R - Não Linear Mínimo Quadrado
Ao modelar dados do mundo real para análise de regressão, observamos que raramente é o caso em que a equação do modelo é uma equação linear que fornece um gráfico linear. Na maioria das vezes, a equação do modelo de dados do mundo real envolve funções matemáticas de alto grau, como um expoente de 3 ou uma função de pecado. Nesse cenário, o gráfico do modelo fornece uma curva em vez de uma linha. O objetivo da regressão linear e não linear é ajustar os valores dos parâmetros do modelo para encontrar a linha ou curva que mais se aproxima de seus dados. Ao encontrar esses valores, seremos capazes de estimar a variável de resposta com boa precisão.
Na regressão por Mínimos Quadrados, estabelecemos um modelo de regressão no qual a soma dos quadrados das distâncias verticais de diferentes pontos da curva de regressão é minimizada. Geralmente começamos com um modelo definido e assumimos alguns valores para os coeficientes. Em seguida, aplicamos onls() função de R para obter os valores mais precisos junto com os intervalos de confiança.
Sintaxe
A sintaxe básica para criar um teste de mínimos quadrados não linear em R é -
nls(formula, data, start)A seguir está a descrição dos parâmetros usados -
formula é uma fórmula de modelo não linear que inclui variáveis e parâmetros.
data é um quadro de dados usado para avaliar as variáveis na fórmula.
start é uma lista nomeada ou vetor numérico nomeado de estimativas iniciais.
Exemplo
Vamos considerar um modelo não linear com suposição de valores iniciais de seus coeficientes. A seguir, veremos quais são os intervalos de confiança desses valores assumidos para que possamos avaliar o quão bem esses valores se encaixam no modelo.
Então, vamos considerar a equação abaixo para este propósito -
a = b1*x^2+b2Vamos supor que os coeficientes iniciais sejam 1 e 3 e ajustar esses valores na função nls ().
xvalues <- c(1.6,2.1,2,2.23,3.71,3.25,3.4,3.86,1.19,2.21)
yvalues <- c(5.19,7.43,6.94,8.11,18.75,14.88,16.06,19.12,3.21,7.58)
# Give the chart file a name.
png(file = "nls.png")
# Plot these values.
plot(xvalues,yvalues)
# Take the assumed values and fit into the model.
model <- nls(yvalues ~ b1*xvalues^2+b2,start = list(b1 = 1,b2 = 3))
# Plot the chart with new data by fitting it to a prediction from 100 data points.
new.data <- data.frame(xvalues = seq(min(xvalues),max(xvalues),len = 100))
lines(new.data$xvalues,predict(model,newdata = new.data))
# Save the file.
dev.off()
# Get the sum of the squared residuals.
print(sum(resid(model)^2))
# Get the confidence intervals on the chosen values of the coefficients.
print(confint(model))Quando executamos o código acima, ele produz o seguinte resultado -
[1] 1.081935
Waiting for profiling to be done...
2.5% 97.5%
b1 1.137708 1.253135
b2 1.497364 2.496484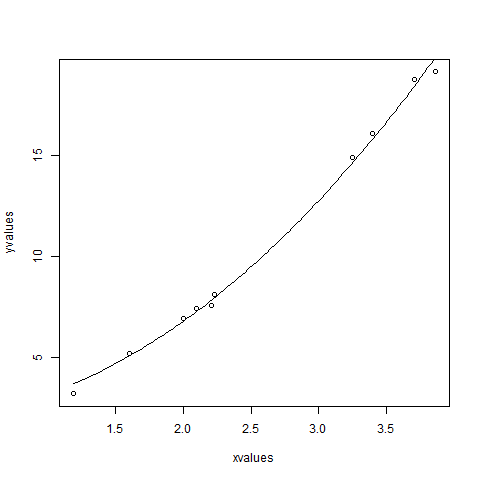
Podemos concluir que o valor de b1 está mais próximo de 1 enquanto o valor de b2 está mais próximo de 2 e não de 3.