Pembelajaran Tanpa Pengawasan
Seperti namanya, pembelajaran jenis ini dilakukan tanpa pengawasan seorang guru. Proses pembelajaran ini mandiri. Selama pelatihan JST dalam pembelajaran tanpa pengawasan, vektor input dari jenis yang sama digabungkan untuk membentuk cluster. Ketika pola masukan baru diterapkan, maka jaringan saraf memberikan tanggapan keluaran yang menunjukkan kelas yang memiliki pola masukan. Dalam hal ini, tidak akan ada umpan balik dari lingkungan tentang apa yang seharusnya menjadi keluaran yang diinginkan dan apakah itu benar atau salah. Oleh karena itu, dalam pembelajaran jenis ini jaringan itu sendiri harus menemukan pola, fitur dari data masukan dan hubungan untuk data masukan melalui keluaran.
Pemenang-Mengambil-Semua Jaringan
Jenis jaringan ini didasarkan pada aturan pembelajaran kompetitif dan akan menggunakan strategi di mana ia memilih neuron dengan total input terbesar sebagai pemenang. Koneksi antara neuron keluaran menunjukkan persaingan di antara mereka dan salah satunya akan menjadi 'ON' yang berarti akan menjadi pemenang dan yang lainnya akan menjadi 'OFF'.
Berikut adalah beberapa jaringan yang didasarkan pada konsep sederhana ini dengan menggunakan pembelajaran tanpa pengawasan.
Jaringan Hamming
Di sebagian besar jaringan saraf yang menggunakan pembelajaran tanpa pengawasan, penting untuk menghitung jarak dan melakukan perbandingan. Jaringan jenis ini adalah jaringan Hamming, dimana untuk setiap vektor masukan yang diberikan akan dikelompokkan menjadi beberapa kelompok yang berbeda. Berikut adalah beberapa fitur penting dari Hamming Networks -
Lippmann mulai mengerjakan jaringan Hamming pada tahun 1987.
Ini adalah jaringan lapisan tunggal.
Input dapat berupa biner {0, 1} bipolar {-1, 1}.
Bobot jaring dihitung dengan vektor contoh.
Ini adalah jaringan beban tetap yang berarti bobot akan tetap sama bahkan selama pelatihan.
Max Net
Ini juga merupakan jaringan bobot tetap, yang berfungsi sebagai subnet untuk memilih node yang memiliki input tertinggi. Semua node saling berhubungan sepenuhnya dan terdapat bobot simetris di semua interkoneksi berbobot ini.
Arsitektur
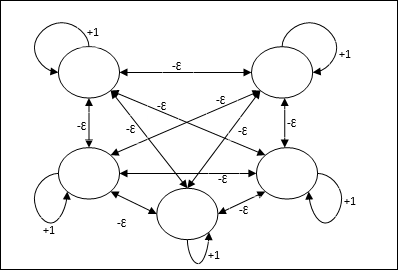
Ini menggunakan mekanisme yang merupakan proses berulang dan setiap node menerima input penghambatan dari semua node lain melalui koneksi. Node tunggal yang nilainya maksimum akan aktif atau menjadi pemenang dan aktivasi semua node lainnya tidak akan aktif. Max Net menggunakan fungsi aktivasi identitas dengan $$ f (x) \: = \: \ begin {cases} x & if \: x> 0 \\ 0 & if \: x \ leq 0 \ end {cases} $$
Tugas jaring ini diselesaikan dengan bobot eksitasi diri +1 dan besaran penghambatan timbal balik, yang ditetapkan seperti [0 <ɛ <$ \ frac {1} {m} $] di mana “m” adalah jumlah total node.
Pembelajaran Kompetitif di ANN
Ini berkaitan dengan pelatihan tanpa pengawasan di mana simpul keluaran mencoba bersaing satu sama lain untuk mewakili pola masukan. Untuk memahami aturan pembelajaran ini kita harus memahami jaring kompetitif yang dijelaskan sebagai berikut -
Konsep Dasar Jaringan Kompetitif
Jaringan ini seperti jaringan umpan-maju lapisan tunggal yang memiliki koneksi umpan balik antara keluaran. Hubungan antar output adalah tipe inhibitory, yang ditunjukkan dengan garis putus-putus, artinya kompetitor tidak pernah menyokong dirinya sendiri.
