KNN Algoritması - En Yakın Komşuları Bulma
Giriş
K-en yakın komşular (KNN) algoritması, hem sınıflandırma hem de regresyon tahmin problemleri için kullanılabilen bir denetimli makine öğrenimi algoritması türüdür. Ancak, esas olarak endüstride sınıflandırma tahmini problemleri için kullanılır. Aşağıdaki iki özellik KNN'yi iyi tanımlayacaktır -
Lazy learning algorithm - KNN, özel bir eğitim aşaması olmadığı ve sınıflandırma sırasında eğitim için tüm verileri kullandığı için tembel bir öğrenme algoritmasıdır.
Non-parametric learning algorithm - KNN ayrıca parametrik olmayan bir öğrenme algoritmasıdır çünkü temeldeki veriler hakkında hiçbir şey varsaymaz.
KNN Algoritmasının Çalışması
K-en yakın komşular (KNN) algoritması, yeni veri noktalarının değerlerini tahmin etmek için 'özellik benzerliği'ni kullanır; bu, yeni veri noktasına eğitim setindeki noktalarla ne kadar yakından eşleştiğine bağlı olarak bir değer atanacağı anlamına gelir. Aşağıdaki adımların yardımıyla çalışmasını anlayabiliriz -
Step 1- Herhangi bir algoritmayı uygulamak için veri setine ihtiyacımız var. Bu nedenle, KNN'nin ilk adımı sırasında, eğitimin yanı sıra test verilerini de yüklemeliyiz.
Step 2- Sonra, K'nin değerini, yani en yakın veri noktalarını seçmemiz gerekiyor. K herhangi bir tam sayı olabilir.
Step 3 - Test verilerindeki her nokta için aşağıdakileri yapın -
3.1- Euclidean, Manhattan veya Hamming distance gibi yöntemlerden herhangi birinin yardımıyla test verileri ile her bir eğitim verisi satırı arasındaki mesafeyi hesaplayın. Mesafeyi hesaplamak için en yaygın kullanılan yöntem Öklid'dir.
3.2 - Şimdi, mesafe değerine göre, bunları artan düzende sıralayın.
3.3 - Sonra, sıralanan diziden en üstteki K sırasını seçecektir.
3.4 - Şimdi, bu satırların en sık kullanılan sınıfına göre test noktasına bir sınıf atayacaktır.
Step 4 - Son
Misal
Aşağıdaki, K kavramını ve KNN algoritmasının çalışmasını anlamak için bir örnektir -
Aşağıdaki gibi çizilebilen bir veri kümemiz olduğunu varsayalım -
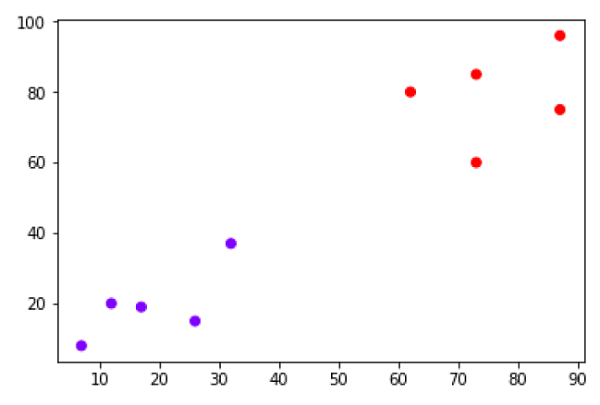
Şimdi, siyah noktalı yeni veri noktasını (60.60 noktasında) mavi veya kırmızı olarak sınıflandırmamız gerekiyor. K = 3 varsayıyoruz, yani en yakın üç veri noktası bulacaktır. Bir sonraki diyagramda gösterilmektedir -

Yukarıdaki diyagramda siyah noktalı veri noktasının en yakın üç komşusunu görebiliriz. Bu üçü arasından ikisi Red sınıfındadır, dolayısıyla siyah nokta da kırmızı sınıfta yer alacaktır.
