Aprendizagem Não Supervisionada
Como o nome sugere, esse tipo de aprendizagem é feito sem a supervisão de um professor. Este processo de aprendizagem é independente. Durante o treinamento de RNA sob aprendizagem não supervisionada, os vetores de entrada de tipo semelhante são combinados para formar clusters. Quando um novo padrão de entrada é aplicado, a rede neural fornece uma resposta de saída indicando a classe à qual o padrão de entrada pertence. Nesse caso, não haveria feedback do ambiente sobre qual deveria ser a saída desejada e se está correta ou incorreta. Portanto, neste tipo de aprendizagem, a própria rede deve descobrir os padrões, características dos dados de entrada e a relação dos dados de entrada sobre a saída.
Vencedor-leva-todas as redes
Esses tipos de redes são baseados na regra de aprendizado competitivo e usarão a estratégia em que ele escolhe o neurônio com o maior total de entradas como vencedor. As conexões entre os neurônios de saída mostram a competição entre eles e um deles seria 'ON', o que significa que seria o vencedor e os outros seriam 'OFF'.
A seguir estão algumas das redes baseadas neste conceito simples, usando aprendizagem não supervisionada.
Hamming Network
Na maioria das redes neurais que usam aprendizagem não supervisionada, é essencial calcular a distância e realizar comparações. Este tipo de rede é a rede de Hamming, onde para cada vetor de entrada fornecido, seria agrupado em grupos diferentes. A seguir estão alguns recursos importantes da Hamming Networks -
Lippmann começou a trabalhar em redes Hamming em 1987.
É uma rede de camada única.
As entradas podem ser binárias {0, 1} ou bipolares {-1, 1}.
Os pesos da rede são calculados pelos vetores exemplares.
É uma rede de pesos fixos, o que significa que os pesos permaneceriam os mesmos mesmo durante o treinamento.
Rede máxima
Esta também é uma rede de peso fixo, que serve como uma sub-rede para selecionar o nó com a entrada mais alta. Todos os nós estão totalmente interconectados e existem pesos simétricos em todas essas interconexões ponderadas.
Arquitetura
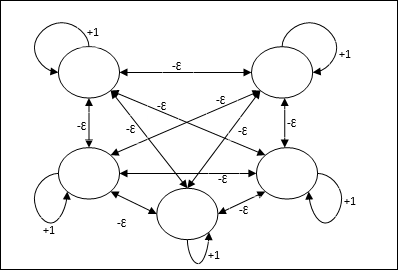
Ele usa o mecanismo que é um processo iterativo e cada nó recebe entradas inibitórias de todos os outros nós por meio de conexões. O único nó cujo valor é máximo seria ativo ou vencedor e as ativações de todos os outros nós seriam inativas. Max Net usa a função de ativação de identidade com $$ f (x) \: = \: \ begin {cases} x & if \: x> 0 \\ 0 & if \: x \ leq 0 \ end {cases} $$
A tarefa desta rede é realizada pelo peso de autoexcitação de +1 e magnitude de inibição mútua, que é definida como [0 <ɛ <$ \ frac {1} {m} $] onde “m” é o número total de nós.
Aprendizagem Competitiva em ANN
Ele está relacionado ao treinamento não supervisionado no qual os nós de saída tentam competir entre si para representar o padrão de entrada. Para entender esta regra de aprendizagem, teremos que entender a rede competitiva, que é explicada a seguir -
Conceito Básico de Rede Competitiva
Essa rede é como uma rede feed-forward de camada única, com conexão de feedback entre as saídas. As conexões entre as saídas são do tipo inibidoras, que são representadas por linhas pontilhadas, o que significa que os concorrentes nunca se sustentam.
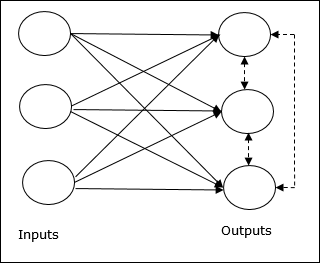
Conceito Básico de Regra de Aprendizagem Competitiva
Como dito anteriormente, haveria competição entre os nós de saída, então o conceito principal é - durante o treinamento, a unidade de saída que tem a maior ativação para um determinado padrão de entrada, será declarada a vencedora. Essa regra também é chamada de O vencedor leva tudo porque apenas o neurônio vencedor é atualizado e o restante dos neurônios são deixados inalterados.
Formulação Matemática
A seguir estão os três fatores importantes para a formulação matemática desta regra de aprendizagem -
Condição para ser um vencedor
Suponha que se um neurônio yk quer ser o vencedor, então haveria a seguinte condição
$$ y_ {k} \: = \: \ begin {cases} 1 & if \: v_ {k}> v_ {j} \: for \: all \: \: j, \: j \: \ neq \ : k \\ 0 & caso contrário \ end {casos} $$
Isso significa que se algum neurônio, digamos, yk quer ganhar, então seu campo local induzido (a saída da unidade de soma), digamos vk, deve ser o maior entre todos os outros neurônios da rede.
Condição da soma total do peso
Outra restrição sobre a regra de aprendizagem competitiva é que a soma total dos pesos para um determinado neurônio de saída será 1. Por exemplo, se considerarmos o neurônio k então
$$ \ displaystyle \ sum \ limits_ {k} w_ {kj} \: = \: 1 \: \: \: \: \: para \: todos \: \: k $$
Mudança de peso para o vencedor
Se um neurônio não responde ao padrão de entrada, então nenhum aprendizado ocorre naquele neurônio. No entanto, se um determinado neurônio vencer, os pesos correspondentes serão ajustados da seguinte forma -
$$ \ Delta w_ {kj} \: = \: \ begin {cases} - \ alpha (x_ {j} \: - \: w_ {kj}), & if \: neuron \: k \: wins \\ 0 e se \: neurônio \: k \: perdas \ end {casos} $$
Aqui $ \ alpha $ é a taxa de aprendizagem.
