벡터 양자화 학습
벡터 양자화 (VQ) 및 코호 넨자가 조직지도 (KSOM)와는 다른 학습 벡터 양자화 (LVQ)는 기본적으로지도 학습을 사용하는 경쟁 네트워크입니다. 각 출력 단위가 클래스를 나타내는 패턴을 분류하는 프로세스로 정의 할 수 있습니다. 지도 학습을 사용하므로 네트워크에는 출력 클래스의 초기 분포와 함께 알려진 분류가있는 일련의 훈련 패턴이 제공됩니다. 훈련 과정을 마친 후 LVQ는 입력 벡터를 출력 유닛과 동일한 클래스에 할당하여 분류합니다.
건축물
다음 그림은 KSOM의 아키텍처와 매우 유사한 LVQ의 아키텍처를 보여줍니다. 우리가 볼 수 있듯이“n” 입력 단위 수 및 “m”출력 단위 수. 레이어는 가중치가있는 상태로 완전히 상호 연결되어 있습니다.

사용 된 매개 변수
다음은 LVQ 훈련 프로세스와 순서도에서 사용되는 매개 변수입니다.
x= 훈련 벡터 (x 1 , ..., x i , ..., x n )
T = 훈련 벡터를위한 클래스 x
wj = 가중치 벡터 jth 출력 유닛
Cj = 관련 클래스 jth 출력 유닛
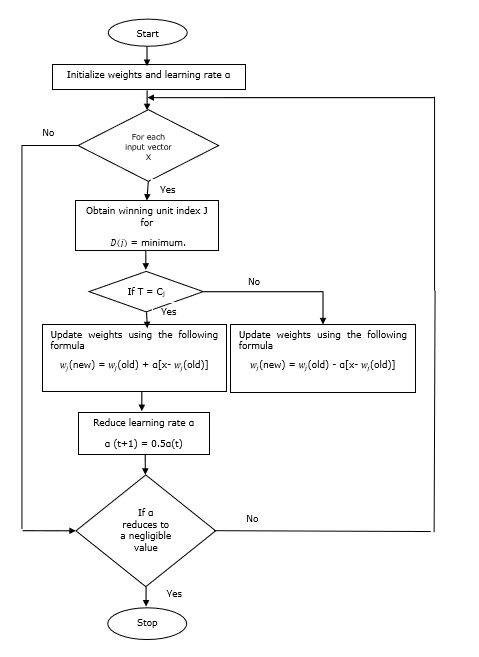
훈련 알고리즘
Step 1 − 다음과 같이 수행 할 수있는 참조 벡터 초기화 −
Step 1(a) − 주어진 훈련 벡터 세트에서 첫 번째 "m”(클러스터 수) 훈련 벡터를 사용하고 가중치 벡터로 사용합니다. 나머지 벡터는 훈련에 사용할 수 있습니다.
Step 1(b) − 초기 가중치와 분류를 무작위로 할당합니다.
Step 1(c) − K- 평균 클러스터링 방법을 적용합니다.
Step 2 − 참조 벡터 $ \ alpha $ 초기화
Step 3 −이 알고리즘을 중지하기위한 조건이 충족되지 않으면 4-9 단계를 계속합니다.
Step 4 − 모든 훈련 입력 벡터에 대해 5-6 단계를 따릅니다. x.
Step 5 −에 대한 유클리드 거리의 제곱 계산 j = 1 to m 과 i = 1 to n
$$ D (j) \ : = \ : \ displaystyle \ sum \ limits_ {i = 1} ^ n \ displaystyle \ sum \ limits_ {j = 1} ^ m (x_ {i} \ :-\ : w_ {ij }) ^ 2 $$
Step 6 − 우승 유닛 획득 J 어디 D(j) 최소입니다.
Step 7 − 다음 관계식으로 우승 한 유닛의 새 가중치를 계산합니다. −
만약 T = Cj 그런 다음 $ w_ {j} (new) \ : = \ : w_ {j} (old) \ : + \ : \ alpha [x \ :-\ : w_ {j} (old)] $
만약 T ≠ Cj $ w_ {j} (new) \ : = \ : w_ {j} (old) \ :-\ : \ alpha [x \ :-\ : w_ {j} (old)] $
Step 8 − 학습률 $ \ alpha $를 줄입니다.
