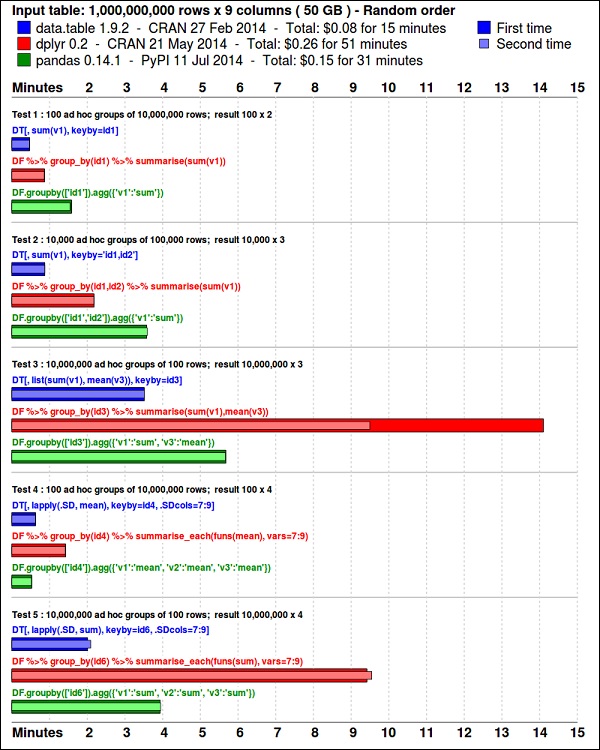
Взгляните на данные, используя следующий код. Этот код также доступен вbda/part1/summarize_data/summarize_data.Rproj файл.
library(nycflights13)
library(ggplot2)
library(data.table)
library(reshape2)
# Convert the flights data.frame to a data.table object and call it DT
DT <- as.data.table(flights)
# The data has 336776 rows and 16 columns
dim(DT)
# Take a look at the first rows
head(DT)
# year month day dep_time dep_delay arr_time arr_delay carrier
# 1: 2013 1 1 517 2 830 11 UA
# 2: 2013 1 1 533 4 850 20 UA
# 3: 2013 1 1 542 2 923 33 AA
# 4: 2013 1 1 544 -1 1004 -18 B6
# 5: 2013 1 1 554 -6 812 -25 DL
# 6: 2013 1 1 554 -4 740 12 UA
# tailnum flight origin dest air_time distance hour minute
# 1: N14228 1545 EWR IAH 227 1400 5 17
# 2: N24211 1714 LGA IAH 227 1416 5 33
# 3: N619AA 1141 JFK MIA 160 1089 5 42
# 4: N804JB 725 JFK BQN 183 1576 5 44
# 5: N668DN 461 LGA ATL 116 762 5 54
# 6: N39463 1696 EWR ORD 150 719 5 54В следующем коде есть пример суммирования данных.
### Data Summarization
# Compute the mean arrival delay
DT[, list(mean_arrival_delay = mean(arr_delay, na.rm = TRUE))]
# mean_arrival_delay
# 1: 6.895377
# Now, we compute the same value but for each carrier
mean1 = DT[, list(mean_arrival_delay = mean(arr_delay, na.rm = TRUE)),
by = carrier]
print(mean1)
# carrier mean_arrival_delay
# 1: UA 3.5580111
# 2: AA 0.3642909
# 3: B6 9.4579733
# 4: DL 1.6443409
# 5: EV 15.7964311
# 6: MQ 10.7747334
# 7: US 2.1295951
# 8: WN 9.6491199
# 9: VX 1.7644644
# 10: FL 20.1159055
# 11: AS -9.9308886
# 12: 9E 7.3796692
# 13: F9 21.9207048
# 14: HA -6.9152047
# 15: YV 15.5569853
# 16: OO 11.9310345
# Now let’s compute to means in the same line of code
mean2 = DT[, list(mean_departure_delay = mean(dep_delay, na.rm = TRUE),
mean_arrival_delay = mean(arr_delay, na.rm = TRUE)),
by = carrier]
print(mean2)
# carrier mean_departure_delay mean_arrival_delay
# 1: UA 12.106073 3.5580111
# 2: AA 8.586016 0.3642909
# 3: B6 13.022522 9.4579733
# 4: DL 9.264505 1.6443409
# 5: EV 19.955390 15.7964311
# 6: MQ 10.552041 10.7747334
# 7: US 3.782418 2.1295951
# 8: WN 17.711744 9.6491199
# 9: VX 12.869421 1.7644644
# 10: FL 18.726075 20.1159055
# 11: AS 5.804775 -9.9308886
# 12: 9E 16.725769 7.3796692
# 13: F9 20.215543 21.9207048
# 14: HA 4.900585 -6.9152047
# 15: YV 18.996330 15.5569853
# 16: OO 12.586207 11.9310345
### Create a new variable called gain
# this is the difference between arrival delay and departure delay
DT[, gain:= arr_delay - dep_delay]
# Compute the median gain per carrier
median_gain = DT[, median(gain, na.rm = TRUE), by = carrier]
print(median_gain)Exploratory data analysis- это концепция, разработанная Джоном Таки (1977), которая заключается в новом подходе к статистике. Идея Таки заключалась в том, что в традиционной статистике данные не анализировались графически, а просто использовались для проверки гипотез. Первая попытка разработать инструмент была сделана в Стэнфорде, проект назывался prim9 . Инструмент был способен визуализировать данные в девяти измерениях, поэтому он мог обеспечить многомерную перспективу данных.
В последние дни исследовательский анализ данных является обязательным и включен в жизненный цикл аналитики больших данных. Способность находить инсайты и иметь возможность эффективно обмениваться информацией в организации подпитывается мощными возможностями EDA.
Основываясь на идеях Таки, Bell Labs разработала S programming languageчтобы предоставить интерактивный интерфейс для ведения статистики. Идея S заключалась в предоставлении обширных графических возможностей с помощью простого в использовании языка. В современном мире, в контексте больших данных,R это основано на S язык программирования - самая популярная программа для аналитики.
Следующая программа демонстрирует использование исследовательского анализа данных.
Ниже приводится пример исследовательского анализа данных. Этот код также доступен вpart1/eda/exploratory_data_analysis.R файл.
library(nycflights13)
library(ggplot2)
library(data.table)
library(reshape2)
# Using the code from the previous section
# This computes the mean arrival and departure delays by carrier.
DT <- as.data.table(flights)
mean2 = DT[, list(mean_departure_delay = mean(dep_delay, na.rm = TRUE),
mean_arrival_delay = mean(arr_delay, na.rm = TRUE)),
by = carrier]
# In order to plot data in R usign ggplot, it is normally needed to reshape the data
# We want to have the data in long format for plotting with ggplot
dt = melt(mean2, id.vars = ’carrier’)
# Take a look at the first rows
print(head(dt))
# Take a look at the help for ?geom_point and geom_line to find similar examples
# Here we take the carrier code as the x axis
# the value from the dt data.table goes in the y axis
# The variable column represents the color
p = ggplot(dt, aes(x = carrier, y = value, color = variable, group = variable)) +
geom_point() + # Plots points
geom_line() + # Plots lines
theme_bw() + # Uses a white background
labs(list(title = 'Mean arrival and departure delay by carrier',
x = 'Carrier', y = 'Mean delay'))
print(p)
# Save the plot to disk
ggsave('mean_delay_by_carrier.png', p,
width = 10.4, height = 5.07)Код должен создавать изображение, подобное следующему:

Чтобы понять данные, часто бывает полезно визуализировать их. Обычно в приложениях с большими данными интерес заключается в поиске понимания, а не в построении красивых графиков. Ниже приведены примеры различных подходов к пониманию данных с помощью графиков.
Чтобы начать анализ данных о рейсах, мы можем начать с проверки, есть ли корреляции между числовыми переменными. Этот код также доступен вbda/part1/data_visualization/data_visualization.R файл.
# Install the package corrplot by running
install.packages('corrplot')
# then load the library
library(corrplot)
# Load the following libraries
library(nycflights13)
library(ggplot2)
library(data.table)
library(reshape2)
# We will continue working with the flights data
DT <- as.data.table(flights)
head(DT) # take a look
# We select the numeric variables after inspecting the first rows.
numeric_variables = c('dep_time', 'dep_delay',
'arr_time', 'arr_delay', 'air_time', 'distance')
# Select numeric variables from the DT data.table
dt_num = DT[, numeric_variables, with = FALSE]
# Compute the correlation matrix of dt_num
cor_mat = cor(dt_num, use = "complete.obs")
print(cor_mat)
### Here is the correlation matrix
# dep_time dep_delay arr_time arr_delay air_time distance
# dep_time 1.00000000 0.25961272 0.66250900 0.23230573 -0.01461948 -0.01413373
# dep_delay 0.25961272 1.00000000 0.02942101 0.91480276 -0.02240508 -0.02168090
# arr_time 0.66250900 0.02942101 1.00000000 0.02448214 0.05429603 0.04718917
# arr_delay 0.23230573 0.91480276 0.02448214 1.00000000 -0.03529709 -0.06186776
# air_time -0.01461948 -0.02240508 0.05429603 -0.03529709 1.00000000 0.99064965
# distance -0.01413373 -0.02168090 0.04718917 -0.06186776 0.99064965 1.00000000
# We can display it visually to get a better understanding of the data
corrplot.mixed(cor_mat, lower = "circle", upper = "ellipse")
# save it to disk
png('corrplot.png')
print(corrplot.mixed(cor_mat, lower = "circle", upper = "ellipse"))
dev.off()Этот код генерирует следующую визуализацию корреляционной матрицы -

На графике видно, что между некоторыми переменными в наборе данных существует сильная корреляция. Например, задержка прибытия и задержка отправления, похоже, сильно взаимосвязаны. Мы можем видеть это, потому что эллипс показывает почти линейную связь между обеими переменными, однако найти причинно-следственную связь из этого результата непросто.
