DAA - szybki przewodnik
Algorytm to zestaw kroków operacji mających na celu rozwiązanie problemu polegającego na wykonywaniu obliczeń, przetwarzania danych i automatycznych zadań wnioskowania. Algorytm to skuteczna metoda, którą można wyrazić w skończonej ilości czasu i przestrzeni.
Algorytm to najlepszy sposób na przedstawienie rozwiązania konkretnego problemu w bardzo prosty i skuteczny sposób. Jeśli mamy algorytm dla konkretnego problemu, możemy go zaimplementować w dowolnym języku programowania, co oznacza, żealgorithm is independent from any programming languages.
Projektowanie algorytmów
Ważnymi aspektami projektowania algorytmów jest stworzenie wydajnego algorytmu do rozwiązania problemu w efektywny sposób przy minimalnym czasie i przestrzeni.
Aby rozwiązać problem, można zastosować różne podejścia. Niektóre z nich mogą być wydajne pod względem zużycia czasu, podczas gdy inne podejścia mogą być wydajne pod względem pamięci. Należy jednak pamiętać, że nie można jednocześnie optymalizować zużycia czasu i pamięci. Jeśli wymagamy, aby algorytm działał w krótszym czasie, musimy zainwestować w więcej pamięci, a jeśli wymagamy, aby algorytm działał z mniejszą ilością pamięci, potrzebujemy więcej czasu.
Kroki rozwoju problemu
Poniższe kroki obejmują rozwiązywanie problemów obliczeniowych.
- Definicja problemu
- Opracowanie modelu
- Specyfikacja algorytmu
- Projektowanie algorytmu
- Sprawdzanie poprawności algorytmu
- Analiza algorytmu
- Implementacja algorytmu
- Testowanie programu
- Documentation
Charakterystyka algorytmów
Główne cechy algorytmów są następujące -
Algorytmy muszą mieć unikalną nazwę
Algorytmy powinny mieć wyraźnie zdefiniowany zestaw wejść i wyjść
Algorytmy są uporządkowane z jednoznacznymi operacjami
Algorytmy zatrzymują się w skończonym czasie. Algorytmy nie powinny działać w nieskończoność, tj. Algorytm musi w pewnym momencie zakończyć się
Pseudo kod
Pseudokod zapewnia opis algorytmu na wysokim poziomie bez niejednoznaczności związanej ze zwykłym tekstem, ale także bez konieczności znajomości składni konkretnego języka programowania.
Czas działania można oszacować w bardziej ogólny sposób, używając pseudokodu do reprezentowania algorytmu jako zestawu podstawowych operacji, które można następnie policzyć.
Różnica między algorytmem a pseudokodem
Algorytm to formalna definicja z pewnymi określonymi cechami opisująca proces, który może zostać wykonany przez maszynę komputerową wyposażoną w Turinga w celu wykonania określonego zadania. Ogólnie rzecz biorąc, słowo „algorytm” może być użyte do opisania dowolnego zadania wysokiego poziomu w informatyce.
Z drugiej strony pseudokod to nieformalny i (często prymitywny) czytelny dla człowieka opis algorytmu, pozostawiający wiele szczegółowych jego szczegółów. Pisanie pseudokodu nie ma ograniczeń stylowych, a jego jedynym celem jest opisanie kroków algorytmu wysokiego poziomu w bardzo realistyczny sposób w języku naturalnym.
Na przykład poniżej przedstawiono algorytm sortowania przez wstawianie.
Algorithm: Insertion-Sort
Input: A list L of integers of length n
Output: A sorted list L1 containing those integers present in L
Step 1: Keep a sorted list L1 which starts off empty
Step 2: Perform Step 3 for each element in the original list L
Step 3: Insert it into the correct position in the sorted list L1.
Step 4: Return the sorted list
Step 5: StopOto pseudokod, który opisuje, jak wyżej wspomniany abstrakcyjny proces wysokiego poziomu w algorytmie Sortowanie przez wstawianie można opisać w bardziej realistyczny sposób.
for i <- 1 to length(A)
x <- A[i]
j <- i
while j > 0 and A[j-1] > x
A[j] <- A[j-1]
j <- j - 1
A[j] <- xW tym samouczku algorytmy zostaną przedstawione w postaci pseudokodu, który jest pod wieloma względami podobny do C, C ++, Java, Python i innych języków programowania.
W analizie teoretycznej algorytmów powszechne jest szacowanie ich złożoności w sensie asymptotycznym, tj. Estymacja funkcji złożoności dla dowolnie dużych danych wejściowych. Termin"analysis of algorithms" został wymyślony przez Donalda Knutha.
Analiza algorytmów jest ważną częścią teorii złożoności obliczeniowej, która zapewnia teoretyczne oszacowanie wymaganych zasobów algorytmu do rozwiązania określonego problemu obliczeniowego. Większość algorytmów jest zaprojektowana do pracy z danymi wejściowymi o dowolnej długości. Analiza algorytmów to określenie ilości czasu i zasobów potrzebnych do jej wykonania.
Zwykle wydajność lub czas działania algorytmu jest określany jako funkcja wiążąca długość wejściową z liczbą kroków, znaną jako time complexitylub wielkość pamięci, znana jako space complexity.
Potrzeba analizy
W tym rozdziale omówimy potrzebę analizy algorytmów oraz sposób doboru lepszego algorytmu do konkretnego problemu, ponieważ jeden problem obliczeniowy można rozwiązać za pomocą różnych algorytmów.
Rozważając algorytm dla konkretnego problemu, możemy zacząć rozwijać rozpoznawanie wzorców, aby podobne typy problemów mogły być rozwiązywane za pomocą tego algorytmu.
Algorytmy często bardzo się od siebie różnią, chociaż cel tych algorytmów jest ten sam. Na przykład wiemy, że zbiór liczb można sortować za pomocą różnych algorytmów. Liczba porównań wykonywanych przez jeden algorytm może się różnić z innymi dla tego samego wejścia. Stąd złożoność czasowa tych algorytmów może się różnić. Jednocześnie musimy obliczyć przestrzeń pamięci wymaganą przez każdy algorytm.
Analiza algorytmu to proces analizy zdolności algorytmu do rozwiązywania problemów pod względem wymaganego czasu i rozmiaru (rozmiar pamięci do przechowywania podczas implementacji). Jednak głównym problemem analizy algorytmów jest wymagany czas lub wydajność. Generalnie wykonujemy następujące rodzaje analiz -
Worst-case - Maksymalna liczba kroków podjętych dla dowolnego rozmiaru a.
Best-case - Minimalna liczba kroków podjętych dla dowolnego rozmiaru a.
Average case - Średnia liczba kroków podjętych dla dowolnego rozmiaru a.
Amortized - sekwencja operacji zastosowana do wprowadzenia rozmiaru a uśrednione w czasie.
Aby rozwiązać problem, musimy wziąć pod uwagę zarówno złożoność czasu, jak i przestrzeni, ponieważ program może działać w systemie, w którym pamięć jest ograniczona, ale dostępna jest odpowiednia przestrzeń, lub może być odwrotnie. W tym kontekście, jeśli porównamybubble sort i merge sort. Sortowanie bąbelkowe nie wymaga dodatkowej pamięci, ale sortowanie przez scalanie wymaga dodatkowej przestrzeni. Chociaż złożoność czasowa sortowania bąbelkowego jest wyższa w porównaniu z sortowaniem przez scalanie, może być konieczne zastosowanie sortowania bąbelkowego, jeśli program musi działać w środowisku, w którym pamięć jest bardzo ograniczona.
Aby zmierzyć zużycie zasobów przez algorytm, stosuje się różne strategie, jak omówiono w tym rozdziale.
Analiza asymptotyczna
Asymptotyczne zachowanie funkcji f(n) odnosi się do wzrostu f(n) tak jak n staje się duży.
Zwykle ignorujemy małe wartości n, ponieważ zwykle jesteśmy zainteresowani oszacowaniem, jak wolno program będzie działał na dużych wejściach.
Ogólna zasada jest taka, że im wolniejsze tempo wzrostu asymptotycznego, tym lepszy algorytm. Chociaż nie zawsze jest to prawda.
Na przykład algorytm liniowy $f(n) = d * n + k$ jest zawsze asymptotycznie lepszy niż kwadratowy, $f(n) = c.n^2 + q$.
Rozwiązywanie równań rekurencyjnych
Rekurencja to równanie lub nierówność opisująca funkcję pod względem jej wartości na mniejszych danych wejściowych. Powtórzenia są generalnie używane w paradygmacie dziel i rządź.
Rozważmy T(n) być czasem wykonywania problemu rozmiaru n.
Powiedzmy, że rozmiar problemu jest wystarczająco mały n < c gdzie c jest stałą, proste rozwiązanie zajmuje stały czas, co jest zapisane jako θ(1). Jeśli podział problemu daje kilka podproblemów związanych z rozmiarem$\frac{n}{b}$.
Aby rozwiązać problem, wymagany jest czas a.T(n/b). Jeśli weźmiemy pod uwagę czas potrzebny na podział toD(n) a czas potrzebny na połączenie wyników podproblemów wynosi C(n)relację powtarzania można przedstawić jako -
$$T(n)=\begin{cases}\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\theta(1) & if\:n\leqslant c\\a T(\frac{n}{b})+D(n)+C(n) & otherwise\end{cases}$$
Relację powtarzania można rozwiązać za pomocą następujących metod -
Substitution Method - W tej metodzie odgadujemy ograniczenie i za pomocą indukcji matematycznej udowadniamy, że nasze założenie było poprawne.
Recursion Tree Method - W tej metodzie tworzone jest drzewo powtarzania, w którym każdy węzeł reprezentuje koszt.
Master’s Theorem - To kolejna ważna technika znajdowania złożoności relacji powtarzania.
Analiza amortyzowana
Analiza amortyzowana jest zwykle stosowana w przypadku niektórych algorytmów, w których wykonywana jest sekwencja podobnych operacji.
Analiza zamortyzowana zapewnia ograniczenie rzeczywistego kosztu całej sekwencji zamiast oddzielnego ograniczania kosztu sekwencji operacji.
Analiza zamortyzowana różni się od analizy przeciętnego przypadku; prawdopodobieństwo nie jest uwzględniane w amortyzowanej analizie. Amortyzowana analiza gwarantuje średnią wydajność każdej operacji w najgorszym przypadku.
To nie tylko narzędzie do analizy, to sposób myślenia o projekcie, ponieważ projektowanie i analiza są ze sobą ściśle powiązane.
Metoda agregacji
Metoda zagregowana daje globalny obraz problemu. W tej metodzie, jeślin operacje wymagają czasu w najgorszym przypadku T(n)razem. Wtedy zamortyzowany koszt każdej operacji wynosiT(n)/n. Chociaż różne operacje mogą zająć różny czas, w tej metodzie różne koszty są pomijane.
Metoda księgowania
W tej metodzie różne opłaty są przypisywane do różnych operacji zgodnie z ich rzeczywistym kosztem. Jeżeli zamortyzowany koszt operacji przekracza jej koszt rzeczywisty, różnica jest przypisywana do obiektu jako kredyt. Kredyt ten pomaga opłacić późniejsze operacje, w przypadku których zamortyzowany koszt jest niższy od kosztu rzeczywistego.
Jeżeli rzeczywisty koszt i zamortyzowany koszt ith operacja są $c_{i}$ i $\hat{c_{l}}$, następnie
$$\displaystyle\sum\limits_{i=1}^n \hat{c_{l}}\geqslant\displaystyle\sum\limits_{i=1}^n c_{i}$$
Potencjalna metoda
Ta metoda przedstawia przedpłaconą pracę jako energię potencjalną, zamiast traktować przedpłaconą pracę jako kredyt. Energia ta może zostać uwolniona, aby zapłacić za przyszłe operacje.
Jeśli wykonamy n operacje rozpoczynające się od początkowej struktury danych D0. Rozważmy,ci jako rzeczywisty koszt i Di jako struktura danych ithoperacja. Potencjalna funkcja Ф odwzorowuje liczbę rzeczywistą Ф (Di), powiązany potencjał Di. Zamortyzowany koszt$\hat{c_{l}}$ można zdefiniować przez
$$\hat{c_{l}}=c_{i}+\Phi (D_{i})-\Phi (D_{i-1})$$
W związku z tym całkowity zamortyzowany koszt wynosi
$$\displaystyle\sum\limits_{i=1}^n \hat{c_{l}}=\displaystyle\sum\limits_{i=1}^n (c_{i}+\Phi (D_{i})-\Phi (D_{i-1}))=\displaystyle\sum\limits_{i=1}^n c_{i}+\Phi (D_{n})-\Phi (D_{0})$$
Dynamiczna tabela
Jeśli przydzielone miejsce na tabelę nie jest wystarczające, musimy skopiować tabelę do tabeli o większej wielkości. Podobnie, jeśli z tabeli usuwana jest duża liczba członków, dobrym pomysłem jest ponowne przydzielenie tabeli o mniejszym rozmiarze.
Korzystając z analizy amortyzowanej, możemy pokazać, że zamortyzowany koszt wstawienia i usunięcia jest stały, a niewykorzystane miejsce w tabeli dynamicznej nigdy nie przekracza stałego ułamka całkowitej przestrzeni.
W następnym rozdziale tego samouczka omówimy w skrócie notacje asymptotyczne.
Przy projektowaniu algorytmu analiza złożoności algorytmu jest istotnym aspektem. Głównie złożoność algorytmiczna dotyczy jego wydajności, szybkości lub wolnej pracy.
Złożoność algorytmu opisuje wydajność algorytmu pod względem ilości pamięci wymaganej do przetwarzania danych i czasu przetwarzania.
Złożoność algorytmu jest analizowana w dwóch perspektywach: Time i Space.
Złożoność czasowa
Jest to funkcja opisująca ilość czasu potrzebnego do uruchomienia algorytmu pod względem rozmiaru wejścia. „Czas” może oznaczać liczbę wykonanych dostępów do pamięci, liczbę porównań między liczbami całkowitymi, liczbę wykonań jakiejś pętli wewnętrznej lub inną naturalną jednostkę związaną z czasem rzeczywistym, jaki zajmie algorytm.
Złożoność przestrzeni
Jest to funkcja opisująca ilość pamięci, jaką zajmuje algorytm, pod względem wielkości danych wejściowych do algorytmu. Często mówimy o potrzebnej „dodatkowej” pamięci, nie licząc pamięci potrzebnej do przechowywania samego wejścia. Ponownie używamy do pomiaru jednostek naturalnych (ale o stałej długości).
Złożoność przestrzeni jest czasami ignorowana, ponieważ wykorzystywana przestrzeń jest minimalna i / lub oczywista, jednak czasami staje się kwestią równie ważną jak czas.
Notacje asymptotyczne
Czas wykonania algorytmu zależy od zestawu instrukcji, szybkości procesora, szybkości operacji wejścia / wyjścia dysku itp. Dlatego asymptotycznie szacujemy wydajność algorytmu.
Funkcja czasu algorytmu jest reprezentowana przez T(n), gdzie n to rozmiar wejściowy.
Do przedstawienia złożoności algorytmu używane są różne typy notacji asymptotycznych. Poniższe notacje asymptotyczne służą do obliczania złożoności czasu działania algorytmu.
O - Wielkie Oh
Ω - Duża omega
θ - Big theta
o - Trochę Oh
ω - Mała omega
O: Asymptotyczna górna granica
„O” (Big Oh) jest najczęściej używaną notacją. Funkcjaf(n) może być reprezentowany to kolejność g(n) to jest O(g(n)), jeśli istnieje wartość dodatniej liczby całkowitej n tak jak n0 i dodatnią stałą c takie, że -
$f(n)\leqslant c.g(n)$ dla $n > n_{0}$ we wszystkich przypadkach
Stąd funkcja g(n) jest górną granicą funkcji f(n), tak jak g(n) rośnie szybciej niż f(n).
Przykład
Rozważmy daną funkcję, $f(n) = 4.n^3 + 10.n^2 + 5.n + 1$
Wobec $g(n) = n^3$,
$f(n)\leqslant 5.g(n)$ dla wszystkich wartości $n > 2$
Stąd złożoność f(n) można przedstawić jako $O(g(n))$, tj $O(n^3)$
Ω: Asymptotyczna dolna granica
Tak mówimy $f(n) = \Omega (g(n))$ kiedy istnieje stała c że $f(n)\geqslant c.g(n)$ dla wszystkich dostatecznie duża wartość n. Tutajnjest dodatnią liczbą całkowitą. Oznacza funkcjęg jest dolną granicą funkcji f; po określonej wartościn, f nigdy nie zejdzie poniżej g.
Przykład
Rozważmy daną funkcję, $f(n) = 4.n^3 + 10.n^2 + 5.n + 1$.
Wobec $g(n) = n^3$, $f(n)\geqslant 4.g(n)$ dla wszystkich wartości $n > 0$.
Stąd złożoność f(n) można przedstawić jako $\Omega (g(n))$, tj $\Omega (n^3)$
θ: asymptotyczna mocno związana
Tak mówimy $f(n) = \theta(g(n))$ gdy istnieją stałe c1 i c2 że $c_{1}.g(n) \leqslant f(n) \leqslant c_{2}.g(n)$ dla wszystkich dostatecznie duża wartość n. Tutajn jest dodatnią liczbą całkowitą.
Oznacza to funkcję g jest ścisłym ograniczeniem funkcji f.
Przykład
Rozważmy daną funkcję, $f(n) = 4.n^3 + 10.n^2 + 5.n + 1$
Wobec $g(n) = n^3$, $4.g(n) \leqslant f(n) \leqslant 5.g(n)$ dla wszystkich dużych wartości n.
