SAS - Veri Kümelerini Birleştir
Birden çok SAS veri kümesi, tek bir veri kümesi verecek şekilde birleştirilebilir. SETBeyan. Birleştirilmiş veri setindeki toplam gözlem sayısı, orijinal veri setlerindeki gözlem sayısının toplamıdır. Gözlemlerin sırası sıralıdır. İlk veri setindeki tüm gözlemleri ikinci veri setindeki tüm gözlemler takip eder ve bu böyle devam eder.
İdeal olarak, tüm birleşik veri kümeleri aynı değişkenlere sahiptir, ancak farklı sayıda değişkene sahip olmaları durumunda, sonuçta tüm değişkenler, daha küçük veri kümesi için eksik değerler ile birlikte görünür.
Sözdizimi
SAS'daki SET ifadesi için temel sözdizimi şöyledir:
SET data-set 1 data-set 2 data-set 3.....;Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
data-set1,data-set2 birbiri ardına yazılan veri kümesi adlarıdır.
Misal
Bir organizasyonun, biri BT departmanı ve diğeri Non-It departmanı için olmak üzere iki farklı veri setinde bulunan çalışan verilerini düşünün. Tüm çalışanların tüm ayrıntılarını elde etmek için, her iki veri setini de aşağıda gösterilen SET ifadesini kullanarak birleştirdik.
DATA ITDEPT;
INPUT empid name $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
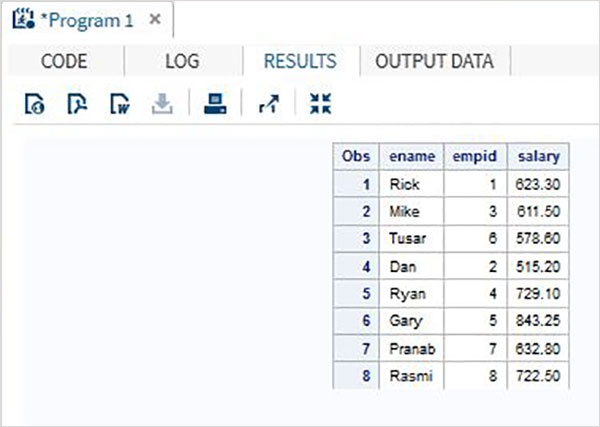
PROC PRINT DATA = All_Dept;
RUN;Yukarıdaki kod çalıştırıldığında aşağıdaki çıktıyı alıyoruz.
Senaryolar
Birleştirme için veri kümelerinde çok sayıda varyasyonumuz olduğunda, değişkenlerin sonucu farklılık gösterebilir ancak birleştirilmiş veri kümesindeki toplam gözlem sayısı her zaman her veri kümesindeki gözlemlerin toplamıdır. Bu varyasyonla ilgili birçok senaryoyu aşağıda ele alacağız.
Farklı sayıda değişken
Orijinal veri kümelerinden birinde daha fazla sayıda değişken varsa, veri kümeleri yine de birleştirilir, ancak daha küçük veri kümesinde bu değişkenler eksik olarak görünür.
Misal
Aşağıdaki örnekte, ilk veri setinin DOJ adında ekstra bir değişkeni vardır. Sonuçta, ikinci veri seti için DOJ değeri eksik olarak görünecektir.
DATA ITDEPT;
INPUT empid name $ salary DOJ date9. ;
DATALINES;
1 Rick 623.3 02APR2001
3 Mike 611.5 21OCT2000
6 Tusar 578.6 01MAR2009
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
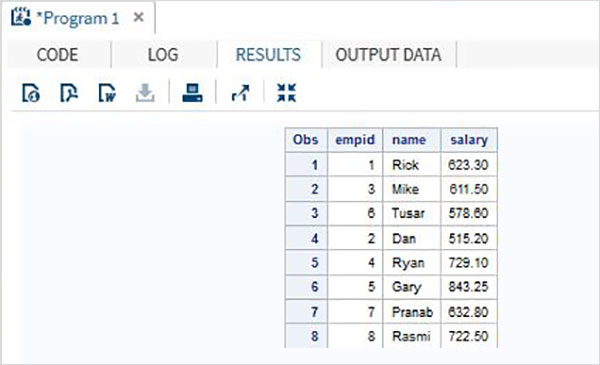
PROC PRINT DATA = All_Dept;
RUN;Yukarıdaki kod çalıştırıldığında aşağıdaki çıktıyı alıyoruz.