Мы не можем сказать, что, поскольку две переменные взаимосвязаны, одна влияет на другую. Также мы обнаруживаем на графике сильную корреляцию между эфирным временем и расстоянием, что вполне разумно ожидать, поскольку с увеличением расстояния время полета должно расти.
Мы также можем провести одномерный анализ данных. Простой и эффективный способ визуализации распределений:box-plots. Следующий код демонстрирует, как создавать блочные диаграммы и решетчатые диаграммы с использованием библиотеки ggplot2. Этот код также доступен вbda/part1/data_visualization/boxplots.R файл.
source('data_visualization.R')
### Analyzing Distributions using box-plots
# The following shows the distance as a function of the carrier
p = ggplot(DT, aes(x = carrier, y = distance, fill = carrier)) + # Define the carrier
in the x axis and distance in the y axis
geom_box-plot() + # Use the box-plot geom
theme_bw() + # Leave a white background - More in line with tufte's
principles than the default
guides(fill = FALSE) + # Remove legend
labs(list(title = 'Distance as a function of carrier', # Add labels
x = 'Carrier', y = 'Distance'))
p
# Save to disk
png(‘boxplot_carrier.png’)
print(p)
dev.off()
# Let's add now another variable, the month of each flight
# We will be using facet_wrap for this
p = ggplot(DT, aes(carrier, distance, fill = carrier)) +
geom_box-plot() +
theme_bw() +
guides(fill = FALSE) +
facet_wrap(~month) + # This creates the trellis plot with the by month variable
labs(list(title = 'Distance as a function of carrier by month',
x = 'Carrier', y = 'Distance'))
p
# The plot shows there aren't clear differences between distance in different months
# Save to disk
png('boxplot_carrier_by_month.png')
print(p)
dev.off()Этот раздел посвящен знакомству пользователей с языком программирования R. R можно скачать с веб-сайта Cran . Для пользователей Windows полезно установить rtools и rstudio IDE .
Общая концепция, лежащая в основе R должен служить интерфейсом для другого программного обеспечения, разработанного на компилируемых языках, таких как C, C ++ и Fortran, и предоставлять пользователю интерактивный инструмент для анализа данных.
Перейдите в папку с zip-файлом книги. bda/part2/R_introduction и откройте R_introduction.Rprojфайл. Это откроет сеанс RStudio. Затем откройте файл 01_vectors.R. Запустите скрипт построчно и следуйте комментариям в коде. Еще одна полезная возможность для обучения - просто набрать код, это поможет вам привыкнуть к синтаксису R. В R комментарии пишутся с символом #.
Чтобы отобразить результаты выполнения кода R в книге, после оценки кода результаты, возвращаемые R, комментируются. Таким образом, вы можете скопировать и вставить код в книгу и попробовать его разделы в R.
# Create a vector of numbers
numbers = c(1, 2, 3, 4, 5)
print(numbers)
# [1] 1 2 3 4 5
# Create a vector of letters
ltrs = c('a', 'b', 'c', 'd', 'e')
# [1] "a" "b" "c" "d" "e"
# Concatenate both
mixed_vec = c(numbers, ltrs)
print(mixed_vec)
# [1] "1" "2" "3" "4" "5" "a" "b" "c" "d" "e"Давайте проанализируем, что произошло в предыдущем коде. Мы видим, что можно создавать векторы с цифрами и буквами. Нам не нужно было заранее сообщать R, какой тип данных нам нужен. Наконец, мы смогли создать вектор как с цифрами, так и с буквами. Вектор mixed_vec преобразовал числа в символы, мы можем увидеть это, визуализировав, как значения печатаются внутри кавычек.
В следующем коде показаны типы данных различных векторов, возвращаемые классом функции. Обычно функцию класса используют для «опроса» объекта, спрашивая его, что это за класс.
### Evaluate the data types using class
### One dimensional objects
# Integer vector
num = 1:10
class(num)
# [1] "integer"
# Numeric vector, it has a float, 10.5
num = c(1:10, 10.5)
class(num)
# [1] "numeric"
# Character vector
ltrs = letters[1:10]
class(ltrs)
# [1] "character"
# Factor vector
fac = as.factor(ltrs)
class(fac)
# [1] "factor"R также поддерживает двухмерные объекты. В следующем коде приведены примеры двух наиболее популярных структур данных, используемых в R: matrix и data.frame.
# Matrix
M = matrix(1:12, ncol = 4)
# [,1] [,2] [,3] [,4]
# [1,] 1 4 7 10
# [2,] 2 5 8 11
# [3,] 3 6 9 12
lM = matrix(letters[1:12], ncol = 4)
# [,1] [,2] [,3] [,4]
# [1,] "a" "d" "g" "j"
# [2,] "b" "e" "h" "k"
# [3,] "c" "f" "i" "l"
# Coerces the numbers to character
# cbind concatenates two matrices (or vectors) in one matrix
cbind(M, lM)
# [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8]
# [1,] "1" "4" "7" "10" "a" "d" "g" "j"
# [2,] "2" "5" "8" "11" "b" "e" "h" "k"
# [3,] "3" "6" "9" "12" "c" "f" "i" "l"
class(M)
# [1] "matrix"
class(lM)
# [1] "matrix"
# data.frame
# One of the main objects of R, handles different data types in the same object.
# It is possible to have numeric, character and factor vectors in the same data.frame
df = data.frame(n = 1:5, l = letters[1:5])
df
# n l
# 1 1 a
# 2 2 b
# 3 3 c
# 4 4 d
# 5 5 eКак показано в предыдущем примере, в одном объекте можно использовать разные типы данных. В общем, именно так данные представлены в базах данных, часть данных API - это текстовые или символьные векторы и другие числа. Задача аналитика - определить, какой тип статистических данных назначить, а затем использовать для него правильный тип данных R. В статистике мы обычно рассматриваем переменные следующих типов:
- Numeric
- Номинальный или категориальный
- Ordinal
В R вектор может быть следующих классов -
- Числовой - Целое число
- Factor
- Заказанный фактор
R предоставляет тип данных для каждого статистического типа переменной. Однако упорядоченный коэффициент используется редко, но может быть создан с помощью функционального коэффициента или упорядочен.
В следующем разделе рассматривается концепция индексации. Это довольно распространенная операция, связанная с проблемой выбора частей объекта и их преобразования.
# Let's create a data.frame
df = data.frame(numbers = 1:26, letters)
head(df)
# numbers letters
# 1 1 a
# 2 2 b
# 3 3 c
# 4 4 d
# 5 5 e
# 6 6 f
# str gives the structure of a data.frame, it’s a good summary to inspect an object
str(df)
# 'data.frame': 26 obs. of 2 variables:
# $ numbers: int 1 2 3 4 5 6 7 8 9 10 ... # $ letters: Factor w/ 26 levels "a","b","c","d",..: 1 2 3 4 5 6 7 8 9 10 ...
# The latter shows the letters character vector was coerced as a factor.
# This can be explained by the stringsAsFactors = TRUE argumnet in data.frame
# read ?data.frame for more information
class(df)
# [1] "data.frame"
### Indexing
# Get the first row
df[1, ]
# numbers letters
# 1 1 a
# Used for programming normally - returns the output as a list
df[1, , drop = TRUE]
# $numbers # [1] 1 # # $letters
# [1] a
# Levels: a b c d e f g h i j k l m n o p q r s t u v w x y z
# Get several rows of the data.frame
df[5:7, ]
# numbers letters
# 5 5 e
# 6 6 f
# 7 7 g
### Add one column that mixes the numeric column with the factor column
df$mixed = paste(df$numbers, df$letters, sep = ’’) str(df) # 'data.frame': 26 obs. of 3 variables: # $ numbers: int 1 2 3 4 5 6 7 8 9 10 ...
# $ letters: Factor w/ 26 levels "a","b","c","d",..: 1 2 3 4 5 6 7 8 9 10 ... # $ mixed : chr "1a" "2b" "3c" "4d" ...
### Get columns
# Get the first column
df[, 1]
# It returns a one dimensional vector with that column
# Get two columns
df2 = df[, 1:2]
head(df2)
# numbers letters
# 1 1 a
# 2 2 b
# 3 3 c
# 4 4 d
# 5 5 e
# 6 6 f
# Get the first and third columns
df3 = df[, c(1, 3)]
df3[1:3, ]
# numbers mixed
# 1 1 1a
# 2 2 2b
# 3 3 3c
### Index columns from their names
names(df)
# [1] "numbers" "letters" "mixed"
# This is the best practice in programming, as many times indeces change, but
variable names don’t
# We create a variable with the names we want to subset
keep_vars = c("numbers", "mixed")
df4 = df[, keep_vars]
head(df4)
# numbers mixed
# 1 1 1a
# 2 2 2b
# 3 3 3c
# 4 4 4d
# 5 5 5e
# 6 6 6f
### subset rows and columns
# Keep the first five rows
df5 = df[1:5, keep_vars]
df5
# numbers mixed
# 1 1 1a
# 2 2 2b
# 3 3 3c
# 4 4 4d
# 5 5 5e
# subset rows using a logical condition
df6 = df[df$numbers < 10, keep_vars]
df6
# numbers mixed
# 1 1 1a
# 2 2 2b
# 3 3 3c
# 4 4 4d
# 5 5 5e
# 6 6 6f
# 7 7 7g
# 8 8 8h
# 9 9 9iSQL означает язык структурированных запросов. Это один из наиболее широко используемых языков для извлечения данных из баз данных в традиционных хранилищах данных и в технологиях больших данных. Чтобы продемонстрировать основы SQL, мы будем работать с примерами. Чтобы сосредоточиться на самом языке, мы будем использовать SQL внутри R. С точки зрения написания кода SQL это точно так же, как и в базе данных.
Ядро SQL - это три оператора: SELECT, FROM и WHERE. В следующих примерах используются наиболее распространенные варианты использования SQL. Перейдите в папкуbda/part2/SQL_introduction и откройте SQL_introduction.Rprojфайл. Затем откройте сценарий 01_select.R. Чтобы написать код SQL на R, нам нужно установитьsqldf package, как показано в следующем коде.
