Computação Gráfica - Guia Rápido
A computação gráfica é uma arte de desenhar imagens na tela do computador com a ajuda da programação. Envolve cálculos, criação e manipulação de dados. Em outras palavras, podemos dizer que a computação gráfica é uma ferramenta de renderização para a geração e manipulação de imagens.
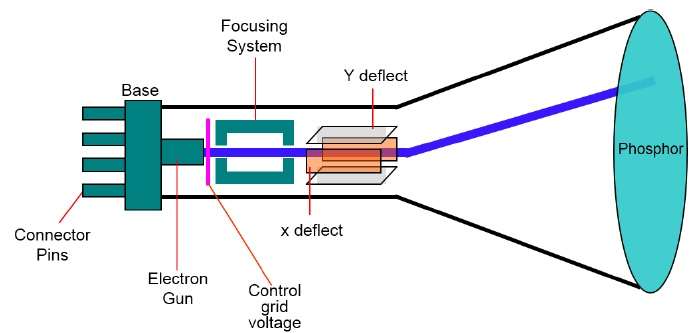
Tubo de raios catódicos
O dispositivo de saída principal em um sistema gráfico é o monitor de vídeo. O principal elemento de um monitor de vídeo é oCathode Ray Tube (CRT), mostrado na ilustração a seguir.
A operação do CRT é muito simples -
O canhão de elétrons emite um feixe de elétrons (raios catódicos).
O feixe de elétrons passa por sistemas de foco e deflexão que o direcionam para posições especificadas na tela revestida de fósforo.
Quando o feixe atinge a tela, o fósforo emite um pequeno ponto de luz em cada posição contatada pelo feixe de elétrons.
Ele redesenha a imagem direcionando o feixe de elétrons de volta sobre os mesmos pontos da tela rapidamente.
Existem duas maneiras (varredura aleatória e varredura raster) pelas quais podemos exibir um objeto na tela.
Raster Scan
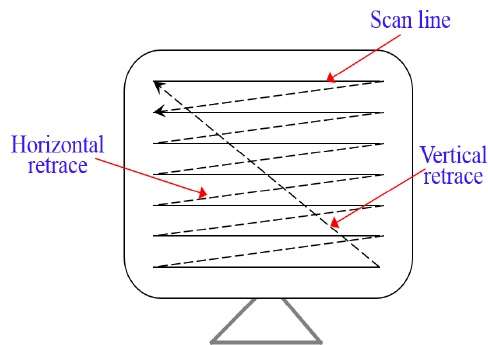
Em um sistema de varredura raster, o feixe de elétrons é varrido pela tela, uma linha de cada vez, de cima para baixo. À medida que o feixe de elétrons se move em cada linha, a intensidade do feixe é ligada e desligada para criar um padrão de pontos iluminados.
A definição da imagem é armazenada na área da memória chamada de Refresh Buffer ou Frame Buffer. Esta área de memória contém o conjunto de valores de intensidade para todos os pontos da tela. Os valores de intensidade armazenados são então recuperados do buffer de atualização e “pintados” na tela, uma linha (linha de varredura) por vez, conforme mostrado na ilustração a seguir.
Cada ponto de tela é conhecido como um pixel (picture element) ou pel. No final de cada linha de varredura, o feixe de elétrons retorna para o lado esquerdo da tela para começar a exibir a próxima linha de varredura.
Varredura aleatória (varredura vetorial)
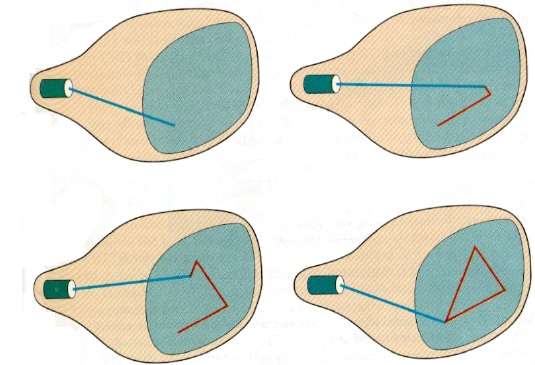
Nesta técnica, o feixe de elétrons é direcionado apenas para a parte da tela onde a imagem deve ser desenhada, em vez de varrer da esquerda para a direita e de cima para baixo como na varredura raster. Também é chamadovector display, stroke-writing display, ou calligraphic display.
A definição da imagem é armazenada como um conjunto de comandos de desenho de linha em uma área da memória conhecida como refresh display file. Para exibir uma imagem especificada, o sistema percorre o conjunto de comandos no arquivo de exibição, desenhando cada linha de componente por vez. Depois que todos os comandos de desenho de linha são processados, o sistema volta para o comando da primeira linha na lista.
Os visores de varredura aleatória são projetados para desenhar todas as linhas componentes de uma imagem 30 a 60 vezes por segundo.
Aplicação de Computação Gráfica
A Computação Gráfica tem inúmeras aplicações, algumas das quais estão listadas abaixo -
Computer graphics user interfaces (GUIs) - Um paradigma gráfico orientado para o mouse que permite ao usuário interagir com um computador.
Business presentation graphics - "Uma imagem vale mais que mil palavras".
Cartography - Desenho de mapas.
Weather Maps - Mapeamento em tempo real, representações simbólicas.
Satellite Imaging - Imagens geodésicas.
Photo Enhancement - Aumentar a nitidez de fotos desfocadas.
Medical imaging - Ressonâncias magnéticas, tomografias etc. - Exame interno não invasivo.
Engineering drawings - mecânica, elétrica, civil, etc. - Substituindo as plantas do passado.
Typography - O uso de imagens de personagens na publicação - substituindo o tipo difícil do passado.
Architecture - Planos de construção, esboços exteriores - substituindo as plantas e desenhos manuais do passado.
Art - Os computadores fornecem um novo meio para os artistas.
Training - Simuladores de vôo, instrução auxiliada por computador, etc.
Entertainment - Filmes e jogos.
Simulation and modeling - Substituição de modelagem física e encenações
Uma linha conecta dois pontos. É um elemento básico em gráficos. Para desenhar uma linha, você precisa de dois pontos entre os quais você pode desenhar uma linha. Nos três algoritmos a seguir, nos referimos a um ponto de linha como$X_{0}, Y_{0}$ e o segundo ponto da linha como $X_{1}, Y_{1}$.
Algoritmo DDA
O algoritmo Digital Differential Analyzer (DDA) é o algoritmo de geração de linha simples que é explicado passo a passo aqui.
Step 1 - Obtenha a entrada de dois pontos finais $(X_{0}, Y_{0})$ e $(X_{1}, Y_{1})$.
Step 2 - Calcule a diferença entre dois pontos finais.
dx = X1 - X0
dy = Y1 - Y0Step 3- Com base na diferença calculada na etapa 2, você precisa identificar o número de etapas para colocar o pixel. Se dx> dy, então você precisa de mais etapas na coordenada x; caso contrário, na coordenada y.
if (absolute(dx) > absolute(dy))
Steps = absolute(dx);
else
Steps = absolute(dy);Step 4 - Calcular o incremento na coordenada xey coordenada y.
Xincrement = dx / (float) steps;
Yincrement = dy / (float) steps;Step 5 - Coloque o pixel incrementando com sucesso as coordenadas xey de acordo e conclua o desenho da linha.
for(int v=0; v < Steps; v++)
{
x = x + Xincrement;
y = y + Yincrement;
putpixel(Round(x), Round(y));
}Linha Geração de Bresenham
O algoritmo de Bresenham é outro algoritmo de conversão de varredura incremental. A grande vantagem desse algoritmo é que ele usa apenas cálculos inteiros. Movendo-se ao longo do eixo x em intervalos de unidades e em cada etapa, escolha entre duas coordenadas y diferentes.
Por exemplo, conforme mostrado na ilustração a seguir, na posição (2, 3) você precisa escolher entre (3, 3) e (3, 4). Você gostaria do ponto que está mais próximo da linha original.
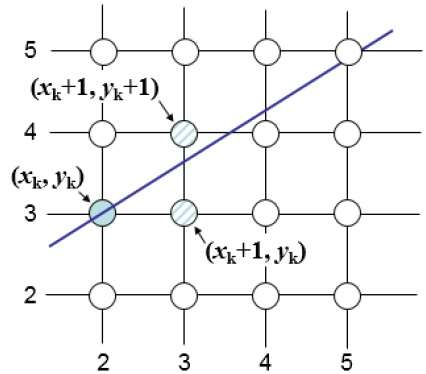
Na posição da amostra $X_{k}+1,$ as separações verticais da linha matemática são rotuladas como $d_{upper}$ e $d_{lower}$.
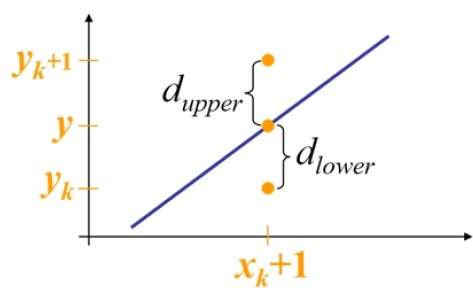
Da ilustração acima, a coordenada y na linha matemática em $x_{k}+1$ é -
Y = m ($X_{k}$+1) + b
Então, $d_{upper}$ e $d_{lower}$ são dados da seguinte forma -
$$d_{lower} = y-y_{k}$$
$$= m(X_{k} + 1) + b - Y_{k}$$
e
$$d_{upper} = (y_{k} + 1) - y$$
$= Y_{k} + 1 - m (X_{k} + 1) - b$
Você pode usá-los para tomar uma decisão simples sobre qual pixel está mais próximo da linha matemática. Esta decisão simples é baseada na diferença entre as duas posições de pixel.
$$d_{lower} - d_{upper} = 2m(x_{k} + 1) - 2y_{k} + 2b - 1$$
Vamos substituir m por dy / dx onde dx e dy são as diferenças entre os pontos finais.
$$dx (d_{lower} - d_{upper}) =dx(2\frac{\mathrm{d} y}{\mathrm{d} x}(x_{k} + 1) - 2y_{k} + 2b - 1)$$
$$ = 2dy.x_{k} - 2dx.y_{k} + 2dy + 2dx(2b-1)$$
$$ = 2dy.x_{k} - 2dx.y_{k} + C$$
Então, um parâmetro de decisão $P_{k}$para o K th passo ao longo de uma linha é dada por -
$$p_{k} = dx(d_{lower} - d_{upper})$$
$$ = 2dy.x_{k} - 2dx.y_{k} + C$$
O sinal do parâmetro de decisão $P_{k}$ é o mesmo de $d_{lower} - d_{upper}$.
E se $p_{k}$ for negativo, escolha o pixel inferior, caso contrário, escolha o pixel superior.
Lembre-se de que as mudanças de coordenadas ocorrem ao longo do eixo x em etapas unitárias, então você pode fazer tudo com cálculos inteiros. Na etapa k + 1, o parâmetro de decisão é dado como -
$$p_{k +1} = 2dy.x_{k + 1} - 2dx.y_{k + 1} + C$$
Subtraindo $p_{k}$ a partir disso, obtemos -
$$p_{k + 1} - p_{k} = 2dy(x_{k + 1} - x_{k}) - 2dx(y_{k + 1} - y_{k})$$
Mas, $x_{k+1}$ é o mesmo que $x_{k+1}$. Então -
$$p_{k+1} = p_{k} + 2dy - 2dx(y_{k+1} - y_{k})$$
Onde, $Y_{k+1} – Y_{k}$ é 0 ou 1 dependendo do sinal de $P_{k}$.
O primeiro parâmetro de decisão $p_{0}$ é avaliado em $(x_{0}, y_{0})$ é dado como -
$$p_{0} = 2dy - dx$$
Agora, tendo em mente todos os pontos e cálculos acima, aqui está o algoritmo de Bresenham para inclinação m <1 -
Step 1 - Insira os dois pontos finais da linha, armazenando o ponto final esquerdo em $(x_{0}, y_{0})$.
Step 2 - Trace o ponto $(x_{0}, y_{0})$.
Step 3 - Calcule as constantes dx, dy, 2dy e (2dy - 2dx) e obtenha o primeiro valor para o parâmetro de decisão como -
$$p_{0} = 2dy - dx$$
Step 4 - Em cada $X_{k}$ ao longo da linha, começando em k = 0, execute o seguinte teste -
E se $p_{k}$ <0, o próximo ponto a traçar é $(x_{k}+1, y_{k})$ e
$$p_{k+1} = p_{k} + 2dy$$ De outra forma,
$$(x_{k}, y_{k}+1)$$
$$p_{k+1} = p_{k} + 2dy - 2dx$$
Step 5 - Repita o passo 4 (dx - 1) vezes.
Para m> 1, descubra se você precisa incrementar x enquanto incrementa y a cada vez.
Depois de resolver, a equação para o parâmetro de decisão $P_{k}$ será muito semelhante, apenas o xey na equação serão trocados.
Algoritmo de Ponto Médio
O algoritmo do ponto médio é devido a Bresenham que foi modificado por Pitteway e Van Aken. Suponha que você já tenha colocado o ponto P na coordenada (x, y) e a inclinação da reta seja 0 ≤ k ≤ 1, conforme mostrado na ilustração a seguir.
Agora você precisa decidir se deve colocar o próximo ponto em E ou N. Isso pode ser escolhido identificando o ponto de interseção Q mais próximo do ponto N ou E. Se o ponto de interseção Q estiver mais próximo do ponto N, então N é considerado o próximo ponto; caso contrário, E.
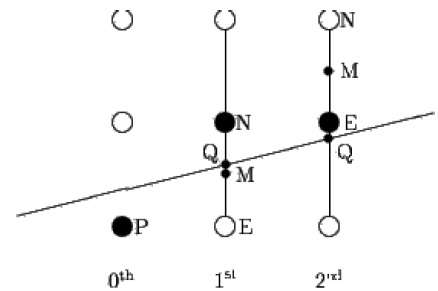
Para determinar isso, primeiro calcule o ponto médio M (x + 1, y + ½). Se o ponto de interseção Q da linha com a linha vertical conectando E e N estiver abaixo de M, considere E como o próximo ponto; caso contrário, tome N como o próximo ponto.
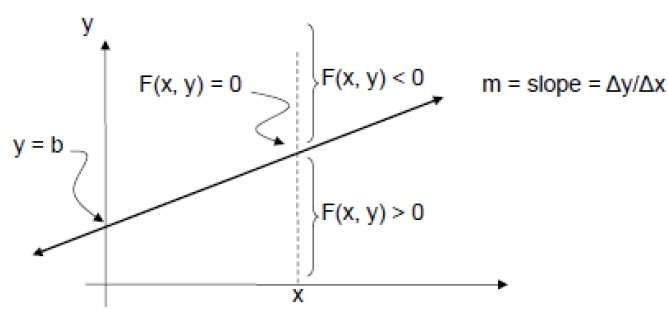
Para verificar isso, precisamos considerar a equação implícita -
F (x, y) = mx + b - y
Para m positivo em qualquer X dado,
- Se y estiver na linha, então F (x, y) = 0
- Se y estiver acima da linha, então F (x, y) <0
- Se y estiver abaixo da linha, então F (x, y)> 0
Desenhar um círculo na tela é um pouco complexo do que desenhar uma linha. Existem dois algoritmos populares para gerar um círculo -Bresenham’s Algorithm e Midpoint Circle Algorithm. Esses algoritmos são baseados na ideia de determinar os pontos subsequentes necessários para desenhar o círculo. Vamos discutir os algoritmos em detalhes -
A equação do círculo é $X^{2} + Y^{2} = r^{2},$ onde r é o raio.
Algoritmo de Bresenham
Não podemos exibir um arco contínuo na exibição raster. Em vez disso, temos que escolher a posição de pixel mais próxima para completar o arco.
Na ilustração a seguir, você pode ver que colocamos o pixel no local (X, Y) e agora precisamos decidir onde colocar o próximo pixel - em N (X + 1, Y) ou em S (X + 1, Y-1).
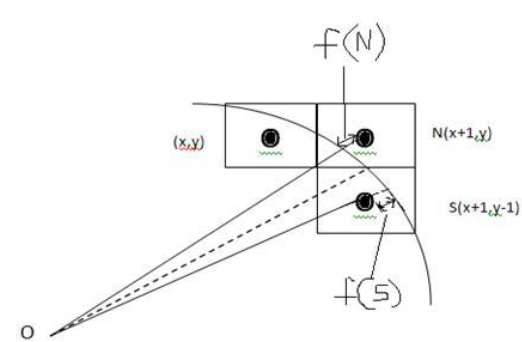
Isso pode ser decidido pelo parâmetro de decisão d.
- Se d <= 0, então N (X + 1, Y) deve ser escolhido como próximo pixel.
- Se d> 0, então S (X + 1, Y-1) deve ser escolhido como o próximo pixel.
Algoritmo
Step 1- Obtenha as coordenadas do centro do círculo e do raio e armazene-as em x, y e R respectivamente. Defina P = 0 e Q = R.
Step 2 - Defina o parâmetro de decisão D = 3 - 2R.
Step 3 - Repita até a etapa 8 enquanto P ≤ Q.
Step 4 - Chame o círculo de desenho (X, Y, P, Q).
Step 5 - Aumente o valor de P.
Step 6 - Se D <0, então D = D + 4P + 6.
Step 7 - Caso contrário, defina R = R - 1, D = D + 4 (PQ) + 10.
Step 8 - Chame o círculo de desenho (X, Y, P, Q).
Draw Circle Method(X, Y, P, Q).
Call Putpixel (X + P, Y + Q).
Call Putpixel (X - P, Y + Q).
Call Putpixel (X + P, Y - Q).
Call Putpixel (X - P, Y - Q).
Call Putpixel (X + Q, Y + P).
Call Putpixel (X - Q, Y + P).
Call Putpixel (X + Q, Y - P).
Call Putpixel (X - Q, Y - P).Algoritmo de Ponto Médio
Step 1 - Raio de entrada r e o centro do círculo $(x_{c,} y_{c})$ e obter o primeiro ponto na circunferência do círculo centrado na origem como
(x0, y0) = (0, r)Step 2 - Calcule o valor inicial do parâmetro de decisão como
$P_{0}$ = 5/4 - r (Veja a descrição a seguir para simplificação desta equação.)
f(x, y) = x2 + y2 - r2 = 0
f(xi - 1/2 + e, yi + 1)
= (xi - 1/2 + e)2 + (yi + 1)2 - r2
= (xi- 1/2)2 + (yi + 1)2 - r2 + 2(xi - 1/2)e + e2
= f(xi - 1/2, yi + 1) + 2(xi - 1/2)e + e2 = 0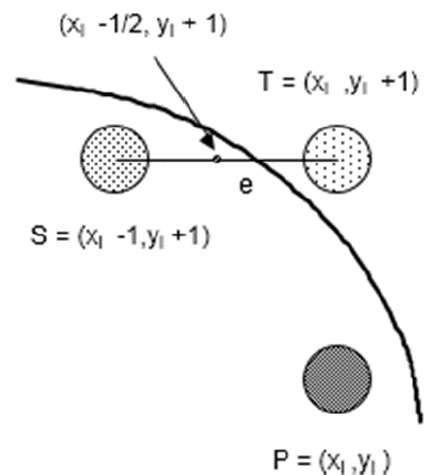
Let di = f(xi - 1/2, yi + 1) = -2(xi - 1/2)e - e2
Thus,
If e < 0 then di > 0 so choose point S = (xi - 1, yi + 1).
di+1 = f(xi - 1 - 1/2, yi + 1 + 1) = ((xi - 1/2) - 1)2 + ((yi + 1) + 1)2 - r2
= di - 2(xi - 1) + 2(yi + 1) + 1
= di + 2(yi + 1 - xi + 1) + 1
If e >= 0 then di <= 0 so choose point T = (xi, yi + 1)
di+1 = f(xi - 1/2, yi + 1 + 1)
= di + 2yi+1 + 1
The initial value of di is
d0 = f(r - 1/2, 0 + 1) = (r - 1/2)2 + 12 - r2
= 5/4 - r {1-r can be used if r is an integer}
When point S = (xi - 1, yi + 1) is chosen then
di+1 = di + -2xi+1 + 2yi+1 + 1
When point T = (xi, yi + 1) is chosen then
di+1 = di + 2yi+1 + 1Step 3 - Em cada $X_{K}$ posição começando em K = 0, execute o seguinte teste -
If PK < 0 then next point on circle (0,0) is (XK+1,YK) and
PK+1 = PK + 2XK+1 + 1
Else
PK+1 = PK + 2XK+1 + 1 – 2YK+1
Where, 2XK+1 = 2XK+2 and 2YK+1 = 2YK-2.Step 4 - Determine os pontos de simetria em outros sete octantes.
Step 5 - Mova cada posição de pixel calculada (X, Y) para o caminho circular centrado em $(X_{C,} Y_{C})$ e plotar os valores das coordenadas.
X = X + XC, Y = Y + YCStep 6 - Repita os passos 3 a 5 até X> = Y.
Polygon é uma lista ordenada de vértices, conforme mostrado na figura a seguir. Para preencher polígonos com cores específicas, você precisa determinar os pixels que ficam na borda do polígono e aqueles que ficam dentro do polígono. Neste capítulo, veremos como podemos preencher polígonos usando diferentes técnicas.

