Grafika komputerowa - szybki przewodnik
Grafika komputerowa to sztuka rysowania obrazów na ekranach komputerów za pomocą programowania. Obejmuje obliczenia, tworzenie i manipulowanie danymi. Innymi słowy, możemy powiedzieć, że grafika komputerowa jest narzędziem renderującym do generowania i manipulowania obrazami.
Kineskop
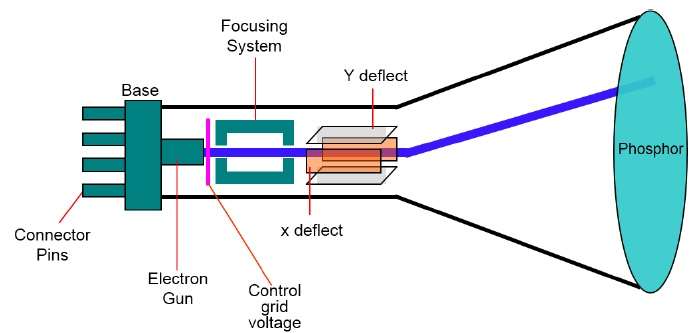
Podstawowym urządzeniem wyjściowym w systemie graficznym jest monitor wideo. Głównym elementem monitora wideo jestCathode Ray Tube (CRT), pokazano na poniższej ilustracji.
Obsługa CRT jest bardzo prosta -
Działo elektronowe emituje wiązkę elektronów (promienie katodowe).
Wiązka elektronów przechodzi przez układy ogniskowania i odchylania, które kierują ją w określone pozycje na ekranie pokrytym luminoforem.
Kiedy wiązka uderza w ekran, luminofor emituje małą plamkę światła w każdym położeniu, z którym styka się wiązka elektronów.
Odświeża obraz, kierując wiązkę elektronów z powrotem na te same punkty ekranu.
Istnieją dwa sposoby (skanowanie losowe i skanowanie rastrowe), za pomocą których możemy wyświetlić obiekt na ekranie.
Skanowanie rastrowe
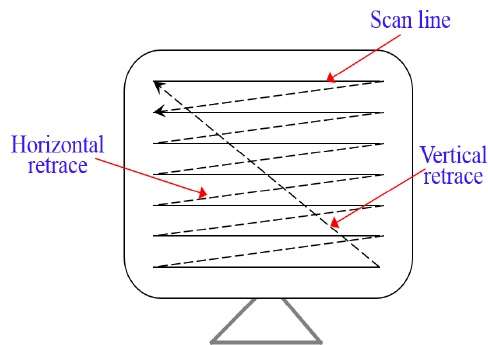
W systemie skanowania rastrowego wiązka elektronów jest przesuwana po ekranie, po jednym rzędzie od góry do dołu. Gdy wiązka elektronów porusza się w każdym rzędzie, intensywność wiązki jest włączana i wyłączana, aby utworzyć wzór oświetlonych punktów.
Definicja obrazu jest przechowywana w obszarze pamięci o nazwie Refresh Buffer lub Frame Buffer. Ten obszar pamięci zawiera zestaw wartości intensywności dla wszystkich punktów ekranu. Przechowywane wartości intensywności są następnie pobierane z bufora odświeżania i „malowane” na ekranie po jednym wierszu (linii skanowania), jak pokazano na poniższej ilustracji.
Każdy punkt ekranu jest określany jako plik pixel (picture element) lub pel. Pod koniec każdej linii skanowania wiązka elektronów powraca do lewej strony ekranu, aby rozpocząć wyświetlanie następnej linii skanowania.
Skanowanie losowe (skanowanie wektorowe)
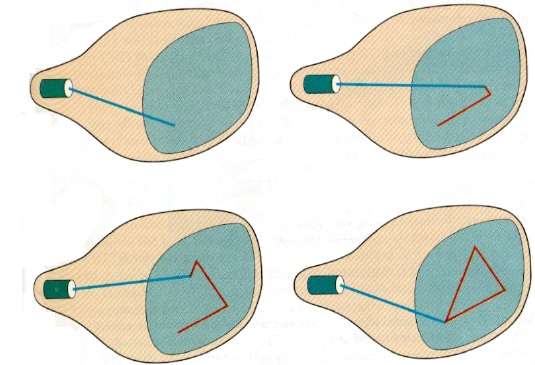
W tej technice wiązka elektronów jest kierowana tylko do części ekranu, w której ma zostać narysowany obraz, zamiast skanowania od lewej do prawej i od góry do dołu, jak w przypadku skanowania rastrowego. Nazywa się to równieżvector display, stroke-writing display, lub calligraphic display.
Definicja obrazu jest przechowywana jako zestaw poleceń rysowania linii w obszarze pamięci zwanym refresh display file. Aby wyświetlić określony obraz, system przechodzi przez zestaw poleceń w pliku wyświetlania, rysując po kolei każdą linię komponentu. Po przetworzeniu wszystkich poleceń rysowania linii system przechodzi z powrotem do pierwszego polecenia wiersza na liście.
Wyświetlacze ze skanowaniem losowym są przeznaczone do rysowania wszystkich linii składowych obrazu od 30 do 60 razy na sekundę.
Zastosowanie grafiki komputerowej
Grafika komputerowa ma wiele aplikacji, z których niektóre są wymienione poniżej -
Computer graphics user interfaces (GUIs) - Graficzny paradygmat zorientowany na mysz, który umożliwia użytkownikowi interakcję z komputerem.
Business presentation graphics - „Jeden obraz jest wart tysiąca słów”.
Cartography - Mapy rysunkowe.
Weather Maps - Mapowanie w czasie rzeczywistym, reprezentacje symboliczne.
Satellite Imaging - Obrazy geodezyjne.
Photo Enhancement - Wyostrzanie niewyraźnych zdjęć.
Medical imaging - MRI, tomografia komputerowa itp. - Nieinwazyjne badanie wewnętrzne.
Engineering drawings - mechaniczne, elektryczne, cywilne itp. - Zastępowanie planów z przeszłości.
Typography - Wykorzystanie wizerunków postaci w publikacjach - zastąpienie twardego typu przeszłości.
Architecture - Plany konstrukcyjne, szkice zewnętrzne - zastępujące plany i rysunki ręczne z przeszłości.
Art - Komputery zapewniają artystom nowe medium.
Training - Symulatory lotu, instrukcje wspomagane komputerowo itp.
Entertainment - Filmy i gry.
Simulation and modeling - Zastępowanie modeli fizycznych i aktów prawnych
Linia łączy dwa punkty. To podstawowy element grafiki. Aby narysować linię, potrzebujesz dwóch punktów, między którymi możesz narysować linię. W poniższych trzech algorytmach jeden punkt prostej nazywamy$X_{0}, Y_{0}$ a drugi punkt linii jako $X_{1}, Y_{1}$.
Algorytm DDA
Algorytm Digital Differential Analyzer (DDA) to prosty algorytm generowania linii, który jest tutaj wyjaśniony krok po kroku.
Step 1 - Uzyskaj dane wejściowe z dwóch punktów końcowych $(X_{0}, Y_{0})$ i $(X_{1}, Y_{1})$.
Step 2 - Oblicz różnicę między dwoma punktami końcowymi.
dx = X1 - X0
dy = Y1 - Y0Step 3- Na podstawie obliczonej różnicy w kroku 2, musisz określić liczbę kroków do umieszczenia piksela. Jeśli dx> dy, potrzebujesz więcej kroków we współrzędnej x; w przeciwnym razie we współrzędnej y.
if (absolute(dx) > absolute(dy))
Steps = absolute(dx);
else
Steps = absolute(dy);Step 4 - Obliczyć przyrost we współrzędnej x i współrzędnej y.
Xincrement = dx / (float) steps;
Yincrement = dy / (float) steps;Step 5 - Umieść piksel, odpowiednio zwiększając współrzędne xiy, i zakończ rysowanie linii.
for(int v=0; v < Steps; v++)
{
x = x + Xincrement;
y = y + Yincrement;
putpixel(Round(x), Round(y));
}Bresenham's Line Generation
Algorytm Bresenham to kolejny algorytm konwersji przyrostowej skanowania. Dużą zaletą tego algorytmu jest to, że używa on tylko obliczeń całkowitych. Poruszając się po osi X w jednostkowych odstępach i na każdym kroku wybieraj jedną z dwóch różnych współrzędnych y.
Na przykład, jak pokazano na poniższej ilustracji, z pozycji (2, 3) należy wybrać pomiędzy (3, 3) a (3, 4). Chciałbyś, aby punkt był bliżej oryginalnej linii.
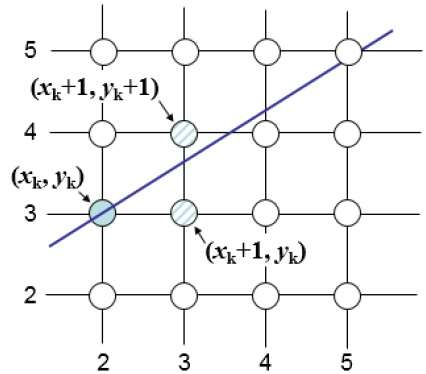
W pozycji próbki $X_{k}+1,$ pionowe separacje od linii matematycznej są oznaczone jako $d_{upper}$ i $d_{lower}$.
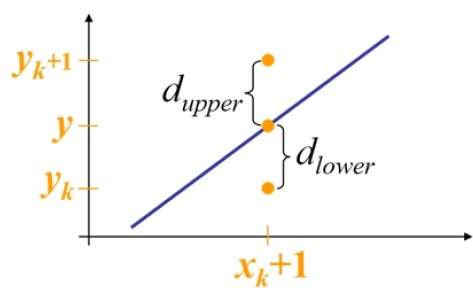
Na powyższej ilustracji współrzędna y na linii matematycznej w $x_{k}+1$ jest -
Y = m ($X_{k}$+1) + b
Więc, $d_{upper}$ i $d_{lower}$ podano w następujący sposób -
$$d_{lower} = y-y_{k}$$
$$= m(X_{k} + 1) + b - Y_{k}$$
i
$$d_{upper} = (y_{k} + 1) - y$$
$= Y_{k} + 1 - m (X_{k} + 1) - b$
Możesz ich użyć, aby podjąć prostą decyzję o tym, który piksel znajduje się bliżej linii matematycznej. Ta prosta decyzja opiera się na różnicy między dwoma położeniami pikseli.
$$d_{lower} - d_{upper} = 2m(x_{k} + 1) - 2y_{k} + 2b - 1$$
Podstawmy m przez dy / dx, gdzie dx i dy to różnice między punktami końcowymi.
$$dx (d_{lower} - d_{upper}) =dx(2\frac{\mathrm{d} y}{\mathrm{d} x}(x_{k} + 1) - 2y_{k} + 2b - 1)$$
$$ = 2dy.x_{k} - 2dx.y_{k} + 2dy + 2dx(2b-1)$$
$$ = 2dy.x_{k} - 2dx.y_{k} + C$$
A więc parametr decyzyjny $P_{k}$ponieważ k- ty krok wzdłuż prostej jest określony wzorem -
$$p_{k} = dx(d_{lower} - d_{upper})$$
$$ = 2dy.x_{k} - 2dx.y_{k} + C$$
Znak parametru decyzji $P_{k}$ jest taki sam jak w przypadku $d_{lower} - d_{upper}$.
Gdyby $p_{k}$ jest ujemna, wybierz dolny piksel, w przeciwnym razie wybierz górny piksel.
Pamiętaj, że zmiany współrzędnych następują wzdłuż osi x w krokach jednostkowych, więc możesz zrobić wszystko z obliczeniami całkowitymi. W kroku k + 1 parametr decyzyjny jest podawany jako -
$$p_{k +1} = 2dy.x_{k + 1} - 2dx.y_{k + 1} + C$$
Odejmowanie $p_{k}$ z tego otrzymujemy -
$$p_{k + 1} - p_{k} = 2dy(x_{k + 1} - x_{k}) - 2dx(y_{k + 1} - y_{k})$$
Ale, $x_{k+1}$ jest taki sam jak $x_{k+1}$. Więc -
$$p_{k+1} = p_{k} + 2dy - 2dx(y_{k+1} - y_{k})$$
Gdzie, $Y_{k+1} – Y_{k}$ wynosi 0 lub 1 w zależności od znaku $P_{k}$.
Pierwszy parametr decyzyjny $p_{0}$ jest oceniany na $(x_{0}, y_{0})$ jest podane jako -
$$p_{0} = 2dy - dx$$
Mając na uwadze wszystkie powyższe punkty i obliczenia, oto algorytm Bresenham dla nachylenia m <1 -
Step 1 - Wprowadź dwa punkty końcowe linii, zapisując lewy punkt końcowy w $(x_{0}, y_{0})$.
Step 2 - Sprecyzuj punkt $(x_{0}, y_{0})$.
Step 3 - Oblicz stałe dx, dy, 2dy i (2dy - 2dx) i uzyskaj pierwszą wartość parametru decyzyjnego jako -
$$p_{0} = 2dy - dx$$
Step 4 - Na każdym $X_{k}$ wzdłuż linii, zaczynając od k = 0, wykonaj następujący test -
Gdyby $p_{k}$ <0, następny punkt do wykreślenia to $(x_{k}+1, y_{k})$ i
$$p_{k+1} = p_{k} + 2dy$$ Inaczej,
$$(x_{k}, y_{k}+1)$$
$$p_{k+1} = p_{k} + 2dy - 2dx$$
Step 5 - Powtórz krok 4 (dx - 1) razy.
Dla m> 1, dowiedz się, czy musisz zwiększać x, zwiększając jednocześnie y za każdym razem.
Po rozwiązaniu równanie na parametr decyzyjny $P_{k}$ będzie bardzo podobny, tylko x i y w równaniu zostaną zamienione.
Algorytm punktu środkowego
Algorytm punktu środkowego zawdzięczamy Bresenhamowi, który został zmodyfikowany przez Pittewaya i Van Akena. Załóżmy, że punkt P został już umieszczony we współrzędnej (x, y), a nachylenie prostej wynosi 0 ≤ k ≤ 1, jak pokazano na poniższej ilustracji.
Teraz musisz zdecydować, czy umieścić następny punkt na E lub N. Można to wybrać, identyfikując punkt przecięcia Q najbliższy punktowi N lub E. Jeśli punkt przecięcia Q jest najbliżej punktu N, wówczas N jest uważane za następny punkt; inaczej E.
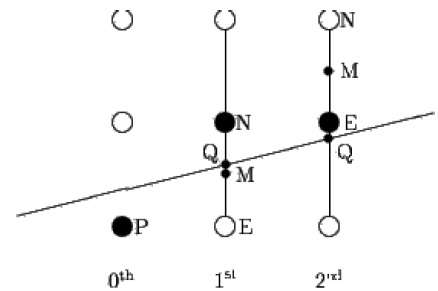
Aby to ustalić, najpierw oblicz punkt środkowy M (x + 1, y + ½). Jeśli punkt przecięcia Q prostej z pionową linią łączącą E i N znajduje się poniżej M, to E jako następny punkt; w przeciwnym razie weź N jako następny punkt.
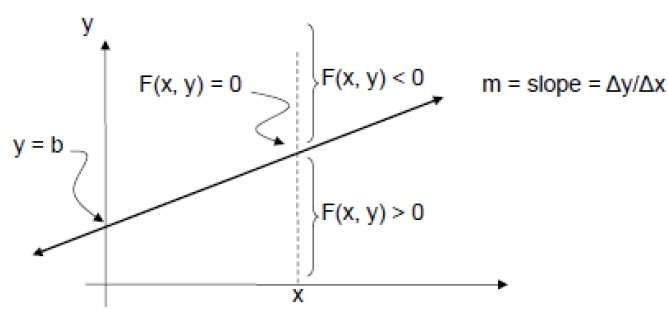
Aby to sprawdzić, musimy wziąć pod uwagę niejawne równanie -
F (x, y) = mx + b - y
Dla dodatniego m w dowolnym podanym X,
- Jeśli y jest na linii, to F (x, y) = 0
- Jeśli y jest powyżej linii, to F (x, y) <0
- Jeśli y jest poniżej linii, to F (x, y)> 0
Rysowanie okręgu na ekranie jest trochę skomplikowane niż rysowanie linii. Istnieją dwa popularne algorytmy generowania okręgu -Bresenham’s Algorithm i Midpoint Circle Algorithm. Algorytmy te opierają się na idei wyznaczania kolejnych punktów potrzebnych do narysowania okręgu. Omówmy szczegółowo algorytmy -
Równanie koła to $X^{2} + Y^{2} = r^{2},$ gdzie r jest promieniem.
Algorytm Bresenham
Nie możemy wyświetlić ciągłego łuku na ekranie rastrowym. Zamiast tego musimy wybrać najbliższą pozycję piksela, aby zakończyć łuk.
Na poniższej ilustracji widać, że umieściliśmy piksel w miejscu (X, Y) i teraz musimy zdecydować, gdzie umieścić następny piksel - w N (X + 1, Y) lub w S (X + 1, Y-1).
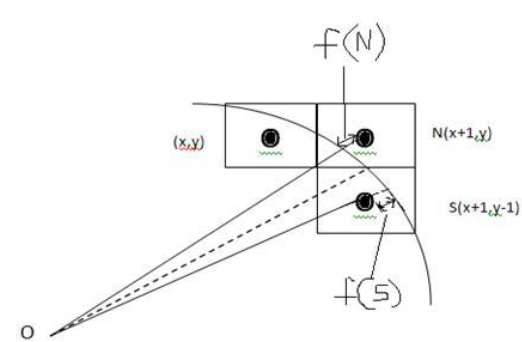
Decyduje o tym parametr decyzyjny d.
- Jeśli d <= 0, to N (X + 1, Y) należy wybrać jako następny piksel.
- Jeśli d> 0, to S (X + 1, Y-1) ma być wybrany jako następny piksel.
Algorytm
Step 1- Uzyskaj współrzędne środka okręgu i promienia i zapisz je odpowiednio w x, y i R. Ustaw P = 0 i Q = R.
Step 2 - Ustaw parametr decyzyjny D = 3 - 2R.
Step 3 - Powtórz krok 8, gdy P ≤ Q.
Step 4 - Call Draw Circle (X, Y, P, Q).
Step 5 - Zwiększ wartość P.
Step 6 - Jeśli D <0, to D = D + 4P + 6.
Step 7 - W przeciwnym razie ustaw R = R - 1, D = D + 4 (PQ) + 10.
Step 8 - Call Draw Circle (X, Y, P, Q).
Draw Circle Method(X, Y, P, Q).
Call Putpixel (X + P, Y + Q).
Call Putpixel (X - P, Y + Q).
Call Putpixel (X + P, Y - Q).
Call Putpixel (X - P, Y - Q).
Call Putpixel (X + Q, Y + P).
Call Putpixel (X - Q, Y + P).
Call Putpixel (X + Q, Y - P).
Call Putpixel (X - Q, Y - P).Algorytm punktu środkowego
Step 1 - Promień wejściowy r i środek koła $(x_{c,} y_{c})$ i uzyskaj pierwszy punkt na obwodzie koła ze środkiem na początku jako
(x0, y0) = (0, r)Step 2 - Obliczyć początkową wartość parametru decyzyjnego jako
$P_{0}$ = 5/4 - r (Zobacz poniższy opis w celu uproszczenia tego równania.)
f(x, y) = x2 + y2 - r2 = 0
f(xi - 1/2 + e, yi + 1)
= (xi - 1/2 + e)2 + (yi + 1)2 - r2
= (xi- 1/2)2 + (yi + 1)2 - r2 + 2(xi - 1/2)e + e2
= f(xi - 1/2, yi + 1) + 2(xi - 1/2)e + e2 = 0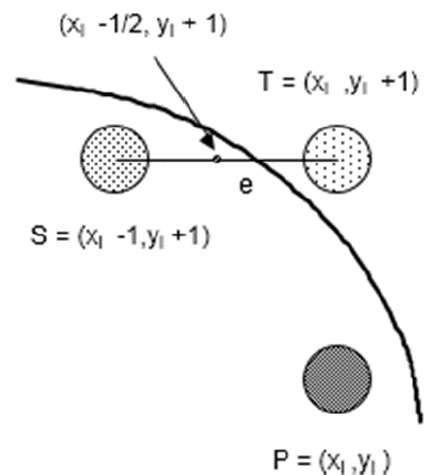
Let di = f(xi - 1/2, yi + 1) = -2(xi - 1/2)e - e2
Thus,
If e < 0 then di > 0 so choose point S = (xi - 1, yi + 1).
di+1 = f(xi - 1 - 1/2, yi + 1 + 1) = ((xi - 1/2) - 1)2 + ((yi + 1) + 1)2 - r2
= di - 2(xi - 1) + 2(yi + 1) + 1
= di + 2(yi + 1 - xi + 1) + 1
If e >= 0 then di <= 0 so choose point T = (xi, yi + 1)
di+1 = f(xi - 1/2, yi + 1 + 1)
= di + 2yi+1 + 1
The initial value of di is
d0 = f(r - 1/2, 0 + 1) = (r - 1/2)2 + 12 - r2
= 5/4 - r {1-r can be used if r is an integer}
When point S = (xi - 1, yi + 1) is chosen then
di+1 = di + -2xi+1 + 2yi+1 + 1
When point T = (xi, yi + 1) is chosen then
di+1 = di + 2yi+1 + 1Step 3 - Na każdym $X_{K}$ zaczynając od K = 0, wykonaj następujący test -
If PK < 0 then next point on circle (0,0) is (XK+1,YK) and
PK+1 = PK + 2XK+1 + 1
Else
PK+1 = PK + 2XK+1 + 1 – 2YK+1
Where, 2XK+1 = 2XK+2 and 2YK+1 = 2YK-2.Step 4 - Określ punkty symetrii w pozostałych siedmiu oktantach.
Step 5 - Przesuń każdą obliczoną pozycję piksela (X, Y) na ścieżkę kołową wyśrodkowaną na $(X_{C,} Y_{C})$ i wykreśl wartości współrzędnych.
X = X + XC, Y = Y + YCStep 6 - Powtórz kroki od 3 do 5, aż X> = Y.
Wielokąt to uporządkowana lista wierzchołków, jak pokazano na poniższym rysunku. Aby wypełnić wielokąty określonymi kolorami, musisz określić piksele mieszczące się na granicy wielokąta i te, które mieszczą się wewnątrz wielokąta. W tym rozdziale zobaczymy, jak wypełnić wielokąty różnymi technikami.

