Fuzzy Logic - คู่มือฉบับย่อ
คำ fuzzyหมายถึงสิ่งที่ไม่ชัดเจนหรือคลุมเครือ เหตุการณ์กระบวนการหรือฟังก์ชันใด ๆ ที่เปลี่ยนแปลงอย่างต่อเนื่องไม่สามารถกำหนดได้ว่าเป็นจริงหรือเท็จเสมอไปซึ่งหมายความว่าเราจำเป็นต้องกำหนดกิจกรรมดังกล่าวในลักษณะที่คลุมเครือ
Fuzzy Logic คืออะไร?
Fuzzy Logic มีลักษณะคล้ายกับวิธีการตัดสินใจของมนุษย์ เกี่ยวข้องกับข้อมูลที่คลุมเครือและไม่ชัดเจน นี่คือการลดความซับซ้อนของปัญหาในโลกแห่งความเป็นจริงและอิงตามระดับความจริงมากกว่าปกติจริง / เท็จหรือ 1/0 เหมือนตรรกะบูลีน
ดูแผนภาพต่อไปนี้ แสดงให้เห็นว่าในระบบฟัซซีค่าจะถูกระบุด้วยตัวเลขในช่วงตั้งแต่ 0 ถึง 1 ในที่นี้ 1.0 แสดงถึงabsolute truth และ 0.0 แสดงถึง absolute falseness. ตัวเลขที่ระบุค่าในระบบฟัซซีเรียกว่าtruth value.

กล่าวอีกนัยหนึ่งเราสามารถพูดได้ว่าตรรกะที่คลุมเครือไม่ใช่ตรรกะที่คลุมเครือ แต่เป็นตรรกะที่ใช้อธิบายความคลุมเครือ อาจมีตัวอย่างอื่น ๆ อีกมากมายเช่นนี้ด้วยความช่วยเหลือซึ่งเราสามารถเข้าใจแนวคิดของตรรกะฟัซซี
Fuzzy Logic เปิดตัวในปี 1965 โดย Lofti A. Zadeh ในเอกสารวิจัยของเขาเรื่อง Fuzzy Sets เขาถือเป็นบิดาของ Fuzzy Logic
ก setเป็นคอลเลกชันที่ไม่เรียงลำดับขององค์ประกอบต่างๆ สามารถเขียนอย่างชัดเจนโดยแสดงรายการองค์ประกอบโดยใช้วงเล็บชุด หากลำดับขององค์ประกอบมีการเปลี่ยนแปลงหรือองค์ประกอบใด ๆ ของชุดซ้ำจะไม่ทำการเปลี่ยนแปลงใด ๆ ในชุด
ตัวอย่าง
- ชุดของจำนวนเต็มบวกทั้งหมด
- ชุดของดาวเคราะห์ทั้งหมดในระบบสุริยะ
- ชุดของรัฐทั้งหมดในอินเดีย
- ชุดตัวอักษรพิมพ์เล็กทั้งหมดของตัวอักษร
การแทนค่าทางคณิตศาสตร์ของเซต
ชุดสามารถแสดงได้สองวิธี -
บัญชีรายชื่อหรือรูปแบบตาราง
ในรูปแบบนี้ชุดจะแสดงโดยการแสดงรายการองค์ประกอบทั้งหมดที่ประกอบด้วยชุดนั้น องค์ประกอบจะอยู่ภายในวงเล็บปีกกาและคั่นด้วยเครื่องหมายจุลภาค
ต่อไปนี้เป็นตัวอย่างของชุดในบัญชีรายชื่อหรือรูปแบบตาราง -
- ชุดเสียงสระในตัวอักษรภาษาอังกฤษ A = {a, e, i, o, u}
- ชุดเลขคี่น้อยกว่า 10, B = {1,3,5,7,9}
ตั้งค่าสัญกรณ์ตัวสร้าง
ในรูปแบบนี้ชุดจะถูกกำหนดโดยการระบุคุณสมบัติที่องค์ประกอบของชุดมีเหมือนกัน ชุดนี้อธิบายว่า A = {x: p (x)}
Example 1 - ชุด {a, e, i, o, u} เขียนเป็น
A = {x: x เป็นสระในตัวอักษรภาษาอังกฤษ}
Example 2 - ชุด {1,3,5,7,9} เขียนเป็น
B = {x: 1 ≤ x <10 และ (x% 2) ≠ 0}
ถ้าองค์ประกอบ x เป็นสมาชิกของเซต S ใด ๆ มันจะแสดงด้วยx∈Sและถ้าองค์ประกอบ y ไม่ใช่สมาชิกของเซต S องค์ประกอบนั้นจะแสดงด้วย y .S
Example - ถ้า S = {1,1.2,1.7,2}, 1 ∈ S แต่ 1.5 ∉ S
Cardinality ของชุด
จำนวนองค์ประกอบของเซต S แสดงโดย | S || S | คือจำนวนองค์ประกอบของเซต หมายเลขนี้เรียกอีกอย่างว่าหมายเลขคาร์ดินัล หากเซตมีองค์ประกอบจำนวนไม่ จำกัด จำนวนองค์ประกอบจะเท่ากับ∞∞
Example- | {1,4,3,5} | = 4, | {1,2,3,4,5, …} | = ∞
หากมีสองชุด X และ Y | X | = | Y | หมายถึงชุด X และ Y สองชุดที่มีความสำคัญเท่ากัน เกิดขึ้นเมื่อจำนวนองค์ประกอบใน X เท่ากับจำนวนองค์ประกอบใน Y ในกรณีนี้มีฟังก์ชัน bijective 'f' จาก X ถึง Y
| X | ≤ | Y | หมายถึงว่าเซตคาร์ดินาลลิตี้ของ X น้อยกว่าหรือเท่ากับเซ็ตคาร์ดินาลลิตี้ของ Y เกิดขึ้นเมื่อจำนวนองค์ประกอบใน X น้อยกว่าหรือเท่ากับ Y ที่นี่มีฟังก์ชันฉีด 'f' จาก X ถึง Y
| X | <| Y | หมายถึงว่าคาร์ดินาลลิตี้ของเซต X น้อยกว่าเซ็ตคาร์ดินาลลิตี้ของ Y เกิดขึ้นเมื่อจำนวนองค์ประกอบใน X น้อยกว่า Y ในที่นี้ฟังก์ชัน 'f' จาก X ถึง Y เป็นฟังก์ชันแบบฉีด แต่ไม่ได้เป็นแบบไบเจ็กทีฟ
ถ้า| X | ≤ | Y | และ| X | ≤ | Y | แล้ว| X | = | Y | . ชุด X และ Y มักเรียกกันว่าequivalent sets.
ประเภทของชุด
ชุดสามารถแบ่งออกเป็นหลายประเภท ซึ่งบางส่วนเป็นแบบ จำกัด , ไม่มีที่สิ้นสุด, เซตย่อย, สากล, เหมาะสม, เซตซิงเกิลตัน ฯลฯ
ชุดไฟไนต์
ชุดที่มีจำนวนองค์ประกอบที่แน่นอนเรียกว่าเซต จำกัด
Example - S = {x | x ∈ N และ 70> x> 50}
ชุดไม่มีที่สิ้นสุด
ชุดที่มีองค์ประกอบจำนวนไม่ จำกัด เรียกว่าเซตไม่มีที่สิ้นสุด
Example - S = {x | x ∈ N และ x> 10}
ชุดย่อย
เซต X คือเซตย่อยของเซต Y (เขียนเป็น X ⊆ Y) ถ้าทุกองค์ประกอบของ X เป็นองค์ประกอบของเซต Y
Example 1- ให้ X = {1,2,3,4,5,6} และ Y = {1,2} เซต Y เป็นเซตย่อยของเซต X เนื่องจากองค์ประกอบทั้งหมดของเซต Y อยู่ในเซต X ดังนั้นเราจึงเขียนY⊆Xได้
Example 2- ให้ X = {1,2,3} และ Y = {1,2,3} เซต Y เป็นเซตย่อย (ไม่ใช่เซตย่อยที่เหมาะสม) ของเซต X เนื่องจากองค์ประกอบทั้งหมดของเซต Y อยู่ในเซต X ดังนั้นเราจึงเขียนY⊆Xได้
ชุดย่อยที่เหมาะสม
คำว่า "ชุดย่อยที่เหมาะสม" สามารถกำหนดเป็น "ชุดย่อย แต่ไม่เท่ากับ" เซต X เป็นเซตย่อยที่เหมาะสมของเซต Y (เขียนเป็น X ⊂ Y) ถ้าทุกองค์ประกอบของ X เป็นองค์ประกอบของเซต Y และ | X | <| Y |.
Example- ให้ X = {1,2,3,4,5,6} และ Y = {1,2} ที่นี่ตั้งค่า Y ⊂ X เนื่องจากองค์ประกอบทั้งหมดใน Y มีอยู่ใน X ด้วยและ X ก็มีอย่างน้อยหนึ่งองค์ประกอบที่มากกว่าชุด Y
ชุดสากล
เป็นการรวบรวมองค์ประกอบทั้งหมดในบริบทหรือแอปพลิเคชันเฉพาะ ชุดทั้งหมดในบริบทหรือแอปพลิเคชันนั้นเป็นส่วนย่อยของชุดสากลนี้ ชุดสากลแสดงเป็น U
Example- เราอาจกำหนด U เป็นเซตของสัตว์ทั้งหมดบนโลก ในกรณีนี้ชุดของสัตว์เลี้ยงลูกด้วยนมทั้งหมดเป็นเซตย่อยของ U ชุดของปลาทั้งหมดเป็นเซตย่อยของ U ชุดของแมลงทั้งหมดเป็นเซตย่อยของ U และอื่น ๆ
ชุดว่างหรือชุดค่าว่าง
ชุดว่างไม่มีองค์ประกอบ แสดงโดยΦ เนื่องจากจำนวนองค์ประกอบในเซตว่างมีจำนวน จำกัด เซตว่างจึงเป็นเซต จำกัด จำนวนเต็มของเซตว่างหรือเซตว่างเป็นศูนย์
Example - S = {x | x ∈ N และ 7 <x <8} = Φ
Singleton Set หรือ Unit Set
ชุด Singleton หรือชุดหน่วยประกอบด้วยองค์ประกอบเดียว ชุดซิงเกิลตันแสดงด้วย {s}
Example - S = {x | x ∈ N, 7 <x <9} = {8}
ชุดที่เท่ากัน
ถ้าสองชุดมีองค์ประกอบเดียวกันก็จะถือว่าเท่ากัน
Example - ถ้า A = {1,2,6} และ B = {6,1,2} จะมีค่าเท่ากันทุกองค์ประกอบของเซต A คือองค์ประกอบของเซต B และทุกองค์ประกอบของเซต B เป็นองค์ประกอบของเซต A
ชุดที่เทียบเท่า
ถ้าความสำคัญของสองชุดเหมือนกันจะเรียกว่าชุดที่เท่ากัน
Example- ถ้า A = {1,2,6} และ B = {16,17,22} จะเทียบเท่ากับคาร์ดินาลลิตี้ของ A เท่ากับคาร์ดินาลลิตี้ของ B คือ | A | = | B | = 3
ชุดที่ทับซ้อนกัน
สองชุดที่มีองค์ประกอบร่วมอย่างน้อยหนึ่งชุดเรียกว่าชุดที่ทับซ้อนกัน กรณีชุดทับ -
$$ n \ left (A \ cup B \ right) = n \ left (A \ right) + n \ left (B \ right) - n \ left (A \ cap B \ right) $$
$$ n \ left (A \ cup B \ right) = n \ left (AB \ right) + n \ left (BA \ right) + n \ left (A \ cap B \ right) $$
$$ n \ left (A \ right) = n \ left (AB \ right) + n \ left (A \ cap B \ right) $$
$$ n \ left (B \ right) = n \ left (BA \ right) + n \ left (A \ cap B \ right) $$
Example- ให้, A = {1,2,6} และ B = {6,12,42} มีองค์ประกอบทั่วไป '6' ดังนั้นชุดเหล่านี้จึงเป็นชุดที่ทับซ้อนกัน
ชุดไม่ปะติดปะต่อ
ชุด A และ B สองชุดเรียกว่าชุดที่ไม่ปะติดปะต่อกันหากไม่มีองค์ประกอบที่เหมือนกันแม้แต่ชิ้นเดียว ดังนั้นชุดที่ไม่ปะติดปะต่อจึงมีคุณสมบัติดังต่อไปนี้ -
$$ n \ left (A \ cap B \ right) = \ phi $$
$$ n \ left (A \ cup B \ right) = n \ left (A \ right) + n \ left (B \ right) $$
Example - ให้ A = {1,2,6} และ B = {7,9,14} ไม่มีองค์ประกอบร่วมกันดังนั้นเซตเหล่านี้จึงเป็นเซตที่ทับซ้อนกัน