Stąd złożoność f(n) można przedstawić jako $\theta (g(n))$, tj $\theta (n^3)$.
O - Notacja
Asymptotyczna górna granica zapewniana przez O-notationmoże, ale nie musi, być asymptotycznie ciasne. Związany$2.n^2 = O(n^2)$ jest asymptotycznie ciasna, ale ograniczona $2.n = O(n^2)$ nie jest.
Używamy o-notation oznaczać górną granicę, która nie jest asymptotycznie ścisła.
Definiujemy formalnie o(g(n)) (little-oh of g of n) jako zbiór f(n) = o(g(n)) dla każdej dodatniej stałej $c > 0$ i istnieje wartość $n_{0} > 0$, takie że $0 \leqslant f(n) \leqslant c.g(n)$.
Intuicyjnie w o-notation, funkcja f(n) staje się nieistotna w stosunku do g(n) tak jak nzbliża się do nieskończoności; to jest,
$$\lim_{n \rightarrow \infty}\left(\frac{f(n)}{g(n)}\right) = 0$$
Przykład
Rozważmy tę samą funkcję, $f(n) = 4.n^3 + 10.n^2 + 5.n + 1$
Wobec $g(n) = n^{4}$,
$$\lim_{n \rightarrow \infty}\left(\frac{4.n^3 + 10.n^2 + 5.n + 1}{n^4}\right) = 0$$
Stąd złożoność f(n) można przedstawić jako $o(g(n))$, tj $o(n^4)$.
ω - notacja
Używamy ω-notationoznaczać dolną granicę, która nie jest asymptotycznie ścisła. Formalnie jednak definiujemyω(g(n)) (mała-omega od g od n) jako zbiór f(n) = ω(g(n)) dla każdej dodatniej stałej C > 0 i istnieje wartość $n_{0} > 0$, takie, że $ 0 \ leqslant cg (n) <f (n) $.
Na przykład, $\frac{n^2}{2} = \omega (n)$, ale $\frac{n^2}{2} \neq \omega (n^2)$. Relacja$f(n) = \omega (g(n))$ oznacza, że istnieje następujący limit
$$\lim_{n \rightarrow \infty}\left(\frac{f(n)}{g(n)}\right) = \infty$$
To jest, f(n) staje się arbitralnie duży w stosunku do g(n) tak jak n zbliża się do nieskończoności.
Przykład
Rozważmy tę samą funkcję, $f(n) = 4.n^3 + 10.n^2 + 5.n + 1$
Wobec $g(n) = n^2$,
$$\lim_{n \rightarrow \infty}\left(\frac{4.n^3 + 10.n^2 + 5.n + 1}{n^2}\right) = \infty$$
Stąd złożoność f(n) można przedstawić jako $o(g(n))$, tj $\omega (n^2)$.
Analiza Apriori i Apostiari
Analiza Apriori oznacza, że analiza jest wykonywana przed uruchomieniem jej w określonym systemie. Analiza ta jest etapem, na którym funkcja jest definiowana za pomocą pewnego modelu teoretycznego. Dlatego określamy złożoność czasową i przestrzenną algorytmu, po prostu patrząc na algorytm, zamiast uruchamiać go w konkretnym systemie z inną pamięcią, procesorem i kompilatorem.
Analiza apostiari algorytmu oznacza, że analizę algorytmu wykonujemy dopiero po uruchomieniu go w systemie. Zależy to bezpośrednio od systemu i zmian między systemem.
W branży nie możemy przeprowadzić analizy Apostiari, ponieważ oprogramowanie jest generalnie przeznaczone dla anonimowego użytkownika, który uruchamia je w systemie innym niż obecny w branży.
W Apriori jest to powód, dla którego używamy notacji asymptotycznych do określania złożoności czasu i przestrzeni, gdy zmieniają się one z komputera na komputer; jednak asymptotycznie są takie same.
W tym rozdziale omówimy złożoność problemów obliczeniowych w odniesieniu do ilości miejsca wymaganego przez algorytm.
Złożoność przestrzeni ma wiele wspólnych cech ze złożonością czasową i służy jako dalszy sposób klasyfikowania problemów według ich trudności obliczeniowych.
Co to jest złożoność przestrzeni?
Złożoność przestrzeni to funkcja opisująca ilość pamięci (przestrzeni), jaką zajmuje algorytm, w kategoriach ilości danych wejściowych do algorytmu.
Często o tym mówimy extra memorypotrzebne, nie licząc pamięci potrzebnej do przechowywania samego wejścia. Ponownie używamy do pomiaru jednostek naturalnych (ale o stałej długości).
Możemy używać bajtów, ale łatwiej jest użyć, powiedzmy, liczby użytych liczb całkowitych, liczby struktur o stałej wielkości itp.
Ostatecznie funkcja, którą wymyślimy, będzie niezależna od rzeczywistej liczby bajtów potrzebnych do reprezentacji jednostki.
Złożoność przestrzeni jest czasami pomijana, ponieważ wykorzystywana przestrzeń jest minimalna i / lub oczywista, jednak czasami staje się tak ważna jak złożoność czasowa
Definicja
Pozwolić M być deterministą Turing machine (TM)który zatrzymuje się na wszystkich wejściach. Złożoność przestrzeniM jest funkcją $f \colon N \rightarrow N$, gdzie f(n) to maksymalna liczba komórek taśmy i M skanuje dowolne dane wejściowe o długości M. Jeśli złożoność przestrzeniM jest f(n), możemy to powiedzieć M działa w kosmosie f(n).
Szacujemy złożoność przestrzenną maszyny Turinga za pomocą notacji asymptotycznej.
Pozwolić $f \colon N \rightarrow R^+$być funkcją. Klasy złożoności przestrzeni można zdefiniować w następujący sposób -
SPACE = {L | L is a language decided by an O(f(n)) space deterministic TM}
SPACE = {L | L is a language decided by an O(f(n)) space non-deterministic TM}
PSPACE jest klasą języków, które są rozstrzygalne w przestrzeni wielomianowej na deterministycznej maszynie Turinga.
Innymi słowy, PSPACE = Uk SPACE (nk)
Twierdzenie Savitcha
Jednym z najwcześniejszych twierdzeń związanych ze złożonością przestrzeni jest twierdzenie Savitcha. Zgodnie z tym twierdzeniem maszyna deterministyczna może symulować maszyny niedeterministyczne, wykorzystując niewielką ilość miejsca.
Wydaje się, że w przypadku złożoności czasowej taka symulacja wymaga wykładniczego wydłużenia czasu. W przypadku złożoności przestrzeni to twierdzenie pokazuje, że każda niedeterministyczna maszyna Turinga, która używaf(n) przestrzeń można przekształcić w deterministyczną bazę TM, która używa f2(n) przestrzeń.
Stąd twierdzenie Savitcha stwierdza, że dla dowolnej funkcji $f \colon N \rightarrow R^+$, gdzie $f(n) \geqslant n$
NSPACE(f(n)) ⊆ SPACE(f(n))
Relacje między klasami złożoności
Poniższy diagram przedstawia relacje między różnymi klasami złożoności.

Do tej pory nie omawialiśmy klas P i NP w tym samouczku. Zostaną one omówione później.
Wiele algorytmów ma charakter rekurencyjny i służy do rozwiązania danego problemu rekurencyjnie rozwiązując podproblemy.
W divide and conquer approach, problem jest dzielony na mniejsze problemy, następnie mniejsze problemy są rozwiązywane niezależnie, a na koniec rozwiązania mniejszych problemów łączy się w rozwiązanie dużego problemu.
Ogólnie algorytmy dziel i rządź składają się z trzech części -
Divide the problem na szereg podproblemów, które są mniejszymi przypadkami tego samego problemu.
Conquer the sub-problemsrozwiązując je rekurencyjnie. Jeśli są wystarczająco małe, rozwiąż podproblemy jako przypadki podstawowe.
Combine the solutions do podproblemów do rozwiązania pierwotnego problemu.
Plusy i minusy podejścia Divide and Conquer
Podejście dziel i zwyciężaj wspiera paralelizm, ponieważ podproblemy są niezależne. W związku z tym algorytm zaprojektowany przy użyciu tej techniki może działać w systemie wieloprocesorowym lub na różnych maszynach jednocześnie.
W tym podejściu większość algorytmów jest projektowanych przy użyciu rekurencji, stąd zarządzanie pamięcią jest bardzo wysokie. W przypadku rekurencyjnych funkcji używany jest stos, w którym stan funkcji musi być przechowywany.
Zastosowanie podejścia dziel i zwyciężaj
Oto kilka problemów, które można rozwiązać za pomocą metody dziel i rządź.
- Znajdowanie maksimum i minimum ciągu liczb
- Mnożenie macierzy Strassena
- Sortuj przez scalanie
- Wyszukiwanie binarne
Rozważmy prosty problem, który można rozwiązać za pomocą techniki dziel i rządź.
Stwierdzenie problemu
Problem Max-Min w analizie algorytmu polega na znalezieniu maksymalnej i minimalnej wartości w tablicy.
Rozwiązanie
Aby znaleźć maksymalną i minimalną liczbę w danej tablicy numbers[] wielkościowy n, można użyć następującego algorytmu. Najpierw reprezentujemynaive method a potem przedstawimy divide and conquer approach.
Metoda naiwna
Metoda naiwna to podstawowa metoda rozwiązania każdego problemu. W tej metodzie maksymalną i minimalną liczbę można znaleźć osobno. Aby znaleźć wartości maksymalne i minimalne, można użyć następującego prostego algorytmu.
Algorithm: Max-Min-Element (numbers[])
max := numbers[1]
min := numbers[1]
for i = 2 to n do
if numbers[i] > max then
max := numbers[i]
if numbers[i] < min then
min := numbers[i]
return (max, min)Analiza
Liczba porównań w metodzie Naive wynosi 2n - 2.
Liczbę porównań można zmniejszyć, stosując metodę dziel i zwyciężaj. Oto technika.
Podejście dziel i zwyciężaj
W tym podejściu tablica jest podzielona na dwie połowy. Następnie przy użyciu podejścia rekurencyjnego znajduje się maksymalne i minimalne liczby w każdej połowie. Później zwróć maksymalnie dwa maksima z każdej połowy i co najmniej dwie minima z każdej połowy.
W tym zadaniu liczba elementów w tablicy wynosi $y - x + 1$, gdzie y jest większa niż lub równa x.
$\mathbf{\mathit{Max - Min(x, y)}}$ zwróci maksymalne i minimalne wartości tablicy $\mathbf{\mathit{numbers[x...y]}}$.
Algorithm: Max - Min(x, y)
if y – x ≤ 1 then
return (max(numbers[x], numbers[y]), min((numbers[x], numbers[y]))
else
(max1, min1):= maxmin(x, ⌊((x + y)/2)⌋)
(max2, min2):= maxmin(⌊((x + y)/2) + 1)⌋,y)
return (max(max1, max2), min(min1, min2))Analiza
Pozwolić T(n) być liczbą porównań wykonanych przez $\mathbf{\mathit{Max - Min(x, y)}}$, gdzie liczba elementów $n = y - x + 1$.
Gdyby T(n) reprezentuje liczby, wówczas relację powtarzania można przedstawić jako
$$T(n) = \begin{cases}T\left(\lfloor\frac{n}{2}\rfloor\right)+T\left(\lceil\frac{n}{2}\rceil\right)+2 & for\: n>2\\1 & for\:n = 2 \\0 & for\:n = 1\end{cases}$$
Załóżmy, że n ma postać mocy 2. W związku z tym,n = 2k gdzie k jest wysokością drzewa rekurencji.
Więc,
$$T(n) = 2.T (\frac{n}{2}) + 2 = 2.\left(\begin{array}{c}2.T(\frac{n}{4}) + 2\end{array}\right) + 2 ..... = \frac{3n}{2} - 2$$
W porównaniu z metodą Naïve, w podejściu dziel i rządź liczba porównań jest mniejsza. Jednak przy użyciu notacji asymptotycznej oba podejścia są reprezentowane przezO(n).
W tym rozdziale omówimy sortowanie przez scalanie i przeanalizujemy jego złożoność.
Stwierdzenie problemu
Problem sortowania listy liczb nadaje się natychmiast do strategii „dziel i rządź”: podziel listę na dwie połowy, rekurencyjnie posortuj każdą połowę, a następnie połącz dwie posortowane listy podrzędne.
Rozwiązanie
W tym algorytmie liczby są przechowywane w tablicy numbers[]. Tutaj,p i q reprezentuje indeks początkowy i końcowy tablicy podrzędnej.
Algorithm: Merge-Sort (numbers[], p, r)
if p < r then
q = ⌊(p + r) / 2⌋
Merge-Sort (numbers[], p, q)
Merge-Sort (numbers[], q + 1, r)
Merge (numbers[], p, q, r)Function: Merge (numbers[], p, q, r)
n1 = q – p + 1
n2 = r – q
declare leftnums[1…n1 + 1] and rightnums[1…n2 + 1] temporary arrays
for i = 1 to n1
leftnums[i] = numbers[p + i - 1]
for j = 1 to n2
rightnums[j] = numbers[q+ j]
leftnums[n1 + 1] = ∞
rightnums[n2 + 1] = ∞
i = 1
j = 1
for k = p to r
if leftnums[i] ≤ rightnums[j]
numbers[k] = leftnums[i]
i = i + 1
else
numbers[k] = rightnums[j]
j = j + 1Analiza
Rozważmy czas działania funkcji Merge-Sort as T(n). W związku z tym,
$T(n)=\begin{cases}c & if\:n\leqslant 1\\2\:x\:T(\frac{n}{2})+d\:x\:n & otherwise\end{cases}$gdzie c i d są stałymi
Dlatego używając tej relacji powtarzania,
$$T(n) = 2^i T(\frac{n}{2^i}) + i.d.n$$
Tak jak, $i = log\:n,\: T(n) = 2^{log\:n} T(\frac{n}{2^{log\:n}}) + log\:n.d.n$
$=\:c.n + d.n.log\:n$
W związku z tym, $T(n) = O(n\:log\:n)$
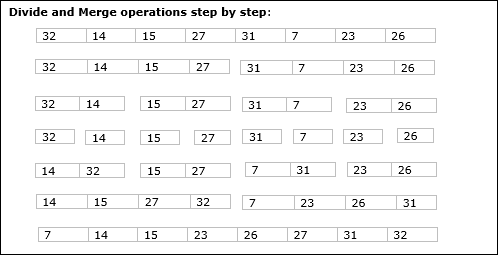
Przykład
W poniższym przykładzie pokazaliśmy krok po kroku algorytm Merge-Sort. Po pierwsze, każda tablica iteracji jest dzielona na dwie pod-tablice, aż podtablica zawiera tylko jeden element. Jeśli tych tablic podrzędnych nie można dalej podzielić, wykonywane są operacje scalania.
W tym rozdziale omówimy inny algorytm oparty na metodzie dziel i rządź.
Stwierdzenie problemu
Wyszukiwanie binarne można przeprowadzić na posortowanej tablicy. W tym podejściu indeks elementuxjest określane, czy element należy do listy elementów. Jeśli tablica jest nieposortowana, do określenia pozycji używane jest wyszukiwanie liniowe.
Rozwiązanie
W tym algorytmie chcemy znaleźć, czy element x należy do zbioru liczb przechowywanych w tablicy numbers[]. Gdziel i r reprezentują lewy i prawy indeks tablicy podrzędnej, w której ma zostać przeprowadzona operacja wyszukiwania.
Algorithm: Binary-Search(numbers[], x, l, r)
if l = r then
return l
else
m := ⌊(l + r) / 2⌋
if x ≤ numbers[m] then
return Binary-Search(numbers[], x, l, m)
else
return Binary-Search(numbers[], x, m+1, r)Analiza
Rozpoczyna się wyszukiwanie liniowe O(n)czas. Podczas gdy wyszukiwanie binarne daje wynik w formacieO(log n) czas
Pozwolić T(n) być liczbą porównań w najgorszym przypadku w tablicy n elementy.
W związku z tym,
$$T(n)=\begin{cases}0 & if\:n= 1\\T(\frac{n}{2})+1 & otherwise\end{cases}$$
Korzystanie z tej relacji powtarzania $T(n) = log\:n$.
Dlatego wyszukiwanie binarne używa $O(log\:n)$ czas.
Przykład
W tym przykładzie wyszukamy element 63.

W tym rozdziale najpierw omówimy ogólną metodę mnożenia macierzy, a później omówimy algorytm mnożenia macierzy Strassena.
Stwierdzenie problemu
Rozważmy dwie macierze X i Y. Chcemy obliczyć wynikową macierzZ przez pomnożenie X i Y.
Metoda naiwna
Najpierw omówimy naiwną metodę i jej złożoność. Tutaj obliczamyZ = X × Y. Używając metody Naïve, dwie macierze (X i Y) można pomnożyć, jeśli kolejność tych macierzy wynosi p × q i q × r. Oto algorytm.
Algorithm: Matrix-Multiplication (X, Y, Z)
for i = 1 to p do
for j = 1 to r do
Z[i,j] := 0
for k = 1 to q do
Z[i,j] := Z[i,j] + X[i,k] × Y[k,j]Złożoność
Tutaj zakładamy, że są wykonywane operacje na liczbach całkowitych O(1)czas. Są trzyforpętle w tym algorytmie, a jedna jest zagnieżdżona w innym. Stąd algorytm przyjmujeO(n3) czas na wykonanie.