Algorytm skanowania linii
Ten algorytm działa poprzez przecięcie linii skanowania z krawędziami wielokątów i wypełnienie wielokąta między parami przecięć. Poniższe kroki przedstawiają sposób działania tego algorytmu.
Step 1 - Znajdź Ymin i Ymax z podanego wielokąta.
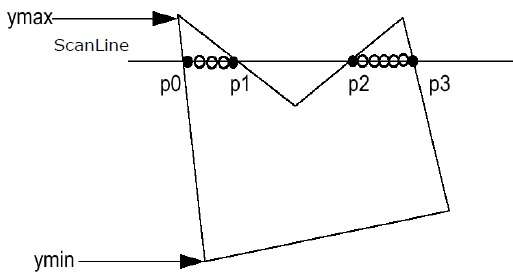
Step 2- ScanLine przecina się z każdą krawędzią wielokąta od Ymin do Ymax. Nazwij każdy punkt przecięcia wielokąta. Zgodnie z powyższym rysunkiem są one nazwane p0, p1, p2, p3.
Step 3 - Uporządkuj punkt przecięcia w kolejności rosnącej współrzędnej X, tj. (P0, p1), (p1, p2) i (p2, p3).
Step 4 - Wypełnij wszystkie te pary współrzędnych, które są wewnątrz wielokątów i zignoruj alternatywne pary.
Algorytm wypełniania powodziowego
Czasami spotykamy obiekt, w którym chcemy wypełnić obszar i jego granicę różnymi kolorami. Możemy pomalować takie obiekty na określony kolor wnętrza, zamiast szukać konkretnego koloru granicy, jak w algorytmie wypełniania granic.
Zamiast polegać na granicy obiektu, opiera się na kolorze wypełnienia. Innymi słowy, zastępuje kolor wnętrza obiektu kolorem wypełnienia. Gdy nie ma już pikseli w oryginalnym kolorze wnętrza, algorytm jest zakończony.
Po raz kolejny algorytm ten opiera się na metodzie czterech połączeń lub ośmiu połączeń wypełniania pikseli. Ale zamiast szukać koloru granicznego, szuka wszystkich sąsiednich pikseli, które są częścią wnętrza.
Algorytm wypełnienia granicy
Algorytm wypełniania granic działa jak jego nazwa. Ten algorytm wybiera punkt wewnątrz obiektu i zaczyna się wypełniać, aż dotrze do granicy obiektu. Aby algorytm zadziałał, kolor granicy i kolor, który wypełniamy, powinny być inne.
W tym algorytmie zakładamy, że kolor granicy jest taki sam dla całego obiektu. Algorytm wypełniania granic można zaimplementować za pomocą 4 połączonych pikseli lub 8 połączonych pikseli.
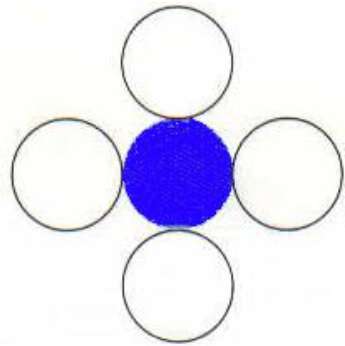
4-połączony wielokąt
W tej technice używa się 4 połączonych pikseli, jak pokazano na rysunku. Umieszczamy piksele powyżej, poniżej, po prawej i po lewej stronie bieżących pikseli i ten proces będzie kontynuowany, dopóki nie znajdziemy granicy o innym kolorze.
Algorytm
Step 1 - Zainicjuj wartość punktu początkowego (seedx, seedy), fcolor i dcol.
Step 2 - Zdefiniuj wartości graniczne wielokąta.
Step 3 - Sprawdź, czy bieżący punkt początkowy ma domyślny kolor, a następnie powtórz kroki 4 i 5, aż osiągną piksele graniczne.
If getpixel(x, y) = dcol then repeat step 4 and 5Step 4 - Zmień domyślny kolor na kolor wypełnienia w punkcie początkowym.
setPixel(seedx, seedy, fcol)Step 5 - Rekurencyjnie postępuj zgodnie z procedurą z czterema punktami sąsiedztwa.
FloodFill (seedx – 1, seedy, fcol, dcol)
FloodFill (seedx + 1, seedy, fcol, dcol)
FloodFill (seedx, seedy - 1, fcol, dcol)
FloodFill (seedx – 1, seedy + 1, fcol, dcol)Step 6 - Wyjdź
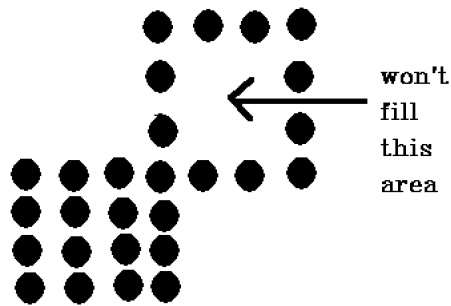
Jest problem z tą techniką. Rozważmy przypadek pokazany poniżej, w którym próbowaliśmy wypełnić cały region. Tutaj obraz jest wypełniony tylko częściowo. W takich przypadkach nie można użyć techniki 4 połączonych pikseli.
8-połączony wielokąt
W tej technice używa się 8 połączonych pikseli, jak pokazano na rysunku. Umieszczamy piksele powyżej, poniżej, prawej i lewej strony obecnych pikseli, tak jak robiliśmy to w technice 4-połączonej.
Oprócz tego umieszczamy piksele na przekątnych, aby pokryć cały obszar bieżącego piksela. Ten proces będzie trwał, dopóki nie znajdziemy granicy o innym kolorze.