Step 9− 정지 조건을 테스트합니다. 다음과 같을 수 있습니다-
- 최대 Epoch 수에 도달했습니다.
- 학습률이 무시할 수있는 값으로 감소했습니다.
순서도
변형
코호 넨은 LVQ2, LVQ2.1 및 LVQ3의 세 가지 다른 변형을 개발했습니다. 이 세 가지 변형 모두의 복잡성은 승자와 2 위 팀이 배울 개념으로 인해 LVQ보다 더 많습니다.
LVQ2
위에서 언급했듯이 LVQ의 다른 변형의 개념, LVQ2의 조건은 창에 의해 형성됩니다. 이 창은 다음 매개 변수를 기반으로합니다.
x − 현재 입력 벡터
yc − 가장 가까운 참조 벡터 x
yr − 다음으로 가장 가까운 다른 참조 벡터 x
dc − 거리 x ...에 yc
dr − 거리 x ...에 yr
입력 벡터 x 창문에 떨어지면
$$ \ frac {d_ {c}} {d_ {r}} \ :> \ : 1 \ :-\ : \ theta \ : \ : and \ : \ : \ frac {d_ {r}} {d_ {c }} \ :> \ : 1 \ : + \ : \ theta $$
여기서 $ \ theta $는 훈련 샘플의 수입니다.
업데이트는 다음 공식으로 수행 할 수 있습니다.
$ y_ {c} (t \ : + \ : 1) \ : = \ : y_ {c} (t) \ : + \ : \ alpha (t) [x (t) \ :-\ : y_ {c} (t)] $ (belongs to different class)
$ y_ {r} (t \ : + \ : 1) \ : = \ : y_ {r} (t) \ : + \ : \ alpha (t) [x (t) \ :-\ : y_ {r} (t)] $ (belongs to same class)
여기서 $ \ alpha $는 학습률입니다.
LVQ2.1
LVQ2.1에서는 가장 가까운 두 벡터를 사용합니다. yc1 과 yc2 윈도우의 조건은 다음과 같습니다.
$$ Min \ begin {bmatrix} \ frac {d_ {c1}} {d_ {c2}}, \ frac {d_ {c2}} {d_ {c1}} \ end {bmatrix} \ :> \ :( 1 \ :-\ : \ theta) $$
$$ Max \ begin {bmatrix} \ frac {d_ {c1}} {d_ {c2}}, \ frac {d_ {c2}} {d_ {c1}} \ end {bmatrix} \ : <\ :( 1 \ : + \ : \ theta) $$
업데이트는 다음 공식으로 수행 할 수 있습니다.
$ y_ {c1} (t \ : + \ : 1) \ : = \ : y_ {c1} (t) \ : + \ : \ alpha (t) [x (t) \ :-\ : y_ {c1} (t)] $ (belongs to different class)
$ y_ {c2} (t \ : + \ : 1) \ : = \ : y_ {c2} (t) \ : + \ : \ alpha (t) [x (t) \ :-\ : y_ {c2} (t)] $ (belongs to same class)
여기서 $ \ alpha $는 학습률입니다.
LVQ3
LVQ3에서 우리는 두 개의 가장 가까운 벡터 즉 yc1 과 yc2 윈도우의 조건은 다음과 같습니다.
$$ Min \ begin {bmatrix} \ frac {d_ {c1}} {d_ {c2}}, \ frac {d_ {c2}} {d_ {c1}} \ end {bmatrix} \ :> \ :( 1 \ :-\ : \ theta) (1 \ : + \ : \ theta) $$
여기 $ \ theta \ approx 0.2 $
업데이트는 다음 공식으로 수행 할 수 있습니다.
$ y_ {c1} (t \ : + \ : 1) \ : = \ : y_ {c1} (t) \ : + \ : \ beta (t) [x (t) \ :-\ : y_ {c1} (t)] $ (belongs to different class)
$ y_ {c2} (t \ : + \ : 1) \ : = \ : y_ {c2} (t) \ : + \ : \ beta (t) [x (t) \ :-\ : y_ {c2} (t)] $ (belongs to same class)
여기서 $ \ beta $는 학습률 $ \ alpha $의 배수입니다. $\beta\:=\:m \alpha(t)$ 모든 0.1 < m < 0.5