# Install the sqldf package
install.packages('sqldf')
# load the library
library('sqldf')
library(nycflights13)
# We will be working with the fligths dataset in order to introduce SQL
# Let’s take a look at the table
str(flights)
# Classes 'tbl_d', 'tbl' and 'data.frame': 336776 obs. of 16 variables:
# $ year : int 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 ...
# $ month : int 1 1 1 1 1 1 1 1 1 1 ... # $ day : int 1 1 1 1 1 1 1 1 1 1 ...
# $ dep_time : int 517 533 542 544 554 554 555 557 557 558 ... # $ dep_delay: num 2 4 2 -1 -6 -4 -5 -3 -3 -2 ...
# $ arr_time : int 830 850 923 1004 812 740 913 709 838 753 ... # $ arr_delay: num 11 20 33 -18 -25 12 19 -14 -8 8 ...
# $ carrier : chr "UA" "UA" "AA" "B6" ... # $ tailnum : chr "N14228" "N24211" "N619AA" "N804JB" ...
# $ flight : int 1545 1714 1141 725 461 1696 507 5708 79 301 ... # $ origin : chr "EWR" "LGA" "JFK" "JFK" ...
# $ dest : chr "IAH" "IAH" "MIA" "BQN" ... # $ air_time : num 227 227 160 183 116 150 158 53 140 138 ...
# $ distance : num 1400 1416 1089 1576 762 ... # $ hour : num 5 5 5 5 5 5 5 5 5 5 ...
# $ minute : num 17 33 42 44 54 54 55 57 57 58 ...Оператор select используется для извлечения столбцов из таблиц и выполнения над ними вычислений. Самый простой оператор SELECT продемонстрирован вej1. Мы также можем создавать новые переменные, как показано наej2.
### SELECT statement
ej1 = sqldf("
SELECT
dep_time
,dep_delay
,arr_time
,carrier
,tailnum
FROM
flights
")
head(ej1)
# dep_time dep_delay arr_time carrier tailnum
# 1 517 2 830 UA N14228
# 2 533 4 850 UA N24211
# 3 542 2 923 AA N619AA
# 4 544 -1 1004 B6 N804JB
# 5 554 -6 812 DL N668DN
# 6 554 -4 740 UA N39463
# In R we can use SQL with the sqldf function. It works exactly the same as in
a database
# The data.frame (in this case flights) represents the table we are querying
and goes in the FROM statement
# We can also compute new variables in the select statement using the syntax:
# old_variables as new_variable
ej2 = sqldf("
SELECT
arr_delay - dep_delay as gain,
carrier
FROM
flights
")
ej2[1:5, ]
# gain carrier
# 1 9 UA
# 2 16 UA
# 3 31 AA
# 4 -17 B6
# 5 -19 DLОдна из наиболее часто используемых функций SQL - это группировка по оператору. Это позволяет вычислить числовое значение для разных групп другой переменной. Откройте скрипт 02_group_by.R.
### GROUP BY
# Computing the average
ej3 = sqldf("
SELECT
avg(arr_delay) as mean_arr_delay,
avg(dep_delay) as mean_dep_delay,
carrier
FROM
flights
GROUP BY
carrier
")
# mean_arr_delay mean_dep_delay carrier
# 1 7.3796692 16.725769 9E
# 2 0.3642909 8.586016 AA
# 3 -9.9308886 5.804775 AS
# 4 9.4579733 13.022522 B6
# 5 1.6443409 9.264505 DL
# 6 15.7964311 19.955390 EV
# 7 21.9207048 20.215543 F9
# 8 20.1159055 18.726075 FL
# 9 -6.9152047 4.900585 HA
# 10 10.7747334 10.552041 MQ
# 11 11.9310345 12.586207 OO
# 12 3.5580111 12.106073 UA
# 13 2.1295951 3.782418 US
# 14 1.7644644 12.869421 VX
# 15 9.6491199 17.711744 WN
# 16 15.5569853 18.996330 YV
# Other aggregations
ej4 = sqldf("
SELECT
avg(arr_delay) as mean_arr_delay,
min(dep_delay) as min_dep_delay,
max(dep_delay) as max_dep_delay,
carrier
FROM
flights
GROUP BY
carrier
")
# We can compute the minimun, mean, and maximum values of a numeric value
ej4
# mean_arr_delay min_dep_delay max_dep_delay carrier
# 1 7.3796692 -24 747 9E
# 2 0.3642909 -24 1014 AA
# 3 -9.9308886 -21 225 AS
# 4 9.4579733 -43 502 B6
# 5 1.6443409 -33 960 DL
# 6 15.7964311 -32 548 EV
# 7 21.9207048 -27 853 F9
# 8 20.1159055 -22 602 FL
# 9 -6.9152047 -16 1301 HA
# 10 10.7747334 -26 1137 MQ
# 11 11.9310345 -14 154 OO
# 12 3.5580111 -20 483 UA
# 13 2.1295951 -19 500 US
# 14 1.7644644 -20 653 VX
# 15 9.6491199 -13 471 WN
# 16 15.5569853 -16 387 YV
### We could be also interested in knowing how many observations each carrier has
ej5 = sqldf("
SELECT
carrier, count(*) as count
FROM
flights
GROUP BY
carrier
")
ej5
# carrier count
# 1 9E 18460
# 2 AA 32729
# 3 AS 714
# 4 B6 54635
# 5 DL 48110
# 6 EV 54173
# 7 F9 685
# 8 FL 3260
# 9 HA 342
# 10 MQ 26397
# 11 OO 32
# 12 UA 58665
# 13 US 20536
# 14 VX 5162
# 15 WN 12275
# 16 YV 601Самая полезная функция SQL - это соединения. Соединение означает, что мы хотим объединить таблицу A и таблицу B в одну таблицу, используя один столбец, чтобы сопоставить значения обеих таблиц. С практической точки зрения существуют различные типы соединений, для начала они будут наиболее полезными: внутреннее соединение и левое внешнее соединение.
# Let’s create two tables: A and B to demonstrate joins.
A = data.frame(c1 = 1:4, c2 = letters[1:4])
B = data.frame(c1 = c(2,4,5,6), c2 = letters[c(2:5)])
A
# c1 c2
# 1 a
# 2 b
# 3 c
# 4 d
B
# c1 c2
# 2 b
# 4 c
# 5 d
# 6 e
### INNER JOIN
# This means to match the observations of the column we would join the tables by.
inner = sqldf("
SELECT
A.c1, B.c2
FROM
A INNER JOIN B
ON A.c1 = B.c1
")
# Only the rows that match c1 in both A and B are returned
inner
# c1 c2
# 2 b
# 4 c
### LEFT OUTER JOIN
# the left outer join, sometimes just called left join will return the
# first all the values of the column used from the A table
left = sqldf("
SELECT
A.c1, B.c2
FROM
A LEFT OUTER JOIN B
ON A.c1 = B.c1
")
# Only the rows that match c1 in both A and B are returned
left
# c1 c2
# 1 <NA>
# 2 b
# 3 <NA>
# 4 cПервый подход к анализу данных - это визуальный анализ. Целью при этом обычно является нахождение отношений между переменными и одномерные описания переменных. Мы можем разделить эти стратегии как -
- Одномерный анализ
- Многомерный анализ
Одномерные графические методы
Univariateстатистический термин. На практике это означает, что мы хотим анализировать переменную независимо от остальных данных. Сюжеты, которые позволяют сделать это эффективно:
Коробчатые диаграммы
Коробчатые диаграммы обычно используются для сравнения распределений. Это отличный способ визуально проверить, есть ли различия между дистрибутивами. Мы можем видеть, есть ли разница в цене на бриллианты разной огранки.
# We will be using the ggplot2 library for plotting
library(ggplot2)
data("diamonds")
# We will be using the diamonds dataset to analyze distributions of numeric variables
head(diamonds)
# carat cut color clarity depth table price x y z
# 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
# 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
# 3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
# 4 0.29 Premium I VS2 62.4 58 334 4.20 4.23 2.63
# 5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
# 6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
### Box-Plots
p = ggplot(diamonds, aes(x = cut, y = price, fill = cut)) +
geom_box-plot() +
theme_bw()
print(p)На графике мы видим различия в распределении цен на бриллианты в разных видах огранки.

Гистограммы
source('01_box_plots.R')
# We can plot histograms for each level of the cut factor variable using
facet_grid
p = ggplot(diamonds, aes(x = price, fill = cut)) +
geom_histogram() +
facet_grid(cut ~ .) +
theme_bw()
p
# the previous plot doesn’t allow to visuallize correctly the data because of
the differences in scale
# we can turn this off using the scales argument of facet_grid
p = ggplot(diamonds, aes(x = price, fill = cut)) +
geom_histogram() +
facet_grid(cut ~ ., scales = 'free') +
theme_bw()
p
png('02_histogram_diamonds_cut.png')
print(p)
dev.off()Вывод приведенного выше кода будет следующим:
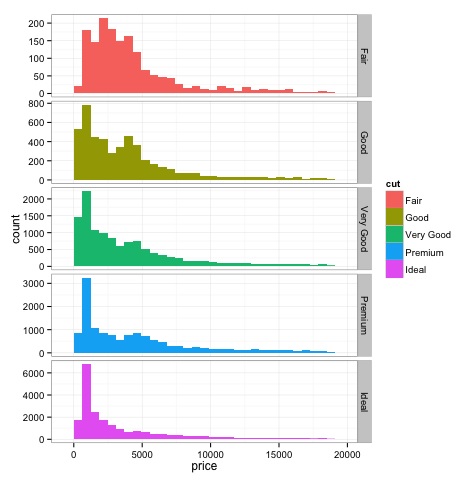
Многомерные графические методы
Многовариантные графические методы в исследовательском анализе данных имеют целью найти взаимосвязи между различными переменными. Для этого есть два обычно используемых способа: построение корреляционной матрицы числовых переменных или просто построение необработанных данных в виде матрицы диаграмм рассеяния.
