디지털 커뮤니케이션-퀵 가이드
우리의 일상 생활에서 일어나는 의사 소통은 신호의 형태입니다. 사운드 신호와 같은 이러한 신호는 일반적으로 아날로그입니다. 먼 거리에서 통신을 설정해야하는 경우 효과적인 전송을 위해 다른 기술을 사용하여 아날로그 신호가 유선을 통해 전송됩니다.
디지털화의 필요성
기존의 통신 방식은 장거리 통신에 아날로그 신호를 사용했는데 왜곡, 간섭 및 보안 위반을 포함한 기타 손실과 같은 많은 손실이 발생했습니다.
이러한 문제를 극복하기 위해 신호는 다른 기술을 사용하여 디지털화됩니다. 디지털화 된 신호를 통해 손실없이보다 명확하고 정확하게 통신 할 수 있습니다.
다음 그림은 아날로그 신호와 디지털 신호의 차이를 나타냅니다. 디지털 신호는1s 과 0s 각각 High 및 Low 값을 나타냅니다.

디지털 커뮤니케이션의 장점
신호가 디지털화됨에 따라 아날로그 통신에 비해 디지털 통신에는 다음과 같은 많은 이점이 있습니다.
왜곡, 잡음 및 간섭의 영향은 덜 영향을 받기 때문에 디지털 신호에서 훨씬 적습니다.
디지털 회로가 더 안정적입니다.
디지털 회로는 설계하기 쉽고 아날로그 회로보다 저렴합니다.
디지털 회로의 하드웨어 구현은 아날로그보다 유연합니다.
디지털 통신에서 누화 발생은 매우 드뭅니다.
펄스가 속성을 변경하기 위해 높은 교란이 필요하기 때문에 신호는 변경되지 않습니다. 이는 매우 어렵습니다.
암호화 및 압축과 같은 신호 처리 기능은 정보의 비밀을 유지하기 위해 디지털 회로에 사용됩니다.
오류 감지 및 오류 정정 코드를 사용하여 오류 발생 확률을 낮 춥니 다.
스펙트럼 확산 기술은 신호 방해를 방지하는 데 사용됩니다.
시분할 다중화 (TDM)를 사용하여 디지털 신호를 결합하는 것이 주파수 분할 다중화 (FDM)를 사용하여 아날로그 신호를 결합하는 것보다 쉽습니다.
디지털 신호의 구성 프로세스는 아날로그 신호보다 쉽습니다.
디지털 신호는 아날로그 신호보다 더 편리하게 저장하고 검색 할 수 있습니다.
많은 디지털 회로는 거의 일반적인 인코딩 기술을 가지고 있으므로 유사한 장치를 여러 목적으로 사용할 수 있습니다.
채널의 용량은 디지털 신호에 의해 효과적으로 활용됩니다.
디지털 커뮤니케이션의 요소
디지털 통신 시스템을 구성하는 요소는 이해하기 쉽도록 다음 블록 다이어그램으로 표시됩니다.
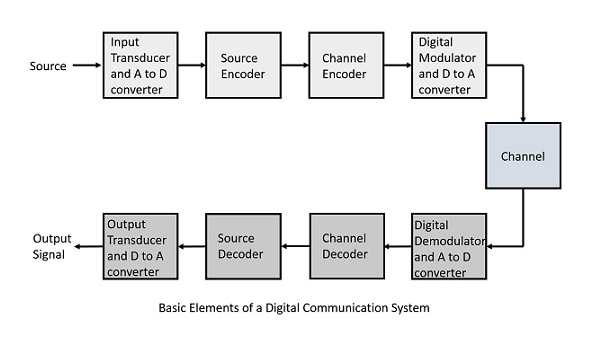
다음은 디지털 통신 시스템의 섹션입니다.
출처
소스는 analog 신호. Example: 소리 신호
입력 변환기
이것은 물리적 입력을 받아 전기 신호로 변환하는 변환기입니다 (Example: 마이크). 이 블록은 또한analog to digital 추가 프로세스를 위해 디지털 신호가 필요한 컨버터.
디지털 신호는 일반적으로 이진 시퀀스로 표시됩니다.
소스 인코더
소스 인코더는 데이터를 최소 비트 수로 압축합니다. 이 프로세스는 대역폭을 효과적으로 활용하는 데 도움이됩니다. 중복 비트 (불필요한 초과 비트, 즉 0)를 제거합니다.
채널 인코더
채널 인코더는 오류 수정을위한 코딩을 수행합니다. 신호를 전송하는 동안 채널의 노이즈로 인해 신호가 변경 될 수 있으므로이를 방지하기 위해 채널 인코더는 전송 된 데이터에 일부 중복 비트를 추가합니다. 오류 수정 비트입니다.
디지털 변조기
전송 될 신호는 여기에서 반송파에 의해 변조됩니다. 신호는 또한 채널이나 매체를 통해 이동하기 위해 디지털 시퀀스에서 아날로그로 변환됩니다.
채널
채널 또는 매체는 아날로그 신호가 송신기 끝에서 수신기 끝으로 전송되도록합니다.
디지털 복조기
이것은 수신자 측의 첫 번째 단계입니다. 수신 된 신호는 복조되고 아날로그에서 디지털로 다시 변환됩니다. 여기에서 신호가 재구성됩니다.
채널 디코더
채널 디코더는 시퀀스를 감지 한 후 몇 가지 오류 수정을 수행합니다. 전송 중에 발생할 수있는 왜곡은 일부 중복 비트를 추가하여 수정됩니다. 이러한 비트 추가는 원래 신호의 완전한 복구에 도움이됩니다.
소스 디코더
결과 신호는 정보 손실없이 순수한 디지털 출력을 얻을 수 있도록 샘플링 및 양자화를 통해 다시 한 번 디지털화됩니다. 소스 디코더는 소스 출력을 재생성합니다.
출력 변환기
이것은 신호를 송신기의 입력에 있던 원래의 물리적 형태로 변환하는 마지막 블록입니다. 전기 신호를 물리적 출력으로 변환합니다 (Example: 시끄러운 스피커).
출력 신호
이것은 전체 프로세스 후에 생성되는 출력입니다. Example − 수신 된 사운드 신호.
이 단원에서는 디지털 통신의 도입, 디지털화, 장점 및 요소에 대해 설명했습니다. 다음 장에서는 디지털 통신의 개념에 대해 자세히 알아볼 것입니다.
Modulation 메시지 신호의 순간 값에 따라 반송파 신호의 하나 이상의 파라미터를 변경하는 프로세스입니다.
메시지 신호는 통신을 위해 전송되는 신호이고 반송파 신호는 데이터가없는 고주파 신호이지만 장거리 전송에 사용됩니다.
사용되는 변조 유형에 따라 분류되는 많은 변조 기술이 있습니다. 그중 사용되는 디지털 변조 기술은 다음과 같습니다.Pulse Code Modulation (PCM).
신호는 아날로그 정보를 이진 시퀀스로 변환하기 위해 변조 된 펄스 코드입니다. 1s 과 0s. PCM의 출력은 이진 시퀀스와 유사합니다. 다음 그림은 주어진 사인파의 순간 값에 대한 PCM 출력의 예를 보여줍니다.
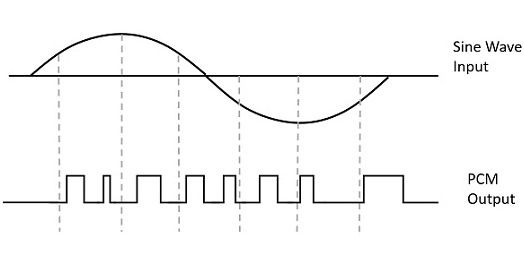
펄스 트레인 대신 PCM은 일련의 숫자 또는 숫자를 생성하므로이 프로세스를 다음과 같이 호출합니다. digital. 이진 코드의 각 숫자는 해당 순간의 신호 샘플의 대략적인 진폭을 나타냅니다.
펄스 코드 변조에서 메시지 신호는 일련의 코딩 된 펄스로 표현됩니다. 이 메시지 신호는 신호를 시간과 진폭 모두에서 이산 형태로 표현함으로써 달성됩니다.
PCM의 기본 요소
펄스 코드 변조기 회로의 송신기 섹션은 다음으로 구성됩니다. Sampling, Quantizing 과 Encoding, 이것은 아날로그-디지털 변환기 섹션에서 수행됩니다. 샘플링 이전의 저역 통과 필터는 메시지 신호의 앨리어싱을 방지합니다.
수신기 섹션의 기본 작업은 다음과 같습니다. regeneration of impaired signals, decoding, 과 reconstruction양자화 된 펄스열의. 다음은 송신기 및 수신기 섹션의 기본 요소를 나타내는 PCM의 블록 다이어그램입니다.
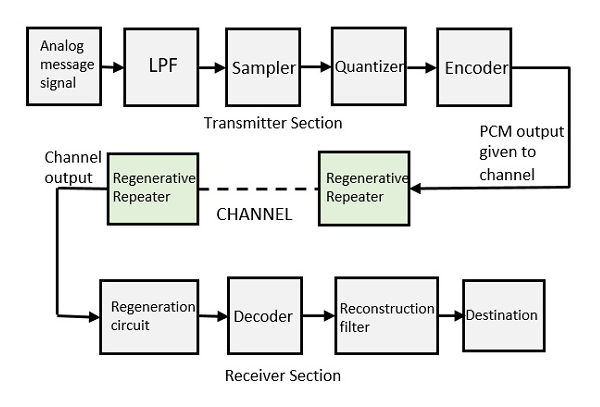
저역 통과 필터
이 필터는 메시지 신호의 앨리어싱을 방지하기 위해 메시지 신호의 최고 주파수보다 큰 입력 아날로그 신호에 존재하는 고주파 성분을 제거합니다.
샘플러
이것은 메시지 신호의 순간 값에서 샘플 데이터를 수집하여 원래 신호를 재구성하는 데 도움이되는 기술입니다. 샘플링 속도는 가장 높은 주파수 성분의 두 배 이상이어야합니다.W 샘플링 정리에 따라 메시지 신호의.
양자화 기
양자화는 과도한 비트를 줄이고 데이터를 제한하는 프로세스입니다. Quantizer에 제공 될 때 샘플링 된 출력은 중복 비트를 줄이고 값을 압축합니다.
인코더
아날로그 신호의 디지털화는 인코더에 의해 수행됩니다. 이진 코드로 각 양자화 된 레벨을 지정합니다. 여기서 수행되는 샘플링은 샘플 앤 홀드 프로세스입니다. 이 세 섹션 (LPF, 샘플러 및 퀀 타이 저)은 아날로그에서 디지털로의 변환기 역할을합니다. 인코딩은 사용되는 대역폭을 최소화합니다.
회생 중계기
이 섹션은 신호 강도를 증가시킵니다. 채널의 출력에는 신호 손실을 보상하고 신호를 재구성하고 강도를 높이기 위해 하나의 재생 리피터 회로도 있습니다.
디코더
디코더 회로는 펄스 코딩 된 파형을 디코딩하여 원래 신호를 재생합니다. 이 회로는 복조기 역할을합니다.
재건 필터
디지털-아날로그 변환이 재생 회로와 디코더에 의해 수행 된 후, 원래 신호를 다시 얻기 위해 재구성 필터라고하는 저역 통과 필터가 사용됩니다.
따라서 펄스 코드 변조기 회로는 주어진 아날로그 신호를 디지털화하고 코딩하고 샘플링 한 다음 아날로그 형식으로 전송합니다. 이 전체 프로세스는 원래 신호를 얻기 위해 역 패턴으로 반복됩니다.
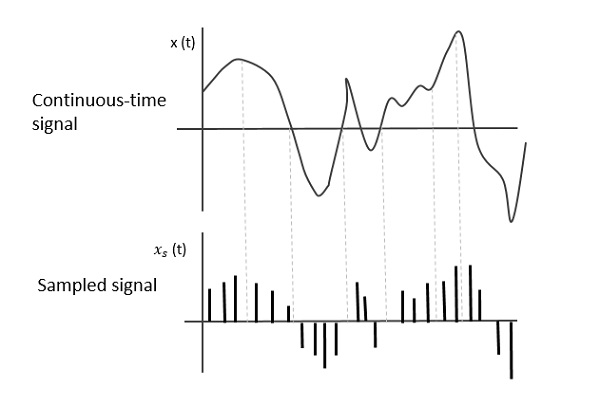
Sampling "연속 시간 신호의 순간 값을 이산 형태로 측정하는 과정"으로 정의됩니다.
Sample 시간 영역에서 연속적인 전체 데이터에서 가져온 데이터 조각입니다.
소스가 아날로그 신호를 생성하고이를 디지털화해야하는 경우 1s 과 0s즉, 높음 또는 낮음, 신호는 시간에 따라 이산화되어야합니다. 이러한 아날로그 신호의 이산화를 샘플링이라고합니다.
다음 그림은 연속 시간 신호를 나타냅니다. x (t) 및 샘플링 된 신호 xs (t). 언제x (t) 주기적인 임펄스 트레인, 샘플링 된 신호를 곱합니다. xs (t) 획득됩니다.
샘플링 속도
신호를 이산화하려면 샘플 간의 간격을 수정해야합니다. 그 격차는sampling period Ts.
$$Sampling \: Frequency = \frac{1}{T_{s}} = f_s$$
어디,
$T_s$ 샘플링 시간입니다
$f_s$ 샘플링 주파수 또는 샘플링 속도
Sampling frequency샘플링 기간의 역수입니다. 이 샘플링 주파수는 간단히 다음과 같이 부를 수 있습니다.Sampling rate. 샘플링 속도는 초당 또는 유한 한 값 집합에 대해 취한 샘플 수를 나타냅니다.
디지털화 된 신호에서 아날로그 신호를 재구성하려면 샘플링 속도를 고려해야합니다. 샘플링 속도는 메시지 신호의 데이터가 손실되거나 겹치지 않아야합니다. 따라서 Nyquist rate라고하는 요금이 고정되었습니다.
나이 퀴 스트 비율
신호가 다음보다 높은 주파수 성분없이 대역 제한이라고 가정합니다. W헤르츠. 그것의 의미는,W가장 높은 주파수입니다. 이러한 신호의 경우 원래 신호를 효과적으로 재생하려면 샘플링 속도가 최고 주파수의 두 배 여야합니다.
즉,
$$f_S = 2W$$
어디,
$f_S$ 샘플링 속도
W 가장 높은 주파수
이 샘플링 속도를 Nyquist rate.
이 나이 퀴 스트 비율 이론에 대해 샘플링 정리라는 정리가 언급되었습니다.
샘플링 정리
다음과 같이 불리는 샘플링 정리 Nyquist theorem, 대역폭이 제한된 함수 클래스에 대한 대역폭 측면에서 충분한 샘플 속도 이론을 제공합니다.
샘플링 정리는 다음과 같이 말합니다.“신호가 속도로 샘플링되면 정확하게 재현 될 수 있습니다. fs 최대 주파수의 두 배보다 큽니다. W.”
이 샘플링 정리를 이해하기 위해 대역 제한 신호, 즉 값이 다음과 같은 신호를 고려해 보겠습니다. non-zero 일부 사이 –W 과 W 헤르츠.
이러한 신호는 다음과 같이 표현됩니다. $x(f) = 0 \: for \: \mid f \mid > W$
연속 시간 신호용 x (t)주파수 영역에서 대역 제한 신호 인는 다음 그림과 같이 나타낼 수 있습니다.
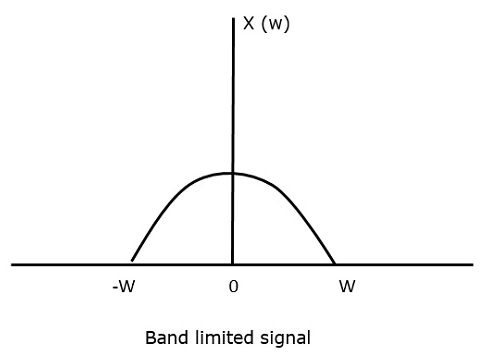
샘플링 후에도 정보 손실이 없어야하는 샘플링 주파수가 필요합니다. 이를 위해 샘플링 주파수가 최대 주파수의 두 배가되어야하는 나이 퀴 스트 속도가 있습니다. 샘플링의 임계 비율입니다.