Algorytm mnożenia macierzy Strassena
W tym kontekście, używając algorytmu mnożenia Matrix Strassena, można nieco poprawić zużycie czasu.
Mnożenie Matrix Strassena można wykonać tylko na square matrices gdzie n jest power of 2. Kolejność obu macierzy ton × n.
Podzielić X, Y i Z na cztery (n / 2) × (n / 2) macierze, jak pokazano poniżej -
$Z = \begin{bmatrix}I & J \\K & L \end{bmatrix}$ $X = \begin{bmatrix}A & B \\C & D \end{bmatrix}$ i $Y = \begin{bmatrix}E & F \\G & H \end{bmatrix}$
Korzystając z algorytmu Strassena, obliczyć następujące -
$$M_{1} \: \colon= (A+C) \times (E+F)$$
$$M_{2} \: \colon= (B+D) \times (G+H)$$
$$M_{3} \: \colon= (A-D) \times (E+H)$$
$$M_{4} \: \colon= A \times (F-H)$$
$$M_{5} \: \colon= (C+D) \times (E)$$
$$M_{6} \: \colon= (A+B) \times (H)$$
$$M_{7} \: \colon= D \times (G-E)$$
Następnie,
$$I \: \colon= M_{2} + M_{3} - M_{6} - M_{7}$$
$$J \: \colon= M_{4} + M_{6}$$
$$K \: \colon= M_{5} + M_{7}$$
$$L \: \colon= M_{1} - M_{3} - M_{4} - M_{5}$$
Analiza
$T(n)=\begin{cases}c & if\:n= 1\\7\:x\:T(\frac{n}{2})+d\:x\:n^2 & otherwise\end{cases}$gdzie c i d są stałymi
Korzystając z tej relacji powtarzania, otrzymujemy $T(n) = O(n^{log7})$
Stąd złożoność algorytmu mnożenia macierzy Strassena $O(n^{log7})$.
Spośród wszystkich podejść algorytmicznych najprostszym i najprostszym podejściem jest metoda Greedy. W tym podejściu decyzja jest podejmowana na podstawie aktualnie dostępnych informacji bez obawy o skutki bieżącej decyzji w przyszłości.
Chciwe algorytmy budują rozwiązanie część po części, wybierając kolejną część w taki sposób, aby dawało natychmiastowe korzyści. Takie podejście nigdy nie powoduje ponownego rozważenia wcześniej dokonanych wyborów. To podejście jest używane głównie do rozwiązywania problemów optymalizacyjnych. Metoda Greedy jest łatwa do wdrożenia i dość skuteczna w większości przypadków. Dlatego możemy powiedzieć, że algorytm Greedy'ego jest paradygmatem algorytmicznym opartym na heurystyce, który śledzi lokalny optymalny wybór na każdym kroku z nadzieją na znalezienie globalnego optymalnego rozwiązania.
W przypadku wielu problemów nie daje optymalnego rozwiązania, chociaż daje przybliżone (prawie optymalne) rozwiązanie w rozsądnym czasie.
Składniki algorytmu zachłannego
Chciwe algorytmy składają się z pięciu następujących elementów -
A candidate set - Rozwiązanie jest tworzone z tego zestawu.
A selection function - Służy do wybierania najlepszego kandydata do dodania do rozwiązania.
A feasibility function - Służy do określania, czy kandydat może przyczynić się do rozwiązania.
An objective function - Służy do przypisywania wartości do rozwiązania lub częściowego rozwiązania.
A solution function - Służy do wskazania, czy osiągnięto pełne rozwiązanie.
Obszary zastosowań
Chciwe podejście służy do rozwiązywania wielu problemów, takich jak
Znalezienie najkrótszej ścieżki między dwoma wierzchołkami za pomocą algorytmu Dijkstry.
Znalezienie minimalnego drzewa rozpinającego na wykresie za pomocą algorytmu Prima / Kruskala itp.
Tam, gdzie chciwe podejście zawodzi
W wielu problemach algorytm Greedy'ego nie znajduje optymalnego rozwiązania, co więcej, może dać najgorsze rozwiązanie. Takim podejściem nie da się rozwiązać problemów takich jak komiwojażer czy plecak.
Algorytm Chciwości można bardzo dobrze zrozumieć dzięki dobrze znanemu problemowi określanemu jako problem plecakowy. Chociaż ten sam problem mógłby zostać rozwiązany przez zastosowanie innych podejść algorytmicznych, podejście Greedy'ego rozwiązuje problem frakcjonalnego plecaka rozsądnie w odpowiednim czasie. Omówmy szczegółowo problem plecaka.
Problem z plecakiem
Mając zestaw elementów, z których każdy ma wagę i wartość, określ podzbiór elementów do uwzględnienia w kolekcji, tak aby całkowita waga była mniejsza lub równa podanemu limitowi, a całkowita wartość była jak największa.
Problem plecakowy jest problemem optymalizacji kombinatorycznej. Pojawia się jako podproblem w wielu bardziej złożonych modelach matematycznych rzeczywistych problemów. Jednym z ogólnych podejść do trudnych problemów jest zidentyfikowanie najbardziej restrykcyjnego ograniczenia, zignorowanie pozostałych, rozwiązanie problemu plecakowego i jakoś dostosować rozwiązanie tak, aby spełniało zignorowane ograniczenia.
Aplikacje
W wielu przypadkach alokacji zasobów, z pewnymi ograniczeniami, problem można wyprowadzić w podobny sposób jak problem Knapsacka. Oto zestaw przykładów.
- Znalezienie najmniej marnotrawnego sposobu na cięcie surowców
- optymalizacja portfela
- Cięcie problemów z zapasami
Scenariusz problemu
Złodziej rabuje sklep i może unieść maksymalny ciężar Wdo jego plecaka. W sklepie dostępnych jest n pozycji i wagaith pozycja jest wi a jego zysk jest pi. Jakie przedmioty powinien zabrać złodziej?
W tym kontekście przedmioty należy dobierać w taki sposób, aby złodziej nosił te przedmioty, za które osiągnie maksymalny zysk. Stąd celem złodzieja jest maksymalizacja zysku.
Ze względu na charakter przedmiotów, problemy plecakowe są klasyfikowane jako
- Ułamkowy plecak
- Knapsack
Ułamkowy plecak
W takim przypadku przedmioty można rozbić na mniejsze części, dzięki czemu złodziej może wybierać ułamki przedmiotów.
Zgodnie ze stwierdzeniem problemu
Tam są n przedmioty w sklepie
Waga ith pozycja $w_{i} > 0$
Zysk za ith pozycja $p_{i} > 0$ i
Pojemność plecaka to W
W tej wersji problemu plecakowego przedmioty można rozbijać na mniejsze kawałki. Więc złodziej może zająć tylko ułamekxi z ith pozycja.
$$0 \leqslant x_{i} \leqslant 1$$
Plik ith pozycja wpływa na wagę $x_{i}.w_{i}$ do całkowitej wagi plecaka i zysku $x_{i}.p_{i}$ do całkowitego zysku.
Stąd celem tego algorytmu jest
$$maximize\:\displaystyle\sum\limits_{n=1}^n (x_{i}.p_{}i)$$
podlegać przymusowi,
$$\displaystyle\sum\limits_{n=1}^n (x_{i}.w_{}i) \leqslant W$$
Oczywiste jest, że optymalne rozwiązanie musi dokładnie wypełnić plecak, w przeciwnym razie moglibyśmy dodać ułamek jednego z pozostałych przedmiotów i zwiększyć ogólny zysk.
W ten sposób optymalne rozwiązanie można uzyskać dzięki
$$\displaystyle\sum\limits_{n=1}^n (x_{i}.w_{}i) = W$$
W tym kontekście najpierw musimy posortować te elementy według wartości $\frac{p_{i}}{w_{i}}$więc to $\frac{p_{i}+1}{w_{i}+1}$ ≤ $\frac{p_{i}}{w_{i}}$. Tutaj,x jest tablicą do przechowywania ułamka elementów.
Algorithm: Greedy-Fractional-Knapsack (w[1..n], p[1..n], W)
for i = 1 to n
do x[i] = 0
weight = 0
for i = 1 to n
if weight + w[i] ≤ W then
x[i] = 1
weight = weight + w[i]
else
x[i] = (W - weight) / w[i]
weight = W
break
return xAnaliza
Jeśli podane elementy są już posortowane w kolejności malejącej $\mathbf{\frac{p_{i}}{w_{i}}}$, następnie whileloop zajmuje trochę czasu O(n); W związku z tym całkowity czas obejmujący sortowanie jest wO(n logn).
Przykład
Rozważmy, że pojemność plecaka W = 60 a listę dostarczonych pozycji przedstawia poniższa tabela -
| Pozycja | ZA | b | do | re |
|---|---|---|---|---|
| Zysk | 280 | 100 | 120 | 120 |
| Waga | 40 | 10 | 20 | 24 |
| Stosunek $(\frac{p_{i}}{w_{i}})$ | 7 | 10 | 6 | 5 |
Ponieważ podane elementy nie są sortowane według $\mathbf{\frac{p_{i}}{w_{i}}}$. Po posortowaniu elementy są pokazane w poniższej tabeli.
| Pozycja | b | ZA | do | re |
|---|---|---|---|---|
| Zysk | 100 | 280 | 120 | 120 |
| Waga | 10 | 40 | 20 | 24 |
| Stosunek $(\frac{p_{i}}{w_{i}})$ | 10 | 7 | 6 | 5 |
Rozwiązanie
Po posortowaniu wszystkich pozycji wg $\frac{p_{i}}{w_{i}}$. Przede wszystkimB jest wybierana jako waga Bjest mniejsza niż pojemność plecaka. Następny przedmiotA jest wybierana, ponieważ dostępna pojemność plecaka jest większa niż waga A. Teraz,Cjest wybierany jako następny element. Nie można jednak wybrać całego przedmiotu, ponieważ pozostała pojemność plecaka jest mniejsza niż wagaC.
Stąd ułamek C (tj. (60 - 50) / 20).
Teraz pojemność plecaka jest równa wybranym przedmiotom. W związku z tym nie można wybrać więcej pozycji.
Całkowita waga wybranych elementów to 10 + 40 + 20 * (10/20) = 60
A całkowity zysk to 100 + 280 + 120 * (10/20) = 380 + 60 = 440
To optymalne rozwiązanie. Nie możemy osiągnąć większego zysku, wybierając inną kombinację przedmiotów.
Stwierdzenie problemu
W przypadku problemu z sekwencjonowaniem zadań celem jest znalezienie sekwencji zadań, które są wykonywane w terminie i dają maksymalny zysk.
Rozwiązanie
Rozważmy zbiór plików ndane zlecenia, które wiążą się z terminami i zyskiem są osiągane, jeśli zlecenie zostanie wykonane w terminie. Te prace należy uporządkować w taki sposób, aby uzyskać maksymalny zysk.
Może się zdarzyć, że wszystkie podane prace nie zostaną ukończone w terminie.
Załóżmy, że termin ith praca Ji jest di a zysk uzyskany z tej pracy wynosi pi. Stąd optymalnym rozwiązaniem tego algorytmu jest rozwiązanie wykonalne z maksymalnym zyskiem.
A zatem, $D(i) > 0$ dla $1 \leqslant i \leqslant n$.
Początkowo te prace są uporządkowane według zysku, tj $p_{1} \geqslant p_{2} \geqslant p_{3} \geqslant \:... \: \geqslant p_{n}$.
Algorithm: Job-Sequencing-With-Deadline (D, J, n, k)
D(0) := J(0) := 0
k := 1
J(1) := 1 // means first job is selected
for i = 2 … n do
r := k
while D(J(r)) > D(i) and D(J(r)) ≠ r do
r := r – 1
if D(J(r)) ≤ D(i) and D(i) > r then
for l = k … r + 1 by -1 do
J(l + 1) := J(l)
J(r + 1) := i
k := k + 1Analiza
W tym algorytmie używamy dwóch pętli, jedna znajduje się w drugiej. Stąd złożoność tego algorytmu$O(n^2)$.
Przykład
Rozważmy zbiór danych zawodów, jak pokazano w poniższej tabeli. Musimy znaleźć sekwencję zleceń, które zostaną zrealizowane w wyznaczonym terminie i dadzą maksymalny zysk. Każde zlecenie wiąże się z terminem realizacji i zyskiem.
| Praca | J1 | J2 | J3 | J4 | J5 |
|---|---|---|---|---|---|
| Ostateczny termin | 2 | 1 | 3 | 2 | 1 |
| Zysk | 60 | 100 | 20 | 40 | 20 |
Rozwiązanie
Aby rozwiązać ten problem, dane zlecenia są sortowane malejąco według ich zysku. W związku z tym po posortowaniu zadania są sortowane zgodnie z poniższą tabelą.
| Praca | J2 | J1 | J4 | J3 | J5 |
|---|---|---|---|---|---|
| Ostateczny termin | 1 | 2 | 2 | 3 | 1 |
| Zysk | 100 | 60 | 40 | 20 | 20 |
Z tego zestawu zadań najpierw wybieramy J2, ponieważ może zostać ukończony w terminie i przynosi maksymalny zysk.
Kolejny, J1 jest wybrany, ponieważ daje większy zysk w porównaniu z J4.
W następnym zegarze J4 nie może zostać wybrany, ponieważ upłynął jej termin J3 jest wybierana, ponieważ jest wykonywana w terminie.
Praca J5 zostaje odrzucona, ponieważ nie może zostać wykonana w terminie.
Zatem rozwiązaniem jest sekwencja zadań (J2, J1, J3), które są realizowane w terminie i dają maksymalny zysk.
Całkowity zysk z tej sekwencji wynosi 100 + 60 + 20 = 180.
Scal zbiór posortowanych plików o różnej długości w jeden posortowany plik. Musimy znaleźć optymalne rozwiązanie, w którym wynikowy plik zostanie wygenerowany w minimalnym czasie.
Jeśli podana jest liczba posortowanych plików, istnieje wiele sposobów na połączenie ich w jeden posortowany plik. To połączenie można przeprowadzić parami. Dlatego ten typ scalania nazywany jest as2-way merge patterns.
Ponieważ różne pary wymagają różnych ilości czasu, w tej strategii chcemy określić optymalny sposób łączenia wielu plików razem. Na każdym kroku łączone są dwie najkrótsze sekwencje.
Aby połączyć plik p-record file i a q-record file wymaga ewentualnie p + q nagrywanie przenosi, a oczywistym wyborem jest połączenie dwóch najmniejszych plików razem na każdym kroku.
Wzorce scalania dwukierunkowego mogą być reprezentowane przez binarne drzewa scalania. Rozważmy zbiórn posortowane pliki {f1, f2, f3, …, fn}. Początkowo każdy element tego jest traktowany jako drzewo binarne z pojedynczym węzłem. Aby znaleźć to optymalne rozwiązanie, używany jest następujący algorytm.
Algorithm: TREE (n)
for i := 1 to n – 1 do
declare new node
node.leftchild := least (list)
node.rightchild := least (list)
node.weight) := ((node.leftchild).weight) + ((node.rightchild).weight)
insert (list, node);
return least (list);Na końcu tego algorytmu waga węzła głównego reprezentuje optymalny koszt.
Przykład
Rozważmy podane pliki, f 1 , f 2 , f 3 , f 4 if 5 z odpowiednio 20, 30, 10, 5 i 30 liczbą elementów.
Jeśli operacje scalania są wykonywane zgodnie z podaną sekwencją, to
M1 = merge f1 and f2 => 20 + 30 = 50
M2 = merge M1 and f3 => 50 + 10 = 60
M3 = merge M2 and f4 => 60 + 5 = 65
M4 = merge M3 and f5 => 65 + 30 = 95
Hence, the total number of operations is
50 + 60 + 65 + 95 = 270
Now, the question arises is there any better solution?
Sortując liczby według ich rozmiaru w porządku rosnącym, otrzymujemy następującą sekwencję -
f4, f3, f1, f2, f5
W związku z tym operacje łączenia mogą być wykonywane na tej sekwencji
M1 = merge f4 and f3 => 5 + 10 = 15
M2 = merge M1 and f1 => 15 + 20 = 35
M3 = merge M2 and f2 => 35 + 30 = 65
M4 = merge M3 and f5 => 65 + 30 = 95
Dlatego całkowita liczba operacji wynosi
15 + 35 + 65 + 95 = 210
Oczywiście jest to lepsze niż poprzednie.
W tym kontekście zamierzamy teraz rozwiązać problem za pomocą tego algorytmu.
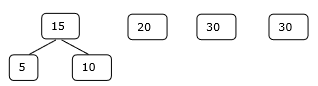
Zestaw początkowy

Krok 1
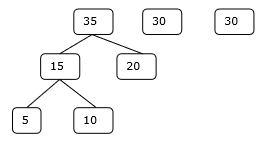
Krok 2
Krok 3
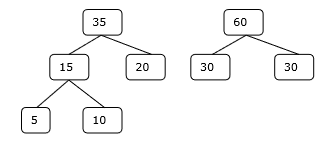
Krok 4
Stąd rozwiązanie wymaga 15 + 35 + 60 + 95 = 205 ilości porównań.
Programowanie dynamiczne jest również wykorzystywane w problemach optymalizacji. Podobnie jak metoda dziel i rządź, programowanie dynamiczne rozwiązuje problemy poprzez łączenie rozwiązań podproblemów. Co więcej, algorytm programowania dynamicznego rozwiązuje każdy podproblem tylko raz, a następnie zapisuje odpowiedź w tabeli, unikając w ten sposób ponownego obliczania odpowiedzi za każdym razem.
