Logic mờ - Hướng dẫn nhanh
Từ fuzzyđề cập đến những điều không rõ ràng hoặc mơ hồ. Bất kỳ sự kiện, quy trình hoặc chức năng nào thay đổi liên tục không thể luôn luôn được xác định là đúng hoặc sai, có nghĩa là chúng ta cần phải xác định các hoạt động đó theo cách Mờ.
Logic mờ là gì?
Logic mờ tương tự như phương pháp ra quyết định của con người. Nó xử lý thông tin mơ hồ và không chính xác. Đây là sự đơn giản hóa quá mức các vấn đề trong thế giới thực và dựa trên mức độ của sự thật chứ không phải là true / false hoặc 1/0 thông thường như logic Boolean.
Hãy xem sơ đồ sau. Nó cho thấy rằng trong các hệ thống mờ, các giá trị được biểu thị bằng một số trong phạm vi từ 0 đến 1. Ở đây 1,0 đại diện choabsolute truth và 0,0 đại diện cho absolute falseness. Số chỉ ra giá trị trong hệ thống mờ được gọi làtruth value.

Nói cách khác, chúng ta có thể nói rằng logic mờ không phải là logic mờ, mà là logic được sử dụng để mô tả sự mờ. Có thể có nhiều ví dụ khác như thế này với sự trợ giúp của chúng ta có thể hiểu khái niệm logic mờ.
Logic mờ được Lofti A. Zadeh giới thiệu vào năm 1965 trong bài báo nghiên cứu của ông “Bộ mờ”. Ông được coi là cha đẻ của Logic mờ.
A setlà một tập hợp không có thứ tự của các phần tử khác nhau. Nó có thể được viết rõ ràng bằng cách liệt kê các phần tử của nó bằng cách sử dụng dấu ngoặc vuông. Nếu thứ tự của các phần tử bị thay đổi hoặc bất kỳ phần tử nào của một tập hợp được lặp lại, nó sẽ không tạo ra bất kỳ thay đổi nào trong tập hợp.
Thí dụ
- Tập hợp tất cả các số nguyên dương.
- Một tập hợp tất cả các hành tinh trong hệ mặt trời.
- Một tập hợp của tất cả các tiểu bang ở Ấn Độ.
- Một tập hợp tất cả các chữ cái viết thường của bảng chữ cái.
Biểu diễn toán học của một tập hợp
Bộ có thể được biểu diễn theo hai cách:
Bảng phân công hoặc dạng bảng
Ở dạng này, một tập hợp được biểu diễn bằng cách liệt kê tất cả các phần tử bao gồm nó. Các phần tử được đặt trong dấu ngoặc nhọn và được phân tách bằng dấu phẩy.
Sau đây là các ví dụ về tập hợp trong Danh sách hoặc Biểu mẫu Bảng -
- Tập hợp các nguyên âm trong bảng chữ cái tiếng Anh, A = {a, e, i, o, u}
- Tập hợp các số lẻ nhỏ hơn 10, B = {1,3,5,7,9}
Đặt ký hiệu trình tạo
Ở dạng này, tập hợp được xác định bằng cách chỉ định một thuộc tính mà các phần tử của tập hợp có điểm chung. Tập hợp được mô tả là A = {x: p (x)}
Example 1 - Tập hợp {a, e, i, o, u} được viết là
A = {x: x là một nguyên âm trong bảng chữ cái tiếng Anh}
Example 2 - Tập hợp {1,3,5,7,9} được viết là
B = {x: 1 ≤ x <10 và (x% 2) ≠ 0}
Nếu một phần tử x là thành viên của tập S bất kỳ, nó được ký hiệu là x S và nếu một phần tử y không phải là thành viên của tập S, nó được ký hiệu là y∉S.
Example - Nếu S = {1,1.2,1.7,2}, 1 ∈ S nhưng 1,5 ∉ S
Số lượng của một tập hợp
Số phần tử của một tập hợp S, ký hiệu là | S || S |, là số phần tử của tập hợp đó. Con số này cũng được gọi là số chính. Nếu một tập hợp có vô số phần tử, thì tổng số của nó là ∞∞.
Example- | {1,4,3,5} | = 4, | {1,2,3,4,5,…} | = ∞
Nếu có hai tập X và Y thì | X | = | Y | biểu thị hai tập hợp X và Y có cùng một bản số. Điều này xảy ra khi số phần tử trong X đúng bằng số phần tử trong Y. Trong trường hợp này, tồn tại một hàm phân tích 'f' từ X đến Y.
| X | ≤ | Y | biểu thị rằng bản số của tập hợp X nhỏ hơn hoặc bằng bản số của tập hợp Y. Nó xảy ra khi số phần tử trong X nhỏ hơn hoặc bằng Y. Ở đây, tồn tại một hàm bất biến 'f' từ X đến Y.
| X | <| Y | biểu thị rằng bản số của tập hợp X nhỏ hơn bản số của tập hợp Y. Nó xảy ra khi số phần tử trong X ít hơn Y. Ở đây, hàm 'f' từ X đến Y là hàm không phân biệt nhưng không phải là hàm phân vị.
Nếu | X | ≤ | Y | và | X | ≤ | Y | thì | X | = | Y | . Tập hợp X và Y thường được gọi làequivalent sets.
Các loại bộ
Bộ có thể được phân thành nhiều loại; một số trong số đó là hữu hạn, vô hạn, tập con, phổ quát, thích hợp, tập đơn, v.v.
Tập hợp hữu hạn
Một tập hợp chứa một số phần tử xác định được gọi là tập hợp hữu hạn.
Example - S = {x | x ∈ N và 70> x> 50}
Bộ vô hạn
Tập hợp chứa vô số phần tử được gọi là tập hợp vô hạn.
Example - S = {x | x ∈ N và x> 10}
Tập hợp con
Tập hợp X là tập con của tập Y (Viết là X ⊆ Y) nếu mọi phần tử của X là phần tử của tập Y.
Example 1- Cho, X = {1,2,3,4,5,6} và Y = {1,2}. Ở đây tập Y là tập con của tập X vì tất cả các phần tử của tập Y đều nằm trong tập X. Do đó, chúng ta có thể viết Y⊆X.
Example 2- Cho, X = {1,2,3} và Y = {1,2,3}. Ở đây tập Y là một tập con (không phải là một tập hợp con thích hợp) của tập X vì tất cả các phần tử của tập Y đều nằm trong tập X. Do đó, chúng ta có thể viết Y⊆X.
Tập số thực
Thuật ngữ "tập hợp con thích hợp" có thể được định nghĩa là "tập hợp con của nhưng không bằng". Tập hợp X là tập con thích hợp của tập Y (Viết là X ⊂ Y) nếu mọi phần tử của X là phần tử của tập Y và | X | <| Y |.
Example- Cho, X = {1,2,3,4,5,6} và Y = {1,2}. Ở đây, tập Y ⊂ X, vì tất cả các phần tử trong Y cũng được chứa trong X và X có ít nhất một phần tử nhiều hơn tập Y.
Bộ phổ quát
Nó là một tập hợp của tất cả các yếu tố trong một ngữ cảnh hoặc ứng dụng cụ thể. Tất cả các tập hợp trong ngữ cảnh hoặc ứng dụng đó về cơ bản là tập hợp con của tập hợp phổ quát này. Tập hợp phổ quát được biểu diễn dưới dạng U.
Example- Chúng ta có thể định nghĩa U là tập hợp tất cả các loài động vật trên trái đất. Trong trường hợp này, một tập hợp tất cả các loài động vật có vú là một tập con của U, một tập hợp tất cả các loài cá là một tập con của U, một tập hợp tất cả các loài côn trùng là một tập con của U, v.v.
Tập hợp rỗng hoặc tập hợp rỗng
Một tập hợp rỗng không chứa phần tử nào. Nó được ký hiệu là Φ. Vì số phần tử trong một tập hợp rỗng là hữu hạn, nên tập hợp rỗng là một tập hợp hữu hạn. Cardinality của tập hợp rỗng hoặc tập hợp rỗng bằng không.
Example - S = {x | x ∈ N và 7 <x <8} = Φ
Bộ Singleton hoặc Bộ đơn vị
Một bộ Singleton hoặc bộ Đơn vị chỉ chứa một phần tử. Một tập hợp singleton được ký hiệu là {s}.
Example - S = {x | x ∈ N, 7 <x <9} = {8}
Tập hợp bằng nhau
Nếu hai tập hợp chứa các phần tử giống nhau, chúng được cho là bằng nhau.
Example - Nếu A = {1,2,6} và B = {6,1,2} thì chúng bằng nhau vì mọi phần tử của tập A đều là phần tử của tập B và mọi phần tử của tập B đều là phần tử của tập A.
Bộ tương đương
Nếu các thẻ số của hai tập hợp giống nhau, chúng được gọi là tập hợp tương đương.
Example- Nếu A = {1,2,6} và B = {16,17,22}, chúng tương đương vì bản số của A bằng với bản số của B. tức là | A | = | B | = 3
Bộ chồng chéo
Hai tập hợp có ít nhất một phần tử chung được gọi là tập hợp trùng nhau. Trong trường hợp các bộ chồng chéo -
$$n\left ( A\cup B \right ) = n\left ( A \right ) + n\left ( B \right ) - n\left ( A\cap B \right )$$
$$n\left ( A\cup B \right ) = n\left ( A-B \right )+n\left ( B-A \right )+n\left ( A\cap B \right )$$
$$n\left ( A \right ) = n\left ( A-B \right )+n\left ( A\cap B \right )$$
$$n\left ( B \right ) = n\left ( B-A \right )+n\left ( A\cap B \right )$$
Example- Cho, A = {1,2,6} và B = {6,12,42}. Có một phần tử chung '6', do đó các tập hợp này là các tập hợp chồng chéo.
Bộ rời
Hai tập hợp A và B được gọi là tập rời rạc nếu chúng không có chung một phần tử. Do đó, các bộ rời rạc có các thuộc tính sau:
$$n\left ( A\cap B \right ) = \phi$$
$$n\left ( A\cup B \right ) = n\left ( A \right )+n\left ( B \right )$$
Example - Cho, A = {1,2,6} và B = {7,9,14}, không có một phần tử chung nào, do đó các tập hợp này là các tập trùng nhau.
