DAA-クイックガイド
アルゴリズムは、計算、データ処理、および自動推論タスクを実行する問題を解決するための一連の操作ステップです。アルゴリズムは、有限の時間と空間で表現できる効率的な方法です。
アルゴリズムは、特定の問題の解決策を非常に単純で効率的な方法で表すための最良の方法です。特定の問題に対するアルゴリズムがある場合は、それを任意のプログラミング言語で実装できます。つまり、algorithm is independent from any programming languages。
アルゴリズム設計
アルゴリズム設計の重要な側面には、最小限の時間とスペースを使用して効率的な方法で問題を解決するための効率的なアルゴリズムの作成が含まれます。
問題を解決するために、さまざまなアプローチに従うことができます。それらのいくつかは時間の消費に関して効率的である可能性がありますが、他のアプローチはメモリ効率的である可能性があります。ただし、時間消費とメモリ使用量の両方を同時に最適化することはできないことに注意する必要があります。より短い時間でアルゴリズムを実行する必要がある場合は、より多くのメモリに投資する必要があり、より少ないメモリでアルゴリズムを実行する必要がある場合は、より多くの時間を必要とします。
問題の開発手順
次の手順は、計算上の問題の解決に関係しています。
- 問題の定義
- モデルの開発
- アルゴリズムの仕様
- アルゴリズムの設計
- アルゴリズムの正しさのチェック
- アルゴリズムの分析
- アルゴリズムの実装
- プログラムテスト
- Documentation
アルゴリズムの特徴
アルゴリズムの主な特徴は次のとおりです-
アルゴリズムには一意の名前を付ける必要があります
アルゴリズムには、入力と出力のセットを明示的に定義する必要があります
アルゴリズムは明確な操作で秩序立っています
アルゴリズムは有限の時間で停止します。アルゴリズムは無限に実行されるべきではありません。つまり、アルゴリズムはある時点で終了する必要があります
擬似コード
擬似コードは、平文に関連するあいまいさなしに、また特定のプログラミング言語の構文を知る必要なしに、アルゴリズムの高レベルの説明を提供します。
実行時間は、擬似コードを使用してアルゴリズムを基本的な操作のセットとして表すことにより、より一般的な方法で見積もることができます。
アルゴリズムと擬似コードの違い
アルゴリズムは、特定のタスクを実行するためにチューリング完全なコンピューターマシンによって実行できるプロセスを説明する、いくつかの特定の特性を備えた正式な定義です。一般に、「アルゴリズム」という言葉は、コンピュータサイエンスの高レベルのタスクを表すために使用できます。
一方、擬似コードは、アルゴリズムの非公式で(多くの場合初歩的な)人間が読める形式の記述であり、アルゴリズムの詳細が多数残されています。擬似コードの記述にはスタイルの制限はなく、その唯一の目的は、アルゴリズムの高レベルのステップを自然言語で非常に現実的な方法で記述することです。
たとえば、以下は挿入ソートのアルゴリズムです。
Algorithm: Insertion-Sort
Input: A list L of integers of length n
Output: A sorted list L1 containing those integers present in L
Step 1: Keep a sorted list L1 which starts off empty
Step 2: Perform Step 3 for each element in the original list L
Step 3: Insert it into the correct position in the sorted list L1.
Step 4: Return the sorted list
Step 5: Stopこれは、アルゴリズムInsertion-Sortで前述した高レベルの抽象プロセスをより現実的な方法で記述する方法を説明する擬似コードです。
for i <- 1 to length(A)
x <- A[i]
j <- i
while j > 0 and A[j-1] > x
A[j] <- A[j-1]
j <- j - 1
A[j] <- xこのチュートリアルでは、アルゴリズムは疑似コードの形式で提示されます。これは、C、C ++、Java、Python、およびその他のプログラミング言語と多くの点で類似しています。
アルゴリズムの理論的分析では、漸近的な意味でそれらの複雑さを推定すること、つまり、任意に大きな入力の複雑さ関数を推定することが一般的です。用語"analysis of algorithms" ドナルド・クヌースによって造られました。
アルゴリズム分析は、特定の計算問題を解決するためにアルゴリズムに必要なリソースの理論的推定を提供する計算複雑性理論の重要な部分です。ほとんどのアルゴリズムは、任意の長さの入力で機能するように設計されています。アルゴリズムの分析は、アルゴリズムの実行に必要な時間とスペースのリソースの量を決定することです。
通常、アルゴリズムの効率または実行時間は、入力長をステップ数に関連付ける関数として表されます。 time complexity、またはメモリのボリューム、 space complexity。
分析の必要性
この章では、アルゴリズムの分析の必要性と、1つの計算問題をさまざまなアルゴリズムで解決できるため、特定の問題に対してより適切なアルゴリズムを選択する方法について説明します。
特定の問題のアルゴリズムを検討することで、パターン認識の開発を開始し、このアルゴリズムを使用して同様のタイプの問題を解決できるようになります。
これらのアルゴリズムの目的は同じですが、アルゴリズムは互いにまったく異なることがよくあります。たとえば、さまざまなアルゴリズムを使用して一連の数値を並べ替えることができることがわかっています。1つのアルゴリズムによって実行される比較の数は、同じ入力に対して他のアルゴリズムと異なる場合があります。したがって、これらのアルゴリズムの時間計算量は異なる場合があります。同時に、各アルゴリズムに必要なメモリスペースを計算する必要があります。
アルゴリズムの分析は、必要な時間とサイズ(実装中のストレージ用のメモリのサイズ)の観点からアルゴリズムの問題解決能力を分析するプロセスです。ただし、アルゴリズムの分析の主な関心事は、必要な時間またはパフォーマンスです。一般的に、以下のタイプの分析を実行します-
Worst-case −サイズの任意のインスタンスで実行される最大ステップ数 a。
Best-case −サイズのインスタンスで実行される最小ステップ数 a。
Average case −サイズの任意のインスタンスで実行された平均ステップ数 a。
Amortized −サイズの入力に適用される一連の操作 a 時間の経過とともに平均化。
問題を解決するには、メモリが限られているが十分なスペースが利用できるシステムでプログラムを実行する場合や、その逆の場合があるため、時間とスペースの複雑さを考慮する必要があります。この文脈で、私たちが比較するとbubble sort そして merge sort。バブルソートは追加のメモリを必要としませんが、マージソートは追加のスペースを必要とします。バブルソートの時間計算量はマージソートに比べて高くなりますが、メモリが非常に限られている環境でプログラムを実行する必要がある場合は、バブルソートを適用する必要があります。
アルゴリズムのリソース消費を測定するために、この章で説明するようにさまざまな戦略が使用されます。
漸近解析
関数の漸近的振る舞い f(n) の成長を指します f(n) なので n 大きくなります。
通常、の小さな値は無視します n、私たちは通常、大きな入力でプログラムがどれだけ遅くなるかを推定することに関心があるためです。
経験則として、漸近成長率が遅いほど、アルゴリズムは優れています。それは常に真実ではありませんが。
たとえば、線形アルゴリズム $f(n) = d * n + k$ 二次のものよりも常に漸近的に優れています、 $f(n) = c.n^2 + q$。
漸化式を解く
漸化式は、より小さな入力での値の観点から関数を記述する方程式または不等式です。再発は通常、分割統治パラダイムで使用されます。
よく考えさせてください T(n) サイズの問題の実行時間になる n。
問題のサイズが十分に小さい場合は、 n < c どこ c は定数であり、単純な解には一定の時間がかかります。これは次のように記述されます。 θ(1)。問題の分割により、サイズのある多数のサブ問題が発生する場合$\frac{n}{b}$。
問題を解決するために必要な時間は a.T(n/b)。除算に必要な時間を考えるとD(n) サブ問題の結果を組み合わせるのに必要な時間は C(n)、漸化式は次のように表すことができます。
$$T(n)=\begin{cases}\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\theta(1) & if\:n\leqslant c\\a T(\frac{n}{b})+D(n)+C(n) & otherwise\end{cases}$$
漸化式は、次の方法を使用して解くことができます-
Substitution Method −この方法では、限界を推測し、数学的帰納法を使用して、仮定が正しいことを証明します。
Recursion Tree Method −この方法では、各ノードがコストを表す繰り返しツリーが形成されます。
Master’s Theorem −これは、漸化式の複雑さを見つけるためのもう1つの重要な手法です。
償却分析
償却分析は通常、一連の同様の操作が実行される特定のアルゴリズムに使用されます。
償却分析は、一連の操作のコストを個別に制限するのではなく、シーケンス全体の実際のコストに制限を提供します。
償却分析は、平均的なケースの分析とは異なります。確率は償却分析には含まれません。償却分析は、最悪の場合の各操作の平均パフォーマンスを保証します。
設計と分析は密接に関連しているため、これは単なる分析ツールではなく、設計についての考え方です。
集計方法
集計メソッドは、問題のグローバルビューを提供します。この方法では、n 操作には最悪の時間がかかります T(n)合計で。次に、各操作の償却コストは次のようになります。T(n)/n。操作が異なれば時間がかかることもありますが、この方法ではコストの変動は無視されます。
会計方法
この方法では、実際のコストに応じて、さまざまな操作にさまざまな料金が割り当てられます。操作の償却原価が実際原価を超える場合、差額はクレジットとしてオブジェクトに割り当てられます。このクレジットは、償却原価が実際の原価よりも少ない後の操作の支払いに役立ちます。
実際の費用との償却費用が ith 操作は $c_{i}$ そして $\hat{c_{l}}$、その後
$$\displaystyle\sum\limits_{i=1}^n \hat{c_{l}}\geqslant\displaystyle\sum\limits_{i=1}^n c_{i}$$
可能な方法
この方法は、プリペイド作業をクレジットと見なすのではなく、プリペイド作業を位置エネルギーとして表します。このエネルギーは、将来の運用に支払うために解放することができます。
演じれば n 初期データ構造から始まる操作 D0。よく考えさせてください、ci 実際の費用として Di のデータ構造として ith操作。ポテンシャル関数Фは実数Ф(Di)、関連する可能性 Di。償却原価$\hat{c_{l}}$ によって定義することができます
$$\hat{c_{l}}=c_{i}+\Phi (D_{i})-\Phi (D_{i-1})$$
したがって、総償却原価は次のようになります。
$$\displaystyle\sum\limits_{i=1}^n \hat{c_{l}}=\displaystyle\sum\limits_{i=1}^n (c_{i}+\Phi (D_{i})-\Phi (D_{i-1}))=\displaystyle\sum\limits_{i=1}^n c_{i}+\Phi (D_{n})-\Phi (D_{0})$$
動的テーブル
テーブルに割り当てられたスペースが十分でない場合は、テーブルをより大きなサイズのテーブルにコピーする必要があります。同様に、多数のメンバーがテーブルから消去される場合は、より小さなサイズでテーブルを再割り当てすることをお勧めします。
償却分析を使用すると、挿入と削除の償却コストが一定であり、動的テーブルの未使用スペースが合計スペースの一定の割合を超えることはないことを示すことができます。
このチュートリアルの次の章では、漸近表記について簡単に説明します。
アルゴリズムの設計では、アルゴリズムの複雑さの分析が重要な側面です。主に、アルゴリズムの複雑さは、そのパフォーマンス、動作の速さまたは遅さに関係します。
アルゴリズムの複雑さは、データの処理に必要なメモリの量と処理時間の観点からアルゴリズムの効率を表します。
アルゴリズムの複雑さは、次の2つの観点から分析されます。 Time そして Space。
時間計算量
これは、入力のサイズの観点からアルゴリズムを実行するために必要な時間を記述する関数です。「時間」とは、実行されたメモリアクセスの数、整数間の比較の数、内部ループが実行された回数、またはアルゴリズムにかかるリアルタイムの量に関連するその他の自然単位を意味します。
スペースの複雑さ
これは、アルゴリズムへの入力のサイズに関して、アルゴリズムが使用するメモリの量を記述する関数です。入力自体を格納するために必要なメモリを数えずに、必要な「追加の」メモリについてよく話します。ここでも、これを測定するために自然な(ただし固定長の)単位を使用します。
使用されるスペースが最小限または明白であるため、スペースの複雑さが無視されることもありますが、時間と同じくらい重要な問題になることもあります。
漸近表記
アルゴリズムの実行時間は、命令セット、プロセッサ速度、ディスクI / O速度などに依存します。したがって、アルゴリズムの効率を漸近的に推定します。
アルゴリズムの時間関数は次の式で表されます。 T(n)、 どこ n 入力サイズです。
アルゴリズムの複雑さを表すために、さまざまなタイプの漸近表記が使用されます。次の漸近表記は、アルゴリズムの実行時間の複雑さを計算するために使用されます。
O −ビッグオー
Ω −ビッグオメガ
θ −ビッグシータ
o −リトルオー
ω −リトルオメガ
O:漸近的な上界
「O」(Big Oh)は、最も一般的に使用される表記法です。機能f(n) 表現できるのは g(n) あれは O(g(n))、正の整数の値が存在する場合 n なので n0 と正の定数 c そのような-
$f(n)\leqslant c.g(n)$ にとって $n > n_{0}$ すべての場合
したがって、機能 g(n) 関数の上限です f(n)、 なので g(n) より速く成長する f(n)。
例
与えられた関数を考えてみましょう、 $f(n) = 4.n^3 + 10.n^2 + 5.n + 1$
検討中 $g(n) = n^3$、
$f(n)\leqslant 5.g(n)$ のすべての値について $n > 2$
したがって、の複雑さ f(n) として表すことができます $O(g(n))$、すなわち $O(n^3)$
Ω:漸近的な下限
私たちはそれを言います $f(n) = \Omega (g(n))$ 定数が存在する場合 c それ $f(n)\geqslant c.g(n)$ のすべての十分に大きな値に対して n。ここにnは正の整数です。機能を意味しますg 関数の下限です f; の特定の値の後n, f 下に行くことはありません g。
例
与えられた関数を考えてみましょう、 $f(n) = 4.n^3 + 10.n^2 + 5.n + 1$。
検討中 $g(n) = n^3$、 $f(n)\geqslant 4.g(n)$ のすべての値について $n > 0$。
したがって、の複雑さ f(n) として表すことができます $\Omega (g(n))$、すなわち $\Omega (n^3)$
θ:漸近的タイトバウンド
私たちはそれを言います $f(n) = \theta(g(n))$ 定数が存在する場合 c1 そして c2 それ $c_{1}.g(n) \leqslant f(n) \leqslant c_{2}.g(n)$ のすべての十分に大きな値に対して n。ここにn は正の整数です。
これは機能を意味します g 機能のタイトバウンドです f。
例
与えられた関数を考えてみましょう、 $f(n) = 4.n^3 + 10.n^2 + 5.n + 1$
検討中 $g(n) = n^3$、 $4.g(n) \leqslant f(n) \leqslant 5.g(n)$ のすべての大きな値に対して n。
したがって、の複雑さ f(n) として表すことができます $\theta (g(n))$、すなわち $\theta (n^3)$。
O-表記
によって提供される漸近的な上限 O-notation漸近的にタイトな場合とそうでない場合があります。バウンド$2.n^2 = O(n^2)$ 漸近的にタイトですが、限界 $2.n = O(n^2)$ ではありません。
を使用しております o-notation 漸近的にタイトではない上限を示します。
正式に定義する o(g(n)) (nのgの少しああ)セットとして f(n) = o(g(n)) 正の定数の場合 $c > 0$ そして価値が存在する $n_{0} > 0$、 そのような $0 \leqslant f(n) \leqslant c.g(n)$。
直感的に、 o-notation、 関数 f(n) に比べて重要ではなくなります g(n) なので n無限に近づく; あれは、
$$\lim_{n \rightarrow \infty}\left(\frac{f(n)}{g(n)}\right) = 0$$
例
同じ関数を考えてみましょう、 $f(n) = 4.n^3 + 10.n^2 + 5.n + 1$
検討中 $g(n) = n^{4}$、
$$\lim_{n \rightarrow \infty}\left(\frac{4.n^3 + 10.n^2 + 5.n + 1}{n^4}\right) = 0$$
したがって、の複雑さ f(n) として表すことができます $o(g(n))$、すなわち $o(n^4)$。
ω–表記
を使用しております ω-notation漸近的にタイトではない下限を示します。ただし、正式には、ω(g(n)) (nのgの小さなオメガ)セットとして f(n) = ω(g(n)) 正の定数の場合 C > 0 そして価値が存在する $n_{0} > 0$、$ 0 \ leqslant cg(n)<f(n)$のように。
例えば、 $\frac{n^2}{2} = \omega (n)$、 だが $\frac{n^2}{2} \neq \omega (n^2)$。関係$f(n) = \omega (g(n))$ 次の制限が存在することを意味します
$$\lim_{n \rightarrow \infty}\left(\frac{f(n)}{g(n)}\right) = \infty$$
あれは、 f(n) に比べて任意に大きくなります g(n) なので n 無限に近づく。
例
同じ機能を考えてみましょう、 $f(n) = 4.n^3 + 10.n^2 + 5.n + 1$
検討中 $g(n) = n^2$、
$$\lim_{n \rightarrow \infty}\left(\frac{4.n^3 + 10.n^2 + 5.n + 1}{n^2}\right) = \infty$$
したがって、の複雑さ f(n) として表すことができます $o(g(n))$、すなわち $\omega (n^2)$。
アプリオリとアポスティアリの分析
アプリオリ分析とは、特定のシステムで実行する前に分析を実行することを意味します。この分析は、何らかの理論モデルを使用して関数を定義する段階です。したがって、異なるメモリ、プロセッサ、およびコンパイラを備えた特定のシステムでアルゴリズムを実行するのではなく、アルゴリズムを調べるだけで、アルゴリズムの時間と空間の複雑さを判断します。
アルゴリズムの事後分析とは、システム上で実行した後にのみアルゴリズムの分析を実行することを意味します。これはシステムに直接依存し、システムごとに異なります。
業界では、ソフトウェアは一般的に匿名ユーザー向けに作成されており、業界に存在するシステムとは異なるシステムで実行されるため、Apostiari分析を実行することはできません。
Aprioriでは、コンピューターごとに変化する時間と空間の複雑さを決定するために漸近表記を使用するのはそのためです。ただし、漸近的には同じです。
この章では、アルゴリズムが必要とするスペースの量に関する計算問題の複雑さについて説明します。
空間の複雑さは、時間の複雑さの多くの機能を共有し、計算の難しさに応じて問題を分類するためのさらなる方法として機能します。
スペースコンプレキシティとは何ですか?
