Pembelajaran yang Diawasi
Seperti namanya, supervised learningberlangsung di bawah pengawasan seorang guru. Proses pembelajaran ini tergantung. Selama pelatihan JST dalam supervised learning, vektor masukan dipresentasikan ke jaringan, yang akan menghasilkan vektor keluaran. Vektor keluaran ini dibandingkan dengan vektor keluaran yang diinginkan / target. Sinyal kesalahan dihasilkan jika ada perbedaan antara keluaran aktual dan vektor keluaran yang diinginkan / target. Berdasarkan sinyal kesalahan ini, bobot akan disesuaikan sampai keluaran aktual sesuai dengan keluaran yang diinginkan.
Perceptron
Dikembangkan oleh Frank Rosenblatt dengan menggunakan model McCulloch dan Pitts, perceptron adalah unit operasional dasar dari jaringan saraf tiruan. Ini menggunakan aturan pembelajaran yang diawasi dan mampu mengklasifikasikan data menjadi dua kelas.
Karakteristik operasional perceptron: Terdiri dari satu neuron dengan jumlah input yang berubah-ubah bersama dengan bobot yang dapat disesuaikan, tetapi output neuron adalah 1 atau 0 tergantung pada ambang batas. Ini juga terdiri dari bias yang bobotnya selalu 1. Gambar berikut memberikan representasi skematis dari perceptron.
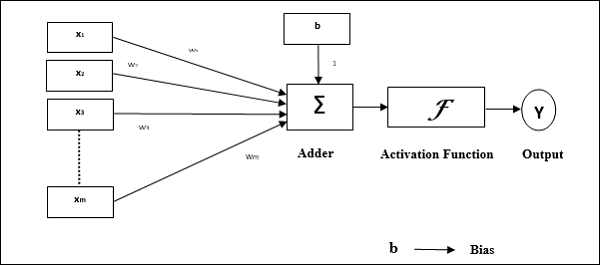
Perceptron dengan demikian memiliki tiga elemen dasar berikut -
Links - Ini akan memiliki satu set link koneksi, yang membawa bobot termasuk bias selalu berbobot 1.
Adder - Menambahkan input setelah dikalikan dengan bobotnya masing-masing.
Activation function- Ini membatasi keluaran neuron. Fungsi aktivasi paling dasar adalah fungsi langkah Heaviside yang memiliki dua kemungkinan keluaran. Fungsi ini mengembalikan 1, jika masukannya positif, dan 0 untuk masukan negatif apa pun.
Algoritma Pelatihan
Jaringan Perceptron dapat dilatih untuk unit keluaran tunggal maupun beberapa unit keluaran.
Algoritma Pelatihan untuk Unit Output Tunggal
Step 1 - Inisialisasi berikut ini untuk memulai pelatihan -
- Weights
- Bias
- Kecepatan pembelajaran $ \ alpha $
Untuk penghitungan dan kesederhanaan yang mudah, bobot dan bias harus disetel sama dengan 0 dan kecepatan pemelajaran harus disetel sama dengan 1.
Step 2 - Lanjutkan langkah 3-8 jika kondisi penghentian tidak benar.
Step 3 - Lanjutkan langkah 4-6 untuk setiap vektor pelatihan x.
Step 4 - Aktifkan setiap unit input sebagai berikut -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: hingga \: n) $$
Step 5 - Sekarang dapatkan input bersih dengan relasi berikut -
$$ y_ {in} \: = \: b \: + \: \ displaystyle \ sum \ limit_ {i} ^ n x_ {i}. \: w_ {i} $$
Sini ‘b’ adalah bias dan ‘n’ adalah jumlah total neuron masukan.
Step 6 - Terapkan fungsi aktivasi berikut untuk mendapatkan hasil akhir.
$$ f (y_ {in}) \: = \: \ begin {cases} 1 & if \: y_ {in} \:> \: \ theta \\ 0 & if \: - \ theta \: \ leqslant \ : y_ {dalam} \: \ leqslant \: \ theta \\ - 1 & if \: y_ {dalam} \: <\: - \ theta \ end {kasus} $$
Step 7 - Sesuaikan bobot dan bias sebagai berikut -
Case 1 - jika y ≠ t kemudian,
$$ w_ {i} (baru) \: = \: w_ {i} (lama) \: + \: \ alpha \: tx_ {i} $$
$$ b (baru) \: = \: b (lama) \: + \: \ alpha t $$
Case 2 - jika y = t kemudian,
$$ w_ {i} (baru) \: = \: w_ {i} (lama) $$
$$ b (baru) \: = \: b (lama) $$
Sini ‘y’ adalah keluaran aktual dan ‘t’ adalah keluaran yang diinginkan / target.
