Yapay Sinir Ağı - Hızlı Kılavuz
Sinir ağları, temelde beynin bir bilgisayar modelini yapma girişimi olan paralel bilgi işlem cihazlarıdır. Temel amaç, çeşitli hesaplama görevlerini geleneksel sistemlerden daha hızlı gerçekleştirmek için bir sistem geliştirmektir. Bu görevler, örüntü tanıma ve sınıflandırmayı, yaklaştırmayı, optimizasyonu ve veri kümelemeyi içerir.
Yapay Sinir Ağı nedir?
Yapay Sinir Ağı (YSA), ana teması biyolojik sinir ağları analojisinden ödünç alınan verimli bir bilgi işlem sistemidir. YSA'lar aynı zamanda "yapay sinir sistemleri" veya "paralel dağıtılmış işlem sistemleri" veya "bağlantısal sistemler" olarak da adlandırılır. YSA, birimler arasında iletişime izin vermek için bazı modellerde birbirine bağlı geniş bir birim koleksiyonu elde eder. Düğümler veya nöronlar olarak da adlandırılan bu birimler, paralel olarak çalışan basit işlemcilerdir.
Her nöron, bir bağlantı bağı aracılığıyla diğer nöronla bağlantılıdır. Her bağlantı bağlantısı, giriş sinyali hakkında bilgi içeren bir ağırlık ile ilişkilidir. Bu, nöronların belirli bir sorunu çözmesi için en yararlı bilgidir çünkü ağırlık genellikle iletilen sinyali uyarır veya engeller. Her nöronun aktivasyon sinyali adı verilen bir iç durumu vardır. Giriş sinyalleri ve aktivasyon kuralı birleştirildikten sonra üretilen çıkış sinyalleri diğer birimlere gönderilebilir.
YSA'nın Kısa Tarihi
YSA geçmişi aşağıdaki üç döneme ayrılabilir:
1940'lardan 1960'lara kadar YSA
Bu dönemin bazı önemli gelişmeleri şu şekildedir:
1943 - Sinir ağı kavramının, 1943'te beyindeki nöronların nasıl çalışabileceğini açıklamak için elektrik devrelerini kullanarak basit bir sinir ağını modellediklerinde, fizyolog Warren McCulloch ve matematikçi Walter Pitts'in çalışmaları ile başladığı varsayılmıştır. .
1949- Donald Hebb'in The Organization of Behavior adlı kitabı, bir nöronun bir başkası tarafından tekrar tekrar etkinleştirilmesinin, her kullanıldığında gücünü artırdığını ortaya koyuyor.
1956 - Bir ilişkisel bellek ağı Taylor tarafından tanıtıldı.
1958 - McCulloch ve Pitts nöron modeli için Perceptron adlı bir öğrenme yöntemi Rosenblatt tarafından icat edildi.
1960 - Bernard Widrow ve Marcian Hoff, "ADALINE" ve "MADALINE" adlı modeller geliştirdi.
1960'lardan 1980'lere kadar YSA
Bu dönemin bazı önemli gelişmeleri şu şekildedir:
1961 - Rosenblatt başarısız bir girişimde bulundu ancak çok katmanlı ağlar için “geri yayılım” şemasını önerdi.
1964 - Taylor, çıkış birimleri arasında engellemelerle kazanan her şeyi alan bir devre kurdu.
1969 - Çok katmanlı algılayıcı (MLP), Minsky ve Papert tarafından icat edildi.
1971 - Kohonen, İlişkisel anılar geliştirdi.
1976 - Stephen Grossberg ve Gail Carpenter Uyarlamalı rezonans teorisini geliştirdi.
1980'lerden Günümüze YSA
Bu dönemin bazı önemli gelişmeleri şu şekildedir:
1982 - En önemli gelişme Hopfield'ın Enerji yaklaşımı oldu.
1985 - Boltzmann makinesi Ackley, Hinton ve Sejnowski tarafından geliştirildi.
1986 - Rumelhart, Hinton ve Williams, Genelleştirilmiş Delta Kuralını tanıttı.
1988 - Kosko, Binary Associative Memory'yi (BAM) geliştirdi ve YSA'da Bulanık Mantık kavramını verdi.
Tarihsel inceleme, bu alanda önemli ilerlemeler kaydedildiğini göstermektedir. Sinir ağı tabanlı çipler ortaya çıkıyor ve karmaşık sorunlara uygulamalar geliştiriliyor. Elbette bugün sinir ağı teknolojisi için bir geçiş dönemi.
Biyolojik Nöron
Sinir hücresi (nöron), bilgiyi işleyen özel bir biyolojik hücredir. Bir tahmine göre , çok sayıda ara bağlantıya sahip yaklaşık 10 11 , yaklaşık 10 15 olmak üzere çok sayıda nöron vardır .
Şematik diyagram
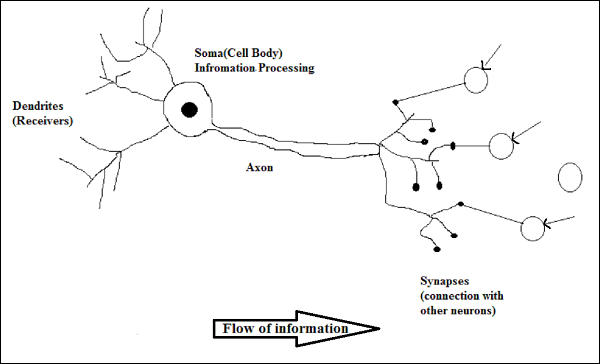
Biyolojik Nöronun Çalışması
Yukarıdaki diyagramda gösterildiği gibi, tipik bir nöron, çalışmasını açıklayabileceğimiz aşağıdaki dört bölümden oluşur -
Dendrites- Bağlı oldukları diğer nöronlardan bilgi almaktan sorumlu ağaç benzeri dallardır. Diğer bir anlamda nöronun kulakları gibi olduklarını söyleyebiliriz.
Soma - Nöronun hücre gövdesidir ve dendritlerden aldıkları bilgilerin işlenmesinden sorumludur.
Axon - Tıpkı nöronların bilgiyi gönderdiği bir kablo gibidir.
Synapses - Akson ile diğer nöron dendritleri arasındaki bağlantıdır.
YSA ve BNN
Yapay Sinir Ağı (YSA) ve Biyolojik Sinir Ağı (BNN) arasındaki farklara bakmadan önce, bu ikisi arasındaki terminolojiye dayalı benzerliklere bir göz atalım.
| Biyolojik Sinir Ağı (BNN) | Yapay Sinir Ağı (YSA) |
|---|---|
| Soma | Düğüm |
| Dendritler | Giriş |
| Sinaps | Ağırlıklar veya Ara Bağlantılar |
| Akson | Çıktı |
Aşağıdaki tablo, bahsedilen bazı kriterlere göre YSA ve BNN arasındaki karşılaştırmayı göstermektedir.
| Kriterler | BNN | YSA |
|---|---|---|
| Processing | Büyük ölçüde paralel, yavaş ama YSA'dan üstün | Büyük ölçüde paralel, hızlı ancak BNN'den daha düşük |
| Size | 10 11 nöron ve 10 15 ara bağlantı | 10 2 ila 10 4 düğüm (esas olarak uygulama türüne ve ağ tasarımcısına bağlıdır) |
| Learning | Belirsizliği tolere edebilirler | Belirsizliği tolere etmek için çok kesin, yapılandırılmış ve biçimlendirilmiş veriler gereklidir |
| Fault tolerance | Kısmi hasarla bile performans düşer | Sağlam performansa sahiptir, dolayısıyla hataya dayanıklı olma potansiyeline sahiptir |
| Storage capacity | Bilgileri sinapsta depolar | Bilgileri sürekli bellek konumlarında saklar |
Yapay Sinir Ağı Modeli
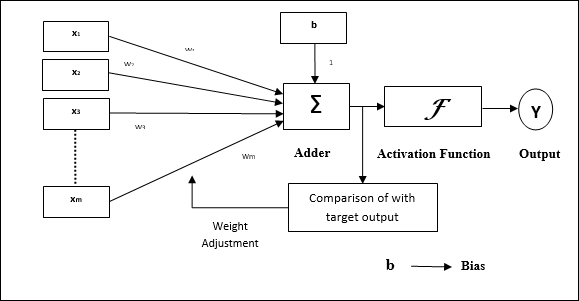
Aşağıdaki diyagram, YSA'nın genel modelini ve ardından işlenmesini temsil etmektedir.
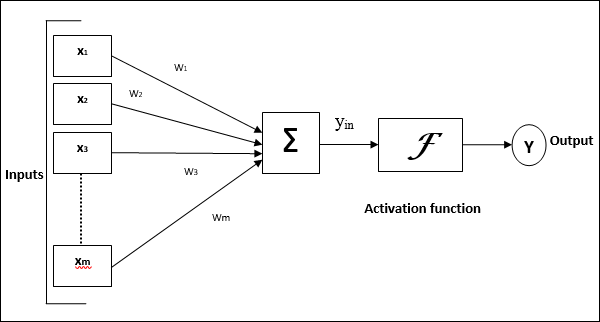
Yapay sinir ağının yukarıdaki genel modeli için, net girdi şu şekilde hesaplanabilir -
$$ y_ {in} \: = \: x_ {1} .w_ {1} \: + \: x_ {2} .w_ {2} \: + \: x_ {3} .w_ {3} \: \ dotso \: x_ {m} .w_ {m} $$
yani, Net girdi $ y_ {in} \: = \: \ sum_i ^ m \: x_ {i} .w_ {i} $
Çıktı, etkinleştirme işlevi net girdinin üzerine uygulanarak hesaplanabilir.
$$ Y \: = \: F (y_ {inç}) $$
Çıktı = işlev (hesaplanan net girdi)
YSA'nın işlenmesi aşağıdaki üç yapı taşına bağlıdır:
- Ağ topolojisi
- Ağırlık Ayarlamaları veya Öğrenme
- Aktivasyon Fonksiyonları
Bu bölümde, YSA'nın bu üç yapı taşı hakkında ayrıntılı olarak tartışacağız.
Ağ topolojisi
Bir ağ topolojisi, bir ağın düğümleri ve bağlantı hatları ile birlikte düzenlenmesidir. Topolojiye göre YSA aşağıdaki türler olarak sınıflandırılabilir -
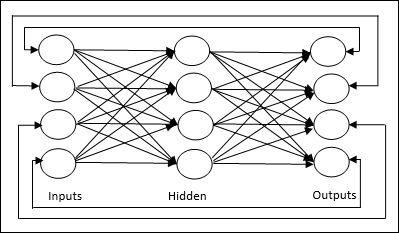
Feedforward Ağı
Katmanlarda işlem birimleri / düğümleri olan ve bir katmandaki tüm düğümler, önceki katmanların düğümlerine bağlanan, yinelenmeyen bir ağdır. Bağlantının üzerlerinde farklı ağırlıkları vardır. Geri besleme döngüsü yoktur, sinyalin girişten çıkışa yalnızca tek yönde akabileceği anlamına gelir. Aşağıdaki iki türe ayrılabilir -
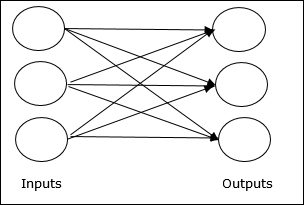
Single layer feedforward network- Kavram, yalnızca bir ağırlıklı katmana sahip ileri beslemeli YSA'dır. Başka bir deyişle, giriş katmanının çıkış katmanına tamamen bağlı olduğunu söyleyebiliriz.
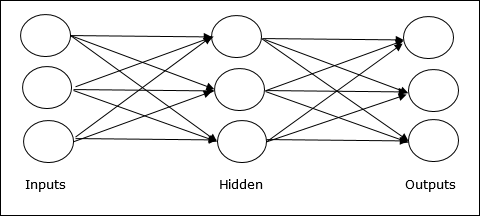
Multilayer feedforward network- Kavram, birden fazla ağırlıklı katmana sahip ileri beslemeli YSA'dır. Bu ağ, giriş ve çıkış katmanı arasında bir veya daha fazla katmana sahip olduğundan, buna gizli katmanlar denir.
Geri Bildirim Ağı
Adından da anlaşılacağı gibi, bir geribildirim ağının geribildirim yolları vardır, bu da sinyalin döngüleri kullanarak her iki yönde de akabileceği anlamına gelir. Bu, onu bir denge durumuna ulaşana kadar sürekli değişen doğrusal olmayan dinamik bir sistem yapar. Aşağıdaki türlere ayrılabilir -
Recurrent networks- Kapalı döngülere sahip geribildirim ağlarıdır. Aşağıda iki tür tekrarlayan ağ bulunmaktadır.
Fully recurrent network - En basit sinir ağı mimarisidir çünkü tüm düğümler diğer tüm düğümlere bağlıdır ve her düğüm hem giriş hem de çıkış olarak çalışır.
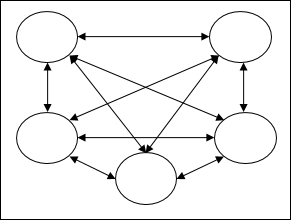
Jordan network - Aşağıdaki şemada gösterildiği gibi çıkışın geri besleme olarak tekrar girişe gideceği kapalı döngü bir ağdır.
Ağırlık Ayarlamaları veya Öğrenme
Yapay sinir ağında öğrenme, belirli bir ağın nöronları arasındaki bağlantıların ağırlıklarını değiştirme yöntemidir. YSA'da öğrenme, denetimli öğrenme, denetimsiz öğrenme ve pekiştirmeli öğrenme olmak üzere üç kategoriye ayrılabilir.
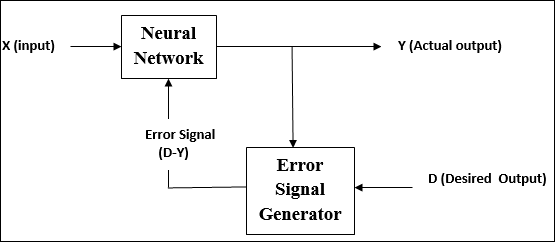
Denetimli Öğrenme
Adından da anlaşılacağı gibi, bu tür bir öğrenme, bir öğretmenin gözetiminde yapılır. Bu öğrenme süreci bağımlıdır.
YSA'nın denetimli öğrenme altındaki eğitimi sırasında, bir çıktı vektörü verecek olan giriş vektörü ağa sunulur. Bu çıktı vektörü, istenen çıktı vektörüyle karşılaştırılır. Gerçek çıkış ile istenen çıkış vektörü arasında bir fark varsa, bir hata sinyali üretilir. Bu hata sinyali temelinde, gerçek çıktı istenen çıktıyla eşleşene kadar ağırlıklar ayarlanır.
Denetimsiz Öğrenme
Adından da anlaşılacağı gibi, bu tür öğrenme, bir öğretmenin gözetimi olmadan yapılır. Bu öğrenme süreci bağımsızdır.
Denetimsiz öğrenme altında YSA eğitimi sırasında, benzer tipteki girdi vektörleri kümeler oluşturmak için birleştirilir. Yeni bir giriş modeli uygulandığında, sinir ağı, giriş modelinin ait olduğu sınıfı belirten bir çıktı yanıtı verir.
Ortamdan istenen çıktının ne olması gerektiği ve bunun doğru mu yanlış mı olduğu konusunda herhangi bir geri bildirim yoktur. Bu nedenle, bu tür öğrenmede, ağın kendisi giriş verilerinden örüntüleri ve özellikleri ve çıktı üzerindeki giriş verilerinin ilişkisini keşfetmelidir.
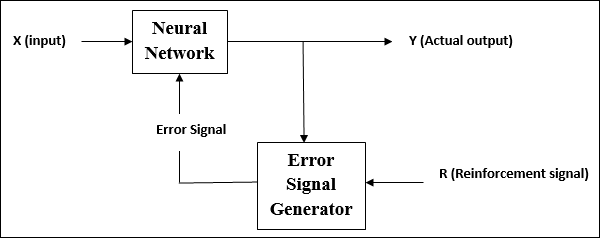
Takviye Öğrenme
Adından da anlaşılacağı gibi, bu tür öğrenme, ağı bazı kritik bilgiler üzerinden güçlendirmek veya güçlendirmek için kullanılır. Bu öğrenme süreci denetimli öğrenmeye benzer, ancak çok daha az bilgiye sahip olabiliriz.
Güçlendirmeli öğrenme altında ağ eğitimi sırasında, ağ çevreden bazı geri bildirimler alır. Bu, onu denetimli öğrenmeye biraz benzer kılar. Bununla birlikte, burada elde edilen geri bildirim öğretici değil değerlendiricidir, yani denetimli öğrenmede olduğu gibi öğretmen yoktur. Geri bildirimi aldıktan sonra ağ, gelecekte daha iyi kritik bilgileri elde etmek için ağırlık ayarlamaları yapar.
