Big Data Analytics - Datenlebenszyklus
Traditioneller Data Mining-Lebenszyklus
Um einen Rahmen für die Organisation der von einer Organisation benötigten Arbeit und klare Erkenntnisse aus Big Data bereitzustellen, ist es hilfreich, sich diesen als einen Zyklus mit verschiedenen Phasen vorzustellen. Es ist keineswegs linear, dh alle Stufen sind miteinander verbunden. Dieser Zyklus weist oberflächliche Ähnlichkeiten mit dem traditionelleren Data Mining-Zyklus auf, wie in beschriebenCRISP methodology.
CRISP-DM-Methodik
Das CRISP-DM methodologyDies steht für den branchenübergreifenden Standardprozess für Data Mining. In diesem Zyklus werden häufig verwendete Ansätze beschrieben, mit denen Data Mining-Experten Probleme im traditionellen BI-Data Mining angehen. Es wird immer noch in traditionellen BI-Data-Mining-Teams verwendet.
Schauen Sie sich die folgende Abbildung an. Es zeigt die Hauptphasen des Zyklus, wie sie in der CRISP-DM-Methodik beschrieben sind, und wie sie miteinander zusammenhängen.
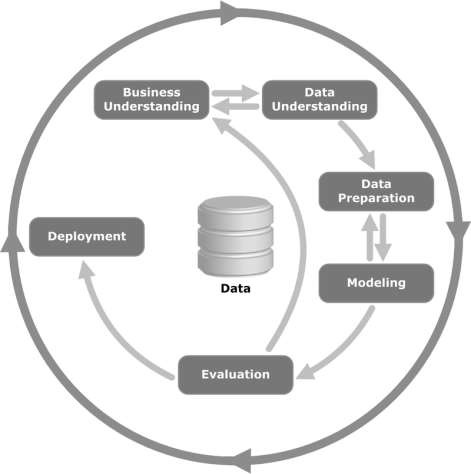
CRISP-DM wurde 1996 konzipiert und im nächsten Jahr als Projekt der Europäischen Union im Rahmen der ESPRIT-Förderinitiative gestartet. Das Projekt wurde von fünf Unternehmen geleitet: SPSS, Teradata, Daimler AG, NCR Corporation und OHRA (eine Versicherungsgesellschaft). Das Projekt wurde schließlich in SPSS aufgenommen. Die Methodik ist äußerst detailliert und orientiert sich daran, wie ein Data Mining-Projekt spezifiziert werden sollte.
Lassen Sie uns nun etwas mehr über die einzelnen Phasen des CRISP-DM-Lebenszyklus erfahren -
Business Understanding- Diese erste Phase konzentriert sich darauf, die Projektziele und -anforderungen aus geschäftlicher Sicht zu verstehen und dieses Wissen dann in eine Data-Mining-Problemdefinition umzuwandeln. Ein vorläufiger Plan soll die Ziele erreichen. Es kann ein Entscheidungsmodell verwendet werden, insbesondere eines, das unter Verwendung des Entscheidungsmodell- und Notationsstandards erstellt wurde.
Data Understanding - Die Datenverständnisphase beginnt mit einer ersten Datenerfassung und setzt Aktivitäten fort, um sich mit den Daten vertraut zu machen, Datenqualitätsprobleme zu identifizieren, erste Einblicke in die Daten zu gewinnen oder interessante Teilmengen zu erkennen, um Hypothesen für versteckte Informationen zu bilden.
Data Preparation- Die Datenaufbereitungsphase umfasst alle Aktivitäten zum Erstellen des endgültigen Datensatzes (Daten, die in die Modellierungswerkzeuge eingespeist werden) aus den anfänglichen Rohdaten. Datenvorbereitungsaufgaben werden wahrscheinlich mehrmals und nicht in einer vorgeschriebenen Reihenfolge ausgeführt. Zu den Aufgaben gehören die Auswahl von Tabellen, Datensätzen und Attributen sowie die Transformation und Bereinigung von Daten für Modellierungswerkzeuge.
