การวิเคราะห์ข้อมูลขนาดใหญ่ - วงจรชีวิตของข้อมูล
วงจรชีวิตการขุดข้อมูลแบบดั้งเดิม
เพื่อให้เป็นกรอบในการจัดระเบียบงานที่องค์กรต้องการและนำเสนอข้อมูลเชิงลึกที่ชัดเจนจาก Big Data การคิดว่าเป็นวงจรที่มีขั้นตอนต่างๆ มันไม่ได้เป็นเชิงเส้นหมายความว่าขั้นตอนทั้งหมดเกี่ยวข้องกัน วัฏจักรนี้มีความคล้ายคลึงกันอย่างผิวเผินกับวงจรการขุดข้อมูลแบบดั้งเดิมตามที่อธิบายไว้ในCRISP methodology.
ระเบียบวิธี CRISP-DM
CRISP-DM methodologyซึ่งย่อมาจากกระบวนการมาตรฐานข้ามอุตสาหกรรมสำหรับการขุดข้อมูลเป็นวงจรที่อธิบายถึงวิธีการที่ใช้กันทั่วไปซึ่งผู้เชี่ยวชาญด้านการขุดข้อมูลใช้เพื่อแก้ไขปัญหาในการขุดข้อมูล BI แบบเดิม ยังคงถูกใช้ในทีมขุดข้อมูล BI แบบเดิม
ดูภาพประกอบต่อไปนี้ แสดงขั้นตอนสำคัญของวัฏจักรตามที่อธิบายโดยวิธีการ CRISP-DM และความสัมพันธ์ระหว่างกันอย่างไร
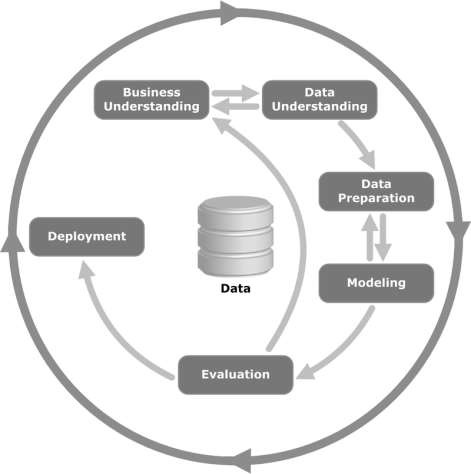
CRISP-DM เกิดขึ้นในปี 2539 และในปีหน้าได้ดำเนินการในฐานะโครงการของสหภาพยุโรปภายใต้โครงการริเริ่มการระดมทุน ESPRIT โครงการนี้นำโดย บริษัท 5 แห่ง ได้แก่ SPSS, Teradata, Daimler AG, NCR Corporation และ OHRA (บริษัท ประกันภัย) ในที่สุดโครงการก็รวมเข้ากับ SPSS วิธีการนี้มีรายละเอียดอย่างมากว่าควรระบุโครงการเหมืองข้อมูลอย่างไร
ตอนนี้ให้เราเรียนรู้เพิ่มเติมเล็กน้อยเกี่ยวกับแต่ละขั้นตอนที่เกี่ยวข้องกับวงจรชีวิต CRISP-DM -
Business Understanding- ระยะเริ่มต้นนี้มุ่งเน้นไปที่การทำความเข้าใจวัตถุประสงค์ของโครงการและข้อกำหนดจากมุมมองทางธุรกิจจากนั้นจึงแปลงความรู้นี้ให้เป็นคำจำกัดความของปัญหาการขุดข้อมูล แผนเบื้องต้นได้รับการออกแบบมาเพื่อให้บรรลุวัตถุประสงค์ สามารถใช้รูปแบบการตัดสินใจโดยเฉพาะแบบจำลองที่สร้างขึ้นโดยใช้แบบจำลองการตัดสินใจและมาตรฐานสัญกรณ์ได้
Data Understanding - ขั้นตอนการทำความเข้าใจข้อมูลเริ่มต้นด้วยการรวบรวมข้อมูลเบื้องต้นและดำเนินกิจกรรมต่างๆเพื่อทำความคุ้นเคยกับข้อมูลเพื่อระบุปัญหาด้านคุณภาพของข้อมูลค้นหาข้อมูลเชิงลึกแรกของข้อมูลหรือตรวจหาชุดย่อยที่น่าสนใจเพื่อสร้างสมมติฐานสำหรับข้อมูลที่ซ่อนอยู่
Data Preparation- ขั้นตอนการเตรียมข้อมูลครอบคลุมกิจกรรมทั้งหมดเพื่อสร้างชุดข้อมูลขั้นสุดท้าย (ข้อมูลที่จะป้อนเข้าในเครื่องมือการสร้างแบบจำลอง) จากข้อมูลดิบเริ่มต้น งานจัดเตรียมข้อมูลมีแนวโน้มที่จะดำเนินการหลายครั้งและไม่เป็นไปตามลำดับที่กำหนด งานรวมถึงตารางบันทึกและการเลือกแอตทริบิวต์ตลอดจนการแปลงและทำความสะอาดข้อมูลสำหรับเครื่องมือสร้างแบบจำลอง