Thao tác trên Bộ cổ điển
Các phép toán tập hợp bao gồm Tập hợp liên kết, Giao điểm tập hợp, Chênh lệch tập hợp, Bổ sung tập hợp và Tích Descartes.
liên hiệp
Hợp của các tập A và B (ký hiệu là A ∪ BA ∪ B) là tập hợp các phần tử nằm trong A, trong B, hoặc trong cả A và B. Do đó, A ∪ B = {x | x ∈ A OR x ∈ B}.
Example - Nếu A = {10,11,12,13} và B = {13,14,15} thì A ∪ B = {10,11,12,13,14,15} - Phần tử chung chỉ xảy ra một lần.
Ngã tư
Giao của tập hợp A và B (ký hiệu là A ∩ B) là tập hợp các phần tử nằm trong cả A và B. Do đó, A ∩ B = {x | x ∈ A VÀ x ∈ B}.

Sự khác biệt / Sự bổ sung tương đối
Tập sai của tập A và B (kí hiệu là A – B) là tập các phần tử chỉ thuộc A mà không thuộc B. Do đó, A - B = {x | x ∈ A VÀ x ∉ B}.
Example- Nếu A = {10,11,12,13} và B = {13,14,15} thì (A - B) = {10,11,12} và (B - A) = {14,15} . Ở đây, chúng ta có thể thấy (A - B) ≠ (B - A)

Sự bổ sung của một bộ
Phần bù của tập A (kí hiệu là A ′) là tập các phần tử không thuộc tập A. Do đó, A ′ = {x | x ∉ A}.
Cụ thể hơn, A ′ = (U − A) trong đó U là một tập phổ quát chứa tất cả các đối tượng.
Example - Nếu A = {x | x thuộc tập hợp các số nguyên} thì A ′ = {y | y không thuộc tập hợp các số nguyên lẻ}

Sản phẩm Descartes / Sản phẩm chéo
Tích Descartes của n số bộ A1, A2,… Một ký hiệu là A1 × A2… × An có thể được định nghĩa là tất cả các cặp có thứ tự có thể (x1, x2,… xn) trong đó x1 ∈ A1, x2 ∈ A2,… xn ∈ An
Example - Nếu chúng ta lấy hai tập A = {a, b} và B = {1,2},
Tích Descartes của A và B được viết là - A × B = {(a, 1), (a, 2), (b, 1), (b, 2)}
Và, tích Descartes của B và A được viết là - B × A = {(1, a), (1, b), (2, a), (2, b)}
Thuộc tính của Bộ cổ điển
Các thuộc tính trên các tập hợp đóng một vai trò quan trọng để có được lời giải. Sau đây là các thuộc tính khác nhau của bộ cổ điển:
Tính chất giao hoán
Có hai bộ A và B, thuộc tính này tuyên bố -
$$A \cup B = B \cup A$$
$$A \cap B = B \cap A$$
Bất động sản kết hợp
Có ba bộ A, B và C, thuộc tính này tuyên bố -
$$A\cup \left ( B\cup C \right ) = \left ( A\cup B \right )\cup C$$
$$A\cap \left ( B\cap C \right ) = \left ( A\cap B \right )\cap C$$
Thuộc tính phân tán
Có ba bộ A, B và C, thuộc tính này tuyên bố -
$$A\cup \left ( B\cap C \right ) = \left ( A\cup B \right )\cap \left ( A\cup C \right )$$
$$A\cap \left ( B\cup C \right ) = \left ( A\cap B \right )\cup \left ( A\cap C \right )$$
Thuộc tính lý tưởng
Đối với bất kỳ bộ A, thuộc tính này tuyên bố -
$$A\cup A = A$$
$$A\cap A = A$$
Thuộc tính nhận dạng
Đối với bộ A và bộ phổ quát X, thuộc tính này tuyên bố -
$$A\cup \varphi = A$$
$$A\cap X = A$$
$$A\cap \varphi = \varphi$$
$$A\cup X = X$$
Thuộc tính bắc cầu
Có ba bộ A, B và C, tài sản nói rằng -
Nếu $A\subseteq B\subseteq C$, sau đó $A\subseteq C$
Thuộc tính Involution
Đối với bất kỳ bộ A, thuộc tính này tuyên bố -
$$\overline{{\overline{A}}} = A$$
Định luật De Morgan
Nó là một luật rất quan trọng và hỗ trợ trong việc chứng minh sự đồng nhất và mâu thuẫn. Luật này tuyên bố -
$$\overline{A\cap B} = \overline{A} \cup \overline{B}$$
$$\overline{A\cup B} = \overline{A} \cap \overline{B}$$
Các tập hợp mờ có thể được coi là sự mở rộng và đơn giản hóa tổng thể của các tập hợp cổ điển. Nó có thể được hiểu tốt nhất trong bối cảnh của thành viên được thiết lập. Về cơ bản, nó cho phép thành viên một phần có nghĩa là nó chứa các phần tử có các mức độ thành viên khác nhau trong tập hợp. Từ đó, chúng ta có thể hiểu được sự khác biệt giữa tập cổ điển và tập mờ. Tập hợp cổ điển chứa các phần tử thỏa mãn các thuộc tính chính xác của thành viên trong khi tập mờ chứa các phần tử thỏa mãn các thuộc tính không chính xác của thành viên.

Khái niệm toán học
Một tập hợp mờ $\widetilde{A}$ trong vũ trụ thông tin $U$ có thể được định nghĩa là một tập hợp các cặp có thứ tự và nó có thể được biểu diễn bằng toán học như sau:
$$\widetilde{A} = \left \{ \left ( y,\mu _{\widetilde{A}} \left ( y \right ) \right ) | y\in U\right \}$$
Đây $\mu _{\widetilde{A}}\left ( y \right )$ = mức độ thành viên của $y$ in \ widetilde {A}, giả định các giá trị trong phạm vi từ 0 đến 1, tức là $\mu _{\widetilde{A}}(y)\in \left [ 0,1 \right ]$.
Biểu diễn tập mờ
Bây giờ chúng ta hãy xem xét hai trường hợp của vũ trụ thông tin và hiểu cách một tập mờ có thể được biểu diễn.
Trường hợp 1
Khi vũ trụ thông tin $U$ là rời rạc và hữu hạn -
$$\widetilde{A} = \left \{ \frac{\mu _{\widetilde{A}}\left ( y_1 \right )}{y_1} +\frac{\mu _{\widetilde{A}}\left ( y_2 \right )}{y_2} +\frac{\mu _{\widetilde{A}}\left ( y_3 \right )}{y_3} +...\right \}$$
$= \left \{ \sum_{i=1}^{n}\frac{\mu _{\widetilde{A}}\left ( y_i \right )}{y_i} \right \}$
Trường hợp 2
Khi vũ trụ thông tin $U$ là liên tục và vô hạn -
$$\widetilde{A} = \left \{ \int \frac{\mu _{\widetilde{A}}\left ( y \right )}{y} \right \}$$
Trong cách biểu diễn trên, ký hiệu tổng thể hiện tập hợp của mỗi phần tử.
Các phép toán trên tập mờ
Có hai tập mờ $\widetilde{A}$ và $\widetilde{B}$, vũ trụ thông tin $U$ và một phần tử ð ?? '¦ của vũ trụ, các quan hệ sau biểu thị phép toán hợp, giao và bù trên tập mờ.
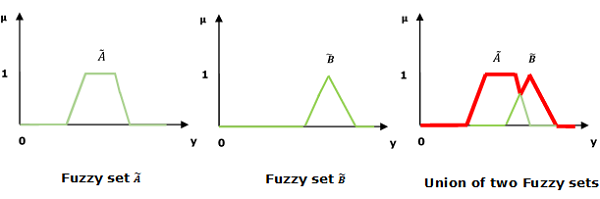
Union / Fuzzy â € ˜ORâ € ™
Chúng ta hãy xem xét biểu diễn sau để hiểu cách Union/Fuzzy ‘OR’ quan hệ công việc -
$$\mu _{{\widetilde{A}\cup \widetilde{B} }}\left ( y \right ) = \mu _{\widetilde{A}}\vee \mu _\widetilde{B} \quad \forall y \in U$$
Ở đây ∨ đại diện cho hoạt động â € ˜maxâ € ™.
Giao lộ / Mờ â € ˜ANDâ € ™
Chúng ta hãy xem xét biểu diễn sau để hiểu cách Intersection/Fuzzy ‘AND’ quan hệ công việc -
$$\mu _{{\widetilde{A}\cap \widetilde{B} }}\left ( y \right ) = \mu _{\widetilde{A}}\wedge \mu _\widetilde{B} \quad \forall y \in U$$
Ở đây ∧ đại diện cho hoạt động â € ˜minâ € ™.

Phần bổ sung / Mờ â € ˜NOTâ € ™
Chúng ta hãy xem xét biểu diễn sau để hiểu cách Complement/Fuzzy ‘NOT’ quan hệ công việc -
$$\mu _{\widetilde{A}} = 1-\mu _{\widetilde{A}}\left ( y \right )\quad y \in U$$

Thuộc tính của tập mờ
Chúng ta hãy thảo luận về các tính chất khác nhau của các tập mờ.