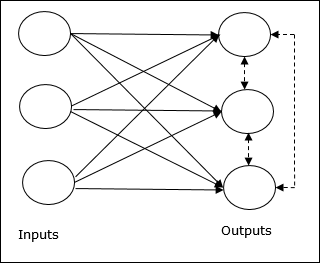
Konsep Dasar Aturan Pembelajaran Bersaing
Seperti yang dikatakan sebelumnya, akan ada persaingan di antara node keluaran sehingga konsep utamanya adalah - selama pelatihan, unit keluaran yang memiliki aktivasi tertinggi ke pola masukan tertentu, akan dinyatakan sebagai pemenang. Aturan ini juga disebut Pemenang-mengambil-semua karena hanya neuron pemenang yang diperbarui dan neuron lainnya dibiarkan tidak berubah.
Rumusan Matematika
Berikut adalah tiga faktor penting untuk perumusan matematika dari aturan pembelajaran ini -
Syarat menjadi pemenang
Misalkan jika neuron yk ingin menjadi pemenang, maka harus ada syarat sebagai berikut
$$ y_ {k} \: = \: \ begin {cases} 1 & if \: v_ {k}> v_ {j} \: for \: all \: \: j, \: j \: \ neq \ : k \\ 0 & sebaliknya \ end {cases} $$
Artinya jika ada neuron, katakanlah, yk ingin menang, kemudian bidang lokalnya yang diinduksi (keluaran unit penjumlahan), katakanlah vk, harus menjadi yang terbesar di antara semua neuron lain di jaringan.
Kondisi penjumlahan total bobot
Kendala lain atas aturan pembelajaran kompetitif adalah jumlah total bobot ke neuron keluaran tertentu akan menjadi 1. Misalnya, jika kita mempertimbangkan neuron k kemudian
$$ \ displaystyle \ sum \ limit_ {k} w_ {kj} \: = \: 1 \: \: \: \: untuk \: semua \: \: k $$
Perubahan bobot untuk pemenang
Jika neuron tidak merespons pola masukan, maka tidak ada pembelajaran yang terjadi di neuron itu. Namun, jika neuron tertentu menang, maka bobot yang sesuai akan disesuaikan sebagai berikut -
$$ \ Delta w_ {kj} \: = \: \ begin {kasus} - \ alpha (x_ {j} \: - \: w_ {kj}), & jika \: neuron \: k \: menang \\ 0 & jika \: neuron \: k \: kerugian \ end {kasus} $$
Di sini $ \ alpha $ adalah kecepatan pemelajaran.
Hal ini jelas menunjukkan bahwa kita lebih menyukai neuron pemenang dengan menyesuaikan bobotnya dan jika neuron hilang, maka kita tidak perlu repot-repot mengatur ulang bobotnya.
Algoritma Pengelompokan K-means
K-means adalah salah satu algoritma pengelompokan paling populer di mana kami menggunakan konsep prosedur partisi. Kami mulai dengan partisi awal dan berulang kali memindahkan pola dari satu cluster ke cluster lain, sampai kami mendapatkan hasil yang memuaskan.
Algoritma
Step 1 - Pilih kmenunjuk sebagai sentroid awal. Inisialisasik prototipe (w1,…,wk), misalnya kita dapat mengidentifikasinya dengan vektor input yang dipilih secara acak -
$$ W_ {j} \: = \: i_ {p}, \: \: \: where \: j \: \ in \ lbrace1, ...., k \ rbrace \: dan \: p \: \ di \ lbrace1, ...., n \ rbrace $$
Setiap cluster Cj dikaitkan dengan prototipe wj.
Step 2 - Ulangi langkah 3-5 hingga E tidak lagi berkurang, atau keanggotaan cluster tidak lagi berubah.