Modeling- ในขั้นตอนนี้เทคนิคการสร้างแบบจำลองต่างๆจะถูกเลือกและนำไปใช้และพารามิเตอร์จะถูกปรับเทียบเป็นค่าที่เหมาะสมที่สุด โดยทั่วไปมีหลายเทคนิคสำหรับปัญหาประเภทการขุดข้อมูลเดียวกัน เทคนิคบางอย่างมีข้อกำหนดเฉพาะเกี่ยวกับรูปแบบของข้อมูล ดังนั้นจึงมักจะต้องย้อนกลับไปสู่ขั้นตอนการเตรียมข้อมูล
Evaluation- ในขั้นตอนนี้ในโครงการคุณได้สร้างแบบจำลอง (หรือแบบจำลอง) ที่ดูเหมือนจะมีคุณภาพสูงจากมุมมองการวิเคราะห์ข้อมูล ก่อนดำเนินการปรับใช้โมเดลขั้นสุดท้ายสิ่งสำคัญคือต้องประเมินโมเดลอย่างละเอียดและทบทวนขั้นตอนที่ดำเนินการเพื่อสร้างโมเดลเพื่อให้แน่ใจว่าโมเดลนั้นบรรลุวัตถุประสงค์ทางธุรกิจอย่างเหมาะสม
วัตถุประสงค์หลักคือเพื่อตรวจสอบว่ามีปัญหาสำคัญทางธุรกิจที่ไม่ได้รับการพิจารณาอย่างเพียงพอหรือไม่ ในตอนท้ายของขั้นตอนนี้ควรมีการตัดสินใจเกี่ยวกับการใช้ผลการขุดข้อมูล
Deployment- การสร้างแบบจำลองโดยทั่วไปไม่ใช่จุดสิ้นสุดของโครงการ แม้ว่าวัตถุประสงค์ของแบบจำลองจะเพื่อเพิ่มความรู้เกี่ยวกับข้อมูล แต่ความรู้ที่ได้รับจะต้องได้รับการจัดระเบียบและนำเสนอในรูปแบบที่เป็นประโยชน์ต่อลูกค้า
ขึ้นอยู่กับความต้องการขั้นตอนการปรับใช้อาจทำได้ง่ายเพียงแค่สร้างรายงานหรือซับซ้อนพอ ๆ กับการใช้การให้คะแนนข้อมูลที่ทำซ้ำได้ (เช่นการจัดสรรเซ็กเมนต์) หรือกระบวนการขุดข้อมูล
ในหลายกรณีจะเป็นลูกค้าไม่ใช่นักวิเคราะห์ข้อมูลที่จะดำเนินการตามขั้นตอนการปรับใช้ แม้ว่านักวิเคราะห์จะปรับใช้แบบจำลอง แต่สิ่งสำคัญคือลูกค้าต้องเข้าใจล่วงหน้าถึงการกระทำที่จะต้องดำเนินการเพื่อให้สามารถใช้ประโยชน์จากแบบจำลองที่สร้างขึ้นได้จริง
ระเบียบวิธี SEMMA
SEMMA เป็นอีกวิธีหนึ่งที่พัฒนาโดย SAS สำหรับการสร้างแบบจำลองการขุดข้อมูล ย่อมาจากSกว้างขวาง Explore, Mโอดิฟาย Model และ Asses. นี่คือคำอธิบายสั้น ๆ ของขั้นตอน -
Sample- กระบวนการเริ่มต้นด้วยการสุ่มตัวอย่างข้อมูลเช่นการเลือกชุดข้อมูลสำหรับการสร้างแบบจำลอง ชุดข้อมูลควรมีขนาดใหญ่พอที่จะมีข้อมูลเพียงพอในการดึงข้อมูล แต่มีขนาดเล็กพอที่จะใช้อย่างมีประสิทธิภาพ ระยะนี้ยังเกี่ยวข้องกับการแบ่งข้อมูล
Explore - ระยะนี้ครอบคลุมความเข้าใจของข้อมูลโดยการค้นหาความสัมพันธ์ที่คาดการณ์ไว้และไม่คาดคิดระหว่างตัวแปรและความผิดปกติด้วยความช่วยเหลือของการแสดงข้อมูล
