การวิเคราะห์ข้อมูลขนาดใหญ่ - วิธีการทางสถิติ
เมื่อวิเคราะห์ข้อมูลเป็นไปได้ที่จะมีแนวทางทางสถิติ เครื่องมือพื้นฐานที่จำเป็นในการวิเคราะห์ขั้นพื้นฐาน ได้แก่ -
- การวิเคราะห์สหสัมพันธ์
- การวิเคราะห์ความแปรปรวน
- การทดสอบสมมติฐาน
เมื่อทำงานกับชุดข้อมูลขนาดใหญ่จะไม่เกี่ยวข้องกับปัญหาเนื่องจากวิธีการเหล่านี้ไม่ได้ใช้การคำนวณอย่างเข้มข้นยกเว้นการวิเคราะห์สหสัมพันธ์ ในกรณีนี้คุณสามารถเก็บตัวอย่างได้เสมอและผลลัพธ์ควรมีประสิทธิภาพ
การวิเคราะห์สหสัมพันธ์
การวิเคราะห์สหสัมพันธ์พยายามค้นหาความสัมพันธ์เชิงเส้นระหว่างตัวแปรตัวเลข สิ่งนี้สามารถใช้ได้ในสถานการณ์ที่แตกต่างกัน การใช้งานทั่วไปอย่างหนึ่งคือการวิเคราะห์ข้อมูลเชิงสำรวจในส่วนที่ 16.0.2 ของหนังสือมีตัวอย่างพื้นฐานของแนวทางนี้ ก่อนอื่นเมตริกสหสัมพันธ์ที่ใช้ในตัวอย่างที่กล่าวถึงจะขึ้นอยู่กับPearson coefficient. อย่างไรก็ตามมีตัวชี้วัดความสัมพันธ์ที่น่าสนใจอีกตัวหนึ่งที่ไม่ได้รับผลกระทบจากค่าผิดปกติ เมตริกนี้เรียกว่าสหสัมพันธ์สเปียร์แมน
spearman correlation เมตริกมีประสิทธิภาพมากกว่าการมีค่าผิดปกติมากกว่าวิธีของเพียร์สันและให้ค่าประมาณของความสัมพันธ์เชิงเส้นระหว่างตัวแปรตัวเลขได้ดีขึ้นเมื่อข้อมูลไม่กระจายตามปกติ
library(ggplot2)
# Select variables that are interesting to compare pearson and spearman
correlation methods.
x = diamonds[, c('x', 'y', 'z', 'price')]
# From the histograms we can expect differences in the correlations of both
metrics.
# In this case as the variables are clearly not normally distributed, the
spearman correlation
# is a better estimate of the linear relation among numeric variables.
par(mfrow = c(2,2))
colnm = names(x)
for(i in 1:4) {
hist(x[[i]], col = 'deepskyblue3', main = sprintf('Histogram of %s', colnm[i]))
}
par(mfrow = c(1,1))จากฮิสโตแกรมในรูปต่อไปนี้เราสามารถคาดหวังความแตกต่างในความสัมพันธ์ของเมตริกทั้งสอง ในกรณีนี้เนื่องจากตัวแปรไม่ได้กระจายอย่างชัดเจนตามปกติความสัมพันธ์ของสเปียร์แมนจึงเป็นการประมาณค่าความสัมพันธ์เชิงเส้นระหว่างตัวแปรตัวเลขได้ดีกว่า
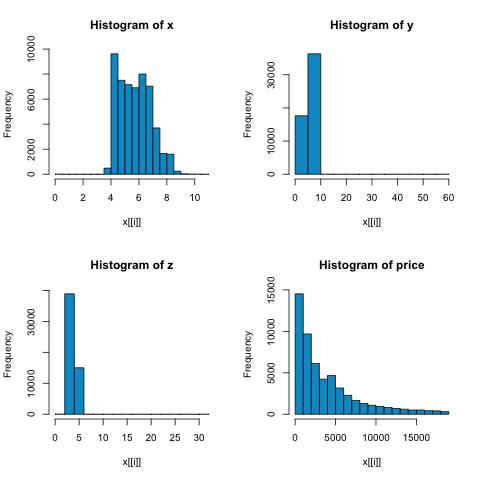
ในการคำนวณความสัมพันธ์ใน R ให้เปิดไฟล์ bda/part2/statistical_methods/correlation/correlation.R ที่มีส่วนรหัสนี้
## Correlation Matrix - Pearson and spearman
cor_pearson <- cor(x, method = 'pearson')
cor_spearman <- cor(x, method = 'spearman')
### Pearson Correlation
print(cor_pearson)
# x y z price
# x 1.0000000 0.9747015 0.9707718 0.8844352
# y 0.9747015 1.0000000 0.9520057 0.8654209
# z 0.9707718 0.9520057 1.0000000 0.8612494
# price 0.8844352 0.8654209 0.8612494 1.0000000
### Spearman Correlation
print(cor_spearman)
# x y z price
# x 1.0000000 0.9978949 0.9873553 0.9631961
# y 0.9978949 1.0000000 0.9870675 0.9627188
# z 0.9873553 0.9870675 1.0000000 0.9572323
# price 0.9631961 0.9627188 0.9572323 1.0000000การทดสอบไคสแควร์
การทดสอบไคสแควร์ช่วยให้เราทดสอบว่าตัวแปรสุ่มสองตัวเป็นอิสระหรือไม่ ซึ่งหมายความว่าการแจกแจงความน่าจะเป็นของแต่ละตัวแปรจะไม่มีผลต่อตัวแปรอื่น ในการประเมินการทดสอบใน R เราต้องสร้างตารางฉุกเฉินก่อนจากนั้นส่งตารางไปที่chisq.test R ฟังก์ชัน