Step 3 - Untuk setiap vektor masukan ip dimana p ∈ {1,…,n}, taruh ip di cluster Cj* dengan prototipe terdekat wj* memiliki hubungan berikut
$$ | i_ {p} \: - \: w_ {j *} | \: \ leq \: | i_ {p} \: - \: w_ {j} |, \: j \: \ in \ lbrace1, ...., k \ rbrace $$
Step 4 - Untuk setiap cluster Cj, dimana j ∈ { 1,…,k}, perbarui prototipe wj menjadi pusat massa dari semua sampel yang ada saat ini Cj , yang seperti itu
$$ w_ {j} \: = \: \ sum_ {i_ {p} \ in C_ {j}} \ frac {i_ {p}} {| C_ {j} |} $$
Step 5 - Hitung total kesalahan kuantisasi sebagai berikut -
$$ E \: = \: \ sum_ {j = 1} ^ k \ sum_ {i_ {p} \ in w_ {j}} | i_ {p} \: - \: w_ {j} | ^ 2 $$
Neokognitron
Ini adalah jaringan feedforward multilayer, yang dikembangkan oleh Fukushima pada 1980-an. Model ini didasarkan pada pembelajaran yang diawasi dan digunakan untuk pengenalan pola visual, terutama karakter tulisan tangan. Ini pada dasarnya merupakan perpanjangan dari jaringan Cognitron, yang juga dikembangkan oleh Fukushima pada tahun 1975.
Arsitektur
Ini adalah jaringan hierarki, yang terdiri dari banyak lapisan dan terdapat pola konektivitas secara lokal di lapisan tersebut.
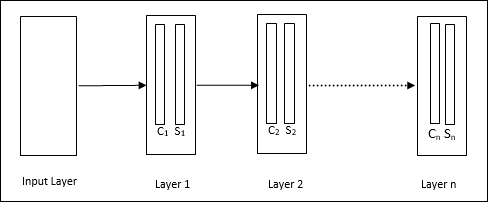
Seperti yang telah kita lihat pada diagram di atas, neokognitron dibagi menjadi beberapa lapisan yang terhubung dan setiap lapisan memiliki dua sel. Penjelasan dari sel-sel tersebut adalah sebagai berikut -
S-Cell - Ini disebut sel sederhana, yang dilatih untuk merespons pola tertentu atau sekelompok pola.
C-Cell- Disebut sel kompleks, yang menggabungkan keluaran dari sel S dan secara bersamaan mengurangi jumlah unit di setiap larik. Dalam arti lain, sel C menggantikan hasil dari sel S.
Algoritma Pelatihan
Pelatihan neokognitron ditemukan berkembang lapis demi lapis. Bobot dari lapisan masukan ke lapisan pertama dilatih dan dibekukan. Kemudian, bobot dari lapisan pertama ke lapisan kedua dilatih, dan seterusnya. Perhitungan internal antara S-cell dan Ccell bergantung pada bobot yang berasal dari lapisan sebelumnya. Oleh karena itu, kita dapat mengatakan bahwa algoritma pelatihan bergantung pada kalkulasi pada sel S dan sel C.
Perhitungan di sel S.
Sel-S memiliki sinyal rangsang yang diterima dari lapisan sebelumnya dan memiliki sinyal penghambatan yang diperoleh dalam lapisan yang sama.
$$ \ theta = \: \ sqrt {\ sum \ sum t_ {i} c_ {i} ^ 2} $$
Sini, ti adalah bobot tetap dan ci adalah keluaran dari sel C.
Input skala S-sel dapat dihitung sebagai berikut -
$$ x \: = \: \ frac {1 \: + \: e} {1 \: + \: vw_ {0}} \: - \: 1 $$
Di sini, $ e \: = \: \ sum_i c_ {i} w_ {i} $
wi adalah bobot yang disesuaikan dari sel C ke sel S.
w0 adalah bobot yang dapat disesuaikan antara input dan sel S.
v adalah input rangsang dari sel C.
Aktivasi sinyal keluaran adalah,
$$ s \: = \: \ begin {cases} x, & if \: x \ geq 0 \\ 0, & if \: x <0 \ end {cases} $$
Perhitungan dalam sel C.
Input bersih dari C-layer adalah
$$ C \: = \: \ displaystyle \ sum \ limit_i s_ {i} x_ {i} $$
Sini, si adalah keluaran dari S-cell dan xi adalah bobot tetap dari sel S ke sel C.
Hasil akhirnya adalah sebagai berikut -
$$ C_ {out} \: = \: \ begin {cases} \ frac {C} {a + C}, & if \: C> 0 \\ 0, & sebaliknya \ end {cases} $$
Sini ‘a’ adalah parameter yang bergantung pada kinerja jaringan.