Aktivasyon Fonksiyonları
Kesin bir çıktı elde etmek için girdiye uygulanan ekstra kuvvet veya çaba olarak tanımlanabilir. YSA'da, kesin çıktıyı elde etmek için girdinin üzerine etkinleştirme işlevlerini de uygulayabiliriz. Aşağıda, ilgilenilen bazı etkinleştirme işlevleri verilmiştir -
Doğrusal Aktivasyon Fonksiyonu
Giriş düzenlemesi yapmadığı için kimlik işlevi olarak da adlandırılır. Şu şekilde tanımlanabilir -
$$ F (x) \: = \: x $$
Sigmoid Aktivasyon Fonksiyonu
Aşağıdaki gibi iki tiptir -
Binary sigmoidal function- Bu aktivasyon işlevi 0 ile 1 arasında giriş düzenlemesi yapar. Doğası gereği pozitiftir. Her zaman sınırlıdır, bu da çıktısının 0'dan küçük ve 1'den fazla olamayacağı anlamına gelir. Ayrıca doğası gereği kesinlikle artmaktadır, bu da daha fazla girdinin çıktı olacağı anlamına gelir. Olarak tanımlanabilir
$$ F (x) \: = \: sigm (x) \: = \: \ frac {1} {1 \: + \: exp (-x)} $$
Bipolar sigmoidal function- Bu aktivasyon işlevi -1 ile 1 arasında girdi düzenleme gerçekleştirir. Doğası gereği pozitif veya negatif olabilir. Her zaman sınırlıdır, yani çıktısı -1'den küçük ve 1'den fazla olamaz. Ayrıca sigmoid işlevi gibi doğası gereği kesinlikle artmaktadır. Olarak tanımlanabilir
$$ F (x) \: = \: sigm (x) \: = \: \ frac {2} {1 \: + \: exp (-x)} \: - \: 1 \: = \: \ frac {1 \: - \: exp (x)} {1 \: + \: exp (x)} $$
Daha önce belirtildiği gibi, YSA tamamen biyolojik sinir sisteminin, yani insan beyninin çalışma biçiminden esinlenmiştir. İnsan beyninin en etkileyici özelliği öğrenmesidir, dolayısıyla aynı özellik YSA tarafından da kazanılmıştır.
YSA'da Öğrenme Nedir?
Temel olarak öğrenme, çevrede bir değişiklik olduğu gibi ve olduğu zaman değişimi de kendi içinde yapmak ve uyarlamak demektir. YSA karmaşık bir sistemdir veya daha doğrusu içinden geçen bilgiye göre iç yapısını değiştirebilen karmaşık bir adaptif sistemdir diyebiliriz.
Neden Önemlidir?
Karmaşık bir uyarlanabilir sistem olan YSA'da öğrenme, bir işleme biriminin ortamdaki değişiklik nedeniyle girdi / çıktı davranışını değiştirebileceğini ifade eder. YSA'da öğrenmenin önemi, sabit aktivasyon işlevi ve belirli bir ağ kurulduğunda giriş / çıkış vektörü nedeniyle artar. Şimdi girdi / çıktı davranışını değiştirmek için ağırlıkları ayarlamamız gerekiyor.
Sınıflandırma
Aynı sınıftaki örnekler arasında ortak özellikler bularak örneklerin verilerini farklı sınıflara ayırmayı öğrenme süreci olarak tanımlanabilir. Örneğin, YSA eğitimini gerçekleştirmek için benzersiz özelliklere sahip bazı eğitim örneklerimiz var ve testlerini gerçekleştirmek için diğer benzersiz özelliklere sahip bazı test örneklerimiz var. Sınıflandırma, denetimli öğrenmeye bir örnektir.
Sinir Ağı Öğrenme Kuralları
YSA öğrenimi sırasında girdi / çıktı davranışını değiştirmek için ağırlıkları ayarlamamız gerektiğini biliyoruz. Bu nedenle, ağırlıkların değiştirilebileceği bir yöntem gereklidir. Bu yöntemlere, basit algoritmalar veya denklemler olan Öğrenme kuralları adı verilir. Sinir ağı için bazı öğrenme kuralları aşağıdadır -
Hebbian Öğrenme Kuralı
En eski ve en basit kurallardan biri olan bu kural, Donald Hebb tarafından 1949'da The Organization of Behavior adlı kitabında tanıtıldı . Bu, bir tür ileri beslemeli, denetimsiz öğrenmedir.
Basic Concept - Bu kural, Hebb tarafından verilen bir öneriye dayanmaktadır, o da -
“A hücresinin bir aksonu, bir B hücresini uyaracak kadar yakın olduğunda ve tekrar tekrar veya ısrarla ateşlemede yer aldığında, B'yi ateşleyen hücrelerden biri olarak A'nın etkinliğini sağlayacak şekilde bir veya iki hücrede bir miktar büyüme süreci veya metabolik değişim gerçekleşir , artar. "
Yukarıdaki varsayımdan, nöronlar aynı anda ateşlenirse iki nöron arasındaki bağlantıların güçlenebileceği ve farklı zamanlarda ateşlenirse zayıflayabileceği sonucuna varabiliriz.
Mathematical Formulation - Hebbian öğrenme kuralına göre, her adımda bağlantının ağırlığını artırmak için formül aşağıdadır.
$$ \ Delta w_ {ji} (t) \: = \: \ alpha x_ {i} (t) .y_ {j} (t) $$
Burada, $ \ Delta w_ {ji} (t) $ = zaman adımında bağlantının ağırlığının arttığı artış t
$ \ alpha $ = pozitif ve sabit öğrenme oranı
$ x_ {i} (t) $ = zaman adımında sinaptik öncesi nöronun giriş değeri t
$ y_ {i} (t) $ = aynı zamanda adımda sinaptik öncesi nöronun çıktısı t
Perceptron Öğrenme Kuralı
Bu kural, Rosenblatt tarafından sunulan, doğrusal etkinleştirme işlevine sahip tek katmanlı ileri besleme ağlarının denetimli öğrenme algoritmasını düzelten bir hatadır.
Basic Concept- Doğası gereği denetlendiği için, hatayı hesaplamak için, istenen / hedef çıktı ile gerçek çıktı arasında bir karşılaştırma yapılacaktır. Herhangi bir fark bulunursa bağlantı ağırlıklarında değişiklik yapılmalıdır.
Mathematical Formulation - Matematiksel formülasyonunu açıklamak için, 'n' sayıda sonlu girdi vektörümüz olduğunu varsayalım, x (n) ve bunun istenen / hedef çıktı vektörü t (n) ile birlikte, burada n = 1'den N'ye.
Şimdi, daha önce net girdiye göre açıklandığı gibi çıktı 'y' hesaplanabilir ve bu net girdiye uygulanan aktivasyon fonksiyonu aşağıdaki gibi ifade edilebilir -
$$ y \: = \: f (y_ {in}) \: = \: \ begin {case} 1, & y_ {in} \:> \: \ theta \\ 0, & y_ {in} \: \ leqslant \: \ theta \ end {case} $$
Nerede θ eşiktir.
Ağırlığın güncellenmesi aşağıdaki iki durumda yapılabilir -
Case I - ne zaman t ≠ y, sonra
$$ w (yeni) \: = \: w (eski) \: + \; tx $$
Case II - ne zaman t = y, sonra
Ağırlıkta değişiklik yok
Delta Öğrenme Kuralı (Widrow-Hoff Kuralı)
Tüm eğitim modellerinde hatayı en aza indirmek için, Bernard Widrow ve Marcian Hoff tarafından, En Az Ortalama Kareler (LMS) yöntemi olarak da adlandırılır. Sürekli aktivasyon işlevine sahip bir tür denetimli öğrenme algoritmasıdır.
Basic Concept- Bu kuralın temeli, sonsuza kadar devam eden gradyan-iniş yaklaşımıdır. Delta kuralı, çıktı birimine ve hedef değere net girdiyi en aza indirgemek için sinaptik ağırlıkları günceller.
Mathematical Formulation - Sinaptik ağırlıkları güncellemek için delta kuralı şu şekilde verilir:
$$ \ Delta w_ {i} \: = \: \ alpha \ :. x_ {i} .e_ {j} $$
Burada $ \ Delta w_ {i} $ = i th pattern için ağırlık değişimi ;
$ \ alpha $ = pozitif ve sabit öğrenme oranı;
$ x_ {i} $ = sinaptik öncesi nöronun giriş değeri;
$ e_ {j} $ = $ (t \: - \: y_ {in}) $, istenen / hedef çıktı ile gerçek çıktı arasındaki fark $ y_ {in} $
Yukarıdaki delta kuralı yalnızca tek bir çıktı birimi içindir.
Ağırlığın güncellenmesi aşağıdaki iki durumda yapılabilir -
Case-I - ne zaman t ≠ y, sonra
$$ w (yeni) \: = \: w (eski) \: + \: \ Delta w $$
Case-II - ne zaman t = y, sonra
Ağırlıkta değişiklik yok
Rekabetçi Öğrenme Kuralı (Kazanan her şeyi alır)
Çıkış düğümlerinin girdi modelini temsil etmek için birbirleriyle rekabet etmeye çalıştıkları denetimsiz eğitimle ilgilidir. Bu öğrenme kuralını anlamak için, aşağıdaki gibi verilen rekabetçi ağı anlamalıyız -
Basic Concept of Competitive Network- Bu ağ, çıkışlar arasında geri besleme bağlantısı olan tek katmanlı ileri beslemeli bir ağ gibidir. Çıkışlar arasındaki bağlantılar engelleyici tiptedir ve noktalı çizgilerle gösterilir, bu da rakiplerin asla kendilerini desteklemeyecekleri anlamına gelir.
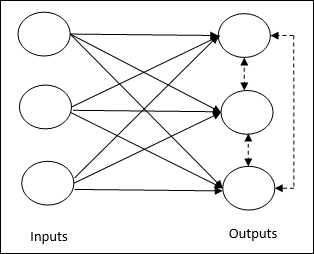
Basic Concept of Competitive Learning Rule- Daha önce de belirtildiği gibi, çıkış düğümleri arasında bir rekabet olacak. Bu nedenle, ana konsept, eğitim sırasında, belirli bir girdi modeline en yüksek aktivasyona sahip çıktı biriminin kazanan ilan edileceğidir. Bu kurala aynı zamanda Kazanan her şeyi alır, çünkü yalnızca kazanan nöron güncellenir ve nöronların geri kalanı değişmeden kalır.
Mathematical formulation - Bu öğrenme kuralının matematiksel formülasyonu için üç önemli faktör aşağıdadır -
Condition to be a winner - Diyelim ki bir nöron $ y_ {k} $ kazanan olmak istiyorsa, o zaman aşağıdaki koşul olacaktır -
$$ y_ {k} \: = \: \ start {case} 1 & if \: v_ {k} \:> \: v_ {j} \: for \: all \: j, \: j \: \ neq \: k \\ 0 & aksi halde \ end {case} $$
Bunun anlamı, eğer $ y_ {k} $ diyelim ki herhangi bir nöron kazanmak istiyorsa, indüklenmiş yerel alanı (toplama biriminin çıktısı), diyelim ki $ v_ {k} $, diğer tüm nöronlar arasında en büyüğü olmalıdır. ağda.
Condition of sum total of weight - Rekabetçi öğrenme kuralı üzerindeki diğer bir kısıtlama, belirli bir çıkış nöronunun ağırlıklarının toplamının 1 olacağıdır. Örneğin, nöronu düşünürsek k sonra -
$$ \ displaystyle \ sum \ limits_ {j} w_ {kj} \: = \: 1 \: \: \: \: \: \: \: \: \: for \: all \: k $$
Change of weight for winner- Bir nöron giriş modeline yanıt vermezse, o nöronda hiçbir öğrenme gerçekleşmez. Bununla birlikte, belirli bir nöron kazanırsa, ilgili ağırlıklar aşağıdaki gibi ayarlanır
$$ \ Delta w_ {kj} \: = \: \ begin {case} - \ alpha (x_ {j} \: - \: w_ {kj}), & if \: neuron \: k \: wins \\ 0, & if \: nöron \: k \: kayıplar \ end {vakalar} $$
Burada $ \ alpha $ öğrenme oranıdır.
Bu açıkça gösteriyor ki, ağırlığını ayarlayarak kazanan nöronu tercih ediyoruz ve eğer bir nöron kaybı varsa, ağırlığını yeniden ayarlamak için uğraşmamıza gerek yok.
Outstar Öğrenme Kuralı
Grossberg tarafından getirilen bu kural, istenen çıktılar bilindiğinden denetimli öğrenmeyle ilgilidir. Aynı zamanda Grossberg öğrenimi olarak da adlandırılır.
Basic Concept- Bu kural, bir katman halinde düzenlenmiş nöronlar üzerine uygulanır. İstenilen çıktıyı üretmek için özel olarak tasarlanmıştır.d katmanının p nöronlar.
Mathematical Formulation - Bu kuraldaki ağırlık ayarlamaları aşağıdaki gibi hesaplanır
$$ \ Delta w_ {j} \: = \: \ alpha \ :( d \: - \: w_ {j}) $$
Buraya d istenen nöron çıktısı ve $ \ alpha $ öğrenme oranıdır.
Adından da anlaşılacağı gibi, supervised learningbir öğretmenin gözetiminde gerçekleşir. Bu öğrenme süreci bağımlıdır. YSA'nın denetimli öğrenme altındaki eğitimi sırasında, bir çıktı vektörü üretecek olan giriş vektörü ağa sunulur. Bu çıktı vektörü, istenen / hedef çıktı vektörü ile karşılaştırılır. Gerçek çıkış ile istenen / hedef çıkış vektörü arasında bir fark varsa bir hata sinyali üretilir. Bu hata sinyali temelinde, gerçek çıktı istenen çıktıyla eşleşene kadar ağırlıklar ayarlanacaktır.
Algılayıcı
Frank Rosenblatt tarafından McCulloch ve Pitts modeli kullanılarak geliştirilen perceptron, yapay sinir ağlarının temel operasyonel birimidir. Denetimli öğrenme kuralı kullanır ve verileri iki sınıfa ayırabilir.
Algılayıcının operasyonel özellikleri: Ayarlanabilir ağırlıkların yanı sıra rastgele sayıda girişi olan tek bir nörondan oluşur, ancak nöronun çıkışı eşiğe bağlı olarak 1 veya 0'dır. Aynı zamanda ağırlığı her zaman 1 olan bir önyargıdan oluşur. Aşağıdaki şekil, algılayıcının şematik bir temsilini verir.
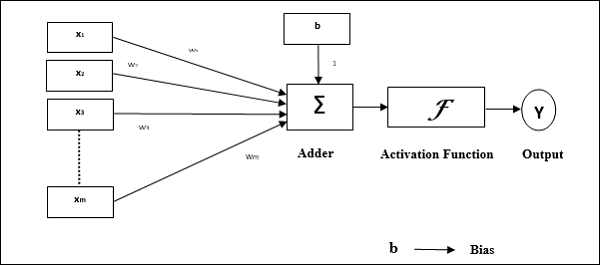
Perceptron bu nedenle aşağıdaki üç temel öğeye sahiptir:
Links - Her zaman 1 ağırlığa sahip bir önyargı içeren bir ağırlık taşıyan bir dizi bağlantı bağlantılarına sahip olacaktır.
Adder - İlgili ağırlıkları ile çarpıldıktan sonra girdiyi ekler.
Activation function- Nöron çıkışını sınırlar. En temel etkinleştirme işlevi, iki olası çıkışı olan bir Heaviside adım işlevidir. Bu işlev, giriş pozitifse 1 ve herhangi bir negatif giriş için 0 döndürür.
Eğitim Algoritması
Perceptron ağı, tek çıkış ünitesi ve çoklu çıkış üniteleri için eğitilebilir.
Tek Çıkışlı Ünite için Eğitim Algoritması
Step 1 - Eğitimi başlatmak için aşağıdakileri başlatın -
- Weights
- Bias
- $ \ Alpha $ öğrenme oranı
Kolay hesaplama ve basitlik için, ağırlıklar ve önyargı 0'a ve öğrenme hızı 1'e eşit ayarlanmalıdır.
Step 2 - Durdurma koşulu doğru olmadığında 3-8 adımlarına devam edin.
Step 3 - Her eğitim vektörü için adım 4-6'ya devam edin x.
Step 4 - Her bir giriş birimini aşağıdaki şekilde etkinleştirin -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: - \: n) $$
Step 5 - Şimdi net girdiyi aşağıdaki ilişkiyle elde edin -
$$ y_ {in} \: = \: b \: + \: \ displaystyle \ sum \ limits_ {i} ^ n x_ {i}. \: w_ {i} $$
Buraya ‘b’ önyargı ve ‘n’ giriş nöronlarının toplam sayısıdır.