スペースの複雑さは、アルゴリズムへの入力量の観点から、アルゴリズムが使用するメモリ(スペース)の量を表す関数です。
私たちはよく話します extra memory入力自体を格納するために必要なメモリはカウントしません。ここでも、これを測定するために自然な(ただし固定長の)単位を使用します。
バイトを使用することもできますが、使用する整数の数、固定サイズの構造体の数などを使用する方が簡単です。
結局、私たちが思いついた関数は、単位を表すために必要な実際のバイト数とは無関係になります。
使用されるスペースが最小限または明白であるため、スペースの複雑さが無視されることがありますが、時間の複雑さと同じくらい重要な問題になる場合があります。
定義
しましょう M 決定論的であること Turing machine (TM)これはすべての入力で停止します。のスペースの複雑さM 機能です $f \colon N \rightarrow N$、 どこ f(n) はテープの最大セル数であり、 M 長さの入力をスキャンします M。のスペースの複雑さM です f(n)、私たちはそれを言うことができます M 宇宙で走る f(n)。
漸近表記を使用して、チューリングマシンの空間の複雑さを推定します。
しましょう $f \colon N \rightarrow R^+$関数になります。空間複雑度クラスは次のように定義できます-
SPACE = {L | L is a language decided by an O(f(n)) space deterministic TM}
SPACE = {L | L is a language decided by an O(f(n)) space non-deterministic TM}
PSPACE は、決定論的チューリングマシンの多項式空間で決定可能な言語のクラスです。
言い換えると、 PSPACE = Uk SPACE (nk)
サヴィッチの定理
空間の複雑さに関連する最も初期の定理の1つは、サヴィッチの定理です。この定理によれば、決定性マシンは、少量のスペースを使用して非決定性マシンをシミュレートできます。
時間の複雑さのために、そのようなシミュレーションは時間の指数関数的な増加を必要とするようです。スペースの複雑さについて、この定理は、を使用する非決定性チューリングマシンがf(n) スペースは、を使用する決定論的TMに変換できます f2(n) スペース。
したがって、サヴィッチの定理は、どの関数についても、 $f \colon N \rightarrow R^+$、 どこ $f(n) \geqslant n$
NSPACE(f(n)) ⊆ SPACE(f(n))
複雑さクラス間の関係
次の図は、さまざまな複雑度クラス間の関係を示しています。

これまで、このチュートリアルではPクラスとNPクラスについては説明していません。これらについては後で説明します。
多くのアルゴリズムは、サブ問題を再帰的に処理する特定の問題を解決するために、本質的に再帰的です。
に divide and conquer approach、問題を小さな問題に分割し、小さな問題を個別に解決し、最後に小さな問題の解決策を組み合わせて大きな問題の解決策にします。
一般に、分割統治アルゴリズムには3つの部分があります-
Divide the problem 同じ問題のより小さなインスタンスであるいくつかのサブ問題に。
Conquer the sub-problemsそれらを再帰的に解くことによって。それらが十分に小さい場合は、基本ケースとしてサブ問題を解決します。
Combine the solutions 元の問題の解決策へのサブ問題に。
分割統治法の長所と短所
分割統治アプローチは、サブ問題が独立しているため、並列処理をサポートします。したがって、この手法を使用して設計されたアルゴリズムは、マルチプロセッサシステムまたは異なるマシンで同時に実行できます。
このアプローチでは、ほとんどのアルゴリズムが再帰を使用して設計されているため、メモリ管理は非常に高度です。再帰的な関数スタックは、関数の状態を格納する必要がある場合に使用されます。
分割統治法の適用
以下は、分割統治法を使用して解決されるいくつかの問題です。
- 一連の数の最大値と最小値を見つける
- Strassenの行列乗算
- マージソート
- 二分探索
分割統治法で解決できる簡単な問題を考えてみましょう。
問題文
アルゴリズム分析の最大値と最小値の問題は、配列の最大値と最小値を見つけることです。
解決
特定の配列の最大数と最小数を見つけるには numbers[] サイズの n、次のアルゴリズムを使用できます。まず、私たちはnaive method そして、私たちは提示します divide and conquer approach。
ナイーブな方法
ナイーブな方法は、あらゆる問題を解決するための基本的な方法です。この方法では、最大数と最小数を別々に見つけることができます。最大数と最小数を見つけるには、次の簡単なアルゴリズムを使用できます。
Algorithm: Max-Min-Element (numbers[])
max := numbers[1]
min := numbers[1]
for i = 2 to n do
if numbers[i] > max then
max := numbers[i]
if numbers[i] < min then
min := numbers[i]
return (max, min)分析
ナイーブ法での比較数は 2n - 2。
分割統治法を使用すると、比較の数を減らすことができます。以下はそのテクニックです。
分割統治法
このアプローチでは、アレイは2つに分割されます。次に、再帰的アプローチを使用して、各半分の最大数と最小数を見つけます。後で、各半分の最大2つの最大値と各半分の最小2つの最小値を返します。
この与えられた問題では、配列内の要素の数は $y - x + 1$、 どこ y 以上 x。
$\mathbf{\mathit{Max - Min(x, y)}}$ 配列の最大値と最小値を返します $\mathbf{\mathit{numbers[x...y]}}$。
Algorithm: Max - Min(x, y)
if y – x ≤ 1 then
return (max(numbers[x], numbers[y]), min((numbers[x], numbers[y]))
else
(max1, min1):= maxmin(x, ⌊((x + y)/2)⌋)
(max2, min2):= maxmin(⌊((x + y)/2) + 1)⌋,y)
return (max(max1, max2), min(min1, min2))分析
しましょう T(n) によって行われた比較の数である $\mathbf{\mathit{Max - Min(x, y)}}$、ここで要素の数 $n = y - x + 1$。
場合 T(n) 数を表す場合、漸化式は次のように表すことができます。
$$T(n) = \begin{cases}T\left(\lfloor\frac{n}{2}\rfloor\right)+T\left(\lceil\frac{n}{2}\rceil\right)+2 & for\: n>2\\1 & for\:n = 2 \\0 & for\:n = 1\end{cases}$$
それを仮定しましょう n の力の形である 2。したがって、n = 2k どこ k は再帰ツリーの高さです。
そう、
$$T(n) = 2.T (\frac{n}{2}) + 2 = 2.\left(\begin{array}{c}2.T(\frac{n}{4}) + 2\end{array}\right) + 2 ..... = \frac{3n}{2} - 2$$
ナイーブ法と比較して、分割統治法では、比較の数が少なくなります。ただし、漸近表記を使用すると、両方のアプローチは次のように表されます。O(n)。
この章では、マージソートについて説明し、その複雑さを分析します。
問題文
数値のリストをソートする問題は、分割統治戦略にすぐに役立ちます。リストを2つに分割し、各半分を再帰的にソートしてから、ソートされた2つのサブリストをマージします。
解決
このアルゴリズムでは、数値は配列に格納されます numbers[]。ここに、p そして q サブ配列の開始インデックスと終了インデックスを表します。
Algorithm: Merge-Sort (numbers[], p, r)
if p < r then
q = ⌊(p + r) / 2⌋
Merge-Sort (numbers[], p, q)
Merge-Sort (numbers[], q + 1, r)
Merge (numbers[], p, q, r)Function: Merge (numbers[], p, q, r)
n1 = q – p + 1
n2 = r – q
declare leftnums[1…n1 + 1] and rightnums[1…n2 + 1] temporary arrays
for i = 1 to n1
leftnums[i] = numbers[p + i - 1]
for j = 1 to n2
rightnums[j] = numbers[q+ j]
leftnums[n1 + 1] = ∞
rightnums[n2 + 1] = ∞
i = 1
j = 1
for k = p to r
if leftnums[i] ≤ rightnums[j]
numbers[k] = leftnums[i]
i = i + 1
else
numbers[k] = rightnums[j]
j = j + 1分析
マージソートの実行時間を次のように考えてみましょう。 T(n)。したがって、
$T(n)=\begin{cases}c & if\:n\leqslant 1\\2\:x\:T(\frac{n}{2})+d\:x\:n & otherwise\end{cases}$ここで、cとdは定数です
したがって、この漸化式を使用すると、
$$T(n) = 2^i T(\frac{n}{2^i}) + i.d.n$$
なので、 $i = log\:n,\: T(n) = 2^{log\:n} T(\frac{n}{2^{log\:n}}) + log\:n.d.n$
$=\:c.n + d.n.log\:n$
したがって、 $T(n) = O(n\:log\:n)$
例
次の例では、マージソートアルゴリズムを段階的に示しています。まず、サブ配列に要素が1つだけ含まれるまで、すべての反復配列が2つのサブ配列に分割されます。これらのサブ配列をさらに分割できない場合は、マージ操作が実行されます。
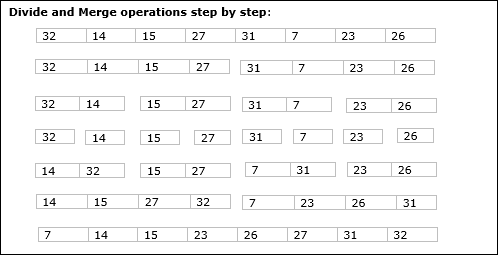
この章では、分割統治法に基づく別のアルゴリズムについて説明します。
問題文
バイナリ検索は、ソートされた配列で実行できます。このアプローチでは、要素のインデックスx要素が要素のリストに属しているかどうかが判別されます。配列がソートされていない場合、線形検索を使用して位置が決定されます。
解決
このアルゴリズムでは、要素が x 配列に格納された一連の数値に属します numbers[]。どこl そして r 検索操作を実行する必要があるサブ配列の左右のインデックスを表します。
Algorithm: Binary-Search(numbers[], x, l, r)
if l = r then
return l
else
m := ⌊(l + r) / 2⌋
if x ≤ numbers[m] then
return Binary-Search(numbers[], x, l, m)
else
return Binary-Search(numbers[], x, m+1, r)分析
線形検索はで実行されます O(n)時間。一方、バイナリ検索は結果を生成しますO(log n) 時間
しましょう T(n) の配列内の最悪の場合の比較の数 n 要素。
したがって、
$$T(n)=\begin{cases}0 & if\:n= 1\\T(\frac{n}{2})+1 & otherwise\end{cases}$$
この漸化式を使用する $T(n) = log\:n$。
したがって、二分探索は $O(log\:n)$ 時間。
例
この例では、要素63を検索します。

この章では、最初に行列乗算の一般的な方法について説明し、後でStrassenの行列乗算アルゴリズムについて説明します。
問題文
2つの行列を考えてみましょう X そして Y。結果の行列を計算したいZ 掛けることによって X そして Y。
ナイーブな方法
最初に、ナイーブな方法とその複雑さについて説明します。ここでは、計算していますZ = X × Y。ナイーブ法を使用して、2つの行列(X そして Y)これらの行列の次数が次の場合は乗算できます p × q そして q × r。以下はアルゴリズムです。
Algorithm: Matrix-Multiplication (X, Y, Z)
for i = 1 to p do
for j = 1 to r do
Z[i,j] := 0
for k = 1 to q do
Z[i,j] := Z[i,j] + X[i,k] × Y[k,j]複雑
ここでは、整数演算にかかると仮定します O(1)時間。3つありますforこのアルゴリズムではループが発生し、一方が他方にネストされます。したがって、アルゴリズムはO(n3) 実行する時間。
Strassenの行列乗算アルゴリズム
このコンテキストでは、Strassenの行列乗算アルゴリズムを使用すると、時間の消費を少し改善できます。
Strassenの行列乗算は、次の場合にのみ実行できます。 square matrices どこ n は power of 2。両方の行列の順序は次のとおりです。n × n。
分割する X、 Y そして Z 以下に示すように、4つの(n / 2)×(n / 2)行列に変換します。
$Z = \begin{bmatrix}I & J \\K & L \end{bmatrix}$ $X = \begin{bmatrix}A & B \\C & D \end{bmatrix}$ そして $Y = \begin{bmatrix}E & F \\G & H \end{bmatrix}$
シュトラッセンのアルゴリズムを使用して、以下を計算します-
$$M_{1} \: \colon= (A+C) \times (E+F)$$
$$M_{2} \: \colon= (B+D) \times (G+H)$$
$$M_{3} \: \colon= (A-D) \times (E+H)$$
$$M_{4} \: \colon= A \times (F-H)$$
$$M_{5} \: \colon= (C+D) \times (E)$$
$$M_{6} \: \colon= (A+B) \times (H)$$
$$M_{7} \: \colon= D \times (G-E)$$
次に、
$$I \: \colon= M_{2} + M_{3} - M_{6} - M_{7}$$
