Jaringan Syaraf Tiruan - Panduan Cepat
Jaringan saraf adalah perangkat komputasi paralel, yang pada dasarnya merupakan upaya untuk membuat model komputer otak. Tujuan utamanya adalah mengembangkan sistem untuk melakukan berbagai tugas komputasi lebih cepat daripada sistem tradisional. Tugas-tugas ini meliputi pengenalan dan klasifikasi pola, perkiraan, pengoptimalan, dan pengelompokan data.
Apa itu Jaringan Syaraf Tiruan?
Artificial Neural Network (ANN) adalah sistem komputasi efisien yang tema utamanya dipinjam dari analogi jaringan saraf biologis. ANN juga disebut sebagai "sistem saraf buatan", atau "sistem pemrosesan terdistribusi paralel", atau "sistem koneksionis". JST memperoleh banyak koleksi unit yang saling berhubungan dalam beberapa pola untuk memungkinkan komunikasi antar unit. Unit-unit ini, juga disebut sebagai node atau neuron, adalah prosesor sederhana yang beroperasi secara paralel.
Setiap neuron terhubung dengan neuron lain melalui tautan koneksi. Setiap tautan koneksi dikaitkan dengan bobot yang memiliki informasi tentang sinyal input. Ini adalah informasi yang paling berguna bagi neuron untuk memecahkan masalah tertentu karena bobot biasanya merangsang atau menghambat sinyal yang sedang dikomunikasikan. Setiap neuron memiliki keadaan internal, yang disebut sinyal aktivasi. Sinyal keluaran, yang dihasilkan setelah menggabungkan sinyal masukan dan aturan aktivasi, dapat dikirim ke unit lain.
Sejarah Singkat ANN
Sejarah JST dapat dibagi menjadi tiga era berikut -
ANN selama 1940-an hingga 1960-an
Beberapa perkembangan utama dari era ini adalah sebagai berikut -
1943 - Diasumsikan bahwa konsep jaringan saraf dimulai dengan karya ahli fisiologi, Warren McCulloch, dan ahli matematika, Walter Pitts, ketika pada tahun 1943 mereka membuat model jaringan saraf sederhana menggunakan sirkuit listrik untuk menggambarkan bagaimana neuron di otak dapat bekerja. .
1949- Buku Donald Hebb, The Organisation of Behavior , mengemukakan fakta bahwa aktivasi berulang dari satu neuron oleh yang lain meningkatkan kekuatannya setiap kali digunakan.
1956 - Jaringan memori asosiatif diperkenalkan oleh Taylor.
1958 - Metode pembelajaran model neuron McCulloch dan Pitts bernama Perceptron ditemukan oleh Rosenblatt.
1960 - Bernard Widrow dan Marcian Hoff mengembangkan model yang disebut "ADALINE" dan "MADALINE".
ANN selama tahun 1960-an hingga 1980-an
Beberapa perkembangan utama dari era ini adalah sebagai berikut -
1961 - Rosenblatt melakukan upaya yang tidak berhasil tetapi mengusulkan skema "propagasi mundur" untuk jaringan multilayer.
1964 - Taylor membangun sirkuit pemenang-ambil-semua dengan hambatan di antara unit keluaran.
1969 - Multilayer perceptron (MLP) ditemukan oleh Minsky dan Papert.
1971 - Kohonen mengembangkan ingatan asosiatif.
1976 - Stephen Grossberg dan Gail Carpenter mengembangkan teori resonansi Adaptif.
ANN dari 1980-an sampai Sekarang
Beberapa perkembangan utama dari era ini adalah sebagai berikut -
1982 - Perkembangan utama adalah pendekatan Energi Hopfield.
1985 - Mesin Boltzmann dikembangkan oleh Ackley, Hinton, dan Sejnowski.
1986 - Rumelhart, Hinton, dan Williams memperkenalkan Generalized Delta Rule.
1988 - Kosko mengembangkan Binary Associative Memory (BAM) dan juga memberikan konsep Fuzzy Logic pada ANN.
Tinjauan sejarah menunjukkan bahwa kemajuan signifikan telah dicapai di bidang ini. Chip berbasis jaringan saraf bermunculan dan aplikasi untuk masalah kompleks sedang dikembangkan. Tentunya, hari ini adalah masa transisi untuk teknologi jaringan saraf.
Neuron Biologis
Sel saraf (neuron) adalah sel biologis khusus yang memproses informasi. Menurut perkiraan, ada jumlah neuron yang sangat besar, kira-kira 10 11 dengan banyak interkoneksi, kira-kira 10 15 .
Diagram skematik
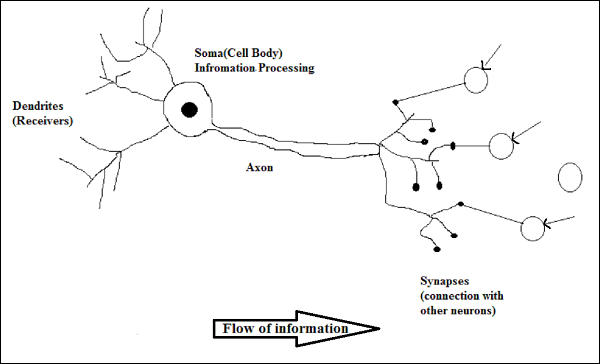
Cara Kerja Neuron Biologis
Seperti yang ditunjukkan pada diagram di atas, neuron tipikal terdiri dari empat bagian berikut dengan bantuan yang dapat kami jelaskan cara kerjanya -
Dendrites- Mereka adalah cabang seperti pohon, bertanggung jawab untuk menerima informasi dari neuron lain yang terhubung dengannya. Dalam pengertian lain, kita dapat mengatakan bahwa mereka seperti telinga neuron.
Soma - Ini adalah badan sel neuron dan bertanggung jawab untuk memproses informasi, yang mereka terima dari dendrit.
Axon - Ini seperti kabel yang digunakan neuron untuk mengirimkan informasi.
Synapses - Ini adalah hubungan antara akson dan dendrit neuron lainnya.
JST versus BNN
Sebelum melihat perbedaan antara Jaringan Syaraf Tiruan (JST) dan Jaringan Saraf Tiruan (BNN), mari kita lihat persamaan berdasarkan terminologi di antara keduanya.
| Jaringan Syaraf Biologis (BNN) | Jaringan Syaraf Tiruan (JST) |
|---|---|
| Soma | Node |
| Dendrit | Memasukkan |
| Sinapsis | Bobot atau Interkoneksi |
| Akson | Keluaran |
Tabel berikut memperlihatkan perbandingan antara JST dan BNN berdasarkan beberapa kriteria yang disebutkan.
| Kriteria | BNN | ANN |
|---|---|---|
| Processing | Paralel besar-besaran, lambat tetapi lebih unggul dari ANN | Paralel secara besar-besaran, cepat tetapi lebih rendah dari BNN |
| Size | 10 11 neuron dan 10 15 interkoneksi | 10 2 hingga 10 4 node (terutama bergantung pada jenis aplikasi dan perancang jaringan) |
| Learning | Mereka bisa mentolerir ambiguitas | Data yang sangat tepat, terstruktur, dan diformat diperlukan untuk mentolerir ambiguitas |
| Fault tolerance | Performa menurun bahkan dengan kerusakan parsial | Ia mampu melakukan kinerja yang kuat, sehingga berpotensi menjadi toleran terhadap kesalahan |
| Storage capacity | Menyimpan informasi di sinapsis | Menyimpan informasi di lokasi memori kontinu |
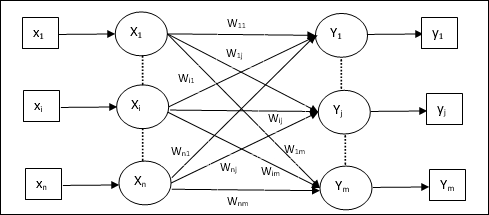
Model Jaringan Syaraf Tiruan
Diagram berikut merepresentasikan model umum JST yang diikuti dengan pemrosesannya.
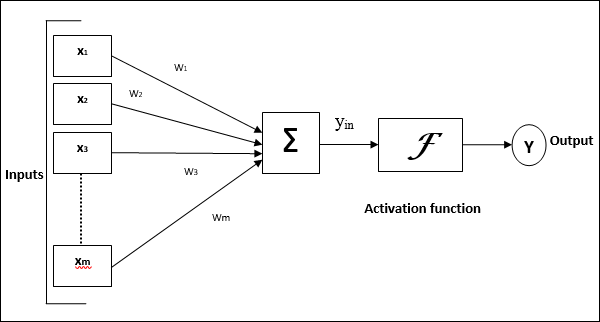
Untuk model umum jaringan saraf tiruan di atas, input bersih dapat dihitung sebagai berikut -
$$ y_ {dalam} \: = \: x_ {1} .w_ {1} \: + \: x_ {2} .w_ {2} \: + \: x_ {3} .w_ {3} \: \ dotso \: x_ {m} .w_ {m} $$
yaitu, masukan bersih $ y_ {in} \: = \: \ sum_i ^ m \: x_ {i} .w_ {i} $
Output dapat dihitung dengan menerapkan fungsi aktivasi melalui input net.
$$ Y \: = \: F (y_ {in}) $$
Output = fungsi (input bersih dihitung)
Pemrosesan JST bergantung pada tiga blok bangunan berikut -
- Topologi Jaringan
- Penyesuaian Bobot atau Pembelajaran
- Fungsi Aktivasi
Dalam bab ini, kita akan membahas secara rinci tentang tiga blok penyusun JST ini
Topologi Jaringan
Topologi jaringan adalah pengaturan jaringan beserta node dan jalur penghubungnya. Menurut topologi, JST dapat diklasifikasikan sebagai jenis berikut -
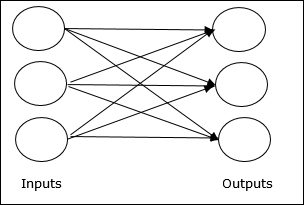
Jaringan Feedforward
Ini adalah jaringan non-berulang yang memiliki unit pemrosesan / node dalam lapisan dan semua node dalam lapisan terhubung dengan node pada lapisan sebelumnya. Koneksi memiliki bobot yang berbeda pada mereka. Tidak ada feedback loop artinya sinyal hanya dapat mengalir dalam satu arah, dari input ke output. Ini dapat dibagi menjadi dua jenis berikut -
Single layer feedforward network- Konsep JST feedforward hanya memiliki satu layer tertimbang. Dengan kata lain, kita dapat mengatakan bahwa lapisan masukan sepenuhnya terhubung ke lapisan keluaran.
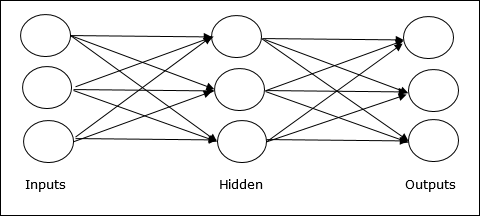
Multilayer feedforward network- Konsep JST feedforward memiliki lebih dari satu layer berbobot. Karena jaringan ini memiliki satu atau lebih lapisan antara lapisan masukan dan keluaran, ini disebut lapisan tersembunyi.
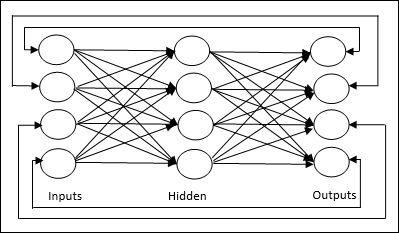
Jaringan Umpan Balik
Seperti namanya, jaringan umpan balik memiliki jalur umpan balik, yang berarti sinyal dapat mengalir ke dua arah menggunakan loop. Ini menjadikannya sistem dinamis non-linier, yang berubah terus menerus hingga mencapai keadaan ekuilibrium. Ini dapat dibagi menjadi beberapa jenis berikut -
Recurrent networks- Mereka adalah jaringan umpan balik dengan loop tertutup. Berikut adalah dua jenis jaringan berulang.
Fully recurrent network - Ini adalah arsitektur jaringan saraf paling sederhana karena semua node terhubung ke semua node lain dan setiap node bekerja sebagai input dan output.
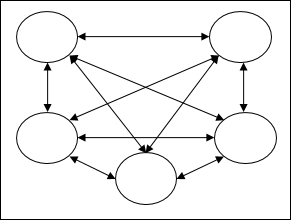
Jordan network - Ini adalah jaringan loop tertutup di mana output akan masuk ke input lagi sebagai umpan balik seperti yang ditunjukkan pada diagram berikut.
Penyesuaian Bobot atau Pembelajaran
Belajar, dalam jaringan saraf tiruan, adalah metode memodifikasi bobot koneksi antara neuron dari jaringan tertentu. Pembelajaran di JST dapat diklasifikasikan menjadi tiga kategori yaitu pembelajaran terbimbing, pembelajaran tanpa pengawasan, dan pembelajaran penguatan.
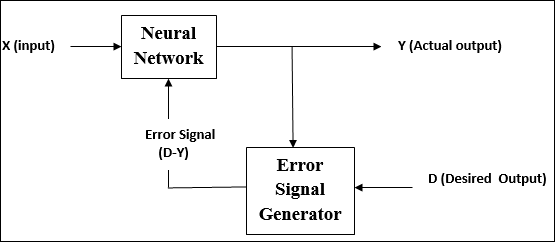
Pembelajaran yang Diawasi
Seperti namanya, pembelajaran jenis ini dilakukan di bawah pengawasan seorang guru. Proses pembelajaran ini tergantung.
Selama pelatihan JST dalam supervised learning, vektor masukan disajikan ke jaringan, yang akan menghasilkan vektor keluaran. Vektor keluaran ini dibandingkan dengan vektor keluaran yang diinginkan. Sinyal kesalahan dihasilkan, jika ada perbedaan antara keluaran aktual dan vektor keluaran yang diinginkan. Atas dasar sinyal kesalahan ini, bobot disesuaikan sampai keluaran aktual sesuai dengan keluaran yang diinginkan.
Pembelajaran Tanpa Pengawasan
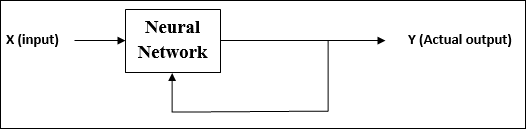
Seperti namanya, pembelajaran jenis ini dilakukan tanpa pengawasan seorang guru. Proses pembelajaran ini mandiri.
Selama pelatihan JST dalam pembelajaran tanpa pengawasan, vektor input dari jenis yang sama digabungkan untuk membentuk cluster. Saat pola masukan baru diterapkan, jaringan saraf tiruan memberikan tanggapan keluaran yang menunjukkan kelas tempat pola masukan tersebut berada.
Tidak ada umpan balik dari lingkungan tentang apa yang harus menjadi keluaran yang diinginkan dan apakah itu benar atau salah. Oleh karena itu, dalam pembelajaran jenis ini, jaringan itu sendiri harus menemukan pola dan fitur dari data masukan, dan hubungan data masukan melalui keluaran.
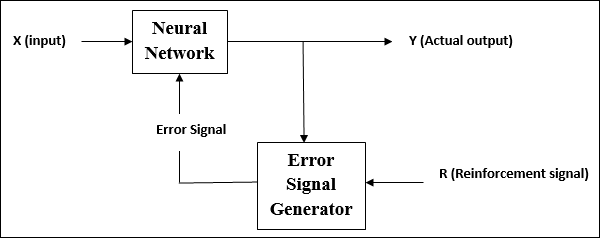
Pembelajaran Penguatan
Seperti namanya, jenis pembelajaran ini digunakan untuk memperkuat atau memperkuat jaringan atas beberapa informasi kritik. Proses pembelajaran ini mirip dengan supervised learning, namun informasi yang kami miliki mungkin sangat sedikit.