Modify - ขั้นตอนการปรับเปลี่ยนประกอบด้วยวิธีการในการเลือกสร้างและแปลงตัวแปรเพื่อเตรียมการสร้างแบบจำลองข้อมูล
Model - ในขั้นตอนของโมเดลมุ่งเน้นไปที่การใช้เทคนิคการสร้างแบบจำลองต่างๆ (การขุดข้อมูล) กับตัวแปรที่เตรียมไว้เพื่อสร้างแบบจำลองที่อาจให้ผลลัพธ์ที่ต้องการ
Assess - การประเมินผลการสร้างแบบจำลองแสดงความน่าเชื่อถือและประโยชน์ของแบบจำลองที่สร้างขึ้น
ความแตกต่างที่สำคัญระหว่าง CRISM – DM และ SEMMA คือ SEMMA มุ่งเน้นไปที่ด้านการสร้างแบบจำลองในขณะที่ CRISP-DM ให้ความสำคัญกับขั้นตอนของวงจรก่อนที่จะสร้างแบบจำลองเช่นการทำความเข้าใจปัญหาทางธุรกิจที่จะแก้ไขทำความเข้าใจและประมวลผลข้อมูลล่วงหน้า ใช้เป็นอินพุตตัวอย่างเช่นอัลกอริทึมการเรียนรู้ของเครื่อง
วงจรชีวิตข้อมูลขนาดใหญ่
ในบริบทข้อมูลขนาดใหญ่ในปัจจุบันแนวทางก่อนหน้านี้อาจไม่สมบูรณ์หรือไม่เหมาะสม ตัวอย่างเช่นวิธีการของ SEMMA จะไม่สนใจการรวบรวมข้อมูลและการประมวลผลล่วงหน้าของแหล่งข้อมูลต่างๆ โดยปกติขั้นตอนเหล่านี้จะเป็นงานส่วนใหญ่ในโครงการข้อมูลขนาดใหญ่ที่ประสบความสำเร็จ
วงจรการวิเคราะห์ข้อมูลขนาดใหญ่สามารถอธิบายได้ในขั้นตอนต่อไปนี้ -
- นิยามปัญหาทางธุรกิจ
- Research
- การประเมินทรัพยากรมนุษย์
- การได้มาของข้อมูล
- ข้อมูล Munging
- การจัดเก็บข้อมูล
- การวิเคราะห์ข้อมูลเชิงสำรวจ
- การเตรียมข้อมูลสำหรับการสร้างแบบจำลองและการประเมิน
- Modeling
- Implementation
ในส่วนนี้เราจะให้ความสำคัญกับแต่ละขั้นตอนของวงจรชีวิตข้อมูลขนาดใหญ่
นิยามปัญหาทางธุรกิจ
นี่เป็นจุดที่พบบ่อยในวงจรชีวิตการวิเคราะห์ BI และข้อมูลขนาดใหญ่แบบดั้งเดิม โดยปกติจะเป็นขั้นตอนที่ไม่สำคัญของโครงการข้อมูลขนาดใหญ่เพื่อกำหนดปัญหาและประเมินอย่างถูกต้องว่าอาจมีโอกาสได้รับมากเพียงใดสำหรับองค์กร ดูเหมือนชัดเจนที่จะพูดถึงเรื่องนี้ แต่ต้องมีการประเมินว่าผลกำไรและต้นทุนที่คาดหวังของโครงการคืออะไร
การวิจัย
วิเคราะห์สิ่งที่ บริษัท อื่นทำในสถานการณ์เดียวกัน สิ่งนี้เกี่ยวข้องกับการมองหาโซลูชันที่เหมาะสมกับ บริษัท ของคุณแม้ว่าจะเกี่ยวข้องกับการปรับใช้โซลูชันอื่น ๆ ให้เข้ากับทรัพยากรและข้อกำหนดที่ บริษัท ของคุณมี ในขั้นตอนนี้ควรกำหนดวิธีการสำหรับขั้นตอนในอนาคต
การประเมินทรัพยากรมนุษย์