Modeling- In dieser Phase werden verschiedene Modellierungstechniken ausgewählt und angewendet und ihre Parameter auf optimale Werte kalibriert. In der Regel gibt es mehrere Techniken für denselben Data Mining-Problemtyp. Einige Techniken stellen spezielle Anforderungen an die Datenform. Daher ist es häufig erforderlich, zur Datenaufbereitungsphase zurückzukehren.
Evaluation- Zu diesem Zeitpunkt im Projekt haben Sie ein Modell (oder Modelle) erstellt, das aus Sicht der Datenanalyse eine hohe Qualität zu haben scheint. Bevor Sie mit der endgültigen Bereitstellung des Modells fortfahren, ist es wichtig, das Modell gründlich zu bewerten und die zur Erstellung des Modells ausgeführten Schritte zu überprüfen, um sicherzustellen, dass die Geschäftsziele ordnungsgemäß erreicht werden.
Ein wichtiges Ziel ist es festzustellen, ob es ein wichtiges Geschäftsproblem gibt, das nicht ausreichend berücksichtigt wurde. Am Ende dieser Phase sollte eine Entscheidung über die Verwendung der Data Mining-Ergebnisse getroffen werden.
Deployment- Die Erstellung des Modells ist in der Regel nicht das Ende des Projekts. Selbst wenn der Zweck des Modells darin besteht, das Wissen über die Daten zu verbessern, muss das gewonnene Wissen so organisiert und präsentiert werden, dass es für den Kunden nützlich ist.
Abhängig von den Anforderungen kann die Bereitstellungsphase so einfach wie das Erstellen eines Berichts oder so komplex wie das Implementieren einer wiederholbaren Datenbewertung (z. B. Segmentzuweisung) oder eines Data Mining-Prozesses sein.
In vielen Fällen ist es der Kunde, nicht der Datenanalyst, der die Bereitstellungsschritte ausführt. Selbst wenn der Analyst das Modell bereitstellt, ist es für den Kunden wichtig, im Voraus zu verstehen, welche Aktionen ausgeführt werden müssen, um die erstellten Modelle tatsächlich nutzen zu können.
SEMMA-Methodik
SEMMA ist eine weitere von SAS entwickelte Methode zur Modellierung von Data Mining. Es steht fürSreichlich, Explore, Modifizieren, Model und Asses. Hier ist eine kurze Beschreibung seiner Stadien -
Sample- Der Prozess beginnt mit der Datenerfassung, z. B. der Auswahl des zu modellierenden Datensatzes. Der Datensatz sollte groß genug sein, um genügend Informationen zum Abrufen zu enthalten, aber klein genug, um effizient verwendet zu werden. Diese Phase befasst sich auch mit der Datenpartitionierung.
Explore - Diese Phase umfasst das Verständnis der Daten, indem mithilfe der Datenvisualisierung erwartete und unerwartete Beziehungen zwischen den Variablen sowie Anomalien ermittelt werden.
Modify - Die Änderungsphase enthält Methoden zum Auswählen, Erstellen und Transformieren von Variablen zur Vorbereitung der Datenmodellierung.
Model - In der Modellphase liegt der Schwerpunkt auf der Anwendung verschiedener Modellierungstechniken (Data Mining) auf die vorbereiteten Variablen, um Modelle zu erstellen, die möglicherweise das gewünschte Ergebnis liefern.
Assess - Die Auswertung der Modellierungsergebnisse zeigt die Zuverlässigkeit und Nützlichkeit der erstellten Modelle.
Der Hauptunterschied zwischen CRISM-DM und SEMMA besteht darin, dass sich SEMMA auf den Modellierungsaspekt konzentriert, während CRISP-DM Phasen des Zyklus vor der Modellierung eine größere Bedeutung beimisst, z. B. das Verstehen des zu lösenden Geschäftsproblems, das Verstehen und die Vorverarbeitung der zu verarbeitenden Daten Als Eingabe werden beispielsweise Algorithmen für maschinelles Lernen verwendet.