ตัวอย่างเช่นลองตรวจสอบว่ามีความสัมพันธ์ระหว่างตัวแปร: การเจียระไนและสีจากชุดข้อมูลของเพชรหรือไม่ การทดสอบถูกกำหนดอย่างเป็นทางการว่า -
- H0: การเจียระไนแบบแปรผันและเพชรเป็นอิสระ
- H1: การเจียระไนแบบแปรผันและเพชรไม่เป็นอิสระ
เราจะถือว่ามีความสัมพันธ์ระหว่างตัวแปรทั้งสองนี้ตามชื่อของพวกมัน แต่การทดสอบสามารถให้ "กฎ" ที่เป็นวัตถุประสงค์เพื่อบอกว่าผลลัพธ์นี้มีความสำคัญเพียงใดหรือไม่
ในข้อมูลโค้ดต่อไปนี้เราพบว่า p-value ของการทดสอบคือ 2.2e-16 ซึ่งแทบจะเป็นศูนย์ในทางปฏิบัติ จากนั้นหลังจากทำการทดสอบโดยทำMonte Carlo simulationเราพบว่าค่า p เท่ากับ 0.0004998 ซึ่งยังค่อนข้างต่ำกว่าเกณฑ์ 0.05 ผลลัพธ์นี้หมายความว่าเราปฏิเสธสมมติฐานว่าง (H0) ดังนั้นเราจึงเชื่อตัวแปรcut และ color ไม่เป็นอิสระ
library(ggplot2)
# Use the table function to compute the contingency table
tbl = table(diamonds$cut, diamonds$color)
tbl
# D E F G H I J
# Fair 163 224 312 314 303 175 119
# Good 662 933 909 871 702 522 307
# Very Good 1513 2400 2164 2299 1824 1204 678
# Premium 1603 2337 2331 2924 2360 1428 808
# Ideal 2834 3903 3826 4884 3115 2093 896
# In order to run the test we just use the chisq.test function.
chisq.test(tbl)
# Pearson’s Chi-squared test
# data: tbl
# X-squared = 310.32, df = 24, p-value < 2.2e-16
# It is also possible to compute the p-values using a monte-carlo simulation
# It's needed to add the simulate.p.value = TRUE flag and the amount of
simulations
chisq.test(tbl, simulate.p.value = TRUE, B = 2000)
# Pearson’s Chi-squared test with simulated p-value (based on 2000 replicates)
# data: tbl
# X-squared = 310.32, df = NA, p-value = 0.0004998การทดสอบ T
ความคิดของ t-testคือการประเมินว่ามีความแตกต่างในการแจกแจงตัวแปรตัวเลข # ระหว่างกลุ่มต่างๆของตัวแปรเล็กน้อยหรือไม่ เพื่อแสดงให้เห็นถึงสิ่งนี้ฉันจะเลือกระดับของระดับยุติธรรมและระดับอุดมคติของการตัดตัวแปรแฟคเตอร์จากนั้นเราจะเปรียบเทียบค่าตัวแปรตัวเลขระหว่างสองกลุ่มนั้น
data = diamonds[diamonds$cut %in% c('Fair', 'Ideal'), ]
data$cut = droplevels.factor(data$cut) # Drop levels that aren’t used from the
cut variable
df1 = data[, c('cut', 'price')]
# We can see the price means are different for each group
tapply(df1$price, df1$cut, mean)
# Fair Ideal
# 4358.758 3457.542การทดสอบ t ถูกนำไปใช้ใน R พร้อมกับ t.testฟังก์ชัน อินเทอร์เฟซของสูตรกับ t.test เป็นวิธีที่ง่ายที่สุดในการใช้แนวคิดก็คือตัวแปรตัวเลขจะถูกอธิบายโดยตัวแปรกลุ่ม
ตัวอย่างเช่น: t.test(numeric_variable ~ group_variable, data = data). ในตัวอย่างก่อนหน้านี้ไฟล์numeric_variable คือ price และ group_variable คือ cut.