Step 8 - Uji kondisi berhenti, yang akan terjadi bila tidak ada perubahan berat.
Algoritma Pelatihan untuk Beberapa Unit Output
Diagram berikut adalah arsitektur perceptron untuk beberapa kelas keluaran.
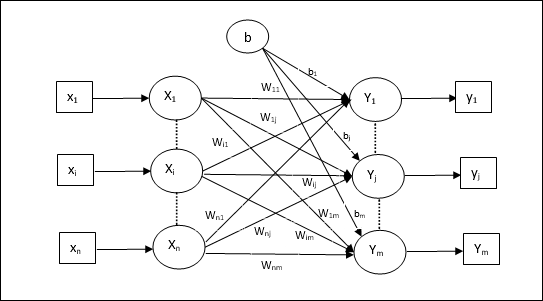
Step 1 - Inisialisasi berikut ini untuk memulai pelatihan -
- Weights
- Bias
- Kecepatan pembelajaran $ \ alpha $
Untuk penghitungan dan kesederhanaan yang mudah, bobot dan bias harus disetel sama dengan 0 dan kecepatan pemelajaran harus disetel sama dengan 1.
Step 2 - Lanjutkan langkah 3-8 jika kondisi penghentian tidak benar.
Step 3 - Lanjutkan langkah 4-6 untuk setiap vektor pelatihan x.
Step 4 - Aktifkan setiap unit input sebagai berikut -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: hingga \: n) $$
Step 5 - Dapatkan input bersih dengan relasi berikut -
$$ y_ {in} \: = \: b \: + \: \ displaystyle \ sum \ limit_ {i} ^ n x_ {i} \: w_ {ij} $$
Sini ‘b’ adalah bias dan ‘n’ adalah jumlah total neuron masukan.
Step 6 - Terapkan fungsi aktivasi berikut untuk mendapatkan hasil akhir untuk setiap unit keluaran j = 1 to m -
$$ f (y_ {in}) \: = \: \ begin {kasus} 1 & if \: y_ {inj} \:> \: \ theta \\ 0 & if \: - \ theta \: \ leqslant \ : y_ {inj} \: \ leqslant \: \ theta \\ - 1 & if \: y_ {inj} \: <\: - \ theta \ end {kasus} $$
Step 7 - Sesuaikan bobot dan biasnya x = 1 to n dan j = 1 to m sebagai berikut -
Case 1 - jika yj ≠ tj kemudian,
$$ w_ {ij} (baru) \: = \: w_ {ij} (lama) \: + \: \ alpha \: t_ {j} x_ {i} $$
$$ b_ {j} (baru) \: = \: b_ {j} (lama) \: + \: \ alpha t_ {j} $$
Case 2 - jika yj = tj kemudian,
$$ w_ {ij} (baru) \: = \: w_ {ij} (lama) $$
$$ b_ {j} (baru) \: = \: b_ {j} (lama) $$
Sini ‘y’ adalah keluaran aktual dan ‘t’ adalah keluaran yang diinginkan / target.
Step 8 - Tes untuk kondisi berhenti, yang akan terjadi bila tidak ada perubahan berat.
Saraf Linear Adaptif (Adaline)
Adaline yang merupakan singkatan dari Adaptive Linear Neuron, merupakan jaringan yang memiliki satuan linier tunggal. Ini dikembangkan oleh Widrow dan Hoff pada tahun 1960. Beberapa poin penting tentang Adaline adalah sebagai berikut -
Ini menggunakan fungsi aktivasi bipolar.
Ini menggunakan aturan delta untuk pelatihan untuk meminimalkan Mean-Squared Error (MSE) antara keluaran aktual dan keluaran yang diinginkan / target.
Bobot dan biasnya bisa disesuaikan.
Arsitektur
Struktur dasar Adaline mirip dengan perceptron yang memiliki umpan balik ekstra dengan bantuan yang keluaran aktualnya dibandingkan dengan keluaran yang diinginkan / target. Setelah dibandingkan berdasarkan algoritma pelatihan, bobot dan bias akan diperbarui.
