DAA - Binäre Suchbäume mit optimalen Kosten
Ein binärer Suchbaum (BST) ist ein Baum, in dem die Schlüsselwerte in den internen Knoten gespeichert sind. Die externen Knoten sind Nullknoten. Die Schlüssel sind lexikografisch geordnet, dh für jeden internen Knoten sind alle Schlüssel im linken Unterbaum kleiner als die Schlüssel im Knoten und alle Schlüssel im rechten Unterbaum sind größer.
Wenn wir die Häufigkeit der Suche nach jedem der Schlüssel kennen, ist es recht einfach, die erwarteten Kosten für den Zugriff auf jeden Knoten im Baum zu berechnen. Ein optimaler binärer Suchbaum ist eine BST, die nur minimale erwartete Kosten für die Lokalisierung jedes Knotens aufweist
Die Suchzeit eines Elements in einer BST beträgt O(n), während in einer Balanced-BST Suchzeit ist O(log n). Auch hier kann die Suchzeit im binären Suchbaum für optimale Kosten verbessert werden, indem die am häufigsten verwendeten Daten in der Wurzel und näher am Wurzelelement platziert werden, während die am seltensten verwendeten Daten in der Nähe von Blättern und in Blättern platziert werden.
Hier wird der optimale binäre Suchbaumalgorithmus vorgestellt. Zuerst erstellen wir eine BST aus einer Reihe von bereitgestelltenn Anzahl der verschiedenen Schlüssel < k1, k2, k3, ... kn >. Hier nehmen wir die Wahrscheinlichkeit des Zugriffs auf einen Schlüssel anKi ist pi. Einige Dummy-Schlüssel (d0, d1, d2, ... dn) werden hinzugefügt, da möglicherweise nach den Werten gesucht wird, die im Schlüsselsatz nicht vorhanden sind K. Wir nehmen für jeden Dummy-Schlüssel andi Zugangswahrscheinlichkeit ist qi.
Optimal-Binary-Search-Tree(p, q, n)
e[1…n + 1, 0…n],
w[1…n + 1, 0…n],
root[1…n + 1, 0…n]
for i = 1 to n + 1 do
e[i, i - 1] := qi - 1
w[i, i - 1] := qi - 1
for l = 1 to n do
for i = 1 to n – l + 1 do
j = i + l – 1 e[i, j] := ∞
w[i, i] := w[i, i -1] + pj + qj
for r = i to j do
t := e[i, r - 1] + e[r + 1, j] + w[i, j]
if t < e[i, j]
e[i, j] := t
root[i, j] := r
return e and rootAnalyse
Der Algorithmus erfordert O (n3) Zeit, seit drei verschachtelt forSchleifen werden verwendet. Jede dieser Schleifen nimmt höchstens ann Werte.
Beispiel
In Anbetracht des folgenden Baums betragen die Kosten 2,80, obwohl dies kein optimales Ergebnis ist.
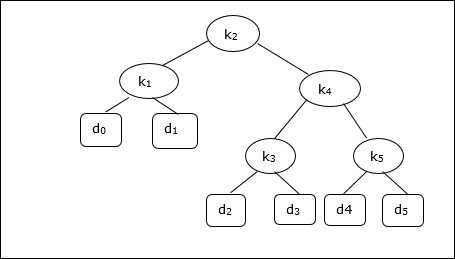
| Knoten | Tiefe | Wahrscheinlichkeit | Beitrag |
|---|---|---|---|
| k 1 | 1 | 0,15 | 0,30 |
| k 2 | 0 | 0,10 | 0,10 |
| k 3 | 2 | 0,05 | 0,15 |
| k 4 | 1 | 0,10 | 0,20 |
| k 5 | 2 | 0,20 | 0,60 |
| d 0 | 2 | 0,05 | 0,15 |
| d 1 | 2 | 0,10 | 0,30 |
| d 2 | 3 | 0,05 | 0,20 |
| d 3 | 3 | 0,05 | 0,20 |
| d 4 | 3 | 0,05 | 0,20 |
| d 5 | 3 | 0,10 | 0,40 |
| Total | 2,80 |
Um eine optimale Lösung zu erhalten, werden mithilfe des in diesem Kapitel beschriebenen Algorithmus die folgenden Tabellen generiert.
In den folgenden Tabellen ist der Spaltenindex i und Zeilenindex ist j.
| e | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 5 | 2,75 | 2.00 | 1.30 | 0,90 | 0,50 | 0,10 |
| 4 | 1,75 | 1,20 | 0,60 | 0,30 | 0,05 | |
| 3 | 1,25 | 0,70 | 0,25 | 0,05 | ||
| 2 | 0,90 | 0,40 | 0,05 | |||
| 1 | 0,45 | 0,10 | ||||
| 0 | 0,05 |
| w | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 5 | 1,00 | 0,80 | 0,60 | 0,50 | 0,35 | 0,10 |
| 4 | 0,70 | 0,50 | 0,30 | 0,20 | 0,05 | |
| 3 | 0,55 | 0,35 | 0,15 | 0,05 | ||
| 2 | 0,45 | 0,25 | 0,05 | |||
| 1 | 0,30 | 0,10 | ||||
| 0 | 0,05 |
| Wurzel | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 5 | 2 | 4 | 5 | 5 | 5 |
| 4 | 2 | 2 | 4 | 4 | |
| 3 | 2 | 2 | 3 | ||
| 2 | 1 | 2 | |||
| 1 | 1 |
Aus diesen Tabellen kann der optimale Baum gebildet werden.