신호가 x(t) Nyquist 속도 이상으로 샘플링되면 원래 신호를 복구 할 수 있으며 Nyquist 속도 미만으로 샘플링하면 신호를 복구 할 수 없습니다.
다음 그림은 다음보다 높은 속도로 샘플링 된 경우 신호를 설명합니다. 2w 주파수 영역에서.
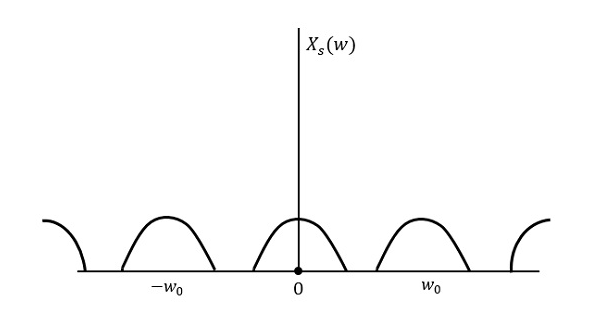
위 그림은 신호의 푸리에 변환을 보여줍니다. xs (t). 여기서 정보는 손실없이 재생산됩니다. 혼동이 없으므로 복구가 가능합니다.
신호의 푸리에 변환 xs (t) 이다
$$X_s(w) = \frac{1}{T_{s}}\sum_{n = - \infty}^\infty X(w-nw_0)$$
어디 $T_s$ = Sampling Period 과 $w_0 = \frac{2 \pi}{T_s}$
샘플링 속도가 가장 높은 주파수의 두 배 (2W)
그것의 의미는,
$$f_s = 2W$$
어디,
$f_s$ 샘플링 주파수
W 가장 높은 주파수
결과는 위 그림과 같습니다. 정보는 손실없이 교체됩니다. 따라서 이것은 또한 좋은 샘플링 속도입니다.
이제 조건을 살펴 보겠습니다.
$$f_s < 2W$$
결과 패턴은 다음 그림과 같습니다.

위의 패턴에서 정보의 겹침이 발생하여 정보의 혼동과 손실이 발생 함을 알 수 있습니다. 이러한 원치 않는 중복 현상을 앨리어싱이라고합니다.
앨리어싱
앨리어싱은 "샘플링 된 버전의 스펙트럼에서 저주파 성분의 동일성을 취하는 신호 스펙트럼의 고주파 성분 현상"이라고 할 수 있습니다.
앨리어싱의 영향을 줄이기 위해 취한 시정 조치는 다음과 같습니다.
PCM의 송신기 섹션에서 low pass anti-aliasing filter 원치 않는 고주파 성분을 제거하기 위해 샘플러 전에 사용됩니다.
필터링 후 샘플링 된 신호는 나이 퀴 스트 속도보다 약간 높은 속도로 샘플링됩니다.
Nyquist 속도보다 높은 샘플링 속도를 선택하면 reconstruction filter 수신기에서.
푸리에 변환의 범위
일반적으로 신호를 분석하고 정리를 증명할 때 푸리에 급수 및 푸리에 변환의 도움을 구하는 것으로 관찰됩니다. 왜냐하면-
푸리에 변환은 비 주기적 신호에 대한 푸리에 시리즈의 확장입니다.
푸리에 변환은 서로 다른 도메인의 신호를 확인하고 신호를 쉽게 분석하는 데 도움이되는 강력한 수학적 도구입니다.
이 푸리에 변환을 사용하여 사인과 코사인의 합으로 모든 신호를 분해 할 수 있습니다.
다음 장에서는 양자화 개념에 대해 논의하겠습니다.
아날로그 신호의 디지털화에는 아날로그 값과 거의 동일한 값의 반올림이 포함됩니다. 샘플링 방법은 아날로그 신호에서 몇 개의 포인트를 선택한 다음 이러한 포인트를 결합하여 값을 거의 안정화 된 값으로 반올림합니다. 이러한 과정을Quantization.
아날로그 신호 양자화
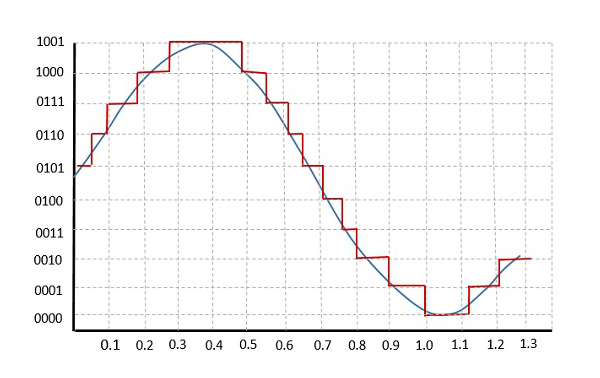
아날로그-디지털 변환기는 이러한 유형의 기능을 수행하여 주어진 아날로그 신호에서 일련의 디지털 값을 생성합니다. 다음 그림은 아날로그 신호를 나타냅니다. 이 신호를 디지털로 변환하려면 샘플링과 양자화를 거쳐야합니다.
아날로그 신호의 양자화는 여러 양자화 레벨로 신호를 이산화함으로써 수행됩니다. Quantization 유한 레벨 세트로 진폭의 샘플링 된 값을 나타내며, 이는 연속 진폭 샘플을 이산 시간 신호로 변환하는 것을 의미합니다.
다음 그림은 아날로그 신호가 양자화되는 방법을 보여줍니다. 파란색 선은 아날로그 신호를 나타내고 갈색 선은 양자화 된 신호를 나타냅니다.
샘플링과 양자화 모두 정보 손실을 초래합니다. 양자화 기 출력의 품질은 사용 된 양자화 수준의 수에 따라 다릅니다. 양자화 된 출력의 이산 진폭은 다음과 같이 호출됩니다.representation levels 또는 reconstruction levels. 인접한 두 표현 수준 사이의 간격을quantum 또는 step-size.
다음 그림은 주어진 아날로그 신호에 대한 디지털 형식 인 결과 양자화 된 신호를 보여줍니다.
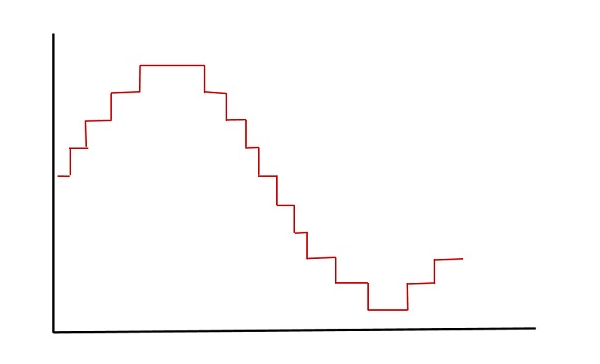
이것은 또한 Stair-case 모양에 따라 파형.
양자화 유형
양자화에는 균일 양자화와 비 균일 양자화의 두 가지 유형이 있습니다.
양자화 레벨이 균일 한 간격으로 배치되는 양자화 유형은 Uniform Quantization. 양자화 수준이 같지 않고 대부분 그들 사이의 관계가 로그인 양자화 유형은Non-uniform Quantization.
균일 한 양자화에는 두 가지 유형이 있습니다. 그들은 Mid-Rise 유형과 Mid-Tread 유형입니다. 다음 그림은 두 가지 유형의 균일 한 양자화를 나타냅니다.
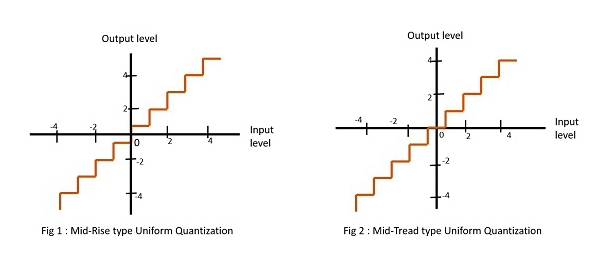
그림 1은 미드 라이즈 유형을 보여주고 그림 2는 미드 트레드 유형의 균일 한 양자화를 보여줍니다.
그만큼 Mid-Rise원점이 그래프와 같은 계단의 상승 부분의 중간에 있기 때문에 타입이라고 불립니다. 이 유형의 양자화 수준은 짝수입니다.
그만큼 Mid-tread원점이 그래프와 같은 계단의 트레드 중간에 있기 때문에 타입이라고합니다. 이 유형의 양자화 레벨은 숫자가 홀수입니다.
미드 라이즈 및 미드 트레드 유형의 균일 한 양자화 기는 모두 원점에 대해 대칭입니다.
양자화 오류
모든 시스템의 경우 작동하는 동안 입력 및 출력 값에 항상 차이가 있습니다. 시스템 처리로 인해 해당 값의 차이 인 오류가 발생합니다.
입력 값과 양자화 된 값의 차이를 Quantization Error. ㅏQuantizer양자화 (값 반올림)를 수행하는 로그 함수입니다. 아날로그-디지털 변환기 (ADC)는 양자화기로 작동합니다.
다음 그림은 원래 신호와 양자화 된 신호의 차이를 나타내는 양자화 오류의 예를 보여줍니다.
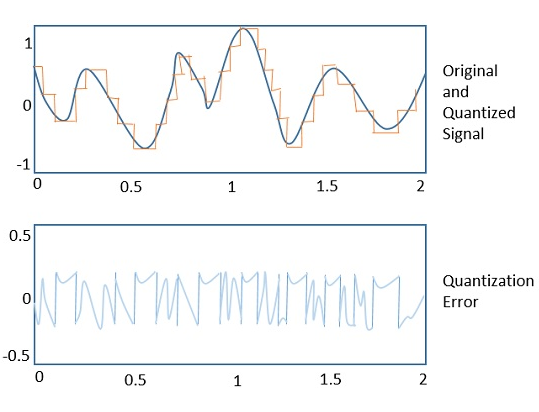
양자화 노이즈
일반적으로 아날로그 오디오 신호에서 발생하는 양자화 오류의 일종으로 디지털로 양자화합니다. 예를 들어, 음악에서 신호는 계속해서 변경되며 오류에서 규칙 성이 발견되지 않습니다. 이러한 오류는 다음과 같은 광대역 잡음을 생성합니다.Quantization Noise.
PCM에서 컴 팬딩
단어 Companding압축과 확장의 조합입니다. 즉, 둘 다 수행합니다. 이것은 송신기에서 데이터를 압축하고 수신기에서 동일한 데이터를 확장하는 PCM에서 사용되는 비선형 기술입니다. 이 기술을 사용하면 노이즈와 누화의 영향을 줄일 수 있습니다.
컴 팬딩 기법에는 두 가지 유형이 있습니다. 그들은-
A-law 컴 팬딩 기법
균일 한 양자화는 A = 1, 특성 곡선이 선형이고 압축이 수행되지 않습니다.
A-law는 원점에서 중간층이 있습니다. 따라서 0이 아닌 값을 포함합니다.
A-law 컴 팬딩은 PCM 전화 시스템에 사용됩니다.
µ-law 컴 팬딩 기법
균일 한 양자화는 µ = 0, 특성 곡선이 선형이고 압축이 수행되지 않습니다.
µ-law는 원점에 중간 트레드가 있습니다. 따라서 0 값을 포함합니다.
µ-law 컴 팬딩은 음성 및 음악 신호에 사용됩니다.
µ-law는 북미와 일본에서 사용됩니다.
상관 관계가 높은 샘플의 경우 PCM 기술로 인코딩 할 때 중복 정보를 남겨 둡니다. 이 중복 정보를 처리하고 더 나은 출력을 얻으려면 이전 출력에서 가정 한 예측 된 샘플 값을 가져와 양자화 된 값으로 요약하는 것이 현명한 결정입니다. 이러한 과정을Differential PCM (DPCM) 기술.
DPCM 송신기
DPCM 송신기는 퀀 타이 저와 두 개의 서머 회로가있는 예측기로 구성됩니다. 다음은 DPCM 송신기의 블록 다이어그램입니다.
각 지점의 신호는 다음과 같이 명명됩니다.
$x(nT_s)$ 샘플링 된 입력입니다.
$\widehat{x}(nT_s)$ 예측 된 샘플입니다.
$e(nT_s)$ 샘플링 된 입력과 예측 된 출력의 차이이며 종종 예측 오류라고합니다.
$v(nT_s)$ 양자화 된 출력
$u(nT_s)$ 예측 자 입력은 실제로 예측 자 출력과 양자화 기 출력의 여름 출력입니다.
예측기는 송신기 회로의 이전 출력에서 가정 된 샘플을 생성합니다. 이 예측기에 대한 입력은 입력 신호의 양자화 된 버전입니다.$x(nT_s)$.
양자화 기 출력은 다음과 같이 표현됩니다.
$$v(nT_s) = Q[e(nT_s)]$$
$= e(nT_s) + q(nT_s)$
어디 q (nTs) 양자화 오류입니다.
예측 자 입력은 양자화 기 출력과 예측 자 출력의 합입니다.
$$u(nT_s) = \widehat{x}(nT_s) + v(nT_s)$$
$u(nT_s) = \widehat{x}(nT_s) + e(nT_s) + q(nT_s)$
$$u(nT_s) = x(nT_s) + q(nT_s)$$
동일한 예측기 회로가 디코더에서 원래 입력을 재구성하는 데 사용됩니다.
DPCM 수신기
DPCM 수신기의 블록 다이어그램은 디코더, 예측기 및 여름 회로로 구성됩니다. 다음은 DPCM 수신기의 다이어그램입니다.

신호의 표기법은 이전 신호와 동일합니다. 노이즈가없는 경우 인코딩 된 수신기 입력은 인코딩 된 송신기 출력과 동일합니다.
앞서 언급했듯이 예측자는 이전 출력을 기반으로 값을 가정합니다. 디코더에 주어진 입력이 처리되고 그 출력은 더 나은 출력을 얻기 위해 예측 자의 출력과 합산됩니다.
더 나은 샘플링을 얻으려면 신호의 샘플링 속도가 Nyquist 속도보다 높아야합니다. 차동 PCM에서이 샘플링 간격이 상당히 줄어들면 샘플 간 진폭 차이가 매우 작습니다.1-bit quantization, 그러면 스텝 크기가 매우 작아집니다. Δ (델타).
델타 변조
샘플링 속도가 훨씬 더 높고 양자화 후 단계 화가 더 작은 값인 변조 유형 Δ, 이러한 변조는 다음과 같이 불립니다. delta modulation.
델타 변조의 특징
다음은 델타 변조의 몇 가지 기능입니다.
신호 상관 관계를 최대한 활용하기 위해 오버 샘플링 된 입력이 사용됩니다.
양자화 설계는 간단합니다.
입력 시퀀스는 Nyquist 속도보다 훨씬 높습니다.
품질이 적당합니다.
변조기와 복조기의 설계는 간단합니다.
출력 파형의 계단식 근사치입니다.
스텝 크기는 매우 작습니다. Δ (델타).
비트 전송률은 사용자가 결정할 수 있습니다.
여기에는 더 간단한 구현이 포함됩니다.
델타 변조는 DPCM 기술의 단순화 된 형태로, 1-bit DPCM scheme. 샘플링 간격이 줄어들면 신호 상관 관계가 높아집니다.
델타 변조기
Delta Modulator는 1 비트 양자화 기 및 지연 회로와 2 개의 여름 회로로 구성됩니다. 다음은 델타 변조기의 블록 다이어그램입니다.
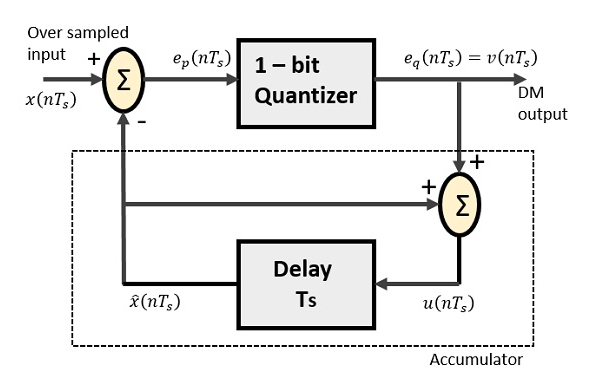
DPCM의 예측 회로는 DM의 간단한 지연 회로로 대체됩니다.