เมื่อกำหนดปัญหาแล้วก็สมเหตุสมผลที่จะวิเคราะห์ต่อไปว่าเจ้าหน้าที่ปัจจุบันสามารถดำเนินโครงการได้สำเร็จหรือไม่ ทีม BI แบบดั้งเดิมอาจไม่สามารถส่งมอบโซลูชันที่ดีที่สุดให้กับทุกขั้นตอนได้ดังนั้นจึงควรพิจารณาก่อนเริ่มโครงการหากจำเป็นต้องจ้างบุคคลภายนอกในส่วนหนึ่งของโครงการหรือจ้างคนเพิ่ม
การได้มาของข้อมูล
ส่วนนี้เป็นกุญแจสำคัญในวงจรชีวิตข้อมูลขนาดใหญ่ กำหนดว่าจะต้องใช้โปรไฟล์ประเภทใดในการส่งมอบผลิตภัณฑ์ข้อมูลที่เป็นผลลัพธ์ การรวบรวมข้อมูลเป็นขั้นตอนที่ไม่สำคัญของกระบวนการ โดยปกติจะเกี่ยวข้องกับการรวบรวมข้อมูลที่ไม่มีโครงสร้างจากแหล่งต่างๆ ในการยกตัวอย่างอาจเกี่ยวข้องกับการเขียนโปรแกรมรวบรวมข้อมูลเพื่อดึงบทวิจารณ์จากเว็บไซต์ สิ่งนี้เกี่ยวข้องกับการจัดการกับข้อความซึ่งโดยปกติแล้วอาจเป็นภาษาที่แตกต่างกันซึ่งต้องใช้เวลานานพอสมควร
ข้อมูล Munging
เมื่อข้อมูลถูกดึงออกมาเช่นจากเว็บข้อมูลจะต้องถูกจัดเก็บในรูปแบบที่ใช้งานง่าย หากต้องการดูตัวอย่างบทวิจารณ์ต่อไปสมมติว่ามีการดึงข้อมูลมาจากไซต์ต่างๆซึ่งแต่ละไซต์มีการแสดงข้อมูลที่แตกต่างกัน
สมมติว่าแหล่งข้อมูลหนึ่งให้บทวิจารณ์ในแง่ของการให้คะแนนเป็นดาวดังนั้นจึงเป็นไปได้ที่จะอ่านสิ่งนี้เป็นการแมปสำหรับตัวแปรการตอบสนอง y ∈ {1, 2, 3, 4, 5}. แหล่งข้อมูลอื่นให้การตรวจสอบโดยใช้ระบบลูกศรสองอันระบบหนึ่งสำหรับการลงคะแนนและอีกระบบหนึ่งสำหรับการลงคะแนน นี่จะบ่งบอกถึงตัวแปรการตอบสนองของแบบฟอร์มy ∈ {positive, negative}.
ในการรวมแหล่งข้อมูลทั้งสองแหล่งต้องมีการตัดสินใจเพื่อให้การแสดงการตอบสนองทั้งสองนี้เทียบเท่ากัน สิ่งนี้อาจเกี่ยวข้องกับการแปลงการแสดงการตอบสนองของแหล่งข้อมูลแรกเป็นรูปแบบที่สองโดยพิจารณาว่าหนึ่งดาวเป็นค่าลบและห้าดาวเป็นบวก กระบวนการนี้มักจะต้องมีการจัดสรรเวลาจำนวนมากเพื่อให้ได้คุณภาพที่ดี
การจัดเก็บข้อมูล
เมื่อประมวลผลข้อมูลแล้วบางครั้งจำเป็นต้องจัดเก็บไว้ในฐานข้อมูล เทคโนโลยีข้อมูลขนาดใหญ่มีทางเลือกมากมายเกี่ยวกับประเด็นนี้ ทางเลือกที่พบบ่อยที่สุดคือการใช้ Hadoop File System สำหรับพื้นที่จัดเก็บข้อมูลที่ให้ SQL เวอร์ชัน จำกัด แก่ผู้ใช้ซึ่งเรียกว่า HIVE Query Language สิ่งนี้ช่วยให้งานการวิเคราะห์ส่วนใหญ่สามารถทำได้ในลักษณะเดียวกันกับที่ทำในคลังข้อมูล BI แบบเดิมจากมุมมองของผู้ใช้ ตัวเลือกการจัดเก็บอื่น ๆ ที่ต้องพิจารณา ได้แก่ MongoDB, Redis และ SPARK