Step 6 - Nihai çıktıyı elde etmek için aşağıdaki aktivasyon işlevini uygulayın.
$$ f (y_ {in}) \: = \: \ begin {case} 1 & if \: y_ {in} \:> \: \ theta \\ 0 & if \: - \ theta \: \ leqslant \ : y_ {in} \: \ leqslant \: \ theta \\ - 1 & if \: y_ {in} \: <\: - \ theta \ end {case} $$
Step 7 - Ağırlığı ve eğilimi aşağıdaki şekilde ayarlayın -
Case 1 - eğer y ≠ t sonra,
$$ w_ {i} (yeni) \: = \: w_ {i} (eski) \: + \: \ alpha \: tx_ {i} $$
$$ b (yeni) \: = \: b (eski) \: + \: \ alpha t $$
Case 2 - eğer y = t sonra,
$$ w_ {i} (yeni) \: = \: w_ {i} (eski) $$
$$ b (yeni) \: = \: b (eski) $$
Buraya ‘y’ gerçek çıktı ve ‘t’ istenen / hedef çıktıdır.
Step 8 - Ağırlıkta bir değişiklik olmadığında meydana gelebilecek durma koşulunu test edin.
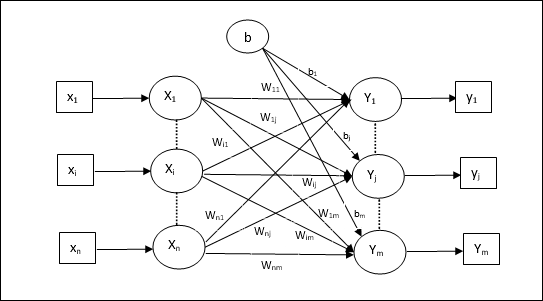
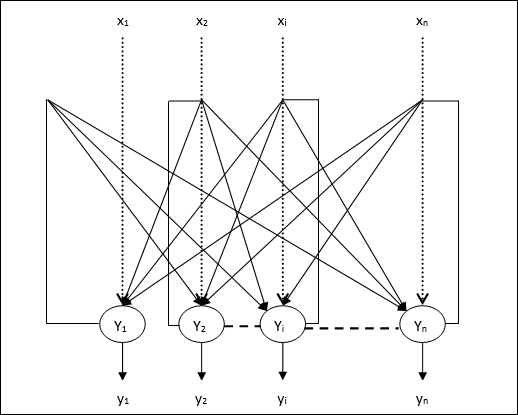
Çoklu Çıkış Üniteleri için Eğitim Algoritması
Aşağıdaki diyagram, çoklu çıktı sınıfları için perceptron mimarisidir.
Step 1 - Eğitimi başlatmak için aşağıdakileri başlatın -
- Weights
- Bias
- $ \ Alpha $ öğrenme oranı
Kolay hesaplama ve basitlik için, ağırlıklar ve önyargı 0'a ve öğrenme hızı 1'e eşit ayarlanmalıdır.
Step 2 - Durdurma koşulu doğru olmadığında 3-8 adımlarına devam edin.
Step 3 - Her eğitim vektörü için adım 4-6'ya devam edin x.
Step 4 - Her bir giriş birimini aşağıdaki şekilde etkinleştirin -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: - \: n) $$
Step 5 - Aşağıdaki ilişkiyle net girdiyi elde edin -
$$ y_ {in} \: = \: b \: + \: \ displaystyle \ sum \ limits_ {i} ^ n x_ {i} \: w_ {ij} $$
Buraya ‘b’ önyargı ve ‘n’ giriş nöronlarının toplam sayısıdır.
Step 6 - Her bir çıktı birimi için son çıktıyı elde etmek için aşağıdaki etkinleştirme işlevini uygulayın j = 1 to m -
$$ f (y_ {in}) \: = \: \ begin {case} 1 & if \: y_ {inj} \:> \: \ theta \\ 0 & if \: - \ theta \: \ leqslant \ : y_ {inj} \: \ leqslant \: \ theta \\ - 1 & if \: y_ {inj} \: <\: - \ theta \ end {case} $$
Step 7 - Ağırlığı ve önyargıyı ayarlayın. x = 1 to n ve j = 1 to m aşağıdaki gibi -
Case 1 - eğer yj ≠ tj sonra,
$$ w_ {ij} (yeni) \: = \: w_ {ij} (eski) \: + \: \ alpha \: t_ {j} x_ {i} $$
$$ b_ {j} (yeni) \: = \: b_ {j} (eski) \: + \: \ alpha t_ {j} $$
Case 2 - eğer yj = tj sonra,
$$ w_ {ij} (yeni) \: = \: w_ {ij} (eski) $$
$$ b_ {j} (yeni) \: = \: b_ {j} (eski) $$
Buraya ‘y’ gerçek çıktı ve ‘t’ istenen / hedef çıktıdır.
Step 8 - Ağırlıkta bir değişiklik olmadığında gerçekleşecek olan durma koşulunu test edin.
Uyarlanabilir Doğrusal Nöron (Adaline)
Uyarlanabilir Doğrusal Nöron anlamına gelen Adaline, tek bir doğrusal birime sahip bir ağdır. Widrow ve Hoff tarafından 1960 yılında geliştirilmiştir. Adaline ile ilgili bazı önemli noktalar aşağıdaki gibidir -
Bipolar aktivasyon işlevini kullanır.
Gerçek çıktı ile istenen / hedef çıktı arasındaki Ortalama Kareli Hatayı (MSE) en aza indirmek için eğitim için delta kuralını kullanır.
Ağırlıklar ve önyargı ayarlanabilir.
Mimari
Adalin'in temel yapısı, gerçek çıktının istenen / hedef çıktıyla karşılaştırıldığı ekstra bir geri bildirim döngüsüne sahip algılayıcıya benzer. Eğitim algoritması temelinde karşılaştırmanın ardından ağırlıklar ve önyargı güncellenecektir.
Eğitim Algoritması
Step 1 - Eğitimi başlatmak için aşağıdakileri başlatın -
- Weights
- Bias
- $ \ Alpha $ öğrenme oranı
Kolay hesaplama ve basitlik için, ağırlıklar ve önyargı 0'a ve öğrenme hızı 1'e eşit ayarlanmalıdır.
Step 2 - Durdurma koşulu doğru olmadığında 3-8 adımlarına devam edin.
Step 3 - Her bipolar eğitim çifti için 4-6. Adıma devam edin s:t.
Step 4 - Her bir giriş birimini aşağıdaki şekilde etkinleştirin -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: - \: n) $$
Step 5 - Aşağıdaki ilişkiyle net girdiyi elde edin -
$$ y_ {in} \: = \: b \: + \: \ displaystyle \ sum \ limits_ {i} ^ n x_ {i} \: w_ {i} $$
Buraya ‘b’ önyargı ve ‘n’ giriş nöronlarının toplam sayısıdır.
Step 6 - Nihai çıktıyı elde etmek için aşağıdaki aktivasyon işlevini uygulayın -
$$ f (y_ {in}) \: = \: \ begin {case} 1 & if \: y_ {in} \: \ geqslant \: 0 \\ - 1 & if \: y_ {in} \: < \: 0 \ end {case} $$
Step 7 - Ağırlığı ve eğilimi aşağıdaki şekilde ayarlayın -
Case 1 - eğer y ≠ t sonra,
$$ w_ {i} (yeni) \: = \: w_ {i} (eski) \: + \: \ alpha (t \: - \: y_ {in}) x_ {i} $$
$$ b (yeni) \: = \: b (eski) \: + \: \ alpha (t \: - \: y_ {in}) $$
Case 2 - eğer y = t sonra,
$$ w_ {i} (yeni) \: = \: w_ {i} (eski) $$
$$ b (yeni) \: = \: b (eski) $$
Buraya ‘y’ gerçek çıktı ve ‘t’ istenen / hedef çıktıdır.
$ (t \: - \; y_ {in}) $ hesaplanan hatadır.
Step 8 - Ağırlıkta herhangi bir değişiklik olmadığında veya antrenman sırasında meydana gelen en yüksek ağırlık değişikliğinin belirtilen toleranstan daha küçük olduğunda meydana gelecek olan durma koşulu için test edin.
Çoklu Uyarlanabilir Doğrusal Nöron (Madaline)
Çoklu Uyarlanabilir Doğrusal Nöron anlamına gelen Madaline, paralel olarak birçok Adalin'den oluşan bir ağdır. Tek bir çıkış ünitesine sahip olacaktır. Madaline ile ilgili bazı önemli noktalar aşağıdaki gibidir -
Tıpkı Adalin'in giriş ile Madaline katmanı arasında gizli bir birim olarak hareket edeceği çok katmanlı bir algılayıcı gibidir.
Adaline mimarisinde gördüğümüz gibi, giriş ve Adaline katmanları arasındaki ağırlıklar ve önyargı ayarlanabilir.
Adaline ve Madaline katmanlarının sabit ağırlıkları ve 1'lik önyargıları vardır.
Delta kuralı yardımı ile eğitim yapılabilir.
Mimari
Madaline mimarisi şunlardan oluşur: “n” giriş katmanının nöronları, “m”Adaline katmanının nöronları ve Madaline katmanının 1 nöronu. Adaline katmanı, girdi katmanı ile çıktı katmanı, yani Madaline katmanı arasında olduğu için gizli katman olarak kabul edilebilir.
Eğitim Algoritması
Şimdiye kadar, yalnızca giriş ve Adaline katmanı arasındaki ağırlıkların ve önyargının ayarlanacağını ve Adaline ile Madaline katmanı arasındaki ağırlıkların ve önyargının sabitlendiğini biliyoruz.
Step 1 - Eğitimi başlatmak için aşağıdakileri başlatın -
- Weights
- Bias
- $ \ Alpha $ öğrenme oranı
Kolay hesaplama ve basitlik için, ağırlıklar ve önyargı 0'a ve öğrenme hızı 1'e eşit ayarlanmalıdır.
Step 2 - Durdurma koşulu doğru olmadığında 3-8 adımlarına devam edin.
Step 3 - Her bipolar eğitim çifti için 4-6. Adıma devam edin s:t.
Step 4 - Her bir giriş birimini aşağıdaki şekilde etkinleştirin -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: - \: n) $$
Step 5 - Her gizli katmandaki net girdiyi, yani aşağıdaki ilişkiye sahip Adaline katmanını elde edin -
$$ Q_ {inj} \: = \: b_ {j} \: + \: \ displaystyle \ sum \ limits_ {i} ^ n x_ {i} \: w_ {ij} \: \: \: j \: = \: 1 \: - \: m $$
Buraya ‘b’ önyargı ve ‘n’ giriş nöronlarının toplam sayısıdır.
Step 6 - Adaline ve Madaline katmanında son çıktıyı elde etmek için aşağıdaki aktivasyon işlevini uygulayın -
$$ f (x) \: = \: \ start {case} 1 & if \: x \: \ geqslant \: 0 \\ - 1 & if \: x \: <\: 0 \ end {case} $ $
Gizli (Adaline) biriminde çıktı
$$ Q_ {j} \: = \: f (Q_ {inj}) $$
Ağın nihai çıkışı
$$ y \: = \: f (y_ {inç}) $$
i.e. $ \: \: y_ {inj} \: = \: b_ {0} \: + \: \ sum_ {j = 1} ^ m \: Q_ {j} \: v_ {j} $
Step 7 - Hatayı hesaplayın ve ağırlıkları aşağıdaki gibi ayarlayın -
Case 1 - eğer y ≠ t ve t = 1 sonra,
$$ w_ {ij} (yeni) \: = \: w_ {ij} (eski) \: + \: \ alpha (1 \: - \: Q_ {inj}) x_ {i} $$
$$ b_ {j} (yeni) \: = \: b_ {j} (eski) \: + \: \ alpha (1 \: - \: Q_ {inj}) $$
Bu durumda ağırlıklar şu tarihte güncellenecektir: Qj net girdinin 0'a yakın olduğu yer, çünkü t = 1.
Case 2 - eğer y ≠ t ve t = -1 sonra,
$$ w_ {ik} (yeni) \: = \: w_ {ik} (eski) \: + \: \ alpha (-1 \: - \: Q_ {mürekkep}) x_ {i} $$
$$ b_ {k} (yeni) \: = \: b_ {k} (eski) \: + \: \ alpha (-1 \: - \: Q_ {mürekkep}) $$
Bu durumda ağırlıklar şu tarihte güncellenecektir: Qk net girdinin pozitif olduğu yer, çünkü t = -1.
Buraya ‘y’ gerçek çıktı ve ‘t’ istenen / hedef çıktıdır.
Case 3 - eğer y = t sonra
Ağırlıklarda değişiklik olmaz.
Step 8 - Ağırlıkta herhangi bir değişiklik olmadığında veya antrenman sırasında meydana gelen en yüksek ağırlık değişikliğinin belirtilen toleranstan daha küçük olduğunda meydana gelecek olan durma koşulu için test edin.
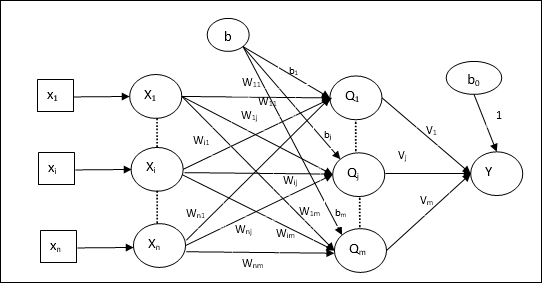
Geri Yayılım Sinir Ağları
Back Propagation Neural (BPN), giriş katmanı, en az bir gizli katman ve çıkış katmanından oluşan çok katmanlı bir sinir ağıdır. Adından da anlaşılacağı gibi, bu ağda geri yayılma gerçekleşecek. Çıktı katmanında hedef çıktı ile gerçek çıktı karşılaştırılarak hesaplanan hata, girdi katmanına doğru geri yayılacaktır.
Mimari
Şemada gösterildiği gibi, BPN'nin mimarisi, üzerlerinde ağırlık bulunan birbirine bağlı üç katmana sahiptir. Gizli katmanın yanı sıra çıktı katmanı da üzerlerinde ağırlığı her zaman 1 olan önyargıya sahiptir. Diyagramdan da anlaşılacağı gibi, BPN'nin çalışması iki aşamalıdır. Bir faz sinyali giriş katmanından çıkış katmanına gönderir ve diğer faz geri hatayı çıkış katmanından giriş katmanına yayar.

Eğitim Algoritması
Eğitim için BPN, ikili sigmoid aktivasyon fonksiyonunu kullanacaktır. BPN eğitimi aşağıdaki üç aşamadan oluşacaktır.
Phase 1 - İleri Besleme Aşaması
Phase 2 - Hatanın Geri Yayılması
Phase 3 - Ağırlıkların güncellenmesi
Tüm bu adımlar algoritmada aşağıdaki gibi sonuçlanacaktır.
Step 1 - Eğitimi başlatmak için aşağıdakileri başlatın -
- Weights
- $ \ Alpha $ öğrenme oranı
Kolay hesaplama ve basitlik için bazı küçük rastgele değerler alın.
Step 2 - Durdurma koşulu doğru olmadığında 3-11 adımlarına devam edin.
Step 3 - Her antrenman çifti için adım 4-10'a devam edin.
Faz 1
Step 4 - Her giriş birimi giriş sinyalini alır xi ve onu herkes için gizli birime gönderir i = 1 to n
Step 5 - Aşağıdaki ilişkiyi kullanarak gizli birimdeki net girdiyi hesaplayın -
$$ Q_ {inj} \: = \: b_ {0j} \: + \: \ sum_ {i = 1} ^ n x_ {i} v_ {ij} \: \: \: \: j \: = \ : 1 \: - \: p $$
Buraya b0j gizli birimdeki önyargı, vij ağırlık açık mı j gelen gizli katmanın birimi i giriş katmanının birimi.
Şimdi aşağıdaki aktivasyon fonksiyonunu uygulayarak net çıktıyı hesaplayın
$$ Q_ {j} \: = \: f (Q_ {inj}) $$
Gizli katman birimlerinin bu çıkış sinyallerini çıktı katmanı birimlerine gönderin.
Step 6 - Aşağıdaki ilişkiyi kullanarak çıktı katmanı birimindeki net girdiyi hesaplayın -
$$ y_ {mürekkep} \: = \: b_ {0k} \: + \: \ sum_ {j = 1} ^ p \: Q_ {j} \: w_ {jk} \: \: k \: = \ : 1 \: - \: m $$
Buraya b0k çıktı birimindeki önyargıdır, wjk ağırlık açık mı k gelen çıktı katmanının birimi j gizli katmanın birimi.