Big Data-Lebenszyklus
Im heutigen Big-Data-Kontext sind die bisherigen Ansätze entweder unvollständig oder suboptimal. Beispielsweise ignoriert die SEMMA-Methodik die Datenerfassung und Vorverarbeitung verschiedener Datenquellen vollständig. Diese Phasen machen normalerweise den größten Teil der Arbeit in einem erfolgreichen Big-Data-Projekt aus.
Ein Big-Data-Analysezyklus kann in der folgenden Phase beschrieben werden:
- Geschäftsproblemdefinition
- Research
- Personalbewertung
- Datenerfassung
- Daten Munging
- Datenspeicher
- Explorative Datenanalyse
- Datenvorbereitung für Modellierung und Bewertung
- Modeling
- Implementation
In diesem Abschnitt werden wir uns mit jeder dieser Phasen des Big-Data-Lebenszyklus befassen.
Geschäftsproblemdefinition
Dies ist ein Punkt, der im traditionellen Lebenszyklus von BI- und Big-Data-Analysen häufig vorkommt. Normalerweise ist es eine nicht triviale Phase eines Big-Data-Projekts, das Problem zu definieren und richtig zu bewerten, wie viel potenziellen Gewinn es für ein Unternehmen haben kann. Es liegt auf der Hand, dies zu erwähnen, aber es muss bewertet werden, welche Gewinne und Kosten das Projekt erwartet.
Forschung
Analysieren Sie, was andere Unternehmen in derselben Situation getan haben. Dies beinhaltet die Suche nach Lösungen, die für Ihr Unternehmen angemessen sind, obwohl andere Lösungen an die Ressourcen und Anforderungen Ihres Unternehmens angepasst werden müssen. In dieser Phase sollte eine Methodik für die zukünftigen Phasen definiert werden.
Personalbewertung
Sobald das Problem definiert ist, ist es sinnvoll, weiter zu analysieren, ob die aktuellen Mitarbeiter das Projekt erfolgreich abschließen können. Herkömmliche BI-Teams sind möglicherweise nicht in der Lage, eine optimale Lösung für alle Phasen zu liefern. Daher sollte vor Beginn des Projekts überlegt werden, ob ein Teil des Projekts ausgelagert oder mehr Mitarbeiter eingestellt werden müssen.
Datenerfassung
Dieser Abschnitt ist der Schlüssel für einen Big-Data-Lebenszyklus. Es definiert, welche Art von Profilen benötigt wird, um das resultierende Datenprodukt zu liefern. Das Sammeln von Daten ist ein nicht trivialer Schritt des Prozesses. Normalerweise werden unstrukturierte Daten aus verschiedenen Quellen gesammelt. Ein Beispiel könnte das Schreiben eines Crawlers sein, um Bewertungen von einer Website abzurufen. Dies beinhaltet den Umgang mit Text, möglicherweise in verschiedenen Sprachen, für deren Fertigstellung normalerweise viel Zeit erforderlich ist.
Daten Munging
Sobald die Daten beispielsweise aus dem Internet abgerufen wurden, müssen sie in einem benutzerfreundlichen Format gespeichert werden. Nehmen wir an, dass die Daten von verschiedenen Standorten abgerufen werden, an denen die Daten jeweils unterschiedlich angezeigt werden.
Angenommen, eine Datenquelle gibt Bewertungen in Bezug auf die Bewertung in Sternen ab, daher ist es möglich, diese als Zuordnung für die Antwortvariable zu lesen y ∈ {1, 2, 3, 4, 5}. Eine andere Datenquelle gibt Überprüfungen mit zwei Pfeilen, eines für die Aufwärtsabstimmung und das andere für die Abwärtsabstimmung. Dies würde eine Antwortvariable des Formulars impliziereny ∈ {positive, negative}.
Um beide Datenquellen zu kombinieren, muss eine Entscheidung getroffen werden, um diese beiden Antwortdarstellungen gleichwertig zu machen. Dies kann das Konvertieren der ersten Datenquellen-Antwortdarstellung in die zweite Form beinhalten, wobei ein Stern als negativ und fünf Sterne als positiv betrachtet werden. Dieser Prozess erfordert oft eine große Zeitzuweisung, um mit guter Qualität geliefert zu werden.