$$J \: \colon= M_{4} + M_{6}$$
$$K \: \colon= M_{5} + M_{7}$$
$$L \: \colon= M_{1} - M_{3} - M_{4} - M_{5}$$
分析
$T(n)=\begin{cases}c & if\:n= 1\\7\:x\:T(\frac{n}{2})+d\:x\:n^2 & otherwise\end{cases}$ここで、cとdは定数です
この漸化式を使用して、次のようになります。 $T(n) = O(n^{log7})$
したがって、Strassenの行列乗算アルゴリズムの複雑さは次のようになります。 $O(n^{log7})$。
すべてのアルゴリズム的アプローチの中で、最も単純で直接的なアプローチは欲張り法です。このアプローチでは、将来の現在の決定の影響を心配することなく、現在入手可能な情報に基づいて決定が行われます。
欲張りアルゴリズムは、ソリューションを部分的に構築し、次の部分をそのような方法で選択して、すぐに利益をもたらします。このアプローチは、以前に行われた選択を再考することはありません。このアプローチは、主に最適化問題を解決するために使用されます。欲張り法は実装が簡単で、ほとんどの場合非常に効率的です。したがって、欲張りアルゴリズムは、グローバルな最適解を見つけることを期待して、各ステップでローカルな最適選択に従うヒューリスティックに基づくアルゴリズムパラダイムであると言えます。
多くの問題では、妥当な時間で近似(ほぼ最適)な解が得られますが、最適な解は生成されません。
欲張りアルゴリズムのコンポーネント
欲張りアルゴリズムには、次の5つのコンポーネントがあります-
A candidate set −このセットからソリューションが作成されます。
A selection function −ソリューションに追加する最適な候補を選択するために使用されます。
A feasibility function −候補を使用してソリューションに貢献できるかどうかを判断するために使用されます。
An objective function −ソリューションまたは部分ソリューションに値を割り当てるために使用されます。
A solution function −完全な解決策に到達したかどうかを示すために使用されます。
適用分野
貪欲なアプローチは、次のような多くの問題を解決するために使用されます
ダイクストラのアルゴリズムを使用して、2つの頂点間の最短経路を見つけます。
プリム/クラスカルのアルゴリズムなどを使用して、グラフ内の最小全域木を見つける。
欲張りアプローチが失敗する場所
多くの問題で、欲張りアルゴリズムは最適な解決策を見つけることができず、さらに最悪の解決策を生み出す可能性があります。巡回セールスマンやナップザックのような問題は、このアプローチでは解決できません。
欲張りアルゴリズムは、ナップサック問題と呼ばれるよく知られた問題で非常によく理解できます。同じ問題は他のアルゴリズムアプローチを採用することで解決できますが、欲張りアプローチはフラクショナルナップサック問題を適度に解決します。ナップサック問題について詳しく説明しましょう。
ナップサック問題
それぞれに重みと値を持つアイテムのセットが与えられた場合、コレクションに含めるアイテムのサブセットを決定して、合計の重みが指定された制限以下になり、合計値が可能な限り大きくなるようにします。
ナップサック問題は、組み合わせ最適化問題にあります。これは、実世界の問題の多くのより複雑な数学的モデルのサブ問題として表示されます。難しい問題に対する一般的なアプローチの1つは、最も制限の厳しい制約を特定し、他の制約を無視し、ナップサック問題を解決し、無視された制約を満たすようにソリューションを調整することです。
アプリケーション
いくつかの制約を伴うリソース割り当ての多くの場合、問題はナップサック問題と同様の方法で導き出すことができます。以下は一組の例です。
- 原材料をカットするための最も無駄の少ない方法を見つける
- ポートフォリオの最適化
- 板取り問題
問題シナリオ
泥棒が店を奪っていて、最大重量を運ぶことができます W彼のナップザックに。店内にはn個の商品があり、ith アイテムは wi そしてその利益は pi。泥棒はどのようなアイテムを取るべきですか?
この文脈では、アイテムは、泥棒が最大の利益を得るアイテムを運ぶように選択する必要があります。したがって、泥棒の目的は利益を最大化することです。
アイテムの性質に基づいて、ナップサック問題は次のように分類されます。
- フラクショナルナップザック
- Knapsack
フラクショナルナップザック
この場合、アイテムを細かく分割できるため、泥棒はアイテムの一部を選択できます。
問題の説明によると、
がある n ストア内のアイテム
の重量 ith 項目 $w_{i} > 0$
の利益 ith 項目 $p_{i} > 0$ そして
ナップザックの容量は W
このバージョンのナップサック問題では、アイテムを細かく分割できます。だから、泥棒はほんの一部しか取ることができませんxi の ith 項目。
$$0 \leqslant x_{i} \leqslant 1$$
ザ・ ith アイテムは重量に貢献します $x_{i}.w_{i}$ ナップザックの総重量と利益に $x_{i}.p_{i}$ 総利益に。
したがって、このアルゴリズムの目的は
$$maximize\:\displaystyle\sum\limits_{n=1}^n (x_{i}.p_{}i)$$
制約の対象、
$$\displaystyle\sum\limits_{n=1}^n (x_{i}.w_{}i) \leqslant W$$
最適なソリューションがナップザックを正確に満たす必要があることは明らかです。そうしないと、残りのアイテムの1つの一部を追加して、全体的な利益を増やすことができます。
したがって、最適解は次の方法で取得できます。
$$\displaystyle\sum\limits_{n=1}^n (x_{i}.w_{}i) = W$$
このコンテキストでは、最初に、の値に従ってこれらのアイテムを並べ替える必要があります。 $\frac{p_{i}}{w_{i}}$、 そのため $\frac{p_{i}+1}{w_{i}+1}$ ≤ $\frac{p_{i}}{w_{i}}$。ここに、x アイテムの端数を格納する配列です。
Algorithm: Greedy-Fractional-Knapsack (w[1..n], p[1..n], W)
for i = 1 to n
do x[i] = 0
weight = 0
for i = 1 to n
if weight + w[i] ≤ W then
x[i] = 1
weight = weight + w[i]
else
x[i] = (W - weight) / w[i]
weight = W
break
return x分析
提供されたアイテムがすでに降順でソートされている場合 $\mathbf{\frac{p_{i}}{w_{i}}}$、その後、whileloopはで時間がかかります O(n); したがって、並べ替えを含む合計時間はO(n logn)。
例
ナップザックの容量を考えてみましょう W = 60 提供されたアイテムのリストを次の表に示します-
| 項目 | A | B | C | D |
|---|---|---|---|---|
| 利益 | 280 | 100 | 120 | 120 |
| 重量 | 40 | 10 | 20 | 24 |
| 比 $(\frac{p_{i}}{w_{i}})$ | 7 | 10 | 6 | 5 |
提供されたアイテムはに基づいてソートされていないため $\mathbf{\frac{p_{i}}{w_{i}}}$。並べ替え後の項目は次の表のようになります。
| 項目 | B | A | C | D |
|---|---|---|---|---|
| 利益 | 100 | 280 | 120 | 120 |
| 重量 | 10 | 40 | 20 | 24 |
| 比 $(\frac{p_{i}}{w_{i}})$ | 10 | 7 | 6 | 5 |
解決
に従ってすべてのアイテムを並べ替えた後 $\frac{p_{i}}{w_{i}}$。まず最初にB の重量として選択されます Bナップザックの容量よりも少ないです。次に、アイテムA ナップザックの利用可能な容量がの重量よりも大きいため、が選択されます A。さて、C次の項目として選択されます。ただし、ナップザックの残り容量が重量より少ないため、アイテム全体を選択することはできません。C。
したがって、 C (つまり、(60 − 50)/ 20)が選択されます。
これで、ナップザックの容量は選択したアイテムと同じになります。したがって、これ以上アイテムを選択することはできません。
選択したアイテムの総重量は 10 + 40 + 20 * (10/20) = 60
そして総利益は 100 + 280 + 120 * (10/20) = 380 + 60 = 440
これが最適なソリューションです。アイテムの異なる組み合わせを選択しても、これ以上の利益を得ることができません。
問題文
ジョブシーケンス問題では、目的は、期限内に完了し、最大の利益をもたらす一連のジョブを見つけることです。
解決
考えてみましょう、のセット n仕事がその期限までに完了した場合、締め切りと利益に関連付けられている特定の仕事が獲得されます。これらの仕事は、最大の利益が得られるような方法で注文する必要があります。
指定されたすべてのジョブが期限内に完了しない場合があります。
仮定、締め切り ith ジョブ Ji です di そしてこの仕事から受け取った利益は pi。したがって、このアルゴリズムの最適解は、最大の利益を伴う実行可能解です。
したがって、 $D(i) > 0$ にとって $1 \leqslant i \leqslant n$。
最初に、これらの仕事は利益に従って順序付けられます。 $p_{1} \geqslant p_{2} \geqslant p_{3} \geqslant \:... \: \geqslant p_{n}$。
Algorithm: Job-Sequencing-With-Deadline (D, J, n, k)
D(0) := J(0) := 0
k := 1
J(1) := 1 // means first job is selected
for i = 2 … n do
r := k
while D(J(r)) > D(i) and D(J(r)) ≠ r do
r := r – 1
if D(J(r)) ≤ D(i) and D(i) > r then
for l = k … r + 1 by -1 do
J(l + 1) := J(l)
J(r + 1) := i
k := k + 1分析
このアルゴリズムでは、2つのループを使用しています。1つは別のループ内にあります。したがって、このアルゴリズムの複雑さは次のとおりです。$O(n^2)$。
例
次の表に示すように、与えられたジョブのセットを考えてみましょう。期限内に完了し、最大の利益をもたらす一連の仕事を見つける必要があります。各仕事は締め切りと利益に関連付けられています。
| ジョブ | J1 | J2 | J3 | J4 | J5 |
|---|---|---|---|---|---|
| 締め切り | 2 | 1 | 3 | 2 | 1 |
| 利益 | 60 | 100 | 20 | 40 | 20 |
解決
この問題を解決するために、指定されたジョブは、利益に従って降順で並べ替えられます。したがって、ソート後、ジョブは次の表に示すように順序付けられます。
| ジョブ | J2 | J1 | J4 | J3 | J5 |
|---|---|---|---|---|---|
| 締め切り | 1 | 2 | 2 | 3 | 1 |
| 利益 | 100 | 60 | 40 | 20 | 20 |
この一連のジョブから、最初に選択します J2、期限内に完了することができ、最大の利益に貢献するため。
次、 J1 に比べて利益が大きいため、 J4。
次の時計では、 J4 締め切りが過ぎたため選択できません。 J3 期限内に実行されるときに選択されます。
仕事 J5 期限内に実行できないため、破棄されます。
したがって、解決策は一連のジョブです(J2, J1, J3)、期限内に実行され、最大の利益をもたらします。
このシーケンスの総利益は 100 + 60 + 20 = 180。
異なる長さのソートされたファイルのセットを単一のソートされたファイルにマージします。結果のファイルが最小時間で生成される最適なソリューションを見つける必要があります。
ソートされたファイルの数が指定されている場合、それらを1つのソートされたファイルにマージする方法はたくさんあります。このマージはペアごとに実行できます。したがって、このタイプのマージは次のように呼ばれます。2-way merge patterns。
ペアリングが異なれば必要な時間も異なるため、この戦略では、多くのファイルをマージする最適な方法を決定する必要があります。各ステップで、2つの最短シーケンスがマージされます。
マージするには p-record file と q-record file おそらく必要です p + q レコードの移動は、当然の選択ですが、各ステップで2つの最小のファイルをマージします。
双方向のマージパターンは、バイナリマージツリーで表すことができます。のセットを考えてみましょうn ソートされたファイル {f1, f2, f3, …, fn}。最初は、この各要素は単一ノードの二分木と見なされます。この最適解を見つけるために、次のアルゴリズムが使用されます。
Algorithm: TREE (n)
for i := 1 to n – 1 do
declare new node
node.leftchild := least (list)
node.rightchild := least (list)
node.weight) := ((node.leftchild).weight) + ((node.rightchild).weight)
insert (list, node);
return least (list);このアルゴリズムの最後では、ルートノードの重みが最適なコストを表します。
例
私たちは、F、所定のファイルを考える1 F、2、fが3で、f 4及びf 5のそれぞれの要素の20、30、10、5及び30の数です。
提供された順序に従ってマージ操作が実行される場合、
M1 = merge f1 and f2 => 20 + 30 = 50
M2 = merge M1 and f3 => 50 + 10 = 60
M3 = merge M2 and f4 => 60 + 5 = 65
M4 = merge M3 and f5 => 65 + 30 = 95
したがって、操作の総数は次のようになります。
50 + 60 + 65 + 95 = 270
さて、疑問が生じます。より良い解決策はありますか?