Aşağıdaki aktivasyon fonksiyonunu uygulayarak net çıktıyı hesaplayın
$$ y_ {k} \: = \: f (y_ {mürekkep}) $$
Faz 2
Step 7 - Hata düzeltme terimini, her bir çıktı biriminde alınan hedef modele uygun olarak aşağıdaki şekilde hesaplayın -
$$ \ delta_ {k} \: = \ :( t_ {k} \: - \: y_ {k}) f ^ {'} (y_ {mürekkep}) $$
Bu temelde, ağırlığı ve sapmayı aşağıdaki gibi güncelleyin -
$$ \ Delta v_ {jk} \: = \: \ alpha \ delta_ {k} \: Q_ {ij} $$
$$ \ Delta b_ {0k} \: = \: \ alpha \ delta_ {k} $$
Sonra $ \ delta_ {k} $ 'ı gizli katmana geri gönderin.
Step 8 - Artık her bir gizli birim, çıktı birimlerinden gelen delta girdilerinin toplamı olacaktır.
$$ \ delta_ {inj} \: = \: \ displaystyle \ sum \ limits_ {k = 1} ^ m \ delta_ {k} \: w_ {jk} $$
Hata terimi şu şekilde hesaplanabilir -
$$ \ delta_ {j} \: = \: \ delta_ {inj} f ^ {'} (Q_ {inj}) $$
Bu temelde, ağırlığı ve sapmayı aşağıdaki gibi güncelleyin -
$$ \ Delta w_ {ij} \: = \: \ alpha \ delta_ {j} x_ {i} $$
$$ \ Delta b_ {0j} \: = \: \ alpha \ delta_ {j} $$
3. Aşama
Step 9 - Her çıktı birimi (ykk = 1 to m) ağırlığı ve önyargıyı aşağıdaki gibi günceller -
$$ v_ {jk} (yeni) \: = \: v_ {jk} (eski) \: + \: \ Delta v_ {jk} $$
$$ b_ {0k} (yeni) \: = \: b_ {0k} (eski) \: + \: \ Delta b_ {0k} $$
Step 10 - Her çıktı birimi (zjj = 1 to p) ağırlığı ve önyargıyı aşağıdaki gibi günceller -
$$ w_ {ij} (yeni) \: = \: w_ {ij} (eski) \: + \: \ Delta w_ {ij} $$
$$ b_ {0j} (yeni) \: = \: b_ {0j} (eski) \: + \: \ Delta b_ {0j} $$
Step 11 - Ulaşılan epoch sayısı veya hedef çıkış gerçek çıkışla eşleşebilen durdurma koşulunu kontrol edin.
Genelleştirilmiş Delta Öğrenim Kuralı
Delta kuralı yalnızca çıktı katmanı için çalışır. Öte yandan, genelleştirilmiş delta kuralı olarak da adlandırılırback-propagation kural, gizli katmanın istenen değerlerini oluşturmanın bir yoludur.
Matematiksel Formülasyon
$ Y_ {k} \: = \: f (y_ {ink}) $ aktivasyon fonksiyonu için, hem gizli katmanda hem de çıktı katmanında net girdinin türetilmesi şu şekilde verilebilir:
$$ y_ {mürekkep} \: = \: \ displaystyle \ sum \ limits_i \: z_ {i} w_ {jk} $$
Ve $ \: \: y_ {inj} \: = \: \ sum_i x_ {i} v_ {ij} $
Şimdi en aza indirilmesi gereken hata
$$ E \: = \: \ frac {1} {2} \ displaystyle \ sum \ limits_ {k} \: [t_ {k} \: - \: y_ {k}] ^ 2 $$
Zincir kuralını kullanarak,
$$ \ frac {\ kısmi E} {\ kısmi w_ {jk}} \: = \: \ frac {\ kısmi} {\ kısmi w_ {jk}} (\ frac {1} {2} \ displaystyle \ toplamı \ limits_ {k} \: [t_ {k} \: - \: y_ {k}] ^ 2) $$
$$ = \: \ frac {\ kısmi} {\ kısmi w_ {jk}} \ lgroup \ frac {1} {2} [t_ {k} \: - \: t (y_ {mürekkep})] ^ 2 \ rgroup $$
$$ = \: - [t_ {k} \: - \: y_ {k}] \ frac {\ kısmi} {\ kısmi w_ {jk}} f (y_ {mürekkep}) $$
$$ = \: - [t_ {k} \: - \: y_ {k}] f (y_ {mürekkep}) \ frac {\ kısmi} {\ kısmi w_ {jk}} (y_ {mürekkep}) $$
$$ = \: - [t_ {k} \: - \: y_ {k}] f ^ {'} (y_ {mürekkep}) z_ {j} $$
Şimdi $ \ delta_ {k} \: = \: - [t_ {k} \: - \: y_ {k}] f ^ {'} (y_ {ink}) $ diyelim
Gizli birime bağlantılardaki ağırlıklar zj tarafından verilebilir -
$$ \ frac {\ kısmi E} {\ kısmi v_ {ij}} \: = \: - \ displaystyle \ sum \ limits_ {k} \ delta_ {k} \ frac {\ kısmi} {\ kısmi v_ {ij} } \ :( y_ {mürekkep}) $$
$ Y_ {ink} $ değerini koyarsak aşağıdakileri elde ederiz
$$ \ delta_ {j} \: = \: - \ displaystyle \ sum \ limits_ {k} \ delta_ {k} w_ {jk} f ^ {'} (z_ {inj}) $$
Ağırlık güncellemesi şu şekilde yapılabilir -
Çıkış ünitesi için -
$$ \ Delta w_ {jk} \: = \: - \ alpha \ frac {\ kısmi E} {\ kısmi w_ {jk}} $$
$$ = \: \ alpha \: \ delta_ {k} \: z_ {j} $$
Gizli birim için -
$$ \ Delta v_ {ij} \: = \: - \ alpha \ frac {\ kısmi E} {\ kısmi v_ {ij}} $$
$$ = \: \ alpha \: \ delta_ {j} \: x_ {i} $$
Adından da anlaşılacağı gibi, bu tür öğrenme, bir öğretmenin gözetimi olmadan yapılır. Bu öğrenme süreci bağımsızdır. Denetimsiz öğrenme altında YSA eğitimi sırasında, benzer tipteki girdi vektörleri kümeler oluşturmak için birleştirilir. Yeni bir giriş modeli uygulandığında, sinir ağı, giriş modelinin ait olduğu sınıfı belirten bir çıktı yanıtı verir. Bunda, istenen çıktının ne olması gerektiği ve bunun doğru mu yanlış mı olduğu konusunda çevreden herhangi bir geri bildirim alınmayacaktır. Bu nedenle, bu tür öğrenmede, ağın kendisi giriş verilerinden modelleri, özellikleri ve çıktı üzerinden giriş verileri için ilişkiyi keşfetmelidir.
Kazanan-Hepsini Alır-Ağlar
Bu tür ağlar, rekabetçi öğrenme kuralına dayanır ve en yüksek toplam girdiye sahip nöronu kazanan olarak seçtiği stratejiyi kullanır. Çıkış nöronları arasındaki bağlantılar, aralarındaki rekabetin 'AÇIK' olacağını gösterir, bu da kazananın ve diğerlerinin 'KAPALI' olacağı anlamına gelir.
Aşağıda, denetimsiz öğrenmeyi kullanan bu basit kavrama dayalı ağlardan bazıları verilmiştir.
Hamming Ağı
Denetimsiz öğrenmeyi kullanan sinir ağlarının çoğunda, mesafeyi hesaplamak ve karşılaştırmalar yapmak önemlidir. Bu tür bir ağ, verilen her giriş vektörü için farklı gruplar halinde kümeleneceği Hamming ağıdır. Aşağıda Hamming Networks'ün bazı önemli özellikleri verilmiştir -
Lippmann, 1987'de Hamming ağları üzerinde çalışmaya başladı.
Tek katmanlı bir ağdır.
Girişler, bipolar {-1, 1} 'in ikili {0, 1} olabilir.
Ağın ağırlıkları, örnek vektörler tarafından hesaplanır.
Sabit ağırlık ağıdır, yani antrenman sırasında bile ağırlık aynı kalır.
Maksimum Net
Bu aynı zamanda, en yüksek girdiye sahip düğümü seçmek için bir alt ağ görevi gören sabit ağırlıklı bir ağdır. Tüm düğümler tamamen birbirine bağlıdır ve tüm bu ağırlıklı ara bağlantılarda simetrik ağırlıklar vardır.
Mimari
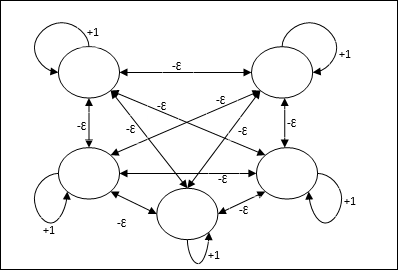
Yinelemeli bir süreç olan mekanizmayı kullanır ve her düğüm, bağlantılar aracılığıyla diğer tüm düğümlerden engelleyici girdiler alır. Değeri maksimum olan tek düğüm etkin veya kazanan olur ve diğer tüm düğümlerin etkinleştirmeleri devre dışı kalır. Max Net, $$ f (x) \: = \: \ begin {case} x & if \: x> 0 \\ 0 & if \: x \ leq 0 \ end {case} $$ ile kimlik etkinleştirme işlevini kullanır
Bu ağın görevi, kendi kendini uyarma ağırlığı olan +1 ve [0 <ɛ <$ \ frac {1} {m} $] gibi ayarlanan karşılıklı engelleme büyüklüğü ile gerçekleştirilir. “m” düğümlerin toplam sayısıdır.
YSA'da Rekabetçi Öğrenme
Çıkış düğümlerinin girdi modelini temsil etmek için birbirleriyle rekabet etmeye çalıştıkları denetimsiz eğitimle ilgilidir. Bu öğrenme kuralını anlamak için, aşağıda açıklanan rekabetçi ağı anlamamız gerekecek -
Rekabetçi Ağın Temel Kavramı
Bu ağ, çıktılar arasında geri beslemeli bağlantıya sahip tek katmanlı ileri beslemeli bir ağ gibidir. Çıkışlar arasındaki bağlantılar engelleyici tiptedir ve noktalı çizgilerle gösterilir, bu da rakiplerin asla kendilerini desteklemeyecekleri anlamına gelir.
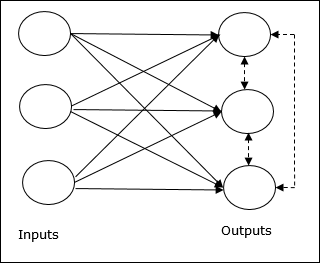
Rekabetçi Öğrenme Kuralı Temel Kavramı
Daha önce de belirtildiği gibi, çıktı düğümleri arasında rekabet olacaktır, bu nedenle ana konsept - eğitim sırasında, belirli bir giriş modeline en yüksek aktivasyona sahip çıktı birimi kazanan ilan edilecektir. Bu kurala aynı zamanda Kazanan her şeyi alır, çünkü yalnızca kazanan nöron güncellenir ve nöronların geri kalanı değişmeden kalır.
Matematiksel Formülasyon
Bu öğrenme kuralının matematiksel formülasyonu için üç önemli faktör aşağıdadır:
Kazanan olma koşulu
Varsayalım ki bir nöron yk kazanan olmak istiyorsa, şu koşul olur
$$ y_ {k} \: = \: \ start {case} 1 & if \: v_ {k}> v_ {j} \: for \: all \: \: j, \: j \: \ neq \ : k \\ 0 & aksi halde \ end {case} $$
Bu, eğer herhangi bir nöron varsa, yk kazanmak istiyor, sonra indüklenen yerel alanı (toplama biriminin çıktısı), diyelim ki vk, ağdaki diğer tüm nöronlar arasında en büyüğü olmalıdır.
Toplam ağırlık toplamının durumu
Rekabetçi öğrenme kuralı üzerindeki başka bir kısıtlama, belirli bir çıkış nöronunun ağırlıklarının toplamının 1 olacağıdır. Örneğin, nöronu düşünürsek k sonra
$$ \ displaystyle \ sum \ limits_ {k} w_ {kj} \: = \: 1 \: \: \: \: için \: tümü \: \: k $$
Kazanan için ağırlık değişimi
Bir nöron giriş modeline yanıt vermezse, o nöronda hiçbir öğrenme gerçekleşmez. Bununla birlikte, belirli bir nöron kazanırsa, ilgili ağırlıklar aşağıdaki gibi ayarlanır -
$$ \ Delta w_ {kj} \: = \: \ begin {case} - \ alpha (x_ {j} \: - \: w_ {kj}), & if \: neuron \: k \: wins \\ 0 & if \: nöron \: k \: kayıplar \ end {vakalar} $$
Burada $ \ alpha $ öğrenme oranıdır.
Bu açıkça gösteriyor ki, ağırlığını ayarlayarak kazanan nöronu tercih ediyoruz ve eğer bir nöron kaybedilirse, ağırlığını yeniden ayarlamak için uğraşmamıza gerek yok.
K-Ortalama Kümeleme Algoritması
K-aracı, bölümleme prosedürü kavramını kullandığımız en popüler kümeleme algoritmalarından biridir. İlk bölümleme ile başlıyoruz ve tatmin edici bir sonuç elde edene kadar desenleri bir kümeden diğerine tekrar tekrar hareket ettiriyoruz.
Algoritma
Step 1 - Seçin kbaşlangıç ağırlık merkezlerini gösterir. Başlatk prototipler (w1,…,wk)örneğin bunları rastgele seçilen giriş vektörleriyle tanımlayabiliriz -
$$ W_ {j} \: = \: i_ {p}, \: \: \: burada \: j \: \ in \ lbrace1, ...., k \ rbrace \: ve \: p \: \ \ lbrace1, ...., n \ rbrace $$ içinde
Her küme Cj prototip ile ilişkilidir wj.
Step 2 - E artık azalmayana veya küme üyeliği artık değişmeyene kadar 3-5. Adımı tekrarlayın.
Step 3 - Her giriş vektörü için ip nerede p ∈ {1,…,n}, koymak ip kümede Cj* en yakın prototip ile wj* aşağıdaki ilişkiye sahip olmak
$$ | i_ {p} \: - \: w_ {j *} | \: \ leq \: | i_ {p} \: - \: w_ {j} |, \: j \: \ içinde \ lbrace1, ...., k \ rbrace $$
Step 4 - Her küme için Cj, nerede j ∈ { 1,…,k}, prototipi güncelle wj şu anda içinde bulunan tüm örneklerin ağırlık merkezi olmak Cj , Böylece
$$ w_ {j} \: = \: \ sum_ {i_ {p} \ in C_ {j}} \ frac {i_ {p}} {| C_ {j} |} $$
Step 5 - Toplam niceleme hatasını aşağıdaki gibi hesaplayın -
$$ E \: = \: \ sum_ {j = 1} ^ k \ sum_ {i_ {p} \ içinde w_ {j}} | i_ {p} \: - \: w_ {j} | ^ 2 $$
Neocognitron
Fukushima tarafından 1980'lerde geliştirilen çok katmanlı bir ileri beslemeli ağdır. Bu model, denetimli öğrenmeye dayanır ve özellikle elle yazılmış karakterler olmak üzere görsel örüntü tanıma için kullanılır. Temelde, 1975'te Fukushima tarafından da geliştirilen Cognitron ağının bir uzantısıdır.
Mimari
Bu, birçok katmanı içeren hiyerarşik bir ağdır ve bu katmanlarda yerel olarak bir bağlantı modeli vardır.
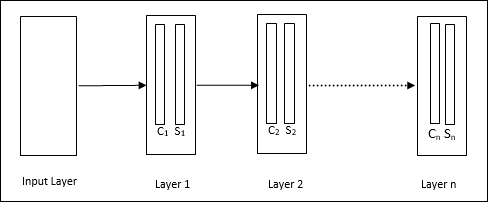
Yukarıdaki diyagramda gördüğümüz gibi, neocognitron farklı bağlantılı katmanlara bölünmüştür ve her katmanın iki hücresi vardır. Bu hücrelerin açıklaması aşağıdaki gibidir -
S-Cell - Belirli bir modele veya bir kalıp grubuna yanıt vermek üzere eğitilmiş basit bir hücre olarak adlandırılır.
C-Cell- S-hücresinden gelen çıktıyı birleştiren ve aynı anda her dizideki birim sayısını azaltan karmaşık bir hücre olarak adlandırılır. Başka bir anlamda, C hücresi, S hücresinin sonucunun yerini alır.
Eğitim Algoritması
Neocognitron eğitiminin katman katman ilerlediği görülmüştür. Giriş katmanından ilk katmana kadar olan ağırlıklar eğitilir ve dondurulur. Daha sonra, birinci katmandan ikinci katmana kadar olan ağırlıklar eğitilir ve bu böyle devam eder. S-hücresi ve Ccell arasındaki dahili hesaplamalar, önceki katmanlardan gelen ağırlıklara bağlıdır. Dolayısıyla, eğitim algoritmasının S hücresi ve C hücresi üzerindeki hesaplamalara bağlı olduğunu söyleyebiliriz.