Selama pelatihan jaringan di bawah pembelajaran penguatan, jaringan menerima beberapa umpan balik dari lingkungan. Ini membuatnya agak mirip dengan pembelajaran yang diawasi. Namun umpan balik yang diperoleh disini bersifat evaluatif tidak bersifat instruktif yang artinya tidak ada guru seperti pada pembelajaran terbimbing. Setelah menerima umpan balik, jaringan melakukan penyesuaian bobot untuk mendapatkan informasi kritikus yang lebih baik di masa mendatang.
Fungsi Aktivasi
Ini dapat didefinisikan sebagai kekuatan atau upaya ekstra yang diterapkan pada input untuk mendapatkan output yang tepat. Di JST, kita juga dapat menerapkan fungsi aktivasi di atas input untuk mendapatkan keluaran yang tepat. Berikut adalah beberapa fungsi aktivasi yang menarik -
Fungsi Aktivasi Linear
Ini juga disebut fungsi identitas karena tidak melakukan pengeditan input. Ini dapat didefinisikan sebagai -
$$ F (x) \: = \: x $$
Fungsi Aktivasi Sigmoid
Ini dari dua jenis sebagai berikut -
Binary sigmoidal function- Fungsi aktivasi ini melakukan pengeditan input antara 0 dan 1. Ini bersifat positif. Itu selalu dibatasi, yang berarti outputnya tidak boleh kurang dari 0 dan lebih dari 1. Ini juga secara ketat meningkat, yang berarti lebih banyak input yang lebih tinggi akan menjadi output. Ini dapat didefinisikan sebagai
$$ F (x) \: = \: sigm (x) \: = \: \ frac {1} {1 \: + \: exp (-x)} $$
Bipolar sigmoidal function- Fungsi aktivasi ini melakukan pengeditan input antara -1 dan 1. Ini bisa bersifat positif atau negatif. Itu selalu dibatasi, yang berarti outputnya tidak boleh kurang dari -1 dan lebih dari 1. Itu juga secara ketat meningkat di alam seperti fungsi sigmoid. Ini dapat didefinisikan sebagai
$$ F (x) \: = \: sigm (x) \: = \: \ frac {2} {1 \: + \: exp (-x)} \: - \: 1 \: = \: \ frac {1 \: - \: exp (x)} {1 \: + \: exp (x)} $$
Seperti yang dikemukakan sebelumnya, JST sepenuhnya terinspirasi oleh cara kerja sistem saraf biologis, yakni otak manusia. Ciri yang paling mengesankan dari otak manusia adalah belajar, oleh karena itu ciri yang sama diperoleh oleh JST.
Apa Itu Belajar di ANN?
Pembelajaran pada dasarnya berarti melakukan dan menyesuaikan dengan perubahan itu sendiri ketika terjadi perubahan lingkungan. JST adalah suatu sistem yang kompleks atau lebih tepatnya dapat dikatakan sebagai sistem adaptif yang kompleks, yang dapat mengubah struktur internalnya berdasarkan informasi yang melewatinya.
Mengapa Itu Penting?
Menjadi sistem adaptif yang kompleks, pembelajaran di JST menyiratkan bahwa unit pemrosesan mampu mengubah perilaku input / outputnya karena perubahan lingkungan. Pentingnya pembelajaran di JST meningkat karena fungsi aktivasi tetap serta vektor input / output, ketika jaringan tertentu dibangun. Sekarang untuk mengubah perilaku input / output, kita perlu menyesuaikan bobotnya.
Klasifikasi
Ini dapat didefinisikan sebagai proses pembelajaran untuk membedakan data sampel ke dalam kelas yang berbeda dengan menemukan ciri-ciri umum antara sampel dari kelas yang sama. Misalnya, untuk melakukan pelatihan JST, kami memiliki beberapa sampel pelatihan dengan fitur unik, dan untuk melakukan pengujiannya kami memiliki beberapa sampel pengujian dengan fitur unik lainnya. Klasifikasi adalah contoh pembelajaran yang diawasi.
Aturan Pembelajaran Jaringan Neural
Kita tahu bahwa selama pembelajaran JST, untuk mengubah perilaku input / output, kita perlu menyesuaikan bobotnya. Oleh karena itu, diperlukan metode dengan bantuan bobot yang dapat dimodifikasi. Metode ini disebut Aturan belajar, yang merupakan algoritma atau persamaan. Berikut adalah beberapa aturan pembelajaran untuk jaringan saraf -
Aturan Belajar Hebbian
Aturan ini, salah satu yang tertua dan paling sederhana, diperkenalkan oleh Donald Hebb dalam bukunya The Organisation of Behavior pada tahun 1949. Ini adalah semacam pembelajaran umpan-maju, tanpa pengawasan.
Basic Concept - Aturan ini berdasarkan proposal yang diberikan oleh Hebb, yang menulis -
“Ketika akson sel A cukup dekat untuk merangsang sel B dan berulang kali atau terus-menerus mengambil bagian dalam menembakkannya, beberapa proses pertumbuhan atau perubahan metabolisme terjadi di satu atau kedua sel sehingga efisiensi A, sebagai salah satu sel yang menembakkan B , meningkat. "
Dari dalil di atas, kita dapat menyimpulkan bahwa hubungan antara dua neuron mungkin diperkuat jika neuron-neuron itu bekerja pada saat yang sama dan mungkin melemah jika mereka bekerja pada waktu yang berbeda.
Mathematical Formulation - Menurut aturan pembelajaran Hebbian, berikut adalah rumus untuk meningkatkan bobot koneksi di setiap langkah waktu.
$$ \ Delta w_ {ji} (t) \: = \: \ alpha x_ {i} (t) .y_ {j} (t) $$
Di sini, $ \ Delta w_ {ji} (t) $ = kenaikan dimana bobot koneksi meningkat pada langkah waktu t
$ \ alpha $ = kecepatan pembelajaran positif dan konstan
$ x_ {i} (t) $ = nilai input dari neuron pra-sinaptik pada langkah waktu t
$ y_ {i} (t) $ = keluaran neuron pra-sinaptik pada langkah waktu yang sama t
Aturan Pembelajaran Perceptron
Aturan ini adalah kesalahan yang mengoreksi algoritma pembelajaran yang diawasi dari jaringan feedforward lapisan tunggal dengan fungsi aktivasi linier, yang diperkenalkan oleh Rosenblatt.
Basic Concept- Sebagaimana sifatnya yang diawasi, untuk menghitung kesalahan akan dilakukan perbandingan antara keluaran yang diinginkan / target dengan keluaran yang sebenarnya. Jika ada perbedaan yang ditemukan, maka perubahan harus dilakukan pada bobot koneksi.
Mathematical Formulation - Untuk menjelaskan formulasi matematisnya, misalkan kita memiliki 'n' sejumlah vektor masukan hingga, x (n), bersama dengan vektor keluaran yang diinginkan / target t (n), di mana n = 1 ke N.
Sekarang keluaran 'y' dapat dihitung, seperti yang dijelaskan sebelumnya berdasarkan masukan bersih, dan fungsi aktivasi yang diterapkan di atas masukan bersih tersebut dapat dinyatakan sebagai berikut -
$$ y \: = \: f (y_ {in}) \: = \: \ begin {kasus} 1, & y_ {in} \:> \: \ theta \\ 0, & y_ {in} \: \ leqslant \: \ theta \ end {kasus} $$
Dimana θ adalah ambang batas.
Pembaruan bobot dapat dilakukan dalam dua kasus berikut -
Case I - kapan t ≠ y, kemudian
$$ w (baru) \: = \: w (lama) \: + \; tx $$
Case II - kapan t = y, kemudian
Tidak ada perubahan berat
Aturan Pembelajaran Delta (Aturan Widrow-Hoff)
Ini diperkenalkan oleh Bernard Widrow dan Marcian Hoff, juga disebut metode Least Mean Square (LMS), untuk meminimalkan kesalahan pada semua pola pelatihan. Ini adalah jenis algoritma pembelajaran yang diawasi dengan memiliki fungsi aktivasi berkelanjutan.
Basic Concept- Basis aturan ini adalah pendekatan penurunan-gradien, yang berlanjut selamanya. Aturan delta memperbarui bobot sinaptik untuk meminimalkan masukan bersih ke unit keluaran dan nilai target.
Mathematical Formulation - Untuk memperbarui bobot sinaptik, aturan delta diberikan oleh
$$ \ Delta w_ {i} \: = \: \ alpha \ :. x_ {i} .e_ {j} $$
Di sini $ \ Delta w_ {i} $ = perubahan berat untuk pola ke- i ;
$ \ alpha $ = kecepatan pembelajaran positif dan konstan;
$ x_ {i} $ = nilai masukan dari neuron pra-sinaptik;
$ e_ {j} $ = $ (t \: - \: y_ {in}) $, perbedaan antara keluaran yang diinginkan / target dan keluaran sebenarnya $ y_ {in} $
Aturan delta di atas hanya untuk satu unit keluaran.
Pembaruan bobot dapat dilakukan dalam dua kasus berikut -
Case-I - kapan t ≠ y, kemudian
$$ w (baru) \: = \: w (lama) \: + \: \ Delta w $$
Case-II - kapan t = y, kemudian
Tidak ada perubahan berat
Aturan Pembelajaran Kompetitif (Pemenang mengambil semua)
Ini berkaitan dengan pelatihan tanpa pengawasan di mana simpul keluaran mencoba bersaing satu sama lain untuk mewakili pola masukan. Untuk memahami aturan pembelajaran ini, kita harus memahami jaringan kompetitif yang diberikan sebagai berikut -
Basic Concept of Competitive Network- Jaringan ini seperti jaringan feedforward satu lapis dengan koneksi umpan balik antar keluaran. Hubungan antar output adalah tipe penghambat, ditunjukkan dengan garis putus-putus, yang berarti kompetitor tidak pernah mendukung dirinya sendiri.
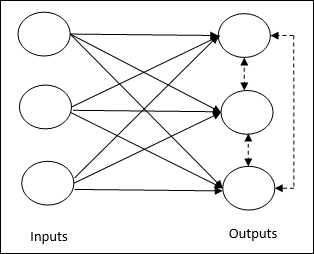
Basic Concept of Competitive Learning Rule- Seperti yang dikatakan sebelumnya, akan ada persaingan antar node keluaran. Oleh karena itu, konsep utamanya adalah selama pelatihan, unit keluaran dengan aktivasi tertinggi ke pola masukan tertentu, akan dinyatakan sebagai pemenang. Aturan ini juga disebut Pemenang-mengambil-semua karena hanya neuron pemenang yang diperbarui dan neuron lainnya dibiarkan tidak berubah.
Mathematical formulation - Berikut adalah tiga faktor penting untuk perumusan matematika dari aturan pembelajaran ini -
Condition to be a winner - Misalkan neuron $ y_ {k} $ ingin menjadi pemenang maka akan ada kondisi sebagai berikut -
$$ y_ {k} \: = \: \ begin {kasus} 1 & jika \: v_ {k} \:> \: v_ {j} \: untuk \: semua \: j, \: j \: \ neq \: k \\ 0 & sebaliknya \ end {kasus} $$
Ini berarti bahwa jika ada neuron, misalnya $ y_ {k} $ , ingin menang, maka bidang lokalnya yang diinduksi (keluaran unit penjumlahan), misalnya $ v_ {k} $, haruslah yang terbesar di antara semua neuron lainnya di jaringan.
Condition of sum total of weight - Batasan lain atas aturan pembelajaran kompetitif adalah, jumlah total bobot ke neuron keluaran tertentu akan menjadi 1. Misalnya, jika kita mempertimbangkan neuron k kemudian -
$$ \ displaystyle \ sum \ limit_ {j} w_ {kj} \: = \: 1 \: \: \: \: \: \: \: \: \: untuk \: semua \: k $$
Change of weight for winner- Jika neuron tidak merespon pola masukan, maka tidak ada pembelajaran yang terjadi di neuron tersebut. Namun, jika neuron tertentu menang, maka bobot yang sesuai akan disesuaikan sebagai berikut
$$ \ Delta w_ {kj} \: = \: \ begin {kasus} - \ alpha (x_ {j} \: - \: w_ {kj}), & jika \: neuron \: k \: menang \\ 0, & jika \: neuron \: k \: kerugian \ end {kasus} $$
Di sini $ \ alpha $ adalah kecepatan pemelajaran.
Hal ini jelas menunjukkan bahwa kita mengunggulkan neuron pemenang dengan cara menyesuaikan bobotnya dan jika ada neuron yang hilang, maka kita tidak perlu bersusah payah menyesuaikan kembali bobotnya.
Aturan Pembelajaran Bintang Luar
Aturan ini, yang diperkenalkan oleh Grossberg, berkaitan dengan pembelajaran yang diawasi karena keluaran yang diinginkan diketahui. Ini juga disebut pembelajaran Grossberg.
Basic Concept- Aturan ini diterapkan pada neuron yang tersusun dalam sebuah lapisan. Ini dirancang khusus untuk menghasilkan keluaran yang diinginkand dari lapisan p neuron.
Mathematical Formulation - Penyesuaian bobot dalam aturan ini dihitung sebagai berikut
$$ \ Delta w_ {j} \: = \: \ alpha \ :( d \: - \: w_ {j}) $$
Sini d adalah keluaran neuron yang diinginkan dan $ \ alpha $ adalah kecepatan pemelajaran.
Seperti namanya, supervised learningberlangsung di bawah pengawasan seorang guru. Proses pembelajaran ini tergantung. Selama pelatihan JST dalam supervised learning, vektor masukan dipresentasikan ke jaringan, yang akan menghasilkan vektor keluaran. Vektor keluaran ini dibandingkan dengan vektor keluaran yang diinginkan / target. Sinyal kesalahan dihasilkan jika ada perbedaan antara keluaran aktual dan vektor keluaran yang diinginkan / target. Berdasarkan sinyal kesalahan ini, bobot akan disesuaikan sampai keluaran aktual sesuai dengan keluaran yang diinginkan.
Perceptron
Dikembangkan oleh Frank Rosenblatt dengan menggunakan model McCulloch dan Pitts, perceptron adalah unit operasional dasar dari jaringan saraf tiruan. Ini menggunakan aturan pembelajaran yang diawasi dan mampu mengklasifikasikan data menjadi dua kelas.
Karakteristik operasional perceptron: Terdiri dari satu neuron dengan jumlah input yang berubah-ubah bersama dengan bobot yang dapat disesuaikan, tetapi output neuron adalah 1 atau 0 tergantung pada ambang batas. Ini juga terdiri dari bias yang bobotnya selalu 1. Gambar berikut memberikan representasi skematis dari perceptron.
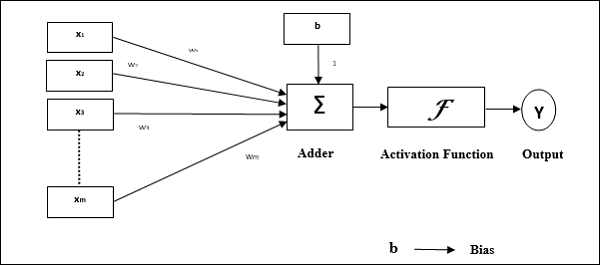
Perceptron dengan demikian memiliki tiga elemen dasar berikut -
Links - Ini akan memiliki satu set link koneksi, yang membawa bobot termasuk bias selalu berbobot 1.
Adder - Menambahkan input setelah dikalikan dengan bobotnya masing-masing.