การดำเนินการกับชุดคลาสสิก
การดำเนินการชุดประกอบด้วย Set Union, Set Intersection, Set Difference, Complement of Set และ Cartesian Product
สหภาพ
การรวมกันของเซต A และ B (แสดงโดย A ∪ BA ∪ B) คือเซตขององค์ประกอบที่อยู่ใน A ใน B หรือทั้ง A และ B ดังนั้น A ∪ B = {x | x ∈ A หรือ x ∈ B}
Example - ถ้า A = {10,11,12,13} และ B = {13,14,15} ดังนั้น A ∪ B = {10,11,12,13,14,15} - องค์ประกอบทั่วไปจะเกิดขึ้นเพียงครั้งเดียว
ทางแยก
จุดตัดของเซต A และ B (แสดงโดย A ∩ B) คือเซตขององค์ประกอบที่อยู่ในทั้ง A และ B ดังนั้น A ∩ B = {x | x ∈ A AND x ∈ B}

ความแตกต่าง / ส่วนเสริมสัมพัทธ์
ความแตกต่างของเซต A และ B (แสดงด้วย A-B) คือเซตขององค์ประกอบที่อยู่ใน A เท่านั้น แต่ไม่ใช่ใน B ดังนั้น A - B = {x | x ∈ A AND x ∉ B}
Example- ถ้า A = {10,11,12,13} และ B = {13,14,15} ดังนั้น (A - B) = {10,11,12} และ (B - A) = {14,15} . ที่นี่เราจะเห็น (A - B) ≠ (B - A)

ส่วนเสริมของชุด
ส่วนประกอบของเซต A (แสดงโดย A ′) คือชุดขององค์ประกอบที่ไม่อยู่ในเซต A ดังนั้น A′ = {x | x ∉ A}
โดยเฉพาะอย่างยิ่ง A ′= (U − A) โดยที่ U เป็นเซตสากลที่มีวัตถุทั้งหมด
Example - ถ้า A = {x | x เป็นของเซตของจำนวนเต็มเพิ่ม} ดังนั้น A ′= {y | y ไม่ได้อยู่ในเซตของจำนวนเต็มคี่}

ผลิตภัณฑ์คาร์ทีเซียน / ผลิตภัณฑ์ข้าม
ผลคูณคาร์ทีเซียนของ n จำนวนเซต A1, A2, …แสดงเป็น A1 × A2 ... × An สามารถกำหนดให้เป็นคู่ลำดับที่เป็นไปได้ทั้งหมด (x1, x2, … xn) โดยที่ x1 ∈ A1, x2 ∈ A2, … xn ∈ An
Example - ถ้าเราใช้สองเซต A = {a, b} และ B = {1,2}
ผลคูณคาร์ทีเซียนของ A และ B เขียนเป็น - A × B = {(a, 1), (a, 2), (b, 1), (b, 2)}
และผลคูณคาร์ทีเซียนของ B และ A เขียนเป็น - B × A = {(1, a), (1, b), (2, a), (2, b)}
คุณสมบัติของชุดคลาสสิก
คุณสมบัติบนชุดมีบทบาทสำคัญสำหรับการได้รับโซลูชัน ต่อไปนี้เป็นคุณสมบัติต่างๆของเซตคลาสสิก -
คุณสมบัติการสับเปลี่ยน
มีสองชุด A และ B, คุณสมบัตินี้ระบุ -
$$ A \ cup B = B \ cup A $$
$$ A \ cap B = B \ cap A $$
ทรัพย์สินที่เกี่ยวข้อง
มีสามชุด A, B และ C, คุณสมบัตินี้ระบุ -
$$ A \ cup \ left (B \ cup C \ right) = \ left (A \ cup B \ right) \ cup C $$
$$ A \ cap \ left (B \ cap C \ right) = \ left (A \ cap B \ right) \ cap C $$
ทรัพย์สินกระจาย
มีสามชุด A, B และ C, คุณสมบัตินี้ระบุ -
$$ A \ cup \ left (B \ cap C \ right) = \ left (A \ cup B \ right) \ cap \ left (A \ cup C \ right) $$
$$ A \ cap \ left (B \ cup C \ right) = \ left (A \ cap B \ right) \ cup \ left (A \ cap C \ right) $$
คุณสมบัติ Idempotency
สำหรับชุดใด ๆ A, คุณสมบัตินี้ระบุ -
$$ A \ cup A = A $$
$$ A \ cap A = A $$
ทรัพย์สินประจำตัว
สำหรับชุด A และชุดสากล X, คุณสมบัตินี้ระบุ -
$$ A \ cup \ varphi = A $$
$$ A \ cap X = A $$
$$ A \ cap \ varphi = \ varphi $$
$$ A \ cup X = X $$
คุณสมบัติสกรรมกริยา
มีสามชุด A, B และ C, สถานะทรัพย์สิน -
ถ้า $ A \ subseteq B \ subseteq C $ ดังนั้น $ A \ subseteq C $
คุณสมบัติการบุกรุก
สำหรับชุดใด ๆ A, คุณสมบัตินี้ระบุ -
$$ \ overline {{\ overline {A}}} = A $$
กฎของเดอมอร์แกน
เป็นกฎหมายที่สำคัญมากและสนับสนุนในการพิสูจน์ความเชื่อและความขัดแย้ง กฎหมายนี้ระบุ -
$$ \ overline {A \ cap B} = \ overline {A} \ cup \ overline {B} $$
$$ \ overline {A \ cup B} = \ overline {A} \ cap \ overline {B} $$
ชุดคลุมเครือถือได้ว่าเป็นส่วนเสริมและการทำให้ชุดคลาสสิกมากเกินไป สามารถเข้าใจได้ดีที่สุดในบริบทของการเป็นสมาชิกชุด โดยทั่วไปจะอนุญาตให้เป็นสมาชิกบางส่วนซึ่งหมายความว่ามีองค์ประกอบที่มีระดับการเป็นสมาชิกที่แตกต่างกันในชุด จากนี้เราสามารถเข้าใจความแตกต่างระหว่างเซตคลาสสิคและเซตฟัซซี่ ชุดคลาสสิกประกอบด้วยองค์ประกอบที่ตอบสนองคุณสมบัติที่แม่นยำของการเป็นสมาชิกในขณะที่ชุดฟัซซีมีองค์ประกอบที่ตอบสนองคุณสมบัติที่ไม่ชัดเจนของการเป็นสมาชิก

แนวคิดทางคณิตศาสตร์
ชุดที่คลุมเครือ $ \ widetilde {A} $ ในจักรวาลของข้อมูล $ U $ สามารถกำหนดเป็นชุดของคู่ที่เรียงลำดับและสามารถแทนค่าทางคณิตศาสตร์เป็น -
$$ \ widetilde {A} = \ left \ {\ left (y, \ mu _ {\ widetilde {A}} \ left (y \ right) \ right) | y \ in U \ right \} $$
ที่นี่ $ \ mu _ {\ widetilde {A}} \ left (y \ right) $ = ระดับการเป็นสมาชิกของ $ y $ in \ widetilde {A} จะถือว่าค่าอยู่ในช่วงตั้งแต่ 0 ถึง 1 นั่นคือ $ \ mu _ {\ widetilde {A}} (y) \ in \ left [0,1 \ right] $.
การแสดงชุดคลุมเครือ
ตอนนี้ให้เราพิจารณาสองกรณีของจักรวาลของข้อมูลและทำความเข้าใจว่าชุดคลุมเครือสามารถแสดงได้อย่างไร
กรณีที่ 1
เมื่อจักรวาลของข้อมูล $ U $ ไม่ต่อเนื่องและ จำกัด -
$$ \ widetilde {A} = \ left \ {\ frac {\ mu _ {\ widetilde {A}} \ left (y_1 \ right)} {y_1} + \ frac {\ mu _ {\ widetilde {A}} \ left (y_2 \ right)} {y_2} + \ frac {\ mu _ {\ widetilde {A}} \ left (y_3 \ right)} {y_3} + ... \ right \} $$
$ = \ left \ {\ sum_ {i = 1} ^ {n} \ frac {\ mu _ {\ widetilde {A}} \ left (y_i \ right)} {y_i} \ right \} $
กรณีที่ 2
เมื่อจักรวาลของข้อมูล $ U $ ต่อเนื่องและไม่มีที่สิ้นสุด -
$$ \ widetilde {A} = \ left \ {\ int \ frac {\ mu _ {\ widetilde {A}} \ left (y \ right)} {y} \ right \} $$
ในการแทนค่าข้างต้นสัญลักษณ์ summation แสดงถึงคอลเล็กชันของแต่ละองค์ประกอบ
การดำเนินการกับ Fuzzy Sets
การมีสองชุดที่คลุมเครือ $ \ widetilde {A} $ และ $ \ widetilde {B} $ จักรวาลของข้อมูล $ U $ และองค์ประกอบð ?? '¦ ของจักรวาลความสัมพันธ์ต่อไปนี้แสดงถึงการรวมกันการตัดกันและการดำเนินการเสริม ในชุดคลุมเครือ
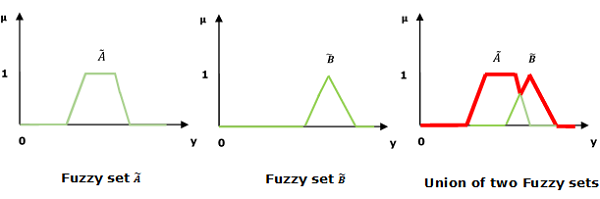
สหภาพ / ฟัซซี่â€âOR’
ให้เราพิจารณาการนำเสนอต่อไปนี้เพื่อทำความเข้าใจว่าไฟล์ Union/Fuzzy ‘OR’ งานสัมพันธ์ -
$$ \ mu _ {{\ widetilde {A} \ cup \ widetilde {B}}} \ left (y \ right) = \ mu _ {\ widetilde {A}} \ vee \ mu _ \ widetilde {B} \ quad \ forall y \ ใน U $$
ในที่นี้∨แสดงถึงการดำเนินการ†˜maxâ €™
ทางแยก / ฟัซซี่†˜ANDâ €™
ให้เราพิจารณาการนำเสนอต่อไปนี้เพื่อทำความเข้าใจว่าไฟล์ Intersection/Fuzzy ‘AND’ งานสัมพันธ์ -
$$ \ mu _ {{\ widetilde {A} \ cap \ widetilde {B}}} \ left (y \ right) = \ mu _ {\ widetilde {A}} \ wedge \ mu _ \ widetilde {B} \ quad \ forall y \ ใน U $$
ในที่นี้∧แสดงถึงการดำเนินการ†˜minâ €™

เติมเต็ม / คลุมเครือ†˜NOTâ €™
ให้เราพิจารณาการนำเสนอต่อไปนี้เพื่อทำความเข้าใจว่าไฟล์ Complement/Fuzzy ‘NOT’ งานสัมพันธ์ -
$$ \ mu _ {\ widetilde {A}} = 1- \ mu _ {\ widetilde {A}} \ left (y \ right) \ quad y \ in U $$

คุณสมบัติของชุดฟัซซี่
ให้เราพิจารณาคุณสมบัติที่แตกต่างกันของเซตฟัซซี
คุณสมบัติการสับเปลี่ยน
มีสองชุดที่คลุมเครือ $ \ widetilde {A} $ และ $ \ widetilde {B} $ คุณสมบัตินี้จะระบุ -
$$ \ widetilde {A} \ cup \ widetilde {B} = \ widetilde {B} \ cup \ widetilde {A} $$
$$ \ widetilde {A} \ cap \ widetilde {B} = \ widetilde {B} \ cap \ widetilde {A} $$
ทรัพย์สินที่เกี่ยวข้อง
การมีชุดคลุมเครือสามชุด $ \ widetilde {A} $, $ \ widetilde {B} $ และ $ \ widetilde {C} $ คุณสมบัตินี้ระบุ -
