인공 신경망-퀵 가이드
신경망은 기본적으로 뇌의 컴퓨터 모델을 만들려는 시도 인 병렬 컴퓨팅 장치입니다. 주요 목표는 기존 시스템보다 빠르게 다양한 계산 작업을 수행 할 수있는 시스템을 개발하는 것입니다. 이러한 작업에는 패턴 인식 및 분류, 근사화, 최적화 및 데이터 클러스터링이 포함됩니다.
인공 신경망이란?
인공 신경망 (ANN)은 생물학적 신경망의 비유에서 차용 한 중심 주제를 가진 효율적인 컴퓨팅 시스템입니다. ANN은 "인공 신경 시스템"또는 "병렬 분산 처리 시스템"또는 "연결 시스템"이라고도합니다. ANN은 장치 간 통신을 허용하기 위해 어떤 패턴으로 상호 연결된 대규모 장치 모음을 획득합니다. 노드 또는 뉴런이라고도하는 이러한 단위는 병렬로 작동하는 간단한 프로세서입니다.
모든 뉴런은 연결 링크를 통해 다른 뉴런과 연결됩니다. 각 연결 링크는 입력 신호에 대한 정보가있는 가중치와 연관됩니다. 가중치는 일반적으로 전달되는 신호를 자극하거나 억제하기 때문에 뉴런이 특정 문제를 해결하는 데 가장 유용한 정보입니다. 각 뉴런에는 활성화 신호라고하는 내부 상태가 있습니다. 입력 신호와 활성화 규칙을 결합하여 생성 된 출력 신호를 다른 장치로 보낼 수 있습니다.
ANN의 간략한 역사
ANN의 역사는 다음과 같은 세 가지 시대로 나눌 수 있습니다.
1940 ~ 1960 년대 ANN
이 시대의 주요 발전은 다음과 같습니다.
1943 − 신경망의 개념은 생리학자인 Warren McCulloch와 수학자 인 Walter Pitts가 1943 년 뇌의 뉴런이 작동하는 방식을 설명하기 위해 전기 회로를 사용하여 단순한 신경망을 모델링했을 때 시작되었다고 가정했습니다. .
1949− Donald Hebb의 저서 The Organization of Behavior 는 한 뉴런을 다른 뉴런에 의해 반복적으로 활성화하면 사용할 때마다 강도가 증가한다는 사실을 설명합니다.
1956 − 연관 기억 네트워크는 Taylor에 의해 도입되었습니다.
1958 − Perceptron이라는 이름의 McCulloch 및 Pitts 뉴런 모델에 대한 학습 방법은 Rosenblatt에 의해 발명되었습니다.
1960 − Bernard Widrow와 Marcian Hoff는 "ADALINE"및 "MADALINE"이라는 모델을 개발했습니다.
1960 ~ 1980 년대 ANN
이 시대의 주요 발전은 다음과 같습니다.
1961 − Rosenblatt는 성공하지 못했지만 다중 계층 네트워크에 대한 "역 전파"방식을 제안했습니다.
1964 − Taylor는 출력 장치 간의 금지를 통해 승자 독식 회로를 구성했습니다.
1969 − 다층 퍼셉트론 (MLP)은 Minsky와 Papert에 의해 발명되었습니다.
1971 − 코호 넨은 연관 기억을 개발했습니다.
1976 − Stephen Grossberg와 Gail Carpenter는 적응 형 공명 이론을 개발했습니다.
1980 년대부터 현재까지의 ANN
이 시대의 주요 발전은 다음과 같습니다.
1982 − 주요 개발은 Hopfield의 에너지 접근 방식이었습니다.
1985 − Boltzmann 기계는 Ackley, Hinton 및 Sejnowski가 개발했습니다.
1986 − Rumelhart, Hinton 및 Williams는 Generalized Delta Rule을 도입했습니다.
1988 − Kosko는 BAM (Binary Associative Memory)을 개발했으며 ANN에서 퍼지 논리 개념도 제공했습니다.
역사적 검토는이 분야에서 상당한 진전이 있었음을 보여줍니다. 신경망 기반 칩이 등장하고 복잡한 문제에 대한 애플리케이션이 개발되고 있습니다. 확실히 오늘은 신경망 기술의 전환기입니다.
생물학적 뉴런
신경 세포 (뉴런)는 정보를 처리하는 특별한 생물학적 세포입니다. 추정에 따르면, 많은 수의 뉴런이 있으며, 약 10 11 , 수많은 상호 연결이있는 약 10 15 .
개략도
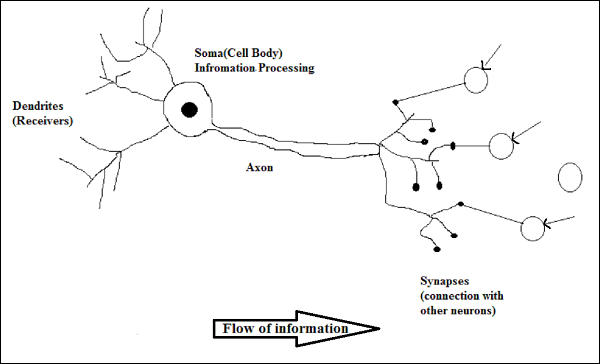
생물학적 뉴런의 작용
위의 다이어그램에서 볼 수 있듯이 일반적인 뉴런은 작동을 설명 할 수있는 다음 네 부분으로 구성됩니다.
Dendrites− 그들은 연결된 다른 뉴런으로부터 정보를 수신하는 역할을하는 나무와 같은 가지입니다. 다른 의미에서 우리는 그들이 뉴런의 귀와 같다고 말할 수 있습니다.
Soma − 뉴런의 세포체이며 수상 돌기로부터받은 정보 처리를 담당합니다.
Axon − 뉴런이 정보를 보내는 케이블과 같습니다.
Synapses − 축삭과 다른 뉴런 수상 돌기 사이의 연결입니다.
ANN 대 BNN
ANN (인공 신경망)과 BNN (생물학적 신경망)의 차이점을 살펴보기 전에이 둘의 용어를 기반으로 유사점을 살펴 보겠습니다.
| 생물학적 신경망 (BNN) | 인공 신경망 (ANN) |
|---|---|
| 소마 | 마디 |
| 수상 돌기 | 입력 |
| 시냅스 | 가중치 또는 상호 연결 |
| 축삭 | 산출 |
다음 표는 언급 된 몇 가지 기준에 따라 ANN과 BNN을 비교 한 것입니다.
| 기준 | BNN | 앤 |
|---|---|---|
| Processing | 대규모 병렬, 느리지 만 ANN보다 우수 | 대규모 병렬, 빠르지 만 BNN보다 열등 |
| Size | 10 개의 11 개의 뉴런과 10 개의 15 개의 상호 연결 | 10 2 ~ 10 4 노드 (주로 애플리케이션 유형 및 네트워크 설계자에 따라 다름) |
| Learning | 모호함을 용인 할 수 있습니다. | 모호함을 허용하려면 매우 정확하고 구조화되고 형식이 지정된 데이터가 필요합니다. |
| Fault tolerance | 부분적인 손상으로도 성능 저하 | 강력한 성능을 제공하므로 내결함성이있을 수 있습니다. |
| Storage capacity | 시냅스에 정보를 저장합니다. | 지속적인 메모리 위치에 정보를 저장합니다. |
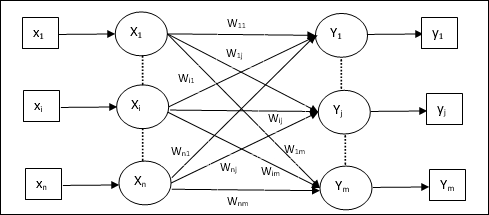
인공 신경망 모델
다음 다이어그램은 ANN의 일반 모델과 그에 따른 처리를 나타냅니다.
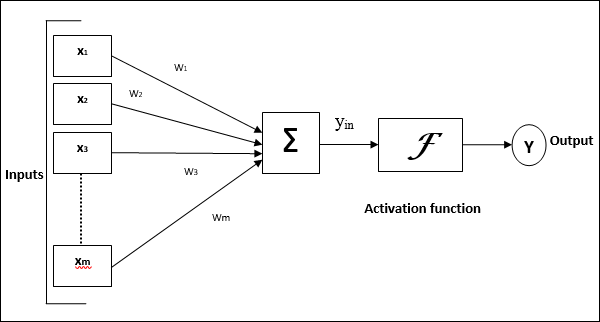
위의 인공 신경망의 일반 모델의 경우 순 입력은 다음과 같이 계산할 수 있습니다.
$$ y_ {in} \ : = \ : x_ {1} .w_ {1} \ : + \ : x_ {2} .w_ {2} \ : + \ : x_ {3} .w_ {3} \ : \ dotso \ : x_ {m} .w_ {m} $$
즉, 순 입력 $ y_ {in} \ : = \ : \ sum_i ^ m \ : x_ {i} .w_ {i} $
출력은 순 입력에 활성화 함수를 적용하여 계산할 수 있습니다.
$$ Y \ : = \ : F (y_ {in}) $$
출력 = 함수 (순 입력 계산 됨)
ANN 처리는 다음 세 가지 구성 요소에 따라 달라집니다.
- 네트워크 토폴로지
- 가중치 조정 또는 학습
- 활성화 기능
이 장에서는 ANN의 세 가지 구성 요소에 대해 자세히 설명합니다.
네트워크 토폴로지
네트워크 토폴로지는 노드 및 연결 라인과 함께 네트워크의 배열입니다. 토폴로지에 따르면 ANN은 다음과 같은 종류로 분류 할 수 있습니다.
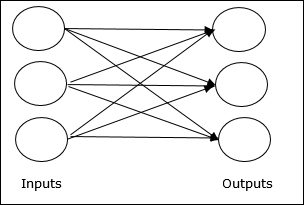
피드 포워드 네트워크
계층에 처리 장치 / 노드가있는 비순환 네트워크이며 계층의 모든 노드는 이전 계층의 노드와 연결됩니다. 연결에는 다른 가중치가 있습니다. 피드백 루프가 없다는 것은 신호가 입력에서 출력으로 한 방향으로 만 흐를 수 있음을 의미합니다. 다음 두 가지 유형으로 나눌 수 있습니다.
Single layer feedforward network− 개념은 단 하나의 가중치 레이어 만있는 피드 포워드 ANN입니다. 즉, 입력 레이어가 출력 레이어에 완전히 연결되어 있다고 말할 수 있습니다.
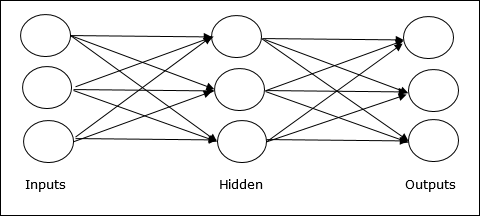
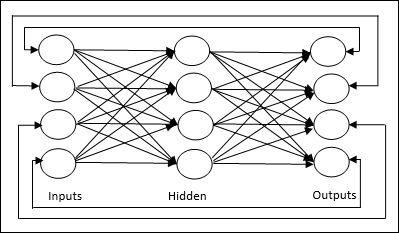
Multilayer feedforward network− 개념은 하나 이상의 가중치 레이어를 갖는 피드 포워드 ANN입니다. 이 네트워크에는 입력 레이어와 출력 레이어 사이에 하나 이상의 레이어가 있으므로 히든 레이어라고합니다.
피드백 네트워크
이름에서 알 수 있듯이 피드백 네트워크에는 피드백 경로가 있으므로 신호가 루프를 사용하여 양방향으로 흐를 수 있습니다. 이것은 평형 상태에 도달 할 때까지 지속적으로 변화하는 비선형 동적 시스템을 만듭니다. 다음과 같은 유형으로 나눌 수 있습니다-
Recurrent networks− 폐쇄 루프가있는 피드백 네트워크입니다. 다음은 두 가지 유형의 반복 네트워크입니다.
Fully recurrent network − 모든 노드가 다른 모든 노드에 연결되고 각 노드가 입력 및 출력으로 작동하기 때문에 가장 단순한 신경망 아키텍처입니다.
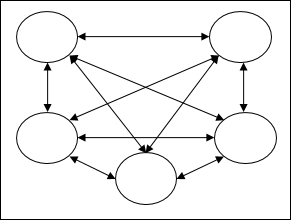
Jordan network − 다음 다이어그램과 같이 출력이 피드백으로 다시 입력으로 이동하는 폐쇄 루프 네트워크입니다.
가중치 조정 또는 학습
인공 신경망에서 학습은 지정된 네트워크의 뉴런 간의 연결 가중치를 수정하는 방법입니다. ANN의 학습은지도 학습, 비지도 학습 및 강화 학습의 세 가지 범주로 분류 할 수 있습니다.
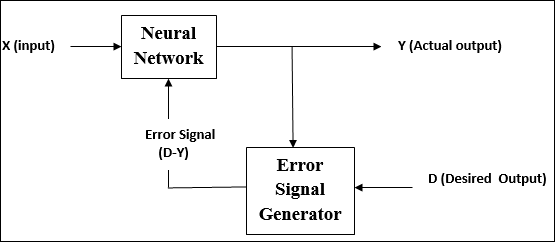
지도 학습
이름에서 알 수 있듯이 이러한 유형의 학습은 교사의 감독하에 이루어집니다. 이 학습 과정은 의존적입니다.
지도 학습 하에서 ANN을 훈련하는 동안 입력 벡터가 네트워크에 제공되어 출력 벡터를 제공합니다. 이 출력 벡터는 원하는 출력 벡터와 비교됩니다. 실제 출력과 원하는 출력 벡터 사이에 차이가 있으면 오류 신호가 생성됩니다. 이 오류 신호를 기반으로 실제 출력이 원하는 출력과 일치 할 때까지 가중치가 조정됩니다.
비지도 학습
이름에서 알 수 있듯이 이러한 유형의 학습은 교사의 감독없이 수행됩니다. 이 학습 과정은 독립적입니다.
비지도 학습에서 ANN을 훈련하는 동안 유사한 유형의 입력 벡터가 결합되어 클러스터를 형성합니다. 새로운 입력 패턴이 적용되면 신경망은 입력 패턴이 속한 클래스를 나타내는 출력 응답을 제공합니다.
원하는 출력이되어야하고 그것이 정확하거나 부 정확한지에 대한 환경으로부터의 피드백이 없습니다. 따라서 이러한 유형의 학습에서 네트워크 자체는 입력 데이터에서 패턴과 특징을 발견하고 출력에 대한 입력 데이터의 관계를 찾아야합니다.
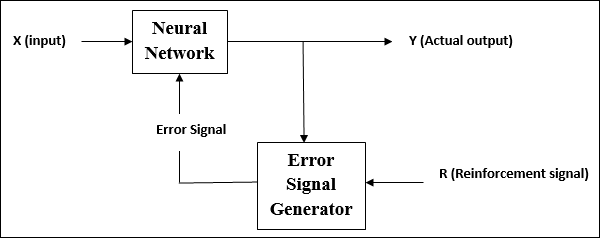
강화 학습
이름에서 알 수 있듯이 이러한 유형의 학습은 일부 비판 정보를 통해 네트워크를 강화하거나 강화하는 데 사용됩니다. 이 학습 과정은지도 학습과 유사하지만 정보가 매우 적을 수 있습니다.
강화 학습에서 네트워크를 훈련하는 동안 네트워크는 환경으로부터 일부 피드백을받습니다. 이것은지도 학습과 다소 유사합니다. 그러나 여기에서 얻은 피드백은 교육적이지 않고 평가 적이므로 감독 학습과 같은 교사가 없음을 의미합니다. 피드백을받은 후 네트워크는 향후 더 나은 비평 정보를 얻기 위해 가중치를 조정합니다.
활성화 기능
정확한 출력을 얻기 위해 입력에 적용되는 추가 힘 또는 노력으로 정의 할 수 있습니다. ANN에서는 입력에 활성화 기능을 적용하여 정확한 출력을 얻을 수도 있습니다. 다음은 관심있는 몇 가지 활성화 기능입니다.