Dwie główne właściwości problemu sugerują, że dany problem można rozwiązać za pomocą programowania dynamicznego. Te właściwości sąoverlapping sub-problems and optimal substructure.
Nakładające się podproblemy
Podobnie jak w przypadku podejścia „dziel i rządź”, programowanie dynamiczne również łączy rozwiązania podproblemów. Jest używany głównie tam, gdzie rozwiązanie jednego podproblemu jest potrzebne wielokrotnie. Obliczone rozwiązania są przechowywane w tabeli, więc nie trzeba ich ponownie obliczać. Stąd ta technika jest potrzebna tam, gdzie istnieje nakładający się podproblem.
Na przykład wyszukiwanie binarne nie ma nakładającego się problemu podrzędnego. Podczas gdy rekurencyjny program liczb Fibonacciego ma wiele nakładających się podproblemów.
Optymalna podstruktura
Dany problem ma optymalną właściwość podstruktury, jeśli optymalne rozwiązanie danego problemu można uzyskać za pomocą optymalnych rozwiązań jego podproblemów.
Na przykład problem Najkrótsza ścieżka ma następującą optymalną właściwość podstruktury -
Jeśli node x leży w najkrótszej ścieżce od węzła źródłowego u do węzła docelowego v, to najkrótsza ścieżka od u do v to połączenie najkrótszej ścieżki z u do xi najkrótsza ścieżka od x do v.
Standardowe algorytmy All Pair Shortest Path, takie jak Floyd-Warshall i Bellman-Ford, są typowymi przykładami programowania dynamicznego.
Etapy dynamicznego podejścia do programowania
Algorytm programowania dynamicznego jest zaprojektowany przy użyciu następujących czterech kroków -
- Scharakteryzuj strukturę optymalnego rozwiązania.
- Rekurencyjnie określ wartość optymalnego rozwiązania.
- Oblicz wartość optymalnego rozwiązania, zazwyczaj w sposób oddolny.
- Skonstruuj optymalne rozwiązanie na podstawie obliczonych informacji.
Zastosowania dynamicznego podejścia do programowania
- Mnożenie łańcucha macierzy
- Najdłuższa wspólna kolejność
- Problem komiwojażera
W tym samouczku omówiliśmy wcześniej problem z ułamkowym plecakiem przy użyciu podejścia Chciwego. Pokazaliśmy, że podejście Greedy daje optymalne rozwiązanie dla Fractional Knapsack. Jednak w tym rozdziale omówimy problem plecakowy 0-1 i jego analizę.
W plecaku 0-1 przedmioty nie mogą zostać zniszczone, co oznacza, że złodziej powinien zabrać przedmiot w całości lub powinien go zostawić. Z tego powodu nazywa się go plecakiem 0-1.
Stąd w przypadku plecaka 0-1 wartość xi może być 0 lub 1, gdzie inne ograniczenia pozostają takie same.
0-1 Plecak nie może być rozwiązany przez Chciwość. Chciwe podejście nie zapewnia optymalnego rozwiązania. W wielu przypadkach podejście Greedy może dać optymalne rozwiązanie.
Poniższe przykłady potwierdzą nasze stwierdzenie.
Przykład 1
Weźmy pod uwagę, że pojemność plecaka wynosi W = 25, a przedmioty są zgodne z poniższą tabelą.
| Pozycja | ZA | b | do | re |
|---|---|---|---|---|
| Zysk | 24 | 18 | 18 | 10 |
| Waga | 24 | 10 | 10 | 7 |
Bez uwzględnienia zysku na jednostkę masy (pi/wi), jeśli zastosujemy podejście Greedy do rozwiązania tego problemu, pierwsza pozycja Azostanie wybrany jako przyczyni max í mama zysk spośród wszystkich elementów.
Po wybraniu pozycji A, żaden element nie zostanie wybrany. Stąd dla tego zbioru pozycji całkowity zysk wynosi24. Natomiast optymalne rozwiązanie można osiągnąć wybierając pozycje,B i C, gdzie całkowity zysk to 18 + 18 = 36.
Przykład-2
Zamiast wybierać elementy na podstawie ogólnej korzyści, w tym przykładzie elementy są wybierane na podstawie współczynnika p I / w I . Weźmy pod uwagę, że pojemność plecaka wynosi W = 60, a pozycje są zgodne z poniższą tabelą.
| Pozycja | ZA | b | do |
|---|---|---|---|
| Cena £ | 100 | 280 | 120 |
| Waga | 10 | 40 | 20 |
| Stosunek | 10 | 7 | 6 |
Korzystając z podejścia Greedy, pierwsza pozycja Ajest zaznaczony. Następnie następny elementBjest wybrany. Stąd całkowity zysk wynosi100 + 280 = 380. Jednak optymalne rozwiązanie tej instancji można osiągnąć wybierając elementy,B i C, gdzie jest całkowity zysk 280 + 120 = 400.
W związku z tym można stwierdzić, że podejście Greedy może nie dać optymalnego rozwiązania.
Aby rozwiązać 0-1 Knapsack, wymagane jest podejście do programowania dynamicznego.
Stwierdzenie problemu
Złodziej jest rabowania do przechowywania i mogą zawierać maksymalny ı mal ciężarWdo jego plecaka. Tam sąn sztuk i wagę ith pozycja jest wi a zysk z wyboru tej pozycji wynosi pi. Jakie przedmioty powinien zabrać złodziej?
Podejście do programowania dynamicznego
Pozwolić i być pozycją o najwyższym numerze w optymalnym rozwiązaniu S dla Wdolarów. NastępnieS' = S - {i} jest optymalnym rozwiązaniem dla W - wi dolarów i wartość rozwiązania S jest Vi plus wartość podproblemu.
Fakt ten możemy wyrazić wzorem: zdefiniuj c[i, w] być rozwiązaniem dla przedmiotów 1,2, … , ioraz maksymalną i ciężar mamaw.
Algorytm przyjmuje następujące dane wejściowe
Maksymalne i ciężar mamaW
Liczba sztuk n
Dwie sekwencje v = <v1, v2, …, vn> i w = <w1, w2, …, wn>
Dynamic-0-1-knapsack (v, w, n, W)
for w = 0 to W do
c[0, w] = 0
for i = 1 to n do
c[i, 0] = 0
for w = 1 to W do
if wi ≤ w then
if vi + c[i-1, w-wi] then
c[i, w] = vi + c[i-1, w-wi]
else c[i, w] = c[i-1, w]
else
c[i, w] = c[i-1, w]Zestaw przedmiotów do wzięcia można wywnioskować z tabeli, zaczynając od c[n, w] i śledzenie wstecz, skąd pochodzą optymalne wartości.
Jeśli c [i, w] = c [i-1, w] , to elementi nie jest częścią rozwiązania i kontynuujemy śledzenie za pomocą c[i-1, w]. W przeciwnym razie pozi jest częścią rozwiązania i kontynuujemy śledzenie za pomocą c[i-1, w-W].
Analiza
Algorytm ten wymaga θ ( n , w ) razy, ponieważ tabela c ma ( n + 1). ( W + 1) wpisów, gdzie każdy wpis wymaga θ (1) czasu do obliczenia.
Najdłuższym wspólnym problemem podciągów jest znalezienie najdłuższej sekwencji istniejącej w obu podanych ciągach.
Następstwo
Rozważmy ciąg S = <s 1 , s 2 , s 3 , s 4 ,…, s n >.
Sekwencja Z = <z 1 , z 2 , z 3 , z 4 ,…, z m > nad S nazywana jest podsekwencją S, wtedy i tylko wtedy, gdy można ją wyprowadzić z delecji S niektórych elementów.
Wspólna konsekwencja
Przypuszczać, X i Yto dwie sekwencje na skończonym zbiorze elementów. Możemy to powiedziećZ jest wspólnym następstwem X i Y, gdyby Z jest podciągiem obu X i Y.
Najdłuższa wspólna kolejność
Jeśli podano zbiór sekwencji, najdłuższym wspólnym problemem podciągów jest znalezienie wspólnego podciągu wszystkich sekwencji o maksymalnej długości.
Najdłuższym wspólnym problemem jest klasyczny problem informatyczny, będący podstawą programów do porównywania danych, takich jak narzędzie diff, i znajduje zastosowanie w bioinformatyce. Jest również szeroko stosowany w systemach kontroli wersji, takich jak SVN i Git, do uzgadniania wielu zmian wprowadzonych w kolekcji plików z kontrolą wersji.
Metoda naiwna
Pozwolić X być sekwencją długości m i Y sekwencja długości n. Sprawdź każdy podciągX czy jest to podciąg Yi zwraca najdłuższy wspólny podciąg znaleziony.
Tam są 2m podciągów X. Testowanie sekwencji bez względu na to, czy jest to podciągY trwa O(n)czas. W ten sposób przyjąłby naiwny algorytmO(n2m) czas.
Programowanie dynamiczne
Niech X = <x 1 , x 2 , x 3 ,…, x m > i Y = <y 1 , y 2 , y 3 ,…, y n > będą sekwencjami. Do obliczenia długości elementu używany jest następujący algorytm.
W tej procedurze tabela C[m, n] jest obliczana w kolejności głównej wiersza i innej tabeli B[m,n] jest obliczana w celu skonstruowania optymalnego rozwiązania.
Algorithm: LCS-Length-Table-Formulation (X, Y)
m := length(X)
n := length(Y)
for i = 1 to m do
C[i, 0] := 0
for j = 1 to n do
C[0, j] := 0
for i = 1 to m do
for j = 1 to n do
if xi = yj
C[i, j] := C[i - 1, j - 1] + 1
B[i, j] := ‘D’
else
if C[i -1, j] ≥ C[i, j -1]
C[i, j] := C[i - 1, j] + 1
B[i, j] := ‘U’
else
C[i, j] := C[i, j - 1]
B[i, j] := ‘L’
return C and BAlgorithm: Print-LCS (B, X, i, j)
if i = 0 and j = 0
return
if B[i, j] = ‘D’
Print-LCS(B, X, i-1, j-1)
Print(xi)
else if B[i, j] = ‘U’
Print-LCS(B, X, i-1, j)
else
Print-LCS(B, X, i, j-1)Ten algorytm wypisze najdłuższy wspólny podciąg X i Y.
Analiza
Aby wypełnić tabelę, plik zewnętrzny for pętla iteruje m czasy i wewnętrzne for pętla iteruje nczasy. Stąd złożoność algorytmu wynosi O (m, n) , gdziem i n to długość dwóch strun.
Przykład
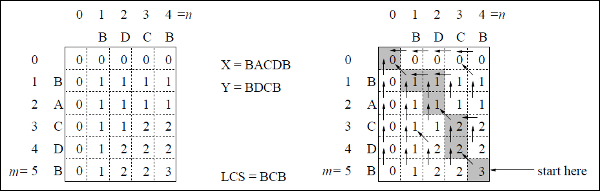
W tym przykładzie mamy dwa ciągi X = BACDB i Y = BDCB znaleźć najdłuższy wspólny podciąg.
Zgodnie z algorytmem LCS-Length-Table-Formulation (jak podano powyżej), obliczyliśmy tabelę C (pokazaną po lewej stronie) i tabelę B (pokazaną po prawej stronie).
W tabeli B zamiast „D”, „L” i „U” używamy odpowiednio strzałki ukośnej, strzałki w lewo i strzałki w górę. Po wygenerowaniu tabeli B LCS jest określane przez funkcję LCS-Print. Wynik to BCB.
ZA spanning tree jest podzbiorem niekierowanego Grafu, który ma wszystkie wierzchołki połączone minimalną liczbą krawędzi.
Jeśli wszystkie wierzchołki są połączone w grafie, istnieje co najmniej jedno drzewo opinające. Na wykresie może istnieć więcej niż jedno drzewo opinające.
Nieruchomości
- Drzewo opinające nie ma żadnego cyklu.
- Do każdego wierzchołka można dotrzeć z dowolnego innego wierzchołka.
Przykład
Na poniższym wykresie podświetlone krawędzie tworzą drzewo opinające.
Minimalne drzewo rozpinające
ZA Minimum Spanning Tree (MST)jest podzbiorem krawędzi połączonego ważonego grafu niekierowanego, który łączy wszystkie wierzchołki razem z minimalną możliwą całkowitą wagą krawędzi. Aby uzyskać MST, można użyć algorytmu Prima lub algorytmu Kruskala. Dlatego w tym rozdziale omówimy algorytm Prim.
Jak omówiliśmy, jeden wykres może mieć więcej niż jedno drzewo opinające. Jeśli tam sąn liczba wierzchołków, jaką powinno mieć drzewo opinające n - 1liczba krawędzi. W tym kontekście, jeśli każda krawędź wykresu jest powiązana z wagą i istnieje więcej niż jedno drzewo opinające, musimy znaleźć minimalne drzewo opinające wykresu.
Ponadto, jeśli istnieją zduplikowane krawędzie ważone, wykres może mieć wiele minimalnych drzew rozpinających.
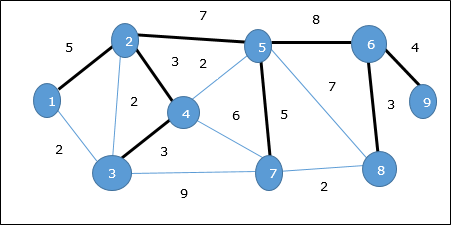
Na powyższym wykresie pokazaliśmy drzewo opinające, chociaż nie jest to minimalne drzewo opinające. Koszt tego drzewa rozpinającego wynosi (5 + 7 + 3 + 3 + 5 + 8 + 3 + 4) = 38.
Użyjemy algorytmu Prim, aby znaleźć minimalne drzewo opinające.
Algorytm Prima
Algorytm Prim jest zachłannym podejściem do znalezienia minimalnego drzewa opinającego. W tym algorytmie, aby utworzyć MST, możemy zacząć od dowolnego wierzchołka.
Algorithm: MST-Prim’s (G, w, r)
for each u є G.V
u.key = ∞
u.∏ = NIL
r.key = 0
Q = G.V
while Q ≠ Ф
u = Extract-Min (Q)
for each v є G.adj[u]
if each v є Q and w(u, v) < v.key
v.∏ = u
v.key = w(u, v)Funkcja Extract-Min zwraca wierzchołek z minimalnym kosztem krawędzi. Ta funkcja działa na min-sterty.
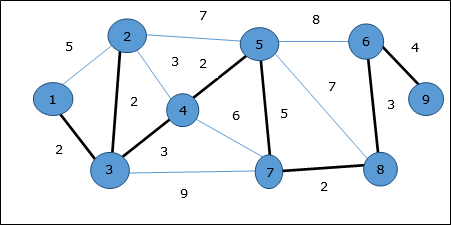
Przykład
Korzystając z algorytmu Prima, możemy zacząć od dowolnego wierzchołka, zacznijmy od wierzchołka 1.
Wierzchołek 3 jest połączony z wierzchołkiem 1 przy minimalnych kosztach krawędzi, a tym samym przewaga (1, 2) jest dodawany do drzewa opinającego.
Następnie krawędź (2, 3) jest uważane, ponieważ jest to minimum między krawędziami {(1, 2), (2, 3), (3, 4), (3, 7)}.
W następnym kroku otrzymujemy przewagę (3, 4) i (2, 4)przy minimalnych kosztach. Brzeg(3, 4) jest wybierany losowo.
W podobny sposób krawędzie (4, 5), (5, 7), (7, 8), (6, 8) i (6, 9)są wybrane. Ponieważ wszystkie wierzchołki są odwiedzane, algorytm się zatrzymuje.
Koszt drzewa opinającego wynosi (2 + 2 + 3 + 2 + 5 + 2 + 3 + 4) = 23. Na tym wykresie nie ma więcej drzewa opinającego o koszcie mniejszym niż 23.
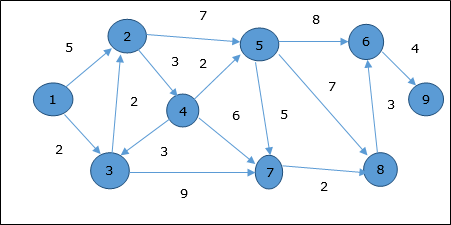
Algorytm Dijkstry
Algorytm Dijkstry rozwiązuje problem najkrótszych ścieżek z jednym źródłem na ukierunkowanym grafie ważonym G = (V, E) , gdzie wszystkie krawędzie są nieujemne (tj. W (u, v) ≥ 0 dla każdej krawędzi (u, v ) Є E ).
W poniższym algorytmie użyjemy jednej funkcji Extract-Min(), która wyodrębnia węzeł za pomocą najmniejszego klucza.
Algorithm: Dijkstra’s-Algorithm (G, w, s)
for each vertex v Є G.V
v.d := ∞
v.∏ := NIL
s.d := 0
S := Ф
Q := G.V
while Q ≠ Ф
u := Extract-Min (Q)
S := S U {u}
for each vertex v Є G.adj[u]
if v.d > u.d + w(u, v)
v.d := u.d + w(u, v)
v.∏ := uAnaliza
Złożoność tego algorytmu jest w pełni zależna od implementacji funkcji Extract-Min. Jeśli funkcja wyodrębniania min jest zaimplementowana przy użyciu wyszukiwania liniowego, złożoność tego algorytmu wynosiO(V2 + E).
W tym algorytmie, jeśli użyjemy min-sterty na której Extract-Min() funkcja działa, aby zwrócić węzeł z Q najmniejszym kluczem można jeszcze bardziej zmniejszyć złożoność tego algorytmu.
