SAS - Hızlı Kılavuz
SAS duruyor Statistical Analysis Software. 1960 yılında SAS Enstitüsü tarafından oluşturuldu. 1 Ocak 1960'tan itibaren SAS, veri yönetimi, iş zekası, Tahmine Dayalı Analiz, Tanımlayıcı ve Kuralcı Analiz vb. İçin kullanıldı. O zamandan beri, yazılımda birçok yeni istatistiksel prosedür ve bileşen tanıtıldı.
İstatistikler için JMP'nin (Jump) tanıtılmasıyla birlikte SAS, Graphical user InterfaceMacintosh tarafından tanıtıldı. Jump temel olarak Altı Sigma, tasarımlar, kalite kontrol ve mühendislik ve bilimsel analiz gibi uygulamalar için kullanılır.
SAS, platformdan bağımsızdır, yani SAS'ı Linux veya Windows herhangi bir işletim sisteminde çalıştırabilirsiniz. SAS, veri analizi için uygun raporlar oluşturmak üzere SAS veri kümelerinde çeşitli işlem dizilerini kullanan SAS programcıları tarafından yönlendirilir.
Yıllar içinde SAS, ürün portföyüne çok sayıda çözüm ekledi. Veri Yönetişimi, Veri Kalitesi, Büyük Veri Analitiği, Metin Madenciliği, Dolandırıcılık yönetimi, Sağlık bilimi vb. İçin çözüme sahiptir. SAS'ın her iş alanı için bir çözümü olduğunu güvenle varsayabiliriz.
Mevcut ürünlerin listesine göz atmak için SAS Bileşenlerini ziyaret edebilirsiniz.
Neden SAS kullanıyoruz
SAS, temelde büyük veri kümeleri üzerinde çalışır. SAS yazılımı yardımıyla veriler üzerinde aşağıdaki gibi çeşitli işlemler gerçekleştirebilirsiniz:
- Veri yönetimi
- İstatistiksel analiz
- Mükemmel grafiklerle rapor oluşturma
- İş planlaması
- Yöneylem Araştırması ve proje Yönetimi
- Kalite iyileştirme
- Uygulama geliştirme
- Veri çıkarma
- Veri dönüşümü
- Veri güncelleme ve değiştirme
SAS'ın bileşenleri hakkında konuşursak, SAS'da 200'den fazla bileşen mevcuttur.
| Sr.No. | SAS Bileşeni ve Kullanımı |
|---|---|
| 1 | Base SAS Veri yönetimi tesisi ve veri analizi için bir programlama dili içeren temel bir bileşendir. Aynı zamanda en yaygın kullanılanıdır. |
| 2 | SAS/GRAPH Sonucu daha iyi anlamak ve uygun bir formatta sergilemek için grafikler, sunumlar oluşturun. |
| 3 | SAS/STAT Varyans analizi, regresyon, çok değişkenli analiz, hayatta kalma analizi ve psikometrik analiz, karma model analizi ile istatistiksel analiz gerçekleştirin. |
| 4 | SAS/OR Yöneylem araştırması. |
| 5 | SAS/ETS Ekonometri ve Zaman Serileri Analizi. |
| 6 | SAS/IML CEtkileşimli matris dili. |
| 7 | SAS/AF Uygulamalar tesisi. |
| 8 | SAS/QC Kalite kontrol. |
| 9 | SAS/INSIGHT Veri madenciliği. |
| 10 | SAS/PH Klinik deneme analizi. |
| 11 | SAS/Enterprise Miner Veri madenciliği. |
SAS Yazılım Türleri
- Windows veya PC SAS
- SAS EG (Kurumsal Kılavuz)
- SAS EM (Enterprise Miner yani Tahmine Dayalı Analiz için)
- SAS Anlamına Gelir
- SAS İstatistikleri
Çoğunlukla Window SAS'ı organizasyonda ve eğitim enstitüsünde kullanıyoruz. Bazı kuruluşlar Linux kullanıyor ancak grafik kullanıcı arabirimi yok, bu nedenle her sorgu için kod yazmanız gerekiyor. Ancak SAS penceresinde, programcılara çok yardımcı olan ve aynı zamanda kodları yazma süresini de azaltan birçok yardımcı program vardır.
Bir SaS Penceresi 5 bölümden oluşur.
| Sr.No. | SAS Penceresi ve Kullanımı |
|---|---|
| 1 | Log Window Günlük penceresi, SAS programının çalışmasını kontrol edebileceğimiz bir yürütme penceresi gibidir. Bu pencerede hataları da kontrol edebiliriz. Programı çalıştırdıktan sonra her seferinde günlük penceresini kontrol etmek çok önemlidir. Böylece programımızın yürütülmesi hakkında doğru bir anlayışa sahip olabiliriz. |
| 2 | Editor Window
Düzenleyici Penceresi, SAS'ın tüm kodları yazdığımız bölümüdür. Bir not defteri gibidir. |
| 3 | Output Window Çıktı penceresi, programımızın çıktısını görebileceğimiz sonuç penceresidir. |
| 4 | Result Window Tüm çıktıların indeksi gibidir. SAS'ın bir oturumunda çalıştırdığımız tüm programlar burada listelenir ve çıktı sonucuna tıklayarak çıktıyı açabilirsiniz. Ancak bunlardan yalnızca SAS'ın bir oturumunda bahsediliyor. Yazılımı kapatıp açarsak Sonuç Penceresi boş olacaktır. |
| 5 | Explore Window Burada listelenen tüm kütüphaneler. Sistem SAS destekli dosyalarınıza buradan da göz atabilirsiniz. |
SAS'daki kütüphaneler
Kitaplıklar, SAS'daki depolama gibidir. Bir kitaplık oluşturabilir ve tüm benzer programları o kitaplığa kaydedebilirsiniz. SAS, birden fazla kitaplık oluşturma olanağı sağlar. Bir SAS kitaplığı yalnızca 8 karakter uzunluğundadır.
SAS'da iki tür kitaplık vardır -
| Sr.No. | SAS Penceresi ve Kullanımı |
|---|---|
| 1 | Temporary or Work Library Bu, varsayılan olarak SAS kitaplığıdır. Oluşturduğumuz tüm programlar, bunlara başka bir kitaplık atamazsak bu çalışma kitaplığında saklanır. Bu çalışma kitaplığını Keşfet Penceresinden kontrol edebilirsiniz. Bir SAS programı oluşturduysanız ve ona herhangi bir kalıcı kitaplık atamadıysanız, daha sonra oturumu sonlandırırsanız yazılımı yeniden başlatırsanız, bu program çalışma kitaplığında olmayacaktır. Çünkü oturumlar devam ettiği sürece yalnızca Çalışma kütüphanesinde olacaktır. |
| 2 | Permanent Library Bunlar, SAS'ın kalıcı kütüphaneleridir. SAS araçlarını kullanarak veya editör penceresine kodları yazarak yeni bir SAS kütüphanesi oluşturabiliriz. Bu kütüphaneler kalıcı olarak adlandırılır çünkü SAS'ta bir program oluşturup bu kalıcı kütüphanelerde kaydedersek, istediğimiz sürece bunlar kullanılabilir olacaktır. |
SAS Institute Inc. ücretsiz bir SAS University EditionSAS programlamayı öğrenmek için yeterince iyi. BASE SAS programlamasında öğrenmeniz gereken tüm özellikleri sağlar ve bu da diğer SAS bileşenlerini öğrenmenizi sağlar.
SAS University Edition'ı indirme ve kurma süreci çok basittir. Sanal ortamda çalışması gereken sanal makine olarak mevcuttur. SAS yazılımını çalıştırmadan önce bilgisayarınızda sanallaştırma yazılımının kurulu olması gerekir. Bu eğitimde kullanacağızVMware. SAS ortamını indirme, kurma ve kurulumu doğrulama adımlarının ayrıntıları aşağıda verilmiştir.
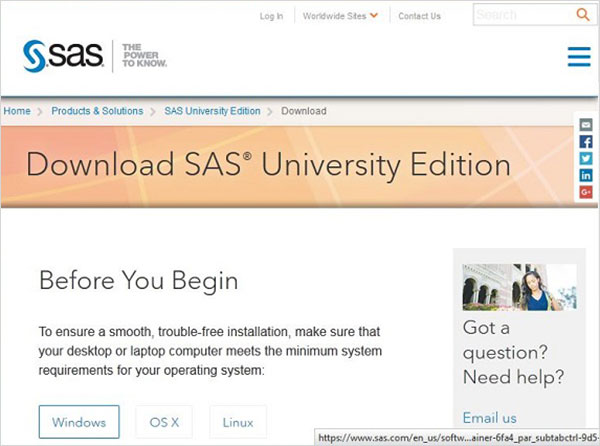
SAS University Edition'ı İndirin
SAS University EditionURL SAS University Edition'dan indirilebilir . İndirmeye başlamadan önce sistem gereksinimlerini okumak için lütfen aşağı kaydırın. Bu URL'yi ziyaret ettiğinizde aşağıdaki ekran görünür.
Sanallaştırma yazılımını kurun
Kurulum stpe-1'i bulmak için aynı sayfada aşağı kaydırın. Bu adım, size uygun sanallaştırma yazılımını elde etmek için bağlantılar sağlar. Bu yazılımlardan herhangi birinin sisteminizde kurulu olması durumunda bu adımı atlayabilirsiniz.

Hızlı başlangıç sanallaştırma yazılımı
Sanallaştırma ortamında tamamen yeniyseniz, 2. adımda sunulan aşağıdaki kılavuzları ve videoları izleyerek kendinizi tanıyabilirsiniz. Zaten aşina olmanız durumunda bu adımı atlayabilirsiniz.

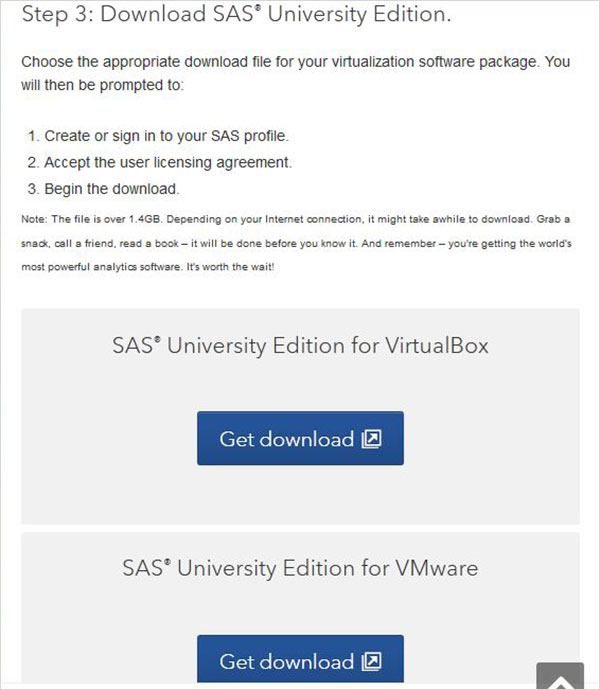
Zip dosyasını indirin
3. adımda, sahip olduğunuz sanallaştırma ortamıyla uyumlu olan SAS Üniversite Sürümünün uygun sürümünü seçebilirsiniz. Unvbasicvapp__9411005__vmx__en__sp0__1.zip ile benzer ada sahip bir zip dosyası olarak indirilir.
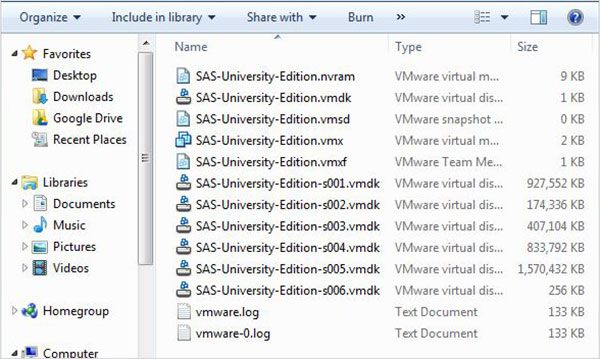
Zip dosyasını açın
Yukarıdaki zip dosyasının açılıp uygun bir dizinde saklanması gerekir. Bizim durumumuzda, sıkıştırmayı açtıktan sonra aşağıdaki dosyaları gösteren VMware zip dosyasını seçtik.
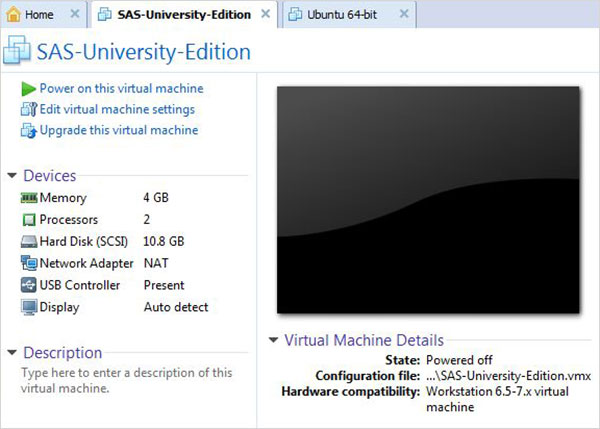
Sanal makineyi yükleme
VMware oynatıcıyı (veya iş istasyonunu) başlatın ve .vmx uzantısıyla biten dosyayı açın. Aşağıdaki ekran belirir. Lütfen vm'ye ayrılan bellek ve sabit disk alanı gibi temel ayarlara dikkat edin.
Sanal makineyi açın
Tıkla Power on this virtual machinesanal makineyi başlatmak için yeşil ok işaretinin yanında. Aşağıdaki ekran belirir.

Aşağıdaki ekran, SAS vm yükleme durumunda olduğunda görünür ve ardından çalışan vm, SAS ortamını açacak olan bir URL konumuna gitme istemi verir.
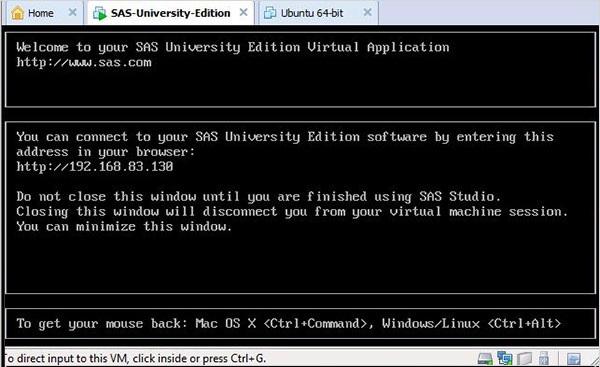
SAS stüdyosunun başlatılması
Yeni bir tarayıcı sekmesi açın ve yukarıdaki URL'yi yükleyin (bir PC'den diğerine farklılık gösterir). Aşağıdaki ekran SAS ortamının hazır olduğunu gösterir.
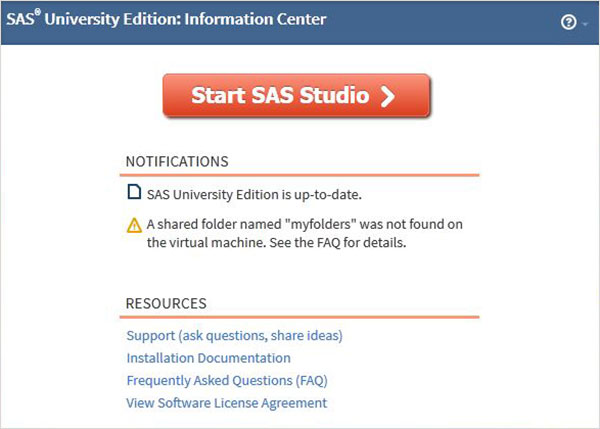
SAS Ortamı
Tıklandığında Start SAS Studio Aşağıda gösterildiği gibi, varsayılan olarak görsel programcı modunda açılan SAS ortamını elde ederiz.
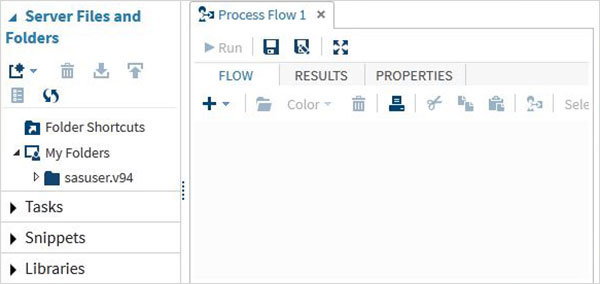
Açılır menüye tıklayarak bunu SAS programcı moduna da değiştirebiliriz.
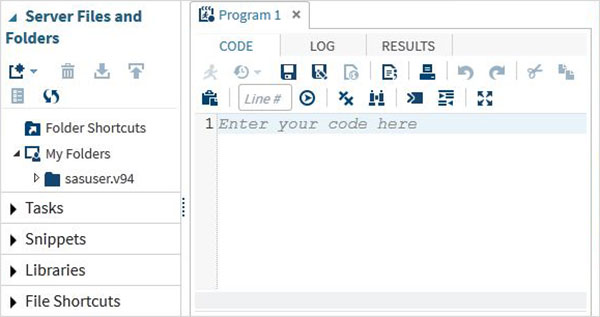
Artık SAS Programları yazmaya hazırız.
SAS Programları, şu adıyla bilinen bir kullanıcı arabirimi kullanılarak oluşturulur: SAS Studio.
Aşağıda çeşitli pencerelerin ve kullanımlarının bir açıklaması bulunmaktadır.
SAS Ana Penceresi
Bu, SAS ortamına girerken gördüğünüz penceredir. SoldaNavigation Paneçeşitli programlama özelliklerinde gezinmek için kullanılır. SağdakiWork Area kod yazmak ve çalıştırmak için kullanılır.

Otomatik Kod Tamamlama
Bu, SAS anahtar sözcüklerinin doğru sözdizimini elde etmeye yardımcı olan ve aynı zamanda bu anahtar sözcük için belgelere bağlantı sağlayan çok güçlü bir özelliktir.
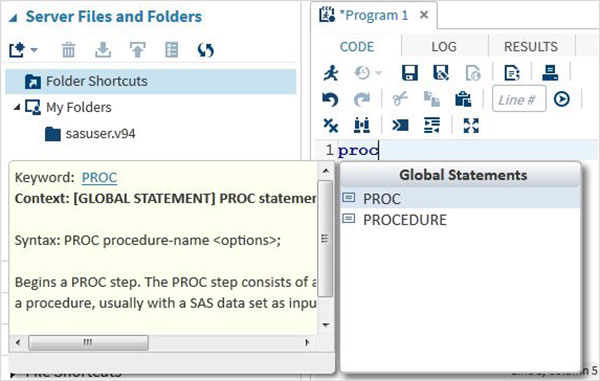
Program Yürütme
Kodun yürütülmesi, soldan ilk simge olan çalıştır simgesine veya F3 düğmesine basılarak yapılır.
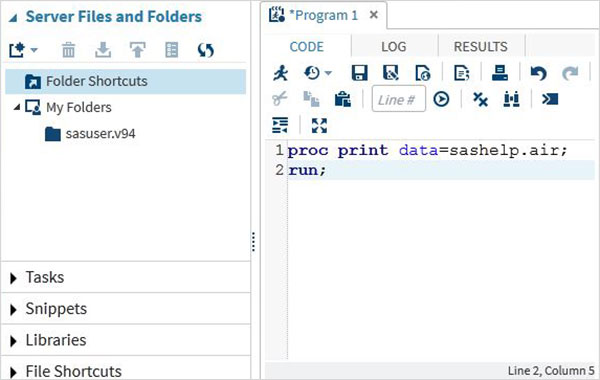
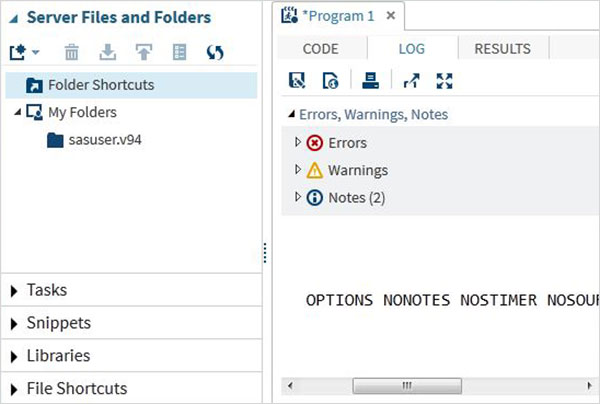
Program Günlüğü
Yürütülen kodun günlüğü, Logsekmesi. Programın çalıştırılmasıyla ilgili hataları, uyarıları veya notları açıklar. Bu, kodunuzun sorunlarını gidermek için tüm ipuçlarını aldığınız penceredir.
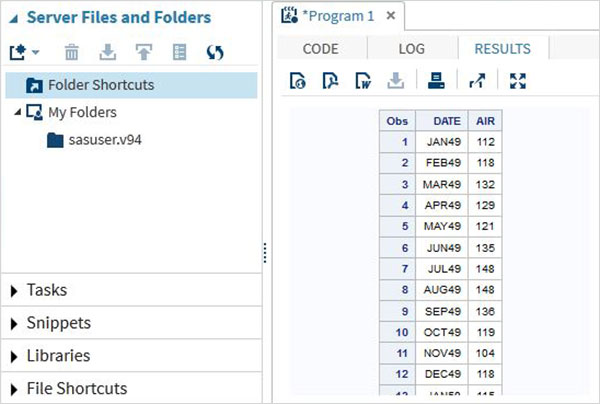
Program Sonucu
Kod yürütmenin sonucu SONUÇLAR sekmesinde görülür. Varsayılan olarak html tabloları olarak biçimlendirilirler.
Program Sekmeleri
Gezinme Alanı, programları oluşturmak ve yönetmek için özellikler içerir. Ayrıca, programınızla birlikte kullanılmak üzere önceden oluşturulmuş işlevleri sağlar.
Sunucu Dosyaları ve Klasörleri
Bu sekme altında ek programlar oluşturabilir, analiz edilecek verileri içe aktarabilir ve mevcut verileri sorgulayabiliriz. Klasör kısayolları oluşturmak için de kullanılabilir.
Görevler
Görevler sekmesi, yalnızca giriş değişkenlerini sağlayarak yerleşik SAS programlarını kullanmak için özellikler sağlar. Örneğin, istatistik klasörünün altında, yalnızca SAS veri kümesi adını ve değişken adlarını sağlayarak doğrusal regresyon yapmak için bir SAS programı bulabilirsiniz.
Snippet'ler
Parçacıklar sekmesi, SAS Makrosunu yazmak ve mevcut veri kümesinden dosyalar oluşturmak için özellikler sağlar