선형 활성화 기능
입력 편집을 수행하지 않기 때문에 식별 기능이라고도합니다. 다음과 같이 정의 할 수 있습니다.
$$ F (x) \ : = \ : x $$
시그 모이 드 활성화 기능
다음과 같이 두 가지 유형입니다-
Binary sigmoidal function−이 활성화 기능은 0과 1 사이의 입력 편집을 수행합니다. 이는 본질적으로 양수입니다. 항상 경계가 지정됩니다. 이는 출력이 0보다 작거나 1보다 클 수 없음을 의미합니다. 또한 본질적으로 엄격하게 증가하고 있습니다. 이는 입력이 높을수록 출력이 될 수 있음을 의미합니다. 다음과 같이 정의 할 수 있습니다.
$$ F (x) \ : = \ : sigm (x) \ : = \ : \ frac {1} {1 \ : + \ : exp (-x)} $$
Bipolar sigmoidal function−이 활성화 기능은 -1과 1 사이의 입력 편집을 수행합니다. 본질적으로 양수 또는 음수 일 수 있습니다. 항상 경계가 지정되어 출력이 -1보다 작거나 1보다 클 수 없음을 의미합니다. 또한 시그 모이 드 함수처럼 본질적으로 엄격하게 증가하고 있습니다. 다음과 같이 정의 할 수 있습니다.
$$ F (x) \ : = \ : sigm (x) \ : = \ : \ frac {2} {1 \ : + \ : exp (-x)} \ :-\ : 1 \ : = \ : \ frac {1 \ :-\ : exp (x)} {1 \ : + \ : exp (x)} $$
앞서 언급했듯이 ANN은 생물학적 신경계, 즉 인간의 뇌가 작동하는 방식에서 완전히 영감을 받았습니다. 인간 두뇌의 가장 인상적인 특징은 학습하는 것이므로 ANN이 동일한 기능을 획득합니다.
ANN에서 학습이란 무엇입니까?
기본적으로 학습이란 환경의 변화가있을 때 그 자체로 변화를 수행하고 적응하는 것을 의미합니다. ANN은 복잡한 시스템이거나보다 정확하게는 그것이 통과하는 정보를 기반으로 내부 구조를 변경할 수있는 복잡한 적응 시스템이라고 말할 수 있습니다.
왜 중요 함?
복잡한 적응 시스템이기 때문에 ANN에서 학습한다는 것은 처리 장치가 환경의 변화로 인해 입력 / 출력 동작을 변경할 수 있음을 의미합니다. ANN에서 학습의 중요성은 특정 네트워크가 구성 될 때 입력 / 출력 벡터뿐만 아니라 고정 된 활성화 함수로 인해 증가합니다. 이제 입력 / 출력 동작을 변경하려면 가중치를 조정해야합니다.
분류
동일한 클래스의 샘플 간의 공통 특징을 찾아 샘플의 데이터를 다른 클래스로 구분하는 학습 과정으로 정의 할 수있다. 예를 들어 ANN 교육을 수행하기 위해 고유 한 기능이있는 일부 교육 샘플이 있고 테스트를 수행하기 위해 다른 고유 한 기능이있는 일부 테스트 샘플이 있습니다. 분류는지도 학습의 한 예입니다.
신경망 학습 규칙
ANN 학습 중에 입력 / 출력 동작을 변경하려면 가중치를 조정해야합니다. 따라서 가중치를 수정할 수있는 방법이 필요합니다. 이러한 방법을 학습 규칙이라고하며 이는 단순히 알고리즘 또는 방정식입니다. 다음은 신경망에 대한 몇 가지 학습 규칙입니다.
Hebbian 학습 규칙
가장 오래되고 단순한 규칙 중 하나 인이 규칙은 Donald Hebb 가 1949 년 그의 저서 The Organization of Behavior 에서 소개했습니다. 일종의 피드 포워드, 비지도 학습입니다.
Basic Concept −이 규칙은 Hebb가 작성한 제안에 기반합니다.
“세포 A의 축색 돌기가 세포 B를 자극 할만큼 충분히 가까워서 반복적으로 또는 지속적으로 그것을 발사하는 데 참여할 때, 일부 성장 과정 또는 대사 변화가 하나 또는 두 세포에서 발생하여 A의 효율성이 B를 발사하는 세포 중 하나처럼 , 증가합니다. "
위의 가정에서 우리는 뉴런이 동시에 발화하면 두 뉴런 사이의 연결이 강화되고 다른 시간에 발화하면 약해질 수 있다는 결론을 내릴 수 있습니다.
Mathematical Formulation − Hebbian 학습 규칙에 따라 매 시간 단계에서 연결 가중치를 높이는 공식은 다음과 같습니다.
$$ \ 델타 w_ {ji} (t) \ : = \ : \ alpha x_ {i} (t) .y_ {j} (t) $$
여기에서 $ \ Delta w_ {ji} (t) $ = 시간 단계에서 연결 가중치가 증가하는 증가분 t
$ \ alpha $ = 긍정적이고 일정한 학습률
$ x_ {i} (t) $ = 시간 단계에서 시냅스 전 뉴런의 입력 값 t
$ y_ {i} (t) $ = 동일한 시간 단계에서 시냅스 전 뉴런의 출력 t
퍼셉트론 학습 규칙
이 규칙은 Rosenblatt에서 도입 한 선형 활성화 함수를 사용하는 단일 레이어 피드 포워드 네트워크의지도 학습 알고리즘을 수정하는 오류입니다.
Basic Concept− 본질적으로 감독되기 때문에 오류를 계산하기 위해 원하는 / 목표 출력과 실제 출력을 비교합니다. 차이가 발견되면 연결 가중치를 변경해야합니다.
Mathematical Formulation − 수학적 공식을 설명하기 위해 원하는 / 타겟 출력 벡터 t (n)와 함께 유한 입력 벡터 x (n)의 'n'개가 있다고 가정합니다. 여기서 n = 1 ~ N입니다.
이제 출력 'y'는 앞서 설명한 순 입력을 기반으로 계산할 수 있으며 해당 순 입력에 적용되는 활성화 함수는 다음과 같이 표현할 수 있습니다.
$$ y \ : = \ : f (y_ {in}) \ : = \ : \ begin {cases} 1, & y_ {in} \ :> \ : \ theta \\ 0, & y_ {in} \ : \ leqslant \ : \ theta \ end {cases} $$
어디 θ 임계 값입니다.
가중치 업데이트는 다음 두 가지 경우에 수행 할 수 있습니다.
Case I − 언제 t ≠ y, 다음
$$ w (신규) \ : = \ : w (이전) \ : + \; tx $$
Case II − 언제 t = y, 다음
체중 변화 없음
델타 학습 규칙 (Widrow-Hoff 규칙)
이는 모든 훈련 패턴에 대한 오류를 최소화하기 위해 LMS (Least Mean Square) 방법이라고도하는 Bernard Widrow와 Marcian Hoff에 의해 도입되었습니다. 지속적인 활성화 기능을 가진 일종의지도 학습 알고리즘입니다.
Basic Concept−이 규칙의 기본은 경사 하강 법으로 영원히 계속됩니다. 델타 규칙은 출력 단위 및 목표 값에 대한 순 입력을 최소화하기 위해 시냅스 가중치를 업데이트합니다.
Mathematical Formulation − 시냅스 가중치를 업데이트하기 위해 델타 규칙은
$$ \ 델타 w_ {i} \ : = \ : \ alpha \ :. x_ {i} .e_ {j} $$
여기서 $ \ Delta w_ {i} $ = i 번째 패턴에 대한 무게 변화 ;
$ \ alpha $ = 긍정적이고 지속적인 학습률;
$ x_ {i} $ = 시냅스 전 뉴런의 입력 값;
$ e_ {j} $ = $ (t \ :-\ : y_ {in}) $, 원하는 / 목표 출력과 실제 출력의 차이 $ y_ {in} $
위의 델타 규칙은 단일 출력 장치에만 적용됩니다.
가중치 업데이트는 다음 두 가지 경우에 수행 할 수 있습니다.
Case-I − 언제 t ≠ y, 다음
$$ w (신규) \ : = \ : w (이전) \ : + \ : \ Delta w $$
Case-II − 언제 t = y, 다음
체중 변화 없음
경쟁 학습 규칙 (승자 독식)
출력 노드가 입력 패턴을 나타 내기 위해 서로 경쟁을 시도하는 비지도 학습과 관련이 있습니다. 이 학습 규칙을 이해하려면 다음과 같은 경쟁 네트워크를 이해해야합니다.
Basic Concept of Competitive Network−이 네트워크는 출력간에 피드백 연결이있는 단일 레이어 피드 포워드 네트워크와 같습니다. 출력 간의 연결은 점선으로 표시되는 금지 유형이므로 경쟁자가 스스로를 지원하지 않음을 의미합니다.
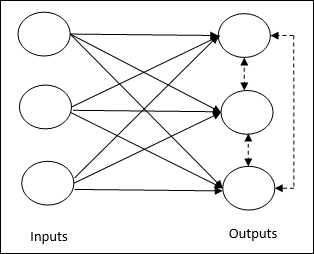
Basic Concept of Competitive Learning Rule− 앞서 언급했듯이 출력 노드간에 경쟁이있을 것입니다. 따라서 주된 개념은 훈련 중에 주어진 입력 패턴에 대해 가장 높은 활성화를 가진 출력 단위가 승자로 선언된다는 것입니다. 이 규칙을 Winner-takes-all이라고도합니다. 우승 한 뉴런 만 업데이트되고 나머지 뉴런은 변경되지 않기 때문입니다.
Mathematical formulation − 다음은이 학습 규칙의 수학적 공식화를위한 세 가지 중요한 요소입니다 −
Condition to be a winner − 뉴런 $ y_ {k} $ 이 승자가 되고자한다면 다음과 같은 조건이 될 것입니다. −
$$ y_ {k} \ : = \ : \ begin {cases} 1 & if \ : v_ {k} \ :> \ : v_ {j} \ : for \ : all \ : j, \ : j \ : \ neq \ : k \\ 0 및 기타 \ end {cases} $$
즉, $ y_ {k} $ 과 같은 뉴런이 이기고 자하면 유도 된 로컬 필드 (합산 단위의 출력), 즉 $ v_ {k} $가 다른 모든 뉴런 중에서 가장 커야합니다. 네트워크에서.
Condition of sum total of weight − 경쟁 학습 규칙에 대한 또 다른 제약은 특정 출력 뉴런에 대한 가중치의 합계가 1이 될 것입니다. 예를 들어, 뉴런을 고려한다면 k 다음-
$$ \ displaystyle \ sum \ limits_ {j} w_ {kj} \ : = \ : 1 \ : \ : \ : \ : \ : \ : \ : \ : \ : for \ : all \ : k $$
Change of weight for winner− 뉴런이 입력 패턴에 반응하지 않으면 해당 뉴런에서 학습이 이루어지지 않습니다. 그러나 특정 뉴런이 이기면 해당 가중치가 다음과 같이 조정됩니다.
$$ \ 델타 w_ {kj} \ : = \ : \ begin {cases}-\ alpha (x_ {j} \ :-\ : w_ {kj}), & if \ : neuron \ : k \ : wins \\ 0, & if \ : neuron \ : k \ : losses \ end {cases} $$
여기서 $ \ alpha $는 학습률입니다.
이것은 우리가 무게를 조정함으로써 승리하는 뉴런을 선호하고 있음을 분명히 보여 주며, 만약 뉴런이 손실되면 우리는 무게를 재조정 할 필요가 없습니다.
Outstar 학습 규칙
Grossberg가 도입 한이 규칙은 원하는 출력이 알려져 있기 때문에지도 학습과 관련이 있습니다. Grossberg 학습이라고도합니다.
Basic Concept−이 규칙은 레이어에 배열 된 뉴런에 적용됩니다. 원하는 출력을 생성하도록 특별히 설계되었습니다.d 층의 p 뉴런.
Mathematical Formulation −이 규칙의 무게 조정은 다음과 같이 계산됩니다.
$$ \ 델타 w_ {j} \ : = \ : \ alpha \ :( d \ :-\ : w_ {j}) $$
여기 d 원하는 뉴런 출력이고 $ \ alpha $는 학습률입니다.
이름에서 알 수 있듯이 supervised learning교사의 감독하에 진행됩니다. 이 학습 과정은 의존적입니다. 지도 학습하에 ANN을 훈련하는 동안 입력 벡터가 네트워크에 제공되어 출력 벡터가 생성됩니다. 이 출력 벡터는 원하는 / 목표 출력 벡터와 비교됩니다. 실제 출력과 원하는 / 목표 출력 벡터 사이에 차이가 있으면 오류 신호가 생성됩니다. 이 오류 신호를 기반으로 실제 출력이 원하는 출력과 일치 할 때까지 가중치가 조정됩니다.
퍼셉트론
McCulloch 및 Pitts 모델을 사용하여 Frank Rosenblatt가 개발 한 퍼셉트론은 인공 신경망의 기본 작동 단위입니다. 지도 학습 규칙을 사용하며 데이터를 두 개의 클래스로 분류 할 수 있습니다.
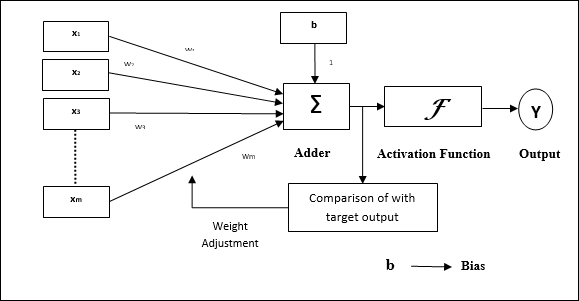
퍼셉트론의 작동 특성 : 조정 가능한 가중치와 함께 임의의 수의 입력이있는 단일 뉴런으로 구성되지만 뉴런의 출력은 임계 값에 따라 1 또는 0입니다. 또한 가중치가 항상 1 인 편향으로 구성됩니다. 다음 그림은 퍼셉트론의 개략도를 보여줍니다.
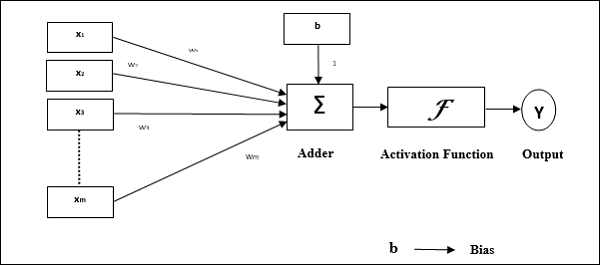
따라서 퍼셉트론은 다음과 같은 세 가지 기본 요소를 가지고 있습니다.
Links − 항상 가중치가 1 인 편향을 포함하는 가중치를 전달하는 연결 링크 세트가 있습니다.
Adder − 각각의 가중치를 곱한 후 입력을 더합니다.
Activation function− 뉴런의 출력을 제한합니다. 가장 기본적인 활성화 함수는 두 개의 가능한 출력이있는 Heaviside 단계 함수입니다. 이 함수는 입력이 양수이면 1을 반환하고 음수 입력이면 0을 반환합니다.
훈련 알고리즘
Perceptron 네트워크는 단일 출력 장치 및 다중 출력 장치에 대해 훈련 될 수 있습니다.
단일 출력 장치에 대한 훈련 알고리즘
Step 1 − 교육을 시작하려면 다음을 초기화하세요 −
- Weights
- Bias
- 학습률 $ \ alpha $
쉬운 계산과 단순성을 위해 가중치와 편향을 0으로 설정하고 학습률을 1로 설정해야합니다.
Step 2 − 정지 조건이 참이 아닌 경우 3-8 단계를 계속합니다.
Step 3 − 모든 훈련 벡터에 대해 4-6 단계를 계속합니다. x.
Step 4 − 다음과 같이 각 입력 장치를 활성화합니다 −
$$ x_ {i} \ : = \ : s_ {i} \ :( i \ : = \ : 1 \ : to \ : n) $$
Step 5 − 이제 다음 관계식으로 net input을 얻습니다.
$$ y_ {in} \ : = \ : b \ : + \ : \ displaystyle \ sum \ limits_ {i} ^ n x_ {i}. \ : w_ {i} $$
여기 ‘b’ 편견이고 ‘n’ 입력 뉴런의 총 수입니다.