Tính chất giao hoán
Có hai tập mờ $\widetilde{A}$ và $\widetilde{B}$, thuộc tính này tuyên bố -
$$\widetilde{A}\cup \widetilde{B} = \widetilde{B}\cup \widetilde{A}$$
$$\widetilde{A}\cap \widetilde{B} = \widetilde{B}\cap \widetilde{A}$$
Bất động sản kết hợp
Có ba tập mờ $\widetilde{A}$, $\widetilde{B}$ và $\widetilde{C}$, thuộc tính này tuyên bố -
$$(\widetilde{A}\cup \left \widetilde{B}) \cup \widetilde{C} \right = \left \widetilde{A} \cup (\widetilde{B}\right )\cup \widetilde{C})$$
$$(\widetilde{A}\cap \left \widetilde{B}) \cap \widetilde{C} \right = \left \widetilde{A} \cup (\widetilde{B}\right \cap \widetilde{C})$$
Thuộc tính phân tán
Có ba tập mờ $\widetilde{A}$, $\widetilde{B}$ và $\widetilde{C}$, thuộc tính này tuyên bố -
$$\widetilde{A}\cup \left ( \widetilde{B} \cap \widetilde{C}\right ) = \left ( \widetilde{A} \cup \widetilde{B}\right )\cap \left ( \widetilde{A}\cup \widetilde{C} \right )$$
$$\widetilde{A}\cap \left ( \widetilde{B}\cup \widetilde{C} \right ) = \left ( \widetilde{A} \cap \widetilde{B} \right )\cup \left ( \widetilde{A}\cap \widetilde{C} \right )$$
Thuộc tính lý tưởng
Đối với bất kỳ tập mờ nào $\widetilde{A}$, thuộc tính này tuyên bố -
$$\widetilde{A}\cup \widetilde{A} = \widetilde{A}$$
$$\widetilde{A}\cap \widetilde{A} = \widetilde{A}$$
Thuộc tính nhận dạng
Đối với tập mờ $\widetilde{A}$ và bộ phổ quát $U$, thuộc tính này tuyên bố -
$$\widetilde{A}\cup \varphi = \widetilde{A}$$
$$\widetilde{A}\cap U = \widetilde{A}$$
$$\widetilde{A}\cap \varphi = \varphi$$
$$\widetilde{A}\cup U = U$$
Thuộc tính bắc cầu
Có ba tập mờ $\widetilde{A}$, $\widetilde{B}$ và $\widetilde{C}$, thuộc tính này tuyên bố -
$$If \: \widetilde{A}\subseteq \widetilde{B}\subseteq \widetilde{C},\:then\:\widetilde{A}\subseteq \widetilde{C}$$
Thuộc tính Involution
Đối với bất kỳ tập mờ nào $\widetilde{A}$, thuộc tính này tuyên bố -
$$\overline{\overline{\widetilde{A}}} = \widetilde{A}$$
Luật của De Morgan
Định luật này đóng một vai trò quan trọng trong việc chứng minh sự đồng nhất và mâu thuẫn. Luật này tuyên bố -
$$\overline{{\widetilde{A}\cap \widetilde{B}}} = \overline{\widetilde{A}}\cup \overline{\widetilde{B}}$$
$$\overline{{\widetilde{A}\cup \widetilde{B}}} = \overline{\widetilde{A}}\cap \overline{\widetilde{B}}$$
Chúng ta đã biết rằng logic mờ không phải là logic mờ mà là logic được sử dụng để mô tả sự mờ. Sự mờ nhạt này được đặc trưng bởi chức năng thành viên của nó. Nói cách khác, chúng ta có thể nói rằng hàm liên thuộc đại diện cho mức độ chân lý trong logic mờ.

Sau đây là một số điểm quan trọng liên quan đến chức năng thành viên:
Các hàm thành viên lần đầu tiên được giới thiệu vào năm 1965 bởi Lofti A. Zadeh trong bài báo nghiên cứu đầu tiên của ông về “tập mờ”.
Các hàm thành viên đặc trưng cho tính mờ (nghĩa là tất cả thông tin trong tập mờ), cho dù các phần tử trong tập mờ là rời rạc hay liên tục.
Chức năng thành viên có thể được định nghĩa như một kỹ thuật để giải quyết các vấn đề thực tế bằng kinh nghiệm hơn là kiến thức.
Các chức năng thành viên được thể hiện bằng các dạng đồ họa.
Các quy tắc xác định độ mờ cũng rất mờ.
Ký hiệu toán học
Chúng tôi đã nghiên cứu rằng một tập mờ Ã trong vũ trụ thông tin U có thể được định nghĩa là một tập hợp các cặp có thứ tự và nó có thể được đại diện về mặt toán học như -
$$\widetilde{A} = \left \{ \left ( y,\mu _{\widetilde{A}} \left ( y \right ) \right ) | y\in U\right \}$$
Đây $\mu \widetilde{A}\left (\bullet \right )$ = chức năng thành viên của $\widetilde{A}$; điều này giả định các giá trị trong phạm vi từ 0 đến 1, tức là$\mu \widetilde{A}\left (\bullet \right )\in \left [ 0,1 \right ]$. Chức năng thành viên$\mu \widetilde{A}\left (\bullet \right )$ bản đồ $U$ đến không gian thành viên$M$.
Dấu chấm $\left (\bullet \right )$trong hàm liên thuộc được mô tả ở trên, biểu diễn phần tử trong một tập mờ; cho dù nó là rời rạc hay liên tục.
Đặc điểm của chức năng thành viên
Bây giờ chúng ta sẽ thảo luận về các tính năng khác nhau của Chức năng thành viên.
Cốt lõi
Đối với bất kỳ tập mờ nào $\widetilde{A}$, cốt lõi của một hàm liên thuộc là vùng vũ trụ đó được đặc trưng bởi thành viên đầy đủ trong tập hợp. Do đó, cốt lõi bao gồm tất cả các yếu tố đó$y$ của vũ trụ thông tin như vậy,
$$\mu _{\widetilde{A}}\left ( y \right ) = 1$$
Ủng hộ
Đối với bất kỳ tập mờ nào $\widetilde{A}$, hỗ trợ của một hàm liên thuộc là vùng vũ trụ được đặc trưng bởi một thành viên khác không trong tập hợp. Do đó cốt lõi bao gồm tất cả các yếu tố đó$y$ của vũ trụ thông tin như vậy,
$$\mu _{\widetilde{A}}\left ( y \right ) > 0$$
Ranh giới
Đối với bất kỳ tập mờ nào $\widetilde{A}$, ranh giới của một hàm liên thuộc là vùng vũ trụ được đặc trưng bởi một thành viên khác không nhưng không đầy đủ trong tập hợp. Do đó, cốt lõi bao gồm tất cả các yếu tố đó$y$ của vũ trụ thông tin như vậy,
$$1 > \mu _{\widetilde{A}}\left ( y \right ) > 0$$

Làm mờ
Nó có thể được định nghĩa là quá trình biến đổi một tập rõ nét thành một tập mờ hoặc một tập mờ thành tập mờ hơn. Về cơ bản, thao tác này chuyển các giá trị đầu vào sắc nét chính xác thành các biến ngôn ngữ.
Sau đây là hai phương pháp làm mờ quan trọng:
Hỗ trợ phương pháp Fuzzification (s-fuzzification)
Trong phương pháp này, tập hợp mờ có thể được biểu diễn với sự trợ giúp của quan hệ sau:
$$\widetilde{A} = \mu _1Q\left ( x_1 \right )+\mu _2Q\left ( x_2 \right )+...+\mu _nQ\left ( x_n \right )$$
Đây tập mờ $Q\left ( x_i \right )$được gọi là hạt nhân của quá trình mờ. Phương pháp này được thực hiện bằng cách giữ$\mu _i$ hằng số và $x_i$ được chuyển thành một tập mờ $Q\left ( x_i \right )$.
Phương pháp làm mờ lớp (g-fuzzification)
Nó khá giống với phương pháp trên nhưng sự khác biệt chính là nó giữ $x_i$ hằng số và $\mu _i$ được biểu diễn dưới dạng một tập mờ.
Khử muối
Nó có thể được định nghĩa là quá trình giảm một tập mờ thành một tập hợp sắc nét hoặc chuyển một tập hợp mờ thành một tập hợp sắc nét.
Chúng tôi đã nghiên cứu rằng quá trình làm mờ bao gồm việc chuyển đổi từ đại lượng rõ nét sang đại lượng mờ. Trong một số ứng dụng kỹ thuật, cần phải làm mờ kết quả hay đúng hơn là “kết quả mờ” để nó phải được chuyển đổi thành kết quả rõ nét. Về mặt toán học, quá trình Defuzzification còn được gọi là "làm tròn".
Các phương pháp khử độc tố khác nhau được mô tả dưới đây:
Phương thức thành viên tối đa
Phương pháp này được giới hạn trong các hàm đầu ra đỉnh và còn được gọi là phương pháp chiều cao. Về mặt toán học, nó có thể được biểu diễn như sau:
$$\mu _{\widetilde{A}}\left ( x^* \right )>\mu _{\widetilde{A}}\left ( x \right ) \: for \:all\:x \in X$$
Đây, $x^*$ là đầu ra được giải mờ.
Phương pháp Centroid
Phương pháp này còn được gọi là phương pháp trọng tâm hay phương pháp trọng tâm. Về mặt toán học, đầu ra được làm mờ$x^*$ sẽ được đại diện là -
$$x^* = \frac{\int \mu _{\widetilde{A}}\left ( x \right ).xdx}{\int \mu _{\widetilde{A}}\left ( x \right ).dx}$$
Phương pháp bình quân gia quyền
Trong phương pháp này, mỗi hàm thành viên được tính theo giá trị thành viên lớn nhất của nó. Về mặt toán học, đầu ra được làm mờ$x^*$ sẽ được đại diện là -
$$x^* = \frac{\sum \mu _{\widetilde{A}}\left ( \overline{x_i} \right ).\overline{x_i}}{\sum \mu _{\widetilde{A}}\left ( \overline{x_i} \right )}$$
Tư cách thành viên Mean-Max
Phương pháp này còn được gọi là giữa cực đại. Về mặt toán học, đầu ra được làm mờ$x^*$ sẽ được đại diện là -
$$x^* = \frac{\displaystyle \sum_{i=1}^{n}\overline{x_i}}{n}$$
Logic, ban đầu chỉ là nghiên cứu về những gì phân biệt lập luận đúng với lập luận không chắc chắn, giờ đây đã phát triển thành một hệ thống mạnh mẽ và chặt chẽ, nhờ đó có thể phát hiện ra các tuyên bố đúng, đưa ra các tuyên bố khác đã được biết là đúng.
Logic định tính
Logic này xử lý các vị từ, là các mệnh đề chứa các biến.
Vị từ là một biểu thức của một hoặc nhiều biến được xác định trên một số miền cụ thể. Một vị từ với các biến có thể được tạo thành một mệnh đề bằng cách gán giá trị cho biến hoặc bằng cách định lượng biến.