Program Kitaplıkları
SAS, veri kümelerini SAS kitaplıklarında depolar. Geçici kütüphane sadece tek bir oturum için mevcuttur ve WORK olarak adlandırılmıştır. Ancak kalıcı kütüphaneler her zaman mevcuttur.
Dosya Kısayolları
Bu sekme, SAS ortamının dışında depolanan dosyalara erişmek için kullanılır. Bu tür dosyaların kısayolları bu sekme altında saklanır.
SAS Programlama, önce veri setlerinin oluşturulmasını / belleğe okunmasını ve ardından bu veriler üzerinde analizin yapılmasını içerir. Bunu başarmak için bir programın yazıldığı akışı anlamamız gerekir.
SAS Program Yapısı
Aşağıdaki şema, bir SAS Programı oluşturmak için verilen sırayla yazılması gereken adımları göstermektedir.
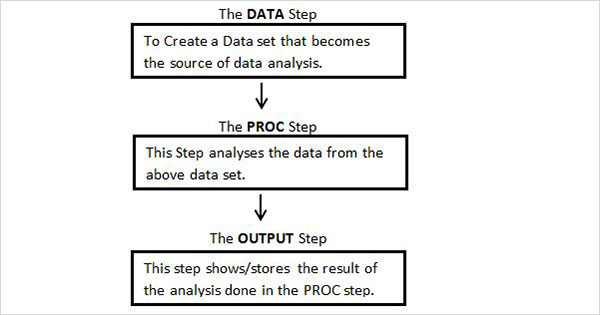
Her SAS programı, giriş verilerini okumayı, verileri analiz etmeyi ve analizin çıktısını vermeyi tamamlamak için tüm bu adımlara sahip olmalıdır. AyrıcaRUN Her adımın sonundaki ifadesinin o adımın yürütülmesini tamamlaması gerekir.
VERİ Adımı
Bu adım, gerekli veri setinin SAS belleğine yüklenmesini ve veri setinin değişkenlerinin (sütunlar olarak da adlandırılır) tanımlanmasını içerir. Ayrıca kayıtları da yakalar (gözlemler veya konular da denir). VERİ ifadesinin sözdizimi aşağıdaki gibidir.
Sözdizimi
DATA data_set_name; #Name the data set.
INPUT var1,var2,var3; #Define the variables in this data set.
NEW_VAR; #Create new variables.
LABEL; #Assign labels to variables.
DATALINES; #Enter the data.
RUN;Misal
Aşağıdaki örnek, veri setini adlandırmanın, değişkenlerin tanımlanmasının, yeni değişkenlerin yaratılmasının ve verilerin girilmesinin basit bir durumunu gösterir. Burada dize değişkenlerinin sonunda bir $ vardır ve sayısal değerler onsuzdur.
DATA TEMP;
INPUT ID $ NAME $ SALARY DEPARTMENT $;
comm = SALARY*0.25;
LABEL ID = 'Employee ID' comm = 'COMMISION';
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 Operations
3 Michelle 611 IT
4 Ryan 729 HR
5 Gary 843.25 Finance
6 Nina 578 IT
7 Simon 632.8 Operations
8 Guru 722.5 Finance
;
RUN;PROC Adımı
Bu adım, verileri analiz etmek için bir SAS yerleşik prosedürünü çağırmayı içerir.
Sözdizimi
PROC procedure_name options; #The name of the proc.
RUN;Misal
Aşağıdaki örnek, MEANS Veri setindeki sayısal değişkenlerin ortalama değerlerini yazdırma prosedürü.
PROC MEANS;
RUN;ÇIKTI Adımı
Veri setlerinden gelen veriler, koşullu çıktı ifadeleriyle görüntülenebilir.
Sözdizimi
PROC PRINT DATA = data_set;
OPTIONS;
RUN;Misal
Aşağıdaki örnek, veri kümesinden yalnızca birkaç kayıt üretmek için çıktıdaki where cümlesini kullanmayı gösterir.
PROC PRINT DATA = TEMP;
WHERE SALARY > 700;
RUN;Tam SAS Programı
Aşağıda, yukarıdaki adımların her biri için tam kod bulunmaktadır.
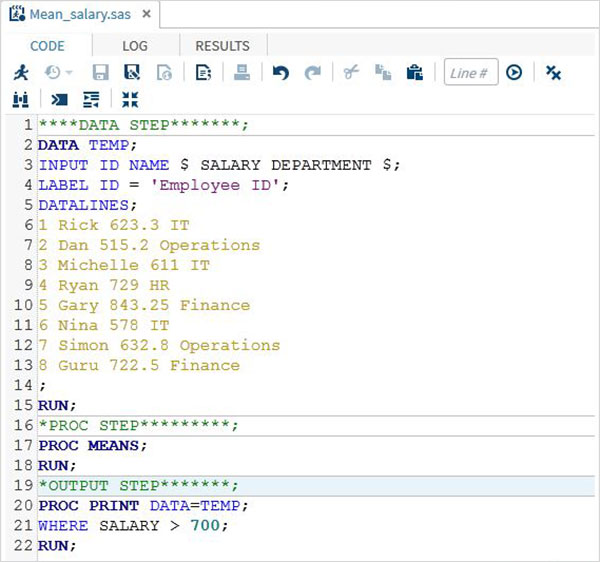
Program Çıkışı
RESULTS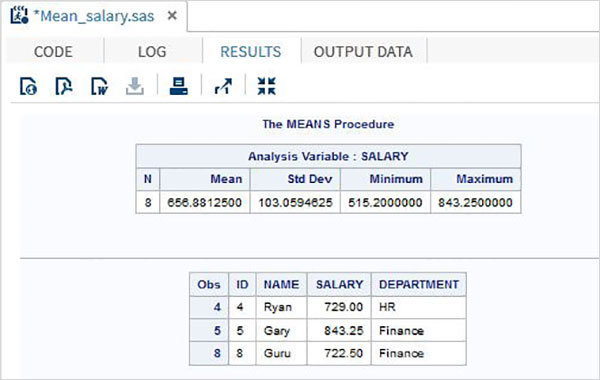
Diğer herhangi bir programlama dili gibi, SAS dili de SAS programlarını oluşturmak için kendi sözdizimi kurallarına sahiptir.
Herhangi bir SAS programının üç bileşeni - İfadeler, Değişkenler ve Veri kümeleri, Sözdiziminde aşağıdaki kuralları izler.
SAS İfadeleri
İfadeler herhangi bir yerde başlayabilir ve herhangi bir yerde bitebilir. Son satırın sonundaki noktalı virgül, ifadenin sonunu gösterir.
Birçok SAS ifadesi aynı satırda olabilir ve her ifade noktalı virgülle biter.
Bir SAS program deyimindeki bileşenleri ayırmak için boşluk kullanılabilir.
SAS anahtar sözcükleri büyük / küçük harfe duyarlı değildir.
Her SAS programı bir RUN ifadesiyle bitmelidir.
SAS Değişken Adları
SAS'daki değişkenler, SAS veri kümesindeki bir sütunu temsil eder. Değişken isimleri aşağıdaki kuralları izler.
Maksimum 32 karakter uzunluğunda olabilir.
Boşluk içeremez.
A'dan Z'ye kadar harflerle (büyük / küçük harfe duyarlı değil) veya alt çizgiyle (_) başlamalıdır.
Sayıları içerebilir ancak ilk karakter olarak içeremez.
Değişken adları büyük / küçük harfe duyarlıdır.
Misal
# Valid Variable Names
REVENUE_YEAR
MaxVal
_Length
# Invalid variable Names
Miles Per Liter #contains Space.
RainfFall% # contains apecial character other than underscore.
90_high # Starts with a number.SAS Veri Seti
DATA ifadesi, yeni bir SAS veri setinin oluşturulduğunu gösterir. VERİ seti oluşturma kuralları aşağıdaki gibidir.
DATA ifadesinden sonraki tek kelime, geçici bir veri seti adını gösterir. Bu, seansın sonunda veri setinin silineceği anlamına gelir.
Veri kümesi adı, onu kalıcı bir veri kümesi yapan bir kitaplık adı ile ön eklenebilir. Bu, veri setinin oturum bittikten sonra da devam ettiği anlamına gelir.
SAS veri kümesi adı atlanırsa, SAS, SAS gibi - DATA1, DATA2, vb. Tarafından üretilen bir adla geçici bir veri kümesi oluşturur.
Misal
# Temporary data sets.
DATA TempData;
DATA abc;
DATA newdat;
# Permanent data sets.
DATA LIBRARY1.DATA1
DATA MYLIB.newdat;SAS Dosya Uzantıları
SAS programları, veri dosyaları ve programların sonuçları çeşitli uzantılarla pencerelerde kaydedilir.
*.sas - SAS Düzenleyicisi veya herhangi bir metin düzenleyicisi kullanılarak düzenlenebilen SAS kod dosyasını temsil eder.
*.log - Sunulan bir SAS programı için hatalar, uyarılar ve veri seti ayrıntıları gibi bilgileri içeren SAS Günlük Dosyasını temsil eder.
*.mht / *.html −SAS Sonuçları dosyasını temsil eder.
*.sas7bdat −Değişken adları, etiketler ve hesaplamaların sonuçlarını içeren bir SAS veri kümesini içeren SAS Veri Dosyasını temsil eder.
SAS'daki yorumlar
SAS kodundaki yorumlar iki şekilde belirtilir. Aşağıda bu iki format bulunmaktadır.
*İleti; yorum yazın
Şeklinde bir yorum *message;içinde noktalı virgül veya eşleşmeyen tırnak işareti bulunamaz. Ayrıca bu tür yorumların içinde herhangi bir makro ifadesine atıfta bulunulmamalıdır. Birden çok satıra yayılabilir ve herhangi bir uzunlukta olabilir .. Aşağıda tek satırlık bir açıklama örneği verilmiştir -
* This is comment ;Aşağıda, çok satırlı bir yorum örneği verilmiştir -
* This is first line of the comment
* This is second line of the comment;/ * mesaj * / açıklama yazın
Şeklinde bir yorum /*message*/daha sık kullanılır ve yuvalanamaz. Ancak birden fazla satıra yayılabilir ve herhangi bir uzunlukta olabilir. Aşağıda tek satırlık bir yorum örneği verilmiştir -
/* This is comment */Aşağıda, çok satırlı bir yorum örneği verilmiştir -
/* This is first line of the comment
* This is second line of the comment */Analiz için bir SAS programı tarafından kullanılabilen veriler, bir SAS Veri Kümesi olarak adlandırılır. DATA adımı kullanılarak oluşturulur.SAS, veri kaynakları gibi çeşitli dosyaları okuyabilir.CSV, Excel, Access, SPSS and also raw data. Ayrıca kullanım için birçok yerleşik veri kaynağına sahiptir.
Veri Kümeleri çağrılır temporary Data Set SAS programı tarafından kullanılıyorlarsa ve oturum çalıştırıldıktan sonra atılırlarsa.
Ancak ileride kullanılmak üzere kalıcı olarak depolanırsa, buna permanent Data set. Tüm kalıcı Veri Kümeleri, belirli bir kitaplık altında saklanır.
SAS Veri seti, satırlar ve sütunlar şeklinde depolanır ve ayrıca SAS Veri tablosu olarak adlandırılır. Aşağıda, dahili ve harici kaynaklardan kırmızı olan kalıcı Veri kümelerinin örneklerini görüyoruz.
SAS Yerleşik Veri Setleri
Bu Veri Kümeleri, kurulu SAS yazılımında zaten mevcuttur. Veri analizi için örnek ifadelerin formüle edilmesinde araştırılabilir ve kullanılabilirler. Bu veri kümelerini keşfetmek için şu adrese gidin:Libraries -> My Libraries -> SASHELP. Genişlettiğimizde, mevcut tüm yerleşik Veri Kümelerinin adlarının listesini görüyoruz.
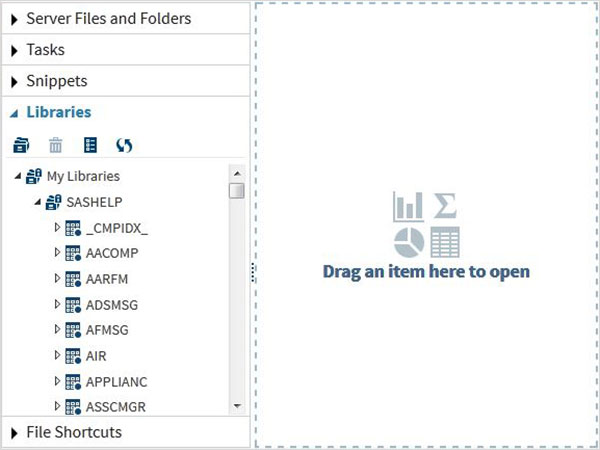
Adında bir Veri Kümesi bulmak için aşağı kaydıralım CARSBu Veri Kümesine çift tıklamak, onu daha fazla inceleyebileceğimiz sağ pencere bölmesinde açar. Sağ bölmenin altındaki görünümü büyüt düğmesini kullanarak da sol bölmeyi küçültebiliriz.
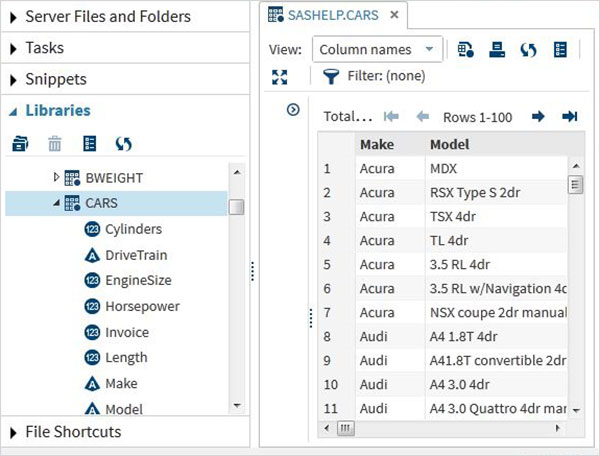
Tablodaki tüm sütunları ve değerlerini keşfetmek için alttaki kaydırma çubuğunu kullanarak sağa kaydırabiliriz.
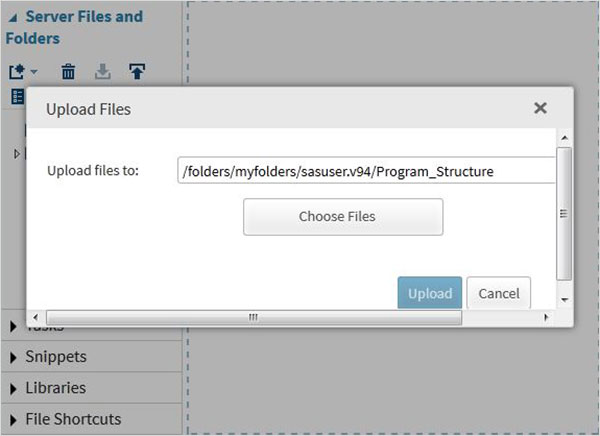
Dış Veri Kümelerini İçe Aktarma
SAS Studio'da bulunan içe aktarma özelliğini kullanarak kendi dosyalarımızı Veri kümeleri olarak dışa aktarabiliriz. Ancak bu dosyaların SAS sunucusu klasörlerinde bulunması gerekir. Bu nedenle, kaynak veri dosyalarını SAS klasörüne, aşağıdaki yükleme seçeneğini kullanarak yüklemeliyiz.Server Files and Folders.
Daha sonra yukarıdaki dosyayı içe aktararak bir SAS programında kullanıyoruz. Bunu yapmak için seçeneği kullanıyoruzTasks -> Utilities -> Import data Aşağıda gösterildiği gibi. Veri Kümesi için dosya seçmek üzere sağdaki pencereyi açan Verileri İçe Aktar düğmesini çift tıklayın.
Sonraki Select FilesSağ bölmedeki verileri içe aktarma programının altındaki düğmesine tıklayın. Aşağıdakiler içe aktarılabilen dosya türlerinin listesidir.
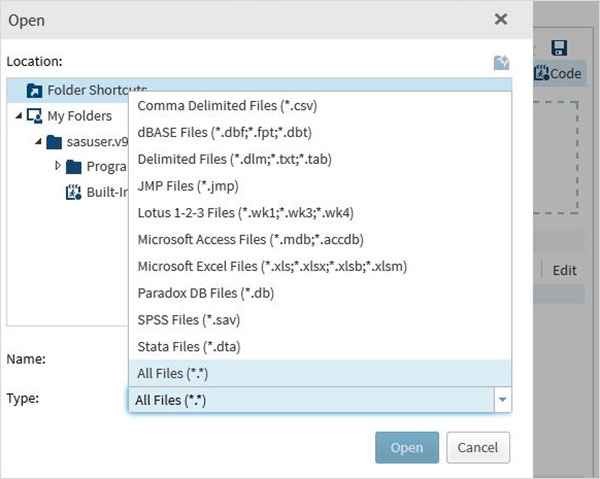
Yerel sistemde depolanan "employee.txt" dosyasını seçiyoruz ve aşağıda gösterildiği gibi içe aktarılan dosyayı alıyoruz.
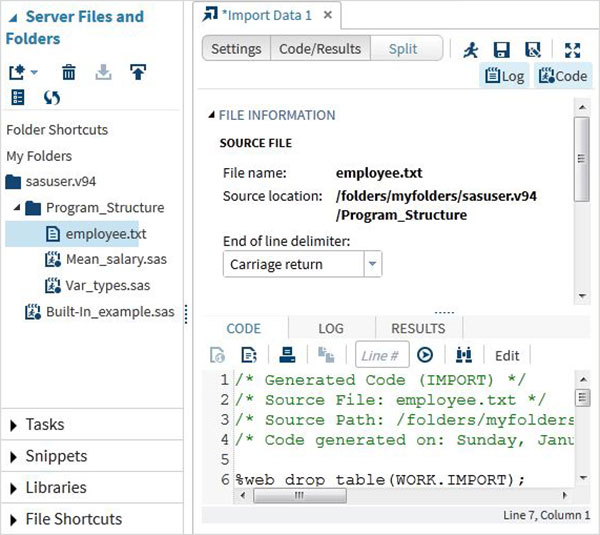
İçe aktarılan verileri görüntüleyin
İçe aktarılan verileri, Çalıştır seçeneği kullanılarak oluşturulan varsayılan içe aktarma kodunu çalıştırarak görüntüleyebiliriz.
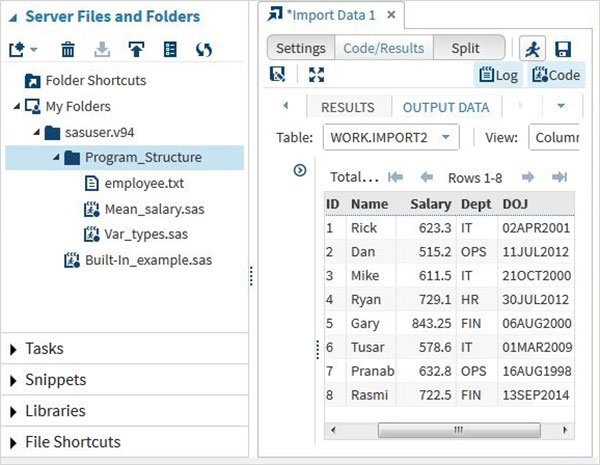
Yukarıdaki ile aynı yaklaşımı kullanarak diğer dosya türlerini içe aktarabilir ve çeşitli SAS programlarında kullanabiliriz.
Genel olarak SAS'daki değişkenler, analiz ettiği veri tablolarının sütun adlarını temsil eder. Ancak bir programlama döngüsünde sayaç olarak kullanmak gibi başka amaçlar için de kullanılabilir. Bu bölümde, SAS değişkenlerinin SAS Veri Kümesinin sütun adları olarak kullanımını göreceğiz.
SAS Değişken Türleri
SAS'ın aşağıdaki gibi üç tür değişkeni vardır -
Sayısal Değişkenler
Bu, varsayılan değişken türüdür. Bu değişkenler matematiksel ifadelerde kullanılır.
Sözdizimi
INPUT VAR1 VAR2 VAR3; #Define numeric variables in the data set.Yukarıdaki söz diziminde, INPUT deyimi sayısal değişkenlerin bildirimini gösterir.
Misal
INPUT ID SALARY COMM_PERCENT;Karakter Değişkenleri
Karakter değişkenleri, Matematiksel ifadelerde kullanılmayan değerler için kullanılır. Metin veya dizeler olarak ele alınırlar. Bir değişken, değişken adının sonuna bir boşluk olan bir $ sing eklenerek bir karakter değişkeni haline gelir.
Sözdizimi
INPUT VAR1 $ VAR2 $ VAR3 $; #Define character variables in the data set.Yukarıdaki sözdiziminde, INPUT deyimi karakter değişkenlerinin bildirimini gösterir.
Misal
INPUT FNAME $ LNAME $ ADDRESS $;Tarih Değişkenleri
Bu değişkenler yalnızca tarih olarak kabul edilir ve geçerli tarih formatlarında olmaları gerekir. Değişken, adının sonunda boşluk bulunan bir tarih biçimi ekleyerek bir tarih değişkeni haline gelir.
Sözdizimi
INPUT VAR1 DATE11. VAR2 MMDDYY10. ; #Define date variables in the data set.Yukarıdaki sözdiziminde, INPUT deyimi tarih değişkenlerinin bildirimini gösterir.
Misal
INPUT DOB DATE11. START_DATE MMDDYY10. ;SAS Programında Değişkenlerin Kullanımı
Yukarıdaki değişkenler, aşağıdaki örneklerde gösterildiği gibi SAS programında kullanılmaktadır.
Misal
Aşağıdaki kod, üç tür değişkenin bir SAS Programında nasıl bildirildiğini ve kullanıldığını gösterir.
DATA TEMP;
INPUT ID NAME $ SALARY DEPT $ DOJ DATE9. ;
FORMAT DOJ DATE9. ;
DATALINES;
1 Rick 623.3 IT 02APR2001
2 Dan 515.2 OPS 11JUL2012
3 Michelle 611 IT 21OCT2000
4 Ryan 729 HR 30JUL2012
5 Gary 843.25 FIN 06AUG2000
6 Tusar 578 IT 01MAR2009
7 Pranab 632.8 OPS 16AUG1998
8 Rasmi 722.5 FIN 13SEP2014
;
PROC PRINT DATA = TEMP;
RUN;Yukarıdaki örnekte, tüm karakter değişkenleri, ardından bir $ işareti ve tarih değişkenleri de bir tarih biçimi ile bildirilmiştir. Yukarıdaki programın çıktısı aşağıdaki gibidir.
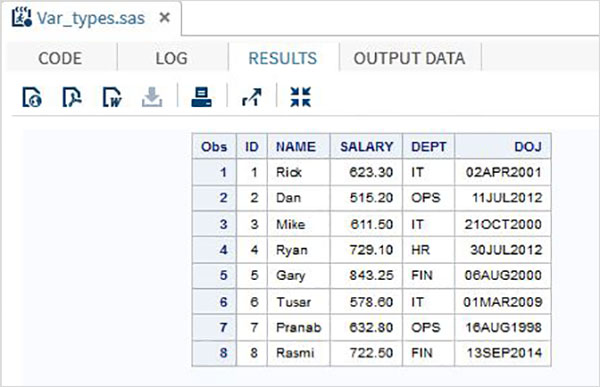
Değişkenleri Kullanma
Değişkenler verileri analiz etmede çok kullanışlıdır. İstatistiksel analizin uygulandığı ifadelerde kullanılırlar. Adlı yerleşik Veri Kümesini analiz etmenin bir örneğini görelimCARS altında bulunan Libraries → My Libraries → SASHELP. Değişkenleri ve veri türlerini keşfetmek için üzerine çift tıklayın.

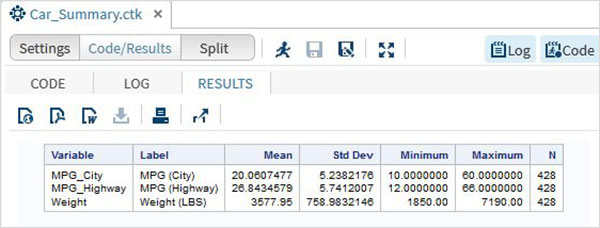
Daha sonra, SAS stüdyosundaki Görevler seçeneklerini kullanarak bu değişkenlerden bazılarının özet istatistiklerini üretebiliriz. GitTasks -> Statistics -> Summary Statisticsve aşağıda gösterildiği gibi pencereyi açmak için çift tıklayın. Veri Kümesini SeçinSASHELP.CARSve Analiz Değişkenleri altında üç değişkeni seçin - MPG_CITY, MPG_Highway ve Weight. Tıklayarak değişkenleri seçerken Ctrl tuşunu basılı tutun. Çalıştıra tıkla.

Yukarıdaki adımlardan sonra sonuçlar sekmesine tıklayın. Seçilen üç değişkenin istatistiksel özetini gösterir. Son sütun, analizde kullanılan gözlemlerin (kayıtların) sayısını gösterir.
SAS'daki dizeler, bir çift tek tırnak içine alınmış değerlerdir. Ayrıca dizge değişkenleri, değişken bildiriminin sonuna bir boşluk ve $ işareti eklenerek bildirilir. SAS, dizeleri analiz etmek ve işlemek için birçok güçlü işleve sahiptir.
Dize Değişkenlerini Bildirme
Dize değişkenlerini ve değerlerini aşağıda gösterildiği gibi tanımlayabiliriz. Aşağıdaki kodda 6 ve 5 uzunluklarında iki karakter değişkenini tanımlıyoruz. LENGTH anahtar sözcüğü, birden çok gözlem oluşturmadan değişkenleri bildirmek için kullanılır.
data string_examples;
LENGTH string1 $ 6 String2 $ 5;
/*String variables of length 6 and 5 */
String1 = 'Hello';
String2 = 'World';
Joined_strings = String1 ||String2 ;
run;
proc print data = string_examples noobs;
run;Yukarıdaki kodu çalıştırırken, değişken isimlerini ve değerlerini gösteren çıktıyı alıyoruz.
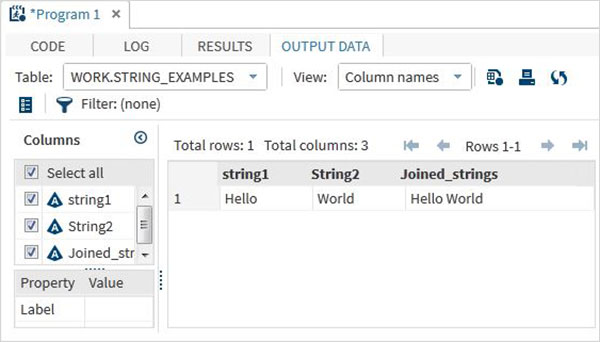
String Fonksiyonları
Aşağıda sık kullanılan bazı SAS işlevlerinin örnekleri verilmiştir.
ALT YAPI
Bu işlev, başlangıç ve bitiş konumlarını kullanarak bir alt dizeyi çıkarır. Son konumdan bahsedilmemesi durumunda dizenin sonuna kadar tüm karakterleri çıkarır.
Sözdizimi
SUBSTRN('stringval',p1,p2)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
- stringval dize değişkeninin değeridir.
- p1 ekstraksiyonun başlangıç konumudur.
- p2 ekstraksiyonun son pozisyonudur.
Misal
data string_examples;
LENGTH string1 $ 6 ;
String1 = 'Hello';
sub_string1 = substrn(String1,2,4) ;
/*Extract from position 2 to 4 */
sub_string2 = substrn(String1,3) ;
/*Extract from position 3 onwards */
run;
proc print data = string_examples noobs;
run;Yukarıdaki kodu çalıştırdığımızda, substrn fonksiyonunun sonucunu gösteren çıktıyı alıyoruz.