Scan Line Algorithm
Este algoritmo funciona cruzando a linha de varredura com as bordas do polígono e preenche o polígono entre pares de interseções. As etapas a seguir descrevem como esse algoritmo funciona.
Step 1 - Descubra o Ymin e Ymax do polígono fornecido.
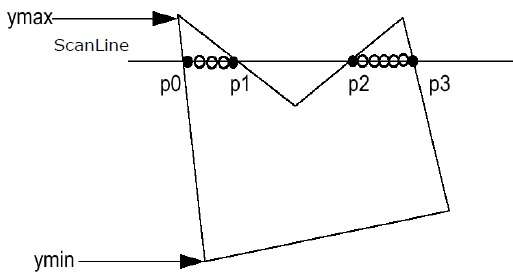
Step 2- ScanLine faz a interseção com cada aresta do polígono de Ymin a Ymax. Nomeie cada ponto de interseção do polígono. Conforme a figura mostrada acima, eles são nomeados como p0, p1, p2, p3.
Step 3 - Classifique o ponto de interseção na ordem crescente da coordenada X, isto é (p0, p1), (p1, p2) e (p2, p3).
Step 4 - Preencha todos os pares de coordenadas que estão dentro dos polígonos e ignore os pares alternativos.
Algoritmo de preenchimento
Às vezes, encontramos um objeto onde queremos preencher a área e seus limites com cores diferentes. Podemos pintar esses objetos com uma cor interior especificada, em vez de procurar uma cor de limite particular como no algoritmo de preenchimento de limite.
Em vez de depender do limite do objeto, ele depende da cor de preenchimento. Em outras palavras, ele substitui a cor interna do objeto pela cor de preenchimento. Quando não houver mais pixels da cor original do interior, o algoritmo estará concluído.
Mais uma vez, esse algoritmo depende do método Four-connect ou Eight-connect para preencher os pixels. Mas em vez de procurar a cor do limite, ele está procurando todos os pixels adjacentes que fazem parte do interior.
Algoritmo de preenchimento de limite
O algoritmo de preenchimento de limite funciona como seu nome. Este algoritmo escolhe um ponto dentro de um objeto e começa a preencher até atingir o limite do objeto. A cor do limite e a cor que preenchemos devem ser diferentes para que esse algoritmo funcione.
Nesse algoritmo, assumimos que a cor da fronteira é a mesma para todo o objeto. O algoritmo de preenchimento de limite pode ser implementado por 4 pixels conectados ou 8 pixels conectados.
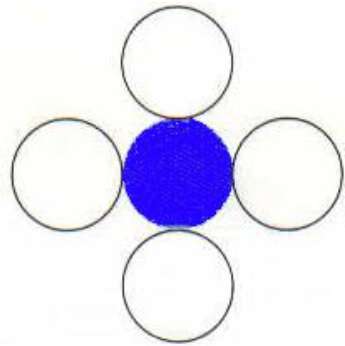
4-polígono conectado
Nesta técnica, 4 pixels conectados são usados conforme mostrado na figura. Estamos colocando os pixels acima, abaixo, à direita e à esquerda dos pixels atuais e esse processo continuará até encontrarmos um limite com cor diferente.
Algoritmo
Step 1 - Inicialize o valor do ponto de semente (seedx, seedy), fcolor e dcol.
Step 2 - Defina os valores limite do polígono.
Step 3 - Verifique se o ponto de semente atual é da cor padrão e repita as etapas 4 e 5 até que os pixels de limite sejam atingidos.
If getpixel(x, y) = dcol then repeat step 4 and 5Step 4 - Altere a cor padrão com a cor de preenchimento no ponto de origem.
setPixel(seedx, seedy, fcol)Step 5 - Siga recursivamente o procedimento com quatro pontos de vizinhança.
FloodFill (seedx – 1, seedy, fcol, dcol)
FloodFill (seedx + 1, seedy, fcol, dcol)
FloodFill (seedx, seedy - 1, fcol, dcol)
FloodFill (seedx – 1, seedy + 1, fcol, dcol)Step 6 - Sair
Existe um problema com esta técnica. Considere o caso mostrado abaixo onde tentamos preencher toda a região. Aqui, a imagem é preenchida apenas parcialmente. Nesses casos, a técnica de 4 pixels conectados não pode ser usada.
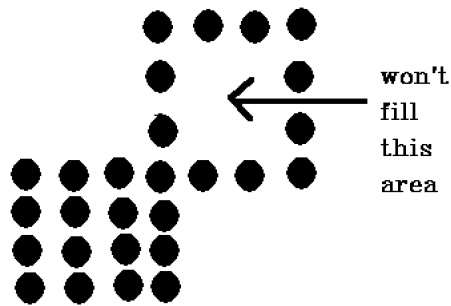
Polígono 8-conectado
Nesta técnica, 8 pixels conectados são usados conforme mostrado na figura. Estamos colocando pixels acima, abaixo, lado direito e esquerdo dos pixels atuais, como fazíamos na técnica de 4 conexões.
Além disso, também colocamos pixels em diagonais para que toda a área do pixel atual seja coberta. Este processo continuará até que encontremos um limite com uma cor diferente.