위의 다이어그램에서 다음과 같은 표기법이 있습니다.
$x(nT_s)$ = 초과 샘플링 된 입력
$e_p(nT_s)$ = 여름 출력 및 양자화 입력
$e_q(nT_s)$ = 양자화 기 출력 = $v(nT_s)$
$\widehat{x}(nT_s)$ = 지연 회로의 출력
$u(nT_s)$ = 지연 회로 입력
이 표기법을 사용하여 이제 우리는 델타 변조의 과정을 알아 내려고 노력할 것입니다.
$e_p(nT_s) = x(nT_s) - \widehat{x}(nT_s)$
--------- 등식 1
$= x(nT_s) - u([n - 1]T_s)$
$= x(nT_s) - [\widehat{x} [[n - 1]T_s] + v[[n-1]T_s]]$
--------- 등식 2
더욱이,
$v(nT_s) = e_q(nT_s) = S.sig.[e_p(nT_s)]$
--------- 등식 3
$u(nT_s) = \widehat{x}(nT_s)+e_q(nT_s)$
어디,
$\widehat{x}(nT_s)$ = 지연 회로의 이전 값
$e_q(nT_s)$ = 양자화 기 출력 = $v(nT_s)$
그 후,
$u(nT_s) = u([n-1]T_s) + v(nT_s)$
--------- 방정식 4
즉,
The present input of the delay unit
= (The previous output of the delay unit) + (the present quantizer output)
누적 조건이 0이라고 가정하면,
$u(nT_s) = S \displaystyle\sum\limits_{j=1}^n sig[e_p(jT_s)]$
Accumulated version of DM output = $\displaystyle\sum\limits_{j = 1}^n v(jT_s)$
--------- 등식 5
이제
$\widehat{x}(nT_s) = u([n-1]T_s)$
$= \displaystyle\sum\limits_{j = 1}^{n - 1} v(jT_s)$
--------- 방정식 6
지연 단위 출력은 하나의 샘플만큼 지연되는 누산기 출력입니다.
방정식 5와 6에서 복조기에 대한 가능한 구조를 얻습니다.
계단 형 근사 파형은 스텝 크기가 델타 () 인 델타 변조기의 출력이됩니다.Δ). 파형의 출력 품질이 보통입니다.
델타 복조기
델타 복조기는 저역 통과 필터, 서머 및 지연 회로로 구성됩니다. 여기서 예측 회로는 제거되므로 복조기에 가정 된 입력이 제공되지 않습니다.
다음은 델타 복조기의 다이어그램입니다.
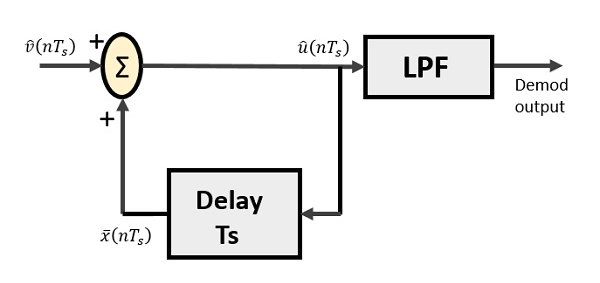
위의 다이어그램에서 다음과 같은 표기법이 있습니다.
$\widehat{v}(nT_s)$ 입력 샘플입니다
$\widehat{u}(nT_s)$ 여름 산출물입니다
$\bar{x}(nT_s)$ 지연된 출력입니다
이진 시퀀스는 복조기에 대한 입력으로 제공됩니다. 계단식 근사 출력이 LPF에 제공됩니다.
저역 통과 필터는 여러 가지 이유로 사용되지만 두드러진 이유는 대역 외 신호에 대한 노이즈 제거입니다. 송신기에서 발생할 수있는 단계 크기 오류를granular noise, 여기에서 제거됩니다. 잡음이없는 경우 변조기 출력은 복조기 입력과 같습니다.
DPCM 대비 DM의 장점
1 비트 양자화 기
변조기와 복조기의 매우 쉬운 설계
그러나 DM에는 약간의 소음이 있습니다.
기울기 과부하 왜곡 ( Δ 작다)
세분화 된 노이즈 ( Δ 크다)
적응 형 델타 변조 (ADM)
디지털 변조에서 우리는 출력 파의 품질에 영향을 미치는 스텝 크기를 결정하는 특정 문제를 발견했습니다.
변조 신호의 가파른 기울기에서는 더 큰 스텝 크기가 필요하고 메시지의 기울기가 작은 경우 더 작은 스텝 크기가 필요합니다. 그 과정에서 세부 사항이 누락됩니다. 따라서 원하는 방식으로 샘플링을 얻기 위해 요구 사항에 따라 스텝 크기 조정을 제어 할 수 있다면 더 좋을 것입니다. 이것은의 개념입니다Adaptive Delta Modulation.
다음은 적응 형 델타 변조기의 블록 다이어그램입니다.
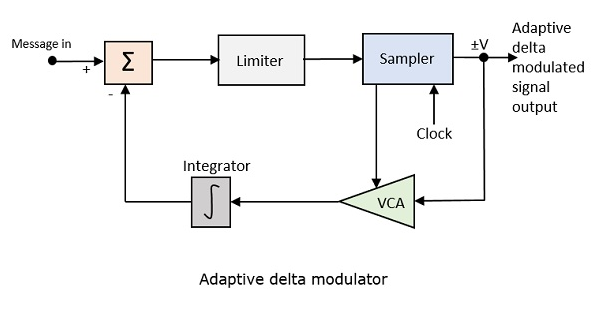
전압 제어 증폭기의 이득은 샘플러의 출력 신호에 의해 조정됩니다. 증폭기 이득은 스텝 크기를 결정하며 둘 다 비례합니다.
ADM은 현재 샘플의 값과 다음 샘플의 예측 값 간의 차이를 양자화합니다. 빠르게 변화하는 값을 충실하게 재현하기 위해 가변 단계 높이를 사용하여 다음 값을 예측합니다.
디지털 커뮤니케이션 프로세스의 기본 경로를 만든 몇 가지 기술이 있습니다. 신호를 디지털화하기 위해 샘플링 및 양자화 기술이 있습니다.
그것들을 수학적으로 표현하기 위해 우리는 LPC와 디지털 멀티플렉싱 기술을 가지고 있습니다. 이러한 디지털 변조 기술에 대해 자세히 설명합니다.
선형 예측 코딩
Linear Predictive Coding (LPC)선형 예측 모델에서 디지털 음성 신호를 나타내는 도구입니다. 이것은 주로 오디오 신호 처리, 음성 합성, 음성 인식 등에 사용됩니다.
선형 예측은 현재 샘플이 과거 샘플의 선형 조합을 기반으로한다는 생각을 기반으로합니다. 분석은 이산 시간 신호의 값을 이전 샘플의 선형 함수로 추정합니다.
스펙트럼 포락선은 선형 예측 모델의 정보를 사용하여 압축 된 형태로 표현됩니다. 이것은 수학적으로 다음과 같이 표현 될 수 있습니다.
$s(n) = \displaystyle\sum\limits_{k = 1}^p \alpha_k s(n - k)$ 어떤 가치를 위해 p 과 αk
어디
s(n) 현재 음성 샘플입니다.
k 특정 샘플입니다
p 가장 최근 값입니다.
αk 예측 자 계수입니다.
s(n - k) 이전 음성 샘플입니다.
LPC의 경우 예측 자 계수 값은 실제 음성 샘플과 선형 예측 샘플 간의 차이 제곱의 합 (유한 간격에 걸쳐)을 최소화하여 결정됩니다.
이것은 매우 유용한 방법입니다. encoding speech낮은 비트 전송률로. LPC 방법은Fast Fourier Transform (FFT) 방법.
멀티플렉싱
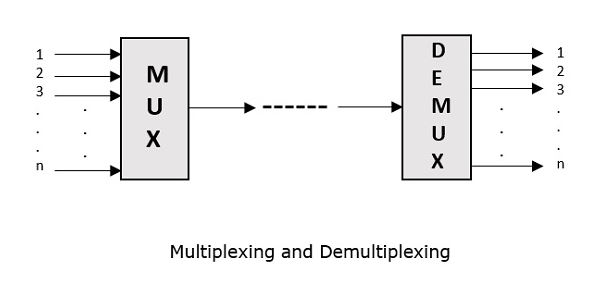
Multiplexing공유 매체를 통해 여러 신호를 하나의 신호로 결합하는 프로세스입니다. 이러한 신호는 본질적으로 아날로그 인 경우 프로세스를 다음과 같이 호출합니다.analog multiplexing. 디지털 신호가 다중화되면 다음과 같이 호출됩니다.digital multiplexing.
멀티플렉싱은 전화 통신에서 처음 개발되었습니다. 여러 신호가 결합되어 단일 케이블을 통해 전송되었습니다. 멀티플렉싱 프로세스는 통신 채널을 여러 개의 논리 채널로 분할하여 서로 다른 메시지 신호 또는 전송할 데이터 스트림에 대해 각각을 할당합니다. 멀티플렉싱을 수행하는 장치는MUX. 그 반대 과정, 즉 하나에서 채널 수를 추출하는 과정이 수신자에서 수행되는 과정을 다음과 같이 호출합니다.de-multiplexing. 역 다중화를 수행하는 장치를DEMUX.
다음 그림은 MUX 및 DEMUX를 나타냅니다. 주요 용도는 통신 분야입니다.
멀티플렉서 유형
주로 아날로그와 디지털의 두 가지 유형의 멀티플렉서가 있습니다. FDM, WDM 및 TDM으로 더 나뉩니다. 다음 그림은이 분류에 대한 자세한 아이디어를 제공합니다.
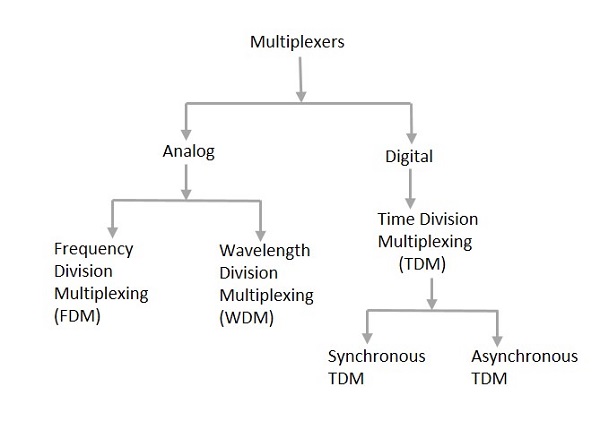
실제로 여러 유형의 다중화 기술이 있습니다. 그중에서도 위의 그림에서 언급 한 일반 분류의 주요 유형이 있습니다.
아날로그 멀티플렉싱
아날로그 멀티플렉싱 기술은 본질적으로 아날로그 신호를 포함합니다. 아날로그 신호는 주파수 (FDM) 또는 파장 (WDM)에 따라 다중화됩니다.
주파수 분할 다중화 (FDM)
아날로그 멀티플렉싱에서 가장 많이 사용되는 기술은 다음과 같습니다. Frequency Division Multiplexing (FDM). 이 기술은 다양한 주파수를 사용하여 데이터 스트림을 결합하여 통신 매체에 단일 신호로 전송합니다.
Example − 단일 케이블을 통해 여러 채널을 전송하는 기존의 TV 송신기는 FDM을 사용합니다.
파장 분할 다중화 (WDM)
파장 분할 다중화는 서로 다른 파장의 많은 데이터 스트림이 광 스펙트럼에서 전송되는 아날로그 기술입니다. 파장이 증가하면 신호의 주파수가 감소합니다. ㅏprism 다른 파장을 단일 라인으로 변환 할 수있는 MUX 출력과 DEMUX 입력에 사용할 수 있습니다.
Example − 광섬유 통신은 WDM 기술을 사용하여 서로 다른 파장을 하나의 빛으로 병합하여 통신합니다.
디지털 멀티플렉싱
디지털이라는 용어는 정보의 개별 비트를 나타냅니다. 따라서 사용 가능한 데이터는 개별적인 프레임 또는 패킷의 형태입니다.
시분할 다중화 (TDM)
TDM에서 시간 프레임은 슬롯으로 나뉩니다. 이 기술은 각 메시지에 대해 하나의 슬롯을 할당하여 단일 통신 채널을 통해 신호를 전송하는 데 사용됩니다.
모든 유형의 TDM 중에서 주요 유형은 동기 및 비동기 TDM입니다.
동기식 TDM
동기식 TDM에서 입력은 프레임에 연결됩니다. 만일 거기에 'n'연결 수, 프레임은'n' 시간대. 각 입력 라인에 하나의 슬롯이 할당됩니다.
이 기술에서 샘플링 속도는 모든 신호에 공통이므로 동일한 클럭 입력이 제공됩니다. MUX는 항상 각 장치에 동일한 슬롯을 할당합니다.
비동기 TDM
비동기식 TDM에서는 샘플링 속도가 신호마다 다르며 공통 클록이 필요하지 않습니다. 할당 된 장치가 시간 슬롯에 대해 아무것도 전송하지 않고 유휴 상태이면 해당 슬롯은 동기식과 달리 다른 장치에 할당됩니다. 이 유형의 TDM은 비동기 전송 모드 네트워크에서 사용됩니다.
회생 중계기
모든 통신 시스템이 신뢰할 수 있으려면 손실없이 효과적으로 신호를 송수신해야합니다. PCM 파는 채널을 통해 전송 된 후 채널에서 유입되는 노이즈로 인해 왜곡됩니다.
원래 및 수신 된 펄스와 비교 한 회생 펄스는 다음 그림과 같습니다.

더 나은 신호 재생을 위해 다음과 같은 회로를 사용합니다. regenerative repeater수신자 앞의 경로에 사용됩니다. 이것은 발생한 손실로부터 신호를 복원하는 데 도움이됩니다. 다음은 다이어그램 표현입니다.
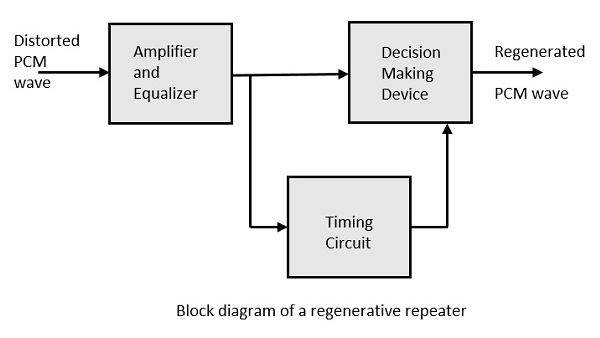
이것은 증폭기, 타이밍 회로 및 의사 결정 장치와 함께 이퀄라이저로 구성됩니다. 각 구성 요소의 작동 방식은 다음과 같습니다.
평형 장치
채널은 신호에 진폭 및 위상 왜곡을 생성합니다. 이는 채널의 전송 특성 때문입니다. 이퀄라이저 회로는 수신 된 펄스를 형성하여 이러한 손실을 보상합니다.
타이밍 회로
품질 출력을 얻으려면 신호 대 잡음비 (SNR)가 최대 인 곳에서 펄스 샘플링을 수행해야합니다. 이 완벽한 샘플링을 달성하려면 수신 된 펄스에서 주기적 펄스 트레인을 유도해야하며, 이는 타이밍 회로에 의해 수행됩니다.
따라서 타이밍 회로는 수신 된 펄스를 통해 높은 SNR에서 샘플링하는 타이밍 간격을 할당합니다.
결정 장치
타이밍 회로는 샘플링 시간을 결정합니다. 이 샘플링 시간에 의사 결정 장치가 활성화됩니다. 결정 장치는 양자화 된 펄스 및 노이즈의 진폭이 미리 결정된 값을 초과하는지 여부에 따라 출력을 결정합니다.