S hücresinde hesaplamalar
S hücresi, önceki katmandan alınan uyarıcı sinyale sahiptir ve aynı katman içinde elde edilen inhibe edici sinyallere sahiptir.
$$ \ theta = \: \ sqrt {\ sum \ sum t_ {i} c_ {i} ^ 2} $$
Buraya, ti sabit ağırlıktır ve ci C-hücresinden çıktıdır.
S-hücresinin ölçeklendirilmiş girişi şu şekilde hesaplanabilir -
$$ x \: = \: \ frac {1 \: + \: e} {1 \: + \: vw_ {0}} \: - \: 1 $$
Burada, $ e \: = \: \ sum_i c_ {i} w_ {i} $
wi C-hücresinden S-hücresine ayarlanmış ağırlıktır.
w0 giriş ve S-hücresi arasında ayarlanabilen ağırlıktır.
v C-hücresinden gelen uyarıcı girdidir.
Çıkış sinyalinin aktivasyonu,
$$ s \: = \: \ begin {case} x, & if \: x \ geq 0 \\ 0, & if \: x <0 \ end {case} $$
C-hücresinde hesaplamalar
C-katmanının net girdisi
$$ C \: = \: \ displaystyle \ sum \ limits_i s_ {i} x_ {i} $$
Buraya, si S-hücresinden çıktıdır ve xi S-hücresinden C-hücresine sabit ağırlıktır.
Nihai çıktı aşağıdaki gibidir -
$$ C_ {out} \: = \: \ begin {case} \ frac {C} {a + C}, & if \: C> 0 \\ 0, & aksi takdirde \ end {case} $$
Buraya ‘a’ ağın performansına bağlı olan parametredir.
Vektör Nicemleme (LVQ), Vektör nicemleme (VQ) ve Kohonen Kendi Kendini Düzenleyen Haritalardan (KSOM) farklı olarak, temelde denetimli öğrenmeyi kullanan rekabetçi bir ağdır. Bunu, her çıktı biriminin bir sınıfı temsil ettiği kalıpları sınıflandırma süreci olarak tanımlayabiliriz. Denetimli öğrenmeyi kullandığı için, ağa, çıktı sınıfının ilk dağıtımı ile birlikte bilinen sınıflandırmaya sahip bir dizi eğitim modeli verilecektir. Eğitim sürecini tamamladıktan sonra, LVQ bir girdi vektörünü çıktı birimiyle aynı sınıfa atayarak sınıflandıracaktır.
Mimari
Aşağıdaki şekil, KSOM mimarisine oldukça benzeyen LVQ mimarisini göstermektedir. Gördüğümüz gibi var“n” giriş birimi sayısı ve “m”çıktı birimlerinin sayısı. Katmanlar, üzerlerinde ağırlıklarla tamamen birbirine bağlıdır.

Kullanılan Parametreler
LVQ eğitim sürecinde ve akış şemasında kullanılan parametreler aşağıdadır.
x= eğitim vektörü (x 1 , ..., x i , ..., x n )
T = eğitim vektörü için sınıf x
wj = ağırlık vektörü jth çıktı ünitesi
Cj = ile ilişkili sınıf jth çıktı ünitesi
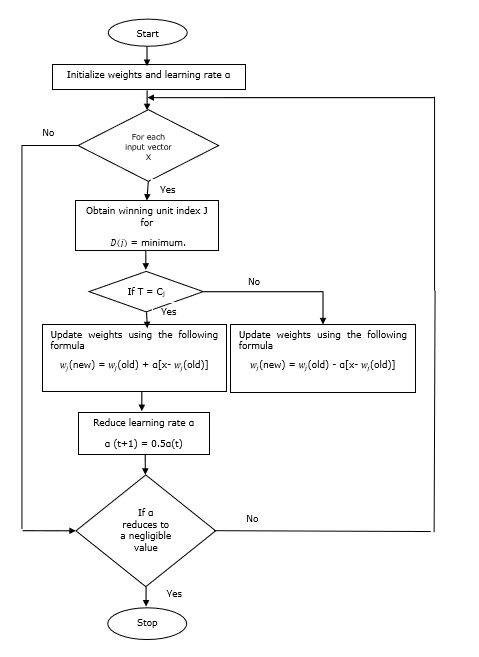
Eğitim Algoritması
Step 1 - Aşağıdaki gibi yapılabilen referans vektörlerini başlatın -
Step 1(a) - Verilen eğitim vektörlerinden ilkini alın "m”(Küme sayısı) eğitim vektörleri ve bunları ağırlık vektörleri olarak kullanın. Kalan vektörler eğitim için kullanılabilir.
Step 1(b) - İlk ağırlığı ve sınıflandırmayı rastgele atayın.
Step 1(c) - K-ortalamalı kümeleme yöntemini uygulayın.
Step 2 - $ \ alpha $ referans vektörünü başlat
Step 3 - Bu algoritmayı durdurma koşulu karşılanmazsa 4-9. Adımlarla devam edin.
Step 4 - Her eğitim giriş vektörü için 5-6 arası adımları izleyin x.
Step 5 - Öklid Mesafesinin Karesini Hesapla j = 1 to m ve i = 1 to n
$$ D (j) \: = \: \ displaystyle \ sum \ limits_ {i = 1} ^ n \ displaystyle \ sum \ limits_ {j = 1} ^ m (x_ {i} \: - \: w_ {ij }) ^ 2 $$
Step 6 - Kazanan birimi edinin J nerede D(j) minimumdur.
Step 7 - Kazanan birimin yeni ağırlığını aşağıdaki ilişkiye göre hesaplayın -
Eğer T = Cj sonra $ w_ {j} (yeni) \: = \: w_ {j} (eski) \: + \: \ alpha [x \: - \: w_ {j} (eski)] $
Eğer T ≠ Cj sonra $ w_ {j} (yeni) \: = \: w_ {j} (eski) \: - \: \ alpha [x \: - \: w_ {j} (eski)] $
Step 8 - $ \ alpha $ öğrenme oranını azaltın.
Step 9- Durdurma koşulunu test edin. Aşağıdaki gibi olabilir -
- Maksimum dönem sayısına ulaşıldı.
- Öğrenme oranı ihmal edilebilir bir değere indirildi.
Akış çizelgesi
Varyantlar
Kohonen tarafından LVQ2, LVQ2.1 ve LVQ3 adlı diğer üç değişken geliştirilmiştir. Kazanan ve ikinci ünitenin öğreneceği konsept nedeniyle tüm bu üç varyanttaki karmaşıklık, LVQ'dan daha fazladır.
LVQ2
Yukarıda tartışıldığı gibi, LVQ'nun diğer varyantlarının kavramı, LVQ2'nin durumu pencere tarafından oluşturulur. Bu pencere aşağıdaki parametrelere dayalı olacaktır -
x - mevcut giriş vektörü
yc - en yakın referans vektörü x
yr - sonraki en yakın diğer referans vektörü x
dc - uzaklık x -e yc
dr - uzaklık x -e yr
Giriş vektörü x pencereye düşerse
$$ \ frac {d_ {c}} {d_ {r}} \:> \: 1 \: - \: \ theta \: \: ve \: \: \ frac {d_ {r}} {d_ {c }} \:> \: 1 \: + \: \ theta $$
Burada $ \ theta $, eğitim örneklerinin sayısıdır.
Güncelleme aşağıdaki formül ile yapılabilir -
$ y_ {c} (t \: + \: 1) \: = \: y_ {c} (t) \: + \: \ alpha (t) [x (t) \: - \: y_ {c} (t)] $ (belongs to different class)
$ y_ {r} (t \: + \: 1) \: = \: y_ {r} (t) \: + \: \ alpha (t) [x (t) \: - \: y_ {r} (t)] $ (belongs to same class)
Burada $ \ alpha $ öğrenme oranıdır.
LVQ2.1
LVQ2.1'de, en yakın iki vektörü alacağız: yc1 ve yc2 ve pencere koşulu aşağıdaki gibidir -
$$ Min \ begin {bmatrix} \ frac {d_ {c1}} {d_ {c2}}, \ frac {d_ {c2}} {d_ {c1}} \ end {bmatrix} \:> \ :( 1 \ : - \: \ theta) $$
$$ Max \ begin {bmatrix} \ frac {d_ {c1}} {d_ {c2}}, \ frac {d_ {c2}} {d_ {c1}} \ end {bmatrix} \: <\ :( 1 \ : + \: \ theta) $$
Güncelleme aşağıdaki formül ile yapılabilir -
$ y_ {c1} (t \: + \: 1) \: = \: y_ {c1} (t) \: + \: \ alpha (t) [x (t) \: - \: y_ {c1} (t)] $ (belongs to different class)
$ y_ {c2} (t \: + \: 1) \: = \: y_ {c2} (t) \: + \: \ alpha (t) [x (t) \: - \: y_ {c2} (t)] $ (belongs to same class)
Burada $ \ alpha $ öğrenme oranıdır.
LVQ3
LVQ3'te, en yakın iki vektörü alacağız: yc1 ve yc2 ve pencere koşulu aşağıdaki gibidir -
$$ Min \ begin {bmatrix} \ frac {d_ {c1}} {d_ {c2}}, \ frac {d_ {c2}} {d_ {c1}} \ end {bmatrix} \:> \ :( 1 \ : - \: \ theta) (1 \: + \: \ theta) $$
Burada $ \ theta \ yaklaşık 0.2 $
Güncelleme aşağıdaki formül ile yapılabilir -
$ y_ {c1} (t \: + \: 1) \: = \: y_ {c1} (t) \: + \: \ beta (t) [x (t) \: - \: y_ {c1} (t)] $ (belongs to different class)
$ y_ {c2} (t \: + \: 1) \: = \: y_ {c2} (t) \: + \: \ beta (t) [x (t) \: - \: y_ {c2} (t)] $ (belongs to same class)
Burada $ \ beta $, $ \ alpha $ öğrenme oranının katıdır ve $\beta\:=\:m \alpha(t)$ her biri için 0.1 < m < 0.5
Bu ağ 1987'de Stephen Grossberg ve Gail Carpenter tarafından geliştirilmiştir. Rekabete dayanmaktadır ve denetimsiz öğrenme modelini kullanır. Adından da anlaşılacağı gibi Uyarlanabilir Rezonans Teorisi (ART) ağları, eski kalıpları (rezonans) kaybetmeden her zaman yeni öğrenmeye (uyarlanabilir) açıktır. Temel olarak ART ağı, bir girdi vektörünü kabul eden ve bunu depolanan modelden hangisine en çok benzediğine bağlı olarak kategorilerden birine sınıflandıran bir vektör sınıflandırıcıdır.
İşletme Sorumlusu
ART sınıflandırmasının ana operasyonu aşağıdaki aşamalara ayrılabilir -
Recognition phase- Giriş vektörü, çıktı katmanındaki her düğümde sunulan sınıflandırmayla karşılaştırılır. Nöronun çıktısı, uygulanan sınıflandırma ile en iyi şekilde eşleşirse "1" olur, aksi takdirde "0" olur.
Comparison phase- Bu aşamada, giriş vektörünün karşılaştırma katmanı vektörüyle bir karşılaştırması yapılır. Sıfırlama koşulu, benzerlik derecesinin dikkat parametresinden daha az olmasıdır.
Search phase- Bu aşamada ağ, yukarıdaki aşamalarda yapılan eşleşmenin yanı sıra sıfırlamayı da arayacaktır. Bu nedenle, sıfırlama olmazsa ve maç oldukça iyiyse, o zaman sınıflandırma biter. Aksi takdirde, işlem tekrarlanır ve doğru eşleşmeyi bulmak için saklanan diğer kalıbın gönderilmesi gerekir.
ART1
İkili vektörleri kümelemek için tasarlanmış bir ART türüdür. Bunu mimarisiyle anlayabiliriz.
ART1 mimarisi
Aşağıdaki iki üniteden oluşur -
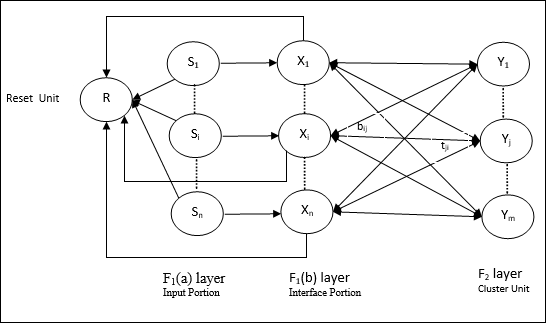
Computational Unit - Aşağıdakilerden oluşur -
Input unit (F1 layer) - Ayrıca aşağıdaki iki porsiyona sahiptir -
F1(a) layer (Input portion)- ART1'de, sadece giriş vektörlerine sahip olmak yerine bu kısımda hiçbir işlem olmayacaktır. F 1 (b) katmanına (arayüz kısmı) bağlıdır.
F1(b) layer (Interface portion)- Bu kısım, giriş kısmından gelen sinyali F 2 katmanınınkiyle birleştirir. F 1 (b) tabakası F 2 tabakasına aşağıdan yukarıya ağırlıklar ile bağlanır.bijve F 2 katmanı F 1 (b) katmanına yukarıdan aşağıya ağırlıklarla bağlanır.tji.
Cluster Unit (F2 layer)- Bu rekabetçi bir katman. Giriş modelini öğrenmek için en büyük net girişe sahip ünite seçilir. Diğer tüm küme birimlerinin aktivasyonu 0 olarak ayarlanmıştır.
Reset Mechanism- Bu mekanizmanın çalışması, yukarıdan aşağıya ağırlık ile giriş vektörü arasındaki benzerliğe dayanmaktadır. Şimdi, bu benzerliğin derecesi, uyanıklık parametresinden daha az ise, kümenin modeli öğrenmesine izin verilmez ve bir dinlenme olur.
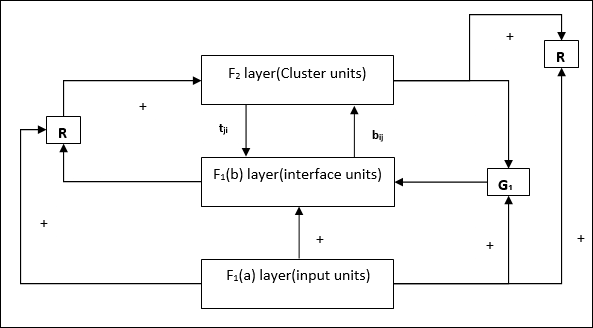
Supplement Unit - Aslında Sıfırlama mekanizmasıyla ilgili sorun, katmanın F2belirli koşullar altında engellenmeli ve bazı öğrenme gerçekleştiğinde de mevcut olmalıdır. Bu nedenle iki ek birim, yaniG1 ve G2 sıfırlama ünitesi ile birlikte eklenir, R. Onlara telefon edildigain control units. Bu birimler ağda bulunan diğer birimlere sinyal alır ve gönderir.‘+’ uyarıcı bir sinyali gösterirken ‘−’ engelleyici bir sinyali gösterir.
Kullanılan Parametreler
Aşağıdaki parametreler kullanılır -
n - Giriş vektöründeki bileşenlerin sayısı
m - Oluşturulabilecek maksimum küme sayısı
bij- F 1 (b) 'den F 2 katmanına kadar ağırlık, yani aşağıdan yukarıya ağırlıklar
tji- F 2'den F 1 (b) katmanına kadar ağırlık, yani yukarıdan aşağıya ağırlıklar
ρ - Dikkat parametresi
||x|| - x vektörünün normu
Algoritma
Step 1 - Öğrenme oranını, uyanıklık parametresini ve ağırlıkları aşağıdaki şekilde başlatın -
$$ \ alpha \:> \: 1 \: \: ve \: \: 0 \: <\ rho \: \ leq \: 1 $$
$$ 0 \: <\: b_ {ij} (0) \: <\: \ frac {\ alpha} {\ alpha \: - \: 1 \: + \: n} \: \: ve \: \: t_ {ij} (0) \: = \: 1 $$
Step 2 - Durdurma koşulu doğru olmadığında adım 3-9'a devam edin.
Step 3 - Her eğitim girdisi için adım 4-6'ya devam edin.
Step 4- Tüm F 1 (a) ve F 1 birimlerinin aktivasyonlarını aşağıdaki gibi ayarlayın
F2 = 0 and F1(a) = input vectors
Step 5- F 1 (a) 'dan F 1 (b) katmanına giriş sinyali aşağıdaki gibi gönderilmelidir.
$$ s_ {i} \: = \: x_ {i} $$
Step 6- Engellenen her F 2 düğümü için
$ y_ {j} \: = \: \ sum_i b_ {ij} x_ {i} $ koşul yj ≠ -1
Step 7 - Sıfırlama doğru olduğunda adım 8-10'u gerçekleştirin.
Step 8 - Bul J için yJ ≥ yj tüm düğümler için j
Step 9- F 1 (b) ' deki aktivasyonu aşağıdaki gibi tekrar hesaplayın
$$ x_ {i} \: = \: sitJi $$
Step 10 - Şimdi, vektörün normunu hesapladıktan sonra x ve vektör s, sıfırlama koşulunu aşağıdaki gibi kontrol etmemiz gerekir -
Eğer ||x||/ ||s|| <vigilance parametresi ρ, sonranode inhibe J ve 7. adıma gidin
Else If ||x||/ ||s|| ≥ uyanıklık parametresi ρdaha sonra devam edin.