จากมุมมองทางสถิติเรากำลังทดสอบว่าการแจกแจงของตัวแปรตัวเลขระหว่างสองกลุ่มมีความแตกต่างกันหรือไม่ โดยปกติการทดสอบสมมติฐานจะอธิบายด้วยสมมติฐานว่าง (H0) และสมมติฐานทางเลือก (H1)
H0: ไม่มีความแตกต่างในการกระจายของตัวแปรราคาระหว่างกลุ่มยุติธรรมและอุดมคติ
H1 มีความแตกต่างในการกระจายของตัวแปรราคาระหว่างกลุ่มยุติธรรมและอุดมคติ
สิ่งต่อไปนี้สามารถนำไปใช้ใน R ด้วยรหัสต่อไปนี้ -
t.test(price ~ cut, data = data)
# Welch Two Sample t-test
#
# data: price by cut
# t = 9.7484, df = 1894.8, p-value < 2.2e-16
# alternative hypothesis: true difference in means is not equal to 0
# 95 percent confidence interval:
# 719.9065 1082.5251
# sample estimates:
# mean in group Fair mean in group Ideal
# 4358.758 3457.542
# Another way to validate the previous results is to just plot the
distributions using a box-plot
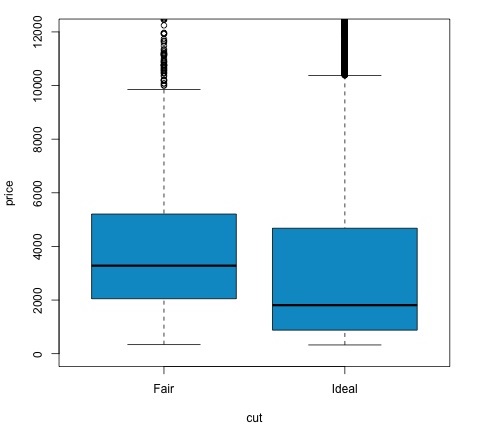
plot(price ~ cut, data = data, ylim = c(0,12000),
col = 'deepskyblue3')เราสามารถวิเคราะห์ผลการทดสอบโดยตรวจสอบว่าค่า p ต่ำกว่า 0.05 หรือไม่ หากเป็นกรณีนี้เราจะคงสมมติฐานทางเลือกไว้ ซึ่งหมายความว่าเราพบความแตกต่างของราคาในสองระดับของปัจจัยตัด ตามชื่อของระดับที่เราคาดหวังผลลัพธ์นี้ แต่เราไม่คาดคิดมาก่อนว่าราคาเฉลี่ยในกลุ่ม Fail จะสูงกว่าในกลุ่ม Ideal เราสามารถเห็นสิ่งนี้ได้โดยการเปรียบเทียบค่าเฉลี่ยของแต่ละปัจจัย
plotคำสั่งสร้างกราฟที่แสดงความสัมพันธ์ระหว่างราคาและตัวแปรตัด มันเป็นกล่องพล็อต เราได้กล่าวถึงพล็อตนี้ในหัวข้อ 16.0.1 แต่โดยทั่วไปแล้วจะแสดงการกระจายของตัวแปรราคาสำหรับการตัดสองระดับที่เรากำลังวิเคราะห์
การวิเคราะห์ความแปรปรวน
การวิเคราะห์ความแปรปรวน (ANOVA) เป็นแบบจำลองทางสถิติที่ใช้ในการวิเคราะห์ความแตกต่างระหว่างการแจกแจงแบบกลุ่มโดยการเปรียบเทียบค่าเฉลี่ยและความแปรปรวนของแต่ละกลุ่มแบบจำลองนี้ได้รับการพัฒนาโดย Ronald Fisher ANOVA จัดให้มีการทดสอบทางสถิติว่าค่าเฉลี่ยของกลุ่มต่างๆมีค่าเท่ากันหรือไม่ดังนั้นจึงสรุปผลการทดสอบทีให้มากกว่าสองกลุ่ม
ANOVA มีประโยชน์ในการเปรียบเทียบกลุ่มสามกลุ่มขึ้นไปอย่างมีนัยสำคัญทางสถิติเนื่องจากการทำการทดสอบ t สองตัวอย่างหลายตัวอย่างจะส่งผลให้มีโอกาสเพิ่มขึ้นในการทำข้อผิดพลาดทางสถิติประเภท I
ในแง่ของการให้คำอธิบายทางคณิตศาสตร์จำเป็นต้องมีสิ่งต่อไปนี้เพื่อทำความเข้าใจการทดสอบ
x ij = x + (x i - x) + (x ij - x)
สิ่งนี้นำไปสู่รูปแบบต่อไปนี้ -
x ij = μ + α i + ∈ ij
โดยที่μคือค่าเฉลี่ยแกรนด์และα iคือค่าเฉลี่ยกลุ่มที่ เงื่อนไขข้อผิดพลาด∈ ijถือว่าเป็น iid จากการแจกแจงปกติ สมมติฐานว่างของการทดสอบคือ -