Isso mostra claramente que estamos favorecendo o neurônio vencedor ajustando seu peso e, se um neurônio for perdido, não precisamos nos preocupar em reajustar seu peso.
Algoritmo de agrupamento K-means
K-means é um dos algoritmos de agrupamento mais populares em que usamos o conceito de procedimento de partição. Começamos com uma partição inicial e movemos repetidamente os padrões de um cluster para outro, até obter um resultado satisfatório.
Algoritmo
Step 1 - Selecione kpontos como os centróides iniciais. Inicializark protótipos (w1,…,wk), por exemplo, podemos identificá-los com vetores de entrada escolhidos aleatoriamente -
$$ W_ {j} \: = \: i_ {p}, \: \: \: onde \: j \: \ in \ lbrace1, ...., k \ rbrace \: e \: p \: \ em \ lbrace1, ...., n \ rbrace $$
Cada cluster Cj está associado ao protótipo wj.
Step 2 - Repita a etapa 3-5 até que E não diminua mais ou a associação do cluster não seja mais alterada.
Step 3 - Para cada vetor de entrada ip Onde p ∈ {1,…,n}, colocar ip no cluster Cj* com o protótipo mais próximo wj* tendo a seguinte relação
$$ | i_ {p} \: - \: w_ {j *} | \: \ leq \: | i_ {p} \: - \: w_ {j} |, \: j \: \ in \ lbrace1, ...., k \ rbrace $$
Step 4 - Para cada cluster Cj, Onde j ∈ { 1,…,k}, atualize o protótipo wj para ser o centroide de todas as amostras atualmente em Cj , de modo a
$$ w_ {j} \: = \: \ sum_ {i_ {p} \ in C_ {j}} \ frac {i_ {p}} {| C_ {j} |} $$
Step 5 - Calcule o erro de quantização total da seguinte forma -
$$ E \: = \: \ sum_ {j = 1} ^ k \ sum_ {i_ {p} \ in w_ {j}} | i_ {p} \: - \: w_ {j} | ^ 2 $$
Neocognitron
É uma rede feedforward multicamadas, desenvolvida por Fukushima na década de 1980. Este modelo é baseado no aprendizado supervisionado e é usado para reconhecimento de padrões visuais, principalmente de caracteres escritos à mão. É basicamente uma extensão da rede Cognitron, que também foi desenvolvida por Fukushima em 1975.
Arquitetura
É uma rede hierárquica, que compreende muitas camadas e há um padrão de conectividade local nessas camadas.
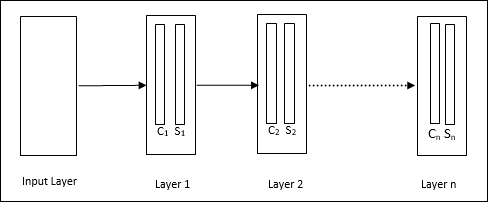
Como vimos no diagrama acima, o neocognitron é dividido em diferentes camadas conectadas e cada camada possui duas células. A explicação dessas células é a seguinte -
S-Cell - É chamada de célula simples, que é treinada para responder a um determinado padrão ou grupo de padrões.
C-Cell- É chamada de célula complexa, que combina a saída da célula S e simultaneamente diminui o número de unidades em cada matriz. Em outro sentido, a célula C desloca o resultado da célula S.
Algoritmo de treinamento
Descobriu-se que o treinamento do neocognitron progride camada por camada. Os pesos da camada de entrada para a primeira camada são treinados e congelados. Em seguida, os pesos da primeira camada para a segunda são treinados e assim por diante. Os cálculos internos entre a célula S e a célula C dependem dos pesos provenientes das camadas anteriores. Portanto, podemos dizer que o algoritmo de treinamento depende dos cálculos nas células S e C.
Cálculos na célula S
A célula S possui o sinal excitatório recebido da camada anterior e possui sinais inibitórios obtidos dentro da mesma camada.
$$ \ theta = \: \ sqrt {\ sum \ sum t_ {i} c_ {i} ^ 2} $$
Aqui, ti é o peso fixo e ci é a saída da célula C.
A entrada em escala da célula S pode ser calculada da seguinte forma -
$$ x \: = \: \ frac {1 \: + \: e} {1 \: + \: vw_ {0}} \: - \: 1 $$
Aqui, $ e \: = \: \ sum_i c_ {i} w_ {i} $
wi é o peso ajustado de célula C para célula S.
w0 é o peso ajustável entre a entrada e a célula S.
v é a entrada excitatória da célula C.
A ativação do sinal de saída é,
$$ s \: = \: \ begin {cases} x, & if \: x \ geq 0 \\ 0, & if \: x <0 \ end {cases} $$
Cálculos na célula C
A entrada líquida da camada C é
$$ C \: = \: \ displaystyle \ sum \ limits_i s_ {i} x_ {i} $$
Aqui, si é a saída da célula S e xi é o peso fixo da célula S para a célula C.
O resultado final é o seguinte -
$$ C_ {out} \: = \: \ begin {cases} \ frac {C} {a + C}, & if \: C> 0 \\ 0, & caso contrário \ end {cases} $$
Aqui ‘a’ é o parâmetro que depende do desempenho da rede.