Sau đây là một vài ví dụ về các vị từ -
- Gọi E (x, y) biểu thị "x = y"
- Gọi X (a, b, c) là "a + b + c = 0"
- Gọi M (x, y) là "x kết hôn với y"
Logic mệnh đề
Mệnh đề là một tập hợp các câu lệnh khai báo có giá trị sự thật "true" hoặc giá trị sự thật "false". Một mệnh đề bao gồm các biến mệnh đề và các liên kết. Các biến mệnh đề được viết hoa (A, B, v.v.). Các phép nối kết nối các biến mệnh đề.
Dưới đây là một vài ví dụ về Mệnh đề -
- "Man is Mortal", nó trả về giá trị sự thật "TRUE"
- "12 + 9 = 3 - 2", nó trả về giá trị sự thật "FALSE"
Sau đây không phải là một Đề xuất -
"A is less than 2" - Đó là bởi vì trừ khi chúng ta đưa ra một giá trị cụ thể của A, chúng ta không thể nói là đúng hay sai.
Kết nối
Trong logic mệnh đề, chúng tôi sử dụng năm kết nối sau:
- HOẶC (∨∨)
- VÀ (∧∧)
- Phủ định / KHÔNG (¬¬)
- Hàm ý / nếu-thì (→ thường)
- Nếu và chỉ khi (⇔⇔)
HOẶC (∨∨)
Phép toán OR của hai mệnh đề A và B (viết là A∨BA∨B) là đúng nếu ít nhất bất kỳ biến mệnh đề A hoặc B nào là đúng.
Bảng sự thật như sau:
| A | B | A ∨ B |
|---|---|---|
| Thật | Thật | Thật |
| Thật | Sai | Thật |
| Sai | Thật | Thật |
| Sai | Sai | Sai |
VÀ (∧∧)
Phép toán AND của hai mệnh đề A và B (viết là A∧BA∧B) là đúng nếu cả biến mệnh đề A và B đều đúng.
Bảng sự thật như sau:
| A | B | A ∧ B |
|---|---|---|
| Thật | Thật | Thật |
| Thật | Sai | Sai |
| Sai | Thật | Sai |
| Sai | Sai | Sai |
Phủ định (¬¬)
Sự phủ định của mệnh đề A (viết là ¬A¬A) là sai khi A đúng và đúng khi A sai.
Bảng sự thật như sau:
| A | ¬A |
|---|---|
| Thật | Sai |
| Sai | Thật |
Hàm ý / nếu-thì (→ thường)
Một ngụ ý A → BA → B là mệnh đề “nếu A thì B”. Nếu A đúng và B sai. Các trường hợp còn lại là đúng.
Bảng sự thật như sau:
| A | B | A → B |
|---|---|---|
| Thật | Thật | Thật |
| Thật | Sai | Sai |
| Sai | Thật | Thật |
| Sai | Sai | Thật |
Nếu và chỉ khi (⇔⇔)
A⇔BA⇔B là liên kết logic hai điều kiện đúng khi p và q giống nhau, tức là cả hai đều sai hoặc cả hai đều đúng.
Bảng sự thật như sau:
| A | B | A⇔B |
|---|---|---|
| Thật | Thật | Thật |
| Thật | Sai | Sai |
| Sai | Thật | Sai |
| Sai | Sai | Thật |
Công thức được hình thành tốt
Công thức Well Formed (wff) là một vị từ chứa một trong những điều sau:
- Tất cả các hằng số mệnh đề và các biến mệnh đề đều là sai.
- Nếu x là biến và Y là biến thì xY và ∃xY cũng là biến.
- Giá trị true và giá trị sai là sai.
- Mỗi công thức nguyên tử là một wff.
- Tất cả các kết nối kết nối wffs đều là wffs.
Bộ định lượng
Biến của vị từ được định lượng bằng các bộ định lượng. Có hai loại định lượng trong logic vị từ -
- Bộ định lượng phổ quát
- Bộ định lượng tồn tại
Bộ định lượng phổ quát
Bộ định lượng phổ quát tuyên bố rằng các tuyên bố trong phạm vi của nó đúng với mọi giá trị của biến cụ thể. Nó được biểu thị bằng ký hiệu ∀.
∀xP(x) được đọc là với mọi giá trị của x, P (x) là true.
Example- "Con người là phàm nhân" có thể được chuyển thành dạng mệnh đề ∀xP (x). Ở đây, P (x) là vị từ biểu thị rằng x là người phàm và vũ trụ của diễn ngôn đều là đàn ông.
Bộ định lượng tồn tại
Bộ định lượng hiện tại nói rằng các câu lệnh trong phạm vi của nó là đúng đối với một số giá trị của biến cụ thể. Nó được biểu thị bằng ký hiệu ∃.
∃xP(x) đối với một số giá trị của x được đọc là P (x) là true.
Example - "Một số người không trung thực" có thể được chuyển thành dạng mệnh đề ∃x P (x) trong đó P (x) là vị từ biểu thị x không trung thực và vũ trụ của diễn ngôn là một số người.
Bộ định lượng lồng nhau
Nếu chúng ta sử dụng một bộ định lượng xuất hiện trong phạm vi của một bộ định lượng khác, nó được gọi là bộ định lượng lồng nhau.
Example
- ∀ a∃bP (x, y) trong đó P (a, b) biểu thị a + b = 0
- ∀ a∀b∀cP (a, b, c) trong đó P (a, b) biểu thị a + (b + c) = (a + b) + c
Note - ∀a∃bP (x, y) ≠ ∃a∀bP (x, y)
Sau đây là các phương thức lập luận gần đúng khác nhau -
Lý luận phân loại
Trong phương thức lập luận gần đúng này, tiền đề, không chứa định lượng mờ và xác suất mờ, được giả định là ở dạng chính tắc.
Lập luận Định tính
Trong phương thức lập luận gần đúng này, tiền đề và hậu quả có các biến ngôn ngữ mờ; mối quan hệ đầu vào - đầu ra của một hệ thống được biểu diễn dưới dạng tập hợp các luật IF-THEN mờ. Lý luận này chủ yếu được sử dụng trong phân tích hệ thống điều khiển.
Lập luận âm tiết
Trong chế độ suy luận xấp xỉ này, tiền đề với các lượng tử mờ có liên quan đến các quy tắc suy luận. Điều này được thể hiện là -
x = S 1 A là B
y = S 2 C là D
------------------------
z = S 3 E là F
Ở đây A, B, C, D, E, F là các vị từ mờ.
S 1 và S 2 là các định lượng mờ.
S 3 là định lượng mờ cần được quyết định.
Lập luận theo từng vị trí
Trong phương thức lập luận xấp xỉ này, tiền đề là những vị trí có thể chứa định lượng mờ “thường”. Bộ định lượngUsuallyliên kết với nhau các lý luận theo định vị và âm tiết; do đó nó đóng một vai trò quan trọng.
Ví dụ, quy tắc dự báo của suy luận trong suy luận theo mệnh lệnh có thể được đưa ra như sau:
thường ((L, M) là R) ⇒ thường (L là [R ↓ L])
Đây [R ↓ L] là phép chiếu của quan hệ mờ R trên L
Cơ sở quy tắc logic mờ
Có một thực tế là con người luôn cảm thấy thoải mái khi nói chuyện bằng ngôn ngữ tự nhiên. Việc trình bày tri thức của con người có thể được thực hiện với sự trợ giúp của cách diễn đạt ngôn ngữ tự nhiên sau:
IF tiền thân THEN hệ quả
Biểu thức như đã nêu ở trên được gọi là cơ sở quy tắc IF-THEN mờ.
Hình thức kinh điển
Sau đây là dạng chính tắc của Cơ sở Quy tắc Logic Mờ -
Rule 1 - Nếu điều kiện C1 thì hạn chế R1
Rule 2 - Nếu điều kiện C1 thì hạn chế R2
.
.
.
Rule n - Nếu điều kiện C1 thì hạn chế Rn
Giải thích các quy tắc IF-THEN mờ
Quy tắc IF-THEN mờ có thể được giải thích dưới bốn dạng sau:
Tuyên bố bài tập
Những loại câu lệnh này sử dụng “=” (dấu bằng) cho mục đích gán. Chúng có dạng sau:
a = xin chào
khí hậu = mùa hè
Câu điều kiện
Các loại câu lệnh này sử dụng dạng cơ sở quy tắc “IF-THEN” cho mục đích điều kiện. Chúng có dạng sau:
NẾU nhiệt độ cao THÌ Khí hậu nóng
NẾU thực phẩm là tươi THÌ ăn.
Tuyên bố vô điều kiện
Chúng có dạng sau:
GOTO 10
tắt quạt
Biến ngôn ngữ
Chúng tôi đã nghiên cứu rằng logic mờ sử dụng các biến ngôn ngữ là các từ hoặc câu trong ngôn ngữ tự nhiên. Ví dụ, nếu chúng ta nói nhiệt độ, nó là một biến ngôn ngữ; các giá trị rất nóng hoặc lạnh, hơi nóng hoặc lạnh, rất ấm, hơi ấm, v.v ... Các từ rất, hơi là rào cản ngôn ngữ.
Đặc điểm của Biến ngôn ngữ
Bốn thuật ngữ sau đặc trưng cho biến ngôn ngữ:
- Tên của biến, thường được biểu diễn bằng x.
- Tập hợp số hạng của biến, thường được biểu diễn bằng t (x).
- Các quy tắc cú pháp để tạo ra các giá trị của biến x.
- Các quy tắc ngữ nghĩa để liên kết mọi giá trị của x và ý nghĩa của nó.
Các mệnh đề trong Logic mờ
Như chúng ta biết rằng mệnh đề là những câu được diễn đạt bằng bất kỳ ngôn ngữ nào thường được diễn đạt dưới dạng chính tắc sau:
s as P
Ở đây, s là Chủ ngữ và P là Vị ngữ.
Ví dụ: “ Delhi là thủ đô của Ấn Độ ”, đây là mệnh đề trong đó “ Delhi ” là chủ ngữ và “ là thủ đô của Ấn Độ ” là vị từ thể hiện thuộc tính của chủ ngữ.