Algorytm
Step 1 - Zainicjuj wartość punktu początkowego (seedx, seedy), fcolor i dcol.
Step 2 - Zdefiniuj wartości graniczne wielokąta.
Step 3 - Sprawdź, czy bieżący punkt początkowy ma domyślny kolor, a następnie powtórz kroki 4 i 5, aż do osiągnięcia pikseli granicznych
If getpixel(x,y) = dcol then repeat step 4 and 5Step 4 - Zmień domyślny kolor na kolor wypełnienia w punkcie początkowym.
setPixel(seedx, seedy, fcol)Step 5 - Rekurencyjnie postępuj zgodnie z procedurą z czterema punktami sąsiedztwa
FloodFill (seedx – 1, seedy, fcol, dcol)
FloodFill (seedx + 1, seedy, fcol, dcol)
FloodFill (seedx, seedy - 1, fcol, dcol)
FloodFill (seedx, seedy + 1, fcol, dcol)
FloodFill (seedx – 1, seedy + 1, fcol, dcol)
FloodFill (seedx + 1, seedy + 1, fcol, dcol)
FloodFill (seedx + 1, seedy - 1, fcol, dcol)
FloodFill (seedx – 1, seedy - 1, fcol, dcol)Step 6 - Wyjdź
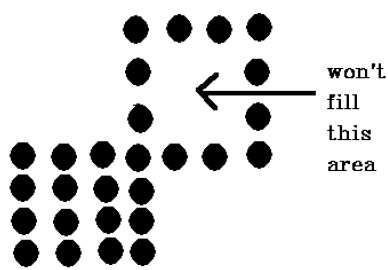
Technika 4 połączonych pikseli nie wypełniła obszaru, jak zaznaczono na poniższym rysunku, co nie nastąpi w przypadku techniki 8 połączonych.
Test wewnątrz-na zewnątrz
Ta metoda jest również znana jako counting number method. Podczas wypełniania obiektu często musimy określić, czy dany punkt znajduje się wewnątrz obiektu, czy na zewnątrz. Istnieją dwie metody, za pomocą których możemy określić, czy dany punkt znajduje się wewnątrz obiektu, czy na zewnątrz.
- Zasada nieparzysta-parzysta
- Niezerowa reguła liczby uzwojeń
Zasada nieparzysta-parzysta
W tej technice liczymy przejście krawędzi wzdłuż linii od dowolnego punktu (x, y) do nieskończoności. Jeśli liczba interakcji jest nieparzysta, to punkt (x, y) jest punktem wewnętrznym. Jeśli liczba interakcji jest parzysta, to punkt (x, y) jest punktem zewnętrznym. Oto przykład, który daje jasny pomysł -
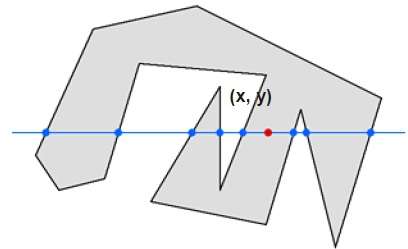
Z powyższego rysunku widzimy, że z punktu (x, y) liczba punktów interakcji po lewej stronie wynosi 5, a po prawej stronie 3. Zatem całkowita liczba punktów interakcji wynosi 8, co jest nieparzyste . W związku z tym punkt jest rozpatrywany w obiekcie.
Niezerowa reguła liczby uzwojeń
Ta metoda jest również używana w przypadku prostych wielokątów, aby sprawdzić, czy dany punkt jest wewnętrzny, czy nie. Można to po prostu zrozumieć za pomocą szpilki i gumki. Zamocuj szpilkę na jednej z krawędzi wielokąta i zawiąż w nim gumkę, a następnie rozciągnij gumkę wzdłuż krawędzi wielokąta.
Kiedy wszystkie krawędzie wielokąta są zakryte gumką, sprawdź szpilkę, która została zamocowana w punkcie, który ma być testowany. Jeśli znajdziemy przynajmniej jeden wiatr w tym punkcie, rozważmy go wewnątrz wielokąta, w przeciwnym razie możemy powiedzieć, że punkt nie znajduje się wewnątrz wielokąta.
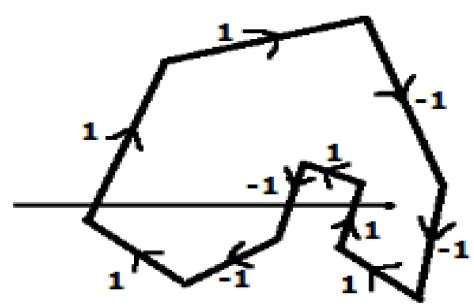
W innej alternatywnej metodzie podaj wskazówki dla wszystkich krawędzi wielokąta. Narysuj linię skanowania od badanego punktu w skrajną lewą stronę kierunku X.
Podaj wartość 1 wszystkim krawędziom, które idą w górę, a wszystkim innym -1 jako wartości kierunku.
Sprawdź wartości kierunku krawędzi, od których przechodzi linia skanowania i zsumuj je.
Jeśli całkowita suma wartości tego kierunku jest różna od zera, to testowany punkt jest interior point, w przeciwnym razie jest to plik exterior point.
Na powyższym rysunku sumujemy wartości kierunku, z którego przechodzi linia skanowania, a następnie suma wynosi 1 - 1 + 1 = 1; która jest różna od zera. Mówi się więc, że punkt jest punktem wewnętrznym.
Podstawowym zastosowaniem obcinania w grafice komputerowej jest usuwanie obiektów, linii lub segmentów linii, które znajdują się poza okienkiem wyświetlania. Transformacja widoku jest niewrażliwa na położenie punktów w stosunku do wielkości widoku - szczególnie tych punktów za widzem - i konieczne jest usunięcie tych punktów przed wygenerowaniem widoku.
Przycinanie punktu
Wycięcie punktu z danego okna jest bardzo proste. Rozważ poniższy rysunek, na którym prostokąt wskazuje okno. Obcinanie punktów mówi nam, czy dany punkt (X, Y) znajduje się w podanym oknie, czy nie; i decyduje, czy użyjemy minimalnych i maksymalnych współrzędnych okna.
Współrzędna X danego punktu znajduje się wewnątrz okna, jeśli X leży pomiędzy Wx1 ≤ X ≤ Wx2. W ten sam sposób współrzędna Y danego punktu znajduje się wewnątrz okna, jeśli Y leży pomiędzy Wy1 ≤ Y ≤ Wy2.

Przycinanie linii
Koncepcja obcinania linii jest taka sama jak ucinania punktów. Podczas obcinania linii wycinamy część linii znajdującą się poza oknem i zachowujemy tylko tę część, która znajduje się wewnątrz okna.
Wycinki z linii Cohena-Sutherlanda
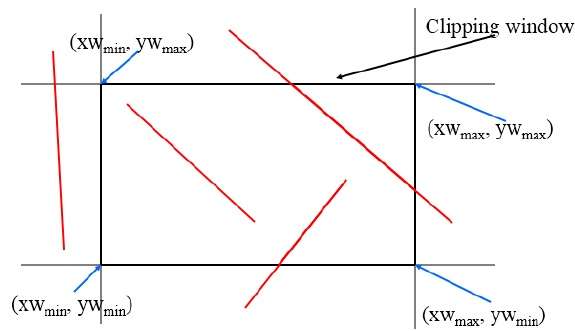
Ten algorytm wykorzystuje okno obcinania, jak pokazano na poniższym rysunku. Minimalna współrzędna regionu przycinania to$(XW_{min,} YW_{min})$ a maksymalna współrzędna regionu przycinania to $(XW_{max,} YW_{max})$.
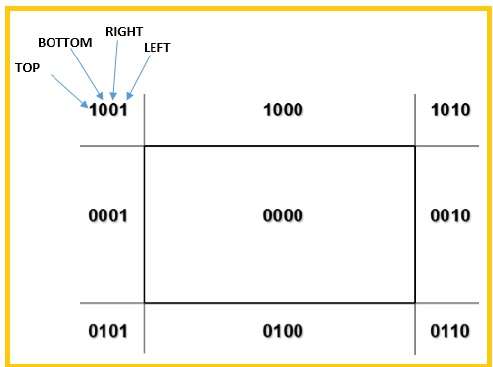
Do podzielenia całego regionu użyjemy 4-bitów. Te 4 bity reprezentują górną, dolną, prawą i lewą część regionu, jak pokazano na poniższym rysunku. TutajTOP i LEFT bit jest ustawiony na 1, ponieważ jest to plik TOP-LEFT kąt.
Istnieją 3 możliwości linii -
Linia może znajdować się w całości wewnątrz okna (tę linię należy zaakceptować).
Linia może być całkowicie poza oknem (ta linia zostanie całkowicie usunięta z regionu).
Linia może znajdować się częściowo wewnątrz okna (znajdziemy punkt przecięcia i narysujemy tylko tę część linii, która jest wewnątrz obszaru).
Algorytm
Step 1 - Przypisz kod regionu dla każdego punktu końcowego.
Step 2 - Jeśli oba punkty końcowe mają kod regionu 0000 następnie zaakceptuj tę linię.
Step 3 - W przeciwnym razie wykonaj czynności logiczne ANDdziałanie dla obu kodów regionu.
Step 3.1 - Jeśli wynik nie jest 0000, następnie odrzuć tę linię.
Step 3.2 - W przeciwnym razie potrzebujesz obcinania.
Step 3.2.1 - Wybierz punkt końcowy linii znajdujący się poza oknem.
Step 3.2.2 - Znajdź punkt przecięcia na granicy okna (na podstawie kodu regionu).
Step 3.2.3 - Zastąp punkt końcowy punktem przecięcia i zaktualizuj kod regionu.
Step 3.2.4 - Powtarzaj krok 2, aż znajdziemy przyciętą linię albo trywialnie zaakceptowaną, albo trywialnie odrzuconą.
Step 4 - Powtórz krok 1 dla innych linii.
Algorytm obcinania linii Cyrusa-Becka
Ten algorytm jest bardziej wydajny niż algorytm Cohena-Sutherlanda. Wykorzystuje parametryczne odwzorowanie linii i proste iloczyny skalarne.
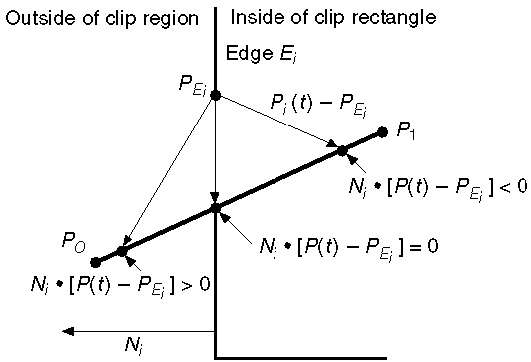
Równanie parametryczne linii to -
P0P1:P(t) = P0 + t(P1-P0)Niech N i będzie zewnętrzną normalną krawędzią E i . Teraz wybierz dowolny punkt P Ei na krawędzi E i, a następnie iloczyn skalarny N i ∙ [P (t) - P Ei ] określa, czy punkt P (t) znajduje się „wewnątrz krawędzi klipu”, czy „na zewnątrz” krawędzi klipu lub „Na” krawędzi klipu.
Punkt P (t) znajduje się wewnątrz, jeśli N i . [P (t) - P Ei ] <0
Punkt P (t) jest na zewnątrz, jeśli N i . [P (t) - P Ei ]> 0
Punkt P (t) znajduje się na krawędzi, jeśli N i . [P (t) - P Ei ] = 0 (punkt przecięcia)
N i . [P (t) - P Ei ] = 0
N i . [P 0 + t (P 1 -P 0 ) - P Ei ] = 0 (Zastąpienie P (t) P 0 + t (P 1 -P 0 ))
N i . [P 0 - P Ei ] + N i. T [P 1- P 0 ] = 0
N i . [P 0 - P Ei ] + N i ∙ tD = 0 (podstawiając D zamiast [P 1 -P 0 ])
N i . [P 0 - P Ei ] = - N i ∙ tD
Równanie t staje się,
$$t = \tfrac{N_{i}.[P_{o} - P_{Ei}]}{{- N_{i}.D}}$$
Dotyczy następujących warunków -
- N i ≠ 0 (błąd nie może się zdarzyć)
- D ≠ 0 (P 1 ≠ P 0 )
- N i ∙ D ≠ 0 (P 0 P 1 nie równolegle do E i )
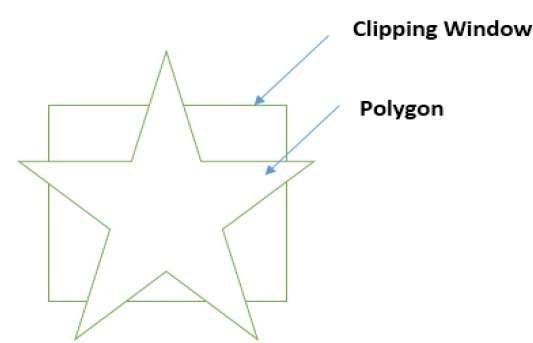
Przycinanie wielokątów (algorytm Sutherlanda Hodgmana)
Wielokąt można również przyciąć, określając okno przycinania. Algorytm obcinania wielokątów Sutherlanda Hodgemana jest używany do przycinania wielokątów. W tym algorytmie wszystkie wierzchołki wielokąta są przycinane do każdej krawędzi okna przycinania.
Najpierw wielokąt jest przycinany do lewej krawędzi okna wielokąta, aby uzyskać nowe wierzchołki wielokąta. Te nowe wierzchołki są używane do przycinania wielokąta do prawej krawędzi, górnej i dolnej krawędzi okna przycinania, jak pokazano na poniższym rysunku.
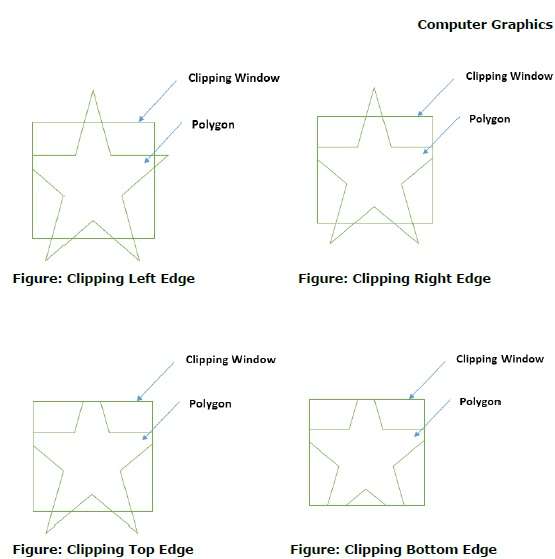
Podczas przetwarzania krawędzi wielokąta z oknem przycinającym, punkt przecięcia zostanie znaleziony, jeśli krawędź nie znajduje się całkowicie wewnątrz okna przycinania, a część krawędzi od punktu przecięcia do krawędzi zewnętrznej zostanie przycięta. Poniższe rysunki przedstawiają ścinki z lewej, prawej, górnej i dolnej krawędzi -
Przycinanie tekstu
Do przycinania tekstu w grafice komputerowej stosowane są różne techniki. Zależy to od metod używanych do generowania znaków i wymagań konkretnej aplikacji. Istnieją trzy metody przycinania tekstu, które są wymienione poniżej -
- Przycinanie wszystkich lub żadnych strun
- Wycinanie wszystkich lub żadnych znaków
- Przycinanie tekstu
Poniższy rysunek przedstawia przycinanie wszystkich sznurków lub ich brak -
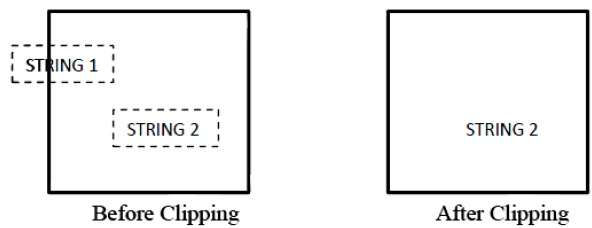
W metodzie obcinania ciągów all lub none, albo zachowujemy cały ciąg, albo odrzucamy cały ciąg na podstawie okna obcinania. Jak pokazano na powyższym rysunku, STRING2 znajduje się całkowicie w oknie obcinania, więc go zachowujemy, a STRING1 jest tylko częściowo wewnątrz okna, odrzucamy.
Poniższy rysunek przedstawia przycinanie wszystkich znaków lub brak -
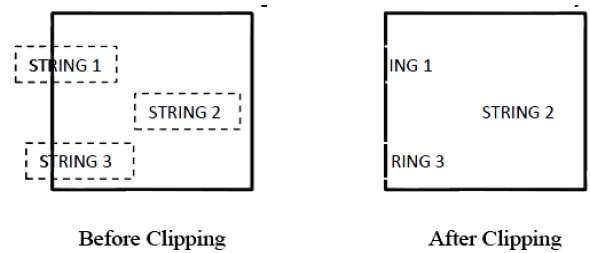
Ta metoda obcinania jest oparta na znakach, a nie na całym łańcuchu. W tej metodzie, jeśli ciąg znajduje się w całości w oknie obcinania, to zachowujemy go. Jeśli jest częściowo za oknem, to -
Odrzucasz tylko część struny znajdującą się na zewnątrz
Jeśli znak znajduje się na granicy okna przycinania, odrzucamy cały znak i zachowujemy resztę ciągu.
Poniższy rysunek przedstawia przycinanie tekstu -
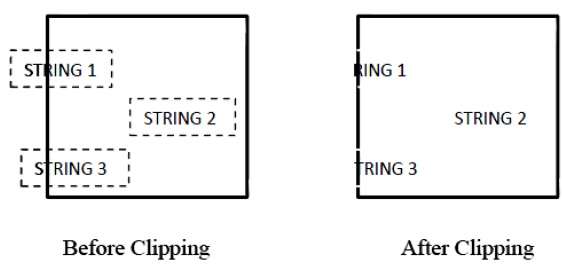
Ta metoda obcinania jest oparta na znakach, a nie na całym ciągu. W tej metodzie, jeśli ciąg znajduje się w całości w oknie obcinania, to zachowujemy go. Jeśli jest częściowo za oknem, to
Odrzucasz tylko część struny znajdującą się na zewnątrz.
Jeśli znak znajduje się na granicy okna przycinania, odrzucamy tylko tę część znaku, która znajduje się poza oknem przycinania.
Grafika bitmapowa
Mapa bitowa to zbiór pikseli opisujących obraz. Jest to rodzaj grafiki komputerowej, której komputer używa do przechowywania i wyświetlania obrazów. W tego typu grafikach obrazy są przechowywane bit po bicie i dlatego nazywa się to grafiką bit-mapową. Dla lepszego zrozumienia rozważmy następujący przykład, w którym rysujemy buźkę za pomocą grafiki bitmapowej.