Step 6 − 다음 활성화 기능을 적용하여 최종 출력을 얻습니다.
$$ f (y_ {in}) \ : = \ : \ begin {cases} 1 & if \ : y_ {in} \ :> \ : \ theta \\ 0 & if \ :-\ theta \ : \ leqslant \ : y_ {in} \ : \ leqslant \ : \ theta \\-1 & if \ : y_ {in} \ : <\ :-\ theta \ end {cases} $$
Step 7 − 다음과 같이 가중치와 편향을 조정합니다 −
Case 1 − 만약 y ≠ t 그때,
$$ w_ {i} (신규) \ : = \ : w_ {i} (이전) \ : + \ : \ alpha \ : tx_ {i} $$
$$ b (신규) \ : = \ : b (이전) \ : + \ : \ alpha t $$
Case 2 − 만약 y = t 그때,
$$ w_ {i} (신규) \ : = \ : w_ {i} (이전) $$
$$ b (신규) \ : = \ : b (이전) $$
여기 ‘y’ 실제 출력이고 ‘t’ 원하는 / 대상 출력입니다.
Step 8 − 중량 변화가 없을 때 발생하는 정지 상태를 테스트합니다.
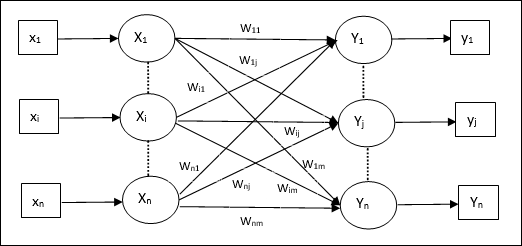
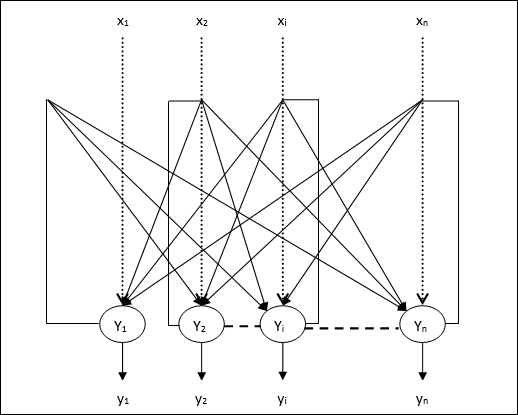
여러 출력 단위에 대한 학습 알고리즘
다음 다이어그램은 여러 출력 클래스에 대한 퍼셉트론의 아키텍처입니다.
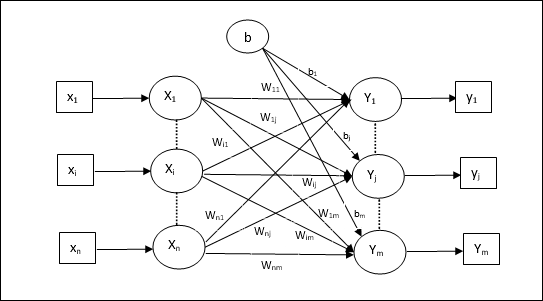
Step 1 − 교육을 시작하려면 다음을 초기화하세요 −
- Weights
- Bias
- 학습률 $ \ alpha $
쉬운 계산과 단순성을 위해 가중치와 편향을 0으로 설정하고 학습률을 1로 설정해야합니다.
Step 2 − 정지 조건이 참이 아닌 경우 3-8 단계를 계속합니다.
Step 3 − 모든 훈련 벡터에 대해 4-6 단계를 계속합니다. x.
Step 4 − 다음과 같이 각 입력 장치를 활성화합니다 −
$$ x_ {i} \ : = \ : s_ {i} \ :( i \ : = \ : 1 \ : to \ : n) $$
Step 5 − 다음 관계식으로 net input 구하기 −
$$ y_ {in} \ : = \ : b \ : + \ : \ displaystyle \ sum \ limits_ {i} ^ n x_ {i} \ : w_ {ij} $$
여기 ‘b’ 편견이고 ‘n’ 입력 뉴런의 총 수입니다.
Step 6 − 다음 활성화 기능을 적용하여 각 출력 유닛에 대한 최종 출력을 얻습니다. j = 1 to m −
$$ f (y_ {in}) \ : = \ : \ begin {cases} 1 & if \ : y_ {inj} \ :> \ : \ theta \\ 0 & if \ :-\ theta \ : \ leqslant \ : y_ {inj} \ : \ leqslant \ : \ theta \\-1 & if \ : y_ {inj} \ : <\ :-\ theta \ end {cases} $$
Step 7 −에 대한 가중치 및 편향 조정 x = 1 to n 과 j = 1 to m 다음과 같이-
Case 1 − 만약 yj ≠ tj 그때,
$$ w_ {ij} (신규) \ : = \ : w_ {ij} (이전) \ : + \ : \ alpha \ : t_ {j} x_ {i} $$
$$ b_ {j} (신규) \ : = \ : b_ {j} (이전) \ : + \ : \ alpha t_ {j} $$
Case 2 − 만약 yj = tj 그때,
$$ w_ {ij} (신규) \ : = \ : w_ {ij} (이전) $$
$$ b_ {j} (신규) \ : = \ : b_ {j} (이전) $$
여기 ‘y’ 실제 출력이고 ‘t’ 원하는 / 대상 출력입니다.
Step 8 − 중량 변화가 없을 때 발생하는 정지 상태를 테스트합니다.
적응 형 선형 뉴런 (Adaline)
Adaptive Linear Neuron의 약자 인 Adaline은 단일 선형 단위가있는 네트워크입니다. 1960 년 Widrow와 Hoff가 개발했습니다. Adaline에 대한 몇 가지 중요한 점은 다음과 같습니다.
바이폴라 활성화 기능을 사용합니다.
학습에 델타 규칙을 사용하여 실제 출력과 원하는 / 목표 출력 사이의 평균 제곱 오차 (MSE)를 최소화합니다.
가중치와 편향은 조정 가능합니다.
건축물
Adaline의 기본 구조는 실제 출력이 원하는 / 목표 출력과 비교되는 도움으로 추가 피드백 루프가있는 퍼셉트론과 유사합니다. 훈련 알고리즘을 기준으로 비교 후 가중치와 편향이 업데이트됩니다.
훈련 알고리즘
Step 1 − 교육을 시작하려면 다음을 초기화하세요 −
- Weights
- Bias
- 학습률 $ \ alpha $
쉬운 계산과 단순성을 위해 가중치와 편향을 0으로 설정하고 학습률을 1로 설정해야합니다.
Step 2 − 정지 조건이 참이 아닌 경우 3-8 단계를 계속합니다.
Step 3 − 모든 양극성 훈련 쌍에 대해 4-6 단계를 계속합니다. s:t.
Step 4 − 다음과 같이 각 입력 장치를 활성화합니다 −
$$ x_ {i} \ : = \ : s_ {i} \ :( i \ : = \ : 1 \ : to \ : n) $$
Step 5 − 다음 관계식으로 net input 구하기 −
$$ y_ {in} \ : = \ : b \ : + \ : \ displaystyle \ sum \ limits_ {i} ^ n x_ {i} \ : w_ {i} $$
여기 ‘b’ 편견이고 ‘n’ 입력 뉴런의 총 수입니다.
Step 6 − 최종 출력을 얻기 위해 다음 활성화 함수를 적용합니다 −
$$ f (y_ {in}) \ : = \ : \ begin {cases} 1 & if \ : y_ {in} \ : \ geqslant \ : 0 \\-1 & if \ : y_ {in} \ : < \ : 0 \ end {cases} $$
Step 7 − 다음과 같이 가중치와 편향을 조정합니다 −
Case 1 − 만약 y ≠ t 그때,
$$ w_ {i} (신규) \ : = \ : w_ {i} (이전) \ : + \ : \ alpha (t \ :-\ : y_ {in}) x_ {i} $$
$$ b (신규) \ : = \ : b (이전) \ : + \ : \ alpha (t \ :-\ : y_ {in}) $$
Case 2 − 만약 y = t 그때,
$$ w_ {i} (신규) \ : = \ : w_ {i} (이전) $$
$$ b (신규) \ : = \ : b (이전) $$
여기 ‘y’ 실제 출력이고 ‘t’ 원하는 / 대상 출력입니다.
$ (t \ :-\; y_ {in}) $는 계산 된 오류입니다.
Step 8 − 체중 변화가 없거나 훈련 중 발생한 가장 높은 체중 변화가 지정된 허용 오차보다 작을 때 발생하는 중지 조건을 테스트합니다.
다중 적응 선형 뉴런 (Madaline)
Multiple Adaptive Linear Neuron의 약자 인 Madaline은 많은 Adaline이 병렬로 구성된 네트워크입니다. 단일 출력 장치가 있습니다. Madaline에 대한 몇 가지 중요한 사항은 다음과 같습니다.
Adaline이 입력과 Madaline 레이어 사이의 숨겨진 단위 역할을하는 다층 퍼셉트론과 같습니다.
Adaline 아키텍처에서 볼 수 있듯이 입력 레이어와 Adaline 레이어 간의 가중치 및 편향은 조정 가능합니다.
Adaline 및 Madaline 레이어는 고정 된 가중치와 편향이 1입니다.
훈련은 델타 규칙의 도움으로 수행 할 수 있습니다.
건축물
Madaline의 아키텍처는 다음으로 구성됩니다. “n” 입력 계층의 뉴런, “m”Adaline 층의 뉴런과 Madaline 층의 1 개의 뉴런. Adaline 레이어는 입력 레이어와 출력 레이어, 즉 Madaline 레이어 사이에 있기 때문에 은닉 레이어로 간주 할 수 있습니다.
훈련 알고리즘
이제 입력과 Adaline 레이어 사이의 가중치와 편향 만 조정되고 Adaline과 Madaline 레이어 사이의 가중치와 편향이 고정된다는 것을 알고 있습니다.
Step 1 − 교육을 시작하려면 다음을 초기화하세요 −
- Weights
- Bias
- 학습률 $ \ alpha $
쉬운 계산과 단순성을 위해 가중치와 편향을 0으로 설정하고 학습률을 1로 설정해야합니다.
Step 2 − 정지 조건이 참이 아닌 경우 3-8 단계를 계속합니다.
Step 3 − 모든 양극성 훈련 쌍에 대해 4-6 단계를 계속합니다. s:t.
Step 4 − 다음과 같이 각 입력 장치를 활성화합니다 −
$$ x_ {i} \ : = \ : s_ {i} \ :( i \ : = \ : 1 \ : to \ : n) $$
Step 5 − 각 은닉 계층, 즉 다음 관계를 갖는 Adaline 계층에서 순 입력을 구합니다 −
$$ Q_ {inj} \ : = \ : b_ {j} \ : + \ : \ displaystyle \ sum \ limits_ {i} ^ n x_ {i} \ : w_ {ij} \ : \ : \ : j \ : = \ : 1 \ : to \ : m $$
여기 ‘b’ 편견이고 ‘n’ 입력 뉴런의 총 수입니다.
Step 6 − Adaline 및 Madaline 레이어에서 최종 출력을 얻기 위해 다음 활성화 함수를 적용합니다. −
$$ f (x) \ : = \ : \ begin {cases} 1 & if \ : x \ : \ geqslant \ : 0 \\-1 & if \ : x \ : <\ : 0 \ end {cases} $ $
숨겨진 (Adaline) 단위에서 출력
$$ Q_ {j} \ : = \ : f (Q_ {inj}) $$
네트워크의 최종 출력
$$ y \ : = \ : f (y_ {in}) $$
i.e. $ \ : \ : y_ {inj} \ : = \ : b_ {0} \ : + \ : \ sum_ {j = 1} ^ m \ : Q_ {j} \ : v_ {j} $
Step 7 − 오차를 계산하고 다음과 같이 가중치를 조정합니다 −
Case 1 − 만약 y ≠ t 과 t = 1 그때,
$$ w_ {ij} (신규) \ : = \ : w_ {ij} (이전) \ : + \ : \ alpha (1 \ :-\ : Q_ {inj}) x_ {i} $$
$$ b_ {j} (신규) \ : = \ : b_ {j} (이전) \ : + \ : \ alpha (1 \ :-\ : Q_ {inj}) $$
이 경우 가중치는 다음에 업데이트됩니다. Qj 순 입력은 0에 가깝습니다. t = 1.
Case 2 − 만약 y ≠ t 과 t = -1 그때,
$$ w_ {ik} (신규) \ : = \ : w_ {ik} (이전) \ : + \ : \ alpha (-1 \ :-\ : Q_ {ink}) x_ {i} $$
$$ b_ {k} (신규) \ : = \ : b_ {k} (이전) \ : + \ : \ alpha (-1 \ :-\ : Q_ {ink}) $$
이 경우 가중치는 다음에 업데이트됩니다. Qk 순 입력이 양수인 경우 t = -1.
여기 ‘y’ 실제 출력이고 ‘t’ 원하는 / 대상 출력입니다.
Case 3 − 만약 y = t 그때
가중치에는 변화가 없습니다.
Step 8 − 체중 변화가 없거나 훈련 중 발생한 가장 높은 체중 변화가 지정된 허용 오차보다 작을 때 발생하는 중지 조건을 테스트합니다.
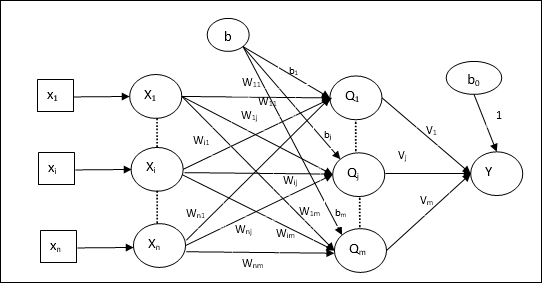
역 전파 신경망
역 전파 신경 (BPN)은 입력 계층, 하나 이상의 은닉 계층 및 출력 계층으로 구성된 다 계층 신경망입니다. 이름에서 알 수 있듯이이 네트워크에서 역 전파가 발생합니다. 대상 출력과 실제 출력을 비교하여 출력 레이어에서 계산 된 오류는 입력 레이어로 다시 전파됩니다.
건축물
다이어그램에서 볼 수 있듯이 BPN의 아키텍처에는 가중치가있는 3 개의 상호 연결된 계층이 있습니다. 히든 레이어와 출력 레이어에도 가중치가 항상 1 인 편향이 있습니다. 다이어그램에서 알 수 있듯이 BPN의 작동은 두 단계로 이루어집니다. 한 위상은 입력 레이어에서 출력 레이어로 신호를 보내고 다른 위상은 출력 레이어에서 입력 레이어로 오류를 다시 전파합니다.

훈련 알고리즘
훈련을 위해 BPN은 이진 시그 모이 드 활성화 함수를 사용합니다. BPN 교육은 다음 세 단계로 구성됩니다.
Phase 1 − 피드 포워드 단계
Phase 2 − 오류의 역 전파
Phase 3 − 가중치 업데이트
이 모든 단계는 다음과 같이 알고리즘에서 마무리됩니다.
Step 1 − 교육을 시작하려면 다음을 초기화하세요 −
- Weights
- 학습률 $ \ alpha $
쉬운 계산과 단순성을 위해 작은 임의 값을 취하십시오.
Step 2 − 중지 조건이 참이 아닌 경우 3-11 단계를 계속합니다.
Step 3 − 모든 훈련 쌍에 대해 4-10 단계를 계속합니다.
1 단계
Step 4 − 각 입력 장치는 입력 신호를받습니다. xi 모두를 위해 숨겨진 유닛으로 보냅니다. i = 1 to n
Step 5 − 다음 관계식을 사용하여 은닉 유닛에서 순 입력을 계산합니다 −
$$ Q_ {inj} \ : = \ : b_ {0j} \ : + \ : \ sum_ {i = 1} ^ n x_ {i} v_ {ij} \ : \ : \ : \ : j \ : = \ : 1 \ : to \ : p $$
여기 b0j 은닉 유닛에 대한 편향입니다. vij 무게입니다 j 숨겨진 레이어의 단위 i 입력 레이어의 단위.
이제 다음 활성화 함수를 적용하여 순 출력을 계산하십시오.
$$ Q_ {j} \ : = \ : f (Q_ {inj}) $$
히든 레이어 유닛의 이러한 출력 신호를 출력 레이어 유닛으로 보냅니다.