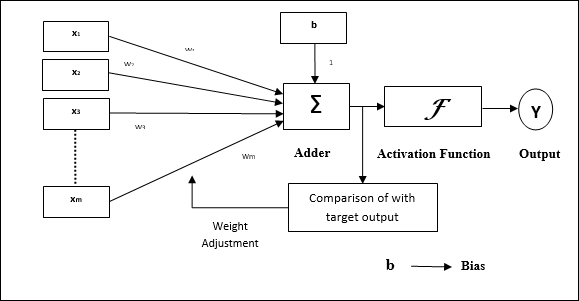
Algoritma Pelatihan
Step 1 - Inisialisasi berikut ini untuk memulai pelatihan -
- Weights
- Bias
- Kecepatan pembelajaran $ \ alpha $
Untuk penghitungan dan kesederhanaan yang mudah, bobot dan bias harus disetel sama dengan 0 dan kecepatan pemelajaran harus disetel sama dengan 1.
Step 2 - Lanjutkan langkah 3-8 jika kondisi penghentian tidak benar.
Step 3 - Lanjutkan langkah 4-6 untuk setiap pasangan latihan bipolar s:t.
Step 4 - Aktifkan setiap unit input sebagai berikut -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: hingga \: n) $$
Step 5 - Dapatkan input bersih dengan relasi berikut -
$$ y_ {in} \: = \: b \: + \: \ displaystyle \ sum \ limit_ {i} ^ n x_ {i} \: w_ {i} $$
Sini ‘b’ adalah bias dan ‘n’ adalah jumlah total neuron masukan.
Step 6 - Terapkan fungsi aktivasi berikut untuk mendapatkan hasil akhir -
$$ f (y_ {in}) \: = \: \ begin {cases} 1 & if \: y_ {in} \: \ geqslant \: 0 \\ - 1 & if \: y_ {in} \: < \: 0 \ end {kasus} $$
Step 7 - Sesuaikan bobot dan bias sebagai berikut -
Case 1 - jika y ≠ t kemudian,
$$ w_ {i} (baru) \: = \: w_ {i} (lama) \: + \: \ alpha (t \: - \: y_ {in}) x_ {i} $$
$$ b (baru) \: = \: b (lama) \: + \: \ alpha (t \: - \: y_ {in}) $$
Case 2 - jika y = t kemudian,
$$ w_ {i} (baru) \: = \: w_ {i} (lama) $$
$$ b (baru) \: = \: b (lama) $$
Sini ‘y’ adalah keluaran aktual dan ‘t’ adalah keluaran yang diinginkan / target.
$ (t \: - \; y_ {in}) $ adalah kesalahan yang dihitung.
Step 8 - Tes untuk kondisi berhenti, yang akan terjadi bila tidak ada perubahan bobot atau perubahan bobot tertinggi yang terjadi selama latihan lebih kecil dari toleransi yang ditentukan.
Saraf Linear Adaptif Ganda (Madaline)
Madaline yang merupakan singkatan dari Multiple Adaptive Linear Neuron, merupakan jaringan yang terdiri dari banyak Adaline secara paralel. Ini akan memiliki satu unit keluaran. Beberapa poin penting tentang Madaline adalah sebagai berikut -
Ini seperti perceptron multilayer, di mana Adaline akan bertindak sebagai unit tersembunyi antara input dan lapisan Madaline.
Bobot dan bias antara input dan layer Adaline, seperti yang kita lihat pada arsitektur Adaline, dapat disesuaikan.
Lapisan Adaline dan Madaline memiliki bobot tetap dan bias 1.
Pelatihan dapat dilakukan dengan bantuan aturan Delta.
Arsitektur
Arsitektur Madaline terdiri dari “n” neuron dari lapisan masukan, “m”neuron dari lapisan Adaline, dan 1 neuron dari lapisan Madaline. Lapisan Adaline dapat dianggap sebagai lapisan tersembunyi karena berada di antara lapisan masukan dan lapisan keluaran, yaitu lapisan Madaline.
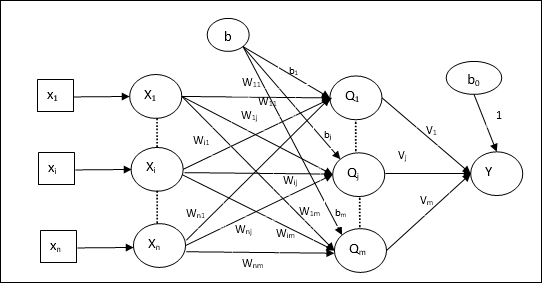
Algoritma Pelatihan
Sekarang kita tahu bahwa hanya bobot dan bias antara input dan lapisan Adaline yang akan disesuaikan, dan bobot serta bias antara lapisan Adaline dan Madaline sudah diperbaiki.