Teraz zobaczymy, jak ta uśmiechnięta buźka jest przechowywana po kawałku w grafice komputerowej.
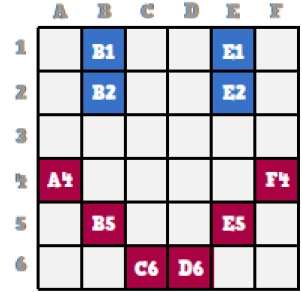
Obserwując uważnie oryginalną uśmiechniętą buźkę, możemy zobaczyć, że istnieją dwie niebieskie linie, które na powyższym rysunku są przedstawione jako B1, B2 i E1, E2.
W ten sam sposób buźka jest reprezentowana za pomocą kombinacji bitów odpowiednio A4, B5, C6, D6, E5 i F4.
Główne wady grafiki bitmapowej to -
Nie możemy zmienić rozmiaru obrazu bitmapowego. Jeśli spróbujesz zmienić rozmiar, piksele zostaną rozmazane.
Kolorowe mapy bitowe mogą być bardzo duże.
Transformacja oznacza zmianę niektórych grafik na coś innego poprzez zastosowanie reguł. Możemy mieć różne typy transformacji, takie jak przesunięcie, skalowanie w górę lub w dół, obrót, ścinanie itp. Kiedy transformacja odbywa się na płaszczyźnie 2D, nazywa się to transformacją 2D.
Transformacje odgrywają ważną rolę w grafice komputerowej w celu zmiany położenia grafiki na ekranie i zmiany jej rozmiaru lub orientacji.
Jednorodne współrzędne
Aby wykonać sekwencję transformacji, na przykład translację, po której następuje obrót i skalowanie, musimy wykonać sekwencyjny proces -
- Przetłumacz współrzędne,
- Obróć przetłumaczone współrzędne, a następnie
- Skaluj obrócone współrzędne, aby zakończyć transformację złożoną.
Aby skrócić ten proces, musimy użyć macierzy transformacji 3 × 3 zamiast macierzy transformacji 2 × 2. Aby przekonwertować macierz 2 × 2 na macierz 3 × 3, musimy dodać dodatkową zastępczą współrzędną W.
W ten sposób możemy przedstawić punkt za pomocą 3 liczb zamiast 2 liczb, co się nazywa Homogenous Coordinatesystem. W tym systemie wszystkie równania transformacji możemy przedstawić w mnożeniu macierzy. Każdy punkt kartezjański P (X, Y) można przekształcić w jednorodne współrzędne za pomocą P '(X h , Y h , h).
Tłumaczenie
Tłumaczenie przenosi obiekt w inne miejsce na ekranie. Możesz przetłumaczyć punkt w 2D, dodając współrzędne translacji (t x , t y ) do oryginalnej współrzędnej (X, Y), aby uzyskać nową współrzędną (X ', Y').
Z powyższego rysunku możesz napisać, że -
X’ = X + tx
Y’ = Y + ty
Para (t x , t y ) nazywana jest wektorem przesunięcia lub wektorem przesunięcia. Powyższe równania można również przedstawić za pomocą wektorów kolumnowych.
$P = \frac{[X]}{[Y]}$ p '= $\frac{[X']}{[Y']}$T = $\frac{[t_{x}]}{[t_{y}]}$
Możemy to zapisać jako -
P’ = P + T
Obrót
Rotując, obracamy obiekt pod określonym kątem θ (theta) od jego początku. Na poniższym rysunku widzimy, że punkt P (X, Y) znajduje się pod kątem φ od poziomej współrzędnej X w odległości r od początku.
Załóżmy, że chcesz go obrócić o kąt θ. Po obróceniu go w nowe miejsce otrzymasz nowy punkt P '(X', Y ').