Farklı değişken adı
Bu senaryoda veri kümeleri aynı sayıda değişkene sahiptir, ancak değişken adı aralarında farklılık gösterir. Bu durumda normal bir birleştirme, sonuç kümesindeki tüm değişkenleri üretir ve farklı olan iki değişken için eksik sonuçlar verir. Orijinal veri kümelerindeki değişken adını değiştiremeyebiliriz ancak oluşturduğumuz birleştirilmiş veri kümesinde RENAME işlevini uygulayabiliriz. Bu, normal bir birleştirme ile aynı sonucu üretecektir, ancak elbette orijinal veri kümesinde bulunan iki farklı değişken adı yerine bir yeni değişken adı ile.
Misal
Aşağıdaki örnek veri kümesinde, ITDEPT değişken adına sahiptir ename oysa veri seti NON_ITDEPT değişken adına sahiptir empname.Ancak bu değişkenlerin her ikisi de aynı türü (karakteri) temsil eder. UygularızRENAME SET ifadesindeki fonksiyon aşağıda gösterildiği gibi.
DATA ITDEPT;
INPUT empid ename $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid empname $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT(RENAME =(ename = Employee) ) NON_ITDEPT(RENAME =(empname = Employee) );
RUN;
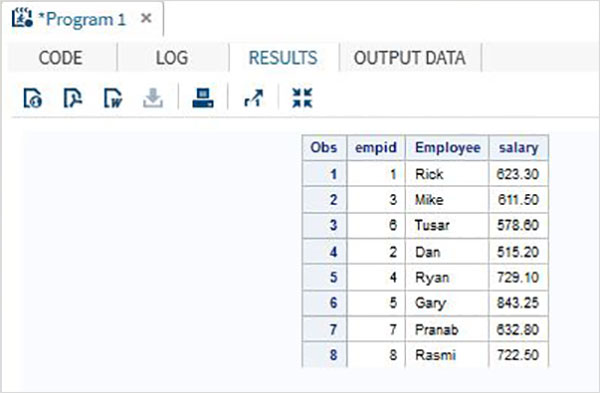
PROC PRINT DATA = All_Dept;
RUN;Yukarıdaki kod çalıştırıldığında aşağıdaki çıktıyı alıyoruz.
Farklı değişken uzunluklar
İki veri kümesindeki değişken uzunluklar birleştirilmiş veri kümesinden farklıysa, bazı verilerin daha küçük uzunluktaki değişken için kesildiği değerlere sahip olacaktır. İlk veri kümesinin daha küçük bir uzunluğu varsa olur. Bunu çözmek için, daha yüksek uzunluğu aşağıda gösterildiği gibi her iki veri kümesine uygularız.
Misal
Aşağıdaki örnekte değişken enameilk veri setinde 5 ve ikincide 7 uzunluğundadır. Birleştirirken, ename uzunluğunu 7'ye ayarlamak için birleştirilmiş veri kümesindeki LENGTH ifadesini uygularız.
DATA ITDEPT;
INPUT empid 1-2 ename $ 3-7 salary 8-14 ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid 1-2 ename $ 3-9 salary 10-16 ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
LENGTH ename $ 7 ;
SET ITDEPT NON_ITDEPT ;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Yukarıdaki kod çalıştırıldığında aşağıdaki çıktıyı alıyoruz.