Przykład
Rozważmy wierzchołek 1 i 9odpowiednio jako wierzchołek początkowy i docelowy. Początkowo wszystkie wierzchołki oprócz wierzchołka początkowego są oznaczone przez ∞, a wierzchołek początkowy jest oznaczony przez0.
| Wierzchołek | Inicjał | Krok 1 V 1 | Krok 2 V 3 | Krok 3 V 2 | Krok 4 V 4 | Krok 5 V 5 | Krok 6 V 7 | Krok 7 V 8 | Step8 V 6 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | ∞ | 5 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| 3 | ∞ | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 4 | ∞ | ∞ | ∞ | 7 | 7 | 7 | 7 | 7 | 7 |
| 5 | ∞ | ∞ | ∞ | 11 | 9 | 9 | 9 | 9 | 9 |
| 6 | ∞ | ∞ | ∞ | ∞ | ∞ | 17 | 17 | 16 | 16 |
| 7 | ∞ | ∞ | 11 | 11 | 11 | 11 | 11 | 11 | 11 |
| 8 | ∞ | ∞ | ∞ | ∞ | ∞ | 16 | 13 | 13 | 13 |
| 9 | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ | 20 |
Stąd minimalna odległość wierzchołka 9 od wierzchołka 1 jest 20. A ścieżka jest
1 → 3 → 7 → 8 → 6 → 9
Ta ścieżka jest określana na podstawie informacji o poprzedniku.
Algorytm Bellmana Forda
Ten algorytm rozwiązuje problem najkrótszej ścieżki z jednego źródła w grafie skierowanym G = (V, E)w którym wagi krawędzi mogą być ujemne. Ponadto algorytm ten można zastosować do znalezienia najkrótszej ścieżki, jeśli nie istnieje żaden cykl ważony ujemnie.
Algorithm: Bellman-Ford-Algorithm (G, w, s)
for each vertex v Є G.V
v.d := ∞
v.∏ := NIL
s.d := 0
for i = 1 to |G.V| - 1
for each edge (u, v) Є G.E
if v.d > u.d + w(u, v)
v.d := u.d +w(u, v)
v.∏ := u
for each edge (u, v) Є G.E
if v.d > u.d + w(u, v)
return FALSE
return TRUEAnaliza
Pierwszy for pętla jest używana do inicjalizacji, która działa w O(V)czasy. Następnyfor działa pętla |V - 1| przechodzi przez krawędzie, które trwaO(E) czasy.
Dlatego działa algorytm Bellmana-Forda O(V, E) czas.
Przykład
Poniższy przykład pokazuje krok po kroku, jak działa algorytm Bellmana-Forda. Ten wykres ma ujemną krawędź, ale nie ma żadnego ujemnego cyklu, dlatego problem można rozwiązać za pomocą tej techniki.
W momencie inicjalizacji wszystkie wierzchołki oprócz źródła są oznaczone przez ∞, a źródło jest oznaczone przez 0.
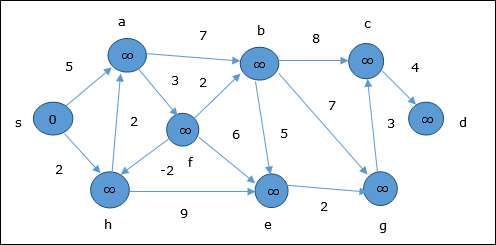
W pierwszym kroku wszystkie wierzchołki, do których można dotrzeć ze źródła, są aktualizowane przy minimalnym koszcie. Stąd wierzchołkia i h są aktualizowane.
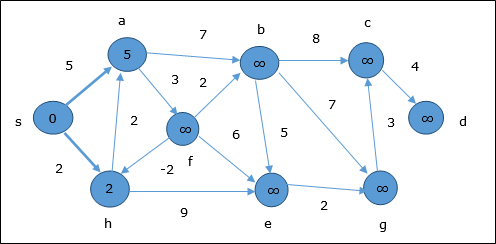
W następnym kroku wierzchołki a, b, f i e są aktualizowane.
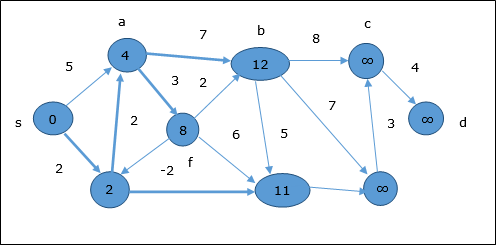
Zgodnie z tą samą logiką, w tym kroku wierzchołki b, f, c i g są aktualizowane.
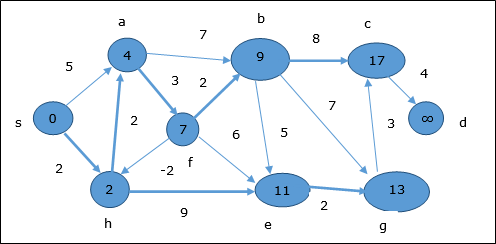
Tutaj wierzchołki c i d są aktualizowane.
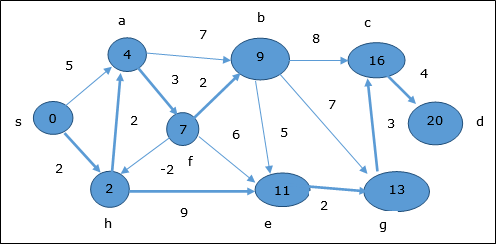
Stąd minimalna odległość między wierzchołkami s i wierzchołek d jest 20.
Opierając się na informacjach poprzednika, ścieżka to s → h → e → g → c → d
Wielostopniowy wykres G = (V, E) jest grafem skierowanym, na który podzielone są wierzchołki k (gdzie k > 1) liczba rozłącznych podzbiorów S = {s1,s2,…,sk}takie, że krawędź (u, v) jest w E, a następnie u Є s i i v Є s 1 + 1 dla niektórych podzbiorów w partycji i |s1| = |sk| = 1.
Wierzchołek s Є s1 nazywa się source i wierzchołek t Є sk jest nazywany sink.
Gzwykle przyjmuje się, że jest to wykres ważony. Na tym wykresie koszt krawędzi (i, j) jest reprezentowany przez c (i, j) . Stąd koszt drogi od źródłas tonąć t to suma kosztów każdej krawędzi na tej ścieżce.
Problem z wykresem wielostopniowym polega na znalezieniu ścieżki przy minimalnych kosztach ze źródła s tonąć t.
Przykład
Rozważ poniższy przykład, aby zrozumieć koncepcję wykresu wielostopniowego.
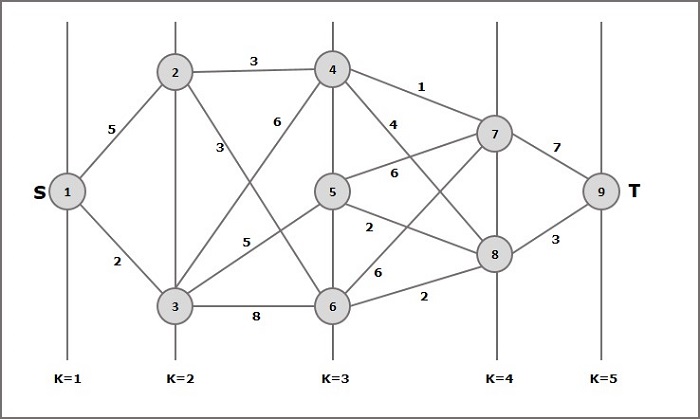
Zgodnie ze wzorem musimy obliczyć koszt (i, j) wykonując następujące czynności
Krok 1: Koszt (K-2, j)
W tym kroku trzy węzły (węzły 4, 5, 6) są wybierane jako j. Dlatego na tym etapie mamy trzy opcje wyboru minimalnego kosztu.
Koszt (3, 4) = min {c (4, 7) + Koszt (7, 9), c (4, 8) + Koszt (8, 9)} = 7
Koszt (3, 5) = min {c (5, 7) + Koszt (7, 9), c (5, 8) + Koszt (8, 9)} = 5
Koszt (3, 6) = min {c (6, 7) + Koszt (7, 9), c (6, 8) + Koszt (8, 9)} = 5
Krok-2: Koszt (K-3, j)
Dwa węzły są wybrane jako j, ponieważ na etapie k - 3 = 2 są dwa węzły, 2 i 3. Zatem wartość i = 2 oraz j = 2 i 3.
Koszt (2, 2) = min {c (2, 4) + Koszt (4, 8) + Koszt (8, 9), c (2, 6) +
Koszt (6, 8) + Koszt (8, 9)} = 8
Koszt (2, 3) = {c (3, 4) + Koszt (4, 8) + Koszt (8, 9), c (3, 5) + Koszt (5, 8) + Koszt (8, 9), c (3, 6) + Koszt (6, 8) + Koszt (8, 9)} = 10
Krok 3: Koszt (K-4, j)
Koszt (1, 1) = {c (1, 2) + Koszt (2, 6) + Koszt (6, 8) + Koszt (8, 9), c (1, 3) + Koszt (3, 5) + Koszt (5, 8) + Koszt (8, 9))} = 12
c (1, 3) + Koszt (3, 6) + Koszt (6, 8 + Koszt (8, 9))} = 13
Stąd ścieżka o minimalnym koszcie to 1→ 3→ 5→ 8→ 9.
Stwierdzenie problemu
Podróżnik musi odwiedzić wszystkie miasta z listy, gdzie znane są odległości między wszystkimi miastami i każde miasto należy odwiedzić tylko raz. Jaka jest najkrótsza możliwa trasa, którą odwiedza on każde miasto dokładnie raz i wraca do miasta pochodzenia?
Rozwiązanie
Problem komiwojażera jest najbardziej znanym problemem obliczeniowym. Możemy użyć metody brutalnej siły, aby ocenić każdą możliwą trasę i wybrać najlepszą. Dlan liczba wierzchołków na wykresie (n - 1)! wiele możliwości.
Zamiast brutalnej siły przy użyciu dynamicznego podejścia do programowania, rozwiązanie można uzyskać w krótszym czasie, chociaż nie ma algorytmu czasu wielomianowego.
Rozważmy wykres G = (V, E), gdzie V to zbiór miast i Eto zbiór ważonych krawędzi. Krawędźe(u, v) reprezentuje te wierzchołki u i vsą połączone. Odległość między wierzchołkamiu i v jest d(u, v), która powinna być nieujemna.
Załóżmy, że zaczęliśmy od miasta 1 a po wizycie w niektórych miastach jesteśmy teraz w mieście j. Dlatego jest to częściowa wycieczka. Z pewnością musimy wiedziećj, ponieważ to określi, które miasta będą najwygodniejsze do odwiedzenia w następnej kolejności. Musimy też znać wszystkie odwiedzone do tej pory miasta, żeby nie powtarzać żadnego z nich. Dlatego jest to odpowiedni problem podrzędny.
Dla podzbioru miast S Є {1, 2, 3, ... , n} to obejmuje 1, i j Є S, pozwolić C(S, j) być długością najkrótszej ścieżki prowadzącej do każdego węzła S dokładnie raz, zaczynając o 1 i kończące się na j.
Kiedy |S| > 1, definiujemyC(S, 1) = ∝, ponieważ ścieżka nie może zaczynać się ani kończyć w 1.
Teraz pozwólmy wyrazić C(S, j)pod względem mniejszych podproblemów. Musimy zacząć od1 i zakończyć o j. Kolejne miasto powinniśmy wybrać w taki sposób
$$C(S, j) = min \:C(S - \lbrace j \rbrace, i) + d(i, j)\:where\: i\in S \: and\: i \neq jc(S, j) = minC(s- \lbrace j \rbrace, i)+ d(i,j) \:where\: i\in S \: and\: i \neq j $$
Algorithm: Traveling-Salesman-Problem
C ({1}, 1) = 0
for s = 2 to n do
for all subsets S Є {1, 2, 3, … , n} of size s and containing 1
C (S, 1) = ∞
for all j Є S and j ≠ 1
C (S, j) = min {C (S – {j}, i) + d(i, j) for i Є S and i ≠ j}
Return minj C ({1, 2, 3, …, n}, j) + d(j, i)Analiza
Jest ich najwyżej $2^n.n$podproblemy, a rozwiązanie każdego z nich wymaga czasu liniowego. Dlatego całkowity czas pracy wynosi$O(2^n.n^2)$.
Przykład
W poniższym przykładzie zilustrujemy kroki w celu rozwiązania problemu komiwojażera.

Z powyższego wykresu przygotowano następującą tabelę.
| 1 | 2 | 3 | 4 | |
| 1 | 0 | 10 | 15 | 20 |
| 2 | 5 | 0 | 9 | 10 |
| 3 | 6 | 13 | 0 | 12 |
| 4 | 8 | 8 | 9 | 0 |
S = Φ
$$\small Cost (2,\Phi,1) = d (2,1) = 5\small Cost(2,\Phi,1)=d(2,1)=5$$
$$\small Cost (3,\Phi,1) = d (3,1) = 6\small Cost(3,\Phi,1)=d(3,1)=6$$
$$\small Cost (4,\Phi,1) = d (4,1) = 8\small Cost(4,\Phi,1)=d(4,1)=8$$
S = 1
$$\small Cost (i,s) = min \lbrace Cost (j,s – (j)) + d [i,j]\rbrace\small Cost (i,s)=min \lbrace Cost (j,s)-(j))+ d [i,j]\rbrace$$
$$\small Cost (2,\lbrace 3 \rbrace,1) = d [2,3] + Cost (3,\Phi,1) = 9 + 6 = 15cost(2,\lbrace3 \rbrace,1)=d[2,3]+cost(3,\Phi ,1)=9+6=15$$
$$\small Cost (2,\lbrace 4 \rbrace,1) = d [2,4] + Cost (4,\Phi,1) = 10 + 8 = 18cost(2,\lbrace4 \rbrace,1)=d[2,4]+cost(4,\Phi,1)=10+8=18$$
$$\small Cost (3,\lbrace 2 \rbrace,1) = d [3,2] + Cost (2,\Phi,1) = 13 + 5 = 18cost(3,\lbrace2 \rbrace,1)=d[3,2]+cost(2,\Phi,1)=13+5=18$$
$$\small Cost (3,\lbrace 4 \rbrace,1) = d [3,4] + Cost (4,\Phi,1) = 12 + 8 = 20cost(3,\lbrace4 \rbrace,1)=d[3,4]+cost(4,\Phi,1)=12+8=20$$
$$\small Cost (4,\lbrace 3 \rbrace,1) = d [4,3] + Cost (3,\Phi,1) = 9 + 6 = 15cost(4,\lbrace3 \rbrace,1)=d[4,3]+cost(3,\Phi,1)=9+6=15$$
$$\small Cost (4,\lbrace 2 \rbrace,1) = d [4,2] + Cost (2,\Phi,1) = 8 + 5 = 13cost(4,\lbrace2 \rbrace,1)=d[4,2]+cost(2,\Phi,1)=8+5=13$$
S = 2
$$\small Cost(2, \lbrace 3, 4 \rbrace, 1)=\begin{cases}d[2, 3] + Cost(3, \lbrace 4 \rbrace, 1) = 9 + 20 = 29\\d[2, 4] + Cost(4, \lbrace 3 \rbrace, 1) = 10 + 15 = 25=25\small Cost (2,\lbrace 3,4 \rbrace,1)\\\lbrace d[2,3]+ \small cost(3,\lbrace4\rbrace,1)=9+20=29d[2,4]+ \small Cost (4,\lbrace 3 \rbrace ,1)=10+15=25\end{cases}= 25$$
$$\small Cost(3, \lbrace 2, 4 \rbrace, 1)=\begin{cases}d[3, 2] + Cost(2, \lbrace 4 \rbrace, 1) = 13 + 18 = 31\\d[3, 4] + Cost(4, \lbrace 2 \rbrace, 1) = 12 + 13 = 25=25\small Cost (3,\lbrace 2,4 \rbrace,1)\\\lbrace d[3,2]+ \small cost(2,\lbrace4\rbrace,1)=13+18=31d[3,4]+ \small Cost (4,\lbrace 2 \rbrace ,1)=12+13=25\end{cases}= 25$$
$$\small Cost(4, \lbrace 2, 3 \rbrace, 1)=\begin{cases}d[4, 2] + Cost(2, \lbrace 3 \rbrace, 1) = 8 + 15 = 23\\d[4, 3] + Cost(3, \lbrace 2 \rbrace, 1) = 9 + 18 = 27=23\small Cost (4,\lbrace 2,3 \rbrace,1)\\\lbrace d[4,2]+ \small cost(2,\lbrace3\rbrace,1)=8+15=23d[4,3]+ \small Cost (3,\lbrace 2 \rbrace ,1)=9+18=27\end{cases}= 23$$
S = 3
$$\small Cost(1, \lbrace 2, 3, 4 \rbrace, 1)=\begin{cases}d[1, 2] + Cost(2, \lbrace 3, 4 \rbrace, 1) = 10 + 25 = 35\\d[1, 3] + Cost(3, \lbrace 2, 4 \rbrace, 1) = 15 + 25 = 40\\d[1, 4] + Cost(4, \lbrace 2, 3 \rbrace, 1) = 20 + 23 = 43=35 cost(1,\lbrace 2,3,4 \rbrace),1)\\d[1,2]+cost(2,\lbrace 3,4 \rbrace,1)=10+25=35\\d[1,3]+cost(3,\lbrace 2,4 \rbrace,1)=15+25=40\\d[1,4]+cost(4,\lbrace 2,3 \rbrace ,1)=20+23=43=35\end{cases}$$
Minimalna ścieżka kosztów to 35.
