Büyük Veri Analitiği - Veri Yaşam Döngüsü
Geleneksel Veri Madenciliği Yaşam Döngüsü
Bir kuruluşun ihtiyaç duyduğu işi organize etmek ve Büyük Veriden net içgörüler sağlamak için bir çerçeve sağlamak için, bunu farklı aşamaları olan bir döngü olarak düşünmek yararlıdır. Hiçbir şekilde doğrusal değildir, yani tüm aşamalar birbiriyle ilişkilidir. Bu döngü, daha geleneksel veri madenciliği döngüsü ile yüzeysel benzerliklere sahiptir.CRISP methodology.
CRISP-DM Metodolojisi
CRISP-DM methodologyVeri Madenciliği için Sektörler Arası Standart Süreç anlamına gelen bu, veri madenciliği uzmanlarının geleneksel BI veri madenciliğindeki sorunları çözmek için kullandığı yaygın olarak kullanılan yaklaşımları açıklayan bir döngüdür. Halen geleneksel BI veri madenciliği ekiplerinde kullanılmaktadır.
Aşağıdaki resme bir göz atın. CRISP-DM metodolojisi tarafından tanımlanan döngünün ana aşamalarını ve bunların birbiriyle nasıl ilişkili olduğunu gösterir.
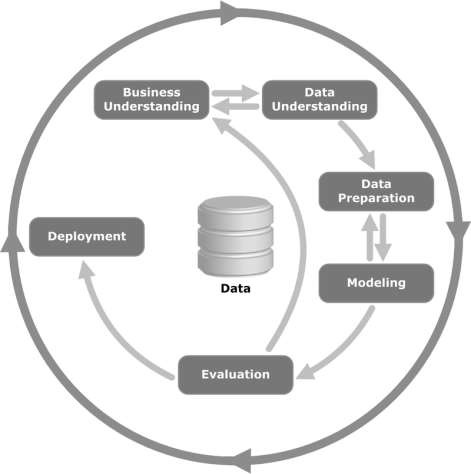
CRISP-DM 1996 yılında tasarlandı ve ertesi yıl ESPRIT finansman girişimi altında bir Avrupa Birliği projesi olarak başladı. Proje beş şirket tarafından yönetildi: SPSS, Teradata, Daimler AG, NCR Corporation ve OHRA (bir sigorta şirketi). Proje nihayet SPSS'ye dahil edildi. Metodoloji, bir veri madenciliği projesinin nasıl belirtilmesi gerektiği konusunda son derece ayrıntılıdır.
Şimdi CRISP-DM yaşam döngüsünün her bir aşaması hakkında biraz daha öğrenelim -
Business Understanding- Bu ilk aşama, proje hedeflerini ve gereksinimlerini bir iş perspektifinden anlamaya ve ardından bu bilgiyi bir veri madenciliği problem tanımına dönüştürmeye odaklanır. Hedeflere ulaşmak için bir ön plan tasarlanır. Bir karar modeli, özellikle Karar Modeli ve Notasyon standardı kullanılarak oluşturulan bir model kullanılabilir.
Data Understanding - Verileri anlama aşaması, ilk veri toplama ile başlar ve verilere aşina olmak, veri kalitesi sorunlarını belirlemek, verilerle ilgili ilk içgörüleri keşfetmek veya gizli bilgiler için hipotezler oluşturmak için ilginç alt kümeleri tespit etmek için faaliyetlerle devam eder.
Data Preparation- Veri hazırlama aşaması, ilk ham verilerden nihai veri setini (modelleme araçlarına / araçlarına beslenecek veriler) oluşturmak için tüm faaliyetleri kapsar. Veri hazırlama görevleri, önceden belirlenmiş herhangi bir sırayla değil, muhtemelen birden çok kez gerçekleştirilecektir. Görevler arasında tablo, kayıt ve öznitelik seçimi ile modelleme araçları için verilerin dönüştürülmesi ve temizlenmesi yer alır.