Step 6 − 다음 관계식을 사용하여 출력 레이어 단위에서 순 입력을 계산합니다. −
$$ y_ {잉크} \ : = \ : b_ {0k} \ : + \ : \ sum_ {j = 1} ^ p \ : Q_ {j} \ : w_ {jk} \ : \ : k \ : = \ : 1 \ : to \ : m $$
여기 b0k 는 출력 장치의 바이어스입니다. wjk 무게입니다 k 출력 레이어의 단위 j 숨겨진 레이어의 단위.
다음 활성화 함수를 적용하여 순 출력을 계산합니다.
$$ y_ {k} \ : = \ : f (y_ {잉크}) $$
2 단계
Step 7 − 다음과 같이 각 출력 장치에서 수신 한 대상 패턴에 따라 오류 정정 항을 계산합니다.
$$ \ delta_ {k} \ : = \ :( t_ {k} \ :-\ : y_ {k}) f ^ { '} (y_ {ink}) $$
이를 바탕으로 가중치와 편향을 다음과 같이 업데이트합니다.
$$ \ 델타 v_ {jk} \ : = \ : \ alpha \ delta_ {k} \ : Q_ {ij} $$
$$ \ 델타 b_ {0k} \ : = \ : \ alpha \ delta_ {k} $$
그런 다음 $ \ delta_ {k} $를 히든 레이어로 다시 보냅니다.
Step 8 − 이제 각 은닉 유닛은 출력 유닛의 델타 입력의 합이됩니다.
$$ \ delta_ {inj} \ : = \ : \ displaystyle \ sum \ limits_ {k = 1} ^ m \ delta_ {k} \ : w_ {jk} $$
오류 항은 다음과 같이 계산할 수 있습니다.
$$ \ delta_ {j} \ : = \ : \ delta_ {inj} f ^ { '} (Q_ {inj}) $$
이를 바탕으로 가중치와 편향을 다음과 같이 업데이트합니다.
$$ \ 델타 w_ {ij} \ : = \ : \ alpha \ delta_ {j} x_ {i} $$
$$ \ 델타 b_ {0j} \ : = \ : \ alpha \ delta_ {j} $$
3 단계
Step 9 − 각 출력 유닛 (ykk = 1 to m) 다음과 같이 가중치와 편향을 업데이트합니다.
$$ v_ {jk} (신규) \ : = \ : v_ {jk} (이전) \ : + \ : \ Delta v_ {jk} $$
$$ b_ {0k} (신규) \ : = \ : b_ {0k} (이전) \ : + \ : \ Delta b_ {0k} $$
Step 10 − 각 출력 유닛 (zjj = 1 to p) 다음과 같이 가중치와 편향을 업데이트합니다.
$$ w_ {ij} (신규) \ : = \ : w_ {ij} (이전) \ : + \ : \ Delta w_ {ij} $$
$$ b_ {0j} (신규) \ : = \ : b_ {0j} (이전) \ : + \ : \ Delta b_ {0j} $$
Step 11 − 정지 조건을 확인합니다. 이는 도달 한 Epoch 수이거나 목표 출력이 실제 출력과 일치 할 수 있습니다.
일반화 된 델타 학습 규칙
델타 규칙은 출력 레이어에 대해서만 작동합니다. 반면에 일반화 된 델타 규칙은 다음과 같습니다.back-propagation 규칙은 숨겨진 레이어의 원하는 값을 만드는 방법입니다.
수학적 공식화
활성화 함수 $ y_ {k} \ : = \ : f (y_ {ink}) $의 경우 히든 레이어와 출력 레이어에 대한 순 입력의 유도는 다음과 같이 주어질 수 있습니다.
$$ y_ {잉크} \ : = \ : \ displaystyle \ sum \ limits_i \ : z_ {i} w_ {jk} $$
그리고 $ \ : \ : y_ {inj} \ : = \ : \ sum_i x_ {i} v_ {ij} $
이제 최소화해야 할 오류는
$$ E \ : = \ : \ frac {1} {2} \ displaystyle \ sum \ limits_ {k} \ : [t_ {k} \ :-\ : y_ {k}] ^ 2 $$
체인 규칙을 사용하여
$$ \ frac {\ partial E} {\ partial w_ {jk}} \ : = \ : \ frac {\ partial} {\ partial w_ {jk}} (\ frac {1} {2} \ displaystyle \ sum \ 한계 _ {k} \ : [t_ {k} \ :-\ : y_ {k}] ^ 2) $$
$$ = \ : \ frac {\ partial} {\ partial w_ {jk}} \ lgroup \ frac {1} {2} [t_ {k} \ :-\ : t (y_ {ink})] ^ 2 \ rgroup $$
$$ = \ :-[t_ {k} \ :-\ : y_ {k}] \ frac {\ partial} {\ partial w_ {jk}} f (y_ {ink}) $$
$$ = \ :-[t_ {k} \ :-\ : y_ {k}] f (y_ {ink}) \ frac {\ partial} {\ partial w_ {jk}} (y_ {ink}) $$
$$ = \ :-[t_ {k} \ :-\ : y_ {k}] f ^ { '} (y_ {ink}) z_ {j} $$
이제 $ \ delta_ {k} \ : = \ :-[t_ {k} \ :-\ : y_ {k}] f ^ { '} (y_ {ink}) $라고 말하겠습니다.
은닉 유닛 연결에 대한 가중치 zj 다음과 같이 주어질 수 있습니다-
$$ \ frac {\ partial E} {\ partial v_ {ij}} \ : = \ :-\ displaystyle \ sum \ limits_ {k} \ delta_ {k} \ frac {\ partial} {\ partial v_ {ij} } \ :( y_ {잉크}) $$
$ y_ {ink} $의 가치를 입력하면 다음과 같은 결과를 얻을 수 있습니다.
$$ \ delta_ {j} \ : = \ :-\ displaystyle \ sum \ limits_ {k} \ delta_ {k} w_ {jk} f ^ { '} (z_ {inj}) $$
가중치 업데이트는 다음과 같이 수행 할 수 있습니다.
출력 장치의 경우-
$$ \ 델타 w_ {jk} \ : = \ :-\ alpha \ frac {\ partial E} {\ partial w_ {jk}} $$
$$ = \ : \ alpha \ : \ delta_ {k} \ : z_ {j} $$
숨겨진 유닛을 위해-
$$ \ 델타 v_ {ij} \ : = \ :-\ alpha \ frac {\ partial E} {\ partial v_ {ij}} $$
$$ = \ : \ alpha \ : \ delta_ {j} \ : x_ {i} $$
이름에서 알 수 있듯이 이러한 유형의 학습은 교사의 감독없이 수행됩니다. 이 학습 과정은 독립적입니다. 비지도 학습에서 ANN을 훈련하는 동안 유사한 유형의 입력 벡터가 결합되어 클러스터를 형성합니다. 새로운 입력 패턴이 적용되면 신경망은 입력 패턴이 속한 클래스를 나타내는 출력 응답을 제공합니다. 이 경우 원하는 출력이되어야하고 그것이 올바른지 잘못된 것인지에 대한 환경으로부터의 피드백이 없을 것입니다. 따라서 이러한 유형의 학습에서 네트워크 자체는 입력 데이터의 패턴, 특징 및 출력에 대한 입력 데이터의 관계를 발견해야합니다.
Winner-Takes-All 네트워크
이러한 종류의 네트워크는 경쟁 학습 규칙을 기반으로하며 총 입력이 가장 많은 뉴런을 승자로 선택하는 전략을 사용합니다. 출력 뉴런 사이의 연결은 그들 사이의 경쟁을 보여 주며 그들 중 하나는 승자가 될 것이고 다른 하나는 'OFF'임을 의미하는 '켜짐'이 될 것입니다.
다음은 비지도 학습을 사용하는이 간단한 개념에 기반한 네트워크의 일부입니다.
해밍 네트워크
비지도 학습을 사용하는 대부분의 신경망에서는 거리를 계산하고 비교를 수행하는 것이 필수적입니다. 이런 종류의 네트워크는 해밍 네트워크로, 주어진 모든 입력 벡터에 대해 서로 다른 그룹으로 클러스터링됩니다. 다음은 Hamming Networks의 몇 가지 중요한 기능입니다.
Lippmann은 1987 년에 Hamming 네트워크 작업을 시작했습니다.
단일 계층 네트워크입니다.
입력은 양극성 {-1, 1}의 바이너리 {0, 1} 일 수 있습니다.
그물의 가중치는 예제 벡터로 계산됩니다.
고정 된 가중치 네트워크로 훈련 중에도 가중치가 동일하게 유지됩니다.
최대 순
이것은 또한 가장 높은 입력을 갖는 노드를 선택하기위한 서브넷 역할을하는 고정 가중치 네트워크입니다. 모든 노드는 완전히 상호 연결되어 있으며 이러한 모든 가중치 상호 연결에는 대칭 가중치가 있습니다.
건축물
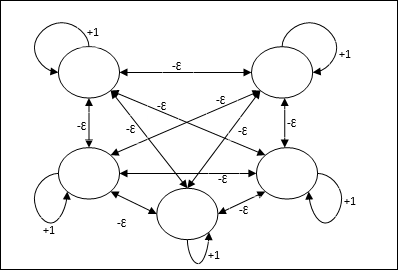
반복 프로세스 인 메커니즘을 사용하며 각 노드는 연결을 통해 다른 모든 노드로부터 금지 입력을받습니다. 값이 최대 인 단일 노드는 활성 또는 승자가되고 다른 모든 노드의 활성화는 비활성화됩니다. Max Net은 $$ f (x) \ : = \ : \ begin {cases} x & if \ : x> 0 \\ 0 & if \ : x \ leq 0 \ end {cases} $$와 함께 ID 활성화 기능을 사용합니다.
이 네트의 작업은 +1의 자기 여기 가중치와 상호 억제 크기에 의해 수행되며, [0 <ɛ <$ \ frac {1} {m} $]와 같이 설정됩니다. “m” 총 노드 수입니다.
ANN의 경쟁 학습
출력 노드가 입력 패턴을 나타 내기 위해 서로 경쟁하려고하는 비지도 학습과 관련이 있습니다. 이 학습 규칙을 이해하려면 다음과 같이 설명되는 경쟁 망을 이해해야합니다.
경쟁 네트워크의 기본 개념
이 네트워크는 출력간에 피드백 연결이있는 단일 레이어 피드 포워드 네트워크와 같습니다. 출력 간의 연결은 금지 유형이며 점선으로 표시되어 경쟁자가 스스로를 지원하지 않음을 의미합니다.
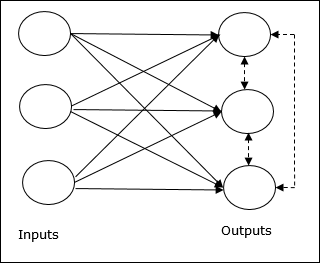
경쟁 학습 규칙의 기본 개념
앞서 말했듯이 출력 노드간에 경쟁이있을 것이므로 기본 개념은-훈련 중에 주어진 입력 패턴에 대해 가장 높은 활성화를 가진 출력 단위가 승자로 선언된다는 것입니다. 이 규칙을 Winner-takes-all이라고도합니다. 우승 한 뉴런 만 업데이트되고 나머지 뉴런은 변경되지 않기 때문입니다.
수학적 공식화
다음은이 학습 규칙의 수학적 공식화에 대한 세 가지 중요한 요소입니다.
승자가되기위한 조건
뉴런이 yk 승자가 되고자한다면 다음과 같은 조건이있을 것입니다.
$$ y_ {k} \ : = \ : \ begin {cases} 1 & if \ : v_ {k}> v_ {j} \ : for \ : all \ : \ : j, \ : j \ : \ neq \ : k \\ 0 및 기타 \ end {cases} $$
뉴런이 있다면 yk 이기기를 원하면 유도 된 로컬 필드 (합산 단위의 출력), vk는 네트워크의 다른 모든 뉴런 중에서 가장 커야합니다.
합계 중량의 상태
경쟁 학습 규칙에 대한 또 다른 제약은 특정 출력 뉴런에 대한 가중치의 합계가 1이되는 것입니다. 예를 들어, 뉴런을 고려한다면 k 그때
$$ \ displaystyle \ sum \ limits_ {k} w_ {kj} \ : = \ : 1 \ : \ : \ : \ : for \ : all \ : \ : k $$
승자의 체중 변경
뉴런이 입력 패턴에 응답하지 않으면 해당 뉴런에서 학습이 이루어지지 않습니다. 그러나 특정 뉴런이 이기면 해당 가중치가 다음과 같이 조정됩니다.
$$ \ 델타 w_ {kj} \ : = \ : \ begin {cases}-\ alpha (x_ {j} \ :-\ : w_ {kj}), & if \ : neuron \ : k \ : wins \\ 0 & if \ : neuron \ : k \ : losses \ end {cases} $$
여기서 $ \ alpha $는 학습률입니다.
이것은 우리가 무게를 조정하여 승리 한 뉴런을 선호하고 있음을 분명히 보여 주며, 뉴런이 손실되면 그 무게를 재조정 할 필요가 없습니다.
K- 평균 클러스터링 알고리즘
K- 평균은 분할 절차의 개념을 사용하는 가장 널리 사용되는 클러스터링 알고리즘 중 하나입니다. 초기 파티션으로 시작하여 만족스러운 결과를 얻을 때까지 한 클러스터에서 다른 클러스터로 반복적으로 패턴을 이동합니다.
연산
Step 1 − 선택 k초기 중심으로 점. 초기화k 프로토 타입 (w1,…,wk)예를 들어 무작위로 선택한 입력 벡터로 식별 할 수 있습니다.
$$ W_ {j} \ : = \ : i_ {p}, \ : \ : \ : 여기서 \ : j \ : \ in \ lbrace1, ...., k \ rbrace \ : and \ : p \ : \ \ lbrace1, ...., n \ rbrace $$
각 클러스터 Cj 프로토 타입과 연관 wj.
Step 2 − E가 더 이상 감소하지 않거나 클러스터 구성원이 더 이상 변경되지 않을 때까지 3-5 단계를 반복합니다.
Step 3 − 각 입력 벡터에 대해 ip 어디 p ∈ {1,…,n}, 넣어 ip 클러스터에서 Cj* 가장 가까운 프로토 타입 wj* 다음과 같은 관계
$$ | i_ {p} \ :-\ : w_ {j *} | \ : \ leq \ : | i_ {p} \ :-\ : w_ {j} |, \ : j \ : \ in \ lbrace1, ...., k \ rbrace $$
Step 4 − 각 클러스터에 대해 Cj, 어디 j ∈ { 1,…,k}, 프로토 타입 업데이트 wj 현재 모든 샘플의 중심이 Cj , 그래서
$$ w_ {j} \ : = \ : \ sum_ {i_ {p} \ in C_ {j}} \ frac {i_ {p}} {| C_ {j} |} $$
Step 5 − 다음과 같이 총 양자화 오류를 계산합니다 −
$$ E \ : = \ : \ sum_ {j = 1} ^ k \ sum_ {i_ {p} \ in w_ {j}} | i_ {p} \ :-\ : w_ {j} | ^ 2 $$
Neocognitron
1980 년대에 후쿠시마에서 개발 한 다층 피드 포워드 네트워크입니다. 이 모델은지도 학습을 기반으로하며 주로 손으로 쓴 문자 인 시각적 패턴 인식에 사용됩니다. 기본적으로 1975 년 후쿠시마에서 개발 한 Cognitron 네트워크의 확장입니다.
건축물
이것은 많은 계층으로 구성된 계층 적 네트워크이며 해당 계층에는 로컬 연결 패턴이 있습니다.
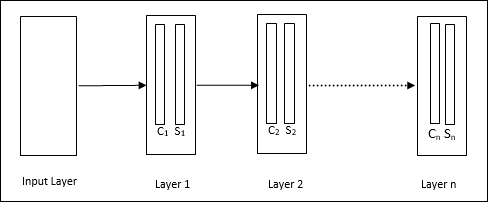
위의 다이어그램에서 보았 듯이 신인 지론은 서로 다른 연결된 계층으로 나뉘며 각 계층에는 두 개의 세포가 있습니다. 이 세포에 대한 설명은 다음과 같습니다.
S-Cell − 특정 패턴 또는 패턴 그룹에 반응하도록 훈련 된 단순 셀이라고합니다.
C-Cell− S- 셀의 출력을 결합하는 동시에 각 배열의 단위 수를 줄이는 복합 셀이라고합니다. 다른 의미에서 C 세포는 S 세포의 결과를 대체합니다.