$$ (\ widetilde {A} \ cup \ left \ widetilde {B}) \ cup \ widetilde {C} \ right = \ left \ widetilde {A} \ cup (\ widetilde {B} \ right) \ cup \ widetilde {C}) $$
$$ (\ widetilde {A} \ cap \ left \ widetilde {B}) \ cap \ widetilde {C} \ right = \ left \ widetilde {A} \ cup (\ widetilde {B} \ right \ cap \ widetilde { C}) $$
ทรัพย์สินกระจาย
การมีชุดคลุมเครือสามชุด $ \ widetilde {A} $, $ \ widetilde {B} $ และ $ \ widetilde {C} $ คุณสมบัตินี้ระบุ -
$$ \ widetilde {A} \ cup \ left (\ widetilde {B} \ cap \ widetilde {C} \ right) = \ left (\ widetilde {A} \ cup \ widetilde {B} \ right) \ cap \ left (\ widetilde {A} \ cup \ widetilde {C} \ right) $$
$$ \ widetilde {A} \ cap \ left (\ widetilde {B} \ cup \ widetilde {C} \ right) = \ left (\ widetilde {A} \ cap \ widetilde {B} \ right) \ cup \ left (\ widetilde {A} \ cap \ widetilde {C} \ right) $$
คุณสมบัติ Idempotency
สำหรับชุดที่คลุมเครือ $ \ widetilde {A} $ คุณสมบัตินี้จะระบุ -
$$ \ widetilde {A} \ cup \ widetilde {A} = \ widetilde {A} $$
$$ \ widetilde {A} \ cap \ widetilde {A} = \ widetilde {A} $$
ทรัพย์สินประจำตัว
สำหรับชุดคลุมเครือ $ \ widetilde {A} $ และชุดสากล $ U $ คุณสมบัตินี้จะระบุ -
$$ \ widetilde {A} \ cup \ varphi = \ widetilde {A} $$
$$ \ widetilde {A} \ cap U = \ widetilde {A} $$
$$ \ widetilde {A} \ cap \ varphi = \ varphi $$
$$ \ widetilde {A} \ cup U = U $$
คุณสมบัติสกรรมกริยา
การมีชุดคลุมเครือสามชุด $ \ widetilde {A} $, $ \ widetilde {B} $ และ $ \ widetilde {C} $ คุณสมบัตินี้ระบุ -
$$ ถ้า \: \ widetilde {A} \ subseteq \ widetilde {B} \ subseteq \ widetilde {C}, \: แล้ว \: \ widetilde {A} \ subseteq \ widetilde {C} $$
คุณสมบัติการบุกรุก
สำหรับชุดที่คลุมเครือ $ \ widetilde {A} $ คุณสมบัตินี้จะระบุ -
$$ \ overline {\ overline {\ widetilde {A}}} = \ widetilde {A} $$
กฎหมายของเดอมอร์แกน
กฎหมายนี้มีบทบาทสำคัญในการพิสูจน์ความไม่แน่นอนและความขัดแย้ง กฎหมายนี้ระบุ -
$$ \ overline {{\ widetilde {A} \ cap \ widetilde {B}}} = \ overline {\ widetilde {A}} \ cup \ overline {\ widetilde {B}} $$
$$ \ overline {{\ widetilde {A} \ cup \ widetilde {B}}} = \ overline {\ widetilde {A}} \ cap \ overline {\ widetilde {B}} $$
เรารู้แล้วว่าตรรกะฟัซซีไม่ใช่ตรรกะที่คลุมเครือ แต่เป็นตรรกะที่ใช้อธิบายความคลุมเครือ ความคลุมเครือนี้โดดเด่นที่สุดด้วยฟังก์ชันการเป็นสมาชิก กล่าวอีกนัยหนึ่งเราสามารถพูดได้ว่าฟังก์ชันการเป็นสมาชิกแสดงถึงระดับของความจริงในตรรกะที่คลุมเครือ

ต่อไปนี้เป็นประเด็นสำคัญบางประการเกี่ยวกับฟังก์ชันการเป็นสมาชิก -
ฟังก์ชั่นการเป็นสมาชิกเปิดตัวครั้งแรกในปี 1965 โดย Lofti A. Zadeh ในเอกสารวิจัยชิ้นแรกของเขาเรื่อง "ชุดคลุมเครือ"
ฟังก์ชันการเป็นสมาชิกจะแสดงลักษณะของความคลุมเครือ (เช่นข้อมูลทั้งหมดในชุดคลุมเครือ) ไม่ว่าองค์ประกอบในชุดฟัซซีจะไม่ต่อเนื่องหรือต่อเนื่อง
ฟังก์ชันการเป็นสมาชิกสามารถกำหนดเป็นเทคนิคในการแก้ปัญหาในทางปฏิบัติโดยอาศัยประสบการณ์มากกว่าความรู้
ฟังก์ชันการเป็นสมาชิกแสดงด้วยรูปแบบกราฟิก
กฎสำหรับการกำหนดความคลุมเครือก็คลุมเครือเช่นกัน
สัญกรณ์คณิตศาสตร์
เราได้ศึกษาแล้วว่าเซตฟัซซี่Ãในจักรวาลของข้อมูลUสามารถกำหนดเป็นเซตของคู่ลำดับและสามารถแทนค่าทางคณิตศาสตร์เป็น -
$$ \ widetilde {A} = \ left \ {\ left (y, \ mu _ {\ widetilde {A}} \ left (y \ right) \ right) | y \ in U \ right \} $$
ที่นี่ $ \ mu \ widetilde {A} \ left (\ bullet \ right) $ = ฟังก์ชันการเป็นสมาชิกของ $ \ widetilde {A} $; สิ่งนี้จะถือว่าค่าอยู่ในช่วงตั้งแต่ 0 ถึง 1 นั่นคือ $ \ mu \ widetilde {A} \ left (\ bullet \ right) \ in \ left [0,1 \ right] $ ฟังก์ชันการเป็นสมาชิก $ \ mu \ widetilde {A} \ left (\ bullet \ right) $ แมป $ U $ กับพื้นที่สมาชิก $ M $
จุด $ \ left (\ bullet \ right) $ ในฟังก์ชันการเป็นสมาชิกที่อธิบายไว้ข้างต้นแสดงถึงองค์ประกอบในชุดที่คลุมเครือ ไม่ว่าจะเป็นแบบไม่ต่อเนื่องหรือต่อเนื่อง
คุณสมบัติของฟังก์ชั่นการเป็นสมาชิก
ตอนนี้เราจะพูดถึงคุณสมบัติต่างๆของฟังก์ชั่นการเป็นสมาชิก
แกน
สำหรับชุดที่คลุมเครือใด ๆ $ \ widetilde {A} $ แกนหลักของฟังก์ชันการเป็นสมาชิกคือขอบเขตของจักรวาลที่กำหนดลักษณะตามการเป็นสมาชิกแบบเต็มในชุด ดังนั้นแกนกลางจึงประกอบด้วยองค์ประกอบทั้งหมด $ y $ ของจักรวาลแห่งข้อมูลเช่นนั้น
$$ \ mu _ {\ widetilde {A}} \ left (y \ right) = 1 $$
สนับสนุน
สำหรับชุดที่คลุมเครือ $ \ widetilde {A} $ การสนับสนุนฟังก์ชันการเป็นสมาชิกคือขอบเขตของจักรวาลที่กำหนดลักษณะโดยการเป็นสมาชิกที่ไม่ใช่ศูนย์ในชุดนั้น ดังนั้นแกนกลางจึงประกอบด้วยองค์ประกอบทั้งหมด $ y $ ของจักรวาลของข้อมูลเช่นนั้น
$$ \ mu _ {\ widetilde {A}} \ left (y \ right)> 0 $$
เขตแดน
สำหรับชุดที่คลุมเครือ $ \ widetilde {A} $ ขอบเขตของฟังก์ชันการเป็นสมาชิกคือขอบเขตของจักรวาลที่มีลักษณะเป็นสมาชิกที่ไม่ใช่ศูนย์ แต่ไม่สมบูรณ์ในชุด ดังนั้นแกนกลางจึงประกอบด้วยองค์ประกอบทั้งหมด $ y $ ของจักรวาลแห่งข้อมูลเช่นนั้น
$$ 1> \ mu _ {\ widetilde {A}} \ left (y \ right)> 0 $$

การทำให้เป็นฝอย
อาจถูกกำหนดให้เป็นขั้นตอนการเปลี่ยนชุดกรอบเป็นชุดฟัซซี่หรือชุดฟัซซี่ให้เป็นชุดฟัซซีเยร์ โดยทั่วไปการดำเนินการนี้จะแปลค่าอินพุตที่คมชัดให้เป็นตัวแปรทางภาษา
ต่อไปนี้เป็นสองวิธีที่สำคัญในการทำให้เป็นฝอย -
สนับสนุนวิธีการ Fuzzification (s-fuzzification)
ในวิธีนี้ชุดฟัซซิไฟด์สามารถแสดงได้ด้วยความช่วยเหลือของความสัมพันธ์ต่อไปนี้ -
$$ \ widetilde {A} = \ mu _1Q \ left (x_1 \ right) + \ mu _2Q \ left (x_2 \ right) + ... + \ mu _nQ \ left (x_n \ right) $$
ที่นี่ชุดฟัซซี่ $ Q \ left (x_i \ right) $ เรียกว่าเป็นเคอร์เนลของฟัซซิฟิเคชัน วิธีนี้ใช้งานได้โดยทำให้ $ \ mu _i $ คงที่และ $ x_i $ ถูกเปลี่ยนเป็นชุดที่คลุมเครือ $ Q \ left (x_i \ right) $
เกรด Fuzzification (g-fuzzification) วิธี
ค่อนข้างคล้ายกับวิธีการข้างต้น แต่ข้อแตกต่างที่สำคัญคือการคงไว้ $ x_i $ คงที่และ $ \ mu _i $ แสดงเป็นชุดคลุมเครือ
การทำให้มึนงง
อาจถูกกำหนดให้เป็นขั้นตอนการลดชุดฟัซซี่ลงในเซ็ตที่คมชัดหรือเพื่อเปลี่ยนสมาชิกฟัซซี่ให้เป็นสมาชิกที่คมชัด
เราได้ศึกษาแล้วว่ากระบวนการฟัซซิฟิเคชันเกี่ยวข้องกับการแปลงจากปริมาณที่คมชัดเป็นปริมาณฟัซซี่ ในการใช้งานทางวิศวกรรมหลายอย่างจำเป็นต้องทำให้ผลลัพธ์เป็นสิ่งที่ผิดปกติหรือ“ ผลลัพธ์ที่ไม่ชัดเจน” เพื่อที่จะต้องแปลงเป็นผลลัพธ์ที่คมชัด ในทางคณิตศาสตร์กระบวนการ Defuzzification เรียกอีกอย่างว่า "ปัดเศษออก"
วิธีการต่างๆในการละลายน้ำแข็งมีคำอธิบายไว้ด้านล่าง -
วิธี Max-Membership
วิธีนี้ จำกัด เฉพาะฟังก์ชันเอาต์พุตสูงสุดและเรียกอีกอย่างว่าวิธีความสูง ในทางคณิตศาสตร์สามารถแสดงได้ดังนี้ -
$$ \ mu _ {\ widetilde {A}} \ left (x ^ * \ right)> \ mu _ {\ widetilde {A}} \ left (x \ right) \: for \: all \: x \ in X $$
ที่นี่ $ x ^ * $ คือเอาต์พุตที่ไม่ถูกทำลาย
วิธี Centroid
วิธีนี้เรียกอีกอย่างว่าจุดศูนย์กลางของพื้นที่หรือวิธีจุดศูนย์ถ่วง ในทางคณิตศาสตร์ผลลัพธ์ defuzzified $ x ^ * $ จะแสดงเป็น -