Używając standardowego trygonometrii, oryginalną współrzędną punktu P (X, Y) można przedstawić jako -
$X = r \, cos \, \phi ...... (1)$
$Y = r \, sin \, \phi ...... (2)$
W ten sam sposób możemy przedstawić punkt P '(X', Y ') jako -
${x}'= r \: cos \: \left ( \phi \: + \: \theta \right ) = r\: cos \: \phi \: cos \: \theta \: − \: r \: sin \: \phi \: sin \: \theta ....... (3)$
${y}'= r \: sin \: \left ( \phi \: + \: \theta \right ) = r\: cos \: \phi \: sin \: \theta \: + \: r \: sin \: \phi \: cos \: \theta ....... (4)$
Zastępując równanie (1) i (2) odpowiednio w (3) i (4), otrzymamy
${x}'= x \: cos \: \theta − \: y \: sin \: \theta $
${y}'= x \: sin \: \theta + \: y \: cos \: \theta $
Przedstawiając powyższe równanie w postaci macierzowej,
$$[X' Y'] = [X Y] \begin{bmatrix} cos\theta & sin\theta \\ −sin\theta & cos\theta \end{bmatrix}OR $$
P '= P ∙ R
Gdzie R jest macierzą rotacji
$$R = \begin{bmatrix} cos\theta & sin\theta \\ −sin\theta & cos\theta \end{bmatrix}$$
Kąt obrotu może być dodatni i ujemny.
Dla dodatniego kąta obrotu możemy użyć powyższej macierzy obrotu. Jednak w przypadku obrotu pod kątem ujemnym macierz zmieni się, jak pokazano poniżej -
$$R = \begin{bmatrix} cos(−\theta) & sin(−\theta) \\ -sin(−\theta) & cos(−\theta) \end{bmatrix}$$
$$=\begin{bmatrix} cos\theta & −sin\theta \\ sin\theta & cos\theta \end{bmatrix} \left (\because cos(−\theta ) = cos \theta \; and\; sin(−\theta ) = −sin \theta \right )$$
skalowanie
Aby zmienić rozmiar obiektu, używana jest transformacja skalowania. W procesie skalowania powiększasz lub kompresujesz wymiary obiektu. Skalowanie można osiągnąć mnożąc oryginalne współrzędne obiektu przez współczynnik skalowania, aby uzyskać pożądany wynik.
Załóżmy, że pierwotne współrzędne to (X, Y), współczynniki skalowania to (S X , S Y ), a otrzymane współrzędne to (X ', Y'). Można to przedstawić matematycznie, jak pokazano poniżej -
X' = X . SX and Y' = Y . SY
Współczynnik skalowania S X , S Y skaluje obiekt odpowiednio w kierunku X i Y. Powyższe równania można również przedstawić w postaci macierzy, jak poniżej -
$$\binom{X'}{Y'} = \binom{X}{Y} \begin{bmatrix} S_{x} & 0\\ 0 & S_{y} \end{bmatrix}$$
LUB
P’ = P . S
Gdzie S to macierz skalowania. Proces skalowania przedstawiono na poniższym rysunku.
Jeśli podamy wartości mniejsze niż 1 do współczynnika skalowania S, wówczas możemy zmniejszyć rozmiar obiektu. Jeśli podamy wartości większe niż 1, możemy zwiększyć rozmiar obiektu.
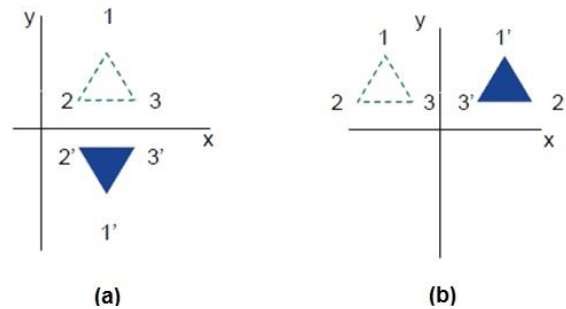
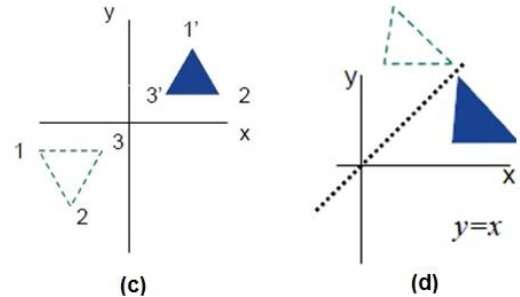
Odbicie
Odbicie jest lustrzanym odbiciem oryginalnego obiektu. Innymi słowy, możemy powiedzieć, że jest to operacja obrotu o 180 °. Przy transformacji odbicia wielkość obiektu nie zmienia się.
Poniższe rysunki przedstawiają odbicia względem osi X i Y oraz odpowiednio początku.
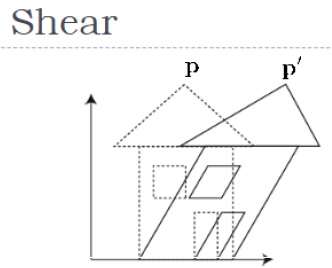
Ścinanie
Transformacja, która pochyla kształt obiektu, nazywana jest transformacją ścinania. Istnieją dwie transformacje ścinaniaX-Shear i Y-Shear. Jeden przesuwa wartości współrzędnych X, a drugi zmienia wartości współrzędnych Y. Jednak; w obu przypadkach tylko jedna współrzędna zmienia swoje współrzędne, a inna zachowuje swoje wartości. Ścinanie jest również określane jakoSkewing.
X-Shear
X-Shear zachowuje współrzędną Y i zmiany są wprowadzane do współrzędnych X, co powoduje, że pionowe linie przechylają się w prawo lub w lewo, jak pokazano na poniższym rysunku.
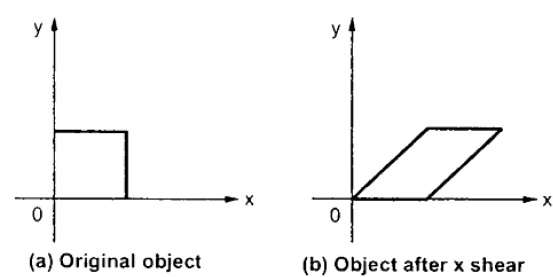
Macierz transformacji dla X-Shear można przedstawić jako -
$$X_{sh} = \begin{bmatrix} 1& shx& 0\\ 0& 1& 0\\ 0& 0& 1 \end{bmatrix}$$
Y '= Y + Sh y . X
X '= X
Y-Shear
Ścinanie Y zachowuje współrzędne X i zmienia współrzędne Y, co powoduje przekształcenie linii poziomych w linie nachylone w górę lub w dół, jak pokazano na poniższym rysunku.
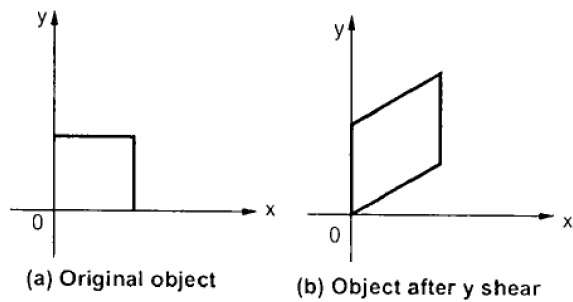
Ścinanie Y można przedstawić w macierzy jako -
$$Y_{sh} \begin{bmatrix} 1& 0& 0\\ shy& 1& 0\\ 0& 0& 1 \end{bmatrix}$$
X '= X + Sh x . Y
Y '= Y
Transformacja złożona
Jeśli po transformacji płaszczyzny T1 następuje transformacja drugiej płaszczyzny T2, to sam wynik może być reprezentowany przez pojedynczą transformację T, która jest złożeniem T1 i T2 wykonanym w tej kolejności. Jest to zapisane jako T = T1 ∙ T2.
Transformację złożoną można osiągnąć przez konkatenację macierzy transformacji w celu uzyskania połączonej macierzy transformacji.
Połączona macierz -
[T][X] = [X] [T1] [T2] [T3] [T4] …. [Tn]
Gdzie [Ti] to dowolna kombinacja
- Translation
- Scaling
- Shearing
- Rotation
- Reflection
Zmiana kolejności transformacji prowadziłaby do różnych wyników, ponieważ generalnie mnożenie macierzy nie jest kumulatywne, to znaczy [A]. [B] ≠ [B]. [A] i kolejność mnożenia. Podstawowym celem tworzenia transformacji jest uzyskanie wydajności poprzez zastosowanie jednej złożonej transformacji do punktu, zamiast stosowania serii przekształceń jedna po drugiej.
Na przykład, aby obrócić obiekt wokół dowolnego punktu (X p , Y p ), musimy wykonać trzy kroki -
- Przenieś punkt (X p , Y p ) na początek.
- Obróć go wokół pochodzenia.
- Na koniec przenieś środek obrotu z powrotem tam, gdzie należał.
W systemie 2D używamy tylko dwóch współrzędnych X i Y, ale w 3D jest dodawana dodatkowa współrzędna Z. Techniki grafiki 3D i ich zastosowanie mają fundamentalne znaczenie dla branży rozrywkowej, gier i projektowania wspomaganego komputerowo. Jest to stały obszar badań naukowych w zakresie wizualizacji.
Co więcej, komponenty grafiki 3D są obecnie częścią prawie każdego komputera osobistego i chociaż tradycyjnie są przeznaczone do oprogramowania intensywnie wykorzystującego grafikę, takiego jak gry, są coraz częściej wykorzystywane przez inne aplikacje.
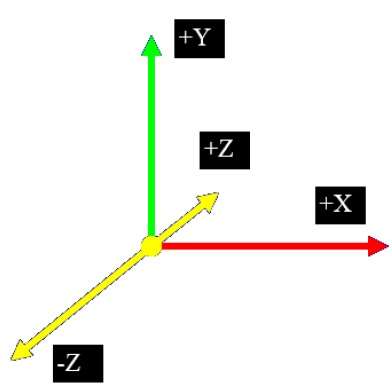
Rzutowanie równoległe
Rzutowanie równoległe odrzuca współrzędną z, a linie równoległe z każdego wierzchołka obiektu są wydłużane do momentu przecięcia płaszczyzny widoku. W rzucie równoległym określamy kierunek rzutowania zamiast środka rzutu.
W rzucie równoległym odległość od środka rzutu do płaszczyzny projekcji jest nieskończona. W tego typu rzutowaniu rzutowane wierzchołki łączymy odcinkami linii, które odpowiadają połączeniom na oryginalnym obiekcie.
Rzuty równoległe są mniej realistyczne, ale nadają się do dokładnych pomiarów. W tego typu rzutach równoległe linie pozostają równoległe, a kąty nie są zachowywane. W poniższej hierarchii przedstawiono różne typy równoległych rzutów.
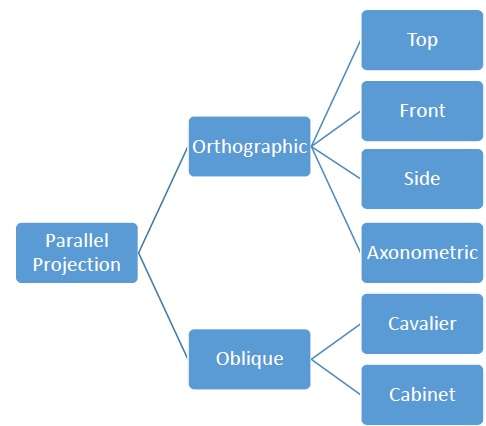
Rzutowanie ortograficzne
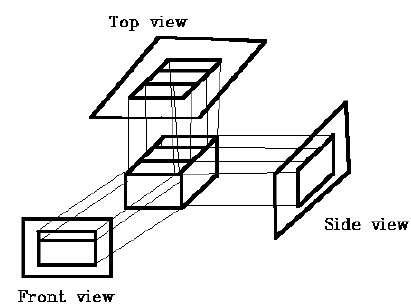
W rzucie prostopadłym kierunek rzutu jest normalny do rzutu płaszczyzny. Istnieją trzy rodzaje rzutów ortograficznych -
- Projekcja przednia
- Projekcja górna
- Projekcja boczna
Ukośna projekcja
W rzucie ukośnym kierunek rzutu nie jest normalny do rzutu płaszczyzny. W rzucie ukośnym możemy zobaczyć obiekt lepiej niż rzut ortograficzny.
Istnieją dwa rodzaje ukośnych projekcji - Cavalier i Cabinet. Projekcja Cavaliera tworzy kąt 45 ° z płaszczyzną projekcji. Rzut linii prostopadłej do płaszczyzny widoku ma taką samą długość jak sama linia w rzucie Cavaliera. W rzucie kawalera czynniki skracające dla wszystkich trzech głównych kierunków są równe.
Rzut szafki tworzy kąt 63,4 ° z płaszczyzną projekcji. W rzucie gabinetowym linie prostopadłe do powierzchni oglądania są rzutowane na ½ ich rzeczywistej długości. Oba występy pokazano na poniższym rysunku -

Rzuty izometryczne
Nazywane są rzuty ortograficzne, które pokazują więcej niż jedną stronę obiektu axonometric orthographic projections. Najczęstszym rzutowaniem aksonometrycznym jestisometric projectiongdzie płaszczyzna rzutowania przecina każdą oś współrzędnych w układzie współrzędnych modelu w równej odległości. W tym rzucie zachowana jest równoległość linii, ale kąty nie są zachowane. Poniższy rysunek przedstawia rzut izometryczny -