Chúng ta biết rằng logic là cơ sở của suy luận và logic mờ mở rộng khả năng suy luận bằng cách sử dụng các vị từ mờ, các bổ ngữ-vị từ mờ, các định lượng mờ và các định lượng mờ trong các mệnh đề mờ tạo ra sự khác biệt so với logic cổ điển.
Các mệnh đề trong logic mờ bao gồm:
Vị ngữ mờ
Hầu hết mọi vị ngữ trong ngôn ngữ tự nhiên đều có bản chất mờ, do đó logic mờ có các vị từ như cao, ngắn, ấm, nóng, nhanh, v.v.
Bổ ngữ mờ-vị từ
Chúng tôi đã thảo luận về các rào cản ngôn ngữ ở trên; chúng ta cũng có nhiều bổ ngữ mờ-vị từ hoạt động như hàng rào. Chúng rất cần thiết để tạo ra các giá trị của một biến ngôn ngữ. Ví dụ, các từ rất, hơi là bổ ngữ và mệnh đề có thể giống như " nước hơi nóng ."
Bộ định lượng mờ
Nó có thể được định nghĩa là một số mờ cho phép phân loại mơ hồ về bản số của một hoặc nhiều tập mờ hoặc không mờ. Nó có thể được sử dụng để ảnh hưởng đến xác suất trong logic mờ. Ví dụ, các từ nhiều, hầu hết, thường xuyên được sử dụng làm định lượng mờ và các mệnh đề có thể giống như " hầu hết mọi người đều dị ứng với nó ."
Vòng loại mờ
Bây giờ chúng ta hãy hiểu về Bộ định lượng mờ. Một định nghĩa mờ cũng là một mệnh đề của Logic mờ. Chứng nhận mờ có các dạng sau:
Chứng nhận mờ dựa trên sự thật
Nó tuyên bố mức độ chân lý của một mệnh đề mờ.
Expression- Nó được biểu diễn dưới dạng x là t . Ở đây, t là một giá trị chân lý mờ.
Example - (Xe màu đen) KHÔNG RẤT ĐÚNG.
Chứng nhận mờ dựa trên xác suất
Nó tuyên bố xác suất, hoặc số hoặc một khoảng, của mệnh đề mờ.
Expression- Biểu diễn x là λ . Ở đây, λ là một xác suất mờ.
Example - (Xe màu đen) rất có thể.
Chứng nhận mờ dựa trên khả năng
Nó tuyên bố khả năng của mệnh đề mờ.
Expression- Biểu thị x là π . Ở đây, π là một khả năng mờ.
Example - (Xe màu đen) là Gần như Không thể.
Hệ thống suy luận mờ là đơn vị chính của hệ thống logic mờ có việc ra quyết định là công việc chính của nó. Nó sử dụng các quy tắc “IF… THEN” cùng với các đầu nối “HOẶC” hoặc “VÀ” để vẽ các quy tắc quyết định cần thiết.
Đặc điểm của hệ thống suy luận mờ
Sau đây là một số đặc điểm của FIS -
Đầu ra từ FIS luôn là một tập mờ bất kể đầu vào của nó có thể mờ hay rõ nét.
Nó là cần thiết để có đầu ra mờ khi nó được sử dụng như một bộ điều khiển.
Một đơn vị giải mờ sẽ ở đó với FIS để chuyển đổi các biến mờ thành các biến rõ nét.
Các khối chức năng của FIS
Năm khối chức năng sau đây sẽ giúp bạn hiểu cấu tạo của FIS -
Rule Base - Nó chứa các quy tắc IF-THEN mờ.
Database - Nó định nghĩa các hàm thuộc của các tập mờ được sử dụng trong các luật mờ.
Decision-making Unit - Nó thực hiện hoạt động trên các quy tắc.
Fuzzification Interface Unit - Nó chuyển đổi các đại lượng rõ nét thành đại lượng mờ.
Defuzzification Interface Unit- Nó chuyển đổi các đại lượng mờ thành đại lượng rõ nét. Sau đây là sơ đồ khối của hệ thống giao thoa mờ.

Hoạt động của FIS
Hoạt động của FIS bao gồm các bước sau:
Một bộ phận làm mờ hỗ trợ việc áp dụng nhiều phương pháp làm mờ và chuyển đổi đầu vào sắc nét thành đầu vào mờ.
Cơ sở kiến thức - tập hợp cơ sở quy tắc và cơ sở dữ liệu được hình thành khi chuyển đổi đầu vào sắc nét thành đầu vào mờ.
Đầu vào mờ của đơn vị giải mờ cuối cùng được chuyển đổi thành đầu ra rõ nét.
Phương pháp FIS
Bây giờ chúng ta hãy thảo luận về các phương pháp khác nhau của FIS. Sau đây là hai phương pháp quan trọng của FIS, có hệ quả khác nhau của các quy tắc mờ -
- Hệ thống suy luận mờ Mamdani
- Mô hình mờ Takagi-Sugeno (Phương pháp TS)
Hệ thống suy luận mờ Mamdani
Hệ thống này được đề xuất vào năm 1975 bởi Ebhasim Mamdani. Về cơ bản, người ta đã dự đoán được việc điều khiển tổ hợp động cơ hơi nước và lò hơi bằng cách tổng hợp một bộ quy tắc mờ thu được từ những người làm việc trên hệ thống.
Các bước tính toán đầu ra
Cần tuân theo các bước sau để tính toán kết quả từ FIS này -
Step 1 - Tập các luật mờ cần được xác định trong bước này.
Step 2 - Trong bước này, bằng cách sử dụng hàm thành viên đầu vào, đầu vào sẽ được làm mờ.
Step 3 - Bây giờ thiết lập độ mạnh của quy tắc bằng cách kết hợp các đầu vào mờ theo các quy tắc mờ.
Step 4 - Trong bước này, xác định hệ quả của quy tắc bằng cách kết hợp độ mạnh của quy tắc và hàm thành viên đầu ra.
Step 5 - Để nhận được phân phối đầu ra, hãy kết hợp tất cả các hệ quả.
Step 6 - Cuối cùng, thu được một phân phối đầu ra đã được làm mờ.
Sau đây là sơ đồ khối của Hệ thống giao diện mờ Mamdani.

Mô hình mờ Takagi-Sugeno (Phương pháp TS)
Mô hình này do Takagi, Sugeno và Kang đề xuất vào năm 1985. Định dạng của quy tắc này được đưa ra là:
NẾU x là A và y là B THÌ Z = f (x, y)
Ở đây, AB là các tập mờ trong tiền đề và z = f (x, y) là một hàm rõ nét trong hệ quả.
Quá trình suy luận mờ
Quá trình suy luận mờ theo Mô hình mờ Takagi-Sugeno (Phương pháp TS) hoạt động theo cách sau:
Step 1: Fuzzifying the inputs - Ở đây, các đầu vào của hệ thống được làm mờ.
Step 2: Applying the fuzzy operator - Trong bước này, các toán tử mờ phải được áp dụng để có kết quả đầu ra.
Định dạng quy tắc của biểu mẫu Sugeno
Định dạng quy tắc của biểu mẫu Sugeno được đưa ra bởi:
nếu 7 = x và 9 = y thì đầu ra là z = ax + by + c
So sánh giữa hai phương pháp
Bây giờ chúng ta hãy hiểu sự so sánh giữa Hệ thống Mamdani và Mô hình Sugeno.
Output Membership Function- Sự khác biệt chính giữa chúng là trên cơ sở của chức năng thành viên đầu ra. Các hàm liên thuộc đầu ra Sugeno là tuyến tính hoặc không đổi.
Aggregation and Defuzzification Procedure - Sự khác biệt giữa chúng còn nằm ở hệ quả của các luật mờ và do cùng một quy trình tổng hợp và giải mờ của chúng cũng khác nhau.
Mathematical Rules - Có nhiều quy tắc toán học hơn cho quy tắc Sugeno so với quy tắc Mamdani.
Adjustable Parameters - Bộ điều khiển Sugeno có nhiều thông số điều chỉnh hơn bộ điều khiển Mamdani.
Chúng ta đã nghiên cứu trong các chương trước rằng Logic mờ là một cách tiếp cận tính toán dựa trên "mức độ chân lý" chứ không phải là logic "đúng hoặc sai" thông thường. Nó đề cập đến suy luận gần đúng thay vì chính xác để giải quyết vấn đề theo cách giống với logic của con người hơn, do đó quy trình truy vấn cơ sở dữ liệu bằng hai nhận thức có giá trị của đại số Boolean là không đầy đủ.
Kịch bản mờ về mối quan hệ trên cơ sở dữ liệu
Có thể hiểu được tình huống mờ của mối quan hệ trên cơ sở dữ liệu với sự trợ giúp của ví dụ sau:
Thí dụ
Giả sử chúng ta có một cơ sở dữ liệu có hồ sơ của những người đã đến thăm Ấn Độ. Trong cơ sở dữ liệu đơn giản, chúng tôi sẽ có các mục nhập được thực hiện theo cách sau:
| Tên | Tuổi tác | Người dân | Quốc gia đã đến thăm | Ngày đã dành | Năm đến thăm |
|---|---|---|---|---|---|
| John Smith | 35 | CHÚNG TA | Ấn Độ | 41 | 1999 |
| John Smith | 35 | CHÚNG TA | Nước Ý | 72 | 1999 |
| John Smith | 35 | CHÚNG TA | Nhật Bản | 31 | 1999 |
Bây giờ, nếu ai đó truy vấn về người đã đến thăm Ấn Độ và Nhật Bản vào năm 99 và là công dân của Hoa Kỳ, thì kết quả đầu ra sẽ hiển thị hai mục nhập có tên của John Smith. Đây là truy vấn đơn giản tạo ra đầu ra đơn giản.
Nhưng nếu chúng ta muốn biết liệu người trong câu hỏi trên có phải là trẻ hay không. Theo kết quả trên thì tuổi của người đó là 35 tuổi. Nhưng chúng ta có thể cho rằng người đó còn trẻ hay không? Tương tự, điều tương tự có thể được áp dụng cho các trường khác như số ngày đã sử dụng, năm đến thăm, v.v.