Activation function- Ini membatasi keluaran neuron. Fungsi aktivasi paling dasar adalah fungsi langkah Heaviside yang memiliki dua kemungkinan keluaran. Fungsi ini mengembalikan 1, jika masukannya positif, dan 0 untuk masukan negatif apa pun.
Algoritma Pelatihan
Jaringan Perceptron dapat dilatih untuk unit keluaran tunggal maupun beberapa unit keluaran.
Algoritma Pelatihan untuk Unit Output Tunggal
Step 1 - Inisialisasi berikut ini untuk memulai pelatihan -
- Weights
- Bias
- Kecepatan pembelajaran $ \ alpha $
Untuk penghitungan dan kesederhanaan yang mudah, bobot dan bias harus disetel sama dengan 0 dan kecepatan pemelajaran harus disetel sama dengan 1.
Step 2 - Lanjutkan langkah 3-8 jika kondisi penghentian tidak benar.
Step 3 - Lanjutkan langkah 4-6 untuk setiap vektor pelatihan x.
Step 4 - Aktifkan setiap unit input sebagai berikut -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: hingga \: n) $$
Step 5 - Sekarang dapatkan input bersih dengan relasi berikut -
$$ y_ {in} \: = \: b \: + \: \ displaystyle \ sum \ limit_ {i} ^ n x_ {i}. \: w_ {i} $$
Sini ‘b’ adalah bias dan ‘n’ adalah jumlah total neuron masukan.
Step 6 - Terapkan fungsi aktivasi berikut untuk mendapatkan hasil akhir.
$$ f (y_ {in}) \: = \: \ begin {cases} 1 & if \: y_ {in} \:> \: \ theta \\ 0 & if \: - \ theta \: \ leqslant \ : y_ {dalam} \: \ leqslant \: \ theta \\ - 1 & if \: y_ {dalam} \: <\: - \ theta \ end {kasus} $$
Step 7 - Sesuaikan bobot dan bias sebagai berikut -
Case 1 - jika y ≠ t kemudian,
$$ w_ {i} (baru) \: = \: w_ {i} (lama) \: + \: \ alpha \: tx_ {i} $$
$$ b (baru) \: = \: b (lama) \: + \: \ alpha t $$
Case 2 - jika y = t kemudian,
$$ w_ {i} (baru) \: = \: w_ {i} (lama) $$
$$ b (baru) \: = \: b (lama) $$
Sini ‘y’ adalah keluaran aktual dan ‘t’ adalah keluaran yang diinginkan / target.
Step 8 - Uji kondisi berhenti, yang akan terjadi bila tidak ada perubahan berat.
Algoritma Pelatihan untuk Beberapa Unit Output
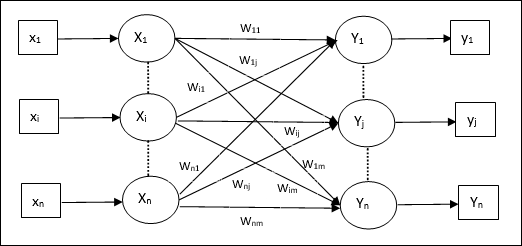
Diagram berikut adalah arsitektur perceptron untuk beberapa kelas keluaran.
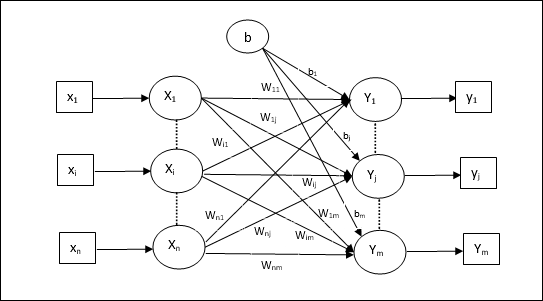
Step 1 - Inisialisasi berikut ini untuk memulai pelatihan -
- Weights
- Bias
- Kecepatan pembelajaran $ \ alpha $
Untuk penghitungan dan kesederhanaan yang mudah, bobot dan bias harus disetel sama dengan 0 dan kecepatan pemelajaran harus disetel sama dengan 1.
Step 2 - Lanjutkan langkah 3-8 jika kondisi penghentian tidak benar.
Step 3 - Lanjutkan langkah 4-6 untuk setiap vektor pelatihan x.
Step 4 - Aktifkan setiap unit input sebagai berikut -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: hingga \: n) $$
Step 5 - Dapatkan input bersih dengan relasi berikut -
$$ y_ {in} \: = \: b \: + \: \ displaystyle \ sum \ limit_ {i} ^ n x_ {i} \: w_ {ij} $$
Sini ‘b’ adalah bias dan ‘n’ adalah jumlah total neuron masukan.
Step 6 - Terapkan fungsi aktivasi berikut untuk mendapatkan hasil akhir untuk setiap unit keluaran j = 1 to m -
$$ f (y_ {in}) \: = \: \ begin {kasus} 1 & if \: y_ {inj} \:> \: \ theta \\ 0 & if \: - \ theta \: \ leqslant \ : y_ {inj} \: \ leqslant \: \ theta \\ - 1 & if \: y_ {inj} \: <\: - \ theta \ end {kasus} $$
Step 7 - Sesuaikan bobot dan biasnya x = 1 to n dan j = 1 to m sebagai berikut -
Case 1 - jika yj ≠ tj kemudian,
$$ w_ {ij} (baru) \: = \: w_ {ij} (lama) \: + \: \ alpha \: t_ {j} x_ {i} $$
$$ b_ {j} (baru) \: = \: b_ {j} (lama) \: + \: \ alpha t_ {j} $$
Case 2 - jika yj = tj kemudian,
$$ w_ {ij} (baru) \: = \: w_ {ij} (lama) $$
$$ b_ {j} (baru) \: = \: b_ {j} (lama) $$
Sini ‘y’ adalah keluaran aktual dan ‘t’ adalah keluaran yang diinginkan / target.
Step 8 - Tes untuk kondisi berhenti, yang akan terjadi bila tidak ada perubahan berat.
Saraf Linear Adaptif (Adaline)
Adaline yang merupakan singkatan dari Adaptive Linear Neuron, merupakan jaringan yang memiliki satuan linier tunggal. Ini dikembangkan oleh Widrow dan Hoff pada tahun 1960. Beberapa poin penting tentang Adaline adalah sebagai berikut -
Ini menggunakan fungsi aktivasi bipolar.
Ini menggunakan aturan delta untuk pelatihan untuk meminimalkan Mean-Squared Error (MSE) antara keluaran aktual dan keluaran yang diinginkan / target.
Bobot dan biasnya bisa disesuaikan.
Arsitektur
Struktur dasar Adaline mirip dengan perceptron yang memiliki umpan balik ekstra dengan bantuan yang keluaran aktualnya dibandingkan dengan keluaran yang diinginkan / target. Setelah dibandingkan berdasarkan algoritma pelatihan, bobot dan bias akan diperbarui.
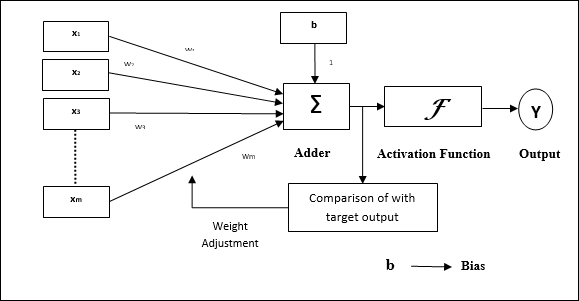
Algoritma Pelatihan
Step 1 - Inisialisasi berikut ini untuk memulai pelatihan -
- Weights
- Bias
- Kecepatan pembelajaran $ \ alpha $
Untuk penghitungan dan kesederhanaan yang mudah, bobot dan bias harus disetel sama dengan 0 dan kecepatan pemelajaran harus disetel sama dengan 1.
Step 2 - Lanjutkan langkah 3-8 jika kondisi penghentian tidak benar.
Step 3 - Lanjutkan langkah 4-6 untuk setiap pasangan latihan bipolar s:t.
Step 4 - Aktifkan setiap unit input sebagai berikut -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: hingga \: n) $$
Step 5 - Dapatkan input bersih dengan relasi berikut -
$$ y_ {in} \: = \: b \: + \: \ displaystyle \ sum \ limit_ {i} ^ n x_ {i} \: w_ {i} $$
Sini ‘b’ adalah bias dan ‘n’ adalah jumlah total neuron masukan.
Step 6 - Terapkan fungsi aktivasi berikut untuk mendapatkan hasil akhir -
$$ f (y_ {in}) \: = \: \ begin {cases} 1 & if \: y_ {in} \: \ geqslant \: 0 \\ - 1 & if \: y_ {in} \: < \: 0 \ end {kasus} $$
Step 7 - Sesuaikan bobot dan bias sebagai berikut -
Case 1 - jika y ≠ t kemudian,
$$ w_ {i} (baru) \: = \: w_ {i} (lama) \: + \: \ alpha (t \: - \: y_ {in}) x_ {i} $$
$$ b (baru) \: = \: b (lama) \: + \: \ alpha (t \: - \: y_ {in}) $$
Case 2 - jika y = t kemudian,
$$ w_ {i} (baru) \: = \: w_ {i} (lama) $$
$$ b (baru) \: = \: b (lama) $$
Sini ‘y’ adalah keluaran aktual dan ‘t’ adalah keluaran yang diinginkan / target.
$ (t \: - \; y_ {in}) $ adalah kesalahan yang dihitung.
Step 8 - Tes untuk kondisi berhenti, yang akan terjadi bila tidak ada perubahan bobot atau perubahan bobot tertinggi yang terjadi selama latihan lebih kecil dari toleransi yang ditentukan.
Saraf Linear Adaptif Ganda (Madaline)
Madaline yang merupakan singkatan dari Multiple Adaptive Linear Neuron, merupakan jaringan yang terdiri dari banyak Adaline secara paralel. Ini akan memiliki satu unit keluaran. Beberapa poin penting tentang Madaline adalah sebagai berikut -
Ini seperti perceptron multilayer, di mana Adaline akan bertindak sebagai unit tersembunyi antara input dan lapisan Madaline.
Bobot dan bias antara input dan layer Adaline, seperti yang kita lihat pada arsitektur Adaline, dapat disesuaikan.
Lapisan Adaline dan Madaline memiliki bobot tetap dan bias 1.
Pelatihan dapat dilakukan dengan bantuan aturan Delta.
Arsitektur
Arsitektur Madaline terdiri dari “n” neuron dari lapisan masukan, “m”neuron dari lapisan Adaline, dan 1 neuron dari lapisan Madaline. Lapisan Adaline dapat dianggap sebagai lapisan tersembunyi karena berada di antara lapisan masukan dan lapisan keluaran, yaitu lapisan Madaline.
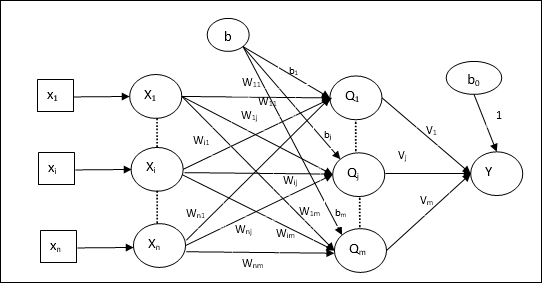
Algoritma Pelatihan
Sekarang kita tahu bahwa hanya bobot dan bias antara input dan lapisan Adaline yang akan disesuaikan, dan bobot serta bias antara lapisan Adaline dan Madaline sudah diperbaiki.
Step 1 - Inisialisasi berikut ini untuk memulai pelatihan -
- Weights
- Bias
- Kecepatan pembelajaran $ \ alpha $
Untuk penghitungan dan kesederhanaan yang mudah, bobot dan bias harus disetel sama dengan 0 dan kecepatan pemelajaran harus disetel sama dengan 1.
Step 2 - Lanjutkan langkah 3-8 jika kondisi penghentian tidak benar.
Step 3 - Lanjutkan langkah 4-6 untuk setiap pasangan latihan bipolar s:t.
Step 4 - Aktifkan setiap unit input sebagai berikut -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: hingga \: n) $$
Step 5 - Dapatkan input bersih di setiap lapisan tersembunyi, yaitu lapisan Adaline dengan relasi berikut -
$$ Q_ {inj} \: = \: b_ {j} \: + \: \ displaystyle \ sum \ batas_ {i} ^ n x_ {i} \: w_ {ij} \: \: \: j \: = \: 1 \: hingga \: m $$
Sini ‘b’ adalah bias dan ‘n’ adalah jumlah total neuron masukan.
Step 6 - Terapkan fungsi aktivasi berikut untuk mendapatkan hasil akhir di lapisan Adaline dan Madaline -
$$ f (x) \: = \: \ begin {cases} 1 & if \: x \: \ geqslant \: 0 \\ - 1 & if \: x \: <\: 0 \ end {cases} $ $
Output di unit tersembunyi (Adaline)
$$ Q_ {j} \: = \: f (Q_ {inj}) $$
Hasil akhir jaringan
$$ y \: = \: f (y_ {in}) $$
i.e. $ \: \: y_ {inj} \: = \: b_ {0} \: + \: \ sum_ {j = 1} ^ m \: Q_ {j} \: v_ {j} $
Step 7 - Hitung kesalahan dan sesuaikan bobot sebagai berikut -
Case 1 - jika y ≠ t dan t = 1 kemudian,
$$ w_ {ij} (baru) \: = \: w_ {ij} (lama) \: + \: \ alpha (1 \: - \: Q_ {inj}) x_ {i} $$
$$ b_ {j} (baru) \: = \: b_ {j} (lama) \: + \: \ alpha (1 \: - \: Q_ {inj}) $$
Dalam hal ini, bobot akan diperbarui Qj dimana masukan bersih mendekati 0 karena t = 1.
Case 2 - jika y ≠ t dan t = -1 kemudian,
$$ w_ {ik} (baru) \: = \: w_ {ik} (lama) \: + \: \ alpha (-1 \: - \: Q_ {ink}) x_ {i} $$
$$ b_ {k} (baru) \: = \: b_ {k} (lama) \: + \: \ alpha (-1 \: - \: Q_ {ink}) $$
Dalam hal ini, bobot akan diperbarui Qk dimana input bersihnya positif karena t = -1.
Sini ‘y’ adalah keluaran aktual dan ‘t’ adalah keluaran yang diinginkan / target.
Case 3 - jika y = t kemudian
Tidak akan ada perubahan bobot.
Step 8 - Tes untuk kondisi berhenti, yang akan terjadi bila tidak ada perubahan bobot atau perubahan bobot tertinggi yang terjadi selama latihan lebih kecil dari toleransi yang ditentukan.
Jaringan Neural Propagasi Kembali
Back Propagation Neural (BPN) adalah jaringan saraf tiruan multilayer yang terdiri dari lapisan masukan, minimal satu lapisan tersembunyi dan lapisan keluaran. Seperti namanya, propagasi balik akan berlangsung di jaringan ini. Kesalahan yang dihitung pada lapisan keluaran, dengan membandingkan keluaran target dan keluaran aktual, akan disebarkan kembali ke lapisan masukan.
Arsitektur
Seperti yang ditunjukkan pada diagram, arsitektur BPN memiliki tiga lapisan yang saling berhubungan yang memiliki bobot di atasnya. Lapisan tersembunyi serta lapisan keluaran juga memiliki bias, yang bobotnya selalu 1, pada lapisan tersebut. Seperti terlihat dari diagram, kerja BPN ada dalam dua tahap. Satu fase mengirimkan sinyal dari lapisan masukan ke lapisan keluaran, dan fase lainnya kembali menyebarkan kesalahan dari lapisan keluaran ke lapisan masukan.