Projekcja perspektywiczna
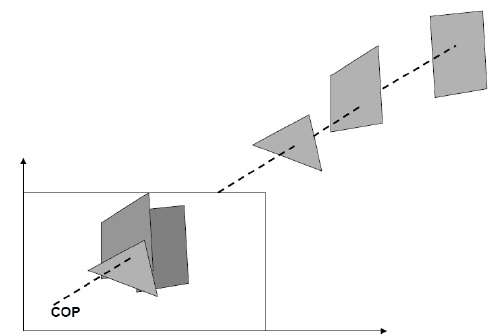
W rzutowaniu perspektywicznym odległość od środka projekcji do płaszczyzny projekcji jest skończona, a rozmiar obiektu zmienia się odwrotnie wraz z odległością, która wygląda bardziej realistycznie.
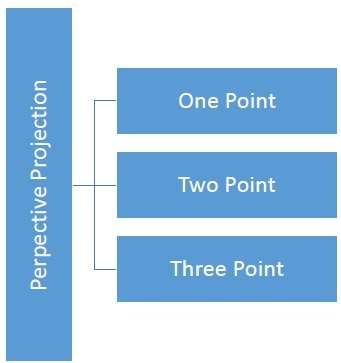
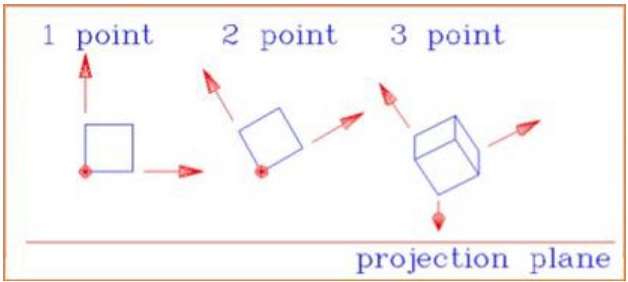
Odległość i kąty nie są zachowywane, a linie równoległe nie pozostają równoległe. Zamiast tego wszystkie zbiegają się w jednym punkcie zwanymcenter of projection lub projection reference point. Istnieją 3 rodzaje rzutów perspektywicznych, które przedstawiono na poniższym wykresie.
One point rzut perspektywiczny jest prosty do narysowania.
Two point rzut perspektywiczny daje lepsze wrażenie głębi.
Three point Rzut perspektywiczny jest najtrudniejszy do narysowania.
Poniższy rysunek przedstawia wszystkie trzy typy rzutowania perspektywicznego -
Tłumaczenie
W translacji 3D przenosimy współrzędną Z wraz ze współrzędnymi X i Y. Proces tłumaczenia w 3D jest podobny do tłumaczenia 2D. Tłumaczenie przenosi obiekt w inne miejsce na ekranie.
Poniższy rysunek przedstawia efekt tłumaczenia -
Punkt można przesunąć w 3D, dodając współrzędne przesunięcia $(t_{x,} t_{y,} t_{z})$ do oryginalnej współrzędnej (X, Y, Z), aby uzyskać nową współrzędną (X ', Y', Z ').
$T = \begin{bmatrix} 1& 0& 0& 0\\ 0& 1& 0& 0\\ 0& 0& 1& 0\\ t_{x}& t_{y}& t_{z}& 1\\ \end{bmatrix}$
P '= P ∙ T
$[X′ \:\: Y′ \:\: Z′ \:\: 1] \: = \: [X \:\: Y \:\: Z \:\: 1] \: \begin{bmatrix} 1& 0& 0& 0\\ 0& 1& 0& 0\\ 0& 0& 1& 0\\ t_{x}& t_{y}& t_{z}& 1\\ \end{bmatrix}$
$= [X + t_{x} \:\:\: Y + t_{y} \:\:\: Z + t_{z} \:\:\: 1]$
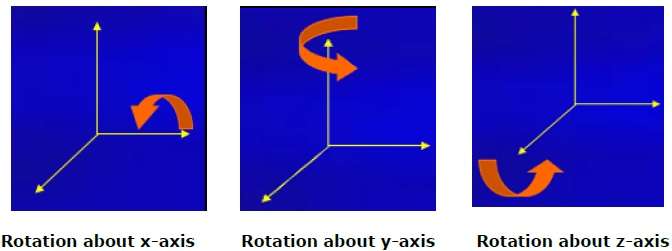
Obrót
Obrót 3D to nie to samo, co obrót 2D. W obrocie 3D musimy określić kąt obrotu wraz z osią obrotu. Możemy wykonywać obrót 3D wokół osi X, Y i Z. Są one przedstawione w postaci macierzy, jak poniżej -
$$R_{x}(\theta) = \begin{bmatrix} 1& 0& 0& 0\\ 0& cos\theta & −sin\theta& 0\\ 0& sin\theta & cos\theta& 0\\ 0& 0& 0& 1\\ \end{bmatrix} R_{y}(\theta) = \begin{bmatrix} cos\theta& 0& sin\theta& 0\\ 0& 1& 0& 0\\ −sin\theta& 0& cos\theta& 0\\ 0& 0& 0& 1\\ \end{bmatrix} R_{z}(\theta) =\begin{bmatrix} cos\theta & −sin\theta & 0& 0\\ sin\theta & cos\theta & 0& 0\\ 0& 0& 1& 0\\ 0& 0& 0& 1 \end{bmatrix}$$
Poniższy rysunek wyjaśnia obrót wokół różnych osi -
skalowanie
Możesz zmienić rozmiar obiektu używając transformacji skalowania. W procesie skalowania powiększasz lub kompresujesz wymiary obiektu. Skalowanie można osiągnąć mnożąc oryginalne współrzędne obiektu przez współczynnik skalowania, aby uzyskać pożądany wynik. Poniższy rysunek przedstawia efekt skalowania 3D -
W operacji skalowania 3D używane są trzy współrzędne. Załóżmy, że oryginalne współrzędne to (X, Y, Z), a współczynniki skalowania to$(S_{X,} S_{Y,} S_{z})$odpowiednio, a otrzymane współrzędne to (X ', Y', Z '). Można to przedstawić matematycznie, jak pokazano poniżej -
$S = \begin{bmatrix} S_{x}& 0& 0& 0\\ 0& S_{y}& 0& 0\\ 0& 0& S_{z}& 0\\ 0& 0& 0& 1 \end{bmatrix}$
P '= P ∙ S
$[{X}' \:\:\: {Y}' \:\:\: {Z}' \:\:\: 1] = [X \:\:\:Y \:\:\: Z \:\:\: 1] \:\: \begin{bmatrix} S_{x}& 0& 0& 0\\ 0& S_{y}& 0& 0\\ 0& 0& S_{z}& 0\\ 0& 0& 0& 1 \end{bmatrix}$
$ = [X.S_{x} \:\:\: Y.S_{y} \:\:\: Z.S_{z} \:\:\: 1]$
Ścinanie
Transformacja, która pochyla kształt obiektu, nazywa się shear transformation. Podobnie jak w przypadku ścinania 2D, możemy ścinać obiekt wzdłuż osi X, osi Y lub osi Z w 3D.
Jak pokazano na powyższym rysunku, istnieje współrzędna P.Można ją ściąć, aby uzyskać nową współrzędną P ', którą można przedstawić w postaci macierzy 3D, jak poniżej -
$Sh = \begin{bmatrix} 1 & sh_{x}^{y} & sh_{x}^{z} & 0 \\ sh_{y}^{x} & 1 & sh_{y}^{z} & 0 \\ sh_{z}^{x} & sh_{z}^{y} & 1 & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix}$
P '= P ∙ Sh
$X’ = X + Sh_{x}^{y} Y + Sh_{x}^{z} Z$
$Y' = Sh_{y}^{x}X + Y +sh_{y}^{z}Z$
$Z' = Sh_{z}^{x}X + Sh_{z}^{y}Y + Z$
Macierze transformacji
Macierz transformacji jest podstawowym narzędziem transformacji. Macierz o wymiarach nxm mnoży się przez współrzędne obiektów. Zwykle do transformacji używa się macierzy 3 x 3 lub 4 x 4. Na przykład rozważ następującą macierz dla różnych operacji.
| $T = \begin{bmatrix} 1& 0& 0& 0\\ 0& 1& 0& 0\\ 0& 0& 1& 0\\ t_{x}& t_{y}& t_{z}& 1\\ \end{bmatrix}$ | $S = \begin{bmatrix} S_{x}& 0& 0& 0\\ 0& S_{y}& 0& 0\\ 0& 0& S_{z}& 0\\ 0& 0& 0& 1 \end{bmatrix}$ | $Sh = \begin{bmatrix} 1& sh_{x}^{y}& sh_{x}^{z}& 0\\ sh_{y}^{x}& 1 & sh_{y}^{z}& 0\\ sh_{z}^{x}& sh_{z}^{y}& 1& 0\\ 0& 0& 0& 1 \end{bmatrix}$ |
| Translation Matrix | Scaling Matrix | Shear Matrix |
| $R_{x}(\theta) = \begin{bmatrix} 1& 0& 0& 0\\ 0& cos\theta & -sin\theta& 0\\ 0& sin\theta & cos\theta& 0\\ 0& 0& 0& 1\\ \end{bmatrix}$ | $R_{y}(\theta) = \begin{bmatrix} cos\theta& 0& sin\theta& 0\\ 0& 1& 0& 0\\ -sin\theta& 0& cos\theta& 0\\ 0& 0& 0& 1\\ \end{bmatrix}$ | $R_{z}(\theta) = \begin{bmatrix} cos\theta & -sin\theta & 0& 0\\ sin\theta & cos\theta & 0& 0\\ 0& 0& 1& 0\\ 0& 0& 0& 1 \end{bmatrix}$ |
| Rotation Matrix | ||
W grafice komputerowej często musimy rysować na ekranie różne typy obiektów. Obiekty nie są cały czas płaskie i aby narysować obiekt, musimy wielokrotnie rysować krzywe.
Rodzaje krzywych
Krzywa to nieskończenie duży zbiór punktów. Każdy punkt ma dwóch sąsiadów z wyjątkiem punktów końcowych. Krzywe można ogólnie podzielić na trzy kategorie -explicit, implicit, i parametric curves.
Ukryte krzywe
Niejawne reprezentacje krzywych definiują zestaw punktów na krzywej, stosując procedurę, która może przetestować, czy punkt na krzywej. Zwykle ukryta krzywa jest definiowana przez niejawną funkcję postaci -
f (x, y) = 0
Może przedstawiać krzywe wielowartościowe (wiele wartości y dla wartości x). Typowym przykładem jest okrąg, którego niejawna reprezentacja to
x2 + y2 - R2 = 0
Wyraźne krzywe
Funkcję matematyczną y = f (x) można przedstawić jako krzywą. Taka funkcja jest jawną reprezentacją krzywej. Jawna reprezentacja nie jest ogólna, ponieważ nie może przedstawiać pionowych linii i jest również jednowartościowa. Dla każdej wartości x funkcja zwykle oblicza tylko jedną wartość y.
Krzywe parametryczne
Krzywe mające postać parametryczną nazywane są krzywymi parametrycznymi. Jawne i niejawne reprezentacje krzywych mogą być używane tylko wtedy, gdy funkcja jest znana. W praktyce wykorzystuje się krzywe parametryczne. Dwuwymiarowa krzywa parametryczna ma następującą postać -
P (t) = f (t), g (t) lub P (t) = x (t), y (t)
Funkcje f i g stają się współrzędnymi (x, y) dowolnego punktu na krzywej, a punkty uzyskuje się, gdy parametr t zmienia się w pewnym przedziale [a, b], zwykle [0, 1].
Krzywe Beziera
Krzywa Beziera została odkryta przez francuskiego inżyniera Pierre Bézier. Krzywe te można generować pod kontrolą innych punktów. Przybliżone styczne przy użyciu punktów kontrolnych są używane do generowania łuku. Krzywą Beziera można przedstawić matematycznie jako -
$$\sum_{k=0}^{n} P_{i}{B_{i}^{n}}(t)$$
Gdzie $p_{i}$ jest zbiorem punktów i ${B_{i}^{n}}(t)$ reprezentuje wielomiany Bernsteina, które są podane przez -
$${B_{i}^{n}}(t) = \binom{n}{i} (1 - t)^{n-i}t^{i}$$
Gdzie n jest stopniem wielomianu, i jest indeksem, a t jest zmienną.
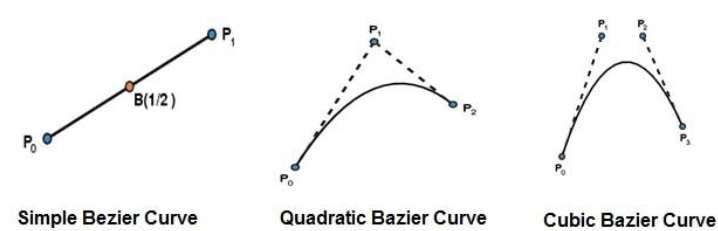
Najprostszą krzywą Béziera jest prosta z punktu $P_{0}$ do $P_{1}$. Kwadratową krzywą Beziera wyznaczają trzy punkty kontrolne. Sześcienna krzywa Beziera jest wyznaczona przez cztery punkty kontrolne.
Właściwości krzywych Beziera
Krzywe Beziera mają następujące właściwości -
Zwykle mają kształt wielokąta kontrolnego, który składa się z segmentów łączących punkty kontrolne.
Zawsze przechodzą przez pierwszy i ostatni punkt kontrolny.
Są zawarte w wypukłym kadłubie ich definiujących punktów kontrolnych.
Stopień wielomianu definiującego segment krzywej jest o jeden mniejszy od liczby definiującego punktu wielokąta. Dlatego dla 4 punktów kontrolnych stopień wielomianu wynosi 3, czyli wielomian sześcienny.
Krzywa Beziera na ogół podąża za kształtem definiującego wielokąta.
Kierunek wektora stycznego w punktach końcowych jest taki sam, jak wektora wyznaczonego przez pierwszy i ostatni odcinek.
Wypukła właściwość kadłuba dla krzywej Beziera zapewnia, że wielomian płynnie podąża za punktami kontrolnymi.
Żadna linia prosta nie przecina krzywej Beziera więcej razy, niż przecina jej wielokąt kontrolny.
Są niezmienne przy transformacji afinicznej.
Krzywe Beziera zapewniają kontrolę globalną, co oznacza, że przesunięcie punktu kontrolnego zmienia kształt całej krzywej.
Daną krzywą Beziera można podzielić w punkcie t = t0 na dwa segmenty Beziera, które łączą się ze sobą w punkcie odpowiadającym wartości parametru t = t0.
Krzywe B-Spline
Krzywa Beziera utworzona przez funkcję podstawy Bernsteina ma ograniczoną elastyczność.
Po pierwsze, liczba określonych wierzchołków wielokąta ustala kolejność wynikowego wielomianu, który definiuje krzywą.
Drugą cechą ograniczającą jest to, że wartość funkcji mieszania jest różna od zera dla wszystkich wartości parametrów na całej krzywej.
Baza B-splajnu zawiera bazę Bernsteina jako przypadek specjalny. Podstawa B-splajnu nie jest globalna.
Krzywa B-spline jest definiowana jako liniowa kombinacja punktów kontrolnych Pi i funkcji bazowej B-spline $N_{i,}$ k (t) dane przez
$C(t) = \sum_{i=0}^{n}P_{i}N_{i,k}(t),$ $n\geq k-1,$ $t\: \epsilon \: [ tk-1,tn+1 ]$
Gdzie,
{$p_{i}$: i = 0, 1, 2… .n} to punkty kontrolne
k jest rzędem segmentów wielomianów krzywej B-splajn. Rząd k oznacza, że krzywa składa się z odcinkowych segmentów wielomianowych stopnia k - 1,
the $N_{i,k}(t)$to „znormalizowane funkcje mieszania B-splajn”. Opisuje je rząd k i nie malejąca sekwencja liczb rzeczywistych zwykle nazywana „sekwencją węzłów”.
$${t_{i}:i = 0, ... n + K}$$
Funkcje N i , k są opisane następująco -
$$N_{i,1}(t) = \left\{\begin{matrix} 1,& if \:u \: \epsilon \: [t_{i,}t_{i+1}) \\ 0,& Otherwise \end{matrix}\right.$$
a jeśli k> 1,
$$N_{i,k}(t) = \frac{t-t_{i}}{t_{i+k-1}} N_{i,k-1}(t) + \frac{t_{i+k}-t}{t_{i+k} - t_{i+1}} N_{i+1,k-1}(t)$$
i
$$t \: \epsilon \: [t_{k-1},t_{n+1})$$
Właściwości krzywej B-splajn
Krzywe B-splajn mają następujące właściwości -
Suma funkcji bazowych B-splajnu dla dowolnej wartości parametru wynosi 1.
Każda funkcja bazowa jest dodatnia lub zerowa dla wszystkich wartości parametrów.
Każda funkcja bazowa ma dokładnie jedną wartość maksymalną, z wyjątkiem k = 1.
Maksymalna kolejność krzywej jest równa liczbie wierzchołków definiującego wielokąta.
Stopień wielomianu B-splajn jest niezależny od liczby wierzchołków wielokąta definiującego.
B-splajn umożliwia lokalną kontrolę nad powierzchnią krzywej, ponieważ każdy wierzchołek wpływa na kształt krzywej tylko w zakresie wartości parametrów, w przypadku których skojarzona z nim funkcja bazowa jest różna od zera.
Krzywa wykazuje właściwość zmniejszania zmienności.
Krzywa na ogół ma kształt definiującego wielokąta.
Dowolną transformację afiniczną można zastosować do krzywej, stosując ją do wierzchołków definiującego wielokąta.
Linia krzywej wewnątrz wypukłego kadłuba definiującego go wielokąta.
Powierzchnie wieloboczne
Obiekty są reprezentowane jako zbiór powierzchni. Reprezentacja obiektów 3D jest podzielona na dwie kategorie.
Boundary Representations (B-reps) - Opisuje obiekt 3D jako zbiór powierzchni oddzielających wnętrze obiektu od otoczenia.
Space–partitioning representations - Służy do opisu właściwości wewnętrznych poprzez podział obszaru przestrzennego zawierającego obiekt na zbiór małych, nie zachodzących na siebie, ciągłych brył (zwykle kostek).
Najczęściej używaną reprezentacją obwiedni obiektu graficznego 3D jest zestaw wielokątów powierzchni, które otaczają wnętrze obiektu. Wiele systemów graficznych korzysta z tej metody. Zbiór wielokątów jest przechowywany do opisu obiektu. Upraszcza to i przyspiesza renderowanie powierzchni i wyświetlanie obiektu, ponieważ wszystkie powierzchnie można opisać równaniami liniowymi.
Powierzchnie wielokątne są powszechne w aplikacjach do projektowania i modelowania brył, ponieważ ich wireframe displaymożna zrobić szybko, aby uzyskać ogólne wskazanie struktury powierzchni. Następnie tworzone są realistyczne sceny, interpolując wzory cieni na powierzchni wielokąta w celu oświetlenia.
Tabele wielokątne
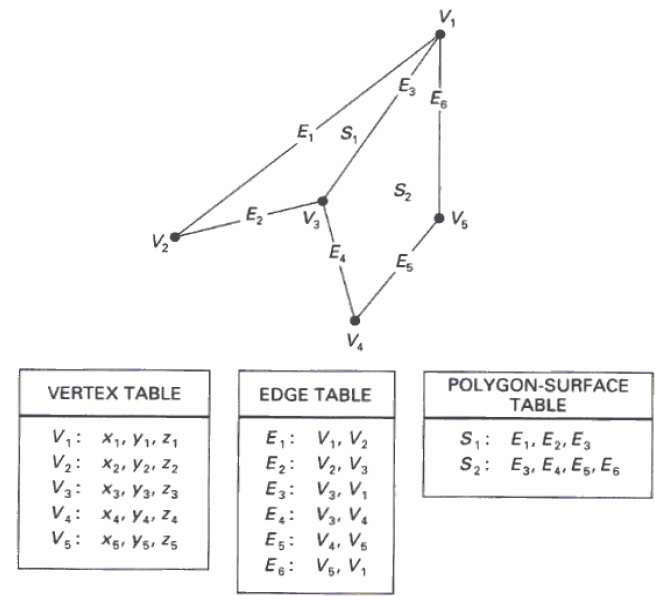
W tej metodzie powierzchnia jest określana przez zestaw współrzędnych wierzchołków i powiązanych atrybutów. Jak pokazano na poniższym rysunku, istnieje pięć wierzchołków, od v 1 do v 5 .
Każdy wierzchołek przechowuje informacje o współrzędnych x, y i z, które są reprezentowane w tabeli jako v 1 : x 1 , y 1 , z 1 .
Tabela Edge służy do przechowywania informacji o krawędziach wielokąta. Na poniższym rysunku krawędź E 1 leży między wierzchołkami v 1 i v 2, które są reprezentowane w tabeli jako E 1 : v 1 , v 2 .
Tabela powierzchni wieloboku przechowuje liczbę powierzchni obecnych w wielokącie. Na poniższym rysunku powierzchnia S 1 jest pokryta krawędziami E 1 , E 2 i E 3, które można przedstawić w tabeli powierzchni wieloboków jako S 1 : E 1 , E 2 i E 3 .
Równania płaszczyznowe
Równanie powierzchni płaskiej można wyrazić jako -
Ax + By + Cz + D = 0
Gdzie (x, y, z) to dowolny punkt na płaszczyźnie, a współczynniki A, B, C i D są stałymi opisującymi właściwości przestrzenne płaszczyzny. Możemy uzyskać wartości A, B, C i D, rozwiązując zestaw trzech równań płaszczyznowych, używając wartości współrzędnych dla trzech niekoliniowych punktów na płaszczyźnie. Załóżmy, że trzy wierzchołki płaszczyzny to (x 1 , y 1 , z 1 ), (x 2 , y 2 , z 2 ) i (x 3 , y 3 , z 3 ).
Rozwiążmy następujące równania równoczesne dla stosunków A / D, B / D i C / D. Otrzymasz wartości A, B, C i D.
(A / D) x 1 + (B / D) y 1 + (C / D) z 1 = -1
(A / D) x 2 + (B / D) y 2 + (C / D) z 2 = -1
(A / D) x 3 + (B / D) y 3 + (C / D) z 3 = -1
Aby otrzymać powyższe równania w formie wyznacznika, zastosuj regułę Cramera do powyższych równań.
$A = \begin{bmatrix} 1& y_{1}& z_{1}\\ 1& y_{2}& z_{2}\\ 1& y_{3}& z_{3} \end{bmatrix} B = \begin{bmatrix} x_{1}& 1& z_{1}\\ x_{2}& 1& z_{2}\\ x_{3}& 1& z_{3} \end{bmatrix} C = \begin{bmatrix} x_{1}& y_{1}& 1\\ x_{2}& y_{2}& 1\\ x_{3}& y_{3}& 1 \end{bmatrix} D = - \begin{bmatrix} x_{1}& y_{1}& z_{1}\\ x_{2}& y_{2}& z_{2}\\ x_{3}& y_{3}& z_{3} \end{bmatrix}$
Dla dowolnego punktu (x, y, z) z parametrami A, B, C i D, możemy powiedzieć, że -
Ax + By + Cz + D ≠ 0 oznacza, że punkt nie znajduje się na płaszczyźnie.
Ax + By + Cz + D <0 oznacza, że punkt znajduje się wewnątrz powierzchni.
Ax + By + Cz + D> 0 oznacza, że punkt znajduje się poza powierzchnią.
Siatki wielokątne
Powierzchnie i bryły 3D można aproksymować za pomocą zestawu elementów wielokątnych i liniowych. Takie powierzchnie nazywane sąpolygonal meshes. W siatce wielokątnej każda krawędź jest wspólna dla co najwyżej dwóch wielokątów. Zestaw wielokątów lub ścian razem tworzy „skórę” obiektu.
Ta metoda może być używana do reprezentowania szerokiej klasy brył / powierzchni w grafice. Siatkę wielokątną można renderować za pomocą algorytmów usuwania ukrytej powierzchni. Siatkę wielokątną można przedstawić na trzy sposoby -
- Jawna reprezentacja
- Wskaźniki do listy wierzchołków
- Wskaźniki do listy krawędzi
Zalety
- Może służyć do modelowania prawie każdego obiektu.
- Można je łatwo przedstawić jako zbiór wierzchołków.
- Łatwo je przekształcić.
- Można je łatwo narysować na ekranie komputera.
Niedogodności
- Zakrzywione powierzchnie można opisać tylko w przybliżeniu.
- Trudno jest symulować niektóre rodzaje obiektów, takie jak włosy lub ciecz.
Kiedy oglądamy obraz zawierający nieprzezroczyste przedmioty i powierzchnie, nie możemy zobaczyć tych obiektów z widoku, które są za obiektami bliżej oka. Musimy usunąć te ukryte powierzchnie, aby uzyskać realistyczny obraz na ekranie. Nazywa się identyfikację i usuwanie tych powierzchniHidden-surface problem.
Istnieją dwa podejścia do usuwania problemów z ukrytą powierzchnią - Object-Space method i Image-space method. Metoda przestrzeni obiektowej jest zaimplementowana w fizycznym układzie współrzędnych, a metoda przestrzeni obrazu w układzie współrzędnych ekranu.
Kiedy chcemy wyświetlić obiekt 3D na ekranie 2D, musimy zidentyfikować te części ekranu, które są widoczne z wybranej pozycji oglądania.
Metoda bufora głębokości (bufor Z)
Ta metoda została opracowana przez Cutmull. Jest to podejście oparte na przestrzeni obrazu. Podstawowym pomysłem jest przetestowanie głębokości Z każdej powierzchni w celu określenia najbliższej (widocznej) powierzchni.
W tej metodzie każda powierzchnia jest przetwarzana oddzielnie, po jednym pikselu na raz na całej powierzchni. Porównywane są wartości głębi piksela, a najbliższa (najmniejsza z) powierzchnia określa kolor, który ma być wyświetlany w buforze klatek.
Bardzo wydajnie nakłada się na powierzchnie wielokąta. Powierzchnie można obrabiać w dowolnej kolejności. Aby nadpisać bliższe wielokąty z odległych, nazwano dwa buforyframe buffer i depth buffer, są używane.
Depth buffer służy do przechowywania wartości głębokości dla pozycji (x, y) podczas obróbki powierzchni (0 ≤ głębokość ≤ 1).
Plik frame buffer służy do przechowywania wartości intensywności wartości koloru na każdej pozycji (x, y).
Współrzędne z są zwykle znormalizowane do zakresu [0, 1]. Wartość 0 dla współrzędnej z oznacza tylny panel obcinania, a wartość 1 dla współrzędnych z oznacza przedni panel obcinania.
Algorytm
Step-1 - Ustaw wartości bufora -
Bufor głębi (x, y) = 0
Framebuffer (x, y) = kolor tła
Step-2 - Przetwarzaj każdy wielokąt (jeden na raz)
Dla każdego rzutowanego (x, y) położenia piksela wielokąta oblicz głębokość z.
Jeśli Z> depthbuffer (x, y)
Oblicz kolor powierzchni,
ustaw głębokość bufora (x, y) = z,
framebuffer (x, y) = surfacecolor (x, y)
Zalety
- Jest łatwy do wdrożenia.
- Zmniejsza problem z szybkością, jeśli zostanie wdrożony w sprzęcie.
- Przetwarza jeden obiekt na raz.
Niedogodności
- Wymaga dużej pamięci.
- Jest to proces czasochłonny.
Metoda linii skanowania
Jest to metoda przestrzeni obrazu służąca do identyfikacji widocznej powierzchni. Ta metoda zawiera informacje o głębi tylko dla jednej linii skanowania. Aby wymagać jednej linii skanowania wartości głębokości, musimy zgrupować i przetworzyć wszystkie wielokąty przecinające daną linię skanowania w tym samym czasie przed przetworzeniem następnej linii skanowania. Dwie ważne tabele,edge table i polygon table, są w tym celu utrzymywane.
The Edge Table - Zawiera punkty końcowe współrzędnych każdej linii w scenie, odwrotne nachylenie każdej linii i wskaźniki do tabeli wielokątów do łączenia krawędzi z powierzchniami.
The Polygon Table - Zawiera współczynniki płaszczyzny, właściwości materiału powierzchniowego, inne dane powierzchni i może być wskaźnikami do tabeli krawędzi.