Чтобы продемонстрировать это, мы будем использовать набор данных алмазов. Чтобы следовать коду, откройте скриптbda/part2/charts/03_multivariate_analysis.R.
library(ggplot2)
data(diamonds)
# Correlation matrix plots
keep_vars = c('carat', 'depth', 'price', 'table')
df = diamonds[, keep_vars]
# compute the correlation matrix
M_cor = cor(df)
# carat depth price table
# carat 1.00000000 0.02822431 0.9215913 0.1816175
# depth 0.02822431 1.00000000 -0.0106474 -0.2957785
# price 0.92159130 -0.01064740 1.0000000 0.1271339
# table 0.18161755 -0.29577852 0.1271339 1.0000000
# plots
heat-map(M_cor)Код выдаст следующий результат -

Это краткое изложение, оно говорит нам о сильной корреляции между ценой и кареткой, а не среди других переменных.
Корреляционная матрица может быть полезной, когда у нас есть большое количество переменных, и в этом случае построение необработанных данных нецелесообразно. Как уже упоминалось, можно также показать необработанные данные -
library(GGally)
ggpairs(df)На графике видно, что результаты, отображаемые на тепловой карте, подтверждаются, существует корреляция 0,922 между ценой и переменными в каратах.
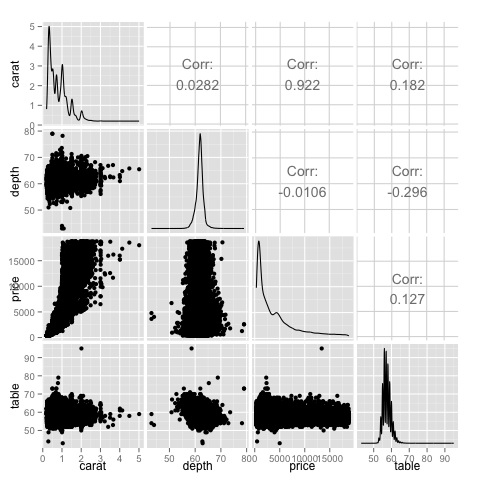
Эту взаимосвязь можно визуализировать на диаграмме рассеяния цена-карат, расположенной в индексе (3, 1) матрицы диаграммы рассеяния.
Существует множество инструментов, которые позволяют специалистам по обработке данных эффективно анализировать данные. Обычно инженерный аспект анализа данных сосредотачивается на базах данных, специалисты по данным сосредоточены на инструментах, которые могут реализовывать продукты данных. В следующем разделе обсуждаются преимущества различных инструментов с упором на статистические пакеты, которые специалисты по данным чаще всего используют на практике.
Язык программирования R
R - это язык программирования с открытым исходным кодом, ориентированный на статистический анализ. Он конкурентоспособен с коммерческими инструментами, такими как SAS, SPSS, с точки зрения статистических возможностей. Считается, что это интерфейс для других языков программирования, таких как C, C ++ или Fortran.
Еще одно преимущество R - это большое количество доступных библиотек с открытым исходным кодом. В CRAN имеется более 6000 пакетов, которые можно скачать бесплатно и вGithub доступно большое количество пакетов R.
С точки зрения производительности R медленный для интенсивных операций, учитывая большое количество доступных библиотек, медленные участки кода написаны на скомпилированных языках. Но если вы собираетесь выполнять операции, требующие глубокого написания циклов for, то R не будет вашей лучшей альтернативой. Для анализа данных есть хорошие библиотеки, такие какdata.table, glmnet, ranger, xgboost, ggplot2, caret которые позволяют использовать R в качестве интерфейса для более быстрых языков программирования.
Python для анализа данных
Python - это язык программирования общего назначения, который содержит значительное количество библиотек, посвященных анализу данных, таких как pandas, scikit-learn, theano, numpy и scipy.
Большая часть того, что доступно в R, также может быть выполнено в Python, но мы обнаружили, что R проще в использовании. Если вы работаете с большими наборами данных, обычно Python - лучший выбор, чем R. Python можно довольно эффективно использовать для очистки и обработки данных построчно. Это возможно из R, но не так эффективно, как Python для задач написания сценариев.
Для машинного обучения scikit-learn- прекрасная среда, в которой доступно большое количество алгоритмов, которые без проблем могут обрабатывать наборы данных среднего размера. По сравнению с эквивалентной библиотекой R (кареткой),scikit-learn имеет более чистый и последовательный API.
Юля
Julia - это высокоуровневый высокопроизводительный язык динамического программирования для технических вычислений. Его синтаксис очень похож на R или Python, поэтому, если вы уже работаете с R или Python, будет довольно просто написать тот же код на Julia. Язык довольно новый и значительно расширился за последние годы, так что на данный момент это определенно вариант.
Мы бы порекомендовали Джулию для создания прототипов алгоритмов, требующих больших вычислительных ресурсов, таких как нейронные сети. Это отличный инструмент для исследования. С точки зрения внедрения модели в производство, вероятно, у Python есть лучшие альтернативы. Однако это становится менее серьезной проблемой, поскольку есть веб-службы, которые занимаются разработкой реализации моделей на R, Python и Julia.
SAS
SAS - это коммерческий язык, который до сих пор используется для бизнес-аналитики. Он имеет базовый язык, который позволяет пользователю программировать самые разные приложения. Он содержит довольно много коммерческих продуктов, которые дают пользователям, не являющимся экспертами, возможность использовать сложные инструменты, такие как библиотека нейронной сети, без необходимости программирования.
Помимо очевидного недостатка коммерческих инструментов, SAS плохо масштабируется для больших наборов данных. Даже средний набор данных будет иметь проблемы с SAS и приведет к сбою сервера. SAS можно рекомендовать только в том случае, если вы работаете с небольшими наборами данных, а пользователи не являются экспертами в области анализа данных. Для опытных пользователей R и Python обеспечивают более производительную среду.
SPSS
SPSS в настоящее время является продуктом IBM для статистического анализа. Он в основном используется для анализа данных опросов, и для пользователей, которые не умеют программировать, это достойная альтернатива. Возможно, его так же просто использовать, как и SAS, но с точки зрения реализации модели он проще, поскольку предоставляет код SQL для оценки модели. Этот код обычно неэффективен, но это только начало, тогда как SAS продает продукт, который оценивает модели для каждой базы данных отдельно. Для небольших данных и неопытной команды SPSS - такой же хороший вариант, как и SAS.
Однако программное обеспечение довольно ограничено, и опытные пользователи будут на порядки более продуктивными, используя R или Python.
Matlab, Octave
Доступны и другие инструменты, такие как Matlab или его версия с открытым исходным кодом (Octave). Эти инструменты в основном используются для исследований. Что касается возможностей, R или Python могут делать все, что доступно в Matlab или Octave. Покупать лицензию на продукт имеет смысл только в том случае, если вы заинтересованы в поддержке, которую они предоставляют.
При анализе данных можно использовать статистический подход. Основные инструменты, необходимые для выполнения базового анализа:
- Корреляционный анализ
- Анализ отклонений
- Проверка гипотезы
При работе с большими наборами данных это не представляет проблемы, поскольку эти методы не требуют больших вычислительных ресурсов, за исключением корреляционного анализа. В этом случае всегда можно взять образец, и результаты должны быть надежными.
Корреляционный анализ
Корреляционный анализ стремится найти линейные отношения между числовыми переменными. Это может быть полезно в разных обстоятельствах. Одним из распространенных способов использования является исследовательский анализ данных, в разделе 16.0.2 книги есть базовый пример этого подхода. Прежде всего, метрика корреляции, используемая в упомянутом примере, основана наPearson coefficient. Однако есть еще одна интересная метрика корреляции, на которую не влияют выбросы. Этот показатель называется корреляцией Спирмена.
В spearman correlation метрика более устойчива к наличию выбросов, чем метод Пирсона, и дает лучшие оценки линейных отношений между числовыми переменными, когда данные не распределены нормально.
library(ggplot2)
# Select variables that are interesting to compare pearson and spearman
correlation methods.
x = diamonds[, c('x', 'y', 'z', 'price')]
# From the histograms we can expect differences in the correlations of both
metrics.
# In this case as the variables are clearly not normally distributed, the
spearman correlation
# is a better estimate of the linear relation among numeric variables.
par(mfrow = c(2,2))
colnm = names(x)
for(i in 1:4) {
hist(x[[i]], col = 'deepskyblue3', main = sprintf('Histogram of %s', colnm[i]))
}
par(mfrow = c(1,1))Из гистограмм на следующем рисунке мы можем ожидать различий в корреляциях обоих показателей. В этом случае, поскольку переменные явно не имеют нормального распределения, корреляция Спирмена является лучшей оценкой линейной связи между числовыми переменными.
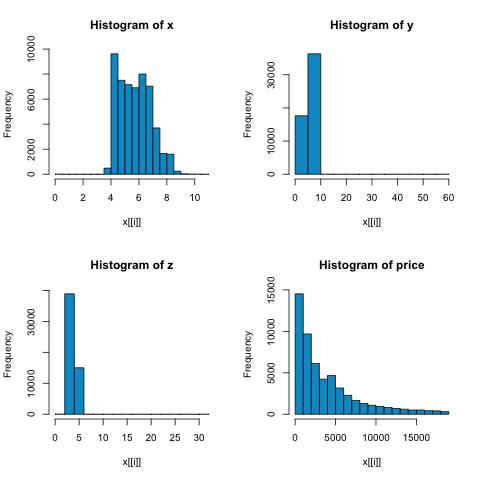
Чтобы вычислить корреляцию в R, откройте файл bda/part2/statistical_methods/correlation/correlation.R который имеет этот раздел кода.