TRIMN
Bu işlev, bir dizeden sonraki boşluğu kaldırır.
Sözdizimi
TRIMN('stringval')Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
- stringval dize değişkeninin değeridir.
data string_examples;
LENGTH string1 $ 7 ;
String1='Hello ';
length_string1 = lengthc(String1);
length_trimmed_string = lengthc(TRIMN(String1));
run;
proc print data = string_examples noobs;
run;Yukarıdaki kodu çalıştırdığımızda, TRIMN fonksiyonunun sonucunu gösteren çıktıyı alıyoruz.
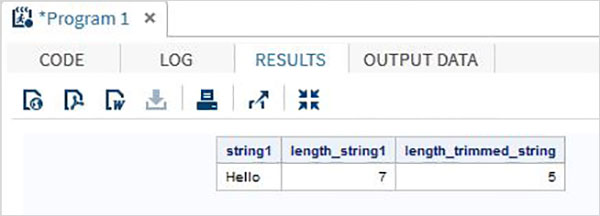
SAS'daki diziler, bir dizin değeri kullanarak bir dizi değeri depolamak ve almak için kullanılır. Dizin, ayrılmış bir bellek alanındaki konumu temsil eder.
Sözdizimi
SAS'da bir dizi aşağıdaki sözdizimi kullanılarak bildirilir -
ARRAY ARRAY-NAME(SUBSCRIPT) ($) VARIABLE-LIST ARRAY-VALUESYukarıdaki sözdiziminde -
ARRAY bir dizi bildirmek için kullanılan SAS anahtar sözcüğüdür.
ARRAY-NAME değişken isimleriyle aynı kuralı izleyen dizinin adıdır.
SUBSCRIPT dizinin depolayacağı değerlerin sayısıdır.
($) yalnızca dizi karakter değerlerini depolayacaksa kullanılacak isteğe bağlı bir parametredir.
VARIABLE-LIST dizi değerleri için yer tutucular olan isteğe bağlı değişkenler listesidir.
ARRAY-VALUESdizide depolanan gerçek değerlerdir. Burada beyan edilebilirler veya bir dosyadan veya veri tabanından okunabilirler.
Dizi Bildirimi Örnekleri
Diziler, yukarıdaki sözdizimi kullanılarak birçok şekilde bildirilebilir. Örnekler aşağıdadır.
# Declare an array of length 5 named AGE with values.
ARRAY AGE[5] (12 18 5 62 44);
# Declare an array of length 5 named COUNTRIES with values starting at index 0.
ARRAY COUNTRIES(0:8) A B C D E F G H I;
# Declare an array of length 5 named QUESTS which contain character values.
ARRAY QUESTS(1:5) $ Q1-Q5;
# Declare an array of required length as per the number of values supplied.
ARRAY ANSWER(*) A1-A100;Dizi Değerlerine Erişim
Bir dizide depolanan değerlere, printaşağıda gösterildiği gibi prosedür. Yukarıdaki yöntemlerden biri kullanılarak bildirildikten sonra, veriler DATALINES ifadesi kullanılarak sağlanır.
DATA array_example;
INPUT a1 $ a2 $ a3 $ a4 $ a5 $; ARRAY colours(5) $ a1-a5;
mix = a1||'+'||a2;
DATALINES;
yello pink orange green blue
;
RUN;
PROC PRINT DATA = array_example;
RUN;Yukarıdaki kodu çalıştırdığımızda, aşağıdaki sonucu verir -
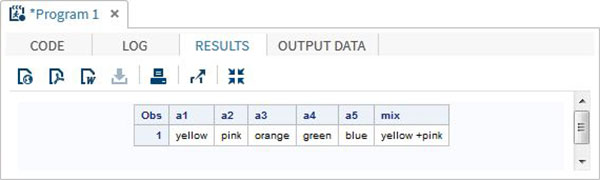
OF operatörünü kullanma
OF operatörü, bir dizinin tüm satırında hesaplamalar gerçekleştirmek için bir Dizi oluşturan verileri analiz ederken kullanılır. Aşağıdaki örnekte, her satıra değerlerin Toplamını ve Ortalamasını uyguluyoruz.
DATA array_example_OF;
INPUT A1 A2 A3 A4;
ARRAY A(4) A1-A4;
A_SUM = SUM(OF A(*));
A_MEAN = MEAN(OF A(*));
A_MIN = MIN(OF A(*));
DATALINES;
21 4 52 11
96 25 42 6
;
RUN;
PROC PRINT DATA = array_example_OF;
RUN;Yukarıdaki kodu çalıştırdığımızda, aşağıdaki sonucu verir -
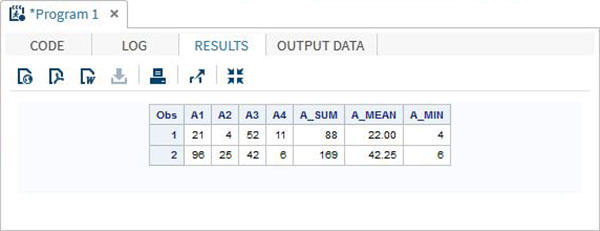
IN operatörünü kullanma
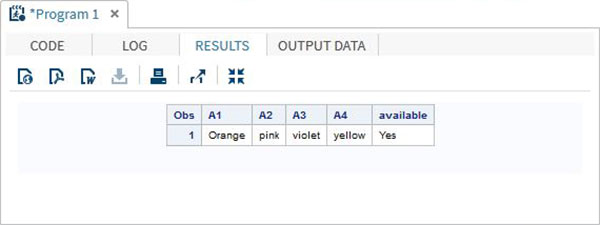
Bir dizideki değere, dizinin satırındaki bir değerin varlığını kontrol eden IN operatörü kullanılarak da erişilebilir. Aşağıdaki örnekte, verilerde "Sarı" renginin varlığını kontrol ediyoruz. Bu değer büyük / küçük harfe duyarlıdır.
DATA array_in_example;
INPUT A1 $ A2 $ A3 $ A4 $;
ARRAY COLOURS(4) A1-A4;
IF 'yellow' IN COLOURS THEN available = 'Yes';ELSE available = 'No';
DATALINES;
Orange pink violet yellow
;
RUN;
PROC PRINT DATA = array_in_example;
RUN;Yukarıdaki kodu çalıştırdığımızda, aşağıdaki sonucu verir -
SAS, çok çeşitli sayısal veri formatlarını işleyebilir. Verilere belirli bir sayısal biçim uygulamak için değişken adlarının sonunda bu biçimleri kullanır. SAS, iki tür sayısal biçim kullanır. Sayısal verilerin belirli formatlarını okumak için birinformat ve sayısal verileri, adı verilen belirli bir biçimde görüntülemek için bir diğeri output format.
Sözdizimi
Sayısal bir bilgi için Sözdizimi -
Varname Formatnamew.dAşağıda kullanılan parametrelerin açıklaması verilmiştir -
Varname değişkenin adıdır.
Formatname değişkene uygulanan sayısal formatın adıdır.
w değişken için saklanmasına izin verilen maksimum veri sütunu sayısı (ondalık basamaklar ve ondalık noktanın kendisi dahil).
d ondalık basamağın sağındaki basamak sayısıdır.
Sayısal biçimleri okuma
Aşağıda, verileri SAS'a okumak için kullanılan formatların bir listesi bulunmaktadır.
Giriş Sayısal Biçimleri
| Biçim | Kullanım |
|---|---|
| n. | Ondalık basamak içermeyen maksimum "n" sütun sayısı. |
| n.p | "P" ondalık noktalı maksimum "n" sütun sayısı. |
| COMMAn.p | Virgül veya dolar işaretlerini kaldıran "p" ondalık basamaklı maksimum "n" sütun sayısı. |
| COMMAn.p | Virgül veya dolar işaretlerini kaldıran "p" ondalık basamaklı maksimum "n" sütun sayısı. |
Sayısal biçimleri görüntüleme
Verileri okurken format uygulamaya benzer şekilde, aşağıda bir SAS programının çıktısında verileri görüntülemek için kullanılan formatların bir listesi bulunmaktadır.
Çıktı Sayısal Biçimleri
| Biçim | Kullanım |
|---|---|
| n. | Ondalık nokta olmadan maksimum "n" rakam yazın. |
| n.p | "P" ondalık nokta ile maksimum "np" sütun sayısı yazın. |
| DOLLARn.p | En fazla "n" sayıda sütun, ondalık basamak sayısı, başında dolar işareti ve bininci basamağa virgül koyarak yazın. |
Lütfen Dikkat -
Ondalık noktadan sonraki hane sayısı biçim belirticisinden daha azsa, o zamanzeros will be appended sonunda.
Ondalık noktadan sonraki hane sayısı biçim belirleyiciden büyükse, son hane olacaktır rounded off.
Örnekler
Aşağıdaki örnekler yukarıdaki senaryoları göstermektedir.
DATA MYDATA1;
input x 6.; /*maxiiuum width of the data*/
format x 6.3;
datalines;
8722
93.2
.1122
15.116
PROC PRINT DATA = MYDATA1;
RUN;
DATA MYDATA2;
input x 6.; /*maximum width of the data*/
format x 5.2;
datalines;
8722
93.2
.1122
15.116
PROC PRINT DATA = MYDATA2;
RUN;
DATA MYDATA3;
input x 6.; /*maximum width of the data*/
format x DOLLAR10.2;
datalines;
8722
93.2
.1122
15.116
PROC PRINT DATA = MYDATA3;
RUN;Yukarıdaki kodu çalıştırdığımızda, aşağıdaki sonucu verir -
# MYDATA1.
Obs x
1 8722.0 # Display 6 columns with zero appended after decimal.
2 93.200 # Display 6 columns with zero appended after decimal.
3 0.112 # No integers before decimal, so display 3 available digits after decimal.
4 15.116 # Display 6 columns with 3 available digits after decimal.
# MYDATA2
Obs x
1 8722 # Display 5 columns. Only 4 are available.
2 93.20 # Display 5 columns with zero appended after decimal.
3 0.11 # Display 5 columns with 2 places after decimal.
4 15.12 # Display 5 columns with 2 places after decimal.
# MYDATA3
Obs x
1 $8,722.00 # Display 10 columns with leading $ sign, comma at thousandth place and zeros appended after decimal.
2 $93.20 # Only 2 integers available before decimal and one available after the decimal. 3 $0.11 # No integers available before decimal and two available after the decimal.
4 $15.12 # Only 2 integers available before decimal and two available after the decimal.SAS'daki bir operatör, matematiksel, mantıksal veya karşılaştırma ifadesinde kullanılan bir semboldür. Bu semboller SAS dilinde yerleşiktir ve birçok operatör son bir çıktı vermek için tek bir ifadede birleştirilebilir.
Aşağıda, operatörlerin SAS kategorisinin bir listesi bulunmaktadır.
- Aritmetik operatörler
- Mantıksal operatörler
- Karşılaştırma Operatörleri
- Minimum / Maksimum Operatör
- Birleştirme Operatörü
Her birine tek tek bakacağız. Operatörler her zaman SAS programı tarafından analiz edilen verilerin parçası olan değişkenlerle kullanılır.
Aritmetik operatörler
Aşağıdaki tablo, aritmetik operatörlerin ayrıntılarını açıklamaktadır. İki veri değişkenini varsayalımV1 ve V2değerlerle 8 ve 4 sırasıyla.
| Şebeke | Açıklama | Misal |
|---|---|---|
| + | İlave | V1 + V2 = 12 |
| - | Çıkarma | V1-V2 = 4 |
| * | Çarpma işlemi | V1 * V2 = 32 |
| / | Bölünme | V1 / V2 = 2 |
| ** | Üs alma | V1 ** V2 = 4096 |
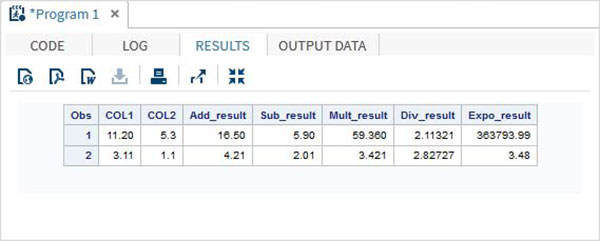
Misal
DATA MYDATA1;
input @1 COL1 4.2 @7 COL2 3.1;
Add_result = COL1+COL2;
Sub_result = COL1-COL2;
Mult_result = COL1*COL2;
Div_result = COL1/COL2;
Expo_result = COL1**COL2;
datalines;
11.21 5.3
3.11 11
;
PROC PRINT DATA = MYDATA1;
RUN;Yukarıdaki kodu çalıştırırken aşağıdaki çıktıyı elde ederiz.
Mantıksal operatörler
Aşağıdaki tablo mantıksal işleçlerin ayrıntılarını açıklamaktadır. Bu operatörler, bir ifadenin Gerçek değerini değerlendirir. Dolayısıyla mantıksal operatörlerin sonucu her zaman 1 veya 0'dır. İki veri değişkenini varsayalım.V1 ve V2değerlerle 8 ve 4 sırasıyla.
| Şebeke | Açıklama | Misal |
|---|---|---|
| & | AND Operatörü. Her iki veri değeri de doğru olarak değerlendirilirse, sonuç 1'dir, aksi takdirde 0'dır. | (V1> 2 & V2> 3) 0 verir. |
| | | Ameliyathane Operatörü. Veri değerlerinden herhangi biri true olarak değerlendirilirse, sonuç 1, aksi takdirde 0'dır. | (V1> 9 & V2> 3) 1'dir. |
| ~ | DEĞİL Operatörü. Değeri YANLIŞ olan veya eksik değeri 1 olan bir ifade biçimindeki NOT işlecinin sonucu, aksi takdirde 0'dır. | DEĞİL (V1> 3) 1'dir. |
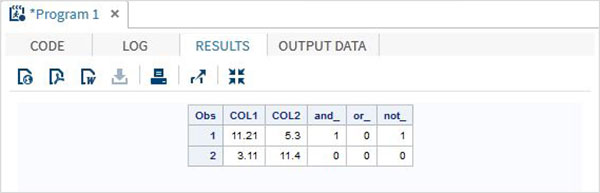
Misal
DATA MYDATA1;
input @1 COL1 5.2 @7 COL2 4.1;
and_=(COL1 > 10 & COL2 > 5 );
or_ = (COL1 > 12 | COL2 > 15 );
not_ = ~( COL2 > 7 );
datalines;
11.21 5.3
3.11 11.4
;
PROC PRINT DATA = MYDATA1;
RUN;Yukarıdaki kodu çalıştırırken aşağıdaki çıktıyı elde ederiz.
Karşılaştırma Operatörleri
Aşağıdaki tablo, karşılaştırma operatörlerinin ayrıntılarını açıklamaktadır. Bu operatörler değişkenlerin değerlerini karşılaştırır ve sonuç, TRUE için 1 ve False için 0 tarafından sunulan bir doğruluk değeridir. İki veri değişkenini varsayalımV1 ve V2değerlerle 8 ve 4 sırasıyla.
| Şebeke | Açıklama | Misal |
|---|---|---|
| = | EQUAL İşleci. Her iki veri değeri eşitse, sonuç 1, aksi takdirde 0'dır. | (V1 = 8) 1 verir. |
| ^ = | EŞİT DEĞİL Operatörü. Her iki veri değeri de eşit değilse, sonuç 1'dir, aksi takdirde 0'dır. | (V1 ^ = V2) 1 verir. |
| < | Operatörden DAHA AZ. | (V2 <V2) 1 verir. |
| <= | Operatöre EŞİT veya DAHA AZ. | (V2 <= 4) 1 verir. |
| > | Operatörden DAHA BÜYÜK. | (V2> V1) 1 verir. |
| > = | Operatöre DAHA BÜYÜK veya EŞİT. | (V2> = V1) 0 verir. |
| İÇİNDE | IN Operatörü. Değişkenin değeri, belirli bir değerler listesindeki değerlerden herhangi birine eşitse, 1 döndürür, aksi takdirde 0 döndürür. | (5,7,9,8) 'deki V1 1 verir. |
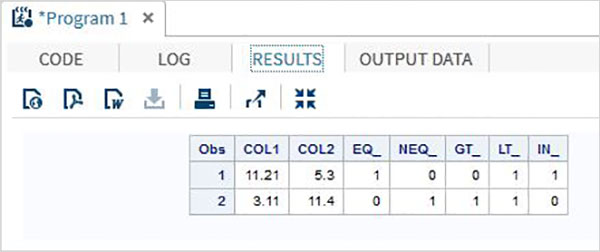
Misal
DATA MYDATA1;
input @1 COL1 5.2 @7 COL2 4.1;
EQ_ = (COL1 = 11.21);
NEQ_= (COL1 ^= 11.21);
GT_ = (COL2 => 8);
LT_ = (COL2 <= 12);
IN_ = COL2 in( 6.2,5.3,12 );
datalines;
11.21 5.3
3.11 11.4
;
PROC PRINT DATA = MYDATA1;
RUN;Yukarıdaki kodu çalıştırırken aşağıdaki çıktıyı elde ederiz.
Minimum / Maksimum Operatör
Aşağıdaki tablo, Minimum / Maksimum operatörlerin ayrıntılarını açıklamaktadır. Bu operatörler, bir satırdaki değişkenlerin değerlerini karşılaştırır ve satırlardaki değerler listesinden minimum veya maksimum değer döndürülür.
| Şebeke | Açıklama | Misal |
|---|---|---|
| MIN | MIN Operatörü. Satırdaki değerler listesinden minimum değeri döndürür. | MIN (45.2,11.6,15.41) 11.6 verir |
| MAX | MAX Operatörü. Satırdaki değerler listesinden maksimum değeri döndürür. | MAX (45.2,11.6,15.41) 45.2 verir |
Misal
DATA MYDATA1;
input @1 COL1 5.2 @7 COL2 4.1 @12 COL3 6.3;
min_ = MIN(COL1 , COL2 , COL3);
max_ = MAX( COL1, COl2 , COL3);
datalines;
11.21 5.3 29.012
3.11 11.4 18.512
;
PROC PRINT DATA = MYDATA1;
RUN;Yukarıdaki kodu çalıştırırken aşağıdaki çıktıyı elde ederiz.
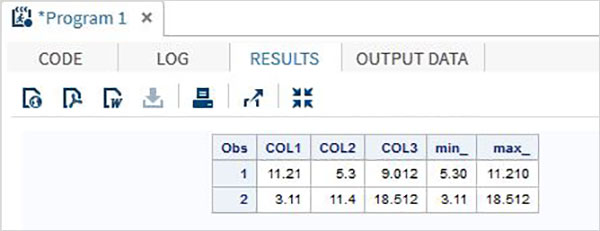
Birleştirme Operatörü
Aşağıdaki tablo, Birleştirme operatörünün ayrıntılarını açıklamaktadır. Bu operatör, iki veya daha fazla dize değerini birleştirir. Tek bir karakter değeri döndürülür.
| Şebeke | Açıklama | Misal |
|---|---|---|
| || | Birleştirme Operatörü. İki veya daha fazla değerin birleşimini döndürür. | 'Merhaba' || ' Dünya 'Merhaba Dünya verir |
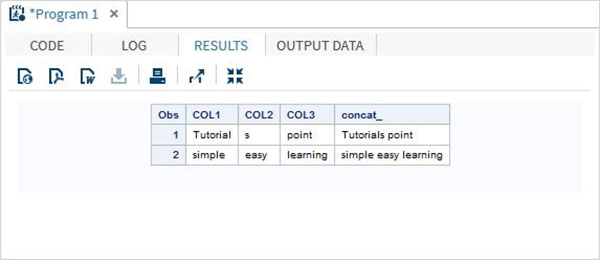
Misal
DATA MYDATA1;
input COL1 $ COL2 $ COL3 $;
concat_ = (COL1 || COL2 || COL3);
datalines;
Tutorial s point
simple easy learning
;
PROC PRINT DATA = MYDATA1;
RUN;Yukarıdaki kodu çalıştırırken aşağıdaki çıktıyı elde ederiz.
Operatör Önceliği
Operatör önceliği, karmaşık ifadede bulunan birden çok operatörün değerlendirme sırasını belirtir. Aşağıdaki tablo, bir grup işleçteki öncelik sırasını açıklamaktadır.
| Grup | Sipariş | Semboller |
|---|---|---|
| Grup I | Sağdan sola | ** + - MIN MAX DEĞİL |
| Grup II | Soldan sağa | * / |
| Grup III | Soldan sağa | + - |
| Grup IV | Soldan sağa | || |
| Grup V | Soldan sağa | <<= => => |
Bir kod bloğunun birkaç kez çalıştırılması gereken durumlarla karşılaşabilirsiniz. Genel olarak, ifadeler sırayla yürütülür - Bir fonksiyondaki ilk ifade önce çalıştırılır, ardından ikincisi yapılır ve bu böyle devam eder. Ancak aynı ifade kümesinin tekrar tekrar çalıştırılmasını istediğinizde, Döngülerin yardımına ihtiyacımız var.
SAS'da döngü DO deyimi kullanılarak yapılır. Aynı zamandaDO Loop. Aşağıda, SAS'daki DO döngü deyimlerinin genel biçimi verilmiştir.
Akış diyagramı

Aşağıdakiler, SAS'daki DO döngü türleridir.
| Sr.No. | Döngü Tipi ve Açıklaması |
|---|---|
| 1 | DO Endeksi. Döngü, başlangıç değerinden indeks değişkeninin durma değerine kadar devam eder. |
| 2 | YAPARKEN. Döngü while koşulu yanlış olana kadar devam eder. |
| 3 | KADAR YAPIN. Döngü, UNTIL koşulu True olana kadar devam eder. |
Karar verme yapıları, programcının, program tarafından değerlendirilecek veya test edilecek bir veya daha fazla koşulu, koşulun geçerli olduğu belirlenirse yürütülecek bir ifade veya ifadeyle birlikte belirtmesini gerektirir. trueve isteğe bağlı olarak, koşul olarak belirlenirse yürütülecek diğer ifadeler false.
Aşağıda, programlama dillerinin çoğunda bulunan tipik bir karar verme yapısının genel biçimi verilmiştir -
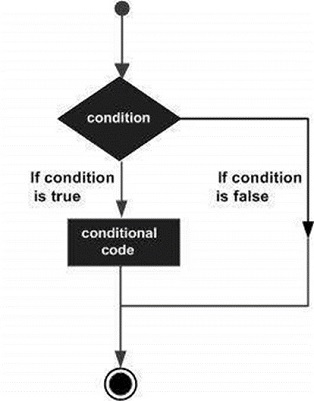
SAS, aşağıdaki türden karar verme beyanları sağlar. Ayrıntılarını kontrol etmek için aşağıdaki bağlantıları tıklayın.
| Sr.No. | İfade Türü ve Açıklaması |
|---|---|
| 1 | IF Beyanı. Bir if statementbir koşuldan oluşur. Koşul doğruysa, belirli veriler alınır. |
| 2 | IF-THEN-ELSE Beyanı. Bir if statement ardından boolean koşulu yanlış olduğunda çalışan else deyimi gelir. |
| 3 | IF-THEN-ELSE-IF Beyanı. Bir if statement Bunu başka bir çift IF-THEN İfadesi takip eden else ifadesi takip eder. |
| 4 | IF-THEN-DELETE Beyanı. Bir if statement true olduğunda belirli verileri gözlemlerden silen bir koşuldan oluşur. |
SAS, verilerin analiz edilmesine ve işlenmesine yardımcı olan çok çeşitli yerleşik işlevlere sahiptir. Bu işlevler DATA ifadelerinin bir parçası olarak kullanılır. Veri değişkenlerini argüman olarak alırlar ve başka bir değişkene depolanan sonucu döndürürler. İşlevin türüne bağlı olarak, aldığı argüman sayısı değişebilir. Bazı işlevler sıfır bağımsız değişkenleri kabul ederken, bazıları sabit sayıda değişken kabul eder. Aşağıda, SAS'ın sağladığı işlev türlerinin bir listesi bulunmaktadır.
Sözdizimi
SAS'da bir işlevi kullanmak için genel sözdizimi aşağıdaki gibidir.
FUNCTIONNAME(argument1, argument2...argumentn)Burada argüman bir sabit, değişken, ifade veya başka bir işlev olabilir.
İşlev Kategorileri
Kullanımlarına bağlı olarak, SAS'daki işlevler aşağıdaki gibi kategorize edilir.
- Mathematical
- Tarih ve saat
- Character
- Truncation
- Miscellaneous
Matematiksel Fonksiyonlar
Bunlar, değişken değerlere bazı matematiksel hesaplamalar uygulamak için kullanılan fonksiyonlardır.
Örnekler
Aşağıdaki SAS programı, bazı önemli matematiksel fonksiyonların kullanımını göstermektedir.
data Math_functions;
v1=21; v2=42; v3=13; v4=10; v5=29;
/* Get Maximum value */
max_val = MAX(v1,v2,v3,v4,v5);
/* Get Minimum value */
min_val = MIN (v1,v2,v3,v4,v5);
/* Get Median value */
med_val = MEDIAN (v1,v2,v3,v4,v5);
/* Get a random number */
rand_val = RANUNI(0);
/* Get Square root of sum of the values */
SR_val= SQRT(sum(v1,v2,v3,v4,v5));
proc print data = Math_functions noobs;
run;Yukarıdaki kod çalıştırıldığında, aşağıdaki çıktıyı alıyoruz -
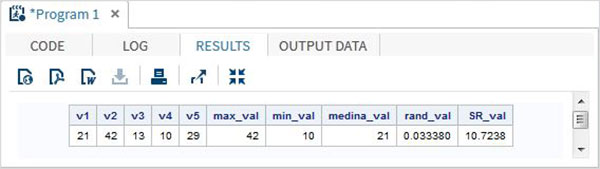
Tarih ve Saat İşlevleri
Bunlar, tarih ve saat değerlerini işlemek için kullanılan işlevlerdir.
Örnekler
Aşağıdaki SAS programı tarih ve saat işlevlerinin kullanımını göstermektedir.
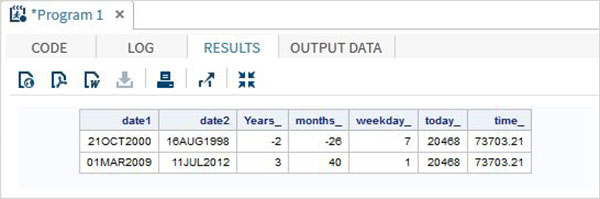
data date_functions;
INPUT @1 date1 date9. @11 date2 date9.;
format date1 date9. date2 date9.;
/* Get the interval between the dates in years*/
Years_ = INTCK('YEAR',date1,date2);
/* Get the interval between the dates in months*/
months_ = INTCK('MONTH',date1,date2);
/* Get the week day from the date*/
weekday_ = WEEKDAY(date1);
/* Get Today's date in SAS date format */
today_ = TODAY();
/* Get current time in SAS time format */
time_ = time();
DATALINES;
21OCT2000 16AUG1998
01MAR2009 11JUL2012
;
proc print data = date_functions noobs;
run;Yukarıdaki kod çalıştırıldığında, aşağıdaki çıktıyı alıyoruz -
Karakter Fonksiyonları
Bunlar, karakter veya metin değerlerini işlemek için kullanılan işlevlerdir.
Örnekler
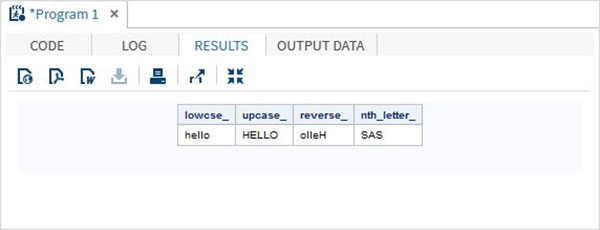
Aşağıdaki SAS programı, karakter işlevlerinin kullanımını göstermektedir.
data character_functions;
/* Convert the string into lower case */
lowcse_ = LOWCASE('HELLO');
/* Convert the string into upper case */
upcase_ = UPCASE('hello');
/* Reverse the string */
reverse_ = REVERSE('Hello');
/* Return the nth word */
nth_letter_ = SCAN('Learn SAS Now',2);
run;
proc print data = character_functions noobs;
run;Yukarıdaki kod çalıştırıldığında, aşağıdaki çıktıyı alıyoruz -
Kesme İşlevleri
Bunlar, sayısal değerleri kesmek için kullanılan işlevlerdir.
Örnekler
Aşağıdaki SAS programı, kesme işlevlerinin kullanımını göstermektedir.
data trunc_functions;
/* Nearest greatest integer */
ceil_ = CEIL(11.85);
/* Nearest greatest integer */
floor_ = FLOOR(11.85);
/* Integer portion of a number */
int_ = INT(32.41);
/* Round off to nearest value */
round_ = ROUND(5621.78);
run;
proc print data = trunc_functions noobs;
run;Yukarıdaki kod çalıştırıldığında, aşağıdaki çıktıyı alıyoruz -