훈련 알고리즘
신인 지론의 훈련은 단계적으로 진행되는 것으로 밝혀졌습니다. 입력 계층에서 첫 번째 계층까지의 가중치는 훈련되고 고정됩니다. 그런 다음 첫 번째 계층에서 두 번째 계층으로의 가중치가 훈련되는 방식입니다. S-cell과 Ccell 사이의 내부 계산은 이전 레이어의 가중치에 따라 달라집니다. 따라서 훈련 알고리즘은 S 세포와 C 세포에 대한 계산에 의존한다고 말할 수 있습니다.
S- 셀 계산
S 세포는 이전 계층에서받은 흥분성 신호를 소유하고 동일한 계층 내에서 얻은 억제 신호를 보유합니다.
$$ \ theta = \ : \ sqrt {\ sum \ sum t_ {i} c_ {i} ^ 2} $$
여기, ti 고정 된 무게이고 ci C 세포의 출력입니다.
S- 셀의 스케일링 된 입력은 다음과 같이 계산할 수 있습니다.
$$ x \ : = \ : \ frac {1 \ : + \ : e} {1 \ : + \ : vw_ {0}} \ :-\ : 1 $$
여기, $ e \ : = \ : \ sum_i c_ {i} w_ {i} $
wi C- 셀에서 S- 셀로 조정 된 무게입니다.
w0 입력과 S- 셀 사이에서 조정 가능한 무게입니다.
v C 세포의 흥분성 입력입니다.
출력 신호의 활성화는 다음과 같습니다.
$$ s \ : = \ : \ begin {cases} x, & if \ : x \ geq 0 \\ 0, & if \ : x <0 \ end {cases} $$
C 세포의 계산
C 레이어의 순 투입량은
$$ C \ : = \ : \ displaystyle \ sum \ limits_i s_ {i} x_ {i} $$
여기, si S- 셀의 출력이며 xi S- 셀에서 C- 셀까지 고정 된 가중치입니다.
최종 출력은 다음과 같습니다.
$$ C_ {out} \ : = \ : \ begin {cases} \ frac {C} {a + C}, & if \ : C> 0 \\ 0, 그렇지 않으면 \ end {cases} $$
여기 ‘a’ 네트워크 성능에 따라 달라지는 매개 변수입니다.
벡터 양자화 (VQ) 및 코호 넨자가 조직지도 (KSOM)와는 다른 학습 벡터 양자화 (LVQ)는 기본적으로지도 학습을 사용하는 경쟁 네트워크입니다. 각 출력 단위가 클래스를 나타내는 패턴을 분류하는 프로세스로 정의 할 수 있습니다. 지도 학습을 사용하므로 네트워크에는 출력 클래스의 초기 분포와 함께 알려진 분류가있는 일련의 훈련 패턴이 제공됩니다. 훈련 과정을 마친 후 LVQ는 입력 벡터를 출력 유닛과 동일한 클래스에 할당하여 분류합니다.
건축물
다음 그림은 KSOM의 아키텍처와 매우 유사한 LVQ의 아키텍처를 보여줍니다. 우리가 볼 수 있듯이“n” 입력 단위 수 및 “m”출력 단위 수. 레이어는 가중치가있는 상태로 완전히 상호 연결되어 있습니다.

사용 된 매개 변수
다음은 LVQ 훈련 프로세스와 순서도에서 사용되는 매개 변수입니다.
x= 훈련 벡터 (x 1 , ..., x i , ..., x n )
T = 훈련 벡터를위한 클래스 x
wj = 가중치 벡터 jth 출력 유닛
Cj = 관련 클래스 jth 출력 유닛
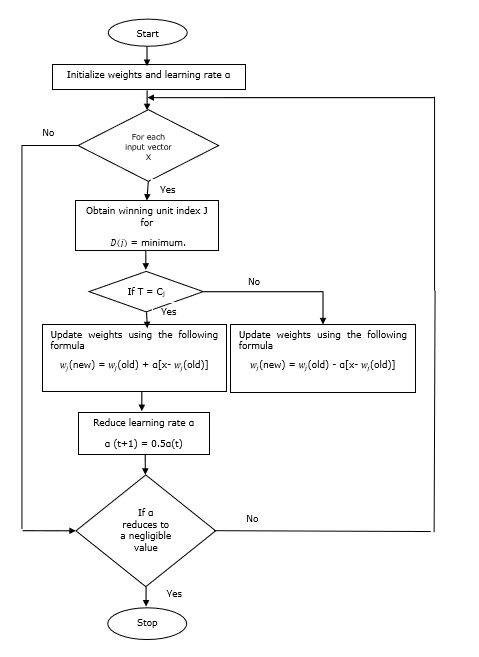
훈련 알고리즘
Step 1 − 다음과 같이 수행 할 수있는 참조 벡터 초기화 −
Step 1(a) − 주어진 훈련 벡터 세트에서 첫 번째 "m”(클러스터 수) 훈련 벡터를 사용하고 가중치 벡터로 사용합니다. 나머지 벡터는 훈련에 사용할 수 있습니다.
Step 1(b) − 초기 가중치와 분류를 무작위로 할당합니다.
Step 1(c) − K- 평균 클러스터링 방법을 적용합니다.
Step 2 − 참조 벡터 $ \ alpha $ 초기화
Step 3 −이 알고리즘을 중지하기위한 조건이 충족되지 않으면 4-9 단계를 계속합니다.
Step 4 − 모든 훈련 입력 벡터에 대해 5-6 단계를 따릅니다. x.
Step 5 −에 대한 유클리드 거리의 제곱 계산 j = 1 to m 과 i = 1 to n
$$ D (j) \ : = \ : \ displaystyle \ sum \ limits_ {i = 1} ^ n \ displaystyle \ sum \ limits_ {j = 1} ^ m (x_ {i} \ :-\ : w_ {ij }) ^ 2 $$
Step 6 − 우승 유닛 획득 J 어디 D(j) 최소입니다.
Step 7 − 다음 관계식으로 우승 한 유닛의 새 가중치를 계산합니다. −
만약 T = Cj 그런 다음 $ w_ {j} (new) \ : = \ : w_ {j} (old) \ : + \ : \ alpha [x \ :-\ : w_ {j} (old)] $
만약 T ≠ Cj $ w_ {j} (new) \ : = \ : w_ {j} (old) \ :-\ : \ alpha [x \ :-\ : w_ {j} (old)] $
Step 8 − 학습률 $ \ alpha $를 줄입니다.
Step 9− 정지 조건을 테스트합니다. 다음과 같을 수 있습니다-
- 최대 Epoch 수에 도달했습니다.
- 학습률이 무시할 수있는 값으로 감소했습니다.
순서도
변형
코호 넨은 LVQ2, LVQ2.1 및 LVQ3의 세 가지 다른 변형을 개발했습니다. 이 세 가지 변형 모두의 복잡성은 승자와 2 위 팀이 배울 개념으로 인해 LVQ보다 더 많습니다.
LVQ2
위에서 언급했듯이 LVQ의 다른 변형의 개념, LVQ2의 조건은 창에 의해 형성됩니다. 이 창은 다음 매개 변수를 기반으로합니다.
x − 현재 입력 벡터
yc − 가장 가까운 참조 벡터 x
yr − 다음으로 가장 가까운 다른 참조 벡터 x
dc − 거리 x ...에 yc
dr − 거리 x ...에 yr
입력 벡터 x 창문에 떨어지면
$$ \ frac {d_ {c}} {d_ {r}} \ :> \ : 1 \ :-\ : \ theta \ : \ : and \ : \ : \ frac {d_ {r}} {d_ {c }} \ :> \ : 1 \ : + \ : \ theta $$
여기서 $ \ theta $는 훈련 샘플의 수입니다.
업데이트는 다음 공식으로 수행 할 수 있습니다.
$ y_ {c} (t \ : + \ : 1) \ : = \ : y_ {c} (t) \ : + \ : \ alpha (t) [x (t) \ :-\ : y_ {c} (t)] $ (belongs to different class)
$ y_ {r} (t \ : + \ : 1) \ : = \ : y_ {r} (t) \ : + \ : \ alpha (t) [x (t) \ :-\ : y_ {r} (t)] $ (belongs to same class)
여기서 $ \ alpha $는 학습률입니다.
LVQ2.1
LVQ2.1에서는 가장 가까운 두 벡터를 사용합니다. yc1 과 yc2 윈도우의 조건은 다음과 같습니다.
$$ Min \ begin {bmatrix} \ frac {d_ {c1}} {d_ {c2}}, \ frac {d_ {c2}} {d_ {c1}} \ end {bmatrix} \ :> \ :( 1 \ :-\ : \ theta) $$
$$ Max \ begin {bmatrix} \ frac {d_ {c1}} {d_ {c2}}, \ frac {d_ {c2}} {d_ {c1}} \ end {bmatrix} \ : <\ :( 1 \ : + \ : \ theta) $$
업데이트는 다음 공식으로 수행 할 수 있습니다.
$ y_ {c1} (t \ : + \ : 1) \ : = \ : y_ {c1} (t) \ : + \ : \ alpha (t) [x (t) \ :-\ : y_ {c1} (t)] $ (belongs to different class)
$ y_ {c2} (t \ : + \ : 1) \ : = \ : y_ {c2} (t) \ : + \ : \ alpha (t) [x (t) \ :-\ : y_ {c2} (t)] $ (belongs to same class)
여기서 $ \ alpha $는 학습률입니다.
LVQ3
LVQ3에서 우리는 두 개의 가장 가까운 벡터 즉 yc1 과 yc2 윈도우의 조건은 다음과 같습니다.
$$ Min \ begin {bmatrix} \ frac {d_ {c1}} {d_ {c2}}, \ frac {d_ {c2}} {d_ {c1}} \ end {bmatrix} \ :> \ :( 1 \ :-\ : \ theta) (1 \ : + \ : \ theta) $$
여기 $ \ theta \ approx 0.2 $
업데이트는 다음 공식으로 수행 할 수 있습니다.
$ y_ {c1} (t \ : + \ : 1) \ : = \ : y_ {c1} (t) \ : + \ : \ beta (t) [x (t) \ :-\ : y_ {c1} (t)] $ (belongs to different class)
$ y_ {c2} (t \ : + \ : 1) \ : = \ : y_ {c2} (t) \ : + \ : \ beta (t) [x (t) \ :-\ : y_ {c2} (t)] $ (belongs to same class)
여기서 $ \ beta $는 학습률 $ \ alpha $의 배수입니다. $\beta\:=\:m \alpha(t)$ 모든 0.1 < m < 0.5
이 네트워크는 1987 년 Stephen Grossberg와 Gail Carpenter가 개발했습니다. 경쟁을 기반으로하고 비지도 학습 모델을 사용합니다. 이름에서 알 수 있듯이 ART (Adaptive Resonance Theory) 네트워크는 이전 패턴 (공명)을 잃지 않고 항상 새로운 학습 (적응)에 개방되어 있습니다. 기본적으로 ART 네트워크는 입력 벡터를 받아들이고 저장된 패턴 중 가장 닮은 패턴에 따라 카테고리 중 하나로 분류하는 벡터 분류기입니다.
운영 원칙
ART 분류의 주요 작업은 다음 단계로 나눌 수 있습니다.
Recognition phase− 입력 벡터는 출력 레이어의 모든 노드에 제시된 분류와 비교됩니다. 뉴런의 출력은 적용된 분류와 가장 일치하면 "1"이되고 그렇지 않으면 "0"이됩니다.
Comparison phase−이 단계에서는 입력 벡터와 비교 계층 벡터를 비교합니다. 재설정 조건은 유사도가 경계 매개 변수보다 적다는 것입니다.
Search phase−이 단계에서 네트워크는 위의 단계에서 수행 된 일치뿐만 아니라 재설정을 검색합니다. 따라서 재설정이없고 경기가 꽤 좋은 경우 분류가 종료됩니다. 그렇지 않으면 프로세스가 반복되고 다른 저장된 패턴이 올바른 일치 항목을 찾기 위해 전송되어야합니다.
ART1
이진 벡터를 클러스터링하도록 설계된 ART 유형입니다. 우리는 그것의 아키텍처로 이것을 이해할 수 있습니다.
ART1의 아키텍처
그것은 다음 두 단위로 구성됩니다-
Computational Unit − 다음으로 구성되어 있습니다 −
Input unit (F1 layer) − 추가로 다음 두 부분이 있습니다 −
F1(a) layer (Input portion)− ART1에서는 입력 벡터 만있는 것이 아니라이 부분에서 처리가 없습니다. F 1 (b) 레이어 (인터페이스 부분)에 연결됩니다.
F1(b) layer (Interface portion)−이 부분은 입력 부분의 신호를 F 2 레이어 의 신호와 결합합니다 . F 1 (b) 레이어는 상향식 가중치를 통해 F 2 레이어에 연결됩니다.bijF 2 레이어는 하향식 가중치를 통해 F 1 (b) 레이어에 연결됩니다.tji.
Cluster Unit (F2 layer)− 이것은 경쟁 계층입니다. 입력 패턴을 학습하기 위해 순 입력이 가장 큰 단위를 선택합니다. 다른 모든 클러스터 장치의 활성화는 0으로 설정됩니다.
Reset Mechanism−이 메커니즘의 작업은 하향식 가중치와 입력 벡터 간의 유사성을 기반으로합니다. 이제이 유사성의 정도가 경계 매개 변수보다 작 으면 클러스터가 패턴을 학습 할 수 없으며 나머지가 발생합니다.
Supplement Unit − 실제로 재설정 메커니즘의 문제는 레이어가 F2특정 조건 하에서 금지되어야하며 학습이 발생할 때도 사용할 수 있어야합니다. 그래서 두 개의 보조 단위 즉,G1 과 G2 리셋 유닛과 함께 추가됩니다. R. 그들 불리는gain control units. 이 장치는 네트워크에있는 다른 장치로 신호를 수신하고 보냅니다.‘+’ 흥분성 신호를 나타내는 반면 ‘−’ 억제 신호를 나타냅니다.
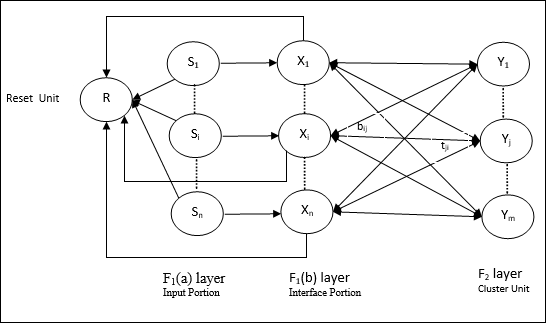
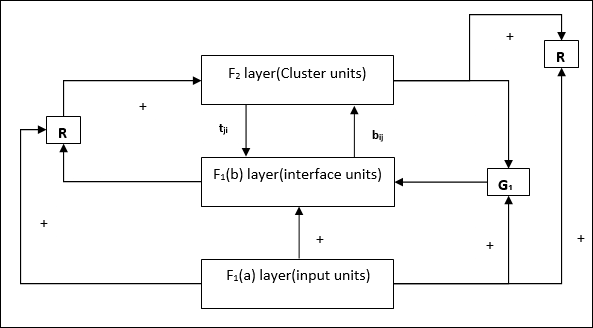
사용 된 매개 변수
다음 매개 변수가 사용됩니다-
n − 입력 벡터의 성분 수
m − 형성 할 수있는 최대 클러스터 수
bij− F 1 (b)에서 F 2 레이어까지의 가중치, 즉 상향식 가중치
tji− F 2 에서 F 1 (b) 레이어까지의 가중치, 즉 하향식 가중치
ρ − 경계 매개 변수
||x|| − 벡터 x의 놈
연산
Step 1 − 다음과 같이 학습률, 경계 매개 변수 및 가중치를 초기화합니다.
$$ \ alpha \ :> \ : 1 \ : \ : and \ : \ : 0 \ : <\ rho \ : \ leq \ : 1 $$
$$ 0 \ : <\ : b_ {ij} (0) \ : <\ : \ frac {\ alpha} {\ alpha \ :-\ : 1 \ : + \ : n} \ : \ : and \ : \ : t_ {ij} (0) \ : = \ : 1 $$
Step 2 − 중지 조건이 참이 아닌 경우 3-9 단계를 계속합니다.