Algoritmo
Step 1 - Inicialize o valor do ponto de semente (seedx, seedy), fcolor e dcol.
Step 2 - Defina os valores limite do polígono.
Step 3 - Verifique se o ponto de semente atual é da cor padrão e repita as etapas 4 e 5 até que os pixels de limite sejam atingidos
If getpixel(x,y) = dcol then repeat step 4 and 5Step 4 - Altere a cor padrão com a cor de preenchimento no ponto de origem.
setPixel(seedx, seedy, fcol)Step 5 - Siga recursivamente o procedimento com quatro pontos de vizinhança
FloodFill (seedx – 1, seedy, fcol, dcol)
FloodFill (seedx + 1, seedy, fcol, dcol)
FloodFill (seedx, seedy - 1, fcol, dcol)
FloodFill (seedx, seedy + 1, fcol, dcol)
FloodFill (seedx – 1, seedy + 1, fcol, dcol)
FloodFill (seedx + 1, seedy + 1, fcol, dcol)
FloodFill (seedx + 1, seedy - 1, fcol, dcol)
FloodFill (seedx – 1, seedy - 1, fcol, dcol)Step 6 - Sair
A técnica de 4 pixels conectados falhou em preencher a área marcada na figura a seguir, o que não acontecerá com a técnica de 8 pixels.
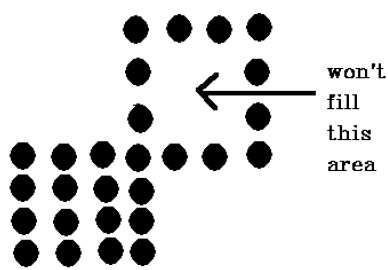
Teste de dentro para fora
Este método também é conhecido como counting number method. Ao preencher um objeto, geralmente precisamos identificar se um ponto específico está dentro ou fora do objeto. Existem dois métodos pelos quais podemos identificar se um determinado ponto está dentro ou fora de um objeto.
- Regra ímpar-par
- Regra de enrolamento diferente de zero
Regra ímpar-par
Nesta técnica, contamos o cruzamento de arestas ao longo da linha de qualquer ponto (x, y) ao infinito. Se o número de interações for ímpar, o ponto (x, y) é um ponto interno. Se o número de interações for par, o ponto (x, y) é um ponto externo. Aqui está o exemplo para lhe dar uma ideia clara -
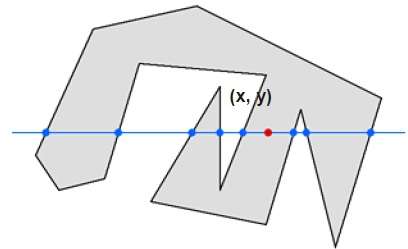
Pela figura acima, podemos ver que do ponto (x, y), o número de pontos de interação no lado esquerdo é 5 e no lado direito é 3. Portanto, o número total de pontos de interação é 8, o que é ímpar . Portanto, o ponto é considerado dentro do objeto.
Regra de número de enrolamento diferente de zero
Este método também é usado com os polígonos simples para testar se o ponto fornecido é interno ou não. Pode ser entendido simplesmente com a ajuda de um alfinete e um elástico. Fixe o pino em uma das bordas do polígono, amarre o elástico nele e estique o elástico ao longo das bordas do polígono.
Quando todas as arestas do polígono estiverem cobertas pelo elástico, verifique o pino que foi fixado no ponto a ser testado. Se encontrarmos pelo menos um vento no ponto, considere-o dentro do polígono, senão podemos dizer que o ponto não está dentro do polígono.
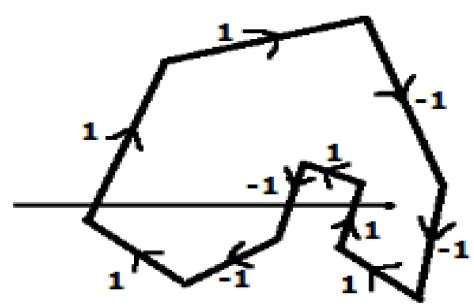
Em outro método alternativo, dê direções para todas as arestas do polígono. Desenhe uma linha de varredura do ponto a ser testado em direção à extrema esquerda na direção X.
Dê o valor 1 para todas as arestas que vão para cima e todas as outras -1 como valores de direção.
Verifique os valores de direção da borda a partir dos quais a linha de varredura está passando e some-os.
Se a soma total deste valor de direção for diferente de zero, então este ponto a ser testado é um interior point, caso contrário, é um exterior point.
Na figura acima, somamos os valores de direção dos quais a linha de varredura está passando, então o total é 1 - 1 + 1 = 1; que é diferente de zero. Portanto, o ponto é considerado um ponto interior.
O principal uso do recorte em computação gráfica é remover objetos, linhas ou segmentos de linha que estão fora do painel de exibição. A transformação da visualização é insensível à posição dos pontos em relação ao volume da visualização - especialmente aqueles pontos atrás do visualizador - e é necessário remover esses pontos antes de gerar a visualização.
Point Clipping
Recortar um ponto de uma determinada janela é muito fácil. Considere a figura a seguir, onde o retângulo indica a janela. O recorte de ponto nos diz se o ponto dado (X, Y) está dentro da janela fornecida ou não; e decide se usaremos as coordenadas mínimas e máximas da janela.
A coordenada X do ponto dado está dentro da janela, se X estiver entre Wx1 ≤ X ≤ Wx2. Da mesma forma, a coordenada Y do ponto dado está dentro da janela, se Y estiver entre Wy1 ≤ Y ≤ Wy2.

Recorte de linha
O conceito de recorte de linha é igual ao recorte de ponto. No recorte de linha, vamos cortar a parte da linha que está fora da janela e manter apenas a parte que está dentro da janela.
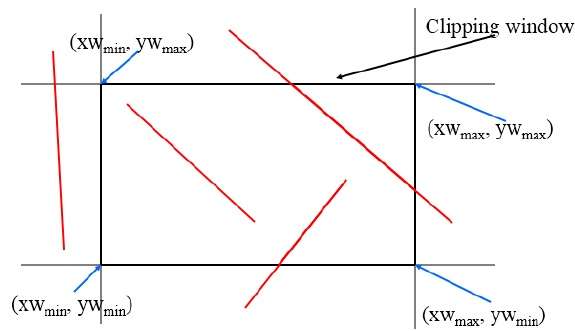
Cohen-Sutherland Line Clippings
Este algoritmo usa a janela de recorte, conforme mostrado na figura a seguir. A coordenada mínima para a região de recorte é$(XW_{min,} YW_{min})$ e a coordenada máxima para a região de recorte é $(XW_{max,} YW_{max})$.
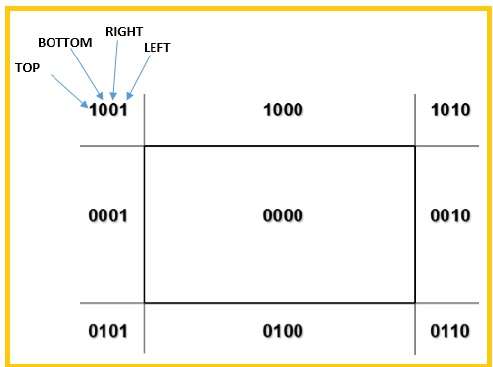
Usaremos 4 bits para dividir toda a região. Esses 4 bits representam as partes superior, inferior, direita e esquerda da região, conforme mostrado na figura a seguir. Aqui oTOP e LEFT bit é definido como 1 porque é o TOP-LEFT canto.
Existem 3 possibilidades para a linha -
A linha pode ficar totalmente dentro da janela (esta linha deve ser aceita).
A linha pode ficar completamente fora da janela (esta linha será completamente removida da região).
A linha pode estar parcialmente dentro da janela (encontraremos o ponto de interseção e desenharemos apenas a parte da linha que está dentro da região).
Algoritmo
Step 1 - Atribua um código de região para cada terminal.
Step 2 - Se ambos os endpoints tiverem um código de região 0000 então aceite esta linha.
Step 3 - Senão, execute o lógico ANDoperação para ambos os códigos de região.
Step 3.1 - Se o resultado não for 0000, então rejeite a linha.
Step 3.2 - Caso contrário, você precisa de recorte.
Step 3.2.1 - Escolha um ponto final da linha que está fora da janela.
Step 3.2.2 - Encontre o ponto de interseção no limite da janela (com base no código da região).
Step 3.2.3 - Substitua o ponto final pelo ponto de interseção e atualize o código da região.
Step 3.2.4 - Repita a etapa 2 até encontrar uma linha recortada aceita ou rejeitada trivialmente.
Step 4 - Repita a etapa 1 para outras linhas.
Algoritmo de recorte de linha de Cyrus-Beck
Este algoritmo é mais eficiente do que o algoritmo de Cohen-Sutherland. Ele emprega representação de linha paramétrica e produtos de ponto simples.
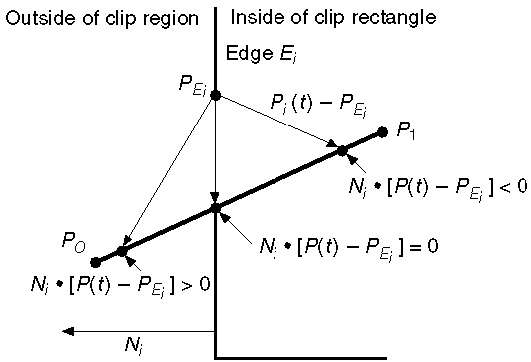
A equação paramétrica da linha é -
P0P1:P(t) = P0 + t(P1-P0)Seja N i a aresta normal externa E i . Agora escolha qualquer ponto P Ei arbitrário na aresta E i, então o produto escalar N i ∙ [P (t) - P Ei ] determina se o ponto P (t) está "dentro da borda do clipe" ou "fora" da borda do clipe ou “Na” borda do clipe.
O ponto P (t) está dentro se N i . [P (t) - P Ei ] <0
O ponto P (t) está fora se N i . [P (t) - P Ei ]> 0
O ponto P (t) está na aresta se N i . [P (t) - P Ei ] = 0 (Ponto de intersecção)
N i . [P (t) - P Ei ] = 0
N i . [P 0 + t (P 1 -P 0 ) - P Ei ] = 0 (Substituindo P (t) por P 0 + t (P 1 -P 0 ))
N i . [P 0 - P Ei ] + N i .t [P 1 -P 0 ] = 0
N i . [P 0 - P Ei ] + N i ∙ tD = 0 (substituindo D por [P 1 -P 0 ])
N i . [P 0 - P Ei ] = - N i ∙ tD
A equação para t torna-se,
$$t = \tfrac{N_{i}.[P_{o} - P_{Ei}]}{{- N_{i}.D}}$$
É válido para as seguintes condições -
- N i ≠ 0 (o erro não pode acontecer)
- D ≠ 0 (P 1 ≠ P 0 )
- N i ∙ D ≠ 0 (P 0 P 1 não paralelo a E i )
Recorte poligonal (algoritmo de Sutherland Hodgman)
Um polígono também pode ser recortado especificando a janela de recorte. O algoritmo de recorte de polígonos de Sutherland Hodgeman é usado para recorte de polígonos. Neste algoritmo, todos os vértices do polígono são recortados contra cada aresta da janela de recorte.
Primeiro, o polígono é recortado contra a borda esquerda da janela do polígono para obter novos vértices do polígono. Esses novos vértices são usados para recortar o polígono contra as arestas direita, superior e inferior da janela de recorte, conforme mostrado na figura a seguir.
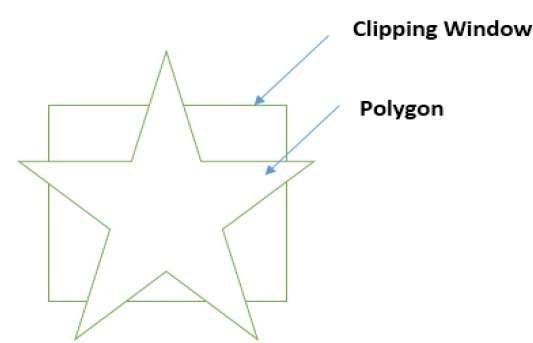
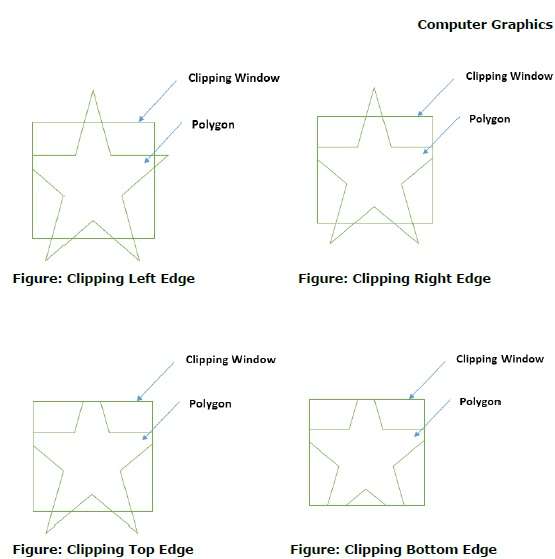
Ao processar uma aresta de um polígono com janela de recorte, um ponto de interseção é encontrado se a aresta não estiver completamente dentro da janela de recorte e uma aresta parcial do ponto de interseção para a aresta externa for recortada. As figuras a seguir mostram recortes das bordas esquerda, direita, superior e inferior -
Recorte de Texto
Várias técnicas são usadas para fornecer recorte de texto em gráficos de computador. Depende dos métodos usados para gerar caracteres e dos requisitos de um determinado aplicativo. Existem três métodos de recorte de texto listados abaixo -
- Corte de string tudo ou nada
- Recorte de caractere tudo ou nenhum
- Recorte de texto
A figura a seguir mostra tudo ou nenhum corte de string -
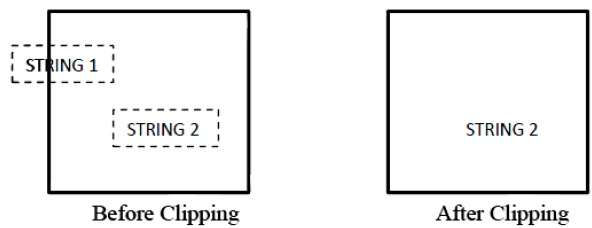
No método de recorte de string tudo ou nenhum, mantemos a string inteira ou rejeitamos toda a string com base na janela de recorte. Conforme mostrado na figura acima, STRING2 está inteiramente dentro da janela de recorte, então o mantemos e STRING1 estando apenas parcialmente dentro da janela, rejeitamos.
A figura a seguir mostra todos ou nenhum recorte de caracteres -
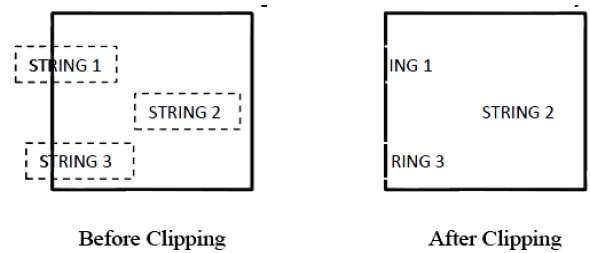
Este método de recorte é baseado em caracteres em vez de string inteira. Neste método, se a string estiver inteiramente dentro da janela de recorte, nós a manteremos. Se estiver parcialmente fora da janela, então -
Você rejeita apenas a parte da corda que está fora
Se o caractere estiver no limite da janela de recorte, descartamos todo o caractere e mantemos a string restante.
A figura a seguir mostra recorte de texto -
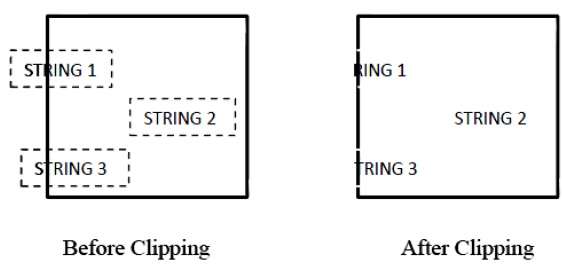
Este método de recorte é baseado em caracteres, e não em toda a string. Neste método, se a string estiver inteiramente dentro da janela de recorte, nós a manteremos. Se estiver parcialmente fora da janela, então
Você rejeita apenas a parte da corda que está fora.
Se o caractere estiver no limite da janela de recorte, descartamos apenas a parte do caractere que está fora da janela de recorte.
Gráficos de bitmap
Um bitmap é uma coleção de pixels que descreve uma imagem. É um tipo de computação gráfica que o computador usa para armazenar e exibir imagens. Neste tipo de gráfico, as imagens são armazenadas bit a bit e, portanto, são denominados gráficos de bitmap. Para melhor compreensão, vamos considerar o exemplo a seguir, onde desenhamos um rosto sorridente usando gráficos de bitmap.