Algoritma Pelatihan
Untuk pelatihan, BPN akan menggunakan fungsi aktivasi sigmoid biner. Pelatihan BPN akan memiliki tiga tahap berikut.
Phase 1 - Fase Umpan Maju
Phase 2 - Back Propagation of error
Phase 3 - Memperbarui bobot
Semua langkah ini akan disimpulkan dalam algoritma sebagai berikut
Step 1 - Inisialisasi berikut ini untuk memulai pelatihan -
- Weights
- Kecepatan pembelajaran $ \ alpha $
Untuk penghitungan dan kesederhanaan yang mudah, ambil beberapa nilai acak kecil.
Step 2 - Lanjutkan langkah 3-11 jika kondisi penghentian tidak benar.
Step 3 - Lanjutkan langkah 4-10 untuk setiap pasangan latihan.
Tahap 1
Step 4 - Setiap unit masukan menerima sinyal masukan xi dan mengirimkannya ke unit tersembunyi untuk semua i = 1 to n
Step 5 - Hitung input bersih pada unit tersembunyi menggunakan hubungan berikut -
$$ Q_ {inj} \: = \: b_ {0j} \: + \: \ sum_ {i = 1} ^ n x_ {i} v_ {ij} \: \: \: \: j \: = \ : 1 \: hingga \: p $$
Sini b0j adalah bias pada unit tersembunyi, vij adalah beratnya j unit dari lapisan tersembunyi yang berasal i unit dari lapisan masukan.
Sekarang hitung keluaran bersih dengan menerapkan fungsi aktivasi berikut
$$ Q_ {j} \: = \: f (Q_ {inj}) $$
Kirim sinyal keluaran ini dari unit lapisan tersembunyi ke unit lapisan keluaran.
Step 6 - Hitung masukan bersih pada unit lapisan keluaran menggunakan hubungan berikut -
$$ y_ {tinta} \: = \: b_ {0k} \: + \: \ sum_ {j = 1} ^ p \: Q_ {j} \: w_ {jk} \: \: k \: = \ : 1 \: hingga \: m $$
Sini b0k Adalah bias pada unit keluaran, wjk adalah beratnya k unit dari lapisan keluaran yang berasal j unit dari lapisan tersembunyi.
Hitung keluaran bersih dengan menerapkan fungsi aktivasi berikut
$$ y_ {k} \: = \: f (y_ {ink}) $$
Tahap 2
Step 7 - Hitung istilah koreksi kesalahan, sesuai dengan pola target yang diterima di setiap unit keluaran, sebagai berikut -
$$ \ delta_ {k} \: = \ :( t_ {k} \: - \: y_ {k}) f ^ {'} (y_ {ink}) $$
Atas dasar ini, perbarui bobot dan bias sebagai berikut -
$$ \ Delta v_ {jk} \: = \: \ alpha \ delta_ {k} \: Q_ {ij} $$
$$ \ Delta b_ {0k} \: = \: \ alpha \ delta_ {k} $$
Kemudian, kirim $ \ delta_ {k} $ kembali ke lapisan tersembunyi.
Step 8 - Sekarang setiap unit tersembunyi akan menjadi jumlah input delta dari unit output.
$$ \ delta_ {inj} \: = \: \ displaystyle \ sum \ limit_ {k = 1} ^ m \ delta_ {k} \: w_ {jk} $$
Istilah kesalahan dapat dihitung sebagai berikut -
$$ \ delta_ {j} \: = \: \ delta_ {inj} f ^ {'} (Q_ {inj}) $$
Atas dasar ini, perbarui bobot dan bias sebagai berikut -
$$ \ Delta w_ {ij} \: = \: \ alpha \ delta_ {j} x_ {i} $$
$$ \ Delta b_ {0j} \: = \: \ alpha \ delta_ {j} $$
Tahap 3
Step 9 - Setiap unit keluaran (ykk = 1 to m) memperbarui bobot dan bias sebagai berikut -
$$ v_ {jk} (baru) \: = \: v_ {jk} (lama) \: + \: \ Delta v_ {jk} $$
$$ b_ {0k} (baru) \: = \: b_ {0k} (lama) \: + \: \ Delta b_ {0k} $$
Step 10 - Setiap unit keluaran (zjj = 1 to p) memperbarui bobot dan bias sebagai berikut -
$$ w_ {ij} (baru) \: = \: w_ {ij} (lama) \: + \: \ Delta w_ {ij} $$
$$ b_ {0j} (baru) \: = \: b_ {0j} (lama) \: + \: \ Delta b_ {0j} $$
Step 11 - Periksa kondisi penghentian, yang mungkin jumlah epoch tercapai atau output target cocok dengan output aktual.
Aturan Pembelajaran Delta Umum
Aturan delta hanya berfungsi untuk lapisan keluaran. Di sisi lain, aturan delta umum, juga disebut sebagaiback-propagation aturan, adalah cara untuk membuat nilai yang diinginkan dari lapisan tersembunyi.
Rumusan Matematika
Untuk fungsi aktivasi $ y_ {k} \: = \: f (y_ {ink}) $ penurunan masukan bersih pada lapisan Tersembunyi serta pada lapisan keluaran dapat diberikan oleh
$$ y_ {ink} \: = \: \ displaystyle \ sum \ limit_i \: z_ {i} w_ {jk} $$
Dan $ \: \: y_ {inj} \: = \: \ sum_i x_ {i} v_ {ij} $
Sekarang kesalahan yang harus diminimalkan adalah
$$ E \: = \: \ frac {1} {2} \ displaystyle \ sum \ limit_ {k} \: [t_ {k} \: - \: y_ {k}] ^ 2 $$
Dengan menggunakan aturan rantai, kami punya
$$ \ frac {\ sebagian E} {\ sebagian w_ {jk}} \: = \: \ frac {\ sebagian} {\ sebagian w_ {jk}} (\ frac {1} {2} \ displaystyle \ sum \ batas_ {k} \: [t_ {k} \: - \: y_ {k}] ^ 2) $$
$$ = \: \ frac {\ sebagian} {\ sebagian w_ {jk}} \ lgroup \ frac {1} {2} [t_ {k} \: - \: t (y_ {ink})] ^ 2 \ rgroup $$
$$ = \: - [t_ {k} \: - \: y_ {k}] \ frac {\ sebagian} {\ sebagian w_ {jk}} f (y_ {tinta}) $$
$$ = \: - [t_ {k} \: - \: y_ {k}] f (y_ {ink}) \ frac {\ partial} {\ partial w_ {jk}} (y_ {ink}) $$
$$ = \: - [t_ {k} \: - \: y_ {k}] f ^ {'} (y_ {tinta}) z_ {j} $$
Sekarang katakanlah $ \ delta_ {k} \: = \: - [t_ {k} \: - \: y_ {k}] f ^ {'} (y_ {ink}) $
Bobot pada koneksi ke unit tersembunyi zj dapat diberikan oleh -
$$ \ frac {\ parsial E} {\ parsial v_ {ij}} \: = \: - \ displaystyle \ sum \ limit_ {k} \ delta_ {k} \ frac {\ parsial} {\ parsial v_ {ij} } \ :( y_ {ink}) $$
Menempatkan nilai $ y_ {ink} $ kita akan mendapatkan yang berikut
$$ \ delta_ {j} \: = \: - \ displaystyle \ sum \ limit_ {k} \ delta_ {k} w_ {jk} f ^ {'} (z_ {inj}) $$
Pembaruan bobot dapat dilakukan sebagai berikut -
Untuk unit keluaran -
$$ \ Delta w_ {jk} \: = \: - \ alpha \ frac {\ sebagian E} {\ sebagian w_ {jk}} $$
$$ = \: \ alpha \: \ delta_ {k} \: z_ {j} $$
Untuk unit tersembunyi -
$$ \ Delta v_ {ij} \: = \: - \ alpha \ frac {\ partial E} {\ partial v_ {ij}} $$
$$ = \: \ alpha \: \ delta_ {j} \: x_ {i} $$
Seperti namanya, pembelajaran jenis ini dilakukan tanpa pengawasan seorang guru. Proses pembelajaran ini mandiri. Selama pelatihan JST dalam pembelajaran tanpa pengawasan, vektor input dari jenis yang sama digabungkan untuk membentuk cluster. Ketika pola masukan baru diterapkan, maka jaringan saraf memberikan tanggapan keluaran yang menunjukkan kelas yang memiliki pola masukan. Dalam hal ini, tidak akan ada umpan balik dari lingkungan tentang apa yang seharusnya menjadi keluaran yang diinginkan dan apakah itu benar atau salah. Oleh karena itu, dalam pembelajaran jenis ini jaringan itu sendiri harus menemukan pola, fitur dari data masukan dan hubungan untuk data masukan melalui keluaran.
Pemenang-Mengambil-Semua Jaringan
Jenis jaringan ini didasarkan pada aturan pembelajaran kompetitif dan akan menggunakan strategi di mana ia memilih neuron dengan total input terbesar sebagai pemenang. Koneksi antara neuron keluaran menunjukkan persaingan di antara mereka dan salah satunya akan menjadi 'ON' yang berarti akan menjadi pemenang dan yang lainnya akan menjadi 'OFF'.
Berikut adalah beberapa jaringan yang didasarkan pada konsep sederhana ini dengan menggunakan pembelajaran tanpa pengawasan.
Jaringan Hamming
Di sebagian besar jaringan saraf yang menggunakan pembelajaran tanpa pengawasan, penting untuk menghitung jarak dan melakukan perbandingan. Jaringan jenis ini adalah jaringan Hamming, dimana untuk setiap vektor masukan yang diberikan akan dikelompokkan menjadi beberapa kelompok yang berbeda. Berikut adalah beberapa fitur penting dari Hamming Networks -
Lippmann mulai mengerjakan jaringan Hamming pada tahun 1987.
Ini adalah jaringan lapisan tunggal.
Input dapat berupa biner {0, 1} bipolar {-1, 1}.
Bobot jaring dihitung dengan vektor contoh.
Ini adalah jaringan beban tetap yang berarti bobot akan tetap sama bahkan selama pelatihan.
Max Net
Ini juga merupakan jaringan bobot tetap, yang berfungsi sebagai subnet untuk memilih node yang memiliki input tertinggi. Semua node saling berhubungan sepenuhnya dan terdapat bobot simetris di semua interkoneksi berbobot ini.
Arsitektur
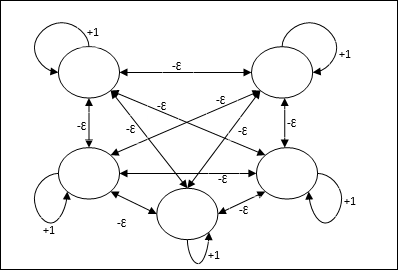
Ini menggunakan mekanisme yang merupakan proses berulang dan setiap node menerima input penghambatan dari semua node lain melalui koneksi. Node tunggal yang nilainya maksimum akan aktif atau menjadi pemenang dan aktivasi semua node lainnya tidak akan aktif. Max Net menggunakan fungsi aktivasi identitas dengan $$ f (x) \: = \: \ begin {cases} x & if \: x> 0 \\ 0 & if \: x \ leq 0 \ end {cases} $$
Tugas jaring ini diselesaikan dengan bobot eksitasi diri +1 dan besaran penghambatan timbal balik, yang ditetapkan seperti [0 <ɛ <$ \ frac {1} {m} $] di mana “m” adalah jumlah total node.
Pembelajaran Kompetitif di ANN
Ini berkaitan dengan pelatihan tanpa pengawasan di mana simpul keluaran mencoba bersaing satu sama lain untuk mewakili pola masukan. Untuk memahami aturan pembelajaran ini kita harus memahami jaring kompetitif yang dijelaskan sebagai berikut -
Konsep Dasar Jaringan Kompetitif
Jaringan ini seperti jaringan umpan-maju lapisan tunggal yang memiliki koneksi umpan balik antara keluaran. Hubungan antar output adalah tipe inhibitory, yang ditunjukkan dengan garis putus-putus, artinya kompetitor tidak pernah menyokong dirinya sendiri.
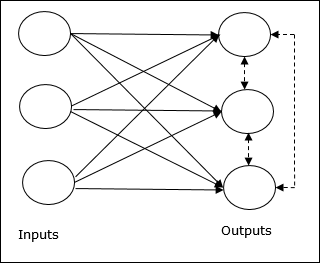
Konsep Dasar Aturan Pembelajaran Bersaing
Seperti yang dikatakan sebelumnya, akan ada persaingan di antara node keluaran sehingga konsep utamanya adalah - selama pelatihan, unit keluaran yang memiliki aktivasi tertinggi ke pola masukan tertentu, akan dinyatakan sebagai pemenang. Aturan ini juga disebut Pemenang-mengambil-semua karena hanya neuron pemenang yang diperbarui dan neuron lainnya dibiarkan tidak berubah.
Rumusan Matematika
Berikut adalah tiga faktor penting untuk perumusan matematika dari aturan pembelajaran ini -
Syarat menjadi pemenang
Misalkan jika neuron yk ingin menjadi pemenang, maka harus ada syarat sebagai berikut
$$ y_ {k} \: = \: \ begin {cases} 1 & if \: v_ {k}> v_ {j} \: for \: all \: \: j, \: j \: \ neq \ : k \\ 0 & sebaliknya \ end {cases} $$
Artinya jika ada neuron, katakanlah, yk ingin menang, kemudian bidang lokalnya yang diinduksi (keluaran unit penjumlahan), katakanlah vk, harus menjadi yang terbesar di antara semua neuron lain di jaringan.
Kondisi penjumlahan total bobot
Kendala lain atas aturan pembelajaran kompetitif adalah jumlah total bobot ke neuron keluaran tertentu akan menjadi 1. Misalnya, jika kita mempertimbangkan neuron k kemudian
$$ \ displaystyle \ sum \ limit_ {k} w_ {kj} \: = \: 1 \: \: \: \: untuk \: semua \: \: k $$
Perubahan bobot untuk pemenang
Jika neuron tidak merespons pola masukan, maka tidak ada pembelajaran yang terjadi di neuron itu. Namun, jika neuron tertentu menang, maka bobot yang sesuai akan disesuaikan sebagai berikut -
$$ \ Delta w_ {kj} \: = \: \ begin {kasus} - \ alpha (x_ {j} \: - \: w_ {kj}), & jika \: neuron \: k \: menang \\ 0 & jika \: neuron \: k \: kerugian \ end {kasus} $$
Di sini $ \ alpha $ adalah kecepatan pemelajaran.
Hal ini jelas menunjukkan bahwa kita lebih menyukai neuron pemenang dengan menyesuaikan bobotnya dan jika neuron hilang, maka kita tidak perlu repot-repot mengatur ulang bobotnya.
Algoritma Pengelompokan K-means
K-means adalah salah satu algoritma pengelompokan paling populer di mana kami menggunakan konsep prosedur partisi. Kami mulai dengan partisi awal dan berulang kali memindahkan pola dari satu cluster ke cluster lain, sampai kami mendapatkan hasil yang memuaskan.
Algoritma
Step 1 - Pilih kmenunjuk sebagai sentroid awal. Inisialisasik prototipe (w1,…,wk), misalnya kita dapat mengidentifikasinya dengan vektor input yang dipilih secara acak -
$$ W_ {j} \: = \: i_ {p}, \: \: \: where \: j \: \ in \ lbrace1, ...., k \ rbrace \: dan \: p \: \ di \ lbrace1, ...., n \ rbrace $$
Setiap cluster Cj dikaitkan dengan prototipe wj.