$$ x ^ * = \ frac {\ int \ mu _ {\ widetilde {A}} \ left (x \ right) .xdx} {\ int \ mu _ {\ widetilde {A}} \ left (x \ right ) .dx} $$
วิธีถัวเฉลี่ยถ่วงน้ำหนัก
ในวิธีนี้ฟังก์ชันการเป็นสมาชิกแต่ละฟังก์ชันจะถ่วงน้ำหนักด้วยมูลค่าสมาชิกสูงสุด ในทางคณิตศาสตร์ผลลัพธ์ defuzzified $ x ^ * $ จะแสดงเป็น -
$$ x ^ * = \ frac {\ sum \ mu _ {\ widetilde {A}} \ left (\ overline {x_i} \ right). \ overline {x_i}} {\ sum \ mu _ {\ widetilde {A }} \ left (\ overline {x_i} \ right)} $$
การเป็นสมาชิก Mean-Max
วิธีนี้เรียกอีกอย่างว่าตรงกลางของแมกซิม่า ในทางคณิตศาสตร์ผลลัพธ์ defuzzified $ x ^ * $ จะแสดงเป็น -
$$ x ^ * = \ frac {\ displaystyle \ sum_ {i = 1} ^ {n} \ overline {x_i}} {n} $$
ลอจิกซึ่งเดิมเป็นเพียงการศึกษาสิ่งที่แยกแยะความแตกต่างของการโต้แย้งที่เป็นเสียงจากการโต้แย้งที่ไม่น่าฟังตอนนี้ได้พัฒนาไปสู่ระบบที่ทรงพลังและเข้มงวดซึ่งสามารถค้นพบข้อความที่เป็นจริงได้เนื่องจากข้อความอื่น ๆ ที่ทราบกันดีอยู่แล้วว่าเป็นจริง
ตรรกะเพรดิเคต
ตรรกะนี้เกี่ยวข้องกับเพรดิเคตซึ่งเป็นประพจน์ที่มีตัวแปร
เพรดิเคตคือนิพจน์ของตัวแปรตั้งแต่หนึ่งตัวขึ้นไปที่กำหนดไว้ในโดเมนเฉพาะบางโดเมน เพรดิเคตที่มีตัวแปรสามารถสร้างเป็นประพจน์ได้โดยการกำหนดค่าให้กับตัวแปรหรือโดยการหาจำนวนตัวแปร
ต่อไปนี้เป็นตัวอย่างบางส่วนของเพรดิเคต -
- ให้ E (x, y) แสดงว่า "x = y"
- ให้ X (a, b, c) แสดงว่า "a + b + c = 0"
- ให้ M (x, y) แสดงว่า "x แต่งงานกับ y"
ตรรกะเชิงเสนอ
ประพจน์คือชุดของข้อความประกาศที่มีทั้งค่าความจริงเป็น "จริง" หรือค่าความจริง "เท็จ" ประพจน์ประกอบด้วยตัวแปรเชิงประพจน์และคอนเนคเตอร์ตัวแปรเชิงประพจน์จะเว้าด้วยตัวพิมพ์ใหญ่ (A, B ฯลฯ ) Connectives เชื่อมต่อตัวแปรเชิงประพจน์
ตัวอย่างบางส่วนของข้อเสนอมีให้ด้านล่าง -
- "มนุษย์เป็นมนุษย์" จะส่งกลับค่าความจริง "TRUE"
- "12 + 9 = 3 - 2" จะส่งกลับค่าความจริง "FALSE"
ต่อไปนี้ไม่ใช่ข้อเสนอ -
"A is less than 2" - เป็นเพราะถ้าเราไม่ให้ค่าเฉพาะของ A เราไม่สามารถบอกได้ว่าข้อความนั้นเป็นจริงหรือเท็จ
Connectives
ในตรรกะเชิงประพจน์เราใช้การเชื่อมต่อห้าประการต่อไปนี้ -
- หรือ (∨∨)
- และ (∧∧)
- การปฏิเสธ / ไม่ (¬¬)
- นัย / ถ้า - แล้ว (→→)
- ถ้าและเฉพาะในกรณีที่ (⇔⇔)
หรือ (∨∨)
การดำเนินการ OR ของสองประพจน์ A และ B (เขียนเป็นA∨BA∨B) เป็นจริงถ้าตัวแปรประพจน์ A หรือ B เป็นจริงอย่างน้อยที่สุด
ตารางความจริงมีดังนี้ -
| ก | ข | ก∨ข |
|---|---|---|
| จริง | จริง | จริง |
| จริง | เท็จ | จริง |
| เท็จ | จริง | จริง |
| เท็จ | เท็จ | เท็จ |
และ (∧∧)
การดำเนินการ AND ของสองประพจน์ A และ B (เขียนเป็นA∧BA∧B) เป็นจริงถ้าทั้งตัวแปรประพจน์ A และ B เป็นจริง
ตารางความจริงมีดังนี้ -
| ก | ข | ก∧ข |
|---|---|---|
| จริง | จริง | จริง |
| จริง | เท็จ | เท็จ |
| เท็จ | จริง | เท็จ |
| เท็จ | เท็จ | เท็จ |
การปฏิเสธ (¬¬)
การปฏิเสธของประพจน์ A (เขียนเป็น¬A¬A) เป็นเท็จเมื่อ A เป็นจริงและเป็นจริงเมื่อ A เป็นเท็จ
ตารางความจริงมีดังนี้ -
| ก | ¬A |
|---|---|
| จริง | เท็จ |
| เท็จ | จริง |
นัย / ถ้า - แล้ว (→→)
ความหมาย A → BA → B คือโจทย์“ ถ้า A แล้ว B” เป็นเท็จถ้า A เป็นจริงและ B เป็นเท็จ กรณีที่เหลือเป็นเรื่องจริง
ตารางความจริงมีดังนี้ -
| ก | ข | ก→ข |
|---|---|---|
| จริง | จริง | จริง |
| จริง | เท็จ | เท็จ |
| เท็จ | จริง | จริง |
| เท็จ | เท็จ | จริง |
ถ้าและเฉพาะในกรณีที่ (⇔⇔)
A⇔BA⇔Bคือการเชื่อมต่อเชิงตรรกะแบบสองเงื่อนไขซึ่งเป็นจริงเมื่อ p และ q เหมือนกันกล่าวคือทั้งสองเป็นเท็จหรือทั้งสองอย่างเป็นจริง
ตารางความจริงมีดังนี้ -
| ก | ข | A⇔B |
|---|---|---|
| จริง | จริง | จริง |
| จริง | เท็จ | เท็จ |
| เท็จ | จริง | เท็จ |
| เท็จ | เท็จ | จริง |
สูตรที่สร้างขึ้นอย่างดี
Well Formed Formula (wff) เป็นเพรดิเคตที่ถือหนึ่งในสิ่งต่อไปนี้ -
- ค่าคงที่เชิงประพจน์และตัวแปรเชิงประพจน์ทั้งหมดเป็น wffs
- ถ้า x เป็นตัวแปรและ Y คือ wff ∀xYและ∃xYก็เป็น wff เช่นกัน
- ค่าความจริงและค่าเท็จคือ wffs
- สูตรอะตอมแต่ละสูตรคือ wff
- การเชื่อมต่อทั้งหมดที่เชื่อมต่อ wffs เป็น wffs
Quantifiers
ตัวแปรของเพรดิเคตถูกหาค่าโดยตัวระบุปริมาณ มีสองประเภทของตัวระบุในตรรกะเพรดิเคต -
- Universal Quantifier
- ตัวบ่งชี้ที่มีอยู่
Universal Quantifier
Universal quantifier ระบุว่าคำสั่งภายในขอบเขตเป็นจริงสำหรับทุกค่าของตัวแปรเฉพาะ มันแสดงด้วยสัญลักษณ์∀
∀xP(x) จะอ่านเป็นค่า x ทุกค่า P (x) เป็นจริง
Example- "มนุษย์เป็นมนุษย์" สามารถเปลี่ยนเป็นรูปแบบประพจน์ proposxP (x) ในที่นี้ P (x) คือเพรดิเคตที่แสดงว่า x เป็นมนุษย์และจักรวาลของวาทกรรมคือผู้ชายทั้งหมด
ตัวบ่งชี้ที่มีอยู่
ตัวบ่งชี้ที่มีอยู่ระบุว่าข้อความภายในขอบเขตเป็นจริงสำหรับค่าบางค่าของตัวแปรเฉพาะ มันแสดงด้วยสัญลักษณ์∃
∃xP(x) สำหรับค่า x บางค่าถูกอ่านว่า P (x) เป็นจริง
Example - "บางคนไม่ซื่อสัตย์" สามารถเปลี่ยนเป็นรูปแบบประพจน์∃x P (x) โดยที่ P (x) คือเพรดิเคตที่แสดงว่า x ไม่ซื่อสัตย์และจักรวาลของวาทกรรมคือบางคน
Quantifier ที่ซ้อนกัน
ถ้าเราใช้ตัวระบุปริมาณที่ปรากฏภายในขอบเขตของตัวระบุตัวระบุอื่นจะเรียกว่าตัวระบุจำนวนที่ซ้อนกัน
Example
- ∀a∃bP (x, y) โดยที่ P (a, b) หมายถึง a + b = 0
- ∀a∀b∀cP (a, b, c) โดยที่ P (a, b) หมายถึง a + (b + c) = (a + b) + c
Note - ∀a∃bP (x, y) ≠∃a∀bP (x, y)
ต่อไปนี้เป็นโหมดต่างๆของการให้เหตุผลโดยประมาณ -
การให้เหตุผลตามหมวดหมู่
ในโหมดของการให้เหตุผลโดยประมาณนี้จะถือว่าสิ่งที่มีอยู่ก่อนหน้าซึ่งไม่มีตัวระบุจำนวนที่คลุมเครือและความน่าจะเป็นแบบฟัซซี่จะถือว่าอยู่ในรูปแบบบัญญัติ
การใช้เหตุผลเชิงคุณภาพ
ในรูปแบบของการให้เหตุผลโดยประมาณนี้เนื้อหาก่อนหน้าและผลที่ตามมามีตัวแปรทางภาษาที่คลุมเครือ ความสัมพันธ์อินพุต - เอาต์พุตของระบบจะแสดงเป็นชุดของกฎ IF-THEN ที่คลุมเครือ การให้เหตุผลนี้ส่วนใหญ่ใช้ในการวิเคราะห์ระบบควบคุม
การให้เหตุผลเชิงพยางค์
ในรูปแบบของการให้เหตุผลโดยประมาณนี้เนื้อหาก่อนหน้าที่มีตัวระบุจำนวนที่คลุมเครือเกี่ยวข้องกับกฎการอนุมาน สิ่งนี้แสดงเป็น -
x = S 1 A เป็น B′s
y = S 2 C คือ D′s
------------------------
z = S 3 E คือ F
ที่นี่ A, B, C, D, E, F เป็นเพรดิเคตที่คลุมเครือ
S 1และS 2ได้รับตัวระบุจำนวนที่คลุมเครือ
S 3เป็นตัวระบุจำนวนที่ไม่ชัดเจนซึ่งต้องตัดสินใจ
เหตุผลในการจัดการ
ในรูปแบบของการให้เหตุผลโดยประมาณนี้คำก่อนหน้าคือการจัดการที่อาจมีตัวระบุจำนวนที่คลุมเครือ“ โดยปกติ” ตัวบ่งชี้Usuallyเชื่อมโยงการให้เหตุผลเชิงการจัดการและการอ้างเหตุผลเข้าด้วยกัน ด้วยเหตุนี้จึงมีบทบาทสำคัญ
ตัวอย่างเช่นกฎการคาดการณ์ของการอนุมานในการให้เหตุผลเชิงการตลาดสามารถระบุได้ดังนี้ -
โดยปกติ ((L, M) คือ R) ⇒โดยปกติ (L คือ [R ↓ L])
ที่นี่ [R ↓ L] คือการฉายภาพของความสัมพันธ์ที่คลุมเครือ R บน L
Fuzzy Logic Rule Base
เป็นที่ทราบกันดีอยู่แล้วว่ามนุษย์มักจะรู้สึกสบายใจในการสนทนาด้วยภาษาที่เป็นธรรมชาติ การแสดงความรู้ของมนุษย์สามารถทำได้ด้วยความช่วยเหลือของการแสดงออกทางภาษาธรรมชาติดังต่อไปนี้ -
IF ก่อนหน้านี้ THEN ตามมา
นิพจน์ตามที่ระบุไว้ข้างต้นเรียกว่าฐานของกฎ IF-THEN ที่คลุมเครือ
รูปแบบบัญญัติ
ต่อไปนี้เป็นรูปแบบบัญญัติของ Fuzzy Logic Rule Base -
Rule 1 - ถ้าเงื่อนไข C1 ข้อ จำกัด R1
Rule 2 - ถ้าเงื่อนไข C1 ข้อ จำกัด R2
.
.
.
