Plotly - Гистограмма
Гистограмма, введенная Карлом Пирсоном, является точным представлением распределения числовых данных, которое является оценкой распределения вероятностей непрерывной переменной (CORAL). Он похож на гистограмму, но гистограмма связывает две переменные, а гистограмма - только одну.
Гистограмма требует bin (или же bucket), который делит весь диапазон значений на серию интервалов, а затем подсчитывает, сколько значений попадает в каждый интервал. Бины обычно задаются как последовательные неперекрывающиеся интервалы переменной. Бункеры должны быть смежными и часто имеют одинаковый размер. Над ячейкой возводится прямоугольник с высотой, пропорциональной частоте - количеству наблюдений в каждой ячейке.
Объект трассировки гистограммы возвращается go.Histogram()функция. Его настройка выполняется с помощью различных аргументов или атрибутов. Одним из важных аргументов является набор x или y в список,numpy array или же Pandas dataframe object который должен быть распределен по ящикам.
По умолчанию Plotly распределяет точки данных по ячейкам с автоматическим размером. Однако вы можете определить собственный размер корзины. Для этого вам нужно установить autobins в false, указатьnbins (количество бункеров), его начальные и конечные значения и размер.
Следующий код генерирует простую гистограмму, показывающую распределение оценок студентов в группах классов (размер автоматически):
import numpy as np
x1 = np.array([22,87,5,43,56,73,55,54,11,20,51,5,79,31,27])
data = [go.Histogram(x = x1)]
fig = go.Figure(data)
iplot(fig)Результат показан ниже -

В go.Histogram() функция принимает histnorm, который указывает тип нормализации, используемый для этой кривой гистограммы. По умолчанию "", диапазон каждой полосы соответствует количеству вхождений (т. Е. Количеству точек данных, лежащих внутри интервалов). Если назначено"percent" / "probability", диапазон каждой полосы соответствует проценту / доле вхождений по отношению к общему количеству точек выборки. Если он равен "density", диапазон каждой полосы соответствует количеству вхождений в ячейке, деленному на размер интервала ячейки.
Есть также histfunc параметр, значение по умолчанию count. В результате высота прямоугольника над ячейкой соответствует количеству точек данных. Может быть установлен на сумму, среднее, минимальное или максимальное значение.
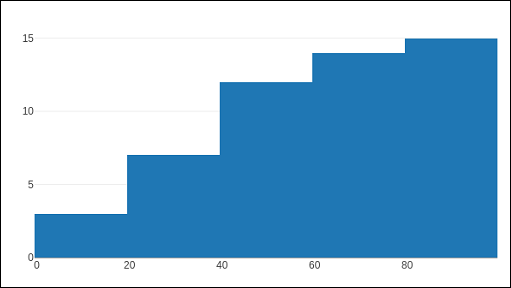
В histogram()функцию можно настроить для отображения совокупного распределения значений в последовательных ячейках. Для этого вам нужно установитьcumulative propertyк включенному. Результат можно увидеть ниже -
data=[go.Histogram(x = x1, cumulative_enabled = True)]
fig = go.Figure(data)
iplot(fig)Результат, как указано ниже -