Step 2 - Ulangi langkah 3-5 hingga E tidak lagi berkurang, atau keanggotaan cluster tidak lagi berubah.
Step 3 - Untuk setiap vektor masukan ip dimana p ∈ {1,…,n}, taruh ip di cluster Cj* dengan prototipe terdekat wj* memiliki hubungan berikut
$$ | i_ {p} \: - \: w_ {j *} | \: \ leq \: | i_ {p} \: - \: w_ {j} |, \: j \: \ in \ lbrace1, ...., k \ rbrace $$
Step 4 - Untuk setiap cluster Cj, dimana j ∈ { 1,…,k}, perbarui prototipe wj menjadi pusat massa dari semua sampel yang ada saat ini Cj , yang seperti itu
$$ w_ {j} \: = \: \ sum_ {i_ {p} \ in C_ {j}} \ frac {i_ {p}} {| C_ {j} |} $$
Step 5 - Hitung total kesalahan kuantisasi sebagai berikut -
$$ E \: = \: \ sum_ {j = 1} ^ k \ sum_ {i_ {p} \ in w_ {j}} | i_ {p} \: - \: w_ {j} | ^ 2 $$
Neokognitron
Ini adalah jaringan feedforward multilayer, yang dikembangkan oleh Fukushima pada 1980-an. Model ini didasarkan pada pembelajaran yang diawasi dan digunakan untuk pengenalan pola visual, terutama karakter tulisan tangan. Ini pada dasarnya merupakan perpanjangan dari jaringan Cognitron, yang juga dikembangkan oleh Fukushima pada tahun 1975.
Arsitektur
Ini adalah jaringan hierarki, yang terdiri dari banyak lapisan dan terdapat pola konektivitas secara lokal di lapisan tersebut.
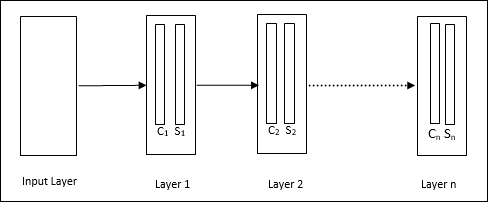
Seperti yang telah kita lihat pada diagram di atas, neokognitron dibagi menjadi beberapa lapisan yang terhubung dan setiap lapisan memiliki dua sel. Penjelasan dari sel-sel tersebut adalah sebagai berikut -
S-Cell - Ini disebut sel sederhana, yang dilatih untuk merespons pola tertentu atau sekelompok pola.
C-Cell- Disebut sel kompleks, yang menggabungkan keluaran dari sel S dan secara bersamaan mengurangi jumlah unit di setiap larik. Dalam arti lain, sel C menggantikan hasil dari sel S.
Algoritma Pelatihan
Pelatihan neokognitron ditemukan berkembang lapis demi lapis. Bobot dari lapisan masukan ke lapisan pertama dilatih dan dibekukan. Kemudian, bobot dari lapisan pertama ke lapisan kedua dilatih, dan seterusnya. Perhitungan internal antara S-cell dan Ccell bergantung pada bobot yang berasal dari lapisan sebelumnya. Oleh karena itu, kita dapat mengatakan bahwa algoritma pelatihan bergantung pada kalkulasi pada sel S dan sel C.
Perhitungan di sel S.
Sel-S memiliki sinyal rangsang yang diterima dari lapisan sebelumnya dan memiliki sinyal penghambatan yang diperoleh dalam lapisan yang sama.
$$ \ theta = \: \ sqrt {\ sum \ sum t_ {i} c_ {i} ^ 2} $$
Sini, ti adalah bobot tetap dan ci adalah keluaran dari sel C.
Input skala S-sel dapat dihitung sebagai berikut -
$$ x \: = \: \ frac {1 \: + \: e} {1 \: + \: vw_ {0}} \: - \: 1 $$
Di sini, $ e \: = \: \ sum_i c_ {i} w_ {i} $
wi adalah bobot yang disesuaikan dari sel C ke sel S.
w0 adalah bobot yang dapat disesuaikan antara input dan sel S.
v adalah input rangsang dari sel C.
Aktivasi sinyal keluaran adalah,
$$ s \: = \: \ begin {cases} x, & if \: x \ geq 0 \\ 0, & if \: x <0 \ end {cases} $$
Perhitungan dalam sel C.
Input bersih dari C-layer adalah
$$ C \: = \: \ displaystyle \ sum \ limit_i s_ {i} x_ {i} $$
Sini, si adalah keluaran dari S-cell dan xi adalah bobot tetap dari sel S ke sel C.
Hasil akhirnya adalah sebagai berikut -
$$ C_ {out} \: = \: \ begin {cases} \ frac {C} {a + C}, & if \: C> 0 \\ 0, & sebaliknya \ end {cases} $$
Sini ‘a’ adalah parameter yang bergantung pada kinerja jaringan.
Learning Vector Quantization (LVQ), berbeda dengan vektor kuantisasi (VQ) dan Kohonen Self-Organizing Maps (KSOM), pada dasarnya adalah jaringan kompetitif yang menggunakan pembelajaran yang diawasi. Kita dapat mendefinisikannya sebagai proses pengklasifikasian pola di mana setiap unit keluaran mewakili sebuah kelas. Karena menggunakan pembelajaran yang diawasi, jaringan akan diberikan serangkaian pola pelatihan dengan klasifikasi yang diketahui bersama dengan distribusi awal kelas keluaran. Setelah menyelesaikan proses pelatihan, LVQ akan mengklasifikasikan vektor masukan dengan menetapkannya ke kelas yang sama dengan yang ada pada unit keluaran.
Arsitektur
Gambar berikut menunjukkan arsitektur LVQ yang sangat mirip dengan arsitektur KSOM. Seperti yang bisa kita lihat, ada“n” jumlah unit masukan dan “m”jumlah unit keluaran. Lapisan tersebut sepenuhnya saling berhubungan dengan memiliki bobot di atasnya.

Parameter yang Digunakan
Berikut adalah parameter yang digunakan dalam proses pelatihan LVQ serta di diagram alir
x= vektor pelatihan (x 1 , ..., x i , ..., x n )
T = kelas untuk vektor pelatihan x
wj = vektor bobot untuk jth unit keluaran
Cj = kelas yang terkait dengan jth unit keluaran
Algoritma Pelatihan
Step 1 - Inisialisasi vektor referensi, yang dapat dilakukan sebagai berikut -
Step 1(a) - Dari kumpulan vektor pelatihan yang diberikan, ambil "m"(Jumlah cluster) vektor pelatihan dan menggunakannya sebagai vektor bobot. Vektor yang tersisa dapat digunakan untuk pelatihan.
Step 1(b) - Tentukan bobot awal dan klasifikasi secara acak.
Step 1(c) - Menerapkan metode pengelompokan K-means.
Step 2 - Inisialisasi vektor referensi $ \ alpha $
Step 3 - Lanjutkan dengan langkah 4-9, jika kondisi untuk menghentikan algoritma ini tidak terpenuhi.
Step 4 - Ikuti langkah 5-6 untuk setiap vektor input pelatihan x.
Step 5 - Hitung Kuadrat Jarak Euclidean untuk j = 1 to m dan i = 1 to n
$$ D (j) \: = \: \ displaystyle \ sum \ limit_ {i = 1} ^ n \ displaystyle \ sum \ limit_ {j = 1} ^ m (x_ {i} \: - \: w_ {ij }) ^ 2 $$
Step 6 - Dapatkan unit pemenang J dimana D(j) minimal.
Step 7 - Hitung bobot baru unit pemenang dengan hubungan berikut -
jika T = Cj lalu $ w_ {j} (baru) \: = \: w_ {j} (lama) \: + \: \ alpha [x \: - \: w_ {j} (lama)] $
jika T ≠ Cj lalu $ w_ {j} (baru) \: = \: w_ {j} (lama) \: - \: \ alpha [x \: - \: w_ {j} (lama)] $
Step 8 - Kurangi kecepatan pembelajaran $ \ alpha $.
Step 9- Uji kondisi berhenti. Mungkin sebagai berikut -
- Jumlah periode maksimum tercapai.
- Kecepatan pembelajaran dikurangi menjadi nilai yang dapat diabaikan.
Diagram alir
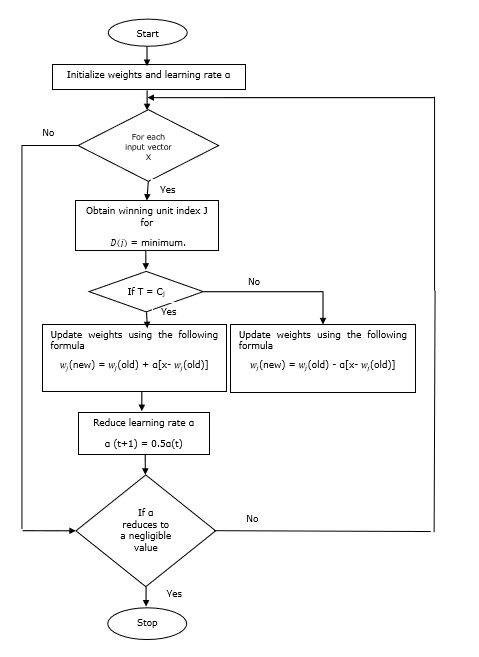
Varian
Tiga varian lainnya yaitu LVQ2, LVQ2.1 dan LVQ3 telah dikembangkan oleh Kohonen. Kompleksitas dalam ketiga varian ini, karena konsep yang akan dipelajari oleh pemenang serta unit runner-up, lebih banyak daripada di LVQ.
LVQ2
Seperti yang dibahas pada konsep varian lain dari LVQ di atas, kondisi LVQ2 dibentuk oleh jendela. Jendela ini akan didasarkan pada parameter berikut -
x - vektor masukan saat ini
yc - vektor referensi yang paling dekat dengan x
yr - vektor referensi lainnya, yang paling dekat dengan x
dc - jarak dari x untuk yc
dr - jarak dari x untuk yr
Vektor masukan x jatuh di jendela, jika
$$ \ frac {d_ {c}} {d_ {r}} \:> \: 1 \: - \: \ theta \: \: dan \: \: \ frac {d_ {r}} {d_ {c }} \:> \: 1 \: + \: \ theta $$
Di sini, $ \ theta $ adalah jumlah sampel pelatihan.
Pembaruan dapat dilakukan dengan rumus berikut -
$ y_ {c} (t \: + \: 1) \: = \: y_ {c} (t) \: + \: \ alpha (t) [x (t) \: - \: y_ {c} (t)] $ (belongs to different class)
$ y_ {r} (t \: + \: 1) \: = \: y_ {r} (t) \: + \: \ alpha (t) [x (t) \: - \: y_ {r} (t)] $ (belongs to same class)
Di sini $ \ alpha $ adalah kecepatan pemelajaran.
LVQ2.1
Di LVQ2.1, kita akan mengambil dua vektor terdekat yaitu yc1 dan yc2 dan kondisi jendela adalah sebagai berikut -
$$ Min \ begin {bmatrix} \ frac {d_ {c1}} {d_ {c2}}, \ frac {d_ {c2}} {d_ {c1}} \ end {bmatrix} \:> \ :( 1 \ : - \: \ theta) $$
$$ Max \ begin {bmatrix} \ frac {d_ {c1}} {d_ {c2}}, \ frac {d_ {c2}} {d_ {c1}} \ end {bmatrix} \: <\ :( 1 \ : + \: \ theta) $$
Pembaruan dapat dilakukan dengan rumus berikut -
$ y_ {c1} (t \: + \: 1) \: = \: y_ {c1} (t) \: + \: \ alpha (t) [x (t) \: - \: y_ {c1} (t)] $ (belongs to different class)
$ y_ {c2} (t \: + \: 1) \: = \: y_ {c2} (t) \: + \: \ alpha (t) [x (t) \: - \: y_ {c2} (t)] $ (belongs to same class)
Di sini, $ \ alpha $ adalah kecepatan pemelajaran.
LVQ3
Di LVQ3, kita akan mengambil dua vektor terdekat yaitu yc1 dan yc2 dan kondisi jendela adalah sebagai berikut -
$$ Min \ begin {bmatrix} \ frac {d_ {c1}} {d_ {c2}}, \ frac {d_ {c2}} {d_ {c1}} \ end {bmatrix} \:> \ :( 1 \ : - \: \ theta) (1 \: + \: \ theta) $$
Di sini $ \ theta \ sekitar 0,2 $
Pembaruan dapat dilakukan dengan rumus berikut -
$ y_ {c1} (t \: + \: 1) \: = \: y_ {c1} (t) \: + \: \ beta (t) [x (t) \: - \: y_ {c1} (t)] $ (belongs to different class)
$ y_ {c2} (t \: + \: 1) \: = \: y_ {c2} (t) \: + \: \ beta (t) [x (t) \: - \: y_ {c2} (t)] $ (belongs to same class)
Di sini $ \ beta $ adalah kelipatan dari kecepatan pembelajaran $ \ alpha $ dan $\beta\:=\:m \alpha(t)$ untuk setiap 0.1 < m < 0.5
Jaringan ini dikembangkan oleh Stephen Grossberg dan Gail Carpenter pada tahun 1987. Berbasis kompetisi dan menggunakan model pembelajaran tanpa pengawasan. Jaringan Adaptive Resonance Theory (ART), seperti namanya, selalu terbuka untuk pembelajaran baru (adaptif) tanpa kehilangan pola lama (resonansi). Pada dasarnya, jaringan ART adalah pengklasifikasi vektor yang menerima vektor input dan mengklasifikasikannya ke dalam salah satu kategori tergantung dari pola tersimpan mana yang paling mirip.
Kepala Operasi
Operasi utama klasifikasi ART dapat dibagi menjadi beberapa fase berikut -
Recognition phase- Vektor masukan dibandingkan dengan klasifikasi yang disajikan pada setiap node pada lapisan keluaran. Keluaran neuron menjadi “1” jika paling cocok dengan klasifikasi yang diterapkan, jika tidak maka menjadi “0”.
Comparison phase- Pada tahap ini dilakukan perbandingan antara vektor masukan dengan vektor lapisan pembanding. Syarat untuk reset adalah bahwa derajat kesamaan akan lebih kecil dari parameter kewaspadaan.
Search phase- Pada fase ini, jaringan akan mencari reset serta kecocokan yang dilakukan pada fase di atas. Karenanya, jika tidak ada pengaturan ulang dan kecocokan cukup baik, maka klasifikasi selesai. Jika tidak, proses akan diulangi dan pola tersimpan lainnya harus dikirim untuk menemukan kecocokan yang benar.
ART1
Ini adalah jenis ART, yang dirancang untuk mengelompokkan vektor biner. Kita bisa memahami hal ini dengan arsitekturnya.
Arsitektur ART1
Ini terdiri dari dua unit berikut -
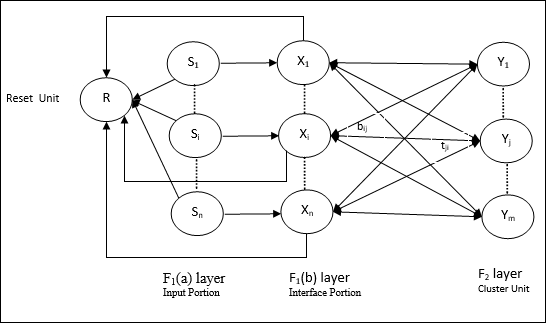
Computational Unit - Ini terdiri dari berikut -
Input unit (F1 layer) - Ini selanjutnya memiliki dua bagian berikut -
F1(a) layer (Input portion)- Dalam ART1, tidak akan ada pemrosesan dalam bagian ini daripada hanya memiliki vektor input. Ini terhubung ke lapisan F 1 (b) (bagian antarmuka).