ขั้นตอนของวงจรนี้เกี่ยวข้องกับความรู้ด้านทรัพยากรมนุษย์ในแง่ของความสามารถในการใช้สถาปัตยกรรมที่แตกต่างกัน คลังข้อมูลแบบดั้งเดิมเวอร์ชันดัดแปลงยังคงถูกใช้ในแอปพลิเคชันขนาดใหญ่ ตัวอย่างเช่น teradata และ IBM นำเสนอฐานข้อมูล SQL ที่สามารถจัดการข้อมูลจำนวนเทราไบต์ โซลูชันโอเพนซอร์สเช่น postgreSQL และ MySQL ยังคงถูกใช้สำหรับแอปพลิเคชันขนาดใหญ่
แม้ว่าจะมีความแตกต่างกันในการทำงานของการจัดเก็บข้อมูลที่แตกต่างกันในพื้นหลัง แต่จากฝั่งไคลเอ็นต์โซลูชันส่วนใหญ่จะมี SQL API ดังนั้นการมีความเข้าใจ SQL เป็นอย่างดีจึงยังคงเป็นทักษะหลักที่ต้องมีสำหรับการวิเคราะห์ข้อมูลขนาดใหญ่
ขั้นตอนนี้เบื้องต้นน่าจะเป็นหัวข้อที่สำคัญที่สุดในทางปฏิบัติไม่เป็นความจริง มันไม่ได้เป็นเวทีสำคัญ เป็นไปได้ที่จะใช้โซลูชันข้อมูลขนาดใหญ่ที่จะทำงานกับข้อมูลแบบเรียลไทม์ดังนั้นในกรณีนี้เราจำเป็นต้องรวบรวมข้อมูลเพื่อพัฒนาแบบจำลองจากนั้นจึงนำไปใช้แบบเรียลไทม์ ดังนั้นจึงไม่จำเป็นต้องจัดเก็บข้อมูลอย่างเป็นทางการเลย
การวิเคราะห์ข้อมูลเชิงสำรวจ
เมื่อข้อมูลได้รับการทำความสะอาดและจัดเก็บในลักษณะที่สามารถดึงข้อมูลเชิงลึกออกมาได้แล้วขั้นตอนการสำรวจข้อมูลจะมีผลบังคับ วัตถุประสงค์ของขั้นตอนนี้คือการทำความเข้าใจข้อมูลโดยปกติจะทำด้วยเทคนิคทางสถิติและการลงจุดข้อมูลด้วย นี่เป็นขั้นตอนที่ดีในการประเมินว่าคำจำกัดความของปัญหานั้นสมเหตุสมผลหรือเป็นไปได้
การเตรียมข้อมูลสำหรับการสร้างแบบจำลองและการประเมิน
ขั้นตอนนี้เกี่ยวข้องกับการปรับรูปร่างข้อมูลที่ล้างแล้วที่ดึงมาก่อนหน้านี้และใช้การประมวลผลล่วงหน้าทางสถิติสำหรับการใส่ค่าที่ขาดหายไปการตรวจจับค่าผิดปกติการทำให้เป็นมาตรฐานการแยกคุณลักษณะและการเลือกคุณสมบัติ
การสร้างแบบจำลอง
ขั้นตอนก่อนหน้านี้ควรมีการสร้างชุดข้อมูลหลายชุดสำหรับการฝึกอบรมและการทดสอบตัวอย่างเช่นแบบจำลองการคาดการณ์ ขั้นตอนนี้เกี่ยวข้องกับการลองใช้โมเดลต่างๆและรอคอยที่จะแก้ไขปัญหาทางธุรกิจที่อยู่ในมือ ในทางปฏิบัติเป็นที่ต้องการโดยปกติที่โมเดลจะให้ข้อมูลเชิงลึกเกี่ยวกับธุรกิจ สุดท้ายโมเดลที่ดีที่สุดหรือการรวมกันของแบบจำลองจะถูกเลือกโดยประเมินประสิทธิภาพของชุดข้อมูลด้านซ้าย
การนำไปใช้
ในขั้นตอนนี้ผลิตภัณฑ์ข้อมูลที่พัฒนาจะถูกนำไปใช้ในท่อส่งข้อมูลของ บริษัท สิ่งนี้เกี่ยวข้องกับการตั้งค่ารูปแบบการตรวจสอบความถูกต้องในขณะที่ผลิตภัณฑ์ข้อมูลกำลังทำงานเพื่อติดตามประสิทธิภาพ ตัวอย่างเช่นในกรณีของการใช้แบบจำลองเชิงคาดการณ์ขั้นตอนนี้จะเกี่ยวข้องกับการใช้โมเดลกับข้อมูลใหม่และเมื่อมีการตอบสนองแล้วให้ประเมินโมเดล