Datenspeicher
Sobald die Daten verarbeitet sind, müssen sie manchmal in einer Datenbank gespeichert werden. Big-Data-Technologien bieten diesbezüglich zahlreiche Alternativen. Die häufigste Alternative ist die Verwendung des Hadoop-Dateisystems für die Speicherung, das Benutzern eine eingeschränkte Version von SQL bietet, die als HIVE Query Language bezeichnet wird. Auf diese Weise können die meisten Analyseaufgaben aus Anwendersicht auf ähnliche Weise ausgeführt werden wie in herkömmlichen BI-Data-Warehouses. Weitere zu berücksichtigende Speicheroptionen sind MongoDB, Redis und SPARK.
Diese Phase des Zyklus hängt mit dem Personalwissen hinsichtlich seiner Fähigkeit zusammen, verschiedene Architekturen zu implementieren. Modifizierte Versionen traditioneller Data Warehouses werden immer noch in großen Anwendungen verwendet. Beispielsweise bieten Teradata und IBM SQL-Datenbanken an, die Terabyte an Daten verarbeiten können. Open Source-Lösungen wie postgreSQL und MySQL werden immer noch für große Anwendungen verwendet.
Obwohl es Unterschiede in der Funktionsweise der verschiedenen Speicher im Hintergrund gibt, bieten die meisten Lösungen auf Clientseite eine SQL-API. Ein gutes Verständnis von SQL ist daher immer noch eine Schlüsselkompetenz für die Big-Data-Analyse.
Diese Phase a priori scheint das wichtigste Thema zu sein, in der Praxis ist dies nicht der Fall. Es ist nicht einmal eine wesentliche Phase. Es ist möglich, eine Big-Data-Lösung zu implementieren, die mit Echtzeitdaten arbeitet. In diesem Fall müssen wir nur Daten sammeln, um das Modell zu entwickeln, und es dann in Echtzeit implementieren. Es wäre also überhaupt nicht erforderlich, die Daten formal zu speichern.
Explorative Datenanalyse
Sobald die Daten so bereinigt und gespeichert wurden, dass Erkenntnisse daraus abgerufen werden können, ist die Datenexplorationsphase obligatorisch. Das Ziel dieser Phase ist es, die Daten zu verstehen. Dies geschieht normalerweise mit statistischen Techniken und zeichnet auch die Daten auf. Dies ist eine gute Phase, um zu bewerten, ob die Problemdefinition sinnvoll oder machbar ist.
Datenvorbereitung für Modellierung und Bewertung
In dieser Phase werden die zuvor abgerufenen bereinigten Daten umgeformt und eine statistische Vorverarbeitung für die Imputation fehlender Werte, die Erkennung von Ausreißern, die Normalisierung, die Merkmalsextraktion und die Merkmalsauswahl verwendet.
Modellieren
In der vorherigen Phase sollten mehrere Datensätze für Training und Test erstellt worden sein, beispielsweise ein Vorhersagemodell. In dieser Phase werden verschiedene Modelle ausprobiert und das Geschäftsproblem gelöst. In der Praxis ist es normalerweise erwünscht, dass das Modell einen Einblick in das Geschäft gibt. Schließlich wird das beste Modell oder die beste Modellkombination ausgewählt, um die Leistung anhand eines ausgelassenen Datensatzes zu bewerten.
Implementierung
In dieser Phase wird das entwickelte Datenprodukt in die Datenpipeline des Unternehmens implementiert. Dazu muss während der Arbeit des Datenprodukts ein Validierungsschema eingerichtet werden, um dessen Leistung zu verfolgen. Im Fall der Implementierung eines Vorhersagemodells würde diese Phase beispielsweise die Anwendung des Modells auf neue Daten umfassen und das Modell bewerten, sobald die Antwort verfügbar ist.