이들은 디지털 통신에 사용되는 몇 가지 기술입니다. 배워야 할 다른 중요한 기술이 있는데이를 데이터 인코딩 기술이라고합니다. 라인 코드를 살펴본 후 다음 장에서 이에 대해 알아 보겠습니다.
ㅏ line code전송 라인을 통한 디지털 신호의 데이터 전송에 사용되는 코드입니다. 이 코딩 프로세스는 심볼 간 간섭과 같은 신호의 겹침 및 왜곡을 피하기 위해 선택됩니다.
라인 코딩의 속성
다음은 라인 코딩의 속성입니다-
단일 신호에서 더 많은 비트를 전송하기 위해 코딩이 수행되므로 사용되는 대역폭이 훨씬 줄어 듭니다.
주어진 대역폭에 대해 전력이 효율적으로 사용됩니다.
오류 가능성이 훨씬 줄어 듭니다.
오류 감지가 수행되고 양극성에도 수정 기능이 있습니다.
전력 밀도는 훨씬 유리합니다.
타이밍 내용이 적절합니다.
긴 문자열 1s 과 0s 투명성을 유지하기 위해 피합니다.
라인 코딩 유형
Line Coding에는 3 가지 유형이 있습니다.
- Unipolar
- Polar
- Bi-polar
단극 신호
단극 신호는 On-Off Keying 또는 단순히 OOK.
맥박의 존재는 1 맥박의 부재는 0.
단극 신호에는 두 가지 변형이 있습니다.
- NRZ (Non Return to Zero)
- 제로로 돌아 가기 (RZ)
유니 폴라 NRZ (Non-Return to Zero)
이러한 유형의 단극 신호에서 높은 데이터는 다음과 같은 양의 펄스로 표시됩니다. Mark, 기간이 있습니다. T0심볼 비트 기간과 같습니다. 낮은 데이터 입력에는 펄스가 없습니다.
다음 그림은이를 명확하게 보여줍니다.
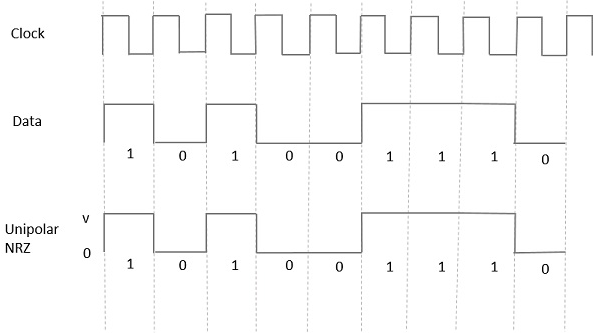
Advantages
Unipolar NRZ의 장점은 다음과 같습니다.
- 간단하다.
- 더 적은 대역폭이 필요합니다.
Disadvantages
Unipolar NRZ의 단점은 다음과 같습니다.
오류 수정이 수행되지 않았습니다.
저주파 구성 요소가 있으면 신호가 늘어날 수 있습니다.
시계가 없습니다.
동기화 손실이 발생할 수 있습니다 (특히 긴 문자열의 경우). 1s 과 0s).
단극 제로 복귀 (RZ)
이러한 유형의 단극 시그널링에서 높은 데이터는 Mark pulse, 기간 T0심볼 비트 기간보다 작습니다. 비트 지속 시간의 절반은 높게 유지되지만 즉시 0으로 돌아가 나머지 비트 지속 시간 동안 펄스가 없음을 나타냅니다.
다음 그림의 도움으로 명확하게 이해됩니다.
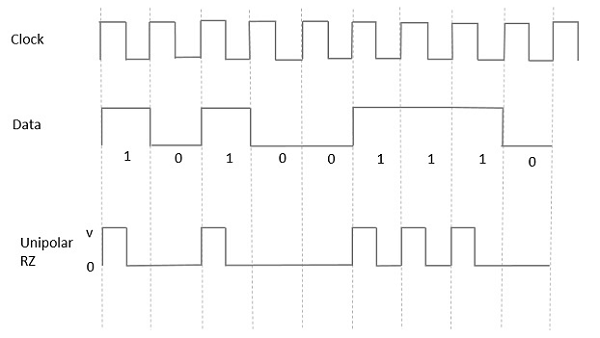
Advantages
Unipolar RZ의 장점은 다음과 같습니다.
- 간단하다.
- 심볼 레이트에 존재하는 스펙트럼 라인은 클럭으로 사용될 수 있습니다.
Disadvantages
Unipolar RZ의 단점은 다음과 같습니다.
- 오류 수정이 없습니다.
- 단극 NRZ보다 2 배의 대역폭을 차지합니다.
- 신호 드룹은 신호가 0Hz에서 0이 아닌 곳에서 발생합니다.
극지 신호
Polar Signaling에는 두 가지 방법이 있습니다. 그들은-
- 극지 NRZ
- 극지 RZ
극지 NRZ
이러한 유형의 Polar 신호에서 High in 데이터는 양의 펄스로 표시되고 Low in 데이터는 음의 펄스로 표시됩니다. 다음 그림은이를 잘 보여줍니다.
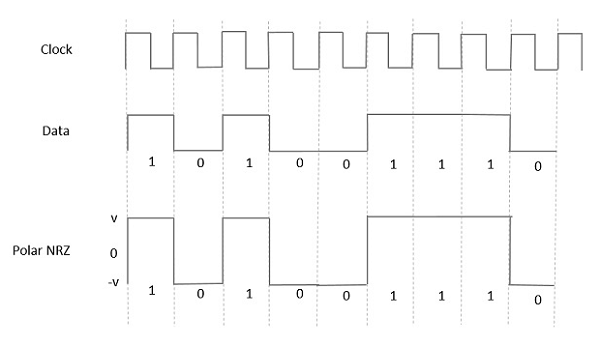
Advantages
Polar NRZ의 장점은 다음과 같습니다.
- 간단하다.
- 저주파 구성 요소가 없습니다.
Disadvantages
Polar NRZ의 단점은 다음과 같습니다.
오류 수정이 없습니다.
시계가 없습니다.
신호 드룹은 신호가 0이 아닌 곳에서 발생합니다. 0 Hz.
극지 RZ
이러한 유형의 극성 신호에서 데이터가 높음 Mark pulse, 기간 T0심볼 비트 기간보다 작습니다. 비트 지속 시간의 절반은 높게 유지되지만 즉시 0으로 돌아가 나머지 비트 지속 시간 동안 펄스가 없음을 나타냅니다.
그러나 Low 입력의 경우 음의 펄스는 데이터를 나타내고 0 레벨은 비트 지속 시간의 나머지 절반 동안 동일하게 유지됩니다. 다음 그림은이를 명확하게 보여줍니다.
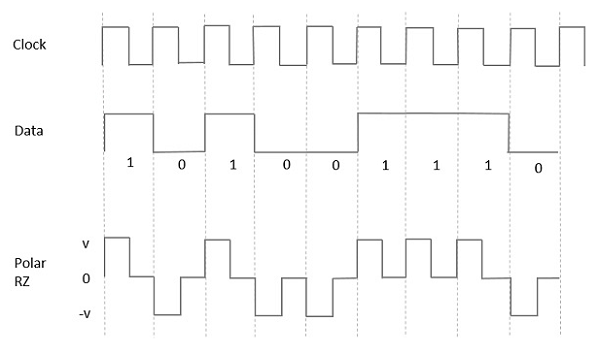
Advantages
Polar RZ의 장점은 다음과 같습니다.
- 간단하다.
- 저주파 구성 요소가 없습니다.
Disadvantages
Polar RZ의 단점은 다음과 같습니다.
오류 수정이 없습니다.
시계가 없습니다.
Polar NRZ 대역폭의 두 배를 차지합니다.
신호 드룹은 신호가 0이 아닌 곳에서 발생합니다. 0 Hz.
양극성 신호
이것은 세 가지 전압 레벨 즉, +, - 과 0. 이러한 신호를 다음과 같이 호출합니다.duo-binary signal.
이 유형의 예는 다음과 같습니다. Alternate Mark Inversion (AMI). 에 대한1, 전압 레벨은 +에서 – 또는 –에서 +로 전환됩니다. 1s같은 극성이어야합니다. ㅏ0 전압 레벨이 0이됩니다.
이 방법에서도 두 가지 유형이 있습니다.
- 양극성 NRZ
- 양극성 RZ
지금까지 논의한 모델에서 NRZ와 RZ의 차이점을 배웠습니다. 여기에서도 같은 방식으로 진행됩니다. 다음 그림은이를 명확하게 보여줍니다.
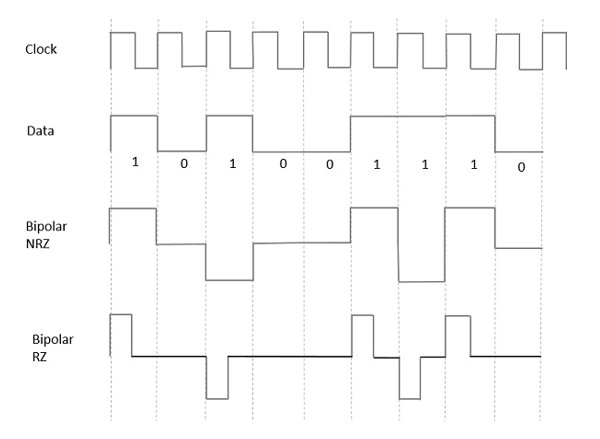
위의 그림에는 바이폴라 NRZ 및 RZ 파형이 모두 있습니다. 펄스 지속 시간과 심볼 비트 지속 시간은 NRZ 유형에서 동일하지만 펄스 지속 시간은 RZ 유형에서 심볼 비트 지속 시간의 절반입니다.
장점
다음은 장점입니다-
간단하다.
저주파 구성 요소가 없습니다.
유니 폴라 및 폴라 NRZ 방식보다 낮은 대역폭을 차지합니다.
이 기술은 여기에서 신호 처짐이 발생하지 않기 때문에 AC 결합 라인을 통한 전송에 적합합니다.
여기에는 단일 오류 감지 기능이 있습니다.
단점
다음은 단점입니다-
- 시계가 없습니다.
- 데이터 문자열이 길면 동기화가 손실됩니다.
전력 스펙트럼 밀도
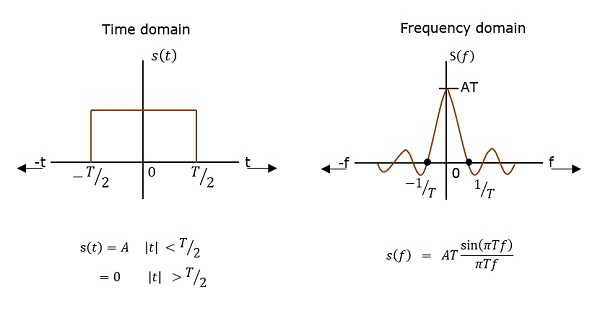
주파수 영역에서 신호의 전력이 다양한 주파수에서 어떻게 분산되는지를 설명하는 함수를 다음과 같이 호출합니다. Power Spectral Density (PSD).
PSD는 자동 상관의 푸리에 변환입니다 (관측치 간의 유사성). 그것은 직사각형 펄스의 형태입니다.
PSD 파생
Einstein-Wiener-Khintchine 정리에 따르면 임의 프로세스의 자기 상관 함수 또는 전력 스펙트럼 밀도를 알고 있으면 다른 하나를 정확하게 찾을 수 있습니다.
따라서 전력 스펙트럼 밀도를 유도하려면 시간 자동 상관 관계를 사용합니다. $(R_x(\tau))$ 전력 신호의 $x(t)$ 아래 그림과 같이.
$R_x(\tau) = \lim_{T_p \rightarrow \infty}\frac{1}{T_p}\int_{\frac{{-T_p}}{2}}^{\frac{T_p}{2}}x(t)x(t + \tau)dt$
이후 $x(t)$ 충동으로 구성되어 있습니다. $R_x(\tau)$ 다음과 같이 쓸 수 있습니다.
$R_x(\tau) = \frac{1}{T}\displaystyle\sum\limits_{n = -\infty}^\infty R_n\delta(\tau - nT)$
어디 $R_n = \lim_{N \rightarrow \infty}\frac{1}{N}\sum_ka_ka_{k + n}$
알아 가기 $R_n = R_{-n}$ 실제 신호의 경우
$S_x(w) = \frac{1}{T}(R_0 + 2\displaystyle\sum\limits_{n = 1}^\infty R_n \cos nwT)$
펄스 필터의 스펙트럼은 $(w) \leftrightarrow f(t)$, 우리는
$s_y(w) = \mid F(w) \mid^2S_x(w)$
$= \frac{\mid F(w) \mid^2}{T}(\displaystyle\sum\limits_{n = -\infty}^\infty R_ne^{-jnwT_{b}})$
$= \frac{\mid F(w) \mid^2}{T}(R_0 + 2\displaystyle\sum\limits_{n = 1}^\infty R_n \cos nwT)$
따라서 우리는 전력 스펙트럼 밀도에 대한 방정식을 얻습니다. 이를 사용하여 다양한 라인 코드의 PSD를 찾을 수 있습니다.
Encoding 데이터의 보안 전송을 위해 데이터 또는 지정된 문자, 기호, 알파벳 등의 시퀀스를 지정된 형식으로 변환하는 프로세스입니다. Decoding 변환 된 형식에서 정보를 추출하는 인코딩의 역 과정입니다.
데이터 인코딩
인코딩은 다양한 패턴의 전압 또는 전류 레벨을 사용하여 1s 과 0s 전송 링크에있는 디지털 신호의.
일반적인 라인 인코딩 유형은 Unipolar, Polar, Bipolar 및 Manchester입니다.
인코딩 기법
데이터 인코딩 기술은 데이터 변환 유형에 따라 다음과 같은 유형으로 나뉩니다.
Analog data to Analog signals − 아날로그 신호의 진폭 변조, 주파수 변조 및 위상 변조와 같은 변조 기술이이 범주에 속합니다.
Analog data to Digital signals−이 프로세스는 PCM (Pulse Code Modulation)에 의해 수행되는 디지털화라고 할 수 있습니다. 따라서 디지털 변조 일뿐입니다. 이미 논의했듯이 샘플링과 양자화는 여기에서 중요한 요소입니다. 델타 변조는 PCM보다 더 나은 출력을 제공합니다.
Digital data to Analog signals− ASK (Amplitude Shift Keying), FSK (Frequency Shift Keying), PSK (Phase Shift Keying) 등과 같은 변조 기술이이 범주에 속합니다. 이에 대해서는 다음 장에서 설명합니다.
Digital data to Digital signals−이 섹션에 있습니다. 디지털 데이터를 디지털 신호에 매핑하는 방법에는 여러 가지가 있습니다. 그들 중 일부는-
NRZ (Non Return to Zero)
NRZ 코드는 1 고전압 레벨 및 0낮은 전압 레벨을 위해. NRZ 코드의 주요 동작은 전압 레벨이 비트 간격 동안 일정하게 유지된다는 것입니다. 비트의 끝 또는 시작은 표시되지 않으며 이전 비트의 값과 현재 비트의 값이 같으면 동일한 전압 상태를 유지합니다.
다음 그림은 NRZ 코딩의 개념을 설명합니다.
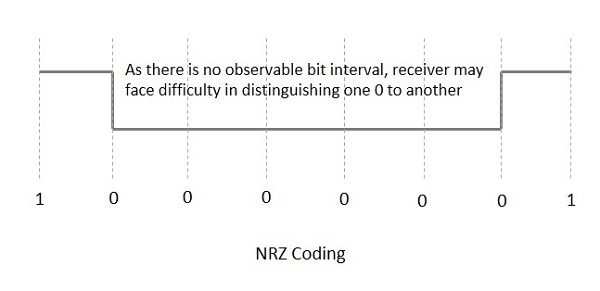
위의 예를 고려하면 일정한 전압 레벨의 시퀀스가 길고 비트 간격이 없어 클럭 동기화가 손실 될 수 있으므로 수신기가 0과 1을 구별하기 어렵게됩니다.