F1(b) layer (Interface portion)- Bagian ini menggabungkan sinyal dari bagian input dengan yang ada di lapisan F 2 . Lapisan F 1 (b) dihubungkan ke lapisan F 2 melalui bobot bottom upbijdan lapisan F 2 dihubungkan ke lapisan F 1 (b) melalui pemberat top downtji.
Cluster Unit (F2 layer)- Ini adalah lapisan kompetitif. Unit yang memiliki masukan bersih terbesar dipilih untuk mempelajari pola masukan. Aktivasi semua unit cluster lainnya disetel ke 0.
Reset Mechanism- Kerja mekanisme ini didasarkan pada kemiripan antara bobot top-down dan vektor input. Nah, jika derajat kemiripan ini lebih kecil dari parameter kewaspadaan, maka cluster tidak diperbolehkan mempelajari pola tersebut dan akan terjadi istirahat.
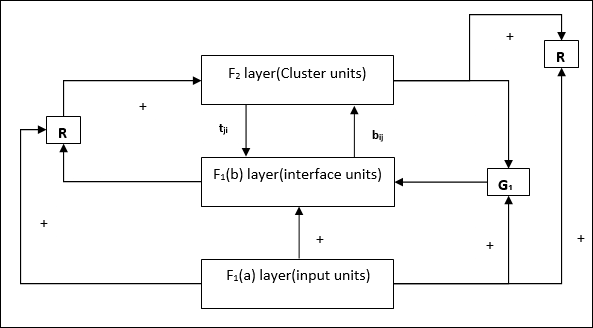
Supplement Unit - Sebenarnya masalah dengan mekanisme Reset adalah lapisannya F2harus dihambat dalam kondisi tertentu dan juga harus tersedia saat pembelajaran terjadi. Itulah mengapa dua unit tambahan yaitu,G1 dan G2 ditambahkan bersama dengan unit reset, R. Mereka disebutgain control units. Unit ini menerima dan mengirim sinyal ke unit lain yang ada di jaringan.‘+’ menunjukkan sinyal rangsang, sementara ‘−’ menunjukkan sinyal penghambatan.
Parameter yang Digunakan
Parameter berikut digunakan -
n - Jumlah komponen dalam vektor masukan
m - Jumlah cluster maksimal yang bisa dibentuk
bij- Bobot dari lapisan F 1 (b) sampai F 2 , yaitu bobot bottom-up
tji- Bobot dari lapisan F 2 sampai F 1 (b), yaitu bobot top-down
ρ - Parameter kewaspadaan
||x|| - Norma vektor x
Algoritma
Step 1 - Inisialisasi kecepatan pembelajaran, parameter kewaspadaan, dan bobot sebagai berikut -
$$ \ alpha \:> \: 1 \: \: dan \: \: 0 \: <\ rho \: \ leq \: 1 $$
$$ 0 \: <\: b_ {ij} (0) \: <\: \ frac {\ alpha} {\ alpha \: - \: 1 \: + \: n} \: \: dan \: \: t_ {ij} (0) \: = \: 1 $$
Step 2 - Lanjutkan langkah 3-9, jika kondisi penghentian tidak benar.
Step 3 - Lanjutkan langkah 4-6 untuk setiap input pelatihan.
Step 4- Atur aktivasi semua unit F 1 (a) dan F 1 sebagai berikut
F2 = 0 and F1(a) = input vectors
Step 5- Sinyal input dari layer F 1 (a) ke F 1 (b) harus dikirim seperti
$$ s_ {i} \: = \: x_ {i} $$
Step 6- Untuk setiap node F 2 yang terhambat
$ y_ {j} \: = \: \ sum_i b_ {ij} x_ {i} $ kondisinya adalah yj ≠ -1
Step 7 - Lakukan langkah 8-10, jika reset benar.
Step 8 - Temukan J untuk yJ ≥ yj untuk semua node j
Step 9- Sekali lagi hitung aktivasi pada F 1 (b) sebagai berikut
$$ x_ {i} \: = \: sitJi $$
Step 10 - Sekarang, setelah menghitung norma vektor x dan vektor s, kita perlu memeriksa kondisi reset sebagai berikut -
Jika ||x||/ ||s|| <parameter kewaspadaan ρ, Kemudian hentikan node J dan lanjutkan ke langkah 7
Lain Jika ||x||/ ||s|| ≥ parameter kewaspadaan ρ, lalu lanjutkan lebih jauh.
Step 11 - Pembaruan bobot untuk node J dapat dilakukan sebagai berikut -
$$ b_ {ij} (baru) \: = \: \ frac {\ alpha x_ {i}} {\ alpha \: - \: 1 \: + \: || x ||} $$
$$ t_ {ij} (baru) \: = \: x_ {i} $$
Step 12 - Kondisi berhenti untuk algoritma harus diperiksa dan mungkin sebagai berikut -
- Tidak ada perubahan berat badan.
- Reset tidak dilakukan untuk unit.
- Jumlah periode maksimum tercapai.
Misalkan kita memiliki beberapa pola dimensi yang berubah-ubah, namun, kita membutuhkannya dalam satu atau dua dimensi. Kemudian proses pemetaan fitur akan sangat berguna untuk mengubah ruang pola lebar menjadi ruang fitur yang khas. Sekarang, muncul pertanyaan mengapa kita membutuhkan peta fitur yang dapat diatur sendiri? Pasalnya, seiring dengan kemampuan untuk mengubah dimensi arbitrer menjadi 1-D atau 2-D, juga harus memiliki kemampuan untuk menjaga topologi tetangga.
Topologi Tetangga di Kohonen SOM
Ada berbagai macam topologi, namun dua topologi berikut paling banyak digunakan -
Topologi Kotak Persegi Panjang
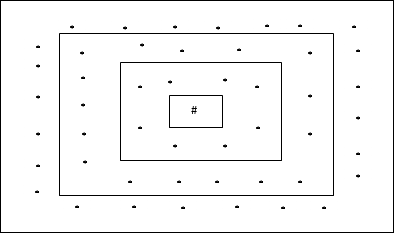
Topologi ini memiliki 24 node pada grid jarak-2, 16 node pada grid jarak-1, dan 8 node pada grid jarak-0, artinya selisih masing-masing grid persegi panjang adalah 8 node. Unit pemenang ditunjukkan dengan #.
Topologi Kisi Heksagonal
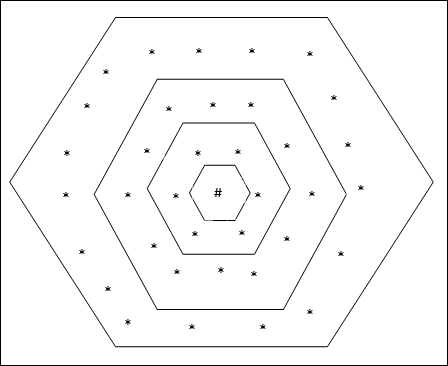
Topologi ini memiliki 18 node pada grid jarak-2, 12 node pada grid jarak-1, dan 6 node pada grid jarak-0, artinya selisih setiap grid persegi panjang adalah 6 node. Unit pemenang ditunjukkan dengan #.
Arsitektur
Arsitektur KSOM mirip dengan jaringan kompetitif. Dengan bantuan skema lingkungan, yang dibahas sebelumnya, pelatihan dapat dilakukan di wilayah jaringan yang diperluas.
Algoritma untuk pelatihan
Step 1 - Inisialisasi bobot, kecepatan pembelajaran α dan skema topologi lingkungan.
Step 2 - Lanjutkan langkah 3-9, jika kondisi penghentian tidak benar.
Step 3 - Lanjutkan langkah 4-6 untuk setiap vektor masukan x.
Step 4 - Hitung Kuadrat Jarak Euclidean untuk j = 1 to m
$$ D (j) \: = \: \ displaystyle \ sum \ limit_ {i = 1} ^ n \ displaystyle \ sum \ limit_ {j = 1} ^ m (x_ {i} \: - \: w_ {ij }) ^ 2 $$
Step 5 - Dapatkan unit pemenang J dimana D(j) minimal.
Step 6 - Hitung bobot baru unit pemenang dengan hubungan berikut -
$$ w_ {ij} (baru) \: = \: w_ {ij} (lama) \: + \: \ alpha [x_ {i} \: - \: w_ {ij} (lama)] $$
Step 7 - Perbarui kecepatan pembelajaran α dengan hubungan berikut -
$$ \ alpha (t \: + \: 1) \: = \: 0.5 \ alpha t $$
Step 8 - Kurangi radius skema topologi.
Step 9 - Periksa kondisi penghentian jaringan.
Jaringan saraf jenis ini bekerja atas dasar asosiasi pola, yang berarti mereka dapat menyimpan pola yang berbeda dan pada saat memberikan keluaran, mereka dapat menghasilkan salah satu pola yang disimpan dengan mencocokkannya dengan pola masukan yang diberikan. Jenis ingatan ini juga disebutContent-Addressable Memory(CAM). Memori asosiatif membuat pencarian paralel dengan pola yang disimpan sebagai file data.
Berikut adalah dua jenis ingatan asosiatif yang dapat kita amati -
- Memori Asosiasi Otomatis
- Memori Hetero Associative
Memori Asosiasi Otomatis
Ini adalah jaringan saraf lapisan tunggal di mana vektor pelatihan input dan vektor target keluaran adalah sama. Bobot ditentukan sehingga jaringan menyimpan sekumpulan pola.
Arsitektur
Seperti yang ditunjukkan pada gambar berikut, arsitektur jaringan memori Auto Associative memiliki ‘n’ jumlah vektor input pelatihan dan sejenisnya ‘n’ jumlah vektor target keluaran.
Algoritma Pelatihan
Untuk pelatihan, jaringan ini menggunakan aturan pembelajaran Hebb atau Delta.
Step 1 - Inisialisasi semua bobot ke nol sebagai wij = 0 (i = 1 to n, j = 1 to n)
Step 2 - Lakukan langkah 3-4 untuk setiap vektor masukan.
Step 3 - Aktifkan setiap unit input sebagai berikut -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: hingga \: n) $$
Step 4 - Aktifkan setiap unit keluaran sebagai berikut -
$$ y_ {j} \: = \: s_ {j} \ :( j \: = \: 1 \: hingga \: n) $$
Step 5 - Sesuaikan bobot sebagai berikut -
$$ w_ {ij} (baru) \: = \: w_ {ij} (lama) \: + \: x_ {i} y_ {j} $$
Menguji Algoritma
Step 1 - Atur bobot yang diperoleh selama pelatihan untuk aturan Hebb.
Step 2 - Lakukan langkah 3-5 untuk setiap vektor masukan.
Step 3 - Atur aktivasi unit input sama dengan vektor input.
Step 4 - Hitung input bersih untuk setiap unit output j = 1 to n
$$ y_ {inj} \: = \: \ displaystyle \ sum \ limit_ {i = 1} ^ n x_ {i} w_ {ij} $$
Step 5 - Terapkan fungsi aktivasi berikut untuk menghitung keluaran
$$ y_ {j} \: = \: f (y_ {inj}) \: = \: \ begin {kasus} +1 & jika \: y_ {inj} \:> \: 0 \\ - 1 & if \: y_ {inj} \: \ leqslant \: 0 \ end {kasus} $$
Memori Hetero Associative
Mirip dengan jaringan Auto Associative Memory, ini juga merupakan jaringan saraf lapisan tunggal. Namun, dalam jaringan ini vektor input training dan vektor target output tidak sama. Bobot ditentukan sehingga jaringan menyimpan sekumpulan pola. Jaringan hetero asosiatif bersifat statis, sehingga tidak akan ada operasi non linier dan penundaan.
Arsitektur
Seperti yang ditunjukkan pada gambar berikut, arsitektur jaringan Hetero Associative Memory memiliki ‘n’ jumlah vektor input pelatihan dan ‘m’ jumlah vektor target keluaran.
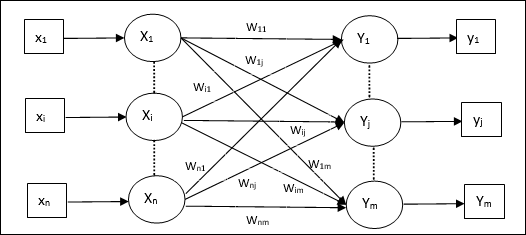
Algoritma Pelatihan
Untuk pelatihan, jaringan ini menggunakan aturan pembelajaran Hebb atau Delta.
Step 1 - Inisialisasi semua bobot ke nol sebagai wij = 0 (i = 1 to n, j = 1 to m)
Step 2 - Lakukan langkah 3-4 untuk setiap vektor masukan.
Step 3 - Aktifkan setiap unit input sebagai berikut -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: hingga \: n) $$
Step 4 - Aktifkan setiap unit keluaran sebagai berikut -
$$ y_ {j} \: = \: s_ {j} \ :( j \: = \: 1 \: hingga \: m) $$
Step 5 - Sesuaikan bobot sebagai berikut -
$$ w_ {ij} (baru) \: = \: w_ {ij} (lama) \: + \: x_ {i} y_ {j} $$
Menguji Algoritma
Step 1 - Atur bobot yang diperoleh selama pelatihan untuk aturan Hebb.
Step 2 - Lakukan langkah 3-5 untuk setiap vektor masukan.
Step 3 - Atur aktivasi unit input sama dengan vektor input.
Step 4 - Hitung input bersih untuk setiap unit output j = 1 to m;
$$ y_ {inj} \: = \: \ displaystyle \ sum \ limit_ {i = 1} ^ n x_ {i} w_ {ij} $$
Step 5 - Terapkan fungsi aktivasi berikut untuk menghitung keluaran
$$ y_ {j} \: = \: f (y_ {inj}) \: = \: \ begin {kasus} +1 & jika \: y_ {inj} \:> \: 0 \\ 0 & if \ : y_ {inj} \: = \: 0 \\ - 1 & if \: y_ {inj} \: <\: 0 \ end {kasus} $$
Jaringan saraf hopfield ditemukan oleh Dr. John J. Hopfield pada tahun 1982. Ini terdiri dari satu lapisan yang berisi satu atau lebih neuron berulang yang terhubung sepenuhnya. Jaringan Hopfield biasanya digunakan untuk asosiasi otomatis dan tugas pengoptimalan.
Jaringan Hopfield Diskrit
Jaringan Hopfield yang beroperasi secara diskrit atau dengan kata lain pola masukan dan keluarannya adalah vektor diskrit, yang dapat berbentuk biner (0,1) atau bipolar (+1, -1). Jaringan memiliki bobot simetris tanpa koneksi mandiri, misalnya,wij = wji dan wii = 0.
Arsitektur
Berikut adalah beberapa poin penting yang perlu diingat tentang jaringan Hopfield yang terpisah -
Model ini terdiri dari neuron dengan satu keluaran pembalik dan satu keluaran non-pembalik.
Keluaran setiap neuron harus merupakan masukan dari neuron lain tetapi bukan masukan diri.
Berat / kekuatan koneksi diwakili oleh wij.
Koneksi bisa menjadi rangsang sekaligus penghambatan. Ini akan menjadi rangsang, jika keluaran neuron sama dengan masukan, jika tidak penghambatan.