## Correlation Matrix - Pearson and spearman
cor_pearson <- cor(x, method = 'pearson')
cor_spearman <- cor(x, method = 'spearman')
### Pearson Correlation
print(cor_pearson)
# x y z price
# x 1.0000000 0.9747015 0.9707718 0.8844352
# y 0.9747015 1.0000000 0.9520057 0.8654209
# z 0.9707718 0.9520057 1.0000000 0.8612494
# price 0.8844352 0.8654209 0.8612494 1.0000000
### Spearman Correlation
print(cor_spearman)
# x y z price
# x 1.0000000 0.9978949 0.9873553 0.9631961
# y 0.9978949 1.0000000 0.9870675 0.9627188
# z 0.9873553 0.9870675 1.0000000 0.9572323
# price 0.9631961 0.9627188 0.9572323 1.0000000Тест хи-квадрат
Тест хи-квадрат позволяет нам проверить, независимы ли две случайные величины. Это означает, что распределение вероятностей каждой переменной не влияет на другую. Чтобы оценить тест в R, нам нужно сначала создать таблицу непредвиденных обстоятельств, а затем передать ее вchisq.test R функция.
Например, давайте проверим, есть ли связь между переменными: огранка и цвет из набора данных бриллиантов. Тест формально определяется как -
- H0: переменная огранка и алмаз независимы
- H1: переменная огранка и алмаз не являются независимыми
Мы могли бы предположить, что между этими двумя переменными существует взаимосвязь по их имени, но тест может дать объективное «правило», говорящее, насколько значим этот результат или нет.
В следующем фрагменте кода мы обнаружили, что p-значение теста составляет 2,2e-16, что практически равно нулю. Затем после запуска теста выполнитеMonte Carlo simulation, мы обнаружили, что значение p равно 0,0004998, что все еще значительно ниже порогового значения 0,05. Этот результат означает, что мы отвергаем нулевую гипотезу (H0), поэтому считаем, что переменныеcut и color не независимы.
library(ggplot2)
# Use the table function to compute the contingency table
tbl = table(diamonds$cut, diamonds$color)
tbl
# D E F G H I J
# Fair 163 224 312 314 303 175 119
# Good 662 933 909 871 702 522 307
# Very Good 1513 2400 2164 2299 1824 1204 678
# Premium 1603 2337 2331 2924 2360 1428 808
# Ideal 2834 3903 3826 4884 3115 2093 896
# In order to run the test we just use the chisq.test function.
chisq.test(tbl)
# Pearson’s Chi-squared test
# data: tbl
# X-squared = 310.32, df = 24, p-value < 2.2e-16
# It is also possible to compute the p-values using a monte-carlo simulation
# It's needed to add the simulate.p.value = TRUE flag and the amount of
simulations
chisq.test(tbl, simulate.p.value = TRUE, B = 2000)
# Pearson’s Chi-squared test with simulated p-value (based on 2000 replicates)
# data: tbl
# X-squared = 310.32, df = NA, p-value = 0.0004998Т-тест
Идея t-testсостоит в том, чтобы оценить, есть ли различия в распределении числовой переменной # между разными группами номинальной переменной. Чтобы продемонстрировать это, я выберу уровни Справедливого и Идеального уровней сокращения факторной переменной, а затем мы сравним значения числовой переменной среди этих двух групп.
data = diamonds[diamonds$cut %in% c('Fair', 'Ideal'), ]
data$cut = droplevels.factor(data$cut) # Drop levels that aren’t used from the
cut variable
df1 = data[, c('cut', 'price')]
# We can see the price means are different for each group
tapply(df1$price, df1$cut, mean)
# Fair Ideal
# 4358.758 3457.542T-тесты реализованы в R с t.testфункция. Интерфейс формулы для t.test - самый простой способ его использования, идея состоит в том, что числовая переменная объясняется групповой переменной.
Например: t.test(numeric_variable ~ group_variable, data = data). В предыдущем примереnumeric_variable является price и group_variable является cut.
Со статистической точки зрения мы проверяем, есть ли различия в распределении числовой переменной между двумя группами. Формально проверка гипотезы описывается нулевой (H0) гипотезой и альтернативной гипотезой (H1).
H0: Нет различий в распределении переменной цены между группами Fair и Ideal.
H1 Существуют различия в распределении переменной цены между группами Fair и Ideal.
Следующее может быть реализовано в R с помощью следующего кода -
t.test(price ~ cut, data = data)
# Welch Two Sample t-test
#
# data: price by cut
# t = 9.7484, df = 1894.8, p-value < 2.2e-16
# alternative hypothesis: true difference in means is not equal to 0
# 95 percent confidence interval:
# 719.9065 1082.5251
# sample estimates:
# mean in group Fair mean in group Ideal
# 4358.758 3457.542
# Another way to validate the previous results is to just plot the
distributions using a box-plot
plot(price ~ cut, data = data, ylim = c(0,12000),
col = 'deepskyblue3')Мы можем проанализировать результат теста, проверив, меньше ли p-значение 0,05. Если это так, мы сохраняем альтернативную гипотезу. Это означает, что мы обнаружили разницу в цене между двумя уровнями фактора сокращения. По названиям уровней мы ожидали такого результата, но не ожидали, что средняя цена в группе Fail будет выше, чем в группе Ideal. Мы можем убедиться в этом, сравнив средние значения каждого фактора.
В plotкоманда создает график, показывающий взаимосвязь между ценой и переменной сокращения. Это коробчатый сюжет; мы рассмотрели этот график в разделе 16.0.1, но в основном он показывает распределение переменной цены для двух уровней сокращения, которые мы анализируем.
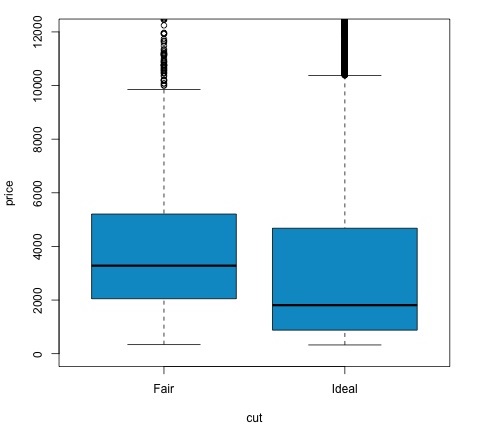
Анализ отклонений
Дисперсионный анализ (ANOVA) - это статистическая модель, используемая для анализа различий между групповым распределением путем сравнения среднего и дисперсии каждой группы, модель была разработана Рональдом Фишером. ANOVA обеспечивает статистический тест того, равны ли средние значения нескольких групп, и поэтому обобщает t-критерий более чем на две группы.
ANOVA полезны для сравнения трех или более групп на предмет статистической значимости, потому что выполнение нескольких t-критериев для двух выборок приведет к увеличению вероятности совершения статистической ошибки типа I.
Что касается математического объяснения, для понимания теста необходимо следующее.
x ij = x + (x i - x) + (x ij - x)
Это приводит к следующей модели -
x ij = μ + α i + ∈ ij
где μ - большое среднее, а α i - i-е групповое среднее. Предполагается, что член ошибки ∈ ij равен iid из нормального распределения. Нулевая гипотеза теста заключается в том, что -
α 1 = α 2 =… = α k
Что касается вычисления статистики теста, нам нужно вычислить два значения:
- Сумма квадратов разницы между группами -
$$SSD_B = \sum_{i}^{k} \sum_{j}^{n}(\bar{x_{\bar{i}}} - \bar{x})^2$$
- Суммы квадратов внутри групп
$$SSD_W = \sum_{i}^{k} \sum_{j}^{n}(\bar{x_{\bar{ij}}} - \bar{x_{\bar{i}}})^2$$
где SSD B имеет степень свободы k − 1, а SSD W имеет степень свободы N − k. Затем мы можем определить среднеквадратичные разности для каждой метрики.
MS B = SSD B / (k - 1)
MS w = SSD w / (N - k)
Наконец, статистика теста в ANOVA определяется как отношение двух вышеуказанных величин.
F = MS B / MS w
которое следует F-распределению с k − 1 и N − k степенями свободы. Если нулевая гипотеза верна, F, вероятно, будет близко к 1. В противном случае среднеквадратическое значение MSB между группами, вероятно, будет большим, что приведет к большому значению F.
По сути, ANOVA исследует два источника общей дисперсии и видит, какая часть вносит больший вклад. Вот почему это называется дисперсионным анализом, хотя целью является сравнение групповых средних.
Что касается вычисления статистики, это довольно просто сделать в R. Следующий пример продемонстрирует, как это делается, и нанесет на график результаты.
library(ggplot2)
# We will be using the mtcars dataset
head(mtcars)
# mpg cyl disp hp drat wt qsec vs am gear carb
# Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
# Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
# Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
# Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
# Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
# Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
# Let's see if there are differences between the groups of cyl in the mpg variable.
data = mtcars[, c('mpg', 'cyl')]
fit = lm(mpg ~ cyl, data = mtcars)
anova(fit)
# Analysis of Variance Table
# Response: mpg
# Df Sum Sq Mean Sq F value Pr(>F)
# cyl 1 817.71 817.71 79.561 6.113e-10 ***
# Residuals 30 308.33 10.28
# Signif. codes: 0 *** 0.001 ** 0.01 * 0.05 .
# Plot the distribution
plot(mpg ~ as.factor(cyl), data = mtcars, col = 'deepskyblue3')Код выдаст следующий результат -

Значение p, которое мы получаем в примере, значительно меньше 0,05, поэтому R возвращает символ «***», чтобы обозначить это. Это означает, что мы отвергаем нулевую гипотезу и находим различия между средними значениями миль на галлон среди разных группcyl переменная.
Машинное обучение - это подраздел компьютерных наук, который занимается такими задачами, как распознавание образов, компьютерное зрение, распознавание речи, анализ текста и тесно связан со статистикой и математической оптимизацией. Приложения включают разработку поисковых систем, фильтрацию спама, оптическое распознавание символов (OCR) среди прочего. Границы между интеллектуальным анализом данных, распознаванием образов и областью статистического обучения неясны, и в основном все они связаны с аналогичными проблемами.
Машинное обучение можно разделить на два типа задач:
- Контролируемое обучение
- Неконтролируемое обучение
Контролируемое обучение
Контролируемое обучение относится к типу проблемы, когда есть входные данные, определенные как матрица X, и мы заинтересованы в предсказании ответа y . Где X = {x 1 , x 2 ,…, x n } имеет n предикторов и имеет два значения y = {c 1 , c 2 } .