NRZ에는 두 가지 변형이 있습니다.
NRZ-L (NRZ – LEVEL)
입력 신호가 1에서 0 또는 0에서 1로 변경되는 경우에만 신호의 극성이 변경됩니다. NRZ와 동일하지만 입력 신호의 첫 번째 비트는 극성이 변경되어야합니다.
NRZ-I (NRZ – 반전 됨)
만약 1들어오는 신호에서 발생하면 비트 간격의 시작 부분에서 전환이 발생합니다. 에 대한0 들어오는 신호에서 비트 간격의 시작 부분에는 전환이 없습니다.
NRZ 코드에는 disadvantage 송신기 클록과 수신기 클록의 동기화가 완전히 방해받습니다. 1s 과 0s. 따라서 별도의 클록 라인이 제공되어야합니다.
2 상 인코딩
신호 레벨은 처음과 중간에 모든 비트 시간에 대해 두 번 확인됩니다. 따라서 클럭 속도는 데이터 전송 속도의 두 배이므로 변조 속도도 두 배가됩니다. 시계는 신호 자체에서 가져옵니다. 이 코딩에 필요한 대역폭은 더 큽니다.
Bi-phase Encoding에는 두 가지 유형이 있습니다.
- 바이 페이즈 맨체스터
- 차동 맨체스터
바이 페이즈 맨체스터
이 유형의 코딩에서 전환은 비트 간격의 중간에 수행됩니다. 결과 펄스에 대한 전환은 입력 비트 1에 대해 간격 중간에 High에서 Low로 전환됩니다. 입력 비트에 대해 Low에서 High로 전환되는 동안0.
차동 맨체스터
이러한 유형의 코딩에서는 항상 비트 간격 중간에 전환이 발생합니다. 비트 간격의 시작 부분에서 전환이 발생하면 입력 비트는0. 비트 간격의 시작 부분에서 전환이 발생하지 않으면 입력 비트는1.
다음 그림은 다른 디지털 입력에 대한 NRZ-L, NRZ-I, Bi-phase Manchester 및 Differential Manchester 코딩의 파형을 보여줍니다.
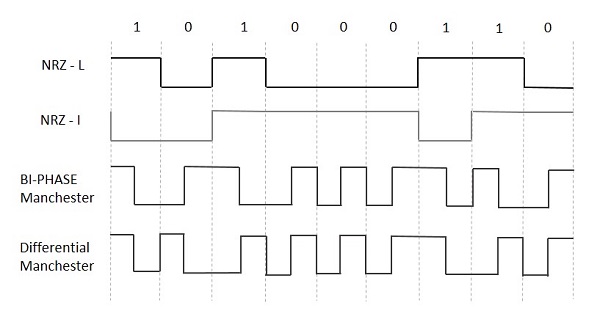
블록 코딩
블록 코딩 유형 중 유명한 것은 4B / 5B 인코딩과 8B / 6T 인코딩입니다. 비트 수는 두 프로세스 모두에서 서로 다른 방식으로 처리됩니다.
4B / 5B 인코딩
맨체스터 인코딩에서 데이터를 전송하려면 NRZ 코딩보다는 배속의 클럭이 필요합니다. 여기서 이름에서 알 수 있듯이 4 비트 코드는 5 비트로 매핑되며 최소 개수는1 그룹의 비트.
NRZ-I 인코딩의 클럭 동기화 문제는 4 개의 연속 비트의 각 블록 대신 5 비트의 등가 워드를 할당함으로써 방지됩니다. 이 5 비트 단어는 사전에 미리 결정되어 있습니다.
5 비트 코드를 선택하는 기본 아이디어는 one leading 0 그리고 그것은 있어야 no more than two trailing 0s. 따라서 이러한 단어는 비트 블록 당 두 개의 트랜잭션이 발생하도록 선택됩니다.
8B / 6T 인코딩
단일 신호를 통해 단일 비트를 전송하기 위해 두 가지 전압 레벨을 사용했습니다. 그러나 3 개 이상의 전압 레벨을 사용하면 신호 당 더 많은 비트를 전송할 수 있습니다.
예를 들어, 단일 신호에서 8 비트를 나타내는 데 6 개의 전압 레벨이 사용되는 경우 이러한 인코딩을 8B / 6T 인코딩이라고합니다. 따라서이 방법에서는 신호에 대해 729 (3 ^ 6) 조합과 비트에 대해 256 (2 ^ 8) 조합이 있습니다.
이들은 데이터의 안정적인 전송을 위해 디지털 데이터를 압축하거나 코딩하여 디지털 데이터를 디지털 신호로 변환하는 데 주로 사용되는 기술입니다.
다양한 유형의 코딩 기술을 살펴본 후 데이터가 왜곡되기 쉬운 방법과 데이터가 영향을받지 않도록 조치를 취하여 안정적인 통신을 설정하는 방법에 대한 아이디어를 얻었습니다.
발생할 가능성이 가장 높은 또 다른 중요한 왜곡이 있습니다. Inter-Symbol Interference (ISI).
인터 심볼 간섭
이것은 신호 왜곡의 한 형태로, 하나 이상의 심볼이 후속 신호를 방해하여 잡음을 일으키거나 출력이 나쁘게 전달됩니다.
ISI의 원인
ISI의 주요 원인은 다음과 같습니다.
- 다중 경로 전파
- 채널의 비선형 주파수
ISI는 원치 않으며 깨끗한 출력을 얻으려면 완전히 제거해야합니다. ISI의 영향을 줄이기 위해서는 ISI의 원인도 해결되어야합니다.
수신기 출력에있는 수학적 형태로 ISI를보기 위해 수신기 출력을 고려할 수 있습니다.
수신 필터 출력 $y(t)$ 시간에 샘플링됩니다 $t_i = iT_b$ (와 i 정수 값을 취), 산출-
$y(t_i) = \mu \displaystyle\sum\limits_{k = -\infty}^{\infty}a_kp(iT_b - kT_b)$
$= \mu a_i + \mu \displaystyle\sum\limits_{k = -\infty \\ k \neq i}^{\infty}a_kp(iT_b - kT_b)$
위 방정식에서 첫 번째 항 $\mu a_i$ 에 의해 생성됩니다 ith 전송 된 비트.
두 번째 용어는 다른 모든 전송 된 비트의 디코딩에 대한 잔여 효과를 나타냅니다. ith비트. 이 잔여 효과는Inter Symbol Interference.
ISI가 없으면 출력은 다음과 같습니다.
$$y(t_i) = \mu a_i$$
이 방정식은 ith전송 된 비트가 올바르게 재생됩니다. 그러나 ISI가 있으면 출력에 비트 오류와 왜곡이 발생합니다.
송신기 또는 수신기를 설계하는 동안 가능한 최소 오류율로 출력을 수신하려면 ISI의 영향을 최소화하는 것이 중요합니다.
상관 코딩
지금까지 ISI는 원치 않는 현상이며 신호를 저하시키는 것에 대해 논의했습니다. 그러나 제어 된 방식으로 사용되는 경우 동일한 ISI는 비트 전송률을 달성 할 수 있습니다.2W 대역폭 채널에서 초당 비트 W헤르츠. 이러한 계획은Correlative Coding 또는 Partial response signaling schemes.
ISI의 양을 알기 때문에 신호에 대한 ISI의 영향을 피하기 위해 요구 사항에 따라 수신기를 설계하는 것이 쉽습니다. 상관 코딩의 기본 아이디어는 다음의 예를 고려하여 달성됩니다.Duo-binary Signaling.
듀오 바이너리 신호
duo-binary라는 이름은 이진 시스템의 전송 기능을 두 배로 늘리는 것을 의미합니다. 이를 이해하기 위해 이진 입력 시퀀스를 고려해 보겠습니다.{ak} 기간이있는 상관 관계가없는 이진수로 구성 Ta초. 이것에서 신호1 로 표시됩니다 +1 볼트와 기호 0 에 의해 -1 볼트.
따라서 듀오 바이너리 코더 출력 ck 현재 이진수의 합으로 주어집니다. ak 및 이전 값 ak-1 다음 방정식과 같이.
$$c_k = a_k + a_{k-1}$$
위의 방정식은 상관 관계가없는 이진 시퀀스의 입력 시퀀스 {ak} 상관 관계가있는 3 단계 펄스의 시퀀스로 변경됩니다. {ck}. 펄스 간의 이러한 상관 관계는 인위적으로 전송 된 신호에 ISI를 도입하는 것으로 이해 될 수 있습니다.
아이 패턴
ISI의 효과를 연구하는 효과적인 방법은 Eye Pattern. Eye Pattern이라는 이름은 이진 파의 인간 눈과 닮았 기 때문에 붙여졌습니다. 눈 패턴의 내부 영역은eye opening. 다음 그림은 눈 패턴의 이미지를 보여줍니다.
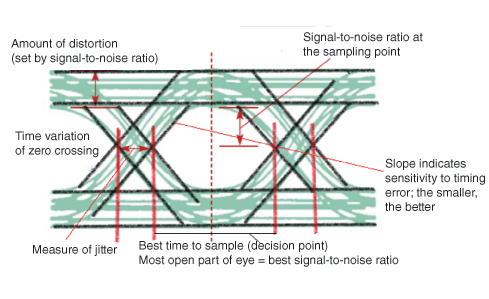
Jitter 이상적인 위치에서 디지털 신호 순간의 단기 변화로 데이터 오류가 발생할 수 있습니다.
ISI의 효과가 증가하면 ISI가 매우 높으면 눈의 위쪽에서 아래쪽까지의 흔적이 증가하고 눈이 완전히 닫힙니다.
아이 패턴은 특정 시스템에 대한 다음 정보를 제공합니다.
실제 아이 패턴은 비트 오류율과 신호 대 잡음비를 추정하는 데 사용됩니다.
아이 오프닝의 너비는 ISI에서 오류없이 수신 된 웨이브를 샘플링 할 수있는 시간 간격을 정의합니다.
아이 오프닝이 넓은 순간이 샘플링에 선호되는 시간입니다.
샘플링 시간에 따른 눈의 폐쇄 속도는 시스템이 타이밍 오류에 얼마나 민감한 지 결정합니다.
지정된 샘플링 시간에서 아이 오프닝의 높이는 노이즈에 대한 마진을 정의합니다.
따라서 아이 패턴의 해석은 중요한 고려 사항입니다.
이퀄라이제이션
안정적인 의사 소통을 위해서는 양질의 결과물이 있어야합니다. 채널의 전송 손실 및 신호 품질에 영향을 미치는 기타 요인을 처리해야합니다. 우리가 논의했듯이 가장 많이 발생하는 손실은 ISI입니다.
신호를 ISI에서 제거하고 최대 신호 대 잡음비를 보장하려면 다음과 같은 메서드를 구현해야합니다. Equalization. 다음 그림은 통신 시스템의 수신기 부분에있는 이퀄라이저를 보여줍니다.
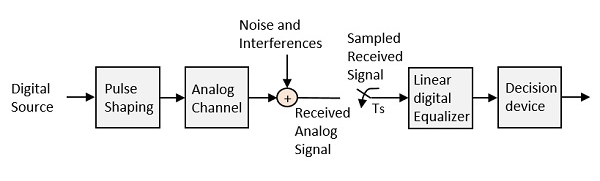
그림에 표시된 노이즈와 간섭은 전송 중에 발생할 가능성이 높습니다. 회생 중계기에는 회로를 형성하여 전송 손실을 보상하는 이퀄라이저 회로가 있습니다. 이퀄라이저를 구현할 수 있습니다.
오류 확률 및 성능 지수
데이터가 통신 할 수있는 속도를 data rate. 데이터를 전송하는 동안 비트에서 오류가 발생하는 비율을Bit Error Rate (BER).
BER 발생 확률은 Error Probability. 신호 대 잡음비 (SNR)가 증가하면 BER이 감소하므로 오류 확률도 감소합니다.
아날로그 수신기에서 figure of merit검출 과정에서 입력 SNR에 대한 출력 SNR의 비율이라고 할 수 있습니다. 더 큰 가치의 가치가 장점이 될 것입니다.
디지털-아날로그 신호는이 장에서 논의 할 다음 변환입니다. 이러한 기술은Digital Modulation techniques.
Digital Modulation더 많은 정보 용량, 높은 데이터 보안, 우수한 품질의 커뮤니케이션으로 더 빠른 시스템 가용성을 제공합니다. 따라서 디지털 변조 기술은 아날로그 변조 기술보다 더 많은 양의 데이터를 전달할 수있는 능력에 대한 수요가 더 많습니다.
필요에 따라 많은 유형의 디지털 변조 기술과 그 조합이 있습니다. 그들 모두 중에서 우리는 저명한 것들에 대해 논의 할 것입니다.
ASK – 진폭 시프트 키잉
결과 출력의 진폭은 반송파 주파수에 따라 0 레벨이되어야하는지 또는 양과 음의 변동이되어야하는지 입력 데이터에 따라 달라집니다.
FSK – 주파수 편이 키잉
출력 신호의 주파수는 적용된 입력 데이터에 따라 높거나 낮습니다.
PSK – 위상 편이 키잉
출력 신호의 위상은 입력에 따라 이동됩니다. 이들은 주로 위상 편이 수에 따라 BPSK (Binary Phase Shift Keying)와 QPSK (Quadrature Phase Shift Keying)의 두 가지 유형이 있습니다. 다른 하나는 이전 값에 따라 위상을 변경하는 DPSK (Differential Phase Shift Keying)입니다.
M-ary 인코딩
M-ary Encoding 기술은 단일 신호에서 동시에 전송하기 위해 2 비트 이상을 만드는 방법입니다. 이것은 대역폭 감소에 도움이됩니다.
M-ary 기술의 유형은 다음과 같습니다.
- M-ary ASK
- M-ary FSK
- M-ary PSK
이들 모두는 다음 장에서 논의됩니다.
Amplitude Shift Keying (ASK) 신호 진폭의 변화 형태로 이진 데이터를 나타내는 진폭 변조의 한 유형입니다.
변조 된 신호에는 고주파 반송파가 있습니다. ASK 변조시 이진 신호는zero 가치 Low 입력하는 동안 carrier output ...에 대한 High 입력.
다음 그림은 입력과 함께 ASK 변조 파형을 나타냅니다.
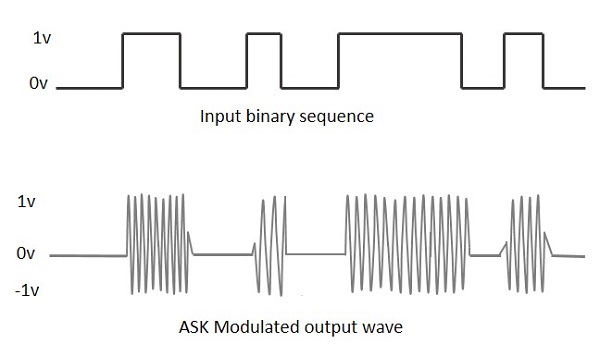
이 ASK 변조 파를 얻는 과정을 찾기 위해 ASK 변조기의 작동에 대해 알아 보겠습니다.
ASK 변조기
ASK 변조기 블록 다이어그램은 반송파 신호 생성기, 메시지 신호의 이진 시퀀스 및 대역 제한 필터로 구성됩니다. 다음은 ASK 변조기의 블록 다이어그램입니다.
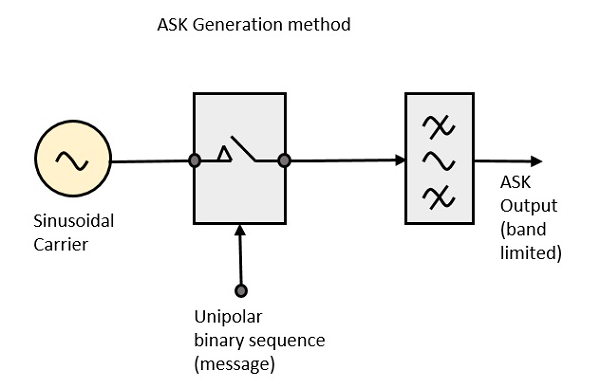
반송파 발생기는 연속 고주파 반송파를 보냅니다. 메시지 신호의 바이너리 시퀀스는 유니 폴라 입력을 높음 또는 낮음으로 만듭니다. 높은 신호는 스위치를 닫아 반송파를 허용합니다. 따라서 출력은 높은 입력에서 반송파 신호가됩니다. 낮은 입력이 있으면 스위치가 열리고 전압이 나타나지 않습니다. 따라서 출력이 낮아집니다.