Giải pháp của các vấn đề trên có thể được tìm thấy với sự trợ giúp của các tập Giá trị mờ như sau:
FV (Tuổi) {rất trẻ, trẻ, hơi già, già}
FV (Số ngày đã Chi) {ít ngày, vài ngày, khá vài ngày, nhiều ngày}
FV (Năm thăm) {quá khứ xa, quá khứ gần đây, gần đây}
Bây giờ nếu bất kỳ truy vấn nào sẽ có giá trị mờ thì kết quả cũng sẽ mờ về bản chất.
Hệ thống truy vấn mờ
Hệ thống truy vấn mờ là một giao diện để người dùng lấy thông tin từ cơ sở dữ liệu bằng các câu ngôn ngữ tự nhiên (gần như). Nhiều triển khai truy vấn mờ đã được đề xuất, dẫn đến các ngôn ngữ hơi khác nhau. Mặc dù có một số biến thể tùy theo đặc điểm của các cách triển khai khác nhau, nhưng câu trả lời cho câu truy vấn mờ nói chung là một danh sách các bản ghi, được xếp hạng theo mức độ phù hợp.
Trong mô hình hóa các câu lệnh ngôn ngữ tự nhiên, các câu lệnh định lượng đóng một vai trò quan trọng. Có nghĩa là NL phụ thuộc nhiều vào việc định lượng cấu trúc thường bao gồm các khái niệm mờ như “hầu hết”, “nhiều”, v.v. Sau đây là một vài ví dụ về việc định lượng các mệnh đề -
- Mọi học sinh đều vượt qua kỳ thi.
- Mỗi chiếc xe thể thao đều đắt tiền.
- Nhiều học sinh đã thi đỗ.
- Nhiều xe thể thao đắt tiền.
Trong các ví dụ trên, các định lượng “Mọi” và “Nhiều” được áp dụng cho các hạn chế rõ nét “sinh viên” cũng như phạm vi rõ nét “(người) đã vượt qua kỳ thi” và “ô tô” cũng như phạm vi sắc nét “thể thao”.
Sự kiện mờ, phương tiện mờ và phương sai mờ
Với sự trợ giúp của một ví dụ, chúng ta có thể hiểu các khái niệm trên. Giả sử rằng chúng ta là cổ đông của một công ty có tên là ABC. Và hiện tại, công ty đang bán mỗi cổ phiếu của mình với giá ₹ 40. Có ba công ty khác nhau có hoạt động kinh doanh tương tự như ABC nhưng những công ty này đang chào bán cổ phiếu của họ với mức giá khác nhau - ₹ 100 một cổ phiếu, 85 một cổ phiếu và ₹ 60 một cổ phiếu tương ứng.
Bây giờ phân phối xác suất của việc tiếp quản giá này như sau:
| Giá bán | ₹ 100 | ₹ 85 | ₹ 60 |
|---|---|---|---|
| Xác suất | 0,3 | 0,5 | 0,2 |
Bây giờ, từ lý thuyết xác suất tiêu chuẩn, phân phối trên cho giá trị trung bình kỳ vọng như sau:
$100 × 0.3 + 85 × 0.5 + 60 × 0.2 = 84.5$
Và, từ lý thuyết xác suất tiêu chuẩn, phân phối trên cho một phương sai của giá kỳ vọng như sau:
$(100 − 84.5)2 × 0.3 + (85 − 84.5)2 × 0.5 + (60 − 84.5)2 × 0.2 = 124.825$
Giả sử mức độ thành viên của 100 trong tập này là 0,7, của 85 là 1 và mức độ thành viên là 0,5 cho giá trị 60. Chúng có thể được phản ánh trong tập mờ sau:
$$\left \{ \frac{0.7}{100}, \: \frac{1}{85}, \: \frac{0.5}{60}, \right \}$$
Tập mờ thu được theo cách này được gọi là sự kiện mờ.
Chúng tôi muốn xác suất của sự kiện mờ mà phép tính của chúng tôi cho -
$0.7 × 0.3 + 1 × 0.5 + 0.5 × 0.2 = 0.21 + 0.5 + 0.1 = 0.81$
Bây giờ, chúng ta cần tính giá trị trung bình mờ và phương sai mờ, cách tính như sau:
Fuzzy_mean $= \left ( \frac{1}{0.81} \right ) × (100 × 0.7 × 0.3 + 85 × 1 × 0.5 + 60 × 0.5 × 0.2)$
$= 85.8$
Fuzzy_Variance $= 7496.91 − 7361.91 = 135.27$
Đây là một hoạt động bao gồm các bước cần thực hiện để lựa chọn một phương án thay thế phù hợp từ những bước cần thiết để thực hiện một mục tiêu nhất định.
Các bước ra quyết định
Bây giờ chúng ta hãy thảo luận về các bước liên quan đến quá trình ra quyết định -
Determining the Set of Alternatives - Trong bước này, phải xác định các phương án thay thế mà từ đó đưa ra quyết định.
Evaluating Alternative - Ở đây, các phương án phải được đánh giá để có thể đưa ra quyết định về một trong các phương án.
Comparison between Alternatives - Trong bước này, việc so sánh giữa các phương án đã được đánh giá được thực hiện.
Các loại quyết định
Thực hiện Bây giờ chúng ta sẽ hiểu các kiểu ra quyết định khác nhau.
Ra quyết định cá nhân
Trong kiểu ra quyết định này, chỉ một người duy nhất chịu trách nhiệm ra quyết định. Mô hình ra quyết định kiểu này có thể được mô tả như sau:
Tập hợp các hành động có thể
Đặt mục tiêu $G_i\left ( i \: \in \: X_n \right );$
Tập hợp các ràng buộc $C_j\left ( j \: \in \: X_m \right )$
Các mục tiêu và ràng buộc nêu trên được thể hiện dưới dạng các tập mờ.
Bây giờ hãy xem xét một tập hợp A. Sau đó, mục tiêu và các ràng buộc cho tập hợp này được đưa ra bởi:
$G_i\left ( a \right )$ = thành phần$\left [ G_i\left ( a \right ) \right ]$ = $G_i^1\left ( G_i\left ( a \right ) \right )$ với $G_i^1$
$C_j\left ( a \right )$ = thành phần$\left [ C_j\left ( a \right ) \right ]$ = $C_j^1\left ( C_j\left ( a \right ) \right )$ với $C_j^1$ cho $a\:\in \:A$
Quyết định mờ trong trường hợp trên được đưa ra bởi -
$$F_D = min[i\in X_{n}^{in}fG_i\left ( a \right ),j\in X_{m}^{in}fC_j\left ( a \right )]$$
Nhiều người ra quyết định
Việc ra quyết định trong trường hợp này bao gồm một số người để kiến thức chuyên môn từ những người khác nhau được sử dụng để đưa ra quyết định.
Tính toán cho điều này có thể được đưa ra như sau:
Number of persons preferring $x_i$ to $x_j$ = $N\left ( x_i, \: x_j \right )$
Total number of decision makers = $n$
Sau đó, $SC\left ( x_i, \: x_j \right ) = \frac{N\left ( x_i, \: x_j \right )}{n}$
Ra quyết định đa mục tiêu
Việc ra quyết định đa mục tiêu xảy ra khi có một số mục tiêu được thực hiện. Có hai vấn đề sau trong kiểu ra quyết định này:
Để có được thông tin thích hợp liên quan đến việc đáp ứng các mục tiêu bằng các phương án khác nhau.
Cân nhắc tầm quan trọng tương đối của từng mục tiêu.
Về mặt toán học, chúng ta có thể định nghĩa một vũ trụ gồm n lựa chọn thay thế là -
$A = \left [ a_1, \:a_2,\:..., \: a_i, \: ..., \:a_n \right ]$
Và tập hợp các mục tiêu "m" như $O = \left [ o_1, \:o_2,\:..., \: o_i, \: ..., \:o_n \right ]$
Ra quyết định đa thuộc tính
Việc ra quyết định đa thuộc tính diễn ra khi việc đánh giá các lựa chọn thay thế có thể được thực hiện dựa trên một số thuộc tính của đối tượng. Các thuộc tính có thể là dữ liệu số, dữ liệu ngôn ngữ và dữ liệu định tính.
Về mặt toán học, đánh giá đa thuộc tính được thực hiện trên cơ sở phương trình tuyến tính như sau:
$$Y = A_1X_1+A_2X_2+...+A_iX_i+...+A_rX_r$$
Logic mờ được áp dụng rất thành công trong các ứng dụng điều khiển khác nhau. Hầu hết tất cả các sản phẩm tiêu dùng đều có sự kiểm soát mờ nhạt. Một số ví dụ bao gồm kiểm soát nhiệt độ phòng của bạn với sự hỗ trợ của máy lạnh, hệ thống chống phanh được sử dụng trên xe, kiểm soát đèn giao thông, máy giặt, hệ thống kinh tế lớn, v.v.
Tại sao sử dụng Logic mờ trong hệ thống điều khiển
Hệ thống điều khiển là sự sắp xếp của các thành phần vật lý được thiết kế để thay đổi một hệ thống vật lý khác để hệ thống này có những đặc điểm mong muốn nhất định. Sau đây là một số lý do sử dụng Logic mờ trong Hệ thống điều khiển -
Trong khi áp dụng điều khiển truyền thống, người ta cần biết về mô hình và hàm mục tiêu được hình thành theo các thuật ngữ chính xác. Điều này làm cho nó rất khó áp dụng trong nhiều trường hợp.
Bằng cách áp dụng logic mờ để điều khiển, chúng ta có thể sử dụng chuyên môn và kinh nghiệm của con người để thiết kế bộ điều khiển.
Các quy tắc điều khiển mờ, về cơ bản là các quy tắc IF-THEN, có thể được sử dụng tốt nhất trong việc thiết kế một bộ điều khiển.
Các giả định trong thiết kế điều khiển logic mờ (FLC)
Trong khi thiết kế hệ thống điều khiển mờ, sáu giả thiết cơ bản sau đây cần được thực hiện:
The plant is observable and controllable - Phải giả định rằng các biến đầu vào, đầu ra cũng như trạng thái đều có sẵn cho mục đích quan sát và điều khiển.