Zacznij od kosztu {1, {2, 3, 4}, 1}, otrzymujemy minimalną wartość d [1, 2]. Gdys = 3wybierz ścieżkę od 1 do 2 (koszt to 10), a następnie przejdź wstecz. Gdys = 2, otrzymujemy minimalną wartość d [4, 2]. Wybierz ścieżkę od 2 do 4 (koszt to 10), a następnie cofnij się.
Gdy s = 1, otrzymujemy minimalną wartość d [4, 3]. Wybierając ścieżkę od 4 do 3 (koszt 9), następnie przejdziemy do, a następnie dos = Φkrok. Otrzymujemy minimalną wartość dlad [3, 1] (koszt 6).

Drzewo wyszukiwania binarnego (BST) to drzewo, w którym wartości kluczy są przechowywane w węzłach wewnętrznych. Węzły zewnętrzne są węzłami pustymi. Klucze są uporządkowane leksykograficznie, tj. Dla każdego węzła wewnętrznego wszystkie klucze w lewym poddrzewie są mniejsze niż klucze w węźle, a wszystkie klucze w prawym poddrzewie są większe.
Znając częstotliwość wyszukiwania każdego z kluczy, dość łatwo jest obliczyć oczekiwany koszt dostępu do każdego węzła w drzewie. Optymalnym drzewem wyszukiwania binarnego jest BST, który ma minimalny oczekiwany koszt lokalizacji każdego węzła
Czas wyszukiwania elementu w BST to O(n), podczas gdy w zbalansowanym czasie wyszukiwania BST jest O(log n). Ponownie czas wyszukiwania można poprawić w drzewie wyszukiwania binarnego optymalnego kosztu, umieszczając najczęściej używane dane w korzeniu i bliżej elementu głównego, jednocześnie umieszczając najrzadziej używane dane w pobliżu liści i liści.
W tym miejscu przedstawiono algorytm optymalnego drzewa wyszukiwania binarnego. Najpierw budujemy BST z zestawu dostarczonych plikówn liczba różnych kluczy < k1, k2, k3, ... kn >. Tutaj zakładamy prawdopodobieństwo uzyskania dostępu do kluczaKi jest pi. Niektóre atrapy kluczy (d0, d1, d2, ... dn) są dodawane, ponieważ niektóre wyszukiwania mogą być wykonywane dla wartości, których nie ma w zestawie kluczy K. Zakładamy, że dla każdego atrapy kluczadi prawdopodobieństwo dostępu wynosi qi.
Optimal-Binary-Search-Tree(p, q, n)
e[1…n + 1, 0…n],
w[1…n + 1, 0…n],
root[1…n + 1, 0…n]
for i = 1 to n + 1 do
e[i, i - 1] := qi - 1
w[i, i - 1] := qi - 1
for l = 1 to n do
for i = 1 to n – l + 1 do
j = i + l – 1 e[i, j] := ∞
w[i, i] := w[i, i -1] + pj + qj
for r = i to j do
t := e[i, r - 1] + e[r + 1, j] + w[i, j]
if t < e[i, j]
e[i, j] := t
root[i, j] := r
return e and rootAnaliza
Algorytm wymaga O (n3) czas, ponieważ trzy zagnieżdżone forpętle są używane. Każda z tych pętli przyjmuje co najwyżejn wartości.
Przykład
Biorąc pod uwagę poniższe drzewo, koszt wynosi 2,80, choć nie jest to wynik optymalny.
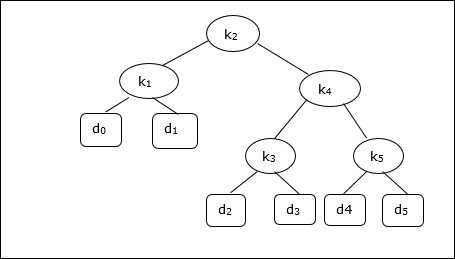
| Węzeł | Głębokość | Prawdopodobieństwo | Wkład |
|---|---|---|---|
| k 1 | 1 | 0,15 | 0,30 |
| k 2 | 0 | 0.10 | 0.10 |
| k 3 | 2 | 0,05 | 0,15 |
| k 4 | 1 | 0.10 | 0,20 |
| k 5 | 2 | 0,20 | 0,60 |
| d 0 | 2 | 0,05 | 0,15 |
| d 1 | 2 | 0.10 | 0,30 |
| d 2 | 3 | 0,05 | 0,20 |
| d 3 | 3 | 0,05 | 0,20 |
| d 4 | 3 | 0,05 | 0,20 |
| d 5 | 3 | 0.10 | 0,40 |
| Total | 2.80 |
Aby uzyskać optymalne rozwiązanie, korzystając z algorytmu omówionego w tym rozdziale, generowane są poniższe tabele.
W poniższych tabelach indeks kolumny to i a indeks wiersza to j.
| mi | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 5 | 2,75 | 2.00 | 1.30 | 0,90 | 0,50 | 0.10 |
| 4 | 1,75 | 1.20 | 0,60 | 0,30 | 0,05 | |
| 3 | 1.25 | 0,70 | 0,25 | 0,05 | ||
| 2 | 0,90 | 0,40 | 0,05 | |||
| 1 | 0,45 | 0.10 | ||||
| 0 | 0,05 |
| w | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 5 | 1,00 | 0,80 | 0,60 | 0,50 | 0.35 | 0.10 |
| 4 | 0,70 | 0,50 | 0,30 | 0,20 | 0,05 | |
| 3 | 0.55 | 0.35 | 0,15 | 0,05 | ||
| 2 | 0,45 | 0,25 | 0,05 | |||
| 1 | 0,30 | 0.10 | ||||
| 0 | 0,05 |
| korzeń | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 5 | 2 | 4 | 5 | 5 | 5 |
| 4 | 2 | 2 | 4 | 4 | |
| 3 | 2 | 2 | 3 | ||
| 2 | 1 | 2 | |||
| 1 | 1 |
Z tych tabel można utworzyć optymalne drzewo.
Istnieje kilka typów stert, jednak w tym rozdziale omówimy stertę binarną. ZAbinary heapto struktura danych, która wygląda podobnie do pełnego drzewa binarnego. Struktura danych sterty jest zgodna z właściwościami porządkowania omówionymi poniżej. Ogólnie sterta jest reprezentowana przez tablicę. W tym rozdziale przedstawiamy stertę wgH.
Ponieważ elementy sterty są przechowywane w tablicy, biorąc pod uwagę indeks początkowy jako 1, pozycja węzła macierzystego ith element można znaleźć pod adresem ⌊ i/2 ⌋. Lewe dziecko i prawe dzieckoith węzeł jest na pozycji 2i i 2i + 1.
Stertę binarną można dalej sklasyfikować jako plik max-heap lub a min-heap na podstawie właściwości zamawiającego.
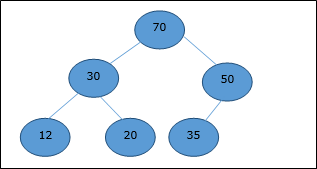
Max-Heap
W tej stercie wartość klucza węzła jest większa lub równa wartości klucza najwyższego elementu potomnego.
W związku z tym, H[Parent(i)] ≥ H[i]
Min-Heap
W mean-heap wartość klucza węzła jest mniejsza lub równa wartości klucza najniższego elementu podrzędnego.
W związku z tym, H[Parent(i)] ≤ H[i]
W tym kontekście podstawowe operacje są pokazane poniżej w odniesieniu do Max-Heap. Wstawianie i usuwanie elementów na stertach i ze stert wymaga zmiany układu elementów. W związku z tym,Heapify funkcja musi zostać wywołana.
Reprezentacja tablicy
Kompletne drzewo binarne może być reprezentowane przez tablicę, przechowującą jego elementy przy użyciu przechodzenia do kolejności poziomów.
Rozważmy stertę (jak pokazano poniżej), która będzie reprezentowana przez tablicę H.
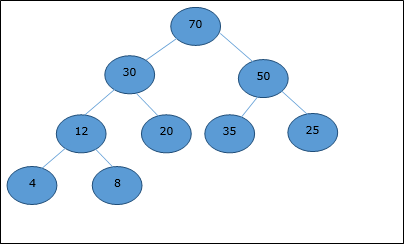
Biorąc pod uwagę indeks początkowy jako 0przy użyciu przechodzenia na poziomie kolejności elementy są przechowywane w tablicy w następujący sposób.
| Index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ... |
| elements | 70 | 30 | 50 | 12 | 20 | 35 | 25 | 4 | 8 | ... |
W tym kontekście operacje na stercie są reprezentowane w odniesieniu do Max-Heap.
Aby znaleźć indeks rodzica elementu w index i, następujący algorytm Parent (numbers[], i) jest używany.
Algorithm: Parent (numbers[], i)
if i == 1
return NULL
else
[i / 2]Indeks lewego dziecka elementu o indeksie i można znaleźć za pomocą następującego algorytmu, Left-Child (numbers[], i).
Algorithm: Left-Child (numbers[], i)
If 2 * i ≤ heapsize
return [2 * i]
else
return NULLIndeks prawego dziecka elementu o indeksie i można znaleźć za pomocą następującego algorytmu, Right-Child(numbers[], i).
Algorithm: Right-Child (numbers[], i)
if 2 * i < heapsize
return [2 * i + 1]
else
return NULLAby wstawić element do sterty, nowy element jest początkowo dołączany na końcu sterty jako ostatni element tablicy.
Po wstawieniu tego elementu, właściwość sterty może zostać naruszona, stąd właściwość sterty jest naprawiana poprzez porównanie dodanego elementu z jego rodzicem i przeniesienie dodanego elementu na wyższy poziom, zamieniając się pozycjami z elementem nadrzędnym. Ten proces nazywa siępercolation up.
Porównanie jest powtarzane do momentu, gdy element nadrzędny jest większy lub równy elementowi przesączającemu.
Algorithm: Max-Heap-Insert (numbers[], key)
heapsize = heapsize + 1
numbers[heapsize] = -∞
i = heapsize
numbers[i] = key
while i > 1 and numbers[Parent(numbers[], i)] < numbers[i]
exchange(numbers[i], numbers[Parent(numbers[], i)])
i = Parent (numbers[], i)Analiza
Początkowo element jest dodawany na końcu tablicy. Jeśli narusza właściwość sterty, element jest wymieniany ze swoim rodzicem. Wysokość drzewa tolog n. Maksymalnylog n liczba operacji do wykonania.
Stąd złożoność tej funkcji O(log n).
Przykład
Rozważmy maksymalny stos, jak pokazano poniżej, w którym należy dodać nowy element 5.
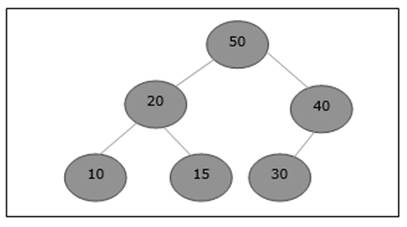
Początkowo na końcu tej tablicy zostanie dodane 55.
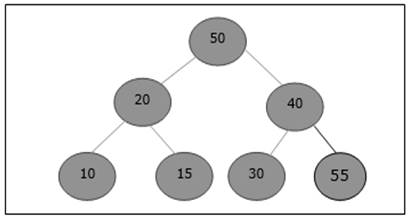
Po wstawieniu narusza właściwość sterty. Dlatego element musi zamienić się ze swoim rodzicem. Po zamianie sterta wygląda następująco.
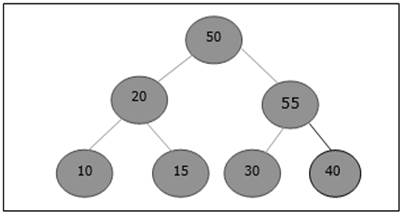
Ponownie element narusza właściwość sterty. W związku z tym jest zamieniany z rodzicem.
Teraz musimy się zatrzymać.
Heapify przestawia elementy tablicy, w których lewe i prawe poddrzewo ith element jest zgodny z właściwością sterty.
Algorithm: Max-Heapify(numbers[], i)
leftchild := numbers[2i]
rightchild := numbers [2i + 1]
if leftchild ≤ numbers[].size and numbers[leftchild] > numbers[i]
largest := leftchild
else
largest := i
if rightchild ≤ numbers[].size and numbers[rightchild] > numbers[largest]
largest := rightchild
if largest ≠ i
swap numbers[i] with numbers[largest]
Max-Heapify(numbers, largest)Gdy podana tablica nie jest zgodna z właściwością sterty, Heap jest budowany na podstawie następującego algorytmu Build-Max-Heap (numbers[]).
Algorithm: Build-Max-Heap(numbers[])
numbers[].size := numbers[].length
fori = ⌊ numbers[].length/2 ⌋ to 1 by -1
Max-Heapify (numbers[], i)Metoda wyodrębniania służy do wyodrębniania elementu głównego sterty. Oto algorytm.
Algorithm: Heap-Extract-Max (numbers[])
max = numbers[1]
numbers[1] = numbers[heapsize]
heapsize = heapsize – 1
Max-Heapify (numbers[], 1)
return maxPrzykład
Rozważmy ten sam przykład omówiony wcześniej. Teraz chcemy wyodrębnić element. Ta metoda zwróci element główny sterty.
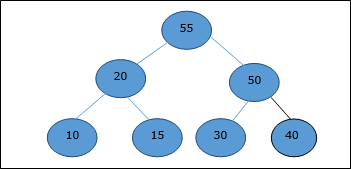
Po usunięciu elementu głównego, ostatni element zostanie przeniesiony do pozycji głównej.
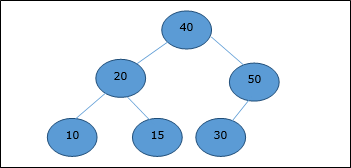
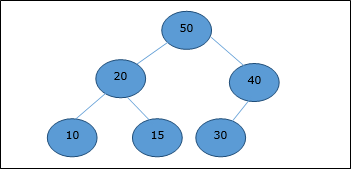
Teraz zostanie wywołana funkcja Heapify. Po Heapify generowana jest następująca sterta.
Sortowanie bąbelkowe to elementarny algorytm sortowania, który działa poprzez wielokrotną wymianę sąsiednich elementów, jeśli to konieczne. Gdy nie są wymagane żadne wymiany, plik jest sortowany.
To najprostsza technika spośród wszystkich algorytmów sortowania.
Algorithm: Sequential-Bubble-Sort (A)
fori← 1 to length [A] do
for j ← length [A] down-to i +1 do
if A[A] < A[j - 1] then
Exchange A[j] ↔ A[j-1]Realizacja
voidbubbleSort(int numbers[], intarray_size) {
inti, j, temp;
for (i = (array_size - 1); i >= 0; i--)
for (j = 1; j <= i; j++)
if (numbers[j - 1] > numbers[j]) {
temp = numbers[j-1];
numbers[j - 1] = numbers[j];
numbers[j] = temp;
}
}Analiza
Oto liczba porównań
1 + 2 + 3 +...+ (n - 1) = n(n - 1)/2 = O(n2)
Oczywiście wykres pokazuje n2 charakter sortowania bąbelkowego.
W tym algorytmie liczba porównań jest niezależna od zbioru danych, tj. Czy podane elementy wejściowe są w kolejności posortowanej, w kolejności odwrotnej lub losowej.
Wymagania dotyczące pamięci
Z powyższego algorytmu jasno wynika, że sortowanie bąbelkowe nie wymaga dodatkowej pamięci.
Przykład
Unsorted list: |
|
1 st iteracja:
5 > 2 swap |
|
|||||||
5 > 1 swap |
|
|||||||
5 > 4 swap |
|
|||||||
5 > 3 swap |
|
|||||||
5 < 7 no swap |
|
|||||||
7 > 6 swap |
|
2 ND iteracji:
2 > 1 swap |
|
|||||||
2 < 4 no swap |
|
|||||||
4 > 3 swap |
|
|||||||
4 < 5 no swap |
|
|||||||
5 < 6 no swap |
|
Nie ma zmiany w 3 rd , 4 TH , 5 TH i 6 -go iteracji.
Wreszcie,
the sorted list is |
|
Sortowanie przez wstawianie to bardzo prosta metoda sortowania liczb w kolejności rosnącej lub malejącej. Ta metoda jest zgodna z metodą przyrostową. Można to porównać z techniką sortowania kart podczas gry.
Liczby, które należy posortować, nazywane są keys. Oto algorytm metody sortowania przez wstawianie.
Algorithm: Insertion-Sort(A)
for j = 2 to A.length
key = A[j]
i = j – 1
while i > 0 and A[i] > key
A[i + 1] = A[i]
i = i -1
A[i + 1] = keyAnaliza
Czas działania tego algorytmu jest bardzo zależny od danych wejściowych.
Jeśli podane liczby są posortowane, działa ten algorytm O(n)czas. Jeśli podane liczby są w odwrotnej kolejności, algorytm działaO(n2) czas.
Przykład
Unsorted list: |
|
1st iteration:
Klucz = a [2] = 13
a [1] = 2 <13
Swap, no swap |
|
2nd iteration:
Klucz = a [3] = 5
a [2] = 13> 5
Zamień 5 i 13 |
|
Następnie a [1] = 2 <13
Swap, no swap |
|
3rd iteration:
Klucz = a [4] = 18
a [3] = 13 <18,
a [2] = 5 <18,
a [1] = 2 <18
Swap, no swap |
|
4th iteration:
Klucz = a [5] = 14
a [4] = 18> 14
Zamień 18 i 14 |
|
Następnie a [3] = 13 <14,
a [2] = 5 <14,
a [1] = 2 <14
Więc nie ma zamiany |
|
Wreszcie,
the sorted list is |
|
Ten typ sortowania nosi nazwę Selection Sortjak to działa poprzez wielokrotne sortowanie elementów. Działa to w następujący sposób: najpierw znajdź najmniejszy w tablicy i zamień go z elementem na pierwszej pozycji, następnie znajdź drugi najmniejszy element i zamień go z elementem na drugiej pozycji i kontynuuj w ten sposób, aż cała tablica będzie posortowane.