Step 3 − 모든 교육 입력에 대해 4-6 단계를 계속합니다.
Step 4− 다음과 같이 모든 F 1 (a) 및 F 1 장치의 활성화를 설정 합니다.
F2 = 0 and F1(a) = input vectors
Step 5− F 1 (a)에서 F 1 (b) 레이어 까지의 입력 신호 는 다음과 같이 전송되어야합니다.
$$ s_ {i} \ : = \ : x_ {i} $$
Step 6− 모든 금지 된 F 2 노드에 대해
$ y_ {j} \ : = \ : \ sum_i b_ {ij} x_ {i} $ 조건은 yj ≠ -1
Step 7 − 재설정이 참이면 8-10 단계를 수행합니다.
Step 8 − 찾기 J ...에 대한 yJ ≥ yj 모든 노드 j
Step 9− F 1 (b) 에 대한 활성화를 다시 다음과 같이 계산 합니다.
$$ x_ {i} \ : = \ : sitJi $$
Step 10 − 이제 벡터의 노름을 계산 한 후 x 및 벡터 s, 다음과 같이 리셋 조건을 확인해야합니다.
만약 ||x||/ ||s|| <경계 매개 변수 ρ, theninhibit node J 7 단계로 이동
Else If ||x||/ ||s|| ≥ 경계 매개 변수 ρ을 누른 다음 계속 진행하십시오.
Step 11 − 노드에 대한 가중치 업데이트 J 다음과 같이 할 수 있습니다-
$$ b_ {ij} (신규) \ : = \ : \ frac {\ alpha x_ {i}} {\ alpha \ :-\ : 1 \ : + \ : || x ||} $$
$$ t_ {ij} (신규) \ : = \ : x_ {i} $$
Step 12 − 알고리즘의 정지 조건을 확인해야하며 다음과 같을 수 있습니다 −
- 체중 변화가 없습니다.
- 장치에 대해서는 재설정이 수행되지 않습니다.
- 최대 Epoch 수에 도달했습니다.
임의의 차원 패턴이 있지만 1 차원 또는 2 차원에서 필요하다고 가정합니다. 그러면 기능 매핑 프로세스는 넓은 패턴 공간을 일반적인 기능 공간으로 변환하는 데 매우 유용합니다. 자, 왜 우리는 자기 조직화 기능 맵이 필요한가? 그 이유는 임의의 차원을 1-D 또는 2-D로 변환하는 기능과 함께 인접 토폴로지를 보존하는 기능도 가져야하기 때문입니다.
Kohonen SOM의 인접 토폴로지
다양한 토폴로지가있을 수 있지만 다음 두 토폴로지가 가장 많이 사용됩니다.
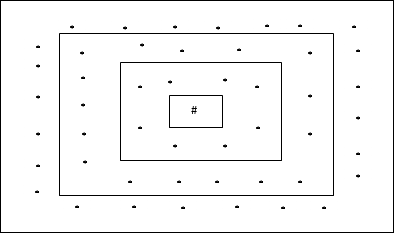
직사각형 그리드 토폴로지
이 토폴로지에는 distance-2 그리드에 24 개 노드, distance-1 그리드에 16 개 노드, distance-0 그리드에 8 개 노드가 있습니다. 즉, 각 직사각형 그리드 간의 차이는 8 개 노드입니다. 우승 한 단위는 #으로 표시됩니다.
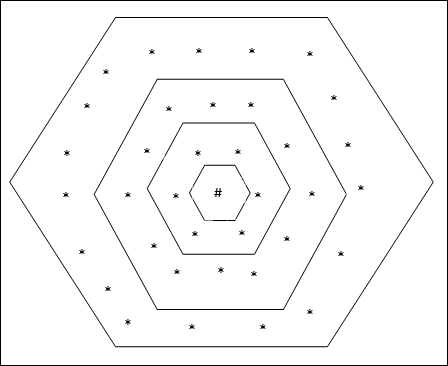
육각 그리드 토폴로지
이 토폴로지에는 distance-2 그리드에 18 개 노드, distance-1 그리드에 12 개 노드, distance-0 그리드에 6 개 노드가 있습니다. 즉, 각 직사각형 그리드 간의 차이는 6 개 노드입니다. 우승 한 단위는 #으로 표시됩니다.
건축물
KSOM의 아키텍처는 경쟁 네트워크의 아키텍처와 유사합니다. 앞에서 논의한 이웃 계획의 도움으로 교육은 네트워크의 확장 된 영역에서 수행 될 수 있습니다.
훈련을위한 알고리즘
Step 1 − 가중치, 학습률 초기화 α 그리고 이웃 토폴로지 체계.
Step 2 − 중지 조건이 참이 아닌 경우 3-9 단계를 계속합니다.
Step 3 − 모든 입력 벡터에 대해 4-6 단계를 계속합니다. x.
Step 4 −에 대한 유클리드 거리의 제곱 계산 j = 1 to m
$$ D (j) \ : = \ : \ displaystyle \ sum \ limits_ {i = 1} ^ n \ displaystyle \ sum \ limits_ {j = 1} ^ m (x_ {i} \ :-\ : w_ {ij }) ^ 2 $$
Step 5 − 우승 유닛 획득 J 어디 D(j) 최소입니다.
Step 6 − 다음 관계식으로 우승 한 유닛의 새 가중치를 계산합니다. −
$$ w_ {ij} (신규) \ : = \ : w_ {ij} (이전) \ : + \ : \ alpha [x_ {i} \ :-\ : w_ {ij} (이전)] $$
Step 7 − 학습률 업데이트 α 다음 관계에 의해-
$$ \ alpha (t \ : + \ : 1) \ : = \ : 0.5 \ alpha t $$
Step 8 − 토폴로지 구조의 반경을 줄입니다.
Step 9 − 네트워크의 정지 상태를 확인하십시오.
이러한 종류의 신경망은 패턴 연관을 기반으로 작동합니다. 즉, 서로 다른 패턴을 저장할 수 있으며 출력을 제공 할 때 지정된 입력 패턴과 일치시켜 저장된 패턴 중 하나를 생성 할 수 있습니다. 이러한 유형의 기억은Content-Addressable Memory(캠). 연관 메모리는 저장된 패턴을 데이터 파일로 사용하여 병렬 검색을 수행합니다.
다음은 우리가 관찰 할 수있는 두 가지 유형의 연관 기억입니다.
- 자동 연관 메모리
- 이종 연관 메모리
자동 연관 메모리
이것은 입력 훈련 벡터와 출력 대상 벡터가 동일한 단일 계층 신경망입니다. 가중치는 네트워크가 패턴 세트를 저장하도록 결정됩니다.
건축물
다음 그림과 같이 Auto Associative 메모리 네트워크의 아키텍처는 ‘n’ 입력 훈련 벡터 및 유사한 수 ‘n’ 출력 대상 벡터의 수.
훈련 알고리즘
훈련을 위해이 네트워크는 Hebb 또는 Delta 학습 규칙을 사용합니다.
Step 1 − 다음과 같이 모든 가중치를 0으로 초기화합니다. wij = 0 (i = 1 to n, j = 1 to n)
Step 2 − 각 입력 벡터에 대해 3-4 단계를 수행합니다.
Step 3 − 다음과 같이 각 입력 장치를 활성화합니다 −
$$ x_ {i} \ : = \ : s_ {i} \ :( i \ : = \ : 1 \ : to \ : n) $$
Step 4 − 다음과 같이 각 출력 장치를 활성화합니다 −
$$ y_ {j} \ : = \ : s_ {j} \ :( j \ : = \ : 1 \ : to \ : n) $$
Step 5 − 다음과 같이 가중치를 조정합니다 −
$$ w_ {ij} (신규) \ : = \ : w_ {ij} (이전) \ : + \ : x_ {i} y_ {j} $$
테스트 알고리즘
Step 1 − Hebb의 규칙에 대해 훈련 중에 얻은 가중치를 설정합니다.
Step 2 − 각 입력 벡터에 대해 3-5 단계를 수행합니다.
Step 3 − 입력 벡터의 활성화와 동일하게 입력 단위의 활성화를 설정합니다.
Step 4 − 각 출력 장치에 대한 순 입력 계산 j = 1 to n
$$ y_ {inj} \ : = \ : \ displaystyle \ sum \ limits_ {i = 1} ^ n x_ {i} w_ {ij} $$
Step 5 − 다음 활성화 함수를 적용하여 출력을 계산합니다.
$$ y_ {j} \ : = \ : f (y_ {inj}) \ : = \ : \ begin {cases} +1 & if \ : y_ {inj} \ :> \ : 0 \\-1 & if \ : y_ {inj} \ : \ leqslant \ : 0 \ end {cases} $$
이종 연관 메모리
Auto Associative Memory 네트워크와 유사하게 이것은 단일 레이어 신경망이기도합니다. 그러나이 네트워크에서 입력 훈련 벡터와 출력 대상 벡터는 동일하지 않습니다. 가중치는 네트워크가 패턴 세트를 저장하도록 결정됩니다. 이종 연관 네트워크는 본질적으로 정적이므로 비선형 및 지연 작업이 없습니다.
건축물
다음 그림과 같이 Hetero Associative Memory 네트워크의 아키텍처는 ‘n’ 입력 훈련 벡터 수 및 ‘m’ 출력 대상 벡터의 수.
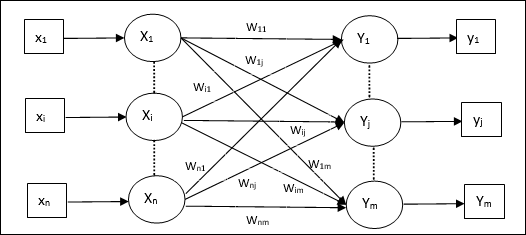
훈련 알고리즘
훈련을 위해이 네트워크는 Hebb 또는 Delta 학습 규칙을 사용합니다.
Step 1 − 다음과 같이 모든 가중치를 0으로 초기화합니다. wij = 0 (i = 1 to n, j = 1 to m)
Step 2 − 각 입력 벡터에 대해 3-4 단계를 수행합니다.
Step 3 − 다음과 같이 각 입력 장치를 활성화합니다 −
$$ x_ {i} \ : = \ : s_ {i} \ :( i \ : = \ : 1 \ : to \ : n) $$
Step 4 − 다음과 같이 각 출력 장치를 활성화합니다 −
$$ y_ {j} \ : = \ : s_ {j} \ :( j \ : = \ : 1 \ : to \ : m) $$
Step 5 − 다음과 같이 가중치를 조정합니다 −
$$ w_ {ij} (신규) \ : = \ : w_ {ij} (이전) \ : + \ : x_ {i} y_ {j} $$
테스트 알고리즘
Step 1 − Hebb의 규칙에 대해 훈련 중에 얻은 가중치를 설정합니다.
Step 2 − 각 입력 벡터에 대해 3-5 단계를 수행합니다.
Step 3 − 입력 벡터의 활성화와 동일하게 입력 단위의 활성화를 설정합니다.
Step 4 − 각 출력 장치에 대한 순 입력 계산 j = 1 to m;
$$ y_ {inj} \ : = \ : \ displaystyle \ sum \ limits_ {i = 1} ^ n x_ {i} w_ {ij} $$
Step 5 − 다음 활성화 함수를 적용하여 출력을 계산합니다.
$$ y_ {j} \ : = \ : f (y_ {inj}) \ : = \ : \ begin {cases} +1 & if \ : y_ {inj} \ :> \ : 0 \\ 0 & if \ : y_ {inj} \ : = \ : 0 \\-1 & if \ : y_ {inj} \ : <\ : 0 \ end {cases} $$
Hopfield 신경망은 1982 년 John J. Hopfield 박사에 의해 발명되었습니다. 이것은 하나 이상의 완전히 연결된 반복 뉴런을 포함하는 단일 계층으로 구성됩니다. Hopfield 네트워크는 일반적으로 자동 연결 및 최적화 작업에 사용됩니다.
이산 홉 필드 네트워크
이산 라인 방식 또는 즉, 입력 및 출력 패턴이 이산 벡터라고 말할 수있는 Hopfield 네트워크는 본질적으로 이진 (0,1) 또는 양극 (+1, -1) 일 수 있습니다. 네트워크에는 자체 연결이없는 대칭 가중치가 있습니다.wij = wji 과 wii = 0.
건축물
다음은 이산 Hopfield 네트워크에 대해 염두에 두어야 할 몇 가지 중요한 사항입니다.
이 모델은 하나의 반전 출력과 하나의 비 반전 출력이있는 뉴런으로 구성됩니다.
각 뉴런의 출력은 다른 뉴런의 입력이어야하지만 self의 입력이 아니어야합니다.
무게 / 연결 강도는 다음과 같이 표시됩니다. wij.
연결은 자극적 일뿐만 아니라 억제적일 수 있습니다. 뉴런의 출력이 입력과 같으면 흥분하고 그렇지 않으면 억제합니다.
가중치는 대칭이어야합니다. 즉 wij = wji
출력 Y1 가는 Y2, Yi 과 Yn 무게가있다 w12, w1i 과 w1n각기. 마찬가지로, 다른 호에는 가중치가 있습니다.
훈련 알고리즘
이산 Hopfield 네트워크를 훈련하는 동안 가중치가 업데이트됩니다. 우리가 알고 있듯이 이진 입력 벡터와 양극 입력 벡터를 가질 수 있습니다. 따라서 두 경우 모두 다음 관계식으로 가중치 업데이트를 수행 할 수 있습니다.
Case 1 − 이진 입력 패턴
바이너리 패턴 세트의 경우 s(p), p = 1 to P
여기, s(p) = s1(p), s2(p),..., si(p),..., sn(p)
가중치 매트릭스는 다음과 같이 제공됩니다.
$$ w_ {ij} \ : = \ : \ sum_ {p = 1} ^ P [2s_ {i} (p)-\ : 1] [2s_ {j} (p)-\ : 1] \ : \ : \ : \ : \ : for \ : i \ : \ neq \ : j $$
Case 2 − 바이폴라 입력 패턴
바이너리 패턴 세트의 경우 s(p), p = 1 to P
여기, s(p) = s1(p), s2(p),..., si(p),..., sn(p)
가중치 매트릭스는 다음과 같이 제공됩니다.
$$ w_ {ij} \ : = \ : \ sum_ {p = 1} ^ P [s_ {i} (p)] [s_ {j} (p)] \ : \ : \ : \ : \ : for \ : i \ : \ neq \ : j $$
테스트 알고리즘
Step 1 − Hebbian 원리를 사용하여 훈련 알고리즘에서 얻은 가중치를 초기화합니다.
Step 2 − 네트워크 활성화가 통합되지 않은 경우 3-9 단계를 수행합니다.
Step 3 − 각 입력 벡터에 대해 X, 4-8 단계를 수행합니다.
Step 4 − 네트워크의 초기 활성화를 외부 입력 벡터와 동일하게 만듭니다. X 다음과 같이-
$$ y_ {i} \ : = \ : x_ {i} \ : \ : \ : for \ : i \ : = \ : 1 \ : to \ : n $$
Step 5 − 각 유닛 Yi, 6-9 단계를 수행합니다.
Step 6 − 다음과 같이 네트워크의 순 입력을 계산합니다 −
$$ y_ {ini} \ : = \ : x_ {i} \ : + \ : \ displaystyle \ sum \ limits_ {j} y_ {j} w_ {ji} $$
Step 7 − 순 입력에 다음과 같이 활성화를 적용하여 출력을 계산합니다. −
$$ y_ {i} \ : = \ begin {cases} 1 & if \ : y_ {ini} \ :> \ : \ theta_ {i} \\ y_ {i} & if \ : y_ {ini} \ : = \ : \ theta_ {i} \\ 0 & if \ : y_ {ini} \ : <\ : \ theta_ {i} \ end {cases} $$
여기서 $ \ theta_ {i} $가 임계 값입니다.
Step 8 −이 출력 브로드 캐스트 yi 다른 모든 단위에.
Step 9 − 연결을 위해 네트워크를 테스트합니다.
에너지 기능 평가
에너지 기능은 결합 된 기능과 시스템 상태의 비 증가 기능으로 정의됩니다.