Agora veremos como esse rosto sorridente é armazenado aos poucos na computação gráfica.
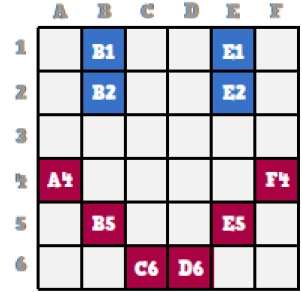
Observando a face sorridente original de perto, podemos ver que há duas linhas azuis representadas como B1, B2 e E1, E2 na figura acima.
Da mesma forma, o smiley é representado usando a combinação de bits de A4, B5, C6, D6, E5 e F4 respectivamente.
As principais desvantagens dos gráficos de bitmap são -
Não podemos redimensionar a imagem bitmap. Se você tentar redimensionar, os pixels ficam borrados.
Os bitmaps coloridos podem ser muito grandes.
Transformação significa transformar alguns gráficos em algo diferente aplicando regras. Podemos ter vários tipos de transformações, como translação, aumento ou redução, rotação, cisalhamento, etc. Quando uma transformação ocorre em um plano 2D, é chamada de transformação 2D.
As transformações desempenham um papel importante na computação gráfica para reposicionar os gráficos na tela e alterar seu tamanho ou orientação.
Coordenadas Homogêneas
Para realizar uma sequência de transformação, como translação seguida de rotação e dimensionamento, precisamos seguir um processo sequencial -
- Traduza as coordenadas,
- Gire as coordenadas traduzidas e, em seguida,
- Dimensione as coordenadas giradas para completar a transformação composta.
Para encurtar esse processo, temos que usar a matriz de transformação 3 × 3 em vez da matriz de transformação 2 × 2. Para converter uma matriz 2 × 2 em matriz 3 × 3, temos que adicionar uma coordenada fictícia extra W.
Desta forma, podemos representar o ponto por 3 números em vez de 2 números, que é chamado Homogenous Coordinatesistema. Neste sistema, podemos representar todas as equações de transformação na multiplicação de matrizes. Qualquer ponto cartesiano P (X, Y) pode ser convertido em coordenadas homogêneas por P '(X h , Y h , h).
Tradução
Uma tradução move um objeto para uma posição diferente na tela. Você pode traduzir um ponto em 2D adicionando a coordenada de translação (t x , t y ) à coordenada original (X, Y) para obter a nova coordenada (X ', Y').
A partir da figura acima, você pode escrever que -
X’ = X + tx
Y’ = Y + ty
O par (t x , t y ) é chamado de vetor de translação ou vetor de deslocamento. As equações acima também podem ser representadas usando os vetores de coluna.
$P = \frac{[X]}{[Y]}$ p '= $\frac{[X']}{[Y']}$T = $\frac{[t_{x}]}{[t_{y}]}$
Podemos escrever como -
P’ = P + T
Rotação
Em rotação, giramos o objeto em um ângulo particular θ (theta) de sua origem. Na figura a seguir, podemos ver que o ponto P (X, Y) está localizado no ângulo φ da coordenada X horizontal com a distância r da origem.
Suponhamos que você queira girá-lo no ângulo θ. Depois de girá-lo para um novo local, você obterá um novo ponto P '(X', Y ').