Existence of a knowledge body - Phải giả định rằng tồn tại một khối tri thức có các quy tắc ngôn ngữ và một tập hợp dữ liệu đầu vào - đầu ra mà từ đó các quy tắc có thể được trích xuất.
Existence of solution - Phải cho rằng tồn tại một giải pháp.
‘Good enough’ solution is enough - Kỹ thuật điều khiển phải tìm kiếm giải pháp 'đủ tốt' hơn là giải pháp tối ưu.
Range of precision - Bộ điều khiển logic mờ phải được thiết kế trong phạm vi chính xác có thể chấp nhận được.
Issues regarding stability and optimality - Các vấn đề về tính ổn định và tính tối ưu phải được mở ra trong việc thiết kế bộ điều khiển logic mờ hơn là được giải quyết một cách rõ ràng.
Kiến trúc của điều khiển logic mờ
Sơ đồ sau đây cho thấy kiến trúc của điều khiển logic mờ (FLC).

Các thành phần chính của FLC
Tiếp theo là các thành phần chính của FLC như thể hiện trong hình trên -
Fuzzifier - Vai trò của fuzzifier là chuyển các giá trị đầu vào sắc nét thành các giá trị mờ.
Fuzzy Knowledge Base- Nó lưu trữ kiến thức về tất cả các mối quan hệ mờ đầu vào - đầu ra. Nó cũng có hàm liên thuộc xác định các biến đầu vào cho cơ sở quy tắc mờ và các biến đầu ra cho nhà máy được kiểm soát.
Fuzzy Rule Base - Nó lưu trữ kiến thức về hoạt động của quá trình miền.
Inference Engine- Nó hoạt động như một hạt nhân của bất kỳ FLC nào. Về cơ bản, nó mô phỏng các quyết định của con người bằng cách thực hiện suy luận gần đúng.
Defuzzifier - Vai trò của bộ làm mờ là chuyển các giá trị mờ thành các giá trị rõ nét nhận được từ công cụ suy luận mờ.
Các bước thiết kế FLC
Sau đây là các bước thiết kế FLC -
Identification of variables - Ở đây, các biến đầu vào, đầu ra và trạng thái phải được xác định của nhà máy đang được xem xét.
Fuzzy subset configuration- Vũ trụ thông tin được chia thành nhiều tập con mờ và mỗi tập con được gán một nhãn ngôn ngữ. Luôn đảm bảo rằng các tập con mờ này bao gồm tất cả các yếu tố của vũ trụ.
Obtaining membership function - Bây giờ lấy hàm liên thuộc cho mỗi tập con mờ mà chúng ta nhận được ở bước trên.
Fuzzy rule base configuration - Bây giờ xây dựng cơ sở quy tắc mờ bằng cách gán mối quan hệ giữa đầu vào và đầu ra mờ.
Fuzzification - Quá trình làm mờ được bắt đầu trong bước này.
Combining fuzzy outputs - Bằng cách áp dụng suy luận gần đúng mờ, xác định vị trí đầu ra mờ và hợp nhất chúng.
Defuzzification - Cuối cùng, bắt đầu quá trình khử mờ để tạo thành đầu ra rõ nét.
Ưu điểm của điều khiển logic mờ
Bây giờ chúng ta hãy thảo luận về những ưu điểm của Điều khiển Logic mờ.
Cheaper - Phát triển một FLC tương đối rẻ hơn so với phát triển dựa trên mô hình hoặc bộ điều khiển khác về hiệu suất.
Robust - Các bộ điều khiển FLC mạnh mẽ hơn bộ điều khiển PID vì khả năng bao phủ một loạt các điều kiện hoạt động.
Customizable - Các FLC có thể tùy chỉnh.
Emulate human deductive thinking - Về cơ bản, FLC được thiết kế để mô phỏng tư duy suy luận của con người, quá trình con người sử dụng để đưa ra kết luận từ những gì họ biết.
Reliability - FLC đáng tin cậy hơn hệ thống điều khiển thông thường.
Efficiency - Logic mờ mang lại hiệu quả cao hơn khi áp dụng trong hệ thống điều khiển.
Nhược điểm của điều khiển logic mờ
Bây giờ chúng ta sẽ thảo luận những nhược điểm của Điều khiển Logic mờ là gì.
Requires lots of data - FLC cần nhiều dữ liệu để áp dụng.
Useful in case of moderate historical data - FLC không hữu ích cho các chương trình nhỏ hơn hoặc lớn hơn nhiều so với dữ liệu lịch sử.
Needs high human expertise - Đây là một nhược điểm do độ chính xác của hệ thống phụ thuộc vào kiến thức và chuyên môn của con người.
Needs regular updating of rules - Các quy tắc phải được cập nhật với thời gian.
Trong chương này, chúng ta sẽ thảo luận về Bộ điều khiển mờ thích ứng là gì và nó hoạt động như thế nào. Bộ điều khiển mờ thích ứng được thiết kế với một số thông số có thể điều chỉnh cùng với cơ chế nhúng để điều chỉnh chúng. Bộ điều khiển thích ứng đã được sử dụng để cải thiện hiệu suất của bộ điều khiển.
Các bước cơ bản để triển khai thuật toán thích ứng
Bây giờ chúng ta hãy thảo luận về các bước cơ bản để triển khai thuật toán thích ứng.
Collection of observable data - Dữ liệu quan sát được thu thập để tính toán hiệu suất của bộ điều khiển.
Adjustment of controller parameters - Bây giờ với sự trợ giúp của hiệu suất bộ điều khiển, tính toán điều chỉnh các thông số bộ điều khiển sẽ được thực hiện.
Improvement in performance of controller - Trong bước này, các thông số bộ điều khiển được điều chỉnh để cải thiện hiệu suất của bộ điều khiển.
Khái niệm hoạt động
Thiết kế bộ điều khiển dựa trên một mô hình toán học giả định giống với một hệ thống thực. Sai số giữa hệ thống thực tế và biểu diễn toán học của nó được tính toán và nếu nó tương đối không đáng kể so với mô hình được cho là hoạt động hiệu quả.
Một hằng số ngưỡng thiết lập ranh giới cho tính hiệu quả của bộ điều khiển, cũng tồn tại. Đầu vào điều khiển được đưa vào cả hệ thống thực và mô hình toán học. Đây, giả sử$x\left ( t \right )$ là đầu ra của hệ thống thực và $y\left ( t \right )$là đầu ra của mô hình toán học. Sau đó, lỗi$\epsilon \left ( t \right )$ có thể được tính như sau:
$$\epsilon \left ( t \right ) = x\left ( t \right ) - y\left ( t \right )$$
Đây, $x$ mong muốn là đầu ra chúng tôi muốn từ hệ thống và $\mu \left ( t \right )$ là đầu ra đến từ bộ điều khiển và đi đến cả mô hình thực cũng như toán học.
Sơ đồ sau đây cho thấy cách theo dõi hàm lỗi giữa đầu ra của một hệ thống thực và mô hình Toán học:

Tham số hóa hệ thống
Bộ điều khiển mờ được thiết kế dựa trên mô hình toán học mờ sẽ có dạng quy tắc mờ sau:
Rule 1 - NẾU $x_1\left ( t_n \right )\in X_{11} \: AND...AND\: x_i\left ( t_n \right )\in X_{1i}$
SAU ĐÓ $\mu _1\left ( t_n \right ) = K_{11}x_1\left ( t_n \right ) + K_{12}x_2\left ( t_n \right ) \: +...+ \: K_{1i}x_i\left ( t_n \right )$
Rule 2 - NẾU $x_1\left ( t_n \right )\in X_{21} \: AND...AND \: x_i\left ( t_n \right )\in X_{2i}$
SAU ĐÓ $\mu _2\left ( t_n \right ) = K_{21}x_1\left ( t_n \right ) + K_{22}x_2\left ( t_n \right ) \: +...+ \: K_{2i}x_i\left ( t_n \right ) $
.
.
.
Rule j - NẾU $x_1\left ( t_n \right )\in X_{k1} \: AND...AND \: x_i\left ( t_n \right )\in X_{ki}$
SAU ĐÓ $\mu _j\left ( t_n \right ) = K_{j1}x_1\left ( t_n \right ) + K_{j2}x_2\left ( t_n \right ) \: +...+ \: K_{ji}x_i\left ( t_n \right ) $
Bộ thông số trên đặc trưng cho bộ điều khiển.
Điều chỉnh cơ chế
Các thông số bộ điều khiển được điều chỉnh để cải thiện hiệu suất của bộ điều khiển. Quá trình tính toán điều chỉnh các tham số là cơ chế điều chỉnh.
Về mặt toán học, hãy $\theta ^\left ( n \right )$ là một tập hợp các tham số được điều chỉnh tại thời điểm $t = t_n$. Điều chỉnh có thể là tính toán lại các thông số,
$$\theta ^\left ( n \right ) = \Theta \left ( D_0,\: D_1, \: ..., \:D_n \right )$$
Đây $D_n$ là dữ liệu được thu thập tại thời điểm $t = t_n$.
Bây giờ công thức này được định dạng lại bằng cách cập nhật bộ tham số dựa trên giá trị trước đó của nó là,
$$\theta ^\left ( n \right ) = \phi ( \theta ^{n-1}, \: D_n)$$
Các thông số để chọn Bộ điều khiển mờ thích ứng
Các tham số sau đây cần được xem xét để chọn bộ điều khiển mờ thích ứng:
Hệ thống có thể được xấp xỉ hoàn toàn bằng một mô hình mờ không?
Nếu một hệ thống có thể được xấp xỉ hoàn toàn bằng mô hình mờ, thì các tham số của mô hình mờ này có sẵn hay phải xác định trực tuyến?
Nếu một hệ thống không thể được xấp xỉ hoàn toàn bằng một mô hình mờ, thì nó có thể được xấp xỉ từng phần bằng một tập mô hình mờ không?
Nếu một hệ thống có thể được xấp xỉ bởi một tập hợp các mô hình mờ, các mô hình này có cùng định dạng với các tham số khác nhau hay chúng có các định dạng khác nhau?