Примером приложения может быть прогнозирование вероятности того, что веб-пользователь нажмет на рекламу, используя демографические характеристики в качестве предикторов. Это часто используется для прогнозирования рейтинга кликов (CTR). Тогда y = {click, not - click}, и предикторами могут быть используемый IP-адрес, день входа на сайт, город пользователя, страна и другие функции, которые могут быть доступны.
Неконтролируемое обучение
Обучение без учителя решает проблему поиска групп, которые похожи друг на друга, не имея класса, у которого можно учиться. Существует несколько подходов к задаче изучения сопоставления от предикторов к поиску групп, которые имеют схожие экземпляры в каждой группе и отличаются друг от друга.
Примером применения обучения без учителя является сегментация клиентов. Например, в телекоммуникационной отрасли распространенной задачей является сегментирование пользователей в соответствии с тем, как они используют телефон. Это позволит отделу маркетинга нацелить каждую группу на разные продукты.
Наивный Байес - вероятностный метод построения классификаторов. Характерное допущение наивного байесовского классификатора состоит в том, чтобы считать, что значение конкретной характеристики не зависит от значения любой другой характеристики с учетом переменной класса.
Несмотря на излишне упрощенные предположения, упомянутые ранее, наивные байесовские классификаторы имеют хорошие результаты в сложных реальных ситуациях. Преимущество наивного байесовского метода состоит в том, что для оценки параметров, необходимых для классификации, требуется лишь небольшой объем обучающих данных, и что классификатор можно обучать постепенно.
Наивный байесовский метод - это модель с условной вероятностью: задан экземпляр проблемы, подлежащий классификации, представленный вектором. x= (x 1 ,…, x n ), представляющий некоторые n характеристик (независимых переменных), он присваивает этому экземпляру вероятности для каждого из K возможных результатов или классов.
$$p(C_k|x_1,....., x_n)$$
Проблема с приведенной выше формулировкой состоит в том, что если количество признаков n велико или если признак может принимать большое количество значений, то основывать такую модель на таблицах вероятности невозможно. Поэтому мы переформулируем модель, чтобы упростить ее. Используя теорему Байеса, условную вероятность можно разложить как -
$$p(C_k|x) = \frac{p(C_k)p(x|C_k)}{p(x)}$$
Это означает, что при указанных выше предположениях о независимости условное распределение по переменной класса C равно -
$$p(C_k|x_1,....., x_n)\: = \: \frac{1}{Z}p(C_k)\prod_{i = 1}^{n}p(x_i|C_k)$$
где свидетельство Z = p (x) - коэффициент масштабирования, зависящий только от x 1 ,…, x n , который является константой, если известны значения переменных признаков. Одно из общих правил - выбирать наиболее вероятную гипотезу; это известно как максимальное апостериорное правило или правило принятия решения MAP. Соответствующий классификатор, байесовский классификатор, является функцией, которая назначает метку класса.$\hat{y} = C_k$ для некоторого k следующим образом -
$$\hat{y} = argmax\: p(C_k)\prod_{i = 1}^{n}p(x_i|C_k)$$
Реализация алгоритма в R - простой процесс. В следующем примере показано, как обучить наивный байесовский классификатор и использовать его для прогнозирования в задаче фильтрации спама.
Следующий сценарий доступен в bda/part3/naive_bayes/naive_bayes.R файл.
# Install these packages
pkgs = c("klaR", "caret", "ElemStatLearn")
install.packages(pkgs)
library('ElemStatLearn')
library("klaR")
library("caret")
# Split the data in training and testing
inx = sample(nrow(spam), round(nrow(spam) * 0.9))
train = spam[inx,]
test = spam[-inx,]
# Define a matrix with features, X_train
# And a vector with class labels, y_train
X_train = train[,-58]
y_train = train$spam X_test = test[,-58] y_test = test$spam
# Train the model
nb_model = train(X_train, y_train, method = 'nb',
trControl = trainControl(method = 'cv', number = 3))
# Compute
preds = predict(nb_model$finalModel, X_test)$class
tbl = table(y_test, yhat = preds)
sum(diag(tbl)) / sum(tbl)
# 0.7217391Как видно из результата, точность модели Наивного Байеса составляет 72%. Это означает, что модель правильно классифицирует 72% экземпляров.
Кластеризация k-средних нацелена на разделение n наблюдений на k кластеров, в которых каждое наблюдение принадлежит кластеру с ближайшим средним, служащим прототипом кластера. Это приводит к разделению пространства данных на ячейки Вороного.
Учитывая набор наблюдений (x 1 , x 2 ,…, x n ) , где каждое наблюдение является d-мерным вещественным вектором, кластеризация k-средних нацелена на разделение n наблюдений на k групп G = {G 1 , G 2 ,…, G k }, чтобы минимизировать внутрикластерную сумму квадратов (WCSS), определяемую следующим образом:
$$argmin \: \sum_{i = 1}^{k} \sum_{x \in S_{i}}\parallel x - \mu_{i}\parallel ^2$$
Более поздняя формула показывает целевую функцию, которая минимизируется, чтобы найти оптимальные прототипы в кластеризации k-средних. Интуиция формулы состоит в том, что мы хотели бы найти группы, которые отличаются друг от друга, и каждый член каждой группы должен быть похож на других членов каждого кластера.
В следующем примере показано, как запустить алгоритм кластеризации k-средних в R.
library(ggplot2)
# Prepare Data
data = mtcars
# We need to scale the data to have zero mean and unit variance
data <- scale(data)
# Determine number of clusters
wss <- (nrow(data)-1)*sum(apply(data,2,var))
for (i in 2:dim(data)[2]) {
wss[i] <- sum(kmeans(data, centers = i)$withinss)
}
# Plot the clusters
plot(1:dim(data)[2], wss, type = "b", xlab = "Number of Clusters",
ylab = "Within groups sum of squares")Чтобы найти хорошее значение для K, мы можем построить сумму квадратов внутри групп для различных значений K. Этот показатель обычно уменьшается по мере добавления новых групп, мы хотели бы найти точку, в которой сумма уменьшения внутри групп квадратов начинает медленно уменьшаться. На графике это значение лучше всего представлено как K = 6.

Теперь, когда значение K определено, необходимо запустить алгоритм с этим значением.
# K-Means Cluster Analysis
fit <- kmeans(data, 5) # 5 cluster solution
# get cluster means
aggregate(data,by = list(fit$cluster),FUN = mean)
# append cluster assignment
data <- data.frame(data, fit$cluster)Пусть I = i 1 , i 2 , ..., i n будет набором из n двоичных атрибутов, называемых элементами. Пусть D = t 1 , t 2 , ..., t m - набор транзакций, называемый базой данных. Каждая транзакция в D имеет уникальный идентификатор транзакции и содержит подмножество элементов в I. Правило определяется как импликация формы X ⇒ Y, где X, Y ⊆ I и X ∩ Y = ∅.
Наборы элементов (для коротких наборов элементов) X и Y называются предшествующими (левая сторона или LHS) и последующими (правая сторона или правая сторона) правила.
Чтобы проиллюстрировать концепции, мы используем небольшой пример из области супермаркетов. Набор элементов - это I = {молоко, хлеб, масло, пиво}, а небольшая база данных, содержащая элементы, показана в следующей таблице.
| номер транзакции | Предметы |
|---|---|
| 1 | молоко, хлеб |
| 2 | хлеб, масло |
| 3 | пиво |
| 4 | молоко, хлеб, масло |
| 5 | хлеб, масло |
Примером правила для супермаркета может быть {молоко, хлеб} ⇒ {масло}, означающее, что если покупаются молоко и хлеб, покупатели также покупают масло. Чтобы выбрать интересные правила из набора всех возможных правил, можно использовать ограничения на различные меры значимости и интереса. Наиболее известные ограничения - это минимальные пороговые значения поддержки и уверенности.
Поддержка supp (X) набора элементов X определяется как доля транзакций в наборе данных, которые содержат этот набор элементов. В примере базы данных в Таблице 1 набор элементов {молоко, хлеб} имеет поддержку 2/5 = 0,4, поскольку он встречается в 40% всех транзакций (2 из 5 транзакций). Нахождение частых наборов заданий можно рассматривать как упрощение проблемы обучения без учителя.
Достоверность правила определяется conf (X ⇒ Y) = supp (X ∪ Y) / supp (X). Например, правило {молоко, хлеб} ⇒ {масло} имеет достоверность 0,2 / 0,4 = 0,5 в базе данных в таблице 1, что означает, что для 50% транзакций, содержащих молоко и хлеб, правило верно. Доверие можно интерпретировать как оценку вероятности P (Y | X), вероятности нахождения правой части правила в транзакциях при условии, что эти транзакции также содержат левую часть правила.
В скрипте, расположенном в bda/part3/apriori.R код для реализации apriori algorithm может быть найден.
# Load the library for doing association rules
# install.packages(’arules’)
library(arules)
# Data preprocessing
data("AdultUCI")
AdultUCI[1:2,]
AdultUCI[["fnlwgt"]] <- NULL
AdultUCI[["education-num"]] <- NULL
AdultUCI[[ "age"]] <- ordered(cut(AdultUCI[[ "age"]], c(15,25,45,65,100)),
labels = c("Young", "Middle-aged", "Senior", "Old"))
AdultUCI[[ "hours-per-week"]] <- ordered(cut(AdultUCI[[ "hours-per-week"]],
c(0,25,40,60,168)), labels = c("Part-time", "Full-time", "Over-time", "Workaholic"))
AdultUCI[[ "capital-gain"]] <- ordered(cut(AdultUCI[[ "capital-gain"]],
c(-Inf,0,median(AdultUCI[[ "capital-gain"]][AdultUCI[[ "capitalgain"]]>0]),Inf)),
labels = c("None", "Low", "High"))
AdultUCI[[ "capital-loss"]] <- ordered(cut(AdultUCI[[ "capital-loss"]],
c(-Inf,0, median(AdultUCI[[ "capital-loss"]][AdultUCI[[ "capitalloss"]]>0]),Inf)),
labels = c("none", "low", "high"))Чтобы сгенерировать правила с использованием априорного алгоритма, нам нужно создать матрицу транзакций. В следующем коде показано, как это сделать в R.