Modeling- Bu aşamada, çeşitli modelleme teknikleri seçilir ve uygulanır ve parametreleri optimum değerlere kalibre edilir. Tipik olarak, aynı veri madenciliği problem türü için birkaç teknik vardır. Bazı tekniklerin veri formuna ilişkin özel gereksinimleri vardır. Bu nedenle, genellikle veri hazırlama aşamasına geri dönmek gerekir.
Evaluation- Projenin bu aşamasında, veri analizi açısından yüksek kalitede görünen bir model (veya modeller) oluşturdunuz. Modelin nihai dağıtımına geçmeden önce, modeli kapsamlı bir şekilde değerlendirmek ve iş hedeflerine uygun şekilde ulaştığından emin olmak için modeli oluşturmak için uygulanan adımları gözden geçirmek önemlidir.
Temel amaçlardan biri, yeterince dikkate alınmamış bazı önemli ticari sorunların olup olmadığını belirlemektir. Bu aşamanın sonunda, veri madenciliği sonuçlarının kullanımına ilişkin bir karara varılmalıdır.
Deployment- Modelin oluşturulması genellikle projenin sonu değildir. Modelin amacı verilere ilişkin bilgiyi artırmak olsa bile, kazanılan bilginin müşteriye yararlı olacak şekilde organize edilmesi ve sunulması gerekecektir.
Gereksinimlere bağlı olarak, konuşlandırma aşaması bir rapor oluşturmak kadar basit veya tekrarlanabilir bir veri puanlaması (örneğin bölüm tahsisi) veya veri madenciliği süreci uygulamak kadar karmaşık olabilir.
Çoğu durumda, dağıtım adımlarını gerçekleştirecek olan veri analisti değil müşteri olacaktır. Analist modeli devreye alsa bile, müşterinin oluşturulan modellerden fiilen faydalanmak için gerçekleştirilmesi gereken eylemleri önceden anlaması önemlidir.
SEMMA Metodolojisi
SEMMA, SAS tarafından veri madenciliği modellemesi için geliştirilen başka bir metodolojidir. Anlamına gelirSbol, Explore, Modify, Model ve Asses. İşte aşamalarının kısa bir açıklaması -
Sample- Süreç, veri örnekleme ile başlar, örn. Modelleme için veri setinin seçilmesi. Veri kümesi, alınacak yeterli bilgiyi içerecek kadar büyük, ancak verimli bir şekilde kullanılacak kadar küçük olmalıdır. Bu aşama aynı zamanda veri bölümleme ile de ilgilenir.
Explore - Bu aşama, veri görselleştirme yardımıyla değişkenler arasındaki beklenen ve beklenmeyen ilişkileri ve anormallikleri keşfederek verilerin anlaşılmasını kapsar.
Modify - Değiştirme aşaması, veri modellemeye hazırlanırken değişkenleri seçmek, oluşturmak ve dönüştürmek için yöntemler içerir.
Model - Model aşamasında, muhtemelen istenen sonucu sağlayacak modeller oluşturmak için hazırlanan değişkenler üzerinde çeşitli modelleme (veri madenciliği) tekniklerinin uygulanmasına odaklanılır.
Assess - Modelleme sonuçlarının değerlendirilmesi, oluşturulan modellerin güvenilirliğini ve kullanışlılığını gösterir.
CRISM-DM ve SEMMA arasındaki temel fark, SEMMA'nın modelleme yönüne odaklanmasıdır, CRISP-DM ise çözülecek iş problemini anlama, veriyi anlama ve ön işleme gibi modellemeden önceki döngünün aşamalarına daha fazla önem verir. girdi olarak kullanılır, örneğin makine öğrenimi algoritmaları.