Bobot harus simetris, yaitu wij = wji
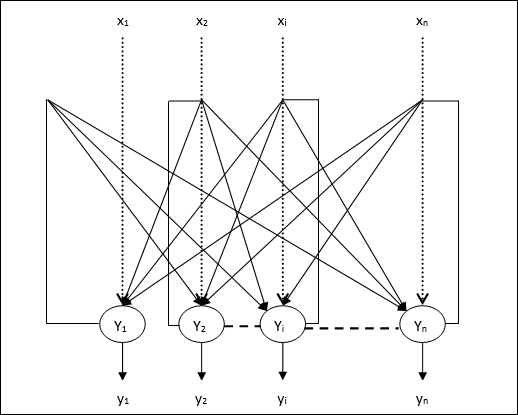
Keluaran dari Y1 pergi ke Y2, Yi dan Yn berbobot w12, w1i dan w1nmasing-masing. Demikian pula, busur lain memiliki bobot pada mereka.
Algoritma Pelatihan
Selama pelatihan jaringan Hopfield diskrit, bobot akan diperbarui. Seperti yang kita ketahui bahwa kita dapat memiliki vektor masukan biner dan juga vektor masukan bipolar. Karenanya, dalam kedua kasus, pembaruan bobot dapat dilakukan dengan relasi berikut
Case 1 - Pola masukan biner
Untuk satu set pola biner s(p), p = 1 to P
Sini, s(p) = s1(p), s2(p),..., si(p),..., sn(p)
Matriks Bobot diberikan oleh
$$ w_ {ij} \: = \: \ sum_ {p = 1} ^ P [2s_ {i} (p) - \: 1] [2s_ {j} (p) - \: 1] \: \: \: \: \: untuk \: i \: \ neq \: j $$
Case 2 - Pola masukan bipolar
Untuk satu set pola biner s(p), p = 1 to P
Sini, s(p) = s1(p), s2(p),..., si(p),..., sn(p)
Matriks Bobot diberikan oleh
$$ w_ {ij} \: = \: \ sum_ {p = 1} ^ P [s_ {i} (p)] [s_ {j} (p)] \: \: \: \: \: untuk \ : i \: \ neq \: j $$
Menguji Algoritma
Step 1 - Inisialisasi bobot, yang diperoleh dari algoritma pelatihan dengan menggunakan prinsip Hebbian.
Step 2 - Lakukan langkah 3-9, jika aktivasi jaringan tidak digabungkan.
Step 3 - Untuk setiap vektor masukan X, lakukan langkah 4-8.
Step 4 - Buat aktivasi awal jaringan sama dengan vektor input eksternal X sebagai berikut -
$$ y_ {i} \: = \: x_ {i} \: \: \: untuk \: i \: = \: 1 \: hingga \: n $$
Step 5 - Untuk setiap unit Yi, lakukan langkah 6-9.
Step 6 - Hitung masukan bersih jaringan sebagai berikut -
$$ y_ {ini} \: = \: x_ {i} \: + \: \ displaystyle \ sum \ limit_ {j} y_ {j} w_ {ji} $$
Step 7 - Terapkan aktivasi sebagai berikut di atas input bersih untuk menghitung output -
$$ y_ {i} \: = \ begin {kasus} 1 & jika \: y_ {ini} \:> \: \ theta_ {i} \\ y_ {i} & if \: y_ {ini} \: = \: \ theta_ {i} \\ 0 & if \: y_ {ini} \: <\: \ theta_ {i} \ end {kasus} $$
Di sini $ \ theta_ {i} $ adalah ambang batas.
Step 8 - Siarkan keluaran ini yi ke semua unit lainnya.
Step 9 - Uji jaringan untuk hubungannya.
Evaluasi Fungsi Energi
Fungsi energi didefinisikan sebagai fungsi yang terikat dan fungsi yang tidak meningkat dari keadaan sistem.
Fungsi energi Ef, juga disebut Lyapunov function menentukan stabilitas jaringan Hopfield diskrit, dan dikarakterisasi sebagai berikut -
$$ E_ {f} \: = \: - \ frac {1} {2} \ displaystyle \ sum \ batas_ {i = 1} ^ n \ displaystyle \ sum \ batas_ {j = 1} ^ n y_ {i} y_ {j} w_ {ij} \: - \: \ displaystyle \ sum \ limit_ {i = 1} ^ n x_ {i} y_ {i} \: + \: \ displaystyle \ sum \ limit_ {i = 1} ^ n \ theta_ {i} y_ {i} $$
Condition - Dalam jaringan yang stabil, setiap kali keadaan node berubah, fungsi energi di atas akan berkurang.
Misalkan saat node i telah mengubah status dari $ y_i ^ {(k)} $ menjadi $ y_i ^ {(k \: + \: 1)} $ lalu perubahan Energi $ \ Delta E_ {f} $ diberikan oleh relasi berikut
$$ \ Delta E_ {f} \: = \: E_ {f} (y_i ^ {(k + 1)}) \: - \: E_ {f} (y_i ^ {(k)}) $$
$$ = \: - \ kiri (\ begin {array} {c} \ displaystyle \ sum \ limit_ {j = 1} ^ n w_ {ij} y_i ^ {(k)} \: + \: x_ {i} \: - \: \ theta_ {i} \ end {larik} \ kanan) (y_i ^ {(k + 1)} \: - \: y_i ^ {(k)}) $$
$$ = \: - \ :( net_ {i}) \ Delta y_ {i} $$
Di sini $ \ Delta y_ {i} \: = \: y_i ^ {(k \: + \: 1)} \: - \: y_i ^ {(k)} $
Perubahan energi bergantung pada fakta bahwa hanya satu unit yang dapat memperbarui aktivasi pada satu waktu.
Jaringan Hopfield Berkelanjutan
Dibandingkan dengan jaringan Discrete Hopfield, jaringan kontinu memiliki waktu sebagai variabel kontinu. Ini juga digunakan dalam masalah asosiasi otomatis dan pengoptimalan seperti masalah penjual keliling.
Model - Model atau arsitektur dapat dibangun dengan menambahkan komponen listrik seperti amplifier yang dapat memetakan tegangan input ke tegangan output melalui fungsi aktivasi sigmoid.
Evaluasi Fungsi Energi
$$ E_f = \ frac {1} {2} \ displaystyle \ sum \ limit_ {i = 1} ^ n \ sum _ {\ substack {j = 1 \\ j \ ne i}} ^ n y_i y_j w_ {ij} - \ displaystyle \ sum \ limit_ {i = 1} ^ n x_i y_i + \ frac {1} {\ lambda} \ displaystyle \ sum \ limit_ {i = 1} ^ n \ sum _ {\ substack {j = 1 \\ j \ ne i}} ^ n w_ {ij} g_ {ri} \ int_ {0} ^ {y_i} a ^ {- 1} (y) dy $$
Sini λ adalah parameter gain dan gri masukan konduktansi.
Ini adalah proses pembelajaran stokastik yang memiliki struktur berulang dan merupakan dasar dari teknik pengoptimalan awal yang digunakan di JST. Mesin Boltzmann ditemukan oleh Geoffrey Hinton dan Terry Sejnowski pada tahun 1985. Lebih jelasnya dapat diamati pada kata-kata Hinton pada Mesin Boltzmann.
“Fitur yang mengejutkan dari jaringan ini adalah ia hanya menggunakan informasi yang tersedia secara lokal. Perubahan bobot hanya bergantung pada perilaku dua unit yang terhubung, meskipun perubahan tersebut mengoptimalkan ukuran global ”- Ackley, Hinton 1985.
Beberapa poin penting tentang Mesin Boltzmann -
Mereka menggunakan struktur berulang.
Mereka terdiri dari neuron stokastik, yang memiliki salah satu dari dua kemungkinan keadaan, baik 1 atau 0.
Beberapa neuron di sini bersifat adaptif (keadaan bebas) dan sebagian lagi dijepit (keadaan beku).
Jika kita menerapkan simulasi anil pada jaringan Hopfield diskrit, maka itu akan menjadi Mesin Boltzmann.
Tujuan Mesin Boltzmann
Tujuan utama dari Mesin Boltzmann adalah untuk mengoptimalkan solusi dari suatu masalah. Ini adalah pekerjaan Mesin Boltzmann untuk mengoptimalkan bobot dan kuantitas yang terkait dengan masalah khusus itu.
Arsitektur
Diagram berikut menunjukkan arsitektur mesin Boltzmann. Jelas dari diagram, bahwa ini adalah array unit dua dimensi. Di sini, bobot pada interkoneksi antar unit adalah–p dimana p > 0. Bobot koneksi diri diberikan olehb dimana b > 0.
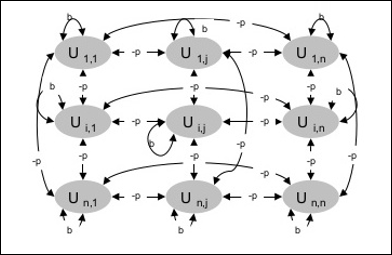
Algoritma Pelatihan
Seperti yang kita ketahui bahwa mesin Boltzmann memiliki bobot tetap, maka tidak akan ada algoritma pelatihan karena kita tidak perlu memperbarui bobot di jaringan. Namun, untuk menguji jaringan kita harus mengatur bobotnya serta menemukan fungsi konsensus (CF).
Mesin Boltzmann memiliki satu set unit Ui dan Uj dan memiliki koneksi dua arah padanya.
Kami sedang mempertimbangkan kata bobot tetap wij.
wij ≠ 0 jika Ui dan Uj terhubung.
Ada juga simetri dalam interkoneksi berbobot, yaitu wij = wji.
wii juga ada, yaitu akan ada hubungan mandiri antar unit.
Untuk unit apa pun Ui, statusnya ui akan menjadi 1 atau 0.
Tujuan utama dari Mesin Boltzmann adalah untuk memaksimalkan Fungsi Konsensus (CF) yang dapat diberikan oleh relasi berikut
$$ CF \: = \: \ displaystyle \ sum \ limit_ {i} \ displaystyle \ sum \ limit_ {j \ leqslant i} w_ {ij} u_ {i} u_ {j} $$
Sekarang, ketika keadaan berubah dari 1 ke 0 atau dari 0 ke 1, maka perubahan konsensus dapat diberikan oleh relasi berikut -
$$ \ Delta CF \: = \ :( 1 \: - \: 2u_ {i}) (w_ {ij} \: + \: \ displaystyle \ sum \ limit_ {j \ neq i} u_ {i} w_ { ij}) $$
Sini ui adalah keadaan saat ini dari Ui.
Variasi koefisien (1 - 2ui) diberikan oleh relasi berikut -
$$ (1 \: - \: 2u_ {i}) \: = \: \ begin {cases} +1, & U_ {i} \: is \: saat ini \: off \\ - 1, & U_ {i } \: adalah \: saat ini \: pada \ end {kasus} $$
Umumnya, satuan Uitidak mengubah statusnya, tetapi jika tidak maka informasi tersebut akan berada di lokasi lokal unit. Dengan perubahan itu, juga akan terjadi peningkatan konsensus jaringan.
Probabilitas jaringan untuk menerima perubahan status unit diberikan oleh relasi berikut -
$$ AF (i, T) \: = \: \ frac {1} {1 \: + \: exp [- \ frac {\ Delta CF (i)} {T}]} $$
Sini, Tadalah parameter pengontrol. Ini akan berkurang saat CF mencapai nilai maksimum.
Menguji Algoritma
Step 1 - Inisialisasi berikut ini untuk memulai pelatihan -
- Bobot mewakili kendala masalah
- Parameter Kontrol T
Step 2 - Lanjutkan langkah 3-8, jika kondisi penghentian tidak benar.
Step 3 - Lakukan langkah 4-7.
Step 4 - Asumsikan bahwa salah satu state telah mengubah bobot dan memilih integer I, J sebagai nilai acak antara 1 dan n.
Step 5 - Hitung perubahan konsensus sebagai berikut -
$$ \ Delta CF \: = \ :( 1 \: - \: 2u_ {i}) (w_ {ij} \: + \: \ displaystyle \ sum \ limit_ {j \ neq i} u_ {i} w_ { ij}) $$
Step 6 - Hitung probabilitas bahwa jaringan ini akan menerima perubahan status
$$ AF (i, T) \: = \: \ frac {1} {1 \: + \: exp [- \ frac {\ Delta CF (i)} {T}]} $$
Step 7 - Terima atau tolak perubahan ini sebagai berikut -
Case I - jika R < AF, terima kembaliannya.
Case II - jika R ≥ AF, tolak kembaliannya.
Sini, R adalah bilangan acak antara 0 dan 1.
Step 8 - Kurangi parameter kontrol (suhu) sebagai berikut -
T(new) = 0.95T(old)
Step 9 - Tes untuk kondisi berhenti yang mungkin sebagai berikut -
- Suhu mencapai nilai yang ditentukan
- Tidak ada perubahan status untuk sejumlah iterasi tertentu
Jaringan saraf Brain-State-in-a-Box (BSB) adalah jaringan saraf nonlinear auto-asosiatif dan dapat diperluas ke hetero-asosiasi dengan dua atau lebih lapisan. Ini juga mirip dengan jaringan Hopfield. Ini diusulkan oleh JA Anderson, JW Silverstein, SA Ritz dan RS Jones pada tahun 1977.
Beberapa hal penting yang perlu diingat tentang BSB Network -
Ini adalah jaringan yang sepenuhnya terhubung dengan jumlah node maksimum tergantung pada dimensinya n dari ruang input.
Semua neuron diperbarui secara bersamaan.
Neuron mengambil nilai antara -1 hingga +1.
Formulasi Matematika
Fungsi node yang digunakan dalam jaringan BSB adalah fungsi ramp, yang dapat didefinisikan sebagai berikut -
$$ f (bersih) \: = \: min (1, \: max (-1, \: net)) $$
Fungsi ramp ini dibatasi dan kontinu.
Seperti yang kita ketahui bahwa setiap node akan mengubah statusnya, itu dapat dilakukan dengan bantuan relasi matematis berikut -
$$ x_ {t} (t \: + \: 1) \: = \: f \ left (\ begin {array} {c} \ displaystyle \ sum \ limit_ {j = 1} ^ n w_ {i, j } x_ {j} (t) \ end {larik} \ kanan) $$
Sini, xi(t) adalah negara bagian ith simpul pada waktu t.
Bobot dari ith node ke jth node dapat diukur dengan relasi berikut -
$$ w_ {ij} \: = \: \ frac {1} {P} \ displaystyle \ sum \ limit_ {p = 1} ^ P (v_ {p, i} \: v_ {p, j}) $$
Sini, P adalah jumlah pola pelatihan, yang bipolar.
Optimasi adalah suatu tindakan untuk membuat sesuatu seperti desain, situasi, sumber daya, dan sistem menjadi seefektif mungkin. Dengan menggunakan kemiripan antara fungsi biaya dan fungsi energi, kita dapat menggunakan neuron yang sangat saling berhubungan untuk memecahkan masalah pengoptimalan. Jaringan saraf semacam itu adalah jaringan Hopfield, yang terdiri dari satu lapisan yang berisi satu atau lebih neuron berulang yang terhubung sepenuhnya. Ini dapat digunakan untuk pengoptimalan.
Poin yang perlu diingat saat menggunakan jaringan Hopfield untuk pengoptimalan -
Fungsi energi harus minimal dari jaringan.
Ini akan menemukan solusi yang memuaskan daripada memilih salah satu dari pola yang disimpan.
Kualitas solusi yang ditemukan oleh jaringan Hopfield sangat bergantung pada status awal jaringan.
Masalah Penjual Bepergian
Menemukan rute terpendek yang ditempuh oleh salesman merupakan salah satu masalah komputasi yang dapat dioptimalkan dengan menggunakan neural network Hopfield.