대역 제한 필터는 대역 제한 필터 또는 펄스 형성 필터의 진폭 및 위상 특성에 따라 펄스를 형성합니다.
ASK 복조기
ASK 복조 기술에는 두 가지 유형이 있습니다. 그들은-
- 비동기 ASK 복조 / 감지
- 동기식 ASK 복조 / 검출
수신기의 클록 주파수와 일치 할 때 송신기의 클록 주파수는 Synchronous method, 주파수가 동기화됨에 따라. 그렇지 않으면 다음과 같이 알려져 있습니다.Asynchronous.
비동기 ASK 복조기
비동기 ASK 검출기는 반파 정류기, 저역 통과 필터 및 비교기로 구성됩니다. 다음은 동일한 블록 다이어그램입니다.
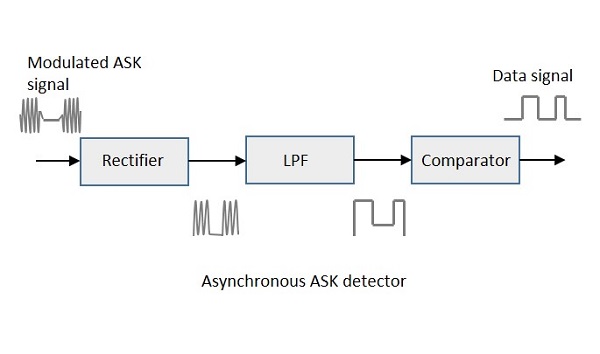
변조 된 ASK 신호는 양의 절반 출력을 제공하는 반파 정류기에 제공됩니다. 로우 패스 필터는 더 높은 주파수를 억제하고 비교기가 디지털 출력을 제공하는 엔벨로프 감지 출력을 제공합니다.
동기식 ASK 복조기
동기식 ASK 검출기는 제곱 법칙 검출기, 저역 통과 필터, 비교기 및 전압 제한기로 구성됩니다. 다음은 동일한 블록 다이어그램입니다.
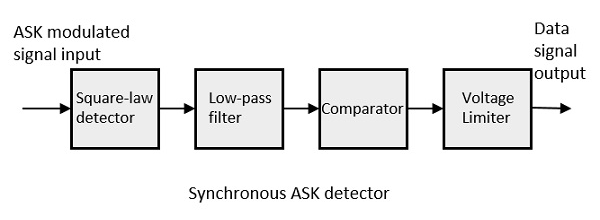
ASK 변조 입력 신호는 제곱 법칙 검출기에 제공됩니다. 제곱 법칙 검출기는 출력 전압이 진폭 변조 입력 전압의 제곱에 비례하는 검출기입니다. 저역 통과 필터는 더 높은 주파수를 최소화합니다. 비교기와 전압 제한 기는 깨끗한 디지털 출력을 얻는 데 도움이됩니다.
Frequency Shift Keying (FSK)디지털 신호 변화에 따라 반송파 신호의 주파수가 달라지는 디지털 변조 기술입니다. FSK는 주파수 변조 방식입니다.
FSK 변조 파의 출력은 바이너리 High 입력의 경우 높은 주파수이고 바이너리 Low 입력의 경우 낮은 주파수입니다. 바이너리1s 과 0s 마크 및 공간 주파수라고합니다.
다음 이미지는 입력과 함께 FSK 변조 파형의 다이어그램 표현입니다.
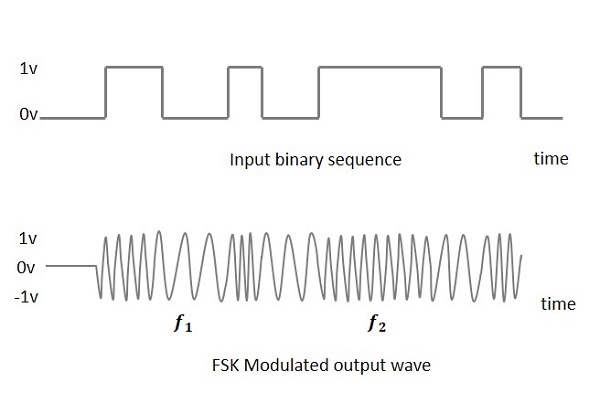
이 FSK 변조 파를 얻는 과정을 찾으려면 FSK 변조기의 작동에 대해 알려주십시오.
FSK 변조기
FSK 변조기 블록 다이어그램은 클럭과 입력 바이너리 시퀀스가있는 2 개의 오실레이터로 구성됩니다. 다음은 블록 다이어그램입니다.
더 높은 주파수와 더 낮은 주파수 신호를 생성하는 두 발진기는 내부 클록과 함께 스위치에 연결됩니다. 메시지를 전송하는 동안 출력 파형의 갑작스러운 위상 불연속을 방지하기 위해 내부적으로 두 발진기에 클록이 적용됩니다. 이진 입력 시퀀스는 이진 입력에 따라 주파수를 선택하기 위해 송신기에 적용됩니다.
FSK 복조기
FSK 파를 복조하는 방법에는 여러 가지가 있습니다. FSK 감지의 주요 방법은 다음과 같습니다.asynchronous detector 과 synchronous detector. 동기 검출기는 일관된 것이고 비동기 검출기는 일관되지 않은 것입니다.
비동기식 FSK 감지기
비동기식 FSK 검출기의 블록 다이어그램은 2 개의 대역 통과 필터, 2 개의 엔벨로프 검출기 및 결정 회로로 구성됩니다. 다음은 다이어그램 표현입니다.
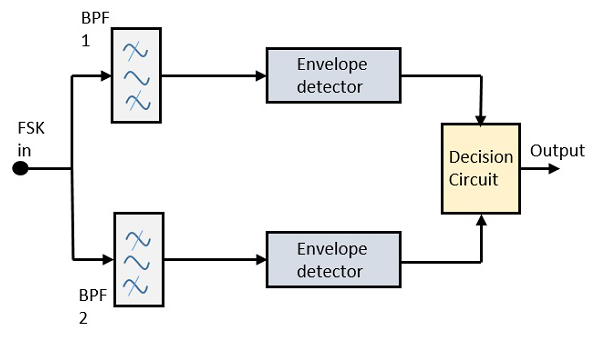
FSK 신호는 두 개의 BPF (Band Pass Filter)를 통해 전달되며 Space 과 Mark주파수. 이 두 BPF의 출력은 엔벨로프 감지기에 제공되는 ASK 신호처럼 보입니다. 각 엔벨로프 감지기의 신호는 비동기식으로 변조됩니다.
결정 회로는 가능성이 더 높은 출력을 선택하고 엔벨로프 감지기 중 하나에서 선택합니다. 또한 파형의 형태를 직사각형 형태로 변경합니다.
동기식 FSK 감지기
동기식 FSK 검출기의 블록 다이어그램은 로컬 발진기 회로가있는 두 개의 믹서, 두 개의 대역 통과 필터 및 결정 회로로 구성됩니다. 다음은 다이어그램 표현입니다.
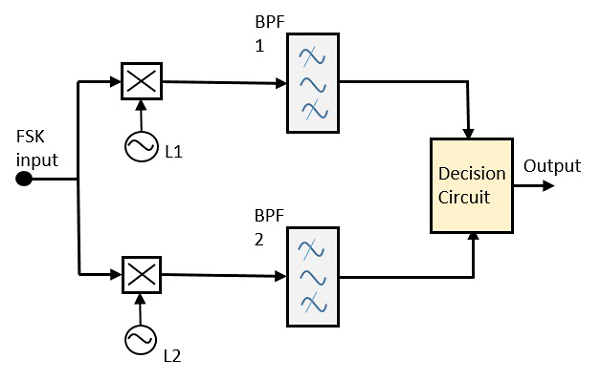
FSK 신호 입력은 로컬 발진기 회로가있는 두 믹서에 제공됩니다. 이 두 가지는 두 개의 대역 통과 필터에 연결됩니다. 이러한 조합은 복조기 역할을하며 결정 회로는 어떤 출력이 더 가능성이 높은지 선택하고 검출기 중 하나에서 선택합니다. 두 신호는 최소 주파수 분리를 갖습니다.
두 복조기의 경우 각각의 대역폭은 비트 전송률에 따라 다릅니다. 이 동기 복조기는 비동기식 복조기보다 약간 복잡합니다.
Phase Shift Keying (PSK)특정 시간에 사인 및 코사인 입력을 변경하여 반송파 신호의 위상을 변경하는 디지털 변조 기술입니다. PSK 기술은 RFID 및 Bluetooth 통신과 함께 무선 LAN, 생체 측정, 비접촉식 작업에 널리 사용됩니다.
PSK는 신호가 이동되는 위상에 따라 두 가지 유형이 있습니다. 그들은-
이진 위상 편이 변조 (BPSK)
이를 2-phase PSK 또는 Phase Reversal Keying이라고도합니다. 이 기술에서 사인파 반송파는 0 ° 및 180 °와 같은 두 위상 반전을 취합니다.
BPSK는 기본적으로 DSBSC (Double Side Band Suppressed Carrier) 변조 방식으로, 메시지는 디지털 정보입니다.
QPSK (Quadrature Phase Shift Keying)
이것은 사인파 반송파가 0 °, 90 °, 180 ° 및 270 °와 같은 4 개의 위상 반전을 취하는 위상 편이 키잉 기술입니다.
이러한 종류의 기술이 더 확장되면 PSK는 요구 사항에 따라 8 개 또는 16 개의 값으로 수행 할 수 있습니다.
BPSK 변조기
Binary Phase Shift Keying의 블록 다이어그램은 반송파 사인파를 하나의 입력으로, 이진 시퀀스를 다른 입력으로 갖는 균형 변조기로 구성됩니다. 다음은 다이어그램 표현입니다.
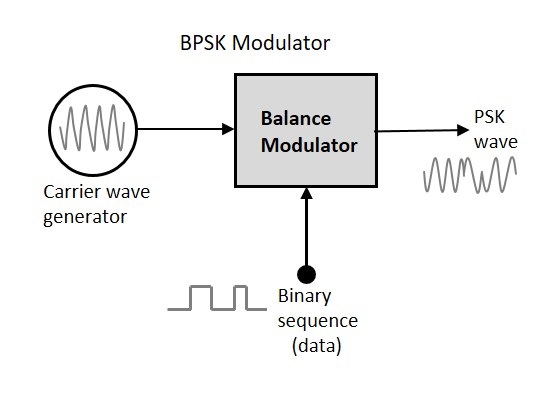
BPSK의 변조는 입력에 적용된 두 신호를 곱하는 밸런스 변조기를 사용하여 수행됩니다. 제로 바이너리 입력의 경우 위상은0° 높은 입력의 경우 위상 반전은 180°.
다음은 주어진 입력과 함께 BPSK 변조 출력 파형의 다이어그램 표현입니다.
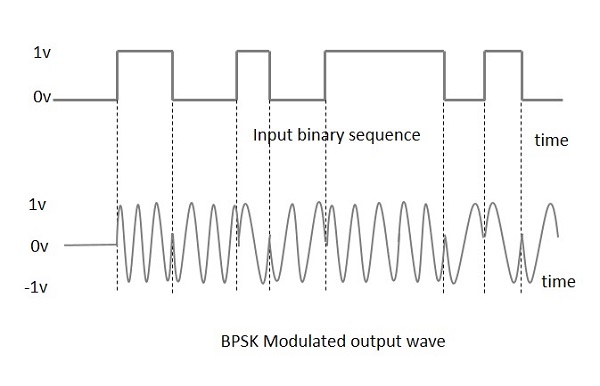
변조기의 출력 사인파는 직접 입력 반송파 또는 데이터 신호의 함수 인 반전 된 (180 ° 위상 이동) 입력 반송파입니다.
BPSK 복조기
BPSK 복조기의 블록 다이어그램은 국부 발진기 회로가있는 믹서, 대역 통과 필터, 2 입력 검출기 회로로 구성됩니다. 다이어그램은 다음과 같습니다.
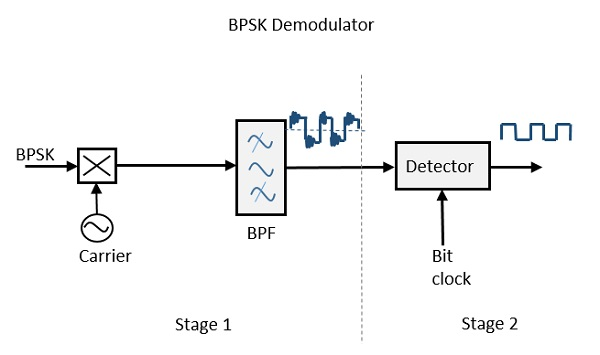
믹서 회로와 대역 통과 필터의 도움으로 대역 제한 메시지 신호를 복구함으로써 복조의 첫 번째 단계가 완료됩니다. 대역이 제한된 기저 대역 신호가 획득되고이 신호는 이진 메시지 비트 스트림을 재생성하는 데 사용됩니다.
복조의 다음 단계에서는 원래 이진 메시지 신호를 생성하기 위해 검출기 회로에서 비트 클럭 속도가 필요합니다. 비트 전송률이 반송파 주파수의 하위 배수이면 비트 클럭 재생이 단순화됩니다. 회로를 쉽게 이해할 수 있도록 두 번째 감지 단계에 의사 결정 회로를 삽입 할 수도 있습니다 .
그만큼 Quadrature Phase Shift Keying (QPSK) BPSK의 변형이며 DSBSC (Double Side Band Suppressed Carrier) 변조 방식으로, 한 번에 2 비트의 디지털 정보를 전송합니다. bigits.
디지털 비트를 일련의 디지털 스트림으로 변환하는 대신 비트 쌍으로 변환합니다. 이렇게하면 데이터 비트 전송률이 절반으로 줄어들어 다른 사용자에게 공간이 허용됩니다.
QPSK 변조기
QPSK 변조기는 비트 스플리터, 로컬 오실레이터가있는 2 개의 곱셈기, 2 비트 직렬-병렬 변환기 및 여름 회로를 사용합니다. 다음은 동일한 블록 다이어그램입니다.

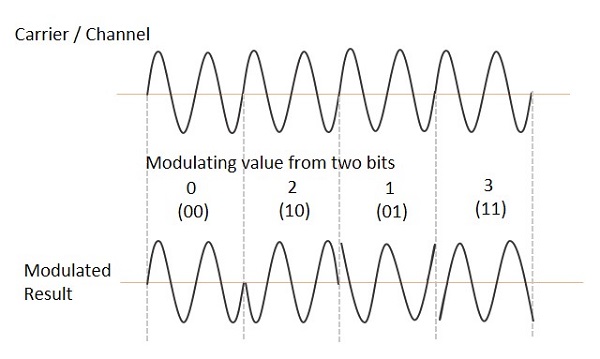
변조기의 입력에서 메시지 신호의 짝수 비트 (예 : 2 번째 비트, 4 번째 비트, 6 번째 비트 등)와 홀수 비트 (즉, 1 번째 비트, 3 번째 비트, 5 번째 비트 등)가 분리됩니다. 비트 스플리터에 의해 홀수 BPSK를 생성하기 위해 동일한 반송파와 곱해집니다.PSKI) 및 BPSK ( PSKQ). 그만큼PSKQ 신호는 변조되기 전에 90 °로 위상이 변합니다.
2 비트 입력에 대한 QPSK 파형은 다음과 같으며 이진 입력의 다른 인스턴스에 대한 변조 결과를 보여줍니다.
QPSK 복조기
QPSK 복조기는 로컬 발진기, 2 개의 대역 통과 필터, 2 개의 적분기 회로 및 2 비트 병렬-직렬 변환기가있는 2 개의 제품 복조기 회로를 사용합니다. 다음은 동일한 다이어그램입니다.