Çeşitli Fonksiyonlar
Şimdi SAS'ın çeşitli işlevlerini bazı örneklerle anlayalım.
Örnekler
Aşağıdaki SAS programı, Çeşitli işlevlerin kullanımını gösterir.
data misc_functions;
/* Nearest greatest integer */
state2=zipstate('01040');
/* Amortization calculation */
payment = mort(50000, . , .10/12,30*12);
proc print data = misc_functions noobs;
run;Yukarıdaki kod çalıştırıldığında, aşağıdaki çıktıyı alıyoruz -

Giriş yöntemleri, ham verileri okumak için kullanılır. Ham veriler, harici bir kaynaktan veya akış içi veri dizinlerinden olabilir. Girdi deyimi, her alana atadığınız adla bir değişken oluşturur. Dolayısıyla, Girdi İfadesinde bir değişken oluşturmalısınız. Aynı değişken SAS Veri Kümesinin çıktısında gösterilecektir. Aşağıda, SAS'da bulunan farklı giriş yöntemleri bulunmaktadır.
- Giriş Yöntemi Listesi
- Adlandırılmış Giriş Yöntemi
- Sütun Giriş Yöntemi
- Biçimlendirilmiş Giriş Yöntemi
Her bir giriş yönteminin ayrıntıları aşağıda açıklanmıştır.
Giriş Yöntemi Listesi
Bu yöntemde değişkenler veri türleriyle birlikte listelenir. Ham veriler, açıklanan değişkenlerin sırasının verilerle eşleşmesi için dikkatlice analiz edilir. Sınırlayıcı (genellikle boşluk), herhangi bir bitişik sütun çifti arasında tek tip olmalıdır. Herhangi bir eksik veri çıktıda soruna neden olacaktır çünkü sonuç yanlış olacaktır.
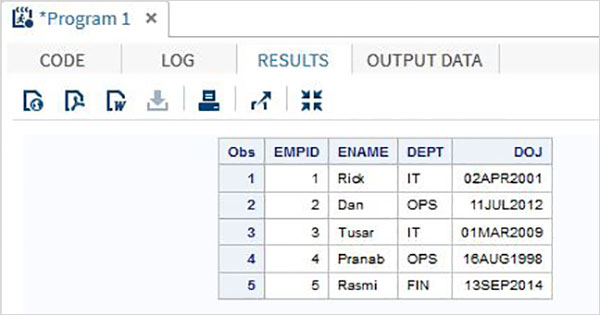
Misal
Aşağıdaki kod ve çıktı liste giriş yönteminin kullanımını gösterir.
DATA TEMP;
INPUT EMPID ENAME $ DEPT $ ;
DATALINES;
1 Rick IT
2 Dan OPS
3 Tusar IT
4 Pranab OPS
5 Rasmi FIN
;
PROC PRINT DATA = TEMP;
RUN;Bove kodunu çalıştırırken aşağıdaki çıktıyı elde ederiz.
Adlandırılmış Giriş Yöntemi
Bu yöntemde değişkenler veri türleriyle birlikte listelenir. Ham veriler, eşleşen verilerin önünde değişken adlarının bildirilmesi için değiştirilir. Sınırlayıcı (genellikle boşluk), herhangi bir bitişik sütun çifti arasında tek tip olmalıdır.
Misal
Aşağıdaki kod ve çıktı, Adlandırılmış Giriş Yönteminin kullanımını gösterir.
DATA TEMP;
INPUT
EMPID= ENAME= $ DEPT= $ ;
DATALINES;
EMPID = 1 ENAME = Rick DEPT = IT
EMPID = 2 ENAME = Dan DEPT = OPS
EMPID = 3 ENAME = Tusar DEPT = IT
EMPID = 4 ENAME = Pranab DEPT = OPS
EMPID = 5 ENAME = Rasmi DEPT = FIN
;
PROC PRINT DATA = TEMP;
RUN;Bove kodunu çalıştırırken aşağıdaki çıktıyı elde ederiz.
Sütun Giriş Yöntemi
Bu yöntemde değişkenler, tek veri sütununun değerini belirten veri türleri ve sütunların genişliğiyle listelenir. Örneğin, bir çalışan adı maksimum 9 karakter içeriyorsa ve her çalışan adı 10. sütundan başlıyorsa, çalışan adı değişkeni için sütun genişliği 10-19 olacaktır.
Misal
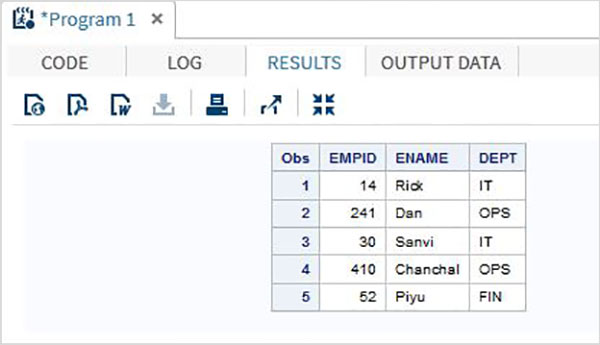
Aşağıdaki kod, Sütun Giriş Yönteminin kullanımını göstermektedir.
DATA TEMP;
INPUT EMPID 1-3 ENAME $ 4-12 DEPT $ 13-16;
DATALINES;
14 Rick IT
241Dan OPS
30 Sanvi IT
410Chanchal OPS
52 Piyu FIN
;
PROC PRINT DATA = TEMP;
RUN;Yukarıdaki kodu çalıştırdığımızda, aşağıdaki sonucu verir -
Biçimlendirilmiş Giriş Yöntemi
Bu yöntemde değişkenler, bir boşlukla karşılaşılıncaya kadar sabit bir başlangıç noktasından okunur. Her değişkenin sabit bir başlangıç noktası olduğundan, herhangi bir değişken çifti arasındaki sütun sayısı ilk değişkenin genişliği olur. '@N' karakteri, bir değişkenin başlangıç sütun konumunu n'inci sütun olarak belirtmek için kullanılır.
Misal
Aşağıdaki kod, Biçimlendirilmiş Giriş Yönteminin kullanımını gösterir.
DATA TEMP;
INPUT @1 EMPID $ @4 ENAME $ @13 DEPT $ ;
DATALINES;
14 Rick IT
241 Dan OPS
30 Sanvi IT
410 Chanchal OPS
52 Piyu FIN
;
PROC PRINT DATA = TEMP;
RUN;Yukarıdaki kodu çalıştırdığımızda, aşağıdaki sonucu verir -
SAS, güçlü bir programlama özelliğine sahiptir. MacrosBu, kodun tekrar eden bölümlerinden kaçınmamızı ve gerektiğinde bunları tekrar tekrar kullanmamızı sağlar. Aynı kodun farklı çalıştırma örnekleri için farklı değerler alabilen kod içinde dinamik değişkenler oluşturmaya da yardımcı olur. Makrolar, makro değişkenlere benzer şekilde birçok kez yeniden kullanılacak kod blokları için de bildirilebilir. Bunların ikisini de aşağıdaki örneklerde göreceğiz.
Makro değişkenler
Bunlar, bir SAS programı tarafından tekrar tekrar kullanılacak bir değeri tutan değişkenlerdir. Bir SAS programının başlangıcında ilan edilirler ve daha sonra programın gövdesinde çağrılırlar. Kapsam olarak Global veya Yerel olabilirler.
Global Makro değişkeni
Bunlar genel makro değişkenleri olarak adlandırılır çünkü bunlar SAS ortamında bulunan herhangi bir SAS programı tarafından erişilebilirler. Genelde, birden çok program tarafından erişilen sistem tarafından atanan değişkenlerdir. Genel bir örnek, sistem tarihidir.
Misal
Aşağıda, sistem tarihini temsil eden SYSDATE adlı SAS değişkeninin bir örneği bulunmaktadır. Raporun oluşturulduğu her gün SAS raporu başlığına sistem tarihini yazdırmak için bir senaryo düşünün. Başlık, onlar için herhangi bir değer kodlamadan geçerli tarihi ve günü gösterecektir. SASHELP kütüphanesinde bulunan CARS adlı yerleşik SAS veri setini kullanıyoruz.
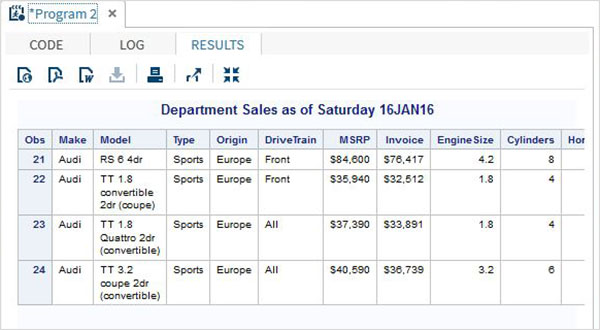
proc print data = sashelp.cars;
where make = 'Audi' and type = 'Sports' ;
TITLE "Sales as of &SYSDAY &SYSDATE";
run;Yukarıdaki kod çalıştırıldığında aşağıdaki çıktıyı alıyoruz.
Yerel Makro değişkeni
Bu değişkenlere, programın bir parçası olarak bildirildikleri SAS programları tarafından erişilebilir. Tipik olarak, bir veri setinin farklı gözlemlerini işleyebilecekleri aynı SAS ifadelerine farklı değişkenler sağlamak için kullanılırlar.
Sözdizimi
Yerel değişkenler aşağıdaki sözdizimi ile etiketlenmiştir.
% LET (Macro Variable Name) = Value;Burada Değer alanı, programın gerektirdiği şekilde herhangi bir sayısal, metin veya tarih değerini alabilir. Makro değişkeni adı, herhangi bir geçerli SAS değişkenidir.
Misal
Değişkenler, SAS ifadeleri tarafından kullanılır. & değişken adının başına eklenen karakter. Aşağıdaki program bize 'Audi' markasının ve 'Spor' türünün tüm gözlemlerini veriyor. Eğer sonucunu istiyorsakdifferent makedeğişkenin değerini değiştirmemiz gerekiyor make_nameprogramın başka herhangi bir bölümünü değiştirmeden. Programları getirme durumunda, bu değişken herhangi bir SAS ifadesinde tekrar tekrar belirtilebilir.
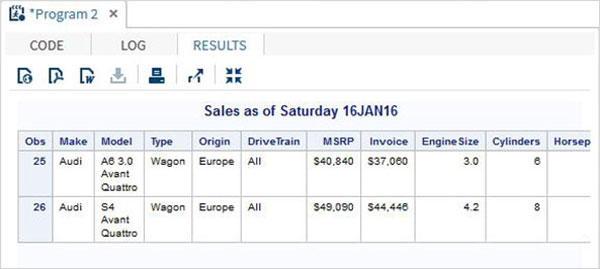
%LET make_name = 'Audi';
%LET type_name = 'Sports';
proc print data = sashelp.cars;
where make = &make_name and type = &type_name ;
TITLE "Sales as of &SYSDAY &SYSDATE";
run;Yukarıdaki kod çalıştırıldığında önceki programla aynı çıktıyı elde ederiz. Ama değiştirelimtype name -e 'Wagon've aynı programı çalıştırın. Aşağıdaki sonucu alacağız.
Makro Programlar
Makro, bir adla atıfta bulunulan ve onu herhangi bir yerde, bu adı kullanarak programda kullanmak için kullanılan bir SAS ifadeleri grubudur. Bir% MACRO ifadesiyle başlar ve% MEND ifadesiyle biter.
Sözdizimi
Yerel değişkenler aşağıdaki sözdizimi ile bildirilmiştir.
# Creating a Macro program.
%MACRO <macro name>(Param1, Param2,….Paramn);
Macro Statements;
%MEND;
# Calling a Macro program.
%MacroName (Value1, Value2,…..Valuen);Misal
Aşağıdaki program, adlı bir makro altında bir grup SAT staemnetini çözer. 'show_result'; Bu Makro, diğer SAS ifadeleri tarafından çağrılıyor.
%MACRO show_result(make_ , type_);
proc print data = sashelp.cars;
where make = "&make_" and type = "&type_" ;
TITLE "Sales as of &SYSDAY &SYSDATE";
run;
%MEND;
%show_result(BMW,SUV);Yukarıdaki kod çalıştırıldığında aşağıdaki çıktıyı alıyoruz.

Yaygın Olarak Kullanılan Makrolar
SAS, SAS programlama dilinde yerleşik birçok MACRO ifadesine sahiptir. Açıkça bildirilmeden diğer SAS programları tarafından kullanılırlar. Yaygın örnekler - bir koşul karşılandığında bir programı sonlandırmak veya program günlüğündeki bir değişkenin çalışma zamanı değerini yakalamaktır. Aşağıda bazı örnekler verilmiştir.
Makro% PUT
Bu makro ifadesi, metin veya makro değişken bilgilerini SAS günlüğüne yazar. Aşağıdaki örnekte 'bugün' değişkeninin değeri program günlüğüne yazılmıştır.
data _null_;
CALL SYMPUT ('today',
TRIM(PUT("&sysdate"d,worddate22.)));
run;
%put &today;Yukarıdaki kod çalıştırıldığında aşağıdaki çıktıyı alıyoruz.

Makro% RETURN
Bu makronun yürütülmesi, belirli koşulların doğru olduğu değerlendirildiğinde, o anda yürütülen makronun normal sonlandırılmasına neden olur. Aşağıdaki örnekte değişkenin değeri"val" 10 olur, makro devam ederse sonlandırır.
%macro check_condition(val);
%if &val = 10 %then %return;
data p;
x = 34.2;
run;
%mend check_condition;
%check_condition(11) ;Yukarıdaki kod çalıştırıldığında aşağıdaki çıktıyı alıyoruz.

Makro% END
Bu makro tanımı, bir %DO %WHILEGerektiği gibi bir% END ifadesiyle biten döngü. Aşağıdaki örnekte test adlı makro bir kullanıcı girdisi alır ve bu girdi değerini kullanarak DO döngüsünü çalıştırır. DO döngüsünün sonu% end ifadesiyle, makronun sonu ise% mend ifadesiyle elde edilir.
%macro test(finish);
%let i = 1;
%do %while (&i <&finish);
%put the value of i is &i;
%let i=%eval(&i+1);
%end;
%mend test;
%test(5)Yukarıdaki kod çalıştırıldığında aşağıdaki çıktıyı alıyoruz.

IN SAS tarihleri, sayısal değerlerin özel bir durumudur. 1 Ocak 1960'tan başlayarak her güne belirli bir sayısal değer atanır. Bu tarihe 0 tarih değeri atanır ve sonraki tarih 1 olarak tarih değerine sahiptir ve bu böyle devam eder. Bu tarihe kadar olan önceki günler -1, -2 vb. İle temsil edilir. Bu yaklaşımla SAS, gelecekteki herhangi bir tarihi ve geçmişteki herhangi bir tarihi temsil edebilir.
SAS, verileri bir kaynaktan okuduğunda, okunan verileri tarih formatının belirtildiği gibi belirli bir tarih formatına dönüştürür. Tarih değerini saklayacak değişken, gerekli uygun bilgi ile bildirilir. Çıkış tarihi, çıktı veri formatları kullanılarak gösterilir.
SAS Tarih Bilgisi
Kaynak veriler, aşağıda gösterildiği gibi belirli tarih bilgileri kullanılarak düzgün bir şekilde okunabilir. Bilginin sonundaki rakam, bilgi kullanılarak tam olarak okunacak tarih dizesinin minimum genişliğini gösterir. Daha küçük bir genişlik yanlış sonuç verecektir. SAS V9 ile genel bir tarih formatı vardıranydtdte15. herhangi bir tarih girişini işleyebilir.
| Giriş Tarihi | Tarih genişliği | Bilgilendirme |
|---|---|---|
| 03/11/2014 | 10 | mmddyy10. |
| 03/11/14 | 8 | mmddyy8. |
| 11 Aralık 2012 | 20 | worddate20. |
| 14mar2011 | 9 | tarih9. |
| 14 Mart 2011 | 11 | tarih11. |
| 14 Mart 2011 | 15 | Anydtdte15. |
Misal
Aşağıdaki kod, farklı tarih formatlarının okunmasını gösterir. Çıkış değerlerine herhangi bir format ifadesi uygulamadığımız için tüm çıkış değerlerinin sadece sayılar olduğunu lütfen unutmayın.
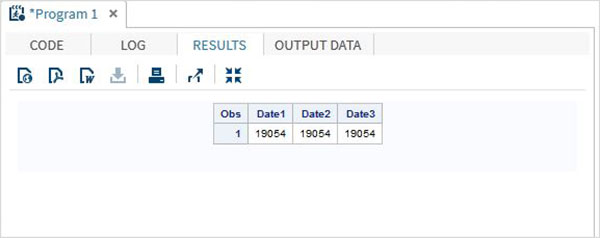
DATA TEMP;
INPUT @1 Date1 date11. @12 Date2 anydtdte15. @23 Date3 mmddyy10. ;
DATALINES;
02-mar-2012 3/02/2012 3/02/2012
;
PROC PRINT DATA = TEMP;
RUN;Yukarıdaki kod çalıştırıldığında aşağıdaki çıktıyı alıyoruz.
SAS Tarih çıktı biçimi
Okunduktan sonraki tarihler, ekranın gerektirdiği şekilde başka bir formata dönüştürülebilir. Bu, tarih türleri için format ifadesi kullanılarak elde edilir. Bilgilendirmeyle aynı formatları alırlar.
Misal
Aşağıdaki örnekte tarih bir formatta okunur, ancak başka bir formatta gösterilir.
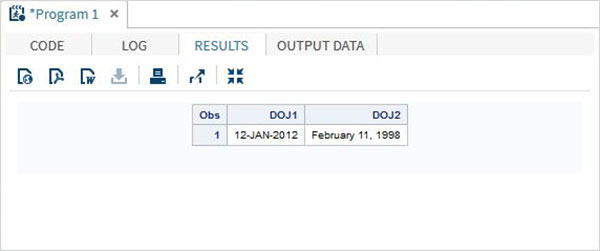
DATA TEMP;
INPUT @1 DOJ1 mmddyy10. @12 DOJ2 mmddyy10.;
format DOJ1 date11. DOJ2 worddate20. ;
DATALINES;
01/12/2012 02/11/1998
;
PROC PRINT DATA = TEMP;
RUN;Yukarıdaki kod çalıştırıldığında aşağıdaki çıktıyı alıyoruz.
SAS, birçok dosya formatını içeren çeşitli kaynaklardan veri okuyabilir. SAS ortamında kullanılan dosya formatları aşağıda tartışılmaktadır.
- ASCII (Metin) Veri Kümesi
- Sınırlandırılmış Veriler
- Excel Verileri
- Hiyerarşik Veriler
ASCII (Metin) Veri Kümesini Okuma
Metin formatındaki verileri içeren dosyalardır. Veriler genellikle bir boşlukla sınırlandırılır, ancak SAS'ın da işleyebileceği farklı sınırlayıcı türleri olabilir. Çalışan verilerini içeren bir ASCII dosyası düşünelim. Bu dosyayı kullanarak okuyoruzInfile açıklama SAS'da mevcuttur.
Misal
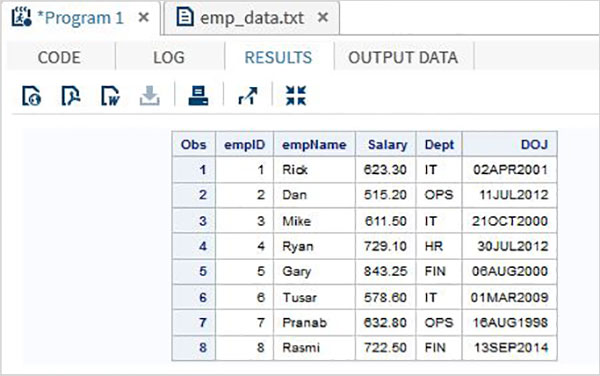
Aşağıdaki örnekte adlı veri dosyasını okuyoruz emp_data.txt yerel çevreden.
data TEMP;
infile
'/folders/myfolders/sasuser.v94/TutorialsPoint/emp_data.txt';
input empID empName $ Salary Dept $ DOJ date9. ;
format DOJ date9.;
run;
PROC PRINT DATA = TEMP;
RUN;Yukarıdaki kod çalıştırıldığında aşağıdaki çıktıyı alıyoruz.
Sınırlandırılmış Verileri Okuma
Bunlar, sütun değerlerinin virgül veya ardışık düzen gibi sınırlayıcı bir karakterle ayrıldığı veri dosyalarıdır. Bu durumda, dlm seçeneği infile Beyan.
Misal
Aşağıdaki örnekte yerel ortamdan emp.csv adlı veri dosyasını okuyoruz.
data TEMP;
infile
'/folders/myfolders/sasuser.v94/TutorialsPoint/emp.csv' dlm=",";
input empID empName $ Salary Dept $ DOJ date9. ;
format DOJ date9.;
run;
PROC PRINT DATA = TEMP;
RUN;Yukarıdaki kod çalıştırıldığında aşağıdaki çıktıyı alıyoruz.
Excel Verilerini Okuma
SAS, içe aktarma aracını kullanarak doğrudan bir excel dosyasını okuyabilir. SAS veri kümeleri bölümünde görüldüğü gibi, MS excel dahil çok çeşitli dosya türlerini işleyebilir. Emp.xls dosyasının SAS ortamında yerel olarak mevcut olduğunu varsayarsak.
Misal
FILENAME REFFILE
"/folders/myfolders/TutorialsPoint/emp.xls"
TERMSTR = CR;
PROC IMPORT DATAFILE = REFFILE
DBMS = XLS
OUT = WORK.IMPORT;
GETNAMES = YES;
RUN;
PROC PRINT DATA = WORK.IMPORT RUN;Yukarıdaki kod, verileri excel dosyasından okur ve yukarıdaki iki dosya türü ile aynı çıktıyı verir.
Hiyerarşik Dosyaları Okuma
Bu dosyalarda veriler hiyerarşik formatta mevcuttur. Belirli bir gözlem için, altında birçok ayrıntı kaydının belirtildiği bir başlık kaydı vardır. Ayrıntı kayıtlarının sayısı bir gözlemden diğerine değişebilir. Aşağıda hiyerarşik bir dosyanın bir resmi bulunmaktadır.
Aşağıdaki dosyada, her departmanın altındaki her çalışanın ayrıntıları listelenmiştir. İlk kayıt, departmandan bahseden başlık kaydıdır ve DTLS ile başlayan sonraki kayıt birkaç kayıt, ayrıntı kaydıdır.
DEPT:IT
DTLS:1:Rick:623
DTLS:3:Mike:611
DTLS:6:Tusar:578
DEPT:OPS
DTLS:7:Pranab:632
DTLS:2:Dan:452
DEPT:HR
DTLS:4:Ryan:487
DTLS:2:Siyona:452Misal
Hiyerarşik dosyayı okumak için, başlık kaydını bir IF cümlesiyle tanımladığımız ve ayrıntı kaydını işlemek için bir do döngüsü kullandığımız aşağıdaki kodu kullanırız.
data employees(drop = Type);
length Type $ 3 Department
empID $ 3 empName $ 10 Empsal 3 ;
retain Department;
infile
'/folders/myfolders/TutorialsPoint/empdtls.txt' dlm = ':';
input Type $ @; if Type = 'DEP' then input Department $;
else do;
input empID empName $ Empsal ;
output;
end;
run;
PROC PRINT DATA = employees;
RUN;Yukarıdaki kod çalıştırıldığında aşağıdaki çıktıyı alıyoruz.

Veri kümelerini okumaya benzer şekilde, SAS veri kümelerini farklı biçimlerde yazabilir. SAS dosyalarından normal metin dosyasına veri yazabilir. Bu dosyalar diğer yazılım programları tarafından okunabilir. SAS kullanırPROC EXPORT veri setleri yazmak için.
PROC İHRACAT
Verileri farklı formatlardaki dosyalara yazmak için SAS veri setlerini dışa aktarmak için kullanılan dahili bir SAS prosedürüdür.
Sözdizimi
SAS'da yordamı yazmak için temel sözdizimi şudur:
PROC EXPORT
DATA = libref.SAS data-set (SAS data-set-options)
OUTFILE = "filename"
DBMS = identifier LABEL(REPLACE);Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
SAS data-setdışa aktarılan veri kümesi adıdır. SAS, farklı işletim sistemleri tarafından okunabilen dosyalar oluşturarak ortamındaki veri setlerini diğer uygulamalarla paylaşabilir. Veri seti dosyalarını çeşitli formatlarda çıkarmak için dahili EXPORT işlevini kullanır. Bu bölümde, SAS veri setlerinin yazımını göreceğiz.proc export seçeneklerle birlikte dlm ve dbms.
SAS data-set-options dışa aktarılacak sütunların bir alt kümesini belirtmek için kullanılır.
filename verinin içine yazıldığı dosyanın adıdır.
identifier dosyaya yazılacak sınırlayıcıyı belirtmek için kullanılır.
LABEL seçeneği dosyaya yazılan değişkenlerin ismini belirtmek için kullanılır.
Misal
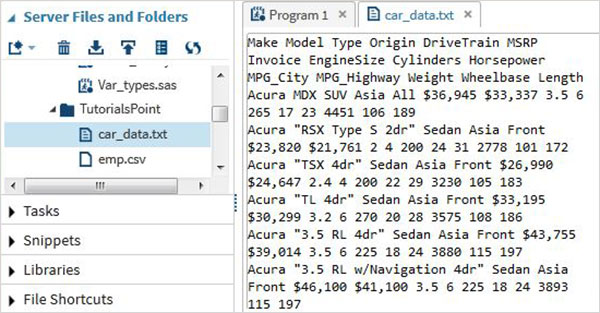
SASHELP kütüphanesinde bulunan arabalar adlı SAS veri setini kullanacağız. Aşağıdaki programda gösterildiği gibi kod ile boşlukla sınırlandırılmış metin dosyası olarak dışa aktarıyoruz.
proc export data = sashelp.cars
outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_data.txt'
dbms = dlm;
delimiter = ' ';
run;Yukarıdaki kodu çalıştırırken, çıktıyı bir metin dosyası olarak görebilir ve aşağıda gösterildiği gibi içeriğini görmek için üzerine sağ tıklayabiliriz.
CSV dosyası yazma
Virgülle ayrılmış bir dosya yazmak için "csv" değerine sahip dlm seçeneğini kullanabiliriz. Aşağıdaki kod car_data.csv dosyasını yazar.
proc export data = sashelp.cars
outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_data.csv'
dbms = csv;
run;Yukarıdaki kodu çalıştırırken aşağıdaki çıktıyı elde ederiz.