Step 11 - Düğüm için ağırlık güncelleme J aşağıdaki gibi yapılabilir -
$$ b_ {ij} (yeni) \: = \: \ frac {\ alpha x_ {i}} {\ alpha \: - \: 1 \: + \: || x ||} $$
$$ t_ {ij} (yeni) \: = \: x_ {i} $$
Step 12 - Algoritma için durdurma koşulu kontrol edilmelidir ve aşağıdaki gibi olabilir -
- Kilo değişikliği yapmayın.
- Üniteler için sıfırlama yapılmaz.
- Maksimum dönem sayısına ulaşıldı.
Bazı rasgele boyut modellerimiz olduğunu varsayalım, ancak onlara bir veya iki boyutta ihtiyacımız var. O zaman özellik haritalama süreci, geniş çoğaltma uzayını tipik bir özellik uzayına dönüştürmek için çok yararlı olacaktır. Şimdi, soru, neden kendi kendini organize eden özellik haritasına ihtiyacımız var? Bunun nedeni, keyfi boyutları 1-D veya 2-D'ye dönüştürme yeteneğinin yanı sıra, aynı zamanda komşu topolojiyi koruma yeteneğine de sahip olması gerektiğidir.
Kohonen SOM'da Komşu Topolojileri
Çeşitli topolojiler olabilir, ancak aşağıdaki iki topoloji en çok kullanılır -
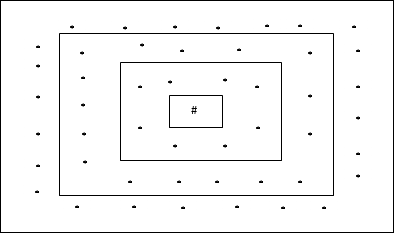
Dikdörtgen Izgara Topolojisi
Bu topolojinin mesafe-2 ızgarasında 24 düğüm, mesafe-1 ızgarasında 16 düğüm ve mesafe-0 ızgarasında 8 düğüm vardır, bu da her dikdörtgen ızgara arasındaki farkın 8 düğüm olduğu anlamına gelir. Kazanan birim # ile belirtilir.
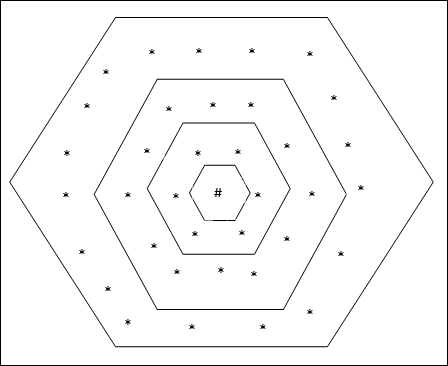
Altıgen Izgara Topolojisi
Bu topolojinin mesafe-2 ızgarasında 18 düğüm, mesafe-1 ızgarasında 12 düğüm ve mesafe-0 ızgarasında 6 düğüm vardır, bu da her dikdörtgen ızgara arasındaki farkın 6 düğüm olduğu anlamına gelir. Kazanan birim # ile belirtilir.
Mimari
KSOM'un mimarisi, rekabetçi ağın mimarisine benzer. Daha önce tartışılan mahalle planlarının yardımıyla, eğitim ağın genişletilmiş bölgesi üzerinden gerçekleştirilebilir.
Eğitim için algoritma
Step 1 - Ağırlıkları, öğrenme oranını başlatın α ve mahalle topolojik şeması.
Step 2 - Durdurma koşulu doğru olmadığında adım 3-9'a devam edin.
Step 3 - Her giriş vektörü için adım 4-6'ya devam edin x.
Step 4 - Öklid Mesafesinin Karesini Hesapla j = 1 to m
$$ D (j) \: = \: \ displaystyle \ sum \ limits_ {i = 1} ^ n \ displaystyle \ sum \ limits_ {j = 1} ^ m (x_ {i} \: - \: w_ {ij }) ^ 2 $$
Step 5 - Kazanan birimi edinin J nerede D(j) minimumdur.
Step 6 - Kazanan birimin yeni ağırlığını aşağıdaki ilişkiye göre hesaplayın -
$$ w_ {ij} (yeni) \: = \: w_ {ij} (eski) \: + \: \ alpha [x_ {i} \: - \: w_ {ij} (eski)] $$
Step 7 - Öğrenme oranını güncelleyin α aşağıdaki ilişkiye göre -
$$ \ alpha (t \: + \: 1) \: = \: 0.5 \ alpha t $$
Step 8 - Topolojik şemanın yarıçapını azaltın.
Step 9 - Ağın durma koşulunu kontrol edin.
Bu tür sinir ağları, örüntü ilişkilendirme temelinde çalışır; bu, farklı örüntüleri depolayabilecekleri ve bir çıktı verirken, bunları verilen girdi örüntüsü ile eşleştirerek depolanan örüntülerden birini üretebilecekleri anlamına gelir. Bu tür anılar da denirContent-Addressable Memory(KAM). İlişkilendirilebilir bellek, veri dosyaları olarak depolanan modellerle paralel bir arama yapar.
Aşağıda, gözlemleyebileceğimiz iki tür çağrışımsal anı bulunmaktadır:
- Otomatik İlişkilendirilebilir Bellek
- Hetero İlişkisel bellek
Otomatik İlişkilendirilebilir Bellek
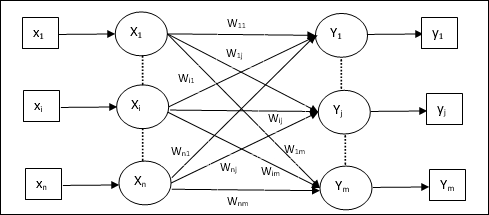
Bu, giriş eğitim vektörünün ve çıktı hedef vektörlerinin aynı olduğu tek katmanlı bir sinir ağıdır. Ağırlıklar, ağın bir dizi modeli depolaması için belirlenir.
Mimari
Aşağıdaki şekilde gösterildiği gibi, Auto Associative bellek ağının mimarisi, ‘n’ girdi eğitim vektörlerinin sayısı ve benzeri ‘n’ çıktı hedef vektörlerinin sayısı.
Eğitim Algoritması
Eğitim için bu ağ Hebb veya Delta öğrenme kuralını kullanıyor.
Step 1 - Tüm ağırlıkları sıfıra ayarlayın. wij = 0 (i = 1 to n, j = 1 to n)
Step 2 - Her giriş vektörü için 3-4. Adımları uygulayın.
Step 3 - Her bir giriş birimini aşağıdaki şekilde etkinleştirin -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: - \: n) $$
Step 4 - Her çıkış birimini aşağıdaki şekilde etkinleştirin -
$$ y_ {j} \: = \: s_ {j} \ :( j \: = \: 1 \: - \: n) $$
Step 5 - Ağırlıkları aşağıdaki gibi ayarlayın -
$$ w_ {ij} (yeni) \: = \: w_ {ij} (eski) \: + \: x_ {i} y_ {j} $$
Test Algoritması
Step 1 - Hebb kuralı için eğitim sırasında elde edilen ağırlıkları ayarlayın.
Step 2 - Her bir giriş vektörü için 3-5 arası adımları gerçekleştirin.
Step 3 - Giriş birimlerinin aktivasyonunu giriş vektörününkine eşit ayarlayın.
Step 4 - Her bir çıktı biriminin net girdisini hesaplayın j = 1 to n
$$ y_ {inj} \: = \: \ displaystyle \ sum \ limits_ {i = 1} ^ n x_ {i} w_ {ij} $$
Step 5 - Çıkışı hesaplamak için aşağıdaki aktivasyon işlevini uygulayın
$$ y_ {j} \: = \: f (y_ {inj}) \: = \: \ başla {vakalar} +1 ve eğer \: y_ {inj} \:> \: 0 \\ - 1 ve eğer \: y_ {inj} \: \ leqslant \: 0 \ end {case} $$
Hetero İlişkisel bellek
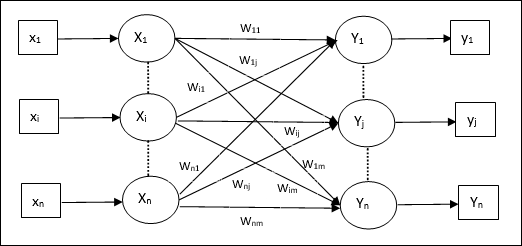
Otomatik İlişkilendirilebilir Bellek ağına benzer şekilde, bu da tek katmanlı bir sinir ağıdır. Bununla birlikte, bu ağda girdi eğitim vektörü ve çıktı hedef vektörleri aynı değildir. Ağırlıklar, ağın bir dizi modeli depolaması için belirlenir. Hetero ilişkisel ağ yapısı gereği statiktir, dolayısıyla doğrusal olmayan ve gecikmeli işlemler olmayacaktır.
Mimari
Aşağıdaki şekilde gösterildiği gibi, Hetero İlişkisel Bellek ağının mimarisi, ‘n’ girdi eğitim vektörlerinin sayısı ve ‘m’ çıktı hedef vektörlerinin sayısı.
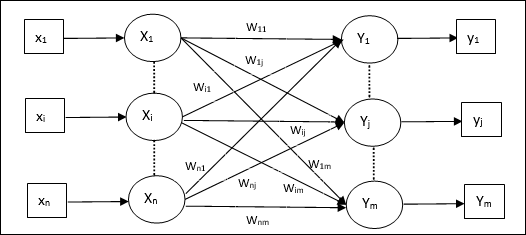
Eğitim Algoritması
Eğitim için bu ağ Hebb veya Delta öğrenme kuralını kullanıyor.
Step 1 - Tüm ağırlıkları sıfıra ayarlayın. wij = 0 (i = 1 to n, j = 1 to m)
Step 2 - Her giriş vektörü için 3-4. Adımları uygulayın.
Step 3 - Her bir giriş birimini aşağıdaki şekilde etkinleştirin -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: - \: n) $$
Step 4 - Her çıkış birimini aşağıdaki şekilde etkinleştirin -
$$ y_ {j} \: = \: s_ {j} \ :( j \: = \: 1 \: - \: m) $$
Step 5 - Ağırlıkları aşağıdaki gibi ayarlayın -
$$ w_ {ij} (yeni) \: = \: w_ {ij} (eski) \: + \: x_ {i} y_ {j} $$
Test Algoritması
Step 1 - Hebb kuralı için eğitim sırasında elde edilen ağırlıkları ayarlayın.
Step 2 - Her bir giriş vektörü için 3-5 arası adımları gerçekleştirin.
Step 3 - Giriş birimlerinin aktivasyonunu giriş vektörününkine eşit ayarlayın.
Step 4 - Her bir çıktı biriminin net girdisini hesaplayın j = 1 to m;
$$ y_ {inj} \: = \: \ displaystyle \ sum \ limits_ {i = 1} ^ n x_ {i} w_ {ij} $$
Step 5 - Çıkışı hesaplamak için aşağıdaki aktivasyon işlevini uygulayın
$$ y_ {j} \: = \: f (y_ {inj}) \: = \: \ başla {vakalar} +1 ve eğer \: y_ {inj} \:> \: 0 \\ 0 ve eğer \ : y_ {inj} \: = \: 0 \\ - 1 & if \: y_ {inj} \: <\: 0 \ end {case} $$
Hopfield sinir ağı, 1982 yılında Dr. John J. Hopfield tarafından icat edilmiştir. Bir veya daha fazla tamamen bağlı tekrarlayan nöron içeren tek bir katmandan oluşur. Hopfield ağı, genellikle otomatik ilişkilendirme ve optimizasyon görevleri için kullanılır.
Ayrık Hopfield Ağı
Ayrık bir çizgi biçiminde çalışan veya başka bir deyişle, giriş ve çıkış modellerinin doğada ikili (0,1) veya iki kutuplu (+1, -1) olabilen ayrık vektörler olduğu söylenebilir. Ağ, kendi kendine bağlantısı olmayan simetrik ağırlıklara sahiptir, yani,wij = wji ve wii = 0.
Mimari
Ayrı Hopfield ağı hakkında akılda tutulması gereken bazı önemli noktalar şunlardır:
Bu model, bir ters çeviren ve bir ters çevirmeyen çıktıya sahip nöronlardan oluşur.
Her bir nöronun çıktısı, diğer nöronların girdisi olmalı ama benliğin girdisi olmamalıdır.
Ağırlık / bağlantı gücü şu şekilde temsil edilir: wij.
Bağlantılar hem uyarıcı hem de inhibe edici olabilir. Nöronun çıktısı girdiyle aynıysa uyarıcı, aksi takdirde engelleyici olur.
Ağırlıklar simetrik olmalıdır, yani wij = wji
Çıkış Y1 gidiyor Y2, Yi ve Yn ağırlıklara sahip olmak w12, w1i ve w1nsırasıyla. Benzer şekilde, diğer yayların üzerinde de ağırlık vardır.
Eğitim Algoritması
Ayrı Hopfield ağının eğitimi sırasında ağırlıklar güncellenecektir. Bildiğimiz gibi ikili giriş vektörlerinin yanı sıra iki kutuplu giriş vektörlerine de sahip olabiliriz. Dolayısıyla her iki durumda da ağırlık güncellemeleri aşağıdaki ilişki ile yapılabilir.
Case 1 - İkili giriş modelleri
Bir dizi ikili desen için s(p), p = 1 to P
Buraya, s(p) = s1(p), s2(p),..., si(p),..., sn(p)
Ağırlık Matrisi şu şekilde verilir:
$$ w_ {ij} \: = \: \ sum_ {p = 1} ^ P [2s_ {i} (p) - \: 1] [2s_ {j} (p) - \: 1] \: \: \: \: \: için \: i \: \ neq \: j $$
Case 2 - Bipolar giriş kalıpları
Bir dizi ikili desen için s(p), p = 1 to P
Buraya, s(p) = s1(p), s2(p),..., si(p),..., sn(p)
Ağırlık Matrisi şu şekilde verilir:
$$ w_ {ij} \: = \: \ sum_ {p = 1} ^ P [s_ {i} (p)] [s_ {j} (p)] \: \: \: \: \: için \ : i \: \ neq \: j $$
Test Algoritması
Step 1 - Hebbian prensibini kullanarak eğitim algoritmasından elde edilen ağırlıkları başlatın.
Step 2 - Ağ etkinleştirmeleri birleştirilmediyse 3-9 arasındaki adımları uygulayın.
Step 3 - Her giriş vektörü için X4-8. adımları gerçekleştirin.
Step 4 - Ağın ilk aktivasyonunu harici giriş vektörüne eşit yapın X aşağıdaki gibi -
$$ y_ {i} \: = \: x_ {i} \: \: \: için \: i \: = \: 1 \: - \: n $$
Step 5 - Her birim için Yi6-9 arası adımları gerçekleştirin.
Step 6 - Ağın net girişini aşağıdaki şekilde hesaplayın -
$$ y_ {ini} \: = \: x_ {i} \: + \: \ displaystyle \ sum \ limits_ {j} y_ {j} w_ {ji} $$
Step 7 - Çıkışı hesaplamak için etkinleştirmeyi aşağıdaki şekilde net girdiye uygulayın -
$$ y_ {i} \: = \ start {case} 1 & if \: y_ {ini} \:> \: \ theta_ {i} \\ y_ {i} & if \: y_ {ini} \: = \: \ theta_ {i} \\ 0 & if \: y_ {ini} \: <\: \ theta_ {i} \ end {case} $$
Burada $ \ theta_ {i} $ eşiktir.
Step 8 - Bu çıktıyı yayınla yi diğer tüm birimlere.
Step 9 - Ağı bağlantı için test edin.
Enerji Fonksiyonu Değerlendirmesi
Enerji fonksiyonu, sistemin durumunun bağlı ve artmayan fonksiyonu olarak tanımlanır.
Enerji fonksiyonu Ef, ayrıca denir Lyapunov function ayrık Hopfield ağının kararlılığını belirler ve aşağıdaki gibi karakterize edilir -
$$ E_ {f} \: = \: - \ frac {1} {2} \ displaystyle \ sum \ limits_ {i = 1} ^ n \ displaystyle \ sum \ limits_ {j = 1} ^ n y_ {i} y_ {j} w_ {ij} \: - \: \ displaystyle \ sum \ limits_ {i = 1} ^ n x_ {i} y_ {i} \: + \: \ displaystyle \ sum \ limits_ {i = 1} ^ n \ theta_ {i} y_ {i} $$
Condition - Kararlı bir ağda, düğümün durumu her değiştiğinde, yukarıdaki enerji işlevi azalacaktır.