Usando trigonométricas padrão, a coordenada original do ponto P (X, Y) pode ser representada como -
$X = r \, cos \, \phi ...... (1)$
$Y = r \, sin \, \phi ...... (2)$
Da mesma forma, podemos representar o ponto P '(X', Y ') como -
${x}'= r \: cos \: \left ( \phi \: + \: \theta \right ) = r\: cos \: \phi \: cos \: \theta \: − \: r \: sin \: \phi \: sin \: \theta ....... (3)$
${y}'= r \: sin \: \left ( \phi \: + \: \theta \right ) = r\: cos \: \phi \: sin \: \theta \: + \: r \: sin \: \phi \: cos \: \theta ....... (4)$
Substituindo a equação (1) e (2) em (3) e (4), respectivamente, obteremos
${x}'= x \: cos \: \theta − \: y \: sin \: \theta $
${y}'= x \: sin \: \theta + \: y \: cos \: \theta $
Representando a equação acima em forma de matriz,
$$[X' Y'] = [X Y] \begin{bmatrix} cos\theta & sin\theta \\ −sin\theta & cos\theta \end{bmatrix}OR $$
P '= P ∙ R
Onde R é a matriz de rotação
$$R = \begin{bmatrix} cos\theta & sin\theta \\ −sin\theta & cos\theta \end{bmatrix}$$
O ângulo de rotação pode ser positivo e negativo.
Para ângulo de rotação positivo, podemos usar a matriz de rotação acima. No entanto, para rotação de ângulo negativo, a matriz mudará conforme mostrado abaixo -
$$R = \begin{bmatrix} cos(−\theta) & sin(−\theta) \\ -sin(−\theta) & cos(−\theta) \end{bmatrix}$$
$$=\begin{bmatrix} cos\theta & −sin\theta \\ sin\theta & cos\theta \end{bmatrix} \left (\because cos(−\theta ) = cos \theta \; and\; sin(−\theta ) = −sin \theta \right )$$
Dimensionamento
Para alterar o tamanho de um objeto, a transformação de escala é usada. No processo de dimensionamento, você expande ou compacta as dimensões do objeto. A escala pode ser alcançada multiplicando as coordenadas originais do objeto com o fator de escala para obter o resultado desejado.
Vamos supor que as coordenadas originais são (X, Y), os fatores de escala são (S X , S Y ) e as coordenadas produzidas são (X ', Y'). Isso pode ser representado matematicamente conforme mostrado abaixo -
X' = X . SX and Y' = Y . SY
O fator de escala S X , S Y dimensiona o objeto na direção X e Y respectivamente. As equações acima também podem ser representadas em forma de matriz como abaixo -
$$\binom{X'}{Y'} = \binom{X}{Y} \begin{bmatrix} S_{x} & 0\\ 0 & S_{y} \end{bmatrix}$$
OU
P’ = P . S
Onde S é a matriz de escala. O processo de dimensionamento é mostrado na figura a seguir.
Se fornecermos valores menores que 1 para o fator de escala S, podemos reduzir o tamanho do objeto. Se fornecermos valores maiores que 1, podemos aumentar o tamanho do objeto.
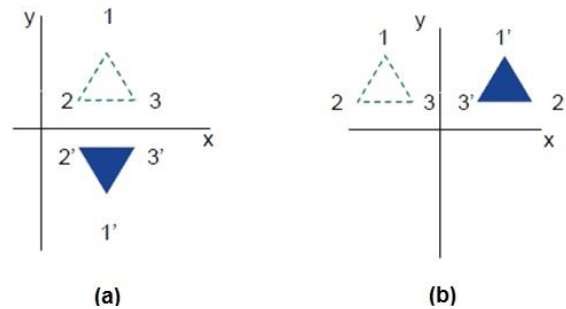
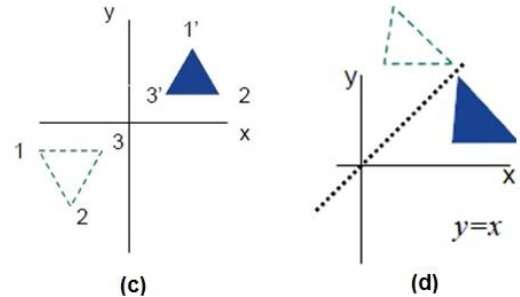
Reflexão
O reflexo é a imagem espelhada do objeto original. Em outras palavras, podemos dizer que é uma operação de rotação com 180 °. Na transformação de reflexão, o tamanho do objeto não muda.
As figuras a seguir mostram reflexos em relação aos eixos X e Y e sobre a origem, respectivamente.
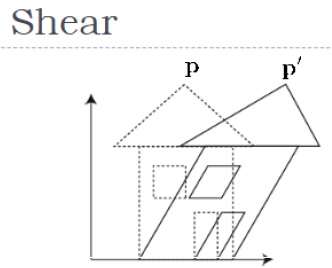
Cisalhamento
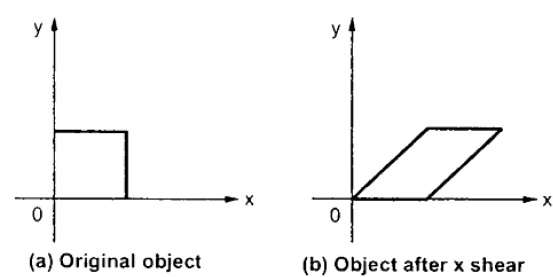
Uma transformação que inclina a forma de um objeto é chamada de transformação de cisalhamento. Existem duas transformações de cisalhamentoX-Shear e Y-Shear. Um muda os valores das coordenadas X e o outro muda os valores das coordenadas Y. Contudo; em ambos os casos, apenas uma coordenada muda suas coordenadas e a outra preserva seus valores. O cisalhamento também é denominado comoSkewing.
X-Shear
O X-Shear preserva a coordenada Y e alterações são feitas nas coordenadas X, o que faz com que as linhas verticais se inclinem para a direita ou esquerda, conforme mostrado na figura abaixo.
A matriz de transformação para X-Shear pode ser representada como -
$$X_{sh} = \begin{bmatrix} 1& shx& 0\\ 0& 1& 0\\ 0& 0& 1 \end{bmatrix}$$
Y '= Y + Sh y . X
X '= X
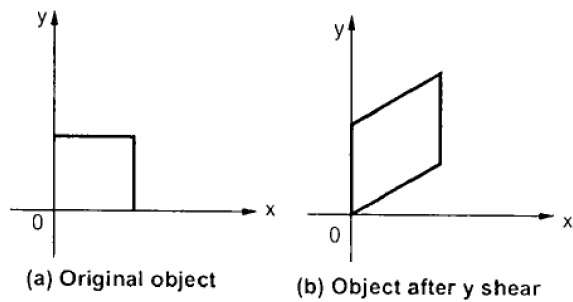
Y-Shear
O Y-Shear preserva as coordenadas X e altera as coordenadas Y, o que faz com que as linhas horizontais se transformem em linhas que se inclinam para cima ou para baixo, conforme mostrado na figura a seguir.
O Y-Shear pode ser representado na matriz como -
$$Y_{sh} \begin{bmatrix} 1& 0& 0\\ shy& 1& 0\\ 0& 0& 1 \end{bmatrix}$$
X '= X + Sh x . Y
Y '= Y
Transformação Composto
Se uma transformação do plano T1 é seguida por uma transformação do segundo plano T2, então o próprio resultado pode ser representado por uma única transformação T, que é a composição de T1 e T2 tomada nessa ordem. Isso é escrito como T = T1 ∙ T2.
A transformação composta pode ser alcançada pela concatenação de matrizes de transformação para obter uma matriz de transformação combinada.
Uma matriz combinada -
[T][X] = [X] [T1] [T2] [T3] [T4] …. [Tn]
Onde [Ti] é qualquer combinação de
- Translation
- Scaling
- Shearing
- Rotation
- Reflection
A mudança na ordem de transformação levaria a resultados diferentes, pois em geral a multiplicação de matrizes não é cumulativa, ou seja, [A]. [B] ≠ [B]. [A] e a ordem de multiplicação. O propósito básico de compor transformações é ganhar eficiência aplicando uma única transformação composta a um ponto, em vez de aplicar uma série de transformações, uma após a outra.
Por exemplo, para girar um objeto sobre um ponto arbitrário (X p , Y p ), temos que realizar três etapas -
- Traduzir ponto (X p , Y p ) para a origem.
- Gire sobre a origem.
- Por fim, translade o centro de rotação de volta para onde ele pertencia.
No sistema 2D, usamos apenas duas coordenadas X e Y, mas no 3D, uma coordenada extra Z é adicionada. As técnicas de gráficos 3D e sua aplicação são fundamentais para as indústrias de entretenimento, jogos e design auxiliado por computador. É uma área contínua de pesquisa em visualização científica.
Além disso, os componentes gráficos 3D agora fazem parte de quase todos os computadores pessoais e, embora tradicionalmente destinados a softwares com uso intensivo de gráficos, como jogos, estão cada vez mais sendo usados por outros aplicativos.
Projeção Paralela
A projeção paralela descarta a coordenada z e as linhas paralelas de cada vértice no objeto são estendidas até que cruzem o plano de vista. Na projeção paralela, especificamos uma direção de projeção em vez do centro de projeção.
Na projeção paralela, a distância do centro de projeção ao plano do projeto é infinita. Neste tipo de projeção, conectamos os vértices projetados por segmentos de reta que correspondem às conexões no objeto original.
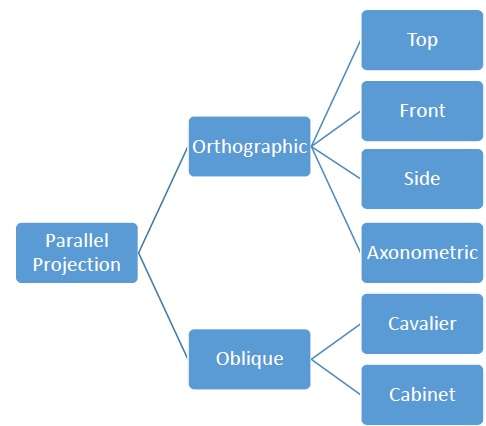
As projeções paralelas são menos realistas, mas são boas para medições exatas. Neste tipo de projeções, as linhas paralelas permanecem paralelas e os ângulos não são preservados. Vários tipos de projeções paralelas são mostrados na hierarquia a seguir.
Projeção ortográfica
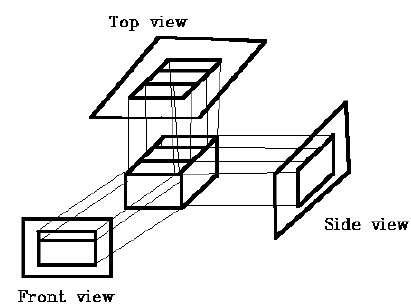
Na projeção ortográfica, a direção da projeção é normal à projeção do plano. Existem três tipos de projeções ortográficas -
- Projeção Frontal
- Projeção superior
- Projeção Lateral
Projeção Oblíqua
Na projeção oblíqua, a direção da projeção não é normal para a projeção do plano. Na projeção oblíqua, podemos ver o objeto melhor do que a projeção ortográfica.
Existem dois tipos de projeções oblíquas - Cavalier e Cabinet. A projeção Cavalier faz um ângulo de 45 ° com o plano de projeção. A projeção de uma linha perpendicular ao plano de vista tem o mesmo comprimento que a própria linha na projeção Cavalier. Em uma projeção descuidada, os fatores de redução para todas as três direções principais são iguais.
A projeção do Gabinete faz um ângulo de 63,4 ° com o plano de projeção. Na projeção do Gabinete, as linhas perpendiculares à superfície de visualização são projetadas em ½ seu comprimento real. Ambas as projeções são mostradas na figura a seguir -

Projeções Isométricas
As projeções ortográficas que mostram mais de um lado de um objeto são chamadas axonometric orthographic projections. A projeção axonométrica mais comum é umisometric projectiononde o plano de projeção cruza cada eixo de coordenadas no sistema de coordenadas do modelo a uma distância igual. Nessa projeção, o paralelismo de linhas é preservado, mas os ângulos não são preservados. A figura a seguir mostra a projeção isométrica -