Sekmeyle ayrılmış dosya yazma
Sekmeyle ayrılmış bir dosya yazmak için, dlm"sekme" değerine sahip seçenek. Aşağıdaki kod dosyayı yazarcar_tab.txt.
proc export data = sashelp.cars
outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_tab.txt'
dbms = csv;
run;Veriler, çıktı dağıtım sistemi bölümünde göreceğimiz HTML dosyası olarak da yazılabilir.
Birden çok SAS veri kümesi, tek bir veri kümesi verecek şekilde birleştirilebilir. SETBeyan. Birleştirilmiş veri kümesindeki toplam gözlem sayısı, orijinal veri kümelerindeki gözlem sayısının toplamıdır. Gözlemlerin sırası sıralıdır. İlk veri setindeki tüm gözlemleri, ikinci veri setindeki tüm gözlemler takip eder ve bu böyle devam eder.
İdeal olarak tüm birleşik veri kümeleri aynı değişkenlere sahiptir, ancak farklı sayıda değişkene sahip olmaları durumunda, sonuçta tüm değişkenler, daha küçük veri kümesi için eksik değerlerle birlikte görünür.
Sözdizimi
SAS'daki SET ifadesi için temel sözdizimi şöyledir:
SET data-set 1 data-set 2 data-set 3.....;Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
data-set1,data-set2 birbiri ardına yazılan veri kümesi adlarıdır.
Misal
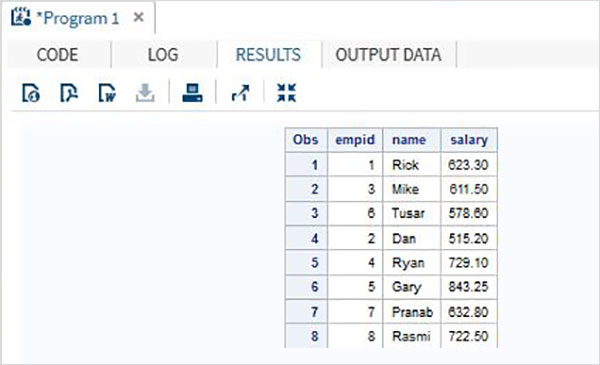
Bir organizasyonun, biri BT departmanı ve diğeri Non-It departmanı için olmak üzere iki farklı veri setinde bulunan çalışan verilerini düşünün. Tüm çalışanların tüm ayrıntılarını elde etmek için, her iki veri setini de aşağıda gösterilen SET ifadesini kullanarak birleştiriyoruz.
DATA ITDEPT;
INPUT empid name $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Yukarıdaki kod çalıştırıldığında aşağıdaki çıktıyı alıyoruz.
Senaryolar
Birleştirme için veri kümelerinde birçok varyasyonumuz olduğunda, değişkenlerin sonucu farklılık gösterebilir ancak birleştirilmiş veri kümesindeki toplam gözlem sayısı her zaman her veri kümesindeki gözlemlerin toplamıdır. Bu varyasyonla ilgili birçok senaryoyu aşağıda ele alacağız.
Farklı sayıda değişken
Orijinal veri kümelerinden birinde daha fazla sayıda değişken varsa, veri kümeleri yine de birleştirilir, ancak daha küçük veri kümesinde bu değişkenler eksik olarak görünür.
Misal
Aşağıdaki örnekte, ilk veri setinin DOJ adında ekstra bir değişkeni vardır. Sonuçta, ikinci veri seti için DOJ değeri eksik olarak görünecektir.
DATA ITDEPT;
INPUT empid name $ salary DOJ date9. ;
DATALINES;
1 Rick 623.3 02APR2001
3 Mike 611.5 21OCT2000
6 Tusar 578.6 01MAR2009
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Yukarıdaki kod çalıştırıldığında aşağıdaki çıktıyı alıyoruz.

Farklı değişken adı
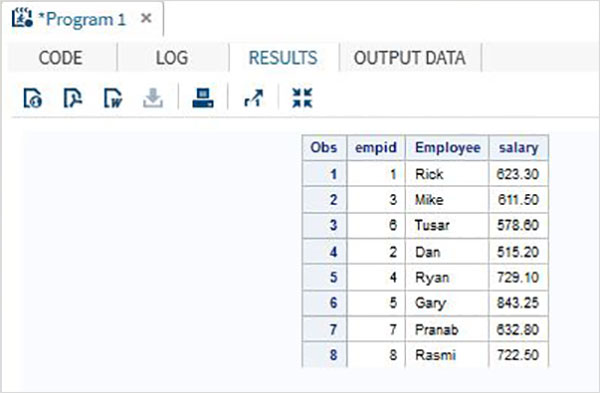
Bu senaryoda veri kümeleri aynı sayıda değişkene sahiptir, ancak değişken adı aralarında farklılık gösterir. Bu durumda, normal bir birleştirme, sonuç kümesindeki tüm değişkenleri üretir ve farklı olan iki değişken için eksik sonuçlar verir. Orijinal veri kümelerindeki değişken adını değiştiremeyebilirken, oluşturduğumuz birleştirilmiş veri kümesinde RENAME işlevini uygulayabiliriz. Bu, normal bir birleştirme ile aynı sonucu üretecektir, ancak elbette orijinal veri kümesinde bulunan iki farklı değişken adı yerine bir yeni değişken adı ile.
Misal
Aşağıdaki örnek veri kümesinde, ITDEPT değişken adına sahiptir ename oysa veri seti NON_ITDEPT değişken adına sahiptir empname.Ancak bu değişkenlerin her ikisi de aynı türü (karakteri) temsil eder. UygularızRENAME SET ifadesindeki fonksiyon aşağıda gösterildiği gibi.
DATA ITDEPT;
INPUT empid ename $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid empname $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT(RENAME =(ename = Employee) ) NON_ITDEPT(RENAME =(empname = Employee) );
RUN;
PROC PRINT DATA = All_Dept;
RUN;Yukarıdaki kod çalıştırıldığında aşağıdaki çıktıyı alıyoruz.
Farklı değişken uzunluklar
İki veri kümesindeki değişken uzunluklar birleştirilmiş veri kümesinden farklıysa, bazı verilerin daha küçük uzunluktaki değişken için kesildiği değerlere sahip olacaktır. İlk veri kümesinin uzunluğu daha küçükse olur. Bunu çözmek için, daha yüksek uzunluğu aşağıda gösterildiği gibi her iki veri kümesine uygularız.
Misal
Aşağıdaki örnekte değişken enameilk veri setinde 5 ve ikincide 7 uzunluğundadır. Birleştirirken, ename uzunluğunu 7'ye ayarlamak için birleştirilmiş veri kümesindeki LENGTH ifadesini uygularız.
DATA ITDEPT;
INPUT empid 1-2 ename $ 3-7 salary 8-14 ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid 1-2 ename $ 3-9 salary 10-16 ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; LENGTH ename $ 7 ;
SET ITDEPT NON_ITDEPT ;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Yukarıdaki kod çalıştırıldığında aşağıdaki çıktıyı alıyoruz.
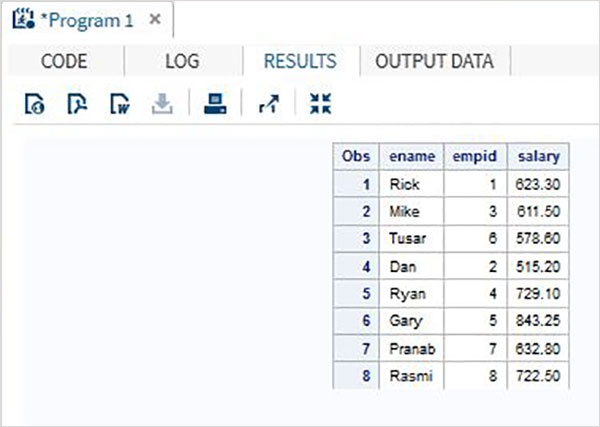
Birden çok SAS veri kümesi, tek bir veri kümesi vermek için belirli bir ortak değişkene dayalı olarak birleştirilebilir. Bu,MERGE ifade ve BYBeyan. Birleştirilmiş veri setindeki toplam gözlem sayısı, genellikle orijinal veri setlerindeki gözlem sayısının toplamından daha azdır. Bunun nedeni, her iki veri setini oluşturan değişkenlerin, ortak değişkenin değerinde bir eşleşme olduğunda tek bir kayıt olarak birleştirilmesidir.
Aşağıda verilen veri setlerini birleştirmek için iki Önkoşul vardır -
- giriş veri setlerinin birleştirilmesi için en az bir ortak değişken olması gerekir.
- girdi veri kümeleri, birleştirmek için kullanılacak ortak değişken (ler) e göre sıralanmalıdır.
Sözdizimi
SAS'daki MERGE ve BY ifadesinin temel sözdizimi şudur:
MERGE Data-Set 1 Data-Set 2
BY Common VariableAşağıda kullanılan parametrelerin açıklaması verilmiştir -
Data-set1,Data-set2 birbiri ardına yazılan veri seti isimleridir.
Common Variable veri kümelerinin eşleşen değerlerine göre birleştirileceği değişkendir.
Veri Birleştirme
Bir örnek yardımıyla veri birleştirmeyi anlayalım.
Misal
Biri ad ve maaşla birlikte çalışan kimliğini, diğeri de çalışan kimliği ve departmanı olan çalışan kimliğini içeren iki SAS veri kümesini düşünün. Bu durumda, her çalışan için eksiksiz bilgi almak için bu iki veri setini birleştirebiliriz. Nihai veri setinde yine de çalışan başına bir gözlem olacaktır, ancak hem maaş hem de departman değişkenlerini içerecektir.
# Data set 1
ID NAME SALARY
1 Rick 623.3
2 Dan 515.2
3 Mike 611.5
4 Ryan 729.1
5 Gary 843.25
6 Tusar 578.6
7 Pranab 632.8
8 Rasmi 722.5
# Data set 2
ID DEPT
1 IT
2 OPS
3 IT
4 HR
5 FIN
6 IT
7 OPS
8 FIN
# Merged data set
ID NAME SALARY DEPT
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FINYukarıdaki sonuç, ortak değişkenin (ID) BY ifadesinde kullanıldığı aşağıdaki kod kullanılarak elde edilir. Lütfen her iki veri kümesindeki gözlemlerin zaten kimlik sütununda sıralandığına dikkat edin.
DATA SALARY;
INPUT empid name $ salary ; DATALINES; 1 Rick 623.3 2 Dan 515.2 3 Mike 611.5 4 Ryan 729.1 5 Gary 843.25 6 Tusar 578.6 7 Pranab 632.8 8 Rasmi 722.5 ; RUN; DATA DEPT; INPUT empid dEPT $ ;
DATALINES;
1 IT
2 OPS
3 IT
4 HR
5 FIN
6 IT
7 OPS
8 FIN
;
RUN;
DATA All_details;
MERGE SALARY DEPT;
BY (empid);
RUN;
PROC PRINT DATA = All_details;
RUN;Eşleşen Sütunda Eksik Değerler
Ortak değişkenin bazı değerlerinin veri kümeleri arasında eşleşmediği durumlar olabilir. Bu gibi durumlarda veri kümeleri yine de birleştirilir ancak sonuçta eksik değerler verir.
Misal
ID NAME SALARY DEPT
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 . . IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 .
7 Pranab 632.8 OPS
8 Rasmi 722.5 FINSadece Maçları Birleştirmek
Sonuçta eksik değerlerden kaçınmak için, yalnızca ortak değişken için eşleşen değerlere sahip gözlemleri tutmayı düşünebiliriz. Bu,INBeyan. SAS programının birleştirme ifadesinin değiştirilmesi gerekiyor.
Misal
Aşağıdaki örnekte, IN= değer yalnızca her iki veri kümesindeki değerlerin bulunduğu gözlemleri tutar SALARY ve DEPT eşleşme.
DATA All_details;
MERGE SALARY(IN = a) DEPT(IN = b);
BY (empid);
IF a = 1 and b = 1;
RUN;
PROC PRINT DATA = All_details;
RUN;Yukarıdaki SAS programının yukarıdaki değiştirilmiş kısım ile yürütülmesi üzerine aşağıdaki çıktıyı alıyoruz.
1 Rick 623.3 IT
2 Dan 515.2 OPS
4 Ryan 729.1 HR
5 Gary 843.25 FIN
7 Pranab 632.8 OPS
8 Rasmi 722.5 FINBir SAS veri kümesinin alt kümelenmesi, daha az sayıda değişken veya daha az sayıda gözlem veya her ikisini birden seçerek veri kümesinin bir bölümünü çıkarmak anlamına gelir. Değişkenlerin alt kümelenmesi kullanılarak yapılırkenKEEP ve DROP ifadesi, gözlemlerin alt ayarı kullanılarak yapılır DELETE Beyan.
Ayrıca, alt kümeleme işleminden elde edilen veriler, daha fazla analiz için kullanılabilecek yeni bir veri setinde tutulur. Alt ortam, esas olarak, analizle ilgili olmayabilecek değişkenleri veya gözlemleri kullanmadan veri setinin bir bölümünü analiz etmek amacıyla kullanılır.
Değişkenleri Alt Kümeleme
Bu yöntemde, tüm veri setinden yalnızca birkaç değişken çıkarıyoruz.
Sözdizimi
SAS'daki alt ayar değişkenleri için temel sözdizimi şudur:
KEEP var1 var2 ... ;
DROP var1 var2 ... ;Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
var1 and var2 saklanması veya bırakılması gereken veri kümesindeki değişken isimleridir.
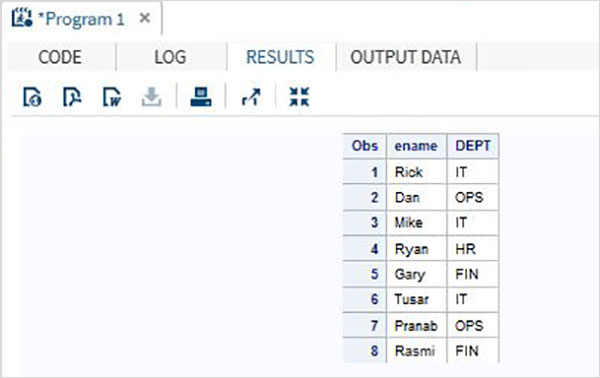
Misal
Bir kuruluşun çalışan ayrıntılarını içeren aşağıdaki SAS veri kümesini göz önünde bulundurun. Veri setinden sadece İsim ve Departman değerlerini almakla ilgileniyorsak, aşağıdaki kodu kullanabiliriz.
DATA Employee;
INPUT empid ename $ salary DEPT $ ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
DATA OnlyDept;
SET Employee;
KEEP ename DEPT;
RUN;
PROC PRINT DATA = OnlyDept;
RUN;Yukarıdaki kod çalıştırıldığında aşağıdaki çıktıyı alıyoruz.
Aynı sonuç, gerekli olmayan değişkenler bırakılarak da elde edilebilir. Aşağıdaki kod bunu göstermektedir.
DATA Employee;
INPUT empid ename $ salary DEPT $ ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
DATA OnlyDept;
SET Employee;
DROP empid salary;
RUN;
PROC PRINT DATA = OnlyDept;
RUN;Gözlemleri Alt Kümeye Alma
Bu yöntemde, tüm veri setinden sadece birkaç gözlem çıkarıyoruz.
Sözdizimi
Yeni veri seti için seçilen gözlemleri takip eden PROC FREQ kullanıyoruz.
Alt ayar gözlemleri için sözdizimi -
IF Var Condition THEN DELETE ;Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
Var değerine dayalı olarak gözlemlerin belirtilen koşul kullanılarak silineceği değişkenin adıdır.
Misal
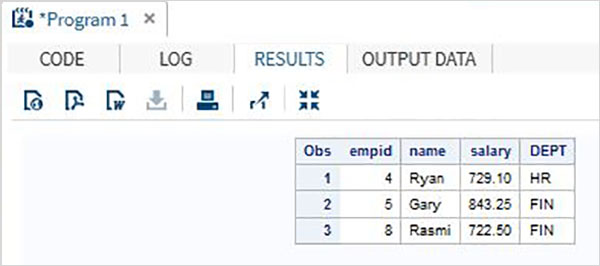
Bir kuruluşun çalışan ayrıntılarını içeren aşağıdaki SAS veri kümesini göz önünde bulundurun. Yalnızca 700'den fazla maaşı olan çalışanların verilerini almakla ilgileniyorsak, aşağıdaki kodu kullanırız.
DATA Employee;
INPUT empid name $ salary DEPT $ ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
DATA OnlyDept;
SET Employee;
IF salary < 700 THEN DELETE;
RUN;
PROC PRINT DATA = OnlyDept;
RUN;Yukarıdaki kod çalıştırıldığında aşağıdaki çıktıyı alıyoruz.
Bazen analiz edilen verileri, veri setinde halihazırda mevcut olduğu formattan farklı bir formatta göstermeyi tercih ederiz. Örneğin, fiyat bilgisi olan bir değişkene dolar işareti ve iki ondalık basamak eklemek istiyoruz. Veya tümü büyük harfle bir metin değişkeni göstermek isteyebiliriz. KullanabilirizFORMAT yerleşik SAS formatlarını uygulamak ve PROC FORMATkullanıcı tanımlı formatları uygulamaktır. Ayrıca birden çok değişkene tek bir format uygulanabilir.
Sözdizimi
Yerleşik SAS biçimlerini uygulamak için temel sözdizimi şudur:
format variable name format nameAşağıda kullanılan parametrelerin açıklaması verilmiştir -
variable name veri kümesinde kullanılan değişken adıdır.
format name değişkene uygulanacak veri formatıdır.
Misal
Bir organizasyonun çalışan detaylarını içeren aşağıdaki SAS veri setini ele alalım. Tüm isimleri büyük harfle göstermek istiyoruz. formatstatement bunu başarmak için kullanılır.
DATA Employee;
INPUT empid name $ salary DEPT $ ;
format name $upcase9. ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
PROC PRINT DATA = Employee;
RUN;Yukarıdaki kod çalıştırıldığında aşağıdaki çıktıyı alıyoruz.

PROC FORMAT'ı kullanma
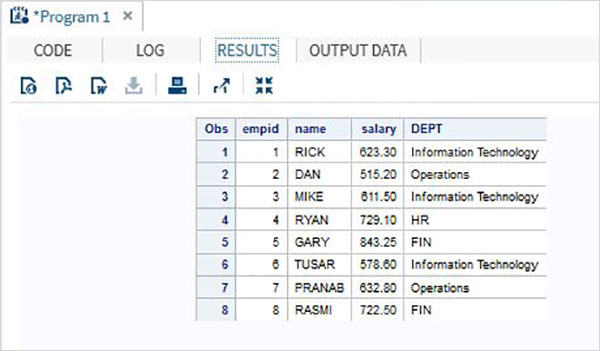
Ayrıca kullanabiliriz PROC FORMATverileri biçimlendirmek için. Aşağıdaki örnekte, DEPT değişkenine departmanın adını açıklayarak yeni değerler atıyoruz.
DATA Employee;
INPUT empid name $ salary DEPT $ ; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN ; proc format; value $DEP 'IT' = 'Information Technology'
'OPS'= 'Operations' ;
RUN;
PROC PRINT DATA = Employee;
format name $upcase9. DEPT $DEP.;
RUN;Yukarıdaki kod çalıştırıldığında aşağıdaki çıktıyı alıyoruz.
SAS, SAS programları içindeki SQL sorgularını kullanarak popüler ilişkisel veritabanlarının çoğuna kapsamlı destek sunar. ÇoğuANSI SQLsözdizimi desteklenmektedir. ProsedürPROC SQLSQL ifadelerini işlemek için kullanılır. Bu prosedür yalnızca bir SQL sorgusunun sonucunu geri vermekle kalmaz, aynı zamanda SAS tabloları ve değişkenleri de oluşturabilir. Tüm bu senaryoların örnekleri aşağıda açıklanmıştır.
Sözdizimi
SAS'da PROC SQL kullanmak için temel sözdizimi şudur:
PROC SQL;
SELECT Columns
FROM TABLE
WHERE Columns
GROUP BY Columns
;
QUIT;Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
SQL sorgusu PROC SQL ifadesinin altına yazılır ve bunu QUIT ifadesi takip eder.
Aşağıda bu SAS prosedürünün aşağıdakiler için nasıl kullanılabileceğini göreceğiz. CRUD SQL'de (Oluşturma, Okuma, Güncelleme ve Silme) işlemleri.
SQL Oluşturma İşlemi
SQL kullanarak ham verilerden yeni veri seti oluşturabiliriz. Aşağıdaki örnekte, önce ham verileri içeren TEMP adlı bir veri kümesi bildiriyoruz. Daha sonra bu veri setinin değişkenlerinden bir tablo oluşturmak için bir SQL sorgusu yazıyoruz.
DATA TEMP;
INPUT ID $ NAME $ SALARY DEPARTMENT $;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 Operations
3 Michelle 611 IT
4 Ryan 729 HR
5 Gary 843.25 Finance
6 Nina 578 IT
7 Simon 632.8 Operations
8 Guru 722.5 Finance
;
RUN;
PROC SQL;
CREATE TABLE EMPLOYEES AS
SELECT * FROM TEMP;
QUIT;
PROC PRINT data = EMPLOYEES;
RUN;Yukarıdaki kod çalıştırıldığında aşağıdaki sonucu alırız -
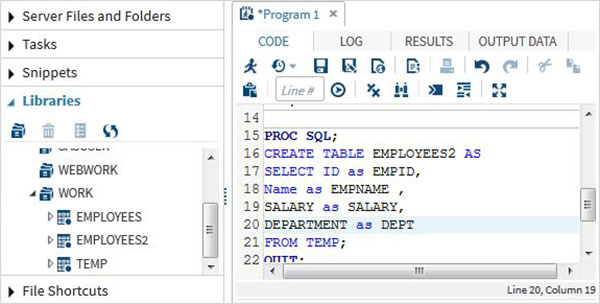
SQL Okuma İşlemi
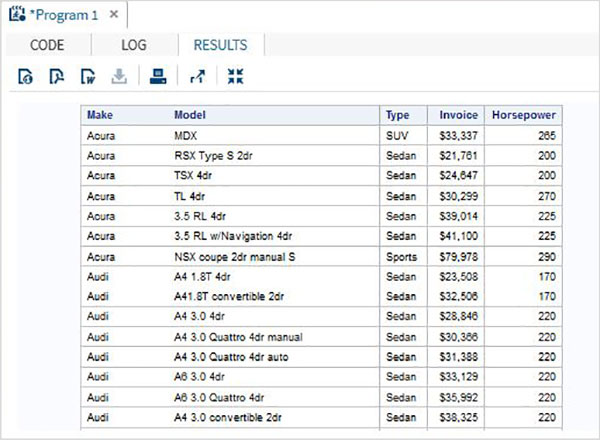
SQL'deki Okuma işlemi, tablolardan verileri okumak için SQL SELECT sorguları yazmayı içerir. Aşağıdaki program, SASHELP kütüphanesinde bulunan CARS adlı SAS veri setini sorgular. Sorgu, veri kümesinin bazı sütunlarını getirir.
PROC SQL;
SELECT make,model,type,invoice,horsepower
FROM
SASHELP.CARS
;
QUIT;Yukarıdaki kod çalıştırıldığında aşağıdaki sonucu alırız -
WHERE Tümcesine sahip SQL SELECT
Aşağıdaki program, CARS veri setini bir wherefıkra. Sonuçta sadece 'Audi' ve türü 'Spor' olarak yapılmış gözlemi elde ederiz.
PROC SQL;
SELECT make,model,type,invoice,horsepower
FROM
SASHELP.CARS
Where make = 'Audi'
and Type = 'Sports'
;
QUIT;Yukarıdaki kod çalıştırıldığında aşağıdaki sonucu alırız -
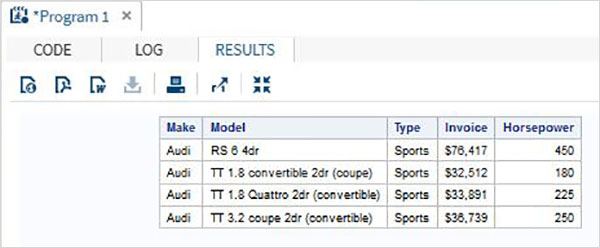
SQL UPDATE İşlemi
SAS tablosunu SQL Update deyimini kullanarak güncelleyebiliriz. Aşağıda önce EMPLOYEES2 adında yeni bir tablo oluşturuyoruz ve daha sonra SQL UPDATE deyimini kullanarak güncelliyoruz.
DATA TEMP;
INPUT ID $ NAME $ SALARY DEPARTMENT $;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 Operations
3 Michelle 611 IT
4 Ryan 729 HR
5 Gary 843.25 Finance
6 Nina 578 IT
7 Simon 632.8 Operations
8 Guru 722.5 Finance
;
RUN;
PROC SQL;
CREATE TABLE EMPLOYEES2 AS
SELECT ID as EMPID,
Name as EMPNAME ,
SALARY as SALARY,
DEPARTMENT as DEPT,
SALARY*0.23 as COMMISION
FROM TEMP;
QUIT;
PROC SQL;
UPDATE EMPLOYEES2
SET SALARY = SALARY*1.25;
QUIT;
PROC PRINT data = EMPLOYEES2;
RUN;Yukarıdaki kod çalıştırıldığında aşağıdaki sonucu alırız -

SQL DELETE İşlemi
SQL'de silme işlemi, SQL DELETE deyimini kullanarak tablodan belirli değerleri kaldırmayı içerir. Yukarıdaki örnekteki verileri kullanmaya devam ediyor ve çalışanların maaşının 900'den fazla olduğu tablodaki satırları silmeye devam ediyoruz.
PROC SQL;
DELETE FROM EMPLOYEES2
WHERE SALARY > 900;
QUIT;
PROC PRINT data = EMPLOYEES2;
RUN;Yukarıdaki kod çalıştırıldığında aşağıdaki sonucu alırız -