# Convert the data into a transactions format
Adult <- as(AdultUCI, "transactions")
Adult
# transactions in sparse format with
# 48842 transactions (rows) and
# 115 items (columns)
summary(Adult)
# Plot frequent item-sets
itemFrequencyPlot(Adult, support = 0.1, cex.names = 0.8)
# generate rules
min_support = 0.01
confidence = 0.6
rules <- apriori(Adult, parameter = list(support = min_support, confidence = confidence))
rules
inspect(rules[100:110, ])
# lhs rhs support confidence lift
# {occupation = Farming-fishing} => {sex = Male} 0.02856148 0.9362416 1.4005486
# {occupation = Farming-fishing} => {race = White} 0.02831579 0.9281879 1.0855456
# {occupation = Farming-fishing} => {native-country 0.02671881 0.8758389 0.9759474
= United-States}Дерево решений - это алгоритм, используемый для задач контролируемого обучения, таких как классификация или регрессия. Дерево решений или дерево классификации - это дерево, в котором каждый внутренний (не конечный) узел помечен входной функцией. Дуги, исходящие из узла, помеченного как объект, помечаются каждым из возможных значений объекта. Каждый лист дерева помечен классом или распределением вероятностей по классам.
Дерево можно «изучить», разделив исходный набор на подмножества на основе теста значения атрибута. Этот процесс повторяется для каждого производного подмножества рекурсивным способом, называемымrecursive partitioning. Рекурсия завершается, когда все подмножество в узле имеет одинаковое значение целевой переменной или когда разделение больше не добавляет значения к прогнозам. Этот процесс индукции деревьев решений сверху вниз является примером жадного алгоритма и наиболее распространенной стратегией изучения деревьев решений.
Деревья решений, используемые в интеллектуальном анализе данных, бывают двух основных типов:
Classification tree - когда ответ является номинальной переменной, например, является ли письмо спамом или нет.
Regression tree - когда прогнозируемый результат можно считать действительным числом (например, зарплата рабочего).
Деревья решений - это простой метод, и у него есть некоторые проблемы. Одна из этих проблем - высокая дисперсия результирующих моделей, создаваемых деревьями решений. Чтобы решить эту проблему, были разработаны методы ансамбля деревьев решений. В настоящее время широко используются две группы ансамблевых методов:
Bagging decision trees- Эти деревья используются для построения нескольких деревьев решений путем многократной повторной выборки обучающих данных с заменой и голосования за деревья для согласованного предсказания. Этот алгоритм получил название случайного леса.
Boosting decision trees- Повышение градиента объединяет слабых учеников; в этом случае деревья решений объединяются в одного сильного ученика итеративно. Он подбирает слабое дерево к данным и итеративно подбирает слабых учеников, чтобы исправить ошибку предыдущей модели.
# Install the party package
# install.packages('party')
library(party)
library(ggplot2)
head(diamonds)
# We will predict the cut of diamonds using the features available in the
diamonds dataset.
ct = ctree(cut ~ ., data = diamonds)
# plot(ct, main="Conditional Inference Tree")
# Example output
# Response: cut
# Inputs: carat, color, clarity, depth, table, price, x, y, z
# Number of observations: 53940
#
# 1) table <= 57; criterion = 1, statistic = 10131.878
# 2) depth <= 63; criterion = 1, statistic = 8377.279
# 3) table <= 56.4; criterion = 1, statistic = 226.423
# 4) z <= 2.64; criterion = 1, statistic = 70.393
# 5) clarity <= VS1; criterion = 0.989, statistic = 10.48
# 6) color <= E; criterion = 0.997, statistic = 12.829
# 7)* weights = 82
# 6) color > E
#Table of prediction errors
table(predict(ct), diamonds$cut)
# Fair Good Very Good Premium Ideal
# Fair 1388 171 17 0 14
# Good 102 2912 499 26 27
# Very Good 54 998 3334 249 355
# Premium 44 711 5054 11915 1167
# Ideal 22 114 3178 1601 19988
# Estimated class probabilities
probs = predict(ct, newdata = diamonds, type = "prob")
probs = do.call(rbind, probs)
head(probs)Логистическая регрессия - это модель классификации, в которой переменная ответа является категориальной. Этот алгоритм основан на статистике и используется для задач контролируемой классификации. В логистической регрессии мы стремимся найти вектор β параметров в следующем уравнении, который минимизирует функцию затрат.
$$logit(p_i) = ln \left ( \frac{p_i}{1 - p_i} \right ) = \beta_0 + \beta_1x_{1,i} + ... + \beta_kx_{k,i}$$
Следующий код демонстрирует, как подобрать модель логистической регрессии в R. Мы будем использовать здесь набор данных о спаме, чтобы продемонстрировать логистическую регрессию, такую же, что и для наивного байесовского метода.
Из результатов прогнозов с точки зрения точности мы находим, что регрессионная модель достигает точности 92,5% в тестовом наборе по сравнению с 72%, достигнутыми классификатором Наивного Байеса.
library(ElemStatLearn)
head(spam)
# Split dataset in training and testing
inx = sample(nrow(spam), round(nrow(spam) * 0.8))
train = spam[inx,]
test = spam[-inx,]
# Fit regression model
fit = glm(spam ~ ., data = train, family = binomial())
summary(fit)
# Call:
# glm(formula = spam ~ ., family = binomial(), data = train)
#
# Deviance Residuals:
# Min 1Q Median 3Q Max
# -4.5172 -0.2039 0.0000 0.1111 5.4944
# Coefficients:
# Estimate Std. Error z value Pr(>|z|)
# (Intercept) -1.511e+00 1.546e-01 -9.772 < 2e-16 ***
# A.1 -4.546e-01 2.560e-01 -1.776 0.075720 .
# A.2 -1.630e-01 7.731e-02 -2.108 0.035043 *
# A.3 1.487e-01 1.261e-01 1.179 0.238591
# A.4 2.055e+00 1.467e+00 1.401 0.161153
# A.5 6.165e-01 1.191e-01 5.177 2.25e-07 ***
# A.6 7.156e-01 2.768e-01 2.585 0.009747 **
# A.7 2.606e+00 3.917e-01 6.652 2.88e-11 ***
# A.8 6.750e-01 2.284e-01 2.955 0.003127 **
# A.9 1.197e+00 3.362e-01 3.559 0.000373 ***
# Signif. codes: 0 *** 0.001 ** 0.01 * 0.05 . 0.1 1
### Make predictions
preds = predict(fit, test, type = ’response’)
preds = ifelse(preds > 0.5, 1, 0)
tbl = table(target = test$spam, preds)
tbl
# preds
# target 0 1
# email 535 23
# spam 46 316
sum(diag(tbl)) / sum(tbl)
# 0.925Временные ряды - это последовательность наблюдений за категориальными или числовыми переменными, индексированными по дате или метке времени. Ярким примером данных временного ряда является временной ряд цены акции. В следующей таблице мы можем увидеть базовую структуру данных временных рядов. В этом случае наблюдения записываются каждый час.
| Отметка времени | Stock - Цена |
|---|---|
| 2015-10-11 09:00:00 | 100 |
| 2015-10-11 10:00:00 | 110 |
| 2015-10-11 11:00:00 | 105 |
| 2015-10-11 12:00:00 | 90 |
| 2015-10-11 13:00:00 | 120 |
Обычно первым шагом в анализе временных рядов является построение ряда, обычно это делается с помощью линейного графика.
Наиболее распространенное применение анализа временных рядов - это прогнозирование будущих значений числового значения с использованием временной структуры данных. Это означает, что доступные наблюдения используются для прогнозирования значений в будущем.
Временное упорядочение данных подразумевает, что традиционные методы регрессии бесполезны. Чтобы построить надежный прогноз, нам нужны модели, которые учитывают временной порядок данных.
Наиболее широко используемая модель для анализа временных рядов называется Autoregressive Moving Average(ARMA). Модель состоит из двух частей:autoregressive (AR) часть и moving average(MA) часть. Затем модель обычно называют моделью ARMA (p, q), где p - это порядок части авторегрессии, а q - порядок части скользящего среднего.
Модель авторегрессии
АР (р) читаются как модель авторегрессии порядка р. Математически это записывается как -
$$ X_t = c + \ sum_ {i = 1} ^ {P} \ phi_i X_ {t - i} + \ varepsilon_ {t} $$
где {φ 1 ,…, φ p } - параметры, которые необходимо оценить, c - постоянная величина, а случайная величина ε t представляет собой белый шум. Необходимы некоторые ограничения на значения параметров, чтобы модель оставалась неподвижной.
Скользящая средняя
Обозначение MA (q) относится к модели скользящего среднего порядка q -
$$ X_t = \ mu + \ varepsilon_t + \ sum_ {i = 1} ^ {q} \ theta_i \ varepsilon_ {t - i} $$
где θ 1 , ..., θ q - параметры модели, μ - математическое ожидание X t , а ε t , ε t - 1 , ... are, члены ошибки белого шума.
Авторегрессионное скользящее среднее
Модель ARMA (p, q) объединяет p членов авторегрессии и q членов скользящего среднего. Математически модель выражается следующей формулой -
$$ X_t = c + \ varepsilon_t + \ sum_ {i = 1} ^ {P} \ phi_iX_ {t - 1} + \ sum_ {i = 1} ^ {q} \ theta_i \ varepsilon_ {ti} $$
Мы видим, что модель ARMA (p, q) представляет собой комбинацию моделей AR (p) и MA (q) .
Чтобы дать некоторую интуицию модели, представьте, что часть AR уравнения пытается оценить параметры для X t - i наблюдений, чтобы предсказать значение переменной в X t . В конце концов, это средневзвешенное значение прошлых значений. В разделе МА используется тот же подход, но с ошибкой предыдущих наблюдений ε t - i . В итоге результат модели - это средневзвешенное значение.