Step 1 - Inisialisasi berikut ini untuk memulai pelatihan -
- Weights
- Bias
- Kecepatan pembelajaran $ \ alpha $
Untuk penghitungan dan kesederhanaan yang mudah, bobot dan bias harus disetel sama dengan 0 dan kecepatan pemelajaran harus disetel sama dengan 1.
Step 2 − Continue step 3-8 when the stopping condition is not true.
Step 3 − Continue step 4-6 for every bipolar training pair s:t.
Step 4 − Activate each input unit as follows −
$$x_{i}\:=\:s_{i}\:(i\:=\:1\:to\:n)$$
Step 5 − Obtain the net input at each hidden layer, i.e. the Adaline layer with the following relation −
$$Q_{inj}\:=\:b_{j}\:+\:\displaystyle\sum\limits_{i}^n x_{i}\:w_{ij}\:\:\:j\:=\:1\:to\:m$$
Here ‘b’ is bias and ‘n’ is the total number of input neurons.
Step 6 − Apply the following activation function to obtain the final output at the Adaline and the Madaline layer −
$$f(x)\:=\:\begin{cases}1 & if\:x\:\geqslant\:0 \\-1 & if\:x\:<\:0 \end{cases}$$
Output at the hidden (Adaline) unit
$$Q_{j}\:=\:f(Q_{inj})$$
Final output of the network
$$y\:=\:f(y_{in})$$
i.e. $\:\:y_{inj}\:=\:b_{0}\:+\:\sum_{j = 1}^m\:Q_{j}\:v_{j}$
Step 7 − Calculate the error and adjust the weights as follows −
Case 1 − if y ≠ t and t = 1 then,
$$w_{ij}(new)\:=\:w_{ij}(old)\:+\: \alpha(1\:-\:Q_{inj})x_{i}$$
$$b_{j}(new)\:=\:b_{j}(old)\:+\: \alpha(1\:-\:Q_{inj})$$
In this case, the weights would be updated on Qj where the net input is close to 0 because t = 1.
Case 2 − if y ≠ t and t = -1 then,
$$w_{ik}(new)\:=\:w_{ik}(old)\:+\: \alpha(-1\:-\:Q_{ink})x_{i}$$
$$b_{k}(new)\:=\:b_{k}(old)\:+\: \alpha(-1\:-\:Q_{ink})$$
In this case, the weights would be updated on Qk where the net input is positive because t = -1.
Here ‘y’ is the actual output and ‘t’ is the desired/target output.
Case 3 − if y = t then
There would be no change in weights.
Step 8 − Test for the stopping condition, which will happen when there is no change in weight or the highest weight change occurred during training is smaller than the specified tolerance.
Back Propagation Neural Networks
Back Propagation Neural (BPN) is a multilayer neural network consisting of the input layer, at least one hidden layer and output layer. As its name suggests, back propagating will take place in this network. The error which is calculated at the output layer, by comparing the target output and the actual output, will be propagated back towards the input layer.
Architecture
As shown in the diagram, the architecture of BPN has three interconnected layers having weights on them. The hidden layer as well as the output layer also has bias, whose weight is always 1, on them. As is clear from the diagram, the working of BPN is in two phases. One phase sends the signal from the input layer to the output layer, and the other phase back propagates the error from the output layer to the input layer.

Training Algorithm
For training, BPN will use binary sigmoid activation function. The training of BPN will have the following three phases.
Phase 1 − Feed Forward Phase
Phase 2 − Back Propagation of error
Phase 3 − Updating of weights
All these steps will be concluded in the algorithm as follows
Step 1 − Initialize the following to start the training −
- Weights
- Learning rate $\alpha$
For easy calculation and simplicity, take some small random values.
Step 2 − Continue step 3-11 when the stopping condition is not true.
Step 3 − Continue step 4-10 for every training pair.
Phase 1
Step 4 − Each input unit receives input signal xi and sends it to the hidden unit for all i = 1 to n
Step 5 − Calculate the net input at the hidden unit using the following relation −
$$Q_{inj}\:=\:b_{0j}\:+\:\sum_{i=1}^n x_{i}v_{ij}\:\:\:\:j\:=\:1\:to\:p$$
Here b0j is the bias on hidden unit, vij is the weight on j unit of the hidden layer coming from i unit of the input layer.
Now calculate the net output by applying the following activation function
$$Q_{j}\:=\:f(Q_{inj})$$
Send these output signals of the hidden layer units to the output layer units.
Step 6 − Calculate the net input at the output layer unit using the following relation −
$$y_{ink}\:=\:b_{0k}\:+\:\sum_{j = 1}^p\:Q_{j}\:w_{jk}\:\:k\:=\:1\:to\:m$$
Here b0k is the bias on output unit, wjk is the weight on k unit of the output layer coming from j unit of the hidden layer.