Bir SAS programından elde edilen çıktı, aşağıdaki gibi daha kullanıcı dostu formlara dönüştürülebilir: .html veya PDF. Bu, ODSaçıklama SAS'da mevcuttur. ODS, şu anlama gelir:output delivery system.Çoğunlukla, bir SAS programının çıktı verilerini, bakılması ve anlaşılması iyi olan güzel raporlara biçimlendirmek için kullanılır. Bu, çıktının diğer platformlar ve yazılımlarla paylaşılmasına da yardımcı olur. Ayrıca, birden çok PROC ifadesinin sonuçlarını tek bir dosyada birleştirebilir.
Sözdizimi
SAS'da ODS ifadesini kullanmak için temel sözdizimi şudur:
ODS outputtype
PATH path name
FILE = Filename and Path
STYLE = StyleName
;
PROC some proc
;
ODS outputtype CLOSE;Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
PATHHTML çıktısı durumunda kullanılan ifadeyi temsil eder. Diğer çıktı türlerinde, dosya adına yolu ekleriz.
Style SAS ortamında bulunan yerleşik stillerden birini temsil eder.
HTML Çıktısı Oluşturma
ODS HTML deyimini kullanarak HTML çıktısı oluşturuyoruz.Aşağıdaki örnekte istediğimiz yolda bir html dosyası oluşturuyoruz. Stil kitaplığında bulunan bir stili uyguluyoruz. Çıktı dosyasını belirtilen yolda görebilir ve SAS ortamından farklı bir ortamda kaydetmek için indirebiliriz. Lütfen iki proc SQL deyimimiz olduğunu ve her ikisinin de çıktısının tek bir dosyaya kaydedildiğini unutmayın.
ODS HTML
PATH = '/folders/myfolders/sasuser.v94/TutorialsPoint/'
FILE = 'CARS2.html'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS HTML CLOSE;Yukarıdaki kod çalıştırıldığında aşağıdaki sonucu alırız -
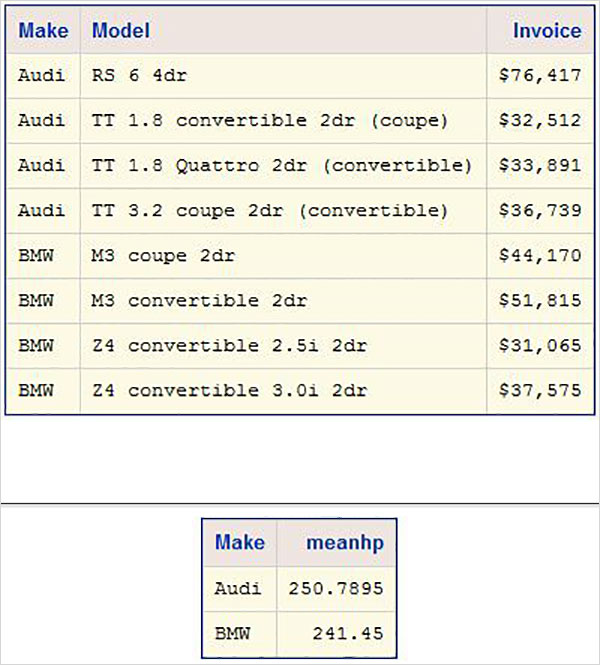
PDF Çıktısı Oluşturma
Aşağıdaki örnekte, istediğimiz yolda bir PDF dosyası oluşturuyoruz. Stil kitaplığında bulunan bir stili uyguluyoruz. Çıktı dosyasını belirtilen yolda görebilir ve SAS ortamından farklı bir ortamda kaydetmek için indirebiliriz. Lütfen iki proc SQL deyimimiz olduğunu ve her ikisinin de çıktısının tek bir dosyaya kaydedildiğini unutmayın.
ODS PDF
FILE = '/folders/myfolders/sasuser.v94/TutorialsPoint/CARS2.pdf'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS PDF CLOSE;Yukarıdaki kod çalıştırıldığında aşağıdaki sonucu alırız -
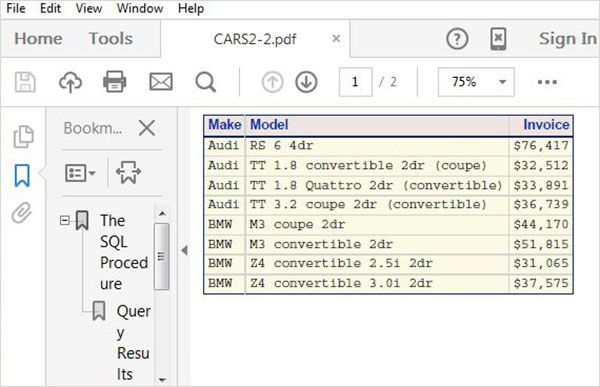
TRF (Word) Çıkışı Oluşturma
Aşağıdaki örnekte istediğimiz yolda bir RTF dosyası oluşturuyoruz. Stil kitaplığında bulunan bir stili uyguluyoruz. Çıktı dosyasını belirtilen yolda görebilir ve SAS ortamından farklı bir ortamda kaydetmek için indirebiliriz. Lütfen iki proc SQL deyimimiz olduğunu ve her ikisinin de çıktısının tek bir dosyaya kaydedildiğini unutmayın.
ODS RTF
FILE = '/folders/myfolders/sasuser.v94/TutorialsPoint/CARS.rtf'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS rtf CLOSE;Yukarıdaki kod çalıştırıldığında aşağıdaki sonucu alırız -
Simülasyon, istatistiksel bir miktarı tahmin etmek için birçok farklı rastgele örnek üzerinde tekrarlayan hesaplamayı kullanan bir hesaplama tekniğidir. SAS kullanarak, gerçek dünya sisteminde istatistiksel özellikleri belirleyen karmaşık verileri simüle edebiliriz. Sistemin bir modelini oluşturmak ve gerçek dünya sisteminin davranışını daha iyi anlamak için kullanabileceğiniz verileri sayısal olarak oluşturmak için yazılım kullanıyoruz. Bir bilgisayar simülasyon modeli tasarlama sanatının bir parçası, gerçek hayattaki sistemin hangi yönlerinin modele dahil edilmesi gerektiğine karar vermektir, böylece model tarafından oluşturulan veriler etkili kararlar almak için kullanılabilir. Bu karmaşıklık nedeniyle, SAS, Simülasyon için özel bir yazılım bileşenine sahiptir.
SAS simülasyonunun oluşturulmasında kullanılan SAS yazılım bileşenine SAS Simulation Studio. Grafik kullanıcı arayüzü, ayrık olay simülasyon modellerinin sonuçlarını oluşturmak, yürütmek ve analiz etmek için eksiksiz bir araç seti sağlar.
SAS simülasyonunun uygulanabileceği farklı istatistiksel dağılım türleri aşağıda listelenmiştir.
- SÜREKLİ DAĞITIMDAN VERİLERİN SİMÜLASYONUNU YAPIN
- AYRINTILI DAĞITIMDAN VERİLERİN SİMÜLASYONU
- DAĞITIMLARIN KARIŞIMINDAN VERİLERİN SİMÜLASYONUNU YAPIN
- KARMAŞIK BİR DAĞITIMDAN VERİLERİN SİMÜLASYONUNU YAPIN
- ÇOK DEĞİŞKENLİ BİR DAĞITIMDAN VERİLERİ SİMÜLASYON
- YAKLAŞIK BİR ÖRNEKLEME DAĞITIMI
- REGRESYON TAHMİNLERİNİ DEĞERLENDİRME
Histogram, farklı yükseklikteki çubuklar kullanılarak verilerin grafik olarak gösterilmesidir. Veri kümesindeki çeşitli sayıları birçok aralıkta gruplandırır. Aynı zamanda sürekli bir değişkenin dağılım olasılığının tahminini temsil eder. SAS'daPROC UNIVARIATE aşağıdaki seçeneklerle histogramlar oluşturmak için kullanılır.
Sözdizimi
SAS'da bir histogram oluşturmak için temel sözdizimi şudur:
PROC UNIVARAITE DATA = DATASET;
HISTOGRAM variables;
RUN;DATASET kullanılan veri kümesinin adıdır.
variables histogramı çizmek için kullanılan değerlerdir.
Basit Histogram
Değişkenin adı ve değerleri gruplamak için dikkate alınacak aralık belirtilerek basit bir histogram oluşturulur.
Misal
Aşağıdaki örnekte, değişken beygir gücünün minimum ve maksimum değerlerini ele alıyoruz ve 50'lik bir aralık alıyoruz. Yani değerler 50'lik adımlarla bir grup oluşturur.
proc univariate data = sashelp.cars;
histogram horsepower
/ midpoints = 176 to 350 by 50;
run;Yukarıdaki kodu çalıştırdığımızda aşağıdaki çıktıyı alıyoruz -
Eğri Uydurmalı Histogram
Ek seçenekler kullanarak bazı dağılım eğrilerini histograma sığdırabiliriz.
Misal
Aşağıdaki örnekte, EST olarak belirtilen ortalama ve standart sapma değerlerine sahip bir dağılım eğrisine uyuyoruz. Bu seçenek, parametreleri kullanır ve tahmin eder.
proc univariate data = sashelp.cars noprint;
histogram horsepower
/
normal (
mu = est
sigma = est
color = blue
w = 2.5
)
barlabel = percent
midpoints = 70 to 550 by 50;
run;Yukarıdaki kodu çalıştırdığımızda aşağıdaki çıktıyı alıyoruz -

Çubuk grafik, değişkenin değeriyle orantılı çubuk uzunluğu ile dikdörtgen çubuklardaki verileri temsil eder. SAS prosedürü kullanırPROC SGPLOTçubuk grafikler oluşturmak için. Çubuk grafikte hem basit hem de yığılmış çubuklar çizebiliriz. Çubuk grafikte, çubukların her birine farklı renkler verilebilir.
Sözdizimi
SAS'da bir çubuk grafik oluşturmak için temel sözdizimi şudur:
PROC SGPLOT DATA = DATASET;
VBAR variables;
RUN;DATASET - kullanılan veri kümesinin adıdır.
variables - histogramı çizmek için kullanılan değerlerdir.
Basit Çubuk grafik
Basit bir çubuk grafik, veri kümesindeki bir değişkenin çubuklarla temsil edildiği bir çubuk grafiktir.
Misal
Aşağıdaki komut dosyası, arabaların uzunluğunu çubuklar olarak temsil eden bir çubuk grafik oluşturacaktır.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc SGPLOT data = work.cars1;
vbar length ;
title 'Lengths of cars';
run;
quit;Yukarıdaki kodu çalıştırdığımızda aşağıdaki çıktıyı alıyoruz -
Yığılmış Çubuk grafik
Yığılmış çubuk grafik, veri kümesindeki bir değişkenin başka bir değişkene göre hesaplandığı bir çubuk grafiktir.
Misal
Aşağıdaki komut dosyası, her araba türü için arabaların uzunluğunun hesaplandığı yığılmış bir çubuk grafik oluşturacaktır. İkinci değişkeni belirtmek için grup seçeneğini kullanıyoruz.
proc SGPLOT data = work.cars1;
vbar length /group = type ;
title 'Lengths of Cars by Types';
run;
quit;Yukarıdaki kodu çalıştırdığımızda aşağıdaki çıktıyı alıyoruz -
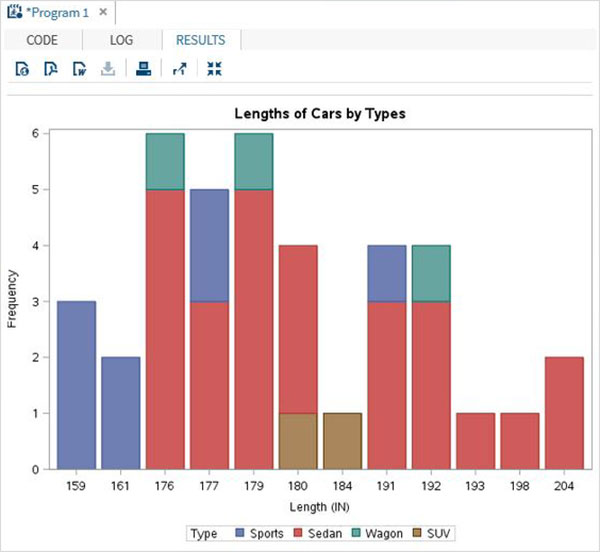
Kümelenmiş Çubuk grafik
Kümelenmiş çubuk grafik, bir değişkenin değerlerinin bir kültüre nasıl yayıldığını göstermek için oluşturulur.
Misal
Aşağıdaki komut dosyası, arabaların uzunluğunun araba türü etrafında toplandığı kümelenmiş bir çubuk grafik oluşturacaktır. Bu nedenle, biri 'Sedan' araç tipi ve diğeri 'Wagon' araba tipi için olmak üzere, 191 uzunluğunda iki bitişik çubuk görüyoruz. .
proc SGPLOT data = work.cars1;
vbar length /group = type GROUPDISPLAY = CLUSTER;
title 'Cluster of Cars by Types';
run;
quit;Yukarıdaki kodu çalıştırdığımızda aşağıdaki çıktıyı alıyoruz -

Pasta grafik, farklı renklere sahip bir dairenin dilimleri olarak değerlerin temsilidir. Dilimler etiketlenir ve her dilime karşılık gelen sayılar da grafikte temsil edilir.
SAS'da pasta grafik kullanılarak oluşturulur PROC TEMPLATE yüzdeyi, etiketleri, rengi, başlığı vb. kontrol etmek için parametreler alır.
Sözdizimi
SAS'da pasta grafik oluşturmak için temel sözdizimi şudur:
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = variable /
DATALABELLOCATION = OUTSIDE
CATEGORYDIRECTION = CLOCKWISE
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = ' ';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;variable pasta grafiği oluşturduğumuz değerdir.
Basit Pasta Grafiği
Bu pasta grafiğinde, veri kümesinden tek bir değişken alıyoruz. Pasta grafik, değişkenin toplam değerine göre değişkenin sayısının kesirini temsil eden dilimlerin değeriyle oluşturulur.
Misal
Aşağıdaki örnekte her dilim, toplam araba sayısından araba tipinin oranını temsil etmektedir.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type /
DATALABELLOCATION = OUTSIDE
CATEGORYDIRECTION = CLOCKWISE
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;Yukarıdaki kodu çalıştırdığımızda aşağıdaki çıktıyı alıyoruz -
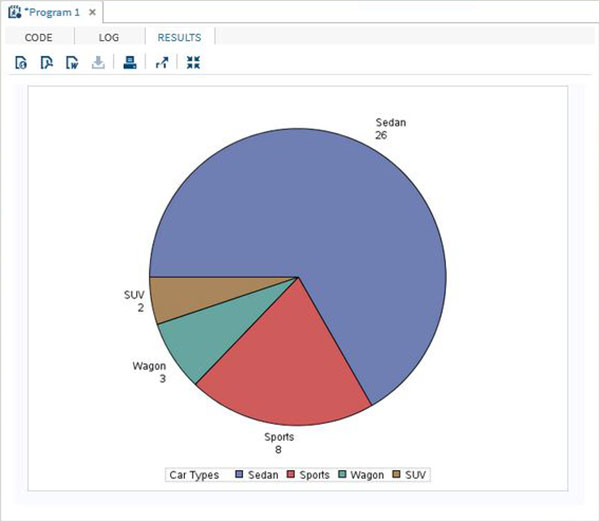
Veri Etiketli Pasta Grafik
Bu pasta grafikte, her dilim için hem kesirli değeri hem de yüzde değerini temsil ediyoruz. Ayrıca etiketin konumunu da grafiğin içinde olacak şekilde değiştiriyoruz. Grafiğin görünüm stili, DATASKIN seçeneği kullanılarak değiştirilir. SAS ortamında bulunan dahili stillerden birini kullanır.
Misal
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type /
DATALABELLOCATION = INSIDE
DATALABELCONTENT = ALL
CATEGORYDIRECTION = CLOCKWISE
DATASKIN = SHEEN
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;Yukarıdaki kodu çalıştırdığımızda aşağıdaki çıktıyı alıyoruz -
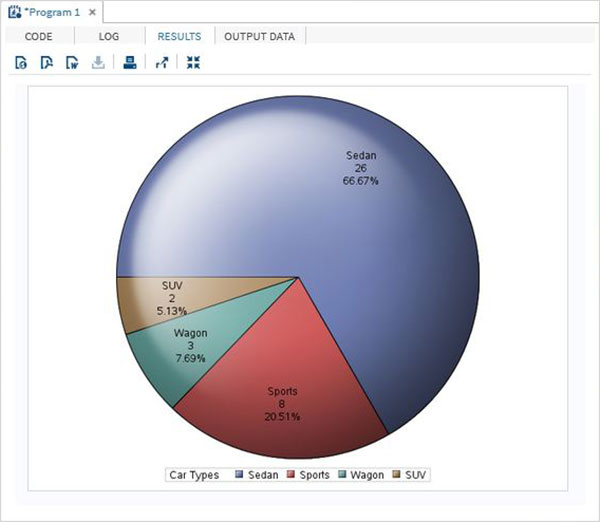
Gruplanmış Pasta Grafiği
Bu pasta grafiğinde, grafikte gösterilen değişkenin değeri aynı veri setinin başka bir değişkenine göre gruplandırılmıştır. Her grup bir daire haline gelir ve grafik, mevcut grup sayısı kadar eş merkezli daireye sahiptir.
Misal
Aşağıdaki örnekte grafiği "Make" adlı değişkene göre gruplandırıyoruz. Kullanılabilir iki değer olduğundan ("Audi" ve "BMW") bu nedenle, her biri kendi markasındaki otomobil türlerinin dilimlerini temsil eden iki eş merkezli daire elde ederiz.
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type / Group = make
DATALABELLOCATION = INSIDE
DATALABELCONTENT = ALL
CATEGORYDIRECTION = CLOCKWISE
DATASKIN = SHEEN
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;Yukarıdaki kodu çalıştırdığımızda aşağıdaki çıktıyı alıyoruz -
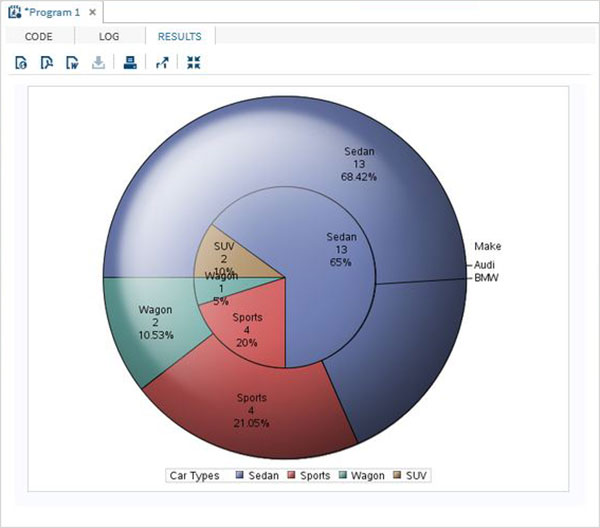
Dağılım grafiği, Kartezyen düzlemde çizilen iki değişkenden gelen değerleri kullanan bir grafik türüdür. Genellikle iki değişken arasındaki ilişkiyi bulmak için kullanılır. SAS'da kullanıyoruzPROC SGSCATTER dağılım grafikleri oluşturmak için.
Lütfen ilk örnekte CARS1 adlı veri setini oluşturduğumuzu ve sonraki tüm veri setleri için aynı veri setini kullandığımızı unutmayın. Bu veri seti, SAS oturumunun sonuna kadar çalışma kitaplığında kalır.
Sözdizimi
SAS'da dağılım grafiği oluşturmak için temel sözdizimi şudur:
PROC sgscatter DATA = DATASET;
PLOT VARIABLE_1 * VARIABLE_2
/ datalabel = VARIABLE group = VARIABLE;
RUN;Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
DATASET veri kümesinin adıdır.
VARIABLE veri kümesinden kullanılan değişkendir.
Basit Dağılım Grafiği
Basit bir dağılım grafiğinde, veri kümesinden iki değişken seçer ve bunları üçüncü bir değişkene göre gruplandırırız. Verileri de etiketleyebiliriz. Sonuç, iki değişkenin nasıl dağıldığını gösterir.Cartesian plane.
Misal
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
TITLE 'Scatterplot - Two Variables';
PROC sgscatter DATA = CARS1;
PLOT horsepower*Invoice
/ datalabel = make group = type grid;
title 'Horsepower vs. Invoice for car makers by types';
RUN;Yukarıdaki kodu çalıştırdığımızda aşağıdaki çıktıyı alıyoruz -
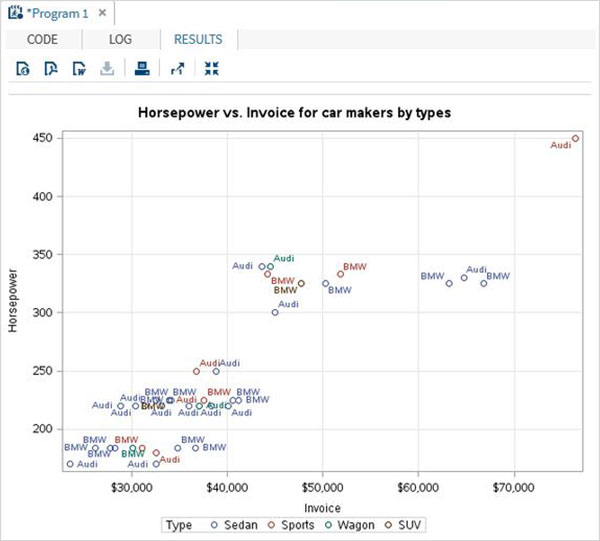
Tahmin ile Dağılım Grafiği
Değerlerin etrafına bir elips çizerek aralarındaki korelasyonun gücünü tahmin etmek için bir tahmin parametresi kullanabiliriz. Elipsi aşağıda gösterildiği gibi çizmek için prosedürdeki ek seçenekleri kullanırız.
Misal
proc sgscatter data = cars1;
compare y = Invoice x = (horsepower length)
/ group = type ellipse =(alpha = 0.05 type = predicted);
title
'Average Invoice vs. horsepower for cars by length';
title2
'-- with 95% prediction ellipse --'
;
format
Invoice dollar6.0;
run;Yukarıdaki kodu çalıştırdığımızda aşağıdaki çıktıyı alıyoruz -