Perspectiva de Projeção
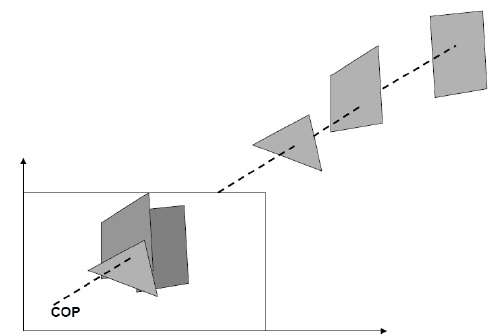
Na projeção em perspectiva, a distância do centro de projeção ao plano do projeto é finita e o tamanho do objeto varia inversamente com a distância que parece mais realista.
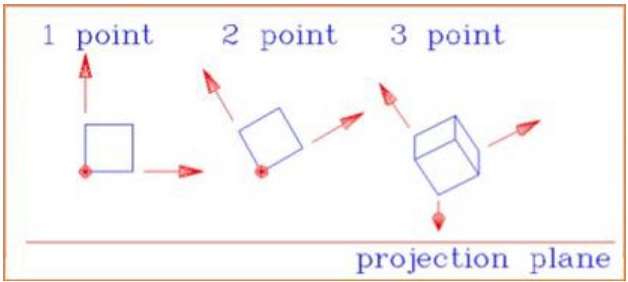
A distância e os ângulos não são preservados e as linhas paralelas não permanecem paralelas. Em vez disso, todos eles convergem em um único ponto chamadocenter of projection ou projection reference point. Existem 3 tipos de projeções em perspectiva que são mostradas no gráfico a seguir.
One point a projeção em perspectiva é simples de desenhar.
Two point a projeção em perspectiva dá uma melhor impressão de profundidade.
Three point a projeção em perspectiva é mais difícil de desenhar.
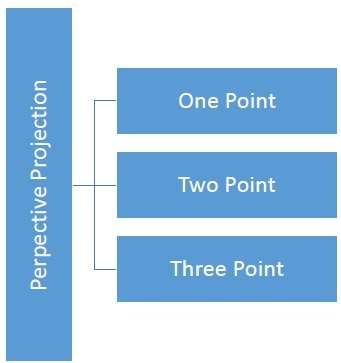
A figura a seguir mostra todos os três tipos de projeção em perspectiva -
Tradução
Na tradução 3D, transferimos a coordenada Z junto com as coordenadas X e Y. O processo de tradução em 3D é semelhante à tradução 2D. Uma tradução move um objeto para uma posição diferente na tela.
A figura a seguir mostra o efeito da tradução -
Um ponto pode ser traduzido em 3D ao adicionar coordenadas de translação $(t_{x,} t_{y,} t_{z})$ para a coordenada original (X, Y, Z) para obter a nova coordenada (X ', Y', Z ').
$T = \begin{bmatrix} 1& 0& 0& 0\\ 0& 1& 0& 0\\ 0& 0& 1& 0\\ t_{x}& t_{y}& t_{z}& 1\\ \end{bmatrix}$
P '= P ∙ T
$[X′ \:\: Y′ \:\: Z′ \:\: 1] \: = \: [X \:\: Y \:\: Z \:\: 1] \: \begin{bmatrix} 1& 0& 0& 0\\ 0& 1& 0& 0\\ 0& 0& 1& 0\\ t_{x}& t_{y}& t_{z}& 1\\ \end{bmatrix}$
$= [X + t_{x} \:\:\: Y + t_{y} \:\:\: Z + t_{z} \:\:\: 1]$
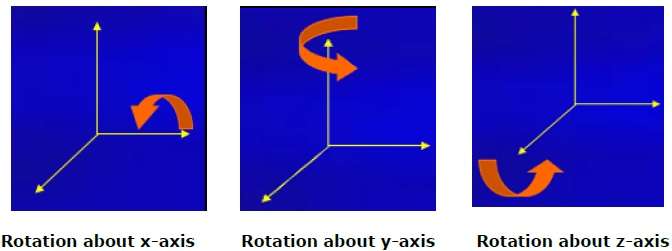
Rotação
A rotação 3D não é igual à rotação 2D. Na rotação 3D, temos que especificar o ângulo de rotação junto com o eixo de rotação. Podemos realizar a rotação 3D sobre os eixos X, Y e Z. Eles são representados na forma de matriz conforme abaixo -
$$R_{x}(\theta) = \begin{bmatrix} 1& 0& 0& 0\\ 0& cos\theta & −sin\theta& 0\\ 0& sin\theta & cos\theta& 0\\ 0& 0& 0& 1\\ \end{bmatrix} R_{y}(\theta) = \begin{bmatrix} cos\theta& 0& sin\theta& 0\\ 0& 1& 0& 0\\ −sin\theta& 0& cos\theta& 0\\ 0& 0& 0& 1\\ \end{bmatrix} R_{z}(\theta) =\begin{bmatrix} cos\theta & −sin\theta & 0& 0\\ sin\theta & cos\theta & 0& 0\\ 0& 0& 1& 0\\ 0& 0& 0& 1 \end{bmatrix}$$
A figura a seguir explica a rotação sobre vários eixos -
Dimensionamento
Você pode alterar o tamanho de um objeto usando a transformação de escala. No processo de dimensionamento, você expande ou compacta as dimensões do objeto. A escala pode ser alcançada multiplicando as coordenadas originais do objeto com o fator de escala para obter o resultado desejado. A figura a seguir mostra o efeito da escala 3D -
Na operação de escala 3D, três coordenadas são usadas. Vamos supor que as coordenadas originais são (X, Y, Z), os fatores de escala são$(S_{X,} S_{Y,} S_{z})$respectivamente, e as coordenadas produzidas são (X ', Y', Z '). Isso pode ser representado matematicamente conforme mostrado abaixo -
$S = \begin{bmatrix} S_{x}& 0& 0& 0\\ 0& S_{y}& 0& 0\\ 0& 0& S_{z}& 0\\ 0& 0& 0& 1 \end{bmatrix}$
P '= P ∙ S
$[{X}' \:\:\: {Y}' \:\:\: {Z}' \:\:\: 1] = [X \:\:\:Y \:\:\: Z \:\:\: 1] \:\: \begin{bmatrix} S_{x}& 0& 0& 0\\ 0& S_{y}& 0& 0\\ 0& 0& S_{z}& 0\\ 0& 0& 0& 1 \end{bmatrix}$
$ = [X.S_{x} \:\:\: Y.S_{y} \:\:\: Z.S_{z} \:\:\: 1]$
Cisalhamento
Uma transformação que inclina a forma de um objeto é chamada de shear transformation. Como no cisalhamento 2D, podemos distorcer um objeto ao longo do eixo X, eixo Y ou eixo Z em 3D.
Conforme mostrado na figura acima, há uma coordenada P. Você pode distorcê-la para obter uma nova coordenada P ', que pode ser representada na forma de matriz 3D como abaixo -
$Sh = \begin{bmatrix} 1 & sh_{x}^{y} & sh_{x}^{z} & 0 \\ sh_{y}^{x} & 1 & sh_{y}^{z} & 0 \\ sh_{z}^{x} & sh_{z}^{y} & 1 & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix}$
P '= P ∙ Sh
$X’ = X + Sh_{x}^{y} Y + Sh_{x}^{z} Z$
$Y' = Sh_{y}^{x}X + Y +sh_{y}^{z}Z$
$Z' = Sh_{z}^{x}X + Sh_{z}^{y}Y + Z$
Matrizes de transformação
Matriz de transformação é uma ferramenta básica para transformação. Uma matriz com dimensões nxm é multiplicada pela coordenada dos objetos. Normalmente, matrizes 3 x 3 ou 4 x 4 são usadas para transformação. Por exemplo, considere a seguinte matriz para várias operações.
| $T = \begin{bmatrix} 1& 0& 0& 0\\ 0& 1& 0& 0\\ 0& 0& 1& 0\\ t_{x}& t_{y}& t_{z}& 1\\ \end{bmatrix}$ | $S = \begin{bmatrix} S_{x}& 0& 0& 0\\ 0& S_{y}& 0& 0\\ 0& 0& S_{z}& 0\\ 0& 0& 0& 1 \end{bmatrix}$ | $Sh = \begin{bmatrix} 1& sh_{x}^{y}& sh_{x}^{z}& 0\\ sh_{y}^{x}& 1 & sh_{y}^{z}& 0\\ sh_{z}^{x}& sh_{z}^{y}& 1& 0\\ 0& 0& 0& 1 \end{bmatrix}$ |
| Translation Matrix | Scaling Matrix | Shear Matrix |
| $R_{x}(\theta) = \begin{bmatrix} 1& 0& 0& 0\\ 0& cos\theta & -sin\theta& 0\\ 0& sin\theta & cos\theta& 0\\ 0& 0& 0& 1\\ \end{bmatrix}$ | $R_{y}(\theta) = \begin{bmatrix} cos\theta& 0& sin\theta& 0\\ 0& 1& 0& 0\\ -sin\theta& 0& cos\theta& 0\\ 0& 0& 0& 1\\ \end{bmatrix}$ | $R_{z}(\theta) = \begin{bmatrix} cos\theta & -sin\theta & 0& 0\\ sin\theta & cos\theta & 0& 0\\ 0& 0& 1& 0\\ 0& 0& 0& 1 \end{bmatrix}$ |
| Rotation Matrix | ||
Na computação gráfica, muitas vezes precisamos desenhar diferentes tipos de objetos na tela. Os objetos não são planos o tempo todo e precisamos desenhar curvas muitas vezes para desenhar um objeto.
Tipos de curvas
Uma curva é um conjunto infinitamente grande de pontos. Cada ponto tem dois vizinhos, exceto pontos finais. As curvas podem ser amplamente classificadas em três categorias -explicit, implicit, e parametric curves.
Curvas implícitas
As representações de curvas implícitas definem o conjunto de pontos em uma curva, empregando um procedimento que pode testar para ver se um ponto está na curva. Normalmente, uma curva implícita é definida por uma função implícita da forma -
f (x, y) = 0
Pode representar curvas de vários valores (vários valores y para um valor x). Um exemplo comum é o círculo, cuja representação implícita é
x2 + y2 - R2 = 0
Curvas explícitas
Uma função matemática y = f (x) pode ser traçada como uma curva. Essa função é a representação explícita da curva. A representação explícita não é geral, uma vez que não pode representar linhas verticais e também tem um valor único. Para cada valor de x, apenas um único valor de y é normalmente calculado pela função.
Curvas Paramétricas
As curvas com forma paramétrica são chamadas de curvas paramétricas. As representações de curvas explícitas e implícitas podem ser usadas apenas quando a função é conhecida. Na prática, as curvas paramétricas são usadas. Uma curva paramétrica bidimensional tem a seguinte forma -
P (t) = f (t), g (t) ou P (t) = x (t), y (t)
As funções feg tornam-se as coordenadas (x, y) de qualquer ponto da curva, e os pontos são obtidos quando o parâmetro t é variado em um determinado intervalo [a, b], normalmente [0, 1].
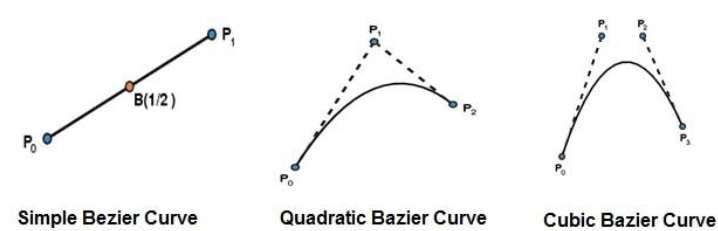
Curvas de Bézier
Curva de Bezier é descoberta pelo engenheiro francês Pierre Bézier. Essas curvas podem ser geradas sob o controle de outros pontos. Tangentes aproximadas usando pontos de controle são usadas para gerar curvas. A curva de Bézier pode ser representada matematicamente como -
$$\sum_{k=0}^{n} P_{i}{B_{i}^{n}}(t)$$
Onde $p_{i}$ é o conjunto de pontos e ${B_{i}^{n}}(t)$ representa os polinômios de Bernstein que são dados por -
$${B_{i}^{n}}(t) = \binom{n}{i} (1 - t)^{n-i}t^{i}$$
Onde n é o grau polinomial, i é o índice, e t é a variável.
A curva de Bézier mais simples é a linha reta do ponto $P_{0}$ para $P_{1}$. Uma curva de Bezier quadrática é determinada por três pontos de controle. Uma curva de Bézier cúbica é determinada por quatro pontos de controle.
Propriedades das curvas de Bézier
As curvas de Bézier têm as seguintes propriedades -
Eles geralmente seguem a forma do polígono de controle, que consiste nos segmentos que unem os pontos de controle.
Eles sempre passam pelo primeiro e último pontos de controle.
Eles estão contidos no casco convexo de seus pontos de controle de definição.
O grau do polinômio que define o segmento da curva é um a menos que o número do ponto do polígono que define. Portanto, para 4 pontos de controle, o grau do polinômio é 3, ou seja, polinômio cúbico.
Uma curva de Bézier geralmente segue a forma do polígono de definição.
A direção do vetor tangente nos pontos finais é a mesma do vetor determinado pelo primeiro e último segmento.
A propriedade de casca convexa de uma curva de Bézier garante que o polinômio siga suavemente os pontos de controle.
Nenhuma linha reta intercepta uma curva de Bézier mais vezes do que seu polígono de controle.
Eles são invariantes sob uma transformação afim.
As curvas de Bézier exibem controle global, significa que mover um ponto de controle altera a forma de toda a curva.
Uma dada curva de Bezier pode ser subdividida em um ponto t = t0 em dois segmentos de Bézier que se unem no ponto correspondente ao valor do parâmetro t = t0.
Curvas B-Spline
A curva de Bezier produzida pela função de base de Bernstein tem flexibilidade limitada.
Primeiro, o número de vértices poligonais especificados fixa a ordem do polinômio resultante que define a curva.
A segunda característica limitante é que o valor da função de combinação é diferente de zero para todos os valores de parâmetro em toda a curva.
A base B-spline contém a base de Bernstein como caso especial. A base B-spline não é global.
Uma curva B-spline é definida como uma combinação linear de pontos de controle Pi e função de base B-spline $N_{i,}$ k (t) dado por
$C(t) = \sum_{i=0}^{n}P_{i}N_{i,k}(t),$ $n\geq k-1,$ $t\: \epsilon \: [ tk-1,tn+1 ]$
Onde,
{$p_{i}$: i = 0, 1, 2… .n} são os pontos de controle
k é a ordem dos segmentos polinomiais da curva B-spline. Ordem k significa que a curva é composta de segmentos polinomiais por partes de grau k - 1,
a $N_{i,k}(t)$são as “funções de combinação B-spline normalizadas”. Eles são descritos pela ordem k e por uma sequência não decrescente de números reais normalmente chamada de “sequência de nós”.
$${t_{i}:i = 0, ... n + K}$$
As funções N i , k são descritas a seguir -
$$N_{i,1}(t) = \left\{\begin{matrix} 1,& if \:u \: \epsilon \: [t_{i,}t_{i+1}) \\ 0,& Otherwise \end{matrix}\right.$$
e se k> 1,
$$N_{i,k}(t) = \frac{t-t_{i}}{t_{i+k-1}} N_{i,k-1}(t) + \frac{t_{i+k}-t}{t_{i+k} - t_{i+1}} N_{i+1,k-1}(t)$$
e
$$t \: \epsilon \: [t_{k-1},t_{n+1})$$
Propriedades da curva B-spline
As curvas B-spline têm as seguintes propriedades -
A soma das funções básicas do B-spline para qualquer valor de parâmetro é 1.
Cada função básica é positiva ou zero para todos os valores dos parâmetros.
Cada função de base tem exatamente um valor máximo, exceto para k = 1.
A ordem máxima da curva é igual ao número de vértices do polígono de definição.
O grau do polinômio B-spline é independente do número de vértices do polígono de definição.
B-spline permite o controle local sobre a superfície da curva porque cada vértice afeta a forma de uma curva apenas em uma faixa de valores de parâmetro onde sua função de base associada é diferente de zero.
A curva exibe a propriedade de diminuição da variação.
A curva geralmente segue a forma de definir polígono.
Qualquer transformação afim pode ser aplicada à curva aplicando-a aos vértices do polígono de definição.
A linha curva dentro do casco convexo de seu polígono de definição.
Superfícies poligonais
Os objetos são representados como uma coleção de superfícies. A representação do objeto 3D é dividida em duas categorias.
Boundary Representations (B-reps) - Descreve um objeto 3D como um conjunto de superfícies que separa o interior do objeto do ambiente.
Space–partitioning representations - É usado para descrever propriedades interiores, particionando a região espacial que contém um objeto em um conjunto de pequenos sólidos contíguos não sobrepostos (geralmente cubos).
A representação de limite mais comumente usada para um objeto gráfico 3D é um conjunto de polígonos de superfície que envolvem o interior do objeto. Muitos sistemas gráficos usam esse método. Conjunto de polígonos são armazenados para a descrição do objeto. Isso simplifica e acelera a renderização da superfície e a exibição do objeto, uma vez que todas as superfícies podem ser descritas com equações lineares.
As superfícies poligonais são comuns em aplicações de design e modelagem de sólidos, uma vez que seus wireframe displaypode ser feito rapidamente para dar uma indicação geral da estrutura da superfície. Em seguida, cenas realistas são produzidas interpolando padrões de sombreamento na superfície do polígono para iluminar.
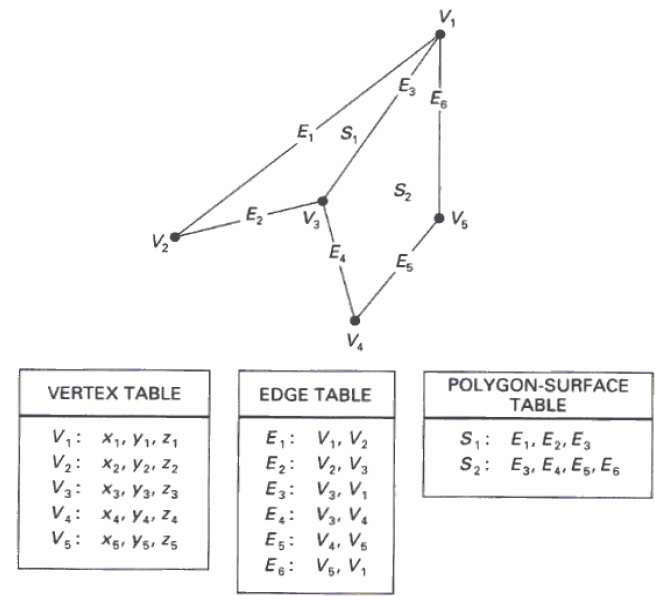
Tabelas Poligonais
Neste método, a superfície é especificada pelo conjunto de coordenadas do vértice e atributos associados. Conforme mostrado na figura a seguir, existem cinco vértices, de v 1 a v 5 .
Cada vértice armazena as informações das coordenadas x, y e z, que são representadas na tabela como v 1 : x 1 , y 1 , z 1 .
A tabela Edge é usada para armazenar as informações da borda do polígono. Na figura a seguir, a aresta E 1 fica entre os vértices v 1 ev 2, que é representado na tabela como E 1 : v 1 , v 2 .
A tabela de superfície do polígono armazena o número de superfícies presentes no polígono. Na figura a seguir, a superfície S 1 é coberta pelas arestas E 1 , E 2 e E 3, que podem ser representadas na tabela de superfície do polígono como S 1 : E 1 , E 2 e E 3 .
Equações planas
A equação para superfície plana pode ser expressa como -
Ax + Por + Cz + D = 0
Onde (x, y, z) é qualquer ponto do plano, e os coeficientes A, B, C e D são constantes que descrevem as propriedades espaciais do plano. Podemos obter os valores de A, B, C e D resolvendo um conjunto de três equações planas usando os valores das coordenadas para três pontos não colineares no plano. Suponhamos que três vértices do plano sejam (x 1 , y 1 , z 1 ), (x 2 , y 2 , z 2 ) e (x 3 , y 3 , z 3 ).
Vamos resolver as seguintes equações simultâneas para as razões A / D, B / D e C / D. Você obtém os valores de A, B, C e D.
(A / D) x 1 + (B / D) y 1 + (C / D) z 1 = -1
(A / D) x 2 + (B / D) y 2 + (C / D) z 2 = -1
(A / D) x 3 + (B / D) y 3 + (C / D) z 3 = -1
Para obter as equações acima na forma determinante, aplique a regra de Cramer às equações acima.
$A = \begin{bmatrix} 1& y_{1}& z_{1}\\ 1& y_{2}& z_{2}\\ 1& y_{3}& z_{3} \end{bmatrix} B = \begin{bmatrix} x_{1}& 1& z_{1}\\ x_{2}& 1& z_{2}\\ x_{3}& 1& z_{3} \end{bmatrix} C = \begin{bmatrix} x_{1}& y_{1}& 1\\ x_{2}& y_{2}& 1\\ x_{3}& y_{3}& 1 \end{bmatrix} D = - \begin{bmatrix} x_{1}& y_{1}& z_{1}\\ x_{2}& y_{2}& z_{2}\\ x_{3}& y_{3}& z_{3} \end{bmatrix}$
Para qualquer ponto (x, y, z) com parâmetros A, B, C e D, podemos dizer que -
Ax + By + Cz + D ≠ 0 significa que o ponto não está no plano.
Ax + By + Cz + D <0 significa que o ponto está dentro da superfície.
Ax + By + Cz + D> 0 significa que o ponto está fora da superfície.
Malhas poligonais
Superfícies e sólidos 3D podem ser aproximados por um conjunto de elementos poligonais e de linha. Essas superfícies são chamadaspolygonal meshes. Na malha poligonal, cada aresta é compartilhada por no máximo dois polígonos. O conjunto de polígonos ou faces, juntos, formam a “pele” do objeto.
Este método pode ser usado para representar uma ampla classe de sólidos / superfícies em gráficos. Uma malha poligonal pode ser renderizada usando algoritmos de remoção de superfície oculta. A malha poligonal pode ser representada de três maneiras -
- Representação explícita
- Ponteiros para uma lista de vértices
- Indicadores para uma lista de borda
Vantagens
- Ele pode ser usado para modelar quase qualquer objeto.
- Eles são fáceis de representar como uma coleção de vértices.
- Eles são fáceis de transformar.
- Eles são fáceis de desenhar na tela do computador.
Desvantagens
- Superfícies curvas só podem ser descritas aproximadamente.
- É difícil simular algum tipo de objeto como cabelo ou líquido.
Quando vemos uma imagem que contém objetos e superfícies não transparentes, não podemos ver os objetos que estão atrás de objetos próximos aos olhos. Devemos remover essas superfícies ocultas para obter uma imagem de tela realista. A identificação e remoção dessas superfícies é chamadaHidden-surface problem.
Existem duas abordagens para remover problemas superficiais ocultos - Object-Space method e Image-space method. O método do espaço do objeto é implementado no sistema de coordenadas físicas e o método do espaço da imagem é implementado no sistema de coordenadas da tela.
Quando queremos exibir um objeto 3D em uma tela 2D, precisamos identificar as partes da tela que são visíveis de uma posição de visualização escolhida.
Método de Depth Buffer (Z-Buffer)
Este método é desenvolvido por Cutmull. É uma abordagem de espaço de imagem. A ideia básica é testar a profundidade Z de cada superfície para determinar a superfície mais próxima (visível).
Neste método, cada superfície é processada separadamente, uma posição de pixel de cada vez na superfície. Os valores de profundidade de um pixel são comparados e a superfície mais próxima (z menor) determina a cor a ser exibida no buffer de quadros.
É aplicado de forma muito eficiente em superfícies de polígono. As superfícies podem ser processadas em qualquer ordem. Para substituir os polígonos mais próximos dos mais distantes, dois buffers chamadosframe buffer e depth buffer, são usados.
Depth buffer é usado para armazenar valores de profundidade para a posição (x, y), conforme as superfícies são processadas (0 ≤ profundidade ≤ 1).
o frame buffer é usado para armazenar o valor da intensidade do valor da cor em cada posição (x, y).
As coordenadas z são normalmente normalizadas para o intervalo [0, 1]. O valor 0 para a coordenada z indica o painel de recorte traseiro e o valor 1 para as coordenadas z indica o painel de recorte frontal.
Algoritmo
Step-1 - Defina os valores do buffer -
Depthbuffer (x, y) = 0
Framebuffer (x, y) = cor de fundo
Step-2 - Processe cada polígono (um de cada vez)
Para cada posição de pixel projetada (x, y) de um polígono, calcule a profundidade z.
Se Z> depthbuffer (x, y)
Calcular a cor da superfície,
definir depthbuffer (x, y) = z,
framebuffer (x, y) = surfacecolor (x, y)
Vantagens
- É fácil de implementar.
- Reduz o problema de velocidade se implementado em hardware.
- Ele processa um objeto por vez.
Desvantagens
- Requer muita memória.
- É um processo demorado.
Método Scan-Line
É um método de espaço de imagem para identificar a superfície visível. Este método tem uma informação de profundidade para apenas uma linha de varredura. A fim de exigir uma linha de varredura de valores de profundidade, devemos agrupar e processar todos os polígonos que cruzam uma determinada linha de varredura ao mesmo tempo antes de processar a próxima linha de varredura. Duas tabelas importantes,edge table e polygon table, são mantidos para isso.
The Edge Table - Ele contém pontos finais de coordenada de cada linha na cena, a inclinação inversa de cada linha e ponteiros na tabela de polígonos para conectar as bordas às superfícies.
The Polygon Table - Ele contém os coeficientes de plano, propriedades do material de superfície, outros dados de superfície e pode ser um indicador para a tabela de arestas.