サイズに従って番号を昇順で並べ替えると、次のシーケンスが得られます。
f4, f3, f1, f2, f5
したがって、マージ操作はこのシーケンスで実行できます
M1 = merge f4 and f3 => 5 + 10 = 15
M2 = merge M1 and f1 => 15 + 20 = 35
M3 = merge M2 and f2 => 35 + 30 = 65
M4 = merge M3 and f5 => 65 + 30 = 95
したがって、操作の総数は次のようになります。
15 + 35 + 65 + 95 = 210
明らかに、これは前のものよりも優れています。
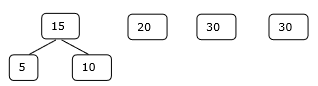
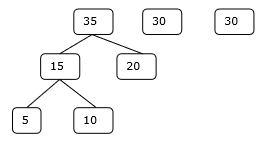
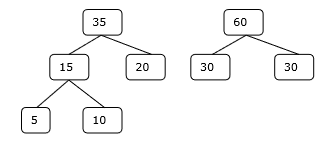
これに関連して、このアルゴリズムを使用して問題を解決します。
初期セット

ステップ1
ステップ2
ステップ-3
ステップ-4
したがって、このソリューションでは15 + 35 + 60 + 95 = 205回の比較が行われます。
動的計画法は、最適化問題でも使用されます。分割統治法と同様に、動的計画法はサブ問題の解を組み合わせることによって問題を解決します。さらに、動的計画法アルゴリズムは、各サブ問題を1回だけ解決してから、その回答をテーブルに保存するため、毎回回答を再計算する作業を回避できます。
問題の2つの主要な特性は、与えられた問題が動的計画法を使用して解決できることを示唆しています。これらのプロパティはoverlapping sub-problems and optimal substructure。
重複するサブ問題
分割統治法と同様に、動的計画法もサブ問題の解決策を組み合わせます。これは主に、1つのサブ問題の解決が繰り返し必要な場合に使用されます。計算された解はテーブルに保存されるため、これらを再計算する必要はありません。したがって、この手法は、重複するサブ問題が存在する場合に必要です。
たとえば、二分探索には重複するサブ問題はありません。一方、フィボナッチ数の再帰的プログラムには、多くの重複するサブ問題があります。
最適な部分構造
与えられた問題の最適解がそのサブ問題の最適解を使用して得られる場合、与えられた問題は最適部分構造特性を持っています。
たとえば、最短経路問題には次の最適な部分構造特性があります。
ノードの場合 x ソースノードからの最短パスにあります u 宛先ノードへ v、次にからの最短経路 u に v からの最短経路の組み合わせです u に x、およびからの最短経路 x に v。
Floyd-WarshallやBellman-Fordなどの標準のAllPair Shortest Pathアルゴリズムは、動的計画法の典型的な例です。
動的計画法アプローチのステップ
動的計画法アルゴリズムは、次の4つのステップを使用して設計されています-
- 最適解の構造を特徴付けます。
- 最適解の値を再帰的に定義します。
- 通常はボトムアップ方式で、最適解の値を計算します。
- 計算された情報から最適解を構築します。
動的計画法アプローチの応用
- 行列の連鎖乗積
- 最長共通部分列
- 巡回セールスマン問題
このチュートリアルでは、以前に貪欲アプローチを使用したフラクショナルナップサック問題について説明しました。貪欲なアプローチがフラクショナルナップザックに最適なソリューションを提供することを示しました。ただし、この章では、0-1ナップサック問題とその分析について説明します。
0-1ナップザックでは、アイテムを壊すことはできません。つまり、泥棒はアイテム全体を受け取るか、そのままにしておく必要があります。これが0-1ナップザックと呼ばれる理由です。
したがって、0-1ナップザックの場合、 xi どちらでもかまいません 0 または 1、他の制約は同じままです。
0-1ナップザックは欲張りアプローチでは解決できません。貪欲なアプローチは、最適なソリューションを保証するものではありません。多くの場合、貪欲なアプローチが最適な解決策を提供する可能性があります。
次の例は、ステートメントを確立します。
例-1
ナップザックの容量がW = 25で、アイテムが次の表のようになっているとしましょう。
| 項目 | A | B | C | D |
|---|---|---|---|---|
| 利益 | 24 | 18 | 18 | 10 |
| 重量 | 24 | 10 | 10 | 7 |
単位重量あたりの利益を考慮せずに(pi/wi)、この問題を解決するために欲張りアプローチを適用する場合、最初の項目 Aそれが最大寄与するように選択されます私のすべての要素の中のお母さんの利益を。
アイテム選択後 A、これ以上アイテムは選択されません。したがって、この特定のアイテムセットの場合、総利益は次のようになります。24。一方、最適なソリューションは、アイテムを選択することで実現できますが、B C、ここで総利益は18 + 18 = 36です。
例-2
代わりに、全体的な利益に基づいてアイテムを選択する、この例では項目は比に基づいて選択されたP I W / I。ナップザックの容量はW = 60であり、アイテムは次の表のとおりであると考えてみましょう。
| 項目 | A | B | C |
|---|---|---|---|
| 価格 | 100 | 280 | 120 |
| 重量 | 10 | 40 | 20 |
| 比 | 10 | 7 | 6 |
欲張りアプローチを使用して、最初の項目 Aが選択されています。次に、次の項目Bが選択されます。したがって、総利益は100 + 280 = 380。ただし、このインスタンスの最適なソリューションは、アイテムを選択することで実現できます。B そして C、ここで総利益は 280 + 120 = 400。
したがって、貪欲なアプローチでは最適な解決策が得られない可能性があると結論付けることができます。
0-1ナップザックを解くには、動的計画法のアプローチが必要です。
問題文
泥棒が店を奪っているとmax運ぶことができる私のMAL重量をW彼のナップザックに。があるn アイテムと重量 ith アイテムは wi このアイテムを選択することの利益は pi。泥棒はどのようなアイテムを取るべきですか?
動的計画法アプローチ
しましょう i 最適解の中で最も番号の大きい項目になる S にとって Wドル。次にS' = S - {i} に最適なソリューションです W - wi ドルとソリューションへの価値 S です Vi プラスサブ問題の値。
この事実は、次の式で表すことができます。 c[i, w] アイテムの解決策になる 1,2, … , iそして、max Iお母さん重量w。
アルゴリズムは次の入力を取ります
最大私のお母さんの重みW
アイテム数 n
2つのシーケンス v = <v1, v2, …, vn> そして w = <w1, w2, …, wn>
Dynamic-0-1-knapsack (v, w, n, W)
for w = 0 to W do
c[0, w] = 0
for i = 1 to n do
c[i, 0] = 0
for w = 1 to W do
if wi ≤ w then
if vi + c[i-1, w-wi] then
c[i, w] = vi + c[i-1, w-wi]
else c[i, w] = c[i-1, w]
else
c[i, w] = c[i-1, w]取るアイテムのセットは、テーブルから推測できます。 c[n, w] 最適値がどこから来たのかを逆方向にトレースします。
もしC [I、W] = C [I-1、W] 、次いでアイテムi はソリューションの一部ではなく、 c[i-1, w]。それ以外の場合、アイテムi はソリューションの一部であり、 c[i-1, w-W]。
分析
このアルゴリズムは、テーブルcに(n + 1)。(w + 1)エントリがあるため、θ(n、w)回かかります。各エントリの計算にはθ(1)時間が必要です。
最長共通部分列問題は、指定された両方の文字列に存在する最長のシーケンスを見つけることです。
サブシーケンス
シーケンスS = <s 1、s 2、s 3、s 4、…、sn >を考えてみましょう。
S上のシーケンスZ = <z 1、z 2、z 3、z 4、…、z m >は、いくつかの要素のS削除から導出できる場合に限り、Sのサブシーケンスと呼ばれます。
共通部分列
仮に、 X そして Y有限の要素セットに対する2つのシーケンスです。私たちはそれを言うことができますZ の一般的なサブシーケンスです X そして Y、もし Z 両方のサブシーケンスです X そして Y。
最長共通部分列
シーケンスのセットが指定されている場合、最長共通部分列問題は、最大長のすべてのシーケンスの共通部分列を見つけることです。
最長共通部分列問題は、diff-utilityなどのデータ比較プログラムの基礎である古典的なコンピュータサイエンスの問題であり、バイオインフォマティクスに応用されています。また、SVNやGitなどのリビジョン管理システムで、リビジョン管理されたファイルのコレクションに加えられた複数の変更を調整するために広く使用されています。
ナイーブな方法
しましょう X 長さのシーケンスである m そして Y 長さのシーケンス n。のすべてのサブシーケンスを確認しますX それがのサブシーケンスであるかどうか Y、および見つかった最長共通部分列を返します。
がある 2m のサブシーケンス X。シーケンスのサブシーケンスであるかどうかをテストするY かかります O(n)時間。したがって、ナイーブなアルゴリズムはO(n2m) 時間。
動的計画法
ましょX = <X 1、X 2、xは3、···、XのM >及びY = <Y 1、Y 2、Y 3、...、Y nは>配列です。要素の長さを計算するには、次のアルゴリズムを使用します。
この手順では、テーブル C[m, n] 行のメジャー順と別のテーブルで計算されます B[m,n] 最適解を構築するために計算されます。
Algorithm: LCS-Length-Table-Formulation (X, Y)
m := length(X)
n := length(Y)
for i = 1 to m do
C[i, 0] := 0
for j = 1 to n do
C[0, j] := 0
for i = 1 to m do
for j = 1 to n do
if xi = yj
C[i, j] := C[i - 1, j - 1] + 1
B[i, j] := ‘D’
else
if C[i -1, j] ≥ C[i, j -1]
C[i, j] := C[i - 1, j] + 1
B[i, j] := ‘U’
else
C[i, j] := C[i, j - 1]
B[i, j] := ‘L’
return C and BAlgorithm: Print-LCS (B, X, i, j)
if i = 0 and j = 0
return
if B[i, j] = ‘D’
Print-LCS(B, X, i-1, j-1)
Print(xi)
else if B[i, j] = ‘U’
Print-LCS(B, X, i-1, j)
else
Print-LCS(B, X, i, j-1)このアルゴリズムは、最長共通部分列を出力します。 X そして Y。
分析
テーブルにデータを入力するには、外側 for ループが繰り返されます m 時間と内側 for ループが繰り返されます n回。したがって、アルゴリズムの複雑さはO(m、n)です。ここで、m そして n 2つの文字列の長さです。
例
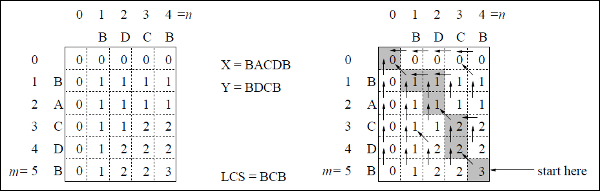
この例では、2つの文字列があります X = BACDB そして Y = BDCB 最長共通部分列を見つけます。
アルゴリズムLCS-Length-Table-Formulation(上記のとおり)に従って、テーブルC(左側に表示)とテーブルB(右側に表示)を計算しました。
表Bでは、「D」、「L」、「U」の代わりに、それぞれ対角矢印、左矢印、上矢印を使用しています。テーブルBを生成した後、LCSは関数LCS-Printによって決定されます。結果はBCBです。
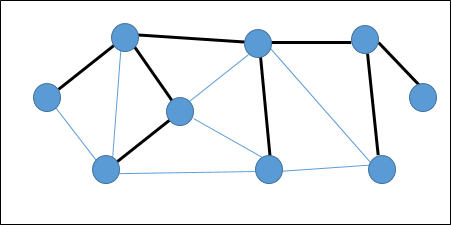
A spanning tree は、すべての頂点が最小数のエッジで接続されている無向グラフのサブセットです。
すべての頂点がグラフで接続されている場合、少なくとも1つのスパニングツリーが存在します。グラフには、複数のスパニングツリーが存在する場合があります。
プロパティ
- スパニングツリーにはサイクルがありません。
- 他の頂点から任意の頂点に到達できます。
例
次のグラフでは、強調表示されたエッジがスパニングツリーを形成しています。
最小スパニングツリー
A Minimum Spanning Tree (MST)は、接続された重み付き無向グラフのエッジのサブセットであり、すべての頂点を可能な限り最小の合計エッジ重みで接続します。MSTを導出するには、プリムのアルゴリズムまたはクラスカルのアルゴリズムを使用できます。したがって、この章ではプリムのアルゴリズムについて説明します。
すでに説明したように、1つのグラフに複数のスパニングツリーが含まれる場合があります。ある場合n 頂点の数、スパニングツリーは n - 1エッジの数。このコンテキストでは、グラフの各エッジが重みに関連付けられており、複数のスパニングツリーが存在する場合、グラフの最小スパニングツリーを見つける必要があります。
さらに、重複する重み付きエッジが存在する場合、グラフには複数の最小全域木が含まれる可能性があります。
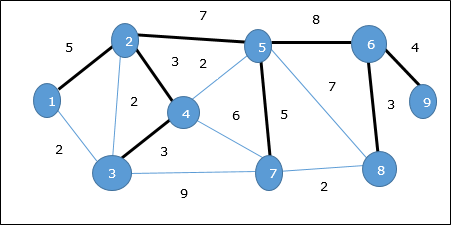
上のグラフでは、最小スパニングツリーではありませんが、スパニングツリーを示しています。このスパニングツリーのコストは(5 + 7 + 3 + 3 + 5 + 8 + 3 + 4)= 38です。
プリムのアルゴリズムを使用して、最小全域木を見つけます。
プリムのアルゴリズム
プリムのアルゴリズムは、最小全域木を見つけるための欲張り法です。このアルゴリズムでは、MSTを形成するために、任意の頂点から開始できます。
Algorithm: MST-Prim’s (G, w, r)
for each u є G.V
u.key = ∞
u.∏ = NIL
r.key = 0
Q = G.V
while Q ≠ Ф
u = Extract-Min (Q)
for each v є G.adj[u]
if each v є Q and w(u, v) < v.key
v.∏ = u
v.key = w(u, v)関数Extract-Minは、最小のエッジコストで頂点を返します。この関数は最小ヒープで機能します。
例
プリムのアルゴリズムを使用して、任意の頂点から開始できます。頂点から開始しましょう。 1。
バーテックス 3 頂点に接続されています 1 最小のエッジコストで、したがってエッジ (1, 2) スパニングツリーに追加されます。
次に、エッジ (2, 3) これはエッジ間の最小値であるため、 {(1, 2), (2, 3), (3, 4), (3, 7)}。
次のステップでは、エッジを取得します (3, 4) そして (2, 4)最小限のコストで。縁(3, 4) ランダムに選択されます。
同様に、エッジ (4, 5), (5, 7), (7, 8), (6, 8) そして (6, 9)が選択されています。すべての頂点にアクセスすると、アルゴリズムが停止します。
スパニングツリーのコストは(2 + 2 + 3 + 2 + 5 + 2 + 3 + 4)= 23です。このグラフには、コストが以下のスパニングツリーはありません。 23。
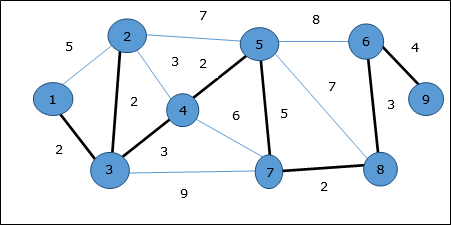
ダイクストラのアルゴリズム
ダイクストラのアルゴリズムは、有向加重グラフG =(V、E)で単一ソースの最短経路問題を解きます。ここで、すべてのエッジは非負です(つまり、各エッジ(u、vに対してw(u、v) ≥0 ))ЄE)。
次のアルゴリズムでは、1つの関数を使用します Extract-Min()、最小のキーを持つノードを抽出します。
Algorithm: Dijkstra’s-Algorithm (G, w, s)
for each vertex v Є G.V
v.d := ∞
v.∏ := NIL
s.d := 0
S := Ф
Q := G.V
while Q ≠ Ф