Python'da Uygulama
Bildiğimiz gibi K-en yakın komşular (KNN) algoritması hem sınıflandırma hem de regresyon için kullanılabilir. Aşağıdakiler, Python'da KNN'yi hem sınıflandırıcı hem de regresör olarak kullanmak için tariflerdir -
Sınıflandırıcı olarak KNN
İlk olarak, gerekli python paketlerini içe aktararak başlayın -
import numpy as np
import matplotlib.pyplot as plt
import pandas as pdArdından, iris veri kümesini web bağlantısından aşağıdaki şekilde indirin -
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"Ardından, veri kümesine aşağıdaki gibi sütun adları atamamız gerekiyor -
headernames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']Şimdi, pandas veri çerçevesine aşağıdaki gibi veri setini okumamız gerekiyor -
dataset = pd.read_csv(path, names=headernames)
dataset.head()| Sl. Yok hayır. | sepal uzunlukta | sepal genişlik | petal uzunlukta | petal genişliği | Sınıf |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
Veri Ön İşleme aşağıdaki kod satırlarının yardımıyla yapılacaktır -
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 4].valuesDaha sonra, verileri tren ve test bölmesine ayıracağız. Aşağıdaki kod, veri kümesini% 60 eğitim verilerine ve test verilerinin% 40'ına böler -
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.40)Ardından, veri ölçeklendirme aşağıdaki gibi yapılacaktır -
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)Ardından, modeli KNeighborsClassifier sklearn sınıfının yardımıyla aşağıdaki gibi eğitin -
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors=8)
classifier.fit(X_train, y_train)Sonunda tahminde bulunmamız gerekiyor. Aşağıdaki komut dosyası yardımıyla yapılabilir -
y_pred = classifier.predict(X_test)Ardından, sonuçları aşağıdaki gibi yazdırın -
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
result = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(result)
result1 = classification_report(y_test, y_pred)
print("Classification Report:",)
print (result1)
result2 = accuracy_score(y_test,y_pred)
print("Accuracy:",result2)Çıktı
Confusion Matrix:
[[21 0 0]
[ 0 16 0]
[ 0 7 16]]
Classification Report:
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 21
Iris-versicolor 0.70 1.00 0.82 16
Iris-virginica 1.00 0.70 0.82 23
micro avg 0.88 0.88 0.88 60
macro avg 0.90 0.90 0.88 60
weighted avg 0.92 0.88 0.88 60
Accuracy: 0.8833333333333333Regresör olarak KNN
İlk olarak, gerekli Python paketlerini içe aktararak başlayın -
import numpy as np
import pandas as pdArdından, iris veri kümesini web bağlantısından aşağıdaki şekilde indirin -
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"Ardından, veri kümesine aşağıdaki gibi sütun adları atamamız gerekiyor -
headernames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']Şimdi, pandas veri çerçevesine aşağıdaki gibi veri setini okumamız gerekiyor -
data = pd.read_csv(url, names=headernames)
array = data.values
X = array[:,:2]
Y = array[:,2]
data.shape
output:(150, 5)Ardından, modele uyması için sklearn'dan KNeighborsRegressor'ı içe aktarın -
from sklearn.neighbors import KNeighborsRegressor
knnr = KNeighborsRegressor(n_neighbors=10)
knnr.fit(X, y)Sonunda, MSE'yi şu şekilde bulabiliriz -
print ("The MSE is:",format(np.power(y-knnr.predict(X),2).mean()))Çıktı
The MSE is: 0.12226666666666669KNN'nin Artıları ve Eksileri
Artıları
Anlaması ve yorumlaması çok basit bir algoritmadır.
Doğrusal olmayan veriler için çok kullanışlıdır çünkü bu algoritmada veriler hakkında herhangi bir varsayım yoktur.
Sınıflandırma ve regresyon için kullanabildiğimiz için çok yönlü bir algoritmadır.
Nispeten yüksek doğruluğa sahiptir, ancak KNN'den çok daha iyi denetlenen öğrenme modelleri vardır.
Eksileri
Hesaplama açısından biraz pahalı bir algoritmadır çünkü tüm eğitim verilerini depolar.
Diğer denetimli öğrenme algoritmalarına kıyasla yüksek bellek deposu gerekir.
Büyük N durumunda tahmin yavaştır.
Veri ölçeğine ve alakasız özelliklere karşı çok hassastır.
KNN uygulamaları
Aşağıdakiler, KNN'nin başarıyla uygulanabileceği alanlardan bazılarıdır -
Banka sistemi
KNN, bir bireyin kredi onayına uygun olup olmadığını tahmin etmek için bankacılık sisteminde kullanılabilir mi? Bu kişi temerrüde düşenlerinkine benzer özelliklere sahip mi?
Kredi Notlarının Hesaplanması
KNN algoritmaları, benzer özelliklere sahip kişilerle karşılaştırılarak bir bireyin kredi notunu bulmak için kullanılabilir.
Siyaset
KNN algoritmalarının yardımıyla, potansiyel bir seçmeni "Oy Verecek", "Oy Vermeyecek", "Partiye Oy Verecek" Kongresi "," Partiye Oy Verecek "BJP" gibi çeşitli sınıflara ayırabiliriz.
KNN algoritmasının kullanılabileceği diğer alanlar Konuşma Tanıma, El Yazısı Algılama, Görüntü Tanıma ve Video Tanıma'dır.