Calculate the net output by applying the following activation function
$$y_{k}\:=\:f(y_{ink})$$
Phase 2
Step 7 − Compute the error correcting term, in correspondence with the target pattern received at each output unit, as follows −
$$\delta_{k}\:=\:(t_{k}\:-\:y_{k})f^{'}(y_{ink})$$
On this basis, update the weight and bias as follows −
$$\Delta v_{jk}\:=\:\alpha \delta_{k}\:Q_{ij}$$
$$\Delta b_{0k}\:=\:\alpha \delta_{k}$$
Then, send $\delta_{k}$ back to the hidden layer.
Step 8 − Now each hidden unit will be the sum of its delta inputs from the output units.
$$\delta_{inj}\:=\:\displaystyle\sum\limits_{k=1}^m \delta_{k}\:w_{jk}$$
Error term can be calculated as follows −
$$\delta_{j}\:=\:\delta_{inj}f^{'}(Q_{inj})$$
On this basis, update the weight and bias as follows −
$$\Delta w_{ij}\:=\:\alpha\delta_{j}x_{i}$$
$$\Delta b_{0j}\:=\:\alpha\delta_{j}$$
Phase 3
Step 9 − Each output unit (ykk = 1 to m) updates the weight and bias as follows −
$$v_{jk}(new)\:=\:v_{jk}(old)\:+\:\Delta v_{jk}$$
$$b_{0k}(new)\:=\:b_{0k}(old)\:+\:\Delta b_{0k}$$
Step 10 − Each output unit (zjj = 1 to p) updates the weight and bias as follows −
$$w_{ij}(new)\:=\:w_{ij}(old)\:+\:\Delta w_{ij}$$
$$b_{0j}(new)\:=\:b_{0j}(old)\:+\:\Delta b_{0j}$$
Step 11 − Check for the stopping condition, which may be either the number of epochs reached or the target output matches the actual output.
Generalized Delta Learning Rule
Delta rule works only for the output layer. On the other hand, generalized delta rule, also called as back-propagation rule, is a way of creating the desired values of the hidden layer.
Mathematical Formulation
For the activation function $y_{k}\:=\:f(y_{ink})$ the derivation of net input on Hidden layer as well as on output layer can be given by
$$y_{ink}\:=\:\displaystyle\sum\limits_i\:z_{i}w_{jk}$$
And $\:\:y_{inj}\:=\:\sum_i x_{i}v_{ij}$
Now the error which has to be minimized is
$$E\:=\:\frac{1}{2}\displaystyle\sum\limits_{k}\:[t_{k}\:-\:y_{k}]^2$$
By using the chain rule, we have
$$\frac{\partial E}{\partial w_{jk}}\:=\:\frac{\partial }{\partial w_{jk}}(\frac{1}{2}\displaystyle\sum\limits_{k}\:[t_{k}\:-\:y_{k}]^2)$$
$$=\:\frac{\partial }{\partial w_{jk}}\lgroup\frac{1}{2}[t_{k}\:-\:t(y_{ink})]^2\rgroup$$
$$=\:-[t_{k}\:-\:y_{k}]\frac{\partial }{\partial w_{jk}}f(y_{ink})$$
$$=\:-[t_{k}\:-\:y_{k}]f(y_{ink})\frac{\partial }{\partial w_{jk}}(y_{ink})$$
$$=\:-[t_{k}\:-\:y_{k}]f^{'}(y_{ink})z_{j}$$
Now let us say $\delta_{k}\:=\:-[t_{k}\:-\:y_{k}]f^{'}(y_{ink})$
The weights on connections to the hidden unit zj can be given by −
$$\frac{\partial E}{\partial v_{ij}}\:=\:- \displaystyle\sum\limits_{k} \delta_{k}\frac{\partial }{\partial v_{ij}}\:(y_{ink})$$
Putting the value of $y_{ink}$ we will get the following
$$\delta_{j}\:=\:-\displaystyle\sum\limits_{k}\delta_{k}w_{jk}f^{'}(z_{inj})$$
Weight updating can be done as follows −
For the output unit −
$$\Delta w_{jk}\:=\:-\alpha\frac{\partial E}{\partial w_{jk}}$$
$$=\:\alpha\:\delta_{k}\:z_{j}$$
For the hidden unit −
$$\Delta v_{ij}\:=\:-\alpha\frac{\partial E}{\partial v_{ij}}$$
$$=\:\alpha\:\delta_{j}\:x_{i}$$