Büyük Veri Yaşam Döngüsü
Günümüzün büyük veri bağlamında, önceki yaklaşımlar ya eksiktir ya da yetersizdir. Örneğin, SEMMA metodolojisi veri toplamayı ve farklı veri kaynaklarının ön işlemesini tamamen göz ardı eder. Bu aşamalar normalde başarılı bir büyük veri projesindeki işin çoğunu oluşturur.
Bir büyük veri analitiği döngüsü aşağıdaki aşamada tanımlanabilir -
- İş Problemi Tanımı
- Research
- İnsan Kaynakları Değerlendirmesi
- Veri toplama
- Veri Parçalama
- Veri depolama
- Keşifsel Veri Analizi
- Modelleme ve Değerlendirme için Veri Hazırlama
- Modeling
- Implementation
Bu bölümde, büyük veri yaşam döngüsünün bu aşamalarının her birine biraz ışık tutacağız.
İş Problemi Tanımı
Bu, geleneksel iş zekası ve büyük veri analitiği yaşam döngüsünde ortak bir noktadır. Normalde, problemi tanımlamak ve bir organizasyon için ne kadar potansiyel kazancı olabileceğini doğru bir şekilde değerlendirmek büyük veri projesinin önemsiz olmayan bir aşamasıdır. Bundan bahsedilmesi açık gibi görünüyor, ancak projenin beklenen kazanımları ve maliyetlerinin neler olduğu değerlendirilmelidir.
Araştırma
Aynı durumda diğer şirketlerin neler yaptığını analiz edin. Bu, diğer çözümleri şirketinizin sahip olduğu kaynaklara ve gereksinimlere uyarlamayı gerektirse de, şirketiniz için makul çözümler aramayı içerir. Bu aşamada, gelecek aşamalar için bir metodoloji tanımlanmalıdır.
İnsan Kaynakları Değerlendirmesi
Sorun tanımlandıktan sonra, mevcut personelin projeyi başarıyla tamamlayıp tamamlamadığını analiz etmeye devam etmek mantıklıdır. Geleneksel iş zekası ekipleri tüm aşamalara en uygun çözümü sunamayabilir, bu nedenle projenin bir bölümünü dış kaynaklara yaptırma veya daha fazla kişiyi işe alma ihtiyacı varsa, projeye başlamadan önce düşünülmelidir.
Veri toplama
Bu bölüm, büyük veri yaşam döngüsünün anahtarıdır; ortaya çıkan veri ürününü sunmak için hangi tip profillerin gerekli olacağını tanımlar. Veri toplama, sürecin önemsiz olmayan bir adımıdır; normalde farklı kaynaklardan yapılandırılmamış verilerin toplanmasını içerir. Bir örnek vermek gerekirse, bir web sitesinden yorumları almak için bir tarayıcı yazmayı içerebilir. Bu, belki de normalde tamamlanması önemli miktarda zaman gerektiren farklı dillerde metinle uğraşmayı içerir.
Veri Parçalama
Veriler örneğin web'den alındıktan sonra, kullanımı kolay bir formatta depolanması gerekir. İnceleme örnekleriyle devam etmek için, verilerin, her birinin farklı bir veri görüntüsüne sahip olduğu farklı sitelerden alındığını varsayalım.
Bir veri kaynağının yıldızlarla derecelendirme açısından yorumlar verdiğini varsayalım, bu nedenle bunu yanıt değişkeni için bir eşleme olarak okumak mümkündür. y ∈ {1, 2, 3, 4, 5}. Başka bir veri kaynağı, biri yukarı oylama, diğeri aşağı oylama için olmak üzere iki ok sistemini kullanarak incelemeler verir. Bu, formun bir yanıt değişkeni anlamına geliry ∈ {positive, negative}.
Her iki veri kaynağını birleştirmek için, bu iki yanıt temsilini eşdeğer kılmak için bir karar verilmesi gerekir. Bu, bir yıldızı negatif ve beş yıldızı pozitif olarak kabul ederek, birinci veri kaynağı yanıt temsilini ikinci forma dönüştürmeyi içerebilir. Bu süreç genellikle iyi kalitede teslim edilmek için büyük bir zaman ayırmayı gerektirir.