Rule n - ถ้าเงื่อนไข C1 ข้อ จำกัด Rn
การตีความกฎ IF-THEN ที่คลุมเครือ
กฎ IF-THEN ที่คลุมเครือสามารถตีความได้ในสี่รูปแบบต่อไปนี้ -
งบการมอบหมายงาน
ข้อความประเภทนี้ใช้“ =” (เท่ากับเครื่องหมาย) เพื่อวัตถุประสงค์ในการมอบหมายงาน มีรูปแบบดังต่อไปนี้ -
a = สวัสดี
ภูมิอากาศ = ฤดูร้อน
งบเงื่อนไข
ข้อความประเภทนี้ใช้รูปแบบฐานของกฎ "IF-THEN" เพื่อจุดประสงค์ของเงื่อนไข มีรูปแบบดังต่อไปนี้ -
ถ้าอุณหภูมิสูงแล้วภูมิอากาศจะร้อน
ถ้าอาหารสดก็กิน
ข้อความที่ไม่มีเงื่อนไข
มีรูปแบบดังต่อไปนี้ -
ก๊อต 10
ปิดพัดลม
ตัวแปรทางภาษา
เราได้ศึกษาว่าฟัซซี่ลอจิกใช้ตัวแปรทางภาษาซึ่งเป็นคำหรือประโยคในภาษาธรรมชาติ ตัวอย่างเช่นถ้าเราพูดว่าอุณหภูมิก็เป็นตัวแปรทางภาษา ค่าที่ร้อนมากหรือเย็นมากร้อนหรือเย็นเล็กน้อยอบอุ่นมากอบอุ่นเล็กน้อย ฯลฯ คำมากเล็กน้อยเป็นการป้องกันความเสี่ยงทางภาษา
ลักษณะเฉพาะของตัวแปรทางภาษา
คำศัพท์สี่คำตามลักษณะของตัวแปรทางภาษา -
- ชื่อของตัวแปรโดยทั่วไปแสดงด้วย x
- ชุดคำของตัวแปรโดยทั่วไปแสดงด้วย t (x)
- กฎไวยากรณ์สำหรับสร้างค่าของตัวแปร x
- กฎความหมายสำหรับการเชื่อมโยงทุกค่าของ x และนัยสำคัญ
ข้อเสนอใน Fuzzy Logic
ดังที่เราทราบว่าประพจน์เป็นประโยคที่แสดงในภาษาใด ๆ ซึ่งโดยทั่วไปจะแสดงในรูปแบบบัญญัติต่อไปนี้ -
s เป็น P
นี่sเป็นเรื่องและPเป็นคำกริยา
ตัวอย่างเช่น“ เดลีเป็นเมืองหลวงของอินเดีย ” นี่คือโจทย์ที่“ เดลี ” เป็นหัวเรื่องและ“ เป็นเมืองหลวงของอินเดีย ” คือคำกริยาที่แสดงคุณสมบัติของหัวเรื่อง
เราทราบดีว่าตรรกะเป็นพื้นฐานของการให้เหตุผลและตรรกะที่คลุมเครือได้ขยายขีดความสามารถในการให้เหตุผลโดยใช้เพรดิเคตแบบฟัซซี่ตัวปรับแต่งฟัซซีเพรดิเคตตัวระบุจำนวนที่คลุมเครือและคุณสมบัติเชิงลบในข้อเสนอที่คลุมเครือซึ่งสร้างความแตกต่างจากตรรกะคลาสสิก
ข้อเสนอในฟัซซีลอจิกมีดังต่อไปนี้ -
พร่าเลือน
เกือบทุกคำกริยาในภาษาธรรมชาติจึงไม่ชัดเจนในธรรมชาติดังนั้นตรรกะที่คลุมเครือจึงมีเพรดิเคตเช่นสูงสั้นอบอุ่นร้อนเร็ว ฯลฯ
ตัวดัดแปลงฟัซซีเพรดิเคต
เราได้กล่าวถึงการป้องกันความเสี่ยงทางภาษาข้างต้น นอกจากนี้เรายังมีตัวปรับแต่งฟัซซีเพรดิเคตจำนวนมากซึ่งทำหน้าที่เป็นตัวป้องกันความเสี่ยง สิ่งเหล่านี้มีความสำคัญมากในการสร้างค่าของตัวแปรทางภาษา ตัวอย่างเช่นคำว่า very เล็กน้อยเป็นตัวปรับแต่งและประพจน์อาจเป็นเช่น " น้ำร้อนเล็กน้อย "
Fuzzy Quantifiers
สามารถกำหนดเป็นจำนวนที่คลุมเครือซึ่งให้การจำแนกที่คลุมเครือของจำนวนคาร์ดินาลลิตี้ของชุดคลุมเครือหรือไม่คลุมเครือหนึ่งชุดขึ้นไป สามารถใช้เพื่อส่งผลต่อความน่าจะเป็นภายในตรรกะที่คลุมเครือ ตัวอย่างเช่นคำที่หลายคนมักใช้เป็นตัวระบุจำนวนที่คลุมเครือและข้อเสนออาจเป็นเช่น " คนส่วนใหญ่แพ้ "
รอบคัดเลือกที่คลุมเครือ
ตอนนี้ให้เราเข้าใจ Fuzzy Qualifiers Fuzzy Qualifier เป็นโจทย์ของ Fuzzy Logic คุณสมบัติฟัซซีมีรูปแบบดังต่อไปนี้ -
คุณสมบัติที่คลุมเครืออยู่บนพื้นฐานของความจริง
มันอ้างระดับความจริงของเรื่องที่คลุมเครือ
Expression- โดยจะแสดงเป็นX เป็นเสื้อ นี่tคือค่าความจริงที่คลุมเครือ
Example - (รถเป็นสีดำ) ไม่เป็นความจริง
คุณสมบัติคลุมเครือขึ้นอยู่กับความน่าจะเป็น
มันอ้างถึงความน่าจะเป็นทั้งตัวเลขหรือช่วงเวลาของประพจน์ที่คลุมเครือ
Expression- โดยจะแสดงเป็นX คือλ ที่นี่λคือความน่าจะเป็นที่คลุมเครือ
Example - (รถเป็นสีดำ) มีแนวโน้ม
คุณสมบัติที่คลุมเครือขึ้นอยู่กับความเป็นไปได้
มันอ้างถึงความเป็นไปได้ของเรื่องที่คลุมเครือ
Expression- โดยจะแสดงเป็นX คือπ ที่นี่πเป็นไปได้ที่คลุมเครือ
Example - (รถเป็นสีดำ) เกือบจะเป็นไปไม่ได้
Fuzzy Inference System เป็นหน่วยหลักของระบบลอจิกฟัซซีที่มีการตัดสินใจเป็นงานหลัก โดยใช้กฎ“ IF … THEN” ร่วมกับตัวเชื่อมต่อ“ OR” หรือ“ AND” เพื่อวาดกฎการตัดสินใจที่สำคัญ
ลักษณะของระบบการอนุมานแบบฟัซซี่
ต่อไปนี้เป็นลักษณะบางประการของ FIS -
เอาต์พุตจาก FIS เป็นชุดที่ไม่ชัดเจนเสมอโดยไม่คำนึงถึงอินพุตซึ่งอาจเลือนหรือคมชัด
จำเป็นต้องมีเอาต์พุตที่ไม่ชัดเจนเมื่อใช้เป็นตัวควบคุม
หน่วย defuzzification จะอยู่ที่นั่นพร้อมกับ FIS เพื่อแปลงตัวแปรฟัซซี่เป็นตัวแปรที่คมชัด
บล็อกการทำงานของ FIS
ห้าบล็อกการทำงานต่อไปนี้จะช่วยให้คุณเข้าใจการสร้าง FIS -
Rule Base - มีกฎ IF-THEN ที่คลุมเครือ
Database - กำหนดฟังก์ชั่นการเป็นสมาชิกของชุดคลุมเครือที่ใช้ในกฎคลุมเครือ
Decision-making Unit - ดำเนินการตามกฎ
Fuzzification Interface Unit - แปลงปริมาณที่คมชัดเป็นปริมาณที่ไม่ชัดเจน
Defuzzification Interface Unit- แปลงปริมาณที่คลุมเครือเป็นปริมาณที่คมชัด ต่อไปนี้เป็นแผนภาพบล็อกของระบบรบกวนที่คลุมเครือ

การทำงานของ FIS
การทำงานของ FIS ประกอบด้วยขั้นตอนต่อไปนี้ -
หน่วยฟัซซิฟิเคชันรองรับการใช้วิธีการฟัซซิฟิเคชันจำนวนมากและแปลงอินพุตที่คมชัดเป็นอินพุตแบบฟัซซี่
ฐานความรู้ - การรวบรวมฐานกฎและฐานข้อมูลเกิดขึ้นจากการแปลงอินพุตที่คมชัดให้เป็นอินพุตที่คลุมเครือ
ในที่สุดอินพุทฟัซซีของหน่วย defuzzification จะถูกแปลงเป็นเอาต์พุตที่คมชัด
วิธีการของ FIS
ตอนนี้ให้เราพูดถึงวิธีการต่างๆของ FIS ต่อไปนี้เป็นวิธีการที่สำคัญสองวิธีของ FIS ซึ่งมีผลลัพธ์ที่แตกต่างกันของกฎที่คลุมเครือ -
- ระบบอนุมานมัมดานีฟัซซี่
- Takagi-Sugeno Fuzzy Model (วิธี TS)
ระบบอนุมานมัมดานีฟัซซี่
ระบบนี้เสนอในปีพ. ศ. 2518 โดย Ebhasim Mamdani โดยทั่วไปคาดว่าจะควบคุมเครื่องยนต์ไอน้ำและหม้อไอน้ำร่วมกันโดยการสังเคราะห์ชุดของกฎที่ไม่ชัดเจนที่ได้รับจากผู้ที่ทำงานกับระบบ
ขั้นตอนในการคำนวณผลลัพธ์
ต้องทำตามขั้นตอนต่อไปนี้เพื่อคำนวณผลลัพธ์จาก FIS นี้ -
Step 1 - ต้องกำหนดชุดกฎที่คลุมเครือในขั้นตอนนี้
Step 2 - ในขั้นตอนนี้โดยใช้ฟังก์ชั่นการเป็นสมาชิกอินพุตอินพุตจะไม่ชัดเจน
Step 3 - ตอนนี้สร้างความแข็งแกร่งของกฎโดยการรวมอินพุตที่คลุมเครือตามกฎที่คลุมเครือ
Step 4 - ในขั้นตอนนี้กำหนดผลลัพธ์ของกฎโดยการรวมความแข็งแกร่งของกฎและฟังก์ชันการเป็นสมาชิกเอาต์พุต
Step 5 - สำหรับการกระจายเอาต์พุตให้รวมผลลัพธ์ทั้งหมด
Step 6 - สุดท้ายจะได้รับการแจกแจงเอาท์พุต defuzzified
ต่อไปนี้เป็นแผนภาพบล็อกของ Mamdani Fuzzy Interface System

Takagi-Sugeno Fuzzy Model (วิธี TS)
โมเดลนี้เสนอโดย Takagi, Sugeno และ Kang ในปี 1985 รูปแบบของกฎนี้กำหนดเป็น -
ถ้า x คือ A และ y คือ B แล้ว Z = f (x, y)
ในที่นี้ABเป็นเซตที่ไม่ชัดเจนในช่วงก่อนหน้าและz = f (x, y)เป็นฟังก์ชันที่คมชัดในผลลัพธ์ที่ตามมา
กระบวนการอนุมานที่คลุมเครือ
กระบวนการอนุมานที่คลุมเครือภายใต้ Takagi-Sugeno Fuzzy Model (TS Method) ทำงานในลักษณะต่อไปนี้ -
Step 1: Fuzzifying the inputs - ที่นี่ปัจจัยการผลิตของระบบถูกทำให้คลุมเครือ
Step 2: Applying the fuzzy operator - ในขั้นตอนนี้ต้องใช้ตัวดำเนินการฟัซซี่เพื่อให้ได้ผลลัพธ์
รูปแบบกฎของแบบฟอร์ม Sugeno
รูปแบบกฎของแบบฟอร์ม Sugeno กำหนดโดย -
ถ้า 7 = x และ 9 = y ผลลัพธ์คือ z = ax + by + c
เปรียบเทียบระหว่างสองวิธี
ตอนนี้ให้เราเข้าใจการเปรียบเทียบระหว่างระบบมัมดานีและโมเดลซูเกโน
Output Membership Function- ความแตกต่างที่สำคัญระหว่างพวกเขาอยู่บนพื้นฐานของฟังก์ชันการเป็นสมาชิกเอาต์พุต ฟังก์ชันการเป็นสมาชิกเอาต์พุตของ Sugeno เป็นแบบเชิงเส้นหรือแบบคงที่
Aggregation and Defuzzification Procedure - ความแตกต่างระหว่างกฎเหล่านี้ยังอยู่ในผลของกฎที่คลุมเครือและเนื่องจากขั้นตอนการรวมและขั้นตอนการละลายน้ำแข็งก็แตกต่างกันเช่นกัน
Mathematical Rules - มีกฎทางคณิตศาสตร์สำหรับกฎ Sugeno มากกว่ากฎมัมดานี
Adjustable Parameters - คอนโทรลเลอร์ Sugeno มีพารามิเตอร์ที่ปรับได้มากกว่าคอนโทรลเลอร์ Mamdani
เราได้ศึกษาในบทก่อนหน้านี้ว่า Fuzzy Logic เป็นแนวทางในการคำนวณตาม "ระดับของความจริง" มากกว่าตรรกะ "จริงหรือเท็จ" ตามปกติ มันเกี่ยวข้องกับการให้เหตุผลโดยประมาณแทนที่จะแม่นยำในการแก้ปัญหาในลักษณะที่คล้ายคลึงกับตรรกะของมนุษย์มากขึ้นดังนั้นกระบวนการสืบค้นฐานข้อมูลโดยการตระหนักถึงคุณค่าของพีชคณิตบูลีนสองค่าจึงไม่เพียงพอ
สถานการณ์ไม่ชัดเจนของความสัมพันธ์บนฐานข้อมูล
สถานการณ์ความสัมพันธ์ที่คลุมเครือบนฐานข้อมูลสามารถเข้าใจได้ด้วยความช่วยเหลือของตัวอย่างต่อไปนี้ -
ตัวอย่าง
