ML - Görselleştirme ile Verileri Anlama
Giriş
Önceki bölümde, verileri istatistiklerle anlamak için bazı Python tarifleriyle birlikte Makine Öğrenimi algoritmaları için verilerin önemini tartıştık. Verileri anlamak için Görselleştirme denen başka bir yol var.
Veri görselleştirme yardımıyla verilerin nasıl göründüğünü ve verilerin nitelikleri tarafından ne tür bir korelasyon olduğunu görebiliriz. Özelliklerin çıktıya karşılık gelip gelmediğini görmenin en hızlı yoludur. Python tariflerini takip ederek makine öğrenimi verilerini istatistiklerle anlayabiliriz.

Tek Değişkenli Grafikler: Öznitelikleri Bağımsız Olarak Anlama
En basit görselleştirme türü, tek değişkenli veya "tek değişkenli" görselleştirmedir. Tek değişkenli görselleştirme yardımıyla, veri setimizin her bir özelliğini bağımsız olarak anlayabiliriz. Aşağıdakiler, tek değişkenli görselleştirmeyi uygulamak için Python'da bazı tekniklerdir -
Histogramlar
Histogramlar verileri bölmelerde gruplandırır ve veri kümesindeki her bir özelliğin dağılımı hakkında fikir edinmenin en hızlı yoludur. Aşağıdakiler histogramların bazı özellikleridir -
Görselleştirme için oluşturulan her bir bölmedeki gözlemlerin sayısını bize sağlar.
Çöp kutusunun şeklinden dağılımı kolaylıkla gözlemleyebiliriz, yani hava durumu Gauss şeklindedir, çarpık veya üsteldir.
Histogramlar ayrıca olası aykırı değerleri görmemize yardımcı olur.
Misal
Aşağıda gösterilen kod, Pima Indian Diabetes veri kümesinin özelliklerinin histogramını oluşturan bir Python komut dosyası örneğidir. Burada, histogramlar oluşturmak için Pandas DataFrame üzerinde hist () işlevini kullanacağız vematplotlib onları çizmek için.
from matplotlib import pyplot
from pandas import read_csv
path = r"C:\pima-indians-diabetes.csv"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=names)
data.hist()
pyplot.show()Çıktı
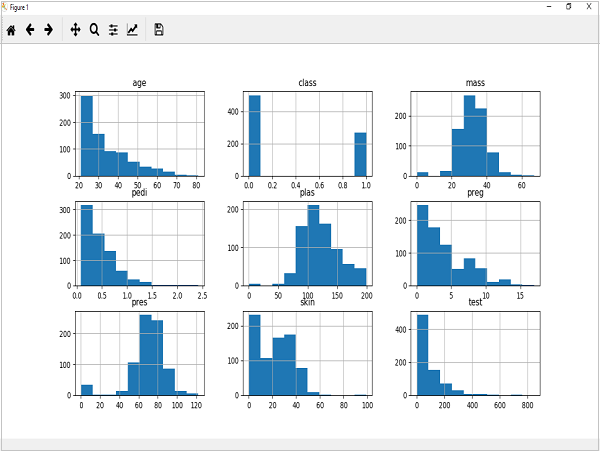
Yukarıdaki çıktı, veri kümesindeki her bir öznitelik için histogramı oluşturduğunu gösterir. Bundan, belki de yaş, pedi ve test özniteliğinin üstel dağılım gösterebileceğini, kütle ve plazmanın Gauss dağılımına sahip olabileceğini gözlemleyebiliriz.
Yoğunluk Grafikleri
Her bir öznitelik dağılımını elde etmek için bir başka hızlı ve kolay teknik, Yoğunluk grafikleridir. Aynı zamanda histogram gibidir, ancak her bölmenin üstünden düzgün bir eğri çizilir. Bunları soyut histogramlar olarak adlandırabiliriz.
Misal
Aşağıdaki örnekte, Python komut dosyası, Pima Indian Diabetes veri kümesinin özelliklerinin dağıtımı için Yoğunluk Grafikleri oluşturacaktır.
from matplotlib import pyplot
from pandas import read_csv
path = r"C:\pima-indians-diabetes.csv"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=names)
data.plot(kind='density', subplots=True, layout=(3,3), sharex=False)
pyplot.show()Çıktı
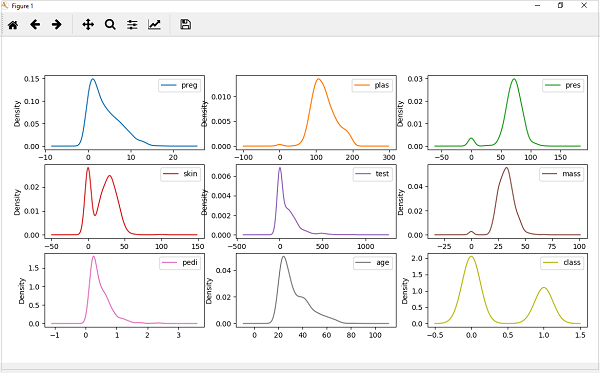
Yukarıdaki çıktıdan, Yoğunluk grafikleri ve Histogramlar arasındaki fark kolayca anlaşılabilir.
Kutu ve Bıyık Grafikleri
Kısaca boxplots olarak da adlandırılan Box ve Whisker grafikleri, her bir özelliğin dağılımının dağılımını gözden geçirmek için başka bir yararlı tekniktir. Aşağıdakiler bu tekniğin özellikleridir -
Doğası gereği tek değişkenlidir ve her bir özelliğin dağılımını özetler.
Orta değer, yani medyan için bir çizgi çizer.
% 25 ve% 75 civarında bir kutu çizer.
Ayrıca bize verilerin yayılması hakkında fikir verecek bıyıklar da çizer.
Bıyıkların dışındaki noktalar, aykırı değerleri belirtir. Aykırı değerler, ortadaki verilerin yayılma boyutundan 1.5 kat daha büyük olacaktır.
Misal
Aşağıdaki örnekte, Python komut dosyası, Pima Indian Diabetes veri kümesinin özelliklerinin dağıtımı için Yoğunluk Grafikleri oluşturacaktır.
from matplotlib import pyplot
from pandas import read_csv
path = r"C:\pima-indians-diabetes.csv"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=names)
data.plot(kind='box', subplots=True, layout=(3,3), sharex=False,sharey=False)
pyplot.show()Çıktı