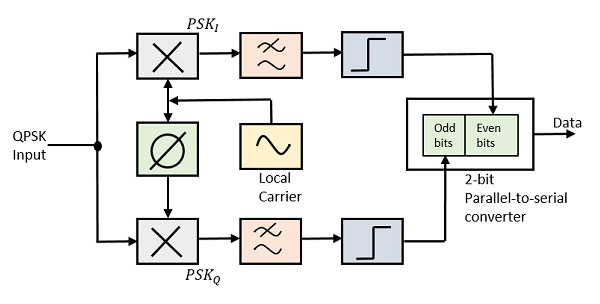
복조기의 입력에있는 두 제품 검출기는 동시에 두 BPSK 신호를 복조합니다. 여기서 비트 쌍은 원래 데이터에서 복구됩니다. 처리 후 이러한 신호는 병렬-직렬 변환기로 전달됩니다.
에 Differential Phase Shift Keying (DPSK)변조 된 신호의 위상은 이전 신호 요소에 상대적으로 이동합니다. 여기서는 참조 신호가 고려되지 않습니다. 신호 위상은 이전 요소의 높음 또는 낮음 상태를 따릅니다. 이 DPSK 기술에는 기준 발진기가 필요하지 않습니다.
다음 그림은 DPSK의 모델 파형을 나타냅니다.
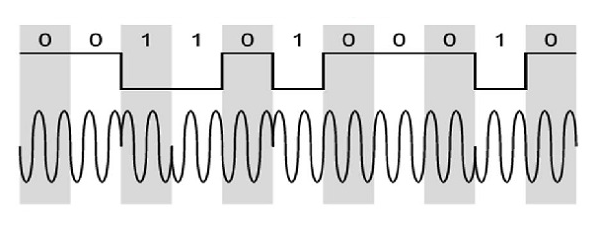
위의 그림에서 데이터 비트가 Low, 즉 0이면 신호의 위상이 반전되지 않고 그대로 계속됨을 알 수 있습니다. 데이터가 High (즉, 1)이면 NRZI와 마찬가지로 신호의 위상이 반전되고 1 (차등 인코딩 형식)에서 반전됩니다.
위의 파형을 관찰하면 High 상태가 M 변조 신호에서 Low 상태는 W 변조 신호에서.
DPSK 변조기
DPSK는 기준 위상 신호가없는 BPSK 기술입니다. 여기서 전송 된 신호 자체를 기준 신호로 사용할 수 있습니다. 다음은 DPSK 변조기의 다이어그램입니다.
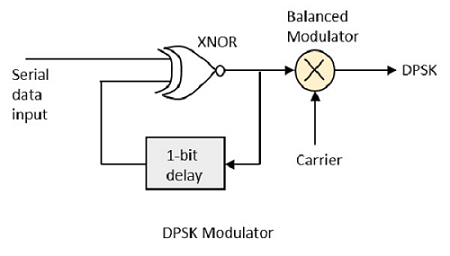
DPSK는 각각 180 ° 위상 편이를 사용하여 반송파와 변조 신호라는 두 가지 신호를 인코딩합니다. 직렬 데이터 입력은 XNOR 게이트에 제공되고 출력은 다시 1 비트 지연을 통해 다른 입력으로 피드백됩니다. 캐리어 신호와 함께 XNOR 게이트의 출력은 DPSK 변조 신호를 생성하기 위해 밸런스 변조기에 제공됩니다.
DPSK 복조기
DPSK 복조기에서 반전 된 비트의 위상은 이전 비트의 위상과 비교됩니다. 다음은 DPSK 복조기의 블록 다이어그램입니다.

위의 그림에서 밸런스 변조기에 1 비트 지연 입력과 함께 DPSK 신호가 제공됨을 알 수 있습니다. 이 신호는 LPF의 도움으로 더 낮은 주파수로 제한됩니다. 그런 다음 비교기 또는 슈미트 트리거 회로 인 셰이퍼 회로로 전달되어 원래 이진 데이터를 출력으로 복구합니다.
바이너리라는 단어는 2 비트를 나타냅니다. M 주어진 수의 이진 변수에 대해 가능한 조건, 수준 또는 조합 수에 해당하는 숫자를 나타냅니다.
데이터 전송에 사용되는 디지털 변조 기술의 한 종류로 한 번에 한 비트가 아닌 두 개 이상의 비트가 전송됩니다. 단일 신호가 다중 비트 전송에 사용되므로 채널 대역폭이 감소합니다.
M-ary 방정식
전압 레벨, 주파수, 위상 및 진폭과 같은 네 가지 조건에서 디지털 신호가 제공되면 M = 4.
주어진 수의 조건을 생성하는 데 필요한 비트 수는 수학적으로 다음과 같이 표현됩니다.
$$N = \log_{2}{M}$$
어디
N 필요한 비트 수입니다.
M 가능한 조건, 수준 또는 조합의 수입니다. N 비트.
위의 방정식은 다음과 같이 재정렬 될 수 있습니다.
$$2^N = M$$
예를 들어 2 비트를 사용하면 22 = 4 조건이 가능합니다.
M-ary 기법의 유형
일반적으로 다중 레벨 (M-ary) 변조 기술은 송신기의 입력에서 3 개 이상의 변조 레벨을 가진 디지털 입력이 허용되므로 디지털 통신에 사용됩니다. 따라서 이러한 기술은 대역폭 효율적입니다.
많은 M-ary 변조 기술이 있습니다. 이러한 기술 중 일부는 진폭, 위상 및 주파수와 같은 반송파 신호의 하나의 매개 변수를 변조합니다.
M-ary ASK
이를 M-ASK (M-ary Amplitude Shift Keying) 또는 M-ary Pulse Amplitude Modulation (PAM)이라고합니다.
그만큼 amplitude 반송파 신호의 M 다른 수준.
M-ary ASK 대표
$S_m(t) = A_mcos (2 \pi f_ct) \quad A_m\epsilon {(2m - 1 - M) \Delta, m = 1,2... \: .M} \quad and \quad 0 \leq t \leq T_s$
M-ary ASK의 몇 가지 두드러진 기능은 다음과 같습니다.
- 이 방법은 PAM에서도 사용됩니다.
- 구현은 간단합니다.
- M-ary ASK는 노이즈와 왜곡에 취약합니다.
M-ary FSK
이를 M-ary FSK (Frequency Shift Keying)라고합니다.
그만큼 frequency 반송파 신호의 M 다른 수준.
M-ary FSK 대표
$S_i(t) = \sqrt{\frac{2E_s}{T_s}} \cos \left ( \frac{\pi}{T_s}\left (n_c+i\right )t\right )$ $0 \leq t \leq T_s \quad and \quad i = 1,2,3... \: ..M$
어디 $f_c = \frac{n_c}{2T_s}$ 일부 고정 정수 n의 경우.
M-ary FSK의 일부 두드러진 특징은 다음과 같습니다.
ASK만큼 소음에 민감하지 않습니다.
전송 M 신호의 수는 에너지와 지속 시간이 동일합니다.
신호는 $\frac{1}{2T_s}$ Hz는 신호를 서로 직교하게 만듭니다.
이후 M 신호는 직각이며 신호 공간에 혼잡이 없습니다.
M-ary FSK의 대역폭 효율성은 감소하고 전력 효율성은 증가할수록 증가합니다. M.
M-ary PSK
이를 M-ary Phase Shift Keying (M-ary PSK)이라고합니다.
그만큼 phase 반송파 신호의 M 다른 수준.
M-ary PSK의 표현
$S_i(t) = \sqrt{\frac{2E}{T}} \cos \left (w_o t + \phi _it\right )$ $0 \leq t \leq T \quad and \quad i = 1,2 ... M$
$$\phi _i \left ( t \right ) = \frac{2 \pi i}{M} \quad where \quad i = 1,2,3 ... \: ...M$$
M-ary PSK의 일부 두드러진 기능은 다음과 같습니다.
포락선은 더 많은 위상 가능성으로 일정합니다.
이 방법은 우주 통신 초기에 사용되었습니다.
ASK 및 FSK보다 더 나은 성능.
수신기에서 최소 위상 추정 오류.
M-ary PSK의 대역폭 효율성은 감소하고 전력 효율성은 증가할수록 증가합니다. M.
지금까지 다양한 변조 기술에 대해 논의했습니다. 이러한 모든 기술의 출력은 다음과 같이 표현되는 이진 시퀀스입니다.1s 과 0s. 이 바이너리 또는 디지털 정보에는 많은 유형과 형식이 있으며 이에 대해 자세히 설명합니다.
정보는 아날로그이든 디지털이든 통신 시스템의 소스입니다. Information theory 정보의 정량화, 저장 및 통신과 함께 정보 코딩 연구에 대한 수학적 접근 방식입니다.
이벤트 발생 조건
이벤트를 고려하면 세 가지 발생 조건이 있습니다.
이벤트가 발생하지 않은 경우 다음과 같은 조건이 있습니다. uncertainty.
이벤트가 방금 발생한 경우 다음과 같은 조건이 있습니다. surprise.
이벤트가 발생하면 시간이 지난 경우 일부가 발생하는 조건이 있습니다. information.
이 세 가지 이벤트는 서로 다른 시간에 발생합니다. 이러한 조건의 차이는 사건 발생 확률에 대한 지식을 얻는 데 도움이됩니다.
엔트로피
사건의 발생 가능성, 그것이 얼마나 놀랍거나 불확실 할 것인지 관찰 할 때, 그것은 우리가 사건의 출처로부터 정보의 평균 내용에 대한 아이디어를 가지려고한다는 것을 의미합니다.
Entropy 소스 심볼 당 평균 정보 콘텐츠의 척도로 정의 할 수 있습니다. Claude Shannon, "정보 이론의 아버지"는 다음과 같은 공식을 제공했습니다.
$$H = - \sum_{i} p_i \log_{b}p_i$$
어디 pi 문자 번호 발생 확률 i 주어진 문자 스트림에서 b사용 된 알고리즘의 기본입니다. 따라서 이것은 또한Shannon’s Entropy.
채널 출력을 관찰 한 후 채널 입력에 대해 남아있는 불확실성의 양을 다음과 같이 호출합니다. Conditional Entropy. 다음과 같이 표시됩니다.$H(x \mid y)$
상호 정보
출력이 다음과 같은 채널을 고려해 보겠습니다. Y 입력은 X
사전 불확실성에 대한 엔트로피를 X = H(x)
(입력이 적용되기 전에 가정합니다.)
출력의 불확실성을 알기 위해 입력이 적용된 후 조건부 엔트로피를 고려해 보겠습니다. Y = yk
$$H\left ( x\mid y_k \right ) = \sum_{j = 0}^{j - 1}p\left ( x_j \mid y_k \right )\log_{2}\left [ \frac{1}{p(x_j \mid y_k)} \right ]$$
이것은 다음에 대한 랜덤 변수입니다. $H(X \mid y = y_0) \: ... \: ... \: ... \: ... \: ... \: H(X \mid y = y_k)$ 확률로 $p(y_0) \: ... \: ... \: ... \: ... \: p(y_{k-1)}$ 각기.
평균값 $H(X \mid y = y_k)$ 출력 알파벳 용 y -
$H\left ( X\mid Y \right ) = \displaystyle\sum\limits_{k = 0}^{k - 1}H\left ( X \mid y=y_k \right )p\left ( y_k \right )$
$= \displaystyle\sum\limits_{k = 0}^{k - 1} \displaystyle\sum\limits_{j = 0}^{j - 1}p\left (x_j \mid y_k \right )p\left ( y_k \right )\log_{2}\left [ \frac{1}{p\left ( x_j \mid y_k \right )} \right ]$
$= \displaystyle\sum\limits_{k = 0}^{k - 1} \displaystyle\sum\limits_{j = 0}^{j - 1}p\left (x_j ,y_k \right )\log_{2}\left [ \frac{1}{p\left ( x_j \mid y_k \right )} \right ]$
이제 불확실성 조건 (입력을 적용하기 전과 후)을 모두 고려하면 그 차이, 즉 $H(x) - H(x \mid y)$ 채널 출력을 관찰하여 해결 된 채널 입력에 대한 불확실성을 나타내야합니다.
이것은 Mutual Information 채널의.
상호 정보를 다음과 같이 표시 $I(x;y)$, 우리는 다음과 같이 방정식에 모든 것을 쓸 수 있습니다.
$$I(x;y) = H(x) - H(x \mid y)$$
따라서 이것은 상호 정보의 방정식 표현입니다.
상호 정보의 속성
이것이 상호 정보의 속성입니다.
채널의 상호 정보는 대칭입니다.
$$I(x;y) = I(y;x)$$
상호 정보는 부정적이지 않습니다.
$$I(x;y) \geq 0$$
상호 정보는 채널 출력의 엔트로피로 표현할 수 있습니다.
$$I(x;y) = H(y) - H(y \mid x)$$
어디 $H(y \mid x)$ 조건부 엔트로피
채널의 상호 정보는 채널 입력과 채널 출력의 결합 엔트로피와 관련이 있습니다.
$$I(x;y) = H(x)+H(y) - H(x,y)$$
조인트 엔트로피 $H(x,y)$ 에 의해 정의된다
$$H(x,y) = \displaystyle\sum\limits_{j=0}^{j-1} \displaystyle\sum\limits_{k=0}^{k-1}p(x_j,y_k)\log_{2} \left ( \frac{1}{p\left ( x_i,y_k \right )} \right )$$
채널 용량
지금까지 상호 정보에 대해 논의했습니다. 시그널링 간격의 순간에 최대 평균 상호 정보는 개별 메모리없는 채널에 의해 전송 될 때 데이터의 최대 신뢰할 수있는 전송 속도의 확률로 이해 될 수 있습니다.channel capacity.
다음과 같이 표시됩니다. C 그리고 측정됩니다 bits per channel 사용하다.
이산 메모리리스 소스
이전 값과 독립적 인 연속 간격으로 데이터를 내보내는 소스는 다음과 같이 불릴 수 있습니다. discrete memoryless source.
이 소스는 연속적인 시간 간격이 아니라 불연속적인 시간 간격으로 고려되므로 불 연속적입니다. 이 소스는 이전 값을 고려하지 않고 매 순간 신선하기 때문에 메모리가 없습니다.
메모리가없는 개별 소스에서 생성 된 코드는 효율적으로 표현되어야하며 이는 통신에서 중요한 문제입니다. 이를 위해 이러한 소스 코드를 나타내는 코드 단어가 있습니다.
예를 들어 전신에서 우리는 알파벳이 다음과 같이 표시되는 모스 부호를 사용합니다. Marks 과 Spaces. 편지가E 주로 사용되는 것으로 간주되며 다음과 같이 표시됩니다. “.” 반면 편지는 Q 거의 사용되지 않으며 다음과 같이 표시됩니다. “--.-”
블록 다이어그램을 살펴 보겠습니다.
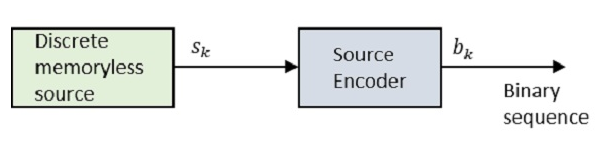
어디 Sk 이산 메모리리스 소스의 출력이며 bk 다음으로 표시되는 소스 인코더의 출력입니다. 0s 과 1s.
인코딩 된 시퀀스는 수신기에서 편리하게 디코딩됩니다.
소스에 알파벳이 있다고 가정합시다. k 다른 기호와 그 kth 상징 Sk 확률로 발생 Pk, 어디 k = 0, 1…k-1.
이진 코드 단어를 기호에 할당하십시오. Sk, 길이가있는 인코더에 의해 lk, 비트 단위로 측정됩니다.
따라서 소스 인코더 의 평균 코드 워드 길이 L 을 다음 과 같이 정의합니다.
$$\overline{L} = \displaystyle\sum\limits_{k=0}^{k-1} p_kl_k$$
L 소스 심볼 당 평균 비트 수를 나타냅니다.