Veri depolama
Veriler işlendikten sonra bazen bir veritabanında saklanması gerekir. Büyük veri teknolojileri bu konuda pek çok alternatif sunuyor. En yaygın alternatif, kullanıcılara HIVE Sorgu Dili olarak bilinen sınırlı bir SQL sürümü sağlayan depolama için Hadoop Dosya Sistemini kullanmaktır. Bu, çoğu analitik görevinin, kullanıcı perspektifinden geleneksel BI veri ambarlarında yapılacağı gibi benzer şekillerde yapılmasına izin verir. Dikkate alınacak diğer depolama seçenekleri MongoDB, Redis ve SPARK'tır.
Döngünün bu aşaması, farklı mimarileri uygulama yetenekleri açısından insan kaynakları bilgisi ile ilgilidir. Geleneksel veri ambarlarının değiştirilmiş sürümleri hala büyük ölçekli uygulamalarda kullanılmaktadır. Örneğin, teradata ve IBM, terabaytlarca veriyi işleyebilen SQL veritabanları sunar; postgreSQL ve MySQL gibi açık kaynaklı çözümler hala büyük ölçekli uygulamalar için kullanılmaktadır.
İstemci tarafından arka planda farklı depoların nasıl çalıştığı konusunda farklılıklar olsa da çoğu çözüm bir SQL API sağlar. Bu nedenle, SQL'i iyi anlamak, büyük veri analitiği için hala sahip olunması gereken önemli bir beceridir.
Bu aşama a priori en önemli konu gibi görünüyor, pratikte bu doğru değil. Hatta gerekli bir aşama bile değil. Gerçek zamanlı verilerle çalışacak bir büyük veri çözümü uygulamak mümkündür, bu nedenle bu durumda, modeli geliştirmek ve ardından gerçek zamanlı olarak uygulamak için yalnızca veri toplamamız gerekir. Dolayısıyla, verilerin resmi olarak saklanmasına hiç gerek kalmaz.
Keşifsel Veri Analizi
Veriler temizlendikten ve içgörüler alınabilecek şekilde depolandıktan sonra, veri araştırma aşaması zorunludur. Bu aşamanın amacı, verileri anlamaktır, bu normalde istatistiksel tekniklerle ve ayrıca verilerin grafiğini çizerek yapılır. Bu, problem tanımının mantıklı mı yoksa uygulanabilir mi olduğunu değerlendirmek için iyi bir aşamadır.
Modelleme ve Değerlendirme için Veri Hazırlama
Bu aşama, önceden alınan temizlenmiş verilerin yeniden şekillendirilmesini ve eksik değerlerin atanması, aykırı değer tespiti, normalleştirme, özellik çıkarma ve özellik seçimi için istatistiksel ön işlemeyi kullanmayı içerir.
Modelleme
Önceki aşama, örneğin tahmine dayalı bir model gibi eğitim ve test için birkaç veri kümesi üretmiş olmalıdır. Bu aşama, farklı modelleri denemeyi ve eldeki iş problemini çözmeyi dört gözle beklemeyi içerir. Uygulamada, normalde modelin işletmeye biraz içgörü vermesi istenir. Son olarak, en iyi model veya model kombinasyonu, dışarıda bırakılmış bir veri kümesindeki performansını değerlendirerek seçilir.
Uygulama
Bu aşamada geliştirilen veri ürünü firmanın veri hattında uygulanmaktadır. Bu, performansını izlemek için veri ürünü çalışırken bir doğrulama şeması oluşturmayı içerir. Örneğin, tahmine dayalı bir modelin uygulanması durumunda, bu aşama, modelin yeni verilere uygulanmasını ve yanıt mevcut olduğunda modeli değerlendirmeyi içerir.