Kümeleme Algoritmaları - Hiyerarşik Kümeleme
Hiyerarşik Kümelemeye Giriş
Hiyerarşik kümeleme, benzer özelliklere sahip etiketlenmemiş veri noktalarını bir arada gruplandırmak için kullanılan başka bir denetimsiz öğrenme algoritmasıdır. Hiyerarşik kümeleme algoritmaları iki kategoriye ayrılır:
Agglomerative hierarchical algorithms- Aglomeratif hiyerarşik algoritmalarda, her veri noktası tek bir küme olarak ele alınır ve ardından küme çiftlerini art arda birleştirir veya kümeleştirir (aşağıdan yukarıya yaklaşım). Kümelerin hiyerarşisi bir dendrogram veya ağaç yapısı olarak temsil edilir.
Divisive hierarchical algorithms - Öte yandan, bölücü hiyerarşik algoritmalarda, tüm veri noktaları tek bir büyük küme olarak ele alınır ve kümeleme işlemi, bir büyük kümeyi çeşitli küçük kümelere bölmeyi içerir (Yukarıdan aşağıya yaklaşım).
Aglomeratif Hiyerarşik Kümeleme Gerçekleştirme Adımları
En çok kullanılan ve en önemli Hiyerarşik kümelemeyi, yani kümeleşmeyi açıklayacağız. Aynısını gerçekleştirme adımları aşağıdaki gibidir -
Step 1- Her veri noktasına tek bir küme olarak davranın. Bu nedenle, başlangıçta K kümelerine sahip olacağız. Veri noktalarının sayısı da başlangıçta K olacaktır.
Step 2- Şimdi, bu adımda iki yakın veri noktasını birleştirerek büyük bir küme oluşturmamız gerekiyor. Bu, toplam K-1 kümeleri ile sonuçlanacaktır.
Step 3- Şimdi, daha fazla küme oluşturmak için iki gizli kümeye katılmamız gerekiyor. Bu, toplam K-2 kümeleri ile sonuçlanacaktır.
Step 4 - Şimdi, büyük bir küme oluşturmak için yukarıdaki üç adımı K 0 olana kadar tekrarlayın, yani birleştirilecek daha fazla veri noktası kalmadı.
Step 5 - Sonunda, tek bir büyük küme yaptıktan sonra, probleme bağlı olarak birden fazla kümeye bölünmek için dendrogramlar kullanılacaktır.
Aglomeratif Hiyerarşik Kümelemede Dendrogramların Rolü
Son adımda tartıştığımız gibi, dendrogramın rolü büyük küme oluştuğunda başlar. Dendrogram, problemimize bağlı olarak kümeleri birden fazla ilgili veri noktası kümesine ayırmak için kullanılacaktır. Aşağıdaki örnek yardımı ile anlaşılabilir -
örnek 1
Anlamak için, gerekli kitaplıkları aşağıdaki gibi içe aktararak başlayalım -
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as npSonra, bu örnek için aldığımız veri noktalarını çizeceğiz -
X = np.array([[7,8],[12,20],[17,19],[26,15],[32,37],[87,75],[73,85], [62,80],[73,60],[87,96],])
labels = range(1, 11)
plt.figure(figsize=(10, 7))
plt.subplots_adjust(bottom=0.1)
plt.scatter(X[:,0],X[:,1], label='True Position')
for label, x, y in zip(labels, X[:, 0], X[:, 1]):
plt.annotate(label,xy=(x, y), xytext=(-3, 3),textcoords='offset points', ha='right', va='bottom')
plt.show()
Yukarıdaki diyagramdan, veri noktalarında iki kümemiz olduğunu görmek çok kolaydır, ancak gerçek dünya verilerinde binlerce küme olabilir. Sonra, Scipy kitaplığını kullanarak veri noktalarımızın dendrogramlarını çizeceğiz -
from scipy.cluster.hierarchy import dendrogram, linkage
from matplotlib import pyplot as plt
linked = linkage(X, 'single')
labelList = range(1, 11)
plt.figure(figsize=(10, 7))
dendrogram(linked, orientation='top',labels=labelList, distance_sort='descending',show_leaf_counts=True)
plt.show()
Şimdi, büyük küme oluşturulduktan sonra, en uzun dikey mesafe seçilir. Ardından aşağıdaki diyagramda gösterildiği gibi dikey bir çizgi çizilir. Yatay çizgi mavi çizgiyi iki noktada geçtiği için küme sayısı iki olacaktır.

Daha sonra, kümeleme için sınıfı içe aktarmamız ve kümeyi tahmin etmek için fit_predict yöntemini çağırmamız gerekir. Sklearn.cluster kitaplığının AgglomerativeClustering sınıfını içe aktarıyoruz -
from sklearn.cluster import AgglomerativeClustering
cluster = AgglomerativeClustering(n_clusters=2, affinity='euclidean', linkage='ward')
cluster.fit_predict(X)Ardından, aşağıdaki kodun yardımıyla kümeyi çizin -
plt.scatter(X[:,0],X[:,1], c=cluster.labels_, cmap='rainbow')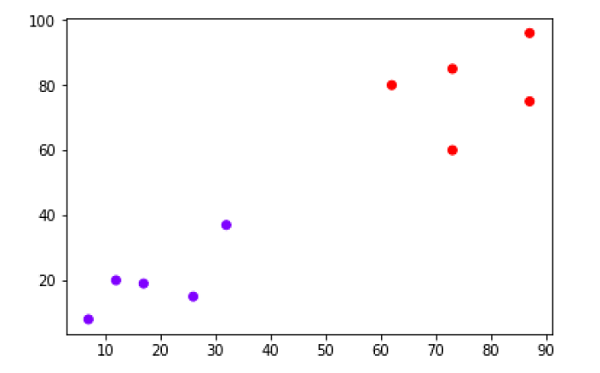
Yukarıdaki diyagram, veri noktalarımızdaki iki kümeyi göstermektedir.
Örnek2
Yukarıda tartışılan basit örnekten dendrogram kavramını anladığımız gibi, hiyerarşik kümeleme kullanarak Pima Indian Diabetes Dataset'teki veri noktalarının kümelerini oluşturduğumuz başka bir örneğe geçelim -
import matplotlib.pyplot as plt
import pandas as pd
%matplotlib inline
import numpy as np
from pandas import read_csv
path = r"C:\pima-indians-diabetes.csv"
headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=headernames)
array = data.values
X = array[:,0:8]
Y = array[:,8]
data.shape
(768, 9)
data.head()| Sl. Yok hayır. | hamilelik | Plas | Pres | cilt | Ölçek | kitle | pedi | yaş | sınıf |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0.167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
patient_data = data.iloc[:, 3:5].values
import scipy.cluster.hierarchy as shc
plt.figure(figsize=(10, 7))
plt.title("Patient Dendograms")
dend = shc.dendrogram(shc.linkage(data, method='ward'))
from sklearn.cluster import AgglomerativeClustering
cluster = AgglomerativeClustering(n_clusters=4, affinity='euclidean', linkage='ward')
cluster.fit_predict(patient_data)
plt.figure(figsize=(10, 7))
plt.scatter(patient_data[:,0], patient_data[:,1], c=cluster.labels_, cmap='rainbow')