Konsep Dasar TSP
Travelling Salesman Problem (TSP) adalah masalah pengoptimalan klasik yang harus dilalui oleh seorang salesman nkota, yang terhubung satu sama lain, menjaga biaya serta jarak tempuh seminimal mungkin. Misalnya, penjual harus melakukan perjalanan ke 4 kota A, B, C, D dan tujuannya adalah menemukan tur melingkar terpendek, ABC – D, sehingga meminimalkan biaya, yang juga termasuk biaya perjalanan dari kota terakhir D ke kota pertama A.
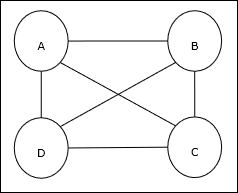
Representasi Matriks
Sebenarnya setiap wisata TSP n-kota bisa dinyatakan sebagai n × n matriks siapa ith baris menjelaskan ithlokasi kota. Matriks ini,M, untuk 4 kota A, B, C, D dapat dinyatakan sebagai berikut -
$$ M = \ begin {bmatrix} A: & 1 & 0 & 0 & 0 \\ B: & 0 & 1 & 0 & 0 \\ C: & 0 & 0 & 1 & 0 \\ D: & 0 & 0 & 0 & 1 \ end {bmatrix} $$
Solusi oleh Jaringan Hopfield
Sambil mempertimbangkan solusi jaringan TSP by Hopfield ini, setiap node dalam jaringan sesuai dengan satu elemen dalam matriks.
Perhitungan Fungsi Energi
Untuk menjadi solusi yang optimal, fungsi energi harus minimum. Berdasarkan batasan berikut, kita dapat menghitung fungsi energi sebagai berikut -
Kendala-I
Batasan pertama, yang menjadi dasar kita akan menghitung fungsi energi, adalah bahwa satu elemen harus sama dengan 1 di setiap baris matriks M dan elemen lain di setiap baris harus sama dengan 0karena setiap kota hanya dapat menempati satu posisi dalam tur TSP. Batasan ini secara matematis dapat ditulis sebagai berikut -
$$ \ displaystyle \ sum \ limit_ {j = 1} ^ n M_ {x, j} \: = \: 1 \: untuk \: x \: \ in \: \ lbrace1, ..., n \ rbrace $ $
Sekarang fungsi energi yang akan diminimalkan, berdasarkan batasan di atas, akan mengandung suku yang sebanding dengan -
$$ \ displaystyle \ sum \ limit_ {x = 1} ^ n \ kiri (\ begin {array} {c} 1 \: - \: \ displaystyle \ sum \ limit_ {j = 1} ^ n M_ {x, j } \ end {larik} \ kanan) ^ 2 $$
Kendala-II
Seperti yang kita ketahui, di TSP satu kota dapat terjadi di posisi manapun dalam tur maka di setiap kolom matriks M, satu elemen harus sama dengan 1 dan elemen lainnya harus sama dengan 0. Batasan ini secara matematis dapat ditulis sebagai berikut -
$$ \ displaystyle \ sum \ limit_ {x = 1} ^ n M_ {x, j} \: = \: 1 \: untuk \: j \: \ in \: \ lbrace1, ..., n \ rbrace $ $
Sekarang fungsi energi yang akan diminimalkan, berdasarkan batasan di atas, akan mengandung suku yang sebanding dengan -
$$ \ displaystyle \ sum \ limit_ {j = 1} ^ n \ kiri (\ begin {array} {c} 1 \: - \: \ displaystyle \ sum \ limit_ {x = 1} ^ n M_ {x, j } \ end {larik} \ kanan) ^ 2 $$
Perhitungan Fungsi Biaya
Misalkan matriks persegi (n × n) dilambangkan dengan C menunjukkan matriks biaya TSP untuk n kota dimana n > 0. Berikut adalah beberapa parameter saat menghitung fungsi biaya -
Cx, y - Elemen matriks biaya menunjukkan biaya perjalanan dari kota x untuk y.
Kedekatan elemen A dan B dapat ditunjukkan oleh relasi berikut:
$$ M_ {x, i} \: = \: 1 \: \: dan \: \: M_ {y, i \ pm 1} \: = \: 1 $$
Seperti yang kita ketahui, dalam Matriks nilai keluaran setiap node bisa 0 atau 1, maka untuk setiap pasangan kota A, B kita dapat menambahkan suku-suku berikut ke fungsi energi -
$$ \ displaystyle \ sum \ limit_ {i = 1} ^ n C_ {x, y} M_ {x, i} (M_ {y, i + 1} \: + \: M_ {y, i-1}) $$
Berdasarkan fungsi biaya di atas dan nilai kendala, fungsi energi final E dapat diberikan sebagai berikut -
$$ E \: = \: \ frac {1} {2} \ displaystyle \ sum \ limit_ {i = 1} ^ n \ displaystyle \ sum \ limit_ {x} \ displaystyle \ sum \ limit_ {y \ neq x} C_ {x, y} M_ {x, i} (M_ {y, i + 1} \: + \: M_ {y, i-1}) \: + $$
$$ \: \ begin {bmatrix} \ gamma_ {1} \ displaystyle \ sum \ limit_ {x} \ kiri (\ begin {array} {c} 1 \: - \: \ displaystyle \ sum \ limit_ {i} M_ {x, i} \ end {array} \ right) ^ 2 \: + \: \ gamma_ {2} \ displaystyle \ sum \ limit_ {i} \ left (\ begin {array} {c} 1 \: - \ : \ displaystyle \ sum \ limit_ {x} M_ {x, i} \ end {array} \ kanan) ^ 2 \ end {bmatrix} $$
Sini, γ1 dan γ2 adalah dua konstanta penimbangan.
Teknik Penurunan Gradien Berulang
Penurunan gradien, juga dikenal sebagai penurunan paling curam, adalah algoritme pengoptimalan berulang untuk menemukan minimum lokal suatu fungsi. Sambil meminimalkan fungsi, kami prihatin dengan biaya atau kesalahan yang akan diminimalkan (Ingat Masalah Penjual Perjalanan). Ini banyak digunakan dalam pembelajaran mendalam, yang berguna dalam berbagai situasi. Hal yang perlu diingat di sini adalah bahwa kami memperhatikan pengoptimalan lokal dan bukan pengoptimalan global.
Ide Kerja Utama
Kita dapat memahami ide kerja utama penurunan gradien dengan bantuan langkah-langkah berikut -
Pertama, mulailah dengan menebak solusi awal.
Kemudian, ambil gradien fungsi pada titik tersebut.
Kemudian, ulangi proses tersebut dengan melangkah solusi ke arah negatif gradien.
By following the above steps, the algorithm will eventually converge where the gradient is zero.
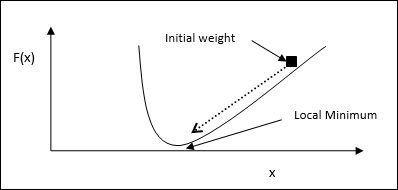
Mathematical Concept
Suppose we have a function f(x) and we are trying to find the minimum of this function. Following are the steps to find the minimum of f(x).
First, give some initial value $x_{0}\:for\:x$
Now take the gradient $\nabla f$ of function, with the intuition that the gradient will give the slope of the curve at that x and its direction will point to the increase in the function, to find out the best direction to minimize it.
Now change x as follows −
$$x_{n\:+\:1}\:=\:x_{n}\:-\:\theta \nabla f(x_{n})$$
Here, θ > 0 is the training rate (step size) that forces the algorithm to take small jumps.
Estimating Step Size
Actually a wrong step size θ may not reach convergence, hence a careful selection of the same is very important. Following points must have to be remembered while choosing the step size
Do not choose too large step size, otherwise it will have a negative impact, i.e. it will diverge rather than converge.
Do not choose too small step size, otherwise it take a lot of time to converge.
Some options with regards to choosing the step size −
One option is to choose a fixed step size.
Another option is to choose a different step size for every iteration.
Simulated Annealing
The basic concept of Simulated Annealing (SA) is motivated by the annealing in solids. In the process of annealing, if we heat a metal above its melting point and cool it down then the structural properties will depend upon the rate of cooling. We can also say that SA simulates the metallurgy process of annealing.
Use in ANN
SA is a stochastic computational method, inspired by Annealing analogy, for approximating the global optimization of a given function. We can use SA to train feed-forward neural networks.
Algorithm
Step 1 − Generate a random solution.
Step 2 − Calculate its cost using some cost function.
Step 3 − Generate a random neighboring solution.
Step 4 − Calculate the new solution cost by the same cost function.
Step 5 − Compare the cost of a new solution with that of an old solution as follows −
If CostNew Solution < CostOld Solution then move to the new solution.
Step 6 − Test for the stopping condition, which may be the maximum number of iterations reached or get an acceptable solution.
Nature has always been a great source of inspiration to all mankind. Genetic Algorithms (GAs) are search-based algorithms based on the concepts of natural selection and genetics. GAs are a subset of a much larger branch of computation known as Evolutionary Computation.
GAs was developed by John Holland and his students and colleagues at the University of Michigan, most notably David E. Goldberg and has since been tried on various optimization problems with a high degree of success.
In GAs, we have a pool or a population of possible solutions to the given problem. These solutions then undergo recombination and mutation (like in natural genetics), producing new children, and the process is repeated over various generations. Each individual (or candidate solution) is assigned a fitness value (based on its objective function value) and the fitter individuals are given a higher chance to mate and yield more “fitter” individuals. This is in line with the Darwinian Theory of “Survival of the Fittest”.
In this way, we keep “evolving” better individuals or solutions over generations, till we reach a stopping criterion.
Genetic Algorithms are sufficiently randomized in nature, however they perform much better than random local search (in which we just try various random solutions, keeping track of the best so far), as they exploit historical information as well.
Advantages of GAs
GAs have various advantages which have made them immensely popular. These include −
Does not require any derivative information (which may not be available for many real-world problems).
Is faster and more efficient as compared to the traditional methods.
Has very good parallel capabilities.
Optimizes both continuous and discrete functions as well as multi-objective problems.
Provides a list of “good” solutions and not just a single solution.
Always gets an answer to the problem, which gets better over the time.
Useful when the search space is very large and there are large number of parameters involved.
Limitations of GAs
Like any technique, GAs also suffers from a few limitations. These include −
GAs are not suited for all problems, especially problems which are simple and for which derivative information is available.
Fitness value is calculated repeatedly, which might be computationally expensive for some problems.
Being stochastic, there are no guarantees on the optimality or the quality of the solution.
If not implemented properly, GA may not converge to the optimal solution.
GA – Motivation
Genetic Algorithms have the ability to deliver a “good-enough” solution “fast-enough”. This makes Gas attractive for use in solving optimization problems. The reasons why GAs are needed are as follows −
Solving Difficult Problems
In computer science, there is a large set of problems, which are NP-Hard. What this essentially means is that, even the most powerful computing systems take a very long time (even years!) to solve that problem. In such a scenario, GAs prove to be an efficient tool to provide usable near-optimal solutions in a short amount of time.
Failure of Gradient Based Methods
Traditional calculus based methods work by starting at a random point and by moving in the direction of the gradient, till we reach the top of the hill. This technique is efficient and works very well for single-peaked objective functions like the cost function in linear regression. However, in most real-world situations, we have a very complex problem called as landscapes, made of many peaks and many valleys, which causes such methods to fail, as they suffer from an inherent tendency of getting stuck at the local optima as shown in the following figure.
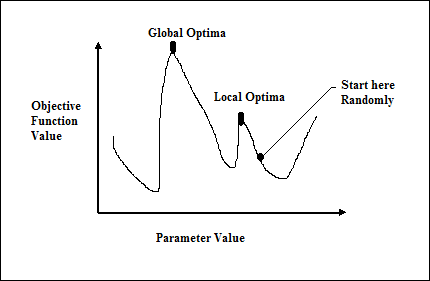
Getting a Good Solution Fast
Some difficult problems like the Travelling Salesman Problem (TSP), have real-world applications like path finding and VLSI Design. Now imagine that you are using your GPS Navigation system, and it takes a few minutes (or even a few hours) to compute the “optimal” path from the source to destination. Delay in such real-world applications is not acceptable and therefore a “good-enough” solution, which is delivered “fast” is what is required.
How to Use GA for Optimization Problems?
We already know that optimization is an action of making something such as design, situation, resource, and system as effective as possible. Optimization process is shown in the following diagram.

Stages of GA Mechanism for Optimization Process
Followings are the stages of GA mechanism when used for optimization of problems.
Generate the initial population randomly.
Select the initial solution with the best fitness values.
Recombine the selected solutions using mutation and crossover operators.
Insert offspring into the population.
Now if the stop condition is met, then return the solution with their best fitness value. Else, go to step 2.
Before studying the fields where ANN has been used extensively, we need to understand why ANN would be the preferred choice of application.
Why Artificial Neural Networks?
We need to understand the answer to the above question with an example of a human being. As a child, we used to learn the things with the help of our elders, which includes our parents or teachers. Then later by self-learning or practice we keep learning throughout our life. Scientists and researchers are also making the machine intelligent, just like a human being, and ANN plays a very important role in the same due to the following reasons −
With the help of neural networks, we can find the solution of such problems for which algorithmic method is expensive or does not exist.
Neural networks can learn by example, hence we do not need to program it at much extent.
Neural networks have the accuracy and significantly fast speed than conventional speed.
Areas of Application
Followings are some of the areas, where ANN is being used. It suggests that ANN has an interdisciplinary approach in its development and applications.
Speech Recognition
Speech occupies a prominent role in human-human interaction. Therefore, it is natural for people to expect speech interfaces with computers. In the present era, for communication with machines, humans still need sophisticated languages which are difficult to learn and use. To ease this communication barrier, a simple solution could be, communication in a spoken language that is possible for the machine to understand.
Great progress has been made in this field, however, still such kinds of systems are facing the problem of limited vocabulary or grammar along with the issue of retraining of the system for different speakers in different conditions. ANN is playing a major role in this area. Following ANNs have been used for speech recognition −
Multilayer networks
Multilayer networks with recurrent connections
Kohonen self-organizing feature map
The most useful network for this is Kohonen Self-Organizing feature map, which has its input as short segments of the speech waveform. It will map the same kind of phonemes as the output array, called feature extraction technique. After extracting the features, with the help of some acoustic models as back-end processing, it will recognize the utterance.
Character Recognition
It is an interesting problem which falls under the general area of Pattern Recognition. Many neural networks have been developed for automatic recognition of handwritten characters, either letters or digits. Following are some ANNs which have been used for character recognition −
- Multilayer neural networks such as Backpropagation neural networks.
- Neocognitron
Though back-propagation neural networks have several hidden layers, the pattern of connection from one layer to the next is localized. Similarly, neocognitron also has several hidden layers and its training is done layer by layer for such kind of applications.
Signature Verification Application
Signatures are one of the most useful ways to authorize and authenticate a person in legal transactions. Signature verification technique is a non-vision based technique.
For this application, the first approach is to extract the feature or rather the geometrical feature set representing the signature. With these feature sets, we have to train the neural networks using an efficient neural network algorithm. This trained neural network will classify the signature as being genuine or forged under the verification stage.
Human Face Recognition
It is one of the biometric methods to identify the given face. It is a typical task because of the characterization of “non-face” images. However, if a neural network is well trained, then it can be divided into two classes namely images having faces and images that do not have faces.
First, all the input images must be preprocessed. Then, the dimensionality of that image must be reduced. And, at last it must be classified using neural network training algorithm. Following neural networks are used for training purposes with preprocessed image −
Fully-connected multilayer feed-forward neural network trained with the help of back-propagation algorithm.
For dimensionality reduction, Principal Component Analysis (PCA) is used.