Nếu một hệ thống có thể được xấp xỉ bằng một tập các mô hình mờ có cùng định dạng, mỗi mô hình có một tập tham số khác nhau, thì các tập tham số này có sẵn hay phải xác định trực tuyến?
Mạng nơ-ron nhân tạo (ANN) là một mạng lưới các hệ thống tính toán hiệu quả, chủ đề trung tâm của nó được mượn từ sự tương tự của mạng nơ-ron sinh học. ANN còn được đặt tên là “hệ thống thần kinh nhân tạo”, hệ thống xử lý phân tán song song ”,“ hệ thống kết nối ”. ANN có được một bộ sưu tập lớn các đơn vị được kết nối với nhau theo một số mẫu để cho phép liên lạc giữa các đơn vị. Những đơn vị này, còn được gọi là nút hoặc nơ-ron, là những bộ xử lý đơn giản hoạt động song song.
Mọi nơron đều được kết nối với nơron khác thông qua một liên kết kết nối. Mỗi liên kết kết nối được liên kết với một trọng số có thông tin về tín hiệu đầu vào. Đây là thông tin hữu ích nhất cho các tế bào thần kinh để giải quyết một vấn đề cụ thể vì trọng lượng thường ức chế tín hiệu đang được truyền đạt. Mỗi tế bào thần kinh đang có trạng thái bên trong được gọi là tín hiệu kích hoạt. Tín hiệu đầu ra, được tạo ra sau khi kết hợp các tín hiệu đầu vào và quy tắc kích hoạt, có thể được gửi đến các đơn vị khác. Nó cũng bao gồm một thiên vị 'b' có trọng số luôn là 1.

Tại sao sử dụng Logic mờ trong mạng thần kinh
Như chúng ta đã thảo luận ở trên rằng mọi nơ-ron trong ANN được kết nối với nơ-ron khác thông qua một liên kết kết nối và liên kết đó được liên kết với một trọng số có thông tin về tín hiệu đầu vào. Do đó, chúng ta có thể nói rằng trọng số có thông tin hữu ích về đầu vào để giải quyết vấn đề.
Sau đây là một số lý do để sử dụng logic mờ trong mạng nơ-ron:
Logic mờ phần lớn được sử dụng để xác định trọng số, từ các tập mờ, trong mạng nơron.
Khi không thể áp dụng các giá trị rõ nét, thì các giá trị mờ được sử dụng.
Chúng tôi đã nghiên cứu rằng việc đào tạo và học tập giúp mạng nơ-ron hoạt động tốt hơn trong các tình huống không mong muốn. Lúc đó các giá trị mờ sẽ được áp dụng nhiều hơn các giá trị rõ nét.
Khi chúng ta sử dụng logic mờ trong mạng nơ-ron thì các giá trị không được sắc nét và quá trình xử lý có thể được thực hiện song song.
Bản đồ nhận thức mờ
Nó là một dạng mờ trong mạng nơ-ron. Về cơ bản FCM giống như một máy trạng thái động với các trạng thái mờ (không chỉ 1 hoặc 0).
Khó khăn khi sử dụng Logic mờ trong mạng thần kinh
Mặc dù có nhiều ưu điểm, nhưng cũng có một số khó khăn khi sử dụng logic mờ trong mạng nơ-ron. Khó khăn liên quan đến các quy tắc thành viên, sự cần thiết phải xây dựng hệ thống mờ, vì đôi khi việc suy diễn nó với tập dữ liệu phức tạp đã cho là rất phức tạp.
Logic mờ được đào tạo bằng thần kinh
Mối quan hệ ngược lại giữa mạng nơron và logic mờ, tức là mạng nơron được sử dụng để đào tạo logic mờ cũng là một lĩnh vực nghiên cứu tốt. Sau đây là hai lý do chính để xây dựng logic mờ được dẫn truyền thần kinh:
Các mẫu dữ liệu mới có thể được học một cách dễ dàng với sự trợ giúp của mạng nơron, do đó, nó có thể được sử dụng để xử lý trước dữ liệu trong các hệ thống mờ.
Mạng nơron, vì khả năng tìm hiểu mối quan hệ mới với dữ liệu đầu vào mới, có thể được sử dụng để tinh chỉnh các quy tắc mờ nhằm tạo ra hệ thống thích ứng mờ.
Ví dụ về hệ thống Mờ được huấn luyện bằng thần kinh
Hệ thống mờ được đào tạo bằng thần kinh đang được sử dụng trong nhiều ứng dụng thương mại. Bây giờ chúng ta hãy xem một vài ví dụ áp dụng hệ thống Mờ được đào tạo bằng thần kinh -
Phòng thí nghiệm Nghiên cứu Kỹ thuật Mờ Quốc tế (LIFE) ở Yokohama, Nhật Bản có một mạng nơron lan truyền ngược tạo ra các quy tắc mờ. Hệ thống này đã được áp dụng thành công cho hệ thống thương mại ngoại hối với khoảng 5000 quy tắc mờ.
Ford Motor Company đã phát triển các hệ thống mờ có thể huấn luyện để điều khiển tốc độ không tải của ô tô.
NeuFuz, sản phẩm phần mềm của National Semiconductor Corporation, hỗ trợ tạo các luật mờ với mạng nơron cho các ứng dụng điều khiển.
Tập đoàn AEG của Đức sử dụng hệ thống điều khiển mờ được đào tạo bằng thần kinh cho máy tiết kiệm năng lượng và nước của mình. Nó có tổng cộng 157 luật mờ.
Trong chương này, chúng ta sẽ thảo luận về các lĩnh vực mà các khái niệm của Logic mờ được áp dụng rộng rãi.
Không gian vũ trụ
Trong không gian vũ trụ, logic mờ được sử dụng trong các lĩnh vực sau:
- Kiểm soát độ cao của tàu vũ trụ
- Kiểm soát độ cao vệ tinh
- Quy định dòng chảy và hỗn hợp trong các phương tiện đóng băng máy bay
Ô tô
Trong ô tô, logic mờ được sử dụng trong các lĩnh vực sau:
- Hệ thống mờ có thể huấn luyện để điều khiển tốc độ không tải
- Phương pháp lập lịch trình thay đổi cho hộp số tự động
- Hệ thống đường cao tốc thông minh
- Điều khiển giao thông
- Nâng cao hiệu quả của hộp số tự động
Kinh doanh
Trong kinh doanh, logic mờ được sử dụng trong các lĩnh vực sau:
- Hệ thống hỗ trợ ra quyết định
- Đánh giá nhân sự trong một công ty lớn
Phòng thủ
Trong phòng thủ, logic mờ được sử dụng trong các lĩnh vực sau:
- Nhận dạng mục tiêu dưới nước
- Tự động nhận dạng mục tiêu bằng hình ảnh hồng ngoại nhiệt
- Hỗ trợ hỗ trợ quyết định của hải quân
- Kiểm soát thiết bị đánh chặn siêu tốc
- Mô hình tập hợp mờ về việc ra quyết định của NATO
Thiết bị điện tử
Trong điện tử, logic mờ được sử dụng trong các lĩnh vực sau:
- Kiểm soát độ phơi sáng tự động trong máy quay video
- Độ ẩm trong phòng sạch
- Hệ thống điều hòa không khí
- Thời gian máy giặt
- Nhiều lò vi sóng
- Máy hút bụi
Tài chính
Trong lĩnh vực tài chính, logic mờ được sử dụng trong các lĩnh vực sau:
- Kiểm soát chuyển khoản tiền giấy
- Quản lý quỹ
- Dự đoán thị trường chứng khoán
Khu vực công nghiệp
Trong công nghiệp, logic mờ được sử dụng trong các lĩnh vực sau:
- Lò xi măng điều khiển điều khiển bộ trao đổi nhiệt
- Kiểm soát quá trình xử lý nước thải bằng bùn hoạt tính
- Kiểm soát nhà máy lọc nước
- Phân tích mẫu định lượng để đảm bảo chất lượng công nghiệp
- Kiểm soát các vấn đề thỏa mãn ràng buộc trong thiết kế kết cấu
- Kiểm soát nhà máy lọc nước
Chế tạo
Trong công nghiệp sản xuất, logic mờ được sử dụng trong các lĩnh vực sau:
- Tối ưu hóa sản xuất pho mát
- Tối ưu hóa sản xuất sữa
Hàng hải
Trong lĩnh vực hàng hải, logic mờ được sử dụng trong các lĩnh vực sau:
- Lái tự động cho tàu
- Lựa chọn tuyến đường tối ưu
- Điều khiển các phương tiện tự lái dưới nước
- Lái tàu
Y khoa
Trong lĩnh vực y tế, logic mờ được sử dụng trong các lĩnh vực sau:
- Hệ thống hỗ trợ chẩn đoán y tế
- Kiểm soát áp lực động mạch khi gây mê
- Kiểm soát đa biến gây mê
- Mô hình hóa các phát hiện bệnh lý thần kinh ở bệnh nhân Alzheimer
- Chẩn đoán X quang
- Chẩn đoán suy luận mờ về bệnh tiểu đường và ung thư tuyến tiền liệt
Chứng khoán
Trong chứng khoán, logic mờ được sử dụng trong các lĩnh vực sau:
- Hệ thống quyết định giao dịch chứng khoán
- Các thiết bị an ninh khác nhau
Vận chuyển
Trong giao thông vận tải, logic mờ được sử dụng trong các lĩnh vực sau:
- Vận hành tàu điện ngầm tự động
- Kiểm soát lịch trình tàu
- Tăng tốc đường sắt
- Phanh và dừng
Nhận dạng và phân loại mẫu
Trong Nhận dạng và Phân loại Mẫu, logic mờ được sử dụng trong các lĩnh vực sau:
- Nhận dạng giọng nói dựa trên logic mờ
- Dựa trên logic mờ
- Nhận dang chu Viet
- Phân tích đặc điểm khuôn mặt dựa trên logic mờ
- Phân tích lệnh
- Tìm kiếm hình ảnh mờ
Tâm lý học
Trong Tâm lý học, logic mờ được sử dụng trong các lĩnh vực sau:
- Phân tích logic mờ về hành vi của con người
- Điều tra và phòng ngừa tội phạm dựa trên suy luận logic mờ