Algorithm: Selection-Sort (A)
fori ← 1 to n-1 do
min j ← i;
min x ← A[i]
for j ←i + 1 to n do
if A[j] < min x then
min j ← j
min x ← A[j]
A[min j] ← A [i]
A[i] ← min xSortowanie przez wybór należy do najprostszych technik sortowania i sprawdza się bardzo dobrze w przypadku małych plików. Ma dość ważne zastosowanie, ponieważ każdy element jest przenoszony najwyżej raz.
Sortowanie sekcji jest metodą z wyboru do sortowania plików z bardzo dużymi obiektami (rekordami) i małymi kluczami. Najgorszy przypadek ma miejsce, gdy tablica jest już posortowana w porządku malejącym i chcemy posortować je w kolejności rosnącej.
Niemniej jednak czas wymagany przez algorytm sortowania przez wybór nie jest bardzo wrażliwy na pierwotną kolejność sortowanej tablicy: test, jeśli A[j] < min x jest wykonywany dokładnie tyle samo razy w każdym przypadku.
Sortowanie przez wybór spędza większość czasu na próbach znalezienia minimalnego elementu w nieposortowanej części tablicy. Wyraźnie pokazuje podobieństwo między sortowaniem przez wybór i sortowaniem bąbelkowym.
Sortowanie bąbelkowe wybiera maksymalną liczbę pozostałych elementów na każdym etapie, ale marnuje trochę wysiłku, nadając porządek nieposortowanej części tablicy.
Sortowanie przez wybór jest kwadratowe zarówno w najgorszym, jak i przeciętnym przypadku, i nie wymaga dodatkowej pamięci.
Dla każdego i od 1 do n - 1, jest jedna wymiana i n - i porównań, więc jest w sumie n - 1 wymiany i
(n − 1) + (n − 2) + ...+ 2 + 1 = n(n − 1)/2 porównania.
Te obserwacje są prawdziwe, bez względu na dane wejściowe.
W najgorszym przypadku może to być kwadrat, ale w przeciętnym przypadku jest to wielkość O(n log n). Oznacza to, żerunning time of Selection sort is quite insensitive to the input.
Realizacja
Void Selection-Sort(int numbers[], int array_size) {
int i, j;
int min, temp;
for (i = 0; I < array_size-1; i++) {
min = i;
for (j = i+1; j < array_size; j++)
if (numbers[j] < numbers[min])
min = j;
temp = numbers[i];
numbers[i] = numbers[min];
numbers[min] = temp;
}
}Przykład
Unsorted list: |
|
1 st iteracja:
Najmniejszy = 5
2 <5, najmniejsza = 2
1 <2, najmniejszy = 1
4> 1, najmniejsza = 1
3> 1, najmniejsza = 1
Zamień 5 i 1 |
|
2 ND iteracji:
Najmniejszy = 2
2 <5, najmniejsza = 2
2 <4, najmniejsza = 2
2 <3, najmniejsza = 2
Brak zamiany |
|
3 rd iteracji:
Najmniejszy = 5
4 <5, najmniejsza = 4
3 <4, najmniejsza = 3
Zamień 5 i 3 |
|
4 p iteracji:
Najmniejszy = 4
4 <5, najmniejsza = 4
Brak zamiany |
|
Wreszcie,
the sorted list is |
|
Jest używany na zasadzie dziel i rządź. Szybkie sortowanie to algorytm z wyboru w wielu sytuacjach, ponieważ nie jest trudny do wdrożenia. Jest to dobre sortowanie ogólnego przeznaczenia i zużywa stosunkowo mniej zasobów podczas wykonywania.
Zalety
Jest na miejscu, ponieważ wykorzystuje tylko mały stos pomocniczy.
Wymaga tylko n (log n) czas posortować n przedmiotów.
Posiada wyjątkowo krótką pętlę wewnętrzną.
Algorytm ten został poddany dogłębnej analizie matematycznej, można bardzo precyzyjnie stwierdzić, co dotyczy problemów z wydajnością.
Niedogodności
Jest rekurencyjna. W szczególności, jeśli rekursja nie jest dostępna, implementacja jest niezwykle skomplikowana.
W najgorszym przypadku wymaga to czasu kwadratowego (tj. N2).
Jest kruchy, tzn. Prosty błąd w implementacji może pozostać niezauważony i spowodować, że będzie źle działać.
Szybkie sortowanie polega na podzieleniu danej tablicy na partycje A[p ... r] na dwie niepuste pod tablice A[p ... q] i A[q+1 ... r] takie, że każdy klucz A[p ... q] jest mniejsze lub równe każdemu kluczowi A[q+1 ... r].
Następnie dwie tablice podrzędne są sortowane według rekurencyjnych wywołań funkcji Szybkie sortowanie. Dokładna pozycja partycji zależy od podanej tablicy i indeksuq jest obliczany jako część procedury partycjonowania.
Algorithm: Quick-Sort (A, p, r)
if p < r then
q Partition (A, p, r)
Quick-Sort (A, p, q)
Quick-Sort (A, q + r, r)Zauważ, że aby posortować całą tablicę, początkowe wywołanie powinno być Quick-Sort (A, 1, length[A])
W pierwszej kolejności funkcja Szybkie sortowanie wybiera jeden z elementów tablicy do posortowania jako przestawny. Następnie macierz jest dzielona na partycje po obu stronach osi. Elementy, które są mniejsze lub równe pivot, będą przesuwać się w lewo, podczas gdy elementy, które są większe lub równe pivot będą przesuwać się w prawo.
Partycjonowanie tablicy
Procedura partycjonowania zmienia lokalnie pod-tablice.
Function: Partition (A, p, r)
x ← A[p]
i ← p-1
j ← r+1
while TRUE do
Repeat j ← j - 1
until A[j] ≤ x
Repeat i← i+1
until A[i] ≥ x
if i < j then
exchange A[i] ↔ A[j]
else
return jAnaliza
Najgorszy przypadek złożoności algorytmu szybkiego sortowania to O(n2). Jednak używając tej techniki, w przeciętnych przypadkach generalnie otrzymujemy wynikO(n log n) czas.
Radix sortto mała metoda, której wiele osób używa intuicyjnie podczas alfabetyzacji dużej listy nazwisk. W szczególności lista nazwisk jest najpierw sortowana według pierwszej litery każdego nazwiska, to znaczy nazwiska są uporządkowane w 26 klasach.
Intuicyjnie można posortować liczby według ich najbardziej znaczącej cyfry. Jednak sortowanie Radix działa wbrew intuicji, sortując najpierw najmniej znaczące cyfry. W pierwszym przebiegu wszystkie liczby są sortowane według najmniej znaczącej cyfry i łączone w tablicę. Następnie w drugim przebiegu całe liczby są ponownie sortowane według drugich najmniej znaczących cyfr i łączone w tablicę i tak dalej.
Algorithm: Radix-Sort (list, n)
shift = 1
for loop = 1 to keysize do
for entry = 1 to n do
bucketnumber = (list[entry].key / shift) mod 10
append (bucket[bucketnumber], list[entry])
list = combinebuckets()
shift = shift * 10Analiza
Każdy klawisz jest sprawdzany od razu pod kątem każdej cyfry (lub litery, jeśli klawisze są alfabetyczne) najdłuższego klucza. Stąd, jeśli najdłuższy klucz mam cyfry i są n klucze, sortowanie radix ma porządek O(m.n).
Jeśli jednak spojrzymy na te dwie wartości, rozmiar kluczy będzie stosunkowo mały w porównaniu z liczbą kluczy. Na przykład, jeśli mamy sześciocyfrowe klucze, moglibyśmy mieć milion różnych rekordów.
Tutaj widzimy, że rozmiar kluczy nie jest znaczący, a ten algorytm ma liniową złożoność O(n).
Przykład
Poniższy przykład pokazuje, jak sortowanie Radix działa na siedmiu 3-cyfrowych liczbach.
| Wejście | 1 st Przełęcz | 2 ND Przełęcz | 3 rd Pass |
|---|---|---|---|
| 329 | 720 | 720 | 329 |
| 457 | 355 | 329 | 355 |
| 657 | 436 | 436 | 436 |
| 839 | 457 | 839 | 457 |
| 436 | 657 | 355 | 657 |
| 720 | 329 | 457 | 720 |
| 355 | 839 | 657 | 839 |
W powyższym przykładzie pierwsza kolumna to dane wejściowe. Pozostałe kolumny pokazują listę po kolejnych sortowaniach na coraz bardziej znaczących pozycjach cyfr. Kod sortowania Radix zakłada, że każdy element w tablicyA z n elementy ma d cyfry, gdzie cyfra 1 to cyfra najniższego rzędu i d to cyfra najwyższego rzędu.
Zrozumieć klasę P i NP, najpierw powinniśmy znać model obliczeniowy. Dlatego w tym rozdziale omówimy dwa ważne modele obliczeniowe.
Obliczenia deterministyczne i klasa P.
Deterministyczna maszyna Turinga
Jednym z tych modeli jest deterministyczna maszyna Turinga z jedną taśmą. Maszyna ta składa się ze skończonej kontroli stanu, głowicy odczytująco-zapisującej i dwukierunkowej taśmy z nieskończoną sekwencją.
Poniżej znajduje się schematyczny diagram deterministycznej maszyny Turinga z jedną taśmą.
Program dla deterministycznej maszyny Turinga określa następujące informacje -
- Skończony zestaw symboli taśmy (symbole wejściowe i pusty symbol)
- Skończony zbiór stanów
- Funkcja przejścia
W analizie algorytmicznej, jeśli problem jest rozwiązany w czasie wielomianowym przez deterministyczną maszynę Turinga z jedną taśmą, to problem należy do klasy P.
Obliczenia niedeterministyczne i klasa NP
Niedeterministyczna maszyna Turinga
Aby rozwiązać problem obliczeniowy, innym modelem jest niedeterministyczna maszyna Turinga (NDTM). Struktura NDTM jest podobna do DTM, jednak tutaj mamy jeden dodatkowy moduł zwany modułem zgadywania, który jest powiązany z jedną głowicą tylko do zapisu.
Poniżej znajduje się schemat ideowy.
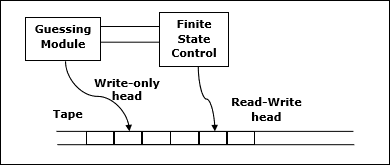
Jeśli problem można rozwiązać w czasie wielomianowym przez niedeterministyczną maszynę Turinga, to problem należy do klasy NP.
Na wykresie nieukierunkowanym a cliquejest pełnym pod-wykresem danego wykresu. Całkowity pod-graf oznacza, że wszystkie wierzchołki tego pod-grafu są połączone ze wszystkimi innymi wierzchołkami tego pod-grafu.
Problem Max-Clique jest obliczeniowym problemem znalezienia maksymalnej kliki grafu. Klika Max jest używana w wielu problemach świata rzeczywistego.
Rozważmy aplikację społecznościową, w której wierzchołki reprezentują profil ludzi, a krawędzie reprezentują wzajemną znajomość na wykresie. Na tym wykresie klika reprezentuje podzbiór ludzi, którzy wszyscy się znają.
Aby znaleźć maksymalną klikę, można systematycznie przeglądać wszystkie podzbiory, ale tego rodzaju przeszukiwanie brutalnej siły jest zbyt czasochłonne dla sieci zawierających więcej niż kilkadziesiąt wierzchołków.
Algorithm: Max-Clique (G, n, k)
S := Φ
for i = 1 to k do
t := choice (1…n)
if t Є S then
return failure
S := S ∪ t
for all pairs (i, j) such that i Є S and j Є S and i ≠ j do
if (i, j) is not a edge of the graph then
return failure
return successAnaliza
Problem Max-Clique jest algorytmem niedeterministycznym. W tym algorytmie najpierw próbujemy określić zbiórk różne wierzchołki, a następnie próbujemy sprawdzić, czy te wierzchołki tworzą pełny wykres.
Nie ma deterministycznego algorytmu wielomianowego do rozwiązania tego problemu. Ten problem jest NP-Complete.
Przykład
Spójrz na poniższy wykres. Tutaj pod-graf zawierający wierzchołki 2, 3, 4 i 6 tworzy pełny wykres. Stąd ten pod-wykres toclique. Ponieważ jest to maksymalny pełny pod-wykres dostarczonego wykresu, jest to4-Clique.

Pokrycie wierzchołka niekierunkowego grafu G = (V, E) jest podzbiorem wierzchołków V' ⊆ V takie, że jeśli krawędź (u, v) jest krawędzią G, to albo u w V lub v w V' lub obydwa.
Znajdź pokrycie wierzchołków o maksymalnym rozmiarze na danym wykresie niekierunkowym. To optymalne pokrycie wierzchołków jest optymalizacyjną wersją problemu NP-zupełnego. Jednak nie jest zbyt trudno znaleźć pokrycie wierzchołków, które jest bliskie optymalnej.
APPROX-VERTEX_COVER (G: Graph) c ← { } E' ← E[G]
while E' is not empty do
Let (u, v) be an arbitrary edge of E' c ← c U {u, v}
Remove from E' every edge incident on either u or v
return cPrzykład
Zbiór krawędzi danego wykresu to -
{(1,6),(1,2),(1,4),(2,3),(2,4),(6,7),(4,7),(7,8),(3,8),(3,5),(8,5)}
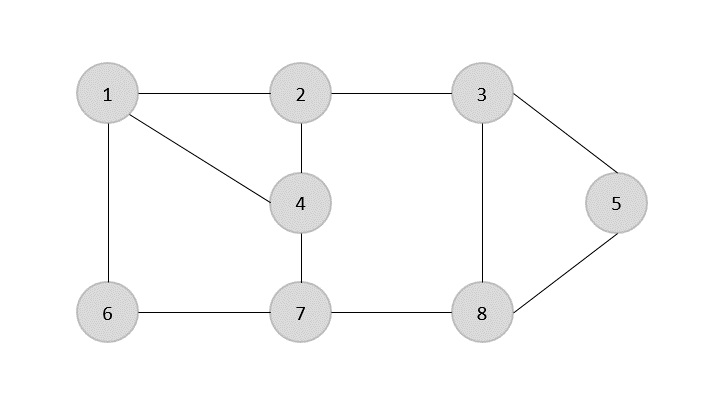
Teraz zaczynamy od wybrania dowolnej krawędzi (1,6). Eliminujemy wszystkie krawędzie, które padają na wierzchołek 1 lub 6 i dodajemy krawędź (1,6) do pokrycia.
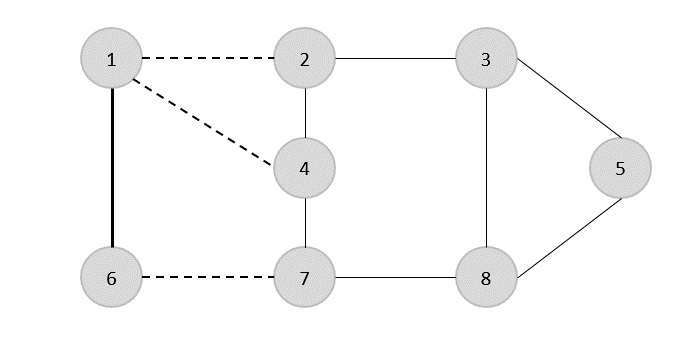
W następnym kroku wybraliśmy losowo kolejną krawędź (2,3)
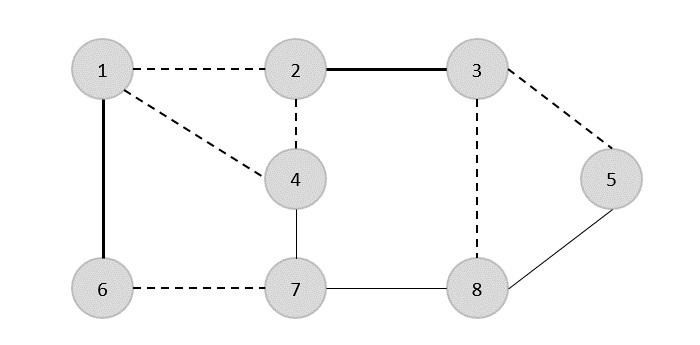
Teraz wybieramy kolejną krawędź (4,7).
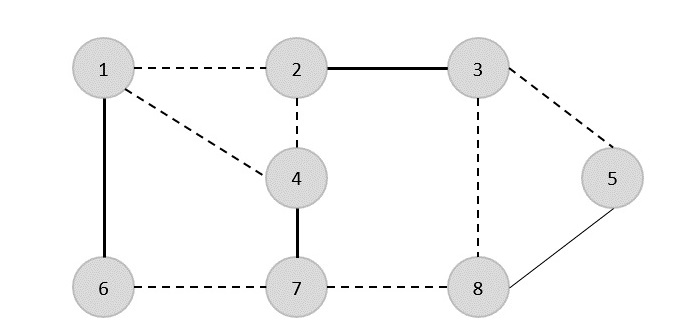
Wybieramy inną krawędź (8,5).