u := Extract-Min (Q)
S := S U {u}
for each vertex v Є G.adj[u]
if v.d > u.d + w(u, v)
v.d := u.d + w(u, v)
v.∏ := u分析
このアルゴリズムの複雑さは、Extract-Min関数の実装に完全に依存しています。最小抽出関数が線形検索を使用して実装されている場合、このアルゴリズムの複雑さは次のようになります。O(V2 + E)。
このアルゴリズムでは、min-heapを使用すると Extract-Min() 関数はからノードを返すように動作します Q 最小のキーを使用すると、このアルゴリズムの複雑さをさらに軽減できます。
例
頂点を考えてみましょう 1 そして 9それぞれ開始頂点と宛先頂点として。最初に、開始頂点を除くすべての頂点は∞でマークされ、開始頂点はでマークされます。0。
| バーテックス | 初期 | ステップ1V 1 | ステップ2V 3 | ステップ3V 2 | ステップ4V 4 | ステップ5V 5 | ステップ6V 7 | ステップ7V 8 | ステップ8V 6 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | ∞ | 5 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| 3 | ∞ | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 4 | ∞ | ∞ | ∞ | 7 | 7 | 7 | 7 | 7 | 7 |
| 5 | ∞ | ∞ | ∞ | 11 | 9 | 9 | 9 | 9 | 9 |
| 6 | ∞ | ∞ | ∞ | ∞ | ∞ | 17 | 17 | 16 | 16 |
| 7 | ∞ | ∞ | 11 | 11 | 11 | 11 | 11 | 11 | 11 |
| 8 | ∞ | ∞ | ∞ | ∞ | ∞ | 16 | 13 | 13 | 13 |
| 9 | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ | 20 |
したがって、頂点の最小距離 9 頂点から 1 です 20。そして、その道は
1→3→7→8→6→9
このパスは、先行情報に基づいて決定されます。
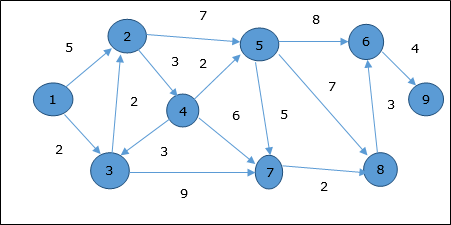
ベルマンフォードアルゴリズム
このアルゴリズムは、有向グラフの単一ソース最短経路問題を解決します G = (V, E)エッジの重みが負になる場合があります。さらに、負の重み付きサイクルが存在しない場合は、このアルゴリズムを適用して最短経路を見つけることができます。
Algorithm: Bellman-Ford-Algorithm (G, w, s)
for each vertex v Є G.V
v.d := ∞
v.∏ := NIL
s.d := 0
for i = 1 to |G.V| - 1
for each edge (u, v) Є G.E
if v.d > u.d + w(u, v)
v.d := u.d +w(u, v)
v.∏ := u
for each edge (u, v) Є G.E
if v.d > u.d + w(u, v)
return FALSE
return TRUE分析
最初 for ループは初期化に使用され、 O(V)回。次for ループ実行|V - 1| エッジを通過します。O(E) 回。
したがって、ベルマンフォードアルゴリズムはで実行されます O(V, E) 時間。
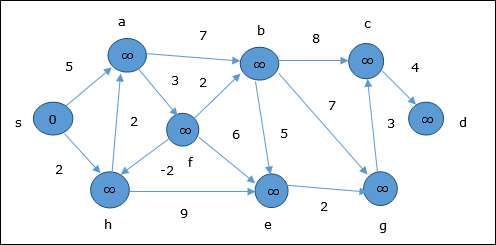
例
次の例は、ベルマンフォードアルゴリズムがどのように機能するかを段階的に示しています。このグラフには負のエッジがありますが、負のサイクルはありません。したがって、この手法を使用して問題を解決できます。
初期化時に、ソースを除くすべての頂点は∞でマークされ、ソースはでマークされます。 0。
最初のステップでは、ソースから到達可能なすべての頂点が最小コストで更新されます。したがって、頂点a そして h 更新されます。
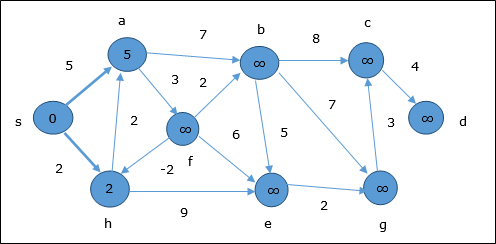
次のステップでは、頂点 a, b, f そして e 更新されます。
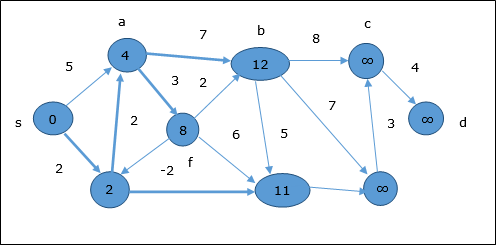
同じロジックに従って、このステップでは頂点 b, f, c そして g 更新されます。
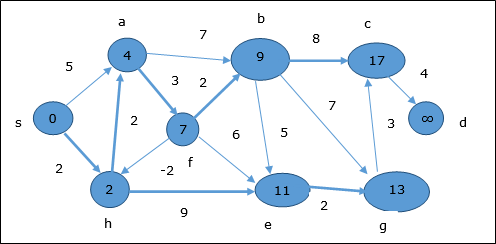
ここでは、頂点 c そして d 更新されます。
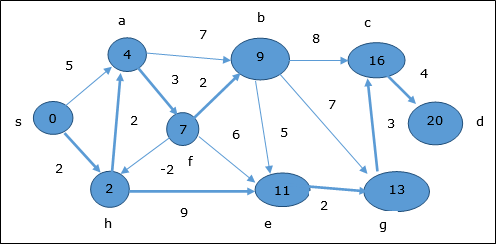
したがって、頂点間の最小距離 s および頂点 d です 20。
先行情報に基づくと、パスはs→h→e→g→c→dです。
多段グラフ G = (V, E) 頂点がに分割されている有向グラフです k (どこ k > 1)互いに素なサブセットの数 S = {s1,s2,…,sk}その結果、エッジ(U、V) Eであり、次いで、UЄS I及びVЄS 1 + 1パーティション内のいくつかのサブセットおよび|s1| = |sk| = 1。
頂点 s Є s1 と呼ばれます source と頂点 t Є sk と呼ばれる sink。
G通常、加重グラフと見なされます。このグラフでは、エッジ(i、j)のコストはc(i、j)で表されます。したがって、ソースからのパスのコストs 沈む t このパスの各エッジのコストの合計です。
多段グラフの問題は、ソースから最小のコストでパスを見つけることです s 沈む t。
例
多段グラフの概念を理解するために、次の例を検討してください。
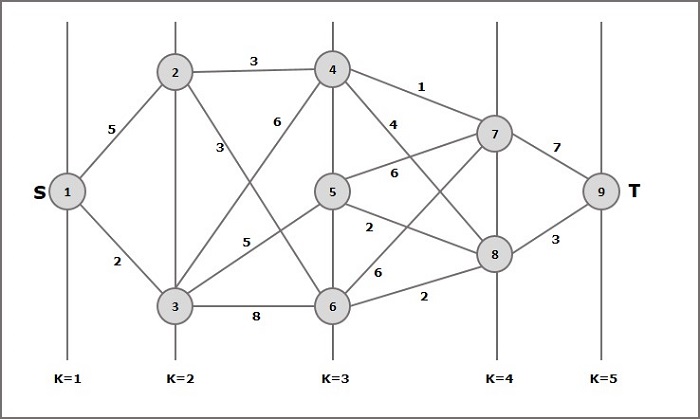
式に従って、コストを計算する必要があります (i, j) 次の手順を使用します
ステップ-1:コスト(K-2、j)
このステップでは、3つのノード(ノード4、5、6)が次のように選択されます。 j。したがって、このステップで最小コストを選択するための3つのオプションがあります。
Cost(3、4)= min {c(4、7)+ Cost(7、9)、c(4、8)+ Cost(8、9)} = 7
Cost(3、5)= min {c(5、7)+ Cost(7、9)、c(5、8)+ Cost(8、9)} = 5
Cost(3、6)= min {c(6、7)+ Cost(7、9)、c(6、8)+ Cost(8、9)} = 5
ステップ2:コスト(K-3、j)
ステージk-3 = 2には2と3の2つのノードがあるため、2つのノードがjとして選択されます。したがって、値i = 2とj = 2と3です。
Cost(2、2)= min {c(2、4)+ Cost(4、8)+ Cost(8、9)、c(2、6)+
Cost(6、8)+ Cost(8、9)} = 8
Cost(2、3)= {c(3、4)+ Cost(4、8)+ Cost(8、9)、c(3、5)+ Cost(5、8)+ Cost(8、9)、 c(3、6)+コスト(6、8)+コスト(8、9)} = 10
ステップ-3:コスト(K-4、j)
コスト(1、1)= {c(1、2)+コスト(2、6)+コスト(6、8)+コスト(8、9)、c(1、3)+コスト(3、5)+ Cost(5、8)+ Cost(8、9))} = 12
c(1、3)+ Cost(3、6)+ Cost(6、8 + Cost(8、9))} = 13
したがって、最小コストのパスは次のようになります。 1→ 3→ 5→ 8→ 9。
問題文
旅行者はリストからすべての都市を訪問する必要があります。ここでは、すべての都市間の距離がわかっており、各都市は1回だけ訪問する必要があります。彼が各都市を一度だけ訪れて元の都市に戻る最短ルートはどれですか?
解決
巡回セールスマン問題は、最も悪名高い計算上の問題です。力ずくのアプローチを使用して、考えられるすべてのツアーを評価し、最適なツアーを選択できます。にとってn グラフ内の頂点の数、 (n - 1)! 可能性の数。
動的計画法を使用したブルートフォースの代わりに、多項式時間アルゴリズムはありませんが、より短い時間で解を得ることができます。
グラフを考えてみましょう G = (V, E)、 どこ V 都市のセットであり、 E重み付きエッジのセットです。縁e(u, v) その頂点を表します u そして v接続されています。頂点間の距離u そして v です d(u, v)、これは負ではないはずです。
私たちが都市で始めたとしましょう 1 そしていくつかの都市を訪れた後、私たちは今都市にいます j。したがって、これは部分的なツアーです。私たちは確かに知る必要がありますj、これにより、次に訪問するのに最も便利な都市が決まります。また、これまでに訪れたすべての都市を知っておく必要があります。そうすれば、どの都市も繰り返さないようになります。したがって、これは適切なサブ問題です。
都市のサブセットの場合 S Є {1, 2, 3, ... , n} それが含まれています 1、および j Є S、 C(S, j) の各ノードを訪問する最短経路の長さ S 一度だけ、 1 で終わる j。
いつ|S| > 1、私たちは定義しますC(S, 1) = ∝パスはで開始および終了できないため 1。
さあ、表現しましょう C(S, j)小さなサブ問題の観点から。から始める必要があります1 そしてで終わる j。次の都市を次のように選択する必要があります
$$C(S, j) = min \:C(S - \lbrace j \rbrace, i) + d(i, j)\:where\: i\in S \: and\: i \neq jc(S, j) = minC(s- \lbrace j \rbrace, i)+ d(i,j) \:where\: i\in S \: and\: i \neq j $$
Algorithm: Traveling-Salesman-Problem
C ({1}, 1) = 0
for s = 2 to n do
for all subsets S Є {1, 2, 3, … , n} of size s and containing 1
C (S, 1) = ∞
for all j Є S and j ≠ 1
C (S, j) = min {C (S – {j}, i) + d(i, j) for i Є S and i ≠ j}
Return minj C ({1, 2, 3, …, n}, j) + d(j, i)分析
せいぜい $2^n.n$サブ問題とそれぞれが解決するのに線形の時間がかかります。したがって、合計実行時間は$O(2^n.n^2)$。
例
次の例では、巡回セールスマン問題を解決する手順を説明します。

上記のグラフから、次の表が作成されます。
| 1 | 2 | 3 | 4 | |
| 1 | 0 | 10 | 15 | 20 |
| 2 | 5 | 0 | 9 | 10 |
| 3 | 6 | 13 | 0 | 12 |
| 4 | 8 | 8 | 9 | 0 |
S =Φ
$$\small Cost (2,\Phi,1) = d (2,1) = 5\small Cost(2,\Phi,1)=d(2,1)=5$$
$$\small Cost (3,\Phi,1) = d (3,1) = 6\small Cost(3,\Phi,1)=d(3,1)=6$$
$$\small Cost (4,\Phi,1) = d (4,1) = 8\small Cost(4,\Phi,1)=d(4,1)=8$$
S = 1
$$\small Cost (i,s) = min \lbrace Cost (j,s – (j)) + d [i,j]\rbrace\small Cost (i,s)=min \lbrace Cost (j,s)-(j))+ d [i,j]\rbrace$$
$$\small Cost (2,\lbrace 3 \rbrace,1) = d [2,3] + Cost (3,\Phi,1) = 9 + 6 = 15cost(2,\lbrace3 \rbrace,1)=d[2,3]+cost(3,\Phi ,1)=9+6=15$$
$$\small Cost (2,\lbrace 4 \rbrace,1) = d [2,4] + Cost (4,\Phi,1) = 10 + 8 = 18cost(2,\lbrace4 \rbrace,1)=d[2,4]+cost(4,\Phi,1)=10+8=18$$
$$\small Cost (3,\lbrace 2 \rbrace,1) = d [3,2] + Cost (2,\Phi,1) = 13 + 5 = 18cost(3,\lbrace2 \rbrace,1)=d[3,2]+cost(2,\Phi,1)=13+5=18$$
$$\small Cost (3,\lbrace 4 \rbrace,1) = d [3,4] + Cost (4,\Phi,1) = 12 + 8 = 20cost(3,\lbrace4 \rbrace,1)=d[3,4]+cost(4,\Phi,1)=12+8=20$$
$$\small Cost (4,\lbrace 3 \rbrace,1) = d [4,3] + Cost (3,\Phi,1) = 9 + 6 = 15cost(4,\lbrace3 \rbrace,1)=d[4,3]+cost(3,\Phi,1)=9+6=15$$
$$\small Cost (4,\lbrace 2 \rbrace,1) = d [4,2] + Cost (2,\Phi,1) = 8 + 5 = 13cost(4,\lbrace2 \rbrace,1)=d[4,2]+cost(2,\Phi,1)=8+5=13$$
S = 2
$$\small Cost(2, \lbrace 3, 4 \rbrace, 1)=\begin{cases}d[2, 3] + Cost(3, \lbrace 4 \rbrace, 1) = 9 + 20 = 29\\d[2, 4] + Cost(4, \lbrace 3 \rbrace, 1) = 10 + 15 = 25=25\small Cost (2,\lbrace 3,4 \rbrace,1)\\\lbrace d[2,3]+ \small cost(3,\lbrace4\rbrace,1)=9+20=29d[2,4]+ \small Cost (4,\lbrace 3 \rbrace ,1)=10+15=25\end{cases}= 25$$
$$\small Cost(3, \lbrace 2, 4 \rbrace, 1)=\begin{cases}d[3, 2] + Cost(2, \lbrace 4 \rbrace, 1) = 13 + 18 = 31\\d[3, 4] + Cost(4, \lbrace 2 \rbrace, 1) = 12 + 13 = 25=25\small Cost (3,\lbrace 2,4 \rbrace,1)\\\lbrace d[3,2]+ \small cost(2,\lbrace4\rbrace,1)=13+18=31d[3,4]+ \small Cost (4,\lbrace 2 \rbrace ,1)=12+13=25\end{cases}= 25$$
$$\small Cost(4, \lbrace 2, 3 \rbrace, 1)=\begin{cases}d[4, 2] + Cost(2, \lbrace 3 \rbrace, 1) = 8 + 15 = 23\\d[4, 3] + Cost(3, \lbrace 2 \rbrace, 1) = 9 + 18 = 27=23\small Cost (4,\lbrace 2,3 \rbrace,1)\\\lbrace d[4,2]+ \small cost(2,\lbrace3\rbrace,1)=8+15=23d[4,3]+ \small Cost (3,\lbrace 2 \rbrace ,1)=9+18=27\end{cases}= 23$$
S = 3
