DAA - Längste gemeinsame Folge
Das längste häufige Teilsequenzproblem besteht darin, die längste Sequenz zu finden, die in beiden angegebenen Zeichenfolgen vorhanden ist.
Folge
Betrachten wir eine Folge S = <s 1 , s 2 , s 3 , s 4 ,…, s n >.
Eine Folge Z = <z 1 , z 2 , z 3 , z 4 ,…, z m > über S wird genau dann als Teilsequenz von S bezeichnet, wenn sie aus der S-Löschung einiger Elemente abgeleitet werden kann.
Gemeinsame Folge
Annehmen, X und Ysind zwei Sequenzen über eine endliche Menge von Elementen. Wir können das sagenZ ist eine häufige Folge von X und Y, wenn Z ist eine Folge von beiden X und Y.
Längste gemeinsame Folge
Wenn ein Satz von Sequenzen angegeben ist, besteht das längste gemeinsame Teilsequenzproblem darin, eine gemeinsame Teilsequenz aller Sequenzen zu finden, die von maximaler Länge ist.
Das längste häufige Teilsequenzproblem ist ein klassisches Informatikproblem, das auf Datenvergleichsprogrammen wie dem Diff-Utility basiert und in der Bioinformatik Anwendung findet. Es wird auch häufig von Revisionskontrollsystemen wie SVN und Git verwendet, um mehrere Änderungen an einer revisionskontrollierten Sammlung von Dateien abzugleichen.
Naive Methode
Lassen X eine Folge von Längen sein m und Y eine Folge von Längen n. Überprüfen Sie für jede Teilsequenz vonX ob es eine Folge von ist Yund geben die längste gefundene gemeinsame Teilsequenz zurück.
Es gibt 2m Teilsequenzen von X. Testen von Sequenzen, ob es sich um eine Teilsequenz von handelt oder nichtY nimmt O(n)Zeit. Somit würde der naive Algorithmus dauernO(n2m) Zeit.
Dynamische Programmierung
Sei X = <x 1 , x 2 , x 3 ,…, x m > und Y = <y 1 , y 2 , y 3 ,…, y n > die Folgen. Um die Länge eines Elements zu berechnen, wird der folgende Algorithmus verwendet.
In diesem Verfahren Tabelle C[m, n] wird in Zeilenreihenfolge und einer anderen Tabelle berechnet B[m,n] wird berechnet, um eine optimale Lösung zu konstruieren.
Algorithm: LCS-Length-Table-Formulation (X, Y)
m := length(X)
n := length(Y)
for i = 1 to m do
C[i, 0] := 0
for j = 1 to n do
C[0, j] := 0
for i = 1 to m do
for j = 1 to n do
if xi = yj
C[i, j] := C[i - 1, j - 1] + 1
B[i, j] := ‘D’
else
if C[i -1, j] ≥ C[i, j -1]
C[i, j] := C[i - 1, j] + 1
B[i, j] := ‘U’
else
C[i, j] := C[i, j - 1]
B[i, j] := ‘L’
return C and BAlgorithm: Print-LCS (B, X, i, j)
if i = 0 and j = 0
return
if B[i, j] = ‘D’
Print-LCS(B, X, i-1, j-1)
Print(xi)
else if B[i, j] = ‘U’
Print-LCS(B, X, i-1, j)
else
Print-LCS(B, X, i, j-1)Dieser Algorithmus druckt die längste gemeinsame Teilsequenz von X und Y.
Analyse
Um die Tabelle zu füllen, die äußere for Schleife iteriert m Zeiten und das Innere for Schleife iteriert nmal. Daher ist die Komplexität des Algorithmus O (m, n) , wobeim und n sind die Länge von zwei Saiten.
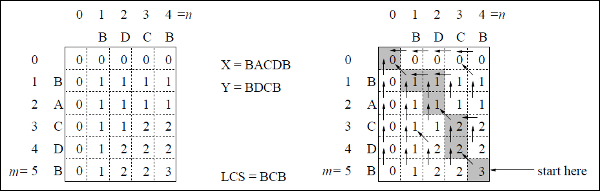
Beispiel
In diesem Beispiel haben wir zwei Zeichenfolgen X = BACDB und Y = BDCB um die längste gemeinsame Teilfolge zu finden.
Nach dem Algorithmus LCS-Length-Table-Formulation (wie oben angegeben) haben wir Tabelle C (auf der linken Seite gezeigt) und Tabelle B (auf der rechten Seite gezeigt) berechnet.
In Tabelle B verwenden wir anstelle von 'D', 'L' und 'U' den diagonalen Pfeil, den Pfeil nach links bzw. den Pfeil nach oben. Nach dem Generieren von Tabelle B wird das LCS durch die Funktion LCS-Print bestimmt. Das Ergebnis ist BCB.