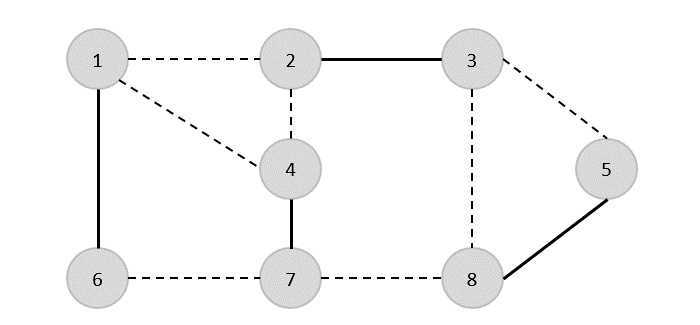
Stąd pokrycie wierzchołków tego wykresu wynosi {1, 2, 4, 5}.
Analiza
Łatwo zauważyć, że czas działania tego algorytmu to O(V + E), używając do reprezentowania listy sąsiedztwa E'.
W informatyce wiele problemów rozwiązuje się, gdy celem jest maksymalizacja lub minimalizacja pewnych wartości, podczas gdy w innych problemach staramy się znaleźć rozwiązanie, czy nie. Stąd problemy można podzielić na następujące kategorie:
Problem optymalizacji
Problemy związane z optymalizacją to te, których celem jest maksymalizacja lub minimalizacja niektórych wartości. Na przykład,
Znalezienie minimalnej liczby kolorów potrzebnych do pokolorowania danego wykresu.
Znajdowanie najkrótszej ścieżki między dwoma wierzchołkami na wykresie.
Problem decyzyjny
Istnieje wiele problemów, na które odpowiedź brzmi tak lub nie. Te typy problemów są znane jako decision problems. Na przykład,
Czy dany wykres można pokolorować tylko czterema kolorami.
Znalezienie cyklu Hamiltona na wykresie nie jest problemem decyzyjnym, podczas gdy sprawdzenie, czy wykres jest hamiltonowem, czy nie, jest problemem decyzyjnym.
Co to jest język?
Każdy problem decyzyjny może mieć tylko dwie odpowiedzi, tak lub nie. W związku z tym problem decyzyjny może należeć do języka, jeśli zapewnia odpowiedź „tak” dla określonego wkładu. Język to ogół danych wejściowych, dla których odpowiedź brzmi „tak”. Większość algorytmów omówionych w poprzednich rozdziałach topolynomial time algorithms.
Dla rozmiaru wejściowego n, jeśli w najgorszym przypadku złożoność czasowa algorytmu wynosi O(nk), gdzie k jest stałą, algorytm jest algorytmem czasu wielomianowego.
Algorytmy, takie jak mnożenie łańcucha macierzy, najkrótsza ścieżka pojedynczego źródła, najkrótsza ścieżka wszystkich par, minimalne drzewo rozpinające itp., Działają w czasie wielomianowym. Istnieje jednak wiele problemów, takich jak podróżujący sprzedawca, optymalne kolorowanie wykresów, cykle Hamiltona, znalezienie najdłuższej ścieżki na wykresie i spełnienie wzoru Boole'a, dla którego nie są znane żadne algorytmy wielomianowe. Te problemy należą do interesującej klasy problemów, zwanejNP-Complete problemy, których stan jest nieznany.
W tym kontekście możemy sklasyfikować problemy w następujący sposób -
Klasa P.
Klasa P składa się z tych problemów, które można rozwiązać w czasie wielomianowym, tj. Problemy te można rozwiązać w czasie O(nk) w najgorszym przypadku, gdzie k jest stała.
Te problemy są nazywane tractable, podczas gdy inni są wzywani intractable or superpolynomial.
Formalnie algorytm jest algorytmem czasu wielomianowego, jeśli istnieje wielomian p(n) tak, że algorytm może rozwiązać każdy rozmiar n za jakiś czas O(p(n)).
Problem wymagający Ω(n50) czas na rozwiązanie jest zasadniczo trudny do rozwiązania dla dużych n. Najbardziej znany algorytm czasu wielomianowego działa w czasieO(nk) za dość niską wartość k.
Zaletą rozważania klasy algorytmów wielomianowych jest to, że wszystko jest rozsądne deterministic single processor model of computation można symulować na sobie co najwyżej wielomianem slow-d
Klasa NP
Klasa NP składa się z tych problemów, które są weryfikowalne w czasie wielomianowym. NP to klasa problemów decyzyjnych, w przypadku których można łatwo sprawdzić poprawność żądanej odpowiedzi przy pomocy dodatkowych informacji. Dlatego nie prosimy o znalezienie rozwiązania, a jedynie o zweryfikowanie, czy rzekome rozwiązanie jest naprawdę poprawne.
Każdy problem w tej klasie można rozwiązać w czasie wykładniczym za pomocą wyszukiwania wyczerpującego.
P kontra NP
Każdy problem decyzyjny, który można rozwiązać za pomocą deterministycznego algorytmu wielomianowego czasu, jest również rozwiązany przez niedeterministyczny algorytm wielomianowy.
Wszystkie problemy w P można rozwiązać za pomocą algorytmów wielomianowych, podczas gdy wszystkie problemy w NP - P są nie do rozwiązania.
Nie wiadomo, czy P = NP. Jednak w NP znanych jest wiele problemów z własnością, że jeśli należą do P, to można udowodnić, że P = NP.
Gdyby P ≠ NP, są problemy w NP, których nie ma ani w P, ani w NP-Complete.
Problem należy do klasy Pczy łatwo jest znaleźć rozwiązanie problemu. Problem należy doNP, jeśli łatwo jest sprawdzić rozwiązanie, które mogło być bardzo uciążliwe.
Stephen Cook przedstawił cztery twierdzenia w swoim artykule „The Complexity of Theorem Proving Procedures”. Te twierdzenia przedstawiono poniżej. Rozumiemy, że w tym rozdziale użyto wielu nieznanych terminów, ale nie mamy możliwości omówienia wszystkiego szczegółowo.
Oto cztery twierdzenia Stephena Cooka:
Twierdzenie 1
Jeśli zestaw S ciągów jest więc akceptowana przez jakąś niedeterministyczną maszynę Turinga w czasie wielomianowym S jest P-redukowalna do {tautologii DNF}.
Twierdzenie-2
Następujące zbiory są P-redukowalne do siebie w parach (a zatem każdy ma ten sam wielomianowy stopień trudności): {tautologies}, {DNF tautologies}, D3, {sub-graph pairs}.
Twierdzenie-3
Dla każdego TQ(k) typu Q, $\mathbf{\frac{T_{Q}(k)}{\frac{\sqrt{k}}{(log\:k)^2}}}$ jest nieograniczony
Tam jest TQ(k) typu Q takie że $T_{Q}(k)\leqslant 2^{k(log\:k)^2}$
Twierdzenie-4
Jeśli zbiór S ciągów zostanie zaakceptowany przez niedeterministyczną maszynę w czasie T(n) = 2n, i jeśli TQ(k) jest uczciwą (tj. policzalną w czasie rzeczywistym) funkcją typu Q, to jest stała K, więc S może być rozpoznany przez deterministyczną maszynę w czasie TQ(K8n).
Po pierwsze, podkreślił znaczenie redukowalności wielomianu w czasie. Oznacza to, że jeśli mamy redukcję czasu wielomianu z jednego problemu do drugiego, zapewnia to, że dowolny algorytm czasu wielomianowego z drugiego problemu można przekształcić w odpowiadający algorytm czasu wielomianu dla pierwszego problemu.
Po drugie, zwrócił uwagę na klasę NP problemów decyzyjnych, które mogą być rozwiązane w czasie wielomianowym przez niedeterministyczny komputer. Większość trudnych do rozwiązania problemów należy do tej klasy NP.
Po trzecie, udowodnił, że jeden konkretny problem w NP ma tę właściwość, że każdy inny problem w NP można zredukować do niej wielomianowo. Jeśli problem spełnialności można rozwiązać za pomocą algorytmu wielomianowego czasu, to każdy problem w NP można rozwiązać również w czasie wielomianowym. Jeśli jakikolwiek problem w NP jest nie do rozwiązania, to problem spełnialności musi być nie do rozwiązania. Zatem problem spełnialności jest najtrudniejszym problemem w NP.
Po czwarte, Cook zasugerował, że inne problemy w NP mogą dzielić z problemem spełnialności tę właściwość, że jest najtrudniejszym członkiem NP.
Problem występuje w NPC klasy, jeśli jest w NP i jest taki sam hardjak każdy problem w NP. Problem w tymNP-hard jeśli wszystkie problemy w NP można zredukować do czasu wielomianu, nawet jeśli nie jest w samym NP.
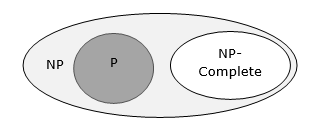
Jeśli dla któregokolwiek z tych problemów istnieje algorytm czasu wielomianowego, wszystkie problemy w NP można by rozwiązać w czasie wielomianowym. Te problemy są nazywaneNP-complete. Zjawisko NP-zupełności jest ważne zarówno ze względów teoretycznych, jak i praktycznych.
Definicja kompletności NP
Język B jest NP-complete jeśli spełnia dwa warunki
B jest w NP
Każdy A w NP jest czas wielomianowy redukowalny do B.
Jeśli język spełnia drugą właściwość, ale niekoniecznie pierwszą, język B jest znany jako NP-Hard. Nieformalnie, problem z wyszukiwaniemB jest NP-Hard jeśli istnieje NP-Complete problem A do której Turing redukuje B.
Problem w NP-Hard nie może być rozwiązany w czasie wielomianowym, dopóki P = NP. Jeśli okaże się, że problemem jest NPC, nie ma potrzeby tracić czasu na szukanie wydajnego algorytmu. Zamiast tego możemy skupić się na algorytmie aproksymacji projektu.
Problemy NP-Complete
Poniżej przedstawiono kilka problemów NP-Complete, dla których nie jest znany algorytm czasu wielomianowego.
- Określenie, czy wykres ma cykl Hamiltona
- Ustalenie, czy formuła boolowska jest satysfakcjonująca itp.
NP-trudne problemy
Następujące problemy są NP-trudne
- Problem zgodności obwodu
- Ustaw osłonę
- Pokrywa wierzchołków
- Problem komiwojażera
W tym kontekście omówimy teraz TSP jest NP-Complete
TSP jest NP-Complete
Problem komiwojażera składa się z komiwojażera i zbioru miast. Sprzedawca musi odwiedzić każde z miast, zaczynając od określonego i wracając do tego samego miasta. Problem polega na tym, że komiwojażer chce zminimalizować całkowitą długość podróży
Dowód
Udowodnić TSP is NP-Complete, najpierw musimy to udowodnić TSP belongs to NP. W TSP znajdujemy wycieczkę i sprawdzamy, czy trasa zawiera jeden wierzchołek. Następnie obliczany jest całkowity koszt krawędzi trasy. Na koniec sprawdzamy, czy koszt jest minimalny. Można to wykonać w czasie wielomianowym. A zatemTSP belongs to NP.
Po drugie, musimy to udowodnić TSP is NP-hard. Aby to udowodnić, jednym ze sposobów jest pokazanie tegoHamiltonian cycle ≤p TSP (jak wiemy, że problem cyklu Hamiltona jest NPkompletny).
Założyć G = (V, E) być przykładem cyklu Hamiltona.
W związku z tym konstruowana jest instancja TSP. Tworzymy pełny wykresG' = (V, E'), gdzie
$$E^{'}=\lbrace(i, j)\colon i, j \in V \:\:and\:i\neq j$$
Zatem funkcja kosztu jest zdefiniowana w następujący sposób -
$$t(i,j)=\begin{cases}0 & if\: (i, j)\: \in E\\1 & otherwise\end{cases}$$
Teraz przypuśćmy, że cykl Hamiltona h istnieje w G. Oczywiste jest, że koszt każdej krawędzi wh jest 0 w G' do której należy każda krawędź E. W związku z tym,h ma koszt 0 w G'. Tak więc, jeśli wykresG ma cykl Hamiltona, a następnie wykres G' ma wycieczkę po 0 koszt.
I odwrotnie, zakładamy, że G' ma wycieczkę h' kosztu najwyżej 0. Koszt krawędzi wE' są 0 i 1zgodnie z definicją. Dlatego każda krawędź musi mieć koszt0 jako koszt h' jest 0. Dlatego wyciągamy z tego wniosekh' zawiera tylko krawędzie w E.
W ten sposób udowodniliśmy to G ma cykl Hamiltona, wtedy i tylko wtedy, gdy G' kosztuje co najwyżej wycieczkę 0. TSP jest NP-kompletny.
Algorytmy omówione w poprzednich rozdziałach działają systematycznie. Aby osiągnąć cel, należy zapisać jedną lub więcej wcześniej zbadanych ścieżek prowadzących do rozwiązania, aby znaleźć optymalne rozwiązanie.
W przypadku wielu problemów droga do celu jest nieistotna. Na przykład w problemie N-Queens nie musimy przejmować się ostateczną konfiguracją hetmanów ani kolejnością dodawania hetmanów.
Wspinaczka górska
Wspinaczka górska to technika rozwiązywania pewnych problemów optymalizacyjnych. W tej technice zaczynamy od nieoptymalnego rozwiązania, a rozwiązanie jest wielokrotnie ulepszane, aż do zmaksymalizowania pewnego warunku.
Pomysł rozpoczęcia od nieoptymalnego rozwiązania jest porównywany do rozpoczynania od podstawy wzgórza, ulepszanie rozwiązania jest porównywane do wchodzenia na wzgórze, a ostatecznie maksymalizacja pewnego stanu jest porównywana do dotarcia na szczyt wzgórza.
Dlatego technikę wspinaczki górskiej można rozpatrywać w następujących fazach -
- Konstruowanie nieoptymalnego rozwiązania uwzględniającego ograniczenia problemu
- Poprawianie rozwiązania krok po kroku
- Ulepszanie rozwiązania, aż nie będzie już możliwe
Technika wspinaczki górskiej jest używana głównie do rozwiązywania trudnych obliczeniowo problemów. Patrzy tylko na stan obecny i najbliższy stan przyszły. Dlatego ta technika jest wydajna pod względem pamięci, ponieważ nie obsługuje drzewa wyszukiwania.
Algorithm: Hill Climbing
Evaluate the initial state.
Loop until a solution is found or there are no new operators left to be applied:
- Select and apply a new operator
- Evaluate the new state:
goal -→ quit
better than current state -→ new current stateIteracyjna poprawa
W iteracyjnej metodzie doskonalenia optymalne rozwiązanie osiąga się poprzez postęp w kierunku optymalnego rozwiązania w każdej iteracji. Jednak ta technika może napotkać lokalne maksima. W tej sytuacji nie ma w pobliżu stanu lepszego rozwiązania.
Tego problemu można uniknąć różnymi metodami. Jedną z tych metod jest symulowane wyżarzanie.
Losowe ponowne uruchomienie
To kolejna metoda rozwiązania problemu optymalizacji lokalnej. Ta technika przeprowadza serię poszukiwań. Za każdym razem zaczyna się od losowo wygenerowanego stanu początkowego. Stąd można uzyskać optymalne lub prawie optymalne rozwiązanie porównując rozwiązania przeprowadzonych poszukiwań.
Problemy techniki wspinaczki górskiej
Local Maxima
Jeśli heurystyka nie jest wypukła, Hill Climbing może zbiegać się do lokalnych maksimów zamiast globalnych maksimów.
Grzbiety i aleje
Jeśli funkcja celu tworzy wąski grzbiet, wówczas wspinacz może wejść na grzbiet lub zejść z alejki tylko zygzakiem. W tym scenariuszu wspinacz musi wykonać bardzo małe kroki, które wymagają więcej czasu, aby osiągnąć cel.
Płaskowyż
Plateau jest napotykane, gdy przestrzeń poszukiwań jest płaska lub dostatecznie płaska, że wartość zwracana przez funkcję docelową jest nie do odróżnienia od wartości zwracanej dla pobliskich regionów, ze względu na precyzję używaną przez maszynę do reprezentowania jej wartości.
Złożoność techniki pokonywania wzniesień
Ta technika nie ma problemów związanych z przestrzenią, ponieważ dotyczy tylko obecnego stanu. Wcześniej zbadane ścieżki nie są zapisywane.
W przypadku większości problemów związanych z techniką wspinaczki pod górę z przypadkowym ponownym uruchomieniem optymalne rozwiązanie można osiągnąć w czasie wielomianowym. Jednak w przypadku problemów NP-Complete czas obliczeniowy może być wykładniczy w oparciu o liczbę lokalnych maksimów.
Zastosowania techniki wspinaczki górskiej
Technika wspinaczki górskiej może być wykorzystana do rozwiązania wielu problemów, w przypadku których obecny stan pozwala na dokładną ocenę funkcji, takich jak Network-Flow, problem Traveling Salesman, problem 8-Queens, projektowanie układów scalonych itp.
Wspinaczka górska jest również wykorzystywana w indukcyjnych metodach uczenia się. Technika ta jest używana w robotyce do koordynacji wielu robotów w zespole. Istnieje wiele innych problemów związanych z tą techniką.
Przykład
Technikę tę można zastosować do rozwiązania problemu komiwojażera. Najpierw ustalane jest wstępne rozwiązanie, które polega na odwiedzeniu wszystkich miast dokładnie raz. Stąd to początkowe rozwiązanie nie jest w większości przypadków optymalne. Nawet to rozwiązanie może być bardzo słabe. Algorytm Hill Climbing zaczyna się od takiego początkowego rozwiązania i wprowadza do niego iteracyjne ulepszenia. W końcu prawdopodobnie zostanie uzyskana znacznie krótsza trasa.