สมมติว่าเรามีฐานข้อมูลที่มีบันทึกของบุคคลที่เคยไปเยือนอินเดีย ในฐานข้อมูลอย่างง่ายเราจะมีรายการดังต่อไปนี้ -
| ชื่อ | อายุ | พลเมือง | เยือนประเทศ | วันที่ใช้ไป | ปีที่เข้าชม |
|---|---|---|---|---|---|
| จอห์นสมิ ธ | 35 | เรา | อินเดีย | 41 | พ.ศ. 2542 |
| จอห์นสมิ ธ | 35 | เรา | อิตาลี | 72 | พ.ศ. 2542 |
| จอห์นสมิ ธ | 35 | เรา | ญี่ปุ่น | 31 | พ.ศ. 2542 |
ตอนนี้หากใครสอบถามเกี่ยวกับบุคคลที่ไปเยือนอินเดียและญี่ปุ่นในปี 99 และเป็นพลเมืองของสหรัฐอเมริกาผลลัพธ์จะแสดงสองรายการที่มีชื่อของจอห์นสมิ ธ นี่คือการสืบค้นง่ายๆที่สร้างผลลัพธ์อย่างง่าย
แต่ถ้าเราต้องการทราบว่าบุคคลในข้อความค้นหาข้างต้นนั้นอายุน้อยหรือไม่ ตามผลข้างต้นอายุของบุคคลคือ 35 ปี แต่เราสามารถสันนิษฐานได้ว่าคน ๆ นั้นอายุน้อยหรือไม่? ในทำนองเดียวกันสามารถใช้สิ่งเดียวกันกับสาขาอื่น ๆ เช่นวันที่ใช้ไปปีที่เยี่ยมชมเป็นต้น
การแก้ปัญหาข้างต้นสามารถพบได้ด้วยความช่วยเหลือของชุดค่า Fuzzy ดังนี้ -
FV (Age) {เด็กมากอ่อนวัยค่อนข้างแก่}
FV (วันที่ใช้ไป) {แทบจะไม่กี่วันสองสามวันไม่กี่วันหลายวัน}
FV (ปีที่เยี่ยมชม) {อดีตอันไกลโพ้น, อดีตล่าสุด, ล่าสุด}
ตอนนี้หากข้อความค้นหาใด ๆ มีค่าฟัซซีผลลัพธ์ก็จะไม่ชัดเจน
ระบบแบบสอบถามที่คลุมเครือ
ระบบเคียวรีแบบคลุมเครือเป็นส่วนต่อประสานกับผู้ใช้เพื่อรับข้อมูลจากฐานข้อมูลโดยใช้ประโยคภาษาธรรมชาติ (เสมือน) มีการเสนอการใช้คำค้นหาที่คลุมเครือจำนวนมากส่งผลให้ภาษาต่างกันเล็กน้อย แม้ว่าจะมีรูปแบบที่แตกต่างกันไปตามลักษณะเฉพาะของการใช้งานที่แตกต่างกัน แต่คำตอบของประโยคคำค้นหาที่คลุมเครือโดยทั่วไปคือรายการของบันทึกซึ่งจัดอันดับตามระดับของการจับคู่
ในการสร้างแบบจำลองข้อความภาษาธรรมชาติข้อความเชิงปริมาณมีบทบาทสำคัญ หมายความว่า NL ขึ้นอยู่กับการสร้างเชิงปริมาณซึ่งมักจะรวมถึงแนวคิดที่คลุมเครือเช่น "เกือบทั้งหมด" "จำนวนมาก" ฯลฯ ต่อไปนี้เป็นตัวอย่างบางส่วนของข้อเสนอเชิงปริมาณ -
- นักเรียนทุกคนสอบผ่าน
- รถสปอร์ตราคาแพงทุกคัน
- นักเรียนหลายคนสอบผ่าน
- รถสปอร์ตหลายคันมีราคาแพง
ในตัวอย่างข้างต้นตัวระบุปริมาณ "ทุกคน" และ "จำนวนมาก" ถูกนำไปใช้กับข้อ จำกัด ที่ชัดเจน "นักเรียน" ตลอดจนขอบเขตที่ชัดเจน "(ผู้ที่) สอบผ่าน" และ "รถยนต์" รวมถึง "กีฬา" ที่ชัดเจน
เหตุการณ์ที่ไม่ชัดเจนวิธีการที่คลุมเครือและความแปรปรวนที่ไม่ชัดเจน
ด้วยความช่วยเหลือของตัวอย่างเราสามารถเข้าใจแนวคิดข้างต้น สมมติว่าเราเป็นผู้ถือหุ้นของ บริษัท ชื่อ ABC และในปัจจุบัน บริษัท กำลังขายหุ้นแต่ละหุ้นในราคา₹ 40 มี บริษัท สามแห่งที่มีธุรกิจคล้ายกับ ABC แต่เสนอขายหุ้นในอัตราที่แตกต่างกัน - ₹ 100 ต่อหุ้น, 85 ต่อหุ้นและ₹ 60 ต่อหุ้นตามลำดับ
ตอนนี้การกระจายความน่าจะเป็นของการครอบครองราคานี้เป็นดังนี้ -
| ราคา | 100 บาท | ฿ 85 | ฿ 60 |
|---|---|---|---|
| ความน่าจะเป็น | 0.3 | 0.5 | 0.2 |
ตอนนี้จากทฤษฎีความน่าจะเป็นมาตรฐานการแจกแจงข้างต้นให้ค่าเฉลี่ยของราคาที่คาดหวังดังต่อไปนี้ -
100 × 0.3 + 85 × 0.5 + 60 × 0.2 = 84.5 $
และจากทฤษฎีความน่าจะเป็นมาตรฐานการแจกแจงข้างต้นให้ความแปรปรวนของราคาที่คาดหวังดังต่อไปนี้ -
$ (100 - 84.5) 2 × 0.3 + (85 - 84.5) 2 × 0.5 + (60 - 84.5) 2 × 0.2 = 124.825 $
สมมติว่าระดับการเป็นสมาชิก 100 ในชุดนี้คือ 0.7, 85 คือ 1 และระดับการเป็นสมาชิกคือ 0.5 สำหรับค่า 60 สิ่งเหล่านี้สามารถสะท้อนให้เห็นได้ในชุดที่คลุมเครือต่อไปนี้ -
$$ \ left \ {\ frac {0.7} {100}, \: \ frac {1} {85}, \: \ frac {0.5} {60}, \ right \} $$
ชุดคลุมเครือที่ได้รับในลักษณะนี้เรียกว่าเหตุการณ์ที่เลือนลาง
เราต้องการความน่าจะเป็นของเหตุการณ์ฟัซซี่ที่การคำนวณของเราให้ -
0.7 × 0.3 + 1 × 0.5 + 0.5 × 0.2 = 0.21 + 0.5 + 0.1 = 0.81 $
ตอนนี้เราต้องคำนวณค่าเฉลี่ยฟัซซีและความแปรปรวนแบบฟัซซีการคำนวณมีดังนี้ -
Fuzzy_mean $ = \ left (\ frac {1} {0.81} \ right) × (100 × 0.7 × 0.3 + 85 × 1 × 0.5 + 60 × 0.5 × 0.2) $
$ = 85.8 $
Fuzzy_Variance $ = 7496.91 - 7361.91 = 135.27 $
เป็นกิจกรรมที่รวมถึงขั้นตอนในการเลือกทางเลือกที่เหมาะสมจากสิ่งที่จำเป็นสำหรับการบรรลุเป้าหมายบางอย่าง
ขั้นตอนในการตัดสินใจ
ตอนนี้ให้เราหารือเกี่ยวกับขั้นตอนที่เกี่ยวข้องในกระบวนการตัดสินใจ -
Determining the Set of Alternatives - ในขั้นตอนนี้จะต้องกำหนดทางเลือกอื่นที่จะต้องใช้ในการตัดสินใจ
Evaluating Alternative - ในที่นี้จะต้องมีการประเมินทางเลือกอื่นเพื่อให้สามารถตัดสินใจเกี่ยวกับทางเลือกใดทางเลือกหนึ่งได้
Comparison between Alternatives - ในขั้นตอนนี้จะทำการเปรียบเทียบระหว่างทางเลือกที่ประเมินแล้ว
ประเภทของการตัดสินใจ
การตัดสินใจตอนนี้เราจะเข้าใจประเภทต่างๆของการตัดสินใจ
การตัดสินใจส่วนบุคคล
ในการตัดสินใจประเภทนี้มีเพียงบุคคลเดียวเท่านั้นที่รับผิดชอบในการตัดสินใจ รูปแบบการตัดสินใจในลักษณะนี้สามารถมีลักษณะเป็น -
ชุดของการกระทำที่เป็นไปได้
ชุดเป้าหมาย $ G_i \ left (i \: \ in \: X_n \ right); $
ชุดของข้อ จำกัด $ C_j \ left (j \: \ in \: X_m \ right) $
เป้าหมายและข้อ จำกัด ที่ระบุไว้ข้างต้นแสดงในรูปแบบของชุดคลุมเครือ
ตอนนี้พิจารณาชุด A จากนั้นเป้าหมายและข้อ จำกัด สำหรับชุดนี้ได้รับจาก -
$ G_i \ left (a \ right) $ = องค์ประกอบ $ \ left [G_i \ left (a \ right) \ right] $ = $ G_i ^ 1 \ left (G_i \ left (a \ right) \ right) $ กับ $ G_i ^ 1 $
$ C_j \ left (a \ right) $ = องค์ประกอบ $ \ left [C_j \ left (a \ right) \ right] $ = $ C_j ^ 1 \ left (C_j \ left (a \ right) \ right) $ กับ $ C_j ^ 1 $ สำหรับ $ a \: \ in \: A $
การตัดสินใจที่คลุมเครือในกรณีข้างต้นให้โดย -
$$ F_D = min [i \ in X_ {n} ^ {in} fG_i \ left (a \ right), j \ in X_ {m} ^ {in} fC_j \ left (a \ right)] $$
การตัดสินใจหลายคน
การตัดสินใจในกรณีนี้รวมถึงบุคคลหลายคนเพื่อให้มีการนำความรู้จากผู้เชี่ยวชาญจากบุคคลต่างๆมาใช้ในการตัดสินใจ
การคำนวณสำหรับสิ่งนี้สามารถให้ได้ดังนี้ -
Number of persons preferring $x_i$ to $x_j$ = $ N \ left (x_i, \: x_j \ right) $
Total number of decision makers = $ n $
จากนั้น $ SC \ left (x_i, \: x_j \ right) = \ frac {N \ left (x_i, \: x_j \ right)} {n} $
การตัดสินใจหลายวัตถุประสงค์
การตัดสินใจหลายวัตถุประสงค์เกิดขึ้นเมื่อมีวัตถุประสงค์หลายประการที่ต้องตระหนัก มีสองประเด็นต่อไปนี้ในการตัดสินใจประเภทนี้ -
เพื่อให้ได้ข้อมูลที่เหมาะสมที่เกี่ยวข้องกับความพึงพอใจของวัตถุประสงค์โดยทางเลือกต่างๆ
เพื่อชั่งน้ำหนักความสำคัญสัมพัทธ์ของแต่ละวัตถุประสงค์
ในทางคณิตศาสตร์เราสามารถกำหนดเอกภพของ n ทางเลือกเป็น -
$ A = \ left [a_1, \: a_2, \: ... , \: a_i, \: ... , \: a_n \ right] $
และชุดของวัตถุประสงค์“ m” เป็น $ O = \ left [o_1, \: o_2, \: ... , \: o_i, \: ... , \: o_n \ right] $
การตัดสินใจหลายแอตทริบิวต์
การตัดสินใจแบบหลายแอตทริบิวต์เกิดขึ้นเมื่อการประเมินทางเลือกสามารถดำเนินการได้โดยพิจารณาจากคุณลักษณะหลายประการของวัตถุ แอตทริบิวต์อาจเป็นข้อมูลตัวเลขข้อมูลทางภาษาและข้อมูลเชิงคุณภาพ
ในทางคณิตศาสตร์การประเมินหลายแอตทริบิวต์จะดำเนินการบนพื้นฐานของสมการเชิงเส้นดังนี้ -
$$ Y = A_1X_1 + A_2X_2 + ... + A_iX_i + ... + A_rX_r $$
ฟัซซี่ลอจิกถูกนำไปใช้กับความสำเร็จอย่างมากในแอปพลิเคชันการควบคุมต่างๆ สินค้าอุปโภคบริโภคเกือบทั้งหมดมีการควบคุมที่ไม่ชัดเจน ตัวอย่างบางส่วน ได้แก่ การควบคุมอุณหภูมิห้องของคุณด้วยเครื่องปรับอากาศระบบป้องกันเบรกที่ใช้ในยานพาหนะการควบคุมสัญญาณไฟจราจรเครื่องซักผ้าระบบเศรษฐกิจขนาดใหญ่เป็นต้น
เหตุใดจึงต้องใช้ Fuzzy Logic ในระบบควบคุม
ระบบควบคุมคือการจัดเรียงองค์ประกอบทางกายภาพที่ออกแบบมาเพื่อปรับเปลี่ยนระบบทางกายภาพอื่นเพื่อให้ระบบนี้แสดงลักษณะที่ต้องการบางประการ ต่อไปนี้เป็นเหตุผลบางประการของการใช้ Fuzzy Logic ในระบบควบคุม -
ในขณะที่ใช้การควบคุมแบบเดิมเราจำเป็นต้องรู้เกี่ยวกับแบบจำลองและฟังก์ชันวัตถุประสงค์ที่กำหนดในรูปแบบที่แม่นยำ ทำให้ยากมากที่จะนำไปใช้ในหลาย ๆ กรณี
ด้วยการใช้ตรรกะที่คลุมเครือในการควบคุมเราสามารถใช้ความเชี่ยวชาญและประสบการณ์ของมนุษย์ในการออกแบบคอนโทรลเลอร์ได้