Varsayalım ki düğüm i durumu $ y_i ^ {(k)} $ 'dan $ y_i ^ {(k \: + \: 1)} $ 'e değiştirdikten sonra Enerji değişimi $ \ Delta E_ {f} $ aşağıdaki ilişki ile verilir
$$ \ Delta E_ {f} \: = \: E_ {f} (y_i ^ {(k + 1)}) \: - \: E_ {f} (y_i ^ {(k)}) $$
$$ = \: - \ left (\ begin {dizi} {c} \ displaystyle \ sum \ limits_ {j = 1} ^ n w_ {ij} y_i ^ {(k)} \: + \: x_ {i} \: - \: \ theta_ {i} \ end {dizi} \ sağ) (y_i ^ {(k + 1)} \: - \: y_i ^ {(k)}) $$
$$ = \: - \ :( net_ {i}) \ Delta y_ {i} $$
Burada $ \ Delta y_ {i} \: = \: y_i ^ {(k \: + \: 1)} \: - \: y_i ^ {(k)} $
Enerjideki değişim, bir seferde yalnızca bir birimin aktivasyonunu güncelleyebilmesine bağlıdır.
Sürekli Hopfield Ağı
Kesikli Hopfield ağına kıyasla, sürekli ağın sürekli bir değişken olarak zamanı vardır. Seyahat eden satıcı problemi gibi otomatik ilişkilendirme ve optimizasyon problemlerinde de kullanılır.
Model - Model veya mimari, giriş voltajını bir sigmoid aktivasyon işlevi üzerinden çıkış voltajına eşleyebilen amplifikatörler gibi elektrikli bileşenler eklenerek oluşturulabilir.
Enerji Fonksiyonu Değerlendirmesi
$$ E_f = \ frac {1} {2} \ displaystyle \ sum \ limits_ {i = 1} ^ n \ sum _ {\ substack {j = 1 \\ j \ ne i}} ^ n y_i y_j w_ {ij} - \ displaystyle \ sum \ limits_ {i = 1} ^ n x_i y_i + \ frac {1} {\ lambda} \ displaystyle \ sum \ limits_ {i = 1} ^ n \ sum _ {\ substack {j = 1 \\ j \ ne i}} ^ n w_ {ij} g_ {ri} \ int_ {0} ^ {y_i} a ^ {- 1} (y) dy $$
Buraya λ kazanç parametresidir ve gri giriş iletkenliği.
Bunlar tekrarlayan yapıya sahip stokastik öğrenme süreçleridir ve YSA'da kullanılan erken optimizasyon tekniklerinin temelini oluşturur. Boltzmann Makinesi 1985 yılında Geoffrey Hinton ve Terry Sejnowski tarafından icat edildi. Hinton'un Boltzmann Machine hakkındaki sözlerinde daha fazla netlik gözlemlenebilir.
"Bu ağın şaşırtıcı bir özelliği, yalnızca yerel olarak mevcut bilgileri kullanmasıdır. Ağırlık değişimi, değişiklik küresel bir ölçüyü optimize etse de, yalnızca bağlandığı iki birimin davranışına bağlıdır ”- Ackley, Hinton 1985.
Boltzmann Makinesi ile ilgili bazı önemli noktalar -
Tekrarlayan yapı kullanırlar.
1 veya 0 olmak üzere iki olası durumdan birine sahip olan stokastik nöronlardan oluşurlar.
Buradaki nöronların bazıları uyarlanabilir (serbest durum) ve bazıları kenetlenir (donmuş durum).
Ayrık Hopfield ağına benzetilmiş tavlama uygularsak, bu Boltzmann Makinesi olur.
Boltzmann Makinasının Amacı
Boltzmann Machine'in temel amacı, bir problemin çözümünü optimize etmektir. Söz konusu problemle ilgili ağırlıkları ve miktarı optimize etmek Boltzmann Machine'in işidir.
Mimari
Aşağıdaki diyagram Boltzmann makinesinin mimarisini göstermektedir. Diyagramdan, iki boyutlu bir birimler dizisi olduğu açıktır. Burada, birimler arasındaki ara bağlantıların ağırlıkları–p nerede p > 0. Kendi kendine bağlantıların ağırlıkları,b nerede b > 0.
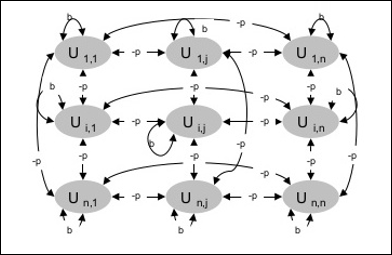
Eğitim Algoritması
Boltzmann makinelerinin sabit ağırlıklara sahip olduğunu bildiğimiz için, ağdaki ağırlıkları güncellememiz gerekmediğinden eğitim algoritması olmayacaktır. Bununla birlikte, ağı test etmek için ağırlıkları belirlememiz ve fikir birliği işlevini (CF) bulmamız gerekir.
Boltzmann makinesi bir dizi üniteye sahiptir Ui ve Uj ve üzerlerinde çift yönlü bağlantılar vardır.
Sabit ağırlığı düşünüyoruz diyelim wij.
wij ≠ 0 Eğer Ui ve Uj bağlılar.
Ağırlıklı arabağlantıda da bir simetri vardır, yani wij = wji.
wii ayrıca vardır, yani birimler arasında kendi kendine bağlantı olacaktır.
Herhangi bir birim için Ui, durumu ui 1 veya 0 olur.
Boltzmann Makinesinin temel amacı, aşağıdaki ilişki ile verilebilecek Konsensüs Fonksiyonunu (CF) maksimize etmektir.
$$ CF \: = \: \ displaystyle \ sum \ limits_ {i} \ displaystyle \ sum \ limits_ {j \ leqslant i} w_ {ij} u_ {i} u_ {j} $$
Şimdi, durum 1'den 0'a veya 0'dan 1'e değiştiğinde, fikir birliğindeki değişiklik aşağıdaki ilişki ile verilebilir:
$$ \ Delta CF \: = \ :( 1 \: - \: 2u_ {i}) (w_ {ij} \: + \: \ displaystyle \ sum \ limits_ {j \ neq i} u_ {i} w_ { ij}) $$
Buraya ui şu anki durumu Ui.
Katsayıdaki değişim (1 - 2ui) aşağıdaki ilişki ile verilir -
$$ (1 \: - \: 2u_ {i}) \: = \: \ begin {case} +1 ve U_ {i} \: eşittir \: şu anda \: off \\ - 1, & U_ {i } \: şu anda \: \ end {case} $$
Genel olarak birim Uidurumunu değiştirmez, ancak değiştirirse, bilgi birim için yerel olarak ikamet ediyor olacaktır. Bu değişiklikle, ağın fikir birliğinde de bir artış olacaktır.
Şebekenin, birimin durumundaki değişikliği kabul etme olasılığı aşağıdaki ilişki ile verilmektedir:
$$ AF (i, T) \: = \: \ frac {1} {1 \: + \: exp [- \ frac {\ Delta CF (i)} {T}]} $$
Buraya, Tkontrol eden parametredir. CF maksimum değere ulaştıkça azalacaktır.
Test Algoritması
Step 1 - Eğitimi başlatmak için aşağıdakileri başlatın -
- Problemin kısıtlamasını temsil eden ağırlıklar
- Kontrol Parametresi T
Step 2 - Durdurma koşulu doğru olmadığında 3-8 adımlarına devam edin.
Step 3 - Adım 4-7'yi gerçekleştirin.
Step 4 - Eyaletlerden birinin ağırlığı değiştirdiğini varsayın ve tamsayıyı seçin I, J rastgele değerler olarak 1 ve n.
Step 5 - Fikir birliğindeki değişikliği aşağıdaki gibi hesaplayın -
$$ \ Delta CF \: = \ :( 1 \: - \: 2u_ {i}) (w_ {ij} \: + \: \ displaystyle \ sum \ limits_ {j \ neq i} u_ {i} w_ { ij}) $$
Step 6 - Bu ağın durumdaki değişikliği kabul etme olasılığını hesaplayın
$$ AF (i, T) \: = \: \ frac {1} {1 \: + \: exp [- \ frac {\ Delta CF (i)} {T}]} $$
Step 7 - Bu değişikliği aşağıdaki şekilde kabul edin veya reddedin -
Case I - eğer R < AFdeğişikliği kabul edin.
Case II - eğer R ≥ AF, değişikliği reddedin.
Buraya, R 0 ile 1 arasındaki rastgele sayıdır.
Step 8 - Kontrol parametresini (sıcaklık) aşağıdaki şekilde azaltın -
T(new) = 0.95T(old)
Step 9 - Aşağıdaki gibi olabilecek durdurma koşullarını test edin -
- Sıcaklık belirli bir değere ulaştı
- Belirli sayıda yineleme için durumda değişiklik yok
Box-State-in-a-Box (BSB) sinir ağı, doğrusal olmayan otomatik birleşik bir sinir ağıdır ve iki veya daha fazla katmanla hetero ilişkiye genişletilebilir. Aynı zamanda Hopfield ağına benzer. JA Anderson, JW Silverstein, SA Ritz ve RS Jones tarafından 1977'de önerildi.
BSB Ağı hakkında hatırlanması gereken bazı önemli noktalar -
Boyutluluğa bağlı olarak maksimum düğüm sayısına sahip tamamen bağlı bir ağdır. n giriş alanı.
Tüm nöronlar aynı anda güncellenir.
Nöronlar -1 ile +1 arasındaki değerleri alır.
Matematiksel Formülasyonlar
BSB ağında kullanılan düğüm işlevi, aşağıdaki gibi tanımlanabilen bir rampa işlevidir -
$$ f (net) \: = \: min (1, \: max (-1, \: net)) $$
Bu rampa işlevi sınırlı ve süreklidir.
Her bir düğümün durumunu değiştireceğini bildiğimiz gibi, aşağıdaki matematiksel ilişki yardımı ile yapılabilir -
$$ x_ {t} (t \: + \: 1) \: = \: f \ left (\ begin {dizi} {c} \ displaystyle \ sum \ limits_ {j = 1} ^ n w_ {i, j } x_ {j} (t) \ end {dizi} \ sağ) $$
Buraya, xi(t) durumu ith an düğüm t.
Ağırlıkları ith düğüm jth düğüm aşağıdaki ilişki ile ölçülebilir -
$$ w_ {ij} \: = \: \ frac {1} {P} \ displaystyle \ sum \ limits_ {p = 1} ^ P (v_ {p, i} \: v_ {p, j}) $$
Buraya, P bipolar olan eğitim modellerinin sayısıdır.
Optimizasyon, tasarım, durum, kaynak ve sistem gibi bir şeyi olabildiğince etkili hale getirme eylemidir. Maliyet fonksiyonu ile enerji fonksiyonu arasındaki benzerliği kullanarak, optimizasyon problemlerini çözmek için birbiriyle yüksek oranda bağlantılı nöronları kullanabiliriz. Bu tür bir sinir ağı, bir veya daha fazla tamamen bağlı tekrarlayan nöron içeren tek bir katmandan oluşan Hopfield ağıdır. Bu, optimizasyon için kullanılabilir.
Optimizasyon için Hopfield ağını kullanırken hatırlanması gereken noktalar -
Enerji işlevi ağın minimum olması gerekir.
Depolanan modellerden birini seçmek yerine tatmin edici bir çözüm bulacaktır.
Hopfield ağı tarafından bulunan çözümün kalitesi, ağın başlangıç durumuna önemli ölçüde bağlıdır.
Seyahat Eden Satıcı Sorunu
Satıcının gittiği en kısa yolu bulmak, Hopfield sinir ağı kullanılarak optimize edilebilen hesaplama problemlerinden biridir.
TSP'nin Temel Kavramı
Seyahat Eden Satıcı Problemi (TSP), bir satıcının seyahat etmek zorunda olduğu klasik bir optimizasyon problemidir. nBirbirleriyle bağlantılı şehirler, maliyeti ve gidilen mesafeyi minimumda tutuyor. Örneğin, satış elemanı A, B, C, D 4 şehirden oluşan bir sette seyahat etmek zorundadır ve amaç, en kısa dairesel tur olan ABC-D'yi bulmaktır, böylece maliyeti en aza indirgemek, son şehir D'den ilk şehir A'ya
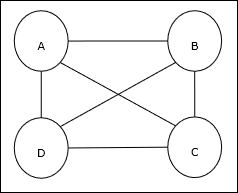
Matris Gösterimi
Aslında her n-city TSP turu şu şekilde ifade edilebilir: n × n matris kimin ith satır açıklar ithşehrin konumu. Bu matris,M4 şehir için A, B, C, D şu şekilde ifade edilebilir -
$$ M = \ başla {bmatrix} A: & 1 & 0 & 0 & 0 \\ B: & 0 & 1 & 0 & 0 \\ C: & 0 & 0 & 1 & 0 \\ D: & 0 & 0 ve 0 ve 1 \ end {bmatrix} $$
Hopfield Ağı Çözümleri
Bu TSP'nin Hopfield ağı tarafından çözümü düşünülürken, ağdaki her düğüm matristeki bir öğeye karşılık gelir.
Enerji Fonksiyonu Hesaplaması
Optimize edilmiş çözüm olmak için enerji işlevi minimum olmalıdır. Aşağıdaki kısıtlamalar temelinde enerji fonksiyonunu şu şekilde hesaplayabiliriz:
Kısıtlama-I
Temelde enerji fonksiyonunu hesaplayacağımız ilk kısıt, her bir matris satırında bir öğenin 1'e eşit olması gerektiğidir. M ve her satırdaki diğer öğeler şuna eşit olmalıdır: 0çünkü her şehir TSP turunda sadece bir konumda gerçekleşebilir. Bu kısıtlama matematiksel olarak şu şekilde yazılabilir -
$$ \ displaystyle \ sum \ limits_ {j = 1} ^ n M_ {x, j} \: = \: 1 \: \: \ lbrace1, ..., n \ rbrace $ içinde \: x \: \ için $
Şimdi, yukarıdaki kısıtlamaya dayalı olarak minimize edilecek enerji fonksiyonu, - ile orantılı bir terim içerecektir.
$$ \ displaystyle \ sum \ limits_ {x = 1} ^ n \ left (\ begin {array} {c} 1 \: - \: \ displaystyle \ sum \ limits_ {j = 1} ^ n M_ {x, j } \ end {dizi} \ sağ) ^ 2 $$
Kısıtlama-II
Bildiğimiz gibi, TSP'de bir şehir turun herhangi bir konumunda olabilir, dolayısıyla her bir matris sütununda M, bir eleman 1'e ve diğer elemanlar 0'a eşit olmalıdır. Bu kısıt matematiksel olarak aşağıdaki gibi yazılabilir -
$$ \ displaystyle \ sum \ limits_ {x = 1} ^ n M_ {x, j} \: = \: 1 \: \: \ lbrace1, ..., n \ rbrace $ için \: j \: \ için $
Şimdi, yukarıdaki kısıtlamaya dayalı olarak minimize edilecek enerji fonksiyonu, - ile orantılı bir terim içerecektir.
$$ \ displaystyle \ sum \ limits_ {j = 1} ^ n \ left (\ begin {array} {c} 1 \: - \: \ displaystyle \ sum \ limits_ {x = 1} ^ n M_ {x, j } \ end {dizi} \ sağ) ^ 2 $$
Maliyet Fonksiyonu Hesaplama
Diyelim ki bir kare matris (n × n) ile gösterilir C TSP'nin maliyet matrisini gösterir. n nerede şehirler n > 0. Maliyet fonksiyonu hesaplanırken kullanılan bazı parametreler aşağıdadır -
Cx, y - Maliyet matrisi unsuru, şehirden seyahat etmenin maliyetini gösterir x -e y.
A ve B öğelerinin bitişikliği aşağıdaki ilişki ile gösterilebilir:
$$ M_ {x, i} \: = \: 1 \: \: ve \: \: M_ {y, i \ pm 1} \: = \: 1 $$
Bildiğimiz gibi, Matrix'te her düğümün çıktı değeri 0 veya 1 olabilir, dolayısıyla her A, B şehir çifti için enerji fonksiyonuna aşağıdaki terimleri ekleyebiliriz -
$$ \ displaystyle \ toplam \ limitler_ {i = 1} ^ n C_ {x, y} M_ {x, i} (M_ {y, i + 1} \: + \: M_ {y, i-1}) $$
Yukarıdaki maliyet fonksiyonu ve kısıtlama değeri temelinde, nihai enerji fonksiyonu E aşağıdaki gibi verilebilir -
$$ E \: = \: \ frac {1} {2} \ displaystyle \ sum \ limits_ {i = 1} ^ n \ displaystyle \ sum \ limits_ {x} \ displaystyle \ sum \ limits_ {y \ neq x} C_ {x, y} M_ {x, i} (M_ {y, i + 1} \: + \: M_ {y, i-1}) \: + $$
$$ \: \ begin {bmatrix} \ gamma_ {1} \ displaystyle \ sum \ limits_ {x} \ left (\ begin {dizi} {c} 1 \: - \: \ displaystyle \ sum \ limits_ {i} M_ {x, i} \ end {dizi} \ sağ) ^ 2 \: + \: \ gamma_ {2} \ displaystyle \ sum \ limits_ {i} \ left (\ begin {dizi} {c} 1 \: - \ : \ displaystyle \ sum \ limits_ {x} M_ {x, i} \ end {dizi} \ sağ) ^ 2 \ end {bmatrix} $$
Buraya, γ1 ve γ2 iki tartım sabitidir.