$$\small Cost(1, \lbrace 2, 3, 4 \rbrace, 1)=\begin{cases}d[1, 2] + Cost(2, \lbrace 3, 4 \rbrace, 1) = 10 + 25 = 35\\d[1, 3] + Cost(3, \lbrace 2, 4 \rbrace, 1) = 15 + 25 = 40\\d[1, 4] + Cost(4, \lbrace 2, 3 \rbrace, 1) = 20 + 23 = 43=35 cost(1,\lbrace 2,3,4 \rbrace),1)\\d[1,2]+cost(2,\lbrace 3,4 \rbrace,1)=10+25=35\\d[1,3]+cost(3,\lbrace 2,4 \rbrace,1)=15+25=40\\d[1,4]+cost(4,\lbrace 2,3 \rbrace ,1)=20+23=43=35\end{cases}$$
最小コストパスは35です。
コストから始める {1, {2, 3, 4}, 1}、の最小値を取得します d [1, 2]。いつs = 3、1から2(コストは10)のパスを選択してから、逆方向に進みます。いつs = 2、の最小値を取得します d [4, 2]。2から4(コストは10)のパスを選択してから、逆方向に進みます。
いつ s = 1、の最小値を取得します d [4, 3]。パス4から3(コストは9)を選択し、次に進みます。s = Φステップ。の最小値を取得しますd [3, 1] (コストは6です)。

二分探索木(BST)は、キー値が内部ノードに格納されているツリーです。外部ノードはヌルノードです。キーは辞書式順序で並べられます。つまり、内部ノードごとに、左側のサブツリーのすべてのキーがノードのキーよりも小さく、右側のサブツリーのすべてのキーが大きくなります。
各キーを検索する頻度がわかっている場合、ツリー内の各ノードにアクセスするための予想コストを計算するのは非常に簡単です。最適な二分探索木はBSTであり、各ノードを見つけるための予想コストは最小限です。
BST内の要素の検索時間は O(n)、一方、平衡BSTでは、検索時間は O(log n)。この場合も、Optimal Cost Binary Search Treeで検索時間を改善し、最も頻繁に使用されるデータをルートおよびルート要素の近くに配置し、最も使用頻度の低いデータを葉の近くおよび葉に配置します。
ここでは、最適な二分探索木アルゴリズムが提示されます。まず、提供されたセットからBSTを構築しますn 個別のキーの数 < k1, k2, k3, ... kn >。ここでは、キーにアクセスする確率を想定していますKi です pi。いくつかのダミーキー(d0, d1, d2, ... dn)キーセットに存在しない値に対して一部の検索が実行される可能性があるため、追加されます K。ダミーキーごとに、di アクセスの確率は qi。
Optimal-Binary-Search-Tree(p, q, n)
e[1…n + 1, 0…n],
w[1…n + 1, 0…n],
root[1…n + 1, 0…n]
for i = 1 to n + 1 do
e[i, i - 1] := qi - 1
w[i, i - 1] := qi - 1
for l = 1 to n do
for i = 1 to n – l + 1 do
j = i + l – 1 e[i, j] := ∞
w[i, i] := w[i, i -1] + pj + qj
for r = i to j do
t := e[i, r - 1] + e[r + 1, j] + w[i, j]
if t < e[i, j]
e[i, j] := t
root[i, j] := r
return e and root分析
アルゴリズムには O (n3) 時間、3つがネストされているので forループが使用されます。これらのループのそれぞれはせいぜい引き受けますn 値。
例
次のツリーを考慮すると、コストは2.80ですが、これは最適な結果ではありません。
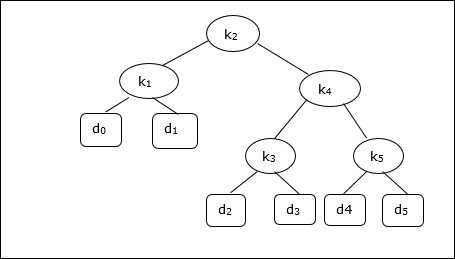
| ノード | 深さ | 確率 | 貢献 |
|---|---|---|---|
| k 1 | 1 | 0.15 | 0.30 |
| k 2 | 0 | 0.10 | 0.10 |
| k 3 | 2 | 0.05 | 0.15 |
| k 4 | 1 | 0.10 | 0.20 |
| k 5 | 2 | 0.20 | 0.60 |
| d 0 | 2 | 0.05 | 0.15 |
| d 1 | 2 | 0.10 | 0.30 |
| d 2 | 3 | 0.05 | 0.20 |
| d 3 | 3 | 0.05 | 0.20 |
| d 4 | 3 | 0.05 | 0.20 |
| d 5 | 3 | 0.10 | 0.40 |
| Total | 2.80 |
この章で説明するアルゴリズムを使用して最適なソリューションを取得するために、次の表が生成されます。
次の表では、列インデックスは i 行インデックスは j。
| e | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 5 | 2.75 | 2.00 | 1.30 | 0.90 | 0.50 | 0.10 |
| 4 | 1.75 | 1.20 | 0.60 | 0.30 | 0.05 | |
| 3 | 1.25 | 0.70 | 0.25 | 0.05 | ||
| 2 | 0.90 | 0.40 | 0.05 | |||
| 1 | 0.45 | 0.10 | ||||
| 0 | 0.05 |
| w | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 5 | 1.00 | 0.80 | 0.60 | 0.50 | 0.35 | 0.10 |
| 4 | 0.70 | 0.50 | 0.30 | 0.20 | 0.05 | |
| 3 | 0.55 | 0.35 | 0.15 | 0.05 | ||
| 2 | 0.45 | 0.25 | 0.05 | |||
| 1 | 0.30 | 0.10 | ||||
| 0 | 0.05 |
| ルート | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 5 | 2 | 4 | 5 | 5 | 5 |
| 4 | 2 | 2 | 4 | 4 | |
| 3 | 2 | 2 | 3 | ||
| 2 | 1 | 2 | |||
| 1 | 1 |
これらのテーブルから、最適なツリーを形成できます。
ヒープにはいくつかの種類がありますが、この章では、バイナリヒープについて説明します。Abinary heapはデータ構造であり、完全な二分木に似ています。ヒープデータ構造は、以下で説明する順序付けプロパティに従います。通常、ヒープは配列で表されます。この章では、ヒープを次のように表します。H。
ヒープの要素は配列に格納されるため、開始インデックスを次のように考慮します。 1、の親ノードの位置 ith 要素はで見つけることができます ⌊ i/2 ⌋。の左子と右子ith ノードは位置にあります 2i そして 2i + 1。
バイナリヒープは、さらに次のいずれかに分類できます。 max-heap または min-heap 注文プロパティに基づきます。
最大ヒープ
このヒープでは、ノードのキー値は最上位の子のキー値以上です。
したがって、 H[Parent(i)] ≥ H[i]
最小ヒープ
平均ヒープでは、ノードのキー値は最下位の子のキー値以下です。
したがって、 H[Parent(i)] ≤ H[i]
これに関連して、最大ヒープに関する基本的な操作を以下に示します。ヒープ内およびヒープからの要素の挿入および削除には、要素の再配置が必要です。したがって、Heapify 関数を呼び出す必要があります。
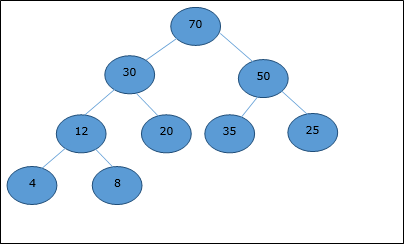
配列表現
完全な二分木は配列で表すことができ、レベル順トラバーサルを使用してその要素を格納します。
配列で表されるヒープ(以下に示す)について考えてみましょう。 H。
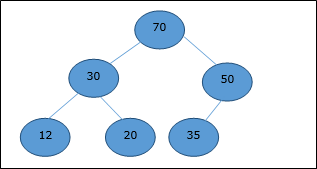
開始インデックスを次のように見なします 0、レベル順トラバーサルを使用して、要素は次のように配列に保持されます。
| Index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ..。 |
| elements | 70 | 30 | 50 | 12 | 20 | 35 | 25 | 4 | 8 | ..。 |
このコンテキストでは、ヒープに対する操作はMax-Heapに関して表されています。
indexで要素の親のインデックスを見つけるには i、次のアルゴリズム Parent (numbers[], i) 使用されている。
Algorithm: Parent (numbers[], i)
if i == 1
return NULL
else
[i / 2]インデックスにある要素の左の子のインデックス i 次のアルゴリズムを使用して見つけることができます、 Left-Child (numbers[], i)。
Algorithm: Left-Child (numbers[], i)
If 2 * i ≤ heapsize
return [2 * i]
else
return NULLインデックスにある要素の右の子のインデックス i 次のアルゴリズムを使用して見つけることができます、 Right-Child(numbers[], i)。
Algorithm: Right-Child (numbers[], i)
if 2 * i < heapsize
return [2 * i + 1]
else
return NULLヒープに要素を挿入するために、新しい要素は最初に配列の最後の要素としてヒープの最後に追加されます。
この要素を挿入した後、ヒーププロパティに違反する可能性があるため、追加された要素をその親と比較し、追加された要素を1レベル上に移動して、親と位置を入れ替えることにより、ヒーププロパティが修復されます。このプロセスはpercolation up。
親が浸透要素以上になるまで、比較が繰り返されます。
Algorithm: Max-Heap-Insert (numbers[], key)
heapsize = heapsize + 1
numbers[heapsize] = -∞
i = heapsize
numbers[i] = key
while i > 1 and numbers[Parent(numbers[], i)] < numbers[i]
exchange(numbers[i], numbers[Parent(numbers[], i)])
i = Parent (numbers[], i)分析
最初に、要素が配列の最後に追加されています。ヒーププロパティに違反している場合、要素はその親と交換されます。木の高さはlog n。最大log n 実行する必要のある操作の数。
したがって、この関数の複雑さは次のとおりです。 O(log n)。
例
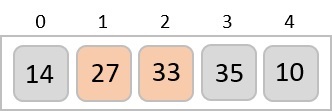
以下に示すように、新しい要素5を追加する必要がある最大ヒープについて考えてみましょう。
最初に、55がこの配列の最後に追加されます。
挿入後、ヒーププロパティに違反します。したがって、要素はその親と交換する必要があります。スワップ後のヒープは次のようになります。
この場合も、要素はヒープのプロパティに違反します。したがって、親と交換されます。
今、私たちはやめなければなりません。
Heapifyメソッドは、配列の要素を再配置します。 ith 要素はヒーププロパティに従います。
Algorithm: Max-Heapify(numbers[], i)
leftchild := numbers[2i]
rightchild := numbers [2i + 1]
if leftchild ≤ numbers[].size and numbers[leftchild] > numbers[i]
largest := leftchild
else
largest := i
if rightchild ≤ numbers[].size and numbers[rightchild] > numbers[largest]
largest := rightchild
if largest ≠ i
swap numbers[i] with numbers[largest]
Max-Heapify(numbers, largest)提供された配列がヒーププロパティに従わない場合、ヒープは次のアルゴリズムに基づいて構築されます Build-Max-Heap (numbers[])。
Algorithm: Build-Max-Heap(numbers[])
numbers[].size := numbers[].length
fori = ⌊ numbers[].length/2 ⌋ to 1 by -1
Max-Heapify (numbers[], i)Extractメソッドは、ヒープのルート要素を抽出するために使用されます。以下はアルゴリズムです。
Algorithm: Heap-Extract-Max (numbers[])
max = numbers[1]
numbers[1] = numbers[heapsize]
heapsize = heapsize – 1
Max-Heapify (numbers[], 1)
return max例
前に説明したのと同じ例を考えてみましょう。次に、要素を抽出します。このメソッドは、ヒープのルート要素を返します。
ルート要素を削除すると、最後の要素がルート位置に移動します。
これで、Heapify関数が呼び出されます。ヒープ化後、次のヒープが生成されます。
バブルソートは基本的なソートアルゴリズムであり、必要に応じて隣接する要素を繰り返し交換することで機能します。交換が不要な場合、ファイルはソートされます。
これは、すべてのソートアルゴリズムの中で最も単純な手法です。
Algorithm: Sequential-Bubble-Sort (A)
fori← 1 to length [A] do
for j ← length [A] down-to i +1 do
if A[A] < A[j - 1] then
Exchange A[j] ↔ A[j-1]実装
voidbubbleSort(int numbers[], intarray_size) {
inti, j, temp;
for (i = (array_size - 1); i >= 0; i--)
for (j = 1; j <= i; j++)
if (numbers[j - 1] > numbers[j]) {
temp = numbers[j-1];
numbers[j - 1] = numbers[j];
numbers[j] = temp;
}
}分析
ここで、比較の数は
1 + 2 + 3 +...+ (n - 1) = n(n - 1)/2 = O(n2)
明らかに、グラフは n2 バブルソートの性質。
このアルゴリズムでは、比較の数はデータセットに関係ありません。つまり、提供された入力要素が並べ替えられた順序であるか、逆の順序であるか、ランダムであるかは関係ありません。
メモリ要件
上記のアルゴリズムから、バブルソートが追加のメモリを必要としないことは明らかです。
例
Unsorted list: |
|
1回目の反復:
5 > 2 swap |
|
|||||||
5 > 1 swap |
|
|||||||
5 > 4 swap |
|
|||||||
5 > 3 swap |
|
|||||||
5 < 7 no swap |
|
|||||||
7 > 6 swap |
|
2回目の反復:
2 > 1 swap |
|
|||||||
2 < 4 no swap |
|
|||||||
4 > 3 swap |
|
|||||||
4 < 5 no swap |
|
|||||||
5 < 6 no swap |
|
3回目、4回目、5回目、6回目の反復に変更はありません。
最終的に、
the sorted list is |
|
挿入ソートは、数値を昇順または降順でソートする非常に簡単な方法です。この方法は、インクリメンタル法に従います。これは、ゲームをプレイするときにカードがどのように分類されるかという手法と比較することができます。
ソートする必要のある番号は、次のように知られています。 keys。これが挿入ソート法のアルゴリズムです。
Algorithm: Insertion-Sort(A)
for j = 2 to A.length
key = A[j]
i = j – 1
while i > 0 and A[i] > key
A[i + 1] = A[i]
