Uczenie maszynowe i uczenie głębokie
Sztuczna inteligencja to jeden z najpopularniejszych trendów ostatnich czasów. Uczenie maszynowe i uczenie głębokie to sztuczna inteligencja. Poniższy diagram Venna wyjaśnia związek między uczeniem maszynowym a uczeniem głębokim -
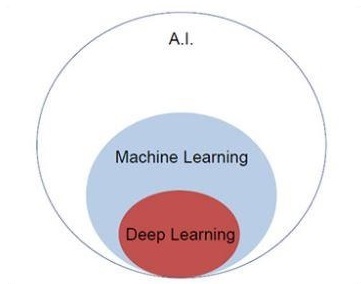
Nauczanie maszynowe
Uczenie maszynowe to sztuka nauki polegająca na zmuszaniu komputerów do działania zgodnie z zaprojektowanymi i zaprogramowanymi algorytmami. Wielu badaczy uważa, że uczenie maszynowe to najlepszy sposób na osiągnięcie postępu w kierunku sztucznej inteligencji na poziomie ludzkim. Uczenie maszynowe obejmuje następujące typy wzorców
- Nadzorowany wzorzec uczenia się
- Nienadzorowany wzorzec uczenia się
Głęboka nauka
Głębokie uczenie jest podobną dziedziną uczenia maszynowego, w której algorytmy są inspirowane strukturą i funkcją mózgu zwanymi sztucznymi sieciami neuronowymi.
Cała wartość uczenia głębokiego polega obecnie na nadzorowanym uczeniu się lub uczeniu się na podstawie oznaczonych danych i algorytmów.
Każdy algorytm w głębokim uczeniu przechodzi przez ten sam proces. Obejmuje hierarchię nieliniowej transformacji danych wejściowych, której można użyć do wygenerowania modelu statystycznego jako wyniku.
Rozważ następujące kroki, które definiują proces uczenia maszynowego
- Identyfikuje odpowiednie zbiory danych i przygotowuje je do analizy.
- Wybiera typ algorytmu do użycia
- Buduje model analityczny w oparciu o zastosowany algorytm.
- Trenuje model na testowych zestawach danych i koryguje go w razie potrzeby.
- Uruchamia model w celu wygenerowania wyników testów.
Różnica między uczeniem maszynowym a uczeniem głębokim
W tej sekcji dowiemy się, jaka jest różnica między uczeniem maszynowym a uczeniem głębokim.
Ilość danych
Uczenie maszynowe działa z dużą ilością danych. Jest to przydatne również w przypadku małych ilości danych. Z drugiej strony, uczenie głębokie działa skutecznie, jeśli ilość danych gwałtownie rośnie. Poniższy diagram przedstawia działanie uczenia maszynowego i uczenia głębokiego z ilością danych -
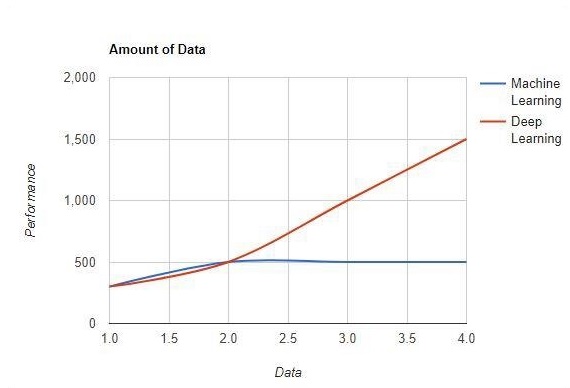
Zależności sprzętowe
Algorytmy głębokiego uczenia są zaprojektowane tak, aby w dużym stopniu polegały na maszynach wysokiej klasy, w przeciwieństwie do tradycyjnych algorytmów uczenia maszynowego. Algorytmy uczenia głębokiego wykonują szereg operacji mnożenia macierzy, które wymagają dużej ilości wsparcia sprzętowego.
Inżynieria funkcji
Inżynieria funkcji to proces polegający na umieszczaniu wiedzy dziedzinowej w określonych funkcjach w celu zmniejszenia złożoności danych i stworzenia wzorców, które są widoczne dla algorytmów uczących się.
Przykład - Tradycyjne wzorce uczenia maszynowego koncentrują się na pikselach i innych atrybutach potrzebnych do procesu inżynierii funkcji. Algorytmy uczenia głębokiego koncentrują się na funkcjach wysokiego poziomu z danych. Zmniejsza to zadanie tworzenia nowego ekstraktora funkcji dla każdego nowego problemu.
Podejście do rozwiązywania problemów
Tradycyjne algorytmy uczenia maszynowego stosują standardową procedurę rozwiązywania problemu. Dzieli problem na części, rozwiązuje każdą z nich i łączy je, aby uzyskać wymagany rezultat. Uczenie głębokie koncentruje się na rozwiązywaniu problemu od początku do końca, zamiast rozbijać je na podziały.
Czas egzekucji
Czas wykonania to czas wymagany do wytrenowania algorytmu. Uczenie głębokie wymaga dużo czasu na trening, ponieważ zawiera wiele parametrów, co zajmuje więcej czasu niż zwykle. Algorytm uczenia maszynowego wymaga stosunkowo krótszego czasu wykonania.
Interpretowalność
Interpretowalność jest głównym czynnikiem służącym do porównywania algorytmów uczenia maszynowego i uczenia głębokiego. Głównym powodem jest to, że głębokie uczenie się wciąż jeszcze zastanawia się nad jego zastosowaniem w przemyśle.
Zastosowania uczenia maszynowego i głębokiego uczenia się
W tej sekcji dowiemy się o różnych zastosowaniach uczenia maszynowego i uczenia głębokiego.
Wizja komputerowa, która służy do rozpoznawania twarzy i oznaczenia obecności na podstawie odcisków palców lub identyfikacji pojazdu za pomocą tablicy rejestracyjnej.
Pobieranie informacji z wyszukiwarek, takich jak wyszukiwanie tekstowe dla wyszukiwania obrazów.
Zautomatyzowany marketing e-mailowy z określoną identyfikacją celu.
Diagnoza medyczna guzów nowotworowych lub identyfikacja anomalii jakiejkolwiek choroby przewlekłej.
Przetwarzanie języka naturalnego do zastosowań, takich jak tagowanie zdjęć. Najlepszym przykładem wyjaśnienia tego scenariusza jest Facebook.
Reklama w Internecie.
Przyszłe trendy
Wraz z rosnącym trendem wykorzystywania nauki o danych i uczenia maszynowego w przemyśle, dla każdej organizacji ważne będzie zaszczepienie uczenia maszynowego w swoich biznesach.
Uczenie głębokie zyskuje na znaczeniu niż uczenie maszynowe. Głębokie uczenie się okazuje się jedną z najlepszych technik w najnowocześniejszej wydajności.
Uczenie maszynowe i uczenie głębokie przyniosą korzyści w dziedzinie badań naukowych i akademickich.
Wniosek
W tym artykule omówiliśmy uczenie maszynowe i głębokie uczenie się z ilustracjami i różnicami, koncentrując się również na przyszłych trendach. Wiele aplikacji AI wykorzystuje algorytmy uczenia maszynowego przede wszystkim do samoobsługi, zwiększania produktywności agentów i bardziej niezawodnych przepływów pracy. Algorytmy uczenia maszynowego i głębokiego uczenia się stanowią ekscytującą perspektywę dla wielu firm i liderów branży.