Büyük Veri Analitiği - Grafikler ve Grafikler
Verileri analiz etmenin ilk yaklaşımı, verileri görsel olarak analiz etmektir. Bunu yapmanın hedefleri normalde değişkenler arasındaki ilişkileri ve değişkenlerin tek değişkenli tanımlarını bulmaktır. Bu stratejileri şu şekilde bölebiliriz -
- Tek değişkenli analiz
- Çok değişkenli analiz
Tek Değişkenli Grafik Yöntemler
Univariateistatistiksel bir terimdir. Uygulamada, bir değişkeni verilerin geri kalanından bağımsız olarak analiz etmek istediğimiz anlamına gelir. Bunu verimli bir şekilde yapmaya izin veren araziler:
Kutu Grafikleri
Kutu Grafikleri normalde dağılımları karşılaştırmak için kullanılır. Dağıtımlar arasında farklılıklar olup olmadığını görsel olarak incelemenin harika bir yoludur. Farklı kesimler için elmas fiyatları arasında fark olup olmadığını görebiliriz.
# We will be using the ggplot2 library for plotting
library(ggplot2)
data("diamonds")
# We will be using the diamonds dataset to analyze distributions of numeric variables
head(diamonds)
# carat cut color clarity depth table price x y z
# 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
# 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
# 3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
# 4 0.29 Premium I VS2 62.4 58 334 4.20 4.23 2.63
# 5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
# 6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
### Box-Plots
p = ggplot(diamonds, aes(x = cut, y = price, fill = cut)) +
geom_box-plot() +
theme_bw()
print(p)Pırlanta fiyatının farklı kesim türlerinde dağılımında farklılıklar olduğunu grafikte görebiliriz.

Histogramlar
source('01_box_plots.R')
# We can plot histograms for each level of the cut factor variable using
facet_grid
p = ggplot(diamonds, aes(x = price, fill = cut)) +
geom_histogram() +
facet_grid(cut ~ .) +
theme_bw()
p
# the previous plot doesn’t allow to visuallize correctly the data because of
the differences in scale
# we can turn this off using the scales argument of facet_grid
p = ggplot(diamonds, aes(x = price, fill = cut)) +
geom_histogram() +
facet_grid(cut ~ ., scales = 'free') +
theme_bw()
p
png('02_histogram_diamonds_cut.png')
print(p)
dev.off()Yukarıdaki kodun çıktısı aşağıdaki gibi olacaktır -
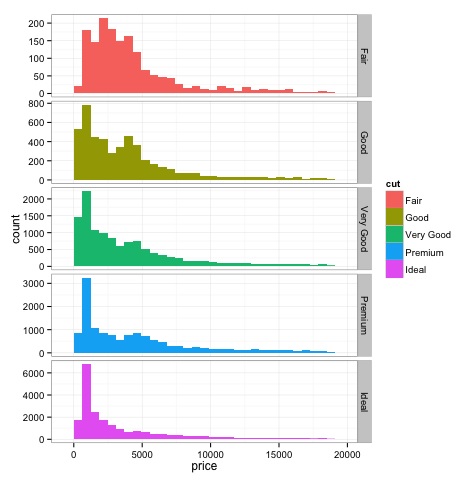
Çok Değişkenli Grafik Yöntemler
Keşifsel veri analizinde çok değişkenli grafik yöntemler, farklı değişkenler arasındaki ilişkileri bulma amacına sahiptir. Bunu başarmanın yaygın olarak kullanılan iki yolu vardır: sayısal değişkenlerden oluşan bir korelasyon matrisini çizmek veya ham verileri basitçe bir dağılım grafikleri matrisi olarak çizmek.
Bunu göstermek için elmas veri setini kullanacağız. Kodu takip etmek için komut dosyasını açınbda/part2/charts/03_multivariate_analysis.R.
library(ggplot2)
data(diamonds)
# Correlation matrix plots
keep_vars = c('carat', 'depth', 'price', 'table')
df = diamonds[, keep_vars]
# compute the correlation matrix
M_cor = cor(df)
# carat depth price table
# carat 1.00000000 0.02822431 0.9215913 0.1816175
# depth 0.02822431 1.00000000 -0.0106474 -0.2957785
# price 0.92159130 -0.01064740 1.0000000 0.1271339
# table 0.18161755 -0.29577852 0.1271339 1.0000000
# plots
heat-map(M_cor)Kod aşağıdaki çıktıyı üretecektir -

Bu bir özettir, bize fiyat ve şapka arasında güçlü bir ilişki olduğunu ve diğer değişkenler arasında pek bir şey olmadığını söyler.
Bir korelasyon matrisi, çok sayıda değişkenimiz olduğunda faydalı olabilir, bu durumda ham verilerin grafiğini çizmek pratik olmaz. Bahsedildiği gibi, ham verileri de göstermek mümkündür -
library(GGally)
ggpairs(df)Isı haritasında gösterilen sonuçların doğrulandığını grafikte görebiliyoruz, fiyat ve karat değişkenleri arasında 0.922 bir korelasyon var.
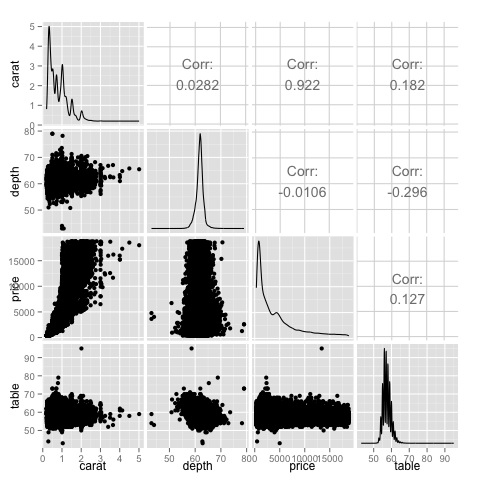
Bu ilişkiyi, dağılım grafiği matrisinin (3, 1) indeksinde yer alan fiyat-karat dağılım grafiğinde görselleştirmek mümkündür.