Yukarıdaki öznitelik dağılım grafiğinden, yaşın, testin ve cildin daha küçük değerlere doğru çarpık göründüğü gözlemlenebilir.
Çok Değişkenli Grafikler: Birden Çok Değişken Arasındaki Etkileşim
Başka bir görselleştirme türü, çok değişkenli veya "çok değişkenli" görselleştirmedir. Çok değişkenli görselleştirme yardımıyla, veri setimizin birden çok özelliği arasındaki etkileşimi anlayabiliriz. Aşağıdakiler, Python'da çok değişkenli görselleştirmeyi uygulamak için bazı tekniklerdir -
Korelasyon Matrisi Grafiği
Korelasyon, iki değişken arasındaki değişiklikler hakkında bir göstergedir. Önceki bölümlerimizde, Pearson Korelasyon katsayılarını ve Korelasyonun önemini tartışmıştık. Hangi değişkenin başka bir değişkene göre yüksek veya düşük bir korelasyona sahip olduğunu göstermek için korelasyon matrisini çizebiliriz.
Misal
Aşağıdaki örnekte, Python komut dosyası, Pima Indian Diabetes veri kümesi için korelasyon matrisi oluşturacak ve grafiğini çizecektir. Pandas DataFrame üzerinde corr () fonksiyonu yardımıyla üretilebilir ve pyplot yardımı ile grafiği çizilebilir.
from matplotlib import pyplot
from pandas import read_csv
import numpy
Path = r"C:\pima-indians-diabetes.csv"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(Path, names=names)
correlations = data.corr()
fig = pyplot.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(correlations, vmin=-1, vmax=1)
fig.colorbar(cax)
ticks = numpy.arange(0,9,1)
ax.set_xticks(ticks)
ax.set_yticks(ticks)
ax.set_xticklabels(names)
ax.set_yticklabels(names)
pyplot.show()Çıktı

Korelasyon matrisinin yukarıdaki çıktısından simetrik olduğunu görebiliriz, yani sol alt sağ üst ile aynıdır. Her bir değişkenin birbiriyle pozitif korelasyon içinde olduğu da gözlenmektedir.
Dağılım Matrisi Grafiği
Dağılım grafikleri, bir değişkenin diğerinden ne kadar etkilendiğini veya aralarındaki ilişkiyi iki boyuttaki noktalar yardımıyla gösterir. Dağılım grafikleri, veri noktalarını çizmek için yatay ve dikey eksenleri kullanma konseptinde çizgi grafiklere çok benzer.
Misal
Aşağıdaki örnekte, Python komut dosyası, Pima Indian Diabetes veri kümesi için Dağılım matrisi oluşturacak ve grafiğini çizecektir. Pandas DataFrame üzerinde scatter_matrix () fonksiyonu yardımıyla oluşturulabilir ve pyplot yardımı ile grafiği çizilebilir.
from matplotlib import pyplot
from pandas import read_csv
from pandas.tools.plotting import scatter_matrix
path = r"C:\pima-indians-diabetes.csv"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=names)
scatter_matrix(data)
pyplot.show()Çıktı