에너지 기능 Ef, 라고도 함 Lyapunov function 이산 Hopfield 네트워크의 안정성을 결정하며 다음과 같은 특징이 있습니다.
$$ E_ {f} \ : = \ :-\ frac {1} {2} \ displaystyle \ sum \ limits_ {i = 1} ^ n \ displaystyle \ sum \ limits_ {j = 1} ^ n y_ {i} y_ {j} w_ {ij} \ :-\ : \ displaystyle \ sum \ limits_ {i = 1} ^ n x_ {i} y_ {i} \ : + \ : \ displaystyle \ sum \ limits_ {i = 1} ^ n \ theta_ {i} y_ {i} $$
Condition − 안정적인 네트워크에서는 노드의 상태가 변할 때마다 위의 에너지 기능이 감소합니다.
노드가 i 상태를 $ y_i ^ {(k)} $에서 $ y_i ^ {(k \ : + \ : 1)} $로 변경 한 다음 에너지 변화 $ \ Delta E_ {f} $는 다음 관계식으로 제공됩니다.
$$ \ 델타 E_ {f} \ : = \ : E_ {f} (y_i ^ {(k + 1)}) \ :-\ : E_ {f} (y_i ^ {(k)}) $$
$$ = \ :-\ left (\ begin {array} {c} \ displaystyle \ sum \ limits_ {j = 1} ^ n w_ {ij} y_i ^ {(k)} \ : + \ : x_ {i} \ :-\ : \ theta_ {i} \ end {array} \ right) (y_i ^ {(k + 1)} \ :-\ : y_i ^ {(k)}) $$
$$ = \ :-\ :( net_ {i}) \ Delta y_ {i} $$
여기 $ \ Delta y_ {i} \ : = \ : y_i ^ {(k \ : + \ : 1)} \ :-\ : y_i ^ {(k)} $
에너지의 변화는 한 번에 하나의 장치 만 활성화를 업데이트 할 수 있다는 사실에 달려 있습니다.
연속 홉 필드 네트워크
Discrete Hopfield 네트워크와 비교하여 연속 네트워크는 연속 변수로 시간이 있습니다. 또한 여행하는 세일즈맨 문제와 같은 자동 연결 및 최적화 문제에도 사용됩니다.
Model − 시그 모이 드 활성화 기능을 통해 입력 전압을 출력 전압에 매핑 할 수있는 증폭기와 같은 전기 부품을 추가하여 모델 또는 아키텍처를 구축 할 수 있습니다.
에너지 기능 평가
$$ E_f = \ frac {1} {2} \ displaystyle \ sum \ limits_ {i = 1} ^ n \ sum _ {\ substack {j = 1 \\ j \ ne i}} ^ n y_i y_j w_ {ij} -\ displaystyle \ sum \ limits_ {i = 1} ^ n x_i y_i + \ frac {1} {\ lambda} \ displaystyle \ sum \ limits_ {i = 1} ^ n \ sum _ {\ substack {j = 1 \\ j \ ne i}} ^ n w_ {ij} g_ {ri} \ int_ {0} ^ {y_i} a ^ {-1} (y) dy $$
여기 λ 이득 매개 변수이고 gri 입력 전도도.
이는 반복적 인 구조를 갖는 확률 적 학습 프로세스이며 ANN에서 사용되는 초기 최적화 기술의 기초입니다. Boltzmann Machine은 1985 년 Geoffrey Hinton과 Terry Sejnowski에 의해 발명되었습니다. Boltzmann Machine에 대한 Hinton의 말에서 더 명확하게 확인할 수 있습니다.
“이 네트워크의 놀라운 기능은 로컬에서 사용 가능한 정보 만 사용한다는 것입니다. 무게의 변화는 비록 변화가 글로벌 측정을 최적화하더라도 연결하는 두 단위의 행동에만 의존합니다.”-Ackley, Hinton 1985.
Boltzmann Machine에 대한 몇 가지 중요한 사항-
그들은 반복적 인 구조를 사용합니다.
그것들은 확률 론적 뉴런으로 구성되며, 1 또는 0의 두 가지 가능한 상태 중 하나를 가지고 있습니다.
이 뉴런 중 일부는 적응 형 (자유 상태)이고 일부는 고정 (고정 상태)입니다.
이산 Hopfield 네트워크에 시뮬레이션 어닐링을 적용하면 Boltzmann Machine이됩니다.
Boltzmann Machine의 목표
Boltzmann Machine의 주요 목적은 문제 해결을 최적화하는 것입니다. 특정 문제와 관련된 무게와 수량을 최적화하는 것이 Boltzmann Machine의 작업입니다.
건축물
다음 다이어그램은 Boltzmann 기계의 아키텍처를 보여줍니다. 다이어그램을 보면 단위의 2 차원 배열임을 알 수 있습니다. 여기서 장치 간의 상호 연결에 대한 가중치는 다음과 같습니다.–p 어디 p > 0. 자기 연결의 가중치는 다음과 같습니다.b 어디 b > 0.
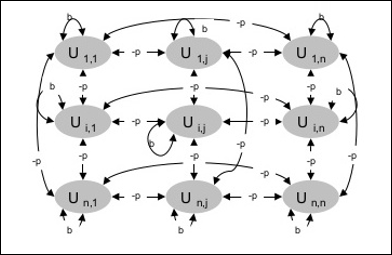
훈련 알고리즘
Boltzmann 기계에는 고정 된 가중치가 있으므로 네트워크에서 가중치를 업데이트 할 필요가 없으므로 훈련 알고리즘이 없습니다. 그러나 네트워크를 테스트하려면 가중치를 설정하고 합의 함수 (CF)를 찾아야합니다.
Boltzmann 기계에는 일련의 단위가 있습니다. Ui 과 Uj 양방향 연결이 있습니다.
우리는 고정 된 무게를 고려하고 있습니다 wij.
wij ≠ 0 만약 Ui 과 Uj 연결되어있다.
가중 상호 연결에도 대칭이 있습니다. wij = wji.
wii 즉, 장치간에 자체 연결이 있습니다.
모든 단위 Ui, 상태 ui 1 또는 0입니다.
Boltzmann Machine의 주요 목적은 다음 관계로 주어질 수있는 합의 함수 (CF)를 극대화하는 것입니다.
$$ CF \ : = \ : \ displaystyle \ sum \ limits_ {i} \ displaystyle \ sum \ limits_ {j \ leqslant i} w_ {ij} u_ {i} u_ {j} $$
이제 상태가 1에서 0으로 또는 0에서 1로 변경되면 합의의 변화는 다음 관계식으로 주어질 수 있습니다.
$$ \ 델타 CF \ : = \ :( 1 \ :-\ : 2u_ {i}) (w_ {ij} \ : + \ : \ displaystyle \ sum \ limits_ {j \ neq i} u_ {i} w_ { ij}) $$
여기 ui 현재 상태 Ui.
계수의 변동 (1 - 2ui)는 다음 관계식으로 주어집니다-
$$ (1 \ :-\ : 2u_ {i}) \ : = \ : \ begin {cases} +1, & U_ {i} \ : is \ : currently \ : off \\-1, & U_ {i } \ : is \ : 현재 \ : on \ end {cases} $$
일반적으로 단위 Ui상태를 변경하지 않지만 변경하면 정보는 해당 장치의 로컬에 상주합니다. 이러한 변화로 인해 네트워크의 합의도 증가 할 것입니다.
네트워크가 장치 상태의 변화를 수용 할 확률은 다음 관계식으로 제공됩니다.
$$ AF (i, T) \ : = \ : \ frac {1} {1 \ : + \ : exp [-\ frac {\ Delta CF (i)} {T}]} $$
여기, T제어 매개 변수입니다. CF가 최대 값에 도달하면 감소합니다.
테스트 알고리즘
Step 1 − 교육을 시작하려면 다음을 초기화하세요 −
- 문제의 제약을 나타내는 가중치
- 제어 매개 변수 T
Step 2 − 중지 조건이 참이 아닌 경우 3-8 단계를 계속합니다.
Step 3 − 4-7 단계를 수행합니다.
Step 4 − 상태 중 하나가 가중치를 변경했다고 가정하고 정수를 선택합니다. I, J 사이의 임의 값으로 1 과 n.
Step 5 − 다음과 같이 합의의 변화를 계산합니다 −
$$ \ 델타 CF \ : = \ :( 1 \ :-\ : 2u_ {i}) (w_ {ij} \ : + \ : \ displaystyle \ sum \ limits_ {j \ neq i} u_ {i} w_ { ij}) $$
Step 6 −이 네트워크가 상태 변화를 받아 들일 확률을 계산합니다.
$$ AF (i, T) \ : = \ : \ frac {1} {1 \ : + \ : exp [-\ frac {\ Delta CF (i)} {T}]} $$
Step 7 − 다음과 같이이 변경 사항을 수락하거나 거부합니다.
Case I − 만약 R < AF, 변경 사항을 수락합니다.
Case II − 만약 R ≥ AF, 변경을 거부합니다.
여기, R 0과 1 사이의 난수입니다.
Step 8 − 다음과 같이 제어 매개 변수 (온도)를 줄입니다.
T(new) = 0.95T(old)
Step 9 − 다음과 같은 정지 조건 테스트 −
- 온도가 지정된 값에 도달
- 지정된 반복 횟수에 대한 상태 변경이 없습니다.
BBS (Brain-State-in-a-Box) 신경망은 비선형 자동 연관 신경망이며 두 개 이상의 계층이있는 이종 연관으로 확장 될 수 있습니다. 또한 Hopfield 네트워크와 유사합니다. 1977 년 JA Anderson, JW Silverstein, SA Ritz 및 RS Jones가 제안했습니다.
BSB 네트워크에 대해 기억해야 할 몇 가지 중요한 사항-
차원에 따라 최대 노드 수로 완전히 연결된 네트워크입니다. n 입력 공간의.
모든 뉴런이 동시에 업데이트됩니다.
뉴런은 -1에서 +1 사이의 값을가집니다.
수학적 공식
BSB 네트워크에서 사용되는 노드 기능은 램프 기능으로 다음과 같이 정의 할 수 있습니다.
$$ f (순) \ : = \ : min (1, \ : max (-1, \ : net)) $$
이 램프 기능은 제한적이고 연속적입니다.
각 노드가 상태를 변경한다는 것을 알고 있으므로 다음과 같은 수학적 관계의 도움으로 수행 할 수 있습니다.
$$ x_ {t} (t \ : + \ : 1) \ : = \ : f \ left (\ begin {array} {c} \ displaystyle \ sum \ limits_ {j = 1} ^ n w_ {i, j } x_ {j} (t) \ end {array} \ right) $$
여기, xi(t) 의 상태입니다 ith 시간에 노드 t.
가중치 ith 노드에 jth 노드는 다음 관계로 측정 할 수 있습니다-
$$ w_ {ij} \ : = \ : \ frac {1} {P} \ displaystyle \ sum \ limits_ {p = 1} ^ P (v_ {p, i} \ : v_ {p, j}) $$
여기, P 양극성 인 훈련 패턴의 수입니다.
최적화는 설계, 상황, 자원 및 시스템과 같은 것을 가능한 한 효과적으로 만드는 조치입니다. 비용 함수와 에너지 함수의 유사점을 사용하여 고도로 상호 연결된 뉴런을 사용하여 최적화 문제를 해결할 수 있습니다. 이러한 종류의 신경망은 하나 이상의 완전히 연결된 반복 뉴런을 포함하는 단일 계층으로 구성된 Hopfield 네트워크입니다. 최적화에 사용할 수 있습니다.
최적화를 위해 Hopfield 네트워크를 사용하는 동안 기억해야 할 사항-
에너지 기능은 네트워크의 최소값이어야합니다.
저장된 패턴 중 하나를 선택하는 대신 만족스러운 솔루션을 찾을 수 있습니다.
Hopfield 네트워크에서 찾은 솔루션의 품질은 네트워크의 초기 상태에 따라 크게 달라집니다.
여행하는 세일즈맨 문제
세일즈맨이 이동 한 최단 경로를 찾는 것은 연산 문제 중 하나이며 Hopfield 신경망을 사용하여 최적화 할 수 있습니다.
TSP의 기본 개념
출장 세일즈맨 문제 (TSP)는 세일즈맨이 출장해야하는 고전적인 최적화 문제입니다. n비용과 이동 거리를 최소화하면서 서로 연결된 도시. 예를 들어, 세일즈맨은 4 개 도시 A, B, C, D를 여행해야하며 목표는 가장 짧은 순환 여행 인 ABC–D를 찾아 비용을 최소화하는 것입니다. 여기에는 여행 비용도 포함됩니다. 마지막 도시 D에서 첫 번째 도시 A까지.
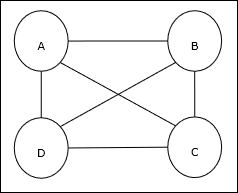
행렬 표현
실제로 n-city TSP의 각 투어는 다음과 같이 표현할 수 있습니다. n × n 매트릭스 ith 행은 ith도시의 위치. 이 매트릭스,M, 4 개 도시의 경우 A, B, C, D는 다음과 같이 표현할 수 있습니다.
$$ M = \ begin {bmatrix} A : & 1 & 0 & 0 & 0 \\ B : & 0 & 1 & 0 & 0 \\ C : & 0 & 0 & 1 & 0 \\ D : & 0 & 0 & 0 & 1 \ end {bmatrix} $$
Hopfield Network의 솔루션
Hopfield 네트워크에서이 TSP의 솔루션을 고려하는 동안 네트워크의 모든 노드는 매트릭스의 한 요소에 해당합니다.
에너지 함수 계산
최적화 된 솔루션이 되려면 에너지 함수가 최소 여야합니다. 다음과 같은 제약을 기반으로 에너지 함수를 다음과 같이 계산할 수 있습니다.
제약 -I
에너지 함수를 계산하는 데 기초한 첫 번째 제약은 행렬의 각 행에서 한 요소가 1과 같아야한다는 것입니다. M 각 행의 다른 요소는 다음과 같아야합니다. 0각 도시는 TSP 투어에서 한 위치에서만 발생할 수 있기 때문입니다. 이 제약은 수학적으로 다음과 같이 작성할 수 있습니다.
$$ \ displaystyle \ sum \ limits_ {j = 1} ^ n M_ {x, j} \ : = \ : 1 \ : for \ : x \ : \ in \ : \ lbrace1, ..., n \ rbrace $ $
이제 최소화 할 에너지 함수는 위의 제약 조건에 따라 다음에 비례하는 항을 포함합니다.
$$ \ displaystyle \ sum \ limits_ {x = 1} ^ n \ left (\ begin {array} {c} 1 \ :-\ : \ displaystyle \ sum \ limits_ {j = 1} ^ n M_ {x, j } \ end {배열} \ right) ^ 2 $$
제약 II
아시다시피, TSP에서 하나의 도시는 여행의 어느 위치에서나 발생할 수 있으므로 행렬의 각 열에서 M, 한 요소는 1과 같아야하고 다른 요소는 0과 같아야합니다.이 제약은 수학적으로 다음과 같이 작성할 수 있습니다.
$$ \ displaystyle \ sum \ limits_ {x = 1} ^ n M_ {x, j} \ : = \ : 1 \ : for \ : j \ : \ in \ : \ lbrace1, ..., n \ rbrace $ $
이제 최소화 할 에너지 함수는 위의 제약 조건에 따라 다음에 비례하는 항을 포함합니다.
$$ \ displaystyle \ sum \ limits_ {j = 1} ^ n \ left (\ begin {array} {c} 1 \ :-\ : \ displaystyle \ sum \ limits_ {x = 1} ^ n M_ {x, j } \ end {배열} \ right) ^ 2 $$
비용 함수 계산
(n × n) 표시 C TSP의 비용 매트릭스를 나타냅니다. n 어디에 n > 0. 다음은 비용 함수를 계산하는 동안 몇 가지 매개 변수입니다.
Cx, y − 비용 매트릭스의 요소는 도시에서 여행하는 비용을 나타냅니다. x ...에 y.