กฎการควบคุมที่คลุมเครือโดยพื้นฐานแล้วกฎ IF-THEN สามารถใช้ประโยชน์ได้ดีที่สุดในการออกแบบคอนโทรลเลอร์
สมมติฐานในการออกแบบ Fuzzy Logic Control (FLC)
ในขณะที่ออกแบบระบบควบคุมที่คลุมเครือควรตั้งสมมติฐานพื้นฐานหกข้อต่อไปนี้ -
The plant is observable and controllable - ต้องถือว่าตัวแปรอินพุตเอาต์พุตและสถานะพร้อมใช้งานเพื่อการสังเกตและควบคุม
Existence of a knowledge body - ต้องสันนิษฐานว่ามีองค์ความรู้ที่มีกฎทางภาษาและชุดข้อมูลอินพุต - เอาท์พุตที่สามารถดึงกฎได้
Existence of solution - ต้องสันนิษฐานว่ามีทางออก
‘Good enough’ solution is enough - วิศวกรรมการควบคุมต้องมองหาโซลูชันที่ 'ดีเพียงพอ' มากกว่าวิธีที่เหมาะสมที่สุด
Range of precision - Fuzzy logic controller ต้องได้รับการออกแบบภายในช่วงความแม่นยำที่ยอมรับได้
Issues regarding stability and optimality - ประเด็นด้านความเสถียรและการเพิ่มประสิทธิภาพต้องเปิดกว้างในการออกแบบตัวควบคุมฟัซซี่ลอจิกแทนที่จะระบุไว้อย่างชัดเจน
สถาปัตยกรรมของ Fuzzy Logic Control
แผนภาพต่อไปนี้แสดงสถาปัตยกรรมของ Fuzzy Logic Control (FLC)

ส่วนประกอบหลักของ FLC
สิ่งต่อไปนี้เป็นองค์ประกอบหลักของ FLC ดังแสดงในรูปด้านบน -
Fuzzifier - บทบาทของฟัซซิไฟเออร์คือการแปลงค่าอินพุตที่คมชัดให้เป็นค่าฟัซซี
Fuzzy Knowledge Base- จัดเก็บความรู้เกี่ยวกับความสัมพันธ์ฟัซซีอินพุต - เอาท์พุตทั้งหมด นอกจากนี้ยังมีฟังก์ชั่นการเป็นสมาชิกซึ่งกำหนดตัวแปรอินพุตให้กับฐานของกฎฟัซซีและตัวแปรเอาต์พุตไปยังโรงงานภายใต้การควบคุม
Fuzzy Rule Base - จัดเก็บความรู้เกี่ยวกับการทำงานของกระบวนการของโดเมน
Inference Engine- ทำหน้าที่เป็นเคอร์เนลของ FLC ใด ๆ โดยพื้นฐานแล้วจะจำลองการตัดสินใจของมนุษย์โดยใช้เหตุผลโดยประมาณ
Defuzzifier - บทบาทของ defuzzifier คือการแปลงค่าฟัซซีให้เป็นค่าที่คมชัดซึ่งได้รับจากกลไกการอนุมานแบบฟัซซี
ขั้นตอนในการออกแบบ FLC
ต่อไปนี้เป็นขั้นตอนที่เกี่ยวข้องในการออกแบบ FLC -
Identification of variables - ในที่นี้ต้องระบุตัวแปรอินพุตเอาต์พุตและสถานะของพืชซึ่งอยู่ระหว่างการพิจารณา
Fuzzy subset configuration- จักรวาลของข้อมูลแบ่งออกเป็นจำนวนย่อยที่คลุมเครือและแต่ละชุดย่อยจะถูกกำหนดป้ายกำกับภาษา ตรวจสอบให้แน่ใจเสมอว่าส่วนย่อยที่คลุมเครือเหล่านี้มีองค์ประกอบทั้งหมดของจักรวาล
Obtaining membership function - ตอนนี้รับฟังก์ชั่นการเป็นสมาชิกสำหรับแต่ละส่วนย่อยที่ไม่ชัดเจนที่เราได้รับในขั้นตอนข้างต้น
Fuzzy rule base configuration - ตอนนี้กำหนดฐานของกฎที่คลุมเครือโดยกำหนดความสัมพันธ์ระหว่างอินพุตและเอาต์พุตที่คลุมเครือ
Fuzzification - ขั้นตอนการทำให้เป็นฟองเริ่มต้นในขั้นตอนนี้
Combining fuzzy outputs - ด้วยการใช้เหตุผลโดยประมาณที่คลุมเครือค้นหาผลลัพธ์ที่คลุมเครือและรวมเข้าด้วยกัน
Defuzzification - ขั้นตอนสุดท้ายเริ่มกระบวนการละลายน้ำแข็งเพื่อสร้างผลลัพธ์ที่คมชัด
ข้อดีของ Fuzzy Logic Control
ตอนนี้ให้เราพูดถึงข้อดีของ Fuzzy Logic Control
Cheaper - การพัฒนา FLC ค่อนข้างถูกกว่าการพัฒนาแบบจำลองตามหรือคอนโทรลเลอร์อื่น ๆ ในแง่ของประสิทธิภาพ
Robust - FLC มีความแข็งแกร่งมากกว่าตัวควบคุม PID เนื่องจากความสามารถในการครอบคลุมสภาพการทำงานที่หลากหลาย
Customizable - FLC สามารถปรับแต่งได้
Emulate human deductive thinking - โดยพื้นฐานแล้ว FLC ได้รับการออกแบบมาเพื่อเลียนแบบการคิดแบบนิรนัยของมนุษย์กระบวนการที่ผู้คนใช้ในการสรุปข้อสรุปจากสิ่งที่พวกเขารู้
Reliability - FLC มีความน่าเชื่อถือมากกว่าระบบควบคุมทั่วไป
Efficiency - Fuzzy logic ให้ประสิทธิภาพมากขึ้นเมื่อใช้ในระบบควบคุม
ข้อเสียของ Fuzzy Logic Control
ตอนนี้เราจะพูดถึงข้อเสียของ Fuzzy Logic Control คืออะไร
Requires lots of data - FLC ต้องการข้อมูลจำนวนมากเพื่อนำไปใช้
Useful in case of moderate historical data - FLC ไม่มีประโยชน์สำหรับโปรแกรมที่เล็กกว่าหรือใหญ่กว่าข้อมูลในอดีต
Needs high human expertise - นี่เป็นข้อเสียเปรียบประการหนึ่งเนื่องจากความแม่นยำของระบบขึ้นอยู่กับความรู้และความเชี่ยวชาญของมนุษย์
Needs regular updating of rules - กฎต้องมีการปรับปรุงตามเวลา
ในบทนี้เราจะพูดถึง Adaptive Fuzzy Controller คืออะไรและทำงานอย่างไร Adaptive Fuzzy Controller ได้รับการออกแบบให้มีพารามิเตอร์ที่ปรับได้บางอย่างพร้อมกับกลไกในตัวสำหรับการปรับแต่ง Adaptive Controller ถูกนำมาใช้เพื่อปรับปรุงประสิทธิภาพของคอนโทรลเลอร์
ขั้นตอนพื้นฐานสำหรับการปรับใช้อัลกอริทึมแบบปรับได้
ตอนนี้ให้เราพูดถึงขั้นตอนพื้นฐานสำหรับการปรับใช้อัลกอริทึมการปรับตัว
Collection of observable data - ข้อมูลที่สังเกตได้จะถูกรวบรวมเพื่อคำนวณประสิทธิภาพของคอนโทรลเลอร์
Adjustment of controller parameters - ตอนนี้ด้วยความช่วยเหลือของประสิทธิภาพของคอนโทรลเลอร์การคำนวณการปรับพารามิเตอร์ตัวควบคุมจะทำได้
Improvement in performance of controller - ในขั้นตอนนี้พารามิเตอร์คอนโทรลเลอร์จะถูกปรับเพื่อปรับปรุงประสิทธิภาพของคอนโทรลเลอร์
แนวคิดในการดำเนินงาน
การออกแบบคอนโทรลเลอร์เป็นไปตามแบบจำลองทางคณิตศาสตร์ที่สมมติขึ้นซึ่งคล้ายกับระบบจริง ข้อผิดพลาดระหว่างระบบจริงและการแทนค่าทางคณิตศาสตร์จะถูกคำนวณและหากมีความสำคัญน้อยกว่าแบบจำลองจะถือว่าทำงานได้อย่างมีประสิทธิภาพ
ค่าคงที่เกณฑ์ที่กำหนดขอบเขตสำหรับประสิทธิภาพของคอนโทรลเลอร์ก็มีอยู่เช่นกัน อินพุตควบคุมจะถูกป้อนลงในทั้งระบบจริงและแบบจำลองทางคณิตศาสตร์ ที่นี่สมมติว่า $ x \ left (t \ right) $ คือผลลัพธ์ของระบบจริงและ $ y \ left (t \ right) $ คือผลลัพธ์ของแบบจำลองทางคณิตศาสตร์ จากนั้นข้อผิดพลาด $ \ epsilon \ left (t \ right) $ สามารถคำนวณได้ดังนี้ -
$$ \ epsilon \ left (t \ right) = x \ left (t \ right) - y \ left (t \ right) $$
ที่นี่ $ x $ ที่ต้องการคือผลลัพธ์ที่เราต้องการจากระบบและ $ \ mu \ left (t \ right) $ คือผลลัพธ์ที่มาจากคอนโทรลเลอร์และไปยังทั้งแบบจำลองจริงและแบบทางคณิตศาสตร์
แผนภาพต่อไปนี้แสดงให้เห็นว่าฟังก์ชันข้อผิดพลาดถูกติดตามระหว่างผลลัพธ์ของระบบจริงและแบบจำลองทางคณิตศาสตร์อย่างไร -

การกำหนดพารามิเตอร์ของระบบ
ตัวควบคุมแบบฟัซซี่ที่ออกแบบตามแบบจำลองทางคณิตศาสตร์ที่คลุมเครือจะมีรูปแบบของกฎที่คลุมเครือดังต่อไปนี้ -
Rule 1 - IF $ x_1 \ left (t_n \ right) \ in X_ {11} \: AND ... AND \: x_i \ left (t_n \ right) \ in X_ {1i} $
แล้ว $ \ mu _1 \ left (t_n \ right) = K_ {11} x_1 \ left (t_n \ right) + K_ {12} x_2 \ left (t_n \ right) \: + ... + \: K_ {1i } x_i \ left (t_n \ right) $
Rule 2 - IF $ x_1 \ left (t_n \ right) \ in X_ {21} \: AND ... AND \: x_i \ left (t_n \ right) \ in X_ {2i} $
แล้ว $ \ mu _2 \ left (t_n \ right) = K_ {21} x_1 \ left (t_n \ right) + K_ {22} x_2 \ left (t_n \ right) \: + ... + \: K_ {2i } x_i \ left (t_n \ right) $
.
.
.
Rule j - IF $ x_1 \ left (t_n \ right) \ in X_ {k1} \: AND ... AND \: x_i \ left (t_n \ right) \ in X_ {ki} $
แล้ว $ \ mu _j \ left (t_n \ right) = K_ {j1} x_1 \ left (t_n \ right) + K_ {j2} x_2 \ left (t_n \ right) \: + ... + \: K_ {ji } x_i \ left (t_n \ right) $
ชุดพารามิเตอร์ด้านบนแสดงลักษณะของคอนโทรลเลอร์
การปรับกลไก
พารามิเตอร์คอนโทรลเลอร์ได้รับการปรับเพื่อปรับปรุงประสิทธิภาพของคอนโทรลเลอร์ กระบวนการคำนวณการปรับค่าพารามิเตอร์คือกลไกการปรับ
ในทางคณิตศาสตร์ให้ $ \ theta ^ \ left (n \ right) $ เป็นชุดของพารามิเตอร์ที่จะปรับในเวลา $ t = t_n $ การปรับเปลี่ยนสามารถคำนวณใหม่ของพารามิเตอร์
$$ \ theta ^ \ left (n \ right) = \ Theta \ left (D_0, \: D_1, \: ... , \: D_n \ right) $$
ที่นี่ $ D_n $ คือข้อมูลที่รวบรวมเมื่อเวลา $ t = t_n $
ตอนนี้สูตรนี้ได้รับการจัดรูปแบบใหม่โดยการอัปเดตชุดพารามิเตอร์ตามค่าก่อนหน้าเป็น
$$ \ theta ^ \ left (n \ right) = \ phi (\ theta ^ {n-1}, \: D_n) $$
พารามิเตอร์สำหรับการเลือก Adaptive Fuzzy Controller
จำเป็นต้องพิจารณาพารามิเตอร์ต่อไปนี้เพื่อเลือกตัวควบคุมฟัซซีแบบปรับได้ -
ระบบสามารถประมาณแบบจำลองทั้งหมดได้หรือไม่?