Aby ułatwić wyszukiwanie powierzchni przecinających daną linię skanowania, tworzona jest aktywna lista krawędzi. Lista aktywna przechowuje tylko te krawędzie, które przecinają linię skanowania w kolejności rosnącego x. Dla każdej powierzchni ustawia się również flagę, aby wskazać, czy pozycja wzdłuż linii skanowania znajduje się wewnątrz lub na zewnątrz powierzchni.
Pozycje pikseli w każdej linii skanowania są przetwarzane od lewej do prawej. Na lewym przecięciu z powierzchnią flaga powierzchni jest włączona, a po prawej flaga jest wyłączona. Musisz wykonać obliczenia głębokości tylko wtedy, gdy wiele powierzchni ma włączone flagi w określonej pozycji linii skanowania.
Metoda podziału obszaru
Metoda podziału obszarów korzysta z zalet lokalizowania tych obszarów widoku, które reprezentują część pojedynczej powierzchni. Podzielić całkowity obszar widzenia na coraz mniejsze prostokąty, aż każdy mały obszar będzie rzutem części pojedynczej widocznej powierzchni lub wcale.
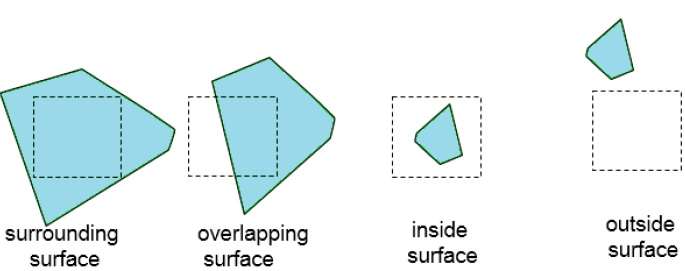
Kontynuuj ten proces, aż podpodziały zostaną łatwo przeanalizowane jako należące do jednej powierzchni lub dopóki nie zostaną zredukowane do rozmiaru pojedynczego piksela. Łatwym sposobem na to jest sukcesywne dzielenie obszaru na cztery równe części w każdym kroku. Istnieją cztery możliwe relacje, jakie powierzchnia może mieć z określoną obwiednią powierzchni.
Surrounding surface - Takiego, który całkowicie otacza obszar.
Overlapping surface - taki, który znajduje się częściowo wewnątrz, a częściowo na zewnątrz obszaru.
Inside surface - Takiego, który znajduje się całkowicie wewnątrz obszaru.
Outside surface - Takiego, który jest całkowicie poza obszarem.
Testy określania widoczności powierzchni w obrębie danego obszaru można określić na podstawie tych czterech klasyfikacji. Dalsze podziały określonego obszaru nie są potrzebne, jeśli spełniony jest jeden z następujących warunków -
- Wszystkie powierzchnie są powierzchniami zewnętrznymi w stosunku do obszaru.
- W tym obszarze znajduje się tylko jedna wewnętrzna, zachodząca lub otaczająca powierzchnia.
- Otaczająca powierzchnia zasłania wszystkie inne powierzchnie w granicach obszaru.
Wykrywanie twarzy
Szybka i prosta metoda określania tylnych ścian wielościanu w przestrzeni obiektowej opiera się na testach „wewnątrz-na zewnątrz”. Punkt (x, y, z) znajduje się „wewnątrz” powierzchni wielokąta z parametrami płaszczyzny A, B, C i D, jeśli Gdy punkt wewnętrzny znajduje się wzdłuż linii wzroku do powierzchni, wielokąt musi być tylną ścianą ( jesteśmy wewnątrz tej twarzy i nie możemy zobaczyć jej przodu z naszej pozycji oglądania).
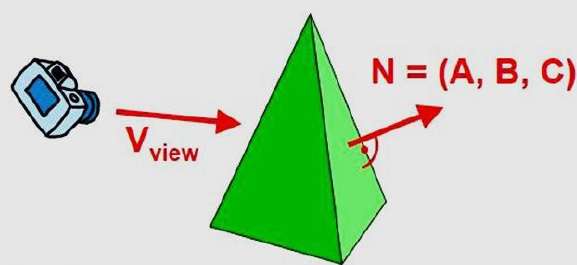
Możemy uprościć ten test, rozważając wektor normalny N do powierzchni wieloboku, która ma komponenty kartezjańskie (A, B, C).
Ogólnie rzecz biorąc, jeśli V jest wektorem w kierunku patrzenia z pozycji oka (lub „kamery”), wówczas ten wielokąt jest tylną ścianą, jeśli
V.N > 0
Ponadto, jeśli opisy obiektów są konwertowane na współrzędne rzutowania, a kierunek patrzenia jest równoległy do osi z widoku, wówczas -
V = (0, 0, V z ) i V.N = V Z C
Musimy więc wziąć pod uwagę tylko znak C jako składową wektora normalnego N.
W praworęcznym systemie oglądania z kierunkiem patrzenia wzdłuż negatywu $Z_{V}$osi, wielokąt jest tylną ścianą, jeśli C <0. Ponadto nie możemy zobaczyć żadnej ściany, której normalna ma składową z C = 0, ponieważ kierunek patrzenia jest w kierunku tego wielokąta. Tak więc, ogólnie rzecz biorąc, możemy oznaczyć dowolny wielokąt jako tylną ścianę, jeśli jego normalny wektor ma wartość składnika az -
C <= 0
Podobne metody mogą być używane w pakietach, które wykorzystują leworęczny system przeglądania. W tych pakietach parametry płaszczyzny A, B, C i D można obliczyć ze współrzędnych wierzchołków wielokąta określonych w kierunku zgodnym z ruchem wskazówek zegara (w przeciwieństwie do kierunku przeciwnym do ruchu wskazówek zegara używanego w systemie praworęcznym).
Ponadto ściany tylne mają wektory normalne, które są skierowane z dala od pozycji oglądania i są identyfikowane przez C> = 0, gdy kierunek patrzenia jest wzdłuż dodatniego $Z_{v}$oś. Badając parametr C dla różnych płaszczyzn definiujących obiekt, możemy natychmiast zidentyfikować wszystkie tylne ściany.
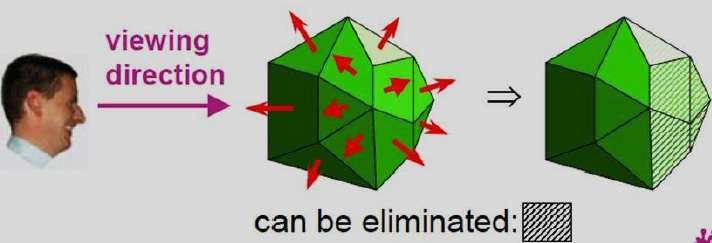
Metoda bufora A.
Metoda bufora A jest rozszerzeniem metody bufora głębokości. Metoda bufora A to metoda wykrywania widoczności opracowana w Lucas film Studios dla systemu renderowania Renders Everything You Ever Saw (REYES).
Bufor A rozszerza się w metodzie bufora głębi, aby umożliwić przezroczystość. Kluczową strukturą danych w buforze A jest bufor akumulacyjny.
Każda pozycja w buforze A ma dwa pola -
Depth field - Przechowuje dodatnią lub ujemną liczbę rzeczywistą
Intensity field - Przechowuje informacje o intensywności powierzchni lub wartość wskaźnika