i = i -1
A[i + 1] = key分析
このアルゴリズムの実行時間は、指定された入力に大きく依存します。
指定された番号がソートされている場合、このアルゴリズムはで実行されます O(n)時間。指定された番号が逆の順序である場合、アルゴリズムはで実行されますO(n2) 時間。
例
Unsorted list: |
|
1st iteration:
キー= a [2] = 13
a [1] = 2 <13
スワップ、スワップなし |
|
2nd iteration:
キー= a [3] = 5
a [2] = 13> 5
5と13を交換します |
|
次に、a [1] = 2 <13
スワップ、スワップなし |
|
3rd iteration:
キー= a [4] = 18
a [3] = 13 <18
a [2] = 5 <18
a [1] = 2 <18
スワップ、スワップなし |
|
4th iteration:
キー= a [5] = 14
a [4] = 18> 14
18と14を交換します |
|
次に、a [3] = 13 <14
a [2] = 5 <14
a [1] = 2 <14
したがって、スワップはありません |
|
最終的に、
the sorted list is |
|
このタイプのソートは、 Selection Sort要素を繰り返しソートすることで機能するためです。これは次のように機能します。最初に配列内で最小のものを見つけて最初の位置の要素と交換し、次に2番目に小さい要素を見つけて2番目の位置の要素と交換し、配列全体が次のようになるまでこの方法を続けます。ソート済み。
Algorithm: Selection-Sort (A)
fori ← 1 to n-1 do
min j ← i;
min x ← A[i]
for j ←i + 1 to n do
if A[j] < min x then
min j ← j
min x ← A[j]
A[min j] ← A [i]
A[i] ← min x選択ソートは、最も単純なソート手法の1つであり、小さなファイルに非常に適しています。各アイテムは実際には最大で1回移動されるため、非常に重要なアプリケーションがあります。
セクションソートは、非常に大きなオブジェクト(レコード)と小さなキーを持つファイルをソートするための最適な方法です。最悪のケースは、配列がすでに降順で並べ替えられており、昇順で並べ替えたい場合に発生します。
それにもかかわらず、選択ソートアルゴリズムに必要な時間は、ソートされる配列の元の順序にあまり敏感ではありません。 A[j] < min x いずれの場合もまったく同じ回数実行されます。
選択ソートは、ほとんどの時間を配列のソートされていない部分で最小の要素を見つけようとすることに費やします。選択ソートとバブルソートの類似性を明確に示しています。
バブルソートは、各段階で残りの最大要素を選択しますが、配列のソートされていない部分に順序を与えるためにいくらかの労力を浪費します。
選択ソートは、最悪の場合と平均的な場合の両方で2次式であり、追加のメモリを必要としません。
それぞれについて i から 1 に n - 1、1つの交換があり、 n - i 比較なので、合計があります n - 1 交換と
(n − 1) + (n − 2) + ...+ 2 + 1 = n(n − 1)/2 比較。
これらの観察結果は、入力データが何であっても当てはまります。
最悪の場合、これは2次式になる可能性がありますが、平均的な場合、この量は次のようになります。 O(n log n)。それは、running time of Selection sort is quite insensitive to the input。
実装
Void Selection-Sort(int numbers[], int array_size) {
int i, j;
int min, temp;
for (i = 0; I < array_size-1; i++) {
min = i;
for (j = i+1; j < array_size; j++)
if (numbers[j] < numbers[min])
min = j;
temp = numbers[i];
numbers[i] = numbers[min];
numbers[min] = temp;
}
}例
Unsorted list: |
|
1回目の反復:
最小= 5
2 <5、最小= 2
1 <2、最小= 1
4> 1、最小= 1
3> 1、最小= 1
5と1を交換します |
|
2回目の反復:
最小= 2
2 <5、最小= 2
2 <4、最小= 2
2 <3、最小= 2
スワップなし |
|
3回目の反復:
最小= 5
4 <5、最小= 4
3 <4、最小= 3
5と3を交換します |
|
4回目の反復:
最小= 4
4 <5、最小= 4
スワップなし |
|
最終的に、
the sorted list is |
|
分割統治の原則に基づいて使用されます。クイックソートは、実装が難しくないため、多くの状況で選択されるアルゴリズムです。これは優れた汎用ソートであり、実行中に消費するリソースは比較的少なくなります。
利点
小さな補助スタックのみを使用するため、インプレースです。
必要なのは n (log n) 並べ替える時間 n アイテム。
それは非常に短い内部ループを持っています。
このアルゴリズムは徹底的な数学的分析を受けており、パフォーマンスの問題について非常に正確なステートメントを作成できます。
短所
再帰的です。特に、再帰が利用できない場合、実装は非常に複雑になります。
最悪の場合、2次(つまり、n2)時間が必要です。
これは壊れやすいものです。つまり、実装の単純な間違いが見過ごされ、パフォーマンスが低下する可能性があります。
クイックソートは、特定の配列を分割することで機能します A[p ... r] 空でない2つのサブ配列に A[p ... q] そして A[q+1 ... r] すべてのキーが A[p ... q] のすべてのキー以下である A[q+1 ... r]。
次に、2つのサブ配列は、クイックソートの再帰呼び出しによってソートされます。パーティションの正確な位置は、指定された配列とインデックスによって異なりますq パーティショニング手順の一部として計算されます。
Algorithm: Quick-Sort (A, p, r)
if p < r then
q Partition (A, p, r)
Quick-Sort (A, p, q)
Quick-Sort (A, q + r, r)配列全体を並べ替えるには、最初の呼び出しは次のようにする必要があることに注意してください Quick-Sort (A, 1, length[A])
最初のステップとして、クイックソートは、ピボットとしてソートする配列内のアイテムの1つを選択します。次に、配列はピボットのいずれかの側で分割されます。ピボット以下の要素は左に移動し、ピボット以上の要素は右に移動します。
アレイのパーティション化
パーティショニング手順により、サブアレイがインプレースで再配置されます。
Function: Partition (A, p, r)
x ← A[p]
i ← p-1
j ← r+1
while TRUE do
Repeat j ← j - 1
until A[j] ≤ x
Repeat i← i+1
until A[i] ≥ x
if i < j then
exchange A[i] ↔ A[j]
else
return j分析
クイックソートアルゴリズムの最悪の場合の複雑さは O(n2)。ただし、この手法を使用すると、通常、次の出力が得られます。O(n log n) 時間。
Radix sortは、多くの人が名前の大きなリストをアルファベット順に並べるときに直感的に使用する小さな方法です。具体的には、名前のリストは最初に各名前の最初の文字に従ってソートされます。つまり、名前は26のクラスに配置されます。
直感的には、最上位桁で数値を並べ替えることができます。ただし、基数ソートは、最下位桁を最初にソートすることにより、直感に反して機能します。最初のパスでは、すべての数値が最下位桁でソートされ、配列に結合されます。次に、2番目のパスで、数値全体が2番目の最下位桁で再度ソートされ、配列に結合されます。
Algorithm: Radix-Sort (list, n)
shift = 1
for loop = 1 to keysize do
for entry = 1 to n do
bucketnumber = (list[entry].key / shift) mod 10
append (bucket[bucketnumber], list[entry])
list = combinebuckets()
shift = shift * 10分析
各キーは、最長のキーの各桁(またはキーがアルファベットの場合は文字)ごとに一度に調べられます。したがって、最長のキーがm 数字とがあります n キー、基数ソートには順序があります O(m.n)。
ただし、これら2つの値を見ると、キーの数と比較すると、キーのサイズは比較的小さくなります。たとえば、6桁のキーがある場合、100万の異なるレコードを持つことができます。
ここでは、キーのサイズは重要ではなく、このアルゴリズムは線形の複雑さであることがわかります。 O(n)。
例
次の例は、基数ソートが7つの3桁の数値でどのように動作するかを示しています。
| 入力 | 1回目のパス | 2回目のパス | 3回目のパス |
|---|---|---|---|
| 329 | 720 | 720 | 329 |
| 457 | 355 | 329 | 355 |
| 657 | 436 | 436 | 436 |
| 839 | 457 | 839 | 457 |
| 436 | 657 | 355 | 657 |
| 720 | 329 | 457 | 720 |
| 355 | 839 | 657 | 839 |
上記の例では、最初の列が入力です。残りの列は、有効数字の位置が連続してソートされた後のリストを示しています。基数ソートのコードは、配列内の各要素を想定していますA の n 要素は持っています d 数字、ここで数字 1 は最下位桁であり、 d は最上位桁です。
クラスを理解する P そして NP、最初に計算モデルを知る必要があります。したがって、この章では、2つの重要な計算モデルについて説明します。
決定論的計算とクラスP
決定論的チューリングマシン
これらのモデルの1つは、決定論的な1テープチューリングマシンです。このマシンは、有限状態制御、読み取り/書き込みヘッド、および無限シーケンスの双方向テープで構成されています。
以下は、決定論的な1テープチューリングマシンの概略図です。
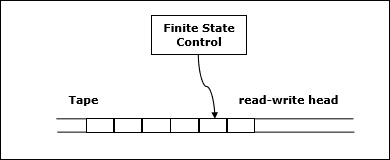
決定論的チューリングマシンのプログラムは、次の情報を指定します-
- テープシンボルの有限セット(入力シンボルと空白シンボル)
- 状態の有限集合
- 遷移関数
アルゴリズム解析では、決定論的な1テープチューリングマシンによって問題が多項式時間で解ける場合、その問題はPクラスに属します。
非決定論的計算とクラスNP
非決定性チューリングマシン
計算上の問題を解決するための別のモデルは、非決定性チューリングマシン(NDTM)です。NDTMの構造はDTMに似ていますが、ここでは、1つの書き込み専用ヘッドに関連付けられた推測モジュールと呼ばれる追加のモジュールが1つあります。
以下は概略図です。
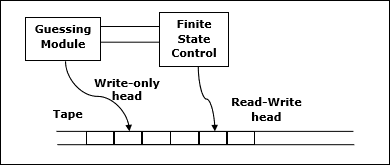
問題が非決定性チューリングマシンによって多項式時間で解ける場合、問題はNPクラスに属します。
無向グラフでは、 clique与えられたグラフの完全なサブグラフです。完全なサブグラフとは、このサブグラフのすべての頂点がこのサブグラフの他のすべての頂点に接続されていることを意味します。
最大クリーク問題は、グラフの最大クリークを見つける計算上の問題です。マックスクリークは、多くの現実の問題で使用されています。
頂点が人々のプロファイルを表し、エッジがグラフ内の相互の知人を表すソーシャルネットワーキングアプリケーションについて考えてみましょう。このグラフでは、クリークはすべてがお互いを知っている人々のサブセットを表しています。
最大クリークを見つけるには、すべてのサブセットを体系的に検査できますが、この種のブルートフォース検索は、数十を超える頂点で構成されるネットワークには時間がかかりすぎます。
Algorithm: Max-Clique (G, n, k)
S := Φ
for i = 1 to k do
t := choice (1…n)
if t Є S then
return failure
S := S ∪ t
for all pairs (i, j) such that i Є S and j Є S and i ≠ j do
if (i, j) is not a edge of the graph then
return failure
return success分析
Max-Clique問題は、非決定論的アルゴリズムです。このアルゴリズムでは、最初に一連のを決定しようとしますk 異なる頂点を作成してから、これらの頂点が完全グラフを形成するかどうかをテストします。
この問題を解決するための多項式時間決定論的アルゴリズムはありません。この問題はNP完全です。
例
次のグラフを見てください。ここで、頂点2、3、4、および6を含むサブグラフは完全グラフを形成します。したがって、このサブグラフはclique。これは提供されたグラフの最大の完全なサブグラフであるため、4-Clique。

無向グラフの頂点被覆 G = (V, E) 頂点のサブセットです V' ⊆ V エッジの場合 (u, v) のエッジです G、次にどちらか u に V または v に V' または両方。
与えられた無向グラフで最大サイズの頂点被覆を見つけます。この最適な頂点被覆は、NP完全問題の最適化バージョンです。ただし、最適に近い頂点被覆を見つけることはそれほど難しくありません。
APPROX-VERTEX_COVER (G: Graph) c ← { } E' ← E[G]
while E' is not empty do
Let (u, v) be an arbitrary edge of E' c ← c U {u, v}
Remove from E' every edge incident on either u or v
return c例
与えられたグラフのエッジのセットは-です
{(1,6),(1,2),(1,4),(2,3),(2,4),(6,7),(4,7),(7,8),(3,8),(3,5),(8,5)}
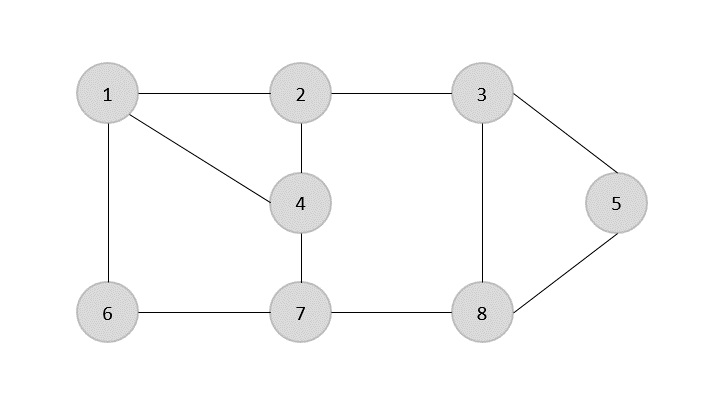
ここで、任意のエッジ(1,6)を選択することから始めます。頂点1または6に入射するすべてのエッジを削除し、カバーにエッジ(1,6)を追加します。
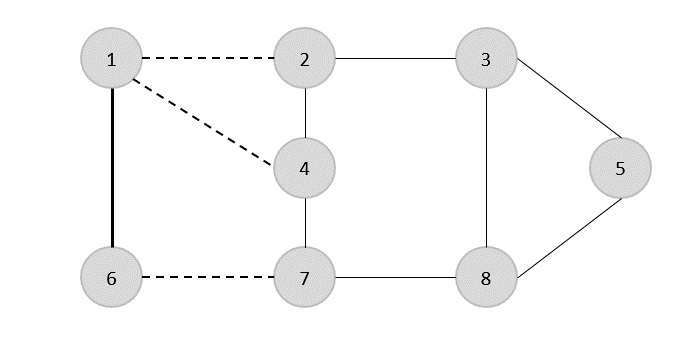
次のステップでは、別のエッジ(2,3)をランダムに選択しました
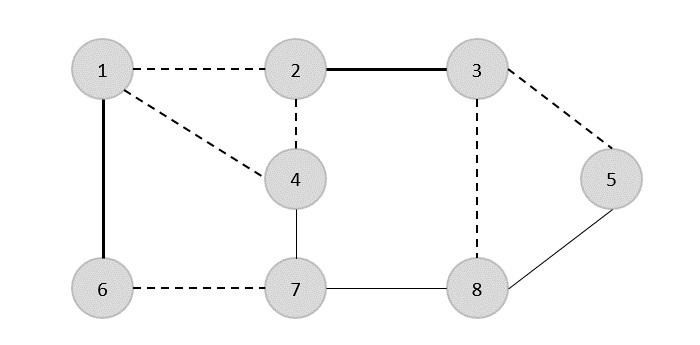
次に、別のエッジ(4,7)を選択します。
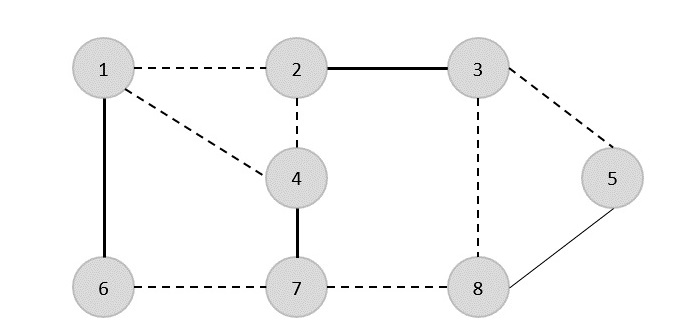
別のエッジ(8,5)を選択します。
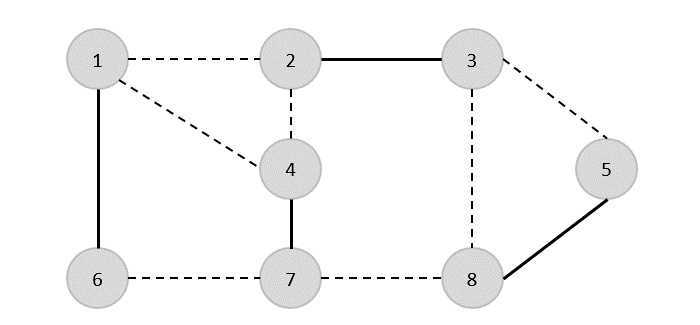
したがって、このグラフの頂点被覆は{1,2,4,5}です。
分析
このアルゴリズムの実行時間は次のとおりです。 O(V + E)、隣接リストを使用して表す E'。
コンピュータサイエンスでは、目的がいくつかの値を最大化または最小化することである場合に多くの問題が解決されますが、他の問題では、解決策があるかどうかを見つけようとします。したがって、問題は次のように分類できます。
最適化問題
最適化問題は、目的がいくつかの値を最大化または最小化することである問題です。例えば、
特定のグラフに色を付けるために必要な最小色数を見つける。
グラフ内の2つの頂点間の最短経路を見つける。
決定問題
答えが「はい」または「いいえ」である多くの問題があります。これらのタイプの問題は、 decision problems。例えば、
特定のグラフを4色のみで色付けできるかどうか。
グラフでハミルトン閉路を見つけることは決定問題ではありませんが、グラフをチェックすることはハミルトンであるかどうかは決定問題です。
言語とは何ですか?