Следующий фрагмент кода демонстрирует , как реализовать АРМА (P, Q) в R .
# install.packages("forecast")
library("forecast")
# Read the data
data = scan('fancy.dat')
ts_data <- ts(data, frequency = 12, start = c(1987,1))
ts_data
plot.ts(ts_data)Построение данных обычно является первым шагом, чтобы выяснить, есть ли в данных временная структура. Из графика видно, что в конце каждого года бывают сильные всплески.
Следующий код соответствует модели ARMA для данных. Он запускает несколько комбинаций моделей и выбирает ту, которая имеет меньше ошибок.
# Fit the ARMA model
fit = auto.arima(ts_data)
summary(fit)
# Series: ts_data
# ARIMA(1,1,1)(0,1,1)[12]
# Coefficients:
# ar1 ma1 sma1
# 0.2401 -0.9013 0.7499
# s.e. 0.1427 0.0709 0.1790
#
# sigma^2 estimated as 15464184: log likelihood = -693.69
# AIC = 1395.38 AICc = 1395.98 BIC = 1404.43
# Training set error measures:
# ME RMSE MAE MPE MAPE MASE ACF1
# Training set 328.301 3615.374 2171.002 -2.481166 15.97302 0.4905797 -0.02521172В этой главе мы будем использовать данные, собранные в части 1 книги. В данных есть текст, который описывает профили фрилансеров и почасовую ставку, которую они взимают в долларах США. Идея следующего раздела состоит в том, чтобы подобрать модель, согласно которой, учитывая навыки фрилансера, мы можем спрогнозировать его почасовую зарплату.
В следующем коде показано, как преобразовать необработанный текст, который в этом случае имеет навыки пользователя в матрице слов. Для этого мы используем библиотеку R под названием tm. Это означает, что для каждого слова в корпусе мы создаем переменную с количеством вхождений каждой переменной.
library(tm)
library(data.table)
source('text_analytics/text_analytics_functions.R')
data = fread('text_analytics/data/profiles.txt')
rate = as.numeric(data$rate)
keep = !is.na(rate)
rate = rate[keep]
### Make bag of words of title and body
X_all = bag_words(data$user_skills[keep])
X_all = removeSparseTerms(X_all, 0.999)
X_all
# <<DocumentTermMatrix (documents: 389, terms: 1422)>>
# Non-/sparse entries: 4057/549101
# Sparsity : 99%
# Maximal term length: 80
# Weighting : term frequency - inverse document frequency (normalized) (tf-idf)
### Make a sparse matrix with all the data
X_all <- as_sparseMatrix(X_all)Теперь, когда у нас есть текст, представленный в виде разреженной матрицы, мы можем подобрать модель, которая даст разреженное решение. Хорошей альтернативой для этого случая является использование LASSO (оператор наименьшей абсолютной усадки и выбора). Это регрессионная модель, которая может выбирать наиболее подходящие функции для прогнозирования цели.
train_inx = 1:200
X_train = X_all[train_inx, ]
y_train = rate[train_inx]
X_test = X_all[-train_inx, ]
y_test = rate[-train_inx]
# Train a regression model
library(glmnet)
fit <- cv.glmnet(x = X_train, y = y_train,
family = 'gaussian', alpha = 1,
nfolds = 3, type.measure = 'mae')
plot(fit)
# Make predictions
predictions = predict(fit, newx = X_test)
predictions = as.vector(predictions[,1])
head(predictions)
# 36.23598 36.43046 51.69786 26.06811 35.13185 37.66367
# We can compute the mean absolute error for the test data
mean(abs(y_test - predictions))
# 15.02175Теперь у нас есть модель, которая с учетом набора навыков может прогнозировать почасовую зарплату фрилансера. Если будет собрано больше данных, производительность модели улучшится, но код для реализации этого конвейера будет таким же.
Онлайн-обучение - это подраздел машинного обучения, которое позволяет масштабировать модели контролируемого обучения до огромных наборов данных. Основная идея состоит в том, что нам не нужно читать все данные в памяти, чтобы соответствовать модели, нам нужно читать только каждый экземпляр за раз.
В этом случае мы покажем, как реализовать алгоритм онлайн-обучения с использованием логистической регрессии. Как и в большинстве алгоритмов контролируемого обучения, существует функция стоимости, которая минимизируется. В логистической регрессии функция затрат определяется как -
$$ J (\ theta) \: = \: \ frac {-1} {m} \ left [\ sum_ {i = 1} ^ {m} y ^ {(i)} log (h _ {\ theta} ( x ^ {(i)})) + (1 - y ^ {(i)}) log (1 - h _ {\ theta} (x ^ {(i)})) \ right] $$
где J (θ) представляет функцию стоимости, а h θ (x) представляет гипотезу. В случае логистической регрессии это определяется следующей формулой -
$$ h_ \ theta (x) = \ frac {1} {1 + e ^ {\ theta ^ T x}} $$
Теперь, когда мы определили функцию стоимости, нам нужно найти алгоритм для ее минимизации. Простейший алгоритм достижения этого называется стохастическим градиентным спуском. Правило обновления алгоритма весов модели логистической регрессии определяется как -
$$ \ theta_j: = \ theta_j - \ alpha (h_ \ theta (x) - y) x $$
Существует несколько реализаций следующего алгоритма, но тот, который реализован в библиотеке vowpal wabbit , на сегодняшний день является наиболее развитым. Библиотека позволяет обучать крупномасштабные регрессионные модели и использует небольшой объем оперативной памяти. По словам самих создателей, он описывается так: «Проект Vowpal Wabbit (VW) - это быстрая внешняя обучающая система, спонсируемая Microsoft Research и (ранее) Yahoo! Research».
Мы будем работать с набором данных titanic из kaggleконкуренция. Исходные данные можно найти вbda/part3/vwпапка. Здесь у нас есть два файла -
- У нас есть данные для обучения (train_titanic.csv), и
- немаркированные данные, чтобы делать новые прогнозы (test_titanic.csv).
Чтобы преобразовать формат csv в формат vowpal wabbit формат ввода используйте csv_to_vowpal_wabbit.pyскрипт на Python. Для этого вам, очевидно, понадобится установленный Python. Перейдите кbda/part3/vw папку, откройте терминал и выполните следующую команду -
python csv_to_vowpal_wabbit.pyОбратите внимание, что в этом разделе, если вы используете Windows, вам нужно будет установить командную строку Unix, для этого войдите на сайт cygwin .
Открываем терминал и тоже в папке bda/part3/vw и выполните следующую команду -
vw train_titanic.vw -f model.vw --binary --passes 20 -c -q ff --sgd --l1
0.00000001 --l2 0.0000001 --learning_rate 0.5 --loss_function logisticДавайте разберемся, что каждый аргумент vw call средства.
-f model.vw - означает, что мы сохраняем модель в файле model.vw для дальнейшего прогнозирования
--binary - Отчеты о потерях как двоичная классификация с метками -1,1
--passes 20 - Данные используются 20 раз для определения веса
-c - создать файл кеша
-q ff - Используйте квадратичные функции в пространстве имен f
--sgd - использовать обычное / классическое / простое обновление стохастического градиентного спуска, то есть неадаптивное, ненормализованное и неинвариантное.
--l1 --l2 - регуляризация норм L1 и L2
--learning_rate 0.5 - Скорость обучения α, определенная в формуле правила обновления
Следующий код показывает результаты запуска регрессионной модели в командной строке. В результате мы получаем среднюю логарифмическую потерю и небольшой отчет о производительности алгоритма.
-loss_function logistic
creating quadratic features for pairs: ff
using l1 regularization = 1e-08
using l2 regularization = 1e-07
final_regressor = model.vw
Num weight bits = 18
learning rate = 0.5
initial_t = 1
power_t = 0.5
decay_learning_rate = 1
using cache_file = train_titanic.vw.cache
ignoring text input in favor of cache input
num sources = 1
average since example example current current current
loss last counter weight label predict features
0.000000 0.000000 1 1.0 -1.0000 -1.0000 57
0.500000 1.000000 2 2.0 1.0000 -1.0000 57
0.250000 0.000000 4 4.0 1.0000 1.0000 57
0.375000 0.500000 8 8.0 -1.0000 -1.0000 73
0.625000 0.875000 16 16.0 -1.0000 1.0000 73
0.468750 0.312500 32 32.0 -1.0000 -1.0000 57
0.468750 0.468750 64 64.0 -1.0000 1.0000 43
0.375000 0.281250 128 128.0 1.0000 -1.0000 43
0.351562 0.328125 256 256.0 1.0000 -1.0000 43
0.359375 0.367188 512 512.0 -1.0000 1.0000 57
0.274336 0.274336 1024 1024.0 -1.0000 -1.0000 57 h
0.281938 0.289474 2048 2048.0 -1.0000 -1.0000 43 h
0.246696 0.211454 4096 4096.0 -1.0000 -1.0000 43 h
0.218922 0.191209 8192 8192.0 1.0000 1.0000 43 h
finished run
number of examples per pass = 802
passes used = 11
weighted example sum = 8822
weighted label sum = -2288
average loss = 0.179775 h
best constant = -0.530826
best constant’s loss = 0.659128
total feature number = 427878Теперь мы можем использовать model.vw мы научились делать прогнозы на новых данных.
vw -d test_titanic.vw -t -i model.vw -p predictions.txtПрогнозы, сгенерированные в предыдущей команде, не нормализованы, чтобы соответствовать диапазону [0, 1]. Для этого мы используем сигмовидное преобразование.
# Read the predictions
preds = fread('vw/predictions.txt')
# Define the sigmoid function
sigmoid = function(x) {
1 / (1 + exp(-x))
}
probs = sigmoid(preds[[1]])
# Generate class labels
preds = ifelse(probs > 0.5, 1, 0)
head(preds)
# [1] 0 1 0 0 1 0