Jeśli głębokość> = 0, liczba przechowywana w tej pozycji jest głębokością pojedynczej powierzchni nakładającej się na odpowiedni obszar pikseli. Pole intensywności przechowuje następnie składowe RGB koloru powierzchni w tym punkcie i procent pokrycia pikseli.
Jeśli głębokość <0, oznacza to udział wielu powierzchni w intensywności pikseli. Pole intensywności przechowuje następnie wskaźnik do połączonej listy danych powierzchni. Odbój powierzchniowy w buforze A zawiera -
- Składowe intensywności RGB
- Parametr krycia
- Depth
- Procent pokrycia obszaru
- Identyfikator powierzchni
Algorytm działa tak samo jak algorytm bufora głębokości. Wartości głębi i krycia są używane do określenia ostatecznego koloru piksela.
Metoda sortowania według głębokości
Metoda sortowania według głębokości wykorzystuje zarówno operacje w przestrzeni obrazu, jak i na przestrzeni obiektów. Metoda sortowania według głębokości spełnia dwie podstawowe funkcje -
Najpierw powierzchnie są sortowane według malejącej głębokości.
Po drugie, powierzchnie są konwertowane w kolejności skanowania, zaczynając od powierzchni o największej głębokości.
Konwersja skanowania powierzchni wielokątów odbywa się w przestrzeni obrazu. Ta metoda rozwiązywania problemu z ukrytą powierzchnią jest często określana jakopainter's algorithm. Poniższy rysunek przedstawia efekt sortowania według głębokości -
Algorytm rozpoczyna sortowanie według głębokości. Na przykład, początkowe oszacowanie „głębokości” wielokąta można przyjąć jako najbliższą wartość z dowolnego wierzchołka wielokąta.
Weźmy wielokąt P na końcu listy. Rozważ wszystkie wielokąty Q, których zakresy z nakładają się na P. Przed rysowaniem P wykonujemy następujące testy. Jeśli którykolwiek z poniższych testów jest pozytywny, możemy założyć, że P można narysować przed Q.
- Czy zakresy x nie pokrywają się?
- Czy zakresy y nie pokrywają się?
- Czy P znajduje się całkowicie po przeciwnej stronie płaszczyzny Q z punktu widzenia?
- Czy Q znajduje się całkowicie po tej samej stronie płaszczyzny P, co punkt widzenia?
- Czy rzuty wielokątów nie pokrywają się?
Jeśli wszystkie testy zakończą się niepowodzeniem, rozdzielamy P lub Q za pomocą płaszczyzny drugiego. Nowe wycięte wielokąty są wstawiane w kolejności głębokości i proces jest kontynuowany. Teoretycznie to partycjonowanie mogłoby wygenerować O (n 2 ) pojedynczych wielokątów, ale w praktyce liczba wielokątów jest znacznie mniejsza.
Binarne drzewa partycji przestrzeni (BSP)
Do obliczania widoczności używane jest partycjonowanie przestrzeni binarnej. Aby zbudować drzewa BSP, należy zacząć od wielokątów i opisać wszystkie krawędzie. Mając do czynienia tylko z jedną krawędzią na raz, wydłuż każdą krawędź tak, aby dzieliła płaszczyznę na dwie. Umieść pierwszą krawędź w drzewie jako korzeń. Dodaj kolejne krawędzie w zależności od tego, czy są wewnątrz, czy na zewnątrz. Krawędzie, które obejmują przedłużenie krawędzi, która jest już w drzewie, są dzielone na dwie części i obie są dodawane do drzewa.

Z powyższego rysunku, najpierw weź A jako root.
Zrób listę wszystkich węzłów na rysunku (a).
Umieść wszystkie węzły, które znajdują się przed katalogiem głównym A po lewej stronie węzła A i umieść wszystkie te węzły, które są za korzeniem A po prawej stronie, jak pokazano na rysunku (b).
Przetwórz najpierw wszystkie przednie węzły, a następnie węzły z tyłu.
Jak pokazano na rysunku (c), najpierw przetworzymy węzeł B. Ponieważ nie ma nic przed węzłemB, umieściliśmy NIL. Mamy jednak nodeC z tyłu węzła B, więc node C przejdzie na prawą stronę węzła B.
Powtórz ten sam proces dla węzła D.
Francuski / amerykański matematyk, dr Benoit Mandelbrot, odkrył fraktale. Słowo fraktal pochodzi od łacińskiego słowa fractus, które oznacza złamany.
Co to są fraktale?
Fraktale to bardzo złożone obrazy generowane przez komputer z jednej formuły. Tworzone są za pomocą iteracji. Oznacza to, że jedna formuła jest wielokrotnie powtarzana z nieco innymi wartościami, biorąc pod uwagę wyniki z poprzedniej iteracji.
Fraktale są używane w wielu obszarach, takich jak -
Astronomy - Do analizy galaktyk, pierścieni Saturna itp.
Biology/Chemistry - Do przedstawiania kultur bakterii, reakcji chemicznych, anatomii człowieka, cząsteczek, roślin,
Others - Do przedstawiania chmur, linii brzegowej i granic, kompresji danych, dyfuzji, ekonomii, sztuki fraktalnej, muzyki fraktalnej, krajobrazów, efektów specjalnych itp.

Generowanie fraktali
Fraktale można generować, powtarzając w kółko ten sam kształt, jak pokazano na poniższym rysunku. Na rysunku (a) pokazuje trójkąt równoboczny. Na rysunku (b) widzimy, że trójkąt powtarza się, tworząc kształt przypominający gwiazdę. Na rysunku (c) widzimy, że kształt gwiazdy z rysunku (b) jest powtarzany raz za razem, aby utworzyć nowy kształt.
Możemy wykonać nieograniczoną liczbę iteracji, aby stworzyć pożądany kształt. Z punktu widzenia programowania, do tworzenia takich kształtów używana jest rekurencja.

Fraktale geometryczne
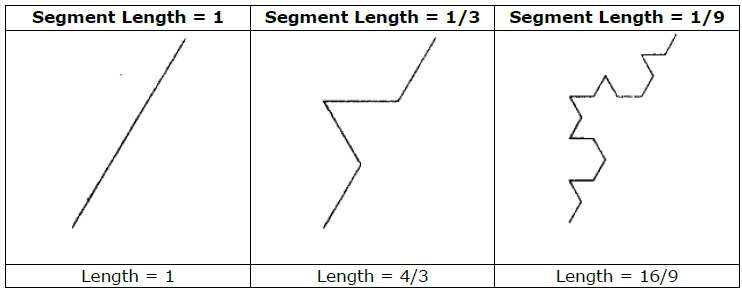
Fraktale geometryczne dotyczą kształtów występujących w naturze, które mają wymiary niecałkowite lub fraktalne. Aby geometrycznie skonstruować deterministyczny (nielosowy) samopodobny fraktal, zaczynamy od danego kształtu geometrycznego, zwanegoinitiator. Podczęści inicjatora są następnie zastępowane wzorcem zwanymgenerator.

Na przykład, jeśli użyjemy inicjatora i generatora pokazanego na powyższym rysunku, możemy skonstruować dobry wzór, powtarzając go. Każdy odcinek linii prostej w inicjatorze jest zastępowany czterema segmentami o jednakowej długości w każdym kroku. Współczynnik skalowania wynosi 1/3, więc wymiar fraktalny to D = ln 4 / ln 3 ≈ 1,2619.
Ponadto długość każdego odcinka linii w inicjatorze zwiększa się o współczynnik 4/3 na każdym kroku, tak że długość krzywej fraktalnej dąży do nieskończoności, gdy do krzywej dodaje się więcej szczegółów, jak pokazano na poniższym rysunku -
Animacja oznacza ożywienie dowolnego obiektu w grafice komputerowej. Ma moc wstrzykiwania energii i emocji w najbardziej pozornie nieożywione przedmioty. Animacja komputerowa i animacja generowana komputerowo to dwie kategorie animacji komputerowej. Można go przedstawić za pomocą filmu lub wideo.
Podstawową ideą animacji jest odtwarzanie zarejestrowanych obrazów z szybkością dostatecznie szybką, aby oszukać ludzkie oko i zinterpretować je jako ciągły ruch. Animacja może ożywić serię martwych obrazów. Animację można wykorzystać w wielu dziedzinach, takich jak rozrywka, projektowanie wspomagane komputerowo, wizualizacje naukowe, szkolenia, edukacja, handel elektroniczny i sztuka komputerowa.
Techniki animacji
Animatorzy wymyślili i wykorzystali wiele różnych technik animacji. Zasadniczo istnieje sześć technik animacji, które omówimy kolejno w tej sekcji.
Tradycyjna animacja (klatka po klatce)
Tradycyjnie większość animacji została wykonana ręcznie. Wszystkie klatki animacji musiały zostać narysowane ręcznie. Ponieważ każda sekunda animacji wymaga 24 klatek (filmu), nakład pracy potrzebny do stworzenia nawet najkrótszego filmu może być olbrzymi.
Klatek kluczowych
W tej technice układany jest scenorys, a następnie artyści rysują główne klatki animacji. Główne ramy to te, w których zachodzą wyraźne zmiany. Są kluczowymi punktami animacji. Klatek kluczowych wymaga, aby animator określił krytyczne lub kluczowe pozycje obiektów. Następnie komputer automatycznie wypełnia brakujące ramki, płynnie interpolując między tymi pozycjami.
Proceduralny
W animacji proceduralnej obiekty są animowane przez procedurę - zestaw reguł - a nie przez klatki kluczowe. Animator określa zasady i warunki początkowe oraz przeprowadza symulację. Reguły często opierają się na fizycznych regułach świata rzeczywistego wyrażonych równaniami matematycznymi.
Behawioralne
W animacji behawioralnej postać autonomiczna decyduje przynajmniej w pewnym stopniu o swoich działaniach. Daje to postaci pewną zdolność do improwizacji i uwalnia animatora od konieczności określania każdego szczegółu ruchu każdej postaci.
Oparte na wydajności (przechwytywanie ruchu)
Inną techniką jest Motion Capture, w której czujniki magnetyczne lub wizyjne rejestrują działania obiektu ludzkiego lub zwierzęcego w trzech wymiarach. Następnie komputer używa tych danych do animowania obiektu.
Ta technologia umożliwiła wielu słynnym sportowcom dostarczanie akcji postaci w sportowych grach wideo. Przechwytywanie ruchu jest dość popularne wśród animatorów, głównie dlatego, że niektóre z typowych ludzkich działań można uchwycić stosunkowo łatwo. Mogą jednak wystąpić poważne rozbieżności między kształtami lub wymiarami przedmiotu a charakterem graficznym, co może prowadzić do problemów z dokładnym wykonaniem.
Oparte fizycznie (dynamika)
W przeciwieństwie do kadrowania kluczowego i filmu, symulacja wykorzystuje prawa fizyki do generowania ruchu obrazów i innych obiektów. Symulacje można łatwo wykorzystać do tworzenia nieco różnych sekwencji przy zachowaniu realizmu fizycznego. Po drugie, symulacje w czasie rzeczywistym zapewniają wyższy stopień interaktywności, w której prawdziwa osoba może manewrować działaniami symulowanej postaci.
W przeciwieństwie do aplikacji opartych na funkcjach ramkowania klawiszy i ruchu, wybierających i modyfikujących ruchy tworzą wstępnie obliczoną bibliotekę ruchów. Jedną z wad symulacji jest wiedza specjalistyczna i czas potrzebny do wykonania odpowiednich systemów sterowania.
Kluczowe ramy
Klatka kluczowa to klatka, w której definiujemy zmiany w animacji. Każda klatka jest klatką kluczową, kiedy tworzymy animację klatka po klatce. Kiedy ktoś tworzy animację 3D na komputerze, zwykle nie określa dokładnej pozycji dowolnego obiektu na każdej klatce. Tworzą klatki kluczowe.
Klatki kluczowe to ważne klatki, podczas których obiekt zmienia swój rozmiar, kierunek, kształt lub inne właściwości. Następnie komputer oblicza wszystkie klatki pośrednie i oszczędza animatorowi ogromną ilość czasu. Poniższe ilustracje przedstawiają ramki narysowane przez użytkownika oraz ramki wygenerowane przez komputer.


Morphing
Przekształcanie kształtów obiektów z jednej postaci w inną nazywa się morfingiem. To jedna z najbardziej skomplikowanych przemian.

Przemiana wygląda tak, jakby dwa obrazy wtapiały się w siebie bardzo płynnym ruchem. Z technicznego punktu widzenia dwa obrazy są zniekształcone i występuje między nimi zanik.