หากระบบสามารถประมาณได้ทั้งหมดโดยแบบจำลองฟัซซีพารามิเตอร์ของโมเดลฟัซซี่นี้พร้อมใช้งานหรือไม่หรือต้องพิจารณาทางออนไลน์
ถ้าระบบไม่สามารถประมาณแบบจำลองแบบฟัซซีได้ทั้งหมดระบบจะประมาณแบบทีละชุดได้หรือไม่
หากระบบสามารถประมาณโดยชุดของโมเดลฟัซซีโมเดลเหล่านี้มีรูปแบบเดียวกันโดยมีพารามิเตอร์ต่างกันหรือมีรูปแบบที่แตกต่างกันหรือไม่
หากระบบสามารถประมาณได้โดยชุดของโมเดลฟัซซีที่มีรูปแบบเดียวกันโดยแต่ละชุดมีพารามิเตอร์ที่แตกต่างกันชุดพารามิเตอร์เหล่านี้จะพร้อมใช้งานหรือไม่หรือต้องกำหนดแบบออนไลน์
โครงข่ายประสาทเทียม (ANN) เป็นเครือข่ายของระบบคอมพิวเตอร์ที่มีประสิทธิภาพซึ่งเป็นธีมหลักที่ยืมมาจากการเปรียบเทียบเครือข่ายประสาทเทียมทางชีววิทยา ANN ยังได้รับการตั้งชื่อว่า "ระบบประสาทเทียม" ระบบประมวลผลแบบกระจายขนาน "" ระบบเชื่อมต่อ " ANN ได้รับชุดอุปกรณ์จำนวนมากที่เชื่อมต่อกันในบางรูปแบบเพื่อให้สามารถสื่อสารระหว่างหน่วยได้ หน่วยเหล่านี้เรียกอีกอย่างว่าโหนดหรือเซลล์ประสาทเป็นตัวประมวลผลอย่างง่ายซึ่งทำงานแบบขนาน
เซลล์ประสาททุกเซลล์เชื่อมต่อกับเซลล์ประสาทอื่น ๆ ผ่านลิงค์การเชื่อมต่อ ลิงค์เชื่อมต่อแต่ละลิงค์เกี่ยวข้องกับน้ำหนักที่มีข้อมูลเกี่ยวกับสัญญาณอินพุต นี่เป็นข้อมูลที่มีประโยชน์ที่สุดสำหรับเซลล์ประสาทในการแก้ปัญหาใดปัญหาหนึ่งเนื่องจากน้ำหนักมักจะยับยั้งสัญญาณที่สื่อสาร เซลล์ประสาทแต่ละเซลล์มีสถานะภายในซึ่งเรียกว่าสัญญาณกระตุ้น สัญญาณเอาต์พุตซึ่งเกิดขึ้นหลังจากรวมสัญญาณอินพุตและกฎการเปิดใช้งานอาจถูกส่งไปยังหน่วยอื่น นอกจากนี้ยังประกอบด้วย bias 'b' ซึ่งมีน้ำหนักเท่ากับ 1 เสมอ

เหตุใดจึงควรใช้ Fuzzy Logic ใน Neural Network
ดังที่เราได้กล่าวไปแล้วข้างต้นว่าเซลล์ประสาททุกเซลล์ใน ANN เชื่อมต่อกับเซลล์ประสาทอื่น ๆ ผ่านลิงค์การเชื่อมต่อและลิงก์นั้นเกี่ยวข้องกับน้ำหนักที่มีข้อมูลเกี่ยวกับสัญญาณอินพุต ดังนั้นเราสามารถพูดได้ว่าตุ้มน้ำหนักมีข้อมูลที่เป็นประโยชน์เกี่ยวกับการป้อนข้อมูลเพื่อแก้ปัญหา
ต่อไปนี้เป็นเหตุผลบางประการในการใช้ตรรกะฟัซซีในโครงข่ายประสาทเทียม -
ฟัซซีลอจิกส่วนใหญ่ใช้เพื่อกำหนดน้ำหนักจากเซตฟัซซีในโครงข่ายประสาทเทียม
เมื่อไม่สามารถใช้ค่าที่คมชัดได้ระบบจะใช้ค่าแบบฟัซซี่
เราได้ศึกษาแล้วว่าการฝึกอบรมและการเรียนรู้ช่วยให้โครงข่ายประสาทเทียมทำงานได้ดีขึ้นในสถานการณ์ที่ไม่คาดคิด ในเวลานั้นค่าที่ไม่ชัดเจนจะใช้ได้มากกว่าค่าที่คมชัด
เมื่อเราใช้ฟัซซีลอจิกในโครงข่ายประสาทเทียมค่าต่างๆจะต้องไม่คมชัดและการประมวลผลสามารถทำควบคู่กันได้
แผนที่ความรู้ความเข้าใจคลุมเครือ
มันเป็นรูปแบบหนึ่งของความเลือนรางในเครือข่ายประสาทเทียม โดยทั่วไป FCM เปรียบเสมือนเครื่องแสดงสถานะแบบไดนามิกที่มีสถานะไม่ชัดเจน (ไม่ใช่แค่ 1 หรือ 0)
ความยากในการใช้ Fuzzy Logic ใน Neural Networks
แม้จะมีข้อได้เปรียบมากมาย แต่ก็มีความยากลำบากในการใช้ตรรกะฟัซซีในโครงข่ายประสาทเทียม ความยากนั้นเกี่ยวข้องกับกฎการเป็นสมาชิกความจำเป็นในการสร้างระบบที่คลุมเครือเนื่องจากบางครั้งการอนุมานด้วยชุดข้อมูลที่ซับซ้อนนั้นมีความซับซ้อน
Neural-Trained Fuzzy Logic
ความสัมพันธ์แบบย้อนกลับระหว่างโครงข่ายประสาทเทียมและฟัซซีลอจิกกล่าวคือเครือข่ายประสาทที่ใช้ในการฝึกตรรกะฟัซซีก็เป็นพื้นที่ศึกษาที่ดีเช่นกัน ต่อไปนี้เป็นเหตุผลหลักสองประการในการสร้างลอจิกฟัซซีระบบประสาท -
รูปแบบใหม่ของข้อมูลสามารถเรียนรู้ได้อย่างง่ายดายด้วยความช่วยเหลือของเครือข่ายประสาทด้วยเหตุนี้จึงสามารถใช้ในการประมวลผลข้อมูลล่วงหน้าในระบบที่คลุมเครือ
โครงข่ายประสาทเทียมเนื่องจากความสามารถในการเรียนรู้ความสัมพันธ์ใหม่กับข้อมูลอินพุตใหม่สามารถใช้เพื่อปรับแต่งกฎที่คลุมเครือเพื่อสร้างระบบปรับตัวที่คลุมเครือ
ตัวอย่างของระบบฟัซซีที่ฝึกประสาท
Neural-Trained Fuzzy ถูกนำมาใช้ในงานเชิงพาณิชย์มากมาย ตอนนี้ให้เราดูตัวอย่างบางส่วนที่ใช้ระบบ Neural-Trained Fuzzy -
ห้องปฏิบัติการเพื่อการวิจัยทางวิศวกรรมฟัซซีระหว่างประเทศ (LIFE) ในโยโกฮาม่าประเทศญี่ปุ่นมีโครงข่ายประสาทที่แพร่กระจายกลับซึ่งเป็นผลมาจากกฎที่คลุมเครือ ระบบนี้ถูกนำไปใช้กับระบบการค้าแลกเปลี่ยนเงินตราต่างประเทศเรียบร้อยแล้วโดยมีกฎประมาณ 5,000 คลุมเครือ
Ford Motor Company ได้พัฒนาระบบฟัซซี่ที่สามารถฝึกได้สำหรับการควบคุมความเร็วรอบเดินเบาของรถยนต์
NeuFuz ซึ่งเป็นผลิตภัณฑ์ซอฟต์แวร์ของ National Semiconductor Corporation สนับสนุนการสร้างกฎที่คลุมเครือด้วยเครือข่ายประสาทเทียมสำหรับแอปพลิเคชันควบคุม
AEG Corporation ของเยอรมนีใช้ระบบควบคุมฟัซซีที่ได้รับการฝึกอบรมด้วยระบบประสาทสำหรับเครื่องอนุรักษ์น้ำและพลังงาน มันมีกฎที่คลุมเครือทั้งหมด 157 ข้อ
ในบทนี้เราจะพูดถึงสาขาที่มีการนำแนวคิดของ Fuzzy Logic ไปใช้อย่างกว้างขวาง
การบินและอวกาศ
ในการบินและอวกาศจะใช้ตรรกะฟัซซีในพื้นที่ต่อไปนี้ -
- การควบคุมระดับความสูงของยานอวกาศ
- การควบคุมระดับความสูงของดาวเทียม
- การควบคุมการไหลและการผสมในยานพาหนะกำจัดอากาศยาน
ยานยนต์
ในรถยนต์ใช้ตรรกะฟัซซีในพื้นที่ต่อไปนี้ -
- ระบบฟัซซี่ที่ฝึกได้สำหรับการควบคุมความเร็วรอบเดินเบา
- วิธีการตั้งเวลาเปลี่ยนเกียร์อัตโนมัติ
- ระบบทางหลวงอัจฉริยะ
- การควบคุมการจราจร
- การปรับปรุงประสิทธิภาพของการส่งสัญญาณอัตโนมัติ
ธุรกิจ
ในทางธุรกิจฟัซซีลอจิกถูกใช้ในพื้นที่ต่อไปนี้ -
- ระบบสนับสนุนการตัดสินใจ
- การประเมินบุคลากรใน บริษัท ขนาดใหญ่
ป้องกัน
ในการป้องกันใช้ตรรกะคลุมเครือในด้านต่อไปนี้ -
- การจดจำเป้าหมายใต้น้ำ
- การจดจำภาพอินฟราเรดความร้อนเป้าหมายโดยอัตโนมัติ
- เครื่องช่วยสนับสนุนการตัดสินใจทางเรือ
- การควบคุมตัวสกัดกั้น hypervelocity
- การสร้างแบบจำลองที่ไม่ชัดเจนของการตัดสินใจของนาโต้
อิเล็กทรอนิกส์
ในอุปกรณ์อิเล็กทรอนิกส์ฟัซซีลอจิกถูกใช้ในพื้นที่ต่อไปนี้ -
- การควบคุมการเปิดรับแสงอัตโนมัติในกล้องวิดีโอ
- ความชื้นในห้องที่สะอาด
- ระบบปรับอากาศ
- เวลาเครื่องซักผ้า
- เตาอบไมโครเวฟ
- เครื่องดูดฝุ่น
การเงิน
ในสาขาการเงินจะใช้ตรรกะฟัซซีในด้านต่อไปนี้ -
- การควบคุมการโอนธนบัตร
- การจัดการกองทุน
- การคาดการณ์ตลาดหุ้น
ภาคอุตสาหกรรม
ในทางอุตสาหกรรมจะใช้ตรรกะฟัซซีในพื้นที่ต่อไปนี้ -
- เตาเผาปูนซีเมนต์ควบคุมการควบคุมการแลกเปลี่ยนความร้อน
- การควบคุมกระบวนการบำบัดน้ำเสียแบบเปิดใช้งานตะกอน
- การควบคุมโรงกรองน้ำ
- การวิเคราะห์รูปแบบเชิงปริมาณสำหรับการประกันคุณภาพอุตสาหกรรม
- การควบคุมปัญหาความพึงพอใจในการออกแบบโครงสร้าง
- การควบคุมโรงกรองน้ำ
การผลิต
ในอุตสาหกรรมการผลิตมีการใช้ตรรกะฟัซซีในด้านต่อไปนี้ -
- การเพิ่มประสิทธิภาพการผลิตชีส
- การเพิ่มประสิทธิภาพการผลิตน้ำนม
มารีน
ในสาขาวิชาทางทะเลจะใช้ตรรกะฟัซซีในพื้นที่ต่อไปนี้ -
- Autopilot สำหรับเรือ
- การเลือกเส้นทางที่เหมาะสมที่สุด
- การควบคุมยานพาหนะใต้น้ำอัตโนมัติ
- พวงมาลัยเรือ
การแพทย์
ในด้านการแพทย์ใช้ตรรกะฟัซซีในด้านต่อไปนี้ -
- ระบบสนับสนุนการวินิจฉัยทางการแพทย์
- การควบคุมความดันโลหิตระหว่างการระงับความรู้สึก
- การควบคุมการระงับความรู้สึกหลายตัวแปร
- การสร้างแบบจำลองของการค้นพบทางระบบประสาทในผู้ป่วยอัลไซเมอร์
- การวินิจฉัยทางรังสีวิทยา
- การวินิจฉัยโรคเบาหวานและมะเร็งต่อมลูกหมากแบบคลุมเครือ
หลักทรัพย์
ในหลักทรัพย์ฟัซซีลอจิกถูกใช้ในพื้นที่ต่อไปนี้ -
- ระบบการตัดสินใจในการซื้อขายหลักทรัพย์
- อุปกรณ์รักษาความปลอดภัยต่างๆ
การขนส่ง
ในการขนส่งใช้ฟัซซีลอจิกในพื้นที่ต่อไปนี้ -
- รถไฟใต้ดินอัตโนมัติ
- การควบคุมตารางรถไฟ
- การเร่งความเร็วทางรถไฟ
- การเบรกและการหยุด
การจดจำรูปแบบและการจำแนกประเภท
ในการจดจำรูปแบบและการจำแนกประเภทจะใช้ตรรกะฟัซซีในพื้นที่ต่อไปนี้ -
- การรู้จำเสียงตามตรรกะที่คลุมเครือ
- ตรรกะคลุมเครือ
- การจดจำลายมือ
- ฟัซซีลอจิกตามการวิเคราะห์ลักษณะใบหน้า
- การวิเคราะห์คำสั่ง
- การค้นหารูปภาพที่คลุมเครือ
จิตวิทยา
ในทางจิตวิทยาใช้ตรรกะคลุมเครือในด้านต่อไปนี้ -
- การวิเคราะห์พฤติกรรมมนุษย์ตามตรรกะคลุมเครือ
- การสืบสวนและการป้องกันอาชญากรรมโดยอาศัยเหตุผลเชิงตรรกะที่คลุมเครือ