Para facilitar a busca de superfícies cruzando uma determinada linha de varredura, uma lista ativa de arestas é formada. A lista ativa armazena apenas as arestas que cruzam a linha de varredura em ordem crescente de x. Além disso, um sinalizador é definido para cada superfície para indicar se uma posição ao longo de uma linha de varredura está dentro ou fora da superfície.
As posições dos pixels em cada linha de varredura são processadas da esquerda para a direita. Na interseção à esquerda com uma superfície, a bandeira da superfície é ativada e à direita, a bandeira é desativada. Você só precisa realizar cálculos de profundidade quando várias superfícies têm seus sinalizadores ativados em uma determinada posição da linha de varredura.
Método de subdivisão de área
O método de subdivisão de área aproveita a localização das áreas de visualização que representam parte de uma única superfície. Divida a área de visualização total em retângulos cada vez menores até que cada pequena área seja a projeção de parte de uma única superfície visível ou nenhuma superfície.
Continue esse processo até que as subdivisões sejam facilmente analisadas como pertencentes a uma única superfície ou até que sejam reduzidas ao tamanho de um único pixel. Uma maneira fácil de fazer isso é dividir sucessivamente a área em quatro partes iguais em cada etapa. Existem quatro relações possíveis que uma superfície pode ter com um limite de área especificado.
Surrounding surface - Um que circunda completamente a área.
Overlapping surface - Um que esteja parcialmente dentro e parcialmente fora da área.
Inside surface - Um que fica totalmente dentro da área.
Outside surface - Um que esteja completamente fora da área.
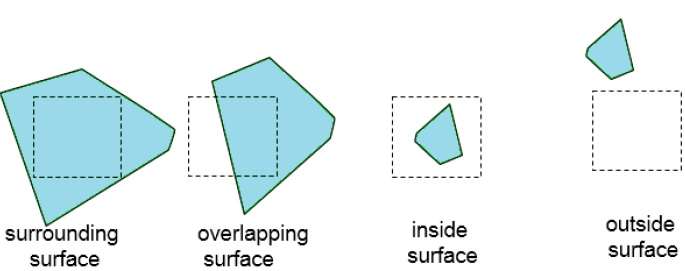
Os testes para determinar a visibilidade da superfície dentro de uma área podem ser declarados em termos dessas quatro classificações. Nenhuma subdivisão adicional de uma área especificada é necessária se uma das seguintes condições for verdadeira -
- Todas as superfícies são superfícies externas em relação à área.
- Apenas uma superfície interna, sobreposta ou circundante está na área.
- Uma superfície circundante obscurece todas as outras superfícies dentro dos limites da área.
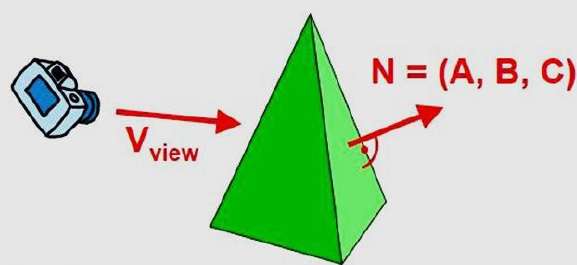
Detecção de face posterior
Um método de espaço-objeto rápido e simples para identificar as faces posteriores de um poliedro é baseado nos testes "de dentro para fora". Um ponto (x, y, z) está "dentro" de uma superfície poligonal com parâmetros de plano A, B, C e D se Quando um ponto interno está ao longo da linha de visão da superfície, o polígono deve ser uma face posterior ( estamos dentro desse rosto e não podemos ver a frente dele de nossa posição de visualização).
Podemos simplificar este teste considerando o vetor normal N a uma superfície poligonal, que possui componentes cartesianos (A, B, C).
Em geral, se V for um vetor na direção de visualização da posição do olho (ou "câmera"), então este polígono é uma face posterior se
V.N > 0
Além disso, se as descrições dos objetos forem convertidas em coordenadas de projeção e sua direção de visualização for paralela ao eixo z de visualização, então -
V = (0, 0, V z ) e V.N = V Z C
Assim, só precisamos considerar o sinal de C o componente do vetor normal N.
Em um sistema de visualização para destros com direção de visualização ao longo do negativo $Z_{V}$eixo, o polígono é uma face posterior se C <0. Além disso, não podemos ver nenhuma face cuja normal tenha componente z C = 0, uma vez que sua direção de visualização é em direção a esse polígono. Assim, em geral, podemos rotular qualquer polígono como uma face posterior se seu vetor normal tiver um valor de componente az -
C <= 0
Métodos semelhantes podem ser usados em pacotes que empregam um sistema de visualização para canhotos. Nesses pacotes, os parâmetros do plano A, B, C e D podem ser calculados a partir das coordenadas do vértice do polígono especificadas no sentido horário (ao contrário do sentido anti-horário usado em um sistema para destros).
Além disso, as faces posteriores têm vetores normais que apontam para longe da posição de visualização e são identificados por C> = 0 quando a direção de visualização está ao longo do positivo $Z_{v}$eixo. Ao examinar o parâmetro C para os diferentes planos que definem um objeto, podemos identificar imediatamente todas as faces posteriores.
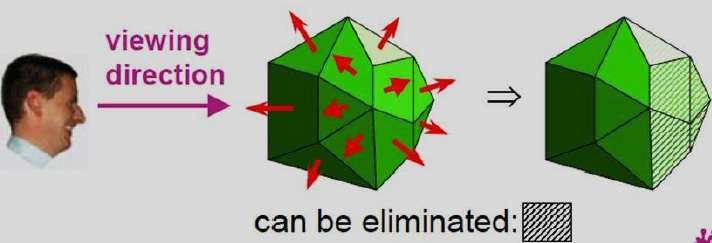
Método A-Buffer
O método A-buffer é uma extensão do método de buffer de profundidade. O método A-buffer é um método de detecção de visibilidade desenvolvido na Lucas film Studios para o sistema de renderização Renders Everything You Ever Saw (REYES).
O A-buffer se expande no método do buffer de profundidade para permitir transparências. A estrutura de dados chave no buffer A é o buffer de acumulação.
Cada posição no A-buffer tem dois campos -
Depth field - Armazena um número real positivo ou negativo
Intensity field - Ele armazena informações de intensidade de superfície ou um valor de ponteiro