Dağılım Matrisi
Ayrıca, ikiden fazla değişkeni içeren bir dağılım grafiğini çiftler halinde gruplayabiliriz. Aşağıdaki örnekte üç değişkeni ele alıyoruz ve bir dağılım grafiği matrisi çiziyoruz. 3 çift sonuç matrisi elde ederiz.
Misal
PROC sgscatter DATA = CARS1;
matrix horsepower invoice length
/ group = type;
title 'Horsepower vs. Invoice vs. Length for car makers by types';
RUN;Yukarıdaki kodu çalıştırdığımızda aşağıdaki çıktıyı alıyoruz -
Kutu grafiği, sayısal veri gruplarının çeyrekleri boyunca grafiksel temsilidir. Kutu grafikleri ayrıca, üst ve alt çeyreklerin dışındaki değişkenliği gösteren kutulardan (bıyıklar) dikey olarak uzanan çizgilere sahip olabilir. Kutunun altı ve üstü her zaman birinci ve üçüncü çeyreklerdir ve kutunun içindeki şerit her zaman ikinci çeyrektir (medyan). SAS'da basit bir Boxplot oluşturulur.PROC SGPLOT ve panelli kutu grafiği kullanılarak oluşturulur PROC SGPANEL.
Lütfen ilk örnekte CARS1 adlı veri setini oluşturduğumuzu ve sonraki tüm veri setleri için aynı veri setini kullandığımızı unutmayın. Bu veri seti, SAS oturumunun sonuna kadar çalışma kitaplığında kalır.
Sözdizimi
SAS'da bir kutu grafiği oluşturmak için temel sözdizimi şudur:
PROC SGPLOT DATA = DATASET;
VBOX VARIABLE / category = VARIABLE;
RUN;
PROC SGPANEL DATA = DATASET;;
PANELBY VARIABLE;
VBOX VARIABLE> / category = VARIABLE;
RUN;DATASET - kullanılan veri kümesinin adıdır.
VARIABLE - Kutu grafiğini çizmek için kullanılan değerdir.
Basit Kutu Grafiği
Basit bir Kutu Çizelgesinde, veri kümesinden bir değişken ve bir kategori oluşturmak için başka bir değişken seçiyoruz. Birinci değişkenin değerleri, ikinci değişkendeki farklı değerlerin sayısı kadar çok sayıda grupta kategorize edilir.
Misal
Aşağıdaki örnekte, ilk değişken olarak beygir gücü değişkenini seçip kategori değişkeni olarak yazıyoruz. Böylece, her araba türü için beygir gücü değerlerinin dağılımı için kutu grafikler elde ederiz.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
PROC SGPLOT DATA = CARS1;
VBOX horsepower
/ category = type;
title 'Horsepower of cars by types';
RUN;Yukarıdaki kodu çalıştırdığımızda aşağıdaki çıktıyı alıyoruz -
Dikey Panellerde Kutu Grafiği
Bir değişkenin Kutu Grafiklerini birçok dikey panele (sütun) bölebiliriz. Her panel, tüm kategorik değişkenler için kutu grafiklerini tutar. Ancak kutu grafikleri, grafiği birden çok panele bölen başka bir üçüncü değişken kullanılarak ayrıca gruplandırılır.
Misal
Aşağıdaki örnekte, 'make' değişkenini kullanarak grafiği panel haline getirdik. İki farklı 'make' değeri olduğundan, iki dikey panel elde ederiz.
PROC SGPANEL DATA = CARS1;
PANELBY MAKE;
VBOX horsepower / category = type;
title 'Horsepower of cars by types';
RUN;Yukarıdaki kodu çalıştırdığımızda aşağıdaki çıktıyı alıyoruz -
Yatay Panellerde Kutu Grafiği
Bir değişkenin Kutu Grafiklerini birçok yatay panele (satırlara) bölebiliriz. Her panel, tüm kategorik değişkenler için kutu grafiklerini tutar. Ancak kutu grafikleri, grafiği birden çok panele bölen başka bir üçüncü değişken kullanılarak ayrıca gruplandırılır. Aşağıdaki örnekte, 'make' değişkenini kullanarak grafiği panel haline getirdik. İki farklı 'make' değeri olduğundan, iki yatay panel elde ederiz.
PROC SGPANEL DATA = CARS1;
PANELBY MAKE / columns = 1 novarname;
VBOX horsepower / category = type;
title 'Horsepower of cars by types';
RUN;Yukarıdaki kodu çalıştırdığımızda aşağıdaki çıktıyı alıyoruz -
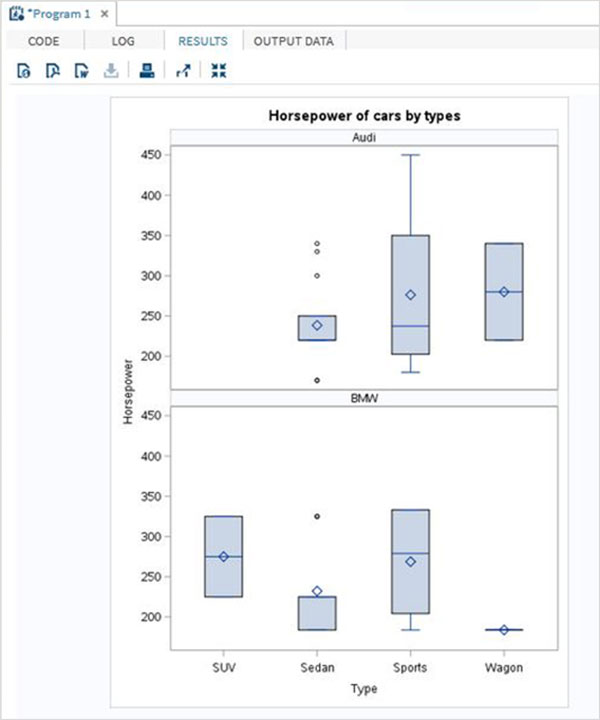
Aritmetik ortalama, sayısal değişkenlerin değerinin toplanması ve ardından toplamın değişkenlerin sayısına bölünmesiyle elde edilen değerdir. Ortalama olarak da adlandırılır. SAS'da aritmetik ortalama kullanılarak hesaplanırPROC MEANS. Bu SAS prosedürünü kullanarak bir veri kümesinin tüm değişkenlerinin veya bazı değişkenlerinin ortalamasını bulabiliriz. Ayrıca gruplar oluşturabilir ve o gruba özgü değerlerin değişkenlerinin ortalamasını bulabiliriz.
Sözdizimi
SAS'da aritmetik ortalamayı hesaplamak için temel sözdizimi şudur:
PROC MEANS DATA = DATASET;
CLASS Variables ;
VAR Variables;Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
DATASET - kullanılan veri kümesinin adıdır.
Variables - veri kümesindeki değişkenin adıdır.
Veri Kümesinin Ortalaması
Bir veri kümesindeki sayısal değişkenlerin her birinin ortalaması, herhangi bir değişken olmadan yalnızca veri kümesi adı sağlanarak PROC kullanılarak hesaplanır.
Misal
Aşağıdaki örnekte, CARS adlı SAS veri kümesindeki tüm sayısal değişkenlerin ortalamasını buluyoruz. Ondalık basamaktan sonraki maksimum basamağı 2 olarak belirleriz ve bu değişkenlerin toplamını da buluruz.
PROC MEANS DATA = sashelp.CARS Mean SUM MAXDEC=2;
RUN;Yukarıdaki kod çalıştırıldığında, aşağıdaki çıktıyı alıyoruz -
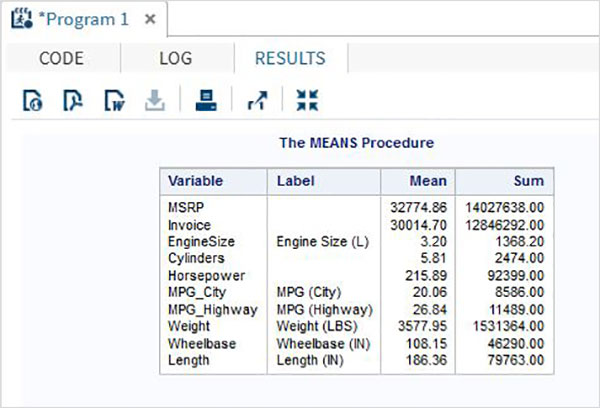
Seçili Değişkenlerin Ortalama Değeri
Adlarını yazarak bazı değişkenlerin ortalamasını alabiliriz. var seçeneği.
Misal
Aşağıda üç değişkenin ortalamasını hesaplıyoruz.
PROC MEANS DATA = sashelp.CARS mean SUM MAXDEC=2 ;
var horsepower invoice EngineSize;
RUN;Yukarıdaki kod çalıştırıldığında, aşağıdaki çıktıyı alıyoruz -
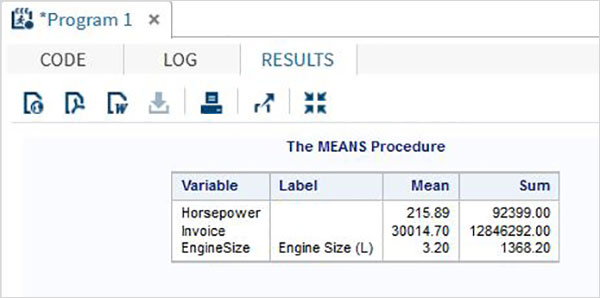
Sınıfa göre demek
Sayısal değişkenlerin ortalamasını, diğer değişkenleri kullanarak gruplara ayırarak bulabiliriz.
Misal
Aşağıdaki örnekte, arabanın her markasının altındaki her tür için değişken beygir gücünün ortalamasını buluyoruz.
PROC MEANS DATA = sashelp.CARS mean SUM MAXDEC=2;
class make type;
var horsepower;
RUN;Yukarıdaki kod çalıştırıldığında, aşağıdaki çıktıyı alıyoruz -
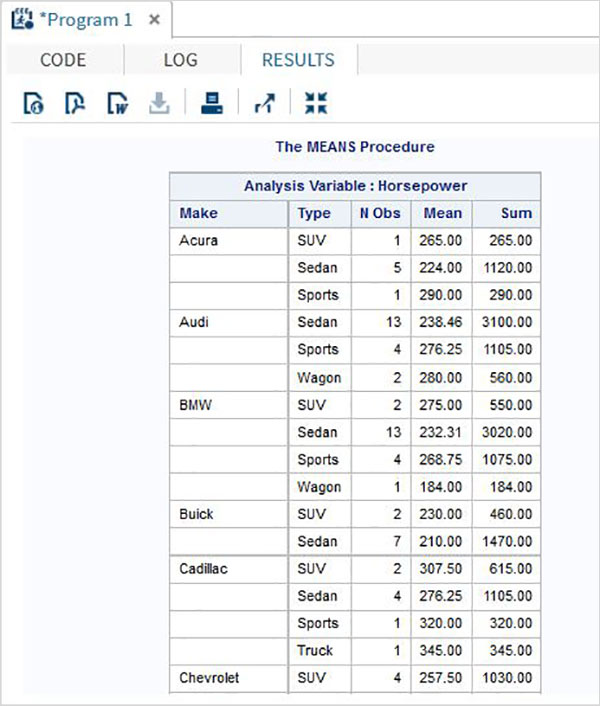
Standart sapma (SD), bir veri kümesindeki verilerin ne kadar çeşitli olduğunun bir ölçüsüdür. Matematiksel olarak, her bir değerin bir veri setinin ortalama değerine ne kadar uzak veya yakın olduğunu ölçer. 0'a yakın bir standart sapma değeri, veri noktalarının veri setinin ortalamasına çok yakın olma eğiliminde olduğunu ve yüksek bir standart sapma, veri noktalarının daha geniş bir değer aralığına yayıldığını gösterir.
SAS'da SD değerleri PROC MEAN ve PROC SURVEYMEANS kullanılarak ölçülür.
PROC MEANS Kullanımı
SD'yi kullanarak ölçmek için proc meansPROC adımında STD seçeneğini seçiyoruz. Veri setinde bulunan her sayısal değişken için SD değerlerini ortaya çıkarır.
Sözdizimi
SAS'daki standart sapmayı hesaplamak için temel sözdizimi şudur:
PROC means DATA = dataset STD;Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
Dataset - veri kümesinin adıdır.
Misal
Aşağıdaki örnekte, SASHELP kütüphanesindeki CARS veri setinden CARS1 veri setini oluşturuyoruz. PROC demek adım ile STD seçeneğini seçiyoruz.
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc means data = CARS1 STD;
run;Yukarıdaki kodu çalıştırdığımızda aşağıdaki çıktıyı verir -
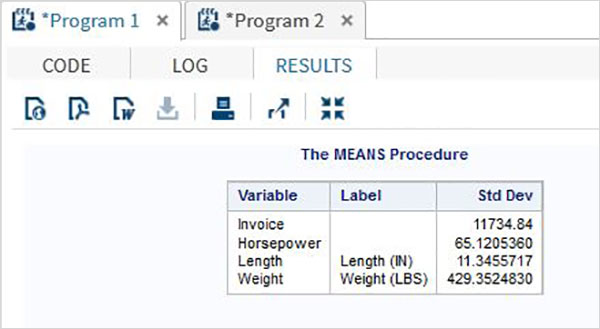
PROC SURVEYMEANS kullanma
Bu prosedür aynı zamanda SD ölçümü için, kategorik değişkenler için SD ölçümü gibi bazı gelişmiş özelliklerin yanı sıra varyansta tahminler sağlamak için de kullanılır.
Sözdizimi
PROC SURVEYMEANS kullanmanın sözdizimi şöyledir:
PROC SURVEYMEANS options statistic-keywords ;
BY variables ;
CLASS variables ;
VAR variables ;Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
BY - gözlem grupları oluşturmak için kullanılan değişkenleri gösterir.
CLASS - kategorik değişkenler için kullanılan değişkenleri gösterir.
VAR - SD'nin hesaplanacağı değişkenleri gösterir.
Misal
Aşağıdaki örnek aşağıdakilerin kullanımını açıklamaktadır: class sınıf değişkenindeki değerlerin her biri için istatistikleri oluşturan seçenek.
proc surveymeans data = CARS1 STD;
class type;
var type horsepower;
ods output statistics = rectangle;
run;
proc print data = rectangle;
run;Yukarıdaki kodu çalıştırdığımızda aşağıdaki çıktıyı verir -
BY seçeneğini kullanma
Aşağıdaki kod, BY seçeneği örneğini vermektedir. İçinde sonuç, BY seçeneğindeki her değer için gruplandırılır.
Misal
proc surveymeans data = CARS1 STD;
var horsepower;
BY make;
ods output statistics = rectangle;
run;
proc print data = rectangle;
run;Yukarıdaki kodu çalıştırdığımızda aşağıdaki çıktıyı verir -
Make = "Audi" sonucu

Marka = "BMW" için sonuç
Sıklık dağılımı, bir veri kümesindeki veri noktalarının sıklığını gösteren bir tablodur. Tablodaki her giriş, belirli bir grup veya aralık içindeki değerlerin oluşumlarının sıklığını veya sayısını içerir ve bu şekilde tablo, örnekteki değerlerin dağılımını özetler.
SAS, PROC FREQ bir veri kümesindeki veri noktalarının frekans dağılımını hesaplamak için.
Sözdizimi
SAS'da frekans dağılımını hesaplamak için temel sözdizimi şudur:
PROC FREQ DATA = Dataset ;
TABLES Variable_1 ;
BY Variable_2 ;Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
Dataset veri kümesinin adıdır.
Variables_1 frekans dağılımı hesaplanması gereken veri kümesinin değişken isimleridir.
Variables_2 frekans dağılımı sonucunu kategorize eden değişkenlerdir.
Tek Değişkenli Frekans Dağılımı
Tek bir değişkenin frekans dağılımını kullanarak belirleyebiliriz PROC FREQ.Bu durumda sonuç, değişkenin her bir değerinin sıklığını gösterecektir. Sonuç ayrıca yüzde dağılımını, kümülatif sıklığı ve kümülatif yüzdeyi de gösterir.
Misal
Aşağıdaki örnekte, adlı veri kümesi için değişken beygir gücünün frekans dağılımını buluyoruz. CARS1 kütüphaneden oluşturulan SASHELP.CARS.Sonucu iki sonuç kategorisine ayrılmış olarak görebiliriz. Arabanın her markası için bir tane.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc FREQ data = CARS1 ;
tables horsepower;
by make;
run;Yukarıdaki kod çalıştırıldığında, aşağıdaki sonucu alırız -

Çoklu Değişken Frekans Dağılımı
Birden çok değişken için, onları tüm olası kombinasyonlara gruplayan frekans dağılımlarını bulabiliriz.
Misal
Aşağıdaki örnekte, bir arabanın markası için frekans dağılımını hesaplıyoruz: grouped by car type ve ayrıca her araba türünün frekans dağılımı grouped by each make.
proc FREQ data = CARS1 ;
tables make type;
run;Yukarıdaki kod çalıştırıldığında, aşağıdaki sonucu alırız -
Ağırlıklı Frekans Dağılımı
Ağırlık seçeneği ile değişkenin ağırlığına bağlı olarak frekans dağılımını hesaplayabiliriz. Burada değişkenin değeri, değer sayısı yerine gözlem sayısı olarak alınır.
Misal
Aşağıdaki örnekte, beygir gücüne atanan ağırlık ile marka ve tip değişkenlerinin frekans dağılımını hesaplıyoruz.
proc FREQ data = CARS1 ;
tables make type;
weight horsepower;
run;Yukarıdaki kod çalıştırıldığında, aşağıdaki sonucu alırız -
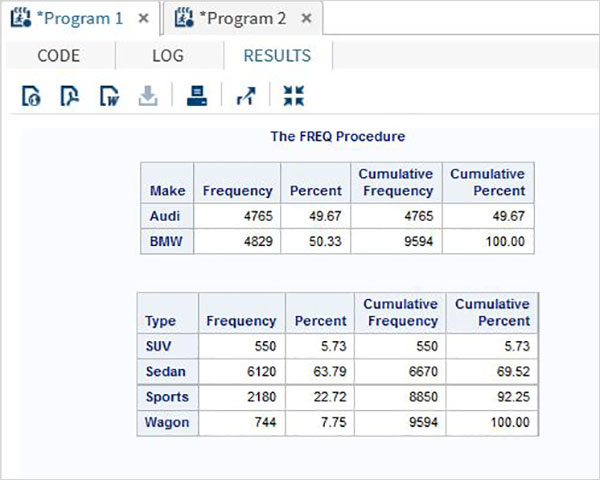
Çapraz tablolama, iki veya daha fazla değişkenin tüm olası kombinasyonlarını kullanarak koşullu tablolar olarak da adlandırılan çapraz tablolar oluşturmayı içerir. SAS'da kullanılarak oluşturulurPROC FREQ ile birlikte TABLESseçeneği. Örneğin - her araba tipi kategorisindeki her marka için her modelin frekansına ihtiyacımız varsa, o zaman PROC FREQ'nun TABLOLAR seçeneğini kullanmamız gerekir.
Sözdizimi
SAS'da çapraz tablolama uygulamak için temel sözdizimi şudur:
PROC FREQ DATA = dataset;
TABLES variable_1*Variable_2;Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
Dataset veri kümesinin adıdır.
Variable_1 and Variable_2 frekans dağılımı hesaplanması gereken veri kümesinin değişken isimleridir.
Misal
Form oluşturulan veri setinden her bir otomobil markası altında kaç otomobil türünün bulunduğunu bulma durumunu düşünün. SASHELP.CARSAşağıda gösterildiği gibi. Bu durumda, bireysel frekans değerlerinin yanı sıra markalar ve türler arasındaki frekans değerlerinin toplamına ihtiyacımız var. Sonucun satırlar ve sütunlar boyunca değerleri gösterdiğini gözlemleyebiliriz.
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc FREQ data = CARS1;
tables make*type;
run;Yukarıdaki kod çalıştırıldığında, aşağıdaki sonucu alırız -
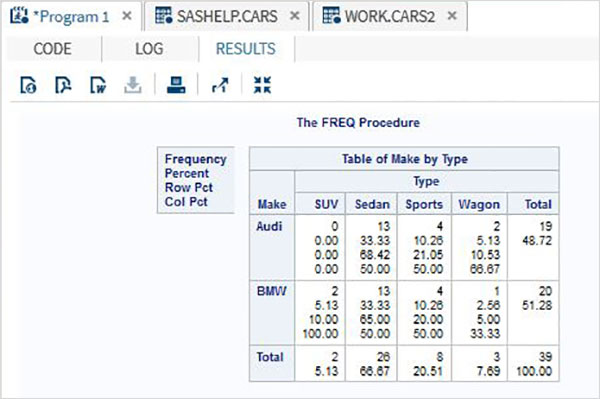
3 Değişkenin çapraz tablolaması
Üç değişkenimiz olduğunda, bunların 2'sini gruplayabilir ve bu ikisinin her birini üçüncü değişkenle karşılaştırabiliriz. Sonuçta iki çapraz tablomuz var.
Misal
Aşağıdaki örnekte, otomobilin markasına göre her bir araba türünün ve her araba modelinin frekansını buluyoruz. Ayrıca, toplam ve yüzde değerlerinden kaçınmak için nocol ve norow seçeneğini kullanıyoruz.
proc FREQ data = CARS2 ;
tables make * (type model) / nocol norow nopercent;
run;Yukarıdaki kod çalıştırıldığında, aşağıdaki sonucu alırız -
4 Değişkenin çapraz tablolaması
4 değişkenle, eşleştirilmiş kombinasyonların sayısı 4'e çıkar. Grup 1'deki her değişken, grup 2'nin her değişkeni ile eşleştirilir.
Misal
Aşağıdaki örnekte, her marka ve her model için arabanın uzunluk sıklığını buluyoruz. Benzer şekilde, her marka ve her model için beygir gücü frekansı.
proc FREQ data = CARS2 ;
tables (make model) * (length horsepower) / nocol norow nopercent;
run;Yukarıdaki kod çalıştırıldığında, aşağıdaki sonucu alırız -
T testleri, ortalamalarını ve ortalama farklılıklarını karşılaştırarak bir örnek veya iki bağımsız örnek için güven sınırlarını hesaplamak için gerçekleştirilir. SAS prosedürüPROC TTEST tek bir değişken ve bir çift değişken üzerinde t testleri yapmak için kullanılır.
Sözdizimi
PROC TTEST'i SAS'ta uygulamak için temel sözdizimi şudur:
PROC TTEST DATA = dataset;
VAR variable;
CLASS Variable;
PAIRED Variable_1 * Variable_2;Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
Dataset veri kümesinin adıdır.
Variable_1 and Variable_2 t testinde kullanılan veri setinin değişken isimleridir.
Misal
Aşağıda, değişken beygir gücü için yüzde 95 güven sınırları ile t testi tahminini bulan bir örnek t testi görüyoruz.
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc ttest data = cars1 alpha = 0.05 h0 = 0;
var horsepower;
run;Yukarıdaki kod çalıştırıldığında, aşağıdaki sonucu alırız -
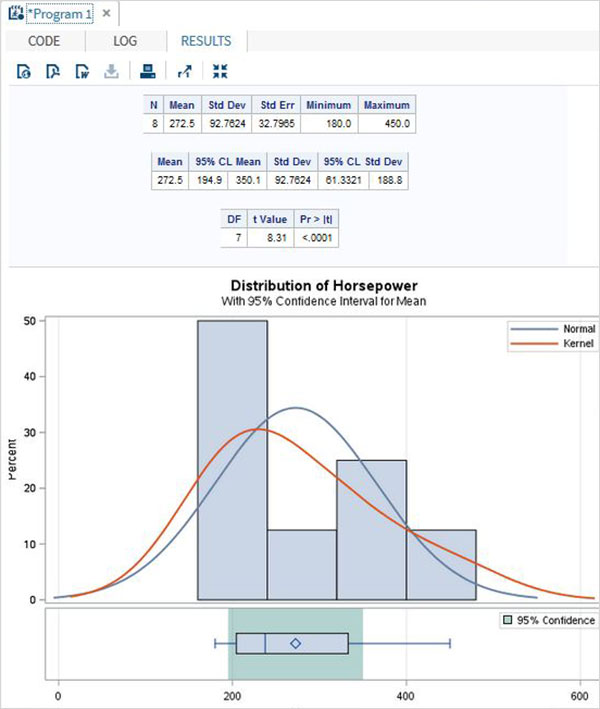
Eşleştirilmiş T testi
Eşleştirilmiş T Testi, iki bağımlı değişkenin istatistiksel olarak birbirinden farklı olup olmadığını test etmek için yapılır.
Misal
Bir arabanın uzunluğu ve ağırlığı birbirine bağlı olacağından, aşağıda gösterildiği gibi eşleştirilmiş T testini uygularız.
proc ttest data = cars1 ;
paired weight*length;
run;Yukarıdaki kod çalıştırıldığında, aşağıdaki sonucu alırız -
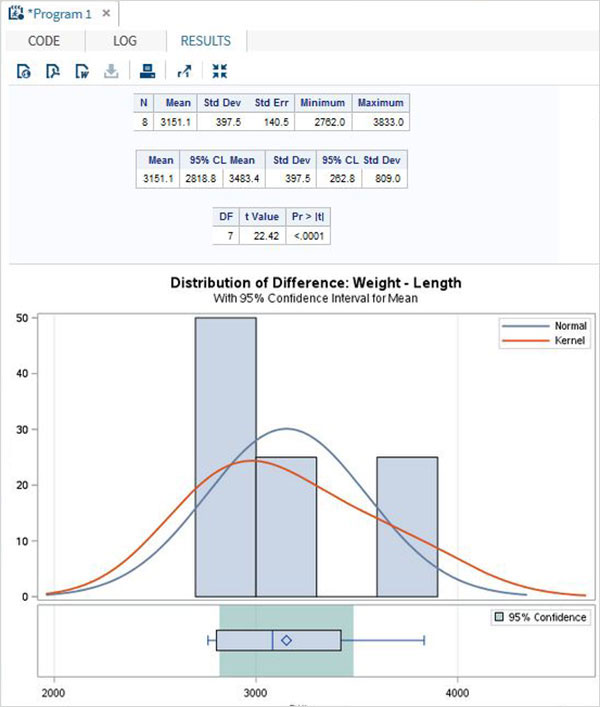
İki örnek t testi
Bu t-testi, iki grup arasında aynı değişkenin ortalamalarını karşılaştırmak için tasarlanmıştır.
Misal
Bizim durumumuzda, iki farklı otomobil markası ("Audi" ve "BMW") arasındaki değişken beygir gücünün ortalamasını karşılaştırıyoruz.
proc ttest data = cars1 sides = 2 alpha = 0.05 h0 = 0;
title "Two sample t-test example";
class make;
var horsepower;
run;Yukarıdaki kod çalıştırıldığında, aşağıdaki sonucu alırız -
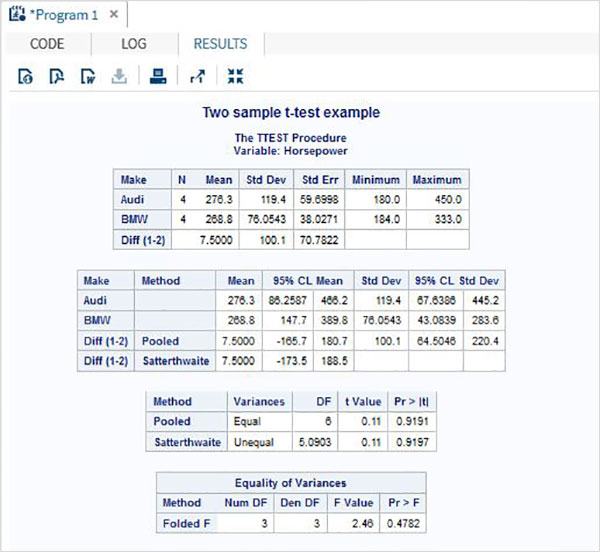
Korelasyon analizi, değişkenler arasındaki ilişkilerle ilgilenir. Korelasyon katsayısı, iki değişken arasındaki doğrusal ilişkinin bir ölçüsüdür. Korelasyon katsayısının değerleri her zaman -1 ile +1 arasındadır. SAS prosedürü sağlarPROC CORR bir veri kümesindeki bir çift değişken arasındaki korelasyon katsayılarını bulmak için.
Sözdizimi
SAS'da PROC CORR uygulamak için temel sözdizimi şudur:
PROC CORR DATA = dataset options;
VAR variable;Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
Dataset veri kümesinin adıdır.
Options bir matris çizimi vb. gibi prosedürlerle ek bir seçenektir.
Variable korelasyonu bulmada kullanılan veri kümesinin değişken adıdır.
Misal
Bir veri setinde bulunan bir çift değişken arasındaki korelasyon katsayıları, VAR deyimindeki isimleri kullanılarak elde edilebilir. Aşağıdaki örnekte, CARS1 veri setini kullanıyoruz ve beygir gücü ile ağırlık arasındaki korelasyon katsayılarını gösteren sonucu elde ediyoruz.
PROC SQL;
create table CARS1 as
SELECT invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc corr data = cars1 ;
VAR horsepower weight ;
BY make;
run;Yukarıdaki kod çalıştırıldığında, aşağıdaki sonucu alırız -
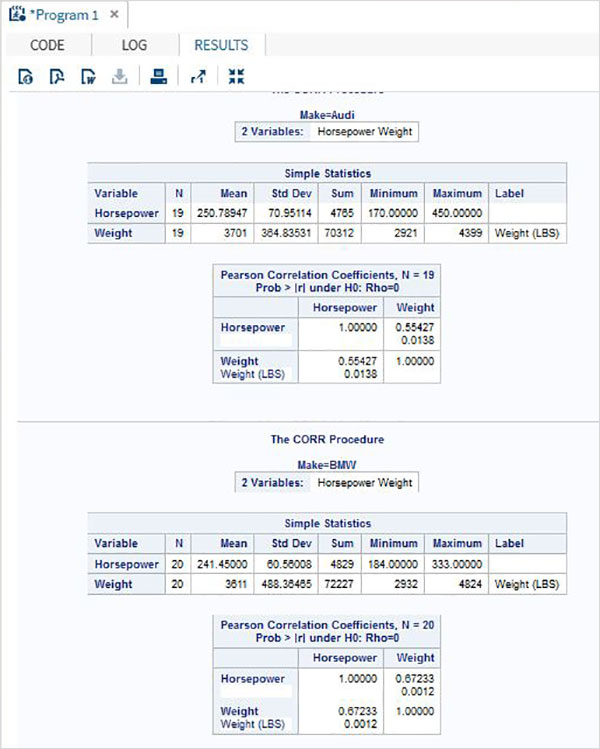
Tüm Değişkenler Arasındaki Korelasyon
Bir veri setinde bulunan tüm değişkenler arasındaki korelasyon katsayıları, basitçe prosedürü veri seti adıyla uygulayarak elde edilebilir.
Misal
Aşağıdaki örnekte, CARS1 veri setini kullanıyoruz ve her değişken çifti arasındaki korelasyon katsayılarını gösteren sonucu elde ediyoruz.
proc corr data = cars1 ;
run;Yukarıdaki kod çalıştırıldığında, aşağıdaki sonucu alırız -
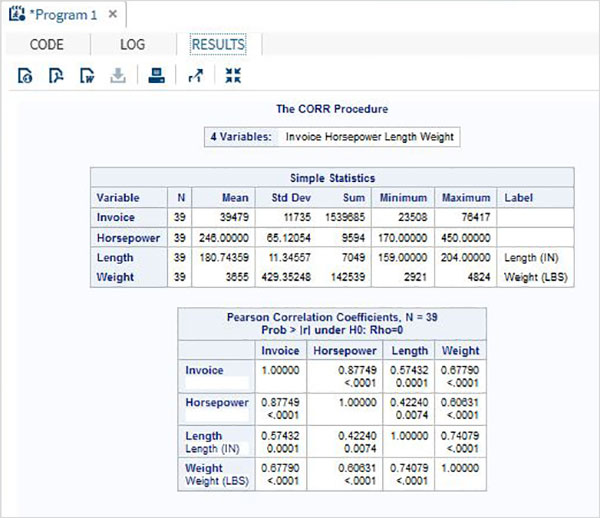
Korelasyon Matrisi
Matrisin grafiğini çizme seçeneğini seçerek değişkenler arasında bir dağılım grafiği matrisi elde edebiliriz. PROC Beyan.
Misal
Aşağıdaki örnekte beygir gücü ve ağırlık arasındaki matrisi elde ediyoruz.
proc corr data = cars1 plots = matrix ;
VAR horsepower weight ;
run;Yukarıdaki kod çalıştırıldığında, aşağıdaki sonucu alırız -
Doğrusal Regresyon, bağımlı bir değişken ile bir veya daha fazla bağımsız değişken arasındaki ilişkiyi tanımlamak için kullanılır. Bir ilişki modeli önerilir ve parametre değerlerinin tahminleri, tahmini bir regresyon denklemi geliştirmek için kullanılır.
Daha sonra modelin tatmin edici olup olmadığını belirlemek için çeşitli testler kullanılır. Öyleyse, tahmin edilen regresyon denklemi, bağımsız değişkenler için değerler verilen bağımlı değişkenin değerini tahmin etmek için kullanılabilir. SAS'da prosedürPROC REG iki değişken arasındaki doğrusal regresyon modelini bulmak için kullanılır.
Sözdizimi
SAS'da PROC REG'i uygulamak için temel sözdizimi şudur:
PROC REG DATA = dataset;
MODEL variable_1 = variable_2;Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
Dataset veri kümesinin adıdır.
variable_1 and variable_2 korelasyonu bulmada kullanılan veri setinin değişken isimleridir.
Misal
Aşağıdaki örnek, iki değişken beygir gücü ve bir arabanın ağırlığı arasındaki ilişkiyi bulmak için süreci göstermektedir. PROC REG. Sonuçta, regresyon denklemini oluşturmak için kullanılabilecek kesişme değerlerini görüyoruz.
PROC SQL;
create table CARS1 as
SELECT invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc reg data = cars1;
model horsepower = weight ;
run;Yukarıdaki kod çalıştırıldığında, aşağıdaki sonucu alırız -
Yukarıdaki kod, aşağıda gösterildiği gibi modelin çeşitli tahminlerinin grafik görünümünü de verir. Gelişmiş bir SAS prosedürü olarak, kesişme değerlerini çıktı olarak vermekle kalmaz.
Bland-Altman analizi, aynı parametreleri ölçmek için tasarlanmış iki yöntem arasındaki anlaşmanın veya anlaşmazlığın kapsamını doğrulamaya yönelik bir süreçtir. Yöntemler arasındaki yüksek korelasyon, veri analizinde yeterince iyi örneklemin seçildiğini göstermektedir. SAS'ta değişken değerlerin ortalamasını, üst sınırını ve alt sınırını hesaplayarak bir Bland-Altman grafiği oluşturuyoruz. Daha sonra Bland-Altman grafiğini oluşturmak için PROC SGPLOT kullanıyoruz.
Sözdizimi
PROC SGPLOT'u SAS'ta uygulamak için temel sözdizimi şudur:
PROC SGPLOT DATA = dataset;
SCATTER X = variable Y = Variable;
REFLINE value;Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
Dataset veri kümesinin adıdır.
SCATTER ifadesi, X ve Y şeklinde sağlanan değerin dağılım grafiği grafiğini onaylar.
REFLINE yatay veya dikey bir referans çizgisi oluşturur.
Misal
Aşağıdaki örnekte, yeni ve eski adlı iki yöntemle oluşturulan iki deneyin sonucunu alıyoruz. Değişkenlerin değerlerindeki farklılıkları ve aynı gözlemin değişkenlerinin ortalamasını da hesaplıyoruz. Ayrıca hesaplamanın üst ve alt sınırında kullanılacak standart sapma değerlerini de hesaplıyoruz.
Sonuç, bir dağılım grafiği olarak bir Bland-Altman grafiğini gösterir.
data mydata;
input new old;
datalines;
31 45
27 12
11 37
36 25
14 8
27 15
3 11
62 42
38 35
20 9
35 54
62 67
48 25
77 64
45 53
32 42
16 19
15 27
22 9
8 38
24 16
59 25
;
data diffs ;
set mydata ;
/* calculate the difference */
diff = new-old ;
/* calculate the average */
mean = (new+old)/2 ;
run ;
proc print data = diffs;
run;
proc sql noprint ;
select mean(diff)-2*std(diff), mean(diff)+2*std(diff)
into :lower, :upper
from diffs ;
quit;
proc sgplot data = diffs ;
scatter x = mean y = diff;
refline 0 &upper &lower / LABEL = ("zero bias line" "95% upper limit" "95%
lower limit");
TITLE 'Bland-Altman Plot';
footnote 'Accurate prediction with 10% homogeneous error';
run ;
quit ;Yukarıdaki kod çalıştırıldığında, aşağıdaki sonucu alırız -
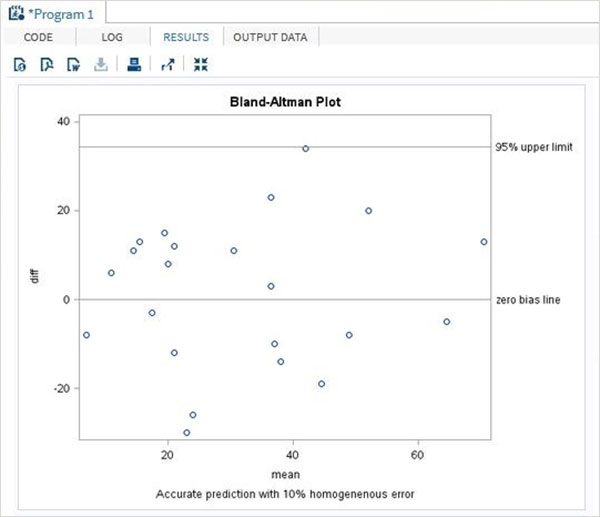
Geliştirilmiş Model
Yukarıdaki programın geliştirilmiş bir modelinde, yüzde 95 güven seviyesi eğri uydurma elde ediyoruz.
proc sgplot data = diffs ;
reg x = new y = diff/clm clmtransparency = .5;
needle x = new y = diff/baseline = 0;
refline 0 / LABEL = ('No diff line');
TITLE 'Enhanced Bland-Altman Plot';
footnote 'Accurate prediction with 10% homogeneous error';
run ;
quit ;Yukarıdaki kod çalıştırıldığında, aşağıdaki sonucu alırız -
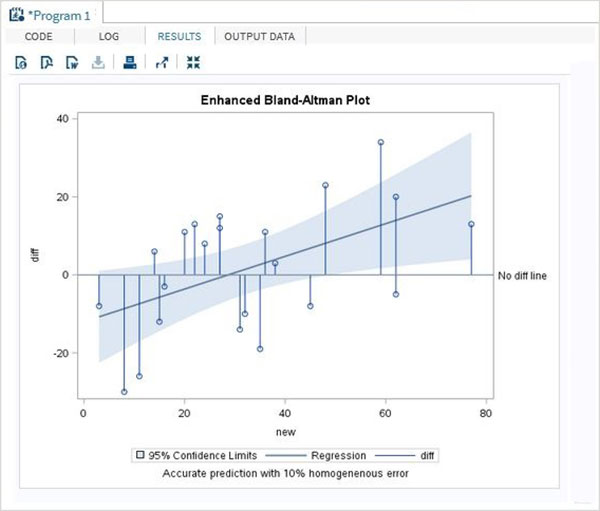
İki kategorik değişken arasındaki ilişkiyi incelemek için bir ki-kare testi kullanılır. Değişkenler arasındaki hem bağımlılık derecesini hem de bağımsızlık derecesini test etmek için kullanılabilir. SAS kullanırPROC FREQ seçenekle birlikte chisq Ki-Kare testinin sonucunu belirlemek için.
Sözdizimi
SAS'da Chi-Square testi için PROC FREQ uygulamak için temel sözdizimi şudur:
PROC FREQ DATA = dataset;
TABLES variables
/CHISQ TESTP = (percentage values);Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
Dataset veri kümesinin adıdır.
Variables ki-kare testinde kullanılan veri setinin değişken isimleridir.
Percentage Values TESTP ifadesinde, değişken düzeylerinin yüzdesini temsil eder.
Misal
Aşağıdaki örnekte, veri kümesindeki tür adlı değişken üzerinde bir ki-kare testi ele alıyoruz. SASHELP.CARS. Bu değişkenin altı seviyesi vardır ve testin tasarımına göre her seviyeye yüzde veriyoruz.
proc freq data = sashelp.cars;
tables type
/chisq
testp = (0.20 0.12 0.18 0.10 0.25 0.15);
run;Yukarıdaki kod çalıştırıldığında, aşağıdaki sonucu alırız -