만약 $L_{min} = \: minimum \: possible \: value \: of \: \overline{L}$
그때 coding efficiency 다음과 같이 정의 할 수 있습니다.
$$\eta = \frac{L{min}}{\overline{L}}$$
와 $\overline{L}\geq L_{min}$ 우리는 가질 것이다 $\eta \leq 1$
그러나 소스 인코더는 다음과 같은 경우 효율적인 것으로 간주됩니다. $\eta = 1$
이를 위해 가치 $L_{min}$ 결정되어야합니다.
정의를 참조하십시오. “엔트로피의 개별 메모리가없는 소스가$H(\delta)$, 평균 코드 워드 길이 L 모든 소스 인코딩은 다음과 같이 제한됩니다. $\overline{L} \geq H(\delta)$. "
간단히 말해서 코드 단어 (예 : QUEUE라는 단어의 모스 부호는 -.- ..-. ..-.)는 항상 소스 코드 (예 : QUEUE)보다 크거나 같습니다. 즉, 코드 단어의 기호가 소스 코드의 알파벳보다 크거나 같습니다.
따라서 $L_{min} = H(\delta)$, 엔트로피 측면에서 소스 인코더의 효율성 $H(\delta)$ 다음과 같이 쓸 수 있습니다.
$$\eta = \frac{H(\delta)}{\overline{L}}$$
이 소스 코딩 정리는 noiseless coding theorem오류없는 인코딩을 설정합니다. 그것은 또한Shannon’s first theorem.
채널에 존재하는 노이즈는 디지털 통신 시스템의 입력 및 출력 시퀀스간에 원치 않는 오류를 생성합니다. 오류 확률은 매우 낮아야합니다.nearly ≤ 10-6 안정적인 커뮤니케이션을 위해
통신 시스템의 채널 코딩은 시스템의 신뢰성을 향상시키기 위해 제어와 중복성을 도입합니다. 소스 코딩은 중복성을 줄여 시스템의 효율성을 향상시킵니다.
채널 코딩은 액션의 두 부분으로 구성됩니다.
Mapping 채널 입력 시퀀스로 들어오는 데이터 시퀀스.
Inverse Mapping 채널 출력 시퀀스를 출력 데이터 시퀀스로 변환합니다.
최종 목표는 channel noise 최소화해야합니다.
매핑은 인코더의 도움으로 송신기에 의해 수행되는 반면 역 매핑은 수신기의 디코더에 의해 수행됩니다.
채널 코딩
개별 메모리가없는 채널을 고려해 보겠습니다. (δ) 엔트로피 H (δ)
Ts δ가 초당주는 기호를 나타냅니다.
채널 용량은 다음과 같이 표시됩니다. C
모든 채널에 사용할 수 있습니다. Tc 초
따라서 채널의 최대 기능은 다음과 같습니다. C/Tc
전송 된 데이터 = $\frac{H(\delta)}{T_s}$
만약 $\frac{H(\delta)}{T_s} \leq \frac{C}{T_c}$ 이는 전송이 양호하고 작은 오류 확률로 재현 할 수 있음을 의미합니다.
이것에서 $\frac{C}{T_c}$ 채널 용량의 임계 비율입니다.
만약 $\frac{H(\delta)}{T_s} = \frac{C}{T_c}$ 그런 다음 시스템은 임계 속도로 신호를 보냅니다.
반대로 $\frac{H(\delta)}{T_s} > \frac{C}{T_c}$이면 전송이 불가능합니다.
따라서 전송의 최대 속도는 개별 메모리없는 채널을 통해 발생할 수있는 신뢰할 수있는 오류없는 메시지에 대해 채널 용량의 임계 속도와 동일합니다. 이것은Channel coding theorem.
잡음 또는 오류는 신호의 주요 문제이며 통신 시스템의 신뢰성을 방해합니다. Error control coding오류 발생을 제어하기 위해 수행되는 코딩 절차입니다. 이러한 기술은 오류 감지 및 오류 수정에 도움이됩니다.
적용된 수학적 원리에 따라 다양한 오류 수정 코드가 있습니다. 그러나 역사적으로 이러한 코드는Linear block codes 과 Convolution codes.
선형 블록 코드
선형 블록 코드에서 패리티 비트와 메시지 비트는 선형 조합을 가지며, 이는 결과 코드 워드가 임의의 두 코드 워드의 선형 조합임을 의미합니다.
다음을 포함하는 데이터 블록을 고려해 보겠습니다. k각 블록의 비트. 이 비트는n각 블록의 비트. 여기n 보다 큼 k. 송신기는 다음과 같은 중복 비트를 추가합니다.(n-k)비트. 비율k/n 이다 code rate. 다음과 같이 표시됩니다.r 그리고 가치 r 이다 r < 1.
그만큼 (n-k) 여기에 추가 된 비트는 parity bits. 패리티 비트는 오류 감지 및 오류 수정, 데이터 찾기에 도움이됩니다. 전송되는 데이터에서 코드 워드의 가장 왼쪽 비트는 메시지 비트에 해당하고 코드 워드의 가장 오른쪽 비트는 패리티 비트에 해당합니다.
체계적인 코드
선형 블록 코드는 변경 될 때까지 체계적인 코드가 될 수 있습니다. 따라서 변경되지 않은 블록 코드는systematic code.
다음은 structure of code word, 할당에 따라.

메시지가 변경되지 않으면 체계적인 코드라고합니다. 즉, 데이터 암호화가 데이터를 변경해서는 안됩니다.
컨볼 루션 코드
지금까지 선형 코드에서 우리는 체계적인 변경되지 않은 코드가 선호된다는 것을 논의했습니다. 여기에서 총 데이터n 전송되는 경우 비트, k 비트는 메시지 비트이며 (n-k) 비트는 패리티 비트입니다.
인코딩 과정에서 전체 데이터에서 패리티 비트를 빼고 메시지 비트를 인코딩합니다. 이제 패리티 비트가 다시 추가되고 전체 데이터가 다시 인코딩됩니다.
다음 그림은 정보 전송에 사용되는 데이터 블록 및 데이터 스트림의 예를 인용합니다.

위에서 언급 한 전체 프로세스는 지루하며 단점이 있습니다. 여기서 버퍼 할당은 시스템이 바쁠 때 주요 문제입니다.
이 단점은 컨볼 루션 코드에서 해결됩니다. 데이터의 전체 스트림에 심볼이 할당 된 다음 전송됩니다. 데이터는 비트 스트림이므로 저장을위한 버퍼가 필요하지 않습니다.
해밍 코드
코드 워드의 선형성 특성은 두 코드 워드의 합이 코드 워드라는 것입니다. 해밍 코드는linear error correcting 코드는 최대 2 개의 비트 오류를 감지하거나 수정되지 않은 오류를 감지하지 않고 1 비트 오류를 수정할 수 있습니다.
해밍 코드를 사용하는 동안 추가 패리티 비트는 단일 비트 오류를 식별하는 데 사용됩니다. 한 비트 패턴에서 다른 비트 패턴으로 이동하려면 데이터에서 몇 비트가 변경되어야합니다. 이러한 비트 수는 다음과 같이 불릴 수 있습니다.Hamming distance. 패리티의 거리가 2이면 1 비트 플립을 감지 할 수 있습니다. 그러나 이것은 고칠 수 없습니다. 또한 2 비트 플립은 감지 할 수 없습니다.
그러나 해밍 코드는 이전에 설명한 오류 감지 및 수정보다 더 나은 절차입니다.
BCH 코드
BCH 코드는 발명가의 이름을 따서 명명되었습니다. Bose, Chaudari 및 Hocquenghem. BCH 코드 설계 중에는 수정할 심볼 수를 제어 할 수 있으므로 다중 비트 수정이 가능합니다. BCH 코드는 오류 수정 코드에서 강력한 기술입니다.
모든 양의 정수 m ≥ 3 과 t < 2m-1BCH 바이너리 코드가 있습니다. 다음은 이러한 코드의 매개 변수입니다.
블록 길이 n = 2m-1
패리티 검사 자릿수 n - k ≤ mt
최소 거리 dmin ≥ 2t + 1
이 코드는 다음과 같이 호출 할 수 있습니다. t-error-correcting BCH code.
순환 코드
코드 단어의 순환 속성은 코드 단어의 순환 이동도 코드 단어라는 것입니다. 순환 코드는이 순환 속성을 따릅니다.
선형 코드의 경우 C, 모든 코드 단어 즉, C = (C1, C2, ...... Cn)from C는 구성 요소의 순환 오른쪽 시프트를 가지며 코드 워드가됩니다. 이 오른쪽 이동은 다음과 같습니다.n-1순환 왼쪽 이동. 따라서 어떤 교대에도 변하지 않습니다. 따라서 선형 코드C, 어떤 근무조에서도 변하지 않기 때문에 Cyclic code.
오류 수정에는 순환 코드가 사용됩니다. 주로 이중 오류 및 버스트 오류를 수정하는 데 사용됩니다.
따라서 이들은 수신기에서 감지되는 몇 가지 오류 수정 코드입니다. 이러한 코드는 오류가 발생하는 것을 방지하고 통신을 방해합니다. 또한 원하지 않는 수신기가 신호를 도청하는 것을 방지합니다. 이를 달성하기위한 시그널링 기법이 있으며, 이에 대해서는 다음 장에서 설명합니다.
보안 통신을 제공하기 위해 신호를 전송하기 전에 집합 적 등급의 신호 기술이 사용됩니다. Spread Spectrum Modulation. 확산 스펙트럼 통신 기술의 가장 큰 장점은 의도적이든 의도적이든 "간섭"을 방지하는 것입니다.
이러한 기술로 변조 된 신호는 간섭하기 어렵고 방해 할 수 없습니다. 공식적인 접근 권한이없는 침입자는 절대로 크래킹 할 수 없습니다. 따라서 이러한 기술은 군사 목적으로 사용됩니다. 이러한 확산 스펙트럼 신호는 낮은 전력 밀도로 전송되며 신호의 폭이 넓습니다.
의사 잡음 시퀀스
코딩 된 시퀀스 1s 과 0s 특정 자동 상관 속성을 사용하여 Pseudo-Noise coding sequence확산 스펙트럼 기술에 사용됩니다. 순환 코드의 한 유형 인 최대 길이 시퀀스입니다.
협 대역 및 확산 스펙트럼 신호
협 대역 및 확산 스펙트럼 신호는 다음 그림과 같이 주파수 스펙트럼을 관찰하여 쉽게 이해할 수 있습니다.
협 대역 신호
협 대역 신호는 다음 주파수 스펙트럼 그림과 같이 집중된 신호 강도를 갖습니다.
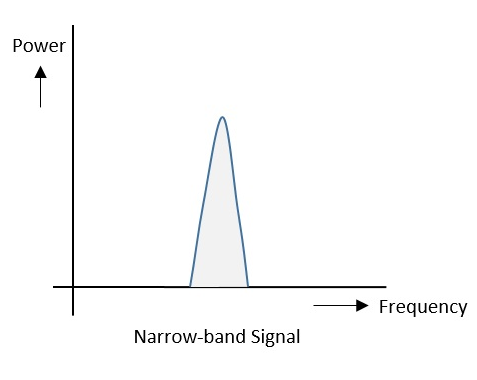
다음은 그 기능 중 일부입니다-
- 신호 대역은 좁은 범위의 주파수를 차지합니다.
- 전력 밀도가 높습니다.
- 에너지의 확산이 적고 집중되어 있습니다.
기능은 좋지만 이러한 신호는 간섭을 받기 쉽습니다.
스펙트럼 신호 확산
확산 스펙트럼 신호에는 다음 주파수 스펙트럼 그림과 같이 분포 된 신호 강도가 있습니다.
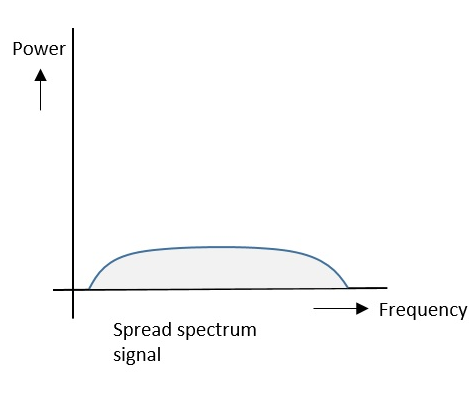
다음은 그 기능 중 일부입니다-
- 신호 대역은 광범위한 주파수를 차지합니다.
- 전력 밀도가 매우 낮습니다.
- 에너지는 널리 퍼져 있습니다.
이러한 기능을 통해 확산 스펙트럼 신호는 간섭 또는 방해 전파에 대한 저항력이 높습니다. 여러 사용자가 서로 간섭하지 않고 동일한 확산 스펙트럼 대역폭을 공유 할 수 있으므로이를 다음과 같이 부를 수 있습니다.multiple access techniques.
FHSS 및 DSSS / CDMA
확산 스펙트럼 다중 액세스 기술은 최소 요구 RF 대역폭보다 큰 전송 대역폭을 갖는 신호를 사용합니다.
두 가지 유형이 있습니다.
- FHSS (Frequency Hopped Spread Spectrum)
- DSSS (Direct Sequence Spread Spectrum)
FHSS (Frequency Hopped Spread Spectrum)
이것은 사용자가 지정된 시간 간격으로 사용 빈도를 서로 변경하도록 만들어지는 주파수 호핑 기술입니다. frequency hopping. 예를 들어, 특정 기간 동안 발신자 1에게 빈도가 할당되었습니다. 이제 잠시 후 보낸 사람 1이 다른 주파수로 이동하고 보낸 사람 2는 이전에 보낸 사람 1이 사용했던 첫 번째 주파수를 사용합니다.frequency reuse.
데이터의 주파수는 안전한 전송을 제공하기 위해 서로 호핑됩니다. 각 주파수 홉에 소요 된 시간은 다음과 같습니다.Dwell time.
DSSS (Direct Sequence Spread Spectrum)
사용자가이 DSSS 기술을 사용하여 데이터를 보내려고 할 때마다 사용자 데이터의 모든 비트에 다음과 같은 비밀 코드가 곱해집니다. chipping code. 이 칩핑 코드는 원본 메시지와 곱 해져 전송되는 확산 코드 일뿐입니다. 수신자는 동일한 코드를 사용하여 원본 메시지를 검색합니다.
FHSS와 DSSS / CDMA의 비교
두 확산 스펙트럼 기술은 그 특성으로 인해 인기가 있습니다. 명확하게 이해하기 위해 비교를 살펴 보겠습니다.
| FHSS | DSSS / CDMA |
|---|---|
| 여러 주파수가 사용됩니다. | 단일 주파수가 사용됩니다. |
| 어떤 순간에도 사용자의 빈도를 찾기가 어렵습니다. | 할당 된 사용자 빈도는 항상 동일합니다. |
| 빈도 재사용이 허용됩니다. | 빈도 재사용은 허용되지 않습니다. |
| 발신자는 기다릴 필요가 없습니다. | 발신자는 스펙트럼이 사용 중이면 기다려야합니다. |
| 신호의 전력 강도가 높습니다. | 신호의 전력 강도가 낮습니다. |
| 더 강하고 장애물을 관통합니다. | FHSS에 비해 약함 |
| 간섭의 영향을받지 않습니다. | 간섭의 영향을받을 수 있습니다. |
| 이것이 더 싸다 | 비쌉니다 |
| 이것은 일반적으로 사용되는 기술입니다 | 이 기술은 자주 사용되지 않습니다. |
확산 스펙트럼의 장점
다음은 스펙트럼 확산의 장점입니다.
- 누화 제거
- 데이터 무결성으로 더 나은 출력
- 다중 경로 페이딩 효과 감소
- 더 나은 보안
- 소음 감소
- 다른 시스템과 공존
- 더 긴 작동 거리
- 감지하기 어려움
- 복조 / 디코딩이 쉽지 않음
- 신호를 방해하기 어려움
확산 스펙트럼 기술은 원래 군사용으로 설계되었지만 이제는 상업적 목적으로 널리 사용되고 있습니다.