すべての決定問題には、「はい」または「いいえ」の2つの答えしかありません。したがって、特定の入力に対して「はい」と答える場合、決定問題は言語に属する可能性があります。言語は、答えが「はい」である入力の全体です。前の章で説明したアルゴリズムのほとんどはpolynomial time algorithms。
入力サイズの場合 n、アルゴリズムの最悪の場合の時間計算量が O(nk)、 どこ k は定数、アルゴリズムは多項式時間アルゴリズムです。
行列の連鎖乗積、単一ソースの最短パス、すべてのペアの最短パス、最小スパニングツリーなどのアルゴリズムは、多項式時間で実行されます。ただし、巡回セールスマン、最適なグラフ彩色、ハミルトン閉路、グラフ内の最長パスの検索、多項式時間アルゴリズムが不明なブール式の充足など、多くの問題があります。これらの問題は、と呼ばれる興味深いクラスの問題に属しています。NP-Complete ステータスが不明な問題。
これに関連して、問題を次のように分類できます。
Pクラス
クラスPは、多項式時間で解ける問題で構成されています。つまり、これらの問題は時間で解くことができます。 O(nk) 最悪の場合、 k は一定です。
これらの問題は tractable、他の人が呼ばれている間 intractable or superpolynomial。
正式には、多項式が存在する場合、アルゴリズムは多項式時間アルゴリズムです。 p(n) アルゴリズムがサイズの任意のインスタンスを解決できるように n 一度に O(p(n))。
必要な問題 Ω(n50) 解決する時間は、大規模な場合は本質的に手に負えません n。最もよく知られている多項式時間アルゴリズムは時間内に実行されますO(nk) のかなり低い値の場合 k。
多項式時間アルゴリズムのクラスを検討することの利点は、すべてが合理的であることです。 deterministic single processor model of computation 最大で多項式slow-dを使用して相互にシミュレートできます
NPクラス
クラスNPは、多項式時間で検証可能な問題で構成されます。NPは、少し余分な情報を使用して、主張された回答の正しさを簡単に確認できる決定問題のクラスです。したがって、私たちは解決策を見つける方法を求めているのではなく、主張されている解決策が本当に正しいことを確認するだけです。
このクラスのすべての問題は、徹底的な検索を使用して指数関数的に解決できます。
P対NP
決定論的多項式時間アルゴリズムによって解決可能なすべての決定問題は、多項式時間非決定論的アルゴリズムによっても解決可能です。
Pのすべての問題は、多項式時間アルゴリズムで解決できますが、NP-Pのすべての問題は手に負えません。
かどうかは不明です P = NP。しかし、NPには多くの問題が知られており、それらがPに属している場合、P = NPであることが証明できます。
場合 P ≠ NP、PにもNP完全でもないNPに問題があります。
問題はクラスに属します P問題の解決策を見つけるのが簡単な場合。問題はに属しますNP、見つけるのが非常に面倒だったかもしれない解決策をチェックするのが簡単なら。
Stephen Cookは、彼の論文「The Complexity of TheoremProvingProcedures」で4つの定理を提示しました。これらの定理は以下のとおりです。この章では多くの未知の用語が使用されていることを理解していますが、すべてを詳細に説明する余地はありません。
以下はスティーブンクックによる4つの定理です-
定理-1
セットの場合 S 文字列の数は、多項式時間内に非決定性チューリングマシンによって受け入れられます。 S {DNFトートロジー}にP還元可能です。
定理-2
次のセットは、ペアで相互にP還元可能です(したがって、それぞれが同じ多項式の難易度を持ちます):{トートロジー}、{DNFトートロジー}、D3、{サブグラフペア}。
定理-3
どんな場合でも TQ(k) タイプの Q、 $\mathbf{\frac{T_{Q}(k)}{\frac{\sqrt{k}}{(log\:k)^2}}}$ 無制限です
あります TQ(k) タイプの Q そのような $T_{Q}(k)\leqslant 2^{k(log\:k)^2}$
定理-4
文字列のセットSが時間内に非決定性マシンによって受け入れられた場合 T(n) = 2n、 で、もし TQ(k) タイプの正直な(つまりリアルタイムの可算)関数です Q、次に定数があります K、 そう S 時間内に決定論的マシンによって認識できます TQ(K8n)。
最初に、彼は多項式の時間計算量の重要性を強調しました。これは、ある問題から別の問題への多項式時間の短縮がある場合、これにより、2番目の問題の多項式時間アルゴリズムを最初の問題の対応する多項式時間アルゴリズムに変換できることを意味します。
第二に、彼は非決定論的コンピューターによって多項式時間で解くことができる決定問題のクラスNPに注意を向けました。困難な問題のほとんどは、このクラスNPに属します。
第三に、彼は、NPの1つの特定の問題には、NPの他のすべての問題を多項式で還元できるという特性があることを証明しました。充足可能性問題が多項式時間アルゴリズムで解決できる場合、NPのすべての問題も多項式時間で解決できます。NPの問題が手に負えない場合、充足可能性問題は手に負えないものでなければなりません。したがって、充足可能性問題はNPで最も難しい問題です。
第4に、クックは、NPの他の問題が、NPの最も難しいメンバーであるというこの特性を充足可能性問題と共有する可能性があることを示唆しました。
それがNPにあり、次のようになっている場合、問題はクラスNPCにあります hardNPの問題として。問題はNP-hard NP自体に問題がない場合でも、NPのすべての問題が多項式時間で削減できる場合。
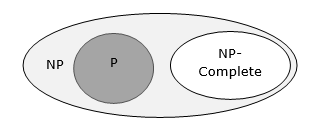
これらの問題のいずれかに多項式時間アルゴリズムが存在する場合、NPのすべての問題は多項式時間で解決できます。これらの問題はNP-complete。NP完全性の現象は、理論的理由と実際的理由の両方で重要です。
NP完全性の定義
言語 B です NP-complete 2つの条件を満たす場合
B NPにあります
すべて A NPでは、多項式時間は次のように還元できます。 B。
言語が2番目のプロパティを満たしているが、必ずしも最初のプロパティを満たしているとは限らない場合、その言語は B として知られている NP-Hard。非公式に、検索問題B です NP-Hard 存在する場合 NP-Complete 問題 A チューリングは B。
NP困難の問題は、多項式時間で解決することはできません。 P = NP。問題がNPCであることが判明した場合、そのための効率的なアルゴリズムを見つけるために時間を無駄にする必要はありません。代わりに、設計近似アルゴリズムに焦点を当てることができます。
NP完全問題
以下は、多項式時間アルゴリズムが知られていないいくつかのNP完全問題です。
- グラフにハミルトン閉路があるかどうかの判断
- ブール式が充足可能かどうかの判断など。
NP困難な問題
次の問題はNP困難です
- 回路の満足度の問題
- セットカバー
- 頂点被覆
- 巡回セールスマン問題
これに関連して、TSPはNP完全であると説明します
TSPはNP完全です
巡回セールスマン問題は、セールスマンと一連の都市で構成されます。セールスマンは、特定の都市から始まり、同じ都市に戻る各都市を訪問する必要があります。問題の課題は、巡回セールスマンが旅行の全長を最小限に抑えたいということです。
証明
証明する TSP is NP-Complete、最初にそれを証明する必要があります TSP belongs to NP。TSPでは、ツアーを見つけて、ツアーに各頂点が1回含まれていることを確認します。次に、ツアーの端の総コストが計算されます。最後に、コストが最小かどうかを確認します。これは、多項式時間で完了することができます。したがって、TSP belongs to NP。
第二に、それを証明する必要があります TSP is NP-hard。これを証明するための1つの方法は、Hamiltonian cycle ≤p TSP (ハミルトン閉路問題はNP完全であることがわかっているため)。
仮定する G = (V, E) ハミルトン閉路のインスタンスになります。
したがって、TSPのインスタンスが構築されます。完全グラフを作成しますG' = (V, E')、 どこ
$$E^{'}=\lbrace(i, j)\colon i, j \in V \:\:and\:i\neq j$$
したがって、コスト関数は次のように定義されます。
$$t(i,j)=\begin{cases}0 & if\: (i, j)\: \in E\\1 & otherwise\end{cases}$$
ここで、ハミルトン閉路を仮定します h に存在します G。の各エッジのコストは明らかですh です 0 に G' 各エッジが属するので E。したがって、h のコストがあります 0 に G'。したがって、グラフの場合G ハミルトン閉路があり、グラフ G' のツアーがあります 0 費用。
逆に、 G' ツアーがあります h' せいぜいコストの 0。のエッジのコストE' です 0 そして 1定義により。したがって、各エッジには次のコストが必要です。0 のコストとして h' です 0。したがって、次のように結論付けます。h' のエッジのみが含まれます E。
したがって、私たちはそれを証明しました G ハミルトン閉路がある場合に限り G' せいぜい費用のツアーがあります 0。TSPはNP完全です。
前の章で説明したアルゴリズムは体系的に実行されます。目標を達成するには、ソリューションに向けて以前に調査した1つ以上のパスを保存して、最適なソリューションを見つける必要があります。
多くの問題では、目標への道は無関係です。たとえば、N-Queensの問題では、クイーンの最終的な構成や、クイーンが追加される順序を気にする必要はありません。
山登り
山登り法は、特定の最適化問題を解決するための手法です。この手法では、次善の解から始めて、ある条件が最大になるまで解を繰り返し改善します。
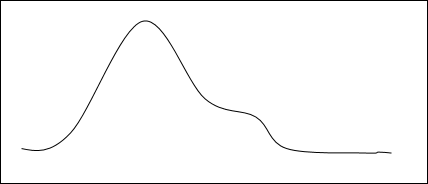
次善の解決策から始めるという考えは、丘のふもとから始めることと比較され、解決策を改善することは丘を歩くことと比較され、最後にいくつかの条件を最大化することは丘の頂上に到達することと比較されます。
したがって、山登り法は次の段階と見なすことができます。
- 問題の制約に従う次善の解を構築する
- ソリューションを段階的に改善する
- 改善が不可能になるまでソリューションを改善する
山登り法は、主に計算上難しい問題を解決するために使用されます。現在の状態と当面の将来の状態のみを調べます。したがって、この手法は検索ツリーを維持しないため、メモリ効率が高くなります。
Algorithm: Hill Climbing
Evaluate the initial state.
Loop until a solution is found or there are no new operators left to be applied:
- Select and apply a new operator
- Evaluate the new state:
goal -→ quit
better than current state -→ new current state反復的な改善
反復改善法では、すべての反復で最適解に向かって前進することにより、最適解が達成されます。ただし、この手法では極大値に遭遇する可能性があります。この状況では、より良い解決策のための近くの州はありません。
この問題は、さまざまな方法で回避できます。これらの方法の1つは、シミュレーテッドアニーリングです。
ランダム再起動
これは、局所最適の問題を解決する別の方法です。この手法は、一連の検索を実行します。毎回、ランダムに生成された初期状態から始まります。したがって、実行された検索のソリューションを比較して、最適またはほぼ最適なソリューションを取得できます。
山登り法の問題点
ローカルマキシマ
ヒューリスティックが凸状でない場合、山登り法はグローバル最大値ではなくローカル最大値に収束する可能性があります。
尾根と路地
ターゲット機能が狭い尾根を作成する場合、登山者はジグザグで尾根を登るか、路地を降りることしかできません。このシナリオでは、クライマーは非常に小さなステップを踏む必要があり、ゴールに到達するまでにさらに時間がかかります。
高原
探索空間が平坦または十分に平坦で、ターゲット関数によって返される値が、その値を表すためにマシンによって使用される精度のために、近くの領域に対して返される値と区別できない場合、プラトーが発生します。
山登り法の複雑さ
この手法は、現在の状態のみを確認するため、スペース関連の問題は発生しません。以前に探索されたパスは保存されません。
ランダムリスタート山登り法の問題のほとんどについて、最適解は多項式時間で達成できます。ただし、NP完全問題の場合、計算時間は極大値の数に基づいて指数関数的になる可能性があります。
山登り法の応用
山登り法は、ネットワークフロー、巡回セールスマン問題、8クイーン問題、集積回路設計など、現在の状態で正確な評価関数が得られる多くの問題を解決するために使用できます。
山登り法は、帰納的学習方法でも使用されます。この手法は、チーム内の複数のロボット間の調整のためにロボット工学で使用されます。この手法を使用する場合、他にも多くの問題があります。
例
この手法は、巡回セールスマン問題を解決するために適用できます。最初に、すべての都市を1回だけ訪問する最初の解決策が決定されます。したがって、この初期ソリューションはほとんどの場合最適ではありません。この解決策でさえ非常に貧弱な場合があります。山登りアルゴリズムは、そのような初期ソリューションから始まり、反復的な方法でそれを改善します。最終的には、はるかに短いルートが得られる可能性があります。