α 1 = α 2 = … = α k
ในแง่ของการคำนวณสถิติทดสอบเราต้องคำนวณค่าสองค่า -
- ผลรวมของกำลังสองระหว่างความแตกต่างของกลุ่ม -
$$ SSD_B = \ sum_ {i} ^ {k} \ sum_ {j} ^ {n} (\ bar {x _ {\ bar {i}}} - \ bar {x}) ^ 2 $$
- ผลรวมของกำลังสองภายในกลุ่ม
$$ SSD_W = \ sum_ {i} ^ {k} \ sum_ {j} ^ {n} (\ bar {x _ {\ bar {ij}}} - \ bar {x _ {\ bar {i}}}) ^ 2 $$
โดยที่ SSD Bมีระดับอิสระ k − 1 และ SSD Wมีระดับอิสระเป็น N − k จากนั้นเราสามารถกำหนดความแตกต่างของค่าเฉลี่ยกำลังสองสำหรับแต่ละเมตริก
MS B = SSD B / (k - 1)
MS w = SSD w / (N - k)
สุดท้ายสถิติการทดสอบใน ANOVA ถูกกำหนดให้เป็นอัตราส่วนของสองปริมาณข้างต้น
F = MS B / MS w
ซึ่งตามด้วยการแจกแจงแบบ F โดยมีองศาอิสระk − 1และN − k ถ้าสมมุติฐานว่างเป็นจริง F น่าจะใกล้เคียงกับ 1 มิฉะนั้นค่าเฉลี่ยระหว่างกลุ่ม MSB จะมีขนาดใหญ่ซึ่งส่งผลให้ค่า F มีค่ามาก
โดยทั่วไป ANOVA จะตรวจสอบแหล่งที่มาทั้งสองของความแปรปรวนทั้งหมดและดูว่าส่วนใดมีส่วนทำให้มากกว่า ด้วยเหตุนี้จึงเรียกว่าการวิเคราะห์ความแปรปรวนแม้ว่าเจตนาจะเปรียบเทียบค่าเฉลี่ยกลุ่มก็ตาม
ในแง่ของการคำนวณทางสถิตินั้นจริงๆแล้วมันค่อนข้างง่ายที่จะทำใน R ตัวอย่างต่อไปนี้จะแสดงให้เห็นถึงวิธีการทำและพล็อตผลลัพธ์
library(ggplot2)
# We will be using the mtcars dataset
head(mtcars)
# mpg cyl disp hp drat wt qsec vs am gear carb
# Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
# Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
# Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
# Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
# Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
# Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
# Let's see if there are differences between the groups of cyl in the mpg variable.
data = mtcars[, c('mpg', 'cyl')]
fit = lm(mpg ~ cyl, data = mtcars)
anova(fit)
# Analysis of Variance Table
# Response: mpg
# Df Sum Sq Mean Sq F value Pr(>F)
# cyl 1 817.71 817.71 79.561 6.113e-10 ***
# Residuals 30 308.33 10.28
# Signif. codes: 0 *** 0.001 ** 0.01 * 0.05 .
# Plot the distribution
plot(mpg ~ as.factor(cyl), data = mtcars, col = 'deepskyblue3')รหัสจะสร้างผลลัพธ์ต่อไปนี้ -

p-value ที่เราได้รับในตัวอย่างมีค่าน้อยกว่า 0.05 อย่างมีนัยสำคัญดังนั้น R จึงส่งคืนสัญลักษณ์ '***' เพื่อแสดงถึงสิ่งนี้ หมายความว่าเราปฏิเสธสมมติฐานว่างและเราพบความแตกต่างระหว่างค่า mpg ในกลุ่มต่างๆของcyl ตัวแปร.