Yinelenen Gradyan İniş Tekniği
En dik iniş olarak da bilinen gradyan inişi, bir fonksiyonun yerel minimumunu bulmak için yinelemeli bir optimizasyon algoritmasıdır. İşlevi en aza indirirken, en aza indirilmesi gereken maliyet veya hata ile ilgileniyoruz (Seyahat Eden Satışçı Problemini Hatırlayın). Çok çeşitli durumlarda faydalı olan derin öğrenmede yaygın olarak kullanılır. Burada hatırlanması gereken nokta, küresel optimizasyonla değil yerel optimizasyonla ilgilendiğimizdir.
Ana Çalışma Fikri
Gradyan inişinin ana çalışma fikrini aşağıdaki adımların yardımıyla anlayabiliriz -
İlk olarak, çözümün ilk tahminiyle başlayın.
Ardından, o noktada fonksiyonun gradyanını alın.
Daha sonra, çözümü gradyanın negatif yönünde adımlayarak işlemi tekrarlayın.
Yukarıdaki adımları izleyerek, algoritma sonunda gradyanın sıfır olduğu yerde birleşecektir.
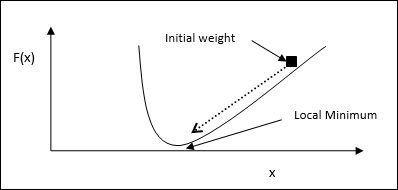
Matematiksel Kavram
Diyelim ki bir fonksiyonumuz var f(x)ve bu fonksiyonun minimumunu bulmaya çalışıyoruz. Aşağıdakilerden en azını bulmak için adımlar verilmiştir.f(x).
Önce, \: x $ için $ x_ {0} \: için bir başlangıç değeri verin
Şimdi $ \ nabla f $ f fonksiyonunun gradyanını alın, sezgisel gradyan eğrinin eğimini o noktadaki x ve yönü, onu en aza indirgemek için en iyi yönü bulmak üzere işlevdeki artışı gösterecektir.
Şimdi x'i aşağıdaki gibi değiştirin -
$$ x_ {n \: + \: 1} \: = \: x_ {n} \: - \: \ theta \ nabla f (x_ {n}) $$
Buraya, θ > 0 algoritmayı küçük sıçramalar yapmaya zorlayan eğitim hızıdır (adım boyutu).
Adım Büyüklüğünü Tahmin Etme
Aslında yanlış bir adım boyutu θyakınsamaya ulaşamayabilir, bu nedenle dikkatli bir şekilde seçilmesi çok önemlidir. Adım boyutunu seçerken aşağıdaki noktaların hatırlanması gerekir
Çok büyük adım boyutu seçmeyin, aksi takdirde olumsuz bir etkisi olacaktır, yani yakınsamak yerine uzaklaşacaktır.
Çok küçük adım boyutu seçmeyin, aksi takdirde yakınsaması çok zaman alır.
Adım boyutunu seçmeyle ilgili bazı seçenekler -
Bir seçenek, sabit bir adım boyutu seçmektir.
Diğer bir seçenek, her yineleme için farklı bir adım boyutu seçmektir.
Benzetimli tavlama
Simüle Tavlamanın (SA) temel konsepti, katılarda tavlama ile motive edilir. Tavlama sürecinde, bir metali erime noktasının üzerinde ısıtıp soğutursak, yapısal özellikler soğuma hızına bağlı olacaktır. SA'nın metalurji tavlama sürecini simüle ettiğini de söyleyebiliriz.
YSA'da kullanın
SA, belirli bir fonksiyonun küresel optimizasyonuna yaklaşmak için Tavlama benzetmesinden esinlenen stokastik bir hesaplama yöntemidir. SA'yı ileri beslemeli sinir ağlarını eğitmek için kullanabiliriz.
Algoritma
Step 1 - Rastgele bir çözüm üretin.
Step 2 - Bazı maliyet işlevlerini kullanarak maliyetini hesaplayın.
Step 3 - Rastgele bir komşu çözüm üretin.
Step 4 - Yeni çözüm maliyetini aynı maliyet fonksiyonu ile hesaplayın.
Step 5 - Yeni bir çözümün maliyetini eski bir çözümün maliyetiyle aşağıdaki gibi karşılaştırın -
Eğer CostNew Solution < CostOld Solution daha sonra yeni çözüme geçin.
Step 6 - Ulaşılan maksimum yineleme sayısı olabilecek veya kabul edilebilir bir çözüm elde edebilecek durdurma koşulunu test edin.
Doğa her zaman tüm insanlık için büyük bir ilham kaynağı olmuştur. Genetik Algoritmalar (GA'lar), doğal seleksiyon ve genetik kavramlarına dayanan arama tabanlı algoritmalardır. GA'lar olarak bilinen çok daha büyük bir hesaplama dalının bir alt kümesidir.Evolutionary Computation.
GA'lar, John Holland ve Michigan Üniversitesi'ndeki öğrencileri ve meslektaşları, özellikle de David E. Goldberg tarafından geliştirildi ve o zamandan beri çeşitli optimizasyon problemlerinde yüksek derecede başarı ile denendi.
GA'larda, verilen probleme yönelik bir havuzumuz veya olası çözümlerden oluşan bir popülasyonumuz var. Bu çözümler daha sonra rekombinasyon ve mutasyona uğrar (doğal genetikte olduğu gibi), yeni çocuklar üretir ve süreç çeşitli nesiller boyunca tekrarlanır. Her bir bireye (veya aday çözüme) bir uygunluk değeri (hedef işlev değerine dayalı olarak) atanır ve daha fit olan kişilere çiftleşme ve daha "fit" bireyler üretme şansı verilir. Bu, Darwin'in "En Güçlü Olanın Hayatta Kalması" Teorisi ile uyumludur.
Bu şekilde, bir durdurma kriterine ulaşana kadar nesiller boyunca daha iyi bireyler veya çözümler “geliştirmeye” devam ediyoruz.
Genetik Algoritmalar, doğaları gereği yeterince rasgeleleştirilmiştir, ancak tarihsel bilgileri de kullandıkları için rasgele yerel aramadan çok daha iyi performans gösterirler (burada sadece çeşitli rasgele çözümler deniyoruz, şimdiye kadarki en iyiyi takip ediyoruz).
GA'ların Avantajları
GA'ların, onları son derece popüler kılan çeşitli avantajları vardır. Bunlar arasında -
Herhangi bir türev bilgisi gerektirmez (gerçek dünyadaki birçok problem için mevcut olmayabilir).
Geleneksel yöntemlere göre daha hızlı ve daha verimlidir.
Çok iyi paralel yeteneklere sahiptir.
Hem sürekli hem de ayrık fonksiyonları ve çok amaçlı problemleri optimize eder.
Tek bir çözüm değil, "iyi" çözümlerin bir listesini sağlar.
Her zaman soruna bir yanıt alır ve bu zamanla düzelir.
Arama alanı çok büyük olduğunda ve çok sayıda parametre söz konusu olduğunda kullanışlıdır.
GA sınırlamaları
Herhangi bir teknik gibi, GA'lar da birkaç sınırlamadan muzdariptir. Bunlar şunları içerir -
GA'lar tüm problemler için uygun değildir, özellikle de basit olan ve türevi bilgilerin mevcut olduğu problemler.
Uygunluk değeri tekrar tekrar hesaplanır ve bu, bazı problemler için hesaplama açısından pahalı olabilir.
Stokastik olduğundan, çözümün optimalliği veya kalitesi konusunda hiçbir garanti yoktur.
Doğru bir şekilde uygulanmazsa, GA en uygun çözüme yakınlaşmayabilir.
GA - Motivasyon
Genetik Algoritmalar, "yeterince iyi" bir çözümü "yeterince hızlı" sunma yeteneğine sahiptir. Bu, Gas'ı optimizasyon problemlerinin çözümünde kullanım için çekici kılar. GA'lara neden ihtiyaç duyulduğunun nedenleri aşağıdaki gibidir -
Zor Sorunları Çözme
Bilgisayar biliminde, çok sayıda sorun vardır. NP-Hard. Bunun esasen anlamı, en güçlü bilgi işlem sistemlerinin bile bu sorunu çözmesinin çok uzun bir süre (hatta yıllar!) Almasıdır. Böyle bir senaryoda, GA'lar, aşağıdakileri sağlamak için verimli bir araç olduğunu kanıtladıusable near-optimal solutions kısa sürede.
Gradyan Bazlı Yöntemlerin Başarısızlığı
Geleneksel analiz tabanlı yöntemler, rastgele bir noktadan başlayarak ve yokuşun tepesine ulaşana kadar eğim yönünde hareket ederek çalışır. Bu teknik etkilidir ve doğrusal regresyondaki maliyet işlevi gibi tek tepeli hedef işlevler için çok iyi çalışır. Bununla birlikte, gerçek dünya durumlarının çoğunda, manzara olarak adlandırılan, birçok tepe ve vadiden oluşan çok karmaşık bir problemimiz var ve bu tür yöntemlerin, gösterildiği gibi yerel optimada sıkışıp kalma eğiliminden muzdarip oldukları için başarısız olmasına neden oluyor. aşağıdaki şekilde.
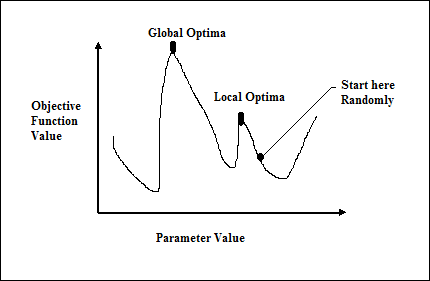
Hızlı Bir Çözüm Bulmak
Traveling Salesman Problem (TSP) gibi bazı zor problemler, yol bulma ve VLSI Design gibi gerçek dünya uygulamalarına sahiptir. Şimdi, GPS Navigasyon sisteminizi kullandığınızı ve kaynaktan hedefe "en uygun" yolu hesaplamanın birkaç dakika (hatta birkaç saat) aldığını hayal edin. Bu tür gerçek dünya uygulamalarında gecikme kabul edilebilir değildir ve bu nedenle gerekli olan "hızlı" teslim edilen "yeterince iyi" bir çözümdür.
Optimizasyon Sorunları için GA Nasıl Kullanılır?
Optimizasyonun tasarım, durum, kaynak ve sistem gibi bir şeyi olabildiğince etkili hale getirme eylemi olduğunu zaten biliyoruz. Optimizasyon süreci aşağıdaki diyagramda gösterilmektedir.

Optimizasyon Süreci için GA Mekanizmasının Aşamaları
Problemlerin optimizasyonu için kullanıldığında GA mekanizmasının aşamaları aşağıdadır.
İlk popülasyonu rastgele oluşturun.
En iyi uygunluk değerlerine sahip ilk çözümü seçin.
Mutasyon ve çaprazlama operatörlerini kullanarak seçilen çözümleri yeniden birleştirin.
Yavruları popülasyona ekleyin.
Şimdi, durdurma koşulu karşılanırsa, çözümü en iyi uygunluk değeriyle iade edin. Aksi takdirde, 2. adıma gidin.
YSA'nın yoğun olarak kullanıldığı alanları incelemeden önce, YSA'nın neden tercih edilen uygulama seçeneği olduğunu anlamamız gerekir.
Neden Yapay Sinir Ağları?
Yukarıdaki sorunun cevabını bir insan örneği ile anlamamız gerekiyor. Çocukken ebeveynlerimiz veya öğretmenlerimiz dahil olmak üzere büyüklerimizin yardımıyla bazı şeyleri öğrenirdik. Daha sonra kendi kendine öğrenerek veya pratik yaparak hayatımız boyunca öğrenmeye devam ederiz. Bilim adamları ve araştırmacılar da makineyi tıpkı bir insan gibi akıllı hale getiriyor ve YSA da aşağıdaki nedenlerden dolayı çok önemli bir rol oynuyor:
Algoritmik yöntemin pahalı olduğu veya bulunmadığı bu tür sorunların çözümünü sinir ağlarının yardımıyla bulabiliriz.
Sinir ağları örnek olarak öğrenebilir, bu nedenle onu çok fazla programlamamıza gerek yoktur.
Sinir ağları, geleneksel hıza göre doğruluk ve önemli ölçüde hızlı hıza sahiptir.
Uygulama alanları
YSA'nın kullanıldığı alanlardan bazıları aşağıda verilmiştir. YSA'nın geliştirilmesinde ve uygulamalarında disiplinler arası bir yaklaşıma sahip olduğunu öne sürmektedir.
Konuşma tanıma
Konuşma, insan-insan etkileşiminde önemli bir rol oynar. Bu nedenle, insanların bilgisayarlarla konuşma arayüzleri beklemesi doğaldır. Günümüzde, makinelerle iletişim için, insanlar öğrenmesi ve kullanması zor olan karmaşık dillere hala ihtiyaç duymaktadır. Bu iletişim engelini hafifletmek için basit bir çözüm, makinenin anlaması mümkün olan konuşulan bir dilde iletişim olabilir.
Bu alanda büyük ilerleme kaydedilmiştir, ancak yine de bu tür sistemler, farklı koşullarda farklı konuşmacılar için sistemin yeniden eğitilmesi sorunuyla birlikte sınırlı kelime veya dilbilgisi sorunu ile karşı karşıyadır. YSA bu alanda önemli bir rol oynuyor. Konuşma tanıma için aşağıdaki YSA'lar kullanılmıştır -
Çok katmanlı ağlar
Tekrarlayan bağlantılara sahip çok katmanlı ağlar
Kohonen kendi kendini organize eden özellik haritası
Bunun için en kullanışlı ağ, konuşma dalga formunun kısa bölümleri olarak girişi olan Kohonen Kendi Kendini Organize Etme özellik haritasıdır. Özellik çıkarma tekniği olarak adlandırılan çıktı dizisi ile aynı türden fonemleri haritalayacaktır. Öznitelikleri çıkardıktan sonra, arka uç işleme olarak bazı akustik modellerin yardımıyla, ifadeyi tanıyacaktır.
Karakter Tanıma
Örüntü Tanıma genel alanına giren ilginç bir sorundur. Harfler veya rakamlar olsun el yazısıyla yazılmış karakterlerin otomatik olarak tanınması için birçok sinir ağı geliştirilmiştir. Aşağıda, karakter tanıma için kullanılan bazı YSA'lar verilmiştir -
- Backpropagation sinir ağları gibi çok katmanlı sinir ağları.
- Neocognitron
Geri yayılım sinir ağlarının birkaç gizli katmanı olmasına rağmen, bir katmandan diğerine bağlantı modeli yerelleştirilmiştir. Benzer şekilde, neocognitron da birkaç gizli katmana sahiptir ve bu tür uygulamalar için eğitimi katman katman yapılır.
İmza Doğrulama Başvurusu
İmzalar, yasal işlemlerde bir kişiyi yetkilendirmenin ve doğrulamanın en kullanışlı yollarından biridir. İmza doğrulama tekniği, vizyona dayalı olmayan bir tekniktir.
Bu uygulama için ilk yaklaşım, özelliği veya daha doğrusu imzayı temsil eden geometrik özellik setini çıkarmaktır. Bu özellik setleriyle, etkili bir sinir ağı algoritması kullanarak sinir ağlarını eğitmemiz gerekiyor. Bu eğitimli sinir ağı, imzayı doğrulama aşamasında gerçek veya sahte olarak sınıflandıracaktır.
İnsan Yüzü Tanıma
Verilen yüzü tanımlamak için biyometrik yöntemlerden biridir. "Yüz olmayan" görüntülerin karakterizasyonu nedeniyle tipik bir görevdir. Bununla birlikte, bir sinir ağı iyi eğitilmişse, o zaman iki sınıfa ayrılabilir, yani yüzleri olmayan görüntüler ve yüzleri olmayan görüntüler.
İlk olarak, tüm girdi görüntüleri önceden işlenmelidir. Daha sonra bu görüntünün boyutluluğunun azaltılması gerekir. Ve sonunda sinir ağı eğitim algoritması kullanılarak sınıflandırılması gerekiyor. Aşağıdaki sinir ağları, önceden işlenmiş görüntü ile eğitim amaçlı kullanılır -
Geriye yayılma algoritmasının yardımıyla eğitilmiş, tam bağlantılı çok katmanlı ileri beslemeli sinir ağı.
Boyutları azaltmak için Temel Bileşen Analizi (PCA) kullanılır.