Se a profundidade> = 0, o número armazenado nessa posição é a profundidade de uma única superfície sobreposta à área de pixel correspondente. O campo de intensidade então armazena os componentes RGB da cor da superfície naquele ponto e a porcentagem de cobertura de pixels.
Se a profundidade <0, indica contribuições de múltiplas superfícies para a intensidade do pixel. O campo de intensidade então armazena um ponteiro para uma lista vinculada de dados de superfície. O buffer de superfície no A-buffer inclui -
- Componentes de intensidade RGB
- Parâmetro de opacidade
- Depth
- Porcentagem de cobertura de área
- Identificador de superfície
O algoritmo prossegue exatamente como o algoritmo do buffer de profundidade. Os valores de profundidade e opacidade são usados para determinar a cor final de um pixel.
Método de classificação de profundidade
O método de classificação de profundidade usa operações de espaço de imagem e espaço de objeto. O método de classificação por profundidade executa duas funções básicas -
Primeiro, as superfícies são classificadas em ordem decrescente de profundidade.
Em segundo lugar, as superfícies são convertidas por varredura em ordem, começando pela superfície de maior profundidade.
A conversão de varredura das superfícies do polígono é realizada no espaço da imagem. Este método para resolver o problema da superfície oculta é frequentemente referido como opainter's algorithm. A figura a seguir mostra o efeito da classificação de profundidade -
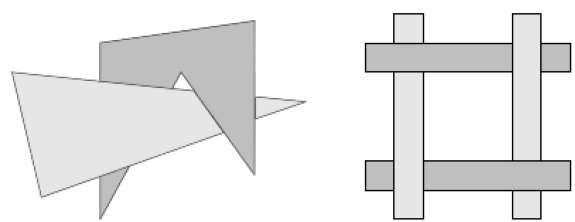
O algoritmo começa classificando por profundidade. Por exemplo, a estimativa inicial de "profundidade" de um polígono pode ser considerada o valor z mais próximo de qualquer vértice do polígono.
Tomemos o polígono P no final da lista. Considere todos os polígonos Q cujas extensões z se sobrepõem aos P's. Antes de desenhar P, fazemos os seguintes testes. Se algum dos testes a seguir for positivo, podemos assumir que P pode ser obtido antes de Q.
- As extensões x não se sobrepõem?
- As extensões y não se sobrepõem?
- P está inteiramente no lado oposto do plano de Q do ponto de vista?
- Q está inteiramente do mesmo lado do plano de P que o ponto de vista?
- As projeções dos polígonos não se sobrepõem?
Se todos os testes falharem, dividimos P ou Q usando o plano do outro. Os novos polígonos de corte estão sendo inseridos na ordem de profundidade e o processo continua. Teoricamente, esse particionamento poderia gerar O (n 2 ) polígonos individuais, mas, na prática, o número de polígonos é muito menor.
Árvores de partição de espaço binário (BSP)
O particionamento do espaço binário é usado para calcular a visibilidade. Para construir as árvores BSP, deve-se começar com polígonos e rotular todas as arestas. Lidando com apenas uma aresta de cada vez, estenda cada aresta de forma que divida o plano em dois. Coloque a primeira aresta da árvore como raiz. Adicione arestas subsequentes com base em se elas estão dentro ou fora. As arestas que se estendem pela extensão de uma aresta que já está na árvore são divididas em duas e ambas são adicionadas à árvore.

Da figura acima, primeiro pegue A como uma raiz.
Faça uma lista de todos os nós na figura (a).
Coloque todos os nós que estão na frente da raiz A para o lado esquerdo do nó A e colocar todos os nós que estão atrás da raiz A para o lado direito conforme mostrado na figura (b).
Processe todos os nós da frente primeiro e depois os nós da parte de trás.
Conforme mostrado na figura (c), vamos primeiro processar o nó B. Como não há nada na frente do nóB, colocamos NIL. No entanto, temos nóC atrás do nó B, então nó C irá para o lado direito do nó B.
Repita o mesmo processo para o nó D.
Um matemático francês / americano Dr. Benoit Mandelbrot descobriu os Fractais. A palavra fractal deriva de uma palavra latina fractus, que significa quebrado.
O que são fractais?
Fractais são imagens muito complexas geradas por um computador a partir de uma única fórmula. Eles são criados usando iterações. Isso significa que uma fórmula é repetida com valores ligeiramente diferentes continuamente, levando em consideração os resultados da iteração anterior.
Fractais são usados em muitas áreas, como -
Astronomy - Para analisar galáxias, anéis de Saturno, etc.
Biology/Chemistry - Para representar culturas de bactérias, reações químicas, anatomia humana, moléculas, plantas,
Others - Para representar nuvens, litoral e limites, compressão de dados, difusão, economia, arte fractal, música fractal, paisagens, efeitos especiais, etc.

Geração de Fractais
Fractais podem ser gerados repetindo a mesma forma indefinidamente, conforme mostrado na figura a seguir. Na figura (a) mostra um triângulo equilátero. Na figura (b), podemos ver que o triângulo é repetido para criar uma forma de estrela. Na figura (c), podemos ver que a forma de estrela da figura (b) é repetida várias vezes para criar uma nova forma.
Podemos fazer um número ilimitado de iterações para criar a forma desejada. Em termos de programação, a recursão é usada para criar essas formas.

Fractais Geométricos
Fractais geométricos lidam com formas encontradas na natureza que têm dimensões não inteiras ou fractais. Para construir geometricamente um fractal auto-semelhante determinístico (não aleatório), começamos com uma determinada forma geométrica, chamada deinitiator. As subpartes do iniciador são então substituídas por um padrão, chamado degenerator.

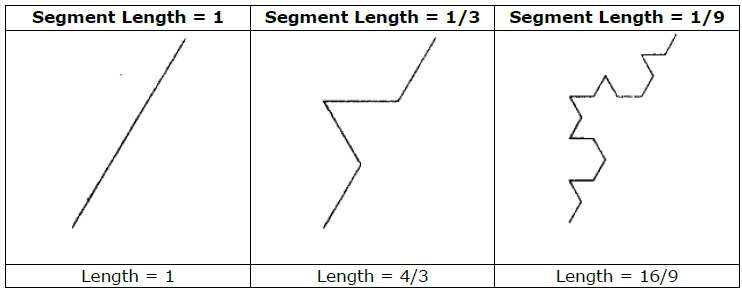
Por exemplo, se usarmos o iniciador e o gerador mostrados na figura acima, podemos construir um bom padrão repetindo-o. Cada segmento de linha reta no iniciador é substituído por quatro segmentos de linha de comprimento igual em cada etapa. O fator de escala é 1/3, então a dimensão fractal é D = ln 4 / ln 3 ≈ 1,2619.
Além disso, o comprimento de cada segmento de linha no iniciador aumenta por um fator de 4/3 em cada etapa, de modo que o comprimento da curva fractal tende ao infinito conforme mais detalhes são adicionados à curva, conforme mostrado na figura a seguir -
Animação significa dar vida a qualquer objeto da computação gráfica. Ele tem o poder de injetar energia e emoções nos objetos aparentemente inanimados. Animação assistida por computador e animação gerada por computador são duas categorias de animação por computador. Pode ser apresentado em filme ou vídeo.
A ideia básica por trás da animação é reproduzir as imagens gravadas em taxas rápidas o suficiente para enganar o olho humano para interpretá-las como um movimento contínuo. A animação pode dar vida a uma série de imagens mortas. A animação pode ser usada em muitas áreas, como entretenimento, design auxiliado por computador, visualização científica, treinamento, educação, comércio eletrônico e arte computacional.
Técnicas de Animação
Os animadores inventaram e usaram uma variedade de técnicas de animação diferentes. Basicamente, existem seis técnicas de animação que discutiríamos uma a uma nesta seção.
Animação tradicional (quadro a quadro)
Tradicionalmente, a maior parte da animação era feita à mão. Todos os quadros em uma animação tiveram que ser desenhados à mão. Como cada segundo de animação requer 24 quadros (filme), a quantidade de esforços necessários para criar até mesmo o mais curto dos filmes pode ser enorme.
Keyframing
Nessa técnica, um storyboard é apresentado e, em seguida, os artistas desenham os quadros principais da animação. Quadros principais são aqueles em que ocorrem mudanças importantes. Eles são os pontos-chave da animação. O quadro-chave requer que o animador especifique as posições críticas ou importantes para os objetos. O computador então preenche automaticamente os quadros ausentes, interpolando suavemente entre essas posições.
Processual
Em uma animação procedural, os objetos são animados por um procedimento - um conjunto de regras - não por keyframing. O animador especifica regras e condições iniciais e executa a simulação. As regras são freqüentemente baseadas em regras físicas do mundo real expressas por equações matemáticas.
Comportamental
Na animação comportamental, um personagem autônomo determina suas próprias ações, pelo menos até certo ponto. Isso dá ao personagem a capacidade de improvisar e libera o animador da necessidade de especificar cada detalhe do movimento de cada personagem.
Com base no desempenho (captura de movimento)
Outra técnica é a captura de movimento, na qual sensores magnéticos ou baseados na visão registram as ações de um objeto humano ou animal em três dimensões. Um computador então usa esses dados para animar o objeto.
Essa tecnologia permitiu que vários atletas famosos fornecessem ações para personagens de videogames esportivos. A captura de movimento é muito popular entre os animadores, principalmente porque algumas das ações humanas comuns podem ser capturadas com relativa facilidade. No entanto, pode haver sérias discrepâncias entre as formas ou dimensões do assunto e o caráter gráfico e isso pode levar a problemas de execução exata.
Fisicamente com base (dinâmica)
Ao contrário do enquadramento chave e do filme, a simulação usa as leis da física para gerar o movimento de imagens e outros objetos. As simulações podem ser facilmente usadas para produzir sequências ligeiramente diferentes, mantendo o realismo físico. Em segundo lugar, as simulações em tempo real permitem um maior grau de interatividade onde a pessoa real pode manobrar as ações do personagem simulado.
Em contraste, os aplicativos baseados em key-framing e motion selecionam e modificam movimentos formam uma biblioteca pré-computada de movimentos. Uma desvantagem da simulação é a experiência e o tempo necessários para criar manualmente os sistemas de controle apropriados.
Enquadramento Chave
Um quadro-chave é um quadro onde definimos as mudanças na animação. Cada quadro é um quadro-chave quando criamos uma animação quadro a quadro. Quando alguém cria uma animação 3D em um computador, geralmente não especifica a posição exata de qualquer objeto em cada quadro. Eles criam quadros-chave.
Quadros-chave são quadros importantes durante os quais um objeto muda seu tamanho, direção, forma ou outras propriedades. O computador então descobre todos os quadros intermediários e economiza uma quantidade extrema de tempo para o animador. As ilustrações a seguir mostram os quadros desenhados pelo usuário e os gerados pelo computador.


Transformando
A transformação das formas dos objetos de uma forma para outra é chamada de metamorfose. É uma das transformações mais complicadas.

Uma transformação parece que duas imagens se fundem uma na outra com um movimento muito fluido. Em termos técnicos, duas imagens são distorcidas e um fade ocorre entre elas.