A와 B 요소의 인접성은 다음 관계식으로 표시 할 수 있습니다.
$$ M_ {x, i} \ : = \ : 1 \ : \ : 및 \ : \ : M_ {y, i \ pm 1} \ : = \ : 1 $$
아시다시피 Matrix에서 각 노드의 출력 값은 0 또는 1이 될 수 있으므로 모든 도시 A, B 쌍에 대해 에너지 함수에 다음 항을 추가 할 수 있습니다.
$$ \ displaystyle \ sum \ limits_ {i = 1} ^ n C_ {x, y} M_ {x, i} (M_ {y, i + 1} \ : + \ : M_ {y, i-1}) $$
위의 비용 함수 및 제약 값을 기반으로 최종 에너지 함수 E 다음과 같이 주어질 수 있습니다-
$$ E \ : = \ : \ frac {1} {2} \ displaystyle \ sum \ limits_ {i = 1} ^ n \ displaystyle \ sum \ limits_ {x} \ displaystyle \ sum \ limits_ {y \ neq x} C_ {x, y} M_ {x, i} (M_ {y, i + 1} \ : + \ : M_ {y, i-1}) \ : + $$
$$ \ : \ begin {bmatrix} \ gamma_ {1} \ displaystyle \ sum \ limits_ {x} \ left (\ begin {array} {c} 1 \ :-\ : \ displaystyle \ sum \ limits_ {i} M_ {x, i} \ end {array} \ right) ^ 2 \ : + \ : \ gamma_ {2} \ displaystyle \ sum \ limits_ {i} \ left (\ begin {array} {c} 1 \ :-\ : \ displaystyle \ sum \ limits_ {x} M_ {x, i} \ end {array} \ right) ^ 2 \ end {bmatrix} $$
여기, γ1 과 γ2 두 개의 계량 상수입니다.
반복 경사 하강 법 기법
가장 가파른 하강이라고도하는 경사 하강 법은 함수의 국소 최솟값을 찾기위한 반복 최적화 알고리즘입니다. 기능을 최소화하면서 최소화해야 할 비용이나 오류를 염려합니다 (여행하는 세일즈맨 문제 기억). 다양한 상황에서 유용한 딥 러닝에 광범위하게 사용됩니다. 여기서 기억해야 할 점은 글로벌 최적화가 아니라 로컬 최적화에 관심이 있다는 것입니다.
주요 작업 아이디어
다음 단계를 통해 경사 하강 법의 주요 작업 아이디어를 이해할 수 있습니다.
먼저 솔루션의 초기 추측으로 시작하십시오.
그런 다음 해당 지점에서 함수의 기울기를 가져옵니다.
나중에 그라디언트의 음의 방향으로 솔루션을 단계적으로 진행하여 프로세스를 반복하십시오.
위의 단계를 따르면 알고리즘은 결국 그라디언트가 0 인 곳에서 수렴합니다.
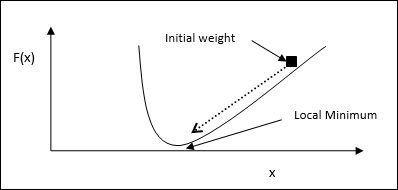
수학적 개념
함수가 있다고 가정 해 보겠습니다. f(x)이 함수의 최소값을 찾으려고합니다. 다음은 최소값을 찾는 단계입니다.f(x).
먼저 초기 값 $ x_ {0} \ : for \ : x $를 지정합니다.
이제 그라디언트가 곡선의 기울기를 제공한다는 직관으로 $ \ nabla f $ of 함수를 사용합니다. x 그리고 그 방향은 함수의 증가를 가리키고 그것을 최소화하는 최선의 방향을 찾습니다.
이제 다음과 같이 x를 변경하십시오-
$$ x_ {n \ : + \ : 1} \ : = \ : x_ {n} \ :-\ : \ theta \ nabla f (x_ {n}) $$
여기, θ > 0 알고리즘이 작은 점프를 수행하도록하는 훈련 속도 (단계 크기)입니다.
단계 크기 추정
실제로 잘못된 단계 크기 θ수렴에 도달하지 못할 수 있으므로 신중하게 선택하는 것이 매우 중요합니다. 스텝 크기를 선택하는 동안 다음 사항을 기억해야합니다.
너무 큰 스텝 크기를 선택하지 마십시오. 그렇지 않으면 부정적인 영향을 미칩니다. 즉, 수렴하지 않고 발산합니다.
너무 작은 단계 크기를 선택하지 마십시오. 그렇지 않으면 수렴하는 데 많은 시간이 걸립니다.
단계 크기 선택에 관한 몇 가지 옵션-
한 가지 옵션은 고정 된 단계 크기를 선택하는 것입니다.
또 다른 옵션은 모든 반복에 대해 다른 단계 크기를 선택하는 것입니다.
시뮬레이션 된 어닐링
시뮬레이션 어닐링 (SA)의 기본 개념은 고체 어닐링에 의해 동기가 부여됩니다. 어닐링 과정에서 금속을 녹는 점 이상으로 가열하고 냉각하면 구조적 특성은 냉각 속도에 따라 달라집니다. SA가 어닐링의 야금 과정을 시뮬레이션한다고 말할 수도 있습니다.
ANN에서 사용
SA는 주어진 함수의 전역 최적화를 근사화하기 위해 Annealing 비유에서 영감을 얻은 확률 적 계산 방법입니다. SA를 사용하여 피드 포워드 신경망을 훈련시킬 수 있습니다.
연산
Step 1 − 랜덤 솔루션을 생성합니다.
Step 2 − 비용 함수를 사용하여 비용을 계산합니다.
Step 3 − 임의의 이웃 솔루션을 생성합니다.
Step 4 − 동일한 비용 함수로 새 솔루션 비용을 계산합니다.
Step 5 − 다음과 같이 새 솔루션의 비용을 기존 솔루션의 비용과 비교합니다.
만약 CostNew Solution < CostOld Solution 그런 다음 새 솔루션으로 이동하십시오.
Step 6 − 최대 반복 횟수에 도달하거나 허용 가능한 솔루션을 얻을 수있는 중지 조건을 테스트합니다.
자연은 항상 모든 인류에게 큰 영감의 원천이었습니다. 유전 알고리즘 (GA)은 자연 선택 및 유전학의 개념을 기반으로하는 검색 기반 알고리즘입니다. GA는 다음과 같이 알려진 훨씬 더 큰 계산 분기의 하위 집합입니다.Evolutionary Computation.
GA는 미시간 대학의 John Holland와 그의 학생 및 동료, 특히 David E. Goldberg에 의해 개발되었으며 이후 다양한 최적화 문제에 대해 높은 수준의 성공을 거두었습니다.
GA에는 주어진 문제에 대한 풀 또는 가능한 솔루션이 있습니다. 그런 다음 이러한 솔루션은 재조합과 돌연변이 (자연 유전학에서와 같이)를 거쳐 새로운 어린이를 생성하며이 과정은 여러 세대에 걸쳐 반복됩니다. 각 개인 (또는 후보 솔루션)에는 (목적 함수 값을 기반으로) 피트니스 값이 할당되고, 피팅 개인에게는 더 많은 "피터"개인을 짝짓기하고 산출 할 수있는 더 높은 기회가 부여됩니다. 이것은“적자 생존”이라는 다윈주의 이론과 일치합니다.
이러한 방식으로, 우리는 중단 기준에 도달 할 때까지 세대에 걸쳐 더 나은 개인이나 솔루션을 "진화"합니다.
유전 알고리즘은 본질적으로 충분히 무작위 화되어 있지만, 역사적 정보도 활용하기 때문에 무작위 로컬 검색 (다양한 무작위 솔루션을 시도하고 지금까지 최고를 추적하는 방식)보다 성능이 훨씬 뛰어납니다.
GA의 장점
GA는 엄청난 인기를 얻은 다양한 장점이 있습니다. 여기에는-
파생 정보가 필요하지 않습니다 (많은 실제 문제에서 사용 가능하지 않을 수 있음).
기존 방법에 비해 더 빠르고 효율적입니다.
매우 우수한 병렬 기능이 있습니다.
연속 및 불연속 기능과 다목적 문제를 모두 최적화합니다.
단일 솔루션이 아닌 "좋은"솔루션 목록을 제공합니다.
항상 문제에 대한 답을 얻습니다.
검색 공간이 매우 크고 관련된 매개 변수가 많을 때 유용합니다.
GA의 한계
다른 기술과 마찬가지로 GA에도 몇 가지 제한 사항이 있습니다. 여기에는-
GA는 모든 문제, 특히 단순하고 파생 정보를 사용할 수있는 문제에 적합하지 않습니다.
피트니스 값은 반복적으로 계산되므로 일부 문제의 경우 계산 비용이 많이들 수 있습니다.
확률론 적이기 때문에 솔루션의 최적 성이나 품질에 대한 보장은 없습니다.
제대로 구현되지 않으면 GA가 최적의 솔루션으로 수렴되지 않을 수 있습니다.
GA – 동기 부여
유전 알고리즘은 "충분한" "충분한"솔루션을 제공 할 수 있습니다. 이것은 최적화 문제를 해결하는 데 사용하기에 가스를 매력적으로 만듭니다. GA가 필요한 이유는 다음과 같습니다.
어려운 문제 해결
컴퓨터 과학에는 많은 문제가 있습니다. NP-Hard. 이것이 본질적으로 의미하는 것은 가장 강력한 컴퓨팅 시스템조차도 그 문제를 해결하는 데 매우 오랜 시간 (심지어 몇 년!)이 걸린다는 것입니다. 이러한 시나리오에서 GA는 다음을 제공하는 효율적인 도구임이 입증되었습니다.usable near-optimal solutions 짧은 시간에.
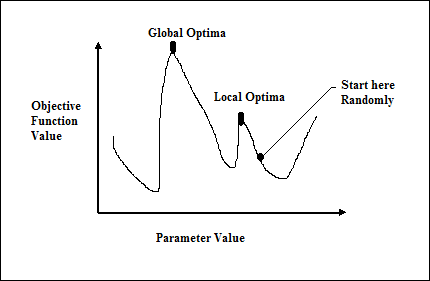
그라디언트 기반 방법의 실패
전통적인 미적분 기반 방법은 임의의 지점에서 시작하여 언덕 꼭대기에 도달 할 때까지 기울기 방향으로 이동하는 방식으로 작동합니다. 이 기술은 효율적이며 선형 회귀의 비용 함수와 같은 단일 피크 목적 함수에 매우 적합합니다. 그러나 대부분의 실제 상황에서는 여러 봉우리와 계곡으로 이루어진 풍경이라는 매우 복잡한 문제가 있습니다. 이러한 방법은 그림과 같이 로컬 옵티마에 고착되는 고유 한 경향으로 인해 실패하기 때문에 실패합니다. 다음 그림에서.
좋은 솔루션을 빠르게 얻기
TSP (Traveling Salesman Problem)와 같은 일부 어려운 문제에는 경로 찾기 및 VLSI 디자인과 같은 실제 응용 프로그램이 있습니다. 이제 GPS 내비게이션 시스템을 사용하고 있으며 소스에서 목적지까지 "최적"경로를 계산하는 데 몇 분 (또는 몇 시간)이 걸린다고 가정 해보십시오. 이러한 실제 응용 프로그램의 지연은 허용되지 않으므로 "빠르게"제공되는 "충분한"솔루션이 필요합니다.
최적화 문제에 GA를 사용하는 방법?
최적화는 설계, 상황, 자원 및 시스템과 같은 것을 가능한 한 효과적으로 만드는 조치라는 것을 이미 알고 있습니다. 최적화 프로세스는 다음 다이어그램에 나와 있습니다.

최적화 프로세스를위한 GA 메커니즘의 단계
다음은 문제 최적화에 사용되는 GA 메커니즘의 단계입니다.
무작위로 초기 모집단을 생성합니다.
최상의 피트니스 값을 가진 초기 솔루션을 선택하십시오.
변형 및 교차 연산자를 사용하여 선택한 솔루션을 다시 결합합니다.
개체군에 자손을 삽입하십시오.
이제 중지 조건이 충족되면 최상의 피트니스 값으로 솔루션을 반환합니다. 그렇지 않으면 2 단계로 이동하십시오.
ANN이 광범위하게 사용 된 분야를 연구하기 전에 ANN이 선호되는 애플리케이션 선택 인 이유를 이해해야합니다.
왜 인공 신경망인가?
우리는 인간의 예를 들어 위의 질문에 대한 답을 이해할 필요가 있습니다. 어렸을 때 우리는 부모님이나 선생님을 포함한 연장자의 도움을 받아 배웠습니다. 그런 다음 나중에 자기 학습이나 연습을 통해 평생 동안 계속 학습합니다. 과학자들과 연구자들은 또한 인간처럼 기계를 지능적으로 만들고 있으며 ANN은 다음과 같은 이유로 동일한 역할을합니다.
신경망의 도움으로 알고리즘 방법이 비싸거나 존재하지 않는 문제에 대한 해결책을 찾을 수 있습니다.
신경망은 예제를 통해 학습 할 수 있으므로 프로그래밍 할 필요가 없습니다.
신경망은 기존 속도보다 정확성과 속도가 상당히 빠릅니다.
적용 분야
다음은 ANN이 사용되는 일부 영역입니다. 이는 ANN이 개발 및 응용 분야에서 학제 간 접근 방식을 가지고 있음을 시사합니다.
음성 인식
음성은 인간과 인간의 상호 작용에서 중요한 역할을합니다. 따라서 사람들이 컴퓨터와 음성 인터페이스를 기대하는 것은 당연합니다. 오늘날에도 기계와의 소통을 위해서는 배우고 사용하기 어려운 정교한 언어가 여전히 필요합니다. 이 통신 장벽을 완화하기 위해 간단한 해결책은 기계가 이해할 수있는 음성 언어로 통신하는 것입니다.
이 분야에서 큰 진전이 있었지만, 이러한 종류의 시스템은 여전히 다른 조건에서 다른 화자를위한 시스템 재교육 문제와 함께 제한된 어휘 또는 문법 문제에 직면 해 있습니다. ANN은이 분야에서 중요한 역할을하고 있습니다. 다음 ANN은 음성 인식에 사용되었습니다.
다층 네트워크
반복 연결이있는 다층 네트워크
Kohonen 자체 구성 기능 맵
이를 위해 가장 유용한 네트워크는 음성 파형의 짧은 세그먼트로 입력되는 Kohonen Self-Organizing 기능 맵입니다. 기능 추출 기술이라고하는 출력 배열과 동일한 종류의 음소를 매핑합니다. 기능을 추출한 후 일부 음향 모델의 도움으로 백엔드 처리로 발화를 인식합니다.
문자 인식
패턴 인식의 일반적인 영역에 속하는 흥미로운 문제입니다. 필기체 문자 (글자 또는 숫자)의 자동 인식을 위해 많은 신경망이 개발되었습니다. 다음은 문자 인식에 사용 된 몇 가지 ANN입니다.
- 역 전파 신경망과 같은 다층 신경망.
- Neocognitron
역 전파 신경망에는 여러 개의 숨겨진 계층이 있지만 한 계층에서 다음 계층으로의 연결 패턴은 지역화됩니다. 마찬가지로, neocognitron에는 여러 숨겨진 계층이 있으며 이러한 종류의 응용 프로그램에 대해 계층별로 훈련이 수행됩니다.
서명 확인 신청서
서명은 법적 거래에서 사람을 승인하고 인증하는 가장 유용한 방법 중 하나입니다. 서명 검증 기술은 비전 기반 기술입니다.
이 응용 프로그램의 경우 첫 번째 접근 방식은 특성 또는 서명을 나타내는 기하학적 특성 집합을 추출하는 것입니다. 이러한 기능 세트를 사용하여 효율적인 신경망 알고리즘을 사용하여 신경망을 훈련해야합니다. 이 훈련 된 신경망은 서명을 인증 단계에서 진짜 또는 위조 된 것으로 분류합니다.
인간의 얼굴 인식
주어진 얼굴을 식별하는 생체 인식 방법 중 하나입니다. "비 얼굴"이미지의 특성화로 인해 일반적인 작업입니다. 그러나 신경망이 잘 훈련 된 경우 얼굴이있는 이미지와 얼굴이없는 이미지라는 두 가지 클래스로 나눌 수 있습니다.
먼저 모든 입력 이미지를 전처리해야합니다. 그런 다음 해당 이미지의 차원을 줄여야합니다. 그리고 마침내 신경망 훈련 알고리즘을 사용하여 분류해야합니다. 다음 신경망은 전처리 된 이미지로 훈련 목적으로 사용됩니다-
역 전파 알고리즘의 도움을 받아 훈련 된 완전히 연결된 다층 피드 포워드 신경망.
차원 감소를 위해 PCA (Principal Component Analysis)가 사용됩니다.