Aşağıdaki ekran görüntüsünde gösterildiği gibi değişken türünün sapmasını gösteren çubuk grafiği de alıyoruz.
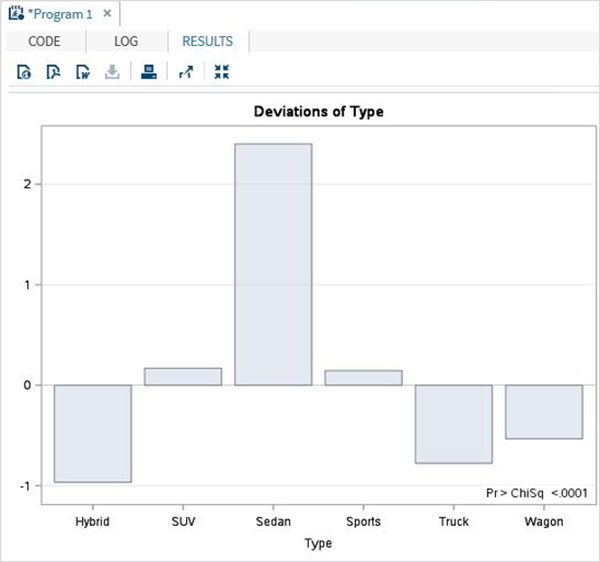
İki Yönlü ki-kare
Testleri veri setinin iki değişkenine uyguladığımızda iki yönlü Ki-Kare testi kullanılır.
Misal
Aşağıdaki örnekte, tür ve orijin adlı iki değişkene ki-kare testi uyguluyoruz. Sonuç, bu iki değişkenin tüm kombinasyonlarının tablo şeklini gösterir.
proc freq data = sashelp.cars;
tables type*origin
/chisq
;
run;Yukarıdaki kod çalıştırıldığında, aşağıdaki sonucu alırız -
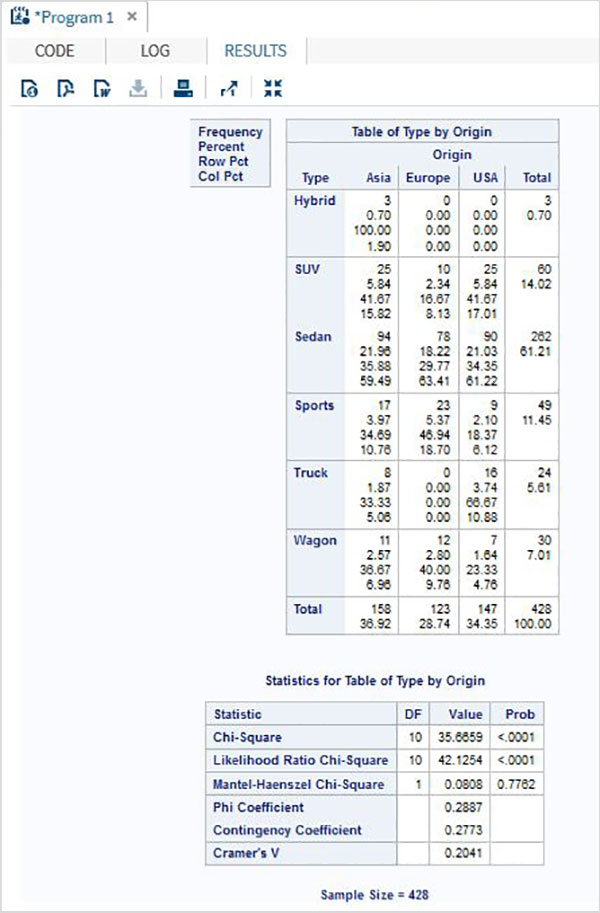
Fisher'in kesin testi, iki kategorik değişken arasında rastgele olmayan ilişkiler olup olmadığını belirlemek için kullanılan istatistiksel bir testtir. PROC FREQ. Fisher Exact testine tabi tutulan iki değişkeni kullanmak için Tablolar seçeneğini kullanıyoruz.
Sözdizimi
SAS'da Fisher Exact testini uygulamak için temel sözdizimi şudur:
PROC FREQ DATA = dataset ;
TABLES Variable_1*Variable_2 / fisher;Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
dataset veri kümesinin adıdır.
Variable_1*Variable_2 veri kümesini oluşturan değişkenlerdir.
Fisher Exact Testini Uygulama
Fisher's Exact Testini uygulamak için Test1 ve Test2 adlı iki kategorik değişken ve bunların sonuçlarını seçiyoruz.Aşağıda gösterilen testi uygulamak için PROC FREQ kullanıyoruz.
Misal
data temp;
input Test1 Test2 Result @@;
datalines;
1 1 3 1 2 1 2 1 1 2 2 3
;
proc freq;
tables Test1*Test2 / fisher;
run;Yukarıdaki kod çalıştırıldığında, aşağıdaki sonucu alırız -
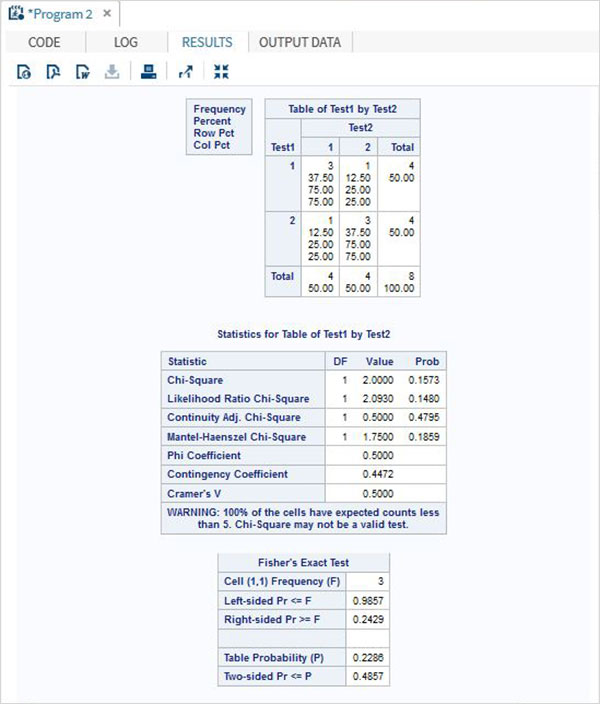
Tekrarlanan ölçüm analizi, rastgele bir numunenin tüm üyeleri bir dizi farklı koşul altında ölçüldüğünde kullanılır. Numune sırayla her koşula maruz bırakıldığında, bağımlı değişkenin ölçümü tekrarlanır. Bu durumda standart bir ANOVA kullanmak uygun değildir çünkü tekrarlanan ölçümler arasındaki korelasyonu modellemede başarısız olur.
Kişi, a arasındaki fark konusunda net olmalıdır. repeated measures design ve bir simple multivariate design. Her ikisi için de, örnek elemanlar çeşitli durumlarda veya denemelerde ölçülür, ancak tekrarlanan ölçüm tasarımında her deneme, aynı özelliğin farklı bir koşul altında ölçümünü temsil eder.
SAS'da PROC GLM tekrarlanan ölçüm analizi yapmak için kullanılır.
Sözdizimi
SAS'daki PROC GLM için temel sözdizimi şudur:
PROC GLM DATA = dataset;
CLASS variable;
MODEL variables = group / NOUNI;
REPEATED TRIAL n;Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
dataset veri kümesinin adıdır.
CLASS değişkenlere sınıflandırma değişkeni olarak kullanılan değişkeni verir.
MODEL Veri setinden belirli değişkenleri kullanarak uydurulacak modeli tanımlar.
REPEATED Hipotezi test etmek için her grubun tekrarlanan ölçümlerinin sayısını tanımlar.
Misal
Bir ilacın etki testine tabi tutulan iki grup insanın olduğu aşağıdaki örneği düşünün. Her kişinin reaksiyon süresi, test edilen dört ilaç türünün her biri için kaydedilir. Burada, dört ilaç türünün etkisi arasındaki ilişkinin gücünü görmek için her bir grup insan için 5 deneme yapılır.
DATA temp;
INPUT person group $ r1 r2 r3 r4;
CARDS;
1 A 2 1 6 5
2 A 5 4 11 9
3 A 6 14 12 10
4 A 2 4 5 8
5 A 0 5 10 9
6 B 9 11 16 13
7 B 12 4 13 14
8 B 15 9 13 8
9 B 6 8 12 5
10 B 5 7 11 9
;
RUN;
PROC PRINT DATA = temp ;
RUN;
PROC GLM DATA = temp;
CLASS group;
MODEL r1-r4 = group / NOUNI ;
REPEATED trial 5;
RUN;Yukarıdaki kod çalıştırıldığında, aşağıdaki sonucu alırız -
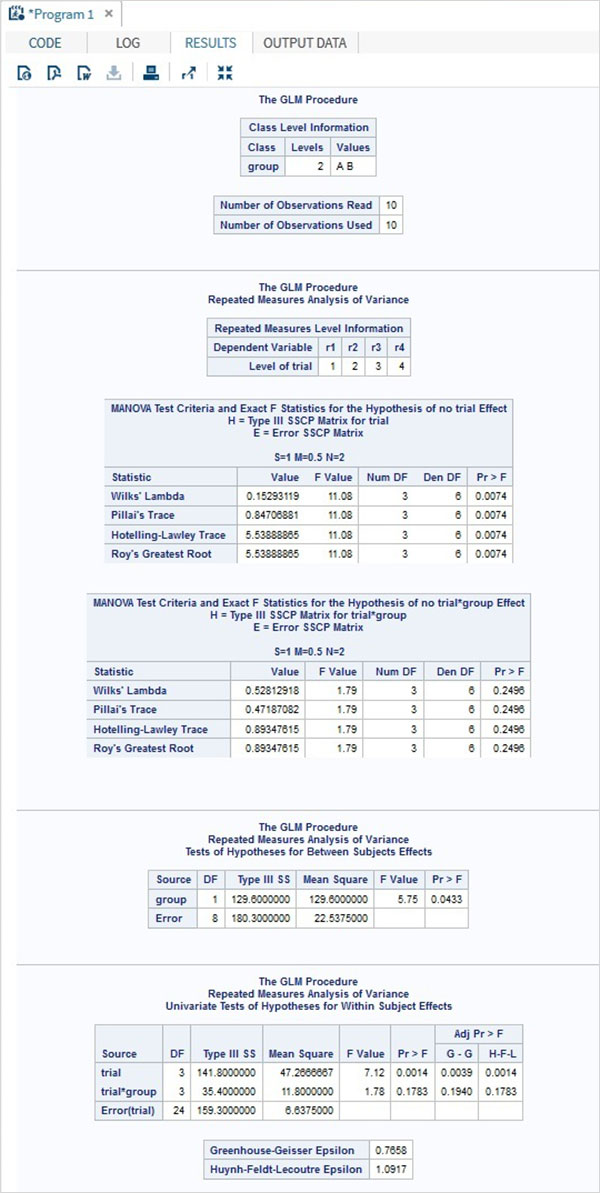
ANOVA, Varyans Analizi anlamına gelir. SAS'da şu kullanılarak yapılırPROC ANOVA. Çok çeşitli deneysel tasarımlardan elde edilen verilerin analizini gerçekleştirir. Bu süreçte, bağımlı değişken olarak bilinen sürekli yanıt değişkeni, bağımsız değişkenler olarak bilinen sınıflandırma değişkenleri tarafından tanımlanan deneysel koşullar altında ölçülür. Yanıttaki farklılığın, sınıflandırmadaki etkilerden kaynaklandığı varsayılır ve kalan varyasyon için rastgele hata hesaplanır.
Sözdizimi
SAS'da PROC ANOVA uygulamak için temel sözdizimi şudur:
PROC ANOVA dataset ;
CLASS Variable;
MODEL Variable1 = variable2 ;
MEANS ;Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
dataset veri kümesinin adıdır.
CLASS değişkenlere sınıflandırma değişkeni olarak kullanılan değişkeni verir.
MODEL Veri kümesindeki belirli değişkenleri kullanarak uydurulacak modeli tanımlar.
Variable_1 and Variable_2 analizde kullanılan veri kümesinin değişken isimleridir.
MEANS Hesaplama türünü ve araçların karşılaştırılmasını tanımlar.
ANOVA uygulamak
Şimdi SAS'da ANOVA uygulama konseptini anlayalım.
Misal
SASHELP.CARS veri kümesini ele alalım. Burada araba tipi ve beygir gücü değişkenleri arasındaki bağımlılığı inceliyoruz. Araba tipi kategorik değerlere sahip bir değişken olduğu için onu sınıf değişkeni olarak alıp MODEL'de bu iki değişkeni de kullanıyoruz.
PROC ANOVA DATA = SASHELPS.CARS;
CLASS type;
MODEL horsepower = type;
RUN;Yukarıdaki kod çalıştırıldığında, aşağıdaki sonucu alırız -

ANOVA'yı MEANS ile uygulama
Şimdi ANOVA'yı SAS'ta MEANS ile uygulama konseptini anlayalım.
Misal
Ayrıca, çeşitli otomobil türlerinin ortalama değerlerini karşılaştırmak için Türkiye'nin Öğrencileştirilmiş yöntemini kullandığımız MEANS ifadesini uygulayarak modeli genişletebiliriz. hata, kare anlamına gelir vb.
PROC ANOVA DATA = SASHELPS.CARS;
CLASS type;
MODEL horsepower = type;
MEANS type / tukey lines;
RUN;Yukarıdaki kod çalıştırıldığında, aşağıdaki sonucu alırız -

Hipotez testi, belirli bir hipotezin doğru olma olasılığını belirlemek için istatistiklerin kullanılmasıdır. Olağan hipotez testi süreci, aşağıda gösterildiği gibi dört adımdan oluşur.
Aşama 1
H0 boş hipotezini (genellikle gözlemlerin saf şansın sonucu olduğu) ve alternatif hipotez H1'i (genellikle gözlemlerin bir şans varyasyon bileşeniyle birlikte gerçek bir etki gösterdiğini) formüle edin.
Adım 2
Boş hipotezin doğruluğunu değerlendirmek için kullanılabilecek bir test istatistiği belirleyin.
Aşama 3
Sıfır hipotezinin doğru olduğu varsayılarak, en az gözlemlenen kadar önemli bir test istatistiğinin elde edilme olasılığı olan P değerini hesaplayın. P değeri ne kadar küçükse, sıfır hipotezine karşı kanıt o kadar güçlüdür.
Adım 4
P değerini kabul edilebilir bir anlamlılık değeri alfa ile karşılaştırın (bazen alfa değeri de denir). Eğer p <= alfa, gözlemlenen etkinin istatistiksel olarak anlamlı olması durumunda, sıfır hipotezi dışlanır ve alternatif hipotez geçerlidir.
SAS programlama dili, aşağıda gösterildiği gibi çeşitli hipotez testi türlerini gerçekleştirecek özelliklere sahiptir.
| Ölçek | Açıklama | SAS PROC |
|---|---|---|
| T-Test | Bir değişkenin ortalamasının varsayılmış bir değerden önemli ölçüde farklı olup olmadığını test etmek için bir t testi kullanılır. İki bağımsız grup için ortalamaların önemli ölçüde farklı olup olmadığını ve bağımlı veya eşleştirilmiş gruplar için ortalamaların önemli ölçüde farklı olup olmadığını da belirleriz. | PROC TTEST |
| ANOVA | Bağımsız bir kategorik değişken olduğunda ortalamaları karşılaştırmak için de kullanılır. Aralığı bağımlı değişkenin araçlarının bağımsız kategorik değişkene göre farklı olup olmadığını test ederken tek yönlü ANOVA kullanmak istiyoruz. | PROC ANOVA |
| Chi-Square | Kategorik bir değişkenin frekanslarının şansa bağlı olarak meydana gelip gelmediğini değerlendirmek için ki kare uyum iyiliğini kullanırız. Kategorik bir değişkenin oranlarının varsayılmış bir değer olup olmadığı konusunda bir ki kare testinin kullanılması gereklidir. | PROC FREQ |
| Linear Regression | Basit doğrusal regresyon, bir değişkenin başka bir değişkeni ne kadar iyi tahmin ettiğini test etmek istediğinde kullanılır. Çoklu doğrusal regresyon, birden çok değişkenin ilgilenilen bir değişkeni ne kadar iyi tahmin ettiğinin test edilmesini sağlar. Çoklu doğrusal regresyon kullanırken, ek olarak yordayıcı değişkenlerin bağımsız olduğunu varsayıyoruz. | PROC REG |